embedded computer architecture 5kk73 tu/e henk corporaal data management part c: scbd, maa, and data...
Post on 22-Dec-2015
227 views
TRANSCRIPT

Embedded Computer Architecture
5KK73 TU/e
Henk Corporaal
Data Management
Part c:
SCBD, MAA, and Data Layout

Embedded Computer Architecture 5KK73 @H.C. 2
Part 3 overview
• Recap on design flow
• Platform dependent steps– SCBD: Storage Cycle Budget Distribution– MAA: Memory Allocation and Assignment– Data layout techniques for RAM– Data layout techniques for Caches
• Results
• Conclusions
Thanks to the IMEC DTSE people

Embedded Computer Architecture 5KK73 @H.C. 3
Dynamic memory mgmtDynamic memory mgmt
Task concurrency mgmtTask concurrency mgmt
Physical memory mgmtPhysical memory mgmt
Address optimizationAddress optimization
SWSWdesigndesignflowflow
HWHWdesigndesignflowflow
SW/HW co-designSW/HW co-design
Concurrent OO specConcurrent OO spec
Remove OO overheadRemove OO overhead

Embedded Computer Architecture 5KK73 @H.C. 4
DM stepsC-in
Preprocessing
Dataflow transformations
Loop transformations
Data reuse Memory hierarchy layer assignment
Cycle budget distribution
Memory allocation and assignment
Data layout
C-out
Address optimization
Today

Embedded Computer Architecture 5KK73 @H.C. 5
Result of Memory hierarchy assignment for cavity detection
L2
L1
L0
N*M
3*1
image_in
M*3
gauss_x gauss_xy comp_edgeimage_out
3*3 1*1 3*3 1*1
N*M
N*M*3 N*M*3 N*M
N*M
0
N*M*3 N*M
N*M*3 N*M*8 N*M*8 N*M*8 N*M*8
M*3 M*3
1MB
SDRAM
16KB
Cache
128 B
RegFile

Embedded Computer Architecture 5KK73 @H.C. 6
Data-reuse - cavity detection code
for (y=0; y<M+3; ++y) { for (x=0; x<N+2; ++x) { /* first in_pixels initialized */ if (x==0 && y>=1 && y<=M-2)
in_pixels[x%3] = image_in[x][y];
/* copy rest of in_pixel's in row */ if (x>=0 && x<=N-2 && y>=1 && y<=M-2) in_pixels[(x+1)%3]= image_in[x+1][y];
if (x>=1 && x<=N-2 && y>=1 && y<=M-2) { gauss_x_tmp=0; for (k=-1; k<=1; ++k) // 3x1 filter gauss_x_tmp += in_pixels[(x+k)%3]*Gauss[Abs(k)]; gauss_x_lines[x][y%3]= foo(gauss_x_tmp); } else if (x<N && y<M) gauss_x_lines[x][y%3] = 0;
Code after reuse transformation (partly)

Storage Cycle Budget Distribution &
Memory Allocation and Assignment

Embedded Computer Architecture 5KK73 @H.C. 8
Define the memory organization which can provide enough bandwidth with minimal cost
for (i = 1 to 100) tm p += A [i] + B [i] + C [i]; A [i] = D [i];
for (j = 1 to 100) B [i] += D [j] + f(A [j]);
for (k = 1 to 100) tm p3 = m ax(tm p3, g(C [k] + B [j]));
A B
D
C
A' B'
Data-path
500
cycl
es

Embedded Computer Architecture 5KK73 @H.C. 9
Balancing memory bandwidth
Reduce max. number of loads/store per cycle:
Memory Bandwidth Required
time
High
Memory Bandwidth Required
time
Low

Embedded Computer Architecture 5KK73 @H.C. 10
Data management approach
R(A)
R(A)
R (C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)
Flow GraphBalancing
C [i] = f(C [i-1])B [i] = C [i];a = A [i];B [i+1] = B [i+1] + a;d = D [i]+1;A [a] = A [a] + d;D [i] = d
Data-flowAnalysis
1
Cyc
le b
ud
get
= 6
3
2
6
4
5
R(A)
R(A)
R (C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)
One of the manypossible schedulesIdea: find a schedule which
• fits in the number of cycles (= budget)• reduces the number of ports• avoids multi-ported memories

