estadistica
DESCRIPTION
La tabla estadisticaTRANSCRIPT

TECSUP - PFR Estadística y Probabilidades
1
UNIDAD I
ESTADÍSTICA 1. INTRODUCCIÓN
El uso de los métodos estadísticos para analizar datos se ha convertido en una práctica común en todas las disciplinas científicas. Este material de ayuda pretende introducir métodos que utilizan los estudiantes en sus carreras de formación tecnológica. La exposición matemática es relativamente modesta. El uso sustancial del cálculo se hace sólo en el capítulo de probabilidades. No se utiliza álgebra matricial en absoluto. Por lo tanto, casi toda la exposición deberá ser accesible para aquellos estudiantes cuyo conocimiento en matemática es básico.
La unidad 1 se inicia con algunos conceptos y terminología básicos (población, muestra, estadística descriptiva e inferencial, variables y tipos) y continúa con la elaboración de tablas de frecuencia para variables cualitativas y cuantitativas y gráficos importantes. La unidad 2 corresponde a las medidas resumen de posición y de dispersión. La unidad 3 se estudia el análisis de dos variables: cualitativas vs cualitativas, cualitativas vs cuantitativas y cuantitativas vs cuantitativas, además de gráficos importantes. En la unidad 4 se ofrece el desarrollo un tanto tradicional de la probabilidad, la probabilidad condicional, la probabilidad total y el teorema de Bayes.
1.1 POBLACIÓN Y MUESTRA
A fin de entender cómo se puede aplicar los métodos estadísticos, se debe distinguir entre población y muestra. Una población o universo es cualquier colección finita o infinita de individuos o elementos, para cada uno de los cuales se tiene que contar o medir una o varias características. Los elementos son los objetos que poseen la información que busca el investigador y acerca del cual deben hacerse las inferencias. Entre posibles elementos se tiene: una sustancia, un compuesto, un mineral, etc. Aunque existe la libertad de llamar población a un grupo cualquiera de elementos definidos en el tiempo y el espacio, en la práctica depende del contexto en el cual se observarán los elementos. Suponga, por ejemplo, el número de total de compuestos que pueden elaborarse con 5 sustancias, puede considerarse como una población.
Una muestra es un subconjunto de elementos de la población que puede servir de base para generalizaciones válidas En trabajos químicos, se toman muestras de un material, se ensayan y se hacen deducciones para la totalidad de dicho material, a partir de los resultados obtenidos. La muestra no es exactamente la población, sino que se supone que la

Estadística y Probabilidades TECSUP - PFR
2
representa, y la validez de cualquier conclusión obtenida de ella depende de la verdadera representatividad que tenga.
La muestra debería ser seleccionada en forma aleatoria, es decir, ca- da elemento tiene una probabilidad conocida y no nula de selección. No siempre es posible obtener una muestra aleatoria. Esto es especialmente cierto cuando el estadístico puede confiar en su propio “juicio” o “conveniencia” al seleccionar los elementos de la muestra. Con la aleatoriedad se per- sigue que la muestra sea “representativa” de la población, para que concentre todas las características y particularidades de interés. Sin embargo, la aleatoriedad no garantiza necesariamente la representatividad.
Los factores que determinan la selección de muestras son: costo, tiempo y la imposibilidad práctica (o destrucción de la unidad de estudio). En tanto, el tamaño de la muestra queda determinado por la variabilidad de la población, el nivel de confianza y el error máximo permisible. Cuando los elementos de una población tienen cierto grado de heterogeneidad entre ellos, el tamaño de la muestra tiende a ser grande. Cabe destacar, que es completamente erróneo asegurar que la muestra depende del tamaño de la población.
Cuando se hace una investigación con todos los elementos de la población, se llama censo o enumeración total. En tanto, cuando se elabora con base en una muestra, se le denomina estudio por muestreo. En la mayoría de los casos los químicos no están interesados en los datos de enumeración total (o censo) sino en datos muestrales.
1.2 ESTADÍSTICA
Disciplina que nos proporciona un conjunto de métodos y procedimientos que nos permitan recopilar, clasificar, presentar y describir datos en forma adecuada para tomar decisiones frente a la incertidumbre o predecir o afirmar algo acerca de la población a partir de los datos extraídos de la misma. Esta definición nos permite distinguir la Estadística Descriptiva de la Inferencial. La estadística descriptiva se puede definir como los métodos estadísticos que pretenden describir las características más importantes de un conjunto de datos, sea que provenga de una muestra o de una población. Utiliza técnicas estadísticas, como la representación gráfica, cuadros estadísticos, medidas de posición y de variabilidad. Uno de los propósitos fundamentales de los métodos estadísticos es utilizar estadísticos muestrales para estimar los parámetros de la población. A este proceso de utilizar los estadísticos muestrales para llegar
TECSUP - PFR Estadística y Probabilidades
3
a conclusiones acerca de los verdaderos parámetros de la población, se le llama inferencia estadística. La estadística inferencial generaliza los resultados observados en una muestra a toda la población bajo estudio, por medio del planteamiento y pruebas de hipótesis y cálculo de intervalos de confianza; se aplica a problemas como estimar, mediante pruebas, el rendimiento promedio de un proceso químico, verificar las especificaciones de producción a partir de mediciones efectuadas sobre muestras o predecir los residuos de cloro en una piscina basándose en una muestra de datos tomados en ciertos periodos de tiempo.
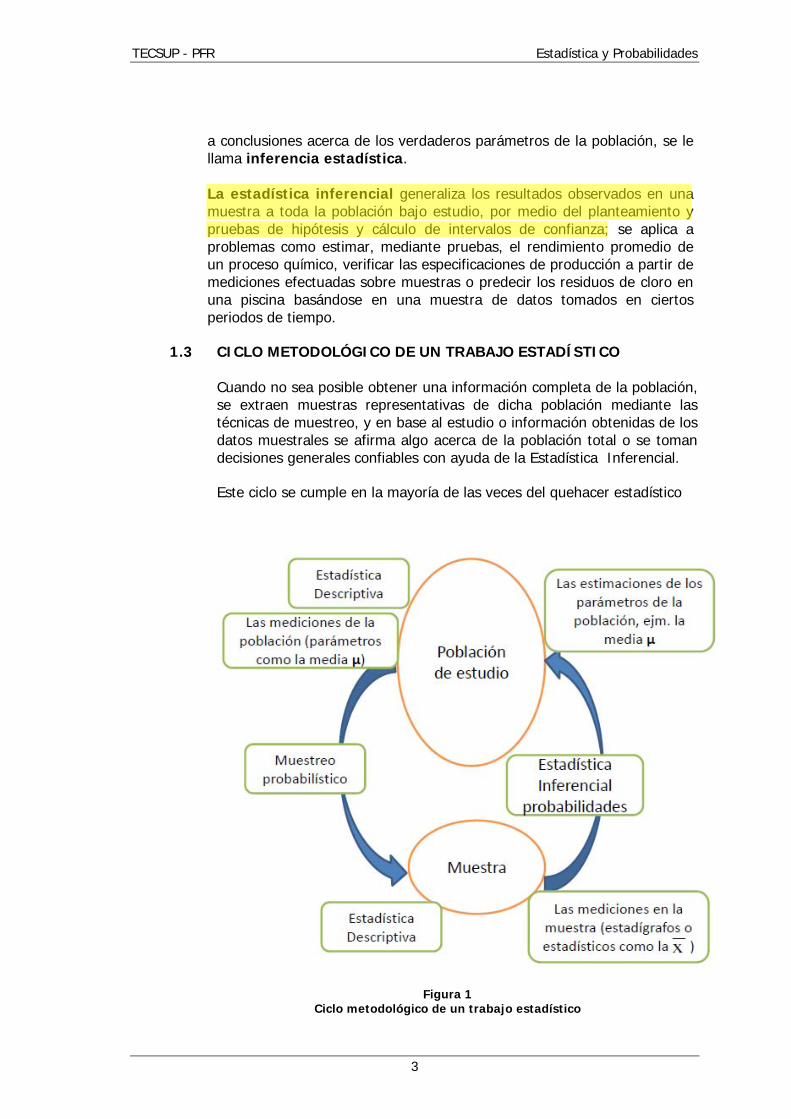
1.3 CICLO METODOLÓGICO DE UN TRABAJO ESTADÍSTICO
Cuando no sea posible obtener una información completa de la población, se extraen muestras representativas de dicha población mediante las técnicas de muestreo, y en base al estudio o información obtenidas de los datos muestrales se afirma algo acerca de la población total o se toman decisiones generales confiables con ayuda de la Estadística Inferencial.
Este ciclo se cumple en la mayoría de las veces del quehacer estadístico
Figura 1 Ciclo metodológico de un trabajo estadístico

Estadística y Probabilidades TECSUP - PFR
4
1.4 VARIABLES
Se dice que algo varía si puede tomar por lo menos dos valores, grados o formas o, incluso, cuando una característica puede estar presente o ausente en una situación específica. Dicho esto, podríamos estar de acuerdo en que nociones como sexo, número de hijos por familia, color de automóvil, número de huelgas anuales, nivel de estudios, etc., son variables, ya que son características que admiten por lo menos dos valores, grados o formas dentro de un universo determinado. No obstante, al empezar a familiarizarse con este tema, se suele confundir la característica que admite variaciones con el universo o con los elementos del mismo. Compárese la lista del párrafo anterior con esta otra: persona, vivienda, lámpara, automóvil. Estos términos se refieren a objetos y no a características de objetos; por lo tanto, no son variables. Variables serían las características que quisiéramos indagar de esos objetos. Por ejemplo, de un universo formado por personas podríamos conocer su edad, lugar de nacimiento, nivel de escolaridad, clase social a que pertenecen, etc. Estas peculiaridades son variables. También son variables, de un universo formado por automóviles, su marca, modelo, color, potencia, etc., ya que son características que van cambiando de auto en auto. Otra confusión frecuente se da con los datos estadísticos. Consideremos estos ejemplos: "número de huelgas" y "producción de azúcar". Si decimos que el número de huelgas en una región y en un periodo determinados es A, estamos aportando información global del fenómeno, que es un dato estadístico, no una variable. El número de huelgas se convierte en variable si se estudia, digamos, en un periodo determinado y en diferentes regiones, o en una sola región y en diferentes periodos (anualmente, sexenalmente, etc.). Lo mismo pasa si afirmamos que la producción de azúcar en el ingenio X es B toneladas: se trata de un dato estadístico, no de una variable. La producción de azúcar se convertirá en variable cuando se indague en diferentes fábricas y en un mismo momento o en una misma fábrica y en distintos momentos. Ahora bien, toda variable tiene dos niveles: uno conceptual o teórico y otro operacional o de medición. Si nos preguntaran qué se entiende por alcoholismo, por ejemplo, podríamos decir que se trata de una enfermedad progresiva y mortal, exclusiva de los seres humanos, que consiste en la ingestión de bebidas alcohólicas. De ser más o menos correcta esta definición, estaríamos en el nivel estrictamente conceptual o teórico, que no permite efectuar ninguna medición. Si, en cambio, a partir de este concepto definimos al alcoholismo como el grado de dependencia de los seres humanos respecto a la ingestión de bebidas alcohólicas, habremos pasado del nivel conceptual a otro donde es posible medir, pues en una población dada encontraríamos desde el que no ha bebido jamás una gota de alcohol, el abstemio, hasta el que no puede dejar de beber.

TECSUP - PFR Estadística y Probabilidades
5
La correspondencia entre el nivel teórico y el operacional de una variable se consigue mediante un procedimiento llamado medición, que no debe entenderse como un procedimiento arbitrario de asignación de números u otros símbolos a las observaciones: esta asignación se efectúa en concordancia con un conjunto de procedimientos admisibles para la variable conceptual que sé esté manejando. A nivel operacional o de medición, variable es un conjunto de números u otros símbolo; asignados a las observaciones, que sirven para clasificarlas con respecto a una variable conceptual Sin embargo, no ahondaremos en esta cuestión; será suficiente, por ahora, que sepamos identificar variables, ya que del tipo a que pertenezcan dependerá el procedimiento estadístico con que se le trate. Tipos de variables Según su naturaleza las variables pueden clasificarse en: a) Variables cuantitativas, son aquellas que consisten de números que
representan conteos o mediciones. Las variables cuantitativas pueden ser: Discreta, corresponde al conteo o numeración de sucesos. Ejemplos: número de computadores en un aula, número de artículos defectuosos en un embarque, número de hijos por familia, etc.
Continua, corresponde a “mediciones” y por tanto sus valores están comprendidos en un intervalo ya que entre dos valores existen infinitos valores intermedios.
Ejemplos: contenido neto en gramos en una lata de café, diámetro de un tornillo, ingreso familiar, etc.
b) Variables cualitativas se dividen en diferentes categorías que se
distinguen por alguna característica no numérica. Ejemplos: genero, nivel socio económico, grado de instrucción, etc. Observación: Los datos pueden estar “codificados” numéricamente, sin que ello signifique que sea una variable cuantitativa. Ejemplo. Clasifica las siguientes variables: Marca de detergente que una ama de casa usa. El grado de instrucción. Número de artículos defectuosos producidos por una máquina en
un periodo de dos horas. La longitud de 1000 tornillos con arandela y tuerca.
Según la función que cumplen en el estudio: Una distinción de particular importancia es aquella entre variables dependientes e independientes. Los términos “dependiente” e

Estadística y Probabilidades TECSUP - PFR
6
independiente” se utilizan para representar una relación de “causalidad” entre dos variables. El problema de la determinación de causalidad (¿cuáles variables son dependientes y cuáles independientes?) es uno de los problemas más serios que enfrenta la estadística. El análisis empírico o estadístico sólo puede decirnos si dos variables parecen estar relacionadas, pero no puede decirnos: (a) si de hecho existe una relación de dependencia y (b) cuál es la dirección de dicha relación (cuál es la “causa” y cuál el efecto o la variable “causada”). Necesitamos una “teoría” para dar plausibilidad a una relación empírica. Independiente (X): Una variable independiente es aquella cuyo valor no depende del de otra variable. La variable independiente se representa en el eje de abscisas. Son las que el investigador escoge para establecer agrupaciones en el estudio, clasificando intrínsecamente a los casos del mismo. Es aquella característica o propiedad que se supone ser la causa del fenómeno estudiado. En investigación experimental se llama así a la variable que el investigador manipula. Dependiente (Y): Una variable dependiente es aquella cuyos valores dependen de los que tomen otra variable. La variable dependiente en una función se suele representar por y. La variable dependiente se representa en el eje ordenadas. Son las variables de respuesta que se observan en el estudio y que podrían estar influidas por los valores de las variables independientes. Hayman (1974: 69) la define como propiedad o característica que se trata de cambiar mediante la manipulación de la variable independiente. La variable dependiente es el factor que es observado y medido para determinar el efecto de la variable independiente. Considere la siguiente cuestión: ¿Es el aumento del ingreso per cápita de un país que causa mejoras en el nivel de educación o la mejora en el nivel de educación que causa mejoras en el ingreso per cápita? ¿O tal vez un tercer factor es la causa de ambos? ¿Cultura? Este complejo y viejo debate no se puede resolver sólo sobre la base del análisis estadístico, aunque la estadística es un importante instrumento en nuestros continuos esfuerzos por dilucidar estas cuestiones. El debate mencionado ha persistido por décadas, además, porque muchas de las teorías que han sido propuestas para explicar la relación entre educación y desarrollo económico no pueden ser refutadas sólo sobre la base del análisis empírico.

