variability in chinese as a foreign language learners’ development of the chinese numeral...
TRANSCRIPT

Variability in Chinese as a ForeignLanguage Learners’ Development ofthe Chinese Numeral Classifier SystemJIE ZHANGThe University of OklahomaDepartment of Modern Languages, Literatures,and Linguistics780 Van Vleet OvalNorman, Oklahoma 73019Email: [email protected]
XIAOFEI LUThe Pennsylvania State UniversityDepartment of Applied Linguistics304 Sparks BuildingUniversity Park, Pennsylvania 16802Email: [email protected]
This study examined variability in Chinese as a Foreign Language (CFL) learners’ developmentof the Chinese numeral classifier system from a dynamic systems approach. Our data consisted ofa longitudinal corpus of 657 essays written by CFL learners at lower and higher intermediatelevels and a corpus of 100 essays written by native speakers (NSs) of Chinese. A combination ofquantitative and qualitativemethods was employed to analyze thefluency, diversity, and accuracyof learners’ andNSs’ classifier use. Usage by 4 focal learners from the higher immediate level wasthen closely examined to discover inter‐ and intraindividual variability in learners’ developmentof these dimensions and to reveal the patterns of interaction among these dimensions. Learnersexhibited varied, nonlinear developmental paths for all three dimensions, with different degreesof fluctuation and regression for each path. The three dimensions did not always develop inparallel, but interacted with each other in divergent ways. Pedagogically, we advocate for acollocational approach to presenting and teaching classifiers and recommend that tailoredassistance be provided to individual learners.
THE VIEW OF LANGUAGE AS A DYNAMIC,complex system and language development as adynamic process is receiving increasing attentionfrom second language acquisition (SLA) research-ers (e.g., de Bot, 2008; de Bot, Lowie, & Verspoor,2007; Ellis & Larsen–Freeman, 2006; Larsen‐Freeman, 1997, 2006). Research from this per-spective has focused on patterns of individuallearners’ language development and on inter‐ andintraindividual variability (de Bot, 2008; Larsen–Freeman & Cameron, 2008; Verspoor, Lowie, &van Dijk, 2008), and recent studies have shownthat second language development (SLD) is notalways linear and stage‐like but in many ways is
characterized by fluctuation, variation, and evenregression (e.g., Larsen–Freeman, 2006). Differ-ent from traditional SLA studies that examinegroup‐level trends in cross‐sectional data, thisstream of research has called for the use of dense,longitudinal data of individual learners to discoverindividual developmental paths, with a heavymethodological emphasis on simulation modelingand quantitative analysis.
The Chinese numeral classifier system (NCS) isnotoriously challenging for Chinese as a ForeignLanguage (CFL) learners, due to the complexityof the structure itself and its absence in non-classifier languages such as English. Previousstudies on SLD of the Chinese NCS have pre-dominantly focused on group performance usingelicited cross‐sectional data and have not exam-ined individual learners’ developmental paths andthe patterns of interaction among different devel-opmental indices using naturalistic longitudinal
The Modern Language Journal, 97, S1, (2013)DOI: 10.1111/j.1540-4781.2012.01423.x0026-7902/13/46–60 $1.50/0© 2012 The Modern Language Journal

data. In adopting the dynamic systems approach toSLD, this study is among the first attempts toexamine inter‐ and intraindividual variability inCFL learners’ development of the Chinese NCS.Using a combination of quantitative measures andqualitative case studies, we analyzed the fluency,diversity, and accuracy of learners’ classifier use ina longitudinal CFL learner corpus. Results re-vealed substantial inter‐ and intraindividual vari-ability in the paths of development for the threedimensions as well as the patterns of interactionamong these dimensions. Our findings underpinthe fundamental concept of variability in the DSTapproach to SLD and offer important insight intothe dynamic nature of learners’ development ofthe Chinese NCS.
A DYNAMIC SYSTEMS APPROACH TOVARIABILITY IN SECOND LANGUAGEDEVELOPMENT
Variability has been approached in several waysin the field of SLD (Ellis, 1994). Within theChomskyan paradigm (Chomsky, 1965), research-ers have been primarily concerned with linguisticcompetence, largely overlooking individual vari-ability manifested in language performance.Researchers who take sociolinguistic and psycho-linguistic approaches to SLD, however, have paidcloser attention to variability and have “attemptedto discover the sources that were responsible forthe variability and what it could tell us about theinterlanguage (IL) system” (Verspoor et al., 2008,p. 215). Various linguistic, psychological, andcontextual factors have been identified to contrib-ute to interindividual variability, but much re-mains unexplained (van Dijk, Verspoor, &Lowie, 2011). Researchers have shown that whatwas previously termed free variability could beinformative of the stages of SLD. For example,citing Cancino, Rosansky, and Schumann’s (1978)study on learners’ use of varied forms of negationin different SLD stages, Ellis (1994) concludedthat free variation occurs in an early developmen-tal stage but disappears in later stages (cited in vanDijk et al., 2011). A recent approach to SLD that isfundamentally interested in variability is DynamicSystems Theory (DST) (e.g., de Bot, 2008; de Botet al., 2007; Ellis & Larsen–Freeman, 2006; Ver-spoor, de Bot, & Lowie, 2011). Contrary to theChomskyan approach to development, the DSTapproach sees variability “as an intrinsic propertyof the developmental process” (van Dijket al., 2011, p. 55). Different from sociolinguisticand psycholinguistic studies that seek to explainthe factors causing variability, DST‐based research
is primarily concerned with the nature of variabili-ty both within an individual (e.g., when and howdoes change happen) and between individuals(e.g., how do the developmental paths of differentindividuals differ) as a step toward better under-standing the nature of the developmental processitself (van Dijk et al., 2011). While traditionalSLD analyses have usually focused on trends andgroup averages and have often attributed variabili-ty to environmental factors, from a DST perspec-tive, inter‐ and intraindividual variability isperceived not as noise in data that should beaveraged away but as a useful source of informa-tion about the developmental process (Larsen–Freeman, 2006; van Dijk et al., 2011; van Geert &Steenbeek, 2005).
DST‐based studies on variability have strived toexamine how different subsystems of language orcombinations of developmental variables interactwith each other, how they “co‐adapt,” andhow they “may display sudden emergence ofnew modes of behavior” (de Bot & Larsen–Freeman, 2011, p. 23). This focus follows naturallyfrom the view of language as a dynamic systemcharacterized by such features as “completeinterconnectedness” of its subsystems, depen-dence on “initial conditions” and “internal andexternal resources,” changes caused by andthrough “internal reorganization and interactionwith the environment,” “nonlinearity of develop-ment,” and “emergent properties” (de Bot &Larsen–Freeman, 2011, p. 9). To produce detaileddescriptions of changing patterns of interactionsand variability over time, researchers have calledfor the collection of dense, longitudinal data ofindividual learners. In light of the paucity of suchdata, some researchers have advocated for simula-tion modeling as a viable methodological ap-proach (Beckner et al., 2009; Larsen–Freeman &Cameron, 2008). However, it has also been arguedthat simulation modeling should not “replaceempirical data but should simulate empirical datato test the theoretical insights” (de Bot, Lowie, &Verspoor, 2011, p. 2).
Larsen–Freeman (2006) analyzed the emer-gence of complexity, fluency, and accuracy inlongitudinal data produced by five Chineselearners of English. She showed that althoughthe group as a whole improved consistently overtime in all three aspects, there was a high degree ofinter‐ and intraindividual variability. For example,with respect to accuracy, some individual perform-ances fluctuated back and forth, while othersremained largely stable, indicating that learnersfollowed varied developmental paths instead ofprogressing in a linear fashion. She concluded that
Jie Zhang and Xiaofei Lu 47

language development “is not discrete and stage‐like but more like the waxing and waning ofpatterns” (p. 590).
