prefixspan with spark at akanoo
TRANSCRIPT

PrefixSpan with Spark
Frank Wolf & Dr. Gundula Meckenhäuser
07.08.2015
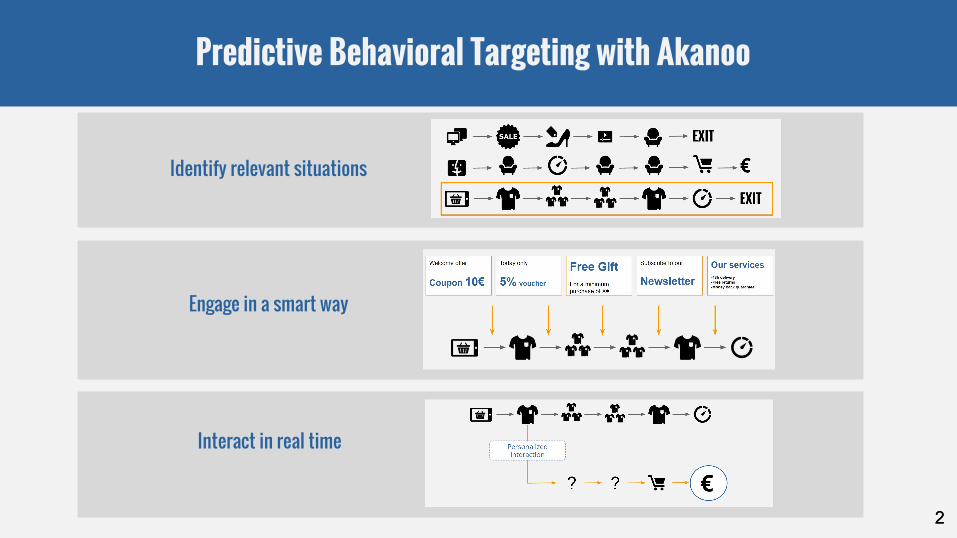
Predictive Behavioral Targeting with Akanoo
22
Identify relevant situations
Interact in real time
Engage in a smart way

Agenda
1. PrefixSpan for Sequential Pattern Mining
2. A PrefixSpan Implementation with Spark
3

Agenda
1. PrefixSpan for Sequential Pattern Mining
2. A PrefixSpan Implementation with Spark
4

cart . . .
Motivation
54% buyers
46% non-buyers
What is going on within the last 5 page impressions?
5

Translating clickstream data into patterns
pagetypes: home, overview, product, sale, account, cart, checkout, search, about
cart . . . overview overview overview product overview
cart . . . 5th last PI 4th last PI 3rd last PI 2nd last PI last PI
pattern: identified by SessionId: < ( overview, add ), ( overview, no ), ( overview, no ), ( product, no ), ( overview, no ) >
cart . . . add no no no nocart changes: add, remove, no
item
itemset6

Problem definition
7
pattern 1 < (overview, no) , ( overview, no ), ( overview, no ), ( product, no ), ( overview, no ) >pattern 2 < (home, no), ( product, no ), ( product, no ), ( product, no ), ( overview, no ) >
. . .
pattern n < (overview, no) , ( product, add ), ( product, no ), ( cart, no ), ( checkout, no ) >
Example < (overview, no), (product, no)> is a subpattern of patterns 1 and n < (overview, no), (product, remove) > is no subpattern
A pattern is frequent with support n if it is n times a subpattern of the database patterns

PrefixSpan
8
Sequential Pattern Mining by Pattern Growth

PrefixSpan with a toy example: frequent patterns of length 1
9
ID pattern
1 < a (a b c) (a c) >
2 < (a d) c >
3 < (e f) (a b) >
Database
ID < a > < b > < c > < d > < e > < f >
1 (0,0), (1,0), (2,0) (1,1) (1,2), (2,1) -- -- --
2 (0,0) -- (1,0) (0,1) -- --
3 (1,0) (1,1) -- -- (0,0) (0,1)
Step1: Occurrences of base letters
ID < a > < b > < c > < d > < e > < f >
1 (0,0), (1,0), (2,0) (1,1) (1,2), (2,1) -- -- --
2 (0,0) -- (1,0) (0,1) -- --
3 (1,0) (1,1) -- -- (0,0) (0,1)
support 3 2 2 1 1 1min support: 2
frequent patterns of length 1 are: < a >, < b >, < c >