Embedded Computer Architecture 5KK73 @H.C. 11
Data management approach; details
R(A)
R(A)
R(C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)
A B CD
Memory Allocation &Assignment
Flow GraphBalancing
A B
C D
C [i] = f(C [i-1 ])B [i] = C [i];a = A [i];B [i+1] = B [i+1] + a;d = D [i]+1;A [a] = A [a] + d;D [i] = d
1
3
2
6
4
5
R(A)
R(A)
R(C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)

Embedded Computer Architecture 5KK73 @H.C. 12
A BB CC DD AA CB
A B
C D
A B CD
FinalSchedule
C onflict G raph A validM em ory C onfiguration
M ax C lique = 3
Conflict cost calculation
Key issues:• Number of conflicts• Self conflicts• Chromatic number = size of maximum clique
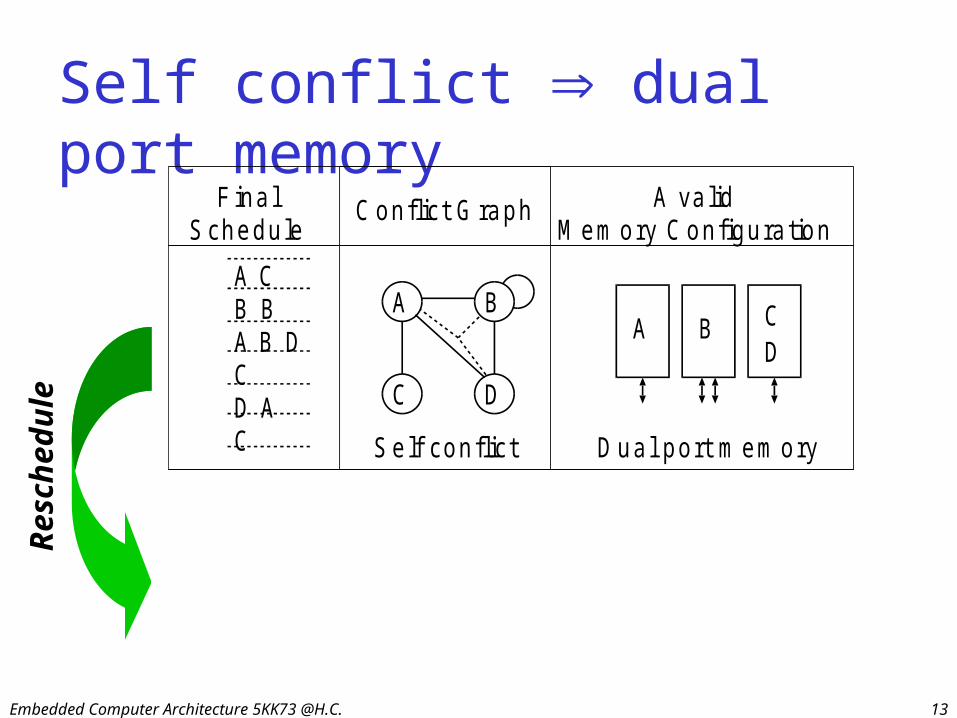
Embedded Computer Architecture 5KK73 @H.C. 13
Self conflict dual port memory
A CB BA B DC D AC
A
C D
A B CD
A BB CC DD AA CB
A BD
A B
C D
FinalSchedule
C onflict G raph A validM em ory C onfiguration
Self conflict
B C
D ual port m em ory
Res
ched
ule
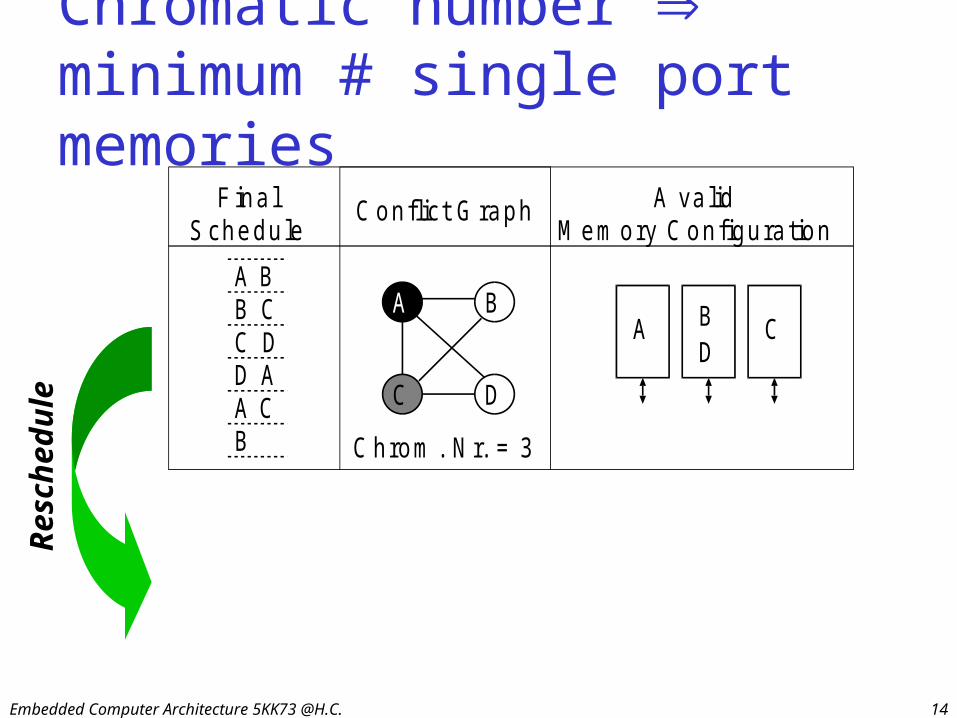
Embedded Computer Architecture 5KK73 @H.C. 14
Chromatic number minimum # single port memories
A BA B
C D
A B CD
AC
BD
A B
DCC
FinalSchedule
C onflict G raph A validM em ory C onfiguration
C hrom . N r. = 3
C hrom . N r. = 2
B CC DD AA CB
A BB CC DD AAB C
Res
ched
ule

