mass estimation - sourceforgemass-estimation.sourceforge.net/acml2016tutorial/massestimatio…a...
TRANSCRIPT

MASS ESTIMATION: ENABLING DENSITY‐BASEDOR DISTANCE‐BASEDALGORITHMS TO DO WHATTHEY CANNOT DO
Kai Ming TingFederation University Australia
16 November 2016
A Tutorial at ACML 2016

Blind Men and Elephant
2

Men in the dark and Mass Estimation
3
It’s discretisation
It’s density
It’sdecision trees
It’s k‐d trees
It’sdata depth
It’s normalisation

4
Contents
1. Existing paradigm: Density estimation2. New paradigm: Mass estimation
– Indirect approach: Space transformation and Density estimation based on mass
– Direct approach: Use mass or mass‐based dissimilarity to solve problems
3. Recent works4. Summary5. Future directions
Software downloadReferences

5
DENCLUE
DBSCAN
LOCI
SOD
Decision Trees
Decision rules
OPTICS
SUBCLU
Frequent Itemsetmining
Grid‐based
methods
Statistical Outlier
Detection
Distance‐based methods
ECLAT
Apriori LOF
ORCA
BayesNet
NB
WaveCluster
STING
HiCSFP‐growth
Anomaly Detection Classification
Clustering
DENSITY

Clustering Anomaly Detection Classification
DENCLUE
DBSCAN
LOF
ORCABayesNet
NB
Data mining tasks
Algorithms
Density estimation
6
1. Existing Paradigm:Density Estimation
‘……estimation of densities is a universal problem of statistics (knowing the densities one can solve various problems.)’ [Vapnik, 2000]
2. Existing paradigm: Density Estimation

Kernel density estimation (KDE) (Silverman 1986)
7
Density at point is estimated as:
is a kernel function.is a bandwidth that
determines the width of
requires some form of distance measure.
(Source: Wikipedia 2013)
2. Existing paradigm: Density Estimation

k‐nearest neighbour density estimation (kNN) (Silverman 1986)
8
Density at point is estimated as:
where is the volume of ‐dimensional hyper‐sphere enclosing nearest neighbours of .
Nearest neighbour search requires some form of distance measure and the search is conducted over instances in
2. Existing paradigm: Density Estimation

KDE and KNN: Involve expensive distance calculations High time and space complexities:
time complexity: space complexity:
Time complexity can be reduced to with some indexing scheme.
Limited to small data sets Inapplicable in big data !!
Limitations of existing density estimation methods
92. Existing paradigm: Density Estimation

• Density‐based clustering algorithms have difficulty in detecting all clusters of varying densities
• K nearest neighbour anomaly detectors cannot detect local anomalies
• K nearest neighbour multi‐label classifier has poor likelihood estimation
102. Existing paradigm: Density Estimation
Effectiveness: Known weaknesses of existingdensity‐based/distance‐based algorithms

New base modelling mechanism – an alternative to density estimation
More fundamental than density (density=mass/volume)‐mass can be estimated more efficiently than density
Properties: (Ting et al KDD 2010)1) Mass distribution stipulates an ordering from core
point to fringe point in the data cloud.2) This ordering accentuates the fringe points with a
concave function.3) Constant time and space complexities
11
2. New Paradigm: Mass Estimation
(Ting et al KDD 2010; Chen,Ting,Washio,Haffari, MLJ 2015)
2. New paradigm: Mass Estimation

12
Mass or Data mass
In its simplest form Mass is defined as the number of points in a
region.
Two groups of data can have the same mass regardless of the characteristics of the regions (e.g., density, shape or volume.)
Mass in a given region is defined by a rectangular function which has the same value for the entire region in which the mass is measured.
2. New paradigm: Mass Estimation

13
Mass vs Density
Same density, different mass
Same mass, different density
2. New paradigm: Mass Estimation

How to estimate mass?Mass base function . as a result of a split ,
Mass distribution:
Level‐ mass distribution:
, , 1
Practically, mass can be estimated using subsets ⊂ , ≪ as:
, 1
, |
14

Examples:Mass vs. Density(Ting et al, KDD 2010)
152. New paradigm: Mass Estimation

