nonlinear regression models and applications in...
TRANSCRIPT

Assim como diversos outros alunos, se apegou demais a uma tradução do artigo, deixando passar um
número bem maior de erros de tradução no meio do texto, como por exemplo “Eles são comumente usados
para descrever leves e N distribuições verticais dentro copa das plantas, resposta” que não faz o mínimo
sentido em português. A única interpretação lógica para uma frase deste tipo é simplesmente não ter lido o
que estava colocando no resumo. Outro ponto semelhante é no terceiro grupo quando fala que o grupo de
equações é a fotossíntese, quando esta não é nunca uma equação, embora este grupo inclua as equações que
podem ser usadas para representar este processo metabólico. 6,0
Nonlinear Regression Models and Applications
in Agricultural Research
Autores: Sotirios V. Archontoulis and Fernando E. Miguez*
Os autores Iniciam a revisão com algumas possíveis dúvidas que surgem quando estamos no processo
de análise de dados, onde as perguntas mais frequentes são: Qual é o melhor modelo para descrever os nossos
dados? Qual é o melhor índice estatístico para avaliar a qualidade do ajuste? Como é que vamos escolher entre
os modelos concorrentes? Deixando claro que não há respostas simples para estas perguntas. Diante disso os
autores tentaram mostrar de uma forma geral aos agrônomos, como abordar as questões ditas acima de forma
mais adequada, onde os objetivos traçados no trabalho foram: (I) fornecer uma visão sucinta dos modelos não
lineares e desenvolver uma diretriz para compreender a família de funções utilizadas em aplicações agrícolas,
(II) indicar técnicas para modificar modelos não lineares e como lidar com múltiplos modelos não lineares,
(III) discutir questões metodológicas importantes sobre estimativa de parâmetros, o desempenho do modelo,
e comparação e (iv) demonstrar passo-a-passo a análise dos dados experimentais utilizando um modelo de
regressão não-linear.
Os autores iniciaram com a definição de modelos de regressão não-linear e posterior discussão sobre
sua principais vantagens e desvantagens, com apresentação de 77 funções não-lineares com referências a
aplicações na agricultura.
No que diz respeito à definição: Modelo de regressão não-linear é descrito pela seguinte notação: 𝑦 = 𝑓 ( 𝑥,Ɵ) + 𝜀, onde 𝑦 é a variável resposta, 𝑓 é a função ou modelo, 𝑥 são as entradas, Ɵ indica os parâmetros
a serem estimados e 𝜀 é o erro. As principais Vantagens do modelo são: Parcimônia, interpretabilidade e
previsão. E em geral, suas previsões tendem a ser mais robustas que polinômios concorrentes, especialmente
fora do intervalo de dados observados (ou seja, extrapolação). Em relação as desvantagens do modelo, eles
Podem ser menos flexíveis do que modelos lineares concorrentes; geralmente não há nenhuma solução
analítica para estimar os parâmetros e o primeiro ponto tem como consequência que a escolha do modelo é
crucial. È quase sempre melhor escolher um modelo com base em se ele tem sido utilizado com sucesso em
aplicações similares e tem os parâmetros com significado biológico.
Em seguida, foi desenvolvido uma tabela de referência como um guia para compreender as funções
utilizadas em aplicações na agricultura onde nessa tabela, foi apresentada 27 equações não-lineares comuns e
quadros suplementares S2 a S6 complementá-las com 45 equações adicionais. Classificaram-se as equações
em seis grupos com base em uma combinação de forma estatística e utilização no domínio agrícola. Todas as
equações têm sido usadas em aplicações agrícolas, e a maioria dos parâmetros tem um significado
interpretável. Com toda essa variedade de equações percebe-se que uma equação não se adéqua a todos os
processos, é necessário que se conheça a biologia por trás de cada experimento, para que se escolha de forma
mais adequada a equação não-linear.
O primeiro grupo, é o grupo exponencial, encontram aplicações numa ampla gama de ciências do solo
e das plantas. Eles são comumente usados para descrever leves e N distribuições verticais dentro copa das
plantas, resposta de emissão de N2O para fertilizantes N, cumulativo respiração do solo, sensibilidade foto
periódica, temperatura ou umidade, respostas a nitrificação, a taxa de infiltração de água e a cinética de
primeira ordem.
O segundo grupo, é o grupo de curvas sigmoides (funções matemáticas que têm uma forma de S) são
outro grupo importante de modelos não lineares. Estes modelos são muitas vezes aplicados para descrever a
altura das plantas, peso, Índice de área de folha, ou a germinação das sementes como uma função de tempo, a
taxa de aplicação de N, dose do herbicida, etc. Equações sigmoide também são usados como modificadores
de 0-1 em modelos processos baseados para incorporar a disponibilidade de umidade ou o pH do solo, etc. Na
tabela S2 são dadas equações sigmoides adicionais que servem para dar uma maior flexibilidade, pois
dependendo do experimento, elas podem ser requisitadas. Dentre as curvas sigmoides existem a equação
Logística que descreve o crescimento simétrica ter um ponto de inflexão na metade do tamanho final, equação
Gompertz que tem um ponto de inflexão que é controlada pelo seu valor assintótico e é de cerca de um terço
e as equações de Richards, Weibull e beta que têm uma maior flexibilidade no tratamento de crescimento
assimétrico. Bom cada função tem suas vantagens e desvantagens, e cabe ao pesquisador escolher a mais
adequado para ajustar os dados experimentais.
O terceiro grupo é a fotossíntese que é o processo biológico mais importante envolvida no crescimento
das plantas, e a sua taxa é influenciada por irradiação, temperatura, disponibilidade de N, o déficit de pressão
de vapor, e concentração de CO2. Diferentes funções não lineares têm sido desenvolvidas para descrever a
resposta fotossíntese para diferentes variáveis ambientais. Entre as equações encontradas na tabela 1 estão:
Blackman (Eq. [3,1]) é o mais simples, e a assintótica exponencial (Eq. [3.2]) e hipérbole não retangular (Eq.
[3,4]) são as mais comuns. A hipérbole retangular (Eq. [3,3], também denominado de equação de Michaelis-
Menten) é utilizado menos frequentemente porque atinge a saturação mais rápida do que a fotossíntese, na
verdade, faz.
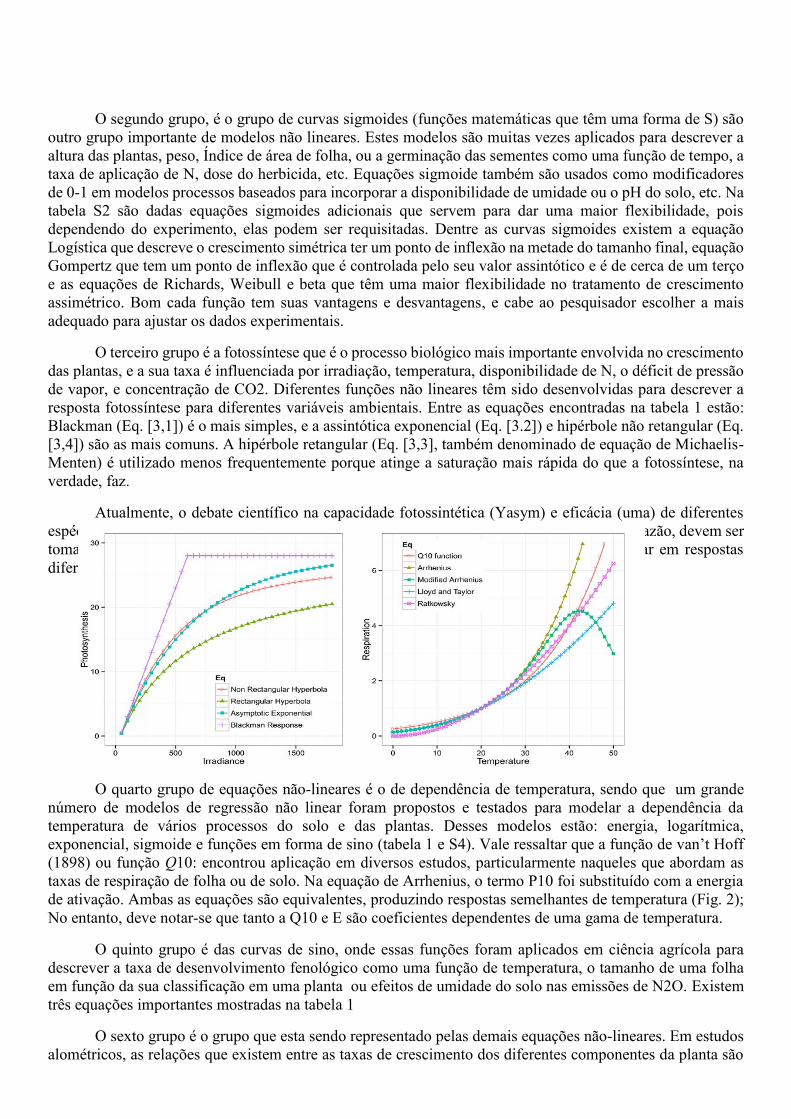
Atualmente, o debate científico na capacidade fotossintética (Yasym) e eficácia (uma) de diferentes
espécies de plantas baseia-se na comparação de estimativas de regressão não-linear; por esta razão, devem ser
tomadas precauções porque as estimativas semelhantes de diferentes equações pode resultar em respostas
diferentes (Fig. 2).
O quarto grupo de equações não-lineares é o de dependência de temperatura, sendo que um grande
número de modelos de regressão não linear foram propostos e testados para modelar a dependência da
temperatura de vários processos do solo e das plantas. Desses modelos estão: energia, logarítmica,
exponencial, sigmoide e funções em forma de sino (tabela 1 e S4). Vale ressaltar que a função de van’t Hoff
(1898) ou função Q10: encontrou aplicação em diversos estudos, particularmente naqueles que abordam as
taxas de respiração de folha ou de solo. Na equação de Arrhenius, o termo P10 foi substituído com a energia
de ativação. Ambas as equações são equivalentes, produzindo respostas semelhantes de temperatura (Fig. 2);
No entanto, deve notar-se que tanto a Q10 e E são coeficientes dependentes de uma gama de temperatura.
O quinto grupo é das curvas de sino, onde essas funções foram aplicados em ciência agrícola para
descrever a taxa de desenvolvimento fenológico como uma função de temperatura, o tamanho de uma folha
em função da sua classificação em uma planta ou efeitos de umidade do solo nas emissões de N2O. Existem
três equações importantes mostradas na tabela 1
O sexto grupo é o grupo que esta sendo representado pelas demais equações não-lineares. Em estudos
alométricos, as relações que existem entre as taxas de crescimento dos diferentes componentes da planta são