Embedded Computer Architecture 5KK73 @H.C. 15
Lower number of conflicts larger assignment freedom
A BC DA BC DA BC
A B
C D
A BB CC DD AAB C
AC
BD
B
C D
FinalSchedule
Conflict Graph A validMemory Configuration
One solution
Multiple solutions
AC
BD
ACB
D
A
Res
ched
ule

Embedded Computer Architecture 5KK73 @H.C. 16
time slots
?
R(C)W(B)W(B)R(B)W(A)R(A)R(A)
R(C)W(C)R(D)W(D)
1 2 3 4 5 6
R(A)
R(A)
R(C)
R(D)
W(D)
R(B)
W(B)
W(A)
W(C)
R(C)
W(B)
Conflict Directed Ordering is used to find a good schedule
• Reduce intervals until all conflicts known• Driven by cost of conflicts• Constructive algorithm

Embedded Computer Architecture 5KK73 @H.C. 17
Local optimization is not good for global optimization
A D
A B
C
A B C
B CA
D BC A
A BC D
B
D
A B
C D
A B
C D
A B
C D
D
A C
A B
C
AB D
B DA
A CB D
A CB D
B
D
A B
C D
A B
C D
A B
C D
C
+ +
Local optim ization G lobal optim izationfor (i = 1 to 5) A [i] = A [i] + B [i] +
C [i]+D [i];
for (j = 1 to 5) B [j] = f(A [j]);
tm p += g(C [j]+D [j]);
for (k = 1 to 10)
B [k] = g(D [k], A [k]) tm p2 += B [k],C [k];

Embedded Computer Architecture 5KK73 @H.C. 18
Budget distribution has large impact on memory cost
for (i = 1 to 100)
A [i] = A [i] + B [i] + C [i];
for (j = 1 to 100)
B [j] = f(A [j]);
for (k = 1 to 100)
C [k] = g(B [j]);
R (A) R (B)
R (C ) W (A)
R (A)
W (B)
R (B) W (C)
R (A) W (B)
R (A) R (B) R (C ) W (A)
200-200-100 200-100-200 100-200-200
A B
C
A B
C
A B
C
R (A) R (B)
R (C ) W (A)
R (B)
W (C )
R (A)
W (B)
R (B)
W (C )
2
2
1
2
2
12
1
2
A B C AB
CA B C
cycle budget = 500 cycles

