oyun teorİsİ ve uygulamalari - idari.cu.edu.tr · a.k. dixit, b.j. nalebuff, stratejik d
TRANSCRIPT

OYUN TEOROYUN TEORİİSSİİ VE VE
UYGULAMALARIUYGULAMALARI
Dr. SanlDr. Sanlıı ATEATEŞŞ

Bu dersin amacı, oyun teorisini teknik olarak tanıtıp, başta
ekonomi alanı olmak üzere değişik alanlara nasıl
uygulanabileceğini tartışmaktır. Günümüzde bireylerden
firmalara, yerel kurumlardan evrensel kurumlara kadar her
noktada karar verme süreçleri stratejik düşünme biçimine
giderek oturmuştur. Karar birimleri daha sağlıklı kararlara
ulaşabilmek için rakiplerinin davranışlarını daha yakından
izlemekte, daha çok bilgi toplamaktadırlar. Bu sürecin bilimsel
düzeyde anlaşılması, oyun teorisinin ilgi alanı içindedir.
22
33
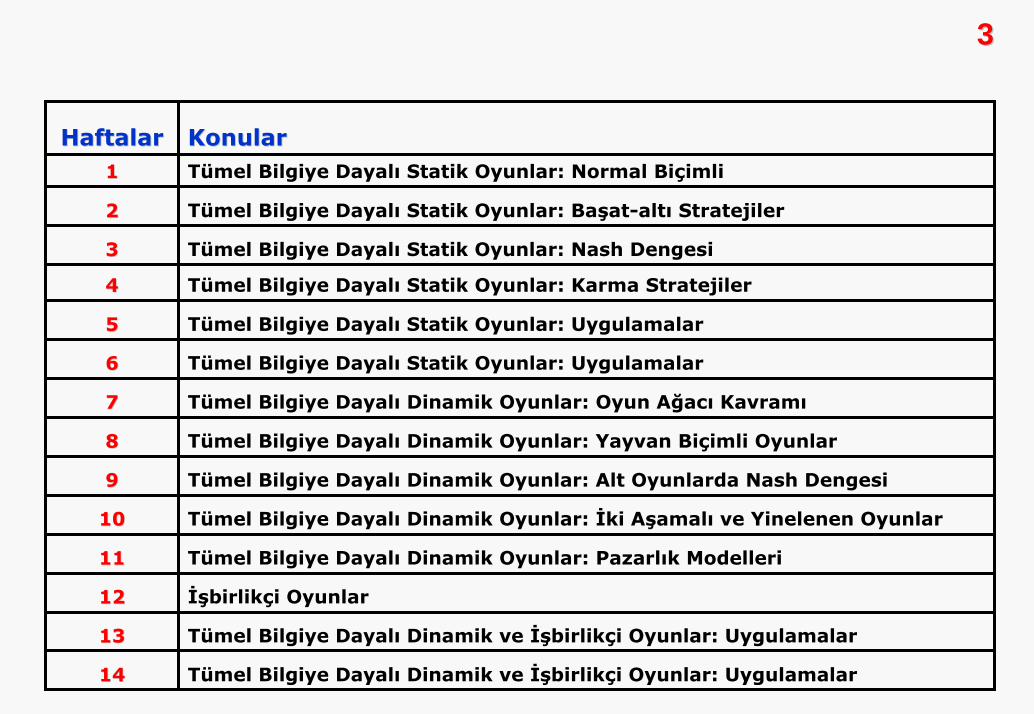
HaftalarHaftalar KonularKonular11 Tümel Bilgiye Dayalı Statik Oyunlar: Normal Biçimli
22 Tümel Bilgiye Dayalı Statik Oyunlar: Başat-altı Stratejiler
33 Tümel Bilgiye Dayalı Statik Oyunlar: Nash Dengesi
44 Tümel Bilgiye Dayalı Statik Oyunlar: Karma Stratejiler
55 Tümel Bilgiye Dayalı Statik Oyunlar: Uygulamalar
66 Tümel Bilgiye Dayalı Statik Oyunlar: Uygulamalar
77 Tümel Bilgiye Dayalı Dinamik Oyunlar: Oyun Ağacı Kavramı
88 Tümel Bilgiye Dayalı Dinamik Oyunlar: Yayvan Biçimli Oyunlar
99 Tümel Bilgiye Dayalı Dinamik Oyunlar: Alt Oyunlarda Nash Dengesi
1010 Tümel Bilgiye Dayalı Dinamik Oyunlar: İki Aşamalı ve Yinelenen Oyunlar
1111 Tümel Bilgiye Dayalı Dinamik Oyunlar: Pazarlık Modelleri
1212 İşbirlikçi Oyunlar
1313 Tümel Bilgiye Dayalı Dinamik ve İşbirlikçi Oyunlar: Uygulamalar
1414 Tümel Bilgiye Dayalı Dinamik ve İşbirlikçi Oyunlar: Uygulamalar

Ders MateryaliDers Materyali
Bu ders için şu yayınlardan yararlanılmıştır.
1. M.J. Osborne, A. Rubinstein, A Course in Game Theory, The
MIT Press, Mass., 1994.
2. Edward T. Dowling, Introduction to Mathematical Economics,
Mc Graw Hill, 1992.
3. A.K. Dixit, B.J. Nalebuff, Stratejik Düşünme, Sabancı Ünv.
Yay., İst., 2003.
4. A.M. Brandenburger, B.J. Nalebuff, Ortaklaşa Rekabet, Scala
Yay., İst., 1998.
44

SSıınavlara navlara İİlilişşkinkin
Yapılması planlanan sınavlar, dekanlıkça belirlenen tarihlerdeki
vize ve final sınavları olmak üzere iki tanedir. Ara sınavın (vize)
%40’ı, yarıyıl sonu (final) sınavının da %60’ı toplanarak başarı
notu belirlenecektir.
İİletiletişşimim
GGöörrüüşşme Gme Güünleri:nleri: Cuma, 10.00 -12.00
I. Blok, Ofis No.221
ee--mail:mail: [email protected]
WEB:WEB: http://idari.cu.edu.tr/sanli
55

TTÜÜMEL BMEL BİİLGLGİİYE YE
DAYALI STATDAYALI STATİİK K
OYUNLAROYUNLAR

Mikro iktisadi analizin bazı konularında ekonomik karar
birimleri, diğer birimlerin davranışlarını dikkate almaksızın
karar verirler. Örneğin fayda teorisinde bireyler faydalarını
maksimize ederlerken, yalnızca veri fiyatlar ve gelir
çerçevesinde, diğer bireylerin kararlarından soyutlanmış olarak
optimal mal seçimini yaparlar.
Benzer şekilde tam rekabetçi ya da monopol piyasalardaki
firma davranışını da söyleyebiliriz.
77

Ancak iktisat biliminde, karar süreçlerinin karşılıklı bağımlılık
içerdiğini gösteren çok sayıda örnek vardır:
1. Duopol piyasada farklılaştırılmış ürün satan iki firma karar
verirken, ürün kalitesini, fiyatı ve reklamı dikkate almalıdır.
2. İki ülke ithalat gümrük oranları, ihracat desteklemeleri gibi
dış ticaret politikalarını belirlemelidirler.
88

3. Bir firma, yöneticilerinin performansını artıracak prim
politikasını belirlemelidir.
Bu örneklerdeki ortak nokta, karşılıklı bağımlılığın varlığıdır. Bir
karar biriminin en iyi seçimi, diğerinin (diğerlerinin) seçimine
bağlıdır.
99

Oyun teorisi, bir karar biriminin kazançlarının, diğerlerinin
kararlarına bağlı olduğu karşılıklı stratejik karar almanın yer
aldığı durumları inceleyen uygulamalı matematiğin bir dalıdır.
Oyunları değişik biçimlerde sınıflandırabiliriz. Bir yaklaşıma
göre statik oyunlarstatik oyunlar ve dinamik oyunlardinamik oyunlar biçiminde bir sınıflama
yapılabilir.
1010

Statik oyunlarStatik oyunlar, veri bir zaman dilimi içerisinde tüm kararların
eşanlı verildiği türden oyunlardır. Yani oyuncular bir kerelik
karar verirler ve oyun sona erer.
Dinamik oyunlarDinamik oyunlar, karar almanın bir dizimselliğe sahip olduğu
türden oyunlardır. Bu anlamda, çok sayıda zaman diliminde
kararlar alınmaktadır.
1111

1212
Statik ve dinamik oyunlar arasındaki farkı daha iyi
anlayabilmek için, Cournot duopol piyasa modelini dikkate
alalım. Temel mikro ders kitaplarında büyük ölçüde statik oyun
çerçevesinde model anlatılmaktadır. Yani her iki firma kendi
kârını maksimize edecek şekilde, aynı anda ve tek üretim kararı
vermektedir.

Ancak bu modeli, firmaların birkaç aşamada karar alarak kârı
maksimize eden üretim düzeylerine ulaştıklarını da düşünerek
inceleyebiliriz. Bu durumda oyun dinamik bir çerçeveye
oturacaktır.
1313

Oyunları, oyuncuların sahip oldukları bilgi açısından da
sınıflayabiliriz. Eğer tüm oyuncular oyunun yapısını tamamıyla
biliyorlarsa, ttüümel bilgi altmel bilgi altıında oyun (nda oyun (complete informationcomplete information) )
dan söz ederiz. Tikel bilgi altTikel bilgi altıında oyunnda oyunda ((incomplete incomplete
informationinformation)) ise, oyunculardan bir kısmı, diğerlerinin sahip
olmadığı özel bir bilgiye sahiptir.
1414

Buna benzeyen, ancak biraz farklı bir başka yaklaşıma göre,
tüm oyuncular karar aşamasından önceki tüm davranışları
biliyorsa, oyun tam bilgiyetam bilgiye ((perfect informationperfect information)) dayalıdır.
Oyunculardan bazıları bunu bilmiyorsa, oyun eksik bilgieksik bilgiye
((imperfect informationimperfect information)) dayalıdır.
1515

Oyunları, sınıflamanın yanında, betimleme ve çözüm yollarını
da sınıflayabiliriz. Bir betimleme yöntemi olan normal binormal biççimim,
stratejiler ve kazançlar üzerine odaklanır. Diğer betimleme
yöntemi olan yayvan (yayvan (extensiveextensive gamegame) bi) biççimim, davranışların ve
kararların dizilimiyle ilgilenir. Her iki biçimde birbirini dışlayan
bir yapıda değildir.
1616

Hangi yöntemin seçileceği, yöntemin kolaylığına ve sezgi
gücüne bağlıdır. Statik oyunlarda daha çok normal biçim,
dinamik oyunlarda da yayvan biçim kullanılmaktadır.
Çözüm yöntemlerine baktığımızda, statik oyunların Nash
dengesi bulunarak çözüldüğünü, dinamik oyunların da ikincil
oyun-mükemmel Nash dengesi üzerine kurulduğunu görebiliriz.
1717

Normal BiNormal Biççimde Oyunlarimde Oyunlar
Her oyunun kendine özgü elemanları ve özelliği vardır. Statik
oyunlarda bu elemanlar, küme ve fonksiyon kavramıyla temsil
edilmektedir. Normal biçimde ifade edilen bir oyunda, bir
oyuncu koyuncu küümesimesi, her bir oyuncu için strateji kstrateji küümesimesi ve her bir
oyuncu için bir kazankazançç fonksiyonufonksiyonu yer alır. Her bir oyuncuyu bir
rakamla gösterebileceğimiz bir oyuncu kümesini şöyle
yazabiliriz: { }1,2, 3, .....,N n=
1818

1919
Her oyuncu, bir strateji kümesine dayanarak karar verir.
Strateji, bir oyunda gerçekleşmesi mümkün olan oyuncu
davranışını tanımlar. Bazı durumlarda strateji kümesi çok
küçük olabilir. Örneğin ya yüksek ya da düşük fiyat uygulama
kararı gibi. Ya da satranç oyunundaki gibi çok sayıda strateji
var olabilir. sij, i. oyuncu için olanaklı j. stratejiyi göstersin. i
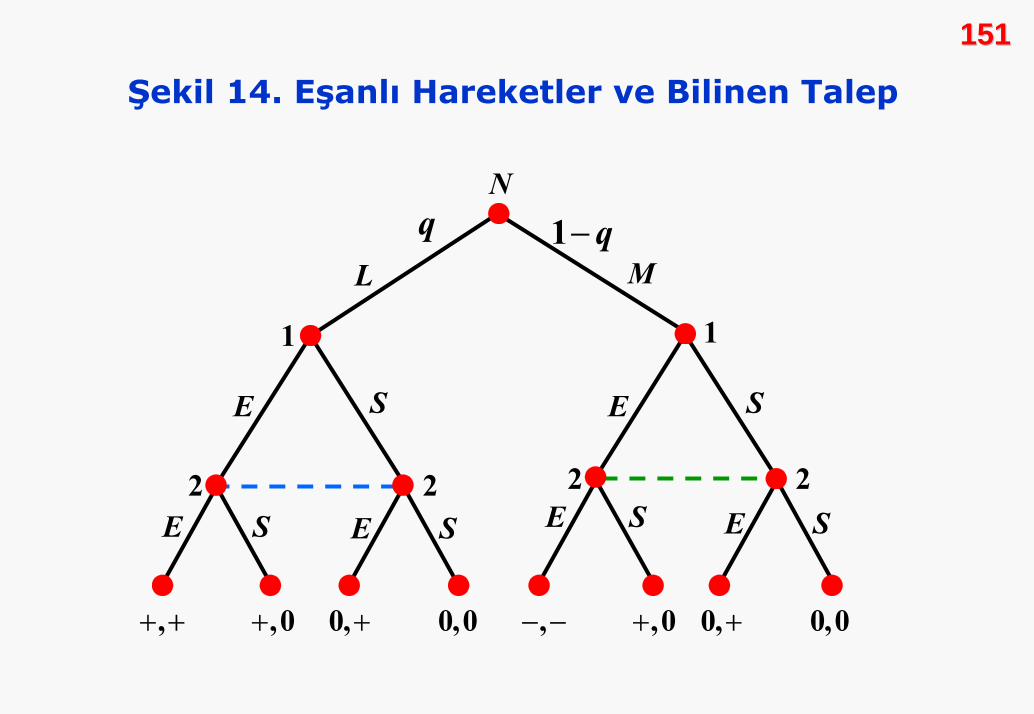
bireyi için tüm olası stratejilerin kümesi:
{ }1 2 3, , , .....,ii i i i itS s s s s=

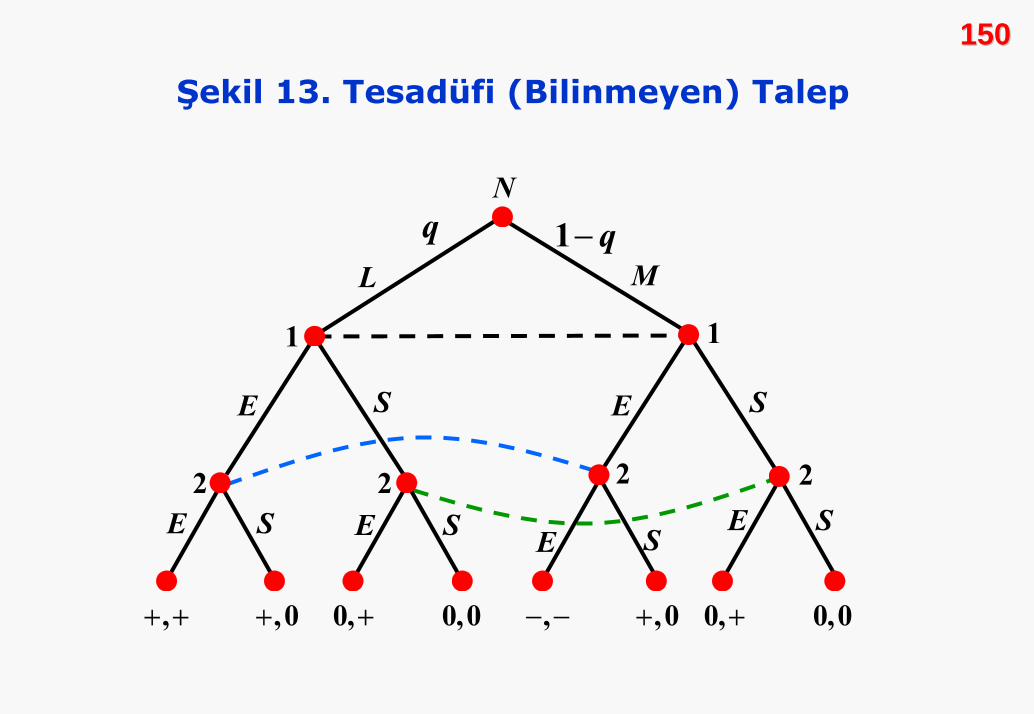
2020Tüm oyuncuların stratejilerinin oluşturduğu küme:
{ }1 2 3, , , ....., nS S S S S=
Son olarak, oyunun sonuç göstergesi olan kazanç
fonksiyonlarını tanımlayalım. Genel olarak bir oyuncunun bir
oyundan elde edeceği kazanç, tüm oyuncuların strateji
seçimlerine bağlıdır. i. birey için kazanç fonksiyonunu yazalım.
{ }1 2 3, , , .....,i i ns s s sΠ = Π

2121
Normal BiNormal Biççimde Oyunlar iimde Oyunlar iççin in ÖÖrneklerrnekler
Firmaların reklam stratejisini seçtikleri bir duopol piyasa
düşünelim. Modelin varsayımları şöyledir:
1. Firmalar ürünlerini sabit (dışsal) bir fiyattan satıyorlar.
2. Reklam, piyasa toplam talep düzeyini etkilememektedir.
3. Firmalar iki reklam düzeyi seçip uygulayabilirler. Yüksek (Y)
ve düşük (D)
4. Firmaların piyasa payları, seçecekleri reklam düzeyine
bağlıdır.

2222
Şimdi bu varsayımları, oyun teorisinin simgeleriyle yazalım. Her
iki oyuncu, ikişer stratejiye sahiptir:
{ }, , 1, 2i Y DS R R i= =
Kazanç matrislerini yazabilmek için bazı ek değişkenlere gerek
var. Π0 endüstrinin kâr düzeyini; mjk , rakip firma k stratejisini
(k=Y , k=D) seçtiğinde, firmanın j stratejisini (j=Y , j=D) seçmesi
durumunda oluşacak piyasa payını göstersin. Değişik reklam
düzeyi seçimlerinde piyasa payı toplamı bire eşittir:
1jk kjm m+ =

2323Dört olası reklam bileşimi vardır. Kazanç fonksiyonu, dört olası
reklam bileşiminin sonuçlarını gösterir. Birinci ve ikinci firma
için kazanç fonksiyonlarını yazalım:
1 0
1 0
1 0
1 0
( , )
( , )
( , )
( , )
Y Y YY Y
Y D YD Y
D Y DY D
D D DD D
R R m R
R R m R
R R m R
R R m R
Π = Π −
Π = Π −
Π = Π −
Π = Π −
2 0
2 0
2 0
2 0
( , )
( , )
( , )
( , )
Y Y YY Y
Y D YD Y
D Y DY D
D D DD D
R R m R
R R m R
R R m R
R R m R
Π = Π −
Π = Π −
Π = Π −
Π = Π −

2424
Şimdi sayısal bir örnek de kullanarak, kazançları matris biçimde
yazalım. Matrisin satır ve sütunları, strateji seçimlerini
gösterecektir. Aşağıdaki değerlere sahip bir piyasa düşünelim.
0 1000 , 400 , 200
1 1 4 1, , ,2 2 5 5
Y D
YY DD YD DY
R R
m m m m
Π = = =
= = = =
Örneğin her iki firma yüksek reklam harcaması yaparsa,
piyasayı yarı yarıya paylaşırlar. Her bir firma 1000 birimlik
endüstri kârının 500’ünü elde eder, reklam harcaması (400)
çıkarıldıktan sonraki net kâr 100’dür.