TECSUP - PFR Estadística y Probabilidades
7
ESCALAS DE MEDICIÓN La medición de una variable consiste en asignar un “valor” a la característica o propiedad observada. Por ejemplo, si la característica observada es el género de las personas, al clasificar a una persona como de sexo “femenino” le estamos asignando un valor, estamos haciendo una medición de la característica. El proceso de medición utiliza diversas escalas: Nominal, Ordinal, Intervalo y Razón. Escala Nominal: Sólo permite asignar un nombre, etiqueta o valor al elemento sometido a medición. Los números que se puedan asignar a las propiedades observadas en los elementos se utilizan sólo como “etiquetas” con la finalidad de clasificarlos. Con esta escala no tiene sentido realizar operaciones aritméticas. Por ejemplo: Género (femenino, masculino), nacionalidad (peruano, colombiano, etc.), marcas de gaseosa preferida (fanta, coca cola, pepsi etc.). Escala Ordinal: Además de asignar un nombre, etiqueta o valor, esta escala permite establecer un orden entre los elementos sometidos a medición. Con esta escala solo se puede establecer una relación de orden. Los números que se asignen a las propiedades deben respetar el orden de la característica que se mide. Cada categoría puede ser comparada con otra en relación de “mayor que” o “menor que”. Por ejemplo: Grado de satisfacción (alto, medio, bajo), estado de salud (bueno, regular, malo), grado de instrucción (primaria, secundaria, superior). Escala de Intervalo: Además de asignar un nombre o etiqueta y establecer un orden entre los elementos, esta escala permite calcular diferencias entre los números asignados a las mediciones (el intervalo entre observaciones que se expresa en términos de una unidad fija de medida). Los datos de intervalo siempre son numéricos. En esta escala el cero es relativo, es decir, no indica la ausencia de la característica medida. Por ejemplo: Temperatura (se puede medir en grado Celsius o grado Fahrenheit), año calendario (el año puede referirse al calendario gregoriano o calendario chino), en el caso de la escala de intervalos podemos asignar el cero a cualquier valor posible (el cero es arbitrario).

Estadística y Probabilidades TECSUP - PFR
8
Escala de Razón: Una variable está medida en escala de razón si los datos tienen todas las propiedades de los datos de intervalo y el cociente de los dos valores es significativa. La escala de medición de razón tiene las propiedades de la escala de intervalo con la propiedad adicional de tener un punto de partida natural o cero (cero absoluto), que indica que ausencia de la variable (no existe nada para una variable). Para esta escala de medición, es posible establecer una relación de proporcionalidad entre sus distintos valores, es decir el cociente de los valores es significativo. Por ejemplo:
Costo de un automóvil, número de aprobados, número de artículos defectuosos.
2. ESTADÍSTICA DESCRIPTIVA
La estadística descriptiva se ocupa de la recopilación, clasificación, presentación y descripción de los datos.
2.1 RECOPILACIÓN
Los datos pueden recopilarse de dos maneras fundamentales: a) Si se consideran todos los elementos de la población y se registran
sus características se denomina censo. b) Si se seleccionan algunos elementos de la población, pero no todos,
se denomina muestra y la información obtenida por este procedimiento se llama por muestreo; si la recopilación de los elementos muestrales se efectúa al azar se dice que el muestreo es aleatorio y la muestra se denomina muestra aleatoria.
Un ejemplo de una recopilación completa o censo es el Censo Poblacional del Perú realizado en el año 1993.
2.2 CLASIFICACIÓN
Los datos obtenidos por observación o medición suelen ser registrados en el orden en que se recopilan. Para facilitar su interpretación y el análisis correspondiente deben ser clasificados y esto equivale a que los datos deben ser organizados de alguna manera sistemática o particionado en clases bien definidas y una manera sencilla de hacerlo es ordenar los datos según su magnitud o agruparlos de acuerdo a sus características.

TECSUP - PFR Estadística y Probabilidades
9
2.3 PRESENTACIÓN DE DATOS
Una vez recolectados los datos y optado por su posible clasificación es necesario presentarlos en forma tal que se facilite su comprensión y su posterior análisis. Para ello se ordenan en cuadros numéricos llamados TABLAS (Tablas de frecuencias) y luego se presentan mediante GRÁFICAS (de barras, sectores circulares, histograma, polígono de frecuencias, ojiva, pictograma, etc.)
3. ELABORACIÓN DE TABLAS SEGÚN LAS NORMAS APA
Cualquier forma de presentación empleada en el trabajo tendrá que ser denominada Tabla o Figura. Según las normas APA, “generalmente las tablas exhiben valores numéricos exactos y los datos están dispuestos de forma organizada en líneas y columnas, facilitando su comparación" (APA, 2001, p. 133). Ya las figuras son “cualquier tipo de ilustración que no sea tabla. Una figura puede ser un cuadro, un gráfico, una fotografía, un dibujo u otra forma de representación” (APA, 2001, p. 149). Título de la tabla El título de la tabla debe ser breve, claro y explicativo. Debe ser puesto arriba de la tabla, en el margen superior izquierdo, debajo de la palabra Tabla (con la inicial en mayúscula) y acompañado del número con que la designa (las tablas deben ser enumeradas con números arábigos secuencialmente dentro del texto y en su totalidad). Ej.: Tabla 1, Tabla 2, Tabla 3, etc. Citar tablas en el cuerpo del texto Al citar tablas en el cuerpo del texto, escriba apenas el número correspondiente a la tabla, por ejemplo: Tabla 1, Tabla 2, Tabla 3, etc. (la palabra Tabla tendrá que ser presentada con la inicial mayúscula) Nunca escriba "tabla abajo/arriba o tabla de la página xx, pues la numeración de las páginas del trabajo puede ser alterada. Cuerpo de la fuente de la tabla Times New Roman, tamaño 10. Fuente de las notas de la tabla Times New Roman, tamaño 9. Notas de la tabla Las tablas presentan tres tipos de notas: notas generales, notas específicas y notas de probabilidad. “Las notas son útiles para eliminar la repetición en el cuerpo de una tabla” (APA, 2001, p. 147). Ellas son presentadas en el margen izquierdo (sin sangría) debajo de la tabla (entre la tabla y la nota hay que inserir dos espacios). Y deben ser ordenadas en esta secuencia: nota general, nota específica y nota de probabilidad, y cada tipo de nota debe ser puesta en una línea nueva.

Estadística y Probabilidades TECSUP - PFR
10
Notas generales: “Una nota general cualifica, explica u ofrece informaciones relacionadas a la tabla como un todo y finaliza con una explicación de abreviaturas, símbolos y afines” (APA, 2001, p. 145). Nota específica se refiere a una columna, línea o ítem específico y debe ser indicada por letra minúscula sobrescrita (a, b, c). Nota de probabilidad indica los resultados de pruebas significativos y se indican con asterisco sobrescrito (*).
Tabla N° 1
Tabla N° 2 4. TABLA DE FRECUENCIAS PARA VARIABLES CUALITITATIVAS
Se deberá representar en la tabla los diferentes valores que asume la variable cualitativa y en la columna de las frecuencias absolutas simples la cantidad de veces con las que aparece esta categoría de la variable. Si la variable cualitativa está medida en escala ordinal, tendrá sentido mostrar las frecuencias

TECSUP - PFR Estadística y Probabilidades
11
acumuladas absolutas o relativas. Si la medición está hecha en escala nominal sólo deberá mostrarse las frecuencias absolutas simples y/o relativas. Por ejemplo:
Tabla N° 3
Calidad en el servicio en el servicio de atención al cliente.
Opinión Frecuencia Frecuencia relativa Porcentaje Deficiente 20 20/160 = 0.1250 0.125*100 = 12.50 % Bueno 35 35/160 = 0.2188 21.88 % Excelente 65 0.4063 40.63 % Otros 40 0.2500 25.00 % Total 160 1 Fuente: Sabadini, (2013)
5. ELABORACIÓN DE FIGURAS SEGÚN LAS NORMAS APA
Según la APA, “una figura es cualquier tipo de ilustración que no sea tabla. Una figura puede ser un cuadro, un gráfico, una fotografía, un dibujo u otra forma de representación” (APA, 2001, p. 149). Tanto para las figuras como para las tablas el interlineados que se utiliza es sencillo (1,0) o de uno punto cinco (1,5). Esto en el contenido de las tablas y figuras como en las notas de las tablas, título de tablas o figuras y leyendas. Según sea el caso. Título de la figura El título explica la figura de forma concisa, pero de forma discursiva. Debe ser puesto debajo de la figura, con números arábigos secuencialmente dentro del texto como un todo, precedido por la palabra Figura (con la inicial en mayúscula). Ej.: Figura 1, Figura 2, Figura 3, etc. Cualquier otra información necesaria para elucidar la figura (como la unidad de medida, símbolos, escalas y abreviaturas) que no están incluidas en la leyenda, tendrán que ser colocadas luego del título. Cuerpo de la fuente de la figura Times New Roman, tamaño 10. Leyenda Se trata de la explicación de los símbolos empleados en la figura y debe ser puesto dentro de los límites de la figura. Citar figuras en el cuerpo del texto Al citar figuras en el cuerpo del texto, escriba apenas el número correspondiente a la figura, por ejemplo: Figura 1, Figura 2, Figura 3, etc. (la palabra Figura tendrá que ser presentada con la inicial mayúscula) Nunca escriba "figura abajo/arriba o figura de la página xx, pues la numeración de las páginas del trabajo puede ser alterada.

Estadística y Probabilidades TECSUP - PFR
12
Figuras reproducidas de otra fuente Las figuras reproducidas de otra fuente deben presentar, debajo de la figura, la referencia del autor original, aunque se trate de una adaptación. Ejemplos Nota Fuente: Sabadini, A. A. Z. P., Sampaio, M. I. C., & Koller, S. H. (2009). Publicar en psicología: un enfoque para a revista científica (p.175). São Paulo: Associação Brasileira de Editores Científicos de Psicología/Instituto de Psicología da Universidade de São Paulo. Nota Fuente: Adaptado de Sabadini, A. A. Z. P., Sampaio, M. I. C., & Koller, S. H. (2009). Publicar en psicología: un enfoque para a revista científica (p. 176). São Paulo: Associação Brasileira de Editores Científicos de Psicología/Instituto de Psicología da Universidade de São Paulo.
6. REPRESENTACIÓN GRÁFICA DE VARIABLES CUALITATIVAS
6.1 DIAGRAMA DE BARRAS
Un diagrama de barras es una gráfica para representar un conjunto de datos cualitativos que se han resumido en una distribución de frecuencias absolutas, relativas o porcentuales. En uno de los ejes de la gráfica, por lo general el eje horizontal, se colocan las categorías de la variable y en el otro eje de la gráfica (por lo general el eje vertical) se pueden usar las frecuencias absolutas, relativas o porcentuales. Luego, se construye una barra de ancho fijo en cada categoría y cuya altura corresponda a la frecuencia utilizada en el gráfico. Las barras deben estar separadas para enfatizar el hecho que las categorías no se superponen. Ejemplo:
Gráfica 1. Rentabilidad por AFP del Sistema Privado de Pensiones
Fuente: Sabadini, (2013)
6.2 DIAGRAMA CIRCULAR
El diagrama circular, también llamado diagrama de pie, es otra forma de representar la distribución de frecuencias relativas o porcentuales. Para su

TECSUP - PFR Estadística y Probabilidades
13
construcción primero se traza un círculo y luego se divide en sectores circulares de forma proporcional a la frecuencia relativa de cada categoría. Puesto que todo el círculo representa un ángulo de 360º en total cada sector es el porcentaje correspondiente de dicho total, es decir, el ángulo del sector que le corresponde a cada categoría se obtiene multiplicando 360º por la respectiva frecuencia relativa.
Ejemplo:
Figura 2. Distribución de la población según lugar de residencia
Fuente: Revista Perú Económico, (2004)
6.3 TABLAS DE FRECUENCIA PARA VARIABLES CUANTITATIVAS
Haremos algunas definiciones en base a un ejemplo: Clasificar los siguientes datos recopilados del número de cabezas de ganado vacuno que posee cada una de las 40 familias de las comunidades campesinas de la Sierra Central del Perú, tomados al azar.
1 2 0 3 5 1 0 8 1 2 4 3 3 5 12 10 4 3 0 10 0 0 4 9 0 1 3 13 1 3 5 4 6 8 11 0 1 3 8 0
Alcance (A): es el intervalo definido por los datos de mayor y menor
valor. En el ejemplo: A 0; 13
Intervalos de clase ( Ii ) y Límites de clase ( Li ): clasificar los
datos en k grupos equivale a particionar el alcance A en k clases o k intervalos Ii ,donde: i=1, 2, ...,k y determinar cuántos datos pertenecen a cada uno.
1, iii LLI , i=1, 2, ...,k
Los intervalos semi-abiertos por la derecha Ii se denominan intervalos de clase.

Estadística y Probabilidades TECSUP - PFR
14
Los Li , i=1, 2, ...,k+1 se denominan los límites de clase. El valor entero de k, fundamentalmente, depende del estadístico y/o investigador, pero es recomendable utilizar la regla de Sturges para determinar un valor aproximado de k: Donde “n” es el número total de datos disponibles. La fórmula es un poco conservadora y nos da un número de intervalos un poco menor del que se utiliza en la práctica. Cuando el número de datos es menor que 100, el número de intervalos se debe tomar menor que 10. Para un número de datos bastante grande, el número de intervalos es mayor que 10, la práctica aconseja los siguientes límites: 5 k 15 . En el ejemplo: k = 1 + 3,3 log(40) = 6,286 Luego k podrá tomar valores enteros: 5, 6 o 7 Tomemos: k = 7 .
Ancho de Clase ( Wi ): es la longitud de un intervalo de clase.
iiii LLIlW 1)(
Para conseguir anchos de clase iguales (W ), como es deseable; se usa la siguiente relación:
,)(
k
AlW donde )(Al es la longitud del alcance.
En el ejemplo:
13W 1,857
7 tomamos W = 2
Frecuencia Absoluta (ni ): una vez decidido el valor de k y calculado
el ancho de clase. Mediante la tabulación se determina el número de datos contenidos en cada clase y este número entero se denomina frecuencia absoluta( ni )
ni : frecuencia absoluta de i – ésima clase .
3,3logn1k

