semantic-based rfid data management
TRANSCRIPT

Semantic-based RFID Data Management
Roberto De Virgilio, Eugenio Di Sciascio, Michele Ruta, Floriano Scioscia,Riccardo Torlone
Abstract Traditional Radio-Frequency IDentification (RFID) applications have beenfocused on replacing bar codes in supply chain management. Leveraging a ubiqui-tous computing architecture, the chapter presents a framework allowing both quickdecentralized on-line item discovery and centralized off-line massive business logicanalysis, according to needs and requirements of supply chain actors. A semantic-based environment, where tagged objects become resources exposing to an RFIDreader not a trivial identification code but a semantic annotation, enables taggedobjects to describe themselveson the flywithout depending on a centralized in-frastructure. On the other hand, facing on data management issues, a proposal isformulated for an effectiveoff-line multidimensional analysis of huge amounts ofRFID data generated and stored along the supply chain.
1 Introduction
A supply chain is a complex system composed by organizationsand people withtheir activities involved in transferring a product or service from a supplier to afinal customer. The key to make a successful supply chain relies on an extendedcollaboration, implying the integration among actors involved in the productive andlogistic network. An integrated and flexible management of logistics (physical andinformation flows) has to be set-up both inside and outside factory boundaries. Spe-cialized production and distribution processes suffer from the limited interactionsallowed by rigid networks. As a result, nowadays a relevant component of compe-tition in the market occurs among logistical chains. The supply chain can no longerbe represented as static or linear, but it needs to be evaluated dynamically, as a com-plex system made of interactions and connections among actors operating along thechain.
Many empirical investigations have demonstrated there is apositive correlationbetween enterprise performances and its propensity and attitude to be integratedinto larger systems. This is the reason why enterprises are more and more atten-tive to the opportunity offered by both coordination and cooperation among their
Roberto De Virgilio and Riccardo TorloneUniversita Roma Tre, Rome, Italy, e-mail:{dvr,torlone}@dia.uniroma3.it
Eugenio Di Sciascio, Michele Ruta and Floriano SciosciaPolitecnico di Bari, Bari, Italy, e-mail:{disciascio,m.ruta,f.scioscia}@poliba.it
1

2 Roberto De Virgilio et al
internal functions and the other external actors contributing in different ways to thebusiness. Hence, information has been an increasingly strategic asset in the last fewyears. It covers a determinant position in both logistics and marketing. The phys-ical flow of raw materials, products and their related information is considered asa strategic element for quality standards of products/services, for business analysisand evaluation and finally to allow corrective actions. In particular, current trends inthe consumer products market assign a growing significance to retailers in the gov-ernance of supply chains. The growing dimension of retail groups –sustained by thereached degree of concentration in that field– increases their power against produc-ers and makes them privileged centers of value accumulation, acting as filters for theinformation flow for the whole chain. As a result, the main retailers are investing innew technology in order to boost the information exchange and are mandating theadoption of interoperable solutions to commercial partners [1, 2].
Radio-Frequency IDentification (RFID) is an AutoID (automatic identification)technology, interconnecting via radio two main components: (1) transponders (com-monly namedtags) carrying data, located on the objects to be identified; (2) inter-rogators (also known asreaders) able to receive the transmitted data. Benefits intro-duced by RFID technology w.r.t. barcodes include: (i) unlike optical scan, alignmentbetween reader and tag is not needed; (ii) longer read range (up to few meters); (iii)nearly simultaneous detection of multiple RFID tags; (iv) higher tag storage capac-ity (up to several kBs [3]). Because of these features, RFID provides better levels ofautomation in the supply chain and helps prevent human errors (e.g., a reader caninventory an entire shipment in one pass while it is loaded into a warehouse, withouthaving to scan each product manually). In latest years, industry is progressively ral-lying around few worldwide standards for RFID technologies. In this effort a leadingrole is played by the EPCglobal consortium [4]. However, twomain issues restrain amore advanced exploitation of RFID capabilities. Firstly,the original identificationmechanism only enables a trivial string matching of ID codes, providing exclusively“yes/no” replies. Furthermore, RFID-based technology usually relies on a stablesupport infrastructure and fixed information servers wheremassive data analysisis quite difficult without the support of proper data management and aggregationschemes. Recall that an accurate evaluation of enhancements in RFID-based supplychains rely on global trend inspections over the supply chain itself which requiremultidimensional analyses of huge amounts of RFID data generated and stored incentral DBMSs. Serious data management issues are then inevitably inherited andthey must be faced on.
In this chapter an innovative model for supply chain management is presented,aiming to overcome these limitations by adopting the Ubiquitous Computing (ubi-comp) paradigm. As originally introduced by Mark Weiser [5], ubicomp requiresboth information and computational capabilities are deeply integrated into commonobjects and/or actions and the user will interact with many computational devicessimultaneously, exploiting data automatically extractedfrom “smart objects” per-meating the environment during her ordinary activities.
Leveraging a distributed architecture, the model providesa unified frameworkfor both quick run-time analysis (with respect to a local fragment of the overall in-

Semantic-based RFID Data Management 3
frastructure) and stand-alone massive business logic elaborations (with respect to acentralized DBMS) following needs and requirements of the supply chain actors.An extension of current RFID technology supporting logic-based formalisms forknowledge representation is exploited. Semantic-based object/product annotationsare stored into RFID tags, exploiting machine-understandableontological languagesoriginally created for the Semantic Web effort and based on Description Logics(DLs) [6], such as RDF (Resource Description Framework)1 and OWL (Web On-tology Language)2. Semantically rich and unambiguous information is allowedtofollow a product in each step of its life cycle. The model allows to trace and dis-cover the information flow –associated to products thanks totheir RFID tags– alongthe supply chain, and to formalize various supply chain analyses. Different perspec-tives can be so followed (e.g., product-centric, node-centric, path-oriented, time-oriented). Exploiting semantic-based queries, product and process information canbe read, updated and integrated during manufacturing, packaging and supply chainmanagement, thus allowing full traceability up to sales, aswell as intelligent andde-localized interrogation of product data.
The chapter is structured as follows: Section 2 highlights the benefits of semantic-based approach for RFID data management in a typical scenario and Section 3 sur-veys relevant related work. In order to make the paper self-contained, Section 4reports on basics of formalism and notation exploited in thedetailed frameworkpresentation of Section 5. Finally, Section 6 recalls some experimental evaluationcorroborating the approach and Section 7 closes the paper.
2 Motivating Scenario
A simple reference example should clarify our approach, also highlighting its ben-efits. Let us suppose to monitor the life cycle of an apparel item, acotton shirt, andto follow every production step surveying and extracting relevant product/processinformation. Each production stage will see the progressive joining of annotationsto enhanced RFID tags attached –for instance– to cotton yarncontainers shippedto the factory (first production stage), shirt pallets (logistic step) and single productpackages (final sale phase). Because of traceability requirements, a tag will store:(1) quantitative data pertaining to the product besides theElectronic Product Code(EPC) identifier; (2) high-level qualitative information about production or deliv-ery/logistics processes, expressed as semantic annotations w.r.t. a reference ontol-ogy of the specific industry domain. Information extracted via RFID can be usedfor a variety of purposes. First of all –at each stage of the product evolution– ac-curate verifications can be performed about expected quality requirements of the
1 RDF Primer, W3C Recommendation, February 10th 2004, available athttp://www.w3.org/TR/rdf-primer/.2 OWL Web Ontology Language, W3C Recommendation, February 10th 2004, available athttp://www.w3.org/TR/owlfeatures/

4 Roberto De Virgilio et al
product/process. Moreover, intelligent deliveries can berouted from warehouse todifferent production departments according to their specific characteristics.
A product can inherit (relevant parts of) the semantically annotated descriptionof its raw materials, through properties defined in the reference ontology for the rel-evant domain. Further product attributes can also be storedon the RFID tag, such assize, production date and (for perishable products) expiration date. Finally, location,entering and exiting times are stamped by each supply chain actor conveying theitem, such that advanced applications can be enabled. Beyond rather basic featuresallowed by a traditional data-oriented usage of RFID, a semantic-based approachmakes possible further interactions.
A relevant aspect of the approach is that the semantic-enhanced RFID technol-ogy allows to share information, so optimizing the supply chain and improving per-formance both in terms of logistics features and by providing innovative servicesavailable for all involved actors. The envisioned framework can support a range ofuse cases, involving different stakeholders along a product life cycle. Several tangi-ble (economic) and intangible benefits are expected. Duringproduct manufacturingand distribution, a wide-area support network interconnecting commercial partnersis not strictly needed. This is a significant innovation withrespect to common RFIDsupply chain management solutions [7].
Semantic-enabled RFID tags contain a structured and detailed description ofproduct features, endowed with unambiguous and machine-understandable seman-tics. Goods auto-expose their description to any RFID-enabled computing environ-ment is reached. This favors decentralized approaches in order to offer context-aware application solutions, based on less expensive and more manageable mobilead-hoc networks. In addition to improved traceability, a semantic-based approachprovides unique value-added capabilities. By combining standard and non-standardinference services devised in [8], several semantic-basedmatchmaking schemes canbe designed to meet goals and requirements of specific applications. Adopting alogic-based approach, query flexibility and expressiveness are much greater thanboth keyword-based information retrieval and standard resource discovery proto-cols, which support code-based exact matches only. This enables an effective queryrefinement process and can increase user trust in the discovery facility. Semantic-enhanced RFID object discovery can be leveraged also for sales and post-sale ser-vices, by assisting customers in using their purchased products more effectively.
3 Related Work
In the latest few years automatic identification technologies are gaining more andmore interest. This is mostly due to their possible use in many industrial applica-tions. AutoID systems allow to exchange information about moving people, animalsor goods for tracking in real time. Now RFID is the fastest growing sector of the Au-toID business [9].

