izgradnja i korišćenje olap kocke -...
TRANSCRIPT

2. Izgradnja i korišćenje OLAP kocke
Krajnji rezultat izgradnje DW sistema predstavlja multidimenziona kocka podataka, koja se sastoji od dimenzija i
mera.
Na slici je prikazana multidimenziona kocka koja se sastoji od sumarnih podataka o prodaji. Dimenzije kocke su
LOKACIJA, VREMENSKI PERIOD i PROIZVOD. Dimenzije se sastoje od članova(members), npr, članovi dimenzije
VREMENSKI PERIOD su četiri kvartala. Dimenzije mogu imati i hijerarhijsku strukturu, tako npr, članovi prvog
nivoa dimenzije VREMENSKI PERIOD su kvartali, drugog nivoa su meseci, tredeg dani, itd. Elementi kocke koji se
nalaze u preseku članova dimenzije su agregirani podaci i predstavljaju mere. Npr, u preseku
Lokacija.Prodavnica1-Period.Kvartal4-Proizvod.Zvezda nalazi se agregirani podatak o vrednosti prodaje.
Dimenzije predstavljaju podatke koji čine strukturu jedne kocke.
Mere predstavljaju agregirane (sumarne) podatke po različitim dimenzijama i članovima dimenzija, koji služi
poboljšanju efikasnosti rada pri postavljanju upita.
Kocka je softversko rešenje koje služi poboljšanju klasičnog načina postavljanja upita i izveštavanja nad bazama
podataka.
U nastavku se prikazuje upotreba OLAP kocke preko Pivot Table Service u Excel okruženju.
Na slededoj slici se vidi interfs koji omogudava upotrebu kocke. U Pivot tabeli (Pivot Table) date su dimenzije i
mere za kocku studentske službe FON-a:
Dimenzije su: GodinaUpisa (čuva podatke godine kada se student upisao, od 1992 do 2002), Ispit (spisak ispita
na FON-u), Ocene (ocene od 5 do 10), Pol (muški i ženski), PolIspiti (broj položenih ispita 0-46), Profesor (spisak
profesora FON-a), Smer (spisak smerova FON-a), Statut (spisak statusa studentata) i Student (spisak svih
studenata).
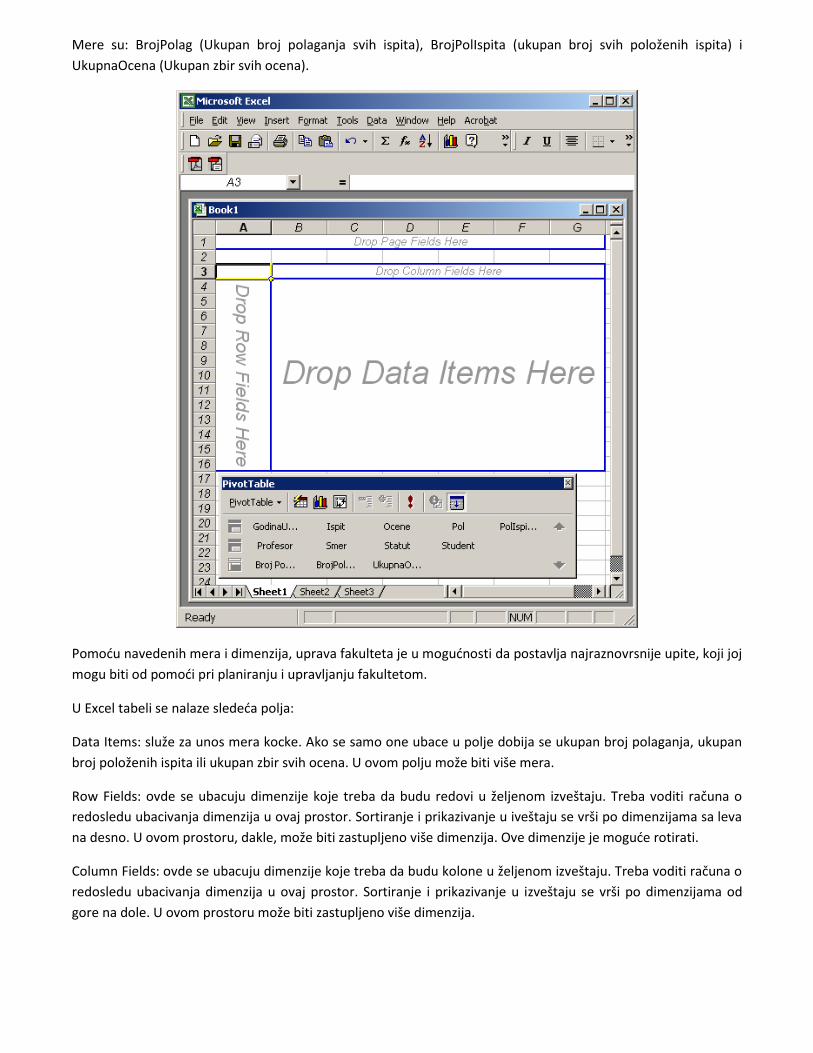
Mere su: BrojPolag (Ukupan broj polaganja svih ispita), BrojPolIspita (ukupan broj svih položenih ispita) i
UkupnaOcena (Ukupan zbir svih ocena).
Pomodu navedenih mera i dimenzija, uprava fakulteta je u mogudnosti da postavlja najraznovrsnije upite, koji joj
mogu biti od pomodi pri planiranju i upravljanju fakultetom.
U Excel tabeli se nalaze slededa polja:
Data Items: služe za unos mera kocke. Ako se samo one ubace u polje dobija se ukupan broj polaganja, ukupan
broj položenih ispita ili ukupan zbir svih ocena. U ovom polju može biti više mera.
Row Fields: ovde se ubacuju dimenzije koje treba da budu redovi u željenom izveštaju. Treba voditi računa o
redosledu ubacivanja dimenzija u ovaj prostor. Sortiranje i prikazivanje u iveštaju se vrši po dimenzijama sa leva
na desno. U ovom prostoru, dakle, može biti zastupljeno više dimenzija. Ove dimenzije je mogude rotirati.
Column Fields: ovde se ubacuju dimenzije koje treba da budu kolone u željenom izveštaju. Treba voditi računa o
redosledu ubacivanja dimenzija u ovaj prostor. Sortiranje i prikazivanje u izveštaju se vrši po dimenzijama od
gore na dole. U ovom prostoru može biti zastupljeno više dimenzija.

