embedded computer architecture tu/e 5kk73 henk corporaal vliw architectures: generating vliw code
TRANSCRIPT

Embedded Computer Architecture
TU/e 5kk73Henk Corporaal
VLIW architectures:Generating VLIW code

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 2
VLIW lectures overview• Enhance performance: architecture methods• Instruction Level Parallelism• VLIW• Examples
– C6– TM– TTA
• Clustering and Reconfigurable components• Code generation
– compiler basics– mapping and scheduling– TTA code generation– Design space exploration
• Hands-on

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 3
Compiler basics• Overview
– Compiler trajectory / structure / passes– Control Flow Graph (CFG)– Mapping and Scheduling– Basic block list scheduling– Extended scheduling scope– Loop scheduling
– Loop transformations• separate lecture
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 4
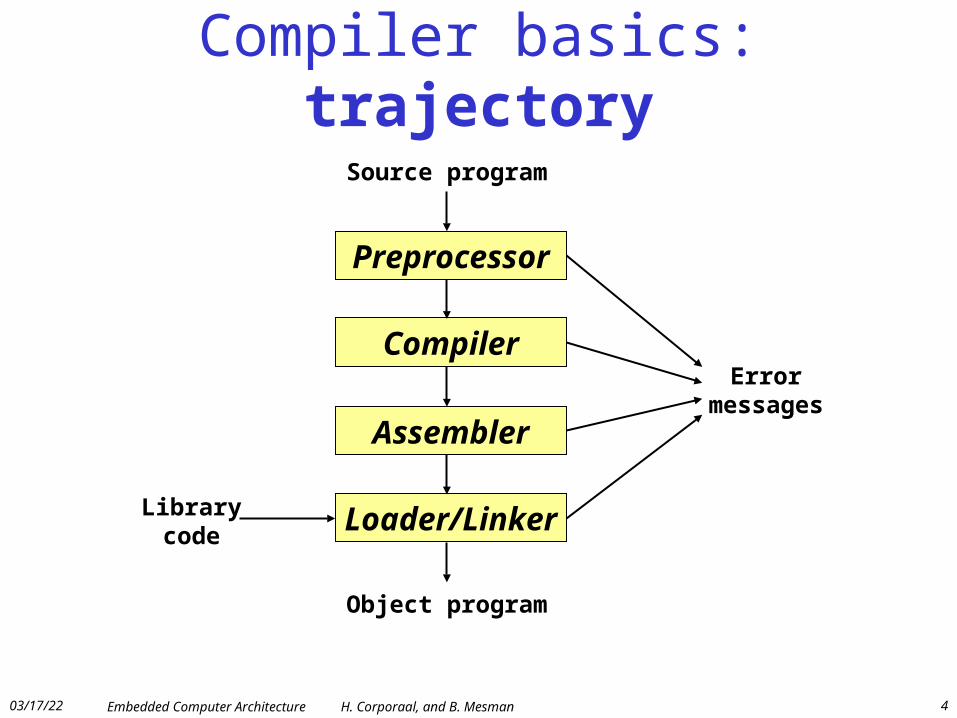
Compiler basics: trajectory
Preprocessor
Compiler
Assembler
Loader/Linker
Source program
Object program
Error messages
Library code
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 5
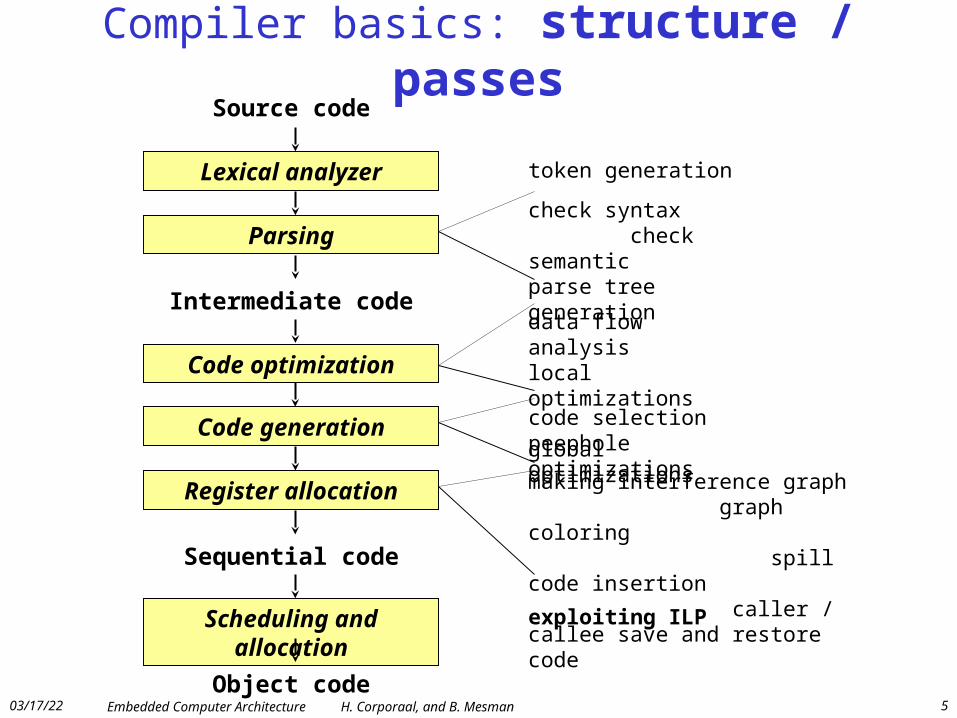
Compiler basics: structure / passes
Lexical analyzer
Parsing
Code optimization
Register allocation
Source code
Sequential code
Intermediate code
Code generation
Scheduling and allocation
Object code
token generation
check syntax check semantic parse tree generation
data flow analysis local optimizations global optimizationscode selection peephole optimizations
making interference graph graph coloring spill code insertion caller / callee save and restore code
exploiting ILP
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 6
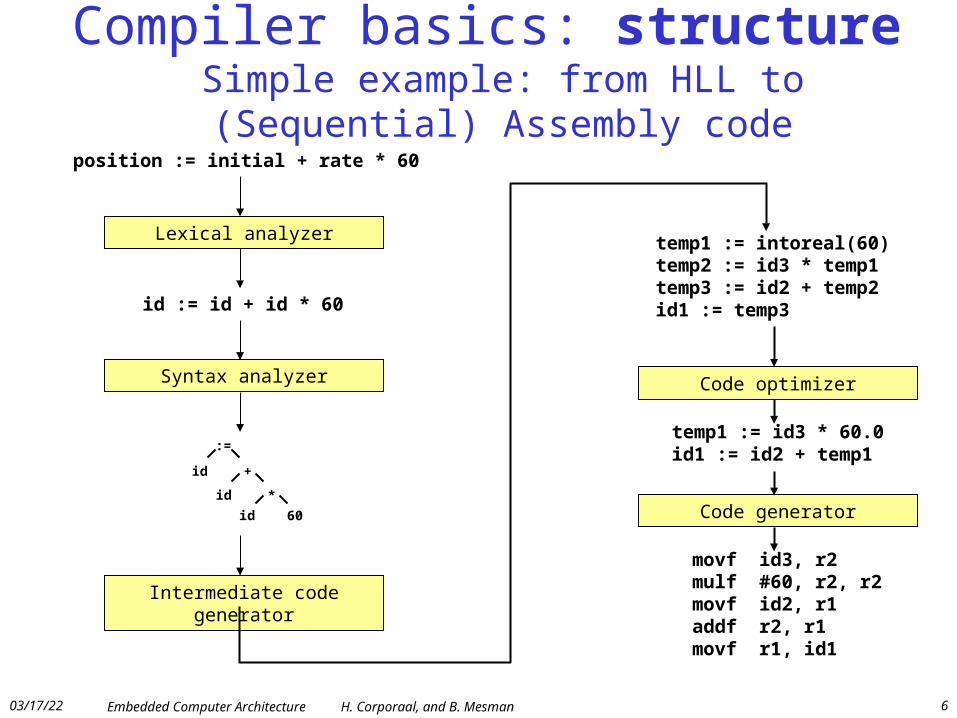
Compiler basics: structure Simple example: from HLL to (Sequential) Assembly code
Lexical analyzer
Syntax analyzer
Intermediate code generator
position := initial + rate * 60
id := id + id * 60
:=
+id
*id
60id
Code optimizer
Code generator
temp1 := intoreal(60)temp2 := id3 * temp1temp3 := id2 + temp2id1 := temp3
temp1 := id3 * 60.0id1 := id2 + temp1
movf id3, r2mulf #60, r2, r2movf id2, r1addf r2, r1movf r1, id1
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 7
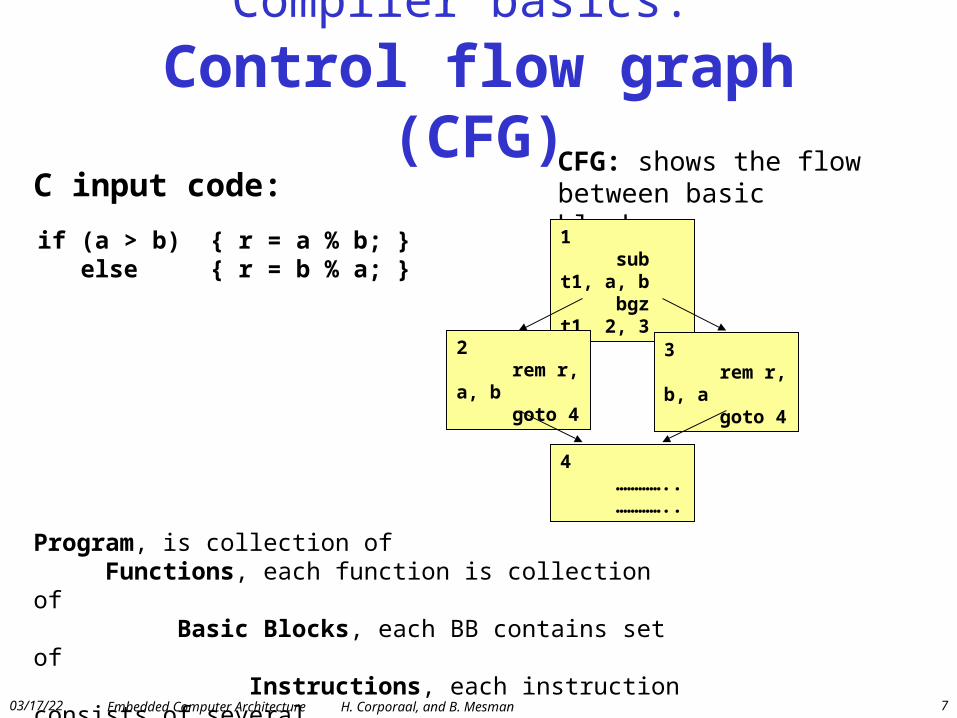
Compiler basics: Control flow graph (CFG)
C input code:CFG: shows the flow between basic blocks
1 sub t1, a, b bgz t1, 2, 3
4 ………….. …………..
3 rem r, b, a goto 4
2 rem r, a, b goto 4
Program, is collection of Functions, each function is collection of Basic Blocks, each BB contains set of Instructions, each instruction consists of several Transports,..
if (a > b) { r = a % b; } else { r = b % a; }

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 8
• Machine independent optimizations
• Machine dependent optimizations
Compiler basics: Basic optimizations

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 9
Compiler basics: Basic optimizations
• Machine independent optimizations– Common subexpression elimination– Constant folding– Copy propagation– Dead-code elimination– Induction variable elimination– Strength reduction– Algebraic identities
• Commutative expressions• Associativity: Tree height reduction
– Note: not always allowed(due to limited precision)
• For details check any good compiler book !

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 10
Compiler basics: Basic optimizations
• Machine dependent optimization example– What’s the optimal implementation of a*34 ?– Use multiplier: mul Tb, Ta, 34
• Pro: No thinking required• Con: May take many cycles
– Alternative:– SHL Tb, Ta, 1– SHL Tc, Ta, 5– ADD Tb, Tb, Tc
• Pros: May take fewer cycles• Cons:• Uses more registers• Additional instructions ( I-cache load / code size)

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 11
Compiler basics: Register allocation
• Register Organization – Conventions needed for parameter passing – and register usage across function calls
r31
r21
r20
r11
r10
r1
r0
Callee saved registers
Caller saved registers
Function Argument and Result transfer
Hard-wired 0
Other temporaries

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 12
Register allocation using graph coloring
Given a set of registers, what is the most efficient mapping of registers to program variables in terms of execution time of the program?Some definitions:
• A variable is defined at a point in program when a value is assigned to it.
• A variable is used at a point in a program when its value is referenced in an expression.
• The live range of a variable is the execution range between definitions and uses of a variable.