quantificados por meio de análise de regressão. Dada a grande variabilidade que existe entre as espécies de
plantas e componentes da planta, inúmeros modelos não-lineares têm sido utilizados, incluindo energia (Eq.
[6.1], por exemplo, planta de concentração de N vs. peso biomassa), hiperbólica (Eq. [6.2]), e curvas sigmoides
(por exemplo, a Eq. [3,1]).
Algumas vezes há a necessidade de modificar uma função não linear "padrão" para encaixar um
conjunto de dados. Isto levou ao desenvolvimento de inúmeras versões de uma equação padrão. Diante disso
podemos modificar a escala, deslocar toda a curva para cima ou para baixo, adicionando ou subtraindo um
novo valor constante e por fim, pode-se substituir X com XK, em que k é um parâmetro de forma, e, em
seguida, a equação assume muitas formas.
Atualmente existem muitos pacotes de software estatísticos disponíveis para modelos não lineares (por
exemplo, SAS, R, JMP, Genstat, MatLab, SigmaPlot, OriginLab, e SPSS). Estimativas de parâmetros não
lineares podem ser obtidos usando métodos diferentes; os mais comuns são: (i) dos mínimos quadrados
ordinários, o que minimiza a soma dos erros quadrados entre observações e previsões, e (ii) o método de
máxima verossimilhança, que visa a distribuição de probabilidade que faz com que os dados observados mais
provável. Para dados não-normal, tais como binomial ou contagens, modelos lineares generalizados não deve
ser utilizados. Não podemos esquecer que todos os procedimentos para a estimação de parâmetros não-linear
exigem valores iniciais. Essas escolhas irão influenciar a convergência do algoritmo de estimativa, no pior
caso que resultou em não convergência e no melhor dos casos a convergência em algumas iterações, no
entanto, não existe um procedimento padrão para a obtenção de estimativas iniciais. Com isso os autores
indicaram cinco métodos práticos: 1. Se o modelo tem parâmetros com significado biológico, em seguida,
usar informações da literatura. 2. Use exploração gráfica (veja o exemplo abaixo e Fig. 4). 3. Transformar o
modelo não-linear em um modelo linear. Por exemplo a transformação logarítmica da Eq. [1.1] produz uma
equação linear (viz lnY = Yo -. Kt) em que estimativas aproximadas dos valores dos parâmetros podem ser
facilmente obtidos por regressão linear. Este método é recomendado para obter estimativas iniciais e para
detectar desvios a partir de linearidade, mas estas estimativas podem também ser usados como as estimativas
finais 4. No caso em que não existem orientações claras para a escolha de valores iniciais, a recomendação é
usar uma pesquisa de rede ou abordagem de "força bruta". Esta pesquisa de grade pode ser feito através da
geração de uma extensa cobertura de possíveis valores de parâmetros (e suas combinações) e depois avaliar o
modelo em cada uma destas combinações de parâmetros. O método numérico pode então ser utilizado
começando com a combinação que resultou no melhor ajuste (menor erro quadrático médio). 5. Use algoritmos
pré-especificados.
Em relação aos critérios para seleção do modelo, devido estarmos lidando com vários modelos,
podemos usar teste F, critério de informação Akaike (AIC), critério de informação Bayesiana (BIC) ou o teste
da relação de probabilidade.
Em suma, os autores afirmam que modelos de regressão não-linear são ferramentas importantes porque
muitos processos de colheita e de solo são melhor representados por não-linear do que os modelos lineares e
ainda afirmam que modelos não lineares de montagem não é um procedimento de etapa única, mas um
processo que requer um exame cuidadoso de cada etapa individual obtendo estimativas de parâmetros
aceitáveis e um bom ajuste do modelo enquanto atende hipóteses-padrão de modelos estatísticos. Diante disso,
os autores Propuseram passos em montagem de modelos não lineares e a discussão de cada passo
separadamente fornecendo exemplos e atualizações sobre os procedimentos utilizados. Não deixando de falar
que os autores apresentaram uma extensa biblioteca de funções não-lineares (77 equações com as definições
de parâmetros associados) e aplicações típicas que, esperam, em tornar a tarefa de escolhas de modelos não-
lineares mais fácil, além de afirmarem que a revisão de equações não-lineares feita por eles é incompleta,
porque há um número incontável de potenciais funções a serem utilizados e modificados.