TECSUP - PFR Estadística y Probabilidades
15
Distribución de Frecuencias Absolutas:
Tabla Nº 4
Cabezas de ganado Tabulación
Nº de familias por clases
Intervalos de clase o clases: Ii
Frecuencias Absolutas: ni
[0; 2> 14
[2; 4> 9
[4; 6> 7
[6; 8> 1
[8; 10> 4
[10; 12> 3
[12; 14> 2
TOTAL 40
En el ejemplo: n = 40 , k = 7 Se verifica que:
1 in 14 k
n n n n n n n n 14 9 7 1 4 3 2 40 ni 1 2 3 4 5 6 7i 1
n3= 3, se lee: “la frecuencia absoluta de la tercera clase es” Los intervalos de clase son:
I 0;2 , I 2;4 , I 4;6 , I 6;8 , I 8;10 , I 10;12 , I 12;141 2 3 4 5 6 7
Los límites de clase son: L 0, L 2, L 4, L 6, L 8, L 10, L 12, L 141 2 3 4 5 6 7 8
Estadística y Probabilidades TECSUP - PFR
16
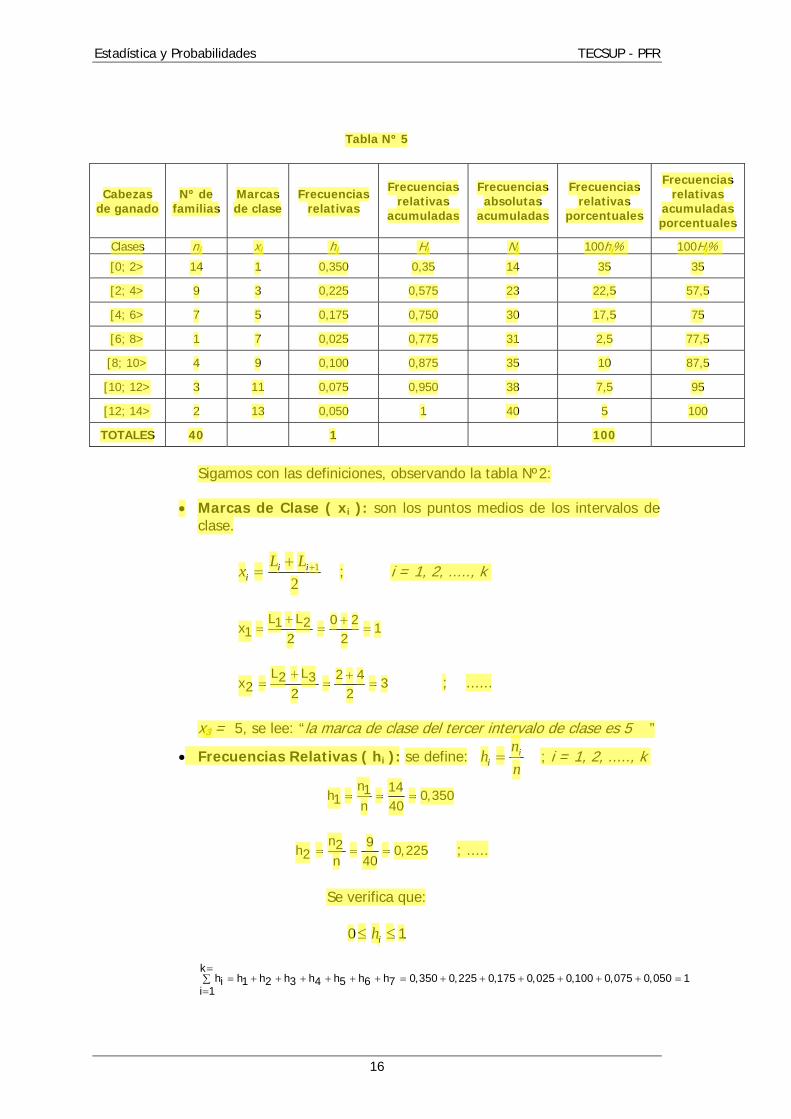
Tabla Nº 5
Cabezas de ganado
Nº de familias
Marcas de clase
Frecuencias relativas
Frecuencias relativas
acumuladas
Frecuencias absolutas
acumuladas
Frecuencias relativas
porcentuales
Frecuencias relativas
acumuladas porcentuales
Clases ni xi hi Hi Ni 100hi% 100Hi%
[0; 2> 14 1 0,350 0,35 14 35 35
[2; 4> 9 3 0,225 0,575 23 22,5 57,5
[4; 6> 7 5 0,175 0,750 30 17,5 75
[6; 8> 1 7 0,025 0,775 31 2,5 77,5
[8; 10> 4 9 0,100 0,875 35 10 87,5
[10; 12> 3 11 0,075 0,950 38 7,5 95
[12; 14> 2 13 0,050 1 40 5 100
TOTALES 40 1 100
Sigamos con las definiciones, observando la tabla Nº2:
Marcas de Clase ( xi ): son los puntos medios de los intervalos de
clase.
2
1 ii
i
LLx ; i = 1, 2, ....., k
L L 0 21 2x 11 2 2
L L 2 42 3x 32 2 2
; ......
x3 = 5, se lee: “la marca de clase del tercer intervalo de clase es 5 ”
Frecuencias Relativas ( hi ): se define: n
nh i
i ; i = 1, 2, ....., k
n 141h 0,3501 n 40
n 92h 0,2252 n 40
; .....
Se verifica que:
0 ih 1
k
h h h h h h h h 0,350 0,225 0,175 0,025 0,100 0,075 0,050 1i 1 2 3 4 5 6 7i 1

TECSUP - PFR Estadística y Probabilidades
17
h3= 0,175, se lee: “la frecuencia relativa de la tercera clase es 0,175 ”
Frecuencia Relativa Porcentual (100 hi%)
Nos permite contestar preguntas del siguiente tipo: ¿Qué porcentaje de familias, de las 40 bajo estudio, tienen 4 ó 5 cabezas de ganado?
Respuesta: 17,5 %
Frecuencia Absoluta Acumulada ( Ni ):
Se define: Ni = n1 + n2 + .... + ni ; i = 1, 2, ....., k En el ejemplo: N n 141 1N n n 14 9 232 1 2N 30,.... N 403 7
Se verifica: 0 N 40i N N 40k 7
4N 31, se lee: “la frecuencia absoluta acumulada hasta la cuarta clase es 31 ”
Frecuencia Relativa Acumulada ( Hi ):
Se define:
kin
NHóhhhH i
iii ,...,2,1;...21
H h 0,3501 1H h h 0,5752 1 2H 0,750,..... H 13 7
Se verifica: 0 H 1i

Estadística y Probabilidades TECSUP - PFR
18
H H 1k 7
2H 0,575, se lee: “la frecuencia relativa acumulada hasta la 2da.clase es 0,575”
Frecuencia Relativa Acumulada Porcentual (100 Hi%):
Nos permite contestar preguntas del siguiente tipo: ¿Qué porcentaje de familias, de las 40 bajo estudio tienen menos de 8 cabezas de ganado? Respuesta: 77,5 %
Gráficas Las distribuciones de frecuencias pueden ser representadas gráficamente mediante:
a) Histogramas
Son gráficas de barras o rectángulos cuyas bases representan los intervalos de clase y las alturas las frecuencias absolutas o relativas.
ó (Fig. 3)
b) Polígonos de frecuencias
Son polígonos construidos uniendo los puntos iiii hxónx ,, mediante segmentos de recta, o uniendo los puntos medios de los “techos” de los rectángulos del histograma. (Fig. N° 3)
ii nvsI . ii hvsI .
15
10
5
0 2 4 6 8 10 12 14
n i
Ii
Histograma
Figura 315
10
5
0 2 4 6 8 10 12 14
ni
Ii
Polígono de Frecuencias
Figura 4

TECSUP - PFR Estadística y Probabilidades
19
c) Diagramas escalonados o funciones escalonadas
Son gráficas de barras o rectángulos cuyas bases representan los intervalos de clase y las alturas las frecuencias absolutas o relativas acumuladas.
ó (Fig. 5)
d) Ojivas
Son poligonales asociadas a distribuciones de frecuencias absolutas o relativas acumuladas construidas como aparece en la Figura 5.
ii NvsI . ii HvsI .
10
20
30
40
0 2 4 6 8 10 12 14
N i
Ii
Figura 5
Función Escalonada
10
20
30
40
0 2 4 6 8 10 12 14
Ni
Ii
Figura 6
Ojiva

Estadística y Probabilidades TECSUP - PFR
20
7. PROBLEMAS PROPUESTOS
1. En un artículo se reportó las siguientes observaciones, listadas en orden
creciente sobre la duración de brocas (número de agujeros que una broca fresa antes de que se rompa) cuando se fresaron agujeros en una cierta aleación de latón.
11 14 20 23 31 36 39 44 47 559 61 65 67 68 71 74 76 78 781 84 85 89 91 93 96 99 101 10
105 105 112 118 123 136 139 141 148 15161 168 184 206 248 263 289 322 388 51
a. ¿Por qué una distribución de frecuencia no puede estar basada en los
intervalos de clase 0-50, 50-100, 100-150 y así sucesivamente? b. Construya una distribución de frecuencia e histograma de los datos con los
límites de clase 0, 50, 100, . . . y luego comente sobre las características interesantes.
c. Construya una distribución de frecuencia e histograma de los logaritmos naturales de las observaciones de duración y comente sobre características interesantes.
d. ¿Qué proporción de las observaciones de duración en esta muestra son menores que 100? ¿Qué proporción de las observaciones son de por lo menos 200?
2. Un diagrama de Pareto es una variación de un histograma de datos
categóricos producidos por un estudio de control de calidad. Cada categoría representa un tipo diferente de no conformidad del producto o problema de producción. Las categorías se ordenaron de modo que la categoría con la frecuencia más grande aparezca a la extrema izquierda, luego la categoría con la segunda frecuencia más grande, y así sucesivamente. Suponga que se obtiene la siguiente información sobre no conformidades en paquetes de circuito: componentes averiados, 126; componentes incorrectos, 210; soldadura insuficiente, 67; soldadura excesiva, 54; componente faltan- te, 131. Construya un diagrama de Pareto.
3. Los accidentes en una planta de papas fritas se clasifican de acuerdo con la
parte del cuerpo lesionada.
Dedos: 17 Ojos: 5 Brazos: 2 Piernas: 1
Trace un diagrama de barras
4. Los siguientes datos constituyen las vidas útiles en horas de una muestra
aleatoria de 60 bombillas de luz de 100 watts:
807 811 620 650 815 725 743 703 844 907 660 753 1050 918 850 876 1027 889 878 890 881 872 869 841 863 842 851 837 822 811

TECSUP - PFR Estadística y Probabilidades
21
766 787 923 792 799 937 816 758 817 753 1056 1076 958 970 765 896 740 891 1075 1074 832 863 852 788 968 817 678 865 759 923
a) Constrúyase una distribución de frecuencias con anchos de clases
iguales b) Trácese el polígono de frecuencias sobre un Histograma de intervalos de
clases vs. frecuencias relativas. c) Trácese la ojiva asociada a la función escalonada representando
intervalos de clases vs. frecuencias absolutas acumuladas. 5. La siguiente tabla muestra la distribución de los empleados de una compañía
aseguradora por sueldos mensuales en nuevos soles (año 2001)
Clases Frecuencias menos de 450 32 450 a menos de 900 47 900 a menos de 1350 75 1350 a menos de 1800 89 1800 a menos de 2500 126 2500 a menos de 4250 38 4250 a más 10
TOTAL 417
a) ¿Qué porcentaje de empleados ganan sueldos mensuales inferiores a 900 nuevos soles?. ¿Qué porcentaje ganan 2500 nuevos soles o más?
b) ¿Qué porcentaje de empleados ganan entre 1350 y 4250 nuevos soles? c) Determinar los anchos y las marcas de clase.
Nota. Se averiguó que el máximo haber percibido en la compañía es de 5500
nuevos soles. Si no se tiene ninguna información se asume un máximo valor de acuerdo al problema en cuestión; así como se supondrá cero, como el haber mínimo.
6. Para un estudio sobre resistencia de un metal, se han realizado cien
experiencias de rotura frente a la carga de un hilo del mismo grosor, y han sido anotados los pesos límites en cada caso.

Estadística y Probabilidades TECSUP - PFR
22
Cargas de rotura de un hilo en gramos
711 862 851 912 922 791 825 935 895 758 915 873 926 864 800 931 722 774 903 925 853 700 885 857 844 907 917 786 820 930 789 790 753 910 847 784 936 706 758 887 941 909 784 882 859 903 925 704 792 888
890 925 895 768 869 892 895 912 850 920 763 805 796 759 916 853 789 943 712 764 892 893 915 890 888 865 909 931 710 798 914 794 931 701 772 935 887 880 933 905 889 791 782 713 724 868 842 892 905 792
a) Reagrupar estos datos en 7 intervalos de clase de igual longitud. b) Trácese el histograma y el polígono de frecuencias. c) Trácese la ojiva correspondiente, y conteste:
¿Qué porcentaje presentan una carga no menor de 770 gramos? ¿Qué porcentaje presentan una carga entre 800 y 900 gramos?
7. Las distribuciones cualitativas o por categorías se suelen presentar en
diagramas de sectores en la que un círculo aparece dividido en sectores proporcionales en su abertura a las frecuencias de las categorías que representan:
a) Construir un diagrama de sectores para trasmitir la información de que
(según las cifras más recientes disponibles) en el Perú el número total de botellas de vino consumidas provienen el 69% de ICA, el 18% de otras partes del país, el 5% se importan de Francia y el resto de otros países.
b) Dibujar un diagrama de sectores para mostrar que en un hospital de
una gran ciudad la distribución de su presupuesto es como sigue: 73% de sueldos, honorarios profesionales médicos y bonificaciones a los empleados; 13% en suministros y equipo médico y quirúrgico; 8% en mantenimiento, alimentación y energía y el 6% en gastos administrativos.
8. En 1972, la población activa de Francia estaba compuesta de:
11,1% de agricultores, 10,6% de patronos, 16,5% de ejecutivos, 16,7% de empleados, 38,6% de obreros, 6,5% de personal de servicios y otras categorías.

TECSUP - PFR Estadística y Probabilidades
23
Representar esta distribución mediante el gráfico que parezca más adecuado.
9. Las pérdidas en una fábrica de papel (en miles de dólares) debidas a
rasgaduras pueden dividirse según el producto:
Papel higiénico: 132 Toallas desechables: 85 Servilletas: 43 Otros: 12 productos
a) Trace un diagrama en barras. b) ¿Qué porcentaje de las pérdidas ocurre en la elaboración de papel
higiénico?. c) ¿Qué porcentaje de las pérdidas ocurre en la elaboración de papel
higiénico o toallas desechables?
10. Los pesos de ciertos especimenes minerales, dados en la décima más cercana de una onza, se agrupan en una tabla con los intervalos: 10,5 – 11,4; 11,5 – 12,4; 12,5 – 13,4; y 13,5 – 14,4 onzas.
a) Determine las marcas de clase. b) ¿Es posible determinar a partir de los datos agrupados cuántos
especimenes minerales pesan?:
Menos de 11, 5 onzas. Más de 11,5 onzas. Al menos 12,4 onzas. Cuando mucho 12,4 onzas. De 11,5 a 13,5 onzas?
11. Los siguientes datos son las velocidades (en km/h) de 80 carros que pasaron
por un punto de control de velocidad:
60 30 31 60 45 20 34 29 35 20 40 54 38 35 27 45 40 55 45 60 49 49 85 83 30 40 46 105 29 38 102 60 80 35 28 60 82 72 63 36 70 60 31 65 34 73 68 81 65 80 25 70 108 26 24 27 40 75 43 85 120 45 39 83 65 72 46 62 43 63 60 70 100 55 50 63 64 65 61 69
Clasifique estos datos convenientemente y:
a) Muestre el histograma y el polígono de frecuencias correspondiente.

Estadística y Probabilidades TECSUP - PFR
24
b) Diseñe la función escalonada y la ojiva respectiva.
c) Los carros con velocidades mayores a 80 km/h, son multados por exceso de velocidad. ¿Qué porcentaje serán multados?
d) Los carros con velocidades entre 45 y 70 km/h, van a ser considerados en premios organizados por una compañía. ¿Qué porcentaje serán premiados?
12. El gráfico muestra el impuesto mensual (en soles) que debe pagar una
persona, según su sueldo mensual (en soles):
¿Cuánto de impuesto mensual paga una persona que gana s/.1500? ¿Cuánto gana una persona que paga mensualmente s/.300 de impuesto?
13. La siguiente tabla de frecuencias muestra los haberes mensuales de 200
obreros de cierta fábrica, en nuevos soles (año2000)
Haberes mensuales Número de obreros
Menores a 500 4
700,500 60
900,700 40
1100,900 48
1300,1100 24
1500,1300 14
1700,1500 8
más de 1700 2
TOTAL 200
IMPUESTO
SUELDO 2200 3400 4000 1000
120
360
900

TECSUP - PFR Estadística y Probabilidades
25
Con referencia a esta tabla, contestar:
a) ¿Qué porcentaje de obreros tienen haberes inferiores a s/.1000 mensuales?
b) ¿Qué porcentaje de obreros tienen haberes superiores a s/.1100
mensuales? c) ¿Qué porcentaje de obreros tienen haberes entre 1000 a 1500 soles
mensuales? d) Graficar el histograma, el polígono de frecuencias y la ojiva
correspondientes.

Estadística y Probabilidades TECSUP - PFR
26
ANOTACIONES: ……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………

TECSUP - PFR Estadística y Probabilidades
27
UNIDAD II
MEDIDAS RESUMEN
En esta etapa nos ocuparemos del cálculo y estudio de los estadígrafos.
Tabla N° 1
Estadígrafos.- Son números que describen alguna característica de la muestra y se obtienen a partir de los datos muestrales o experimentales. Existen básicamente dos tipos de estadígrafos:
a) Estadígrafos de Posición: Localizan el “centro” de la distribución de frecuencias.
Se denominan también medidas de tendencia central o de localización. Ejemplos: media, mediana, moda, cuartiles, deciles, etc.
b) Estadígrafos de Dispersión: Nos indican como están dispersos los datos con
respecto a algún estadígrafo de posición. Miden el grado de variabilidad de los datos alrededor de alguna medida de tendencia central, por esta razón, se les denomina también estadígrafos de variabilidad. Ejemplos: rango, la desviación media, varianza, desviación típica, coeficiente de variación, rango intercuartílico, etc.
1. MEDIA ( x )
Llamada también media aritmética o promedio aritmético es un estadígrafo que localiza el “centro” de la distribución en base a su “centro de gravedad” y se obtiene a partir de las siguientes fórmulas.