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 13
Program:
a := c := b := := bd := := a := c := d
a b c dLive Ranges
Register allocation using graph coloring
define
use
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 14
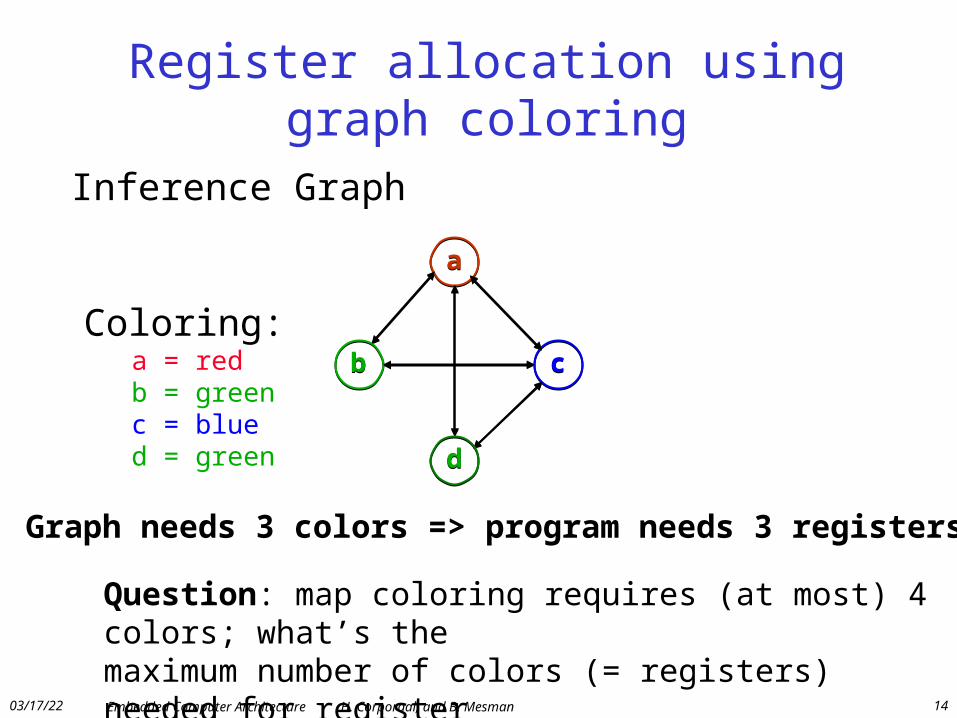
Register allocation using graph coloring
a
b c
d
Inference Graph
a
b c
d
Coloring:a = redb = greenc = blued = green
Graph needs 3 colors => program needs 3 registers
Question: map coloring requires (at most) 4 colors; what’s the maximum number of colors (= registers) needed for register interference graph coloring?

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 15
Register allocation using graph coloringSpill/ Reload code Spill/ Reload code is needed when there are not enough colors (registers) to color the interference graph
Example: Only two registers available !!
Program:
a := c := store cb := := bd := := aload c := c := d
a b c dLive Ranges
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 16
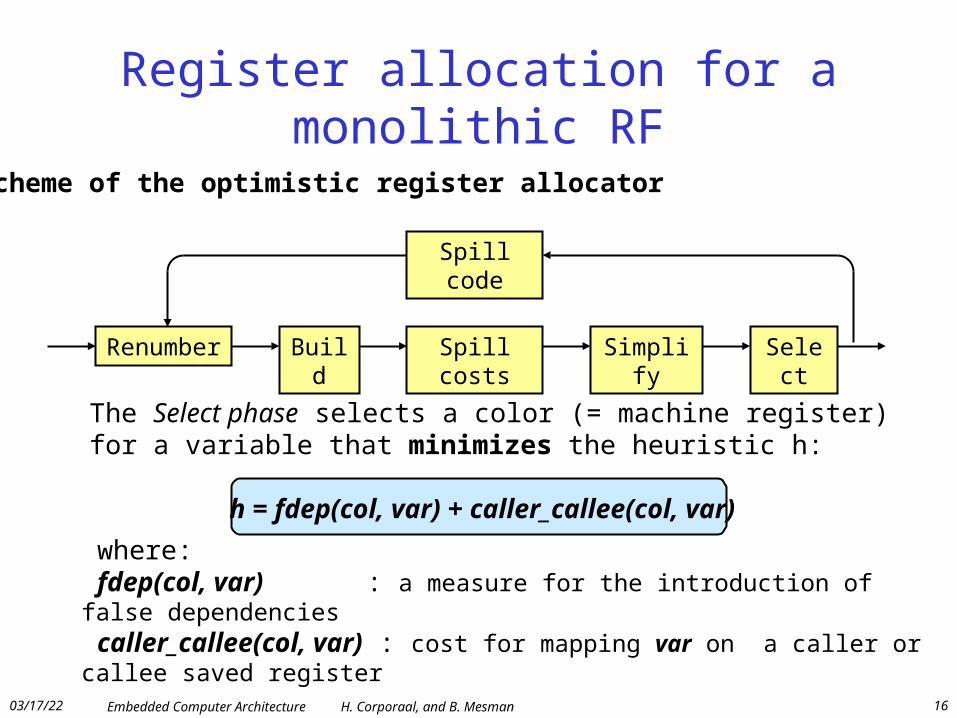
Register allocation for a monolithic RF
Scheme of the optimistic register allocator
Renumber Build Spill costs Simplify Select
Spill code
The Select phase selects a color (= machine register) for a variable that minimizes the heuristic h:
h = fdep(col, var) + caller_callee(col, var)
where: fdep(col, var) : a measure for the introduction of false dependencies caller_callee(col, var) : cost for mapping var on a caller or callee saved register

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 17
Some explanation of reg allocation phases• [Renumber:] The first phase finds all live ranges in a procedure• and numbers (renames) them uniquely.
• [Build:] This phase constructs the interference graph.
• [Spill Costs:] In preparation for coloring, a spill cost estimate• is computed for every live range. The cost is simply the sum of the• execution frequencies of the transports that define or use the variable• of the live range.
• [Simplify:] This phase removes nodes with degree < k in an• arbitrary order from the graph and pushes them on a stack. Whenever• it discovers that all remaining nodes have degree >= k, it chooses• a spill candidate. This node is also removed from the graph and• optimistically pushed on the stack, hoping a color will be available in• spite of its high degree.
• [Select:] Colors are selected for nodes. In turn, each node is• popped from the stack, reinserted in the interference graph and given a• color distinct from its neighbors. Whenever it discovers that it has no• color available for some node, it leaves the node uncolored and• continues with the next node.
• [Spill Code:] In the final phase spill code is• inserted for the live ranges of all uncolored nodes.
• Some symbolic registers must be mapped on a specific machine register• (like stack pointer). These registers get their color in the simplify• stage instead of being pushed on the stack.
• The other machine registers are divided in caller-saved and callee-saved• registers. The allocator computes the caller-saved and callee-saved cost.
• The caller-saved cost for the symbolic registers is computed when they have• live-ranges across a procedure call. The cost per symbolic register is twice• the execution frequency of its transport. • The callee-saved cost of a• symbolic register is twice the execution frequency of the procedure to which• the transport of the symbolic register belongs. With these two costs in mind• the allocator chooses a machine register.

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 18
• CISC era (before 1985)– Code size important– Determine shortest sequence of code
• Many options may exist
– Pattern matchingExample M68029:
D1 := D1 + M[ M[10+A1] + 16*D2 + 20 ] ADD ([10,A1], D2*16, 20) D1
• RISC era– Performance important– Only few possible code sequences– New implementations of old architectures optimize RISC part of
instruction set only; for e.g. i486 / Pentium / M68020
Compiler basics: Code selection