2525Yukarıda hesapladığımız gibi, diğer kazançları da her bir firma
için hesaplayalım ve kazanç matrisini oluşturalım.
1 0
1 0
1 0
1 0
1( , ) 1000 400 1002
4( , ) 1000 400 4005
1( , ) 1000 200 05
1( , ) 1000 200 3002
Y Y YY Y
Y D YD Y
D Y DY D
D D DD D
R R m R
R R m R
R R m R
R R m R
Π = Π − = − =
Π = Π − = − =
Π = Π − = − =
Π = Π − = − =

2626
2 0
2 0
2 0
2 0
1( , ) 1000 400 1002
4( , ) 1000 400 4005
1( , ) 1000 200 05
1( , ) 1000 200 3002
Y Y YY Y
Y D YD Y
D Y DY D
D D DD D
R R m R
R R m R
R R m R
R R m R
Π = Π − = − =
Π = Π − = − =
Π = Π − = − =
Π = Π − = − =

2727
Firma 2
D YD
Y1 2 1 2
1 2 1 2
( ) , ( ) ( ) , ( )
( ) , ( ) ( ) , ( )
DD DD DY YD
YD DY YY YY
R R R R
R R R R
Π Π Π Π⎡ ⎤⎢ ⎥⎢ ⎥Π Π Π Π⎣ ⎦
Firma 1
Firma 2
300, 300 0,400
400,0 100,100
⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦
D YD
YFirma 1

Şimdi Firma 1’in kararını dikkate alalım. Firma 2 düşük reklam
harcamasını seçtiğinde, Firma 1 düşük reklam harcaması
kararında 300, yüksek harcamada 400 net kâr elde edecektir.
Buna göre, Firma 2’nin düşük reklam harcaması stratejisi
karşısında Firma 1’in en iyi seçimi yüksek harcamadır.
2828

Firma 2 yüksek reklam harcamasını seçtiğinde, Firma 1 düşük
reklam harcaması kararında 0, yüksek harcamada 100 net kâr
elde edecektir. Bu durumda da Firma 1 için en iyi strateji
yüksek reklam harcamasıdır. Benzer durum Firma 2 için de
geçerlidir. Aynı anda her ki firma için de en iyi strateji yüksek
reklam harcamasıdır.
2929

Yukarıdaki örnek oyunun genel biçimi, “tutsaklar atutsaklar aççmazmazıı” dır
(prisonerprisoner’’s dilemmas dilemma). Bu oyunda suç işlemiş olan iki bireyin
suçun itiraf etmesi ile sessiz kalması arasındaki durumlar
incelenmektedir. Mahkumiyet kararları, değişik stratejiler
karşısındaki kazançları oluşturmaktadır. İktisatta oldukça
yaygın olan tutsaklar açmazı biçimindeki oyunlar şu
durumlarda oluşur:
1. Ekonomik karar birimleri işbirliği ve işbirliğinden kaçınma
arasında seçim yaparlarsa.
2. İşbirliği ortak optimalken, işbirliğinden kaçınma bireysel
rasyoneldir.
3030

Duopolda reklam modeli, firmalararası rekabete iyi bir tutsaklar
açmazı örneğidir. Benzer biçimde kamu maliyesi teorisinden
kamusal mallara katkı yapmak (işbirliği) ve bedava
yararlanmak (işbirliğinden kaçınma) örneği verilebilir.
3131

Reklam örneğinde dengeyi şöyle tanımlayabiliriz. (Y,Y) durumu,
diğer firmanın seçimi belirliyken, hiçbir firmanın kendini
seçimini değiştirmek için hiçbir neden olmaması anlamında bir
dengedir. Her bir firma, rakibinin stratejisine en iyi tepkiyi
vermektedir. Bu denge kavramı, Nash DengesiNash Dengesi olarak ifade
edilmektedir.
3232

Kesin BaKesin Başşat Altat Altıı Stratejilerin Yinelemeli Eleme Stratejilerin Yinelemeli Eleme
Yoluyla Yoluyla ÇöÇözzüümmüü
Tutsaklar açmazında olduğu gibi, bazı oyunlarda tüm başat altı
stratejileri eleyerek bir dengeye ulaşılabilir. Eleme işlemi
sürecinin sonunda bir çift strateji kalırsa, bu denge değeridir.
3333

n oyunculu bir oyunda, gibi bir strateji mevcutken aşağıdaki
koşul sağlanıyorsa, i. oyuncu için stratejisinin kesin başat
altı olduğunu söyleyebiliriz.
is′
is′′
3434
( ) ( )1 2 1 2, , ....., , ....., , , ....., , .....,i i n i i ns s s s s s s s′′ ′Π > Π

3535
Yukarıdaki koşul şunu söylemektedir: Daima daha yüksek
kazanç sağlayan başka bir strateji varken, bir strateji başat
altıdır. Buna göre bir strateji karşısında daha egemen bir
stratejinin varlığı yeterlidir.

Rasyonel birey başat-altı stratejiyi seçmeyeceğinden, bunu
karar sürecinde eleyebiliriz. Aslında daha kesin olarak
söylersek, ortak bir rasyonalite varsayımı gereklidir. Bu, tüm
oyuncuların rasyonel olması anlamına gelmemektedir.
Oyuncular, kendileri dışında kalanların dominant-altı stratejiyi
seçmeyeceklerinin farkındadırlar.
3636

3737
Şimdi bu koşulu ve başat-altı stratejilerin elenerek denge
değerlerine ulaşılmasına bir örnek verelim. İki oyuncu ve her
birinin seçebileceği üç strateji olsun. Başlangıçtaki bu duruma
G oyunu diyelim.
2. Oyuncu
3, 3 2,6 3,1
2,4 1,4 0,4
1,5 0, 2 6,0
L C RT
M
B
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu

1. oyuncu için M stratejisi, T stratejisine göre başat altıdır.
Diğer bir ifadeyle, T stratejisi M ’ye başattır. B stratejisinin M
’ye başat olduğunu söyleyemeyiz. 2. oyuncunun L, C, R
stratejisini seçtiği durumlarda, 1. oyuncu için T ve M
stratejilerini kıyaslayalım:
3838

3939
: T, M ’ye kesin başattır.
Şimdi de T ve B stratejilerini kıyaslayalım:
: T, B ’ye kesin başat değildir.3 1 , 2 0 , 3 6> > <
3 2 , 2 1 , 3 0> > >

4040
Kesin başat-altı strateji olan M stratejisini eleyerek oyunu
sürdürelim. Bu yeni oyuna G′ diyelim.
2. Oyuncu
3,3 2,6 3,1
1,5 0,2 6,0
L C RT
B
⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu
Bu durumda 1. oyuncunun hiçbir stratejisi kesin başat değildir.
Ancak 2. oyuncunun stratejilerine bakarsak, hem L hem de C
’nin R ’ye başat olduğunu görürüz. Bu nedenle R stratejisini
eleyebiliriz.

4141
R ’nin elenmesi sonucu oluşan oyuna G″ diyelim.
2. Oyuncu
3,3 2,6
1,5 0,2
L CT
B
⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu

4242
Bu durumda 1. oyuncunun T stratejisi, B ’ye kesin başattır. B ’yi
eledikten sonra, 2. oyuncu için C başat olduğundan L ’yi eleriz.
En sonunda denge değerine (G*) ulaşmış oluruz.
2. Oyuncu
[ ]2,6C
T1. Oyuncu

4343
Nash DengesiNash Dengesi
İktisat bilimindeki çoğu oyunlarda peşi sıra eleme yöntemiyle
denge değerine ulaşmak mümkün değildir. Bu tür durumlarda
daha güçlü bir çözüm yöntemine gerek duyarız. Nash dengesi,
bu aracı sağlar.
Diğer oyuncuların strateji seçimleri belirliyken, hiçbir oyuncu
seçimini değiştirmek için bir neden görmüyorsa, strateji
bileşimi bir Nash dengesidirNash dengesidir. Bu tanımı biçimsel olarak verelim.

4444
n oyuncu için biçiminde bir vektörel strateji seçim kümesi
olsun. Aşağıdaki koşulu sağlayan strateji bileşimi, Nash
dengesidir.
( ) ( )* * * * * * *1 1 1 1, , ....., , ....., , , ....., , .....,i i n i i ns s s s s s s s′Π ≥ Π

4545
Nash dengesinde hiçbir oyuncu stratejisini değiştirmek
istemeyecektir. stratejisi, i. oyuncu için var olan stratejilerin
içinde daha iyisidir. Zayıf eşitsizlik, en az stratejisi kadar iyi
oyunların da olabileceğini ifade etmektedir. Ayrıca bir oyuncu
için aynı anda birden çok strateji vektörü Nash dengesini
sağlayabilir.
*is
*is

4646
Yinelemeli eleme yöntemi ile Nash dengesi arasındaki bağı şu
iki teoremle kurabiliriz:
Teorem 1:Teorem 1: Başat-altı stratejiler eleme yöntemiyle bir denge
değerine ulaşabiliniyorsa, bu değer aynı zamanda oyunun tek
Nash dengesidir.

4747
Teorem 2:Teorem 2: Herhangi bir Nash dengesi, kesin başat-altı strateji
eleme yöntemine de olanak sağlar.
Burada dikkat edilmesi gereken nokta şudur: Ne eleme yöntemi
Nash dengesinin bir parçası olabilir ne de Nash dengesi bir
eleme yöntemi çözümü değildir.

4848
Nash dengesini anlatmanın bir başka yolu, en iyi tepki en iyi tepki
fonksiyonudurfonksiyonudur. Bu yöntem özellikle strateji kümesi sürekli
biçimdeyse yararlı olur. Örneğin iki oyunculu bir oyunda, 2.
oyuncunun her seçimi karşısında 1. oyuncu için en iyi olan
stratejiyi seçeriz. 2. oyuncunun stratejisi biliniyorken, aşağı-
daki problemi çözerek en iyi tepkiyi belirleriz.
( )1 1 2max ,s sΠ

Bu problemi maksimizasyon için gereken birinci ve ikinci sıra
koşulları elde ederek ve sınayarak çözebiliriz. Kazanç
fonksiyonları, türev alma yoluyla belirlenmiş olacaktır. Birinci
sıra koşuldan elde edilen en iyi tepki fonksiyonlarının eşanlı
çözümünden, denge değerlerine ulaşılır.
4949

5050Nash Dengesine Nash Dengesine ÖÖrneklerrnekler
Aşağıdaki iki oyunculu örneği dikkate alalım.
2. Oyuncu
3,3 2,1 3,1
2,4 2,4 0,4
1,5 0,2 6,5
L C RT
M
B
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu

Bu matriste hiçbir oyuncunun kesin başat-altı stratejisinin
bulunmadığına dikkat edin. Dolayısıyla çözüm yöntemi olarak
en iyi tepki yoluyla Nash dengesinin belirlenmesi olacaktır.
1. oyuncunun en iyi tepkilerini 2. oyuncunun seçimi belirliyken
bulacağız. Aşağıdaki matriste altı çizgili mavi değerler, 1.
oyuncunun en iyi strateji seçimlerini göstermektedir. Örneğin
2. oyuncunun seçimi L stratejisiyken, 1. oyuncunun seçebilece-
ği en iyi strateji T ’dir.
5151

5252
2. Oyuncu
, 3 ,1 3,1
2,4 ,4 0,4
1,5 0,2 ,5
3 2
2
6
L C RT
M
B
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu
Yukarıdakine benzer biçimde, 2. oyuncu için de en iyi tepkileri
belirleriz (altı çizgili kırmızı seçenekler). Aynı anda her iki
oyuncunun birden en iyi seçiminin oluştuğu strateji, Nash
dengesini verecektir.

5353
Aşağıdaki kazanç matrisi, 2. oyuncunun da seçimlerini
içermektedir. Her iki oyuncuya en iyiyi sağlayan (T,L), (M,C) ve
(B,R) stratejileri Nash dengesini göstermektedir.
2. Oyuncu
, ,1 3,1
2, , 0,
1, 0,
3 2
2
6
3
4 4 4
5 52 ,
L C RT
M
B
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu

5454
Şimdi iki oyunculu sürekli biçimdeki bir oyunu inceleyelim. Her
bir oyuncu için strateji kümesinin şöyle olduğunu varsayalım:
{ }: 0i i iS s s= ≥
Bunun anlamı şudur: Her bir oyuncu strateji değişkeninin
negatif olmayan düzeyini seçmelidir. Örneğin iktisatta miktar,
fiyat, tüketim gibi değişkenlerin seçimi negatif değerler alamaz.

5555
1. ve 2. oyuncunun kazanç fonksiyonlarının şu şekilde bildiğini
varsayalım.
21 1 1 1 2 1
22 2 2 1 2 2
10 3
10 2
s s s s s
s s s s s
Π = − − −
Π = − − −
Oyun sürekli biçimde olduğundan, kazanç matrisini önceki
örnekteki gibi oluşturamayız. Bunun yerine, her ki kazancı da
aynı anda maksimize edecek olan s1 ve s2 değerlerini ararız.

5656
( ) ( )
1 21 2 2 1
1 2
1 1 2 2 2 2 1 1
10 2 3 , 10 2 2
1 1( ) 7 , ( ) 82 2
s s s ss s
s R s s s R s s
∂Π ∂Π= − − − = − − −
∂ ∂
= = − = = −
En iyi tepki fonksiyonları
* *1 22 , 3s s= =
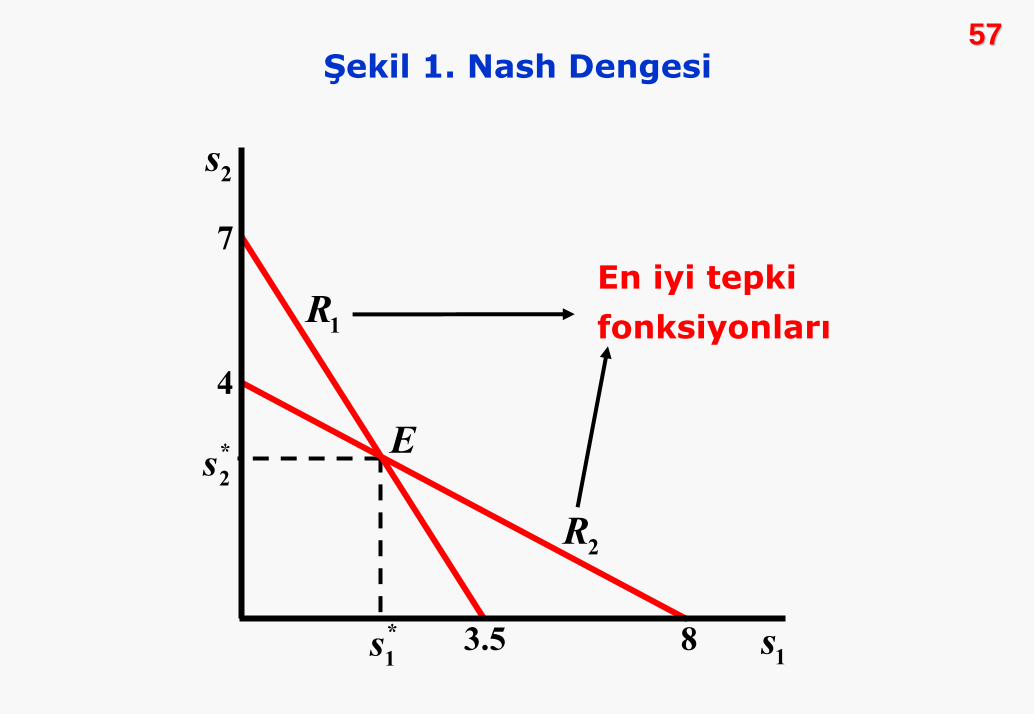
5757Şekil 1. Nash Dengesi
1s
2s
7
4
3.5 8
E
2R
1R
*1s
*2s
En iyi tepki
fonksiyonları

5858
Karma Stratejilere GiriKarma Stratejilere Girişş
Tüm oyunlar, her bir oyuncunun %100 olasılıkla yalnızca tek
strateji seçtiği bir safsaf--strateji Nash dengesistrateji Nash dengesi biçiminde değildir.
Bazı iktisadi uygulamalarda oyuncular, olanaklı saf stratejileri
tesadüfi (olasılıklara dayalı) seçerler. Bu tür oyunlar karma karma
stratejiyestratejiye sahiptir.

5959
Şimdi her bir oyuncunun m kadar saf stratejiye sahip olduğu,
iki oyunculu, sürekli olmayan bir durum düşünelim. sij, i. oyuncu
için j. stratejiyi göstersin. Bir karma stratejikarma strateji, i. oyuncunun her
bir olanaklı saf stratejiyi oynayacağı olasılığı tanımlamaktadır.

6060
pj, 1. oyuncunun saf j stratejisini seçme olasılığını; qk, 2.
oyuncunun saf k stratejisini seçme olasılığını; p ve q da olasılık
vektörlerini göstersin. 1. ve 2. oyuncular için karma strateji
kümesini şöyle yazabiliriz:
11
21
p : 0 1 , 1
q : 0 1 , 1
m
j jj
m
k kk
S p p
S q q
=
=
⎧ ⎫= ≤ ≤ =⎨ ⎬⎩ ⎭
⎧ ⎫= ≤ ≤ =⎨ ⎬⎩ ⎭
∑
∑

6161
Bir saf strateji, karma stratejinin alt kümesidir. sij saf stratejisi,
ve olduğunda karma stratejiye özdeştir.
Karma stratejili Nash dengesini nitelendirebilmek için,
oyuncuların kazanç matrisinin beklenen değerlerini
hesaplamamız gerekir. 1. oyuncu j , 2. oyuncu da k saf strateji-
lerini seçtiklerinde i. oyuncunun kazancının Πijk olduğunu kabul
edelim.
1jp = 0 ( )ip i j= ≠

6262
i. oyuncunun beklenen kazancı, ortaya çıkacak her bir sonucun
kazancı ile bu sonucun çıkma olasılığının çarpımının toplamına
eşittir:
( )1 1 1 111 1 2 112 1 11
2 1 121 2 2 122 1 12
1 1 1 2 1 2 1
.....
.....
.....
m m
m m
m m m m m m mm
E p q p q p q
p q p q p q
p q p q p q
Π = Π + Π + + Π
+ Π + Π + + Π
+ Π + Π + + Π

6363
Bunu kısaltılmış (toplama) simgeleri kullanarak yeniden
yazalım:
( )1 11 1
m m
j k jkj k
E p q= =
Π = Π∑∑
Şimdi tanım olarak Karma Strateji Nash Dengesini yazalım.

6464
Aşağıdaki koşullar sağlanırsa, p* ve q* olasılık vektörleri Nash
dengesidir.
* * *1 1
1 1 1 1
* * *2 2
1 1 1 1
m m m m
j k jk j k jkj k j k
m m m m
j k jk j k jkj k j k
p q p q
p q p q
= = = =
= = = =
′Π ≥ Π
′Π ≥ Π
∑∑ ∑∑
∑∑ ∑∑
Diğer bir ifadeyle bu iki koşul, daha yüksek kazanç sağlayan
karma strateji mevcut değilse, p* ve q* vektörlerinin Nash
dengesi olduğunu söylemektedir.

6565
Teorem 3:Teorem 3: Sonlu sayıda saf strateji kümesine sahip her n
oyunculu oyun, en azından bir saf ya da karma strateji Nash
dengesine sahiptir.
Bu teorem, her oyunun bir çözümü olacağını garanti
etmektedir. Şimdi iki oyunculu ve iki stratejili bir oyunu dikkate
alalım. Bunun kazanç matrisi aşağıda verilmiştir.

66662. Oyuncu
, ,
, ,
L RT A a B b
B C c D d
⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu
Bu oyunda her bir oyuncu bir olasılığı seçmektedir. Strateji 1 p
olasılığı ile oynanırsa, strateji 2 (1-p) stratejisiyle oynanacaktır.
Buna göre 1. oyuncunun beklenen (olasılıklı) kazanç matrisini
yazalım:
( )1 (1 ) (1 ) (1 )(1 )E pqA p q B p qC p q DΠ = + − + − + − −

6767Şimdi kazanç matrisinin p ’ye göre türevini alalım.
( )1 (1 ) (1 )E
qA q B qC q Dp
∂ Π= + − + − − −
∂
Bu sonuca göre, türevde p yer almadığından, 1. oyuncu türevin
işaretini belirleyemez. Türev pozitif ise, p ’deki artış, 1.
oyuncunun kazancının beklenen değerini artırır. Bu nedenle 1.
oyuncu en yüksek p değeri olan 1’i seçmelidir. Bu saf strateji
anlamına gelir. Türevin işareti negatifse, 1. oyuncunun en
uygun seçimi p=0 ‘dır. Böyle bir durum, 2. oyuncu için saf
strateji seçimi anlamına gelir.

