genome evolution: a sequence-centric approach lecture 4: beyond trees. inference by sampling...
Post on 21-Dec-2015
216 views
TRANSCRIPT

Genome evolution: a sequence-centric approach
Lecture 4: Beyond Trees. Inference by sampling
Pre-lecture draft – update your copy after the lecture!

Course outline
Probabilistic models
Inference
Parameter estimation
Genome structure
Mutations
Population
Inferring Selection
(Probability, Calculus/Matrix theory, some graph theory, some statistics)
CT Markov ChainsSimple Tree ModelsHMMs and variants
Dynamic Programming
EM

What we can do so far (not much..):
Given a set of genomes (sequences), phylogeny
Align them to generate a set of loci (not covered)
Estimate a ML simple tree model (EM)
Infer ancestral sequences posteriors
Inferring a phylogeny is generally hard..but quite trivial given entire genomes that are evolutionary close to each other
Multi alignment is quite difficult when ambiguous..Again easy when genomes are similar
EM is improving and convergingTend to stuck at local maximaInitial condition is criticalFor simple tree - not a real problem
Inference is easy and accurate for trees
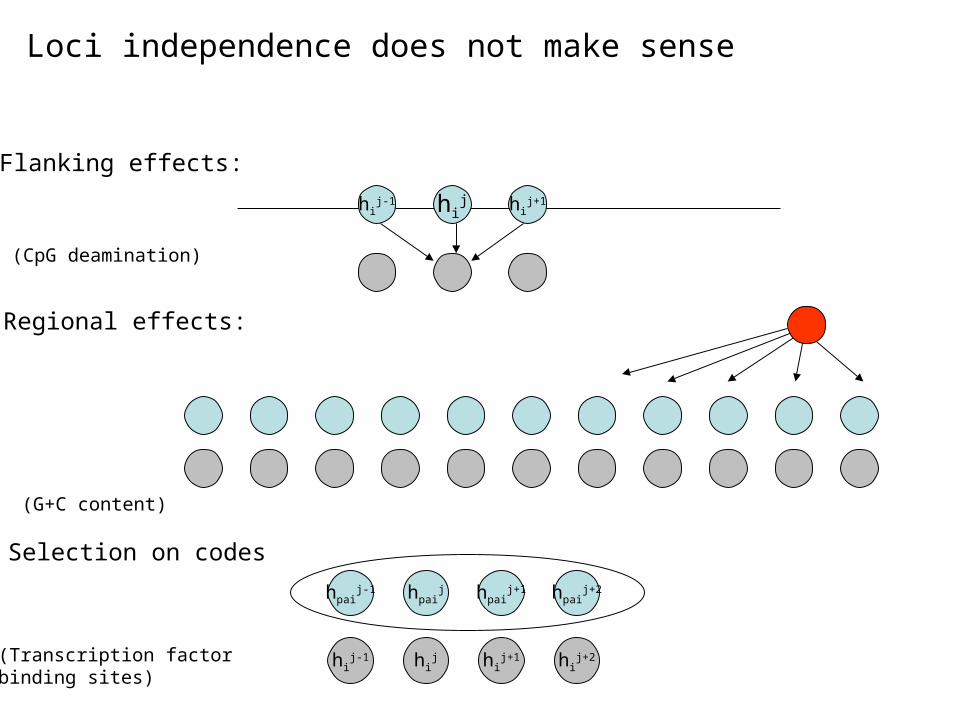
Loci independence does not make sense
hij hi
j+1hij-1
Flanking effects:
Selection on codes
hij hi
j+1hij-1
hpaij hpai
j+1hpaij-1
hij+2
hpaij+2
Regional effects:
(CpG deamination)
(G+C content)
(Transcription factor binding sites)

Bayesian Networks
Defining the joint probability for a set of random variables given:1) a directed acyclic graph 2) Conditional probabilities
)pa|Pr()Pr( iii xxx
)pa|Pr( ii xxpa),(XG
Claim: The Up-Down algorithm is correct for treesProof: Given a node, the distributions of the evidence on
two subtrees are independent…
Claim: 1)pa|Pr( x
iii xx
Proof: we use a topological order on the graph (what is this?)
Claim/Definition: In a Bayesian net, a node is independent of its non descendents given its parents (The Markov property for BNs)
Definition: the descendents of a node X are those accessible from it via a directed path
whiteboard/ exercise

Stochastic Processes and Stationary Distributions
StationaryModel
ProcessModel
t

Dynamic Bayesian Networks
1
2 3
4
1
2
3
4
1
2
3
4
1
2
3
4
1
2
3
4
1
2
3
4
Synchronous discrete time process
T=1 T=2 T=3 T=4 T=5
Conditional probabilities
Conditional probabilities
Conditional probabilities
Conditional probabilities