Embora bem melhor do que o outro resumo deste capitulo, em particular no que tange à legibilidade,
apresenta exatamente o mesmo erro de português sem sentido no Grupo 1 de equações, o que chega a ser
curioso em termos de coincidência 7.0
Modelo de regressão não linear e aplicações na pesquisa agrícola Archontoulis e Miguez 2015
Os autores começam relatando a importância da regressão não linear como sendo modelos que melhor
representa alguns processos biológicos, que a regressão linear não consegue linear explicar. Como todo
modelo requer cuidado em cada etapa de montagem.
Com isso, os objetivos do artigo foram fornecer uma visão geral dos modelos não lineares, dividindo
em grupos para melhor compreensão e interpretação dos modelos. Os autores listaram uma extensa biblioteca
de funções não-lineares (77 equações com os significados dos parâmetros associados) e exemplos de
aplicações típicas na agricultura, com intuito de esclarecer algumas dificuldades e confusões na escolha do
melhor modelo a ser escolhido. Discutindo questões metodológicas importantes na estimativa de parâmetros,
desempenho do modelo e comparação.
De forma geral, a regressão não linear pode ser descrita por: y = f (x, Ɵ) + ɛ. Onde y é a variável
resposta, f é a função ou modelo, x são as entradas, Ɵ denota q os parâmetros a ser estimada, e ɛ é o erro.
As principais vantagens dos modelos não lineares são parcimônia (consegue explicar o máximo com
o mínimo de parâmetros), interpretabilidade (vem do fato de que os parâmetros podem ser associados com
processos biológicos) e previsão (mas robustas, e fora do intervalo de dados observados, extrapolação). Os
modelos não lineares são capazes de acomodar uma grande variedade de funções médias, embora cada modelo
não-linear apresente menor flexibilidade do que os modelos lineares.
Suas principais desvantagens, além da baixa flexibilidade em relação aos outros modelos. Geralmente
não há nenhuma solução analítica para estimar os parâmetros. Sendo assim, a escolha do modelo é crucial.
A escolha de um modelo com parâmetros com significado biológico faz com que o processo de escolha
de valores iniciais seja mais fácil, porque os valores de partida podem geralmente ser facilmente determinada
por inspeção visual dos dados.
Os autores desenvolveram uma tabela de referência como um guia para compreender a família de
funções utilizadas em aplicações agrícolas. Foram listadas 77 equações no artigo (27 presente numa
tabela/quadro e as outras 45 presente nas informações complementares). As 27 equações presente na tabela
foram classificadas em seis grupos com base em uma combinação de forma estatística e utilização no domínio
agrícola.
Segundo os autores, as equações têm sido usadas em aplicações agrícolas, e a maioria dos parâmetros
têm um significado interpretável. A variedade de equações apresentadas na tabela/quadro reflete bem o fato
de que uma equação não se adequa a todos os processos.
Grupo 1: Exponencial
Eles são comumente usados para descrever: Níveis de N e distribuição vertical dentro da copa das
plantas; Resposta à emissão de N2O para fertilizantes N; Respiração do solo; Sensibilidade ao fotoperíodo;
Taxa de infiltração de água.
Grupo 2: Curvas Sigmoide
São comumente usados para descrever: Altura e peso das plantas; Índice de área foliar; Germinação
das sementes em função do tempo; Taxa de aplicação de N; Dose de herbicida.

Grupo 3: Fotossíntese
Processo biológico mais importante envolvido no crescimento das plantas. Sua taxa é influenciada por:
Irradiação Temperatura Disponibilidade de N Déficit de pressão de vapor Concentração de CO2.
Todas as equações assumem que a respiração no escuro é independente de luz.
Grupo 4: Dependência de temperatura
Grande número de modelos de regressão não linear foram propostos e testados para modelar a
dependência da temperatura de vários processos de solo e planta.
O van't Hoff ou função Q10 (Q10 é o factor pelo qual a velocidade de um processo aumenta para cada
10 ° C de aumento de temperatura) encontrou aplicação em diversos estudos, particularmente naqueles que
abordam as taxas de respiração de folha ou de solo, por exemplo.
Grupo 5: Curvas de sino (Funções em forma de sino ou de pico)
São comumente usados para descrever: Dependência de temperatura na fotossíntese; Taxas de
desenvolvimento fenológico em função da temperatura; Tamanho da folha em função da sua posição na planta
; Efeitos da umidade do solo nas emissões de N2O.

Grupo 5: Outros
Em estudos alométricos, as relações que existem entre as taxas de crescimento dos diferentes
componentes da planta são quantificadas pela análise de regressão.
Grande variabilidade entre as espécies de plantas e seus componentes e muitos modelos não-lineares
são utilizados.
A necessidade de modificar uma função não linear "padrão" para encaixar um conjunto de dados, levou
ao desenvolvimento de inúmeras versões de uma equação padrão.
Quando funções não-lineares são modificadas ou combinados para descrever um fenômeno, devemos
estar cientes de que há um limite superior do número de parâmetros que podem ser estimados a partir da
análise de regressão não-linear padrão. Isto depende da complexidade do modelo e o número de pontos de
dados. Por exemplo, para ajustar as curvas de crescimento com três parâmetros, precisamos de pelo menos
quatro pontos de dados.
Os autores citam muitos pacotes de software estatísticos disponíveis para modelos não lineares de
montagem (por exemplo, SAS, R, JMP, Genstat, MatLab, SigmaPlot, OriginLab, e SPSS).
Estimativas de parâmetros não lineares podem ser obtidos usando métodos diferentes, os mais comuns
são: dos mínimos quadrados ordinários (minimiza a soma dos erros quadrados entre observações e previsões);
método de máxima verossimilhança.
Baseado na literatura os autores falaram que para dados não-normal, tais como binomial ou contagens,
modelos lineares generalizados (não) deve ser utilizada. A maioria dos problemas encontrados durante o uso
de funções de software de regressão não-linear padrão são devidos a uma má escolha de modelos concorrentes
ou uma equação incorreta ou valores iniciais. E que a escolha do método de estimação pode afetar as
estimativas dos parâmetros, mas em geral, as estimativas de mínimos quadrados e métodos de probabilidade
máxima tendem a diferir apenas quando os dados não estão normalmente distribuídos e são aproximadamente
idênticos quando os dados seguem uma distribuição normal.
Todos os procedimentos para a estimação de parâmetros não-lineares requerem valores iniciais. A
escolha de valores irão influenciar a convergência do algoritmo de estimativa, resultando em não convergência
ou convergência em algumas interações.
Não existe procedimento padrão para obter estimativas iniciais. Mas pode utilizar gráficos de
exploração ou usar algoritmos pré-especificados.
Para encontrar o melhor modelo, entre tantos modelos disponíveis, diferentes critérios estatísticos
podem ser usados para encontrar o melhor modelo: teste F, informação Akaike critério (AIC), critério de
informação Bayesiano (BIC), ou o teste da razão de verossimilhança.

