m-invariance and dynamic datasets - emory...
TRANSCRIPT

m-Invariance and Dynamic Datasetsbased on:
Xiaokui Xiao, Yufei Tao m-Invariance: Towards Privacy Preserving Re-publication of Dynamic Datasets
Slawomir Goryczka

Panta rhei (Heraclitus)"everything is in a state of flux"
● To provide most recent anonymized data publisher needs to re-publish them
● Most of the current approaches do not consider this!
● Exception:– Support only insertions of data– J.-W. Byun, Y. Sohn, E. Bertino, and N. Li Secure
anonymization for incremental datasets. (2006)● Where is the problem?

Maybe it's simple?
We just need to ensure that:● Dataset is not published too often (movie effect)● We use different algorithm for each dataset
snapshot (“white” noise instead of the movie effect, but may be used to identify part of the data!)
● Play with data to keep similar statistics of attribute values – what with long time trends, i.e. flu pandemic, which change global and local statistics of the data

Deletion of tuples
● Deletion of data may introduce critical absence:

Deletion of tuples
● Deletion of data may introduce critical absence:

Deletion of tuples
● Deletion of data may introduce critical absence:

Deletion of tuples
● Deletion of data may introduce critical absence:

Deletion of tuples
● Deletion of data may introduce critical absence:
Bob has dyspepsia

Deletion of tuples
● Deletion of data may introduce critical absence:
Bob has dyspepsia
Solution(?)
Ignore deletions

Counterfeit generalization
● Add some counterfeit tuples to avoid critical absence
● Publish number and location of these tuples (utility)

Counterfeit generalization
● Add some counterfeit tuples to avoid critical absence
● Publish number and location of these tuples (utility)

Counterfeit generalization
● Add some counterfeit tuples to avoid critical absence
● Publish number and location of these tuples (utility)

Counterfeit generalization(continued)
● Crucial to preserve privacy is to ensure certain invariance in all quasi-identifier groups that a tuple (here: Bob's tuple) is generalized to in different snapshots
● Existing generalization schemas are special cases of counterfeited generalization, where there is no counterfeits
● Goal: minimize number of counterfeit tuples, but ensure privacy among all snapshots. How?

m-Invariance
m-unique each QI group in anonymized table T*(j) contains ≥m tuples with different sensitive data among themm-invariant
● T*(j) is m-unique for all 1≤j≤n● For each tuple t, for each data snapshot where this
tuple appears, its QI generalized group have the same set of distinct sensitive values(For each QI generalized group its set of distinct sensitive values is constant – no problems with critical absence, but each tuple have limited number of QI generalized groups where it can belongs to)

Privacy disclosure risk● Privacy disclosure
risk for tuple t:risk(t) = nis(t)/nrs
– nis(t) – number of reasonable surjective functions that correctly reconstruct t
– nrs – number of all reasonable surjections

m-Invariance (properties)
● If {T*(1), ..., T*(n)} is m-invariant, thenrisk(i) ≤ 1/m, 1 ≤ i ≤ n
● If {T*(1), ..., T*(n-1)} is m-invariant, then {T*(1), ..., T*(n)} is also m-invariant if and only if:
– T*(n) is m-unique– For any tuple its generalized QI
groups in snapshots T*(n-1) and T*(n) have the same signature (set of distinct sensitive values).
t∈T n−1∩T n