Verspoor et al. (2008) examined several varia-bles pertaining to lexical and syntactic complexityin a longitudinal study of the development of anadvanced English learner and reported severalinteresting patterns of interaction in the learner’sdevelopment. The relationship between certainmeasures changed dynamically over time, al-though that between others appearedmore stable.For example, type–token ratio and sentencelength correlated positively in the earlier andlater observations but negatively between obser-vations 4 and 15. All measures showed a highdegree of variability and nonlinear patterns ofdevelopment, with some maintaining roughly thesame amount of variation throughout the trajec-tory. They concluded that the patterns andinteractions found confirmed the assumptionthat variability in SLD “behaves according toprinciples of dynamic systems” (p. 229).
In examining the dynamics of second language(L2) writing development, Caspi (2010) analyzedessays written weekly by four advanced Englishlearners of different first language (L1) back-grounds over 36 weeks, focusing on lexical andsyntactic accuracy and complexity. Results fromher analysis and mathematical modeling sug-gested weakly competitive lexical complexity–accuracy interaction, strongly competitive interac-tion between lexical accuracy and syntacticcomplexity, and supportive syntactic complexity–accuracy interaction.
The motivations and goals of the present studyalign well with the DST approach to variability inSLD. We employ longitudinal data to discoverinter‐ and intraindividual variability in CFLlearners’ development of the Chinese NCS. Inline with the concerns of most DST‐based studieson the interactions among different developmen-tal variables, our quantitative and qualitativeanalyses are focused on the developmental pathsof and interactional patterns among the dimen-sions of fluency, diversity, and accuracy.
SECOND LANGUAGE DEVELOPMENT OFTHE CHINESE NUMERAL CLASSIFIERSYSTEM
Numeral Classifier System in Mandarin Chinese
Typologically, languages can be divided intoclassifier and nonclassifier languages. MandarinChinese is a numeral classifier language (Allan,1977). A numeral classifier is a morpheme that
must be used between the determiner and thenoun (Li & Thompson, 1981) when a noun ispreceded by a determiner such as a number (e.g.,yi ‘one’), demonstrative (e.g., zhe ‘this’), orquantifier (e.g., mei ‘every’). A classifier phrasethus consists of a determiner, a numeral classifier(CL), and a noun phrase (1). However, adeterminer and a classifier can also occur withouta noun phrase, in which case they take on ananaphoric or discourse function.
According to Zhang (2007), there are over 900classifiers in Chinese. These classifiers can becategorized into two types: sortal and mensural(Grinevald, 2000). Sortal classifiers categorize andquantify objects. The choice of sortal classifiers isoften determined by the physical properties of theobject, andmany classifier–noun collocations havebeen conventionalized in the process of gram-maticalization. The classifier tiao, for example, isprototypically used with a two‐dimensional, longand thin object, such as a fish or a snake. Thegeneral classifier ge can be used with many nouns,subject to certain semantic constraints.
Mensural classifiers are used to measure quanti-ties of uncountable objects and, therefore, arefrequently used with mass nouns. Mensuralclassifiers exist in nonclassifier languages, as well.In Chinese, they have been categorized based onthe manner in which they organize uncountableobjects into countable units (Li & Thompson,1981). Collective classifiers aggregate entities intolarger units (e.g., qun in yi qun ren, ‘a crowd ofpeople’), container classifiers group things ac-cording to the containers they come in (e.g., pingin yi ping shui, ‘a bottle of water’), and measure-ment units indicate units of length, weight, orvolume.
The classifier system is enormously complex inthat, although individual classifiers tend to collo-cate with nouns with certain semantic properties,exceptions abound. Mainstream beginning‐levelChinese textbooks for CFL learners usually intro-duce the topic by providing a list of commonlyused classifiers, a set of nouns they collocate with,and a brief explanation of the semantic features ofthese nouns, as illustrated in Table 1. Once thegrammatical functions of classifiers are intro-duced, new classifiers are subsequently presentedin the vocabulary list as stand‐alone items. Thisapproach falls short of presenting learners withthe complex nature of the classifier system. In the
(1) yi zhi mao[one CL cat]‘a cat’
48 The Modern Language Journal 97 (2013)

list, the general classifier ge is described as ‘forpeople and things in general,’ without explainingthe numerous types of nouns that cannot collocatewith it. The classifier zhi is listed as the classifier foranimal nouns, which is not without exceptions; zhicannot collocate with yu ‘fish’ or ma ‘horse,’ forwhich the appropriate classifiers are tiao and pi,respectively. In addition, zhi can also collocate withother nouns such as xie ‘shoe’ and yanjing ‘eye.’The lack of one‐to‐one mappings between classi-fiers and semantic categories of nouns is at the rootof the complex nature of the Chinese NCS,making the system pedagogically challenging.
Previous Research on Second Language Developmentof the Chinese Numeral Classifier System
Chinese classifiers, particularly sortal classifiers,are notoriously challenging for CFL learners (e.g.,Li, 2010; Polio, 1994), both because of theirabsence in nonclassifier languages and because ofthe complex nature of the syntax and semantics ofthe NCS itself, with a large number of specialclassifiers exhibiting numerous semantic andcollocational idiosyncrasies.
In an earlier study, Polio (1994) examined theuse of classifiers by 21 English‐speaking and 21Japanese‐speaking learners of Chinese in Taiwan.She found that her participants rarely omittedclassifiers in obligatory contexts but often includedmultiple classifiers when only one was needed.They overused the general classifier ge, and theiroccasional uses of special classifiers were ofteninappropriate. While this analysis provided asnapshot of how the subjects used classifiers andwhat problems they had encountered at a specificstage of learning, it offered little informationabout their developmental process.
Hansen and Chen (2001) examined L2 acquisi-tion and attrition sequences in the syntax andsemantics of the NCS in Chinese and Japanese,
using data elicited from English‐speaking learnersof Chinese and Japanese who were still living(acquirers) or had previously lived (attriters) inTaiwan and Japan for different lengths of time.They concluded that in general, learners initiallyused no classifiers, at a later stage became aware ofthe classifiers’ obligatory grammatical role, andgradually acquired the semantic rules on their use.Although this study focused on the relationshipbetween L2 acquisition and attrition sequences,the authors also briefly commented on thesubstantial interindividual variation they observed:Some learners acquired all of the semanticcategories in their first year in Taiwan or Japan,while others attained little knowledge of specificcategories throughout their stay.
Liang (2009) examined the acquisition of eightshape classifiers denoting one‐ (e.g., snake), two‐(e.g., leaf), and three‐dimensional (e.g., ball)objects by American and Korean learners ofChinese at novice, intermediate, and advancedlevels. The participants were asked to complete aclassifier comprehension, production, and proto-type test. The Korean participants generally out-performed their American counterparts, but bothgroups showed some degree of regression. Forexample, a reverse U‐shaped progression patternwas found for two‐dimensional classifiers. Liangconcluded that two‐dimensional classifiers are bestlearned, followed by one‐ and then three‐dimen-sional classifiers. This study offered useful insightsinto group‐level trends in the acquisition ofclassifiers but said nothing about the developmen-tal paths of individual learners.