Com toda essa explanação sobre modelos não lineares, os autores concluíram que a escolha da função
principal é crítica e isso pode ser difícil sem uma orientação adequada. E que com a leitura desse artigo fique
mais fácil a tarefa de escolher da melhor equação que explique seu conjunto de dados.
Bom resumo, embora pudesse ser mais detalhado. No entanto, demonstrou que realmente leu o artigo, e tenta
tocar nos pontos mais importantes. Faltou uma discussão mais aprofundada do que é interação, a meu ver. 9,0
Avaliação e interpretação das interações
Jose Crossa,* Mateo Vargas, C. Mariano Cossani, Gregorio Alvarado, Juan Burgueno, Ky L. Mathews, and
Matthew P. Reynolds
O texto de Crossa e colaboradores explica que entender quais fatores definem uma determinada interação é
importante em diversas áreas, tais como na agricultura, pesquisa agronomica e no melhoramento de plantas. Nesse
sentido os tratamentos agronômicos ou genéticos são avaliados sob várias condições ambientais e nesse contexto as
interações podem complicar as decisões do pesquisador. Neste texto os escritores dão exemplos de como examinar
interações em experimentos agrícolas comuns utilizando informações disponíveis no termo de interação do modelo.
São abordados alguns exemplos com diferentes níveis de complexidade de interação para ilustrar como analisar e
interpretar as interações. É uma ferramenta aos pesquisadores que oferece maior compreensão de como explorar
informações de interação indo além dos testes estatísticos mais usados na análise de variância de costume.
O ideal é que, ao estabelecer experimentos, sejam priorizados os objetivos de forma clara, indicando sobre o
que se pretende estudar em uma dada população, assim o autor entende que algumas perguntas devem ser
respondidas: “Primeiro, como é que cada tratamento afetará as variáveis de resposta? Segundo, que tipos de
interações ocorrem entre os tratamentos? Terceiro, é possível tirar conclusões sobre os efeitos principais mesmo com
a existência de interações significativas? Quarto, níveis específicos dos efeitos do tratamento estão causando a
interação? E quinto, é possível fazer inferências sobre os principais efeitos de um tratamento por meio da combinação
de dados entre os outros tratamentos?”(Crossa et al, 2015)
Muitas vezes os experimentos são caros, de modo que o pesquisador tem que usar um número limitado de
tratamentos e combinações de tratamento, de acordo com os recursos financeiros e humanos disponíveis. Em
experimentos informações sobre a interação entre os tratamentos nunca devem ser ignorados, pois daí pode surgir
uma melhor compreensão de como os níveis de um determinado tratamento respondem aos diferentes níveis de
outro tratamento. Em vez de ignorar esta parte importante do modelo, deve ser utilizado informações sobre a
interação.
Modelos e métodos para avaliar as interações são discutidos mostrando a descrição e estudo de interações
em experimentos agrícolas comuns. São apresentados alguns exemplos, com diferentes níveis de complexidade, que
ilustram a forma de se analisar e interpretar as interações. É mostrado como os componentes de interação podem ser
particionados em contrastes, o que possibilita interpretações biológicas lógicas.

Um experimento é denominado fatorial quando duas ou mais séries de tratamento são estudadas,
simultaneamente, no mesmo experimento. Os tratamentos que compõem cada fator são chamados níveis do fator e
as combinações entre os níveis dos fatores formam os tratamentos dos experimento fatorial.
O modelo de Regressão Fatorial pode ser usado para examinar as causas da interação. Esse modelo pode ser
usado no contexto de qualquer tabela de duas vias para definir conjuntos de variáveis que podem ser usados de forma
combinada. O uso de contrastes bem definidas podem ajudar a entender as interações entre fatores e detectar
possíveis níveis ou combinações de níveis de um fator que interagem com os níveis do outro fator.
Regressão fatorial também pode ser usada para a incorporação de covariáveis externas não controladas, a
exemplo de variáveis climáticas (geralmente registradas em estações experimentais) assim como variáveis genotípicas.
Essas podem ser usados para examinar as causas da interação. Variáveis externas ambientais e/ou genotípicas são
introduzidos como covariáveis em uma análise de regressão para explicar a interação.
Interações em experimentos de agronomia e melhoramento de plantas referem-se a resposta diferenciais de
tratamentos ou genótipos a diferentes condições ambientais. Foi mostrado como trabalhar com interações em ensaios
agronômicos e de melhoramento de plantas. Para isso foram utilizados três diferentes exemplos: Primeiro, uma
avaliação agronômica, Segundo, uma avaliação de melhoramento, e Terceiro, uma avaliação agronômica em diversos
ambientes.
Os resultados do Exemplo 1 mostram como interações de efeitos fixos em contrastes ortogonais (ou não)
podem ser construídos para fornecer informações biológicas úteis presentes nos graus de liberdade disponíveis. A
regressão fatorial de efeitos fixos provou ser útil para combinar um único grau de liberdade em contraste ortogonal
em comparações específicas definindo covariáveis de interesse do pesquisador.
No Exemplo 2 foi possível mostrar interações quando tratados como efeitos fixos ou aleatórios. Ele também
mostrou como covariáveis ambientais e genotípicas são definidos no modelo de regressão fatorial com a finalidade de
explicar a interação. Seus dados foram postos juntamente com modelos lineares-bilineares e mistos para mostrar o
efeito da modelagem da interação na precisão das médias do tratamento. Por fim, os dados do Exemplo 3 ilustram a
utilização de regressão PLS multivariada para explicar interações de um grande número de covariáveis ambientais
e/ou genotípicos.
Bom resumo, mais detalhado do que o outro do mesmo artigo, também demonstrou que leu o artigo, mas de
forma semelhante a vários outros resumos, se ateve mais aos exemplos do que a como eles afetam o caso mais geral,
o que deveria ser na verdade o foco central do trabalho. 9,0
Evaluation and Interpretation of Interactions
(Avaliação e interpretação de interações)
Crossa et al. (2015)