Estadística y probabilidades TECSUP - PFR
28
Para datos no clasificados:
Sean nxxx ,...,, 21 las variables matemáticas que representan los datos
muestrales, entonces: n
xx
n
ii
1
Para datos clasificados:
n
nxx
i
k
ii
1 o
k
iiihxx
1
Donde: k : número de clases kxxx ,...,, 21 : marcas de clase n: número total de datos knnn ,...,, 21 : frecuencias absolutas
khhh ,...,, 21 : frecuencias relativas.
Media Ponderada:
k
ii
i
k
ii
P
Pxx
1
1
Siendo kPPP ,...,, 21 pesos asociados a las variables kxxx ,...,, 21 respectivamente.
Media global:
Si una muestra de tamaño n se particiona en k submuestras y kxxx ,...,, 21 son las medias de las k submuestras de tamaños knnn ,...,, 21 respectivamente.
Entonces: n
xnx
ii
k
i 1 se denomina la media global de la muestra
particionada. Ejemplos:

TECSUP - PFR Estadística y Probabilidades
29
Media de datos no clasificados:
91 x , 52 x , 33 x , 104 x , 85 x
5xi
x x x x x 9 5 3 10 81 2 3 4 5i 1x 75 5 5
Media de datos clasificados:
Halle la velocidad media de los 30 carros que pasaron por un punto de control de velocidad, del problema 2. Use las fórmulas que incluyen frecuencias absolutas y relativas.
Tabla N° 2
Intervalos de clase
ni
[10, 26 4
[26, 42 12
[42, 58 7
[58, 74 4
[74, 90 2
[90, 106 1
Total 30
x ni i1356i 1x 45,2
n 30
o x x h 45,15i i
i 1
Media ponderada:
Tabla N° 3
Notas Pesos
ix iP iiPx
Ex. Parcial 05 1 5 Ex. Final 13 3 39
4 44
k
x Pi i44i 1x 11
k 4Pi
i 1

Estadística y probabilidades TECSUP - PFR
30
)( mX
Media Global:
Si una muestra de tamaño 60 se divide en 5 sub-muestras de tamaños 8, 18, 12, 9, 13 con medias 15, 14, 12, 8,11 respectivamente. Entonces, la media global será:
x ni i8 * 15 18 * 14 12 * 12 9 * 8 13 * 11 731i 1x 12,18
n 60 60
2. MEDIANA
La mediana es un valor que divide a un conjunto de observaciones ordenadas en forma ascendente o descendente en dos grupos de igual número de observaciones.
Para datos no clasificados:
Sean nxxx ,...,, 21 los datos muestrales tales que nxxx ...21 . Entonces:
paresnsixx
imparesnsix
X
nn
n
m
;)(2
1
;
2
2
2
2
1
En palabras: una vez ordenados los datos en orden creciente (o decreciente) de sus magnitudes: Si n es impar, la mediana es el valor del dato que equidista de los extremos. Si n es par, la mediana es el promedio aritmético de dos datos consecutivos equidistantes de los extremos. Ejemplos: Hallar la mediana de los siguientes conjuntos de datos: 10, 9, 3, 6, 14 Previamente ordenamos los datos: x 3 x 6 x x 10 x 141 2 3 9 4 5 como n es impar ( n = 5 )
mX 5 1 x 9x 3
2

TECSUP - PFR Estadística y Probabilidades
31
5, 10, 29, 43, 21, 17 Previamente ordenados los datos: x 5 x 10 x 17 x 21 x 29 x 431 2 3 4 5 6 como n es par ( n = 6 ) X 19m
Para datos clasificados:
Está dada por la fórmula:
m
m
mmm n
Nn
WLX12
donde:
mL : Límite inferior de la clase mediana (*) n : Número total de datos
:1mN Frecuencia absoluta acumulada hasta la clase inmediata
anterior a la clase mediana
1
11
m
iim nN
mn : Frecuencia absoluta de la clase mediana.
mW : Ancho de clase de la clase mediana: mmm LLW 1
2.1 CLASE MEDIANA
Es el intervalo de clase que contiene el dato que ocupa la posición media o central. Se identifica observando las frecuencias acumuladas absolutas o relativas y es aquella que hasta ese nivel acumuló la mitad del número
total de datos ( 2
n
ó 0,5) o superó por primera vez a la mitad.
Clase mediana= 1,[ mm LL ; mX 1,[ mm LL Ejemplo:
Estadística y probabilidades TECSUP - PFR
32
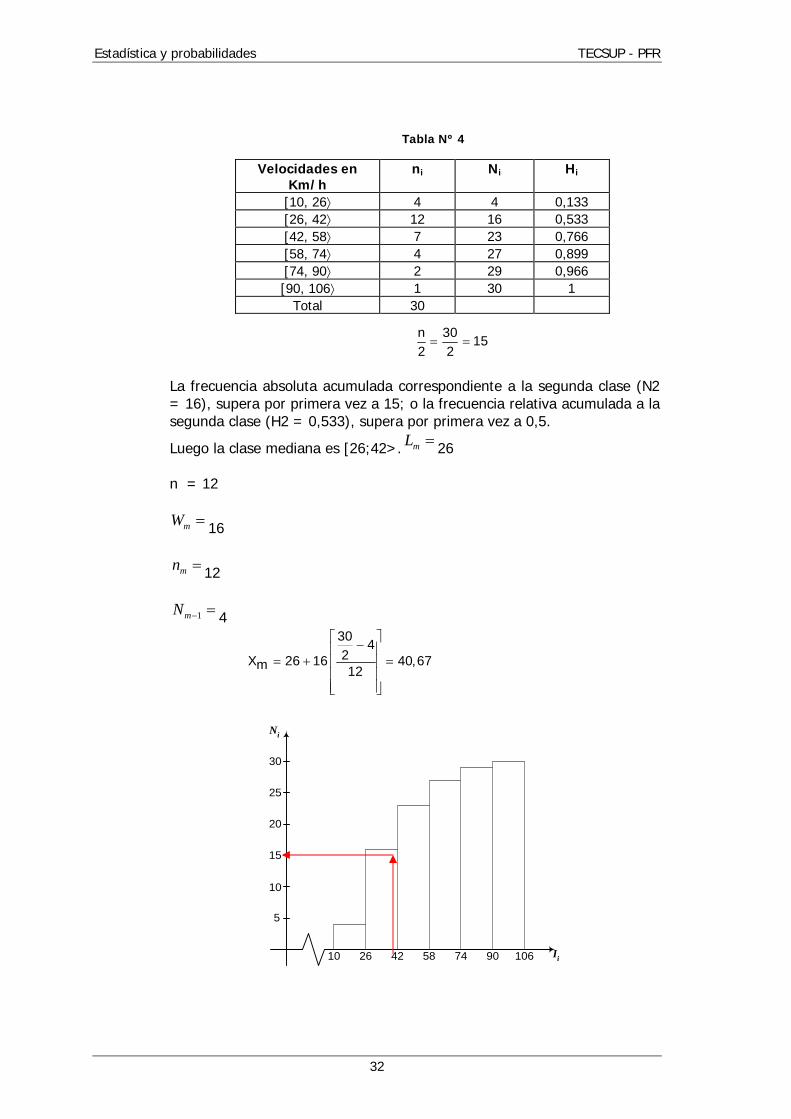
Tabla Nº 4
n 3015
2 2
La frecuencia absoluta acumulada correspondiente a la segunda clase (N2 = 16), supera por primera vez a 15; o la frecuencia relativa acumulada a la segunda clase (H2 = 0,533), supera por primera vez a 0,5.
Luego la clase mediana es [26;42>. mL 26 n = 12
mW 16
mn 12
1mN 4 30
42X 26 16 40,67m 12
Velocidades en Km/h
ni Ni Hi
[10, 26 4 4 0,133 [26, 42 12 16 0,533 [42, 58 7 23 0,766 [58, 74 4 27 0,899 [74, 90 2 29 0,966 [90, 106 1 30 1
Total 30
5
10
15
20
25
30
10 26 42 58 74 90 106 Ii
Ni

TECSUP - PFR Estadística y Probabilidades
33
2.2 MEDIANA COMO UNA MEDIDA DE TENDENCIA CENTRAL MÁS REPRESENTATIVA
La media es un estadígrafo bastante sensible a los valores extremos y como medida del “centro de gravedad” de la distribución tiende a inclinarse a los datos de mayor valor. Si existen valores extremos que difieren considerablemente del resto no localiza como se debe el “centro” de la distribución. En tanto que la mediana por no ser sensible a los valores extremos y localizar el “centro” de la distribución en base a la posición central que ocupa resulta siendo mejor que la media o más representativa en el sentido que localiza mejor el “centro” de la distribución; pero, en general, la media es más representativa que la mediana, como estadígrafo de localización: Ejemplo: Un empleador dice que el promedio mensual de salario pagado a los ingenieros de su firma es de 3 500, esto sugiere que esta firma paga bien. Sin embargo, un examen posterior indica que se trata de una pequeña compañía que emplea 5 jóvenes ingenieros con 1 000 soles de haber mensuales c/u y la renta del ingeniero Jefe es de 16 000 soles mensuales. ¿Ud. puede seguir afirmando que la firma paga bien?. No. Halle la mediana y compare, ¿cuál de los estadígrafos es más representativo?
X 3500; x 1000, x 1000, x 1000, x 1000, x 1000, x 16 0001 2 3 4 5 6
mX = 1000
En este caso, la mediana es la más representativa en el sentido que localiza mejor que la media el “centro” de los datos bajo consideración. Existe un valor extremo bastante discrepante o exagerado ( 6x 16 000).
2.3 USOS DE LA MEDIA ARITMÉTICA
La media de la muestra se usa cuando se necesita una medida de
tendencia central que no varíe mucho entre una y otra muestra extraída de la misma población, esta es la razón para preferirla cuando se desea la máxima confiabilidad en la estimación de la media poblacional.
También se usa la media cuando la distribución de frecuencias de los
datos es simétrica o tiene poca asimetría. Se calcula la media cuando en un estudio también se debe calcular la
varianza o la desviación estándar.

Estadística y probabilidades TECSUP - PFR
34
oM
2.4 USOS DE LA MEDIANA
Se prefiere a la mediana como medida de concentración, cuando en los datos existen valores extremos muy grandes o muy pequeños, o sea, valores muy altos o muy bajos que obligan a la media aritmética a desplazarse a la derecha o izquierda del punto medio de la distribución. En cambio la Mediana siempre señala al punto que divide a los datos en dos partes iguales: 50% a un lado y 50% al otro, sin importar donde se halle ese punto.
Cuando simplemente necesitamos conocer si los datos que nos
interesan están dentro de la mitad superior o inferior de la distribución de los datos y no tiene importancia saber particularmente su alejamiento con respecto al centro de la distribución.
3. MODA ( )
La moda es un valor de la variable que tiene la más alta frecuencia, esto es, es el valor más frecuente de la distribución. Si la distribución de frecuencias tiene un solo máximo (máximo absoluto), se dice que la distribución es unimodal; en cambio si tiene más de un máximo (máximos relativos), se dice que la distribución es multimodal. Si todas las frecuencias son iguales se dice que la distribución no tiene moda y se trata de una distribución uniforme.
a) Para datos no clasificados
Determinar la moda del siguiente conjunto de datos:
2, 2, 3, 4, 5, 5, 6, 7, 7, 7, 9, 9, 12. La moda es el número 7 porque es el dato más repetido (3 veces). Esta distribución se llama unimodal porque sólo posee una moda.
El siguiente conjunto de datos no tiene moda.
15, 19, 20, 35, 47, 58, 63. Porque ninguno de ellos está repetido
La siguiente distribución es bimodal es decir, tiene dos modas:
8, 9, 9, 13, 13, 13, 18, 20, 24,24,24, 33, 59, 78, 78. Mo = 13 y también Mo = 24

TECSUP - PFR Estadística y Probabilidades
35
La siguiente distribución es trimodal: 4, 8, 8, 8, 8, 15, 15, 15, 20, 20, 21, 21, 21, 21,32, 40, 40,40, 40, 80, 80, 90. Mo = 8, Mo = 21, Mo = 40 Tiene tres modas.
b) Para datos clasificados
21
1iio WLM
1,[ iii LLI : clase modal, es aquella que tiene la frecuencia máxima
iL : límite inferior de la clase modal.
:iW ancho de la clase modal
11 ii nn : exceso de la frecuencia modal sobre la frecuencia de la clase contigua inferior.
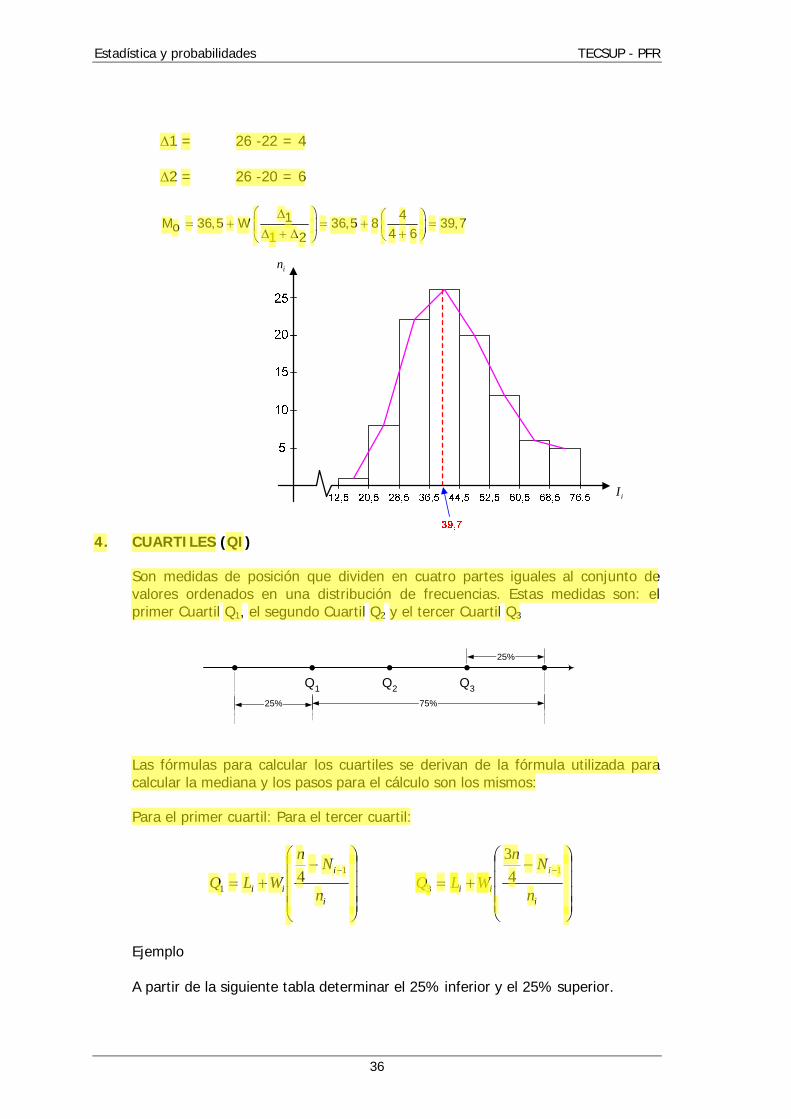
12 ii nn : exceso de la frecuencia modal sobre la frecuencia de la clase contigua superior. Ejemplo: Determinar la moda de la siguiente distribución de frecuencias:
Tabla Nº 5
La clase modal será: I = [36,5; 44,5 Además es una distribución unimodal.
iI in
[12,5 20,5 1
[20,5 28,5 8
[28,5 36,5 22
[36,5 44,5 26
[44,5 52,5 20
[52,5 60,5 12
[60,5 68,5 6
[68,5 76,5 5
TOTALES
Estadística y probabilidades TECSUP - PFR
36
1 = 26 -22 = 4
2 = 26 -20 = 6
41M 36,5 W 36,5 8 39,7o 4 61 2
4. CUARTILES (QI)
Son medidas de posición que dividen en cuatro partes iguales al conjunto de valores ordenados en una distribución de frecuencias. Estas medidas son: el primer Cuartil Q1, el segundo Cuartil Q2 y el tercer Cuartil Q3
Las fórmulas para calcular los cuartiles se derivan de la fórmula utilizada para calcular la mediana y los pasos para el cálculo son los mismos: Para el primer cuartil: Para el tercer cuartil:
i
i
ii n
Nn
WLQ1
14
i
i
ii n
Nn
WLQ1
34
3
Ejemplo A partir de la siguiente tabla determinar el 25% inferior y el 25% superior.
Q1 Q2 Q3
25% 75%
25%
in
iI

TECSUP - PFR Estadística y Probabilidades
37
Tabla Nº 6
Altura en pulgadasin iN iH
[60, 63 5 5 0,05
[63, 66 18 23 0,23
[66, 69 42 65 0,65
[69, 72 27 92 0,92
[72, 75 8 100 1
TOTALES
Para determinar el 25% inferior debemos calcular el primer cuartil. Para determinar el 25% superior debemos calcular el tercer cuartil Cálculo de Q1 : n 100
254 4 . Luego tomamos la clase: I = [66; 69
Luego:
10023
4Q 66 3 66,141 42
Cálculo de Q3 : 3n 3x100
754 4
. Luego tomamos la clase: I = [69; 72
Luego:
3x10065
4Q 69 3 70,113 27
5. DECILES ( DI )
Son medidas de posición que dividen en 10 puntos iguales al conjunto de los valores ordenados de una distribución de frecuencias. Estas medidas son: el primer decil D1, el segundo decil D2 y así sucesivamente hasta el noveno decil D9. El primer decil distribuye al lado izquierdo el 10% de los datos y al otro lado el 90%, es decir, ocupa la posición n/10. En igual forma para los demás deciles hasta el noveno decil 9n/10 que deja a la izquierda el 90% de los datos y a la derecha el 10%.