To summarize, previous research on SLD of theChinese NCS has predominantly used experimen-tal methods to elicit cross‐sectional data and hasshed useful light on group performance, with aprimary focus on the accuracy of classifier use.From a DST perspective, different learners at thesame developmental stage and individual learners
TABLE 1Example Tabular Presentation of Classifiers in Beginning Level Chinese as a Foreign Language (CFL)Textbooks
Classifiers Semantic Features Noun Collocates
ge For people and things in general ren ‘person,’ xuesheng ‘student,’ fangjian ‘room’
ben For bound items shu ‘book,’ cidian ‘dictionary’liang For vehicles che ‘car,’ gongche ‘bus’zhi For animals mao ‘cat,’ niao ‘bird,’ laohu ‘tiger’jian For clothing chenshan ‘shirt,’ dayi ‘overcoat’zhang For sheet‐like things zhi ‘paper,’ piao ‘ticket,’ zhuozi ‘table’shuang For pairs of certain things kuaizi ‘chopsticks,’ xie ‘shoes,’ yanjing ‘eyes’
Note. The classifiers and their presentations in Table 1 are based on Wu et al. (2007).
Jie Zhang and Xiaofei Lu 49

at different learning times show great variation indevelopment. Viewed as a complex system, learnerdevelopment of the Chinese NCS needs to bedescribed in multiple dimensions (e.g., fluency,diversity, and accuracy of use), rather than alonga single dimension. The present study followsthat recommendation by analyzing naturalisticlongitudinal data and examining inter‐ and intra-individual variability in CFL learners’ develop-ment of the Chinese NCS.
METHOD
Research Question
The study addressed the following researchquestion: What is the inter‐ and intraindividualvariability in CFL learners’ development of theChinese NCS?We operationalized development aslearners’ progression in fluency, diversity, andaccuracy with learning time. Specifically, wefocused on variability in the developmental pathsfor the three dimensions and in the patterns ofinteraction among these dimensions, both amongdifferent learners and within individual learners atdifferent time points. Developmental paths aredefined as patterns of progression and regressionof the three dimensions, and interactional pat-terns refer to ways in which these dimensions co‐develop and co‐adapt during the developmentalprocess.
Data
Our data consisted of 657 essays written by CFLlearners at the lower intermediate level (LIL) andhigher intermediate level (HIL), with proficiencydetermined by means of program level, theconceptualization of which Wolfe–Quintero, In-agaki, and Kim (1998) considered to be most validdevelopmentally. We also used 100 essays writtenby native Chinese speakers as a baseline forgauging the overall language performance of the
learners. Table 2 summarizes the composition ofthe data.
The learner data were longitudinal in nature.The writing samples from the LIL learners werecollected from students enrolled in the thirdChinese course of a six‐course sequence in the fallsemester of 2009 at a large North Americanuniversity. The class met five times a week for 50‐minute sessions. The primary textbook used forthis course was Chinese Link: Intermediate ChineseLevel 2 Part 1 (Wu, Yu, & Zhang, 2008a). Classifiersare listed as stand‐alone vocabulary items in thisbook.
The HIL essays were collected from the samecohort of students enrolled in the fifth course ofthe sequence in the fall semester of 2009 and thesubsequent sixth course in the spring semester of2010. Students met three times a week for 50‐minute sessions. The textbooks used for thesecourses were Chinese Link: Intermediate ChineseLevel 2 Part 2 (Wu, Yu, & Zhang, 2008b) and ATrip to China: Intermediate Reader of ModernChinese (Chou & Chao, 1996), respectively. Thestudents in both levels were mostly second‐ orthird‐year undergraduate students between theages of 18 and 22. The overwhelming majoritywere L1 English speakers. There were noheritage learners in the LIL groups becausethe university offered a separate track for themat this level. Heritage learners in the HILgroup were excluded based on the informationthey provided in the background informationquestionnaire.
As part of the curricula, students were requiredto write short essays after each unit, roughly everyother week. Most writing topics came from thecourse textbooks, with a few supplemental topicsprovided by the instructors (see Appendices A andB). All but one essay in the data were assigned ashomework, for which students could use anyreference material and take as much time asnecessary. The curriculum of the spring 2010course had a stronger focus on the reading of
TABLE 2Data Sources by Proficiency Level, Number, and Length of Essays
Group byProficiency Level
Number ofEssays
Average Length(Chinese Characters)
Total Size(Chinese Characters)
LIL 409 231 94,461HIL 248 354 87,702NS 100 873 87,320Total 757 486 269,483
Note. LIL ¼ Lower Intermediate Level, HIL ¼ Higher Intermediate Level; NS ¼ Native Speaker.
50 The Modern Language Journal 97 (2013)

authentic Chinese texts and hence included fewerwriting tasks than that of the fall 2009 semester. Asour data were collected in a naturalistic classroomsetting, students were not given additional assign-ments beyond what was required by the curricu-lum. With consent from the students, thehandwritten essays were collected from theinstructors before being graded, photocopied,and then returned to them. They were manuallytyped into the computer, proofread by two nativespeakers, and saved as separate plain text files.Electronically submitted essays were collecteddirectly.
For the LIL group, 57 students produced 409essays over the 15‐week period of the fall semester,with an average of 231 characters per essay.Appropriate for their proficiency level, most essayswere narrative or descriptive. For the HIL group,30 students produced 248 essays over 30 weeks,with an average of 354 characters per essay. Awider range of genres was covered at this level,including narrative, descriptive, expository, andargumentative. Again, due to the naturalisticclassroom setting of our data collection proce-dure, the writing tasks were not designed specifi-cally to elicit the usage of classifiers or otherparticular grammatical constructions. Neverthe-less, due to the obligatory nature and highfrequency of classifiers in Chinese language use,the scale of our data collection, and the range ofgenres and topics covered, students had asufficiently expansive opportunity to use a widerange of classifiers in both obligatory and non-obligatory environments.
The native speaker (NS) component was acollection of essays written by Chinese high schoolstudents taking or preparing for the CollegeEntrance Examination, the highest stakes stan-dardized test in China (Ross & Wang, 2010).Several genres were represented in the essays,including argumentative, expository, narrative,and prose. The essays were downloaded fromofficial educational Web sites Zhongguo JiaoyuZaixian1 (China Education Online) and RenminWang 2 (People’s Daily Online). Ideally, the NSdata would consist of essays written by NSs inresponse to the same writing tasks as thoseassigned to the learners. However, this collectionof NS essays provided a workable baseline tocompare learners’ classifier use against, as theywere produced by students of similar age ininstitutional settings covering similar genres.Because the NS essays were longer in length, wecollected 100 essays so that the overall size wascomparable to that of the LIL and HILcomponents.
Procedure
All essays were word‐segmented and part‐of‐speech (POS)‐tagged using the Chinese LexicalAnalysis System developed by the Institute ofComputing Technology at the Chinese Academyof Sciences.3 We then manually identified inap-propriate classifier uses as well asmissing classifiersin obligatory environments and annotated theseinstances following the tagging scheme summa-rized in Table 3.
