using reinforcement learning to play angry birds
TRANSCRIPT

Technische Universität Dresden faculty of computer science, ICCL
USING REINFORCEMENTLEARNING TO PLAY ANGRYBIRDS
colloquium
Peter Hirsch
Dresden, 2017/9/26

Table of Contents
1 Angry Birds
2 Neural Networks
3 Reinforcement Learning
4 Deep Deterministic Policy Gradient
5 RL Agent: Dr. L. Bird
6 Results
TU Dresden, 2017/9/26 slide 2

Angry Birds in a Nutshell
TU Dresden, 2017/9/26 Angry Birds slide 3

Neural Networks
...input output
output =∑
weights · inputs
TU Dresden, 2017/9/26 Neural Networks slide 4

Deep Neural Networks
input
hidden
output
TU Dresden, 2017/9/26 Neural Networks slide 5

Deep Neural Networks
TU Dresden, 2017/9/26 Neural Networks slide 6

Deep Neural Networks
TU Dresden, 2017/9/26 Neural Networks slide 6

RL in a Nutshell
Environment
Agent
actionstate,reward
TU Dresden, 2017/9/26 Reinforcement Learning slide 7

RL in a Nutshell
Angry Birds
Agent
shootbird
image,score
TU Dresden, 2017/9/26 Reinforcement Learning slide 7

RL: Policy-based Methods
deterministic policy
stochastic policy
(with state approximation, gray states not distinguishable)
TU Dresden, 2017/9/26 Reinforcement Learning slide 8

RL: Value-based Methods
Value Estimator:- table- neural network- ...
Action 1: <value1>Action 2: <value2>Action 3: <value3>...
state s
a greedy or ε-greedy policy is used to act(a.k.a. go to neighboring state with highest (Q-)value)
TU Dresden, 2017/9/26 Reinforcement Learning slide 9

RL: Actor-Critic Methods
Critic(~value) state s
Q(s, a)
Actor(~policy)
action astate s
Combination of policy-based and value-based
TU Dresden, 2017/9/26 Reinforcement Learning slide 10

Deep Deterministic Policy Gradient
state s
Q(s, a)
action astate s
Evaluation
Optimization
Actor
Critic
TU Dresden, 2017/9/26 DDPG slide 11

DDPG: Acting
action astate sActor
Experience Buffer
store store
execute
Evaluation
Optimization
TU Dresden, 2017/9/26 DDPG slide 12

DDPG: Buffer
Experience Buffer
state s
action a
next state s'
reward r
TU Dresden, 2017/9/26 DDPG slide 13

DDPG: Learning - Part 1
Q(s', a')
Actor
Critic
Experience Buffer
action a'
Evaluation
Optimization
samples, a, s', r
s'
TU Dresden, 2017/9/26 DDPG slide 14

DDPG: Learning - Part 2
Q(s, a)
Actor
Critic
Experience Buffer
Evaluation
Optimization
samples, a, s', r
s, a
TU Dresden, 2017/9/26 DDPG slide 15

DDPG: Learning - Part 3
Loss(MSE):
Actor
Critic
Experience Buffer
sample
backprop
s, a, s', raction
gradient
Evaluation
Optimization
Q(s, a)r+Q(s', a')
Optimization: Backpropagation using chain rule across the two networks
TU Dresden, 2017/9/26 DDPG slide 16

Dr. L. Bird
state sQ(s, a)
action a
state s
Evaluation
Optimization
Actor
Critic
? ?
?TU Dresden, 2017/9/26 Dr. L. Bird slide 17

Dr. L. Bird: State
TU Dresden, 2017/9/26 Dr. L. Bird slide 18

Dr. L. Bird: Action
x
y
t
TU Dresden, 2017/9/26 Dr. L. Bird slide 19

Dr. L. Bird - Agent
x
y
t
state sQ(s, a)
action a
state s
Evaluation
Optimization
Actor
Critic
TU Dresden, 2017/9/26 Dr. L. Bird slide 20

Results
0 100 200 300 400 500 600 700 800Games
0 0
1 1
2 2
3 3
4 4
5 5
6 6Sc
ore
per G
ame
[in 1
0000
]TrainingTraining (moving average)
TU Dresden, 2017/9/26 Results slide 21

Results
0 1000 2000 3000 4000 5000 6000Games
0 0
1 1
2 2
3 3
4 4
5 5
6 6
Scor
e pe
r Gam
e [in
100
00]
TrainingTraining (moving average)
0 200 400 600 800 1000 1200 1400Games
0 0
1 1
2 2
3 3
4 4
5 5
6 6
Scor
e pe
r Gam
e [in
100
00]
TrainingTraining (moving average)
0 100 200 300 400 500 600 700 800 900Games
0 0
1 1
2 2
3 3
4 4
5 5
6 6
Scor
e pe
r Gam
e [in
100
00]
TrainingTraining (moving average)
0 100 200 300 400 500 600 700 800 900Games
0 0
1 1
2 2
3 3
4 4
5 5
6 6
Scor
e pe
r Gam
e [in
100
00]
TrainingTraining (moving average)
TU Dresden, 2017/9/26 Results slide 22
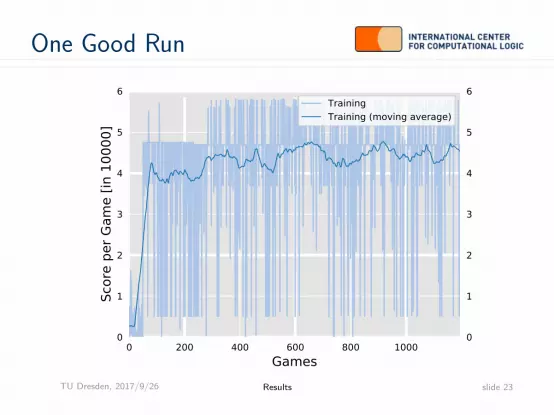
One Good Run
0 200 400 600 800 1000Games
0 0
1 1
2 2
3 3
4 4
5 5
6 6Sc
ore
per G
ame
[in 1
0000
]TrainingTraining (moving average)
TU Dresden, 2017/9/26 Results slide 23

Tested Versions
• DDPG loss function:– Q-Learning-based (off-policy)– Sarsa-based (on-policy)– TD-based (estimated value)– Monte-Carlo-based (cumulative return)
• Stochastic Policy Gradient:– policy-based– uses statistics of probability distribution– output (sampled for action):
• mean• variance
• A3C (asynchronous advantage actor-critic)– actor-critic– stochastic policy– parallel (asynchronous) execution of multiple agents– advantage instead of Q-value (relative value of actions)
→ no success so far
TU Dresden, 2017/9/26 Results slide 24

Sources neural network schematics:• http://www.asimovinstitute.org/neural-network-zoo/• http://cs231n.github.io/neural-networks-1/
Source policy-based method example:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
TU Dresden, 2017/9/26 End slide 25

Discussion
TU Dresden, 2017/9/26 End slide 26