Estadística y probabilidades TECSUP - PFR
38
Entre cada dos deciles consecutivos debe encontrarse comprendido el 10% del número de datos.
La fórmula para calcular deciles es:
i
i
iir n
Nrn
WLD110
Donde: Dr = el decil buscado. Li = límite inferior del intervalo donde se halla el decil buscado r = indica el decil. Por ejemplo si queremos el tercer decil r = 3.
10
rnindica la situación del decil, es decir, la clase donde está el decil
Los demás signos: n , Ni-1 , Wi , ni tienen los mismos significados que para el caso de la mediana. Ejemplo Se presenta la distribución de frecuencias de los puntajes obtenidos por 250 alumnos en una prueba de rendimiento de Física. Determinar qué puntajes deben tener los que se hallen en el 20% inferior y cuáles puntajes los que se encuentren en el décimo superior.
D1 D510%
90%
30%
D2 D3 D4 D6 D7 D8 D9

TECSUP - PFR Estadística y Probabilidades
39
Tabla N° 7
Primero debemos determinar el segundo decil a fin de determinar el 20% inferior. Cálculo de D2: 2n 2x250
5010 10
; Luego el segundo decil está en la clase: I = [55, 60
Por fórmula: 50 32D 55 5 58,6
25
Para hallar los que se encuentran en el décimo superior calculamos el noveno decil. Cálculo de D9: 9n 9x250
22510 10
; Luego el noveno decil está en la clase: I = 80; 85
Por fórmula: 225 222D 80 5 80,83
18
CARACTERÍSTICAS DE DISPERSIÓN Las dos siguientes series de datos:
Intervalos ni Ni
4
10
18
25
46
53
4
14
32
57
103
156
45;40
50;45
55;50
60;55
65;60
Totales
70;65
75;70
80;75
85;80
90;85
37
29
18
10
250
193
222
240
250

Estadística y probabilidades TECSUP - PFR
40
Tienen la misma media aritmética y la misma mediana (100). Sin embargo difieren profundamente. Lo que las hace diferentes es lo que, en estadística, se llama dispersión; la segunda serie es mucho más dispersa que la primera. Es pues importante resumir una serie estadística no sólo por características de tendencia central, sino por características de dispersión. Veremos de dos tipos: las ligadas a la media: desviación típica; las ligadas a la mediana: intervalo intercuartílico, intervalo interdecílico.
6. MEDIDAS DE DISPERSIÓN
Varianza ( )(2
xx VóS )
Se define:
osclasificaddatosn
nxx
sclasifcadonodatosn
xx
SV k
iii
n
ii
xx
,)(
,)(
1
2
1
2
2)(
Se interpreta como la media aritmética de los cuadrados de las desviaciones de las xi con respecto a x . A menudo el cálculo de la varianza es muy laborioso, sobre todo si la media no es entera, para facilitar los cálculos podemos usar una segunda forma:
osclasificaddatosxn
xnV
k
iii
x ;2
1
2
)(
Desviación Típica xS
)( xx VS
Una idea sencilla del significado de la desviación típica se obtiene cuando se comparan dos series de la misma naturaleza: la que posee una desviación típica más alta es la más dispersa.
Coeficiente de variación (C.V.)
x
SVC x..

TECSUP - PFR Estadística y Probabilidades
41
Generalmente se expresa en porcentajes. Es útil para la comparación en términos relativos del grado de concentración en torno a la media de dos distribuciones distintas.
Rango o extensión (e)
Indica la extensión del intervalo en donde se halla toda la población estudiada.
e = Lk – L1 =l(A)
Por ejemplo de la Tabla Nº8, tenemos e = 90 - 40 = 50
Rango interdecílico = D9 – D1
Rango intercuartílico = Q3 – Q1 Por ejemplo, a partir de la tabla Nº8, tenemos: Rango intercuartil = 74,26 – 60.97 = 13,99 Rango interdecílico = 80,83 – 53,06 = 27,77
7. GRÁFICAS DE CAJA
Los histogramas transmiten impresiones un tanto generales sobre un conjunto de datos, mientras que un resumen único tal como la media o la desviación estándar se enfoca en sólo un aspecto de los datos. En años recientes, se ha utilizado con éxito un resumen gráfico llamado gráfica de caja para describir varias de las características más prominentes de un conjunto de datos. Estas características incluyen 1) el centro, 2) la dispersión, 3) el grado y naturaleza de cualquier alejamiento de la simetría y 4) la identificación de las observaciones “extremas o apartadas” inusualmente alejadas del cuerpo principal de los datos. Como incluso un solo valor extremo puede afectar drásticamente los valores de -x y s, una gráfica de caja está basada en medidas “resistentes” a la presencia de unos cuantos valores apartados, la mediana y una medida de variabilidad llamada dispersión de los cuartos. Se ordenan las observaciones de la más pequeña a la más grande y se separa la mitad más pequeña de la más grande; se incluye la mediana Xm en ambas mitades si n es impar. En tal caso el cuarto inferior es la mediana de la mitad más pequeña y el cuarto superior es la mediana de la mitad más grande. Una medida de dispersión que es resistente a los valores apartados es la dispersión de los cuartos fs o también conocido como rango intercuartilico, dada por:
fs = cuarto superior – cuarto inferior

Estadística y probabilidades TECSUP - PFR
42
Ejemplo Se utilizó ultrasonido para reunir los datos de corrosión adjuntos de la placa de piso de un tanque elevado utilizado para almacenar petróleo crudo (“Statistical Analysis of UT Corro- sion Data from Floor Plates of a Crude Oil Aboveground Storage Tank”, Materials Eval; 1994: 846-849); cada observación es la profundidad de picadura más grande en la placa, ex- presada en milésimas de pulgada. 40 52 55 60 70 75 85 85 90 90 92 94 94 95 98 100 115 125 125 El resumen de cinco números es como sigue: xi más pequeña = 40 xi más grande = 125 cuarto inferior = 72.5 cuarto superior = 96.5 Mediana = Xm = 90 La figura muestra la gráfica de caja resultante. El lado derecho de la caja está mucho más cerca a la mediana que el izquierdo, lo que indica una asimetría sustancial en la mitad derecha de los datos. El ancho de la caja (fs) también es razonablemente grande con respecto al rango de datos (distancia entre las puntas de los bigotes).
Figura 1. Gráfica de caja de los datos de corrosión
8. ASIMETRÍA
Es la deformación horizontal de las curvas de frecuencias. Cuando la curva está inclinada o alargada hacia la derecha se denomina asimetría a la derecha o asimetría positiva (Fig.2). Observamos que la media aritmética queda hacia el lado más largo (el derecho) y que om MXx . Cuando la curva está inclinada o alargada al lado izquierdo se denomina asimetría a la izquierda o negativa (Fig.3). Notamos que la media aritmética está del lado más largo (el izquierdo) y que om MXx .
TECSUP - PFR Estadística y Probabilidades
43
En la Fig. 4 observamos que la curva está igualmente inclinada a los dos lados por eso se llama curva simétrica. En este caso: om MXx
Primer coeficiente de Asimetría de Pearson
x
o
S
MxAS
estándardesviación
ModaMediaAS
1
1
Notar que el valor del Primer coeficiente de Asimetría de Pearson nos indica el tipo de asimetría que tendrá la curva. Ejemplo: Considerando la tabla del Problema 1, calcular: la varianza, la desviación típica, el coeficiente de variación, el rango, el rango intercuartil, el rango interdecílico y con ayuda del primer coeficiente de Pearson indicar que tipo de asimetría presenta a la curva.
Tabla Nº 9
x Md
Mo
x Md Mo Mo Md x
Fig. 1 Fig. 2 Fig. 3
Ii ni xi
Total
4
12
7
4
2
1
30
18
34
50
66
82
98
26;10
42;26
58;42
74;58
90;74
106;90
2959,36
1505,28
161,28
1730,56
2708,48
2787,84
11852,8
xi.ni
72
408
350
264
164
98
1356
1296
13872
17500
17424
13448
9604
73144
ii nXx2 2
ii xn

Estadística y probabilidades TECSUP - PFR
44
304
4Q 26 16 30,671 12
9016
4Q 42 16 56,863 7
R Q Q 56,86 30,67 26,19IQ 3 1
300
10D 10 16 221 4
27023
10D 58 16 749 4
R D D 74 22 52ID 9 1
X MoAS1 Sx
45,2 35,85
AS 0,471 19,88
11852,8V 395,09(x) 30
73144 2V 45,2 395,09(x) 30
S 395,09 19,88x 1356X 45,2
30
S 19,88xC.V. 0,4445,2X
8M 26 16 35,850 8 5
e l(A) 105 10 95

TECSUP - PFR Estadística y Probabilidades
45
Asimetría a la derecha o positiva. 9. VALORES APARTADOS O ANÓMALOS
Gráficas de caja que muestran valores apartados Una gráfica de caja puede ser embellecida para indicar explícitamente la presencia de valores apartados. Muchos procedimientos inferenciales se basan en la suposición de que la distribución de la población es normal (un cierto tipo de curva en forma de campana). Incluso DEFINICIÓN Cualquier observación a más de 1.5 fs del cuarto más cercano es un valor apartado (o atípico). Un valor apartado es extremo si se encuentra a más de 3fs del cuarto más cercano y moderado de lo contrario. Un solo valor apartado extremo que aparezca en la muestra advierte al investigador que tales procedimientos pueden ser no confiables y la presencia de varios valores apartados transmite el mismo mensaje. Modifíquese ahora la construcción previa de una gráfica de caja trazando un bigote que sale de cada extremo de la caja hacia las observaciones más pequeñas y más grandes que no son valores apartados. Cada valor apartado moderado está representado por un círculo cerrado y cada valor apartado extremo por uno abierto. Algunos programas de computadora estadísticos no distinguen entre valores apartados moderados y extremos. Ejemplo Los efectos de descargas parciales en la degradación de materiales para cavidades aislantes tienen implicaciones importantes en relación con las duraciones de componentes de alto voltaje. Considérese la siguiente muestra de n = 25 anchos de pulso de descargas lentas en una cavidad cilíndrica de polietileno. (Estos datos son consistentes con un histograma de 250 observaciones en el artículo “Assessment of Dielectric Degradation by Ultrawide-band PD Detection”, IEEE Trans. on Dielectrics and Elec. Insul., 1995: 744-760.) El autor del artículo señala el impacto de una amplia variedad de herramientas estadísticas en la interpretación de datos de descarga. 5.3 8.2 13.8 74.1 85.3 88.0 90.2 91.5 92.4 92.9 93.6 94.3 94.8 94.9 95.5 95.8 95.9 96.6 96.7 98.1 99.0 101.4 103.7 106.0 113.5 Las cantidades pertinentes son:
x = 94.8 cuarto inferior = 90.2 cuarto superior = 96.7
fs = 6.5 1.5fs = 9.75 3fs = 19.50

Estadística y probabilidades TECSUP - PFR
46
Por lo tanto, cualquier observación menor que 90.2 - 9.75 = 80.45 o mayor que 96.7 + 9.75 = 106.45 es un valor apartado. Hay un valor apartado en el extremo superior de la muestra y cuatro en el extremo inferior. Debido a que 90.2 - 19.5 = 70.7, las tres observaciones 5.3, 8.2 y 13.8 son valores apartados extremos; los otros dos son moderados. Los bigotes se extienden a 85.3 y 106.0, las observaciones más extremas que no son valores apartados. La gráfica de caja resultante aparece en la figura. Existe una gran cantidad de asimetría negativa en la mitad media de la muestra así como también en toda la muestra.
Gráfica 2. Gráfica de caja de los datos de ancho de pulso que muestra valores apartados
10. PROBLEMAS PROPUESTOS
1. Los siguientes datos son los tiempos de ignición de ciertos materiales expuestos al fuego, dados a la más cercana centésima de segundo:
2,58 5,50 6,75 2,65 7,60 6,25 3,78 4,90 5,21 2,51
6,20 5,92 5,84 7,86 8,79 4,79 3,90 3,75 3,49 4,04 3,87 6,90 4,72 9,45 7,41 2,45 3,24 5,15 3,81 2,50 1,52 4,56 8,80 4,71 5,92 5,33 3,10 6,77 9,20 6,43 1,38 2,46 7,40 6,25 9,65 8,64 6,43 5,62 1,20 1,58
a) Construya una distribución de frecuencias utilizando un intervalo de
clase de 2 minutos. b) Represente la distribución de frecuencias por medio de un polígono de
frecuencias. c) Calcule la mediana mediante un método gráfico.
2. Se le pide a un analista experimentado la evaluación de dos métodos
diferentes para la determinación de trazas de plomo en ácido acético glacial, y se le entrega una muestra que contiene precisamente 1.282 ppm. de Pb, por litro (dato des- conocido por el analista). Se realizaron cinco determinaciones mediante cada método, que dieron los siguientes resultados para la concentración del plomo, en partes por millón (ppm):

TECSUP - PFR Estadística y Probabilidades
47
Método A: 1,34 1,33 1,32 1,34 1,31 Método B: 1,30 1,26 1,30 1,33 1,24
Compare ambos métodos.
3. En un laboratorio se preparó una serie de compuestos que contienen las siguientes masas de nitrógeno y oxígeno (en gramos):
Compuesto N2 O2
A 16,8 19,2 B 17,1 39,0 C 33,6 57,3 D 25,4 28,2 E 27,9 26,1 F 14,3 45,8 G 35,2 53,5
a) Calcule e interprete la masa de nitrógeno promedio de los compuestos. b) Calcule e interprete la mediana de la masa de oxígeno de los
compuestos. c) ¿Cuál elemento de los compuestos presenta una menor variabilidad
relativa? Justifique la respuesta. 4. Si el salario promedio semanal de n obreros es de 150 soles y cada obrero
recibe un aumento general de 7,5 soles semanales y una bonificación semanal del 1,5% del salario incrementado.
¿Cuál es el salario promedio actual semanal de los obreros?
5. En una fábrica trabajan 20 mujeres y 45 hombres, el salario promedio
semanal de las mujeres es de 100 soles y el de los hombres 120 soles.
¿Cuál es el promedio del salario semanal de todos los trabajadores de la fábrica?
6. Para los siguientes datos:
55.31 81.47 64.90 70.88 86.02 77.25 76.76 84.21 56.02
84.92 90.23 78.01 88.05 73.37 87.09 57.41 85.43
74.76 86.51 86.37 76.15 88.64 84.71 66.05 83.91
a) Calcular la mediana antes de clasificar los datos.

