iejoin and big data cleansing
TRANSCRIPT

Fast and Scalable Inequality Joins-- for Data Cleansing on Scale --
Zuhair Khayyat
PhD Candidate @ InfoCloud groupKing Abdullah University of Science and Technology (KAUST)

● Two customers having the same zip cannot be in different cities
Data Cleansing
Name Zip City
Winnie 91340 San Francisco
Robbert 91340 New York
Emma 91340 San Francisco

● Two customers having the same zip cannot be in different cities
● “inaccurate data has a direct impact ... the average company losing 12% of its revenue” -- Ben Davis (Econsultancy)
Data Cleansing
Name Zip City
Winnie 91340 San Francisco
Robbert 91340 New York
Emma 91340 San Francisco

● Two customers having the same zip cannot be in different cities
● “inaccurate data has a direct impact ... the average company losing 12% of its revenue” -- Ben Davis (Econsultancy)
● “This is the digital universe. It is growing 40% a year into the next decade” -- EMC2
BigData Cleansing
Name Zip City
Winnie 91340 San Francisco
Robbert 91340 New York
Emma 91340 San Francisco

Data Cleansing System
Data(Dirty)
Quality Rules Violations

Data Cleansing System
Data(Dirty)
Quality Rules Violations
Repair AlgorithmsFixes

Data Cleansing System
Data(Partially
Clean)
Quality Rules Violations
Repair AlgorithmsFixes
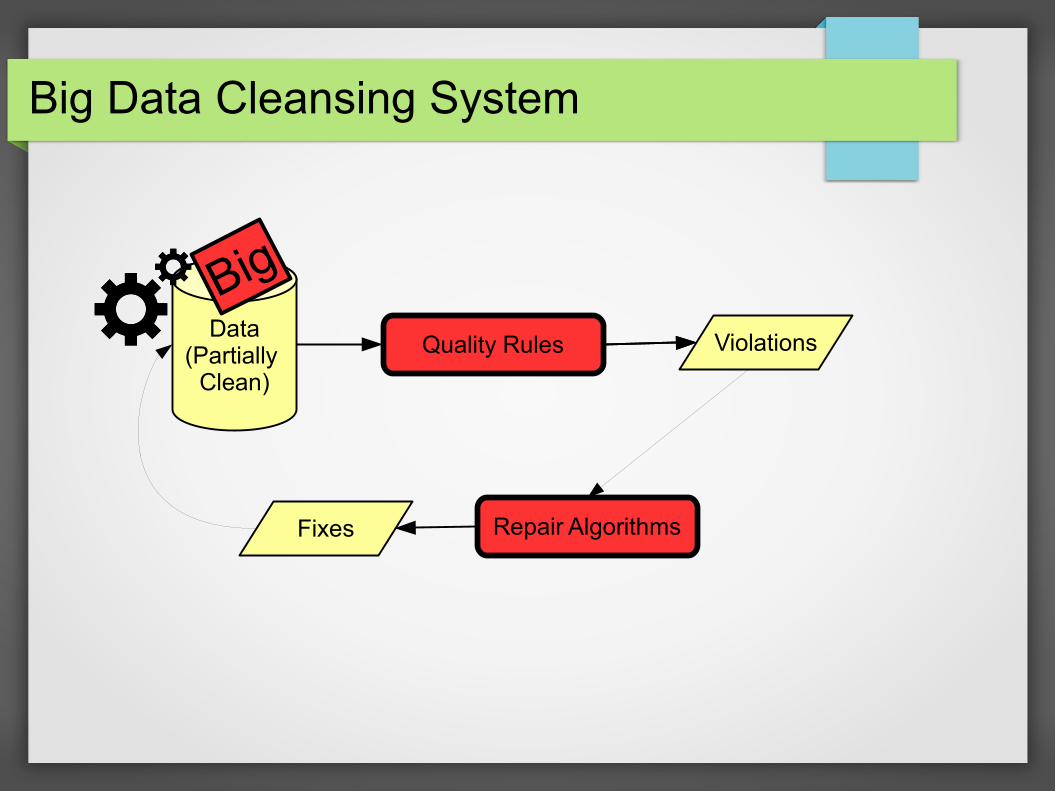
Big Data Cleansing System
Data(Partially
Clean)
Quality Rules Violations
Repair AlgorithmsFixes
Big