After the corpus was annotated, we usedAntConc 3.2.2.1 (Anthony, 2011), a freewareconcordance program, to retrieve all instancesof classifiers (using the POS tags [q] standing forquantifiers and [m] standing for measure words)and instances of missing classifiers in obligatoryoccasions (using the error tags). It was necessary tosearch for the tag [q] as the POS tagger annotatedsome classifiers as quantifiers. The extractedconcordance lines were exported to Excel spread-sheets for further examination (lines that did notcontain classifiers were manually removed) andanalysis of fluency, diversity, and accuracy oflearners’ classifier use. The indices used tomeasure these dimensions are summarized inTable 4. Fluency was measured using normalizedfrequency of classifier tokens and types (i.e.,unique classifiers) per 100 characters. Wolfe–Quintero et al. (1998) conceptualized writingfluency as “a measure of the sheer number ofwords or structural units a writer is able to includein their writing within a particular period of time”and operationalized it as counts of “the number,length, or rate of production units” (p. 14). It wasthis operationalization of writing fluency thatinspired our use of normalized frequency ofclassifier tokens and types as loose measures oflearners’ fluency of classifier use in writing.Diversity was assessed using the type–token ratio(TTR) of classifiers. Finally, accuracy was comput-ed along two axes; namely, Accuracy of ProducedClassifiers and Accuracy of Classifiers in Obligato-ry Environments (which included counting miss-ing classifiers). These quantitative analyses weresupplemented by a qualitative examination of theclassifiers and classifier–noun collocations pro-duced as well as the classifiers that were inappro-priately omitted.
RESULTS
This section reports the results of the quantita-tive and qualitative analyses of our data. In ourquantitative analysis, we first assessed quantitativedifferences in the frequency, diversity, and
Jie Zhang and Xiaofei Lu 51

accuracy of classifier usage by learners and NSsand then investigated inter‐ and intraindividualvariability evidenced in the data by 4 focal learnersat the HIL. In our qualitative analysis, we firstexamined qualitative differences in the classifierusage by learners and NSs and then furtherprobed the variability evident in the data by the4 focal learners from a microgenetic perspective.
Quantitative Analysis
Classifier Usage by Learners and Native Speakers.Table 5 summarizes classifier usage by learnersand NSs. For measures based on token frequen-cies, chi‐square tests were run to determinewhether significant differences existed amongthe LIL, HIL, and NS groups, and post hoc
analyses with the Marascuilo procedure were thenused to compare each pair of groups. Both LIL(x2 ¼ 21.821, p < .0001) and HIL (x2 ¼ 20.765,p < .001) learners produced significantly moreclassifier tokens than NSs, but no significantdifference existed between the LIL and HILgroups. Both learner groups used a higherproportion of the general classifier ge than NSs(for LIL and NS groups, x2 ¼ 220.101, p < 0.0001;for HIL andNS groups, x2 ¼ 336.656, p < 0.0001).Notably, the HIL group also had a higherproportion of ge than the LIL group (x2 ¼13.490, p ¼ 0.0012). The number of inappropri-ate classifiers did not differ significantly betweenthe LIL and HIL groups, but the HIL groupomitted significantly fewer classifiers in obligatoryenvironments (x2 ¼ 36.318, p < 0.0001). In
TABLE 4Measures of Fluency, Diversity, and Accuracy
Dimension Measure
Fluency Number of classifier tokens per hundred charactersNumber of classifier types per hundred characters
Diversity Type–token ratio of classifiersAccuracy of Produced Classifiers Accuracy rate of classifiers produced by learnersAccuracy of Classifiers in ObligatoryEnvironments
Accuracy rate of classifiers in all obligatory environments
TABLE 3Classifier Error Tags, Legends, and Examples from the Corpus
Tag Legend
<c‐lac> Missing classifier in an obligatory context, e.g.,Zuotian wo ding liang <c‐lac> jipiao.Yesterday I book two flight‐tickets‘Yesterday, I booked two flight tickets.’
<q‐c‐lac> Missing numeral/quantifier and classifier in an obligatory context, e.g.,Wo de jia shi <q‐c‐lac> xiao zhen.I GEN home be small town‘My home is a small town.’
<d‐c‐lac> Missing determiner and classifier in an obligatory context, e.g.,Wo zui xihuan <d‐c‐lac> ‘Man Cheng Jin Dai Huangjin Jia’ de zhongguo dianying.I most like ‘Curse of the Golden Flower’ GEN China movie‘I like the Chinese movie “Curse of the Golden Flower” most.’
<c‐red> Redundant classifier, e.g.,Na ge <c‐red> tian wanshang, wo gen wo mama qu le gongche zhan.That CL day evening, I together my mom go PERF bus station‘That evening, my mom and I went to the bus station.’
<q‐c‐red> Redundant numeral/quantifier and classifier, e.g.,Wo meiyou yi ge <q‐c‐red> yusan, suoyi ni gei wo ni de yusan.I no one CL umbrella, so you give me you GEN umbrella.‘I didn’t have an umbrella, so you gave me yours.’
<c‐wro> Inappropriate classifier, e.g.,Xiaomei de mama kan le na zhang <c‐wro> xin.Xiaomei GEN mom look PERF that CL letter.‘Xiaomei’s mom read that letter.’
Note. CL ¼ classifier; GEN ¼ genitive (–de); PERF ¼ perfective aspect (–le).
52 The Modern Language Journal 97 (2013)
addition, theHIL group showedmarked growth intype frequency and TTR compared with the LILgroup, and the NS group produced far moreclassifier types with a much higher TTR than thelearner groups.
Inter‐ and Intraindividual Variability. To investi-gate inter‐ and intraindividual variability, weconducted an analysis of 4 focal learners—3females (S, W, and T) and 1 male (J) at theHIL. We chose learners at the HIL because theHIL learners’ data, which was collected over twoconsecutive academic semesters, offered us aricher dataset for examining longitudinal devel-opment than the LIL learners’ data, which wascollected over one academic semester only. The 4focal learners were selected based on threecriteria: They shared similar language back-grounds, submitted at least 10 of the 11 requiredessays, and their overall language performancerepresented high‐, average‐, and low‐achievinglearners within the HIL group. All 4 were nativeEnglish speakers in the third year of college intheir early 20s. Tables 6 and 7 summarize the
lengths of their essays and the number of classifiersin each essay. The second essay in the springsemester was excluded from the analysis, as not allfocal students submitted that essay.
We grouped each learner’s essays by monthto alleviate the potential effect of topics onlearners’ classifier usage. The learners’ develop-mental paths for the dimensions of fluency,diversity, and accuracy are presented in Figures1 (by measure) and 2 (by learner). Fluency wasmeasured using the number of classifier tokensand types per 100 characters. Diversity wasmeasured by TTR. As very few instances ofclassifier omissions existed among the focallearners, only accuracy of classifiers in obligatoryenvironments was considered here.