Example of data modelling(Ting and Wells ICDM 2010)
2 4 6
162. New paradigm: Mass Estimation

Characteristics of Mass‐based approaches
Require a much smaller sample size Utilize no distance or density measures – very fast Scale up to handle extremely large data size Model well the underlying data distribution in terms
of mass distribution Do not assume any data distribution
172. New paradigm: Mass Estimation

Implementations of mass estimation
18
Like density estimation, mass estimation can be implemented in different ways: Tree-based:
• (Liu et al ICDM 2008)• -Trees (Ting and Wells ICDM 2010)• -Trees (Tan et al IJCAI 2011)
Non-tree based: • Half-Space (Ting et al KDD 2010; Chen et al MLJ 2015)
• Nearest neighbour (Wells et al PRJ 2014)
2. New paradigm: Mass Estimation

19
Core
compo
nent
Ensemble of mass models
Indirect approachAB
Mass space mapping
→
Density estimation
Existing algorithms(As they are)
Existing density‐based algorithms(Conceptually)
Decision rule
2. New paradigm: Mass Estimation
Mass‐based formalism for data mining

20
Core
compo
nent
Ensemble of mass models
Direct approachIII
Replace distance metric with mass‐based dissimilarity
Mass estimation
Existing distance‐based algorithms(As they are)
Mass‐based algorithms(“New”)
Decision rule
2. New paradigm: Mass Estimation
Mass‐based formalism for data mining

21
How Mass has been appliedTASK How mass is applied
Regression Indirect A
Information Retrieval
Indirect A and Direct I & II
Anomaly Detection
Indirect B and Direct I & II
Clustering Indirect B and Direct I & II
Classification Indirect B and Direct I & II
2. New paradigm: Mass Estimation

Existing Algorithm
Existing Algorithm
Information Retrieval Regression Information
Retrieval Regression
22Indirect Approach [A] ‐Mass space
Indirect Approach [A]: Solving problem in mass space
(Ting et al KDD 2010)
Existing Algorithm
Existing Algorithm
Data in Original Space
Data in Mass Space

DEMass‐DBSCAN
DEMass‐LOF
DEMass‐Bayes
Clustering Anomaly Detection Classification
Mass estimationDensity Estimationusing Mass (DEMass)
23Indirect Approach [B] Density estimation
Indirect Approach [B]: Density estimation based on mass
(Ting et al ICDM 2011, Ting et al KAIS 2013, Wells et al PRJ 2014)
Unplug the density estimator in existing density‐based algorithms and plug in DEMass

