new trends in the astrophysics data management (part...
TRANSCRIPT

New Trends in the Astrophysics data management (part I)
Public Outreach & Education Lectures
Massimo Brescia

Gli odierni dati astrofisici
In campo astrofisico i dati scientifici con i quali fare scienza possono essere suddivisi nelle seguenti categorie:
• Datacube o classi di array: blocchi multi-dimensionali di dati, sottoforma di serie temporali, spettrimonodimensionali, immagini, spettri nel dominio del tempo o della frequenza (bidimensionali); dataset compostida voxel (virtual observation pixels), immagini iper-spettrali in 3D. Tali tipologie sono processabili mediante leodierne tecnologie computazionali;
• Record o tabelle di eventi: anche noti come dati multi-parametro. Questi dataset possono provenire dasingoli strumenti (ad esempio accelleratori di particelle) o derivare da suddivisioni di datacube (ad esempioladdove le stelle sono identificate da immagini astronomiche). Tali tipologie sono processabili mediante lemoderne tecniche di information retrieval nei database relazionali;
• Sequenze simboliche: lo spazio dei parametri (ossia il luogo dei punti che identificano la rappresentazione diuno specifico problema scientifico) può essere rappresentato mediante ontologie atte ad identificarnedeterminate caratteristiche peculiari. Ad esempio nomi, etichette che identificano univocamente una o piùcaratteristiche note o ipotizzate dei dati a disposizione. Tali tipologie sono processabili mediante tecniche dipattern matching;

Da dove provengono i dati astrofisici
1910
Final settling of stellar statistics, by
the work of Kapteyn, Oort, etc.)
S.I.L.
XXI century(synoptic surveys,
simulations,
Mosaic CCDs)
Rush for the larger and the bigger
1960’s Photographic wide field
plates (POSS)
HookerPalomar
1990’s Digital surveys
(SDSS)J. Kapteyn
LSST - EELT
Rush for the faster and the larger memory
1910
Papers & catalogues
Rulers … Stellar statistics
1970’s Digitized plates
Main frames
image processing (POSS)
1990’s public archives
(HST, ESO, SDSS)
PC’s and clusters
astrostatistics
2010’s panchromatic
(multiwavelength),
huge telescopes, GRID,
Cloud, etc.
Virtual Obs.

LSST – Large Synoptic Survey Telescope - 1
Il telescopio
http://www.lsst.org
• 8.4m, f/1.25;
• 3.5 deg di FOV coprente un piano focale flat di 64 cm di diametro (on sky 9.6 gradi quadrati di FOV);
•survey di 20000 gradi quadrati in 6 bande (0.3 – 1.1 micron);
• CCD array da 3200 Megapixel;
• immagine mosaico in output da 3 Gigapixel;
• 30 TB di dati per notte;
Il sito ufficiale
Edificio completo

LSST – Large Synoptic Survey Telescope - 2
Il telescopio
http://www.lsst.org
• 8.4m, f/1.25;
• 3.5 deg di FOV coprente un piano focale flat di 64 cm di diametro (on sky 9.6 gradi quadrati di FOV);
•survey di 20000 gradi quadrati in 6 bande (0.3 – 1.1 micron);
• CCD array da 3200 Megapixel;
• immagine mosaico in output da 3 Gigapixel;
• 30 TB di dati per notte;
Configurazione ottica
Il primario
Configurazione ottica

LSST – Large Synoptic Survey Telescope - 3
Configurazione ottica e Strumentazione
• ottiche convesse e asferiche più grandi del mondo;
•CCD array da 3200 Megapixel, segmenti da 64cm di diametro;
• immagine mosaico in output da 3 Gigapixel;
• secondario convesso da 3.4m;
• terziario da 5m;
• 80% EE ( diffraction limited, 0.3 arcsec in tutte le bande);
Disegno della camera
Scala strumento (luna)