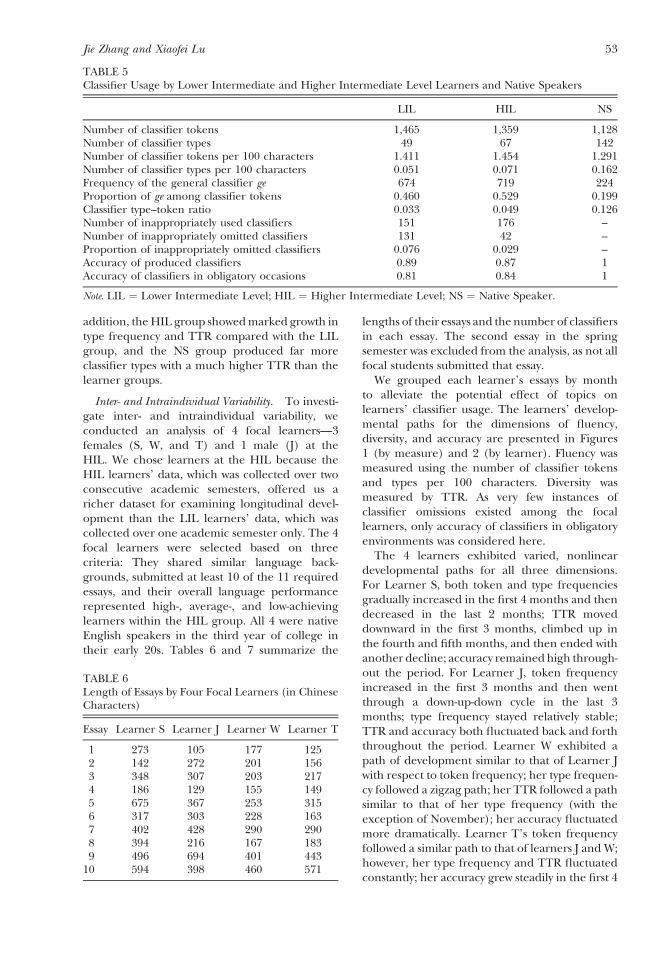
The 4 learners exhibited varied, nonlineardevelopmental paths for all three dimensions.For Learner S, both token and type frequenciesgradually increased in the first 4 months and thendecreased in the last 2 months; TTR moveddownward in the first 3 months, climbed up inthe fourth and fifth months, and then ended withanother decline; accuracy remained high through-out the period. For Learner J, token frequencyincreased in the first 3 months and then wentthrough a down‐up‐down cycle in the last 3months; type frequency stayed relatively stable;TTR and accuracy both fluctuated back and forththroughout the period. Learner W exhibited apath of development similar to that of Learner Jwith respect to token frequency; her type frequen-cy followed a zigzag path; her TTR followed a pathsimilar to that of her type frequency (with theexception of November); her accuracy fluctuatedmore dramatically. Learner T’s token frequencyfollowed a similar path to that of learners J and W;however, her type frequency and TTR fluctuatedconstantly; her accuracy grew steadily in the first 4
TABLE 5Classifier Usage by Lower Intermediate and Higher Intermediate Level Learners and Native Speakers
LIL HIL NS
Number of classifier tokens 1,465 1,359 1,128Number of classifier types 49 67 142Number of classifier tokens per 100 characters 1.411 1.454 1.291Number of classifier types per 100 characters 0.051 0.071 0.162Frequency of the general classifier ge 674 719 224Proportion of ge among classifier tokens 0.460 0.529 0.199Classifier type–token ratio 0.033 0.049 0.126Number of inappropriately used classifiers 151 176 –
Number of inappropriately omitted classifiers 131 42 –
Proportion of inappropriately omitted classifiers 0.076 0.029 –
Accuracy of produced classifiers 0.89 0.87 1Accuracy of classifiers in obligatory occasions 0.81 0.84 1
Note. LIL ¼ Lower Intermediate Level; HIL ¼ Higher Intermediate Level; NS ¼ Native Speaker.
TABLE 6Length of Essays by Four Focal Learners (in ChineseCharacters)
Essay Learner S Learner J Learner W Learner T
1 273 105 177 1252 142 272 201 1563 348 307 203 2174 186 129 155 1495 675 367 253 3156 317 303 228 1637 402 428 290 2908 394 216 167 1839 496 694 401 443
10 594 398 460 571
Jie Zhang and Xiaofei Lu 53
months, regressed in February, and ended with asubstantial increase.
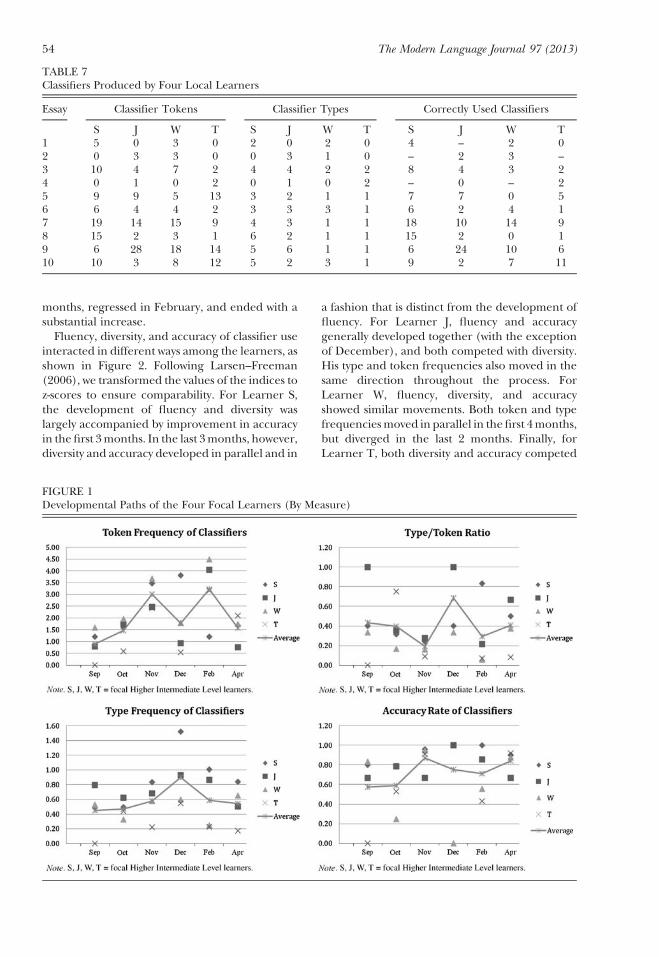
Fluency, diversity, and accuracy of classifier useinteracted in different ways among the learners, asshown in Figure 2. Following Larsen–Freeman(2006), we transformed the values of the indices toz‐scores to ensure comparability. For Learner S,the development of fluency and diversity waslargely accompanied by improvement in accuracyin thefirst 3months. In the last 3months, however,diversity and accuracy developed in parallel and in
a fashion that is distinct from the development offluency. For Learner J, fluency and accuracygenerally developed together (with the exceptionof December), and both competed with diversity.His type and token frequencies also moved in thesame direction throughout the process. ForLearner W, fluency, diversity, and accuracyshowed similar movements. Both token and typefrequenciesmoved in parallel in thefirst 4months,but diverged in the last 2 months. Finally, forLearner T, both diversity and accuracy competed
TABLE 7Classifiers Produced by Four Local Learners
Essay Classifier Tokens Classifier Types Correctly Used Classifiers
S J W T S J W T S J W T1 5 0 3 0 2 0 2 0 4 – 2 02 0 3 3 0 0 3 1 0 – 2 3 –
3 10 4 7 2 4 4 2 2 8 4 3 24 0 1 0 2 0 1 0 2 – 0 – 25 9 9 5 13 3 2 1 1 7 7 0 56 6 4 4 2 3 3 3 1 6 2 4 17 19 14 15 9 4 3 1 1 18 10 14 98 15 2 3 1 6 2 1 1 15 2 0 19 6 28 18 14 5 6 1 1 6 24 10 610 10 3 8 12 5 2 3 1 9 2 7 11
FIGURE 1Developmental Paths of the Four Focal Learners (By Measure)
54 The Modern Language Journal 97 (2013)
with fluency. As token frequency moved up, TTRtended to move down, and as accuracy increased,both token and type frequencies tended todecrease. Similar to S, Learner T’s token andtype frequencies alsomoved in opposite directionsin the later months.