Mass can be used directly to solve various problems.
Use the properties of mass estimation:• A mass distribution stipulates an ordering from core
points to fringe points in a data cloud.
• This ordering accentuates the fringe points with a concave function.
These are the essential properties that can be exploited to solve anomaly detection, information retrieval, clustering and classification problems.
24
Direct Approach I:Mass‐based methods
Direct Approach
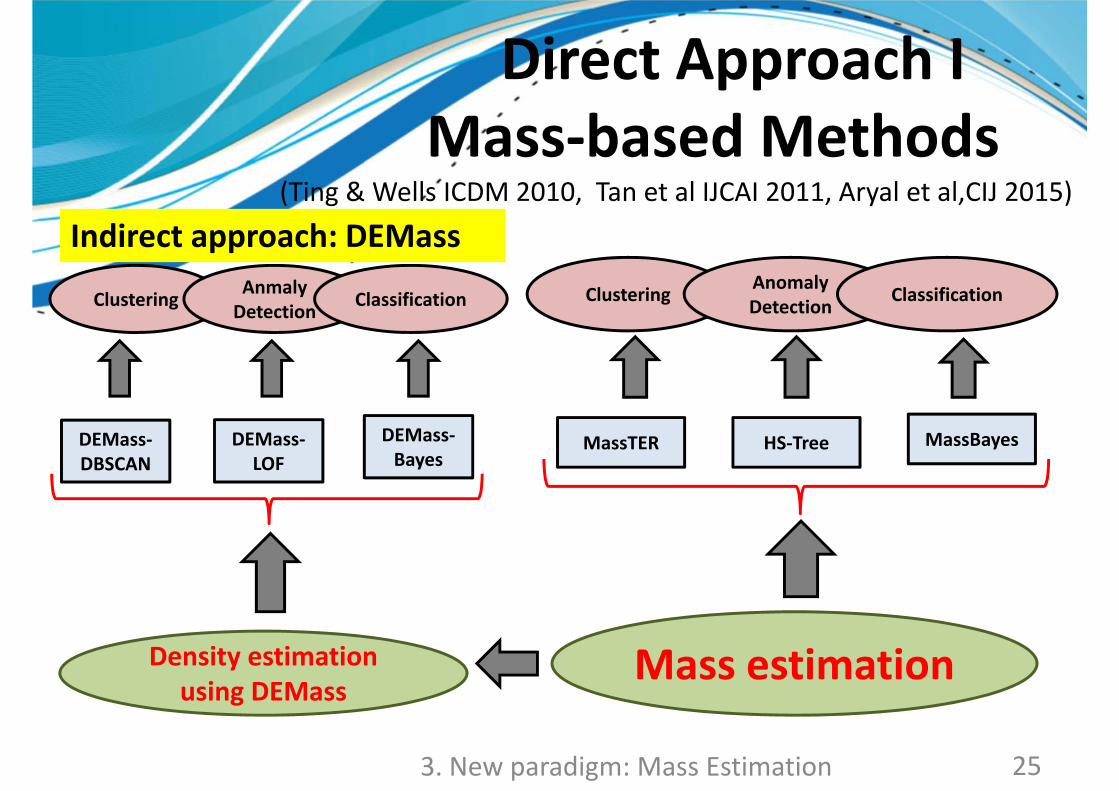
Direct Approach IMass‐based Methods
(Ting & Wells ICDM 2010, Tan et al IJCAI 2011, Aryal et al,CIJ 2015)
DEMass‐DBSCAN
DEMass‐LOF
DEMass‐Bayes
Clustering AnmalyDetection Classification Clustering Anomaly
Detection Classification
Mass estimationDensity estimation using DEMass
MassBayesMassTER HS‐Tree
253. New paradigm: Mass Estimation
Indirect approach: DEMass

Direct Approach IIMass‐based Dissimilarity
(Ting et al, KDD 2016)
DBSCAN kNN MLkNN
Clustering AnmalyDetection Classification Clustering Anomaly
Detection Classification
Mass‐based Dissimilarity
Distance measure
M‐MLkNNMBSCAN M‐kNN
263. New paradigm: Mass Estimation
Distance‐based methods
Replace with

Clustering ‐ Density‐based methods: DBSCAN or DENCLUE
Steps:1. Build density distribution f(x)2. Apply threshold to identity core points
– Noise points identified and ignored3. Link all neighbouring core points into a cluster
Source: Hinneburg & Keim KDD-1998.

An example of applying mass to density‐based clustering
28
a) Replace f(x) with DEMass [Indirect B]b) Replace f(x) with mass distribution [Direct I]c) Replace distance measure in f(x) with
mass‐based dissimilarity measure [Direct II]
All of these use the same (or almost the same) procedure of the original density‐based algorithms• (a) & (b) significantly improve the runtime• (c) overcomes some fundamental weakness
# ∈ ℓ , # ∈ ,

Task specific application of massbased on Direct Approach ITask Interpretation
Clustering High mass indicates core regions and low mass indicates noise regions
Anomaly Detection
High mass signifies normal pointsLow mass signifies anomalies
Classification Use mass to estimate likelihood
Information retrieval
High (low) mass signifies that a database object is highly (less) relevant to the query
29

Direct Approach II: applying mass to dissimilarity measure
• A fundamental change in perspective in finding closest match neighbourhood: Change from nearest neighbour
to lowest probability mass neighbour
• Lowest probability mass neighbours represent the most similar neighbours
30

3. Recent Works
1. Half‐Space Mass [Direct Approach I]2. Mass‐based similarity [Direct Approach II]3. DEMass – density estimation based on mass
[Indirect Approach B]
31

3.1 Generalised mass estimation & its relation to Data Depth methods
32
(Chen,Ting,Washio,Haffari, MLJ 2015)
Half‐Space Mass is level‐1 mass estimation in multi‐dimensionand can be viewed as a data depth method.