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 19
Overview• Enhance performance: architecture methods• Instruction Level Parallelism• VLIW• Examples
– C6– TM– TTA
• Clustering• Code generation
– Compiler basics– Mapping and Scheduling of Operations
• Design Space Exploration: TTA framework
•What is scheduling•Basic Block Scheduling•Extended Basic Block Scheduling•Loop Scheduling
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 20
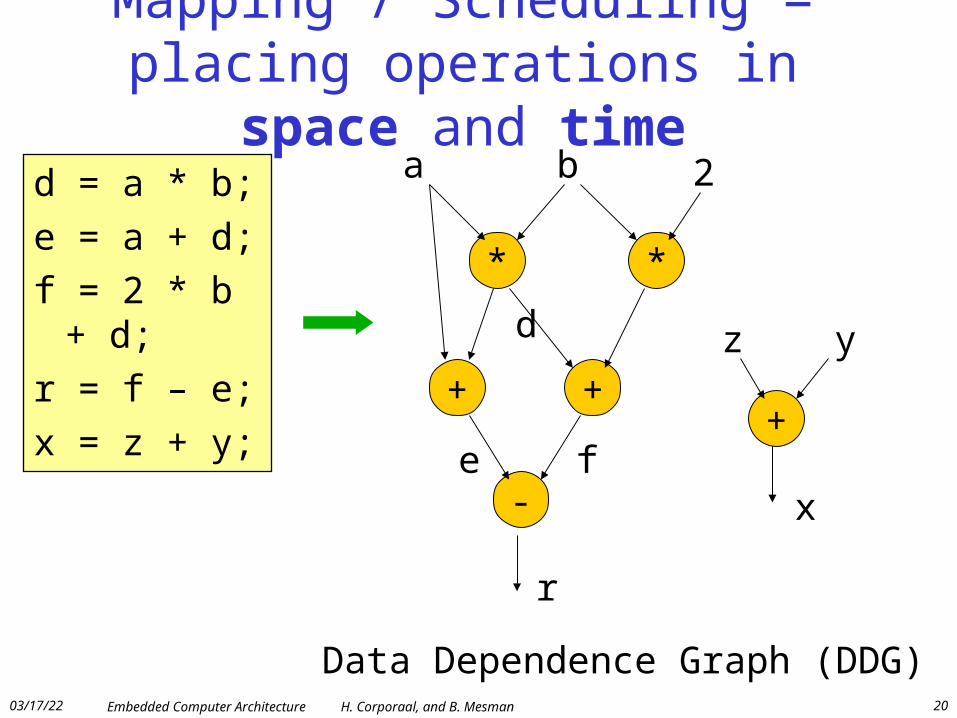
Mapping / Scheduling =placing operations in space and time
d = a * b;
e = a + d;
f = 2 * b + d;
r = f – e;
x = z + y;
* *
+ +
-
+
a b 2
z yd
e f
r
x
Data Dependence Graph (DDG)
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 21
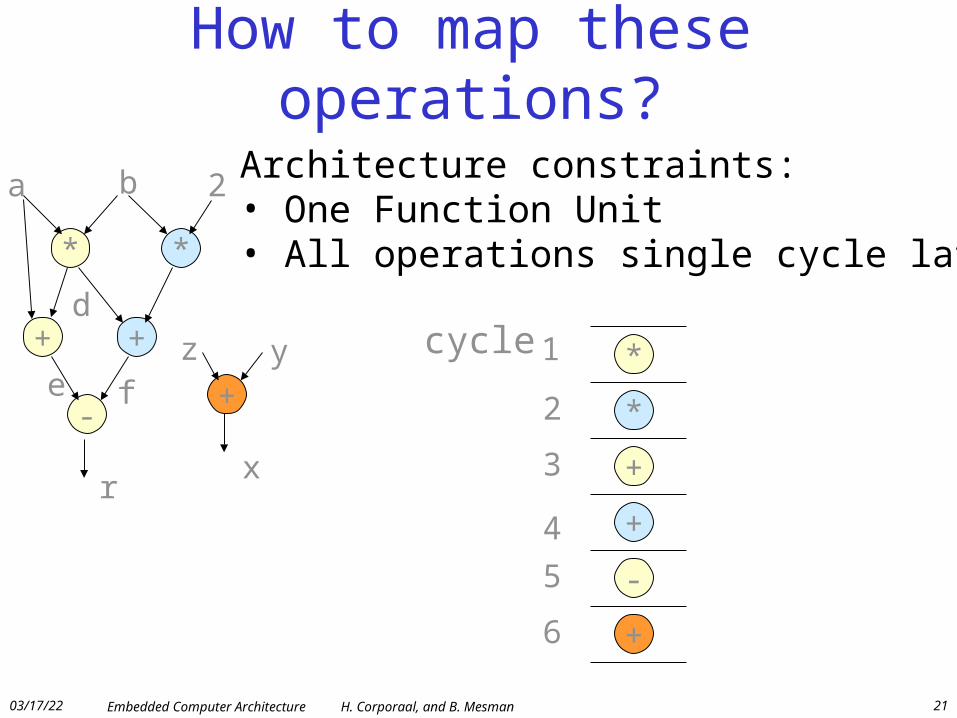
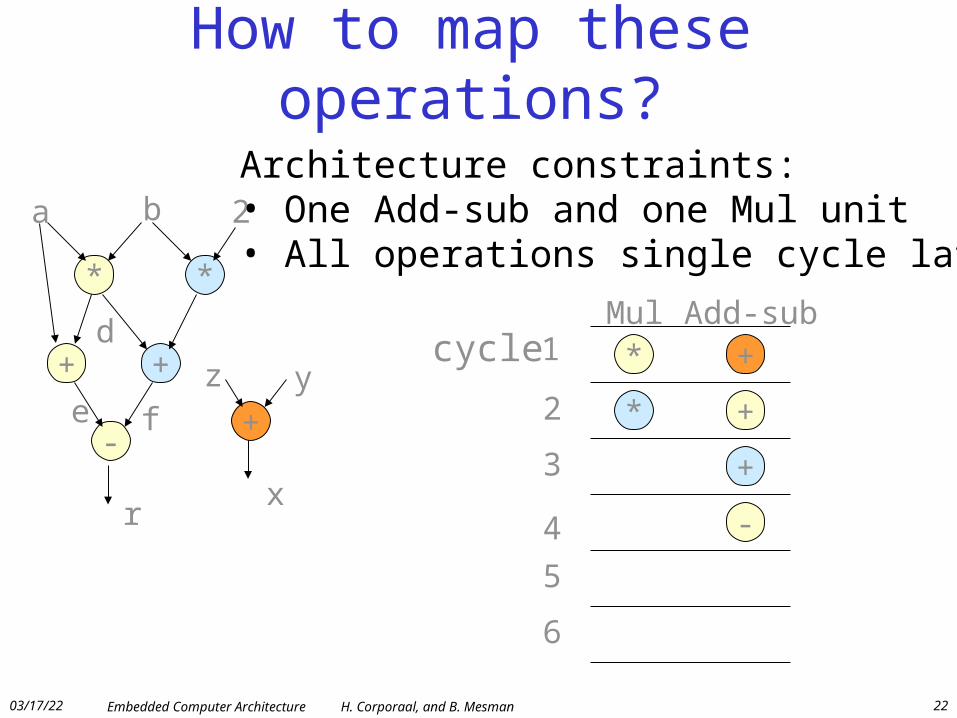
How to map these operations?
Architecture constraints:• One Function Unit• All operations single cycle latency
*
*
+
+
-
+
cycle 1
2
3
4
5
6
* *
+ +
-+
a b 2
z y
d
e f
rx
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 22
How to map these operations?
* *
+ +
-+
a b 2
z y
d
e f
rx
Architecture constraints:• One Add-sub and one Mul unit• All operations single cycle latency
*
* +
+
-
+cycle 1
2
3
4
5
6
Mul Add-sub
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 23
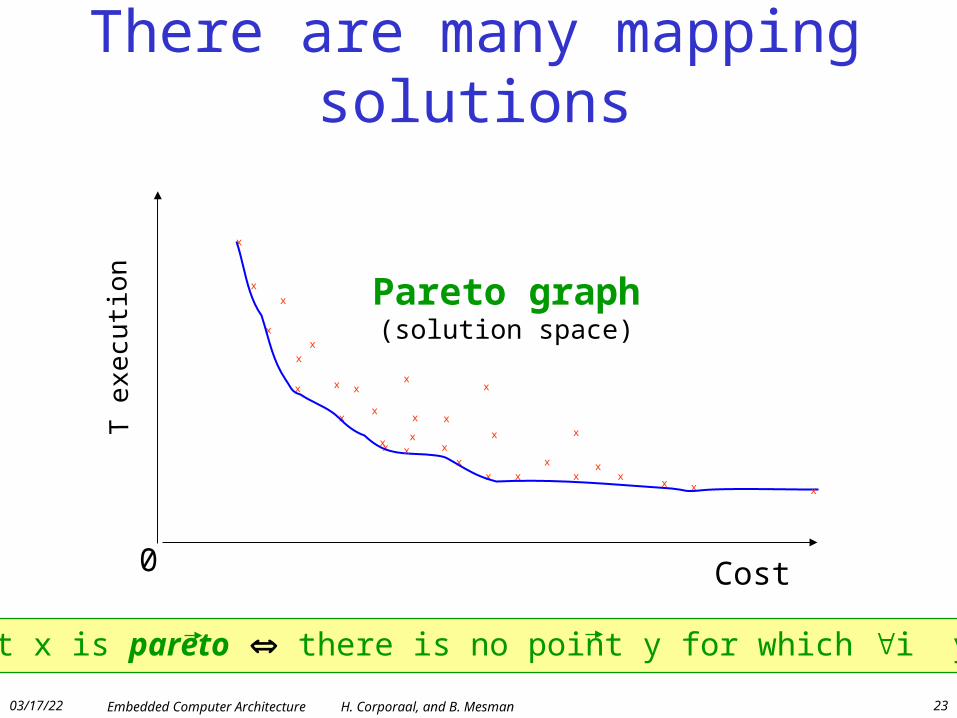
There are many mapping solutions
Pareto graph(solution space)
T e
xecu
tion
x
x
x
x
xx
x
xx
x
x
x
x
x
x
xxx
x
x
xx
x
x
x
x
x
xx
x
xx
Cost0
Point x is pareto there is no point y for which i yi<xi

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 24
Scheduling: OverviewTransforming a sequential program into a parallel program:
read sequential program read machine description file for each procedure do
perform function inlining
for each procedure dotransform an irreducible CFG into a reducible CFG perform control flow analysis perform loop unrolling perform data flow analysis perform memory reference disambiguation perform register allocation for each scheduling scope do
perform instruction scheduling write out the parallel program

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 25
Basic Block Scheduling• Basic Block =
piece of code which can only be entered from the top (first instruction) and left at the bottom (final instruction)
• Scheduling a basic block = Assign resources and a cycle to every operation
• List Scheduling =Heuristic scheduling approach, scheduling the operation one-by-one– Time_complexity = O(N), where N is #operations
• Optimal scheduling has Time_complexity = O(exp(N)
• Question: what is a good scheduling heuristic

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 26
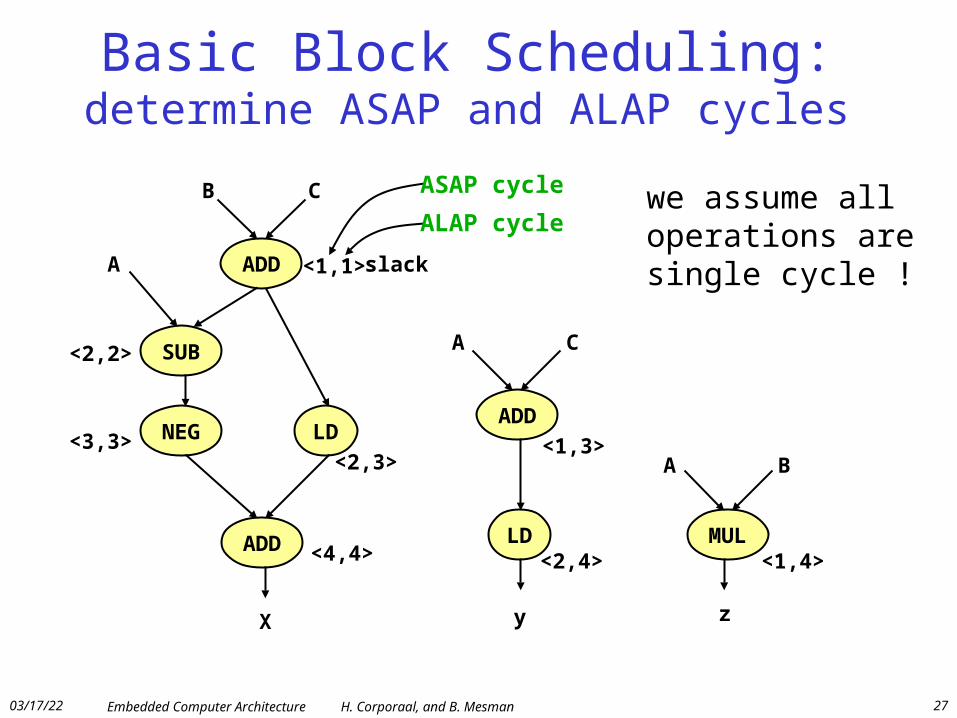
Basic Block Scheduling• Make a Data Dependence Graph (DDG)
• Determine minimal length of the DDG (for the given architecture)– minimal number of cycles to schedule the graph (assuming sufficient resources)
• Determine:– ASAP (As Soon As Possible) cycle = earliest cycle instruction can be scheduled– ALAP (As Late As Possible) cycle = latest cycle instruction can be scheduled– Slack of each operation = ALAP – ASAP– Priority of operations = f (Slack, #decendants, #register impact, …. )
• Place each operation in first cycle with sufficient resources
• Notes:– Basic Block = a (maximal) piece of consecutive instructions which can only be entered at the
first instruction and left at the end
– Scheduling order sequential– Scheduling Priority determined by used heuristic; e.g. slack + other contributions
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 27
Basic Block Scheduling:determine ASAP and ALAP cycles
ADD
LD
A C
y
<1,3>
<2,4>MUL
A B
z
<1,4>
ADD
ADD
SUB
NEG LD
A
B C
X
<3,3>
<4,4>
<2,2>
<2,3>
<1,1>
ASAP cycle
ALAP cycle
slack
we assume all operations aresingle cycle !