Estadística y probabilidades TECSUP - PFR
48
b) Agrupar los datos en una tabla de frecuencias cuyas marcas de clase sean: 60, 70, etc. y calcular la desviación típica y la mediana.
7. El salario medio semanal pagado a los trabajadores de una compañía es de
300 soles. Los salarios medios semanales pagados a hombres y mujeres de la compañía son 315 y 240 soles respectivamente. Determinar el porcentaje de hombres y mujeres que trabajan en la compañía.
Un estudio final realizado determinó que existen 800 trabajadores, ¿Cuántos son hombres?
8. Sea la siguiente distribución de lados X en mm medidos en 10 piezas: 1,20 – 2,40 – 6,00 – 7,20 – 12,00 – 13,20 – 16,80 – 21,60 – 22,80 y 25,20 mm.
a) Determinar la media x y la desviación típica Sx de la variable X.
b) Tras emplear el cambio de variable 6/545 XY determinar la media y y la desviación típica Sy de la nueva variable Y.
9. Los siguientes datos son las temperaturas registradas en grados Farenheit:
415 510 460 475 420
490 480 450 435 485
470 465 500 455 435
Encontrar x y Sx a partir de los datos.
10. La siguiente tabla muestra la distribución de salarios de 150 trabajadores de TECSUP durante el mes de Abril del año 2001.
Haberes Número de
trabajadores 900,600 15
1400,900 24
1700,1400 29
2100,1700 38
2400,2100 24
2600,2400 20
Tabla N° 8
Por incremento del costo de vida se plantean dos alternativas de aumento para el mes siguiente. La primera propuesta consiste en un aumento general de 350 soles mensuales. La segunda propuesta consiste en un aumento del 30% de los salarios de Abril a los trabajadores que ganan menos de 2100 soles y del 5% a los

TECSUP - PFR Estadística y Probabilidades
49
trabajadores que ganan más de 2100 soles y un aumento adicional de 100 soles para todos los trabajadores.
a) ¿Cuál de las propuestas convendría a los trabajadores? b) Para los trabajadores que ganan menos de 2100 soles ¿Qué propuesta
les convendría?
11. El ingreso per cápita anual de un país es de 9000 dólares. El sector obrero
que constituye el 60% de la población percibe 5
1
del ingreso total. Calcular el ingreso per cápita del sector no obrero.
12. La distribución siguiente corresponde a las lecturas con un contador Geiger
del número de partículas emitidas por una sustancia radiactiva en 100 intervalos sucesivos de 40 segundos:
Número de partículas Frecuencia
5-9 1 10-14 10 15-19 37 20-24 36 25-29 13 30-34 2 35-39 1
a) Calcule la frecuencia absoluta acumulada “a menos de” y la frecuencia relativa “a más de”. Interprete el valor de la tercera clase de ambas frecuencias acumuladas.
b) Represente gráficamente la distribución de frecuencias por medio de un histograma.
c) Calcule e interprete: el promedio aritmético, la moda y la mediana. d) Calcule la desviación estándar y el coeficiente de variación. e) Calcule e interprete el percentil 75%.
13. El artículo (“A Thin-Film Oxygen Uptake Test for the Evaluation of
Automotive Crankcase Lubricants”, Lubric. Engr.,1984: 75-83) reportó los siguientes datos sobre tiempo de inducción de oxidación (min) de varios aceites comerciales:
87 103 130 160 180 195 132 145 211 105 145 153 152 138 87 99 93 119 129
a. Calcule la varianza muestral y la desviación estándar. b. Si las observaciones se volvieran a expresar en horas, ¿cuáles serían
los valores resultantes de la varianza de la muestra y la desviación estándar muestral?

Estadística y probabilidades TECSUP - PFR
50
14. Se seleccionó una muestra de 20 botellas de vidrio de un tipo particular y se determinó la resistencia a la presión inter- na de cada botella. Considere la siguiente información parcial sobre la muestra:
mediana = 202.2 cuarto inferior = 196.0 cuarto superior = 216.8 Las tres observaciones más pequeñas 125.8 188.1 193.7 Las tres observaciones más grandes 221.3 230.5 250.2 a. ¿Hay valores apartados en la muestra? ¿Algunos valores apartados
extremos? b. Construya una gráfica de caja que muestre valores apartados y comente
sobre cualesquiera características interesantes.

TECSUP – PFR Estadística y Probabilidades
51
UNIDAD III
ANÁLISIS DE DATOS BIVARIADOS
Hemos estudiado ahora datos provenientes de una sola variable, sin embargo con frecuencia es necesario analizar respecto a la relación entre dos variables. La relación entre dos variables puede darse de la siguiente manera: 1. Cualitativa vs cualitativa 2. Cualitativa vs cuantitativa 3. Cuantitativa vs cuantitativa Para el segundo caso “cualitativa vs cuantitativa” puede trabajarse la variable cuantitativa con sus datos originales o puede elaborarse intervalos y analizarlo como el primer caso “cualitativa vs cualitativa”. Para el tercer caso puede utilizarse el análisis de correlación, regresión o puede categorizarse (convertirlo en una variable cualitativa o formar intervalos) la variable y trabajarlo como el primer o segundo caso.
1. CUALITATIVA VS CUALITATIVA
Supongamos que se toma una muestra de tamaño “n” de una población que se está investigando. Sean X e Y las variables a estudiar, tal que los datos obtenidos son:
( X1,Y1 ),( X2,Y2), ….,( Xn,Yn).
Distribución conjunta y marginal La tabla de frecuencia que agrupa a esta información se conoce “tabla de contingencia“. Por ejemplo, para el caso de dos variables cualitativas con dos modalidades o categorías, la tabla sería:
Y
Categoría 1 Categoría 2 Total
Categoría 1 Celda f11
Celda f12
Total marginal f1.
Categoría 2 Celda f21
Celda f22
Total marginal f2.
Total Total
marginal f.1
Total marginal
f.2
Total de individuos
n

Estadística y Probabilidades TECSUP – PFR
52
Distribución Marginal Cuando sólo interesa conocer la frecuencia de ocurrencia de cada una de las variables por separado se habla de Frecuencia Marginal de la variable Por ejemplo:
Hábitos de Fumar
SEXO SI NO Total
VARON
MUJER
DISTRIBUCION CONJUNTA
DISTRIBUCION MARGINAL
Total
DISTRIBUCION MARGINAL
Tamaño de
muestra
¿Cuántas variables tenemos? ……………………………………………………………………………………………………….. ¿Cuáles son? ……………………………………………………………………………………………………….. Ejemplo 1: Frecuencia absoluta: conjunta y marginal
Hábitos de Fumar SEXO
SI NO Total
VARON
800 1200 2000
MUJER
1000 2000 3000
Total 1800 3200 5000

TECSUP – PFR Estadística y Probabilidades
53
Frecuencia relativa: conjunta y marginal
X / Y Categoría variable Y
Categoría variable Y
To tal
Categoría variable X
f11 n
f12 n
Total marginal
f1./n Categoría variable X
f21 n
f22 n
Total marginal
f2./n
Total
Total marginal
f.1/n
Total marginal
f.2/n
Total de individuos
n/n
Hábitos de Fumar SEXO
SI NO Total
VARON 0.16 0.24 0.40 MUJER 0.20 0.40 0.60 Total 0.36 0.64 1
Frecuencia Condicional
Cuando se “pregunta” por la frecuencia relativa de una de las variables, digamos X, restringida a los elementos observados de una clase dada de la otra; esto es, estudiar el comportamiento de una variable dado un valor fijo de la otra.
Y
Categoría variable Y
Categoría variable Y
Categoría 1 f1 / f.1 f12/f.2
Categoría 2 f21/f.1 f22/f.2
Total 1 1 2. ANÁLISIS DE UNA VARIABLE CUALITATIVA VS CUANTITATIVA
Al estudiar los métodos de análisis de datos cuantitativos, primero se trataron problemas que implican una sola muestra de números. En problemas de una muestra, los datos se componían de observaciones sobre respuestas de individuos u objetos experimentales seleccionados de una sola población.

Estadística y Probabilidades TECSUP – PFR
54
El análisis de una variable cualitativa vs una cuantitativa, se refiere al análisis de datos muestreados de más de dos poblaciones (grupos) numéricas o de datos de experimentos en los cuales se utilizaron más de dos tratamientos. La característica que diferencia los grupos o poblaciones una de otra se llama factor (variable cualitativa) en estudio y los distintos tratamientos o poblaciones se conocen como niveles del factor (categorías de la variable cualitativa). Ejemplos de tales situaciones incluyen los siguientes:
1. Un experimento para estudiar los efectos de cinco marcas diferentes de
gasolina con respecto a la eficiencia de operación de un motor automotriz (mpg).
2. Un experimento para estudiar los efectos de la presencia de cuatro
soluciones azucaradas diferentes (glucosa, sucrosa, fructosa y una mezcla de las tres) en cuanto a crecimiento de bacterias.
3. Un experimento para investigar si la concentración de madera dura en la
pulpa (%) afecta la resistencia a la tensión de bolsas hechas de la pulpa. 4. Un experimento para decidir si la densidad de color de un espécimen de tela
depende de la cantidad de tinte utilizado. En el caso 1) el factor de interés (variable cualitativa) es la marca de la gasolina y existen cinco niveles diferentes del factor. En 2) el factor es el azúcar con cuatro niveles (o cinco, si se utiliza una solución de control que no contenga azúcar). Tanto en 1) como en 2), el factor es de naturaleza cualitativa y los niveles corresponden a posibles categorías del factor. En 3) y 4), los factores son concentración de madera dura y cantidad de tinte, respectivamente; estos dos factores son de naturaleza cuantitativa, por lo que los niveles identifican diferentes ajustes del factor. Cuando el factor de interés es cuantitativo, también se pueden utilizar técnicas estadísticas de análisis de regresión (ver análisis de dos variables cuantitativas).
3. ANÁLISIS DE DOS VARIABLES CUANTITATIVAS
Regresión lineal simple y correlación En muchos trabajos es necesario, a menudo, determinar el efecto que una variable ejerce sobre otra. Así, por ejemplo, se desea comprobar si una reacción colorimétrica sigue la ley de Beer-Lambert, medir la velocidad de una reacción química o conocer la validez de nuevo método en relación con una serie de normas conocidas. Un experimento de laboratorio es una medida del efecto de una variable sobre la otra; con base a una cantidad de muestra, se efectúa la reacción y posteriormente, se cuantifica la respuesta. Al estudiar el comportamiento conjunto de dos variables es ver si están relacionadas, en lugar de utilizar una para predecir el valor de la otra.

TECSUP – PFR Estadística y Probabilidades
55
Iniciaremos con el desarrollo del coeficiente de correlación muestral r como una medida de qué tan fuerte es la relación entre dos variables x y y en un muestra.
Coeficientes de correlación “r”
Existen diversos coeficientes que miden el grado de correlación, adaptados a la naturaleza de los datos. El más conocido es el coeficiente de correlación de Pearson (introducido en realidad por Francis Galton), que se obtiene dividiendo la covarianza de dos variables entre el producto de sus desviaciones estándar. r = cosα
Propiedades de r Las propiedades más importantes de r son las siguientes:
1. El valor de r no depende de cuál de las dos variables estudiadas es x
y cual es y. 2. El valor de r es independiente de las unidades en las cuales x y y
estén medidas. 3. -1 < r < 1 4. r = 1 si y sólo si todos los pares (xi, yi) quedan en una línea recta con
pendiente positiva y r = -1 si y sólo si los pares (xi, yi) quedan en una línea recta con pendiente negativa.
5. El cuadrado del coeficiente de correlación muestral da el valor del coeficiente de determinación que resultaría de ajustar el modelo de regresión lineal simple, en símbolos (r)2 = r2.
La propiedad 3 dice que el valor máximo de r, correspondiente al grado más grande posible de relación positiva, es r = 1, mientras que la relación más negativa está identifica- da con r = -1. De acuerdo con la propiedad 4, las

Estadística y Probabilidades TECSUP – PFR
56
correlaciones positivas y negativas más grandes se obtienen sólo cuando todos los puntos quedan a lo largo de una línea recta. Cualquier otra configuración de puntos, aun cuando la configuración sugiere una relación determinística entre las variables, dará un valor r menor que 1 en magnitud absoluta. Por consiguiente, r mide el grado de relación lineal entre las variables. Un valor de r cercano a 0 no es evidencia de la falta de una fuerte relación, sino sólo de la ausencia de una relación lineal, de modo que tal valor de r debe ser interpretado con precaución. La siguiente figura ilustra varias configuraciones de puntos asociadas con valores diferentes de r.
Una pregunta planteada es ¿cuándo existe correlación fuerte entre las variables y cuándo es débil? Una regla empírica notable es decir que la correlación es débil si 0 < r< 0.5, fuerte si 0.8 < r< 1, y moderada de lo contrario. Puede sorprender que r = 0.5 se considere débil, pero r2 = 0.25 implica que en una regresión de y en x (modelo: y = mx + b), solo 25% de la variación de y observada sería explicada por el modelo.
4. REGRESIÓN
La regresión es una técnica estadística para estudiar la naturaleza de la relación entre dos o más variables. Aunque puede utilizarse en esto las ecuaciones no lineales, la presenta unidad se limitará a la explicación de las ecuaciones de regresión del tipo lineal (línea recta). Un caso práctico de análisis es construir las curvas de calibración utilizadas en los métodos fotométricos: hay que proceder a la medición de la respuesta de un aparato en relación con cantidades variables del constituyente a estudiar. En análisis gravimétrico, puede presentarse la necesidad de relacionar el peso de precipitado con la temperatura, el pH, el contenido en electrolito inerte o con otras variables.

TECSUP – PFR Estadística y Probabilidades
57
Los objetivos de la regresión son mostrar la forma como la variable in- dependiente (X) se relaciona con la variable dependiente (Y), hacer pronósticos sobre los valores de la variable dependiente, con base en el conocimiento de los valores de la variable independiente.
5. PROBLEMAS PROPUESTOS
1. Numerosos factores contribuyen al funcionamiento suave de un motor eléctrico (“Increasing Market Share Through Improved Product and Process Design: An Experimental Approach”, Quality Engineering, 1991: 361-369). En particular, es deseable mantener el ruido del motor y vibraciones a un mínimo. Para estudiar el efecto que la marca de los cojinetes tiene en la vibración del motor, se examinaron cinco marcas diferentes de cojinetes instalando cada tipo de cojinete en muestras aleatorias distintas de seis motores. Se registró la cantidad de vibración del motor (medida en micrones) cuando cada uno de los 30 motores estaba funcionando. Los datos de este estudio se dan a continuación. Realice un análisis de comparaciones múltiples, es decir, entre todos los grupos.
Marca 1 13.1 15.0 14.0 14.4 14.0 11.6 Marca 2 16.3 15.7 17.2 14.9 14.4 17.2 Marca 3 13.7 13.9 12.4 13.8 14.9 13.3 Marca 4 15.7 13.7 14.4 16.0 13.9 14.7 Marca 5 13.5 13.4 13.2 12.7 13.4 12.3
2. Un fabricante sospecha que el contenido de nitrógeno en un producto varía
de un lote a otro. Selecciona una muestra aleatoria de cuatro lotes y realiza cinco determinaciones del contenido de nitrógeno en cada lote. ¿Existe una diferencia en el contenido de nitrógeno de un lote a otro?
Lote Observaciones
1
26,15
26,25
26,39
26,18
26,20 2 24,95 25,01 24,89 24,85 25,13
3 25,00 25,36 25,20 25,09 25,12
4 26,81 26,75 26,15 26,50 26,70
3. El Turbine Oil Oxidation Test (TOST) y el Rotating Bomb Oxidation Test
(RBOT) son dos procedimientos diferentes de evaluar la estabilidad ante la oxidación de aceites para turbina de vapor. El artículo “Dependence of Oxidation Stability of Steam Turbine Oil on Base Oil Composition” (J. of the Society of Tribologists and Lubrication Engrs., octubre de 1997: 19-24) reportó las observaciones adjuntas sobre x = tiempo para realizar TOST (h) y y = tiempo para realizar RBOT (min) con 12 especímenes de aceite.