Embedded Computer Architecture 5KK73 @H.C. 19
Decreasing basic block length until target cycle budget is met
for (i = 1 to 5) A [i] = A [i] + B [i] +
C [i]+D [i];
for (j = 1 to 5)
B [j] = f(A [j]); D [j] = g(C [j]);
for (k = 1 to 10)
B [k] = g(B [k], A [k]); D [k] = C [k];
5 4
25 20
Target Cycle Budget (75 Cycles)
5 450 40
25 C ycles
Targ
et c
ycle
bud
get (
75 c
ycle
s)
20 C ycles
50 C ycles
4 3
40 30
95 C ycles 90 C ycles
80 C ycles
70 C yles

Embedded Computer Architecture 5KK73 @H.C. 20
for (i = 1 to 100)
b_tm p = B [i];
A [2*i] = b_tm p + C [i];
A [2*i+1] = b_tm p;
for (j = 1 to 100)
D [j] = f(C [j+100]);
for (i = 1 to 100)
b_tm p = B [i];
A [2*i] = b_tm p + C [i];
A [2*i+1] = b_tm p;
D [i] = f(C [i+100]);
A [i]
C [j]
D [j]
1
2
1
2
Cycle budget: 400 cycles
B[i]
A [i]
C [i] 1 B [i]
A B
C
2 C[i]
3 D [i]
C [i]
A [i]
A [i]
D
A B
C D
BD
CAAB
CD
What's the effect of merging loops?
• More scheduling freedom !!
Reschedule

Embedded Computer Architecture 5KK73 @H.C. 21
Memory allocation and assignment

Embedded Computer Architecture 5KK73 @H.C. 22
Memory Allocation and Assignment Substeps
Array-to-memory Assignment
DC
A
B
Port AssignmentBus Sharing
DC
A
B
Memory Allocation 1 2 3
Allocation = Select numberand typeof memories

Embedded Computer Architecture 5KK73 @H.C. 23
Influence of MAA
• Bit width• Address range• Nr. memories• Nr. ports
• Assign arrays to memory • Memory interconnect• Minimize power & Area
Bitwidth
(maximum)Size
Nr. ports (R/W/RW)
MEMORY-1
A
B
Bitwidth
(maximum)Size
Nr. ports (R/W/RW)
MEMORY-N
K
L
1001001110101001
100100111010XXXX
1001XXXXXX
0101110010
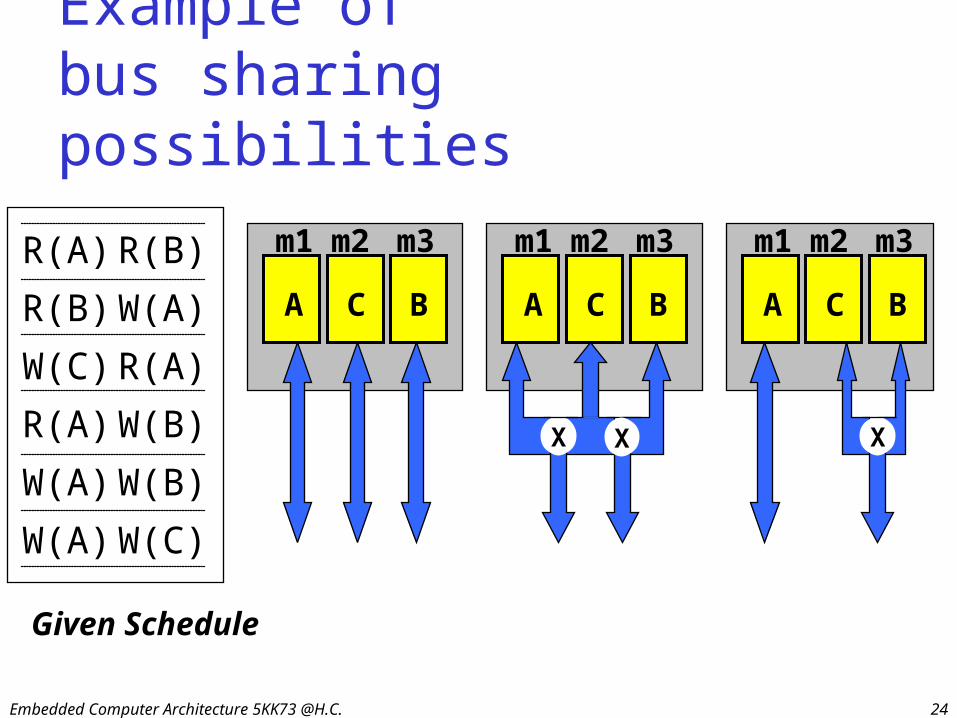
Embedded Computer Architecture 5KK73 @H.C. 24
Example of bus sharing possibilities
R(A) R(B)
R(B) W(A)
W(C) R(A)
R(A) W(B)
W(A) W(B)
W(A) W(C)
m1 m2 m3
A B
X X
C
m1 m2 m3
A BC
m1 m2 m3
A B
X
C
Given Schedule