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 28
Cycle based list schedulingproc Schedule(DDG = (V,E))beginproc ready = { v | (u,v) E } ready’ = ready sched = current_cycle = 0 while sched V do for each v ready’ (select in priority order) do if ResourceConfl(v,current_cycle, sched) then cycle(v) = current_cycle sched = sched {v} endif endfor current_cycle = current_cycle + 1 ready = { v | v sched (u,v) E, u sched } ready’ = { v | v ready (u,v) E, cycle(u) + delay(u,v) current_cycle} endwhileendproc
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 29
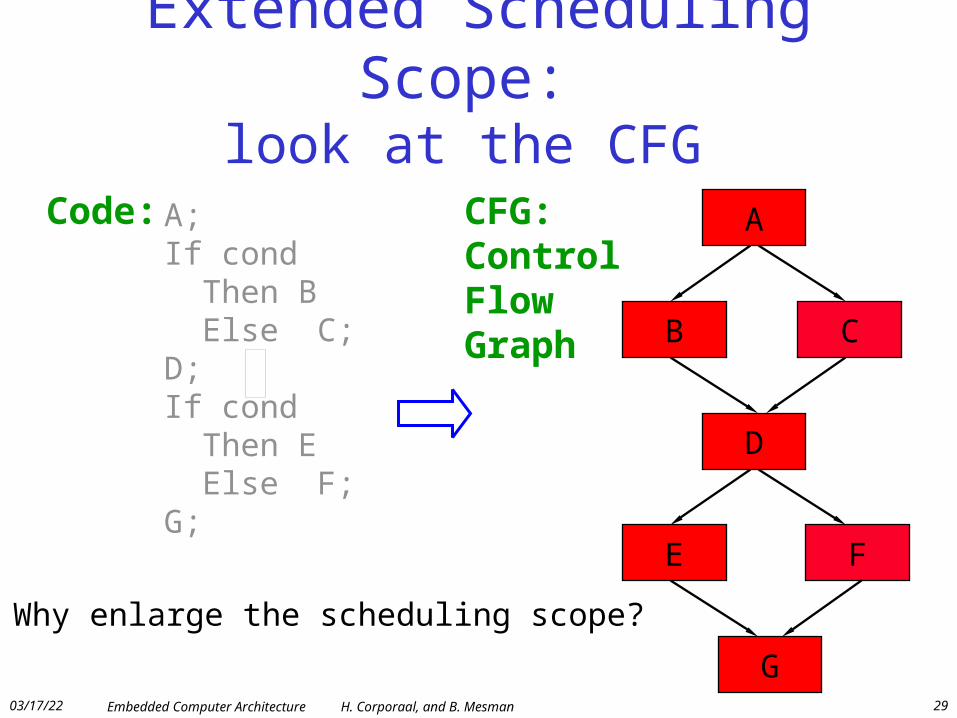
Extended Scheduling Scope: look at the CFG
A
C
F
B
D
E
G
A;If cond Then B Else C;D;If cond Then E Else F;G;
Code: CFG:ControlFlowGraph
Q: Why enlarge the scheduling scope?
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 30
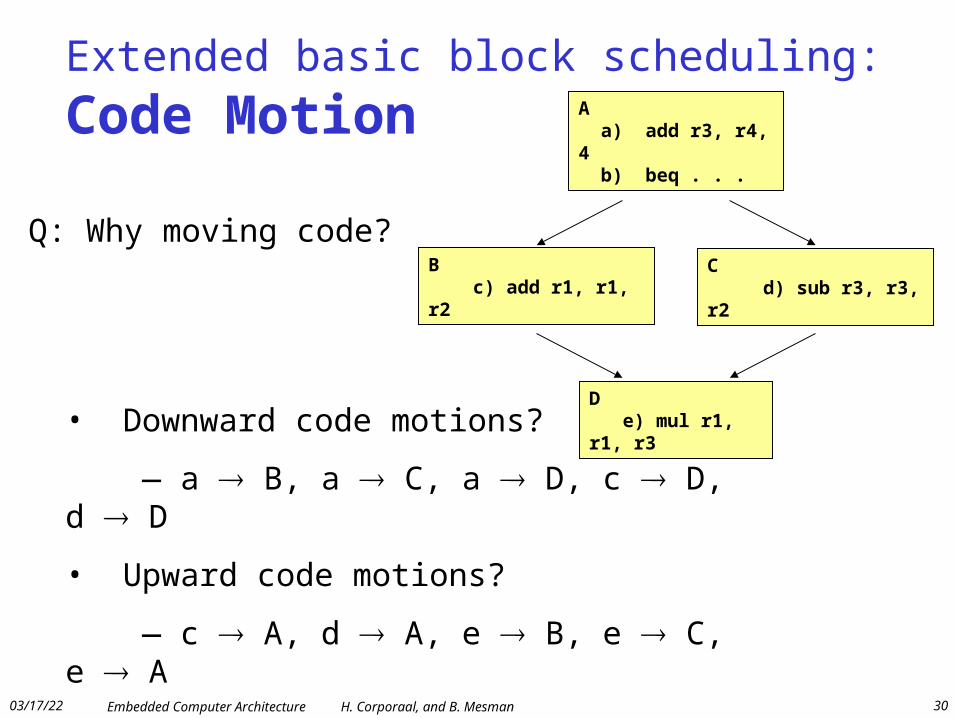
Extended basic block scheduling: Code Motion A
a) add r3, r4, 4 b) beq . . .
D e) mul r1, r1, r3
C d) sub r3, r3, r2
B c) add r1, r1, r2
• Downward code motions?
— a B, a C, a D, c D, d D
• Upward code motions?
— c A, d A, e B, e C, e A
Q: Why moving code?
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 31
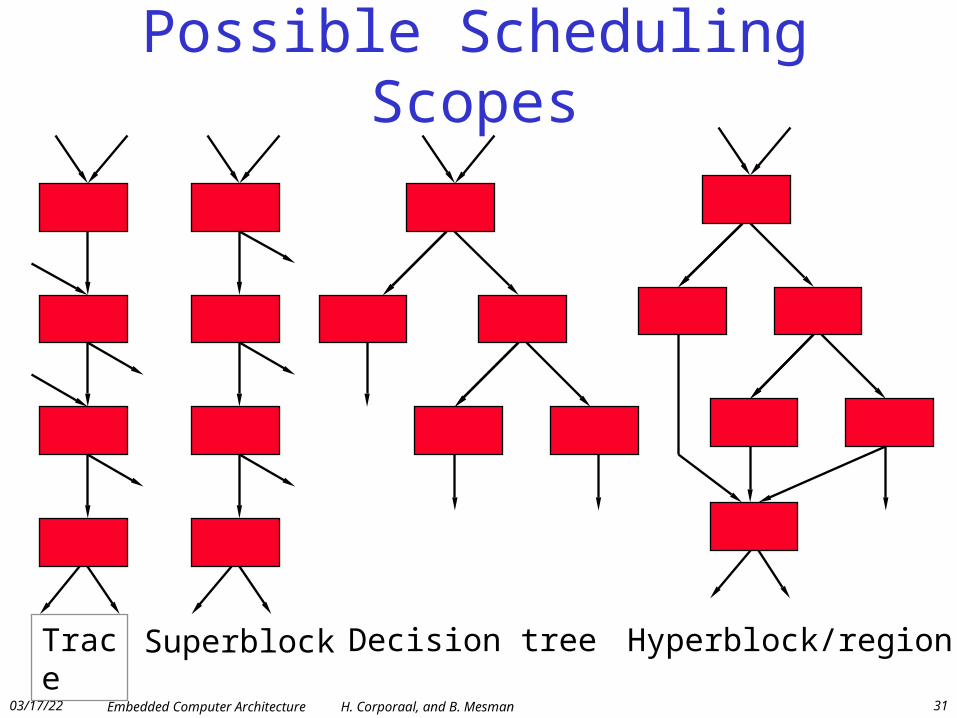
Possible Scheduling Scopes
Trace Superblock Decision tree Hyperblock/region
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 32
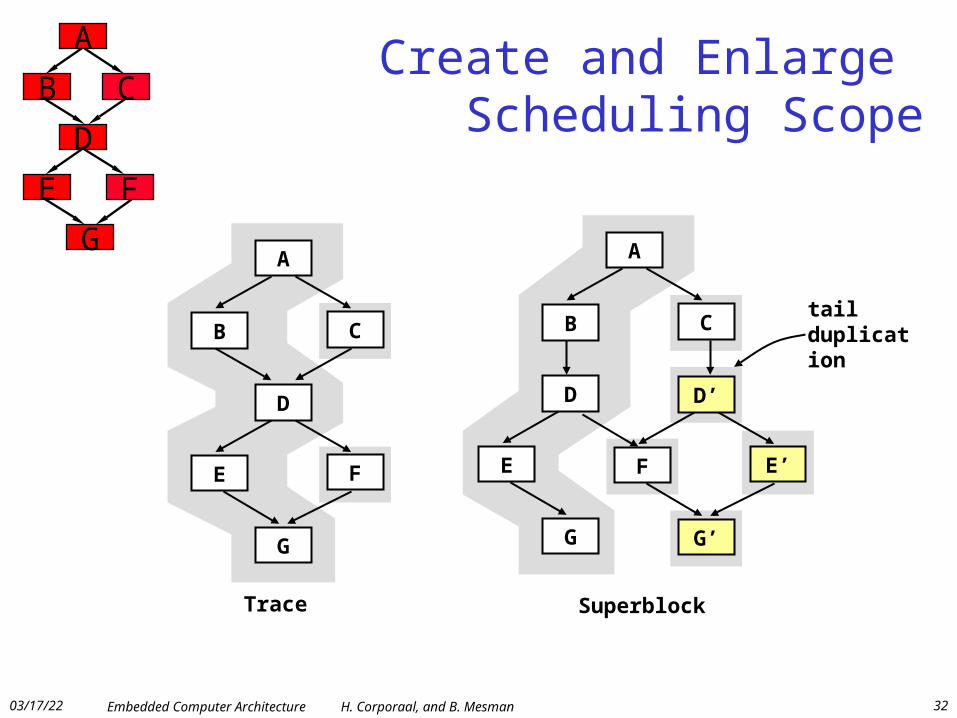
Create and Enlarge Scheduling Scope
B C
E F
D
G
A
Trace Superblock
B C
F E’
D’
G’
A
E
D
G
tail duplication
A
C
F
B
D
E
G
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 33
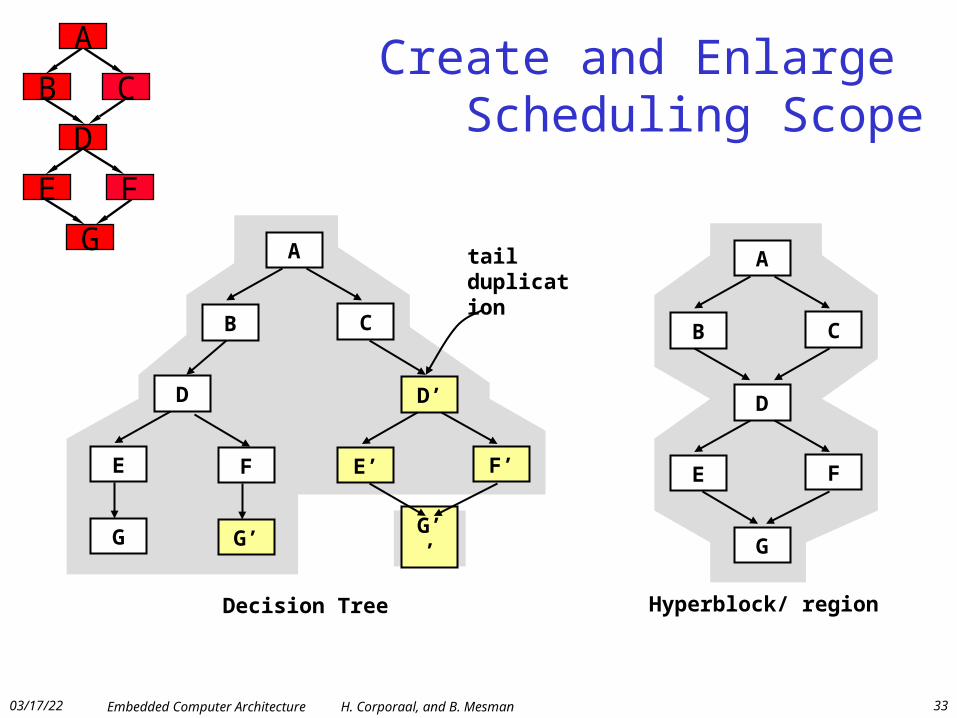
Create and Enlarge Scheduling Scope
B C
E F
D
G
A
Hyperblock/ region
B C
E’ F’
D’
G’’
A
E
D
G
Decision Tree
tail duplication
F
G’
A
C
F
B
D
E
G
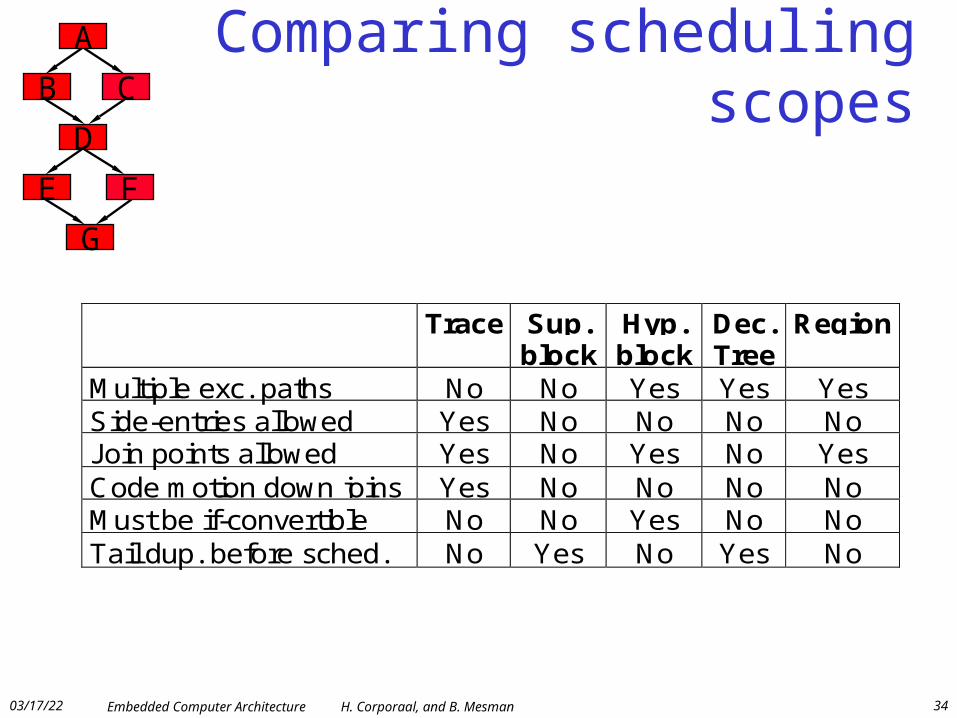
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 34
Trace Sup.block
Hyp.block
Dec.Tree
Region
