what is spark? - uhgabriel/courses/cosc6339_s17/bda_11_spark.pdf · what is spark? •in-memory...
TRANSCRIPT

1
COSC 6339
Big Data Analytics
Introduction to Spark
Edgar Gabriel
Spring 2017
What is SPARK?
• In-Memory Cluster Computing for Big Data Applications
• Fixes the weaknesses of MapReduce
– Iterative applications
– Streaming data processing
– Keep data in memory across different functions
• Sparks works across many environments
– Standalone,
– Hadoop,
– Mesos,
• Spark support accessing data from diverse sources ( HDFS,
HBase, Cassandra, …)

2
What is SPARK (II)• Three modes of execution
– Spark shell
– Spark scripts
– Spark code
• API defined for multiple languages
– Scala
– Python
– Java
– R
A couple of words on Scala
• Object-oriented language: everything is an object and
every operation is a method-call.
• Scala is also a functional language
– Functions are first class values
– Can be passed as arguments to functions
– Functions have to be free of side effects
– Can defined functions inside of functions
• Scala runs on the JVM
– Java and Scala classes can be freely mixed

3
Spark Essentials
• Spark program has to create a SparkContext object,
which tells Spark how to access a cluster
• Automatically done in the shell for Scala or Python: accessible through the sc variable
• Programs must use a constructor to instantiate a new SparkContext
gabriel@whale:> pyspark
…
Using Python version 2.7.6 (default, Nov 21 2013 15:55:38)
SparkSession available as 'spark'.
>>> sc
<pyspark.context.SparkContext object at 0x2609ed0>
Spark Essentials
• The master parameter for a SparkContext
determines which resources to use, e.g. whale>pyspark --master yarn
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf

4
SPARK cluster utilization
1. master connects to a cluster manager to allocate
resources across applications
2. acquires executors on cluster nodes – processes run
compute tasks, cache data
3. sends app code to the executors
4. sends tasks for the executors to run
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf
SPARK master parameterMaster URL Meaning
local Run Spark locally with one worker thread (i.e.
no parallelism at all).
local[K] Run Spark locally with K worker threads (ideally,
set this to the number of cores on your
machine).
spark://HOST:PORT Connect to the given Spark standalone
cluster master. The port must be whichever one
your master is configured to use, which is 7077
by default.
mesos://HOST:PORT Connect to the given Mesos cluster. The port
must be whichever one your is configured to
use, which is 5050 by default. Or, for a Mesos
cluster using ZooKeeper, use mesos://zk://....
yarn Connect to a YARN cluster in cluster mode. The
cluster location will be found based on
HADOOP_CONF_DIR.
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf

5
Programming Model
• Resilient distributed datasets (RDDs)
– Immutable collections partitioned across cluster nodes that can be rebuilt if a partition is lost
– Created by transforming data in stable storage using data flow operators (map, filter, group-by, …)
• Two types of RDDs defined today:
– parallelized collections – take an existing collection and
run functions on it in parallel
– Hadoop datasets – run functions on each record of a file
in Hadoop distributed file system or any other storage
system supported by HadoopSlide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf
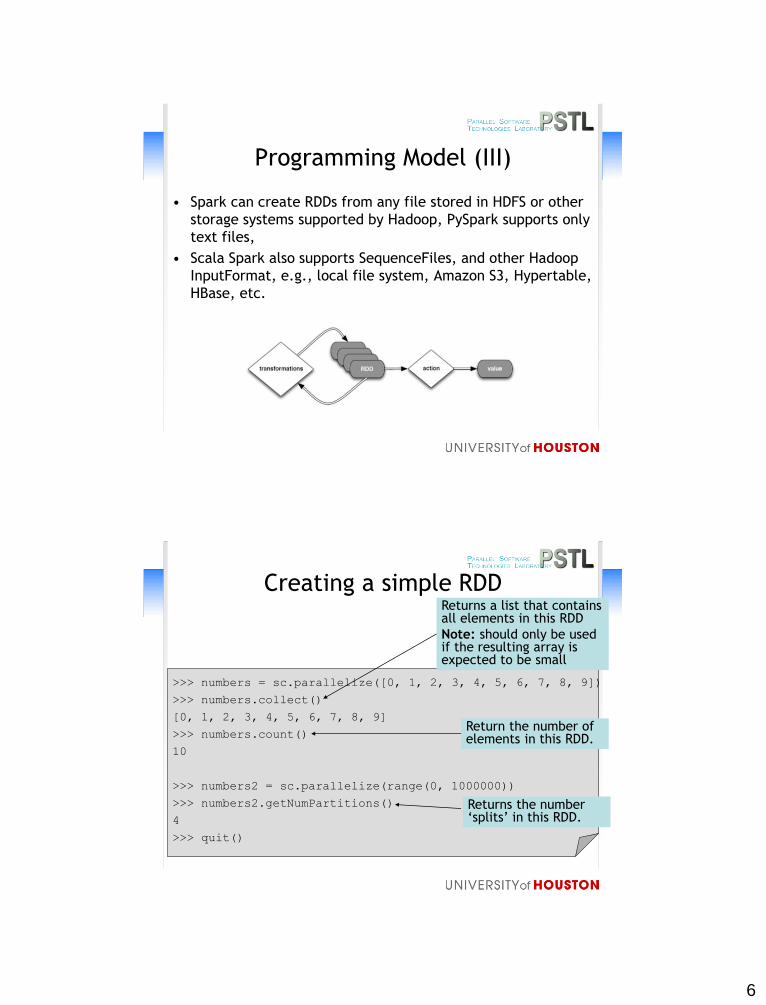
Programming Model (II)
• Two types of operations on RDDs: transformations and
actions
– transformations are lazy (not computed immediately)
– the transformed RDD gets recomputed when an action is
run on it (default)
– instead they remember the transformations applied to
some base dataset
• optimize the required calculations
• recover from lost data partitions
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf
6
Programming Model (III)
• Spark can create RDDs from any file stored in HDFS or other
storage systems supported by Hadoop, PySpark supports only
text files,
• Scala Spark also supports SequenceFiles, and other Hadoop
InputFormat, e.g., local file system, Amazon S3, Hypertable,
HBase, etc.
Creating a simple RDD
>>> numbers = sc.parallelize([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> numbers.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> numbers.count()
10
>>> numbers2 = sc.parallelize(range(0, 1000000))
>>> numbers2.getNumPartitions()
4
>>> quit()
Returns a list that contains all elements in this RDD
Note: should only be used if the resulting array is expected to be small
Return the number of elements in this RDD.
Returns the number ‘splits’ in this RDD.
7
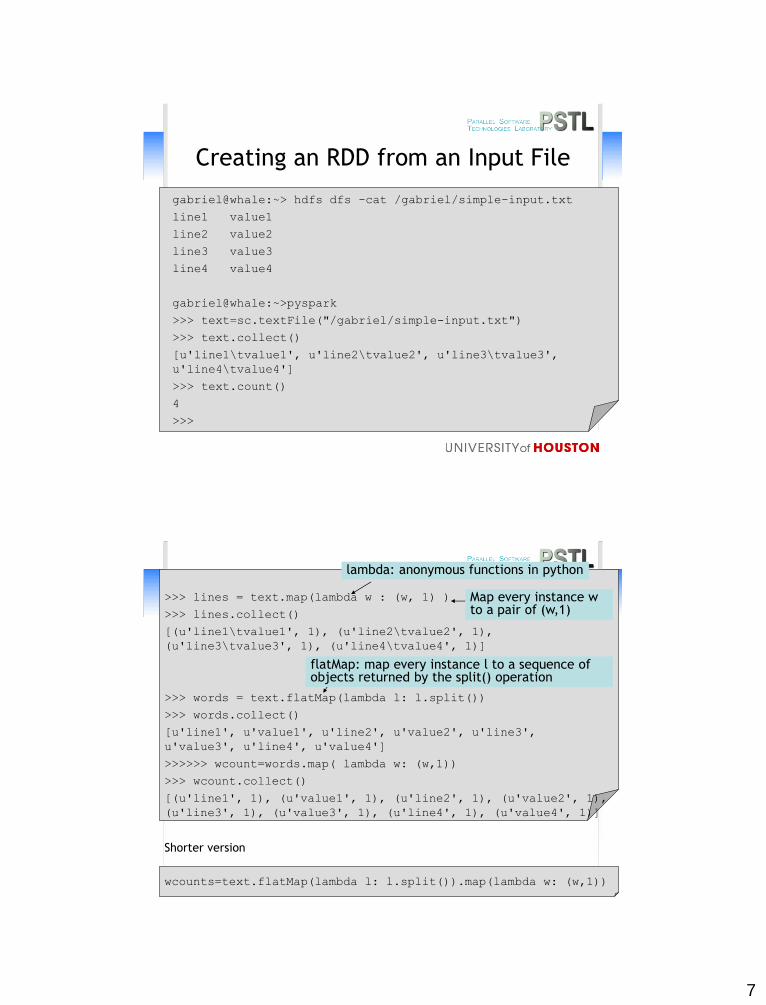
Creating an RDD from an Input File
gabriel@whale:~> hdfs dfs -cat /gabriel/simple-input.txt
line1 value1
line2 value2
line3 value3
line4 value4
gabriel@whale:~>pyspark
>>> text=sc.textFile("/gabriel/simple-input.txt")
>>> text.collect()
[u'line1\tvalue1', u'line2\tvalue2', u'line3\tvalue3',
u'line4\tvalue4']
>>> text.count()
4
>>>
>>> lines = text.map(lambda w : (w, 1) )
>>> lines.collect()
[(u'line1\tvalue1', 1), (u'line2\tvalue2', 1),
(u'line3\tvalue3', 1), (u'line4\tvalue4', 1)]
>>> words = text.flatMap(lambda l: l.split())
>>> words.collect()
[u'line1', u'value1', u'line2', u'value2', u'line3',
u'value3', u'line4', u'value4']
>>>>>> wcount=words.map( lambda w: (w,1))
>>> wcount.collect()
[(u'line1', 1), (u'value1', 1), (u'line2', 1), (u'value2', 1),
(u'line3', 1), (u'value3', 1), (u'line4', 1), (u'value4', 1)]
Shorter version
wcounts=text.flatMap(lambda l: l.split()).map(lambda w: (w,1))
Map every instance w to a pair of (w,1)
flatMap: map every instance l to a sequence of objects returned by the split() operation
lambda: anonymous functions in python