Page Fields: Služe za prikazivanje sumarnih podataka za jednu dimenziju. Kada je dimenzija postavljena na ovo
polje, tada možemo da vršimo filtriranje, npr. izaberemo samo jednog studenta ili jednog profesora ili određenu
ocenu. Kod drugih polja bi bilo potrebno da deselektujemo sve studente ili profesore ili druge vrednosti
dimenzija, pa da onda izaberemo željenu vrednost. Znajudi ovo, ovo polje koristimo da bismo dobili rezultate
određene dimenzije. U ovom prostoru može biti zastupljeno više dimenzija.
Treba redi da dimenzije služe za sužavanje domena mera (agregacija) i time možemo da dođemo do željene
informacije. Kocka je i smišljena sa namerom lakog postavljanja upita i izveštavanja, što bi u klasičnim bazama
podataka iziskivalo daleko više vremena i daleko više znanja za postavljanje upita i pravljenje izveštaja.
Primer. Date su sledede dimenzije i mere jedne OLAP kocke. Dimenzije: GodinaUpisa, Ispit, Ocene, Pol, PolIspiti,
Profesor, Smer, Statut i Student.Mere su: BrojPolag, BrojPolIspita i UkupnaOcena.
A) Formirajte izveštaj u kojoj se vidi ocena studenta Borisa Delibašida iz ispita Sistemi za podršku odlučivanju.
Komentar: U ovom slučaju je bilo svejedno gde stavljamo dimenziju Ocena, u polja za redove ili polja za kolone.
Dimenzija Student i Ispit su stavljeni u polje Page Fields radi selekcije tačno određenih podataka. U našem
slučaju nije bilo potrebno koristiti polje za redove.
B) Prikazati broj polaganja ispita i broj položenih ispita, studenata iz generacije 1996 i 1997 kod profesora
Milutina Čupida na ispitu Sistemi za podršku odlučivanju (SPO). U redovima treba da se vidi godina upisa. Za
svaku godinu treba da se vidi i pol studenta. U kolonama treba da se vidi ocene studenata.