BigDansing: A System for Big Data CleansingIn SIGMOD 2015
BigDansing
Quality rules
Repair Algorithms
Dirtydatasets
Cleandatasets

BigDansing: A System for Big Data CleansingIn SIGMOD 2015
BigDansing
Quality rules
Repair Algorithms
Dirtydatasets
Cleandatasets

BigDansing: A System for Big Data Cleansing
Functional dependencies
Inclusiondependencies
Denialconstraints
Entityresolution
Domain Specific Language
Optimized execution plan
In SIGMOD 2015
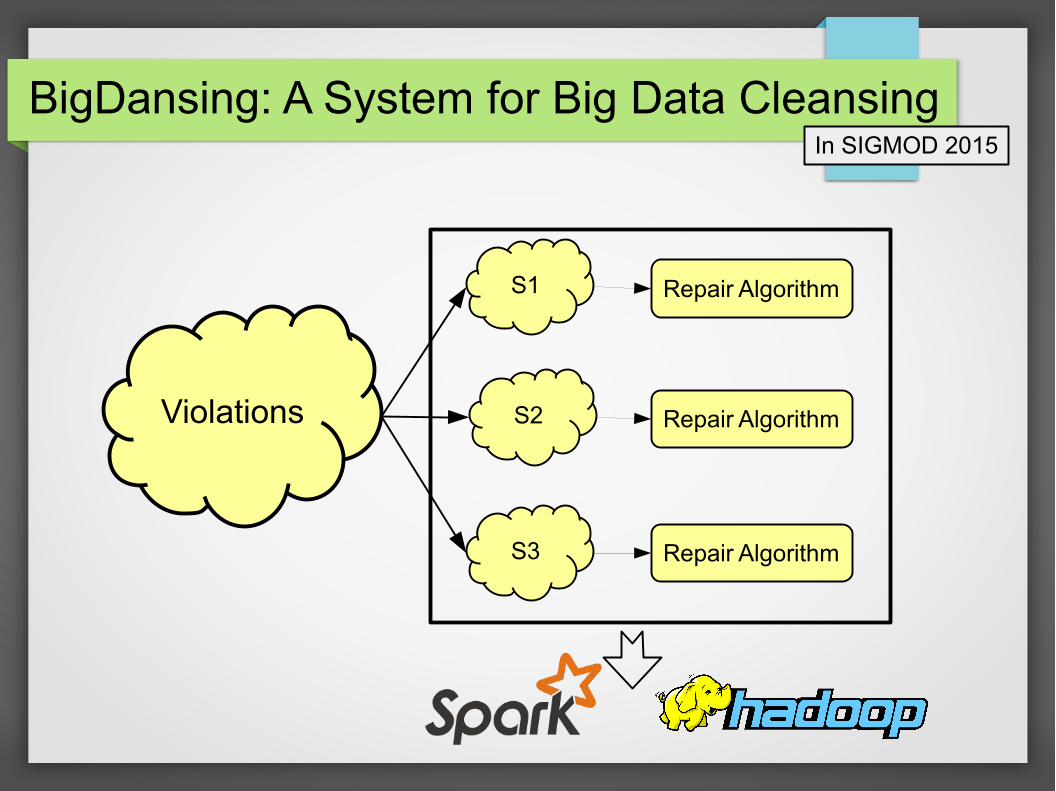
BigDansing: A System for Big Data CleansingIn SIGMOD 2015
Violations
S1
S2
S3
Repair Algorithm
Repair Algorithm
Repair Algorithm

In SIGMOD 2015
10M 20M 40M0
100
200
300
400
500
600
700BigDansing on Spark Spark SQL
Dataset Size
Tim
e (
Se
c)
Two customers having the same zip cannot be in different cities(FD: Zip → City)
BigDansing: A System for Big Data Cleansing

Complex Quality rule: Inequality joins
● If a person has a higher salary, he must pay more taxes compared to others