O artigo faz uma abordagem à métodos para avaliação de interações e fornece exemplos
mostrando como as interações com diferentes níveis complexos podem ser estudadas e exploradas em
experimentos agronômicos comuns. São dados exemplos de modelos de efeito fixo linear e modelos de efeito
misto linear com estrutura de variância e covariância para modelar as interações.
O modelo básico de duas vias é expresso como: 𝑌𝑖𝑗𝑟=µ+τ𝑖+ẟ𝑗+(τẟ)𝑖𝑗+ε𝑖𝑗𝑟. Normalmente, os
pesquisadores estão interessados em saber como os níveis dos tratamentos τ e ẟ afetam a variável resposta e
se τ e ẟ interagem ou são independentes. A falta de interação entre a média dos tratamentos pode ser testada
pela hipótese: (τẟ)𝑖𝑗=0. Se a hipótese de interação é rejeitada, então surge a dúvida de como usar
eficientemente as informações disponíveis nos graus de liberdade (𝐼-1) x (𝐽-1). Para isso existem dois métodos:
primeiro, testar a significância do termo de interação e se (τẟ)𝑖𝑗 é de fato significativa e segundo, ter um melhor
entendimento das interações e suas causas. A regressão fatorial utilizada nos dados dos exemplos foi usada
para definir contrastes de interação usando covariáveis.
No exemplo 1, intitulado Combinação de Densidade-Cultivar Avaliadas sob Contraste de
Estresse Hídrico, foi simulado um experimento agronômico com dois cultivares (C1 e C2) plantadas em duas
densidades de plantas diferentes (D1 e D2) e avaliadas sob três níveis de disponibilidade de água: estresse
hídrico severo (SS), estresse hídrico intermediário (IS) e condições ótimas de água (WW), com três repetições
para rendimento de grãos (em Mg ha-1). O objetivo nesse exemplo foi o de comparar os níveis de dois efeitos
principais (densidade-cultivar e tipos de estresse) bem como suas interações. Para o fator densidade-cultivar,
os autores quiseram testar os efeitos das duas densidades na Cultivar 1 e 2 (Contrate 1 e 2) e examinar as
diferenças entre o desempenho dos dois cultivares sobre as duas densidades (Contraste 3, Tabela 1). Para o
fator tipos de estresse o objetivo foi testar diferentes performances entre SS e IS (Contraste 4, estresse) e a
média de dois ambientes de estresse (SS e IS) vs. Condições ótimas de água (WW) (Contraste 5, tipos de
estresse).
Os resultados da análise de variância são apresentados na Tabela 2 e indica que a interação é
causada principalmente por C1 ter diferentes respostas sob as duas condições de estresse comparados com a
condição ótima (C1 x tipos de estresse, Tabela 2). Pelo fato de não haver interação entre cultivar e os níveis
de estresse (SS e IS), SS e IS podem ser comparados após uma média entre as duas cultivares. A significância
dessa comparação é P=0,337, portanto, não há diferença significativa entre SS e IS. Também não há interação
entre a Cultivar 2 sob Densidade 1 e 2 e os três tipos de estresse (SS, IS e WW), assim, C2D1 e C2D2 também
podem ser comparadas após combinar seus valores entre SS, IS e WW. O valor F desta comparação é 25,92,
indicando uma diferença significativa (P<0,001) entre C2 sob D1 e C2 sob D2. A diferença entre C1 sob D1
e C1 sob D2 também é significativa (valor F=13,52). Para este primeiro exemplo, os autores finalizam
afirmando que é importante saber onde as interações ocorrem no experimento para que as conclusões sejam
obtidas com mais certeza.
O exemplo 2, intitulado Avaliação de Cultivares em Ambientes Contrastantes, incluiu 40
genótipos de trigo (Triticum aestivum L.) avaliados em dois anos consecutivos sob quatro condições
ambientais: Seco (D), Irrigado (I), e duas condições de estresse térmico (H) sendo calor intermediário (IH) e
calor severo (SH). Foi utilizado o modelo α-lattice incluindo oito blocos incompletos com cinco genótipos e
duas repetições. As quatro condições ambientais nos dois anos poderiam ter sido consideradas separadamente

no modelo linear, mas para o propósito dos autores, as condições ambientais e os anos foram combinados,
resultando em um total de oito ambientes. A característica analisada foi rendimento de grão, que foi medida
em gramas de grãos por unidade de terra (gm-2). Comparações incluindo contrastes ambientais entre D, I e os
dois níveis de H nos dois anos foram analisadas. Além disso, contrastes nas respostas dos diferentes grupos
de genótipos diferindo em características agronômicas e genéticas foram testadas.
Após definir e testar os contrastes de interação individualmente (para ambiente e genótipo), os
contrastes de ambiente e genótipo foram usados simultaneamente em PROC GLMSELECT com um
procedimento de etapas para seleção das comparações mais importantes para explicar as interações. A
comparações dos contrastes de interação foram feitas definindo covariáveis apropriadas, como por exemplo:
H vs. I (Covar_1), D vs. I (Covar_2), D vs. H (Covar_3), e (D e H) vs. I (Covar_4), e seus efeitos nos genótipos
foram testados.
A Tabela 3 apresenta os resultados da análise de variância e todos os contrastes de interação
individual de ambiente e genótipos. O contraste de interação individual para o ambiente mostra que as
Covariáveis 1, 2, 3 e 4 explicam 34,6, 38,6, 22,0, 39,7%, respectivamente, da interação total, quando as
interações foram consideradas individualmente. Quando foi utilizado o procedimento de etapas do PROC
GLMSELECT, foi observado que a Covar_4 e Covar_3 explicaram uma porção significativa de interação. Os
contrastes de interação (seco vs. ambiente quente com genótipos [Covar_3] e interações de seco e quente vs.
ambiente irrigado com genótipos [Covar_4]) juntos explicaram 61,6% da interação com apenas 28,6% de
graus de liberdade.
Os contrastes de interação individual para os genótipos mostraram que a única interação do
genótipo significativa com o ambiente está relacionada com a comparação do Genótipo Grupo 1 vs. Genótipo
Grupo 2 (Covar_1). Esta comparação explicou apenas 4,0% da variabilidade total de interação e as outras
nove comparações também não contribuíram para a variabilidade de interação.
No exemplo 3, intitulado Usando Covariáveis para Explicar Interações de Tratamento x Ambiente, é
feita uma pequena abordagem sobre mínimos quadrados parciais e modelos de regressão fatorial. Os autores
iniciam este exemplo afirmando que muitos fatores complicam a interpretação dos coeficientes de regressão
no modelo de RF. Como por exemplo, quando covariáveis de ambiente e genótipo mostram alta colinearidade,
os coeficientes de regressão não são estimados precisamente. Um método alternativo de estimativa é a
regressão dos mínimos quadrados parciais (PLS).
Para o exemplo 3, foram explicados dados e resultados apresentados por Crossa et al. (2010) em um
ensaio em vários ambientes incluindo 12 tratamentos de aplicação de Zn em quatro locais da India´s Eastern

Gangetic Plains utilizando o cultivar de trigo mais semeado nesta região. Concentrações de Zn e Fe nos grãos
foram registrados e análises de RF e PLS foram aplicadas no tratamento de Zn x ambiente (TE).
Os resultados na Tabela 5 demonstram que, primeiro, a análise de RF mostrou que para os grãos Zn,
duas covariáveis (aplicação no solo de Zn e Fe numa profundidade de 0 a 30 cm) foram significativos e
contribuíram em 91,0% da variação. Segundo, duas covariáveis (Zn numa profundidade de 0 a 30 cm do solo
e umidade relativa antes da floração) foram significativos e representaram 92,0% da variação para as
concentrações de Fe nos grãos. A resposta da localização variou amplamente para a concentração de Zn nos
grãos de trigo e a interação TE foi significativo para as concentrações de Zn nos grãos. As maiores
concentrações de Zn foram registradas quando os tratamentos foliar e de solo foram aplicados juntos.
Como conclusão do artigo, é afirmado que as interações em experimentos agronômicos e
melhoramento de plantas referem-se à resposta diferencial dos tratamentos ou genótipos aos vários tipos de
ambientes e os autores mostram como lidar conceitualmente e na prática com interações em experimentos
agronômicos e melhoramento de plantas através da apresentação de três exemplos diferentes, onde o exemplo
1 é um experimento agronômico, exemplo 2 é um experimento de melhoramento de plantas e o exemplo 3,
que mostra um experimento agronômico em diversos ambientes.
Boa discussão, embora como tem sido comum ainda apresente pontos com o texto excessivamente
influenciado pelo inglês do original. Gostei particularmente do último parágrafo. 9,5
Resumo - Análise e interpretação de interações na pesquisa agrícola
Interação mais importante na área da Agricultura é devido à mudança de classificação (interação
“crossover”), dado que interação não “crossover” não impede de fazer recomendações gerais ao nível de um
fator através de todos níveis de outros fatores. Diversos modelos são usados para descrever a média resposta
de tratamentos através de ambientes e para estudar e interpretar tanto tratamento x ambiente como genótipo x
ambiente.
Interações de três vias podem surgir em experimentos agrícolas que incluem tratamentos estabelecidos
em vários ambientes através do tempo. Também, podem ocorrer, assim como as de quatro vias, para outras
condições ou tratamentos aplicados pelo pesquisador, tais como data de semeadura, taxa de fertilizantes e/ou