Multiple exc. paths No No Yes Yes YesSide-entries allowed Yes No No No NoJoin points allowed Yes No Yes No YesCode motion down joins Yes No No No NoMust be if-convertible No No Yes No NoTail dup. before sched. No Yes No Yes No
Comparing scheduling scopesA
C
F
B
D
E
G
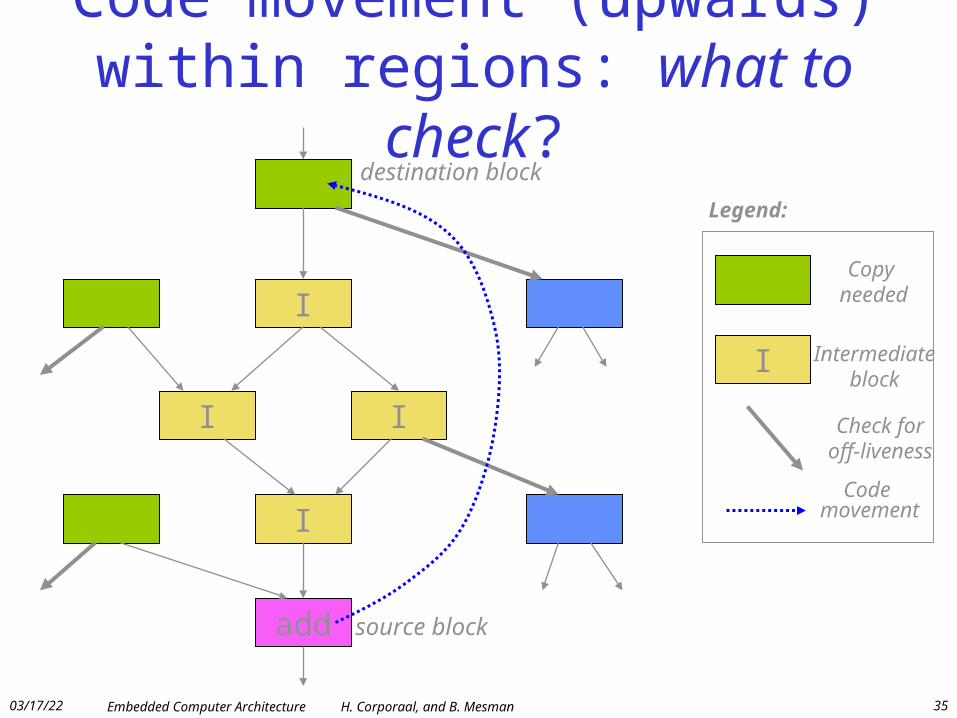
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 35
Code movement (upwards) within regions: what to check?
I
I I
add
I
source block
destination block
I
Copy needed
Intermediateblock
Check foroff-liveness
Legend:
Code movement
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 36
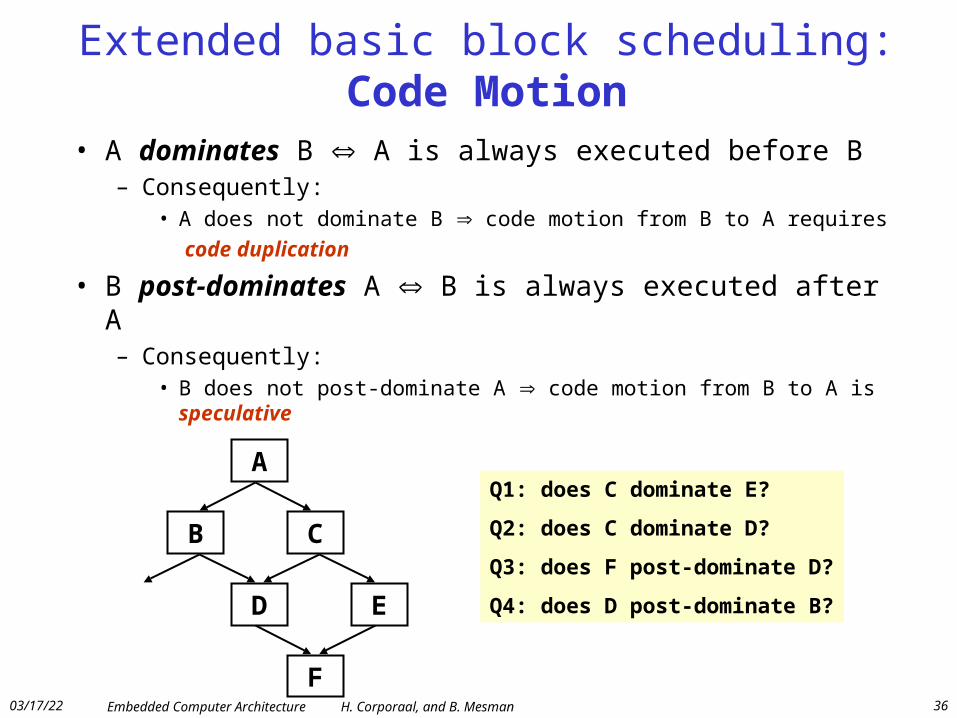
Extended basic block scheduling:Code Motion
• A dominates B A is always executed before B– Consequently:
• A does not dominate B code motion from B to A requires
code duplication
• B post-dominates A B is always executed after A– Consequently:
• B does not post-dominate A code motion from B to A is speculative
A
CB
ED
F
Q1: does C dominate E?
Q2: does C dominate D?
Q3: does F post-dominate D?
Q4: does D post-dominate B?
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 37
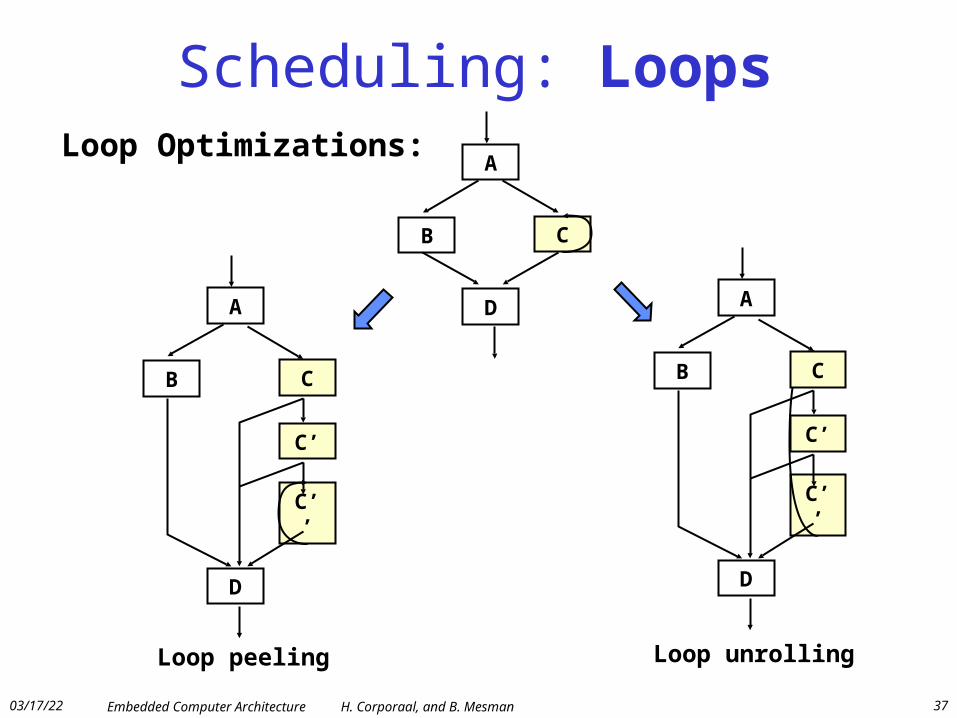
Scheduling: Loops
B C
D
ALoop Optimizations:
B
C’’
D
A
C’
C
Loop peeling
B
C’’
D
A
C’
C
Loop unrolling
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 38
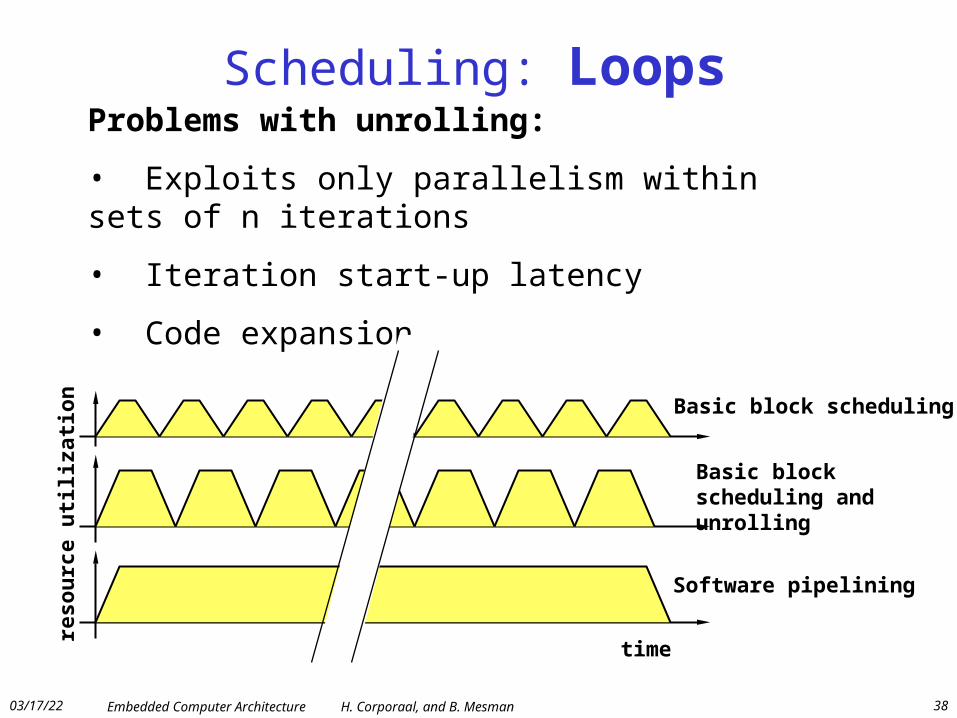
Scheduling: LoopsProblems with unrolling:
• Exploits only parallelism within sets of n iterations
• Iteration start-up latency
• Code expansion
Basic block scheduling
Basic block scheduling and unrolling
Software pipelining
reso
urc
e u
tiliz
atio
n
time
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 39
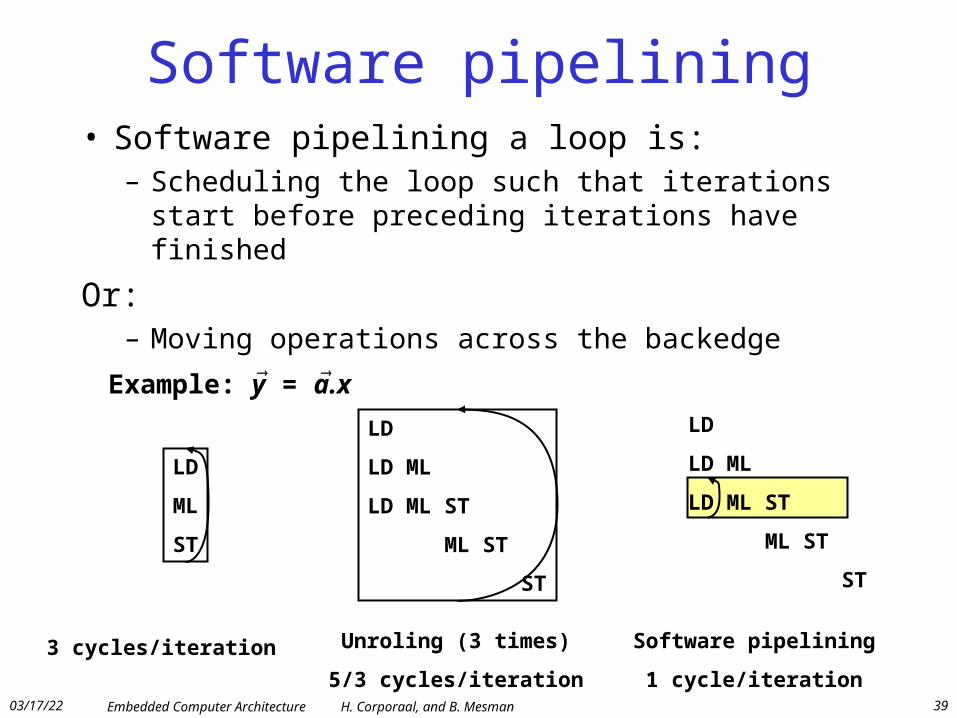
Software pipelining• Software pipelining a loop is:
– Scheduling the loop such that iterations start before preceding iterations have finished
Or:– Moving operations across the backedge
LD
ML
ST
LD
LD ML
LD ML ST
ML ST
ST
LD
LD ML
LD ML ST
ML ST
ST
Example: y = a.x
3 cycles/iteration Unroling (3 times)
5/3 cycles/iteration
Software pipelining
1 cycle/iteration