Complex Quality rule: Inequality joins
● If a person has a higher salary, he must pay more taxes compared to others
● Select * from D t1 JOIN D t2 on
t1.Salary > t2.Salary AND
t1.Tax < t2.Tax;
● Processed as a Cartesian product: O(n2)

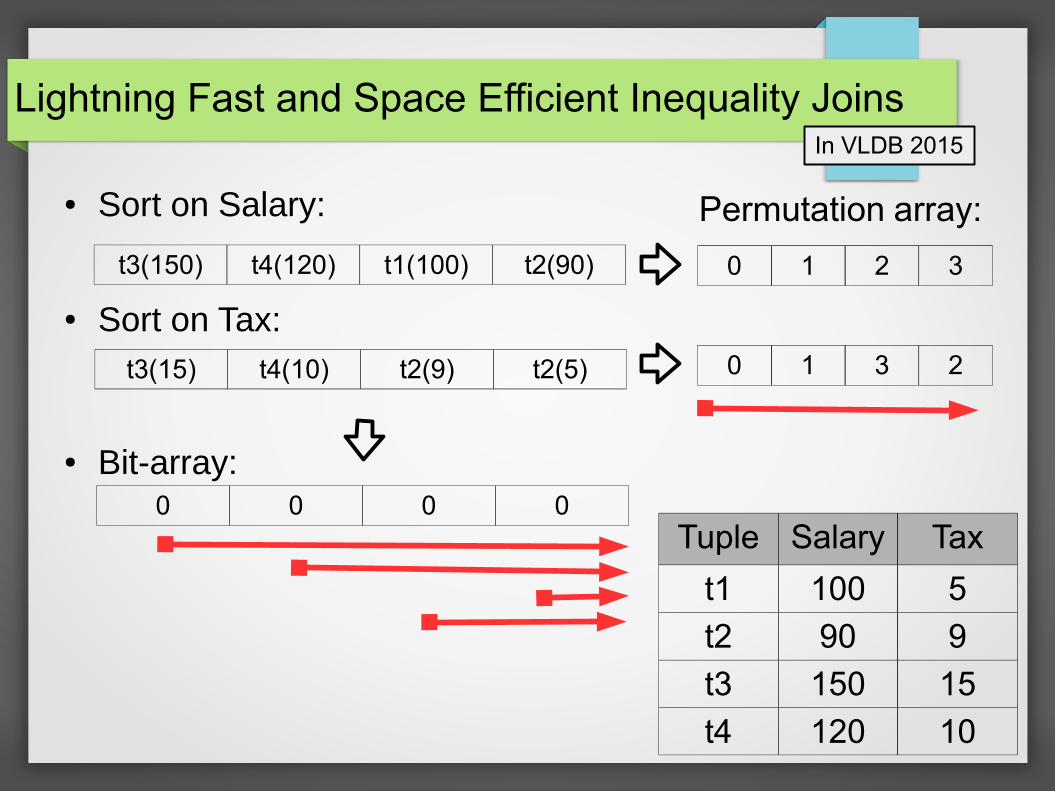
Lightning Fast and Space Efficient Inequality Joins
● Sort on Salary:
● Sort on Tax:
● Bit-array:
In VLDB 2015
Tuple Salary Tax
t1 100 5
t2 90 9
t3 150 15
t4 120 10
t3(150) t4(120) t1(100) t2(90)
t3(15) t4(10) t2(9) t2(5)
0 1 2 3
0 1 3 2
0 0 0 0
Permutation array:
Lightning Fast and Space Efficient Inequality Joins
● Sort on Salary:
● Sort on Tax:
● Bit-array:
In VLDB 2015
Tuple Salary Tax
t1 100 5
t2 90 9
t3 150 15
t4 120 10
t3(150) t4(120) t1(100) t2(90)
t3(15) t4(10) t2(9) t2(5)
0 1 2 3
0 1 3 2
0 0 0 0
Permutation array:
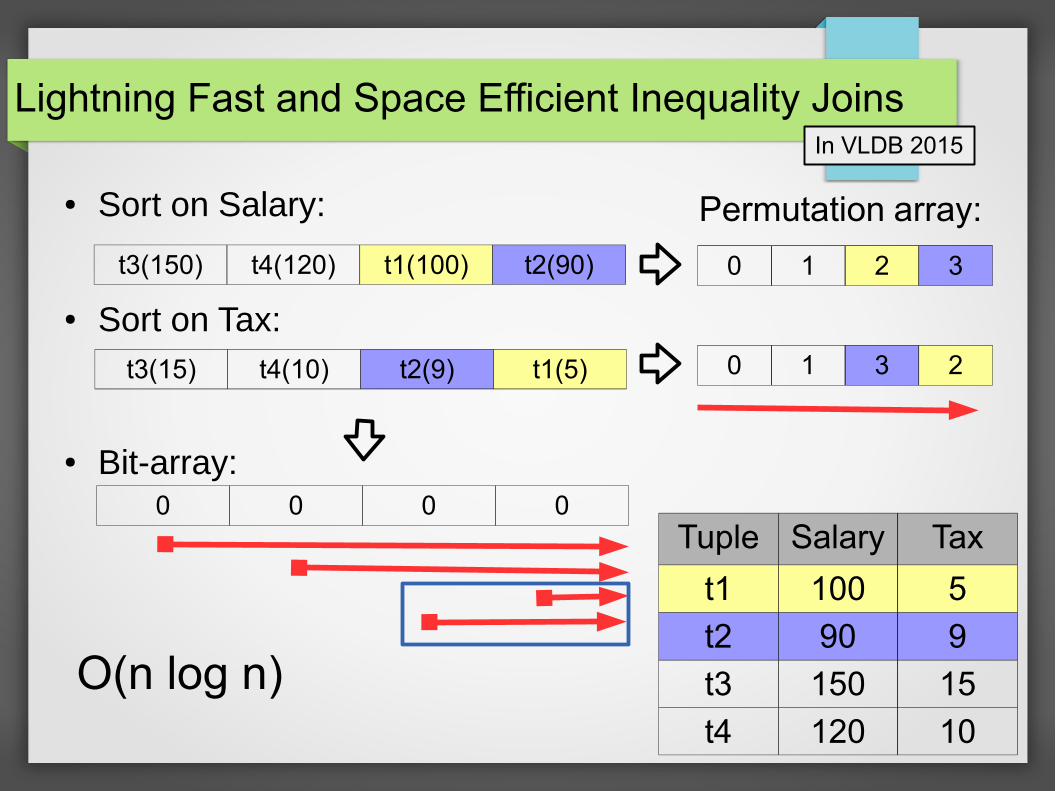
Lightning Fast and Space Efficient Inequality Joins