V) Prikazati broj polaganja studenata koji imaju statut 90 (vanredni)koji su polagali SPO kod profesora Milutina
Čupida. U kolonama ubaciti pregled svih ocena.
G) Prikazati ukupnu ocenu sve studente koji su položili Ekspertne sisteme sa ocenom vedom od sedam (7) kod
profesora Milutina Čupida. U kolonama treba da se vide ocene. Studenti treba da budu u redovima razvrstani po
polu, pa zatim statusu.

D) Prikazati ocene svih studenata koji su položili Ekspertne sisteme sa ocenom vedom od sedam (7) kod
profesora Milutina Čupida. U kolonama treba da se vide ocene. Studentima treba da se vidi pol, pa zatim status.

2.1. Izgradnja OLAP kocke
Pošto smo naučili da koristimo OLAP kocku kroz prethodne primere, prelazimo na samu izgradnju OLAP kocke iz spoljnog izvora podataka. Kao izvori podataka mogu se koristiti baze podataka , upiti ,“spreadsheet“-ovi ili neki predefinisani skupovi podataka.
U ovom primeru objasnidemo postupak kreiranja kocke iz CSV (comma separated values) datoteke „sales“.
Slika 1. Sirovi podaci iz eksternog izvora (CSV fajl)
Prva linija označava nazive kolona, dok ostali redovi predstavljaju vrednosti. Odmah možemo uočiti da nam ovakav prikaz podataka ne može pomodi pri efikasnom donošenju odluka. Zbog toga prelazimo na struktuiranje kocke na osnovu datih podataka. Kao alat koristidemo “Microsoft Excel”.
Prvo je potrebno odrediti izvore podataka. Pod menijem Data, iz padajude liste biramo opciju Import External Data i njenu podopciju New Database Query (Slika 2).

Slika 2. Učitavanje podataka
U okviru dialog box-a Choose Data Source biramo opciju New Data Source.
Slika 2. Kreiranje izvora podataka
Otvara se Dijalog Create New Data Source.
1. Unosimo ime izvora podataka (Prodaja) 2. Biramo drajver (Microsoft Text Driver) 3. Biramo opciju Connect

Slika 3. Kreiranje izvora podataka – nastavak
4. U okviru ODBC Setup Dialog Box-a definišemo putanju ka našem izvoru podataka. (Isključujemo opciju
Use Current Directory). Biramo opciju Select Directory.
Slika 4. Podešavanje formata unosa
5. Biramo direktorijum u kome se nalazi baza (u našem slučaju CSV datoteka)
Slika 5. Dolazak do foldera sa podacima
6. Idemo na OK tri puta dok se ne vratimo na Choose Data Source dijalog, gde možemo videti naš izvor
podataka Prodaja.

Slika 6. Uspešno kreirana veza sa izvorom podataka
Klikom na OK prelazimo na Query Wizard koji de nam pomodi u izgradnji kocke. Prikazane su tabele i kolone koje možemo videti u padajudoj listi. Za našu kocku prenosimo sve kolone i idemo na Next.
Slika 7. Formiranje upita
Ukoliko postoji potreba za uključivanjem samo nekih podataka koji zadovoljavaju odredjeni uslov, možemo ih odrediti pod opcijom Filter Data. U našem primeru to nije potrebno, pa idemo na Next.
Slika 8. Filtriranje podataka
Takođe, možemo sortirati podatke, prema odredjenim poljima, u opadajudem ili rastudem redosledu. Ni ovu opciju ne koristimo i idemo na Next.

Slika 9. Sortiranje podataka
Konačno uvezli smo podatke, prilagodili ih našim potrebama i možemo kreirati kocku u meniju pritiskom na taster Finish.
Slika 10. Formiranje kocke
Klikom na Finish pokrenuli smo OLAP Cube Query Wizard (Slika 11)
Slika 11. Čarobnjak za pravljenje OLAP kocke
U prvom koraku definišemo mere i dimenzije naše kocke. Kada smo ih izabrali možemo definisati imena naših mera (Prodaja, Prodaja po Komadu).