6868
Türev sıfıra eşitse, tüm p düzeylerinde 1. oyuncunun kazancı
aynıdır. Bu nedenle 1. oyuncu tüm karma strateji seçimleri
karşısında kayıtsızdır ve dengeyi göstermektedir. Karma
stratejinin çözümünü bulmak için, yukarıdaki süreci 2. oyuncu
içinde yaparız.
( )
( )
2
2
(1 ) (1 ) (1 )(1 )
(1 ) (1 )
E pqa p q b p qc p q d
Epa pb p c p d
q
Π = + − + − + − −
∂ Π= + + − − −
∂

6969
Her ikisi için aynı anda denge, birinci türevlerin sıfıra
eşitlenmesi ve p ile q değerlerinin çözülmesiyle belirlenir.
( )
( )
1
2
* *
(1 ) (1 ) 0
(1 ) (1 ) 0
,
EqA q B qC q D
p
Epa pb p c p d
q
d c D Bp qa b c d A B C D
∂ Π= + − + − − − =
∂
∂ Π= + + − − − =
∂
− −= =
− − + − − +

7070Yukarıdaki oyuna sayısal bir örnek verelim. Aşağıdaki oyunu
inceleyelim.
3,1 2,4
2,2 3,1
L RT
B
⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦
2. Oyuncu
1. Oyuncu
Dikkat edilirse bu oyunun saf strateji Nash dengesi yoktur.
Ancak teorem 3, karma stratejili bir Nash dengesinin elde
edilebileceğini söylemektedir. Çözüme ulaşabilmek için ilk
olarak her iki oyuncuya ait beklenen kazanç fonksiyonlarını
yazalım.
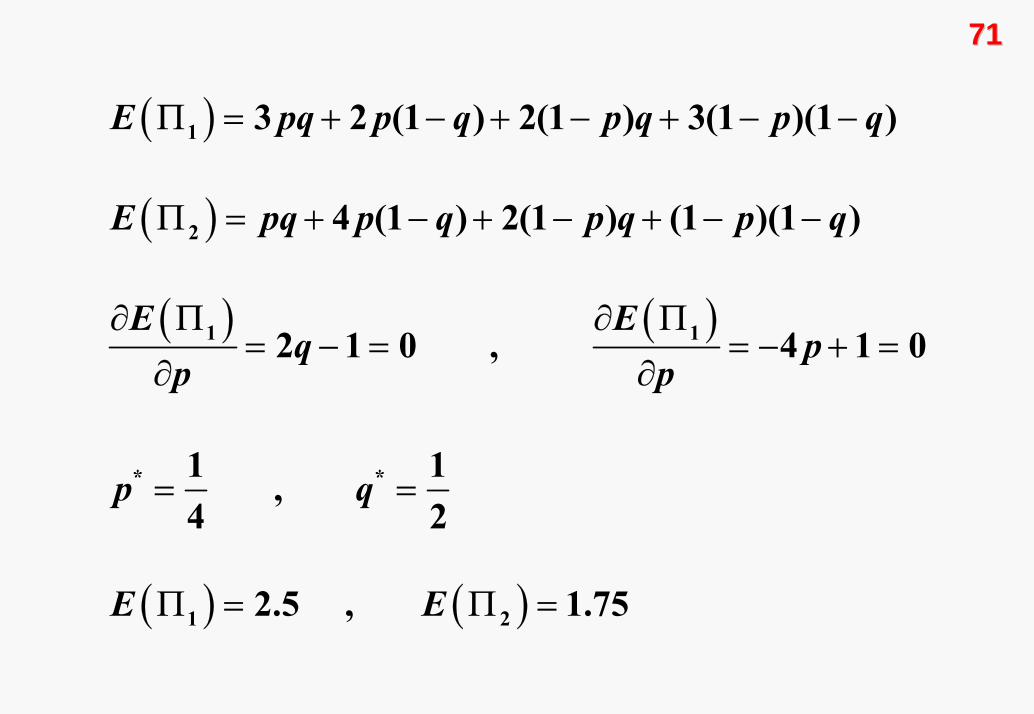
7171
( )
( )
( ) ( )
( ) ( )
1
2
1 1
* *
1 2
3 2 (1 ) 2(1 ) 3(1 )(1 )
4 (1 ) 2(1 ) (1 )(1 )
2 1 0 , 4 1 0
1 1,4 2
2.5 , 1.75
E pq p q p q p q
E pq p q p q p q
E Eq p
p p
p q
E E
Π = + − + − + − −
Π = + − + − + − −
∂ Π ∂ Π= − = = − + =
∂ ∂
= =
Π = Π =

7272
DoDoğğal Tekel Yatal Tekel Yatıırrıım Oyunum Oyunu
Bir piyasada doğal tekel oluşmasının ana nedeni, yalnızca bir
firmanın ekonomik kâr elde edebilecek kadar piyasa ölçeğinin
büyük olmasıdır. Piyasa ölçeği, hem talep düzeyine hem de
firma maliyet düzeyine bağlıdır. Aşağıdaki Şekil 2, bir doğal
tekeli göstermektedir. ½D talep eğrisi, iki firmalı bir durumda,
her iki firmanın da zarar edeceğine dikkat çekmektedir.

7373
Şimdi iki firmalı bir durumu dikkate alalım. Ancak bu iki firma
yeni bir ürün geliştirmek, fabrika binası kurmak gibi bir alanda
ortak yatırım kararı almış olsunlar.
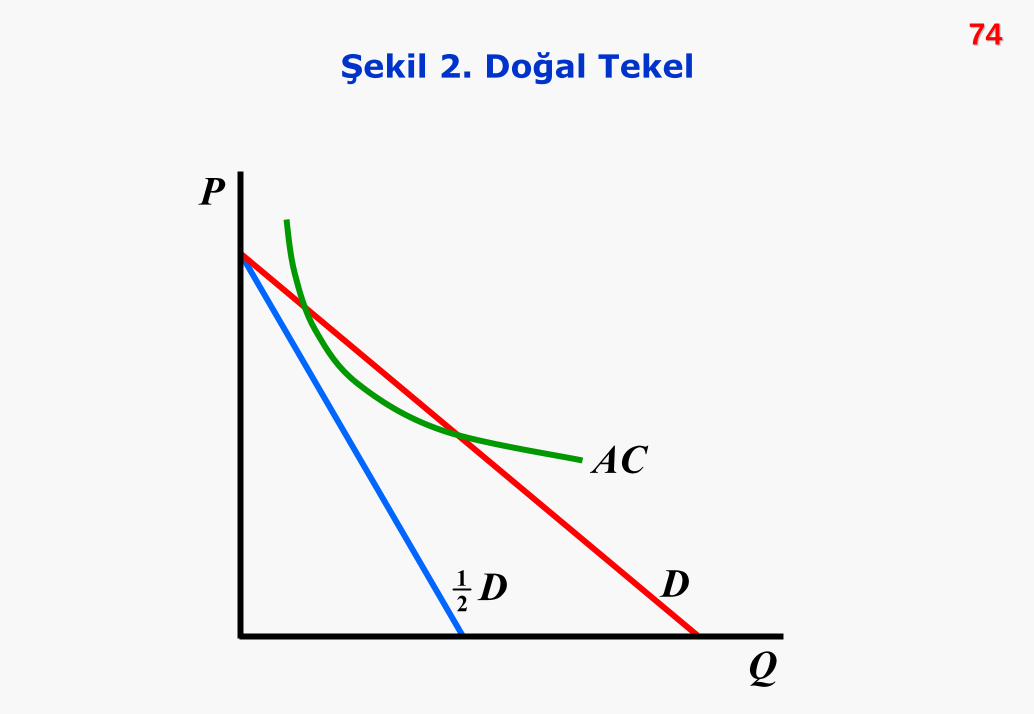
7474Şekil 2. Doğal Tekel
P
Q
AC
D12 D

7575
Bu durumda her bir firmanın karşısında iki strateji vardır:
1.Firmanın piyasaya girişine olanak sağlayan bir yatırım
kararının verilmesi: E
2.Yatırım kararından vazgeçilmesi ve piyasadan uzak kalmak: S
Piyasaya bir firma girerse pozitif bir kâr elde edecek: Π>0; iki
firma girerse, zarar elde edecekler: -L<0.
Buna göre kazanç matrisi:

76762. Oyuncu
, ,0
0, 0,0
E SE L L
S
− − Π⎡ ⎤⎢ ⎥⎢ ⎥Π⎣ ⎦
1. Oyuncu
İlk çözüm denemesi olarak başat altı strateji eleme yöntemine
baktığımızda, hiçbir firmanın başat altı stratejiye sahip
olmadığını görebiliriz. Ancak her iki firma açısından birer saf
strateji Nash dengesi vardır: (E,S) ve (S,E). Bunun dışında
oyunda bir de karma strateji dengesi vardır. Bunu
belirleyebilmek için, beklenen kazanç fonksiyonlarını yazarak
başlayalım.
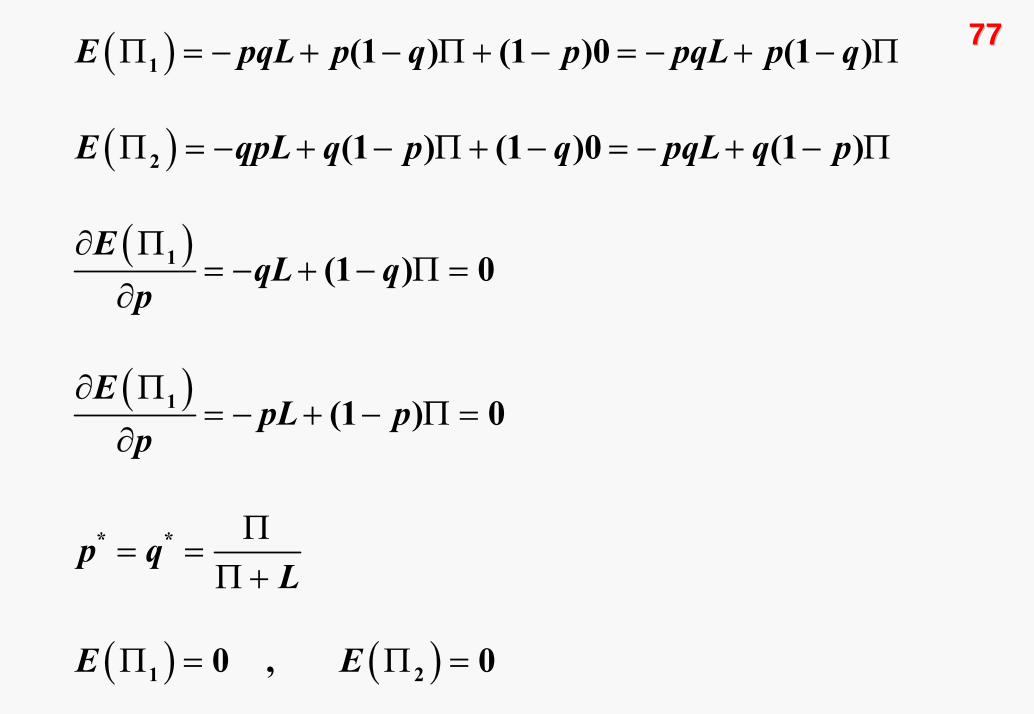
7777( )
( )
( )
( )
( ) ( )
1
2
1
1
* *
1 2
(1 ) (1 )0 (1 )
(1 ) (1 )0 (1 )
(1 ) 0
(1 ) 0
0 , 0
E pqL p q p pqL p q
E qpL q p q pqL q p
EqL q
p
EpL p
p
p qL
E E
Π = − + − Π + − = − + − Π
Π = − + − Π + − = − + − Π
∂ Π= − + − Π =
∂
∂ Π= − + − Π =
∂
Π= =
Π +
Π = Π =

7878
Yukarıdaki sonucun anlamı şudur: Eğer piyasaya giriş yüksek
kârlar ya da düşük zararlar nedeniyle çok cazipse, firma giriş
olasılığını artırır. Ancak giriş olasılığının artması, giriş
cazibesini azaltacağı için kârlar sıfırlanır.

7979Cournot Duopol ModeliCournot Duopol Modeli
Cournot modelinde bir firmanın stratejisi, çıktı miktarının
seçimidir. i. firma için strateji kümesini yazalım.
{ }: 0i i iS q q= ≥
Buna göre, firmanın strateji uzayı, negatif olmayan tüm çıktı
kümesidir. Aşağıdaki talep ve maliyet fonksiyonlarına göre,
kazanç fonksiyonu şöyle oluşacaktır:

8080( )
( ) [ ] ( )
( )1
, i
i i i i i
n
i j i ij
P a bQ TC c t q
Pq c t q a bQ q c t q
a b q q c t q=
= − = +
Π = − + = − − +
⎡ ⎤Π = − − +⎢ ⎥
⎣ ⎦∑
Diğer firmaların strateji seçimi belirliyken, i. firma en iyi tepki
fonksiyonuna sahip olacaktır. En iyi tepki fonksiyonlarını
bulabilmek için, diğer firmaların stratejileri sabitken kârı
maksimize ederiz.
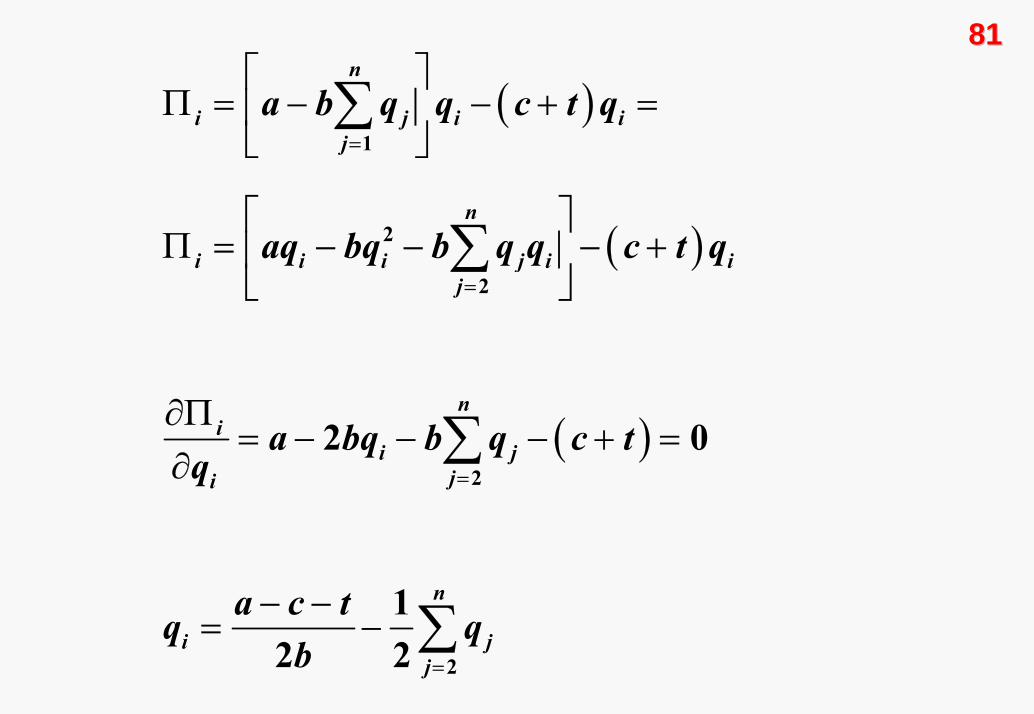
( )
( )
( )
1
2
2
2
2
2 0
12 2
n
i j i ij
n
i i i j i ij
ni
i jji
n
i jj
a b q q c t q
aq bq b q q c t q
a bq b q c tq
a c tq qb
=
=
=
=
⎡ ⎤Π = − − + =⎢ ⎥
⎣ ⎦
⎡ ⎤Π = − − − +⎢ ⎥
⎣ ⎦
∂Π= − − − + =
∂
− −= −
∑
∑
∑
∑
8181

8282
Nash dengesi, n tane en iyi tepki fonksiyonunun eşanlı
çözümüyle elde edilir. Her bir firmanın oynayacağı Nash denge
stratejisi (optimal üretim düzeyi) :
*
( 1)ia c tqn b− −
=+
Nash denge stratejisini, her bir firmanın kazanç
fonksiyonundaki yerine yazarak, denge kazanç değerlerini
hesaplayabiliriz.
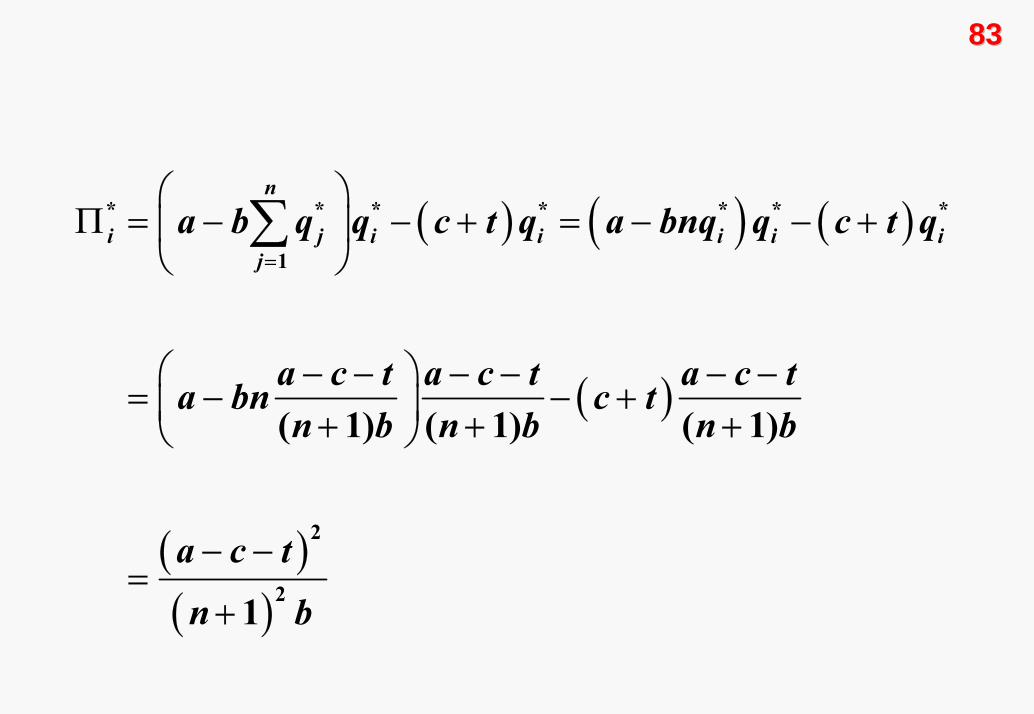
8383
( ) ( ) ( )
( )
( )( )
* * * * * * *
1
2
2
( 1) ( 1) ( 1)
1
n
i j i i i i ij
a b q q c t q a bnq q c t q
a c t a c t a c ta bn c tn b n b n b
a c t
n b
=
⎛ ⎞Π = − − + = − − +⎜ ⎟
⎝ ⎠
⎛ ⎞− − − − − −= − − +⎜ ⎟+ + +⎝ ⎠
− −=
+
∑

8484
Bu çözüm, her bir firmanın, diğer firmaların üretim düzeyi
sabitken karar aldığı biçimindeki Cournot varsayımı üzerine
kuruludur. Bu nedenle denge, literatürde Cournot-Nash dengesi
olarak anılmaktadır.

8585
Bertrand Duopol ModeliBertrand Duopol Modeli
Cournot duopol modeli firmaların strateji seçimini üretim
miktarı üzerine oturtmaktadır. Cournot’un makalesinden 45 yıl
sonra Joseph Bertrand, aksak rekabet nedeniyle firmaların
üretim belirlemek yerine, fiyat stratejisine göre hareket
edeceklerini öne sürmüştür. Bertrand’ın bu yaklaşımı, piyasa
dengesi üzerinde Cournot’ya göre önemli bir farklılık
yaratmaktadır.