Relation to Data Depth (Liu et al 1999; Agostinelli & Romanazzi, 2011)
6. Recent work 33
Similarities with mass:• Both delineate the centrality of a data cloud (density is about data compactness)
• The centre of data cloud has the maximum value • Ordering from the centre to the fringe point
Key differences with mass:• Unimodal vs multi modal• Expensive to compute• No guarantee of concavity• Sensitive to parameters

Half‐Space Mass: Two examples
34

Properties: Median, Maximally Robust, Extension across dimension, Time complexity
35
Breakdown point is the minimum proportion of strategically chosen contaminating points required to render the estimated location arbitrarily far away from the original estimation.

36

Extension across dimension
37

K‐Means versus K‐Mass
38
K‐Means:Initialisation: Split data into k groupsRepeat until stopping criterion is met1. Compute a mean for each group2. Regroup based on nearest mean
K‐Mass:Initialisation: Split data into k groupsRepeat until stopping criterion is met1. Build a mass distribution for each group2. Regroup based on maximum mass

39
Clusters with different densities
K‐Mass versus K‐Means (1)

40
Clusters with different sizes
K‐Mass versus K‐Means (2)

41
Caveat: Do not have a proof that K‐mass will always converge like K‐means.
Clusters in the presence of noise
K‐Mass versus K‐Means (3)

42
Basic Measures & Implementations
MassSimilarityMeasure
DEMass
Basic Measures:
Implementations:

3. Recent Works
2. Mass‐based similarity [Direct Approach II]
43

3.2 Overcoming Key Weaknesses ofDistance‐based Neighbourhood
Methods usinga Mass‐based Dissimilarity Measure
44

Contentsa) Introduction
Many weaknesses of existing machine learning algorithms are due to a root problem, i.e., the use of distance measure.
b) Data‐dependent dissimilarity is one solution to the root problem.
c) Evidence in three tasks: density‐based clustering, anomaly detection and multi‐label classification
d) A change in perspective and its implicationse) Relation to Shared Nearest Neighboursf) Section Summary
45

Distance measures do not possess the key properties of judged dissimilarity
Despite the widespread use of distance measures, research in psychology has pointed out since 1970's that distance measures do not possess the key property of dissimilarity as judged by humans, i.e., the characteristic where two instances in a dense region are less similar to each other than two instances (of the same inter point distance) in a sparse region.For example, two Caucasians will be judged as less similar when compared in Europe (where there are many Caucasians) than in Asia (where there are few Caucasians and many Asians.)
46a) Introduction

Judged similarity:
, | , | &
47a) Introduction

What is common to these algorithms?
• Density‐based clustering algorithms have difficulty in detecting all clusters of varying densities
• K nearest neighbour anomaly detectors cannot detect local anomalies
• K nearest neighbour multi‐label classifier has poor likelihood estimation in datasets with varying densities
48a) Introduction
Known weaknesses of existing algorithms

They all use distance measure
• Compute the dissimilarity of two points solely based on their geometric positions.
• A data independent measure, i.e., it produces the same dissimilarity for any two points of equal interpoint distance regardless of the data distribution.
• We identify that distance measure is the root cause of the weaknesses of the three algorithms.
49a) Introduction

Solution to the root problem
data dependent dissimilarity
# ∈ ℓ , # ∈ ,
50
data independent distance measure
Use rather than
b) Data Dependent Dissimilarity

Data‐dependent dissimilarity• Compute the dissimilarity between two points based primarily on the data distribution around and between them.
• Two points in the sparse region is more similar to each other than two points of the same inter‐point distance in the dense region.
• Simply replacing the distance measure with the data‐dependent dissimilarity overcomes the key weaknesses of density‐based clustering, kNNanomaly detector and kNN multi‐label classifier, particularly in data with varying densities.
51b) Data Dependent Dissimilarity