Semantic-based RFID Data Management 5
RFID benefits in supply chains have been widely acknowledgedin both distri-bution and warehousing sectors. In latest years, they are becoming evident also inthe retail and post-sales domains. RFID-derived benefits include timeliness, accu-racy and completeness [2]. Wal-Mart world leading retailerhas been at the forefrontof RFID experimentation, leveraging its retail power to mandate RFID adoptionamongst selected suppliers [10, 11]. Significant retailer cost savings associated withRFID-monitored short-shelf-life products are achieved and the introduction of RFIDtechnology by retailers might improve their supply chain efficiency, accuracy andsecurity [12, 13]. Deet al. [7] introduced a reference system for real time track-ing of items in a ubiquitous context. That work constitutes aresearch prototypeof current technological architectures for supply chain management, endorsed byworldwide special interest groups such as the EPCglobal consortium [14]. A furtherrelevant example outlines a retail shopping scenario with RFID technology allowingthe consumer to engage in a seamless shopping experience [15].
The benefits of RFID have been always associated with the powerful and dy-namic automated data acquiring capabilities of the technology [1]. Nevertheless,RFID has received a relatively little investigation from the informative standpoint.RFID technology should actually be viewed as an informationfacilitator that candirectly improve the decision-making capabilities of personnel within an organiza-tion and information sharing across boundaries of partner organizations. Currently,researchers appear to overlook the important process of using RFID-derived infor-mation, which is a significant factor in deriving benefits such as visibility of the sup-ply chain, product traceability and retailer’s inventory monitoring. In other words,supply chains should be considered not only as product flow networks, but also asinformation flow networks. Effective exploitation of the supply chain informationinfrastructure can increase business process awareness and thus improve both per-formance analysis and support to decision processes.
Innovative information technology solutions are requiredfor RFID-based datastorage and analysis, in order to enable such a new kind of smart supply chain. Withreference to business processes for deep analysis with respect to great lapse andhuge amounts of data, the most interesting research field is in defining new storagemodels for a more expressive and sophisticated descriptionof RFID data. There aretwo main directions.
The first one concerns run-time processing of data streams [16, 17, 18, 19]. Mostcurrent approaches, however, track only very basic information, namelyraw dataproduced by RFID readers. Raw data consist in(EPC, location, time)triples, whereEPC is a unique product identifier, while location and time mark each RFID read-ing event. More advanced information and knowledge representation techniqueshave not been significantly integrated yet within RFID technology in smarter supplychain management solutions able to support analyses with higher-level semantics.
The second research direction focuses on off-line computation and efficient datastorage [20, 21, 22]. Wang [20] formalized some features andsemantics of RFIDevents, proposing an extension of the Entity-Relationshipmodel. Based on such ex-tended conceptual model, data streams are analyzed w.r.t. temporal aspects. Bai [17]studied limits of using SQL to detect temporal events in a database and illustrated

6 Roberto De Virgilio et al
a SQL-like language to query such events in an efficient way. Ban [21] presented alocation-oriented indexing which traces paths registeredby RFID readers through anovel representation model. The exploited indexing schemais namedTime Param-eterized Interval R-Tree, as a variant of common R-Tree. Gonzalez [22] providedinstead a new storage model borrowed from datawarehouse literature. Its core ideais to group items moving together so that the multidimensional analysis can be basedon dimensions and measurements like in a typical datawarehouse.
For what concerns quick chain interactions aiming at an object/group discov-ery given a semantically annotated request, we refer to the Semantic Web initiativeand adapt techniques and technologies to RFID-based supplychains. The basic goalis to fully characterize products equipped with RFID tags bymeans of semanticlanguages such as RDF, OWL or DIG. Semantic Web technologiesallow a formal-ization of annotations in a machine understandable way, so promoting interoper-ability. A range of tools can be used for information processing and analysis, in-cluding rule-based systems, logic-based inference engines and query engines basedon declarative languages like SPARQL3. The validity of the Open World Assump-tion (OWA) enables meaningful analyses even in the presenceof incomplete infor-mation. This feature allows to overcome shortcomings of widely adopted “closedworld” paradigms –such as the relational model– that often arise when interfacingheterogeneous information systems of independent partnerorganizations. This isindeed the case of supply chain management architectures. By means of formal on-tologies, knowledge about a specific domain can be modeled and exploited in orderto derive new implied information from the one stated withinmetadata associatedto each resource [8].
Few proposals for semantic-based annotation of physical products can be foundin literature. A solution applied to ubiquitous commerce environments was intro-duced in [23]. RFID tags, however, stored only a product code, which was used asa key to retrieve the corresponding RDF annotation from a central backend infor-mation system. This “virtual counterpart” approach [24], inherited from traditionalRFID applications in supply chain management, poses major architectural and orga-nizational challenges for information sharing in complex multi-party supply chains.Conversely, our core idea is that, as physical products flow among supply chain part-ners,ipso factorelevant high-level information about them is conveyed andcan beexploited for meaningful business analysis at different levels.
Finally the graph-based nature of semantic models producesrelevant challenges.Although simple and general, these models cannot be used in their basic form asstorage models. Many proposals can be found in literature concerning alternativelogic organizations to efficiently analyze semantic data [25]. The contribution, how-ever, is based on optimizations strongly dependent on the physical structures used(i.e., dependent on tools that support these structures). Our proposal is enrichedby the provisioning of data models that describe semantic information at differentlevels of abstraction (non only at the physical one). Therefore the optimization isindependent from any physical environment.
3 SPARQL Query Language for RDF, W3C Recommendation 15 January 2008,http://www.w3.org/TR/rdf-sparql-query/

Semantic-based RFID Data Management 7
4 Preliminaries
In order to make the chapter self-contained, hereafter somedetails about adoptedformalisms and languages will be provided.
4.1 Semantic-based matchmaking
Semantic-based object discovery is grounded on Description Logics (DLs) whichprovides the Ontology Web Language (OWL-DL) semantics. Furthermore, thereis a strict correspondence between the OWL-DL syntax and theDIG (DescriptionLogic Implementation Group) one which is exploited as interface for HTTP-basedreasoners [26]. Particularly, when facing on implementation issues, DIG 2.0 formal-ism should be adopted to express both requests and resource descriptions, because itis less verbose and more compact, a mandatory requirement inmobile ad-hoc appli-cations. Anyway, here we formalize examples by adopting DL syntax for the sakeof readability.
DLs are a family of logic formalisms for Knowledge Representation [27] whosebasic syntax elements areconcept names, role names, individuals. Intuitively, con-cepts stand for sets of objects in the domain, and roles link objects in differentconcepts. Individuals are used for special named elements belonging to concepts.Formally, concepts are interpreted as subsets of a domain ofinterpretation∆ , androles as binary relations (subsets of∆ ×∆).
DL formulas give a semantics by defining the interpretation function ·I overeach construct. For example, ifA andD are two generic concepts, their conjunctionA⊓D is interpreted as set intersection:(A⊓D)I = AI ∩DI , and also the otherboolean connectives⊔ and¬, when present, give the usual set-theoretic interpreta-tion of union and complement.
Concepts can be used ininclusion assertions O⊑ D, and definitions O≡ D,which impose restrictions on possible interpretations according to the knowledgeelicited for a specific domain. A DL theory (a.k.a.TBoxor ontology) is basically aset of inclusion assertions and definitions. Amodelof a TBoxT is an interpretationsatisfying all inclusions and definitions inT . Many other constructs can be defined,so increasing the expressiveness of the DL. Nevertheless, this usually leads to agrowth in computational complexity of inference services [28]. Hence a trade-off isnecessary.
The core idea of the Semantic Web initiative [29] is to annotate information bymeans of markup languages, based on XML, such as RDF, RDFS andOWL. Theselanguages have been conceived to allow machine understandable, unambiguous rep-resentation of Web contents through the creation of domain ontologies, increasingopenness and interoperability in the WWW. The strong relationship between DLsand the above referenced languages [30] is also evident in the classification of theOWL sub-languages.