8686
Bertrand modeli (Cournot modelindeki gibi) ürünü homojen
varsaymıştır. Ancak firmalar fiyat farklılaştırmasına gitmek-
tedirler. Ürünler homojen olduğundan, tüketiciler ucuz malı
alacak, yüksek fiyattan satan firmanın satış miktarı sıfır
olacaktır. Bertrand modelinde firmalar fiyat stratejisi seçerler.
i. firma için strateji kümesini yazalım.
{ }: 0i i iS p p= ≥

8787
Kazanç fonksiyonlarını yazabilmek için, piyasa talep
fonksiyonuna ihtiyaç duyarız. İlk olarak fiyat değişkenini
tanımlayalım:
1 2min( , )p p p=
Piyasa talep fonksiyonu:
( )Q Q p=

8888
Bireysel firma için talep miktarı üç olasılığa sahiptir. Örneğin i.
firma için bu üç olasılığı yazalım:
( )
( )2
0
i j i
i j i
i j i
p p q Q p
Q pp p q
p p q
< ⇒ =
= ⇒ =
> ⇒ =

8989
Her iki firmanın da aynı marjinal maliyetle (c) çalıştığını
varsayalım. i. firmanın kâr fonksiyonu:
12
( ) ( )
( ) ( )
0
i j i i i i
i j i i i i
i j i
p p p Q p cQ p
p p p Q p cQ p
p p
< ⇒ Π = −
= ⇒ Π = −⎡ ⎤⎣ ⎦
> ⇒ Π =

Kâr fonksiyonu süreksiz biçimde olduğundan en iyi tepki
fonksiyonlarını türev yoluyla elde edemeyiz. Nash dengesini,
tüm olası sonuç uzayı içinde arayacağız. Potansiyel denge, her
iki firmanın da tüm pozitif fiyat bileşimlerini içerir. Uygulanacak
fiyat, tekelci fiyattan (pm) küçük, marjinal maliyetten (c) büyük
olamaz. Diğer olasılıklar, aşağıdaki Şekil 3’de L biçimindeki
mavi alanla belirtilmiştir.
9090
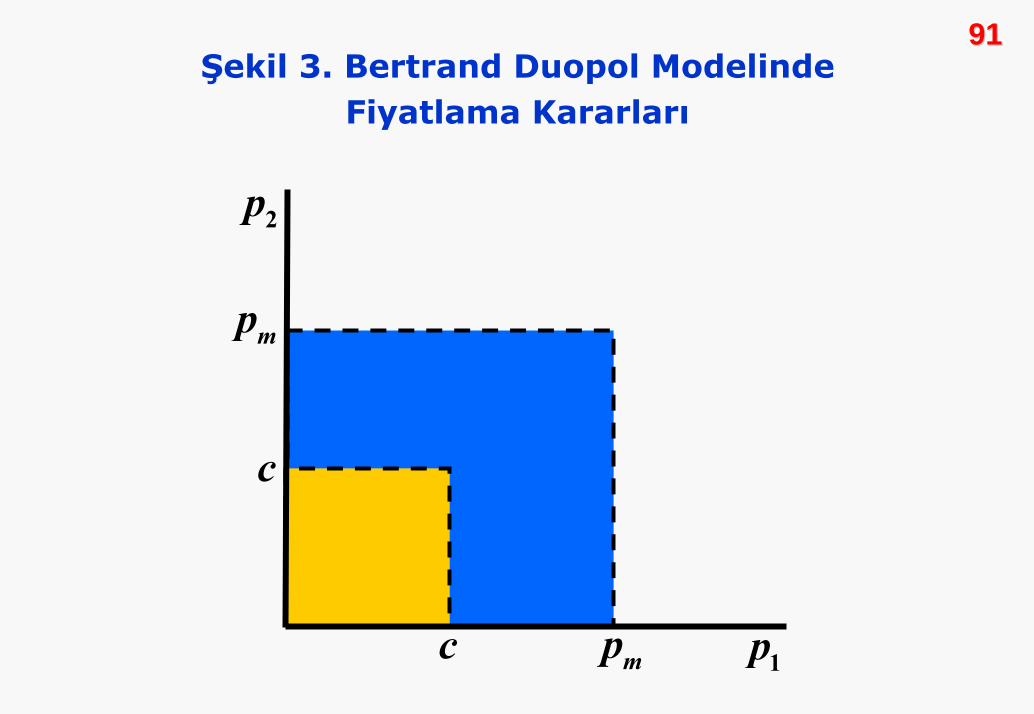
9191Şekil 3. Bertrand Duopol Modelinde
Fiyatlama Kararları
2p
1pmp
mp
c
c

İki tür denge durumunu dışarıda bırakarak modelin çözümünü
yaparız. Birincisi, pozitif kâr sonuçları denge değildir. Her iki
firmanın fiyatı eşitse, bir firma çok küçük bir fiyat indirimiyle
piyasanın tamamını eline geçirir ve iki kat kâr elde eder.
Fiyatlar eşit değilse, yüksek fiyatlı firma, diğer firma fiyatının
biraz altına fiyatı çekerek sıfır kârdan pozitif kâra geçebilir. Bu
nedenle, pozitif kâr Nash dengesi için gereken koşulu
sağlayamaz.
9292

Denge, her iki firmanın da sıfır kâr elde etmesini
gerektirmektedir. Yani düşük fiyat uygulayan firma, marjinal
maliyete eşit bir fiyatlama yapmalıdır. Yüksek fiyat uygulayan
firma marjinal maliyetten yüksek bir fiyatlama yapsaydı,
marjinal maliyetten büyük, pozitif kâr elde etmiş olan ilk
firmanın yüksek fiyatından küçük bir fiyat aralığı oluşurdu. Bu
nedenle, Nash dengesi olmaya aday tek olası durum şudur:
9393
* * * *1 1 1 1, 0p p c= = Π = Π =

Bunun bir denge olduğunu görebilmek için, bir firma fiyatını
düşürdüğünde negatif kâr elde edeceğini, fiyatını yükselttiğinde
de sıfır düzeyinde kalacağına dikkat edelim. Nash dengesi,
dengedeki stratejiden daha yüksek bir kazanç sağlayan strateji
çiftinin olmamasını gerektirmektedir.
Görüldüğü gibi Bertrand-Nash dengesi, Cournot-Nash
dengesinden çok farklıdır. Şimdi de ürün farklılaştırması altında
Bertrand modelini inceleyelim.
9494

9595
ÜÜrrüün Farkln Farklıılalaşşttıırmasrmasıı
Ürün farklılaştırması varsa, düşük ve yüksek fiyat stratejisi
önemini yitirir. i. firmanın üretiminin, fiyatın doğrusal bir
fonksiyonu olduğunu varsayalım:
, 0 1i i jq a p bp b= − + < <

9696
Her iki firma için de marjinal maliyetin sabit ve aynı (c)
olduğunu varsayıyoruz. i. firmanın kâr fonksiyonu:
( ) ( ) ( )i i i i i i i i jp q cq p c q p c a p bpΠ = − = − = − − +
Maksimizasyon birinci sıra koşulu oluşturalım ve buradan en iyi
tepki fonksiyonunu bulalım.
2 02 2
ii j i j
i
a c ba p bp c p pp
∂Π + ⎛ ⎞= − + + = → = + ⎜ ⎟∂ ⎝ ⎠

Her iki firmaya ait tepki fonksiyonları aşağıdaki Şekil 4’de
gösterilmiştir. a>c olduğundan, her iki firma fiyatı, marjinal
maliyetten büyüktür. Ayrıca tepki fonksiyonları, Cournot
modelindekinin tersine, pozitif eğimlidir. Her bir firma rakibinin
fiyat artışına, kendi fiyatını artırarak tepki veriyor. Fiyatlama
stratejisi, piyasa payına da değil, kârı korumaya yöneliktir.
9797
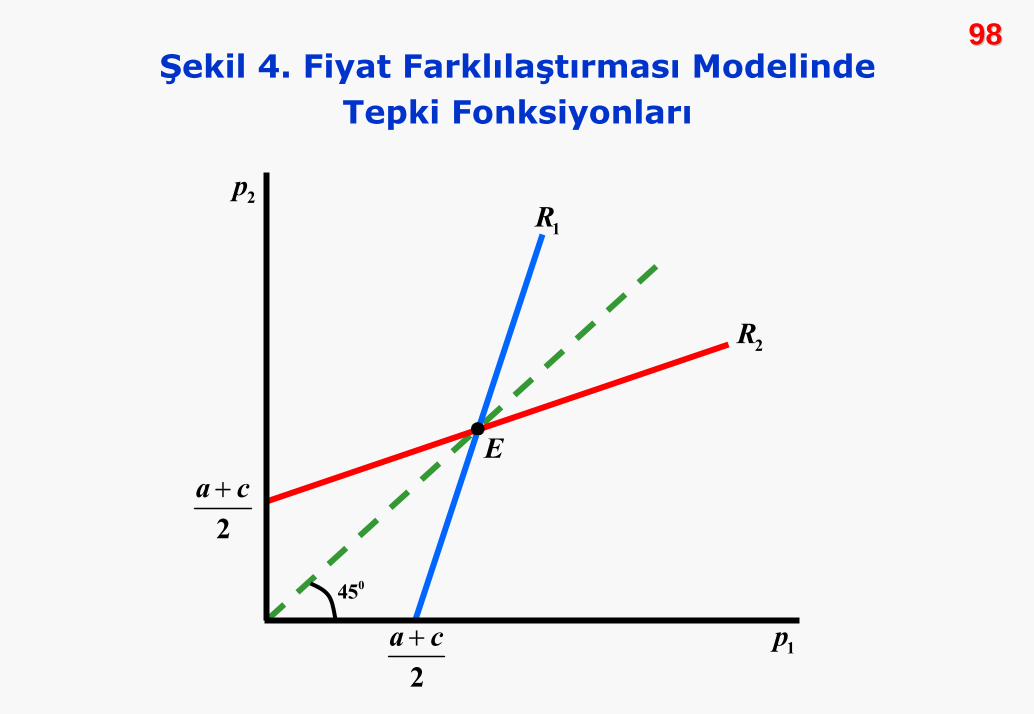
9898Şekil 4. Fiyat Farklılaştırması Modelinde
Tepki Fonksiyonları
045
1R
2R
E
2p
1p
2a c+
2a c+

9999
Birinci sıra koşullardan elde ettiğimiz tepki fonksiyonlarını
eşanlı olarak çözersek, denge fiyatlarını elde ederiz.
1 2 2 1
* *1 2
,2 2 2 2
2
a c b a c bp p p p
a cp pb
+ +⎛ ⎞ ⎛ ⎞= + = +⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
+= =
−

100100Rant Kollama DavranRant Kollama Davranışıışı
Bu uygulamada, belirli miktardaki bir iktisadi pastanın,
rekabetçi çerçevede paylaşımını inceleyeceğiz. Bazı durumlarda
iktisadi karar birimleri ranttan pay alabilmek için rekabetçi
davranış sergilerler. Örneğin vergi indirimlerini ya da gümrük
koruma oranlarının düşürülmesini isteyen sanayi lobilerinin bu
davranışı birer rant kollama davranışıdır.

101101
Bu türden rantlar elde edebilmek için, girişimciler bir de
harcamaya katlanırlar. Elde edilecek rantın büyüklüğü, bunun
için yapılacak harcamaya bağlıdır. Rant kollama davranışı
bireysel olarak rasyonel olmakla birlikte, tüm oyuncular
açısından kazanç azaltıcıdır.

İlk olarak iki oyunculu bir modeli dikkate alalım, daha sonra
bunu n oyunculu duruma genelleştirelim.
R kadar bir iktisadi rantı paylaşan iki oyuncu varsayalım. Her
bir oyuncu ranttan pay alabilmek için belirli bir harcama da
yapmaktadır. Sırasıyla x1 ve x2 birinci ve ikinci oyuncunun bu
harcamasını göstersin. Her bir oyuncunun ranttan alacağı pay,
rant için yapılan toplam harcamadaki harcama payına eşit
olsun:
ii
i j
xs
x x=
+
102102

103103i. oyuncunun kazanç fonksiyonu:
ii i i i
i j
xs R x R x
x x⎛ ⎞
Π = − = −⎜ ⎟⎜ ⎟+⎝ ⎠
Birinci sıra koşul:
( )( )2 1 0i j ii
i j ji i j
x x xR x x R x
x x x
⎛ ⎞+ −∂Π ⎜ ⎟= − = → = −⎜ ⎟∂ +⎝ ⎠

104104
Oyuncular simetrik olduğundan, harcama düzeyleri dengede
eşit olacaktır.
*
4Rx xR x x= − → =
Aşağıdaki Şekil 5, oyuncuların en iyi tepki fonksiyonlarını ve
dengeyi göstermektedir. Tepki fonksiyonlarının doğrusal
olmadığına dikkat edelim.

Bunu yorumlayabilmek için 2. oyuncuyu dikkate alalım. Tepki
eğrisinin pozitif eğime sahip bölümünde 2. oyuncu rantın
yarısından çoğunu alır. Eğrinin negatif eğimli bölümünde ise,
bunun tersi geçerlidir. Dengede toplam rantların yarısı, iki
oyuncu arasında eşit paylaşılmıştır. Geri kalan yarı ise, verimsiz
rant harcamasına gitmiştir.
105105
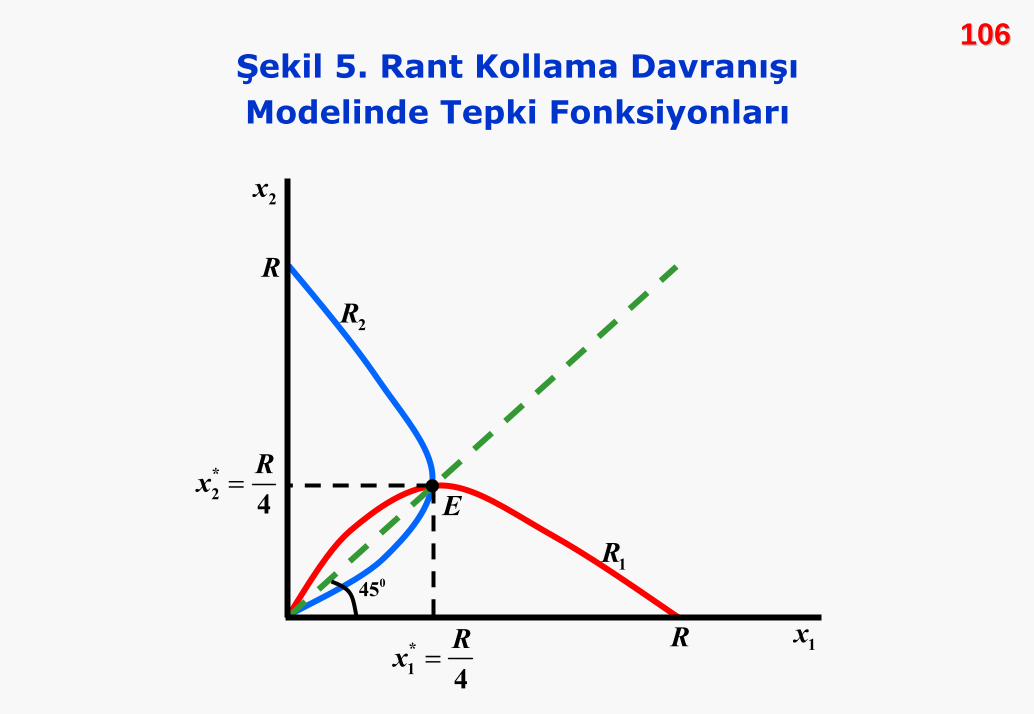
106106Şekil 5. Rant Kollama DavranışıModelinde Tepki Fonksiyonları
0451R
2R
E
2x
1x
*2 4
Rx =
R
R*1 4
Rx =

107107
Şimdi rant kollama davranışı modelini n oyunculu duruma
genelleştirelim. Her bir oyuncunun rant payı:
1,
ni
i jj
xs X x
X =
= = ∑
i. oyuncunun kazanç fonksiyonu:
1
in
i ij
j
xR xx
=
⎛ ⎞⎜ ⎟Π = −⎜ ⎟⎜ ⎟⎝ ⎠∑

108108Birinci sıra koşul:
12
1
1 0
n
j iji
ni
jj
x x
Rx
x
=
=
⎛ ⎞−⎜ ⎟
∂Π ⎜ ⎟= − =⎜ ⎟⎛ ⎞∂⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
∑
∑
Tüm oyuncuların simetrik olduğunu düşünerek x ’i çözelim.
( )*
2 2
11 0nx x nR x Rnnx
− −− = → =

109109
Toplam rant harcaması ve oyuncuların kazanç fonksiyonları da
şöyle oluşacaktır.
* *
** *
* 2
1nX nx Rn
x RR xX n
−= =
Π = − =

110110Şimdi karşılaştırmalı durağanlığı kullanarak, oyuncu sayısındaki
değişimin denge değerini nasıl değiştirdiğine bakalım:
* 2
4 3
*
2 2
*
3
2 ( 1) 2 0 , 2
( 1) 1 0
2 0
x n n n nR R nn n n
X n n R Rn n n
Rn n
∂ − − −= = < >
∂
∂ − −= = >
∂
∂Π −= <
∂

111111
Kamusal MallarKamusal Mallar
Yukarıda incelediğimiz rant kollama davranışı modelinde sabit
miktardaki bir ekonomik kaynak (çıkar) oyuncular arasında, her
bir oyuncunun bu ranttan pay almak için yaptığı rekabetçi
harcama ölçüsünde bölüşülmekteydi. Buradaki uygulamada
rant oyuncuların harcamasına bağlıdır ve kamusal mal
niteliğindedir.

112112
Tam kamusal mallar (örneğin devlet televizyonu) iki özelliğe
sahiptir: Birincisi, oyunculardan birinin tüketim artışı, diğerinin
tüketim düzeyini düşürmez. İkincisi, bu tür malın üretimine
katkı yapmayanlar, tüketimden dışlanamazlar.

113113
Bu uygulamada şu sorulara yanıt arayacağız.
1. Bireysel olarak seçilen Nash dengesi katkısı, toplumsal ola-
rak optimal midir?
2. Oyuncu sayısındaki değişim, Nash dengesindeki ve toplumsal
optimal olan kamusal mallar düzeyini nasıl etkilemektedir?

114114
xi , i. oyuncunun harcama ya da kamusal mala katkı düzeyini
göstersin. Kamusal malın sağlayacağı toplam yarar (B), toplam
harcamanın bir fonksiyonudur:
1( ) ,
n
jj
B B X X x=
= = ∑

115115
Yarar fonksiyonunun konkav olduğunu, yani kamusal mallara
yapılan harcama artışının azalan marjinal getiriye sahip
olduğunu varsayalım.
2 2
2 2( ) 0 , ( ) 0i i
B B B BB X B XX x X x∂ ∂ ∂ ∂′ ′′= = > = = <∂ ∂ ∂ ∂
Bir bireyin kazancı, kamusal malın yararı eksi kamusal malı
sağlamak için oyuncu tarafından yapılan harcamadır:
( )i iB X xΠ = −

116116
Kazancın maksimizasyonu için gereken birinci ve ikinci sıra
koşullara bakalım:
2
2( ) 1 0 , ( ) 0i i
i i
B X B Xx x
∂Π ∂ Π′ ′′= − = = <∂ ∂

117117
Birinci sıra koşulların çözümünden, X* değerini elde ederiz.
Birinci sıra koşulda n yer almadığından, toplam harcama
kamusal malın denge düzeyi, oyuncu sayısından bağımsızdır.
Toplumsal optimalite için de, kamusal maldan kaynaklanan
toplam net yararların maksimize edilmesi gerekir. Toplam net
yararlar, her bir bireyin kazançlarının toplamıdır:
( )1 1
( ) ( )n n
j jj j
B X x nB X X= =
Π = Π = − = −∑ ∑

118118Birinci ve ikinci sıra koşullara bakalım:
**
2*
2
1( ) 1 0 ( )
( ) 0 ( ) 1
j
j
nB X B XX n
nB X B XX
∂Π′ ′= − = → =
∂
∂ Π′′ ′= < =
∂
Toplumsal Optimal
Nash Dengesi
Birinci sıra koşulun çözümünden elde ettiğimiz sonuç, Nash
dengesi ile toplumsal optimalın farklı olduğunu göstermektedir.
Şekil 6, kamusal mal düzeylerini göstermektedir.

119119Şekil 6. Kamusal Mallar Durumunda
Toplumsal Optimalite ve Nash Dengesi
X
1
( )B X′
*X **X
1n
( )B X′

B(X) içbükey olduğundan, marjinal yarar fonksiyonu B′(X),
negatif eğimlidir. Özel Nash dengesinin (X*), toplumsal
optimaldan (X**) küçük olmasının nedeni, her bireyin kamusal
mal için yaptığı katkının, diğer bireyler için dışsal yararlar
yaratmasıdır. Bireysel maksimizasyon da bu yararlar göz
önünde bulundurulmamaktadır.
120120

121121
Ayrıca etkinsizlik derecesi (iki çözüm arasındaki fark), n
arttıkça büyür. Tüketici sayısının artması, bireysel tüketicinin
diğer katkı yapanlar üzerinden bedavacılığını artırır. Bunun
sonucu olarak da fark büyür.