Slika 11. Definisanje mera i dimenzija
Kada smo definisali mere (sumirane podatke),prelazimo na definiciju dimenzija(Slika 12). Ovde možemo videti jednu od prednosti OLAP kocke u odnosu na jednostavno korišdenje Excel Pivot Tabele za pogled na podatke: Dimenzije OLAP kocke možemo struktuirati u hijerarhiju (što nam omogudava “drill down” tehniku pri korišdenju kocke). Tako smo jednostavnim prevlačenjem dimenzija države podelili na republike, a republike na gradove. Takođe vremensku dimenziju smo podelili na godine, kvartale i mesece, što de nam koristiti u kasnijem izveštavanju.
Slika 12. Strukturiranje dimenzija
Na kraju sačuvamo kocku u direktorijum koji nam odgovara (Slika 13).

Slika 13. Čuvanje kocke
Klikom na Finish kreiramo kocku prelazimo u poznato okruženje Excel-a. Tu kreiramo Pivot Tabelu koju demo kasnije koristiti za izveštavanje.
Slika 14. Učitavanje kocke u Excel

Slika 15. OLAP kocka spremna za upotrebu
Korišdenje ove kocke opisano je u odeljku Primena Olap-a. U nastavku se prikazuje šta je najčešde neophodno, preduslov, da bi se formirala kocka. Reč je o mukotrpnom procesu ETL-a (Extract, Transform & Load)
2.2. Priprema skladišta podataka za izgradnju kocke (ETL)
U prethodnom odeljku skripte smo naučili kako se kreira kocka korišdenjem spoljnih izvora podataka. Ispostavilo se da je to softverski jako jednostavno rešiti uz pomod raznih Wizarda i Drag’n’Drop tehnike.
Međutim, moramo uzeti u obzir činjenicu da je skladište podataka Sales bilo jako dobro struktuirano i pripremljeno za kreiranje kocke.
U praksi se jako često (skoro uvek) dešava da podaci nisu potpuni (nedostaju određena polja), da nisu prikazani u merljivom obliku (znakovi ili boje za podatke koji nam trebaju za sumarne vrednosti), netačni podaci, nepotrebni podaci koji zauzimaju resurse itd. Iz takvih podataka ne mogu se uvek dobiti pravovremene i validne informacije, a samim tim se ne mogu ni donositi pravilne odluke.
Da bismo takve stvari izbegli, pre izgradnje same kocke mi demo iz postojedih izvora podataka kreirati svoje skladište i truditi se da greške i nekonzistentnost podataka svedemo na minimum. Proces kojim se ispunjavaju ovi ciljevi naziva se ETL (Extract, Transform, Load) proces.
1. Extract – kao što samo ime kaže, u ovoj fazi izvlačimo podatke iz različitih izvora. 2. Transform – transformišemo podatke, tako da otklonimo što je više mogude navedenih nedostataka.
(dodeljujemo vrednosti nedostajudim podacima ili ih brišemo, kvalitativne pretvaramo u kvantitativne...) 3. Load – učitavamo transformisane podatke u skladište koje nam je pogodno za korišdenje.
Kao jednostavan primer ove procedure, koristidemo dobro poznate podatke o rezultatima grupa sa vežbi TO. Podaci su dati u Excel tabeli rangirani po broju bodova, sa bojama koje označavaju beneficije zaslužene na vežbama i grafikonom na kome su jasno rangirane grupe.