Embedded Computer Architecture 5KK73 @H.C. 25
Decreasing cycle budget limits freedom and raises cost
Cost
Cycle Budget
A B
C D
C hrom N r=3
Minimum budget Fully sequentialLarge
M any obligatoryC ould be m any
B
C D
A
Lim ited freedom
LowFreeN oneFull freedom
R(A) R(B)
W (A)
W (A)
R(C)
1
2
3
R(A)
R(B)
W (A)
W (A)
R(C)1
2
3
4
5
N eeded bandw idth N r. m em ories
Self conflicts (m ult. port) Assignm ent
A[i] = A[i] + B[i];A[i+1] = C[i];
U nintrestingalternatives

Embedded Computer Architecture 5KK73 @H.C. 26
MinimumBudget
SequentialBudget
Conflict graph changed,but no impact on assignment
Conflict graph changed,change in assignment
Self conflict,forcing dual port mem.
Example: Resulting Pareto curve for DAB synchro application
En
ergy
cos
t

Embedded Computer Architecture 5KK73 @H.C. 27
Example conflict graph for cavity detection

Embedded Computer Architecture 5KK73 @H.C. 28
MAA result
Power:On-chip area:

Embedded Computer Architecture 5KK73 @H.C. 29
Data layout
how to put data into memory

Embedded Computer Architecture 5KK73 @H.C. 30
A
C
?
?
B
MEM1
F
G?
?
H
MEM2
PE
PE
A'B'?
?
CACHE
Memory data layout forcustom and cache architectures
PE
PE
A'
B'
CACHE
A
C
MEM1
B
F
MEM2
G
H
C
A
B
C
B

Embedded Computer Architecture 5KK73 @H.C. 31
for (i=1; i<5; i++) for (j=0; j<5; j++) a[i][j] = f(a[i-1][j]); i-1
i
j
Window
Intra-array in-place mappingreduces size of one array
aij
time
max nr. of life elementsThis number depends on the layout !!Compare e.g. row major and column major ordering.
mem
ory
addr
esse
s

Embedded Computer Architecture 5KK73 @H.C. 32
arraydomains
C
A
B
Two-phase mapping of array elements onto addresses
abstractaddresses
aA
aC
aB
Sto
rage
ord
er
realaddresses
aA
llocation
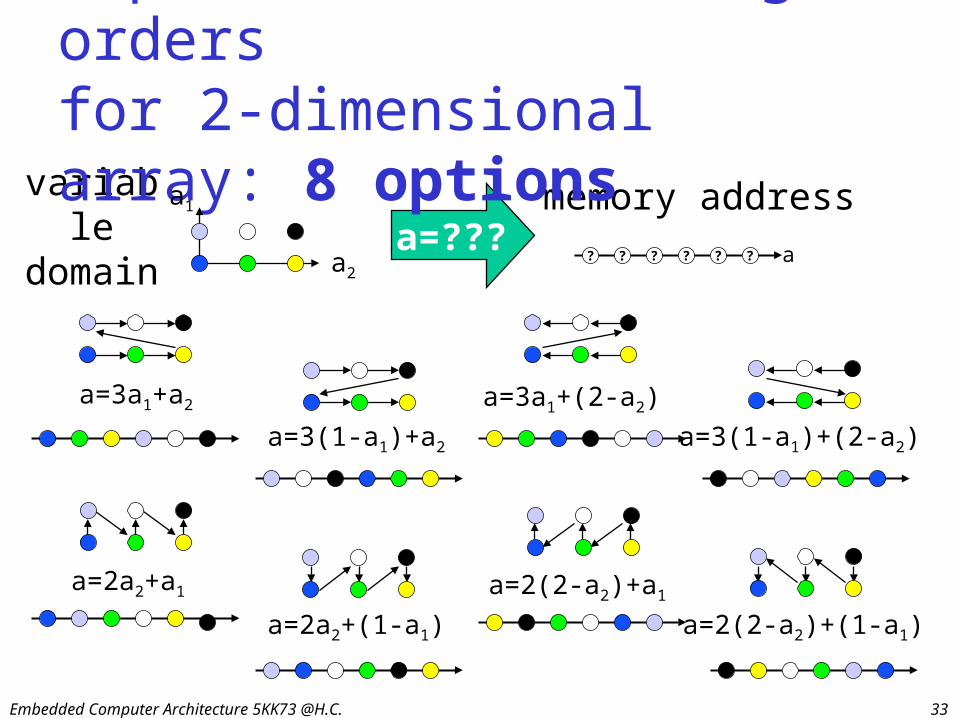
Embedded Computer Architecture 5KK73 @H.C. 33
aa=???
memory addressvariable domain
Exploration of storage ordersfor 2-dimensional array: 8 options
a2
a1
? ?? ? ? ?
a=3a1+a2
a=3(1-a1)+a2
a=3a1+(2-a2)
a=2a2+a1
a=2a2+(1-a1)
a=2(2-a2)+a1
a=3(1-a1)+(2-a2)
a=2(2-a2)+(1-a1)