m-Invariant algorithm
● n-th publication is allowed, only if T(n)-T(n-1) is m-eligible, that is, at most 1/m of the tuples in T(n)-T(n-1) have an identical sensitive value
● Algorithm (4 phases):1.Division2.Balancing3.Assignment4.Split
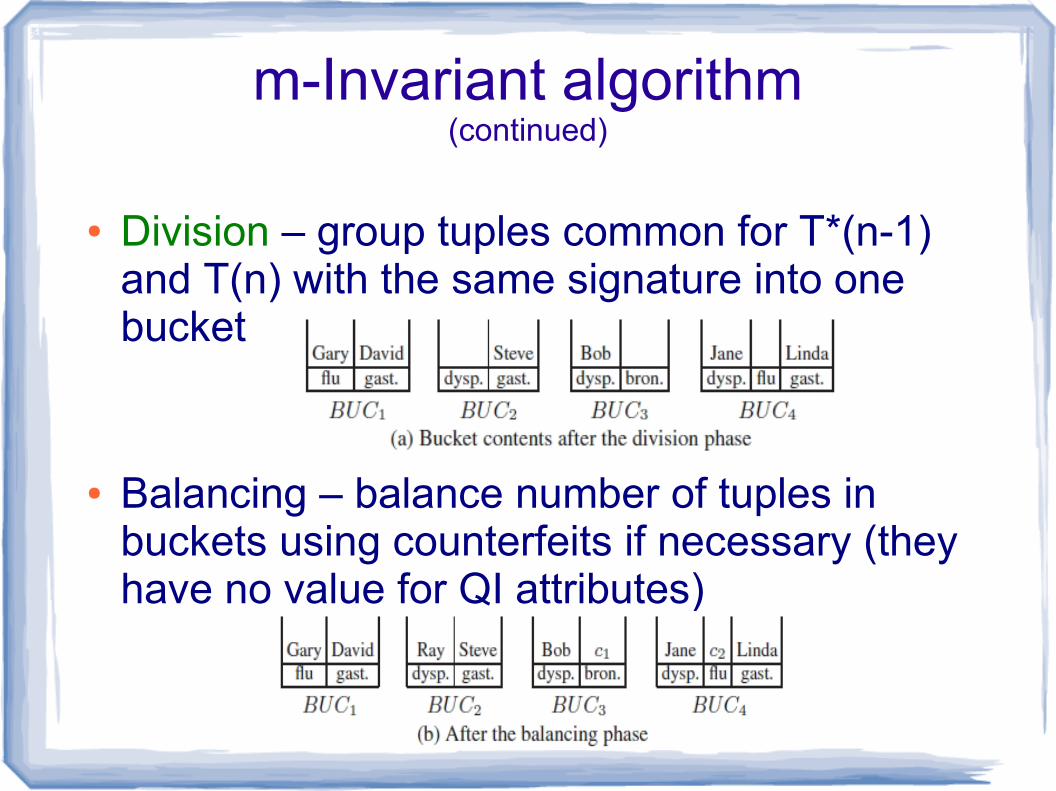
m-Invariant algorithm(continued)
● Division – group tuples common for T*(n-1) and T(n) with the same signature into one bucket
● Balancing – balance number of tuples in buckets using counterfeits if necessary (they have no value for QI attributes)
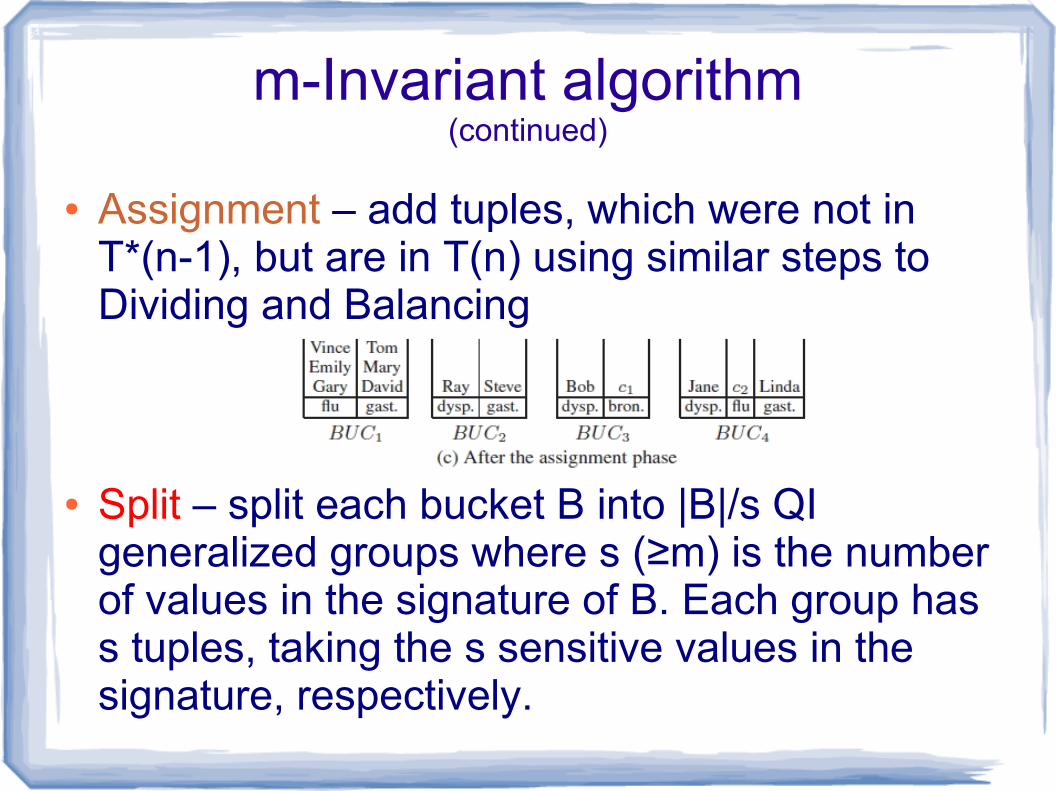
m-Invariant algorithm(continued)
● Assignment – add tuples, which were not in T*(n-1), but are in T(n) using similar steps to Dividing and Balancing
● Split – split each bucket B into |B|/s QI generalized groups where s (≥m) is the number of values in the signature of B. Each group has s tuples, taking the s sensitive values in the signature, respectively.