• An extension of mass estimation (Ting et al, KDD2010, Chen et al, MLJ2015) of one point to a dissimilarity of two points.
• A general definition of data dependent dissimilarity in which ‐dissimilarity (Aryal et al, ICDM2014) is a special case.
• Analogous to the shortest distance between and used in the distance measure, the data‐dependent
dissimilarity uses the smallest local region covering and in model generated from sample , i.e.,
Data‐dependent dissimilarity : Generic definition
52b) Data Dependent Dissimilarity

Let be a data sample from pdf (probability density function) ; and ∈be a hierarchical partitioning model of the space into non‐
overlapping and non‐empty regions.
Definition 1. , | ; is the smallest local region covering and wrtand is defined as:
, ; argmin⊂ . . , ∈
∈∈
where . is an indicator function.Definition 2. Mass‐based dissimilarity of and wrt and is defined as the expected probability of a random data point would lie in region
, | ; :
, | , , | ;
where . is the probability wrt .
53b) Data Dependent Dissimilarity
Definitions of Data‐dependent dissimilarity (1)
(1)
(2)

In practice, the mass‐based dissimilarity would be estimated from a finite number of models , as follows:
where | | ∈ .
54b) Data Dependent Dissimilarity
Definitions of Data‐dependent dissimilarity (2)
(3)

Implementation using Isolation Forest (iForest)
We use a recursive partitioning scheme called iForest (Liu et al, 2008), consisting of iTrees as the partitioning structure to define regions. Test points and are parsed through each iTree to calculate the mass of the lowest node containing both and , i.e.,
. Finally, ( ) is the mean of these mass values over iTrees as defined below:
55b) Data Dependent Dissimilarity
(4)

Implementation : An Example using iTree
b) Data Dependent Dissimilarity 56
Four instances partitioned by a 2‐level iTree.
,

# ∈ ℓ , # ∈ ,
Density distribution due to density neighbourhood function
Mass distribution due to mass neighbourhood function
57c) Evidence in Density‐based Clustering
Application 1: Density‐based clustering (a)DBSCAN is unable to find all clusters of varying densities

Application 1: Density‐based clustering (b)DBSCAN is unable to find all clusters of varying densities
Easy Distribution Hard DistributionDBSCAN (using distance measure)
0.94 0.34
DBSCAN (using mass‐based dissimilarity)
0.993 0.62
Clustering results in terms of F1‐measure
58c) Evidence in Density‐based Clustering

Application 2: kNN anomaly detector‐ unable to detect local anomalies
kNN using distance measure kNN using mass‐based dissimilarity
59c) Evidence in Anomaly Detection
Contour based on kth nearest distance Contour based on probability mass

Application 3: Multi‐Label ClassificationMLkNN ‐ poor likelihood estimation in varying densities
An example using Multi‐Dimensional Scaling (MDS) plot on the Emotion data set.Green and red points represent the positive and negative instances of the majority label, respectively.
Birds CAL500 Emotions Enron SceneMLkNN (ℓ ) 0.392 0.489 0.692 0.604 0.774MLkNN ( ) 0.600 0.489 0.776 0.640 0.794
Classification result in terms of Average Precision
60c) Evidence in Multi‐Label Classification
MDS using ℓ MDS using

Runtime comparison: Dissimilarity matrix calculations
Data set(Data size)
(#Dimenisons)
Segment(2310)(19)
Pendigit(10992)
(16)
P53Mutant(10387)(5408)
Time complexity
Euclidean distance
5 110 8182 O(n2d)
Mass‐based dissimilarity
31 600 548 O(n2C)
SNN‐similarity 26 573 9141 O(n2k2+n2d)
Time in seconds (n:data size, d:#dimensions, C:constant, k: parameter in kNN)
61c) Evidence in Runtime comparison

A fundamental change in perspective
• Finding closest match neighbourhood: Change from nearest neighbour
to lowest probability mass neighbour• Lowest probability mass neighbours represent the most similar neighbours
62
Distance‐based or Density‐based Mass‐basedk‐nearest neighbour k‐lowest probability mass neighbourDBSCAN (density‐based method) MBSCAN (mass‐based method)
d) Change in perspective