Slika 16. Podaci o rezultatima studenata
Na prvi pogled tabela sa Slike 16 deluje kao jako pregledan i jasan način za informaciju studenata o njihovom radu i beneficijama sa vežbi. Međutim ako bismo želeli da napravimo OLAP Kocku ili Pivot tabelu na osnovu koje bismo vršili neke dalje analize imali bismo dosta poteškoda. Kao prvi problem javlja se polje beneficije. Ono je obeleženo bojama, a za rad sa kockom, neophodni su nam merljivi podaci. To rešavamo tako što umesto boja, unosimo broj zadataka kojih su studenti oslobodjeni. Grafikon takođe uklanjamo, jer sama kocka može dinamički kreirati grafikone u svakom trenutku.
Slika 17. Prečišdavanje podataka
Sumarni podaci nam takođe ne trebaju jer de se pri radu sa kockom sumirati kada bude zahtevao donosilac odluke. Ovako sumirani u okviru skladišta podataka samo stvaraju nepotrebnu redudantnost. Naravno, ovde to nije strašno, ali realna skladišta imaju količine podataka reda terabajta, i tada bi takva redudansa pravila i hardverske probleme (smeštanje podataka) i drastično bi pogoršala performanse sistema.

Nedostajudi podaci moraju se ili izbrisati ili zameniti nekim default vrednostima, koje de prepoznavati softver u kojem se koriste i koje de se modi uključiti u neka eventualna izračunavanja i operacije izveštavanja. U našem slučaju nedostajude podatke zamenjujemo sa nulama, jer ne želimo da izgubimo podatke o celoj grupi koja je vezana za te rezultate. Kada smo sve to prepravili ostaju nam podaci koji su prikazani na Slici 17.
Na Slici 17 se vidi da su ostali prečišdeni podaci i da nije izgubljena ni jedna bitna informacija. Sve što je odstranjeno može se rekonstruisati iz postojedih podataka. Međutim, podaci još nisu spremni za učitavanje u kocku (LOAD). Podaci treba da dobiju oblik denormalizovane relacione tabele, gde kolone predstavljaju osobine, dok redovi predstavljaju pojavljivanja skupa tih osobina. Zato demo ovu tabelu dalje transformisati do tog oblika, nakon čega dobijamo slededi Excel Sheet.
Slika 18. Denormalizacija je ključ?
Tabela kao na Slici 18 je spremna za učitavanje u Pivot tabelu. Iz nje možemo dobiti razne izveštaje o uspehu grupa, smerova, beneficijama koje su ostvarene na vežbama. Na slici 19 je prikazana kocka spremna za analizu.
Slika 19. OLAP kocka spremna za upotrebu

2.3. Primena OLAP kocke
U nastavku se prikazuju neke karakteristične primene OLAP kocke u rešavanju realnih problema odlučivanja. Problem „Igrači Statistike”: Igra se penal završnica, potrebni su igrači sa velikim brojem skokova i sa što manje izgubljenih lopti protiv određenog tima. Rešenje: Podatke o statistikama pojedinih igrača protiv određenih protivnika imamo u tabeli „IgraciStatistike“. Kao što primedujete na Slici 20 data tabela je vrlo nepregledna i jako je teško analizirati podatke u ovom obliku, i nikako nije pogodna za donošenje „ad hoc“ odluka, koje najčešde treba da se donesu u jako kratkom vremenskom periodu (kao što je ovaj slučaj odluke trenera).
Slika 20. Statistike sa utakmica
Rešenje ovog problema daje nam “Pivot Tabela” koja je integrisana u “Microsoft Excel”-u. Korišdenje ovog alata je opisano u narednih nekoliko koraka: 1. Pod opcijom “Data” odabiramo “Pivot Table and Pivot Chart Report”

Slika 21. Pokretanje čarobnjaka za kreiranje OLAP kocke
Pokrenuli smo “Wizard” prikazan na Slici 22.
Slika 22. Prvi korak u izgradnji OLAP kocke
Zatim biramo izvor naših podataka(u ovom slučaju Excel tabela) I idemo na opciju Next.Wizard nam omoguduje da biramo opseg podataka. Za naš problem koristidemo sve podatke što je dato kao “default” opcija.
Slika 23. Drugi korak u izgradnji OLAP kocke
Na kraju biramo New worksheet opciju, koja nam kreira Pivot tabelu u novom, a ne ved postojedem Sheet-u Excel-a. Idemo na opciju Finish. Kao rezultat dobijamo kreiranu Pivot Tabelu.(Slika 24).