8 Roberto De Virgilio et al
• OWL-Lite. It allows class hierarchy and simple constraints on relations betweenclasses.
• OWL-DL. Based on DLs theoretical studies, it allows a great expressivenesskeeping computational completeness and decidability.
• OWL-Full. It has a huge syntactic flexibility and expressiveness. This freedom ispaid in terms of no computational guarantee.
In this chapter we will refer to theAttributive Language with unqualified Num-ber restrictions and Concrete Domains(A L N (D)) DL, a subset of OWL-DL,which has a polynomial complexity both for standard and non-standard inferences.Constructs ofA L N (D) DL are reported in what follows:
• ⊤, universal concept. All the objects in the domain.• ⊥, bottom concept. The empty set.• A, atomic concepts. All the objects belonging to the setA.• ¬A, atomic negation. All the objects not belonging to the setA.• C⊓D, intersection. The objects belonging to bothC andD sets.• ∀R.C, universal restriction. All the objects participating in theR relation whose
range are all the objects belonging toC set.• ∃R, unqualified existential restriction. At least one object participating in the
relationR.• (≥ n R)4,(≤ n R),(= n R)5, unqualified number restrictions. Respectively the
minimum, the maximum and the exact number of objects participating in therelationR.
• f , concrete features. An extension to basic DLs that allows to link concepts to aconcrete domainD (e.g., integers, reals, time and so on) through a set of unarypredicatesp. Each concrete featuref can be expressed asp( f ) with p : δ → D,whereδ is the feature domain. In this chapter only the concrete domain of inte-gers and the following unary predicates will be considered:(≥k g),(≤k g),(=k
g), with g a feature andk an integer value.
Knowledge Representation (KR) approaches to matchmaking usually exploitclassical deductive services, namelyclassification(also known assubsumption)andconsistency(i.e., satisfiability). Basically, given a request/resource pair anno-tated w.r.t. a common reference ontology, classification allows to check whether allrequest specifications are included within the resource description, whereas con-sistency verifies whether some specification in the request contradicts (some of)the ones within the resource annotation. In both cases, the response is then a bi-narytrue/falsevalue. Although these inference services are very useful inthe earlyphases of a discovery process, they are not sufficient to ranka set of resources withrespect to a request.
GivenR (for Request) andO (for Offer) both consistent with respect to an ontol-ogyT , logic-based approaches to matchmaking proposed in literature [31, 32] useclassification and consistency to grade match results in fivecategories:
4 Notice that∃R is equivalent to(≥ 1 R)5 We write(= n R) for (≥ n R)⊓ (≤ n R)

Semantic-based RFID Data Management 9
– Exact. All the features requested inR are exactly provided byO and vice versa–in formulaeT |= R⇔ O.– Full-Subsumption. All the features requested inRare contained inO –in formu-laeT |= O⇒ R.– Plug-In. All the features offered inOare contained inR–in formulaeT |= R⇒O.– Potential-Intersection. There is an intersection between the features offered inOand the ones requested inR –in formulaeT 6|= ¬(R∧O).– Partial-Disjoint . Some features requested inR are conflicting with some offeredin O –in formulaeT |= ¬(R∧O).
While exact and full matches seldom occur, a user may get several potential andpartial matches. Then a logic-based matchmaker should provide a –logic– rankingof available resources w.r.t. the request, but what we get using classification andconsistency is a boolean answer. Also partial matches mightbe just “near miss”(e.g., maybe just one requirement is in conflict), but a pure consistency check re-turns a hopelessfalseresult, whereas it could be interesting to retrieve “not so bad”resources according to their similarity to the request.
Let us consider conceptsR andO and an ontologyT . If a partial match occurs,i.e., if they are not compatible with each other with respect toT , one may want toretract some specifications inR, G (for Give up), to obtain a conceptK (for Keep)such thatK ⊓O is satisfiable inT .
In [33] the Concept Contraction problem was first defined as:– Concept Contraction. LetL be a DL,R, O be two concepts inL andT be a setof axioms inL , where bothR andO are satisfiable inT . A Concept ContractionProblem(CCP), identified by〈L ,R,O,T 〉, consists of finding a pair〈G,K〉 ∈L ×L such thatT |= R≡ G⊓K, andK⊓O is satisfiable inT . ThenK is acontractionof Raccording toO andT .If nothing can be kept inRduring the contraction process, we get the worst solution–from a matchmaking standpoint–〈G,K〉 = 〈R,⊤〉, that is give up everything ofR.Conversely, ifR ⊓O is satisfiable inT , that is a potential match occurs, nothing hasto be given up and the solution is〈⊤,R〉. Hence, a Concept Contraction problemamounts to an extension of a satisfiability one. Since usually one wants to give up asfew things as possible, some minimality criteria in the contraction must be defined[34].
If the offered resourceO is a potential match forR, it is necessary to assess whatshould be hypothesizedH in O in order to completely satisfyR and then move to afull match. In [35] the Concept Abduction problem was first defined as:– Concept Abduction. Let L be a DL,R, O be two concepts inL , andT be a setof axioms inL , where bothO andR are satisfiable w.r.t.T . A Concept AbductionProblem(CAP), identified by〈L ,R,O,T 〉, is to find a conceptH ∈ L such thatT |= O⊓H ⊑ R, and moreoverO⊓H is satisfiable inT . We defineH ahypothesisaboutO according toR andT .
If O⊑ R then we haveH = ⊤ as a solution to the related CAP. Hence, ConceptAbduction amounts to extending subsumption. On the other hand, if O ≡ ⊤ thenH ⊑ R.

10 Roberto De Virgilio et al
4.2 RFID data representation
Whatever RFID application usually generates a tuple streamin the form of a triple(E, l , t), where:
• E is anEPC (Electronic Product Code),i.e., a unique identifier stored in a tagand associated to each tagged object;
• l is thelocationwhere an RFID reader has scanned an object having theE EPC;• t is thetimewhen the reading took place.
As a single tag may have multiple readings at the same location –thus producinga great amount of raw data– cleaning techniques have to be applied. The most usedcompression converts raw data instay recordsin the form:(E, l ,tin,tout) wheretin isthe time when the object enters the locationl , andtout is the time when the objectleaves it. Although this basic solution reduces the amount of data to be stored (evenif not considerably), previous data representation loses object transitions informa-tion. So an alternative representation of RFID data has beenproposed in [36]. Itinvolvestrace recordsand has the form:
E : l1[t1in; t1
out] → . . . → lk[tkin; tk
out]
where:
• l1, . . . , lk are locations along the path followed by the tag withE EPC ;• t i
in is the entering time at locationl i ;• t i
out is the exiting time from the locationl i ;• the sequence is ordered byt i
in.
The drawback of such data representations is that they are path-dependent, andtherefore only path queries over objects moving together can benefit from them (e.g.,find the average time for jackets to go from tailor’s to storesin Rome). To overcomethis limitation, the notion ofentry recordsis introduced, which describes productinformation that can be used in multidimensional analysis.Entry records have theform:
E : [A1,v1], [A2,v2], . . . , [An,vn]
where:
• Ai describes an attribute representing the object withE EPC;• vi is the value associated toAi for this object.
Notice that: (i) an entry record can be used to represent collections of RFID dataat different level of details (e.g., raw data or stay records) and (ii) aggregates arebased on different combinations of attributesAi .

Semantic-based RFID Data Management 11
4.3 Supply chain indexing
In supply chain management, a basic need is to analyze objecttransitions. A productwith an RFID tag can cross many locations in a chain. Tracing its movements, tran-sitions can be expressed as a pathl1, . . . , ln in a graph describing the supply chainitself. Different approaches and techniques have been proposed for supply chain in-dexing in order to effectively compute the path of a tag. Currently they are supportedby DBMS physical optimizations. In [37] and [38], EPC data features are exploitedto group tags and arrange them through bitmap indexes. Leeet al. [36] devised analternative encoding scheme that assigns to each path a pair(Element List EncodingNumber (ELEN)- Order Encoding Number (OEN)). By assigning a prime numberto each node in the chain, ELEN is obtained by multiplying path nodes (with relatedvalues) among them. In this way, the path followed by a tag is computed as fac-torization of the integer assigned to the path itself. Primality of assigned numbersguarantees the correctness of the result. Additionally, OEN is a value able to encodethe arrangement among nodes in the path.
Both the above solutions present some not negligible drawback. Approaches in[37] and [38] are dependent on DBMS optimizations and on the similarity assump-tion between EPCs, whereas framework in [36] does not cope with computationalcomplexity of prime factorization of an integer. Since a supply chain can presentseveral levels (typically from four to ten), to the best of our knowledge, no efficientalgorithms are available for very large values.
In order to efficiently manage the object transitions, an elementary method wasintroduced in [39] for encoding each pathl1, . . . , ln. The basic idea is to model asupply chains by a directedsc-graph Gs whose nodes are locations ofs and thereis an edge from a nodel1 to a nodel2 if there is some movement of objects froml1 to l2 in s. The source nodesof a sc-graph,i.e., the nodes having no incomingedge, usually represent the place where objects are produced, whereastarget nodesof a sc-graph,i.e., nodes having no outgoing edge, are usually the final stores whereproducts are sold. Then, atokenis associated to each possible path from a sourceto a target node. Finally, the encoding is performed in each noden of a sc-graph byassigning ton the set of tokens representing each path from a source to a target nodetraversingn. The supply chain in Figure1 shows as an example the proposedpathencoding.
Data Compression In order to aggregate queries over a large amount of RFIDdata, it is useful to compress them with respect to differentaggregation factors.For instance, considering location, data can be aggregatedeither at city, region orcountry levels. Similarly, a product can be grouped by brand, category or price.
Let us consider a set of attributesS= {A1,A2, . . . ,An} describing available entryrecords. By borrowing a typical OLAP (on-line Analytical Processing) approach,attributes are grouped inS according to differentfactorssuch as location, time orproduct. Moreover, each factor allow to build a setR= {(x, r,y) : x,y ∈ S}, wherer is a binary relationship between attributes such asis-a, part-of, and so on. Inthis way taxonomiescan be build starting from the original attribute set. Figure 2