densidade de plantas. Vale salientar que McIntosh (1983) forneceu orientações para análise de experimentos
combinados através de vários locais ou anos.
Ao analisar dados experimentais, pesquisadores precisam responder questões relacionadas a diferentes
hipóteses como, por exemplo, como cada tratamento afeta variável resposta? Que tipo de interação há entre
tratamentos? Se conclusões sobre os efeitos principais podem ser alcançados apesar da existência de interações
significativas e se ou não existem níveis específicos de efeitos de tratamentos causando interação. Crossa et
al. (2014) faz um relato detalhado de como lidar com interações em diversas situações práticas relacionadas
com a agricultura, melhoramento de plantas, e outras áreas de pesquisa fazendo uso de modelos linear fixo e
de efeitos mistos.
Geralmente quando níveis de um fator são discretos utilizam-se, entre eles, comparações médias
(Carmer, 1976; Carmer e Swanson, 1971, 1973; Saville, 2014), enquanto que contrastes ortogonais
polinomiais são recomendados para Níveis quantificativos de um fator (Swallow, 1984; Little, 1978; Saville,
2014). Para comparações múltiplas entre médias aconselham-se diferença mínima significativa (Glaz e Dean,
1988; Saville, 2014).
Modelos de linha de base: Modelo de 2 vias sem interação: Modelo linear de efeito fixo de 2 vias
considera que resposta média empírica Yij , de tratamento ith (i = 1, 2, ..., I) em ambiente jth (j = 1, 2, ..., J)
com n replicações em cada uma das células I x J é expressa como , onde é a
média através de todos tratamentos e ambientes, Ti é efeito aditivo em tratamento ith, é efeito aditivo no
ambiente jth e é erro médio de tratamento ith no ambiente jth, assumido ser normalmente, de forma
idêntica e independentemente distribuído , onde é erro dentro do ambiente e In representa
identidade matrix de ordem n x n. A existência possível de interação tratamento x ambiente e genótico x
ambiente é ignorada e seus efeitos são estimados em conjunto com o erro médio.
Modelo de 2 vias com interação: Tomando o modelo dado na equação anteriormente mencionada
como ponto de partida, a inclusão do termo de interação no modelo linear de efeito fixo de 2 vias para análise
de interação tratamento x ambiente e genótipo x ambiente torna-se:
, onde é interação fixa não aditiva (tratamento x ambiente ou genótipo x ambiente) efeito de tratamento
ith no jth ambiente.
Modelo de 3 vais com interação: Considere uma situação em que os dados do ensaio do modelo
representado na equação anterior são efetuados em diversos anos (isto é, tratamento x ambiente x ano) (k = 1,
2, ..., K). Normalmente na Agronomia, anos são considerados efeitos aleatórios. Suponha que efeitos
principais de tratamentos e ambientes, assim como suas interações, são considerados como efeitos fixos. O

modelo linear representado na equação anterior é agora estendido para incluir os efeitos aleatórios de anos e
suas interações aleatórias de 2 e 3 vias com tratamento e ambientes:
, onde é efeito aleatório do ano kth assumido ser
, onde é a variação entre anos e Ik é a identidade matrix de ordem K x K, é os efeitos de
interação aleatória do tratamento ith no ano kth assumido ser , onde é a variância da interação
tratamento x ano e IIK é a identidade matrix da ordem IK x IK, é a interação do ambiente jth no ano
kth assumido sendo onde é a variância da interação ambiente x ano e IJK é a identidade
matrix da ordem JK x JK e é a interação aleatória de 3 vias no tratamento ith no ambiente jth e o ano
kth assumido , onde é a variância da interação tratamento x ambiente x ano e IIJK é a
identidade matrix da ordem IJK x IJK.
É de fundamental importância analisar e interpretar todas interações possíveis entre tratamentos em
experimentos com mais de um tratamento. Não existem regras estatísticas para conduzir como resultados
podem ser descritos baseado sobre quais interações foram significativas. A explicação final do pesquisador
pode focar sobre interações de 2 vias quando interações de ordem superior foram significativas ou pode se
concentrar sobre efeitos principais quando interações de 2 vias foram significativas. Frequentemente será
necessário usar a maior ordem de interações que foram significativas. A mensagem de maior valia ao
pesquisador é que todas as pesquisas significativas devem ser analisadas pela interpretação de todas as
interações possíveis; todas interações que são estatisticamente significativas devem ser relatadas. Relatórios
finais de resultados e conclusões necessitam ser baseados em conhecimento biológico e interpretação de
procedimentos estatísticos que foram devidamente conduzidos e interpretados.
Por favor, alguém pode me explicar qual a grande dificuldade de ler o que escreve. Eu reclamei o
mesmo ponto em todos (ou pelo menos a vasta maioria dos resumos)... uma frase como “...experimentos de
agronômicos...” não pode ter sido lida por quem escreveu... e neste caso está na primeira linha do resumo.
Como alguém pode achar que o autor do resumo realmente estava pensando no que estava fazendo, o que é
um pré-requisito essencial para resumir um texto, pelo menos até onde sei. Este problema se repete em outros
pontos do texto, combinado com uma fixação excessiva no teor exato dos exemplos, ao invés de se preocupar
com o que pode servir dos exemplos para os caso mais gerais, o que é o grande objetivo de TODOS estes
artigos. Repito que este problema tem acontecido em maior ou menor grau na vasta maioria dos resumos, mas