TTÜÜMEL BMEL BİİLGLGİİYE YE
DAYALI DDAYALI DİİNAMNAMİİK K
OYUNLAROYUNLAR

Önceki bölümde, oyuncuların eşanlı seçim yaptıkları statik
oyunları inceledik. Şimdi oyuncuların peşi sıra seçim yaptıkları
dinamik oyunları inceleyelim. Bu tür oyunlar, iktisadi ilişkilerin
tarihsel bir süreçte geliştiği durumlara uygundur. Bir piyasada
yerleşik olan firmaların, kararlarını piyasa için potansiyel
firmaların girip girmeyeceği hesapları üzerine kurması buna bir
örnektir.
123123

Ayrıca piyasadaki yerleşik firmalar arasındaki pazarlık süreci de
dinamik oyunlar ile incelemeye uygundur. Statik oyunlarda
kazanç matrisi, tepki fonksiyonu gibi araçları kullandık. Ancak
bu araçlar dinamik oyunlara uygun değildir. Dinamik oyunda Dinamik oyunda
strateji bir hareket destrateji bir hareket değğil, oyun anil, oyun anıında olunda oluşşabilecek tabilecek tüüm olasm olasıı
durumlar kardurumlar karşışıssıında bir oyuncunun hareketlerinin bnda bir oyuncunun hareketlerinin büüttüünsel bir nsel bir
tantanıımmııddıır.r.
124124

Statik oyundaki normal biçimi dinamik bir oyunda
kullandığımızda, peşi sıra gelen hareketleri göstermemiz
olanaksızlaşır. Bu nedenle yayvan biyayvan biççimim adını verdiğimiz bir
araç kullanırız. Yayvan biçim, oyundaki dizimsel hareketleri en
iyi anlatabilecek olan oyun ağacı ile betimlenmektedir.
125125

Statik ve dinamik oyunlar arasındaki fark yukarıda söz ettiğimiz
bir araç yöntemi farkından ibaret değildir. Statik oyunlarda
çözüm Nash dengesi ile ifade edilmektedir. Ancak bu kavram
dinamik oyunlar için çok yetersizdir. Dinamik oyunlarda Nash
dengesi, oyuncuların başat altı hareketleri (stratejileri değil)
seçmelerine olanak sağlanması anlamında mantıksız sonuçları
içerebilir.
126126

Dinamik oyunlarda Nash dengesinin güçlü biçimi, alt oyunlualt oyunlu--
tam Nash dengesitam Nash dengesi olarak ifade edilmektedir. Şimdi yayvan
biçime ilişkin tanımdan başlayarak, ayrıntılı incelemesine
girişelim. Oyunlarda oyuncular 0,1,.....,n biçiminde numaralan-
dırılmıştır. 0 doğayı, yani n sayıda oyuncu asıl kararları alırken,
oluşabilecek tesadüfi olayları temsil etmektedir.
127127

128128
Bir oyunun yayvan biçimi şunları tanımlar:
1. Oyuncular kümesini.
2. Hareketlerin sırasını.
3. Oyuncunun yer alabileceği her bir hareketteki olası
davranışlarını ve bu olası davranışları ile olasılık dağılım
fonksiyonunca tanımlanmış olan doğa karşısındaki
hareketleri.

129129
4. Her bir harekette bir oyuncunun sahip olacağı bilgiyi.
5. Her olası hareket bileşimlerine karşılık gelen n oyuncunun
kazançları.
Oyun ağacının en basit biçimini tanımlayarak başlayalım: İki
seçim ve bir oyuncu. Oyun ağacı, çok sayıda dallar ve bu
dalların birleştiği (ya da alt dallara ayrıldığı) noktalardan
oluşur. Bağlantı noktaları kararları ya da sonuçları, dallar da
mevcut kararları gösterir.

130130
Şekil 7’de bir oyunculu oyun ağacı gösterilmiştir. Oyuncu iki
olası karara sahiptir. L ve R. Başlangıç noktası, 1. oyuncunun
karar noktası olması anlamında 1’dir. Sol ve sağ dalların
ucundaki noktalar, varış noktalarıdır ve kazançları
göstermektedir. Bu oyunda denge, bireye en yüksek kazancı
sağlayan davranışın seçilmesidir.
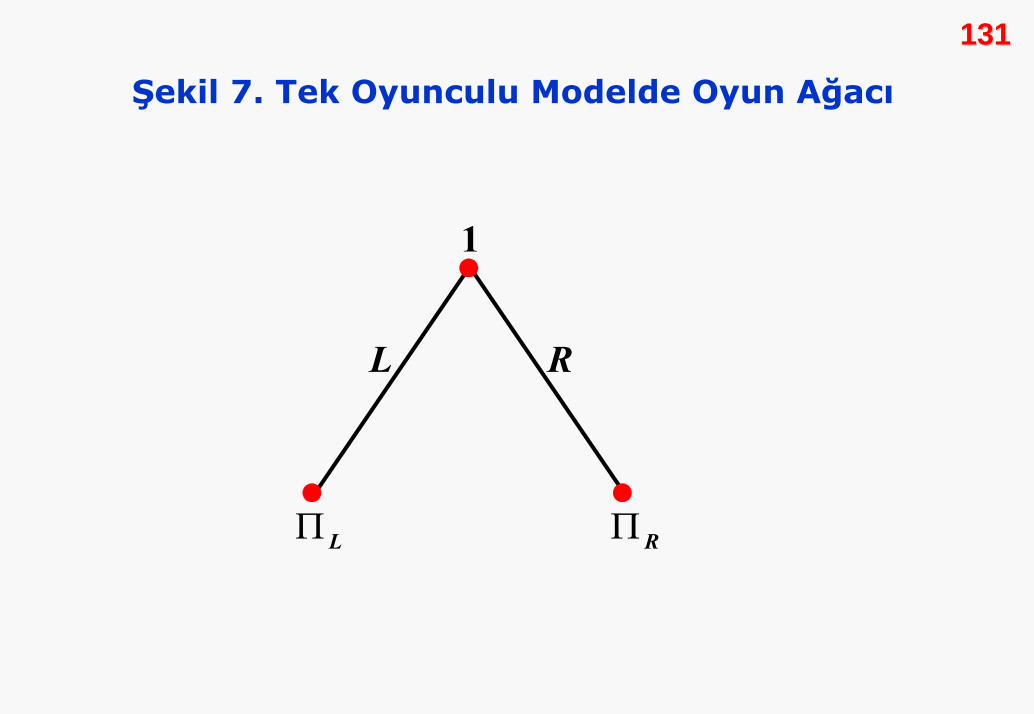
131131
Şekil 7. Tek Oyunculu Modelde Oyun Ağacı
1
L R
LΠ RΠ

Buna benzer biçimde, iki oyunculu dinamik oyunu da
oluşturabiliriz. Bir yatırım kararı oyununu dikkate alalım. Her
bir firma piyasaya girişe olanak sağlayan bir yatırımı yapıp
yapmama kararı karşısında seçim yapma durumunda bulunsun.
Firma yatırım yapmazsa, piyasa dışında kalır ve sıfır kâr elde
eder. Bu örneği eşanlı kararların verildiği bir statik oyun olarak
görmüştük.
132132

133133
Kararlar peşi sıra (dizimsel) verilirse ne olur? 1. oyuncunun ilk
karar veren olduğunu kabul edelim. 2. oyuncu, 1. oyuncunun
davranışını öğrendikten sonra kendi kararını verecektir. Bu
oyunun ağacı Şekil 8 ile verilmiştir. Şekilde E piyasaya girişi, S
piyasa dışında kalma kararını; Π kârı, -L zararı simgelemek-
tedir. Kazanç bileşimlerindeki ilk kazanç 1. oyuncuyu, diğeri 2.
oyuncuyu göstermektedir.
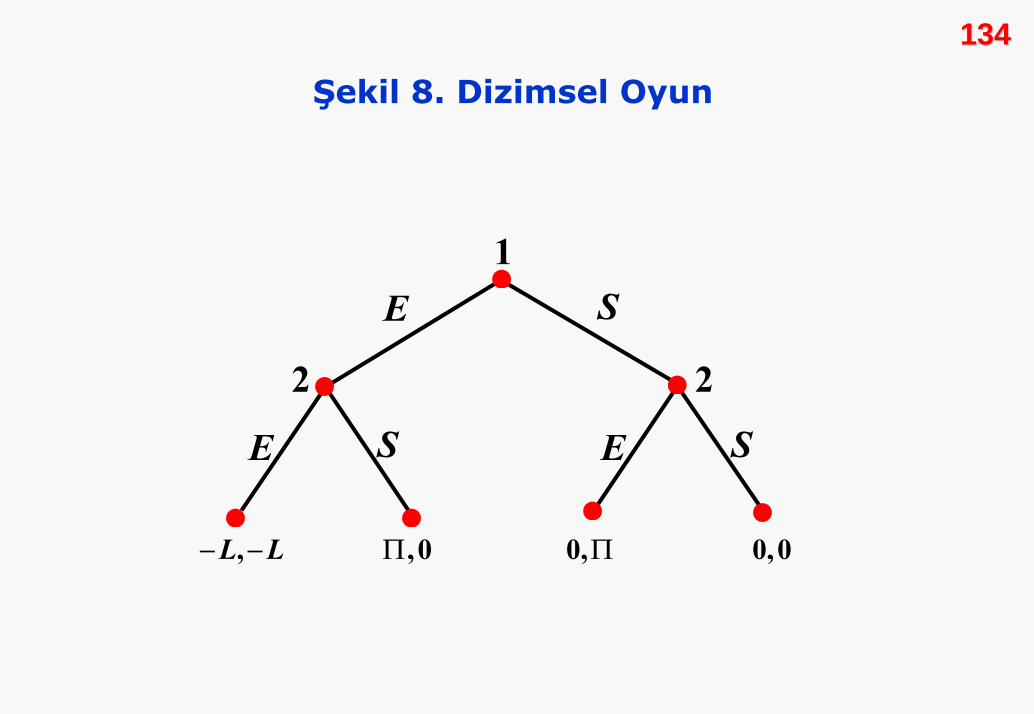
134134
Şekil 8. Dizimsel Oyun
1E S
E S SE
,L L− − ,0Π 0,Π 0,0
2 2

135135
Bu oyunda dengeyi bulabilmek için geriye dogeriye doğğru tru tüümevarmevarıımm
tekniğini kullanacağız. Bu teknik şunları içerir:
1. Oyundaki son karar noktasının incelenmesi.
2. Oynanmamış davranışların elenmesi.
3. Bu elenmiş davranışların silinmesi.
4. Oyun ağacının yeniden çizilmesi.
5. Yukarıdaki sürecin yinelenmesi.

136136
Yukarıda ele aldığımız iki oyunculu (firmalı) yatırım oyununda
son karar noktası, 2. oyuncununkidir. 1. firma (oyuncu)
piyasaya giriş kararı aldığında (ağacın sol dalı), 2. firma için en
iyi seçim piyasa dışında kalmaktır (çünkü piyasaya giriş kararı
verirse, L kadar zarar edecektir). 1. firma piyasa dışında kalma
kararı aldığında (sağdaki dal), 2. firma için en iyi karar
piyasaya giriş yapmaktır. Şekil 9, bu durumlar dikkate alınarak
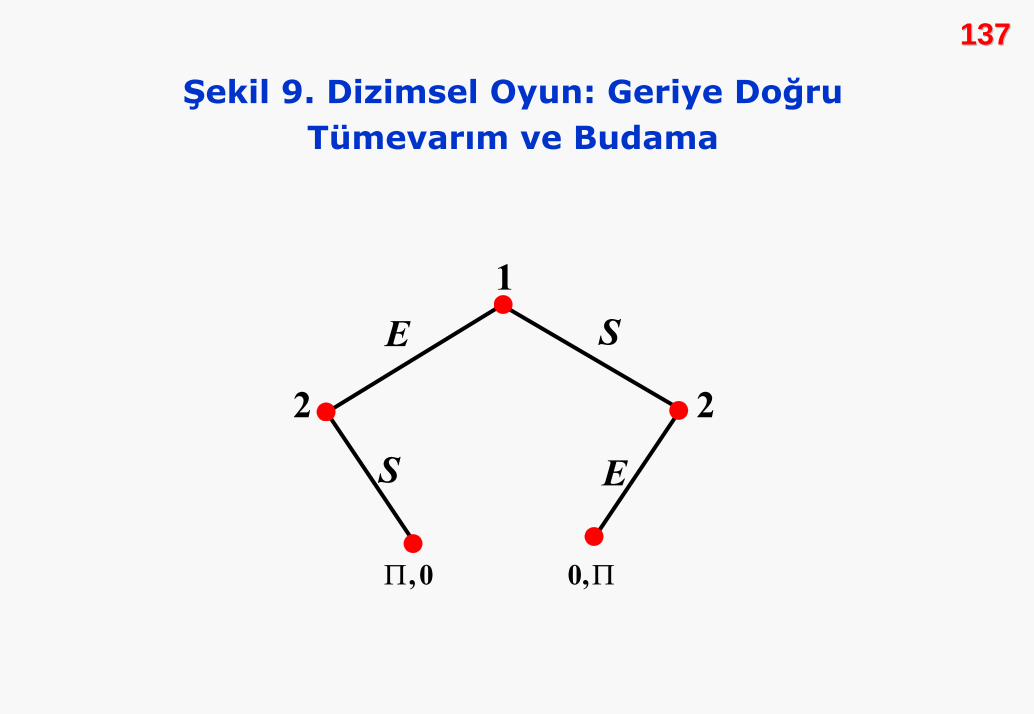
yeniden çizilmiş olan budanmbudanmışış oyun aoyun ağğacacıınnıı göstermektedir.
137137
Şekil 9. Dizimsel Oyun: Geriye Doğru Tümevarım ve Budama
1E S
S E
,0Π 0,Π
2 2

138138
Şimdi oyunu çözebiliriz. Her iki oyuncunun da rasyonel
olduğunu ve rasyonelliğin de herkesçe bilindiğini varsayıyoruz.
Bu durumda, 2. firmanın rasyonel davranışı gerçekleştireceğini
bilen 1. firma, kendisi için rasyonel olan piyasaya girişi
seçecektir. Çünkü bu durumda, kendisi Π kadar bir pozitif kâr,
rakibi de sıfır kâr elde etmektedir. Bu nedenle denge, 1.
firmanın piyasaya girme kararı, 2. firmanın piyasa dışında
kalma kararıdır.

139139
Bilgi KBilgi Küümesimesi
Yukarıdaki piyasaya giriş kararı örneğinde 2. firma, 1. firma
kararından sonra karar alacağını bilmekteydi. Fakat 2. firma
bunu başından bilmeseydi ne olurdu? Şimdi eşanlı bir karar
verme süreci çerçevesinde oyun ağacını inceleyelim. Bunun için
bilgi kümesi kavramını tanıyalım.

Bir bilgi kümesi, aynı karar dallarına sahip olan fakat oyunun
hangi karar noktasına ulaşıp ulaşmadığını bilmeyen bir
oyuncunun karar noktaları bütünüdür.
Tüm bilgi kümesinin tek karar noktalarından oluştuğu oyunlar,
tam bilgiye dayaltam bilgiye dayalıı oyunlaroyunlar olarak ifade edilmektedir. Eğer bazı
oyunlarda karar noktaları tek değilse, eksik bilgiye dayaleksik bilgiye dayalıı
oyunlaroyunlar söz konusudur.
140140

Şekil 10, piyasaya giriş oyununun eşanlı-hareket durumunu
göstermektedir. Bu, eksik bilgiye dayalı statik oyunun yaygın
biçimdeki gösterimidir. Kesikli çizgi, 2. oyuncu için bir bilgi
kümesidir. Kesikli çizgi, 2. oyuncunun piyasaya giriş yapma ya
da yapmama kararlarından birini seçeceği bir karar noktasında
bulunduğunu, ancak 1. firmanın hangi kararı almış olduğunu
bilmediğini göstermektedir. Şekil 11, Şekil 10’un alternatif bir
gösterimidir. Her iki şekilde özdeştir.
141141
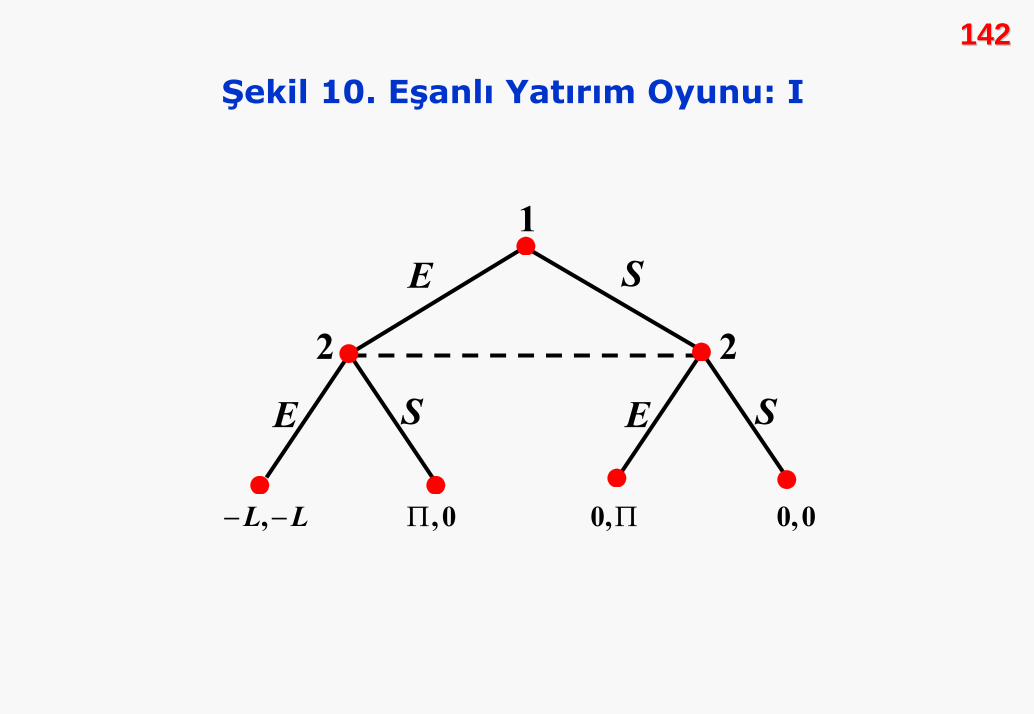
142142
Şekil 10. Eşanlı Yatırım Oyunu: I
1E S
E S SE
,L L− − ,0Π 0,Π 0,0
2 2
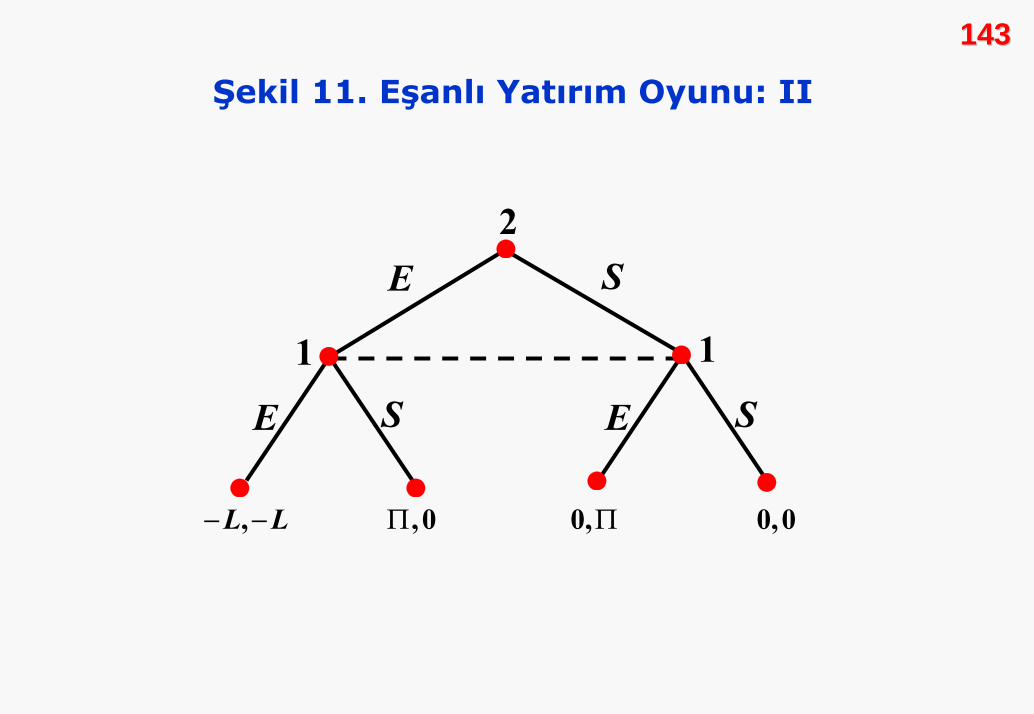
143143
Şekil 11. Eşanlı Yatırım Oyunu: II
2E S
E S SE
,L L− − ,0Π 0,Π 0,0
1 1

144144
Belirsizlik ve TesadBelirsizlik ve Tesadüüfi Durumlara Gfi Durumlara Gööre Hareketre Hareket
Yeniden yukarıdaki piyasaya giriş örmeğimizi dikkate alalım ve
potansiyel tüketici talebinde bir belirsizlik olduğunu
varsayalım. İki piyasa ölçeği dikkate alalım. Büyük ölçekli
piyasa (L) ve orta ölçekli piyasa (M).