12 Roberto De Virgilio et al
Fig. 1 Supply chain indexing
shows possible taxonomies: thin arrows representpart-of relationships, thick onesrepresentis-aones between attributes.
Fig. 2 A taxonomy example
The setR, augmented with taxonomies defined over proper factors inR, sug-gests interesting attribute aggregations. Anaggregation factoris defined as a propo-sitional logic expressionϕ involving attributes occurring inA1, . . . ,An. It can beeasily noticed thatϕ depends on taxonomies defined over them. For instance, ifAi ∧A j occurs inϕ and(Ai , part-of,A j) then the conjunction can be replaced byA j , becauseA j has a higher aggregation degree higher thanAi . Hence, a set of rulescan be defined to simplify an aggregation factor using taxonomies. With respect tothe set of attributes in Figure 2, possible aggregation factors for that domain are:ϕ1 = (location∧ time in∧ time out) andϕ2 = (model). Intuitively, ϕ1 aggregatesrecords for items entering and leaving the same location at the same time, whileϕ2
aggregates records for items which are similar among them.Given two entry recordsr1 = {E1; [A′
1,v′1], . . . , [A
′n,v
′n]} andr2 = {E2; [A′′
1,v′′1], . . . , [A
′′m,v′′m]},
anaggregated record rA has the form:{ErA; [r1, r2]}. Two entry recordsr1 andr2 areaggregated w.r.t. an aggregation factorϕ if r1 andr2 satisfyϕ as follows.

Semantic-based RFID Data Management 13
Definition 4.1 (ϕ-satisfiability) Given an expressionϕ over a set of attributesA1, . . . ,An, and two entry records r1 = {E1; [A1,v′1], . . . , [A j ,v′j ], . . . , [Am,v′m]} andr2 = {E2; [A1,v′′1], . . . , [A j ,v′′j ], . . . , [Am,v′′m]}, r1 and r2 satisfyϕ if, by replacing eachAi in ϕ with the atom (v′i = v′′i ) for 1≤ i ≤ n, the obtained formula is true.
This notion can be used to introduce the one of aggregation based on a givenaggregation factor.
Definition 4.2 (ϕ-aggregation) Given an aggregated record rA, rA is aϕ-aggregateif for each pair of entry records r1 and r2 occurring in rA: r1 and r2 satisfyϕ .
Hence, an aggregationF can be obtained by a sequence of aggregation factorsϕ1,ϕ2, . . . ,ϕn. Basically, in a supply chain an aggregated record is an itemstock. Ob-ject movement can be seen as a collection of stocks that splitmoving from sourcesto targets. Under this assumption, a useful definition is reported hereafter.
Definition 4.3 (Subsumption) Given two aggregated records rA1 = {ErA1; [r1, r2, . . . , rn]}
and rA2 = {ErA2; [r ′1, r
′2, . . . , r
′m]}, rA1 is subsumed by rA2, denoted by rA1 ⊳ rA2, if each
r i occurring in rA1 also occurs in rA2.
An object transition can be then seen as a movement from a stock to anotherone. Hence, anobservationis defined as an object transition event and it can berepresented by a pair(s1,s2), wheres1 is a stock including a set of items comingfrom the stocks2. It ensues thats1 ⊳ s2.
5 Framework and Approach
Analyses related to a supply chain could be basically intended as involving twodifferent aspects:on-productandbatchcontrol. The former is performed on-lineand aims at an object (product) discovery, given features explicitly stated in a requestby either controller or customer. The latter happens off-line and refers to a higherlevel abstraction related to product batches flow. Both kinds of analysis help variousactors involved in a supply chain (from producers to retailers to customers) in takingunder control large amounts of goods with their related properties as well as to easilytrack and retrieve specific things or groups of things.
This section describes an integrated EPCglobal RFID-basedframework wheretagged goods can be either individually and automatically discovered in a pervasivecomputing scenario or aggregated for enabling centralizedmassive analysis involv-ing off-line data storage. In what follows both components will be examined indetail.

14 Roberto De Virgilio et al
5.1 On-line object discovery
On-line object discovery requires an in-depth comparison between product charac-teristics and user requirements. In order to quickly produce useful results, advanced(possibly automated) matchmaking techniques are requiredwhere both user’s re-quest and resource characterization are expressed in a machine understandable for-mat, which allows the needed expressiveness while keeping an acceptable com-putational complexity. Due to space, power and cost constraints, RFIDs are stillcurrently endowed with low storage, no processing capability and short-range, low-throughput wireless links. Furthermore, each mobile reader in the field can accessinformation only on micro devices in its range. As a consequence, approaches basedon centralized control and unique information storage are impractical. On the otherhand, when effective network infrastructures are lacking and exploited devices areresource-constrained, the discovery process can be strongly enhanced by exploitingKR techniques and technologies. Semantic-based resource annotation and match-making, as well as logic-based ranking and explanation services [8], seriously im-prove resource retrieval experience. Furthermore, the enhancements to EPCglobalRFID standard protocol let users interact with the system without requiring depend-able wired infrastructures while hiding technicalities from them.
In the research paper [40] we introduced a knowledge-based variant of EPC-global RFID, whose primary goal was to keep a backward compatibility with theoriginal technology as much as possible. Protocols to read/write tags were pre-served, maintaining original code-based access, in order to ensure compatibility andsmooth coexistence of new semantic-based object discoveryapplications and legacyidentification and tracking ones. In our framework we refer to RFID transpondersconforming to the EPCglobal standard for class I - second generation UHF tags [14](we assume the reader be familiar with basics of this technology). The proposal wastested in a simulation campaign and in application case studies, showing the benefitsof the approach for stakeholders involved each stage of the product lifecycle [41]–from raw materials to production, retail and post-sale services. Here an evolutionof the approach is presented.
The practical feasibility of advanced semantic-based usage of RFID technologiesmust take into account some important constraints. First ofall the severe bandwidthand memory limitations of current RFID systems, in order to meet cost requirementsfor large-scale adoption. Due to technological advances and growing demand, pas-sive RFID tags with greater memory amounts are expected to beavailable [3]. Nev-ertheless, XML-based ontological languages like OWL and DIG are far too verbosefor a direct storage on RFID tags. Moreover, a mechanism is clearly required todistinguish semantic enabled tags from standard ones, so that semantic based appli-cations can exploit the new features without interfering with legacy applications.
In order to enable the outlined enhancements, RFID tags and the air interfaceprotocol must provide read/write capabilities for semantically annotated product de-scriptions with respect to a reference ontology, along withadditional data-orientedattributes. Neither new commands nor modification to existing ones have been in-