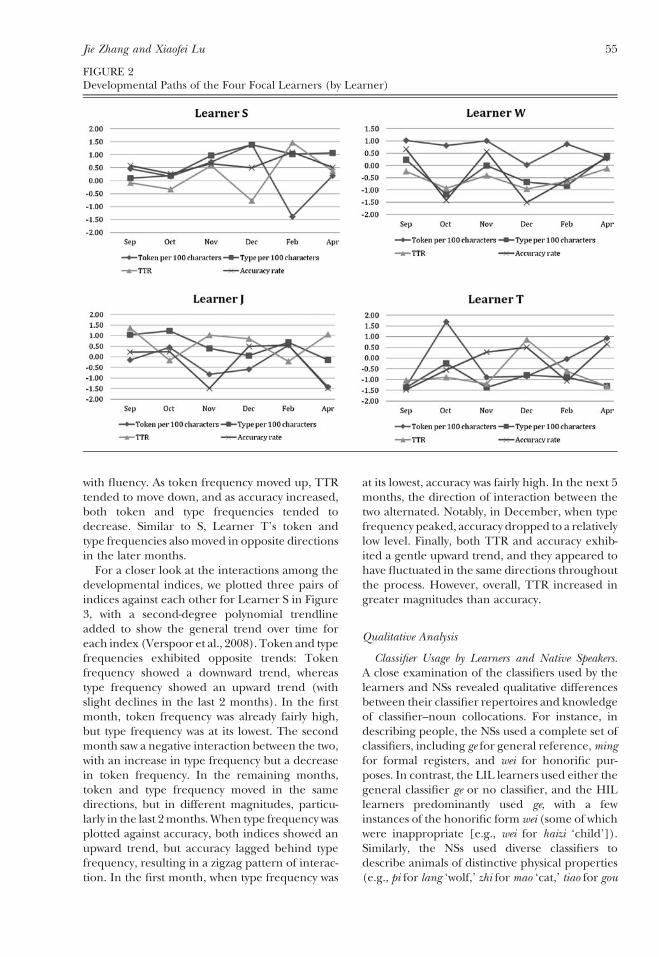
For a closer look at the interactions among thedevelopmental indices, we plotted three pairs ofindices against each other for Learner S in Figure3, with a second‐degree polynomial trendlineadded to show the general trend over time foreach index (Verspoor et al., 2008). Token and typefrequencies exhibited opposite trends: Tokenfrequency showed a downward trend, whereastype frequency showed an upward trend (withslight declines in the last 2 months). In the firstmonth, token frequency was already fairly high,but type frequency was at its lowest. The secondmonth saw a negative interaction between the two,with an increase in type frequency but a decreasein token frequency. In the remaining months,token and type frequency moved in the samedirections, but in different magnitudes, particu-larly in the last 2months.When type frequency wasplotted against accuracy, both indices showed anupward trend, but accuracy lagged behind typefrequency, resulting in a zigzag pattern of interac-tion. In the first month, when type frequency was
at its lowest, accuracy was fairly high. In the next 5months, the direction of interaction between thetwo alternated. Notably, in December, when typefrequency peaked, accuracy dropped to a relativelylow level. Finally, both TTR and accuracy exhib-ited a gentle upward trend, and they appeared tohave fluctuated in the same directions throughoutthe process. However, overall, TTR increased ingreater magnitudes than accuracy.
Qualitative Analysis
Classifier Usage by Learners and Native Speakers.A close examination of the classifiers used by thelearners and NSs revealed qualitative differencesbetween their classifier repertoires and knowledgeof classifier–noun collocations. For instance, indescribing people, the NSs used a complete set ofclassifiers, including ge for general reference,mingfor formal registers, and wei for honorific pur-poses. In contrast, the LIL learners used either thegeneral classifier ge or no classifier, and the HILlearners predominantly used ge, with a fewinstances of the honorific form wei (some of whichwere inappropriate [e.g., wei for haizi ‘child’]).Similarly, the NSs used diverse classifiers todescribe animals of distinctive physical properties(e.g., pi for lang ‘wolf,’ zhi for mao ‘cat,’ tiao for gou
FIGURE 2Developmental Paths of the Four Focal Learners (by Learner)
Jie Zhang and Xiaofei Lu 55

‘dog,’ and tou for zhu ‘pig’), while theHIL learnersused ge and zhi only, resulting in several inappro-priate collocations (e.g., ge for lu ‘deer’ and gongji‘rooster’).
In line with the highly formal nature of theirwriting, the NSs sometimes used noun phraseswithout classifiers to achieve a formal style. Forexample, in (2), the numeral and classifier wereomitted altogether after the demonstrative zhe‘this.’ Such uses contributed to the lower classifier–token frequency in the NS data.
Inter‐ and Intraindividual Variability. To furtherexplore each focal learner’s developmental pathand the interaction between different develop-mental indices, we examined their essays from amicrogenetic perspective. Overall, Learner S’smastery of classifiers was superior to that ofher peers. She produced the greatest number ofclassifier tokens (80) and types (17) with an
accuracy rate of 91%. Her essays showed an overallconsistent improvement in the diversity of uniqueclassifiers. She used the general classifier geappropriately and produced a variety of specialclassifiers (jian for shi ‘matter,’ ke for shu ‘tree,’ jiafor shangdian ‘store,’ dun for fan ‘meal,’ and zhi forqingwa ‘frog,’ songshu ‘squirrel,’ and mao ‘cat’).Her accuracy started out high and improved withlearning time. The few inappropriate usages of geweremostly with abstract concepts (e.g., in place ofzhong in *you ge manzu gan ‘have CL satisfactionsense’) or events (e.g., in place of ci in *you ge dachaojia ‘haveCLbig quarrel’). She alsomisused theclassifier ke ( ) in place of a homophonic classifierke ( ) in collocations with yao ‘pill’ and xiao shitou‘small rock.’ While the former is semanticallycongruent with plants, the latter usually collocateswith small and round objects such as pills androcks.
Learner J produced 68 classifier tokens and 13classifier types with an accuracy rate of 77%. In hisearlier essays, he correctly produced the followingclassifiers for a range of concrete nouns: shuang forshoutao ‘glove,’ ding for maozi ‘hat,’ jian for maoyi
FIGURE 3Interaction Between Pairs of Measures for Learner S
(2) zhe liulangde haizi yijing likai muqinde biwan tai jiu.[this wandering child already leave mother’s arm too long]‘This wandering child has been away from his mother’sarms for too long.’
56 The Modern Language Journal 97 (2013)

‘sweater,’ zhi for qingwa ‘frog’ and lu ‘deer,’ feng forxin ‘letter,’ chang for yinyuehui ‘concert,’ jian for shi‘matter,’ and jie for ke ‘a class period.’ As heexpanded his classifier repertoire, the accuracyof his classifier use fluctuated. His earlier essayscontained many instances of overgeneralizationof ge for both concrete and abstract nouns, forexample, in place of feng in *yi ge xin ‘oneCL letter’and zhong in *zhe ge wuru ‘this CL insult.’ In his lateressays, the earlier overgeneralization with ge forconcrete nouns was reduced but overgeneraliza-tion persisted for abstract nouns and concepts. Forinstance, he correctly used feng for xin ‘letter’ butmisused ge in place of ju for shiju ‘verse.’ He alsoincorrectly omitted ge in wu zi ‘five word’ and zhegushi ‘this story.’
Learner W produced 66 classifier tokens and 8classifier types with an accuracy rate of 58%.Compared with learners S and J, she showed astronger tendency of ge overgeneralization. A casein point was her use of ge for all animal nouns, suchas qingwa ‘frog,’ maotouying ‘owl,’ and shanyang‘goat’; in these cases, zhi should have been used.She also produced redundant classifiers in yi ge ri‘one CL day,’ where ri ‘day’ is conventionally usedas the classifier and ge is superfluous. Learner Wdid experiment with several special classifiers,mastering some and struggling with others atdifferent time points. For example, she incorrectlyused pian for dianying ‘movie’ in an October essaybut correctly used bu in a November essay.Conversely, she correctly used feng for dianziyoujian ‘email’ in aNovember essay, but incorrectlyused zhang for the related concept xin ‘letter’ in aDecember essay. Her later errors primarily in-volved abstract concepts, such as the use of ge inplace of shou for gushi ‘ancient poem’ and in placeof zhong for miaoshu ‘description.’