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 40
Software pipelining (cont’d)Basic loop scheduling techniques:
• Modulo scheduling (Rau, Lam)– list scheduling with modulo resource constraints
• Kernel recognition techniques– unroll the loop
– schedule the iterations
– identify a repeating pattern
– Examples:• Perfect pipelining (Aiken and Nicolau)
• URPR (Su, Ding and Xia)
• Petri net pipelining (Allan)
• Enhanced pipeline scheduling (Ebcioğlu)– fill first cycle of iteration
– copy this instruction over the backedge
This algorithm most used in commercial compilers

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 41
Software pipelining: Modulo scheduling
Example: Modulo scheduling a loop
for (i = 0; i < n; i++)
A[i+6] = 3* A[i] - 1;
(a) Example loop
ld r1,(r2)
mul r3,r1,3
sub r4,r3,1
st r4,(r5)
(b) Code (without loop control)
ld r1,(r2)
mul r3,r1,3
sub r4,r3,1
st r4,(r5)
ld r1,(r2)
mul r3,r1,3
sub r4,r3,1
st r4,(r5)
ld r1,(r2)
mul r3,r1,3
sub r4,r3,1
st r4,(r5)
ld r1,(r2)
mul r3,r1,3
sub r4,r3,1
st r4,(r5)
Prologue
Kernel
Epilogue
(c) Software pipeline
• Prologue fills the SW pipeline with iterations
• Epilogue drains the SW pipeline
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 42
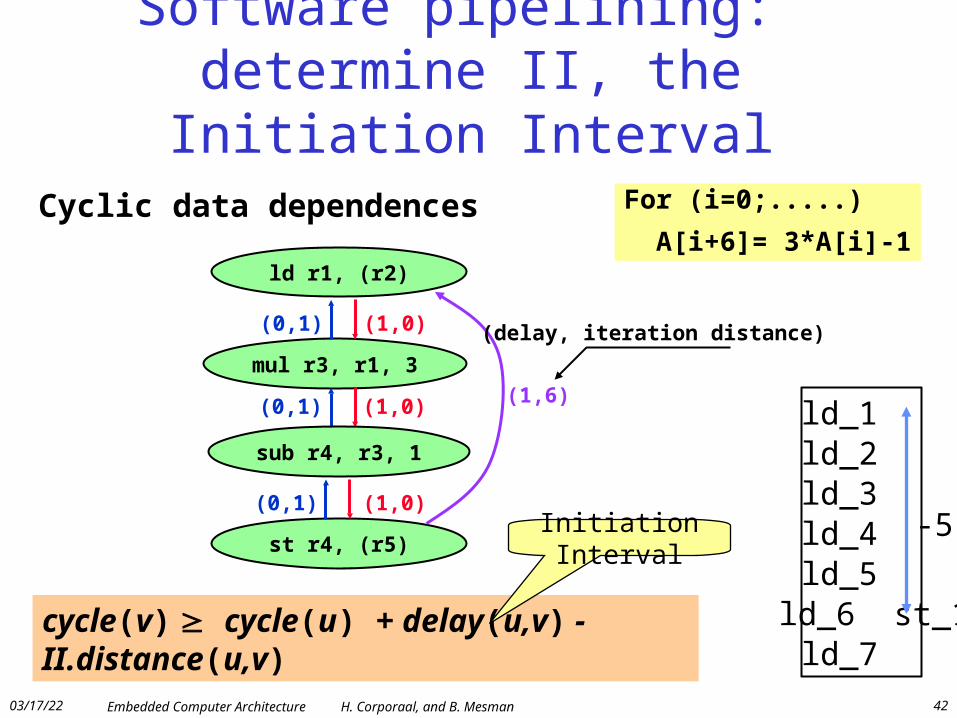
Software pipelining: determine II, the Initiation Interval
ld r1, (r2)
mul r3, r1, 3
(0,1) (1,0)
sub r4, r3, 1
st r4, (r5)
(0,1) (1,0)
(0,1) (1,0) (1,6)
(delay, iteration distance)
Cyclic data dependences
cycle(v) cycle(u) + delay(u,v) - II.distance(u,v)
For (i=0;.....)
A[i+6]= 3*A[i]-1
Initiation Interval
ld_1ld_2ld_3ld_4ld_5ld_6 st_1ld_7
-5

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 43
Modulo scheduling constraintsMII, minimum initiation interval, bounded by cyclic dependences and resources:
MII = max{ ResMinII, RecMinII }
Resources:
)(
)(maxResMinII
ravailable
rusedresourcesr
Cycles:
ce
edistanceIIedelayvcyclevcycle )(.)()()(
Therefore:
ce
cyclesc eIIedelayNII )(distance.)(0,|minRecMinII
Or:
ce
)(distance
)(maxRecMinII
e
edelayce
cyclesc