Semantic-based RFID Data Management 15
troduced. In order to accomplish that, we extend the memory organization of tagscompliant with the above referenced standard.
Contents of TID memory area up to1Fh bit are invariable. For tags having classidentifier valueE2h stored in the first byte of the TID bank, optional informationcould be stored in additional TID memory from20h address. There we store:
• a 16 bit word for optional protocol features, stored starting from 20h addressmost significant bit first: currently only the most significant bit is used to indicatewhether the tag is semantic-enabled or not; other bits are reserved for future uses;
• a 32-bitOntology Universally Unique Identifier(OUUID) marking the ontologywith respect to the description stored in the tag is expressed [42].
In this way, a reader can easily distinguish semantic based tags by meansof a Selectcommand with parameter values as in Table 1. Values for the triple〈MemBank,Pointer,Length〉 identify the bit at20h address in the TID memory bank.The reader commands each tag in range to compare it with bit mask12. The matchoutcome will be positive for semantic enabled tags only. TheTargetandActionpa-rameter values mean that in case of positive match the tag must set itsSLflag andclear it otherwise. The following inventory step will skip tags having SL flag cleared,thus allowing a reader to identify only semantic enabled tags. Protocol commandsbelonging to the inventory step have not been described, because they are used inthe standard fashion.
PARAMETER Target Action MemBank Pointer Length Mask
VALUE 1002 0002 102 001000002 000000012 12
DESCRIPTION SL flag set (if match) TID bank initial addressbit to be comparedbit mask
Table 1 Selectcommand able to detect only semantic enabled tags
In order to retrieve the OUUID stored within a tag, a reader will exploit a Readcommand by adopting parameter values as in Table 2.MemBankparameter iden-tifies the TID memory bank and theWordPtr value specifies that the reading muststart from the third 16-bit memory word,i.e., from 20h address. Finally, theWord-Countparameter indicates that 32 bits (two 16-bit words) have to be read.
PARAMETER MemBank WordPtr WordCount
VALUE 102 0000000102 000000102DESCRIPTION TID memory bankstarting addressread 2 words (32 bits)
Table 2 Readcommand able to extract the OUUID from the TID memory bank
Contextual parameters (whose meaning may depend on the specific application)are stored within theUser memory bankof the tag. There, we also store the productannotation. In order to overcome storage space limitations, it is encoded with aspecialized compression algorithm designed for XML-basedontological languages.An RFID reader can perform extraction and storing of a description from/on a tag by
16 Roberto De Virgilio et al
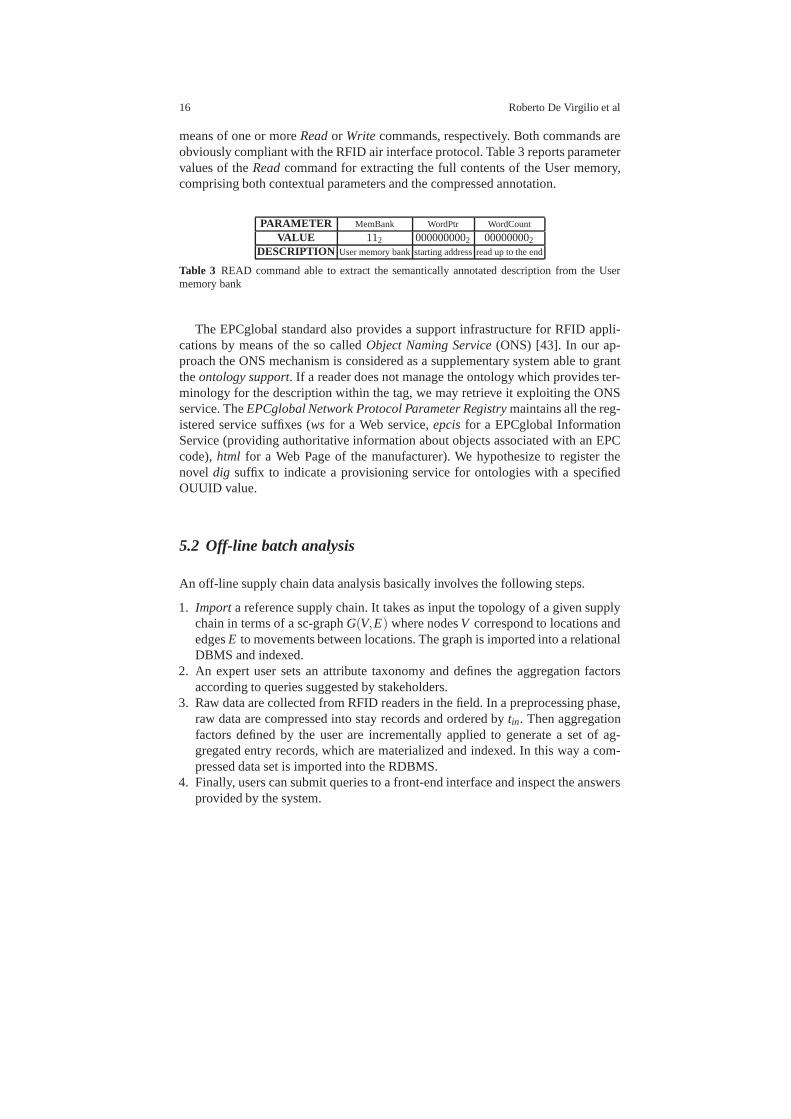
means of one or moreReador Write commands, respectively. Both commands areobviously compliant with the RFID air interface protocol. Table 3 reports parametervalues of theReadcommand for extracting the full contents of the User memory,comprising both contextual parameters and the compressed annotation.
PARAMETER MemBank WordPtr WordCount
VALUE 112 0000000002 000000002DESCRIPTION User memory bankstarting addressread up to the end
Table 3 READ command able to extract the semantically annotated description from the Usermemory bank
The EPCglobal standard also provides a support infrastructure for RFID appli-cations by means of the so calledObject Naming Service(ONS) [43]. In our ap-proach the ONS mechanism is considered as a supplementary system able to granttheontology support. If a reader does not manage the ontology which provides ter-minology for the description within the tag, we may retrieveit exploiting the ONSservice. TheEPCglobal Network Protocol Parameter Registrymaintains all the reg-istered service suffixes (ws for a Web service,epcisfor a EPCglobal InformationService (providing authoritative information about objects associated with an EPCcode),html for a Web Page of the manufacturer). We hypothesize to register thenovel dig suffix to indicate a provisioning service for ontologies with a specifiedOUUID value.
5.2 Off-line batch analysis
An off-line supply chain data analysis basically involves the following steps.
1. Import a reference supply chain. It takes as input the topology of a given supplychain in terms of a sc-graphG(V,E) where nodesV correspond to locations andedgesE to movements between locations. The graph is imported into arelationalDBMS and indexed.
2. An expert user sets an attribute taxonomy and defines the aggregation factorsaccording to queries suggested by stakeholders.
3. Raw data are collected from RFID readers in the field. In a preprocessing phase,raw data are compressed into stay records and ordered bytin. Then aggregationfactors defined by the user are incrementally applied to generate a set of ag-gregated entry records, which are materialized and indexed. In this way a com-pressed data set is imported into the RDBMS.
4. Finally, users can submit queries to a front-end interface and inspect the answersprovided by the system.

Semantic-based RFID Data Management 17
In the following subsections we present in greater detail the aggregation process andillustrate the proposed storage schema for aggregated records able to guarantee anefficient query processing.
5.2.1 Data aggregation
Given an aggregationF = [ϕ1,ϕ2, . . . ,ϕn] and a stay records sequenceSRordered bytin, F is applied toSRto generate a set of aggregated entry recordsARS. Notice thatan aggregation makes sense if it is locally applied. In otherwords, only records hav-ing the same location are aggregated. Since information details are contained withintagged items, there is no need for a centralized backend for the whole supply chain.Each supply chain partner has visibility of the relevant attributes and entry recordsof items passing through its premises and can use its own support infrastructure foroff-line data analysis. For each node, aggregation can be then performed accord-ing to the most relevant factors for business analysis, selected according to specificmanagement goals. This approach also solves the problem of change of item “own-ership” when items flow among different partners (and even across country borders)or they are redistributed in different packages.
Hereafter a straightforward aggregation strategy is outlined.
1. Records characterized by the same location are grouped ina setL.2. The aggregation factorsϕi are sequentially applied to elements inL: if there
exists an aggregated recordrdA such that current elementR′ of L andrdA satisfyϕ , thenR′ can be inserted intordA; otherwise a new aggregated record fromR′ iscreated.
For example, let us consider three entry records representing clothes (i.e., items)moving into the supply chain shown in Figure 1, as in Table 4.
record EPC model price count Loc tin tout
r1 clt01 Polo 160 1 L12 4 6r2 clt02 Polo 160 1 L12 4 6r3 clt03 Suit 400 1 L12 4 6
Table 4 Entry records aggregation
Now, let us consider an aggregationF = [ϕ1,ϕ2] resulting from factorsϕ1 =(time in∧ time out) andϕ2 = (model). With respect toϕ2 two aggregated recordsare produced:rA1 = {r1, r2} and rA2 = {r3}. Finally, applyingϕ1, the aggregatedrecordrA3 = {rA1, rA2} is obtained.
The final step consists in building observations, assigninga token to each ofthem. The algorithm summarized in what follows illustratesthat process. It takes asinput: a sequence of aggregated recordsARSincreasingly ordered bytime in, thechainC in terms of a sc-graphC(VC,EC) and a mapLM where a list of tokens is