Learner T produced the smallest number ofclassifier tokens (55) and types (3) with an accu-racy rate of 63%. She demonstrated good under-standing of the semantic functions of classifiers,omitting only one classifier in obligatory occasionsin the first essay. However, she did not expandher classifier repertoire with learning time butrelied heavily on the general classifier ge, using itfor nearly all nouns, including persons, animals,objects, cultural artifacts, and abstract concepts.The only two special classifiers she produced werezhang for fadan ‘traffic ticket’ and ben for shu‘book.’ She did not seem to have internalized thezhang–fadan collocation. While she correctlyproduced this collocation in an October essay, inNovember she returned to ge for the samenoun, which is semantically acceptable but lessdesirable.
DISCUSSION AND CONCLUSION
Taking the dynamic systems approach to SLD,this study examined variability in CFL learners’development of the Chinese NCS by analyzinglongitudinal data from a corpus of 657 essayswritten by CFL learners at lower and higherintermediate levels and comparing learner andNSperformance. Our findings have useful implica-tions for understanding the complexity of theclassifier system, the paths of development ofindividual learners, the patterns of interactionamong different dimensions or subsystems of alanguage system in the developmental process,and more generally, the dynamic, nonlinearnature of the SLD process.
The comparison of learner and NS data showeddistinctive patterns of classifier use. TheNSs used awide range of classifiers with appropriate classifier–noun collocations; they also omitted classifiers inways that were appropriate for the context andformal genre of writing to achieve the desireddegree of formality. Similar to what was reportedin previous research (e.g., Polio, 1994), learnersoverused the general classifier ge and engageda smaller range of special classifiers. The LILlearners showed a strong tendency to missclassifiers in obligatory occasions; both the LILand HIL learners struggled with classifier–nouncollocations, particularly for abstract nouns.
Our analyses of the longitudinal data of the 4focal learners revealed varied, nonlinear paths ofdevelopment among them for the dimensions offluency, diversity, and accuracy, all characterizedby varying degrees of progression, fluctuation, andregression. Intraindividual variability was visibleacross different time points and across differentdimensions for the same learner. In short, vari-ability is ubiquitous and should be treated as anintrinsic property of the SLD process. This reality,however, suggests that, in addition to group‐levelinstruction, learners may benefit from differenttypes of assistance and the same learner mayalso benefit from different types of assistance atdifferent time points. It is essential for languageeducators to be aware of this property, as this willhelp us appreciate the variable developmentalpaths among learners and tailor assistance toindividual learners’ emerging needs based ontheir emerging L2 system (Lantolf & Poehner,2004; Poehner & Lantolf, 2005).
Our analyses also yielded varied patterns ofinteraction among the dimensions of fluency,diversity, and accuracy. In particular, developmentin fluency was not always accompanied by growthin diversity or accuracy, and vice versa (Caspi,
Jie Zhang and Xiaofei Lu 57

2010; Spoelman & Verspoor, 2010). A major chal-lenge in learners’ acquisition of the classifiersystem appeared to be the development ofsystematic knowledge of classifier–noun colloca-tions. As the learners’ noun repertoire expands,their classifier repertoire and knowledge ofrelevant classifier–noun collocations need toexpand accordingly. Such collocational knowl-edge cannot be acquired automatically and shouldnot be taken for granted in pedagogical practice.In prevalent CFL pedagogical materials andtextbooks, systematic treatment of classifiers andnouns as collocations is scant, and it is common tointroduce a new classifier by listing it as a stand‐alone vocabulary item along with a few nouns thatit collocates with for illustrative purposes. Thispedagogical practice may have contributed to thefact that, when learners encounter new nounsor classifiers with insufficient information onclassifier–noun collocations, they are likely toproduce ill‐formed collocations as a result ofexperimenting with the new classifiers or resortingto the general classifier ge.
SLD of the Chinese NCS and interactionsamong different dimensions are certainly nottaking place in isolation but are subject to in-fluence by external factors. Recall that declines intype frequency and accuracy were observed in theFebruary and April essays. The challenging writingtasks for those essays may have contributed to thisdecline. Writing commentaries on classical Chi-nese poems and prose demanded the use of moreabstract nouns and concepts, most of whichrequired less common special classifiers.
Liang (2009) discussed several issues pertainingto the presentation of classifiers in mainstreamCFL textbooks. For example, he mentioned thatthe frequency with which classifiers appeared inthe text input was not high enough, and manylessons introduced classifiers unrelated to eachother, making it difficult for learners to internalizenew classifiers. Furthermore, he pointed out thatin CFL instruction, “the grammatical functionsand meanings of classifiers are usually notexplained in classrooms” (Liang, 2009, p. 192).He argued that it is important to teach not only thegrammatical functions and meanings of classifiersbut also their collocations with nouns. Based onour results and following Liang’s recommenda-tion, we also advocate a collocational approach topresenting classifiers and nouns in CFL teachingmaterials. In other words, new nouns and theircorresponding classifiers should be introducedconcomitantly. More importantly, they should beintroduced in a systematic way, allowing learnersto understand the prototypical meanings and
semantic categories of the classifiers, as well as thecultural and conceptual knowledge underlyingtheir collocational patterns (e.g., Lakoff, 1987; Tai,1994).
This study was based on the analysis of alongitudinal learner corpus collected in a naturalclassroom setting, in which the curricula were keptintact during the data collection process. In otherwords, students were not given extra assignmentsbeyond what the curricula required to elicit theuse of specific linguistic constructions. On the onehand, this approach allowed us to capture andscrutinize what learners actually produced overtime in a natural classroom context, a desirablefeature of learner corpus design. On the otherhand, it also resulted in several limitations.Specifically, our data were limited in terms ofdensity of data collection and control over writingtasks, topics, and genres. The relatively long lapsebetween the December and February assignments(due to the winter break) may also have inter-rupted the learning process. These factors mayhave had a stronger impact on the analysis ofintraindividual variability than that of interindivid-ual variability, as in the latter case, the individuallearners under scrutiny performed the same tasksat each time point. The naturalistic approach todata collection could be complemented by a morecontrolled approach in order to gain a morethorough understanding of learners’ developmen-tal process.
NOTES
1 http://gaokao.eol.cn/2 http://edu.people.com.cn/GB/gaokao/3 http://www.ictclas.org
REFERENCES
Allan, K. (1977). Classifiers. Language, 53, 285–311.Anthony, L. (2011). AntConc (Version 3.2.2.1) [Com-
puter Software]. Tokyo: Waseda University.Beckner, C., Blythe, R., Bybee, J., Christiansen, M. H.,
Croft, W., Ellis, N. C., Holland, J., Ke, J., Larsen–Freeman, D., & Schoenemann, T. (2009). Lan-guage is a complex adaptive system: Position paper.Language Learning, 59 (Suppl. 1), 1–26.
Cancino, H., Rosansky, E., & Schumann, J. (1978). Theacquisition of English negatives and interrogativesby native Spanish speakers. In E. M. Hatch (Ed.),Second language acquisition: A book of readings(pp. 207–230). Rowley, MA: Newbury House.