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 44
Let's go back to: The Role of the Compiler
9 steps required to translate an HLL program:(see online bookchapter)
1. Front-end compilation
2. Determine dependencies
3. Graph partitioning: make multiple threads (or tasks)
4. Bind partitions to compute nodes
5. Bind operands to locations
6. Bind operations to time slots: Scheduling
7. Bind operations to functional units
8. Bind transports to buses
9. Execute operations and perform transports
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 45
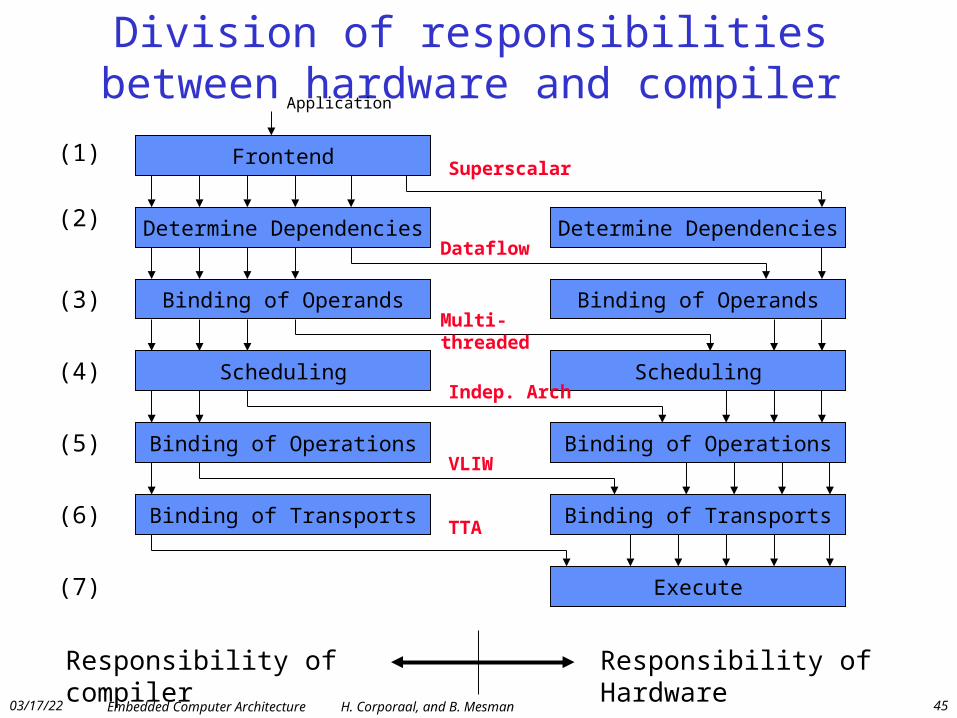
Division of responsibilities between hardware and compiler
Frontend
Binding of Operands
Determine Dependencies
Scheduling
Binding of Transports
Binding of Operations
Execute
Binding of Operands
Determine Dependencies
Scheduling
Binding of Transports
Binding of Operations
Responsibility of compiler Responsibility of Hardware
Application
Superscalar
Dataflow
Multi-threaded
Indep. Arch
VLIW
TTA
(1)
(2)
(3)
(4)
(5)
(6)
(7)
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 46
Overview• Enhance performance: architecture methods• Instruction Level Parallelism• VLIW• Examples
– C6
– TM
– TTA
• Clustering• Code generation• Design Space Exploration: TTA framework
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 47
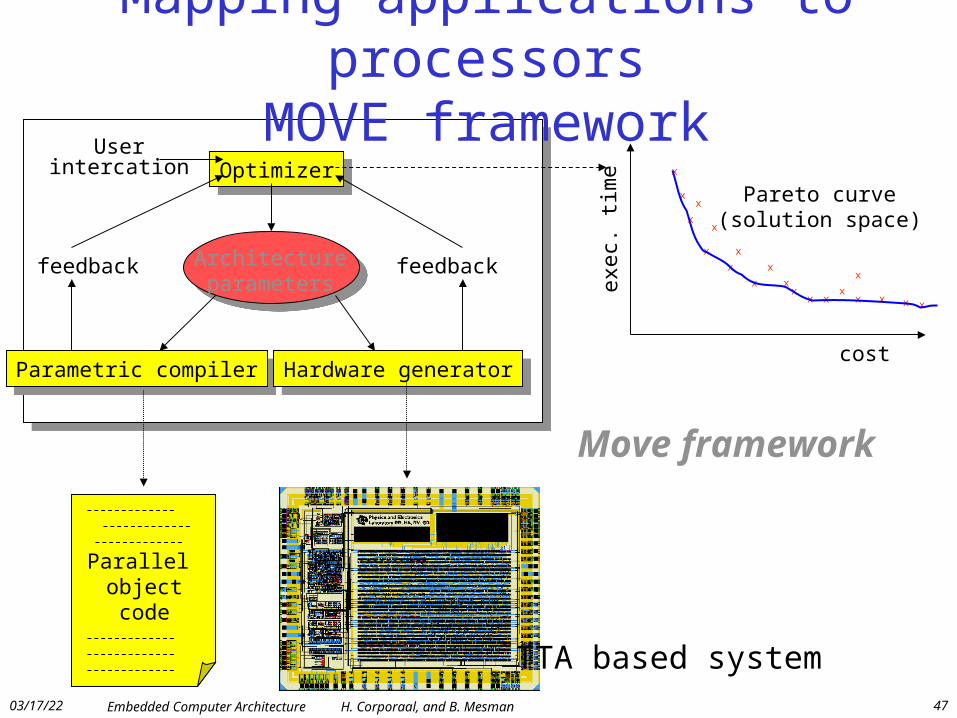
Mapping applications to processorsMOVE framework
Architectureparameters
OptimizerOptimizer
Parametric compilerParametric compiler Hardware generatorHardware generator
feedbackfeedback
Userintercation
Parallel object code chip
Pareto curve(solution space)
cost
exec
. tim
e
x
x
x
x
xx
x
xx
x
x
x
x
x
x
xx x
x
x
Move framework
TTA based system
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 48
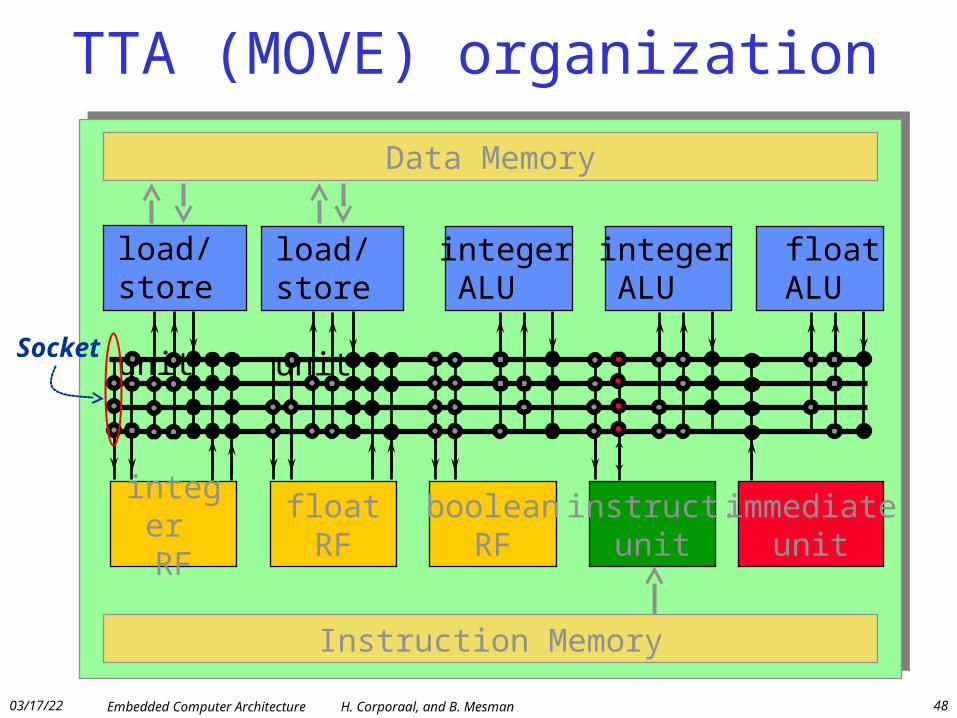
TTA (MOVE) organization
Socket
integer RF
floatRF
booleanRF
instruct.unit
immediateunit
load/store unit
integer ALU
float ALU
integer ALU
load/store unit
Data Memory
Instruction Memory
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 49
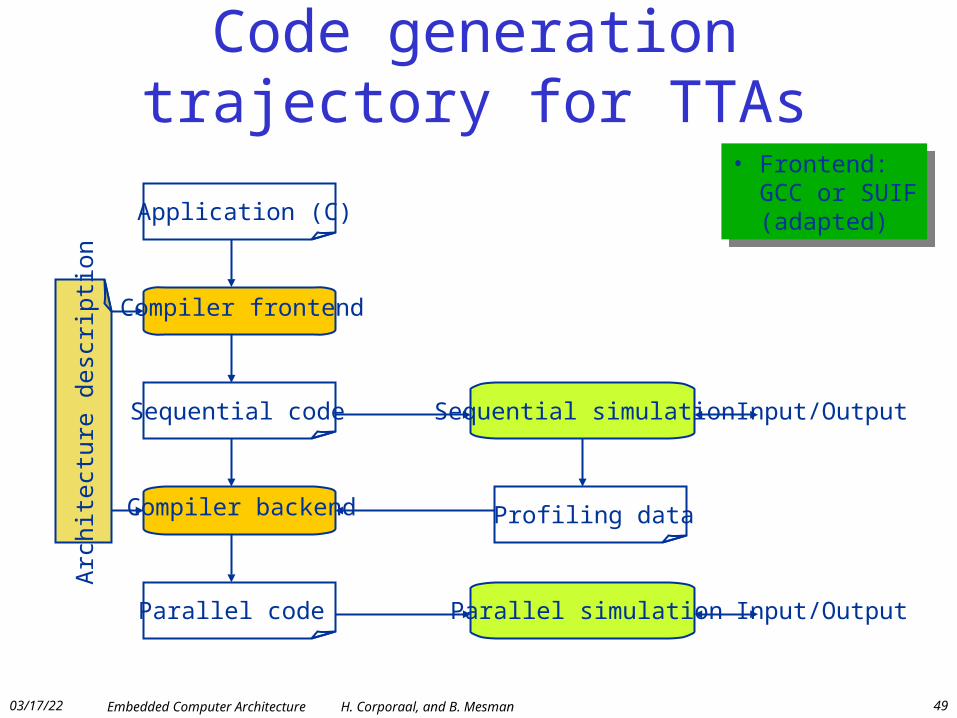
Code generation trajectory for TTAs
Application (C)
Compiler frontend
Sequential code
Compiler backend
Parallel code
Sequential simulation
Parallel simulation
Arc
hite
ctur
e de
scri
ptio
n
Profiling data
Input/Output
Input/Output
• Frontend: GCC or SUIF (adapted)
• Frontend: GCC or SUIF (adapted)
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 50
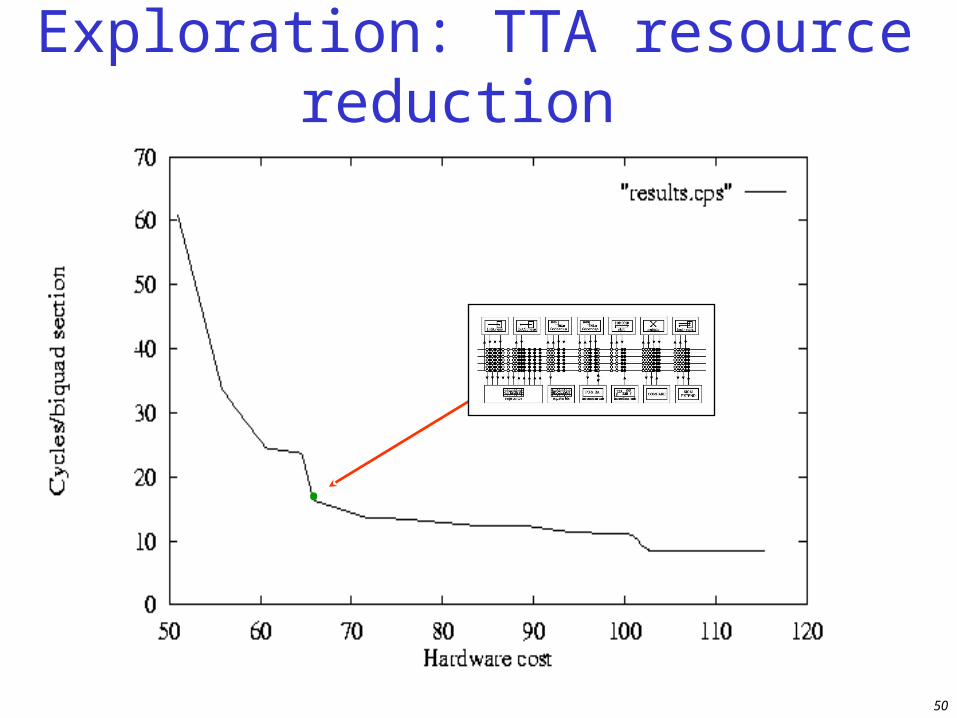
Exploration: TTA resource reduction
•
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 51
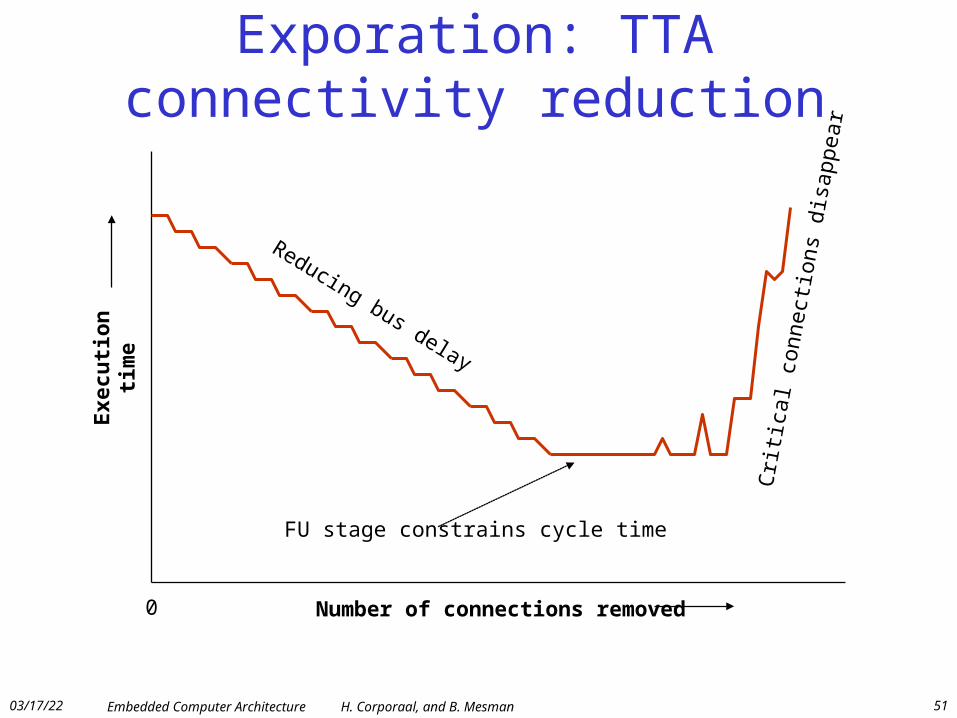
Exporation: TTA connectivity reduction
Number of connections removed
Exe
cuti
on t
ime
Reducing bus delay
FU stage constrains cycle time
Cri
tical
con
nect
ions
dis
appe
ar
0
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 52
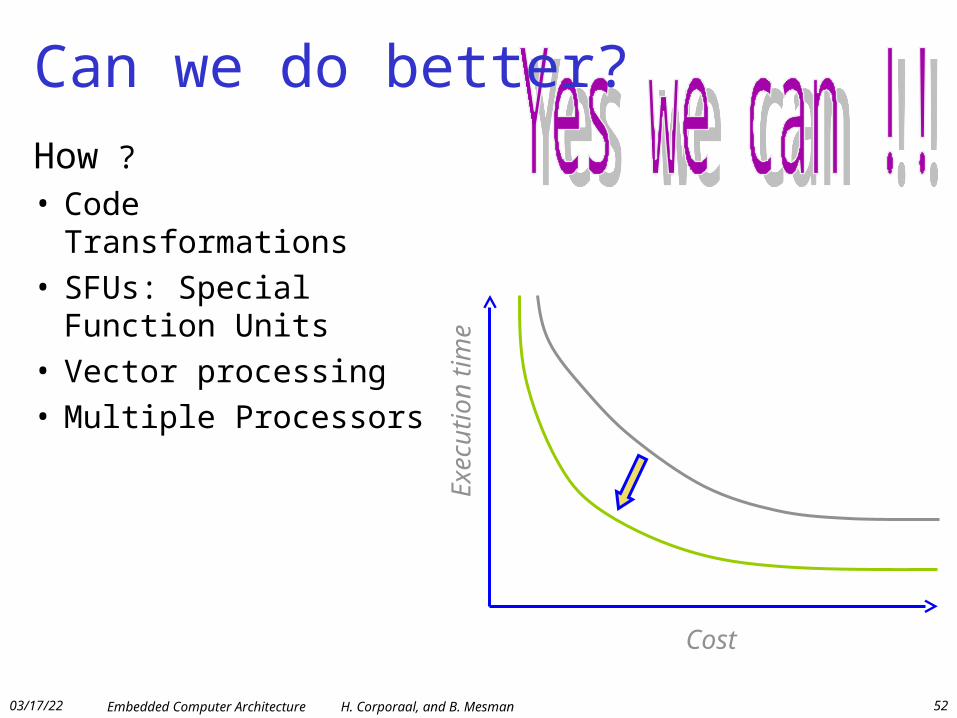
Can we do better?
How ?
• Code Transformations• SFUs: Special Function
Units• Vector processing• Multiple Processors
Cost
Exe
cutio
n tim
e
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 53
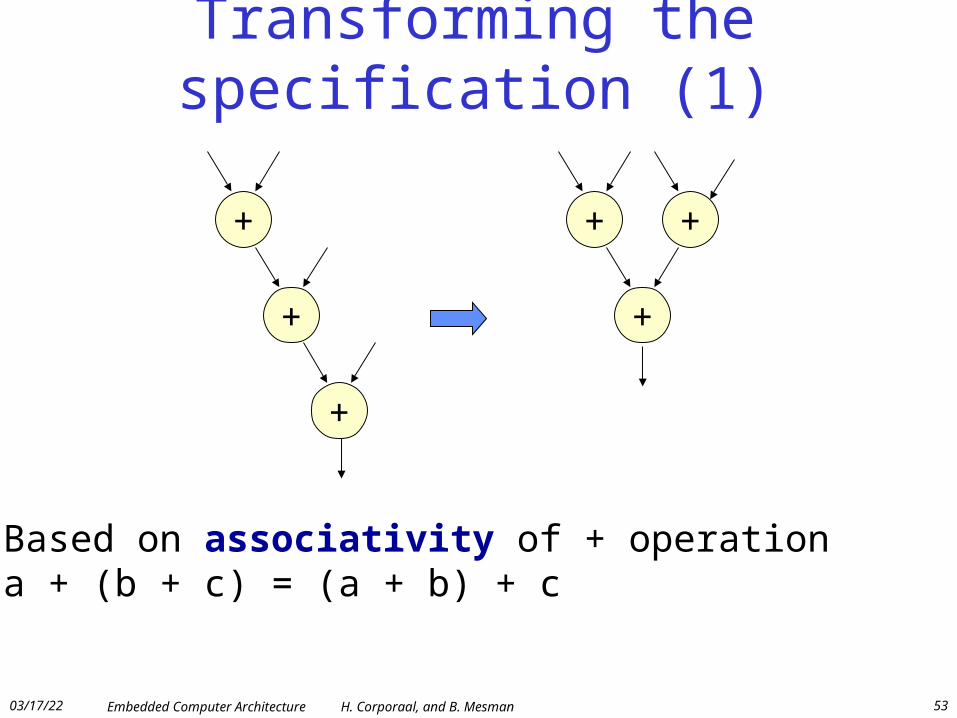
Transforming the specification (1)
+
+
+
+
+
+
Based on associativity of + operationa + (b + c) = (a + b) + c
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 54
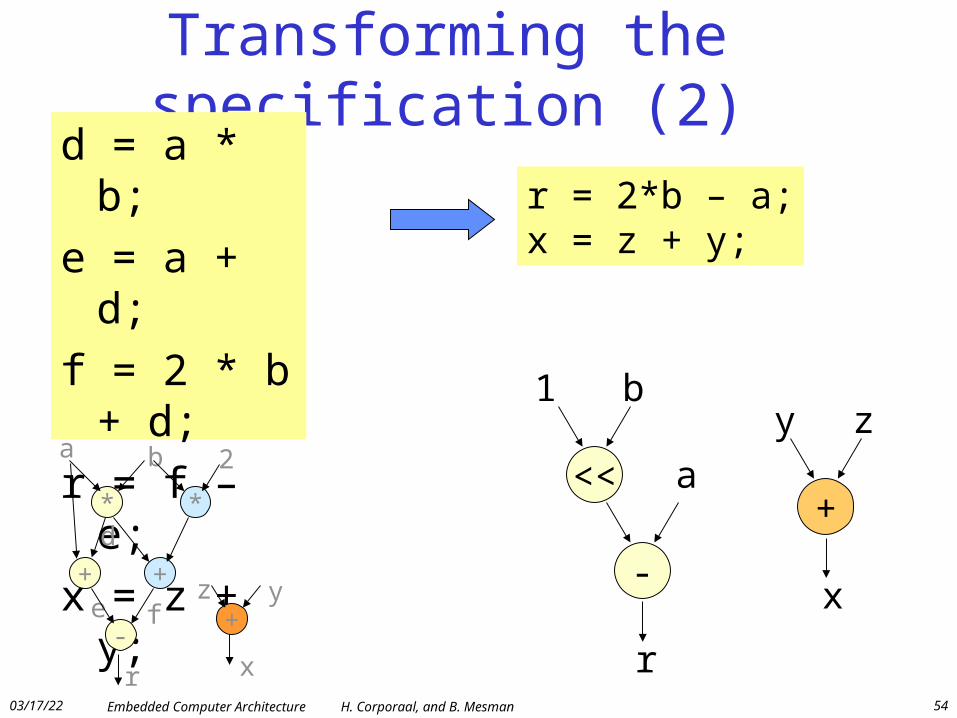
Transforming the specification (2)d = a * b;
e = a + d;
f = 2 * b + d;
r = f – e;
x = z + y;
r = 2*b – a;x = z + y;
<<
-
a
1 b
+
x
zy
r
a
* *
+ +
-+
b 2
z y
d
e f
r x
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 55
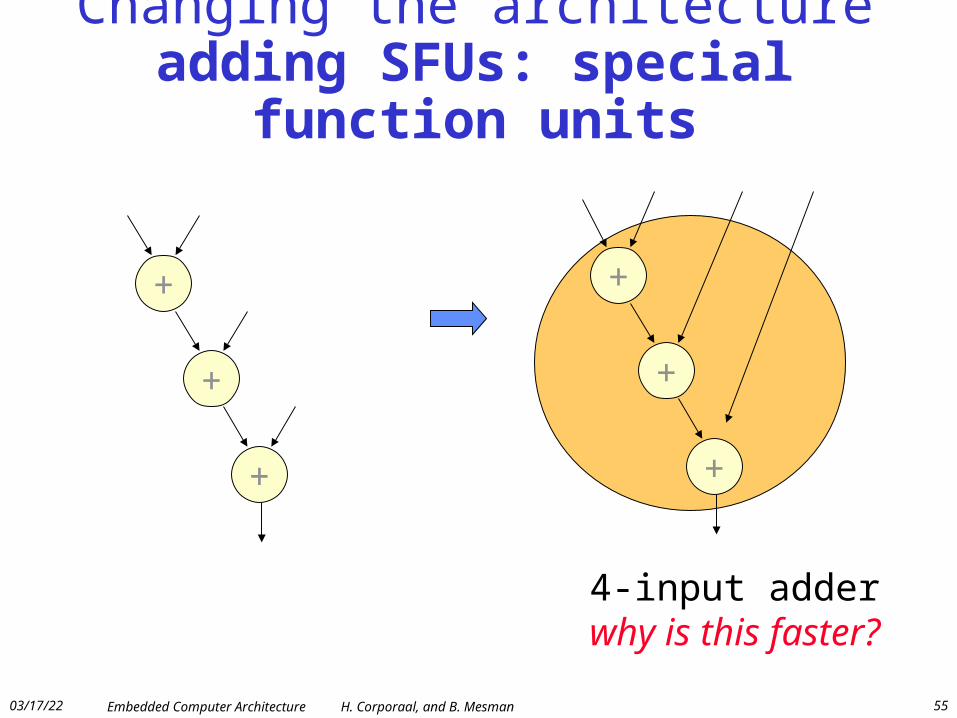
Changing the architectureadding SFUs: special function units
+
+
+
+
+
+
4-input adderwhy is this faster?