18 Roberto De Virgilio et al
assigned to each location. The output is a mapOM whose observations have a giventoken.
1. Starting from the last recordARof ARS, go back to find the aggregated recordthat subsumesAR.
2. If it does not exist, a new observation is generated, the list of tokens correspond-ing toARlocation is extracted fromLM and the first token is assigned to the newobservation.
3. Otherwise, a new observation is generated whereAR⊳ AR′. The token to be as-signed results from the intersection between the lists of tokens of both locationsin ARandAR′ excluding the ones coming from other paths reachingAR′ location.
5.2.2 Data storage
Figure 3 shows the relational schema to contain RFID data processed as describedabove.PATHMAP andLOCATION store chain information. Each entry inPATHMAPhas an external referenceLOC ID to LOCATION with an associatedtoken. If moretokens are associated to a given location, thenPATHMAP will have more entries forthat location. TheDEPTH attribute measures the current path length up to locationidentified byLOC ID. ITEM stores information about products, in terms of EPCand last stock where the item was aggregated.ATTRIBUTE gathers attributes fea-turing bothITEM andLOCATION and they are related to an attribute list throughATTRIBUTE LIST which associates a value to each attribute.OBSERVATIONtraces all transitions of aggregates. There, theSTOCK attribute is the current aggre-gate, containing items coming fromPREV STOCK, observed in a givenLOCATION.Each observation stores stock items number as well as traversed locations (COUNTandDEPTH attributes), assigned token and time when the stock enteredand left thelocation respectively (T START andT END attributes).
Fig. 3 Storage schema
As resulting tables could be very large, relational DBMS capabilities have beendeeply exploited tuning the above schema to obtain better performances. The firstoptimization is the horizontal partitioning of tables intosmaller physical ones,namelypartitions. Each partition inherits the same structure (e.g., columns anddatatypes) of the original table, namelymaster. Partitioning is performed row byrow and it is based on column value (range). For instance, inOBSERVATION table,the columnLOCATION is exploited as range (see Figure 4). If needed, resulting
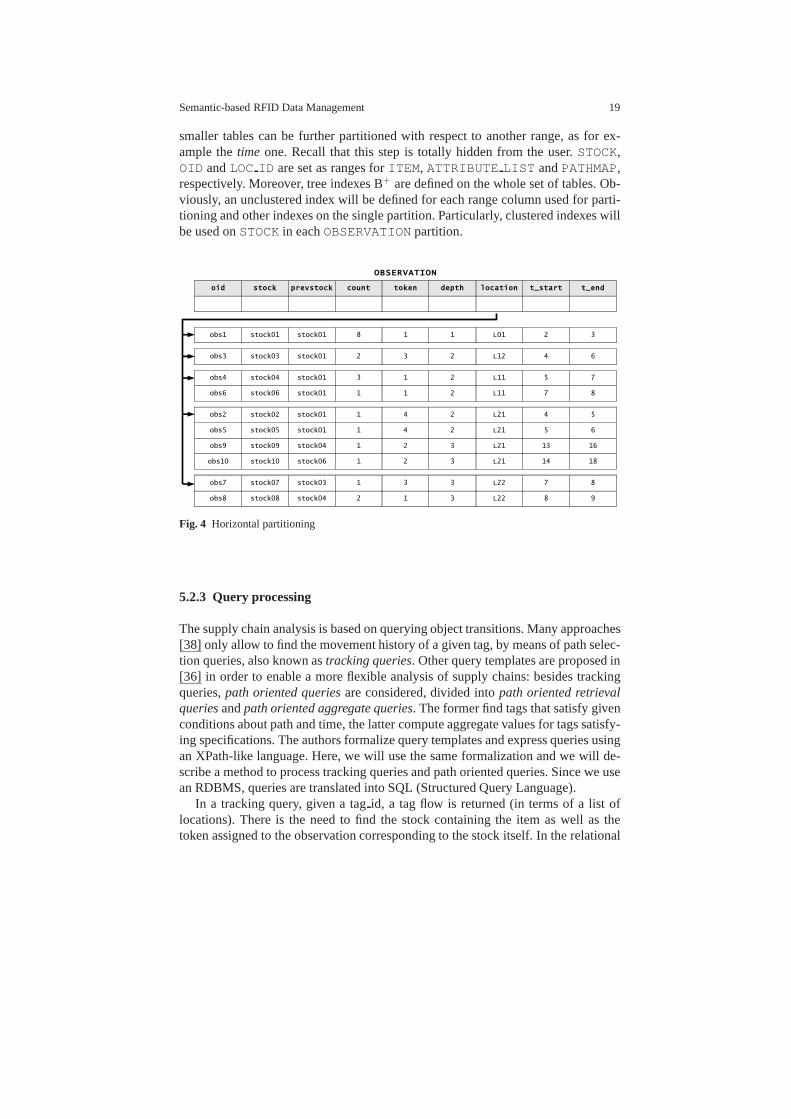
Semantic-based RFID Data Management 19
smaller tables can be further partitioned with respect to another range, as for ex-ample thetime one. Recall that this step is totally hidden from the user.STOCK,OID andLOC ID are set as ranges forITEM, ATTRIBUTE LIST andPATHMAP,respectively. Moreover, tree indexes B+ are defined on the whole set of tables. Ob-viously, an unclustered index will be defined for each range column used for parti-tioning and other indexes on the single partition. Particularly, clustered indexes willbe used onSTOCK in eachOBSERVATION partition.
Fig. 4 Horizontal partitioning
5.2.3 Query processing
The supply chain analysis is based on querying object transitions. Many approaches[38] only allow to find the movement history of a given tag, by means of path selec-tion queries, also known astracking queries. Other query templates are proposed in[36] in order to enable a more flexible analysis of supply chains: besides trackingqueries,path oriented queriesare considered, divided intopath oriented retrievalqueriesandpath oriented aggregate queries. The former find tags that satisfy givenconditions about path and time, the latter compute aggregate values for tags satisfy-ing specifications. The authors formalize query templates and express queries usingan XPath-like language. Here, we will use the same formalization and we will de-scribe a method to process tracking queries and path oriented queries. Since we usean RDBMS, queries are translated into SQL (Structured QueryLanguage).
In a tracking query, given a tagid, a tag flow is returned (in terms of a list oflocations). There is the need to find the stock containing theitem as well as thetoken assigned to the observation corresponding to the stock itself. In the relational

20 Roberto De Virgilio et al
schema presented above, the tableITEM will be queried to extract the stockid andtheOBSERVATION table to extract the token assigned to the related observation.FinallyPATHMAPwill be queried to return all locations annotated with the extractedtoken. The list of locations is ordered by the attributeDEPTH. The correspondingSQL code ensues.
SELECT P.LOC_IDFROM PATHMAP P, OBSERVATION O, ITEM IWHERE I.EPC=<tag_id> AND O.STOCK=I.STOCKAND P.TOKEN=O.TOKEN
ORDER BY P.DEPTH
In a path oriented retrieval query, given a path expressed interms of an XPath-like syntax, the list of tags that followed it is returned. Also in this case both stockand token information intoOBSERVATION are exploited to select items. Moreover,ancestor and/or parent relationships between locations have to be processed. Giventwo locationsl1 andl2, if they are in a parent-child relationship (i.e.,l1/l2), thenPATHMAP is queried and tokens are selected such that the depth ofl2 is the depthof l1 incremented by 1. Otherwise, if locations are in the ancestor-descendant rela-tionship (i.e., l1//l2), tokens such that the depth ofl2 is greater than the depthof l1 are selected. Let us consider the query//L1/L2. In this case we translate itinto SQL as reported hereafter:
SELECT I.EPCFROM PATHMAP P1, PATHMAP P2, OBSERVATION O, ITEM IWHERE P1.LOC_ID=MD5(’L1’) AND P2.LOC_ID=MD5(’L2’)AND P2.DEPTH=(P1.DEPTH+1) AND O.LOCATION=’L2’AND O.TOKEN=P2.TOKEN AND I.STOCK=O.STOCK
When translating//l1//l2 in SQL, the conditionP2.depth > P1.depth
has been considered. Anyway, path oriented retrieval queries may present differ-ent conditions and, in that case, selection conditions has to be added toITEM andOBSERVATION. For instance, we can enrich the previous query with time condi-tions such as//l1/l2[t end < 200]. With respect to the previous SQL code,conditionO.t end < 200 must be added to theWHERE clause. Path oriented aggre-gate queries present aggregate functions which can be considered in theSELECTclause of the SQL query such asCOUNT, SUM, MAX and so on.
6 Experimental Evaluation
As stated in the above Section 5, the proposed framework enables analyses at twodifferent stages. In what follows, an on-line object discovery toy example is pre-sented exploiting semantic-based object annotation in a given u-commerce context;furthermore a massive data examination conducted off-lineon large amount of datais outlined. The benchmarking system is a dual quad core 2.66GHz Intel Xeon PC,

Semantic-based RFID Data Management 21
running Linux Gentoo OS, with 8 GB RAM memory, 6 MB cache memory, anda 2-disk 1Tbyte striped RAID array. We carried out our experiments using Post-greSQL 8.3, because it has been proved (see Beckmann et al. in[44]) that it is sig-nificantly more efficient with respect to commercial database tools. Two differentsupply chains in the field of clothing production and distribution (namelyChain20
andChain100) have been defined with 20 and 100 nodes, respectively. Both chainspresent seven levels,i.e., in both cases a path has a maximum length equal to 7.
6.1 On-line resource discovery
The on-the-fly discovery basically involves the end part of the supply chain, that iscustomers and retailers, but it can be also applied to different stages in product man-ufacturing and distribution, when real-time knowledge-based decision support inneeded. Our matchmaking framework, leveraging the inference services describedin Section 4, can be adapted to a wide range of resource discovery use cases. Theexample scenario reported here refers to the apparel product domain. A typical sup-ply chain interaction sequence is outlined hereafter, but for the sake of brevity onlythe last step will be described in detail.
1. Selection of raw materials.Several yarn deliveries are directed to a jacket fac-tory. Each one is identified and described by means of semantic-enabled RFIDtags attached to containers, which are scanned upon arrivalat the factory ware-house. Due to traceability requirements, a tag must store quantitative data such asvolume, weight and a production time stamp besides the EPC code. Qualitativeinformation about yarn and its production process are also stored within the tag,expressed as a semantic annotation with reference to an apparel industry ontol-ogy. Information extracted via RFID readers at warehouse gate can be used forseveral purposes by workers equipped with handheld devices:
• product/process requirements established in the contractwith supplier can beimmediately verified by means of a semantic query upon yarn characteristics;
• each yarn type can be routed to a different warehouse area, according to spe-cific storage requirements (e.g., temperature, humidity) [45];
2. Manufacturing and packaging. Each yarn type can be routedfrom the warehouseto a different production department according to its properties. Subsequently,during product packaging operations, RFID semantic-enabled tags are writtenand then attached to each item before shipping. Relevant portions of the semanti-cally annotated description of raw materials can be inherited by the final product;in our scenario, a jacket can inherit information from yarn such as type of clothand color. It is important to note that a centralized backendinfrastructure is notrequired for this operation: just like production takes materials as input and re-turns products as output, information can be transferred from tags of materials totags of products by a mobile RFID-enabled ad-hoc network within the factory.