145145
Büyük ölçekli piyasaya her iki firmanın da giriş yaparak pozitif
kâr elde edebileceğini; orta ölçekli piyasada ise yalnızca bir
firmanın pozitif kâr elde edebileceğini varsayalım. q , büyük
piyasa olma olasılığını; 1-q , orta ölçekli piyasa olma olasılığını
göstersin.

146146
Şekil 12-15, bu oyunun dört olası durumunu göstermektedir.
İlk iki şekil dizimsel oyunu (1. oyuncu ilk karar veren ve
açıklayandır), diğer ikisi eşanlı oyunu betimlemektedir. Sonuç
noktalarında pozitif kazançlar (+), zarar (-) ile simgelenmiştir.
Şekil 12, tüm bilgi kümelerinin tek karar noktasından oluştuğu
bir durumu göstermektedir. Bu nedenle, bu oyunda:

147147
1. Piyasa büyüklüğü (ölçeği) tesadüfi olarak belirlenmektedir.
2. Firmalar piyasa büyüklüğünü (L ya da M) öğrenmektedir.
3. 1. firma piyasaya giriş (E) ya da piyasa dışında kalma (S)
seçeneklerinden birini seçmektedir.
4. 2. firma, 1. firmanın kararını öğrendikten sonra piyasaya
girme ya da dışında kalmaya karar vermektedir.
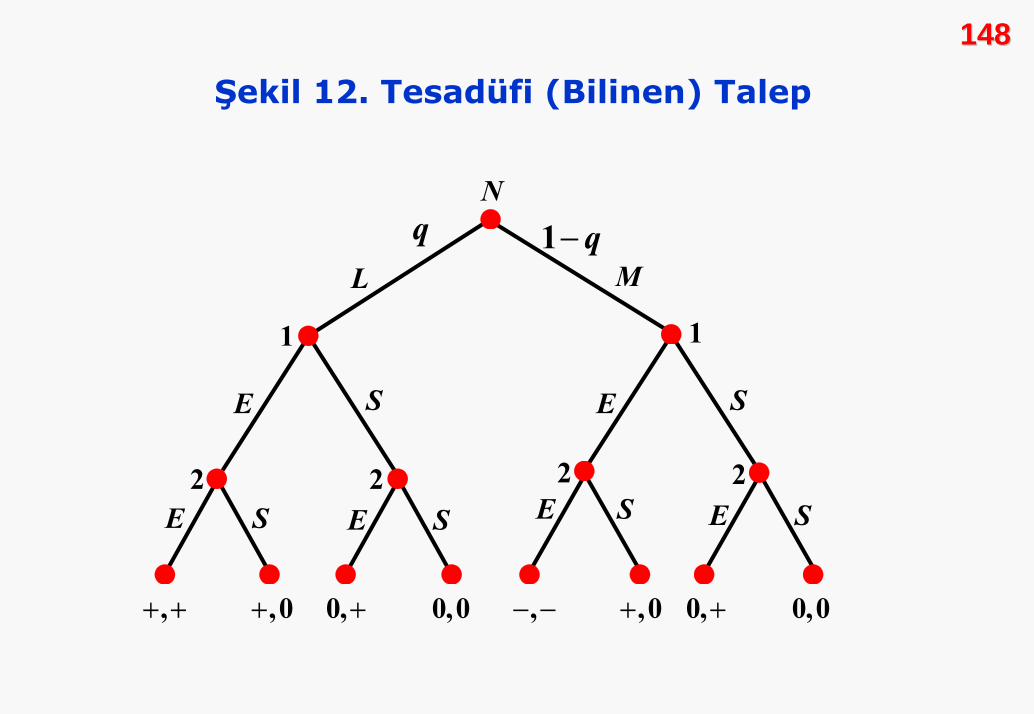
148148
Şekil 12. Tesadüfi (Bilinen) Talep
N
L M
E S SE
1 1
q 1 q−
E S E S E S E S2 2 2 2
,+ + ,0+ 0,+ 0,0 ,− − ,0+ 0,+ 0,0

Şekil 13 firmaların yine dizimsel seçim yaptıkları, ancak bu
sefer piyasa büyüklüğünü bilmeden karar aldıkları bir oyunu
göstermektedir. Bu durumda 1. firma için iki karar noktası tek
bilgi kümesi anlamına gelir. 2. firma içinse iki bilgi kümesi
vardır. Bunlardan birisi, 1. firmanın piyasaya girmesi (ancak
piyasa büyüklüğünü bilmiyor), ikincisi de piyasa dışında
kalması (yine piyasa büyüklüğünü bilmiyor) durumlarında
oluşmaktadır.
149149
150150
Şekil 13. Tesadüfi (Bilinmeyen) Talep
N
L M
E S SE
1 1
q 1 q−
E S E S E SE S
2 2 2 2
,+ + ,0+ 0,+ 0,0 ,− − ,0+ 0,+ 0,0
151151
Şekil 14. Eşanlı Hareketler ve Bilinen Talep
N
L M
E S SE
1 1
q 1 q−
E S E S E S E S2 2 2 2
,+ + ,0+ 0,+ 0,0 ,− − ,0+ 0,+ 0,0

152152
Şekil 15. Eşanlı Hareketler ve Bilinmeyen Talep
N
L M
E S SE
1 1
q 1 q−
E S E S E S E S
2 2 2 2
,+ + ,0+ 0,+ 0,0 ,− − ,0+ 0,+ 0,0

153153
Yayvan BiYayvan Biççimli Oyunlarda Dengeimli Oyunlarda Denge
Statik oyunlarda olduğu gibi, dinamik oyunlarda da Nash
dengesi vardır. Ancak çok zayıf olması nedeniyle, dinamik
oyunların çözümünde Nash dengesi kavramını kullanamayız.
Nash dengesinin çok zayıf olmasından, bazı yayvan oyunların
anlamsızlığını kastediyoruz.
Anlamlı ve anlamsız Nash dengesini ayırt edebilmek için, alt-
oyun kavramını tanımamız ve yayvan biçimli bir oyunda
stratejiyi tanımlamamız gerekir.

154154
AltAlt--OyunlarOyunlar
Bir oyunun bir bölümü olan alt-oyun, şu özelliklere sahiptir:
1. Tek bir bilgi kümesine sahip bir karar noktasında başlar.
2. Başlangıç karar noktasından sonra, asıl oyunun tüm karar
noktalarını ve dallarını kapsar.
3. Asıl oyunun hiçbir bilgi kümesini kesmez.

155155
Şimdi yukarıda verdiğimiz alt-oyun tanımına bakarak, önceki
örneklerimizde yer alan alt oyunları görebiliriz. Örneğin, Şekil
12’de altı tane alt-oyun vardır. İki tanesi 1. firmanın her bir tek
karar noktasında, Dört tanesi 2. firmanın her bir tek karar
noktasında. Şekil 13’de yalnızca 1. firmanın her bir tek karar
noktasında olmak üzere iki tanedir.

156156
Şekil 13 ve 14’de tek karar noktaları bulunmadığından, alt-oyun
yoktur. Üçüncü özelliği vurgulamak açısından, piyasaya giriş
oyununun son bir olası durumunu dikkate alalım. 1. firmanın
piyasa büyüklüğünü öğrendiğini, ancak 2. firmanın ne piyasa
büyüklüğünü ne de 1. firmanın kararını bilmediğini varsayalım.
1. firma için tek karar noktası vardır. Fakat asıl oyunun alt-
oyunu yoktur. Bu, Şekil 16’da gösterilmiştir.
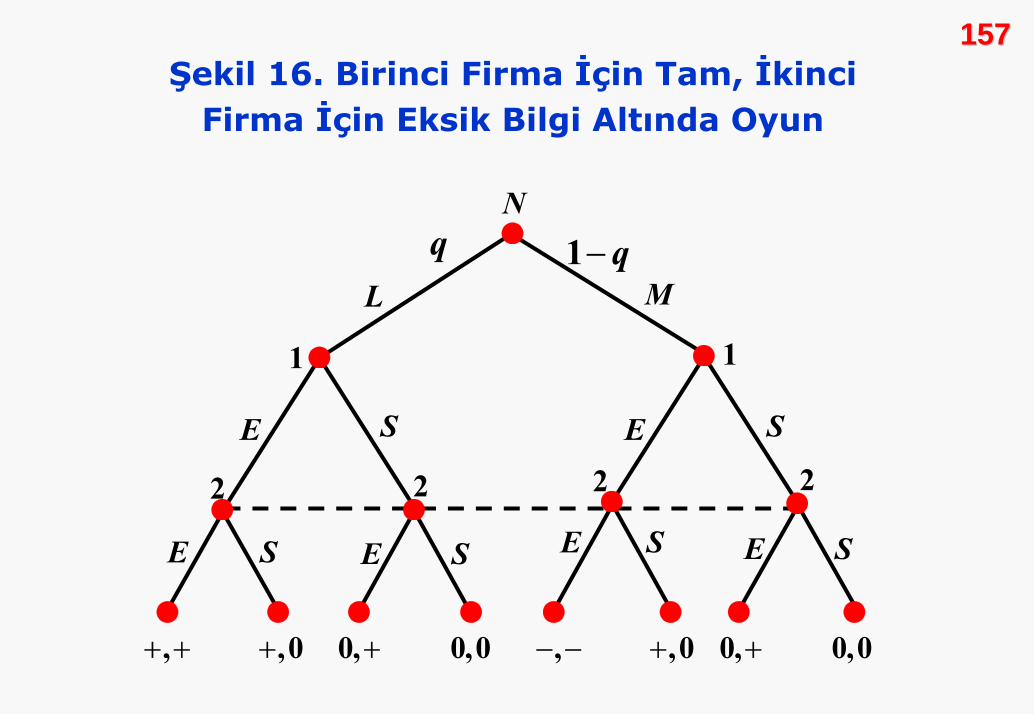
157157Şekil 16. Birinci Firma İçin Tam, İkinci
Firma İçin Eksik Bilgi Altında Oyun
N
L M
E S SE
1 1
q 1 q−
E S E S E S E S
2 2 2 2
,+ + ,0+ 0,+ 0,0 ,− − ,0+ 0,+ 0,0

158158StratejilerStratejiler
Eşanlı hareketli bir oyunda strateji, doğrudan yapılan eylemdir.
Örneğin Cournot duopol modelinde firmanın stratejisi, üretim
miktarının seçilmesiydi. Buna karşın dinamik oyunlarda
oyuncular yalnızca bir eylemi değil, aynı zamanda karşı eylemi
de gerçekleştirirler. Aynı zamanda, oyunun ilerleyen
aşamalarında oluşabilecek tüm durumlarda nasıl bir karşı
eylemde bulunacağını da planlar. Dolayısıyla dinamik bir
oyunda strateji tanımı, bu unsurları içerir.

159159
Buna göre dinamik oyunda strateji;
Bir oyuncunun oyun ağacındaki tüm olası karar noktalarını
dikkate aldığı eylemleri tanımlayan geniş kapsamlı bir plandır.
Bu tür bir plan oyunun kronolojik sürecine bağımlı olabilir ve
karma stratejileri içerebilir.

Yayvan biçimli bir oyunda strateji kavramını, farklı bir piyasaya
giriş oyunuyla görelim. 1. firma hali hazırda piyasada faaliyet
gösteriyor olsun. 2. firma ise piyasaya giriş yapıp yapmama
kararını verecektir. 2. firmanın piyasaya giriş kararı karşısında,
1. firma yüksek fiyat (H) ve düşük fiyat (L) stratejilerini
seçebilecektir.
160160

Şekil 17’de bu oyun yer almaktadır. 2. firma bir karar
noktasına, iki de eyleme sahiptir. Strateji seçimleri piyasaya
giriş (E) ve piyasa dışında kalmaktır (S). 1. firma iki eyleme (H
ya da L), dört stratejiye sahiptir. Tüm olasılıklar çerçevesinde
bir strateji, bir eylem tanımlar.
161161

162162
Burada 1. firma için bir strateji, bir çift olası eylem demektir:
Birincisi 2. firma piyasaya giriş yaparsa, ikincisi de piyasa
dışında kalırsa ortaya çıkmaktadır. 1. firma için olası strateji
kümesini yazalım:
( ) ( ) ( ) ( ){ }1 , , , , , , ,S H H H L L H L L=
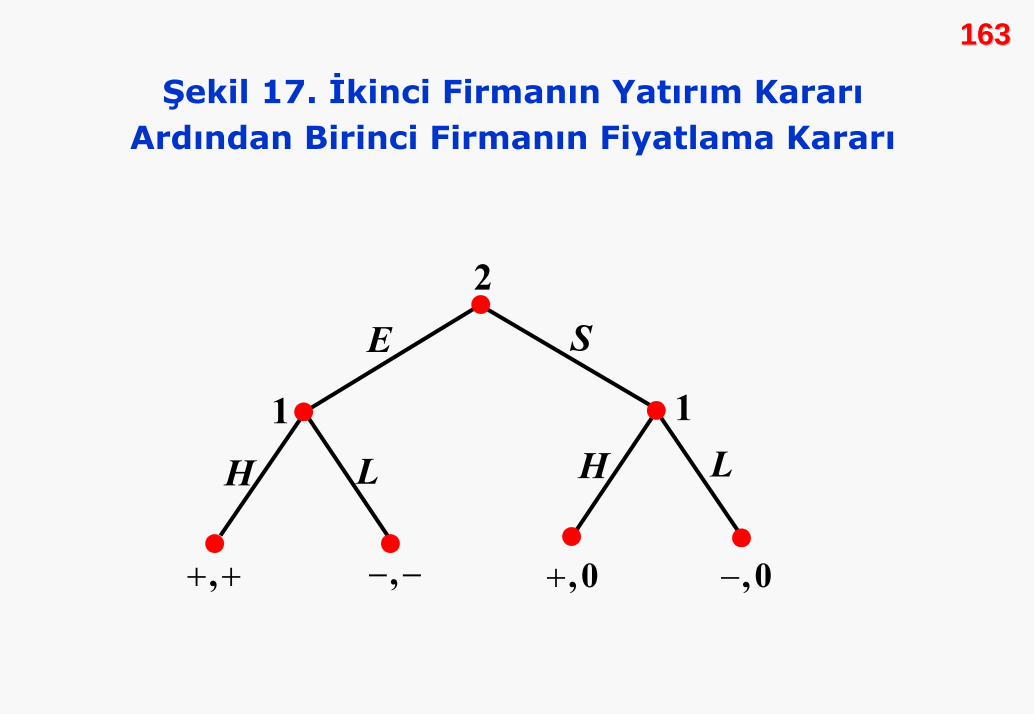
163163
Şekil 17. İkinci Firmanın Yatırım KararıArdından Birinci Firmanın Fiyatlama Kararı
2
E S
H L
,+ + ,− − ,0+ ,0−
1 1H L

164164
AltAlt--Oyun Tam Nash DengesiOyun Tam Nash Dengesi
Nash dengesinin dinamik oyundaki tanımı, statik oyundakiyle
aynıdır: Eğer oyuncular farklı bir strateji seçmek için bir neden
görmüyorlarsa, bu durum Nash dengesidir. Nash dengesini
bulabilmek için normal biçimli bir oyundan yararlanalım.
165165
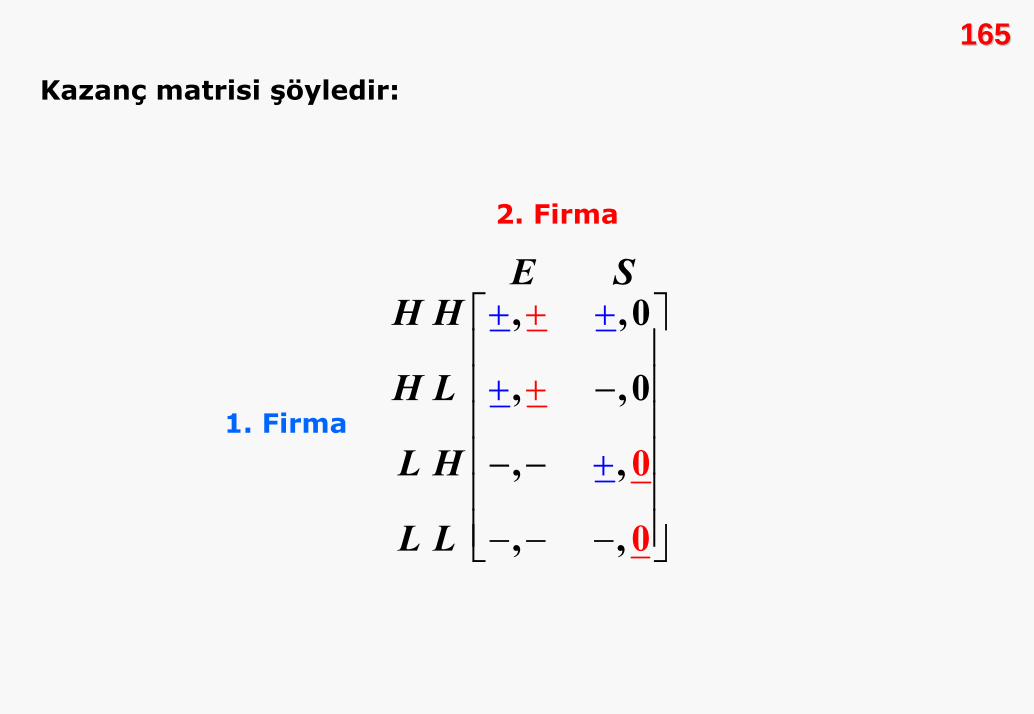
Kazanç matrisi şöyledir:
2. Firma
0
0
, ,0
, ,0
, ,
, ,
E SH H
H L
L H
L L
+ +
+
+
⎡ ⎤⎢ ⎥⎢ ⎥−⎢ ⎥⎢ ⎥− −⎢ ⎥⎢ ⎥− − ⎦
+
−
+
⎣
1. Firma

166166
Yukarıdaki kazanç matrisinde her bir oyuncunun rakibinin
strateji seçimi karşısındaki en iyi tepkisi altı çizgili (renkli)
gösterilmiştir. Aynı anda altı çizili olan üç seçim, Nash
dengesidir. Bunları E1, E2 ve E3 olarak gösterelim.
2. Firma1. Firma
1 :E ( , )H H E
2 :E ( , )H L E
3 :E ( , )L H S

167167
Bu oyunda üç Nash dengesi olmasına karşın, E2 ve E3 sorunlu
dengelerdir. Şekil 17’yi yeniden inceleyerek bunu görebiliriz. 2.
firma piyasaya giriş kararı aldığında, 1. firma için en iyi alt-
oyun yüksek fiyat uygulamaktır. Aynı durum, 2. firma piyasa
dışında kalmaya karar verdiğinde de geçerlidir.

168168
Dolayısıyla her iki alt-oyunda da H başattır. Ancak E2 ve E3
Nash dengesi olmakla beraber, potansiyel olarak başat-altı
oyunları da (düşük fiyatlama) içermektedir.Her hangi bir
nedenle 2. firma kendisi için en iyi olan stratejiden sapma
gösterirse, 1. firmanın rasyonel seçim yapması olanak dışı olur.

Asıl oyunun tüm alt oyunlarında bir strateji kümesine
dayanarak yapılan eylemler Nash dengesine yol açıyorsa,
yayvan biçimli oyundaki bu strateji kümesi alt-oyun tam Nash
dengesidir.
Statik oyunlar için kullandığımız Nash dengesi kavramını,
dinamik oyunlarda alt-oyun tam Nash dengesi olarak
kullanıyoruz. Bir tam bilgiye dayalı oyunda geriye doğru
tümevarım tekniğiyle, alt-oyun tam Nash dengesi aynı
şeylerdir. Dinamik oyunlar, karma strateji dengesine sahip
olabilirler.
169169

170170
AltAlt--Oyun Tam Nash Dengesi iOyun Tam Nash Dengesi iççin in ÖÖrnekrnek
Şimdiki örneğimiz iki oyunculu, sürekli değişkenler içeren bir
biçime sahiptir. Oyunun kurgusu şöyledir:
1. 1. oyuncu x1 eylemini seçer.
2. 2. oyuncu bunu izler ve ardından x2 eylemini seçer.
3. Oyuncular П1(x1,x2) ve П2(x1,x2) fonksiyonlarınca tanımlanan
kazançları elde ederler.