EELT – European Extremely Large Telescope - 1
Il telescopio
• 42m f/16, 985 segmenti con ottica attiva e adattiva;• configurazione ottica multipla;• due stazioni Nasmyth, ciascuna grande quanto un campo da tennis;• diffraction limited;• edificio con diametro 100m e altezza 80m, peso totale 5000 tons;• fino a 10 strumenti di piano focale installati in contemporanea;• nuove frontiere in risoluzione e sensibilità dello spazio dei parametri;• sito ufficiale in fase di esplorazione (Marocco, Cile, Canarie, Argentina);• 4 anni previsti per la sola progettazione e studio di fattibilità;• 8 anni previsti per la realizzazione (prima luce prevista nel 2020);
http://www.eso.org/public/astronomy/teles-instr/e-elt.htmlhttp://www.eso.org/public/astronomy/teles-instr/e-elt.html
Modello edificio EELT – fonte ESO

EELT – European Extremely Large Telescope - 2
Configurazioni ottiche
• Primario f/1, 42m segmentato (984 segmenti da 1.45m), spesso 50mm;• secondario da 6m;• terziario da 4.2m con sistema di ottica adattiva composta da 2 specchi(2.5m con 5000 attuatori e freq. 1 KhZ, 2.7m per correzione finale);• 2 fuochi Nasmyth mediante 3 specchi anastigmatici, f/17.7, FOV 10’;• Qualità ottica diffraction limited in tutta la banda;• La curvatura di campo è bassa e centrata sulla pupilla d’uscita;• Nasmyth trasformabile in un fuoco gravity-invariant;• un fuoco Coudè f/60 e 20” di FOV,• un fuoco intermedio f/4.15 dopo la riflessione da M2, con un camposeeing-limited di 1’, che può essere usato come piano focale per un ADC;
Fuoco Nasmith Fuoco intermedio
Fuoco Gravity-Invariant Fuoco Coudè
M1+cella in sezione

EELT – European Extremely Large Telescope - 3
Strumentazione di piano focale
• fino a 10 strumenti in contemporanea;• ottica attiva per M1 e M2;• ottica adattiva da M3 in poi con frequenza di 1 KhZ;
Stazione Nasmyth - ESO
Scienza
• pianeti extra-solari; formazione pianeti, evoluzione stellareextra-galattica, buchi neri, fisica delle galassie ad altoredshift;• espansione dell’Universo con osservazione diretta;
Copertura della banda di lunghezze d’onda prevista - ESO

ALMA - 1
Sito cileno di ALMA a 5000m di quota.
Atacama Large Millimiter/submillimeter Array
http://www.alma.nrao.edu/
Oltre 64 antenne da 12m nel sito cileno di Llano de Chajnantor a oltre 5000m di altitudine;
Consorzio ESO (32 antenne europee) – NRAO (32 antenne USA)
Operativo dal 2012;
Configurazione spaziale variabile da 150m a 10Km; Sito cileno di ALMA a 5000m di quota.
Simulazione del sito di Alma con varie antenne installate
Configurazione spaziale variabile da 150m a 10Km;
Osservazioni 24h al giorno;
Imaging tra 10mm e 350µm (onde radio – onde infrarosse);
Risoluzione spaziale di 10 milliarcsec, 10 volte quelladi Hubble Space Telescope;

ALMA - 2
Simulazione del trasporto di un’antenna in sito
Atacama Large Millimiter/submillimeter Array
http://www.alma.nrao.edu/
Fisica del freddo Universo, regioni otticamente troppobuie;
Immagini radio di galassie in formazione risalenti aoltre 12 miliardi di anni fa;
Composizione chimica di stelle e pianeti ignoti ancora infase di formazione;
Strumentazione basata su STJ mixers, operanti a circa Simulazione del trasporto di un’antenna in sito
Il mezzo di trasporto reale delle antenne
Strumentazione basata su STJ mixers, operanti a circa4K (-269°°°°C);
ALMA formerà immagini combinando segnali da varieconfigurazioni di antenne, con larghezza di banda di 16GHz;
L’elettronica sarà digitalizzata con tempo diquantizzazione di 1.6 x 1016 operazioni al secondo;
Speciali mezzi di trasporto, progettati per muovereun’antenna di circa 115 tons, posizionandola nellefondamenta con precisione millimetrica;