22 Roberto De Virgilio et al
3. Sales. A customer enters an outlet, where a ubiquitous commerce system is ableto assist her in discovering additional available items. Details follow.
Shop items are tagged with RFID transponders containing theEPC code, OU-UID, compressed semantic description and data-oriented attributes. For our casestudy, we adopted a simplified apparel ontology; price and body area are used asdata-oriented attributes. Body area parameter is referredto a specific part of thebody, as shown in Table 5.
Value 1 2 3 4 5 6Body area handshead chest chest legs feet
(outer layer)(inner layer)
Table 5 Correspondence between human body and values of contextualattribute
A request is performed on behalf of the user when she enters a dressing room totry a product on. The request is based on the semantically annotated description ofthe product selected by the user, which is read by an RFID interrogator installed intothe dressing room. In order to satisfy the request, a local shop hotspot retrieves re-source descriptions referred to the specified ontology fromthe enterprise back-enddatabase and performs a semantic-based matchmaking. RFID readers and wirelessdevices deployed in the outlet cooperate through an agent-based, message-orientedmiddleware infrastructure. A prototype has been built uponIBM WebSphere RFIDTracking Kit [46], which provides a general framework for the orchestration of sev-eral heterogeneous devices in mobile applications. A semantic-based layer has beenintegrated in order to support features specific to our approach.
Let us consider the following case study:a man enters the outlet to buy someelegant clothing. He notices a fine dark green jacket and decides to try it on.Sen-sors detect the customer entering the dressing room. The RFID reader is triggeredand reads data stored within the tag attached to the jacket, then it is deactivatedagain. Annotated data correspond to an elegant, large-sized, dark green jacket, inmostly linen cloth, suitable for young adult men and fall season, with buttons andfive pockets. The corresponding DL expression w.r.t. the reference ontology (notreported here for the sake of conciseness) is:
• Jacket⊓ = 1 hasColors ⊓ ∃ hasFastenings⊓ ∀ hasFastenings.Buttons ⊓∀ hasMainColor.DarkGreen⊓∃ hasMaterials⊓ ∀ hasMainMaterial.Linen ⊓∀ hasPattern.Plain ⊓ = 5 hasPockets ⊓ ∀ hasSize.Large ⊓∀ hasSleeves.LongSleeves ⊓ ∀ hasStyle.Elegant ⊓∀ suitableForAge.YoungAdult ⊓ ∀ suitableForGender.Male ⊓∀ suitableForSeason.Fall
The equivalent DIG representation of this fairly simple annotation is 1592 Blong. Realistic object descriptions can be a few times larger. Compression bringsthe annotation to 210 B, so that it can be stored on the RFID tag, along with theitem EPC, ontology identifier and its data-oriented parameters. In this case price is$195 and body area value is 3.

Semantic-based RFID Data Management 23
The customer is trying on the jacket, as usual in a dressing room. Meanwhile,an embedded touchscreen is activated and item details are shown. Those elementswill be used by the customer for building his semantic request. Let us note that therequest is a DL conjunctive query, where each concept represents a desired feature.User can customize it through a graphical user interface.
Customer likes his jacket, so he would like to look for similar ones. He sets atarget price of$200 and only removes the constraint on season from the systemrecommendation. The DL expression for user request thus becomes:
• D: Jacket ⊓ = 1 hasColors ⊓ ∃ hasFastenings ⊓∀ hasFastenings.Buttons⊓ ∀ hasMainColor.DarkGreen⊓ ∃ hasMaterials⊓∀ hasMainMaterial.Linen ⊓ ∀ hasPattern.Plain ⊓ = 5 hasPockets ⊓∀ hasSize.Large ⊓ ∀ hasSleeves.LongSleeves⊓ ∀ hasStyle.Elegant ⊓∀ suitableForAge.YoungAdult⊓ ∀ suitableForGender.Male
Customer confirms his request.It is now translated into a compressed DIG de-scription, in the same way as above, and associated with user-supplied target valuesfor data-oriented attributes. Let us suppose the followingproducts are available inthe apparel store knowledge base:
• S1: an elegant, large-sized, gray suit, in mostly linen cloth, suitable for adultmen and spring climate, with two button fastenings and ten pockets. Price is$678; body area is 3:Suit ⊓ ∀ hasMainColor.LightGray ⊓ ∀ hasMainMaterial.Cotton ⊓ =10 hasPockets⊓ ≥ 2 hasFastenings ⊓ ∀ hasFastenings.Buttons ⊓∀ hasPattern.Plain ⊓ ∀ hasSize.Large ⊓ = 2 hasLegs ⊓∀ hasLegs.PipeLegs⊓ ∀ suitableForAge.Adult ⊓ ∀ suitableForGender.Male⊓∀ suitableForSeason.Spring ⊓ = 2 hasMaterials ⊓ ∃ hasColors ⊓ ≤1 hasColors
• S2: medium-sized blue jeans, suitable for casual young adult men and springclimate, with pipe legs and five pockets. Price is $38; body area is 5:Trousers ⊓ = 1 hasColors ⊓ ∀ hasMainColor.MediumBlue ⊓ ≥2 hasFastenings⊓ ≤ 2 hasFastenings ⊓ ∀ hasLegs.PipeLegs ⊓∀ hasMainMaterial.Jeans⊓ = 1 hasMaterials ⊓ ∀ hasPattern.Plain ⊓ =5 hasPockets ⊓ ∀ hasSize.Medium ⊓ ∀ hasStyle.Casual ⊓∀ suitableForAge.YoungAdult ⊓ ∀ suitableForGender.Male ⊓∀ suitableForSeason.Spring
• S3: an elegant, large-sized, midnight blue jacket, in mostly linen cloth, suitablefor young adult men and fall climate, with buttons and five pockets. Price is$190; body area is 3:Jacket⊓ = 1 hasColors ⊓ ∃ hasFastenings⊓ ∀ hasFastenings.Buttons ⊓∀ hasMainColor.MidnightBlue ⊓ ∃ hasMaterials ⊓∀ hasMainMaterial.Linen ⊓ ∀ hasPattern.Plain ⊓ = 5 hasPockets ⊓∀ hasSize.Large ⊓ ∀ hasSleeves.LongSleeves⊓ ∀ hasStyle.Elegant ⊓∀ suitableForAge.YoungAdult ⊓ ∀ suitableForGender.Male ⊓∀ suitableForSeason.Fall

24 Roberto De Virgilio et al
SupplyCompatibility(Y/N)
score(·)
S1: Men gray suit Y 4.458S2: Men blue jeans N 4.618S3: Men midnight blue jacket Y 0.97S4: Women lavender jacket N 8.974
Table 6 Matchmaking results
• S4: an elegant, medium-sized striped lavender jacket, in mostly syntheticmaterial, suitable for adult women and spring climate, withbuttons and twopockets. Price is $194; body area is 3:Jacket ⊓ = 3 hasColors ⊓ ∃ hasFacings⊓ = 1 hasFastenings ⊓∀ hasFastenings.Buttons⊓ ∀ hasMainColor.Lavender⊓ = 3 hasMaterials⊓∀ hasMainMaterial.Synthetic⊓ ∀ hasPattern.Striped⊓ = 2 hasPockets⊓∀ hasSize.Medium ⊓ ∀ hasSleeves.LongSleeves⊓ ∀ hasStyle.Elegant ⊓∀ suitableForAge.Adult ⊓ ∀ suitableForGender.Female ⊓∀ suitableForSeason.Spring
The shop server performs the matchmaking. Results are reported in Table 6where scores are shown in the last column; being a distance measure, a lower valueimplies a better match.S3 is by far the best supply for similarity search. Among oth-ers,S4 is incompatible withD, as they both represent jackets butS4 is a women’sgarment.
Customer can reserve one or more items.Reservation will then be notified to thelocal server, so that products could be prepared in advance.Otherwise, if customer isnot satisfied with the results, he can refine his request and issue it again. Eventuallyhe exits the dressing room to finalize his purchase.Sensor detects the exit event andthe dressing room becomes ready for another customer.
A thorough experimental evaluation of system performance is ongoing with oursoftware-simulated RFID platform. Two kinds of experimental results can be re-ported so far:
1. compression rates for semantically annotated products descriptions and queriesin DIG;
2. performance of reading and decoding compressed semanticresource annotationsfrom simulated RFID tags.
Compression rate was tested with 70 DIG documents of varioussize (from 609B to 793 kB). Our aim was to evaluate compression performancefor both smallerinstance descriptions and larger ontologies. Overall average compression rate is92.58±3.58%. Higher compression rates were obviously achieved for larger docu-ments, but even for DIG files shorter than 2 kB the result is 87.05±2.80%, whichis surely satisfactory for our purposes.
Reading and decoding times referred to compressed semanticresource annota-tions from simulated RFID tags was evaluated to the aim of providing insight intothe possible impact of our approach on RFID system performance. In preliminary