8
Transformations
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf
Transformations
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf

9
Actions
Slide based on a talk found at http://cdn.liber118.com/workshop/itas_workshop.pdf
Actions
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf
10
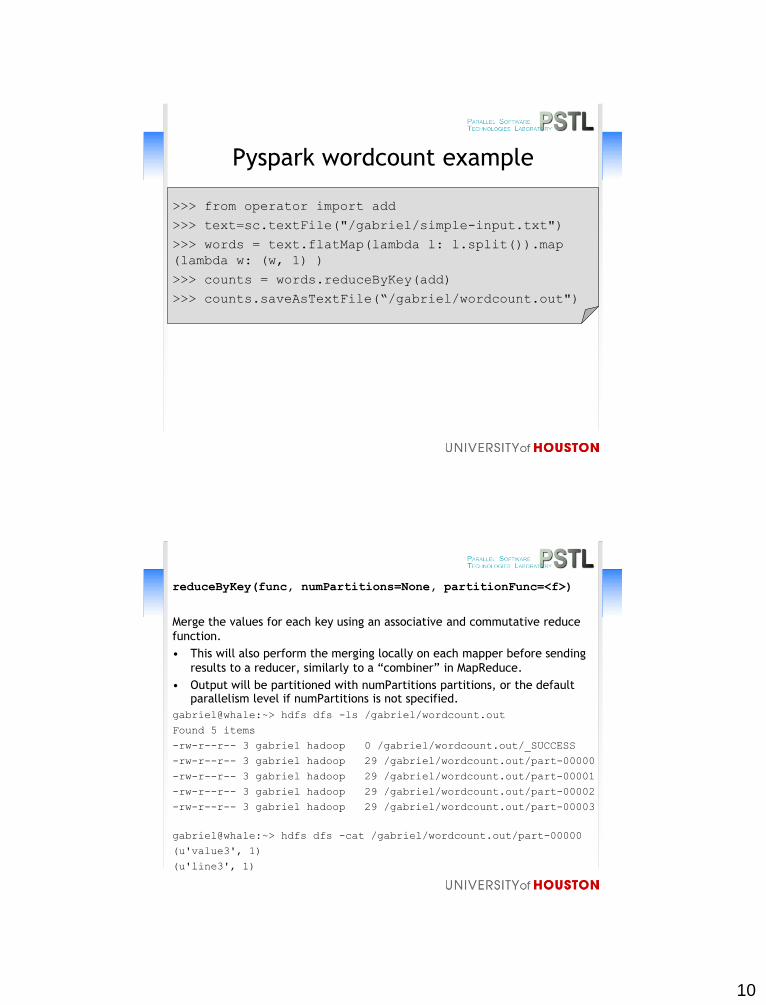
Pyspark wordcount example
>>> from operator import add
>>> text=sc.textFile("/gabriel/simple-input.txt")
>>> words = text.flatMap(lambda l: l.split()).map
(lambda w: (w, 1) )
>>> counts = words.reduceByKey(add)
>>> counts.saveAsTextFile(“/gabriel/wordcount.out")
reduceByKey(func, numPartitions=None, partitionFunc=<f>)
Merge the values for each key using an associative and commutative reduce
function.
• This will also perform the merging locally on each mapper before sending
results to a reducer, similarly to a “combiner” in MapReduce.
• Output will be partitioned with numPartitions partitions, or the default parallelism level if numPartitions is not specified.
gabriel@whale:~> hdfs dfs -ls /gabriel/wordcount.out
Found 5 items
-rw-r--r-- 3 gabriel hadoop 0 /gabriel/wordcount.out/_SUCCESS
-rw-r--r-- 3 gabriel hadoop 29 /gabriel/wordcount.out/part-00000
-rw-r--r-- 3 gabriel hadoop 29 /gabriel/wordcount.out/part-00001
-rw-r--r-- 3 gabriel hadoop 29 /gabriel/wordcount.out/part-00002
-rw-r--r-- 3 gabriel hadoop 29 /gabriel/wordcount.out/part-00003
gabriel@whale:~> hdfs dfs -cat /gabriel/wordcount.out/part-00000
(u'value3', 1)
(u'line3', 1)
11
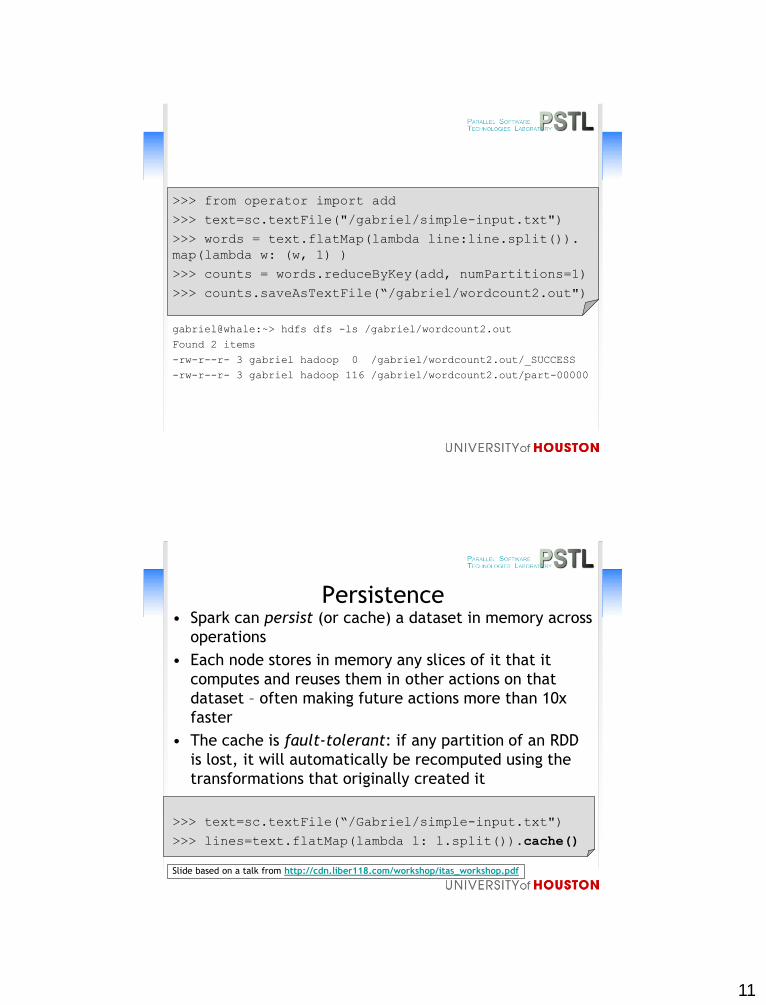
>>> from operator import add
>>> text=sc.textFile("/gabriel/simple-input.txt")