que também tenho comentado isto consistentemente , ou seja, já deveria ter dado tempo de vocês aprenderem
com os erros dos outros 7
Analysis and Interpretation of Interactions in Agricultural Research Análise e Interpretação de Interações em Pesquisa Agrícola
Vargas et al. (2015) A presença de interação de um tratamento X ambiente (TE) em experimentos de agronômicos e uma
interação genótipo X ambiente (GE) em ensaios de melhoramento são expressados como respostas inconsistentes de alguns tratamentos em relação a outros devido a mudanças na classificação do tratamento (interação cruzada, COI) ou como mudanças nas diferenças absolutas entre os tratamentos sem alteração da classificação, ou seja, uma mudança de escala ou interação não-cruzado (NCOI). A interação cruzada é a mais importante, uma vez que a NCOI não impede a formulação de recomendações gerais ao nível de um fator em todos os níveis de outros fatores.
Interações triplas podem surgir em experimentos agrícolas que incluem tratamentos estabelecidos em vários ambientes ao longo dos anos. Além disso, interações triplas e quadruplicas podem surgir em outras condições ou tratamentos aplicados pelo pesquisador, como época de semeadura, quantidade de fertilizantes e/ou densidade de plantas. Apesar de anos em si podem não ser intrinsecamente interessante, eles fornecem as condições ambientais em que a cultura é cultivada, e as respostas diferentes de ambientes em anos podem ser relevantes para a identificação de tratamentos estáveis em todas as regiões geográficas e anos.
Alguns tratamentos podem responder de forma semelhante em alguns ambientes e diferentemente em outros, e alguns ambientes podem ser mais associado com os outros em alguns anos. Uma abordagem para a obtenção de idéias sobre as interações triplas é importante e útil e, quando possível, este tipo de abordagem é mais útil do que condensar dados de três vias em dados de duas vias. Uma abordagem menos útil é para excluir anos e analisar o TE (tratamento x ambiente) em cada ano separadamente. As limitações desta abordagem é que ela não explica a significância do TE ao longo dos anos e que há perda de informação porque os dados não são analisados no seu formato original, que é a interação de três vias.
Normalmente, quando os níveis de um fator são discretos, comparações de médias entre eles são utilizados, enquanto que contrastes ortogonais polinomiais são recomendados para níveis quantitativos de um fator. Para comparações múltiplas entre as médias, um procedimento recomendado para os pesquisadores que estão igualmente preocupados com os erros Tipo I e II, e também sobre a comparação adequada, em vez de taxas de erro experimentais, é a diferença mínima significativa (LSD).
Este estudo analisou conjunto de dados agronômicos e de melhoramento com efeitos aleatórios e fixos. As análises de dois experimentos agronómicas (Exp. 1 e 2) e um ensaio de melhoramento em vários ambientes com conjuntos não estruturados de linhagens de trigo são descritos para ilustrar algumas das análises básicas que podem ser executadas para estudar e destrinchar TE (Exp. 1 e 2) e avaliar e estudar GE (3 Exp.).
DADOS EXPERIMENTAIS Experimento 1 – realizado em latitude altas com trigo de sequeiro na primavera no norte do
Cazaquistão em dois locais com tipos de solos diferentes (castanho e preto), duas doses de N (0 e 30 kg ha-
1), e quatro doses de P (0, 50, 150 e 250 kg ha-1), com rendimento de grãos (GY, Mg ha-1) em um genótipo de trigo em 2007. O experimento foi realizado utilizando um delineamento de blocos ao acaso com duas repetições em cada um dos dois locais.
Experimento 2 – foi realizado no México e compreendeu oito híbridos de milho que representam 8 anos de seu lançamento (1-8) avaliados em quatro doses de N (0, 75, 150 e 300 kg ha- 1) por 3 anos com o objetivo de estudar as respostas de híbridos de milho sob diferentes históricos de doses de N. Cada