● Sort on Salary:
● Sort on Tax:
● Bit-array:
In VLDB 2015
Tuple Salary Tax
t1 100 5
t2 90 9
t3 150 15
t4 120 10
t3(150) t4(120) t1(100) t2(90)
t3(15) t4(10) t2(9) t1(5)
0 1 2 3
0 1 3 2
0 0 0 0
Permutation array:
O(n log n)

IEJoin vs. DBMS (Single machine)
10K 50K 100K0.01
0.1
1
10
100
1000
10000PG-IEJoin Postgres MonetDB DBMS-X
Dataset size
Run
time
(S
ec)

IEJoin vs. Spark SQL (Distributed)
Salary-Tax Range Intersection0
4
8
12
16
20
24
IEJoin on Spark SQL Spark SQL
Run
time
(H
ou
rs)
100M rows on 6 machines

IEJoin on 8B Rows
● A cluster of 16 workers
● 8B rows, 287 GB on Disk
● Runtime in 13 hours
● Close to the ideal speedup
0 2 4 6 8 10 12 14 16 180
20
40
60
80
100
IEJoin on Spark SQL
Ideal Speedup
Cluster Size
Hou
rs

Visit us!
● Zuhair Khayyat– cloud.kaust.edu.sa
● SIGMOD 15 – BigDansing paper
● VLDB 15 – IEJoin Paper -----> to be presented in VLDB 16
● SIGMOD 16 – Demo Paper