Embedded Computer Architecture 5KK73 @H.C. 34
Chosen storage order determines window sizefor (i=1; i<5; i++) for (j=0; j<5; j++) a[i][j] = f(a[i-1][j]);
row-major ordering: a=5i+j
for (i=1; i<5; i++) for (j=0; j<5; j++) a[5*i+j] = f(a[5*i+j-5]);
Highest live address:
Lowest live address:
5*i+j
5*i+j-5
Difference + 1= Window: 6
column-major: a=5j+i
for (i=1; i<5; i++) for (j=0; j<5; j++) a[5*j+i] = f(a[5*j+i-1]);
5*4+i-1
5*0+i-1
21
j
i

Embedded Computer Architecture 5KK73 @H.C. 35xx caa abstrreal
x
A
B
C
D
E
Memory Size
Static allocation:no in-place mapping
E
aE
C
aC
A
aA
D
aD
BaB
time

Embedded Computer Architecture 5KK73 @H.C. 36
C
Memory Size
A
D
B
E
xxx cWmodaa abstrrealx
Static, windowed
C
Memory Size
A
DB
E
Dynamic, windowed
Windowed Allocation:intra-array in-place mapping
WA

Embedded Computer Architecture 5KK73 @H.C. 37xx caa abstrreal
x
Dynamic allocation:inter-array in-place mapping
E
aE
C
aC
A
aA
D
aD
BaB
A B
C
D
EMemory
Size

Embedded Computer Architecture 5KK73 @H.C. 38
A
BC
ED
Wmodcaa abstrrealxxx
A C
ED
BMemory
Size
Dynamic, common window
Dynamic allocation strategy with common window

Embedded Computer Architecture 5KK73 @H.C. 39
Before:
bit8 B[10][20];bit6 A[30];for(x=0;x<10;++x) for (y=0;y<20;++y) … = A[3*x-y]; B[x][y] = …;
After:
bit8 memory[334];bit8* B =(bit8*)&memory[134];bit6* A =(bit6*)&memory[120];for(x=0;x<10;++x) for (y=0;y<20;++y) … = A[3*x-y]; B[(x*20+y*2)%78] = …;
Expressing memory data layoutin source code
Example: array of 10x20 elements
A: offset 120, no windowB: storage order [20, 2], offset 134, window 78

Embedded Computer Architecture 5KK73 @H.C. 40
int x[W], y[W];for (i1=0; i1 < W; i1++) x[i1] = getInput();for (i2=0; i2 < W; i2++) { sum = 0; for (di2=-N; di2 <=N; di2++) { sum += c[N+di2] * x[wrap(i2+di2,W)]; } y[i2] = sum;}for (i3=0; i3 < W; i3++) putOutput(y[i3]);
Example of memory data layoutfor storage size reduction