PrefixSpan with a toy example: frequent patterns of length 2
10
Occurrences of frequent patterns of length 1
ID < a > < b > < c >
1 (0,0), (1,0), (2,0) (1,1) (1,2), (2,1)
2 (0,0) -- (1,0)
3 (1,0) (1,1) --
ID <a a> <a b> <a c> <b a> <b b> <b c> <c a> <c b> <c c>
1 (1,0), (2,0) (1,1) (1,2), (2,1) (2,0) -- (2,1) (2,0) (2,0) (2,1)
2 -- -- (1,0) -- -- -- -- -- --
3 -- -- -- -- -- -- -- --
Step 2: Occurrences of patterns of length 2
frequent patterns of length 2 are: < a c >
ID < a > < b > < c >
1 (0,0), (1,0), (2,0) (1,1) (1,2), (2,1)
2 (0,0) -- (1,0)
3 (1,0) (1,1) --
Occurrences of frequent base letters

11
PrefixSpan with a toy example: frequent patterns of length 3
Occurrences of frequent base letters
ID < a > < b > < c >
1 (0,0), (1,0), (2,0) (1,1) (1,2), (2,1)
2 (0,0) -- (1,0)
3 (1,0) (1,1) --
ID <a c>
1 (1,2), (2,1)
2 (1,0)
3 --
ID <a c a> <a c b> <a c c>
1 (2,0) -- --
2 -- -- --
3 -- -- --
Occurrences of frequent patterns of length 2
Step 3: Occurrences of patterns of length 3
no frequent patterns of length 3

PrefixSpan with a toy example: all frequent patterns
12
ID pattern
1 < a (a b c) (a c) >
2 < (a d) c >
3 < (e f) (a b) >
Database Results: frequent patterns
pattern support
< a > 3
< b > 2
< c > 2
< a c > 2min Support: 2

Agenda
1. PrefixSpan for Sequential Pattern Mining
2. A PrefixSpan Implementation with Spark
13

PrefixSpan with a toy example: all frequent patterns
14
ID pattern
1 < a (a b c) (a c) >
2 < (a d) c >
3 < (e f) (a b) >
DatabaseResults: frequent patterns
pattern support
< a > 3
< b > 2
< c > 2
< a c > 2
< (a b) > 2min Support: 2
?

Main class, main function
15
Pattern composition
Main class:
class SequenceRDDFunctions( database: RDD[(SessionId, Pattern)])
Main function:
def mineFrequentPatterns( patternGenerator: PatternGenerator, minSupFraction: Double = 0.05): List[PatternWithOccRddAndSupport]
Patterncase class Pattern( elements: Seq[ItemSet])
val p = Pattern( elements: Seq(a, d, c))
ItemSet case class ItemSet( items: Seq[Item])
val a = ItemSet(items = Seq(item1))
Item case class Item( letter: Letter)
val item1 = Item( letter = pageTypeOverviewLetter)
Letter type Letter = Int val pageTypeOverviewLetter: Letter = 1

From Session to Pattern (1 / 2)
16
{ "SessionID":"49624d7e", ... },{ "pageType":"overview", ... },{ "pageType":"product", ... },{ "pageType":"checkout", ... },
Session(json) Visit
case class Visit( session: Session, viewList: List[View]…)
case class View ( viewId: String, time: Long, pageType: PageType, …)
val a: View = View( viewId= "view-id", pageType = PageType.OVERVIEW,...
val d: View = View( viewId= "view-id", pageType = PageType.PRODUCT,...)
val c: View = View( viewId= "view-id", pageType = PageType.CHECKOUT,...))
Views

From Session to Pattern (2 / 2)
Creating a pattern from a visit
def pageTypeLetterForView(view: View): Letter = visits.viewList.view.pageType match { case PageType.OVERVIEW => pageTypeOverviewLetter case PageType.PRODUCT => pageTypeProductLetter case PageType.ACCOUNT => pageTypeCheckoutLetter })
def generatePattern(visit: Visit): Pattern = { val itemSets = visit.map { (view) => val itemSet = pageTypeLetterForView(view) .map(Item) .map(ItemSet) } Pattern(itemSets)}
Toy alphabet: pageTypeAlphabet
// letters
val pageTypeOverviewLetter: Letter = 1val pageTypeCheckoutLetter: Letter = 3val pageTypeProductLetter: Letter = 4
// alphabet
val pageTypeAlphabet: Alphabet = List( pageTypeOverviewLetter, pageTypeProductLetter, pageTypeCheckoutLetter)

Towards a database of patterns
Creating a pattern from a visit
def generatePattern(visit: Visit): Pattern = { val itemSets = visit.map { (view) => val itemSet = pageTypeLetterForView(view) .map(Item) .map(ItemSet) } Pattern(itemSets)}
Creating databse ...… which is an RDD[(SessionId, Pattern)
def mapToPattern(visits: Seq(Visit)): RDD[(SessionId, Pattern)] = { visits.map( visit => (visit.session.sessionId,generatePattern(visit)))}