Implication
Dissimilarity measures are assumed to be a metric as a necessary criterion for all data mining tasks. This work shows that this assumption can be an impediment to producing good performing models in three tasks: clustering, anomaly detection and multi‐label classification.
63d) Implications

Relation to Shared Nearest Neighbours (SNN)
SNN is a similarity measure based on kNN:
“Data points are similar to the extent that they share the same nearest neighbours; in particular, two data points are similar to the extent that their respective k nearest neighbour lists match. In addition, for this similarity measure to be valid, it is required that the tested points themselves belong to the common neighbourhood.”
Jarvis & Patrick (1973)
64e) Relation to SNN

Relation to Shared Nearest Neighbours (SNN)• SNN (Ertoz, Steinbach & Kumar, 2003) was previously used to replace distance measure in DBSCAN.
• SNN clustering was considered to be a density‐based clustering.
Let , where is the number of shared nearest neighbours of nearest neighbours of and , which include both and ; if both and are not
included.The neighbourhood function based on the similarity can be expressed as:
65

Section Summary• The data dependent dissimilarity overcomes key weaknesses
of three existing algorithms that rely on distance, and effectively improves their task‐specific performance on density‐based clustering, kNN anomaly detection and multi‐label classification
• These existing algorithms are transformed by simply replacing the distance measure with the mass‐based dissimilarity, leaving the rest of each procedure unchanged.
• As the transformation heralds a fundamental change of perspective in finding the closest match neighbourhood, the converted algorithms are more aptly called lowest probability mass neighbour algorithms than nearest neighbour algorithms, since the lowest mass neighbours represent the most similar neighbours.
66

3. Recent Works
3. DEMass – density estimation based on mass [Indirect Approach B]
67

68
Basic Measures & Implementations
MassSimilarityMeasure
DEMass
Basic Measures:
Implementations:

69
3.3 DEMass: Two implementations Construct local regions (LRs), from a small subsample, using
either Tree‐based feature space partitioning or Nearest neighbour (called LiNearN for linear time nearest
neighbour) Estimate density as follows:
A parameter (subsample size) is used to trade off between bias and variance.

70
LiNearN vs kNN
kNN kNN with indexing (k:d‐tree) LiNearN
Time
Advantages: Instead of focusing on speeding up the nearest neighbour
search, LiNearN generates many local regions from small subsamples and then produces final result in an ensemble method.
Achieve significant speed up because the size of subsamples required is significantly smaller than the given data set.
Run orders of magnitude faster than the existing nearest neighbour density estimators.
The only linear time complexity nearest neighbour algorithm, as far as we know; achieved without indexing.

71
LiNearN vs kNN(Wells et al PRJ 2014)

Clustering: Scale up test
72
1 million instances
98 hours
77 hours
26 minutes

Anomaly Detection: Scale up test
73
50 dimensions
18.3 hours
> 6 hours
134 secs
Ran out of 200GB
memory in 100
dimensions

4. Summary (a)
74
Mass estimation is a new paradigm that enables big data mining.
It is a fundamental data modelling mechanism that can be applied to solve various data mining problems.
4. Summary

4. Summary (b)
75
The existing paradigm based on density estimation can be reinvigorated using DEMass; otherwise it cannot be applied to big data because of its fundamental limitations in terms of time and space complexities.
Weaknesses of existing distance‐based neighbourhood methods can be overcome from their root cause: replacing distance measure with mass‐based dissimilarity
4. Summary

4. Summary (How to apply mass)
76
Transform data based on mass [Indirect A] Replace density estimator with DEMass
[Indirect B] Replace density with mass: solve the problem
directly using mass, instead of density [Direct I] Replace geometric‐model based measure with
mass‐based dissimilarity measure [Direct II]
All of these can reuse existing algorithms.
4. Summary