Slika 24. OLAP kocka spremna za upotrebu
U tabeli možemo uočiti četiri oblasti:
1. Data Items – oblast za unos mera 2. Row Fields - oblast za unos dimenzija po redovima 3. Column Fields – oblast za unos dimenzija po kolonama 4. Page Fields – takodje oblast za unos dimenzija, ali onih koje nam služe za filtriranje podataka po jednoj
vrednosti. Sada se vradamo na rešavanje našeg konkretnog problema. Biramo igrača koji ima najviše skokova u napadu i u odbrani protiv odredjenog tima (npr. Boston Celtics). Dakle prvo, prevlacimo dimenziju Player u Row Fields i dobijamo spisak naših igrača.
Slika 25. Spisak potencijalnih igrača
Zatim prevlačimo mere Off i Def (broj ofanzivnih i defanzivnih skokova) u “Data Items” i dobijamo sume ofanzivnih i defanzivnih skokova svakog igrača protiv svih timova u ovoj sezoni.

Slika 26. Broj ofanzivnih i defanzivnih skokova po svakom igraču
Pošto nas zanimaju statistike protiv konkretnog tima (Boston Celtics) prevlačimo dimenziju Opp (protivnici) u “Page Fields”.
Slika 27. Filtriranje protivnika
Na kraju iz padajude liste biramo željeni tim.

Slika 28. Izbor protivnika
Slika 29. Željeni izveštaj
Dakle, na vrlo jednostavan način iz mase nestruktuiranih podataka dobili smo vrlo pregledan izveštaj koji olakšava trenersku odluku i naš zadatak. Da bi sve bilo još lepše i preglednije možemo kliknuti na “Chart” koji nam kreira grafički izveštaj.

Slika 30. Grafički prikaz rešenja
Sada je zaista jasno da je najbolje rešenje za ovaj problem uvodjenje L. Johnsona u igru, koji je po oba kriterijuma daleko iznad svih ostalih igrača. Legenda: Off - skokovi u napadu; Def - Skokovi u odbrani TO - izgubljene lopte : Mere Players,Opponents : Dimenzije Source - IgraciStatistikeQuery. Problem “Optimizacija Porudzbina Maloprodajnog Lanca” (Drill Down tehnika): Menadžer trgovinskog lanca želi da poboljša poslovanje svojih prodajnih objekata u narednoj godini, tako što de optimizovati porudžbine određenih artikala u zavisnosti od lokacije objekta i perioda godine. Rešenje: Kreiramo slededu Pivot Tabelu: Row Fields - Time, Product Column Fields – Location Data Items – Store Sales
Slika 31. OLAP izveštaj o prodaji po lokacijama i vremenu

Dakle, dobili smo podatke o prodaji određenih grupa proizvoda , po određenim zemljama u 1998. godini. Ali, kako nas zanima prodaja po odredjenim periodima godine iz padajudeg menija dimenzije Time (Year) produbidemo godinu u kvartale.
Slika 32. Izbor kvartala
Dobijamo prodaju grupe proizvoda po kvartalima i po zemljama:
Slika 33. Izveštaj po kvartalima
Daljim “Drill Down” – om možemo kvartale podeliti na mesece, grupe proizvoda na pojedinačne proizvode, a države na gradove
Slika 34. Opcija drill-down omogudava dolaženje do „detalja“
Konačno, dobili smo izveštaj, koji nam pokazuje kako su se alkoholna i bezalkoholna pida prodavala po kvartalima i mesecima u Mexiku, Zucatanu i Washingtonu, što našem menadžeru olakšava odluku o optimizaciji tj. odluci o tome, koju de vrstu pida da plasira po gradovima u odredjenim vremenskim periodima.

Slika 35. Željeni izveštajDO
Pitanja za studente:
1. Objasnite čemu služi OLAP kocka. 2. Objasnite pojam Pivot tabele. 3. Objasnite proces ETL-a. 4. Koje su prednosti i nedostaci OLAP kocke. 5. Objasnite proces pravljenja OLAP kocke. 6. Navedite nekoliko primera u kojima bi upotreba OLAP kocka imala smisla. 7. Objasnite drill-down. 8. Šta su dimenzije i mere? 9. Šta je Query Wizard i kakve veze ima sa OLAP kockom? 10. Kako se vrši filtriranje podataka u OLAP kocki?