Motivi del burst tecnologico in Astronomia
Lo shutter del mosaic CCD OmegaCAM può ospitare 20 bottiglie di vino
L’odierno fenomeno di burst tecnologico è primariamente dovutoal fatto che:
Molte fra le principali scoperte astronomiche provengono dalconfronto incrociato di moli di dati presi a diverse lunghezzed’onda;
Oltre a permettere la ricerca di:QuasarsGamma-ray burstsGalassie IR ultra-luminoseBuchi neri binari nell’X-rayRadio galaxies
Il mosaico CCD 16K x 16K di OmegaCAM
- . . .Dunque l’odierna tecnologia deve permettere l’accesso a enormidatabase multi-banda distribuiti, oltre all’analisi, mining edesplorazione dei dati.
Ciò conduce a:
. ���� X-INFORMATICS

Alla ricerca di un altro modo di fare astrofisica

X-Informatics
X-Informatics è la disciplina dedicata alla strutturazione , memorizzazione,accesso e distribuzione dell’informazione che descrive sist emi complessiEsempi:
1. Biology and brain research (= Bioinformatics)2. Geographic Information Systems (= Geoinformatics)3. New! Discovery Informatics for Astronomy (= Astroinform atics)
Discipline X Common ToolsObject Granules• Bioinformatics
• Geoinformatics
• Astroinformatics
• BLAST, FASTA
• GIS
• Classification, Clustering,
Bayes Inference, Cross
Correlations, Principal
Components, ???
• Gene Sequence
• Points, Vectors, Polygons
• Time Series, Event List,
Catalog, Astronomical
Object

X-Informatics – elementi chiave
Estrazione e processamento dell’informazione, integrazione di dati da domini e sorgenti eterogenei, rivelazione dieventi, riconoscimento di caratteristiche;
Strumenti per analizzare e memorizzare enormi archivi di dati;
Rappresentazione della conoscenza, inclusi vocabolari, ontologie, simulazioni, realtà virtuale;
Unione di risultati su modelli ed esperimenti;
Uso innovativo di IT (Information Technology) in applicazioni scientifiche, incluso il supporto alle decisioni,riduzione degli errori, analisi dei risultati;
Efficiente utilizzo e gestione dei dati, incluse l’acquisizione e la gestione della conoscenza, modellazione diprocessi, data mining, acquisizione e disseminazione, presentazione grafica, amministrazione di archivi di dati sularga scala;
Interazione uomo-macchina, inclusi progettazione di interfacce, uso e comprensione di agenti per il flusso dianalisi delle informazioni, gestione di pipeline custom;analisi delle informazioni, gestione di pipeline custom;
HPC (High Performance Computing) legato ad applicazioni scientifiche, inclusi calcolo distribuito, trasmissione esupporto alle decisioni in real-time;
Elemento chiave per nuove scoperte in grandi basi di datiStandard tools per integrazione, esplorazione e scoperta dei datiX-Informatics diventa una disciplina autonoma nell’ambit o della ricerca scientificaX-informatics rappresenta la 4 a legge della ricerca scientifica (doposperimentazione, teoria, simulazioni)