Main class, main function
19
Input paramsMain class:
class SequenceRDDFunctions( database: RDD[(SessionId, Pattern)])
Main function:
def mineFrequentPatterns( patternGenerator: PatternGenerator, minSupFraction: Double = 0.05): List[PatternWithOccRddAndSupport]
patternGenerator a function that lets us grab the alphabet
minSupFraction: Double = 0.05
a pattern is frequent if it occurrs in at least 5% of all database patterns
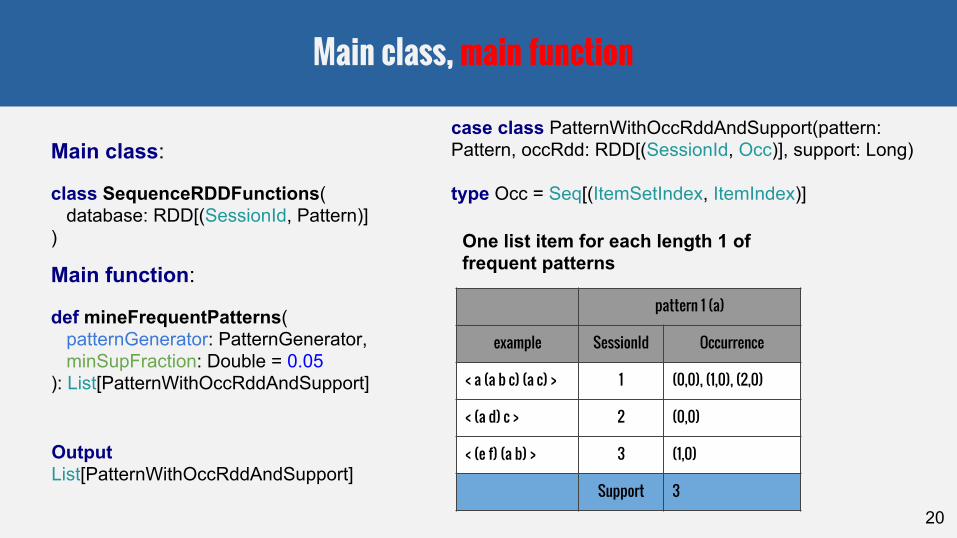
Main class, main function
20
Main class:
class SequenceRDDFunctions( database: RDD[(SessionId, Pattern)])
Main function:
def mineFrequentPatterns( patternGenerator: PatternGenerator, minSupFraction: Double = 0.05): List[PatternWithOccRddAndSupport]
case class PatternWithOccRddAndSupport(pattern: Pattern, occRdd: RDD[(SessionId, Occ)], support: Long)
type Occ = Seq[(ItemSetIndex, ItemIndex)]
pattern 1 (a)
example SessionId Occurrence
< a (a b c) (a c) > 1 (0,0), (1,0), (2,0)
< (a d) c > 2 (0,0)
< (e f) (a b) > 3 (1,0)
Support 3
OutputList[PatternWithOccRddAndSupport]
One list item for each length 1 of frequent patterns

How frequent patterns are found (1/6)
1. Calculate the occurrence table of the baseLetters
def occurrencesOfBaseLetters(baseLetter: Letter): RDD[(SessionId, Occ)] = { database.mapValues(sessionPattern => { sessionPattern.occurrence(Item(baseLetter)) })}
case class Pattern(elements: Seq[ItemSet]) { def occurrence(item: Item): Occ = { elements.zipWithIndex.filter({ case (itemSet, itemSetIndex) => itemSet.contains(item) }) .map({ case (itemSet, itemSetIndex) => (itemSetIndex, itemSet.indexOf(item)) })}}
Reminder:type Occ = Seq[(ItemSetIndex, ItemIndex)]

How frequent patterns are found (2/6)
22
One instance of PatternWithOccRddAndSupport for any letter
letter 1
SessionId Occurrence
1 (1,2), (2,1)
2 (1,0)
3 --
Support 2
letter 2
SessionId Occurrence
1 (1,2), (2,1)
2 (1,0)
3 --
Support 2
ID < a > < b > < c >
1 (0,0), (1,0), (2,0) (1,1) (1,2), (2,1)
2 (0,0) -- (1,0)
3 (1,0) (1,1) --
...
… corresponds to this table of the letter occurrence table in the theory part
1. Calculate the occurrence table of the baseLetters