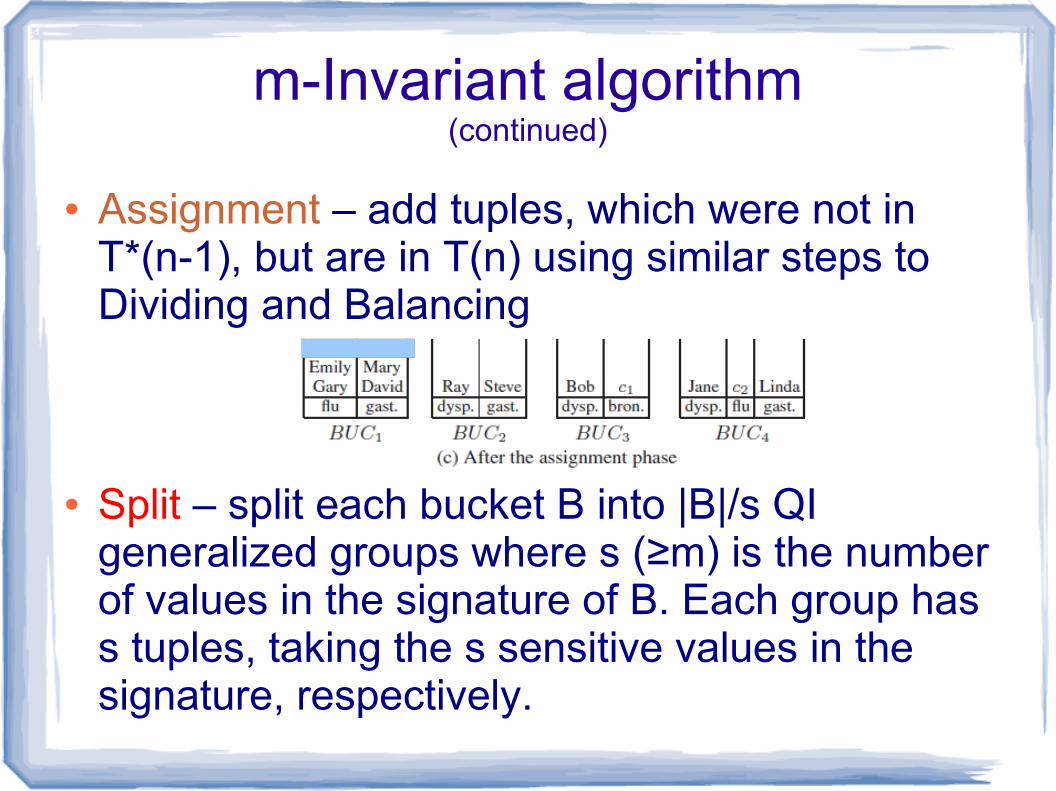
m-Invariant algorithm(continued)
● Assignment – add tuples, which were not in T*(n-1), but are in T(n) using similar steps to Dividing and Balancing
● Split – split each bucket B into |B|/s QI generalized groups where s (≥m) is the number of values in the signature of B. Each group has s tuples, taking the s sensitive values in the signature, respectively.

● Datasets (Tooc, Tsal):– 400k tuples (600k in total)– Attributes: Age, Gender, Education, Birthplace,
Occupation, Salary
Experiments

Pros and cons
● Incremental● Small data
disturbance● High data utility
(measured as a median relative error for queries)
● ...
● Preserving current statistics of attribute values – what if they change?
● What about continues attributes (numbers)?
● ...

Q & I*
* Ideas