AstroInformatics – I livelli di conoscenza
Associative networksClustering
Principal componentsSelf-Organizing Maps
Unsupervised methods
In the future, the rapidity with which any given discipline advances is likely to depend onhow well the community acquires the necessary expertise in database, workflowmanagement, visualization and cloud computing technologies.
Data SourcesImagesCatalogs
Time seriesSimulations
InformationExtracted
Shapes & PatternsScience MetadataDistributions &
FrequenciesModel Parameters
KDDTools
New Knowledgeor causal
connectionsbetween
physical eventswithin the
science domain
Neural NetworksBayesian Networks
Supervised methods
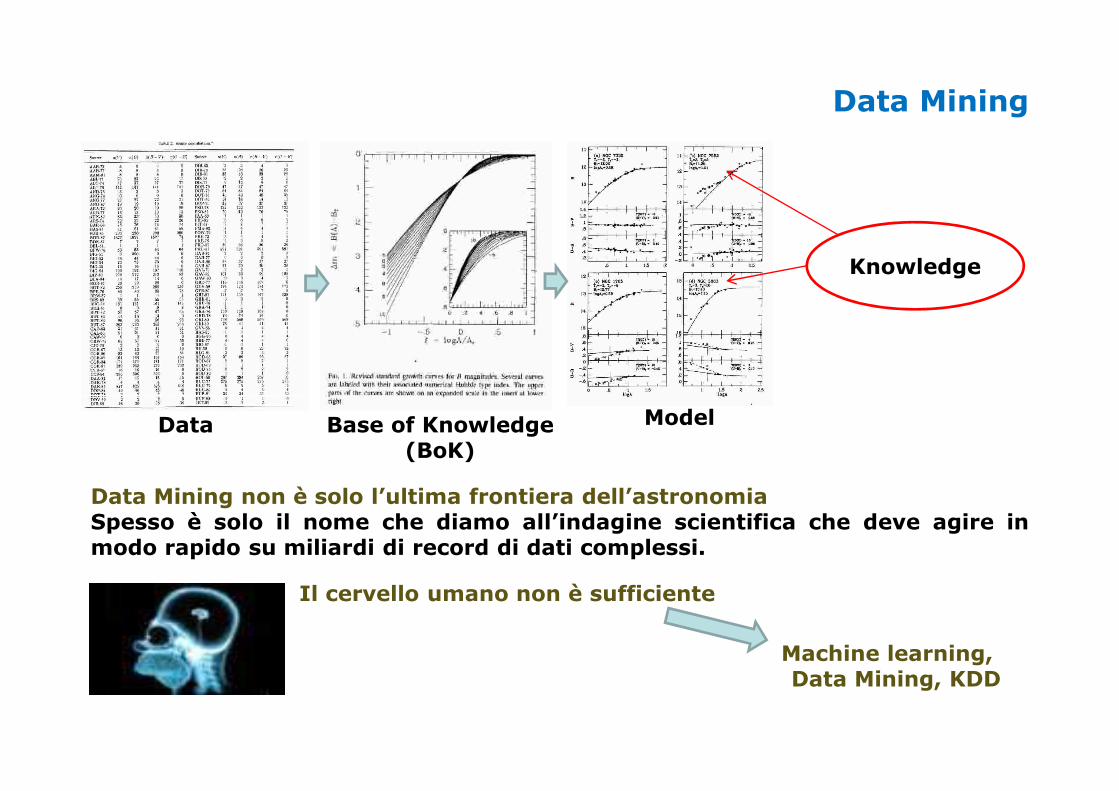
Data Mining
Knowledge
Data Base of Knowledge(BoK)
Model
Data Mining non è solo l’ultima frontiera dell’astronomiaSpesso è solo il nome che diamo all’indagine scientifica che deve agire inmodo rapido su miliardi di record di dati complessi.
Il cervello umano non è sufficiente
Machine learning, Data Mining, KDD

I dati astrofisici
L’esplorazione scientifica moderna dell’Universo multi-banda e K-epocaimplica la ricerca di pattern, trend tra N punti in uno spazio multi-dimensionale DxK:
N >109, D>>100, K>10 R.Aδδδδ
t
λλλλ
Ogni dato osservato/simulato definisceun punto (regione) in un sottoinsieme diRN.
• RA and dec• time• λλλλ λλλλ• λλλλ• setup sperimentale (risoluzione spaziale
e spettrale, mag limite, brillanza, etc.) • flusso• polarizzazione• etc…

I dati astrofisici – Ingestione di moli di dati
N >109, D>>100, K>10

L’indagine sui dati
La determinazione dello spazio dei parametri è cruciale per:
1. Guidare la scoperta scientifica(esplorazione di regioni poco conosciute, …)
2. Trovare nuove leggi fisiche (patterns)
3. Identificare nuove correlazioni fra variabili di un fenomeno
N = no. di dati, D = no. di dimensioni• Querying: nearest-neighbor O(logN), spherical range-search O(logN)• Density estimation: mixture of Gaussians O(logN)• Regression: linear regression O(D), Gaussian process regression O(N)• Classification: nearest-neighbor classifier O(N), support vector machine O(N)• Dimension reduction: principal component analysis O(D)• Clustering: k-means O(logN), hierarchical clustering O(NlogN)• Time series analysis: Kalman filter O(D), hidden Markov model, trajectory tracking• Cross-matching: O(N)

Data Analysis – Tassonomia funzionale
1. To catalogue the known (classification)
2. Characterize the unknown (clustering)
3. Find functional dependencies (regression)
1. Catalogare le cose note (classification)
2. Caratterizzare l’ignoto (clustering)
(regression)
4. Find exceptions (outliers)
Metodi Supervised
Patterns scoperti mediante uso intensivo di template (Base of Knowledge = BoK)
Metodi Unsupervised
Patterns scoperti usando i dati stessi
3. Trovare dipendenze funzionali (regression)
4. Trovare eccezioni (outliers)