Estadística y Probabilidades TECSUP – PFR
58
TOST 4200 3600 3750 3675 4050 2770 RBOT 370 340 375 310 350 200 TOST 4870 4500 3450 2700 3750 3300 RBOT 400 375 285 225 345 285
a. Calcule e interprete el valor del coeficiente de correlación muestral (como
lo hicieron los autores del artículo). b. ¿Cómo se vería afectado el valor de r si se hubiera hecho x = tiempo para
realizar RBOT y y = tiempo para realizar TOST? c. ¿Cómo se vería afectado el valor de r si el tiempo para realizar RBOT
estuviera expresado en horas? d. Construya gráficas de probabilidad normal y comente. e. Interprete los coeficientes del modelo de regresión lineal y el R2.
4. Los datos siguientes se refieren a los días desde la inoculación(X) y al
crecimiento de una colonia de bacterias (Y) en un cultivo.
X 3 6 9 12 15 18 Y 115 147 239 356 579 864
a) Calcule el coeficiente de correlación b) Calcule e interprete el coeficiente de determinación c) Interprete la constante de regresión en términos del problema
5. La tenacidad y fibrosidad de los espárragos son determinantes importantes
de su calidad. Éste fue el enfoque de un estudio reportado en “Post-Harvest Glyphosphate Application Reduces Toughening, Fiber Content, and Lignification of Stored Asparagus Spears” (J. of the Amer. Soc. of Horticultural Science, 1988: 569-572). El artículo reportó los datos adjuntos (tomados de una gráfica) sobre x = fuerza cortante (kg) y y = porcentaje de peso de fibra en seco.
X : 46 48 55 57 60 72 81 85 94 Y: 2.18 2.10 2.13 2.28 2.34 2.53 2.28 2.62 2.63 X: 109 121 132 137 148 149 184 185 187 Y: 2.50 2.66 2.79 2.80 3.01 2.98 3.34 3.49 3.26
a. Calcule el valor del coeficiente de correlación muestral. Basado en este
valor, ¿cómo describiría la naturaleza de la relación entre las dos variables?
b. Si un primer espécimen tiene un valor más grande de fuerza cortante que un segundo espécimen, ¿qué tiende a ser cierto del porcentaje de peso de fibra en seco para los dos especímenes?
c. Si la fuerza cortante se expresa en libras, ¿qué le pasa al valor de r? ¿Por qué?

TECSUP – PFR Estadística y Probabilidades
59
d. Si el modelo de regresión lineal simple fuera ajustado a estos datos, ¿qué proporción de la variación observada en porcentaje de peso de fibra en seco podría ser explicada por la relación de modelo?
6. Los datos adjuntos sobre x = tasa de consumo de diesel medida por el
método pesaje de drenaje y y = tasa medida por el método de trazado de intervalo de confianza, ambos en g/h, se tomaron de una gráfica incluida en el artículo “A New Measurement Method of Diesel Engine Oil Consumption Rate” (J. Society Auto Engr., 1985: 28-33).
x : 4 5 8 11 12 16 17 20 22 28 30 31 39 y : 5 7 10 10 14 15 13 25 20 24 31 28 39
a. Suponiendo que x y y están relacionadas por el modelo de regresión lineal
simple, realice una prueba para decidir si es factible que en promedio el cambio de la tasa medida por el método de trazado de intervalo de con- fianza sea idéntico al cambio de la tasa medido mediante el método de pesaje de drenaje.
b. Calcule e interprete el valor del coeficiente de correlación muestral. 7. Los siguientes datos corresponden al tiempo de secado (en horas) de
cierto barniz y la cantidad de un aditivo (en gramos) con el que se intenta reducir el tiempo de secado:
Aditivo 1 1,5 2 2,5 3 3,5 Tiempo 2 4 6 8 9 11
a) Construya el diagrama de dispersión. b) Calcule el coeficiente de correlación. c) Estime el tiempo de secado del barniz cuando se han utilizado 4 gramos
del aditivo.
8. Los resultados de varias determinaciones de cobre en un mineral son los que siguen (en % Cu). El primer grupo de determinaciones fue realizado por el analista A, el segundo por el analista B. Comparar las precisiones de los dos analistas.
A 6,2 5,7 6,5 6,0 6,3 5,8 5,7 6,0 6,0 5,8 B 5,6 5,9 5,6 5,8 6,0 5,5 5,7 5,5
9. En la ciudad de Lima se ha incrementado durante los últimos cinco años el
número de restaurantes de comida rápida. Debido a esto los expertos la empresa de investigación de mercado Consultores-ECE se pregunta. ¿La preferencia de un cliente por la comida rápida tiene que ver la edad?. La empresa eligió una muestra aleatoria de 500 clientes de comida rápida mayores de 16 años y se les preguntó su restaurante favorito, obteniéndose los siguientes datos:

Estadística y Probabilidades TECSUP – PFR
60
Kentuky McDonalds Burger-King Otro16 - 21 75 34 10 621 - 30 89 42 19 1030 - 49 54 52 28 18
50 a más 21 25 7 10
Grupo de edad
Restaurant
¿Cuáles serán las conclusiones que llegarán los expertos de la empresa Consultores-ECE?
10. Los resultados de un experimento para evaluar el efecto del petróleo crudo
en parásitos de peces se describen en el artículo “Effects of Crude Oils on the Gastrointestinal Parasites of Two Species of Marine Fish” (J. Wildlife Diseases, 1983: 253-258). Se compararon tres tratamientos (correspondientes a poblaciones del procedimiento descrito):
1) sin contaminación, 2) contaminación por petróleo de 1 año de antigüedad, y 3) contaminación por petróleo nuevo. Para cada condición de tratamiento se tomó una muestra de peces, y cada uno de éstos se clasificó como con parásitos o sin parásitos. Se da información compatible con la del artículo. ¿La información indica que los tres tratamientos difieren con respecto a la verdadera proporción de peces con parásitos o sin parásitos? Tratamiento Con parásitos Sin parásitos
Control 30 3 Petróleo viejo 16 8 Petróleo nuevo 16 16
11. Una compañía empaca un producto particular en latas de tres tamaños
diferentes, cada uno con una línea de producción distinta. La mayor parte de las latas se apegan a especificaciones, pero un ingeniero de control de calidad ha identificado las siguientes razones de no cumplimiento de especificaciones:
1. Defecto en lata 2. Grieta en lata 3. Ubicación incorrecta de arillo 4. Arillo faltante 5. Otras
Se selecciona una muestra de unidades fuera de especificación de cada una de las tres líneas de producción, y cada unidad se clasifica según la razón por la que están fuera de especificación; dio por resultado la siguiente información de tabla de contingencia: ¿existe alguna relación entre la línea de producción y las razones por las que las latas no cumplan las especificaciones?

TECSUP – PFR Estadística y Probabilidades
61

Estadística y Probabilidades TECSUP – PFR
62
ANOTACIONES: ……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………
……………………………………………………………………………………………………

TECSUP - PFR Estadística y Probabilidades
63
UNIDAD IV
PROBABILIDAD El término probabilidad se refiere al estudio de azar y la incertidumbre en cualquier situación en la cual varios posibles sucesos pueden ocurrir; la disciplina de la probabilidad proporciona métodos de cuantificar las oportunidades y probabilidades asociadas con varios sucesos. El lenguaje de probabilidad se utiliza constantemente de manera informal tanto en el contexto escrito como en el hablado. Algunos ejemplos incluyen enunciados tales como “es probable que el índice Dow-Jones se incremente al final del año”, “existen 50-50 probabilidades de que la persona con posesión de su cargo busque la reelección”, “probablemente se ofrecerá por lo menos una sección del curso el próximo año”, “las probabilidades favorecen la rápida solución de la huelga” y “se espera que se vendan por lo menos 20 000 boletos para el concierto”. En esta unidad, se introducen algunos conceptos de probabilidad, se indica cómo pueden ser interpretadas las probabilidades y se demuestra cómo pueden ser aplicadas las reglas de probabilidad para calcular las probabilidades de muchos eventos interesantes. La metodología de probabilidad permite entonces expresar en lenguaje preciso enunciados informales como los antes expresados.
1. EXPERIENCIA ALEATORIA Y ESPACIO MUESTRAL
Un experimento es cualquier acción o proceso cuyo resultado está sujeto a la incertidumbre. Aunque la palabra experimento en general sugiere una situación de prueba cuidadosamente controlada en un laboratorio, se le utiliza aquí en un sentido mucho más amplio. Por lo tanto, experimentos que pueden ser de interés incluyen lanzar al aire una moneda una vez o varias veces, seleccionar una carta o cartas de un mazo, pesar una hogaza de pan, el tiempo de recorrido de la casa al trabajo en una mañana particular, obtener tipos de sangre de un grupo de individuos o medir las resistencias a la compresión de diferentes vigas de acero. El espacio muestral de un experimento denotado por S o por Ω, es el conjunto de todos los posibles resultados de dicho experimento. Ejemplos: Si se examinan tres fusibles en secuencia y se anota el resultado de cada examen, entonces un resultado del experimento es cualquier secuencia de letras N y D de longitud 3, por lo tanto
Ω = NNN, NND, NDN, NDD, DNN, DND, DDN, DDD
Dos gasolineras están localizadas en cierta intersección. Cada una dispone de 6 bombas de gasolina. Considérese el experimento en el cual se determina el número de bombas en uso a una hora particular del día en cada una de las gasolineras. Un resultado experimental especifica cuántas bombas están en uso en la primera gasolinera y cuántas están en uso en la segunda. Un posible resultado es (2, 2), otro es (4, 1) y otro más es (1, 4). Los 49 resultados en S se

Estadística y Probabilidades TECSUP – PFR
64
muestran en la tabla adjunta. El espacio muestral del experimento en el cual un dado de 6 lados es lanzado dos veces se obtiene eliminando la fila 0 y la columna 0 de la tabla y se obtienen 36 resultados.
2. SUCESOS O EVENTOS En el estudio de la probabilidad, interesan no sólo los resultados individuales de Ω sino también varias recopilaciones de resultados de .
Un evento es cualquier recopilación (subconjunto) de resultados contenidos en el espacio muestral Ω. Un evento es simple si consiste en exactamente un resultado y compuesto si consiste en más de un resultado. Podemos combinar sucesos para formar nuevos sucesos, utilizando las diferentes operaciones con conjuntos: AB es el suceso que ocurre si y sólo si A o B o ambos ocurren; AB es el suceso que ocurre si y sólo si A y B ocurren simultáneamente. A , (Complemento de A ó contrario de A), es el suceso que ocurre si y sólo si
A no ocurre.
2.1 SUCESOS O EVENTOS INCOMPATIBLES
Dos sucesos que no puedan ocurrir simultáneamente, reciben el nombre de sucesos incompatibles; para que dos sucesos sean incompatibles, deben carecer de elementos comunes. Por ejemplo, en el caso de la ruleta anterior, son incompatibles los sucesos elementales. El contrario de 1 , 3 es 2, 4, 5, para la ruleta del ejemplo anterior. Desde luego, dos sucesos contrarios deben ser incompatibles, pero no basta con ello; además, la unión de ambos debe dar el espacio muestral. Ejemplo:

TECSUP - PFR Estadística y Probabilidades
65
Láncese un dado y obsérvese el número que aparece en la cara superior. Entonces el espacio muestral es: = 1, 2, 3, 4, 5, 6 Sea A el suceso de salir un número par, B de salir impar y C de salir primo; A = 2, 4, 6, B = 1, 3, 5, C = 2, 3, 5 Entonces: AC = 2, 3, 4, 5, 6 BC =3, 5 C = 1, 4, 6
3. APLICACIÓN FRECUENCIAL
Tres caras de un cubo se han pintado de color azul, dos de color rojo, y se ha dejado una de color blanco. Si vamos lanzando el cubo y anotando el color de la cara sobre la que queda apoyado, ¿cuántas veces saldrá cada color? ¿Cuál será su frecuencia relativa? Es razonable pensar que, ya que la mitad de las caras son de color azul, este color aparecerá la mitad de las veces que se tire el cubo; la frecuencia relativa del color azul tenderá a 1/2 si repetimos las tiradas muchas veces. Análogamente, una tercera parte de las veces saldrá de color rojo, y una sexta parte el color blanco; la frecuencia relativa del color rojo tenderá a 1/3, y la del blanco a 1/6 si los lanzamientos se repiten muchas veces. De este modo, asignando a cada color un número que exprese la frecuencia relativa esperada para dicho color, tendremos la siguiente aplicación:
Azul 1/2 Rojo 1/3 Blanco 1/6
Observa que la frecuencia relativa esperada para cada color es un número positivo menor que uno, y que la suma de todas es igual a uno.

Estadística y Probabilidades TECSUP – PFR
66
4. PROBABILIDAD
Consideremos la experiencia aleatoria que consiste en lanzar el cubo anterior y anotar el color de la cara sobre la que queda apoyado, el conjunto de resultados posibles o espacio muestral de la experiencia es: azul, rojo, blanco Recuerda que un suceso de esta experiencia es un subconjunto del espacio muestral. Ahora queremos precisar, con números adecuados, el mayor o menor grado de confianza que nos merece cada suceso; y este número lo obtendremos a partir de las frecuencias relativas a las que parecen tender cada uno de los resultados. La aplicación que obtengamos recibirá el nombre de probabilidad definida en el espacio muestral . El criterio a seguir será el de asignar a cada suceso el número obtenido como suma de las frecuencias relativas esperadas de cada uno de sus resultados.
1 1 10 azul . . rojo . blanco
2 3 61 1 1 1 1 1
azul,rojo . azul,blanco . rojo,blanco2 3 2 6 3 6
1 1 1azul,rojo,blanco
2 3 6
Observa que, para disponer de un probabilidad definida en un espacio muestral, basta conocer las probabilidades de los suceso elementales. La terna formada por el conjunto , el conjunto S de sus sucesos y la probabilidad p, recibe el nombre de espacio de probabilidad.
AXIOMAS DE PROBABILIDAD Aparecen para esta aplicación tres propiedades esenciales:
Con ello, la probabilidad del suceso imposible (conjunto vacío) será 0, la probabilidad de un suceso elemental será la frecuencia relativa a la que tienda su único resultado; y a los demás sucesos, les corresponderá la suma de las probabilidades de los sucesos elementales que lo componen.
a) 1)(0 Ap , para cualquier suceso A. b) 1)( p c) Si A y B son dos sucesos incompatibles: )()()( BpApBAp

TECSUP - PFR Estadística y Probabilidades
67
Las tres propiedades se toman como axiomas para definir una probabilidad en un espacio muestral finito . Toda aplicación entre el conjunto de los sucesos de una experiencia aleatoria y los números reales, con estas tres características, reciben el nombre de probabilidad definida en el espacio muestral correspondiente. Teorema 1: dado un suceso A, entonces: )(1)( ApAp Teorema 2: dados dos sucesos A y B, entonces: )()()( BApApBAp Teorema 3: dados dos sucesos A y B, entonces:
)()()()( BApBpApBAp
4.1 PROBABILIDAD UNIFORME
En algunas experiencias aleatorias, todos los resultados tienen la misma frecuencia relativa esperada, el mismo peso; entonces, los sucesos elementales son equiprobables y la probabilidad se llama probabilidad uniforme. Por ejemplo, si tiramos un dado, cada resultado posible tiene el mismo peso, 1/6 En general, si el espacio muestral tiene n elementos, la probabilidad uniforme de cualquier suceso elemental será 1/n y la probabilidad de un suceso que conste de m resultados, será m/n En este caso de sucesos elementales equiprobables, puede indicarse una expresión sencilla par el cálculo de la probabilidad de un suceso cualquiera. Si llamamos casos favorables a los elementos de dicho suceso, se tendrá:
Ejemplo
Calcula la probabilidad de sacar un as de una baraja, en una sola extracción. Resolución. Puesto que en la baraja hay 4 ases (de oros, de copas, de espadas y de bastos) y un total de 52 cartas será:
4
p52
Tener en cuenta que se trata de probabilidad uniforme
casos favorablesprobabilidad del suceso
casos totales