171171
Bu problemi çözmek için, asıl oyunun alt-oyunu olan 2.
oyuncunun x2 seçimiyle başlarız. 2. oyuncunun kazancının
maksimizasyonu problemini çözeriz. 2. Oyuncu için birinci sıra
koşul:
2 1 2
2
( , )0
x xx
∂Π=
∂

172172
Bu denklemin çözümünden, biçimindeki tepki fonksi-
yonunu bulabiliriz. 2. oyuncunun stratejisini belirledikten
sonra, 1. oyuncunun kararına bakarız. Ortak rasyonellik
varsayımını benimsersek, 1. oyuncu, 2. oyuncunun rasyonel
seçim yapacağını düşünecektir. Buna göre 1. oyuncunun kazanç
fonksiyonunu ve birinci sıra koşulu yazalım:
*2 2 1( )x R x=
( ) ( )
( )
*1 1 2 1 2 1
1 1 2 1 1 1 2
1 1 2 1
, , ( )
, ( )0
x x x R x
d x R x Rdx x x x
Π =
Π ∂Π ∂Π ∂= + =∂ ∂ ∂

Yukarıdaki birinci sıra koşul iki etkiyi barındırmaktadır. Birinci
terim statik oyun dengesi (eşanlı), ikinci terim dizimsel
seçimlere sahip dinamik oyun dengesini yansıtmaktadır.
Şimdi daha önce verdiğimiz bir örnekteki sayısal kazanç
fonksiyonlarını kullanarak açık çözüm elde edelim.
173173

1741742
1 1 1 1 2 1
22 2 2 1 2 1
10 3
10 2
x x x x x
x x x x x
Π = − − −
Π = − − −
Statik oyundaki en iyi tepki fonksiyonları şöyleydi:.
( ) ( )1 11 1 2 2 2 2 1 12 2
* *1 1 2 2
( ) 7 , ( ) 8
2 , 4 , 3 , 9
x R x x x R x x
x x
= = − = = −
= Π = = Π =

175175
Şimdi de ilk olarak 1. oyuncunun oyuna başladığı bir dinamik
model düşünelim. Statik oyunda elde ettiğimiz (2. oyuncuya
ait) tepki fonksiyonu, 2. oyuncunun strateji kuralını oluşturur.
Bu fonksiyonu 1. oyuncunun kazanç fonksiyonuna uygulayarak,
denge değerini bulabiliriz.
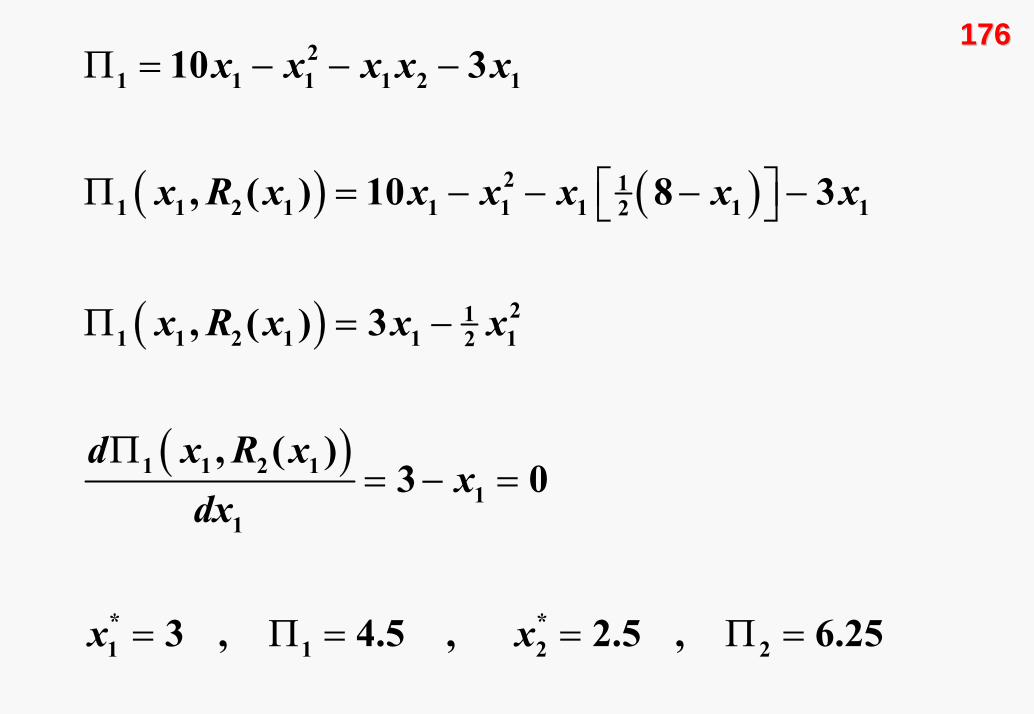
( ) ( )
( )
( )
21 1 1 1 2 1
2 11 1 2 1 1 1 1 1 12
211 1 2 1 1 12
1 1 2 11
1
* *1 1 2 2
10 3
, ( ) 10 8 3
, ( ) 3
, ( )3 0
3 , 4.5 , 2.5 , 6.25
x x x x x
x R x x x x x x
x R x x x
d x R xx
dx
x x
Π = − − −
⎡ ⎤Π = − − − −⎣ ⎦
Π = −
Π= − =
= Π = = Π =
176176

Statik ve dinamik oyunların sonuçlarını karşılaştırdığımızda,
dinamik oyunda 1. oyuncunun oyuna ilk başlayan olma
avantajıyla daha iyi bir sonuç elde ettiğini görebiliriz. Ancak
buradaki sonuçtan, tüm oyunlarda ilk hareket eden olmanın
avantaj sağladığı sonucunu çıkaramayız. Sonuçlar, oyunun
yapısına bağlıdır.
177177

İİki Aki Aşşamalamalıı OyunlarOyunlar
İki aşamalı oyun, bir oyunun diğerini izlediği biçimde bir
oyundur. İktisadi uygulamalara baktığımızda, genellikle ilk
oyun aşamayı ya da oyun ortamını oluşturur; ikinci aşamada da
oyun oynanır. Örneğin ilk aşamada firmalar ürün kalitesini,
ikinci aşamada da fiyatı belirlerler. Bir başka örneği de dış
ticaretten verebiliriz. İlk aşamada hükümet, dış ticarete katılan
firmalar için birinci aşama (ya da çevresel koşullar) olan dış
ticaret politikasını belirler, ikinci aşamada firmalar ihracat ve
ithalat kararlarını verirler.
178178

Şimdi her aşamada eşanlı, ancak aşamalar arasında dizimsel
olan oyunlar üzerinde duracağız. Hareketlerin de kesikli değil,
sürekli olduğunu varsayıyoruz. İlk aşamada 1. ve 2. oyuncular
sırasıyla x1 ve x2 seçimlerini yaparlar. 3. ve 4. oyuncular bu
seçimi izledikten sonra, ikinci aşamada eşanlı olarak kendi
seçim kararlarını (x3 ve x4) verirler.
179179

Alt-oyunun tamlığı, asıl oyunda dengenin var olabilmesi için,
ikinci aşamadaki alt-oyunda da Nash dengesinin var olmasını
gerektirir. İkinci aşama alt-oyunu x1 ve x2 seçimlerini veri
almaktadır. Bu nedenle 3. ve 4. oyuncular, kendi kazanç
fonksiyonlarını maksimize edecek olan x3 ve x4 seçimlerini
gerçekleştirirler.
180180
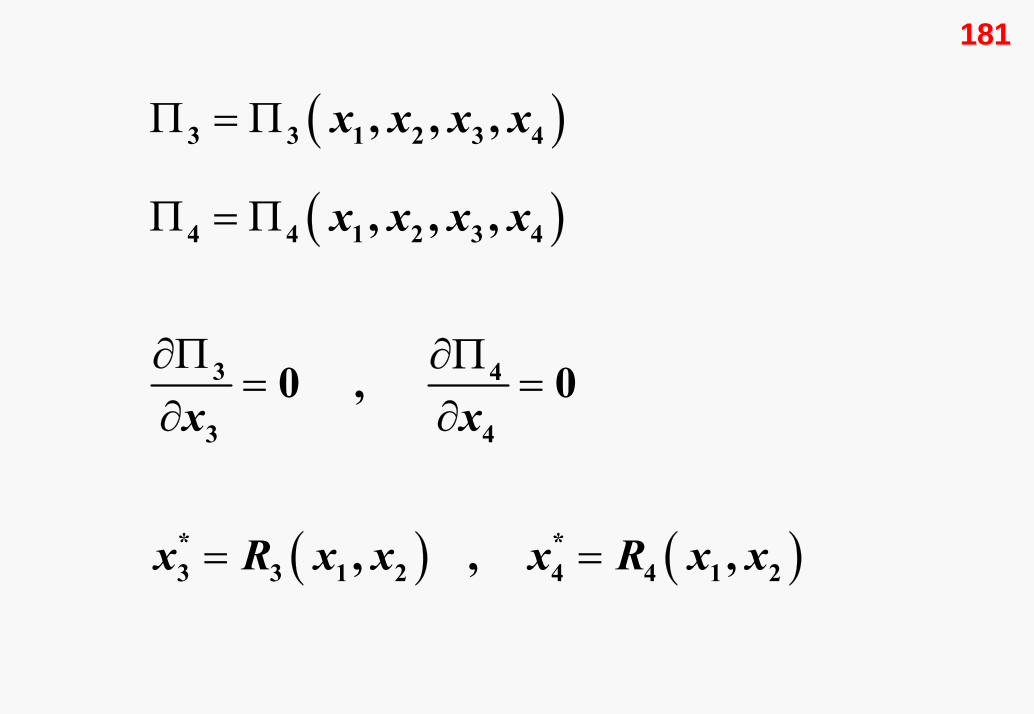
181181
( )
( )
( ) ( )
3 3 1 2 3 4
4 4 1 2 3 4
3 4
3 4
* *3 3 1 2 4 4 1 2
, , ,
, , ,
0 , 0
, , ,
x x x x
x x x x
x x
x R x x x R x x
Π = Π
Π = Π
∂Π ∂Π= =
∂ ∂
= =

182182
Burada dikkati çeken nokta, x1 ve x2 seçimleri içsel olmakla
beraber, x3 ve x4 seçimleri yıldız (asteriks) işaretiyle gösterilmiş
olmasıdır. Bu sanal sıkıntıyı aşmanın yolu, yeniden birinci
aşamaya dönerek, 1. ve 2. oyuncular için kazanç
maksimizasyonunu, ve veriyken belirlemektir. *3x *
4x
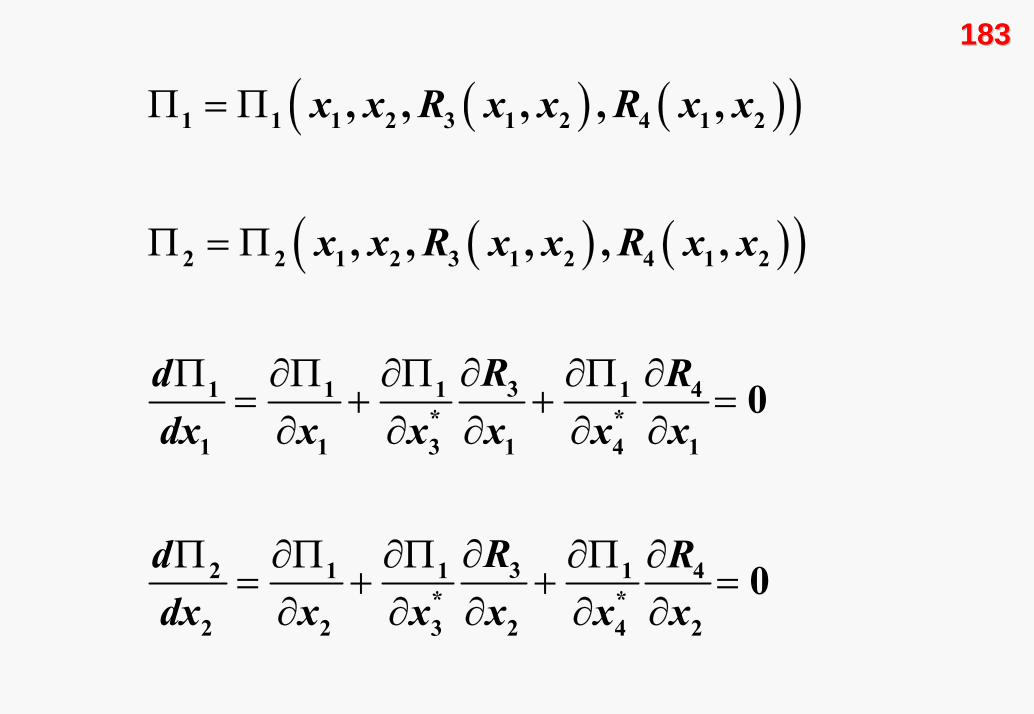
183183
( ) ( )( )
( ) ( )( )
1 1 1 2 3 1 2 4 1 2
2 2 1 2 3 1 2 4 1 2
31 1 1 1 4* *
1 1 3 1 4 1
32 1 1 1 4* *
2 2 3 2 4 2
, , , , ,
, , , , ,
0
0
x x R x x R x x
x x R x x R x x
Rd Rdx x x x x x
Rd Rdx x x x x x
Π = Π
Π = Π
∂Π ∂Π ∂Π ∂Π ∂= + + =∂ ∂ ∂ ∂ ∂
∂Π ∂Π ∂Π ∂Π ∂= + + =∂ ∂ ∂ ∂ ∂

1. ve 2. oyuncular arasında oynanan basit statik oyunla, birinci
aşamada seçim yapılan dinamik oyun arasındaki farka dikkat
edelim. Dinamik oyun, birinci aşamadaki oyuncuların
kararlarının, ikinci aşama kararları üzerindeki dolaylı ya da
stratejik etkilerini içerir.
184184

185185
Tüm oyunun çözümü, dört oyuncunun da birinci sıra
koşullarından elde edilen stratejileri sağlayan alt-oyun tam
Nash dengesidir. Bu dengeyi şöyle yazabiliriz:
( ) ( ){ }* * * * * * * *1 2 3 3 1 2 4 4 1 2, , , , ,E x x x R x x x R x x= = =

186186
Yinelenen OyunlarYinelenen Oyunlar
Yinelenen oyunlar, bir başka önemli oyunlar türüdür. Örneğin
tutsaklar açmazı ya da Cournot duopol modelini yeniden
dikkate alalım. Bu oyunlar, bir statik oyunda oyuncuların
birbirlerini bir kerelik etkilemelerine izin vermektedir.

Gerçek iktisadi yaşamda oyun belirli bir dönemde oynanmasına
karşın, alınan kararların etkileri izleyen dönemlerde de
sürebilmektedir. Yani statik oyunun yinelenen oyunlarından
oluşan bir dinamik oyundan söz ediyoruz. Yinelemeler, izleyen
oyunlarda yeni beklentilerin oluşmasına yol açması bakımından
önemlidir.
187187

Örneğin tutsaklar açmazında her bir oyuncunun önünde iki
strateji vardır: işbirliği yapmak ya da işbirliğinden kaçınmak.
Yinelenen tutsaklar açmazında, strateji uzayı daha karmaşıktır.
Bir oyuncu, diğer oyuncunun geçmişte verdiği kararların etkisi
altındadır.
188188

189189
Şimdi G olarak adlandıracağımız bir statik oyunu dikkate alalım.
G(T), T kere yinelenen bir dinamik oyun olsun. Örneğin G
oyununu iki oyunculu bir tutsaklar açmazı olarak düşünelim.
Kazanç matrisi şöyledir:
2. Oyuncu
, ,
, ,
C DC R R L W
D W L P P
⎡ ⎤⎢ ⎥⎢ ⎥⎣ ⎦
1. Oyuncu

190190
C, işbirliği yapma; D, işbirliğinden kaçınma; R, ödül; L, kayıp,
W, kazanma; P, ceza olarak kullanılmıştır. Aynı zamanda şu
eşitsizliklerin de sağlanması gerektiğini varsayalım:
,2
W LW R P L R +> > > >

Yukarıdaki ilk eşitsizlik tutsakların çıkmazı oyununu
tanımlamakta, ikincisi de oyuncunun işbirliğine gitmekle elde
edeceği kazancının, işbirliği ve işbirliğinden kaçınma kararları
arasında değişikliğe gitmekle elde edeceği kazancını aşacağını
söylemektedir. Daha önce ele aldığımız statik oyunda her iki
tutsak için işbirliğinden kaçınmak tek Nash dengesiydi.
191191

Şimdi oyunun T sayıda yineleme ile oynandığını varsayalım ve
son dönemi dikkate alalım. Artık bu dönemde iki tutsağın
birbiriyle işbirliğine girip girmeyeceği davranışlarının ne
olacağının bir önemi yoktur. Yani adete bir statik tutsak çıkmazı
oyunuyla karşı karşıyayızdır. Bu nedenle her iki tutsak için de
bu alt oyunun dengesi, işbirliği yapmamak stratejilerinin
seçimidir.
192192

Şimdi de T-1 dönemini dikkate alalım. Tutsaklar son dönemde
(T) işbirliğine girmeyeceklerinden, T-1 dönemi için de
işbirliğine gitmemek davranışı tek dengedir. Bu süreci geriye
doğru tümevarım tekniğiyle götürürsek, tüm dönemlerde
dinamik oyunun alt-oyun tam Nash dengesinin işbirliği
yapmamak stratejisi olduğunu söyleyebiliriz.
193193

194194
Teorem 4:Teorem 4: G, T kere yinelenen bir statik oyun olsun. G tek
Nash dengesine sahipse, tek alt-oyun tam Nash dengesi, tüm T
dönemlerinde G ’nin bu statik denge stratejisini oynamaktır.

195195
Eğer yinelenen oyunun zaman ufku sınırsızsa, gelecekte
oluşacak kazançların bugünkü değerine indirgenmesi gerekir.
Sınırsız zaman ufkunda yinelemeli bir oyunda bir oyuncunun
kazancı, her bir dönemde elde edilen kazançların toplamının
bugünkü değeridir.

196196
Oyuncunun t döneminde elde ettiği kazanca Πt ve indirgeme
oranına da δ diyelim. Buna göre bugünkü değer:
0
1, 11
tt
tV
r
∞
=
= δ Π δ = <+∑

Sınırsız zaman ufkuna sahip bir oyunda son dönem belirli
olmadığından, denge değerine geriye doğru tümevarım yoluyla
ulaşamayız. Bunun yerine, şimdi tanımlayacağımız farklı bir
yöntem kullanırız. Bu yöntemde stratejiyi, her bir t döneminde
yaptıklarının özeti olarak tanımlayabiliriz. Yani t dönemindeki
durum, oyuncunun tüm geçmiş davranışlarını göstermektedir.
197197

198198
Ancak dengenin bu şekildeki aranışı bizi sonsuz sayıda dengeye
götürebilir. Bu türden sorunlardan uzak kalmak için genellikle
belirli bir sonuca odaklanırız. Örneğin Pareto optimal sonuca
göre, herkesin kazancını aynı anda artıramayız. Tutsaklar
açmazı oyunu açısından bakarsak bu, her bir dönemde
tutsakların işbirliğine girmesi demektir.

İlk olarak iki oyunculu bir pazarlık modelini inceleyelim.
Örneğin firmalar ile sendikalar arasındaki ücret pazarlık süreci.
Önce ister al ister alma biçiminde bir sürece bakalım. Ardından,
bir anlaşmaya ulaşıncaya kadar kıyasıya bir pazarlığı ele alalım.
İkinci uygulama olarak dış ticaret teorisi çerçevesinde iki
aşamalı bir oyuna bakıyoruz. Üçüncü uygulamamız, önce birinci
firmanın ve ardından ikincinin karar aldığı bir duopol piyasada
liderlik konusu inceleniyor. Son olarak statik oligopol teori,
yinelemeli oyun olarak ele alınıyor.
199199

Dizimsel PazarlDizimsel Pazarlıık Modelik Modeli
Bu oyunda oyuncular, önerilerini zaman içinde peşi sıra
vermektedirler. Ortak bir girişim yapacak olan iki firma
düşünelim. Her bir firma teknolojisi ya da uzmanlığıyla bu
girişime katılabilir ve girişimin başarısında etkili olabilir.
Girişimin belirli bir kâr sağladığını ve bunu firmaların bildiğini
varsayalım. Firmalar açısından sorun, bu kârın nasıl paylaşıla-
cağıdır. Firmalar paylaşımda anlaşabilirlerse, girişim gerçek-
leşir, aksi halde iptal edilir.
200200

Pazarlık modelinin ilk dönemini ele alalım. x ve y oyuncularının
bir liralık bir kazancı pazarlık yoluyla nasıl paylaşacaklarına
bakalım. t0 anında x ’in s0 kadar bir pay alma önerisinde
bulunduğunu varsayalım. Buna göre y, 1-s0 kadar pay alacaktır. y
bu öneriyi kabul ederse, bu kazanç paylaşımı üzerinde
anlaşırlar. Reddederse, anlaşma olmaz ve oyun t1 döneminde
yeniden başlar. Ancak t1 dönemindeki kazancın, indirgenmesi
gerekir. Bu, anlaşma geciktikçe, taraflara bir yük gelmesi
demektir.
201201

202202
Şekil 18, bu oyunu göstermektedir. A, önerinin kabulünü, R
reddini ifade etmektedir. Oyunu çözmek için geriye doğru
tümevarım yöntemini kullanalım. Son karar noktasında oyuncu
y, x’in önerisini kabul ederse 1-s0 , reddederse δΠy kadar
(indirgenmiş) kazanç elde eder. Eğer,
0 01 1y ys s− ≥ δΠ → ≤ − δΠ
olursa, oyuncu y öneriyi kabul edecektir.