Data Analysis – Classificazione
Elementi singoli raggruppati in base a informazioni su una o più caratteristiche interne eattraverso una procedura supervised (training con dati noti);
Un classificatore compie una mappatura da uno spazio di parametri X ad un insieme dilabel Y (assegna una label predefinita ad ogni campione);
Formalmente: classificatore h:X->Y associa xєX ad una label yєY.
a) crispy: dato un pattern input x (vettore), restituisce la sua label y (scalare);b) probabilistic: dato un pattern input x (vettore), restituisce un vettore y contenente leprobabilità di appartenenza di x agli elementi della classe di y;probabilità di appartenenza di x agli elementi della classe di y;
Entrambi i casi si possono applicare ai casi di classificazione “2-class” e “multi-class”;
La classificazione è basata su almeno tre step:training, mediante un training set (coppie input-output);testing, mediante un test set di dati input, il cui output è una statistica relativa al gradodi appartenenza a diverse classi (confusion matrix, fuzzy, probabilità etc.);evaluation, mediante un dataset non etichettato, il cui output è l’etichettatura rispettoalle classi predefinite;
La classificazione ha chiaramente una natura supervised;

Data Analysis – Regressione
Ricerca supervisionata di un’associazione da un dominio Rn ad uno Rm, con n>m
distinguiamo 2 tipi: curve fitting e statistical correlation.La prima tenta di validare un’ipotesi che la distribuzione dei dati segua una certafunzione;la seconda tenta di trovare una funzione che correli i dati senza alcuna assunzione apriori circa la forma funzionale della distribuzione dei dati;
•Curve fitting: date le coppie di vettori (x, y) e la forma funzionale che si v uole associare, il sistema trova imigliori parametri che identificano l’associazione ipotizzata ;migliori parametri che identificano l’associazione ipotizzata ;•Function approximation: date le coppie di vettori (x, y), il sistema trova il modello che meglio identifica lacorrelazione tra i dati (ad esempio una “black box” neurale c he approssima una funzione analitica);

Data Analysis – Clustering
Suddivisione di un insieme di elementi, (rappresentati in forma varia all’interno di unospazio di parametri), in clusters significa identificare dei sottogruppi accomunati dadeterminate caratteristiche (parametri).
Gli algoritmi che associano elementi a vari clusters possono essere probabilistici o deterministici. Nel primo caso, perogni elemento vi è associata una probabilità o grado di appartenenza ad uno o più clusters. In questo tipo diassociazione, generalmente, la somma delle probabilità associate ad un elementoè pari ad 1, ma non è sempre questoil caso.Altri algoritmi sono in grado di generare una struttura gera rchica di clusters (struttura ad albero), in cui sullasommità della struttura lo spaziodei parametri vienesuddivisain un numero limitato di clusters,ciascunodei quali asommità della struttura lo spaziodei parametri vienesuddivisain un numero limitato di clusters,ciascunodei quali asua volta viene suddiviso in vari sub-clusters, proseguendo tale suddivisione fino al livello base con granularitàmassima
Un qualunque metodo di clustering è generalmente caratterizzato da una fase in cui siapplica una regola o insieme di regole che associano (raggruppano) i vari elementi traloro. In questo senso, il clustering può divenire una fase intermedia di un processocomplesso di “esplorazione” di uno spazio di parametri, piuttosto che il suo fine ultimo(esempio tipico: un processo di “classificazione”)

Data Analysis = approssimazione di funzioni
variable characteristics Type Functionality
Quantitative Numerical with orderingrelationship and possibility to define a metric
Actual measurement RegressionPhotometric redshifts
Data Analysis in generale come “function approximation”
metric
Categorical(non ordered)
Membership into a finite number of classes.No ordering relationship.
Numerical codes(targets) arbitrarilyordered
ClassificationSearch for peculiarobjects, QSO’s,Star/galaxy, etc.
Orderedcategorical
Classes ordered by a relationship but there isno metric
Numerical codes non arbitrarily ordered
Clustering & ClassificationMorphological and physical classificationof galaxies, etc.