tratamento híbrido x dose de N foi disposta em um delineamento em blocos casualizados com três repetições a cada ano.
Experimento 3 – é um ensaio de melhoramento realizado no México com o objetivo de avaliar a resposta de sete linhagens de trigo (1-7) semeadas em dois ambientes de baixo rendimento (1 e 2) e quatro ambientes de rendimento intermediário (3-6). As sete linhagens de trigo foram dispostos em um delineamento em blocos casualizados com duas repetições em cada ambiente.
RESULTADOS E DISCUSSÃO Experimento 1 A interação solo x N x P não foi significativa e nenhuma das suas respostas foram linear, quadrática
ou polinomial cúbica. Isto pode ter sido devido à resposta quase paralela do GY (rendimento de grãos) no solo preto para N30 e N0 em todas as doses de P e devido às respostas semelhantes em todas as doses de P para cada uma das duas doses de N. A interação não significativa entre os dois tipos de solo e as duas doses de N para todas as doses de P está claramente representada na Fig. 1.
- Separando as interações duplas: Neste conjunto de dados, todas as interações duplas (solo X N, solo X P e N X P) foram significativas,
incluindo as respostas lineares da interação P x solo e as respostas cúbicas de P na interação N x P. Primeiro, a tendência significativa cúbica de P na interação de N x P apresenta maior GY para N30 do
que para N0 com uma tendência NCOI. Segundo, a interação linear significativa de solo x P mostra uma resposta linear muito maior para P em todas as doses no solo preto do que no solo castanho; a interação NCOI entre solo e P é claramente descrita. Este NCOI indica que, as respostas de rendimento de grãos foram significativas em ambos os solos, porém, a resposta linear no solo Preto foi significativamente mais positiva do que no solo Chestnut. Assim, dependendo do custo do fertilizante fosfatado, pode não ser econômica aplicá-lo no solo castanha.
- Efeitos principais: Se tivéssemos analisado somente o efeito principal do P no presente estudo, teríamos que concluir
que o GY responde positivamente e de forma semelhante ao P em ambos os solos. De fato, a interação solo
x P indicou que os agricultores com solo preto poderia esperar uma resposta muito maior de P do que os agricultores com solo castanha.
Da mesma forma ocorre para a resposta de N para cada solo, ou seja, se tivéssemos analisado somente os efeitos principais, teríamos que dizer a todos os agricultores para aplicar taxas mais elevadas de N e P. No entanto, com base nas interações significativas, é muito mais clara que a maior parte da resposta positiva para cada elemento foi devido à resposta no solo preto.
Experimento 2 O modelo linear misto considera ano e as interações com N e o híbrido de milho como efeitos
aleatórios. Os resultados indicam que, depois do componente de variância residual, ano foi o fator mais importante em termos de componentes de variância, seguida pela interação ano X N. As interações anos X híbridos e anos X híbridos x N foram insignificantes.
No entanto, o componente de variância ano teve o maior valor de p para a hipótese de variação igual a zero, utilizando o teste Z aproximado. Além disso, o zero (ou negativos) dos componentes de variação de ano x híbrido e ano x híbrido x N pode ser devida a um artefato de optimização do algoritmo que inclui uma restrição não-negativa, bem como poderia representar efeitos da concorrência entre lotes adjacentes no mesmo bloco no campo.
Os efeitos principais fixos de N e seus contrastes ortogonais linear e quadrática foram significativamente diferentes de zero, indicando que os híbridos tiveram uma resposta curvilínea em níveis mais elevados de fertilizantes nitrogenados. Além disso, como esperado, não foram detectadas diferenças altamente significativas entre os híbridos de milho históricos.
- Separando as interações duplas: O teste da resposta linear na interacção híbrida X N foi significativa, porque os híbridos mais
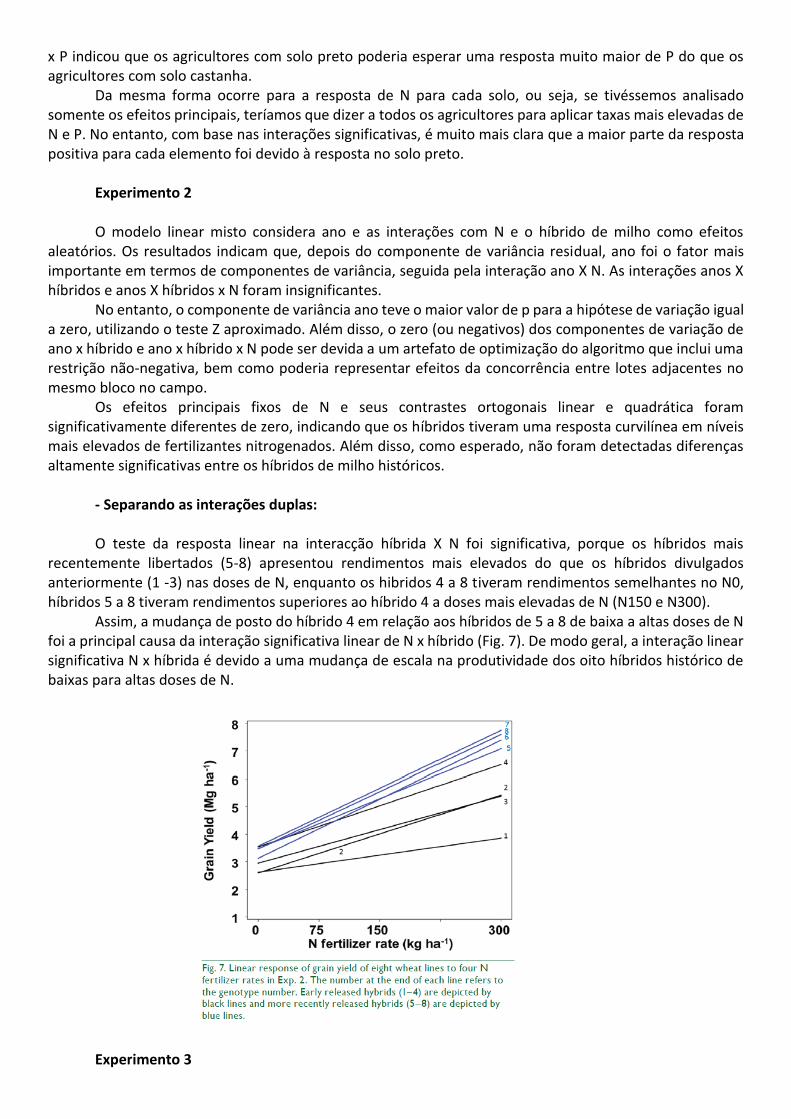
recentemente libertados (5-8) apresentou rendimentos mais elevados do que os híbridos divulgados anteriormente (1 -3) nas doses de N, enquanto os hibridos 4 a 8 tiveram rendimentos semelhantes no N0, híbridos 5 a 8 tiveram rendimentos superiores ao híbrido 4 a doses mais elevadas de N (N150 e N300).
Assim, a mudança de posto do híbrido 4 em relação aos híbridos de 5 a 8 de baixa a altas doses de N foi a principal causa da interação significativa linear de N x híbrido (Fig. 7). De modo geral, a interação linear significativa N x híbrida é devido a uma mudança de escala na produtividade dos oito híbridos histórico de baixas para altas doses de N.
Experimento 3
Os efeitos fixos, ambientes e linhagens de trigo, bem como suas interações foram altamente
significativas. A comparação entre os dois ambientes de baixo rendimento de grãos e os quatro ambientes de rendimento de grãos intermediário explicou quase 98,6% da soma de quadrados do efeito principal do ambiente.
- Separando as interações duplas: Considerando que o fator linhagem de trigo não foi estruturado, ou seja, não se sabe com podem ser
agrupadas para dissecar a interação e, que o fator ambiente, com seis níveis, pode ser mais bem estudadas, porque tem um grupo com dois ambientes, temos duas estratégias para dissecar a interação dupla: a decomposição em valores simples e contrastes de regressão fatorial.
- Decomposição em valores simples da interação dupla Uma descrição mais útil e completa pode ser conseguida através do ajuste do modelo de efeito fixo
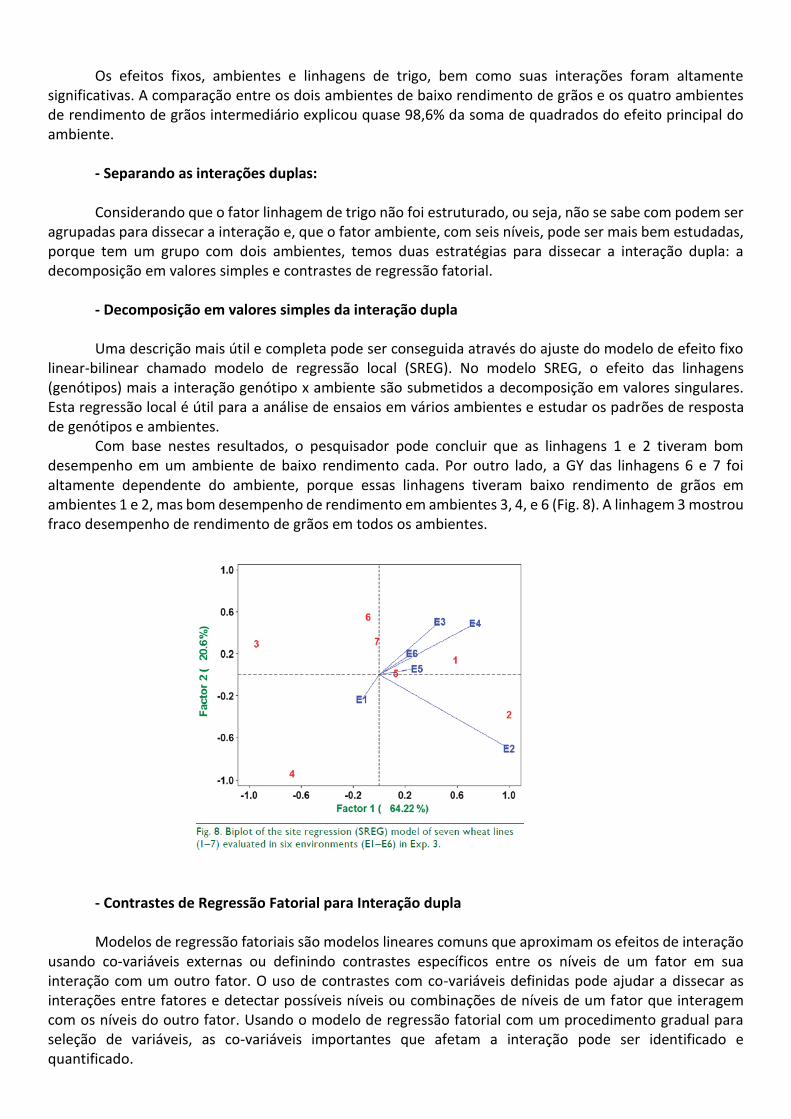
linear-bilinear chamado modelo de regressão local (SREG). No modelo SREG, o efeito das linhagens (genótipos) mais a interação genótipo x ambiente são submetidos a decomposição em valores singulares. Esta regressão local é útil para a análise de ensaios em vários ambientes e estudar os padrões de resposta de genótipos e ambientes.
Com base nestes resultados, o pesquisador pode concluir que as linhagens 1 e 2 tiveram bom desempenho em um ambiente de baixo rendimento cada. Por outro lado, a GY das linhagens 6 e 7 foi altamente dependente do ambiente, porque essas linhagens tiveram baixo rendimento de grãos em ambientes 1 e 2, mas bom desempenho de rendimento em ambientes 3, 4, e 6 (Fig. 8). A linhagem 3 mostrou fraco desempenho de rendimento de grãos em todos os ambientes.
- Contrastes de Regressão Fatorial para Interação dupla Modelos de regressão fatoriais são modelos lineares comuns que aproximam os efeitos de interação
usando co-variáveis externas ou definindo contrastes específicos entre os níveis de um fator em sua interação com um outro fator. O uso de contrastes com co-variáveis definidas pode ajudar a dissecar as interações entre fatores e detectar possíveis níveis ou combinações de níveis de um fator que interagem com os níveis do outro fator. Usando o modelo de regressão fatorial com um procedimento gradual para seleção de variáveis, as co-variáveis importantes que afetam a interação pode ser identificado e quantificado.

CONCLUSÕES O pesquisador deve apresentar um relatório sobre o significado de todas as interações no estudo e
explicar a natureza das interações significativas. Em seguida, deve traçar estratégias sobre a melhor forma de comunicar os resultados do estudo. Não existem regras de estatísticas que comandam como os resultados devem ser descritos com base em quais interações foram significativas.