Caspi, T. (2010). A dynamic perspective on second languagedevelopment (Unpublished doctoral dissertation).University of Groningen, Netherlands.
58 The Modern Language Journal 97 (2013)

Chomsky, N. (1965). Aspects of the theory of syntax.Cambridge, MA: MIT Press.
Chou, C.‐P., & Chao, D.‐L. (1996). A trip to China:Intermediate reader of modern Chinese. Princeton, NJ:Princeton University Press.
de Bot, K. (2008). Introduction: Second languagedevelopment as a dynamic process. Modern Lan-guage Journal, 92, 166–178.
de Bot, K., & Larsen–Freeman, D. (2011). Researchingsecond language development from a DynamicSystems Theory perspective. In M. H. Verspoor,K. de Bot, & W. Lowie (Eds.), A dynamic approachto second language development: Methods and techniques(pp. 5–24). Philadelphia/Amsterdam: JohnBenjamins.
de Bot, K., Lowie, W., & Verspoor, M. H. (2007). ADynamic Systems Theory approach to secondlanguage acquisition. Bilingualism: Language andCognition, 10, 7–21.
de Bot, K., Lowie, W., & Verspoor, M. H. (2011).Introduction. InM.H. Verspoor&K. deBot (Eds.),A dynamic approach to second language development:Methods and techniques (pp. 1–4). Philadelphia/Amsterdam: John Benjamins.
Ellis, N., & Larsen–Freeman, D. (2006). Languageemergence: Implications for applied linguistics—introduction to the special issue. Applied Linguistics,27, 558–589.
Ellis, R. (1994). The study of second language acquisition.Oxford: Oxford University Press.
Grinevald, C. (2000). A morphosyntactic typology ofclassifiers. In G. Senft (Ed.), Systems of nominalclassification (pp. 50–92). Cambridge: CambridgeUniversity Press.
Hansen, L., & Chen, Y.‐L. (2001). What counts in theacquisition and attrition of numeral classifiers?JALT Journal, 23, 83–100.
Lakoff, G. (1987).Women, fire, and dangerous things: Whatcategories reveal about the mind. Berkeley: Universityof California Press.
Lantolf, J. P., & Poehner, M. (2004). Dynamic assessmentof L2 development: Bringing the past into thefuture. Journal of Applied Linguistics, 1, 49–72.
Larsen–Freeman, D. (1997). Chaos/complexity scienceand second language acquisition. Applied Linguis-tics, 18, 141–165.
Larsen–Freeman, D. (2006). The emergence of com-plexity, fluency, and accuracy in the oral andwritten production of five Chinese learners ofEnglish. Applied Linguistics, 27, 590–619.
Larsen–Freeman, D., & Cameron, L. (2008). Researchmethodology on language development from acomplex systems perspective. Modern LanguageJournal, 92, 200–213.
Li, C. N., & Thompson, S. A. (1981).Mandarin Chinese: Afunctional reference grammar. Berkeley/Los Angeles:University of California Press.
Li, S. (2010). Corrective feedback in perspective: The interfacebetween feedback type, proficiency, the choice of targetstructure, and learners’ individual differences in working
memory and language analytic ability (Unpublisheddoctoral dissertation). Michigan State University.
Liang, S.‐Y. (2009). The acquisition of Chinese nominalclassifiers by L2 adult learners (Unpublished doctoraldissertation). The University of Texas at Arlington.
Poehner, M. E., & Lantolf, J. P. (2005). Dynamicassessment in the language classroom. LanguageTeaching Research, 9, 233–265.
Polio, C. (1994). Non‐native speakers’ use of nominalclassifiers in Mandarin Chinese. Journal of theChinese Language Teachers Association, 29, 51–66.
Ross, H., & Wang, Y. (2010). The College EntranceExamination in China: An overview of its social‐cultural foundations, existing problems, and con-sequences. Chinese Education and Society, 43(4),3–10.
Spoelman, M., & Verspoor, M. (2010). Dynamic patternsin development of accuracy and complexity: Alongitudinal case study in the acquisition ofFinnish. Applied Linguistics, 31, 532–553.
Tai, J. H.‐Y. (1994). Chinese classifier systems andhuman categorization. In M. Chen & O. Tseng(Eds.), In honor of Professor William S.‐Y. Wang:Interdisciplinary studies on language and languagechange (pp. 479–494). Taiwan: Pyramid PublishingCompany.
van Dijk, M., Verspoor, M. H., & Lowie, W. (2011).Variability and DST. In M. H. Verspoor, K. deBot, & W. Lowie (Eds.), A dynamic approach tosecond language development: Methods and techniques(pp. 55–84). Philadelphia/Amsterdam: JohnBenjamins.
van Geert, P., & Steenbeek, H. (2005). Explaining afterby before: Basic aspects of a dynamic systemsapproach to the study of development. Developmen-tal Review, 25, 408–442.
Verspoor, M. H., de Bot, K., Lowie, W. (Eds.) (2011). Adynamic approach to second language development.Philadelphia/Amsterdam: John Benjamins.
Verspoor, M. H., Lowie, W., & van Dijk, M. (2008).Variability in second language development from adynamic systems perspective. Modern LanguageJournal, 92, 214–231.
Wolfe–Quintero, K., Inagaki, S., & Kim, H. Y., (1998).Second language development in writing: Measures offluency, accuracy, and complexity (Report No. 17).Honolulu: University of Hawai’i, Second LanguageTeaching and Curriculum Center.
Wu, S.‐M., Yu, Y., Zhang, Y., & Tian, W. (2007). Chineselink: Elementary Chinese, Level 1. Upper Saddle River,NJ: Prentice Hall.
Wu, S.‐M., Yu, Y., & Zhang, Y. (2008a). Chinese link:Intermediate Chinese, Level 2 Part 1. Upper SaddleRiver, NJ: Prentice Hall.
Wu, S.‐M., Yu, Y., & Zhang, Y. (2008b). Chinese link:Intermediate Chinese, Level 2 Part 2. Upper SaddleRiver, NJ: Prentice Hall.
Zhang, H. (2007). Numeral classifiers in MandarinChinese. Journal of East Asian Linguistics, 16,43–59.
Jie Zhang and Xiaofei Lu 59

APPENDIX A
Writing Topics for Chinese as a Foreign LanguageLearners at the Lower Intermediate Level (LIL)
APPENDIX B
Writing Topics for Chinese as a Foreign LanguageLearners at the Higher Intermediate Level (HIL)
Writing Topic Date of Writing
1 A travel experience Sept. 8, 20092 A letter to parents Sept. 17, 20093 An invitation letter Sept. 29, 20094 My hometown Oct. 12. 20095 A thank‐you email Oct. 20, 20096 A banking experience Oct. 30, 20097 A travel plan for the
winter breakNov. 9, 2009
8 Introduce a Chinese movie Nov. 18, 20099 Stay fit Dec. 4, 200910 Free topic Dec. 8, 2009
Writing Topic Date of Writing
Fall 20091 An unpleasant experience Sept. 4, 20092 A thank‐you card Sept. 19, 20093 A diary entry Oct. 11, 20094 A prose Oct. 21, 20095 Frog story Oct. 26, 20096 An experience of being
misunderstoodNov. 18, 2009
7 Pear story Nov. 20, 20098 Picture description Dec. 5, 2009
Spring 20109 Comment on three poems Feb. 9, 201010 Comment on an essay Feb. 23, 201011 Comment on a prose Apr. 9, 2010
60 The Modern Language Journal 97 (2013)