Context dependent Markov Processes
A AA C AA G AA
AAQ CAQ GAQ
Context determines A markov process rate matrix
Any dependency structure make sense, including loops
A AA
AQ?C
When context is changing, computing probabilities is difficult.Think of the hidden variables as the trajectories Continuous time Bayesian Networks
Koller-Noodleman 2002
1 2 3 4
)(pa iQi
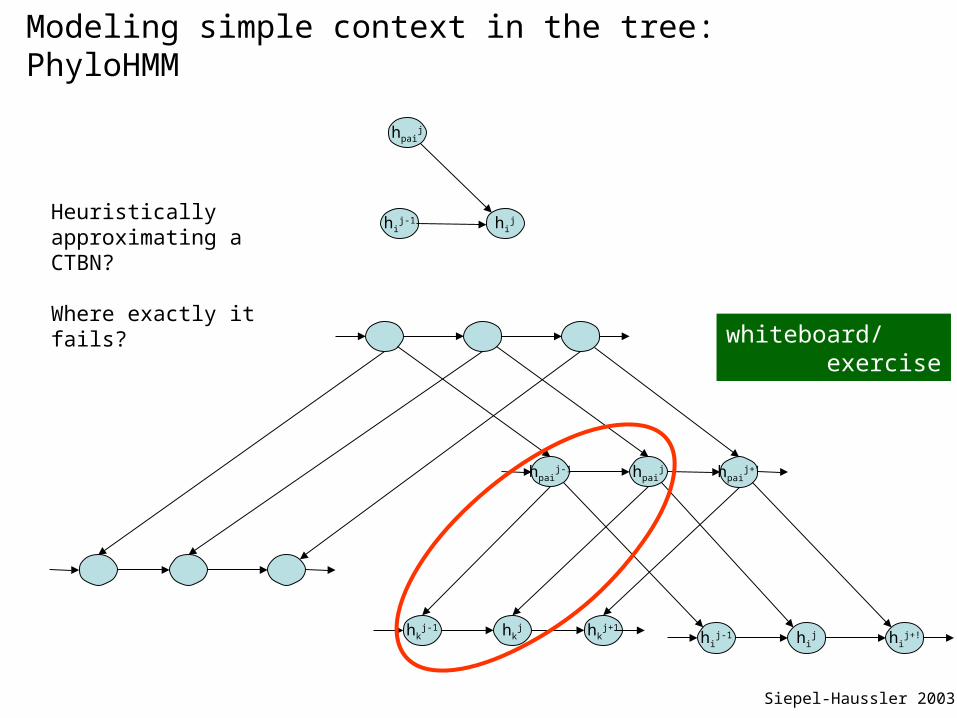
Modeling simple context in the tree: PhyloHMM
Siepel-Haussler 2003
hpaij
hij-1 hi
j
hpaij
hij-1 hi
j hij+!
hpaij+!hpai
j-1
hkj-1 hk
j hkj+1
Heuristically approximating a CTBN?
Where exactly it fails?
whiteboard/ exercise