Chronicle of Mass‐based approaches IEEE ICDM‐2008 : iForest (predecessor and a special case of mass) KDD‐2010 : First paper on mass estimation IEEE ICDM‐2010 : Multi‐dimensional mass estimation & clustering IEEE ICDM‐2011 & KAIS, 2013 : Density estimation based on mass IJCAI‐2011 : Anomaly Detection in data streams Pattern Recognition 2012 : Information retrieval using iForest Machine Learning 2012 : Mass estimation in multi‐dimension implementations ACM TKDD, 2012 : Isolation‐based anomaly detection AusDM‐2012 : Application of iForest to vehicle‐related time series PAKDD‐2013 : MassBayes classifier PAKDD‐2014 : First paper on Relative Mass Pattern Recognition 2014: A new approach to nearest neighbour density
estimation IEEE‐ICDM‐2014: First version of mass‐based dissimilarity measure IEEE ICDM‐2014 workshop: Isolation using nearest neighbour ensemble AIRS‐2015: Mass‐based measure for text retrieval Computational Intelligence 2015: Generic approach to estimate likelihood in
Bayesian classifier learning Machine Learning 2015: Half‐Space mass ICDM‐2016: Multi‐label learning with emerging new labels in data streams KDD‐2016: Generic version of mass‐based dissimilarity
77

5. Future Directions
785. Future Directions
The relative strengths and weaknesses of mass‐based and density‐based algorithms
Different ways to estimate mass Optimisation based on mass estimation or
mass‐based dissimilarity Similarity measures/Relative Mass Comparison with existing data dependent measures
Data Streams Concept change: change detection and change adaptation Emerging new classes/labels problem

Acknowledgement Joint works with
• Sunil Aryal, Ye Zhu, Bo Chen (current students)• Tony Fei Liu, James Tan Swee Chuan, Guansong Pang, Tharindu
Bandaragoda, Jonathan Wells (past students)• Takashi Washio (Osaka University)• Guang‐Tong Zhou, Yilong Yin (Shandong University)• Zhi‐hua Zhou, Yang Yu, Mu Xin, Yue Zhu (Nanjing University)• Naiwala P. Chandrasiri (Toyoto InfoTechnology Center) • Reza Haffari, Mark Carmen, David Albrecht (Monash University)
Funding support:• US Air Force Office of Scientific Research and Asian Office of Aerospace Research & Development (2009‐2016)
• Toyoto InfoTechnology Center (2012)79

Software Download
iForest http://sourceforge.net/projects/iforest/ Mass estimation and its associated
algorithms for clustering and classification.http://mass‐estimation.sourceforge.net/
Mass‐based dissimilarity. https://sourceforge.net/projects/mass‐based‐dissimilarity/
80

Mass‐based papers1. Liu F.T., Ting K.M. and Zhou Z.H. (2008) Isolation Forest. Proceedings of IEEE
ICDM, p:413–422.2. Ting K.M., Zhou G.T., Liu F.T. and Tan S.C. (2010) Mass Estimation and Its
Applications. Proceedings of SIGKDD, p:989‐998.3. Ting K.M. and Wells J.R. (2010) Multi‐dimensional mass estimation and
mass‐based clustering. Proceedings of IEEE ICDM, p:511–520.4. Tan S.C., Ting K.M. and Liu F.T. (2011) Fast anomaly detection for streaming
data. Proceedings of IJCAI, p:1151–1156.5. Ting K.M., Washio T., Wells J.R. and Liu F.T. (2011) Density estimation based
on mass. Proceedings of IEEE ICDM, p:715–7246. Liu F.T., Ting K.M., Yu Y. and Zhou Z.H. (2012) Isolation‐Based Anomaly
Detection. ACM Transactions on Knowledge Discovery from Data. Vol.6, Issue.1, Article No.3.
7. Wells J.R., Ting K.M. and Chandrasiri N.P. (2012) A non‐time series approach to vehicle related time series problems. Proceedings of AusDM.
8. Zhou G.T., Ting K.M., Liu F.T. and Yin Y. (2012) Relevance feature mapping for content‐based multimedia information retrieval. Pattern Recognition, 45(4), p:1707‐1720. 81