How frequent patterns are found (3/6)
2. Calculate the occurrence tables of (n+1)-Patterns from n-Patterns
val frequentPatterns = Stream.iterate(frequentBaseLettersAndOcccurences)(previousPatterns => { previousPatterns.par.flatMap((previousPattern: PatternWithOccRddAndSupport) => { previousPattern.occurrences.persist()
// creates n+1 patterns with enough support val nextPatterns = getNextFrequentPatterns(previousPattern.pattern, previousPattern.occurrences)
previousPattern.occurrences.unpersist() nextPatterns }).toList}).takeWhile(_.nonEmpty).flatten.toList

How frequent patterns are found (4/6)
2. Calculate the occurrence tables of (n+1)-Patterns from n-Patterns
// based on pattern of length n, identifies frequent patterns of length n+1 by appending and assembling frequent lettersdef getNextFrequentPatterns(previousPattern: Pattern, previousPatternOccurrences: RDD[(SessionId, Occ)]): List[PatternWithOccRddAndSupport] = { val appendedFreqPatterns = frequentBaseLettersAndOcccurences.par.map(baseLetterAndOccs => {
//make <a b> + <b> => <a b b> val nextPattern = previousPattern ++ baseLetterAndOccs.pattern // joins occurrences of previous pattern and any letter val joinedOccurrences: RDD[(SessionId, (Occ, Occ))] = previousPatternOccurrences.join(baseLetterAndOccs.occurrences) // returns occurrences of new pattern val nextPatternOccurrences: RDD[(SessionId, Occ)] = joinedOccurrences.mapAppendedOccPairToOcc()
PatternWithOccRddAndSupport(nextPattern, nextPatternOccurrences, nextPatternOccurrences.countSupport())}) // only leaves pattern with enough support .filter(_.support >= minSup).toList
appendedFreqPatterns}

How frequent patterns are found (5/6)
2. Calculate the occurrence tables of (n+1)-Patterns from n-Patterns
// based on pattern of length n, identifies frequent patterns of length n+1 by appending and assembling frequent lettersdef getNextFrequentPatterns(previousPattern: Pattern, previousPatternOccurrences: RDD[(SessionId, Occ)]): List[PatternWithOccRddAndSupport] = { … // prefix OCC, suffix OCC val joinedOccurrences: RDD[(SessionId, (Occ, Occ))] = previousPatternOccurrences.join(baseLetterAndOccs.occurrences) // returns occurrences of new pattern val nextPatternOccurrences: RDD[(SessionId, Occ)] = joinedOccurrences.mapAppendedOccPairToOcc()
...
def mapAppendedOccPairToOcc(): RDD[(SessionId, Occ)] = { self.mapValues((occPair: (Occ, Occ)) => { // occP = occ(<a b>) , occS = occ(<c>) val (occPrefix, occSuffix) = occPair PseudoProjection.pseudoProjectionAppend(occPrefix, occSuffix) })}
joinedOccurrences example entry:
<ac> append <a><ac> - prefixOcc: [(1,0), (2,1)]<a> - suffixOcc: [(0,0), (1,0), (2,0)]
-> (2,0)

How frequent patterns are found (6/6)
2. Calculate the occurrence tables of (n+1)-Patterns from n-Patterns
def pseudoProjectionAppend(prefixOcc: Occ, suffixOcc: Occ): Occ = suffixOcc.filter({ case (suffixItemSetIndex, suffixItemIndex) => // suffix occurrence after first occurrence of prefix suffixItemSetIndex > prefixOcc.map( { case (prefixItemSetIndex, _) => prefixItemSetIndex }).min })
def mapAppendedOccPairToOcc(): RDD[(SessionId, Occ)] = { self.mapValues((occPair: (Occ, Occ)) => { // occP = occ(<a b>) , occS = occ(<c>) val (occPrefix, occSuffix) = occPair PseudoProjection.pseudoProjectionAppend(occPrefix, occSuffix) })}
joinedOccurrences example entry:
<ac> append <a><ac> - prefixOcc: [(1,0), (2,1)]<a> - suffixOcc: [(0,0), (1,0), (2,0)]
-> (2,0)

Results: Mining frequent patterns of conversions and abandonments
KäuferKaufabbrecherHäufigkeit
Handlungsempfehlung: Mit potentiellen Abbrechern nach mehrfachen Besuch von zwei Übersichtsseiten interagieren (Erinnerung an den Warenkorb, Abschluss-orientierte Kaufanreize)

Thank you for your attention!
Any further questions?Find more information on akanoo.com or
write us a mail to [email protected]!