>>> words = text.flatMap(lambda line:line.split()).
map(lambda w: (w, 1) )
>>> counts = words.reduceByKey(add, numPartitions=1)
>>> counts.saveAsTextFile(“/gabriel/wordcount2.out")
gabriel@whale:~> hdfs dfs -ls /gabriel/wordcount2.out
Found 2 items
-rw-r--r- 3 gabriel hadoop 0 /gabriel/wordcount2.out/_SUCCESS
-rw-r--r- 3 gabriel hadoop 116 /gabriel/wordcount2.out/part-00000
Persistence• Spark can persist (or cache) a dataset in memory across
operations
• Each node stores in memory any slices of it that it
computes and reuses them in other actions on that
dataset – often making future actions more than 10x
faster
• The cache is fault-tolerant: if any partition of an RDD
is lost, it will automatically be recomputed using the
transformations that originally created it
>>> text=sc.textFile(“/Gabriel/simple-input.txt")
>>> lines=text.flatMap(lambda l: l.split()).cache()
Slide based on a talk from http://cdn.liber118.com/workshop/itas_workshop.pdf

12
Broadcast variables
• Broadcast variables let programmer keep a read-only
variable cached on each machine rather than shipping a
copy of it with tasks
• For example, to give every node a copy of required
accuracy, number of iterations, etc.
• Spark attempts to distribute broadcast variables using
efficient broadcast algorithms to reduce
communication cost
>>>b = sc.broadcast([1, 2, 3])
>>>b.value
[1, 2, 3]
>>>
Literature
• http://spark.apache.org/docs/latest/api/python/index.html
• https://www.codementor.io/jadianes/spark-python-rdd-
basics-du107x2ra
• A large number of books available meanwhile for Spark and
friends.