9. Ting K.M., Zhou G.T., Liu F.T. and Tan S.C. (2013) Mass estimation. Machine Learning, p:1–34.
10. Ting K.M., Washio T., Wells J.R., Liu F.T. and Aryal S. (2013). DEMass: a new density estimator for big data. Knowledge and Information Systems, p:1‐32.
11. Aryal S. and Ting K.M. (2013) MassBayes: A new generative classifier with multi‐dimensional likelihood estimation. Proceedings of PAKDD, p:136‐148.
12. Aryal S., Ting K.M, Wells J.R. and Washio T. (2014) Improving iForest with Relative Mass. Proceedings of PAKDD, p: 510‐512.
13. Aryal S., Ting K.M, Haffari G and Washio T. (2014). Mp‐Dissimilarity: A Data Dependent Dissimilarity Measure. Proceedings of IEEE ICDM, p: 707‐712.
14. Wells J.R., Ting K.M. and Washio T. (2014) LiNearN: A New Approach to Nearest Neighbour Density Estimator. Pattern Recognition. Vol.47, 8, p:2702‐2720.
15. Bandaragoda T.R., Ting K.M., Albrecht D., Liu F.T. and Wells J.R. (2014). Efficient Anomaly Detection by Isolation Using Nearest Neighbour Ensemble. Proceedings of 2014 IEEE ICDM Workshop, p: 698‐705.
16. Aryal S., Ting K.M, Haffari G and Washio T. (2015) Beyond tf‐idf and cosine distance in documents dissimilarity measure. AIRS, p:400‐406.
82

17. Aryal S. and Ting K.M, (2015) A generic ensemble approach to estimate multi‐dimensional likelihood in Bayesian classifier learning. Computational Intelligence.
18. Chen B., Ting K.M., Washio T. and Haffari G. (2015) Half‐Space Mass: A maximally robust and efficient data depth method. Machine Learning. 100(2‐3): 677:699.
19. Zhu Y., Ting, K.M. and Zhou Z‐H (2016) Multi‐Label Learning with Emerging New Labels. Proceedings of IEEE ICDM (to appear).
20. Ting K.M., Zhu Y., Carman M., Zhu Y. and Zhou Z‐H (2016) Overcoming Key Weaknesses of Distance‐based Neighbourhood Methods using a Data Dependent Dissimilarity Measure. Proceedings of KDD. 1205‐1214
83

84
Categories of referencesTASK Reference paper #Regression 2
Information Retrieval
2,8,9,12,13,16
Anomaly Detection
1,2,4,6,7,9,10,12,14,15,18,20
Clustering 5,10,14,18,20
Classification 11,13,17,19,20
Approach Reference paper #
Indirect A 2,9
Indirect B 5,10,14
Direct I 1,2,3,4,6,7,8,9,11,12,15,17,18,19
Direct II 13,16,20

Other ReferencesDensity estimation• B. W. Silverman (1986). Density estimation for statistics and data analysis, volume 26. CRC press.Data Depth• J. W. Tukey (1975). Mathematics and picturing data. In Proceedings of the international congress
on mathematics Vol. 2, 525–531.• R. Liu, J.M. Parelius, & K. Singh (1999). Multivariate analysis by data depth. The Annals of
Statistics, 27(3), 783–840.• Y. Zuo, & R. Serfling (2000). General notion of statistical depth function. The Annal of Statistics,
28, 461–482.• G. Aloupis (2006). Geometric measures of data depth. DIMACS Series in Discrete Math and
Theoretical Computer Science, 72, 147–158.• C. Agostinelli, & M. Romanazzi (2011). Local depth. Journal of Statistical Planning and Inference,
141, 817–830.Shared Nearest Neighbours• R. A. Jarvis and E. A. Patrick (1973) Clustering using a similarity measure based on shared near
neighbors. IEEE Transactions on Computers, 100(11):1025‐1034.• L. Ert oz, M. Steinbach, and V. Kumar (2003). Finding clusters of different sizes, shapes, and
densities in noisy, high dimensional data. In Proceedings of the SIAM Data Mining Conference, 47‐58.
Psychology: Similarity• A. Tversky (1977) Features of similarity. Psychological Review, 84(4):327‐352.• C. L. Krumhansl (1978) Concerning the applicability of geometric models to similarity data: The
interrelationship between similarity and spatial density. Psychological Review, 85(5):445‐463.85

Thank you for your attention!