So why inference becomes hard (for real, not in worst case and even in a crude heuristic like phylo-hmm)?
hpaij
hij-1 hi
j hij+!
hpaij+!hpai
j-1
hkj-1 hk
j hkj+1
We know how to work out the chains or the treesTogether the dependencies cannot be controlled (even given its parents, a path can be found from each node to everywhere.
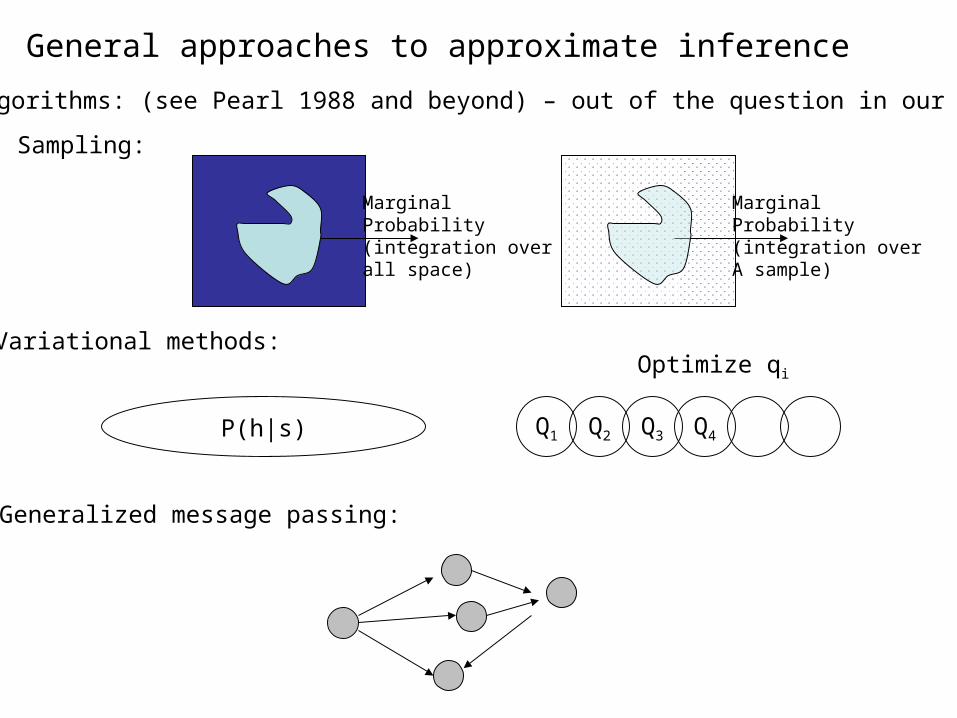
General approaches to approximate inference
Sampling:
Variational methods:
Generalized message passing:
MarginalProbability(integration overall space)
MarginalProbability(integration overA sample)
P(h|s) Q1 Q2 Q3 Q4
Optimize qi
Exact algorithms: (see Pearl 1988 and beyond) – out of the question in our case

Sampling from a BN
Naively: If we could sample from Pr(h,s) then: Pr(s) ~ (#samples with s)/(# samples)
Forward sampling: use a topological order on the network. Select a node whose parents are already determined sample from its conditional distribution
2 31
whiteboard/ exercise
How to sample from the CPD?
4 5 6
7 8 9

Focus on the observations
Naïve sampling is terribly inefficient, why? whiteboard/ exercise
A word on sampling error
Why don’t we constraint the sampling to fit the evidence s?
2 31
4 5 6
7 8 9
Two tasks: P(s) and P(f(h)|s), how to approach each/both?
This can be done, but we no longer sample from P(h,s), and not from P(h|s) (why?)

Likelihood weighting
Likelihood weighting: weight = 1use a topological order on the network.
Select a node whose parents are already determined if no evidence exists: sample from its conditional distributionelse: weight *= P(xi|paxi), add evidence to sample
Report weight, sample
Pr(h|s) = (total weights of sample with h)/(total weights)
7 8 9
),|Pr( 211 ij
iij shs
),|Pr( 1ij
iij shs
),|Pr( 11 ij
iij shs ),|Pr( 211 i
jii
j shs),|Pr( 1i
jii
j shs),|Pr( 11 ij
iij shs
Weight=

Generalizing likelihood weighting: Importance sampling
M
mmP xf
MfE
1
)(1
][ f is any function (think 1(hi))
We will use a proposal distribution Q
We should have Q(x)>0 whenever P(x)>0
Q should combine or approximate P and f, even if we cannot sample from P
(imagine that you like to sample from P(h|s) to recover Pr(hi|s)).

Correctness of likelihood weighting: Importance sampling
M
mmP hf
MfE
1
)(1
][
])(
)()([)]([ )()( HQ
HPHfEHfE HQHP
M
D mhQ
mhPmhf
MfE
mhhD
1 ])[(
])[(])[(
1][ˆ
]}[],..,1[{whiteboard/ exerciseSample:
UnnormalizedImportance sampling:
])[(
])[()(
mhQ
mhPhw So we sample with a weight:
)(|)(|)( HPHfHQ To minimize the variance, use a Q distribution is proportional to the target function:(Think of the variance of f=1 : We are left with the variance of w)
22
22
)])()([(]))()([(
)])()([(]))()([(
HwHfEHwHfE
HwHfEHwHfEVar
PQ
whiteboard/ exercise
f is any function (think 1(hi))

Normalized Importance sampling
hh
HQ hPhQ
hPhQHwE )('
)(
)(')()]([)(
/)]()([)]([ )()( HwHfEXfE HQHP whiteboard/ exercise
M
M
Dmhw
mhwmhf
MfE
mhhD
1
1
])[(
])[(])[(1][ˆ
]}[],..,1[{Sample:
NormalizedImportance sampling:
])[(
])[(')(
mhQ
mhPhw
When sampling from P(h|s) we don’t know P, so cannot compute w=P/Q
We do know P(h,s)=P(h|s)P(s)=P(h|s)=P’(h)
So we will use sampling to estimate both terms:

Normalized Importance sampling
How many samples?
Biased vs. unbiased estimator
whiteboard/ exercise
)])([1)](([1
)]((ˆ[ XwVarXfVarM
XfEVar QPDP
Compare to an idealSampler from P(h): )]([
1)]((ˆ[ XfVar
MXfEVar PDP
)])([1/( hwVarM The ratio represent how effective your sample was so far:
Sampling from P(h|s) could generate posteriors quite rapidlyIf you estimate Var(w) you know how close your sample is to this ideal
The variance of the normalized estimator (not proved):

Back to likelihood weighting:
Our proposal distribution Q is defined by fixing the evidence and ignoring the CPDs of variable with evidence.
It is like forward sampling from a network that eliminated all edges going into evidence nodes
The weights are:
The importance sampling machinery now translates to likelihood weighting:
Unnormalized version to estimate P(s)
Unnormalized version to estimate P(h|s)
Normalized version to estimate P(h|s)
)][(1
)(ˆ1M
D mhwM
sP
)][(''
1/)][(
1)|(ˆ
'
11MM
iD mhwM
mhwM
shP
Q forces sQ forces s and hi
)][(1/)][()(1
1)|(ˆ
'
11MM
D mhwM
mhwhM
shP
)pa|Pr(),(
),()( ii
iss
shQ
shPhw

Likelihood weighting is effective here:
But not here:
observed
unobserved
Limitations of forward sampling

Markov Chain Monte Carlo (MCMC)
We don’t know how to sample from P(h)=P(h|s) (or any complex distribution for that matter)
The idea: think of P(h|s) as the stationary distribution of a Reversible Markov chain
)()|()()|( yPyxxPxy
Find a process with transition probabilities for which:
Then sample a trajectory ,,...,, 21 myyy
)()(1
lim xPxyCn i
n
Theorem: (C a counter)
Process must be irreducible (you can reach from anywhere to anywhere with p>0)
(Start from anywhere!)

The Metropolis(-Hastings) Algorithm
Why reversible? Because detailed balance makes it easy to define the stationary distribution in terms of the transitions
So how can we find appropriate transition probabilities?
)()|()()|( yPyxxPxy
)|()|( xyFyxF
))(/)(,1min( xPyP
We want:
Define a proposal distribution:
And acceptance probability:
)|()(
)1,)(
)(min()|())(),(min()|(
))(
)(,1min()|()()|()(
yxyP
yP
xPyxFyPxPxyF
xP
yPxyFxPxyxP
What is the big deal? we reduce the problem to computing ratios between P(x) and P(y)
x yF
))(/)(,1min( xPyP

Acceptance ratio for a BN
We must compute min(1,P(Y)/P(X)) (e.g. min(1, Pr(h’|s)/Pr(h|s))
But this usually quite easy since e.g., Pr(h’|s)=Pr(h,s)/Pr(s)
)),(/),'(,1min())|(/)|'(,1min( shPshPshPshP
We affected only the CPDs of hi and its children
Definition: the minimal Markov blanket of a node in BN include its children, Parents and Children’s parents.
To compute the ratio, we care only about the values of hi and its Markov Blanket
For example, if the proposal distribution changes only one variable h i what would be the ratio?
?))|,..,,,..,Pr(/)|,..,',,..,Pr(,1min( 11111111 shhhhhshhhhh niiiniii
whiteboard/ exercise
What is a markov blanket?

Gibbs sampling
)|..,,,..,Pr(/),,..,',..,Pr()|,..,,..,Pr(
),..,,,..,|'Pr()|,..,,..,Pr(),|'()|(
11111111
111111
shhhhshhhshhh
shhhhhshhhshhshP
niinini
niiini
A very similar (in fact, special case of the metropolis algorithm):
Start from any state hIterate:
Chose a variable Hi
Form ht+1 by sampling a new hi from Pr(hi|ht)
This is a reversible process with our target stationary distribution:
Gibbs sampling easy to implement for BNs:
ihiij
jiii
iijji
ii
niii
hhhhh
hhhhhshhhhh
''pa
pa1111
)ˆ,''|Pr()ˆ|''Pr(
)ˆ,'|Pr()ˆ|'Pr(),..,,,..,|'Pr(
ih

Sampling in practice
)()(1
lim xPxyCn i
n
How much time until convergence to P?(Burn-in time)
Mixing
Burn in Sample
Consecutive samples are still correlated! Should we sample only every n-steps?
We sample while fixing the evidence. Starting from anywere but waiting some time before starting to collect data
A problematic space would be loosely connected:
whiteboard/ exercise
Examples for bad spaces