203203
Şekil 18. Bir Dönemlik Pazarlık Modelinin Oyun Ağacı
A0 0,1s s−
x
y
0s
R
,x yδΠ δΠ

204204
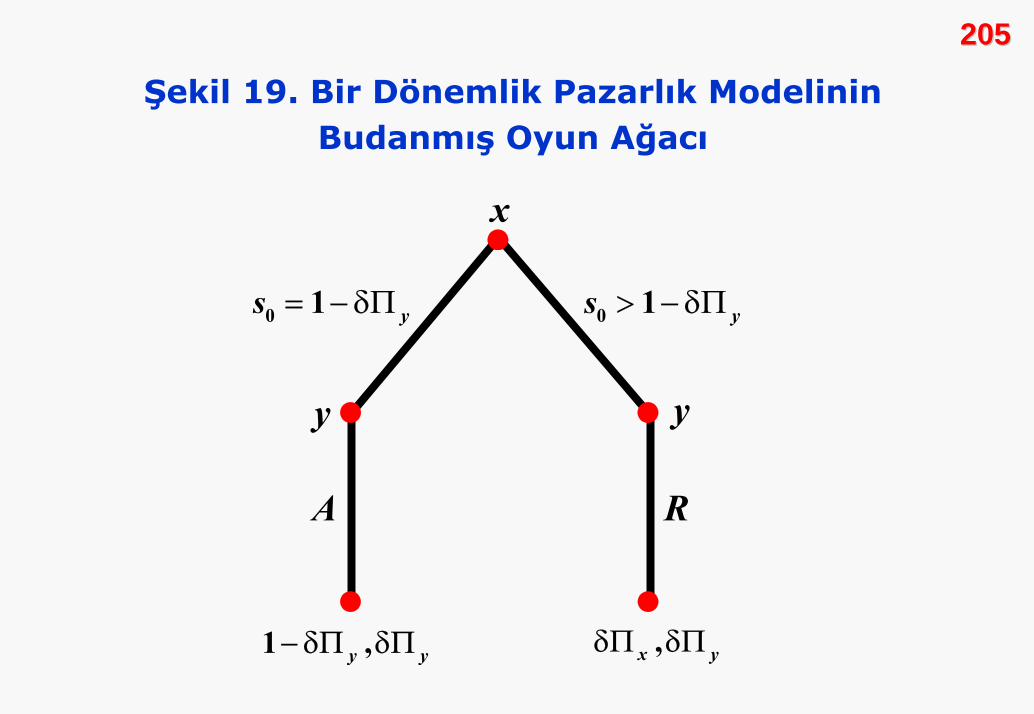
Şekil 19, oyuncu y ’nin seçim kuralına göre budanmış olan oyun
ağacını göstermektedir. Oyuncu x kendisi için payını
isterse, önerisi reddedilmektedir. durumu kabul
edilmektedir. x kabul edilecek bir öneri götürürse, x açısından
optimal öneri ‘dir. Bu nedenle, bu öneri oyunun
dengesidir ve x ile y sırasıyla, kazançlarını elde
etmektedirler.
0 1 ys ≤ − δΠ
0 1 ys > − δΠ
0 1 ys = − δΠ
1 ,y y− δΠ δΠ
205205
Şekil 19. Bir Dönemlik Pazarlık Modelinin Budanmış Oyun Ağacı
A
x
y
0 1 ys = − δΠ
R
y
0 1 ys > − δΠ
1 ,y y− δΠ δΠ ,x yδΠ δΠ

206206
Şimdi bir uç durum dikkate alalım. Eğer olursa, x
tüm kazancı alır: . Bu durum, y çok zayıf bir pazarlık
gücüne sahipse gerçekleşir. Diğer uç durum, ‘dir. y
bugünkü değer ( ) ölçüsünde, x bugünkü değerden daha
büyük bir kazanç elde eder:
0x yΠ = Π =
0 1s =
1x yΠ = Π =
yδΠ
0 1 1 (1 ) (1 )y x x xs = − δΠ = − δ −Π = − + δΠ >δΠδ

207207
İİki Dki Döönemli (nemli (İİki ki ÖÖnerili) Bir Pazarlnerili) Bir Pazarlıık Modelik Modeli
Bu modelde oyuncuların öneriler yapabilme fırsatlarının
bulunduğunu varsayıyoruz. Peşi sıra oluşacak hareketler
şöyledir:
1. x, s0 kadar bir öneri yapar.
2. y bunu kabul ederse oyun biter, reddederse oyun sürer.
3. y , s0 önerisini reddederse, x ’e s1 önerisini götürür.

208208
4. x , y ’nin karşı önerisini kabul ya da reddeder.
5. x karşı öneriyi reddederse, x’in s , y’nin de 1-s kadar bir
dışsal pay aldıkları bir paylaşımla oyun biter.

5. aşamada kazancın zaman içinde azalmadığı varsayılmıştır.
Ancak ödemelerin bugünkü değeri azalacaktır. Bu oyunun
ağacı, Şekil 20’dedir.
Çözüm geriye doğru tümevarım yöntemiyle yapılmaktadır. Son
karar noktasında x , gibi bir öneriyi kabul eder. y,
gereğinden fazla bir miktar önermeyeceğinden, önerisi
olarak gerçekleşir. Şekil 20, son iki kararı çözdükten sonra
çizilmiştir. Bir sonraki aşamada, s0 önerisinin kabul görüp
görmeyeceğine bakıyoruz.
1s s≥ δ
1s s= δ
209209
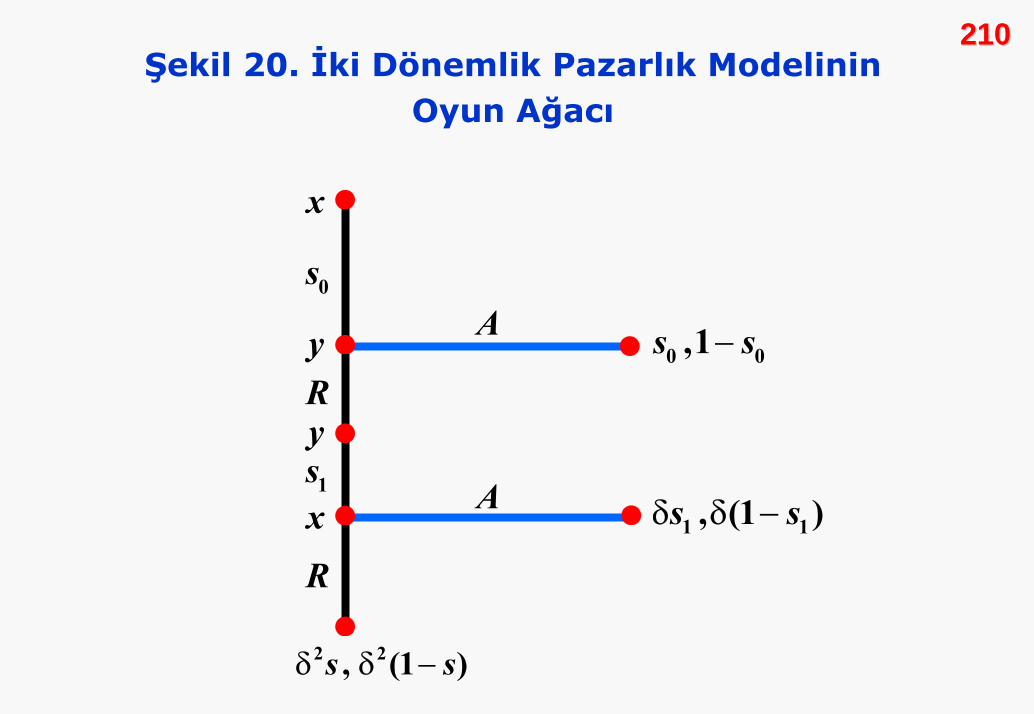
210210Şekil 20. İki Dönemlik Pazarlık Modelinin
Oyun Ağacı
A0 0,1s s−
x
y
0s
R
1sx
R
2 2, (1 )s sδ δ −
y
A1 1, (1 )s sδ δ −

211211
Şu koşullar gerçekleşirse, y, (1-s0) önerisini kabul eder:
( ) 20 01 1 1s s s s− ≥ δ − δ → ≤ − δ + δ
s0 ’ın maksimum değeri (δ2s), x ’in başlangıç önerisinden gelen
kazancını aşar. Denge, x tarafından önerisi yapı-
lırsa ve bu y tarafından kabul edilirse gerçekleşir. x ve y ’nin
kazançları da sırasıyla şöyledir:
* 20 1s s= − δ + δ
2 21 ,s s− δ + δ δ + δ

ise, pazarlık sürecinin denge sonucuna göre x yarıdan
fazla, y yarıdan az kazanç elde eder:
12s =
212212
* *0 0
2 2 2 21 12 2
2
1
1 1
1 2 0
s s
s s
≥ −
− δ + δ ≥ δ + δ → − δ + δ ≥ δ + δ
− δ + δ ≥
Son aşamada dışsal paylaşım eşit olsa da, kazançlar bugünkü
değere indirgendiğinde, x daha yüksek bir kazanca sahip
olacaktır.

213213
Dinamik pazarlık modelindeki son örnek modelimiz, oyuncuların
bir anlaşmaya varılıncaya kadar birbirine sürekli öneriler
getirdiği bir durumdur. Öneri sayısında herhangi bir sınır
yoktur; oyun bir sınırsızlığa sahip olabilir. Ancak ilk öneri kabul
edilirse, oyun başlar başlamaz sona erer. Şekil 21, iki dönemli
bir pazarlık sürecini, son aşamadaki kazanç noktaları çıkarılmış
biçimiyle sunmaktadır. Oyunun bu kısmına G diyelim. Sınırsız
bir yinelemeli oyunda, sonsuz sayıda yineleme peşi sıra gelir:
G(∞).

214214
Şekil 21. Yinelenen Pazarlık Oyununun Bir Aşaması
A0 0,1s s−
x
y
0s
R
1sx
R
y
A1 1, (1 )s sδ δ −

Çözüm yöntemi olarak geriye doğru tümevarımı kullanamayız.
Bu nedenle, oyunu ilk ele alış biçimimizdeki gibi, s ve 1-s
oyuncuların dengedeki kazancını göstersin. Şimdi ikinci biçime
gidelim ve oyuncuların peşi sıra öneriler yaptığını varsayalım.
Eğer bir anlaşmaya varamazlarsa, G(∞) sürecinde oyunu
sürdürürler. Kazançları s ve 1-s olur. Ancak diğer yandan iki
dönemli pazarlık modelinde x ve y’nin denge kazançlarını
sırasıyla ve olarak elde etmiştik.21 s− δ + δ 2sδ + δ
215215

216216
Aynı modelde görünürdeki bu iki farklı sonuç sıkıntısından
kurtulmak için şunu kullanalım: ya da G(∞) oyunu ile G
’nin G(∞) oyununu izlemesi özdeş oyunlardır. Buna göre, her iki
sonucun da kazançları aynıdır, Bu denklemi, s* için
matematiksel olarak çözelim:
( )s f s=

217217
( )2 2
*2
( ) 1 1 1
1 11 1
s f s s s
s s
= = − δ + δ → − δ = − δ
− δ= → =
− δ + δ
Bu sonuca göre, x ’in önerdiği ve y ’nin kabul ettiği s* yinelemeli
oyunun dengesidir. Sınırsız bir yineleme söz konusu olsa da, ilk
önerinin avantajı devam edecektir. Göreli kazançlar, indirgeme
oranına bağlıdır.

218218
İndirgeme oranı 1’den küçükken, x ’in kazancı y ’nin
kazancından yüksektir. İki öneri arasındaki zaman dilimi
küçüldükçe faiz oranı sıfıra, indirgeme oranı da 1’e yaklaşır.
Dolayısıyla her iki oyuncunun kazançları eşitlenme eğilimine
girer.

219219
Yukarıda ele aldığımız pazarlık modeli, tümel bilgi varsayımı
üzerine kuruludur. Yani oyuncular birbirlerinin kazanç
fonksiyonlarını bilmektedirler. Ancak gerçek dünyada genellikle
bu bilgiler ya eksiktir ya da asimetriktir (bakışımsız). Örneğin
bir firma ile işçi sendikası arasındaki ücret pazarlığı sürecinde
firma, gelecek dönemdeki talep ve kârlar konusunda daha çok
bilgiye sahip olabilir. Dolayısıyla firma daha iyi bir pazarlık
gücü yakalayabilir.

220220
DDışış Ticaret PolitikasTicaret Politikasıı ve Oligopolve Oligopol
Burada oligopol piyasadaki ihracat desteğini, iki aşamalı bir
oyun çerçevesinde ele almaktayız. Birinci aşamada hükümet dış
ticaret politikasını oluşturmakta, ikinci aşamada firmalar
yapacakları ihracata karar vermektedirler. Oyunu geriye dönük
tümevarımla çözüyoruz. Bu model için aşağıdaki varsayımları
yapıyoruz.

221221
1. Üç ülke vardır: X, Y ve Z.
2. X ve Y ülkelerinde, homojen mal üreten birer firma vardır (x
ve y firmaları). Z ülkesinde üretim yoktur.
3. Her bir firmanın toplam maliyet fonksiyonu: .
, ,i i iTC c q i x y= =

222222
4. X ve Y ülkelerinde mal tüketimi yoktur. Tüm üretim Z ’ye
ihraç edilmektedir.
5. Z ’deki talep fonksiyonu: , x yP a Q Q q q= − = +
6. X ve Y ülkeleri, birim ürün başına ihracat desteği (sx ve sy)
uygulamaktadır. Z ülkesi tamamen serbest dış ticaret
uygulamaktadır.

223223
Yukarıdaki varsayımlara göre x ve y firmalarının kâr
fonksiyonlarını şöyle yazabiliriz:
( )
( )
x x x x x x x y x x x x x
y y y y y y x y y y y y y
Pq c q s q a q q q c q s q
Pq c q s q a q q q c q s q
Π = − + = − − − +
Π = − + = − − − +
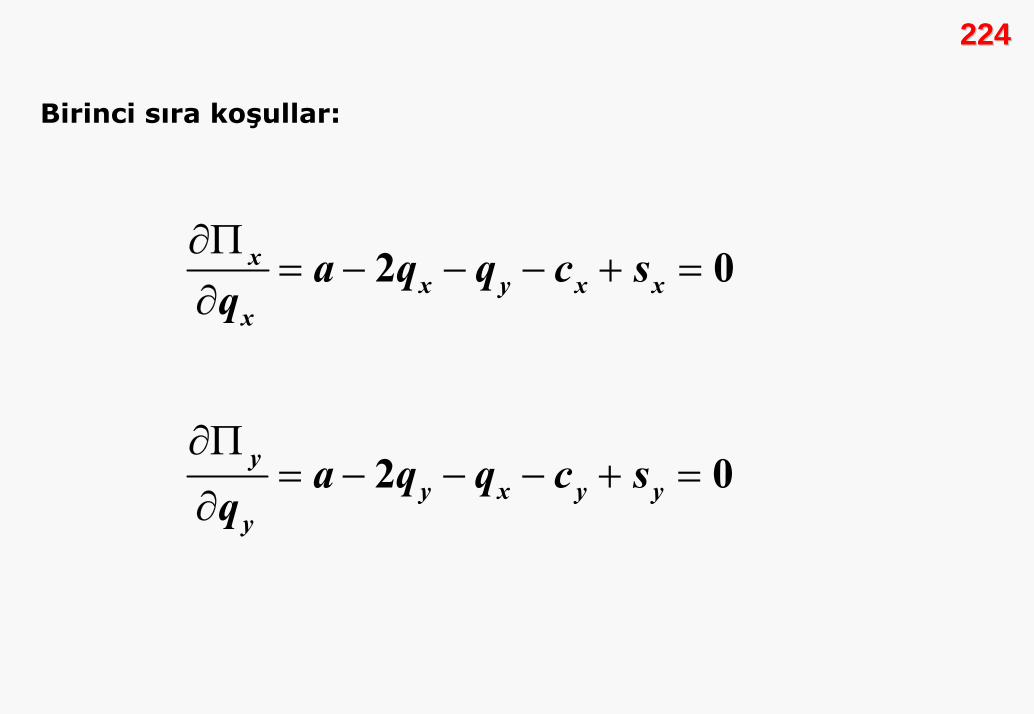
224224
Birinci sıra koşullar:
2 0
2 0
xx y x x
x
yy x y y
y
a q q c sq
a q q c sq
∂Π= − − − + =
∂
∂Π= − − − + =
∂

225225Birinci sıra koşulları çözelim:
*
*
* * *
* *
2 23
2 23
23
3
x x y yx
y y x xy
x y x yx y
x y x y
a c s c sq
a c s c sq
a c c s sQ q q
a c c s sP a Q
− + + −=
− + + −=
− − + += + =
+ + − −= − =

226226
Bu çözümler, firmalar için ikinci aşamadaki dengelerdir. Birinci
aşamada ülke hükümetleri, iktisadi refah düzeyini maksimize
edebilmek için dış ticaret politikasını belirlemektedirler. Her bir
ülkenin mal ihracatından elde ettiği özel kazanç, firma
kârlarıdır. Tüm ülkedeki net refah artışını ise, toplam kâr
düzeyinden toplam ihracat desteğini düşerek buluruz.

227227
X ve Y ülkelerinin iktisadi refah fonksiyonları:
( ) ( )
( ) ( )
x x x x x x x x x x x
y y y y y y y y y y y
W s q P c s q s q P c q
W s q P c s q s q P c q
= Π − = − + − = −
= Π − = − + − = −

228228
İkinci aşamada elde ettiğimiz optimal değerleri, bu refah
fonksiyonlarındaki yerlerine yazarak, refah fonksiyonlarını
tümüyle parametrelere ve dış ticaret politikalarına
bağlayabiliriz:
2 2 23 3
2 2 23 3
x y x y x x y yx
y x y x y y x xy
a c c s s a c s c sW
a c c s s a c s c sW
− + − − − + + −⎛ ⎞⎛ ⎞= ⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
− + − − − + + −⎛ ⎞⎛ ⎞= ⎜ ⎟⎜ ⎟⎝ ⎠ ⎝ ⎠

229229
Her bir ülke, refah düzeyini maksimize edecek olan dış ticaret
politikasını seçecektir.
* *
2 4 0
2 4 0
3 2 3 2,
5 5
xx y x y
x
yy x y x
y
x y y xx y
Wa c c s s
s
Wa c c s s
s
a c c a c cs s
∂= − + − − =
∂
∂= − + − − =
∂
− + − += =

230230
Bu sonuçtan ilk olarak şunu çıkarabiliriz: Her iki ülke pozitif
miktarda ihracat yaparsa, destekleme oranları da pozitif
olacaktır. Bunu görebilmek için, yukarıdaki değerleri, ikinci
aşamadaki üretim miktarlarının yerlerine yazmalıyız.

231231
Her iki ülkenin üretim maliyetleri aynıysa, pozitif denge destek
değeri, dış ticaret politikası seçiminde tutsaklar açmazı
durumunu yansıtır. İhracat desteği olmazsa, her bir firma
toplam piyasayı eşit paylaşırlar ve pozitif bir kâr elde ederler.

232232
Ancak her iki ülke destek politikası uygularsa, firmalar yine
piyasayı eşit paylaşırlar ve daha yüksek kârlar elde ederler.
Ancak fiyatların düşmesi sonucu, sübvansiyon maliyeti kâr
artışını aşacağından, ihracatçı ülke refah kaybına uğrar. Tek
kazançlı, Z ülkesidir.