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 56
Changing the architectureadding SFUs: special function units
In the extreme case put everything into one unit!
Spatial mapping- no control flow
However: no flexibility / programmability !!
but could use FPGAs

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 57
SFUs: fine grain patterns• Why using fine grain SFUs:
– Code size reduction
– Register file #ports reduction
– Could be cheaper and/or faster
– Transport reduction
– Power reduction (avoid charging non-local wires)
– Supports whole application domain !• coarse grain would only help certain specific applications
Which patterns do need support?
• Detection of recurring operation patterns needed
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 58
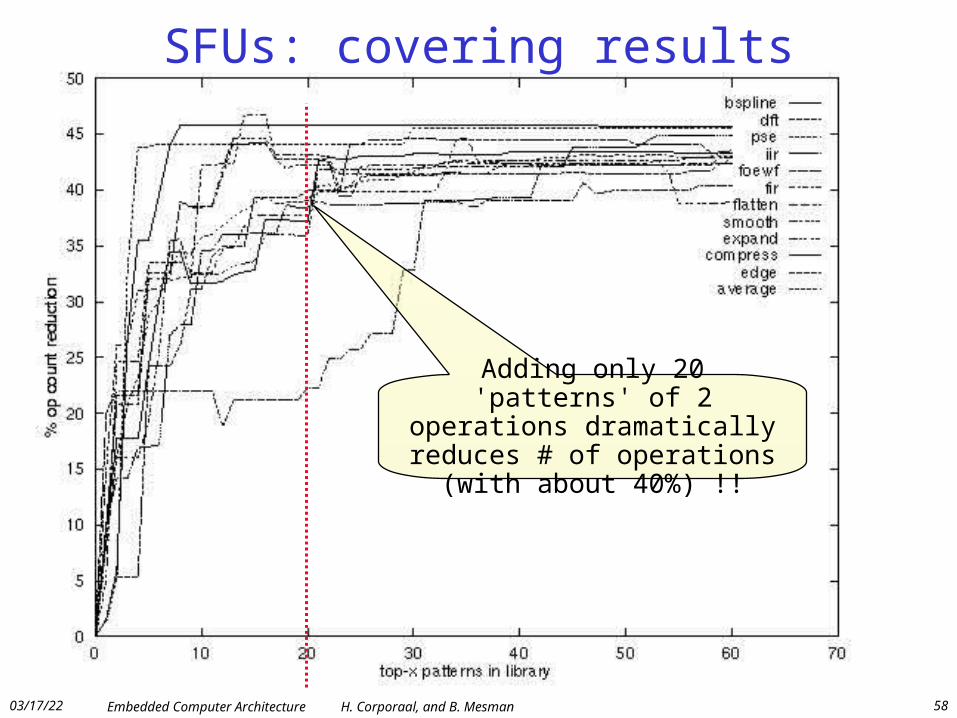
SFUs: covering results
Adding only 20 'patterns' of 2 operations dramatically reduces # of operations (with about 40%) !!
04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 59
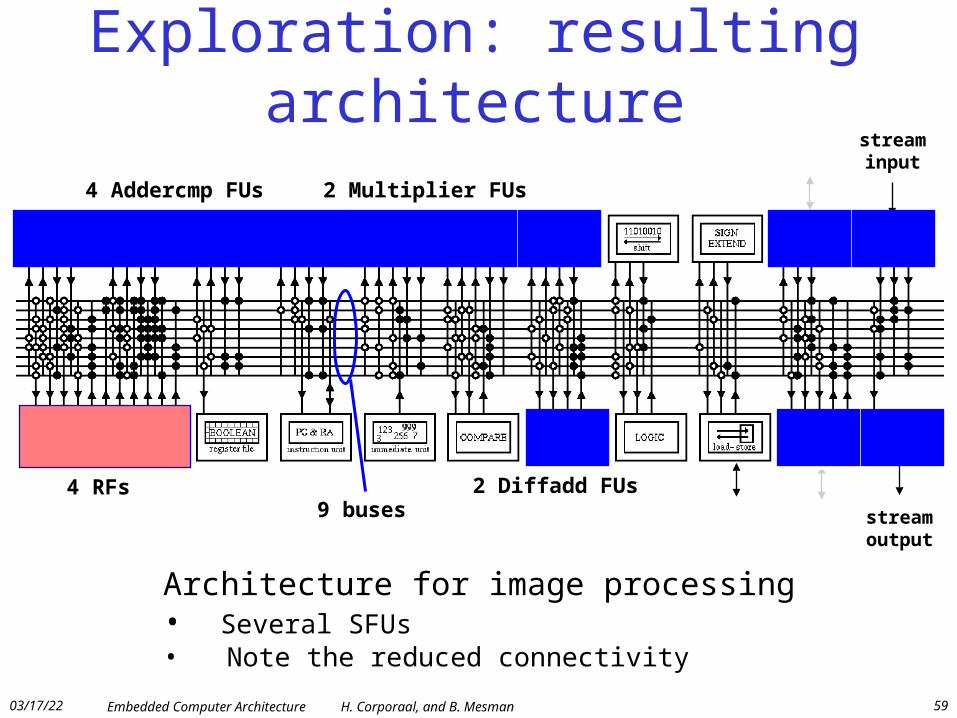
Exploration: resulting architecture
9 buses4 RFs
4 Addercmp FUs 2 Multiplier FUs
2 Diffadd FUs
streamoutput
streaminput
Architecture for image processing• Several SFUs• Note the reduced connectivity

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 60
Conclusions• Billions of embedded processing systems / year
– how to design these systems quickly, cheap, correct, low power,.... ?
– what will their processing platform look like?
• VLIWs are very powerful and flexible– can be easily tuned to application domain
• TTAs even more flexible, scalable, and lower power

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 61
Conclusions• Compilation for ILP architectures is mature
– used in commercial compilers
• However– Great discrepancy between available and exploitable
parallelism
• Advanced code scheduling techniques needed to exploit ILP

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 62
Bottom line:

04/19/23 Embedded Computer Architecture H. Corporaal, and B. Mesman 63
Handson-1 (2014)
• HOW FAR ARE YOU?• VLIW processor of Silicon Hive (Intel)• Map your algorithm• Optimize the mapping• Optimize the architecture• Perform DSE (Design Space Exploration) trading off
(=> Pareto curves)– Performance, – Energy and – Area (= Cost)