Embedded Computer Architecture 5KK73 @H.C. 41
i1=0 i1=W-1 i2=0 i2=W-1 i3=0 i3=W-1i2=N
x[0]
x[N]
x[W-1]
y[W-1]
x[]
y[]
y[0]
y[N]
W+W
Occupied address-time domainof x[] and y[]

Embedded Computer Architecture 5KK73 @H.C. 42
int mem1[N+W];for (i1=0; i1 < W; i1++) mem1[N+i1] = getInput();for (i2=0; i2 < W; i2++) { sum = 0; for (di2=-N; di2 <=N; di2++) { sum += c[N+di2] * mem1[N+wrap(i2+di2,W)]; } mem1[i2] = sum;}for (i3=0; i3 < W; i3++) putOutput(mem1[i3]);
Optimized source codeafter memory data layout

Embedded Computer Architecture 5KK73 @H.C. 43
i1=0 i1=W-1 i2=0 i2=W-1 i3=0 i3=W-1i2=N
mem1[0]
mem1[N]
mem1[W-1]x[]
y[]
mem1[W+N-1]
N+W
Optimized OAT domainafter memory data layout

Embedded Computer Architecture 5KK73 @H.C. 44
In-place mapping for cavity detection example• Input image is partly consumed by the time
first results for output image are ready
index
time
Image_in
time
address
Image
time
index
Image_out

Embedded Computer Architecture 5KK73 @H.C. 45
In-place - cavity detection code
for (y=0; y<=M+3; ++y) { for (x=0; x<N+5; ++x) { image_out[x-5][y-3] = …; /* code removed */
… = image_in[x+1][y]; }}
for (y=0; y<=M+3; ++y) { for (x=0; x<N+5; ++x) { image[x-5][y-3] = …; /* code removed */
… = image [x+1][y]; }}

Embedded Computer Architecture 5KK73 @H.C. 46
Cavity detection summary
0
100
200
300
400
500
600
accesses size cycles
Overall result:
• Local accesses reduced by factor 3
• Memory size reduced by factor 5
• Power reduced by factor 5
• System bus load reduced by factor 12
• Performance worsened by factor 6

Embedded Computer Architecture 5KK73 @H.C. 47
The last step: ADOPT (Address OPTimization)
• Increased execution time introduced by DTSE– Complicated address arithmetic (modulo: a%b)
– Additional complex control flow
• Additional transformations needed to– Simplify control flow
– Simplify address arithmetic: common sub-expression elimination, modulo expansion, …
– Match remaining expressions on target machine

Embedded Computer Architecture 5KK73 @H.C. 48
ADOPT principles
• How to avoid % in address expressions, likeint A[7];for (i=0; i<… ; i++) … A[i % 7]
• Increase buffer size to power of 2i % 8 => i && 0x07
• Use if-statementint A[7];for (i=0,j=0; i<… ; i++,j++) … A[j] if (j==8) j=0

Embedded Computer Architecture 5KK73 @H.C. 49
for (i=-8; i<=8; i++) { for (j=- 4; j<=3; j++) { for (k=- 4; k<=3; k++) { B[ ] = A[ ]; }} dist += A[ ]- B[ ]; }
cse1 = (33025*i+6869616)*2; cse3 = 1040+i; cse4 = j*257+1032; cse5 = k+cse4; cse5+cse1 = cse5+cse3 3096 cse1
ADOPT principles: CSE
for (i=- 8; i<=8; i++) { for (j=- 4; j<=3; j++) { for (k=- 4; k<=3; k++) A[((208+i)*257+8+j)*257+ 16+i+k] = B[(8+j)*257+16+i+k]; } dist += A[3096] - B[((208+i)*257+4)*257+ 16+i-4]; }
Example: Full-search Motion Estimation- applying Common Subexpression Elimination (CSE)
Algebraic transformationsat word-level

Embedded Computer Architecture 5KK73 @H.C. 50
Conclusion on Data Management
• In multi-media applications exploring data transfer and storage issues should be done at source code level
• DMM method
– Reducing number of external memory accesses
– Reducing external memory size
– Trade-offs between internal memory complexity and speed
– Platform independent high-level transformations
– Platform dependent transformations exploit platform
characteristics (efficient use of memory, cache, …)
– Substantial energy reduction