Estadística y Probabilidades TECSUP – PFR
68
4.2 PROBABILIDAD DE EXPERIENCIAS COMPUESTAS
Efectuemos la siguiente experiencia compuesta:
Lanzar una moneda Hacer girar una ruleta. Representemos el lanzamiento de moneda y el giro de ruleta por separado, mediante unos diagramas circulares en los que se ha señalado tantas zonas como resultados posibles, escribiendo en cada zona la frecuencia relativa esperada para el resultado correspondiente.
¿Cuáles son los resultados posibles en la experiencia compuesta?. Utilicemos un diagrama de árbol:
= (cara, a); (cara, b); (cara, c); (cruz, a); (cruz, b); (cruz, c)
Nuestro objetivo es definir una probabilidad en el conjunto , para lo que necesitamos hallar la probabilidad de cada suceso elemental. Fijémonos, por ejemplo, en el resultado (cara, c). Si repetimos muchas veces la doble prueba, saldrá cara aproximadamente la mitad de los casos; y en esta doble prueba, al jugar a la ruleta saldrán las zonas a,b,c cada una con la frecuencia relativa indicada en el gráfico. En particular, la zona c saldrá la tercera parte de esta mitad del total; ello supone pues, la sexta parte del total. De ahí que se asigna al par (cara, c) el número: 1/6.
cruz1/2
cara1/2
a1/2
b1/6
c1/3
cara
cruz
1/2
1/2
ab
c
a
b
c
1/2
1/6
1/31/2
1/6
1/3

TECSUP - PFR Estadística y Probabilidades
69
4.3 PROBABILIDAD CONDICIONAL DEFINICIÓN Para dos eventos cualesquiera A y B con P(B) > 0, la probabilidad condicional de A dado que B ha ocurrido está definida por:
Las probabilidades asignadas a varios eventos dependen de lo que se sabe sobre la situación experimental cuando se hace la asignación. Subsiguiente a la asignación inicial puede llegar a estar disponible información parcial pertinente al resultado del experimento. Tal información puede hacer que se revisen algunas de las asignaciones de probabilidad. Para un evento particular A, se ha utilizado P(A) para representar la probabilidad asignada a A; ahora se considera P(A) como la probabilidad original no condicional del evento A. En esta sección, se examina cómo afecta la información de que “un evento B ha ocurrido” a la probabilidad asignada a A. Por ejemplo, A podría referirse a un individuo que sufre una enfermedad particular en la presencia de ciertos síntomas. Si se realiza un examen de sangre en el individuo y el resultado es negativo (B = examen de sangre negativo), entonces la probabilidad de que tenga la enfermedad cambiará (deberá reducirse, pero no a cero, puesto que los exámenes de sangre no son infalibles). Se utilizará la notación P(A | B) para representar la probabilidad condicional de A dado que el evento B haya ocurrido. B es el “evento condicionante”. Por ejemplo, considérese el evento A en que un estudiante seleccionado al azar en su universidad obtuvo todas las clases deseadas durante el ciclo de inscripciones del semestre anterior. Presumiblemente P(A) no es muy grande. Sin embargo, supóngase que el estudiante seleccionado es un atleta con prioridad de inscripción especial (el evento B). Entonces P(A | B) deberá ser sustancialmente más grande que P(A), aunque quizá aún no cerca de 1. Ejemplo En una planta se ensamblan componentes complejos en dos líneas de ensamble diferentes, A y A'. La línea A utiliza equipo más viejo que A', por lo que es un poco más lenta y menos confiable. Suponga que en un día dado la línea A ensambla 8 componentes, de los cuales 2 han sido identificados como defectuosos (B) y 6 como no defectuosos (B'), mientras que A' ha producido 1 componente defectuoso y 9 no defectuosos. Esta información se re sume en la tabla adjunta:

Estadística y Probabilidades TECSUP – PFR
70
No obstante, si el componente seleccionado resulta defectuoso, entonces el evento B ha ocurrido, por lo que el componente debe haber sido 1 de los 3 de la columna B de la tabla. como estos 3 componentes son igualmente probables entre ellos mismos una vez que B ha ocurrido, No obstante, si el componente seleccionado resulta defectuoso, entonces el evento B ha ocurrido, por lo que el componente debe haber sido 1 de los 3 de la columna B de la tabla. Como estos 3 componentes son igualmente probables entre ellos mismos una vez que B ha ocurrido, La probabilidad condicional está expresada como una razón de probabilidades incondicionales. El numerador es la probabilidad de la intersección de los dos eventos, en tanto que el denominador es la probabilidad del evento condicionante B. Un diagrama de Venn ilustra esta relación.
Dado que B ha ocurrido, el espacio muestral pertinente ya no es S pero consta de resultados en B; A ha ocurrido si y sólo si uno de los resultados en la intersección ocurrió, así que la probabilidad condicional de A dado B es proporcional a P(A n B). Se utiliza la constante de proporcionalidad 1/P(B) para garantizar que la probabilidad P(B | B) del nuevo espacio muestral B sea igual a 1.
4.4 PROBABILIDAD TOTAL Y TEOREMA DE BAYES El cálculo de una probabilidad posterior P(Aj | B) a partir de probabilidades previas dadas P(Ai) y probabilidades condicionales P(B | Ai) ocupa una posición central en la probabilidad elemental. La regla general de dichos cálculos, los que en realidad son una aplicación sim- ple de la regla de multiplicación, se remonta al reverendo Thomas Bayes, quien vivió en el siglo XVIII. Para formularla primero se requiere otro resultado. Recuérdese que los eventos A1, . . . , Ak son mutuamente excluyentes si ninguno de los dos tiene resultados comunes.

TECSUP - PFR Estadística y Probabilidades
71
5. LEY DE LA PROBABILIDAD TOTAL
Sean A1, . . . , Ak eventos mutuamente excluyentes y exhaustivos. Entonces para cualquier otro evento B,
6. TEOREMA DE BAYES
Sean A1, A2, . . . , Ak un conjunto de eventos mutuamente excluyentes y exhaustivos con probabilidades previas P(Ai) (i = 1, . . . , k). Entonces para cualquier otro evento B para el cual P(B) > 0, la probabilidad posterior de Aj dado que B ha ocurrido es
La transición de la segunda a la tercera expresión en formula del teorema de Bayes se apoya en el uso de la regla de multiplicación en el numerador y la ley de probabilidad total en el denominador. La proliferación de eventos y subíndices en esta fórmula puede ser un poco intimidante para los recién llegados a la probabilidad. Mientras existan relativamente pocos eventos en la repartición, se puede utilizar un diagrama de árbol como base para calcular probabilidades posteriores sin jamás referirse de manera explícita al teorema de Bayes. INDEPENDENCIA La definición de probabilidad condicional permite revisar la probabilidad P(A) originalmente asignada a A cuando después se informa que otro evento B ha ocurrido; la nueva probabilidad de A es P(A | B). En los ejemplos, con frecuencia fue el caso de que P(A | B) difería de la probabilidad no condicional P(A), lo que indica que la información “B ha ocurrido” cambia la probabilidad de que ocurra A. A menudo la probabilidad de que ocurra o haya ocurrido A no se ve afectada por el conocimiento de que B ha ocurrido, así que P(A | B) = P(A). Es entonces natural considerar a A y B como eventos independientes, es decir que la ocurrencia o no ocurrencia de un evento no afecta la probabilidad de que el otro ocurra. Definición Los eventos A y B son independientes si P(A | B) = P(A) y son dependientes de lo contrario.

Estadística y Probabilidades TECSUP – PFR
72
Regla de la multiplicación Con frecuencia la naturaleza de un experimento sugiere que dos eventos A y B deben suponerse independientes. Este es el caso, por ejemplo, si un fabricante recibe una tarjeta de circuito de cada uno de dos proveedores diferentes, cada tarjeta se somete a prueba al llegar y A = la primera está defectuosa y B = la segunda está defectuosa. Si P(A) = 0.1, también deberá ser el caso de que P(A | B) = 0.1; sabiendo que la condición de la segunda tarjeta no informa sobre la condición de la primera. El siguiente resultado muestra cómo calcular P(A _ B) cuando los eventos son independientes. A y B son independientes si y sólo si
7. EJERCICIOS PROPUESTOS
1. Que A denote el evento en que la siguiente solicitud de asesoría de un consultor de “software” estadístico tenga que ver con el paquete SPSS y que B denote el evento en que la siguiente solicitud de ayuda tiene que ver con SAS. Suponga que P(A ) = 0.30 y P(B) = 0.50.
a. ¿Por qué no es el caso en que P(A) + P(B) = 1? b. Calcule P(A'). c. Calcule P(A U B). d. Calcule P(A' n B').
2. Una caja contiene 220 tornillos iguales, de los cuales 80 son producidos por
la máquina A, 60 por la máquina B, 50 por la máquina C y 30 por la máquina D. Si se elige un tornillo al azar de la caja, determinar:
a) ¿Cuál es la probabilidad que el tornillo elegido haya sido producido por
las máquinas A o C? b) ¿Cuál es la probabilidad que el tornillo elegido haya sido producido por
las máquinas A y D?.
3. Una tienda de departamentos vende camisas sport en tres tallas (chica, mediana y grande), tres diseños (a cuadros, estampadas y a rayas) y dos largos de manga (larga y corta). Las tablas adjuntas dan las proporciones de camisas vendidas en las combinaciones de categoría.

TECSUP - PFR Estadística y Probabilidades
73
a. ¿Cuál es la probabilidad de que la siguiente camisa vendida sea una camisa mediana estampada de manga larga?
b. ¿Cuál es la probabilidad de que la siguiente camisa vendida sea una camisa estampada mediana?
c. ¿Cuál es la probabilidad de que la siguiente camisa vendida sea de manga corta? ¿De manga larga?
d. ¿Cuál es la probabilidad de que la talla de la siguiente camisa vendida sea mediana? ¿Que la siguiente camisa vendida sea estampada?
e. Dado que la camisa que se acaba de vender era de manga corta a cuadros, ¿cuál es la probabilidad de que fuera mediana?
f. Dado que la camisa que se acaba de vender era mediana a cuadros, ¿cuál es la probabilidad de que fuera de manga corta? ¿De manga larga?
4. Cada vez que se recibe un lote de llantas, un inspector de calidad adopta la
siguiente política: extrae dos llantas una después de otra y sin restitución, si al menos una de ellas es defectuosa revisa todo el lote. Si se recibe un lote de 50 llantas y se sabe que en él hay tres llantas defectuosas. ¿Cuál es la probabilidad que al aplicar la política de revisión se tenga que revisar todo el lote?
5. Un empresario tiene una máquina automática en su fábrica que produce
tapas para lapiceros. con su pasada experiencia ha comprobado que si la máquina se ajusta en forma apropiada, la máquina producirá un 90 % de tapas aceptables, mientras que si su acondicionamiento no es adecuado, sólo producirá un 30 % de tapas aceptables. El empresario también ha observado que el 75 % de los acondicionamientos se hace en forma

Estadística y Probabilidades TECSUP – PFR
74
correcta. Si la primera tapa producida es aceptable, ¿qué probabilidad existe que el acondicionamiento se haya hecho correctamente?
6. Un laboratorio somete a los choferes que cometen accidentes de tránsito a
un test de “dosaje etílico”. Se ha determinado que:
Cuando un chofer está ebrio, el test proporciona resultado positivo en el 95 % de los casos.
cuándo el chofer no está ebrio, el test proporciona resultado negativo en el 94 % de los casos.
El 2 % de los conductores que cometen accidentes manejan ebrios.
¿Cuál es la probabilidad que el chofer esté ebrio dado que el resultado fue positivo?
7. Componentes de cierto tipo son enviados a un distribuidor en lotes de diez.
Suponga que 50% de dichos lotes no contienen componentes defectuosos, 30% contienen un componente defectuoso y 20% contienen dos componentes defectuosos. Se seleccionan al azar dos componentes de un lote y se prueban. ¿Cuáles son las probabilidades asociadas con 0, 1 y 2 componentes defectuosos que están en el lote en cada una de las siguientes condiciones? a. Ningún componente probado está defectuoso. b. Uno de los dos componentes probados está defectuoso. [Sugerencia:
Trace un diagrama de árbol con tres ramas de primera generación correspondientes a los tres tipos diferentes de lotes.]
8. En una gasolinería, 40% de los clientes utilizan gasolina regular (A1), 35%
usan gasolina plus (A2) y 25% utilizan premium (A3). De los clientes que utilizan gasolina regular, sólo 30% llenan sus tanques (evento B). De los clientes que utilizan plus, 60% llenan sus tanques, mientras que los que utilizan premium, 50% llenan sus tanques.
a. ¿Cuál es la probabilidad de que el siguiente cliente pida gasolina plus y
llene el tanque (A2 n B)? b. ¿Cuál es la probabilidad de que el siguiente cliente llene el tanque?
9. En el ejercicio 8, considere la siguiente información adicional sobre el uso de
tarjetas de crédito:
El 70% de todos los clientes que utilizan gasolina regular y que llenan el tanque usan una tarjeta de crédito.
El 50% de todos los clientes que utilizan gasolina regular y que no
llenan el tanque usan una tarjeta de crédito. El 60% de todos los clientes que llenan el tanque con gasolina plus
usan una tarjeta de crédito.

TECSUP - PFR Estadística y Probabilidades
75
El 50% de todos los clientes que utilizan gasolina plus y que no llenan el tanque usan una tarjeta de crédito.
El 50% de todos los clientes que utilizan gasolina premium y que llenan
el tanque usan una tarjeta de crédito. El 40% de todos los clientes que utilizan gasolina premium y que no
llenan el tanque usan una tarjeta de crédito. Calcule la probabilidad de cada uno de los siguientes eventos para el siguiente cliente que llegue (un diagrama de árbol podría ayudar). a. Plus, tanque lleno y tarjeta de crédito b. Premium, tanque no lleno y tarjeta de crédito c. Premium y tarjeta de crédito d. Tanque lleno y tarjeta de crédito e. Tarjeta de crédito f. Si el siguiente cliente utiliza una tarjeta de crédito, ¿cuál es la
probabilidad de que pida premium?
10. La costura de un avión requiere 25 remaches. La costura tendrá que ser retrabajada si alguno de los remaches está defectuoso. Suponga que los remaches están defectuosos independientemente uno de otro, cada uno con la misma probabilidad.
a. Si 20% de todas las costuras tienen que ser retrabajadas, ¿cuál es la
probabilidad de que un remache esté defectuoso? b. ¿Qué tan pequeña deberá ser la probabilidad de un re- mache
defectuoso para garantizar que sólo 10% de las costuras tienen que ser retrabajadas?
11. Considere el sistema de componentes conectados como en la figura adjunta. Los componentes 1 y 2 están conectados en paralelo, de modo que el subsistema trabaja si y sólo si 1 o 2 trabaja; como 3 y 4 están conectados en serie, qué sub- sistema trabaja si y sólo si 3 y 4 trabajan. Si los componentes funcionan independientemente uno de otro y P(el componente trabaja) = 0.9, calcule P(el sistema trabaja).
1
12. Una compañía de exploración petrolera en la actualidad tiene dos proyectos
activos, uno en Asia y el otro en Europa. Sea A el evento en que el proyecto asiático tiene éxito y B el evento en que el proyecto europeo tiene éxito. Suponga que A y B son eventos independientes con P(A) = 0.4 y P(B) = 0.7.

Estadística y Probabilidades TECSUP – PFR
76
a. Si el proyecto asiático no tiene éxito, ¿cuál es la probabilidad de que el europeo también fracase? Explique su razonamiento.
b. ¿Cuál es la probabilidad de que por lo menos uno de los dos proyectos tenga éxito?
c. Dado que por lo menos uno de los dos proyectos tiene éxito, ¿cuál es la probabilidad de que sólo el proyecto asiático tenga éxito?