Semantic-based RFID Data Management 25
tests using the above-mentioned RFID simulation platform,a read rate of nearly 500tags/s was obtained, whereas independent sources estimated read rates ranging from7 to approximately 100 tags/s with standard Class 1 Generation 2 UHF RFID sys-tems in typical conditions [47]. This is an early evidence that semantic-based RFIDapplications can have comparable performance with respectto traditional ones. Thelatter, in turn, will not suffer any direct performance degradation from the newlyintroduced features, as they will read the EPC only.
6.2 Off-line data analysis
Off-line batch data analysis can be performed at each node ofthe supply chain. Letus consider the above apparel scenario. A retail outlet can monitor sales performanceby aggregating records according to attributes and performing queries in order toextract relevant information for its business goals.
Stay records stored in the outlet database contain timestamps of arrival and de-parture (i.e., sale) for sold items, along with EPC codes. They are aggregated bymodel and then by arrival time and departure time(like in the example in Section5.2.1).The outlet management wants to check performance of sales ofjackets in thecurrent year. In particular, there is the need to compare sales figures among differentsuppliers, in order to see what jackets are most successful.
Let us suppose that the outlet is labeled byL0 in the supply chain location graphand that it has three suppliersL1, L2 andL3. In that case, for each supplierLx,the number of sold jackets since January 1st 2010 can be retrieved through a pathoriented aggregate query. It corresponds to the following expression in our adoptedXPath-like language://Lx/L0[tend >′ 2010−01−0100 : 00 : 00′andmodel=′ Jacket′]
This information can be retrieved from the relational database described in theprevious section by means of the following SQL query:
SELECT COUNT(I.EPC)FROM PATHMAP P1, PATHMAP P2, OBSERVATION O, ITEM I,ATTRIBUTE_LIST L, ATTRIBUTE AWHERE P1.LOC_ID=MD5(Lx) AND P2.LOC_ID=MD5(L0)AND P2.DEPTH=(P1.DEPTH+1) AND O.LOCATION=L0AND O.TOKEN=P2.TOKEN AND I.STOCK=O.STOCKAND I.T_END>’2010-01-01 00:00:00’AND I.STOCK=L.OID AND L.ATTRIBUTE=A.OIDAND A.NAME=’Jacket’
Note thatCOUNT aggregate operator has been used in order to evaluate sold itemnumber. In a very similar way other interesting informationcan be extracted. Forexample, the management could be interested in knowing the average time trousersfrom each supplier stay in the outlet before a sale occurs, sothat ordered quantitiescan be adjusted. It is important to point out that the selection of data aggregation

26 Roberto De Virgilio et al
attributes has a direct impact on applicable queries, therefore it must descend fromKPI (Key Performance Indicators) decided by managers. Of course, the approachis general and can be applied by whatever actor in the supply chain to evaluateappropriate performance metrics with respect to its own business goals, by exploit-ing attribute-based data aggregation and a combination of tracking queries and pathoriented queries.
An experimental campaign has been carried out to evaluate framework perfor-mance also from the massive data analysis standpoint. Here,we report main results.Performance of the proposed approach has been compared withthe one provided byLee and Chung in [36], from now on namedPath. The authors devise a relationalschema to store RFID data as in what follows:
PATH_TABLE(PATH_ID, ELEN, OEN)TAG_TABLE(TAG_ID, PATH_ID, START, END, TYPE)TIME_TABLE(START, END, LOC, START_TIME, END_TIME)INFO_TABLE(TYPE, MODEL, BRAND, CATEGORY, PRICE)
In this schema,TAG TABLE contains information related to the trace records rep-resentation.PATH TABLE stores information about path movements, according tothe ELEN and OEN coefficients (recalled in Section 4), andTIME TABLE is relatedto temporal information (i.e., tin andtout for each location). Finally,INFO TABLEdescribes product information (e.g., model, brand, category and price). The attributetaxonomy described in Section 4 has been exploited synthetic stay records havebeen generated by setting movement and time information randomly along eachchain. For both chains 5 x 105 stay records were created. Then two aggregationswere used:F1 = [(tin∧ tout),(EPC)] andF2 = [(tin∧ tout),(model)]. Note thatF1 cor-responds to a low aggregation whereasF2 compresses records considerably. Usingtemplates provided in [36], we formulate 8 queries. They areshown in Table 7.Q1 isa tracking query,Q2, Q3, Q4 andQ5 are path oriented retrieval queries and finallyQ6, Q7 andQ8 are path oriented aggregate queries. Figure 5 shows performancetest results. First of all, it has to be noticed that times inChain20 are higher than inChain100. Object transitions are more widely spread in the latter, due to a greaternumber of nodes.
For the tracking queryQ1, Path is faster than our approach with respect toF1.However, in that system the query returns ELEN and OEN numbers, hence anotherapplication has to compute the factorization of ELEN ordering numbers with OEN.This is a high complexity task because the computation for large numbers is notefficient. Instead, the proposed approach directly returnsthe ordered list of traversedlocations. Moreover performances are comparable if we use the aggregationF2. Thisproves the usefulness of our aggregation mechanism.
For the path oriented retrieval queriesQ2, Q3, Q4, Q5, our system exhibits bet-ter performance thanPath. In all queries,Pathhas to execute a heavy join betweenTAG TABLE, containing information of all items, andPATH TABLE, containingELEN and OEN numbers. Our system accessesOBSERVATION to extract all stocksfollowing the input path, and thenITEM is accessed to return the EPC of corre-sponding items in those stocks. Furthermore, the partitioning technique supports

Semantic-based RFID Data Management 27
Q1 751517281
Q2 //L45//L628
Q3 /L01/L12/L22/L33/L45/L03/L16/L29/L321/L422/L628
Q4 //L12//L34//L16//L524
Q5 /L01/L12//L33/L45[t start = 336501 AND tend = 514515]/L03/L16//L321/L422/L628[tstart = 919250 AND tend = 1023517]
Q6 COUNT()://L45COUNT()://L628
Q7 COUNT()://L12//L34COUNT()://L16//L524
Q8 COUNT():/L01/L12//L33/L45[tstart = 336501 AND tend = 514515]COUNT():/L03/L16//L321/L422/L628[tstart = 919250 AND tend = 1023517]
Table 7 Test queries
the query process. EachOBSERVATION partition corresponds to a given location,therefore a direct access to interesting items is possible.Also in this case, the addedvalue of aggregation is straightforward. With respect toF1, the two approaches arecomparable, whereas our system provides a better performance for the aggregationF2. In Q5 time conditions lighten the processing of results. WhilePathhas to intro-duce a new join withTIME TABLE, containing timing information of transitions,our system adds a selection condition toWHERE clause; therefore also for the ag-gregationF1 it has better performances. The path oriented aggregate queriesQ6,Q7andQ8 produce a similar behavior. In this caseChain100 significantly exploits thepartitioning technique, making aggregationsF1 andF2 comparable.
7 Conclusions
This chapter presented an innovative approach for data management in supplychains based on RFID identification technology. Bothon-linesemantic-based objectdiscovery andoff-line analyses involving large amounts of RFID data are enabled.Distinguishing features are: (i) definite modifications to the EPCglobal standardsallowing to exploit ontology-based data as well as to support non standard inferenceservices, while keeping backward compatibility, (ii) advanced compression tech-niques enabling a significant space saving also maintaininga logical representationof data aggregation.
Such an approach may provide several benefits. Information about a product isstructured and complete; it accurately follows the producthistory within the supplychain, being progressively built or updated during object lifecycle. This improvestraceability of production and distribution, facilitatessales and post-sale services

28 Roberto De Virgilio et al
Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8
F1 675 382 105 153 107 81 53 36
F2 153 152 101 90 68 43 40 22
Path 200 689 698 612 418 218 311 188
0
100
200
300
400
500
600
700
800
ResponseTime(ms)
Chain 100
Re
sp
on
se
Tim
e (
ms
)
Chain 100
Re
sp
on
se
Tim
e (
ms
)
Chain 20
Fig. 5 Execution times
thanks to an advanced and selective discovery infrastructure. Indexing techniquesthat guarantees an efficient data access have been also proposed in a tool imple-menting the proposed approach.
Some experimental results are presented to show the feasibility of the proposedframework also evidencing its effectiveness. The coherentdevelopment of the ap-proach allows a strengthening of the information to be shared between the actorsinvolved in supply chains, reducing the costs of adoption ofRFID in business. Fur-thermore, an increase in transparency and trust is achievednot only between supply

Semantic-based RFID Data Management 29
chain partners, but also between retailers and customers. This may be a direct com-petitive advantage for companies that adopt the technology.
References
1. Smith, A. (2005) Exploring radio frequency identification technology and its impact on busi-ness systems.Information Management & Computer Security, 13, 16–28.
2. Karkkainen, M. (2003) Increasing efficiency in the supplychain for short shelf life goods usingRFID tagging.International Journal of Retail & Distribution Management, 31, 529–536.
3. Ayoub Khan M., B. R., Manoj S. (2009) A Survey of RFID Tags.International Journal ofRecent Trends in Engineering, 1, 68–71.
4. EPCglobal http://www.epcglobalinc.org.5. Weiser, M. (1999) The computer for the 21st century.SIGMOBILE Mob. Comput. Commun.
Rev., 3, 3–11.6. Borgida, A. Description Logics in Data Management.IEEE Transactions on Knowledge and
Data Engineering, 7, 671–682.7. De, P., Basu, K., and Das, S. (2004) An ubiquitous architectural framework and protocol for
object tracking using RFID tags.1st Int. Conf. on Mobile and Ubiquitous Systems:Networkingand Services (MOBIQUITOUS 2004), pp. 174–182.
8. Di Noia, T., Di Sciascio, E., Donini, F., and Mongiello, M.(2004) A System for PrincipledMatchmaking in an Electronic Marketplace.International Journal of Electronic Commerce,8, 9–37.
9. N.Raza, Bradshaw, V., and Hague, M. (1999) Applications of RFID technology.IEE Collo-quium on RFID Technology, pp. 1–5.
10. Pepe, M. F., C. and Risso, M. SME food suppliers versus large retailers: perspectives in theinternational supply chains.XV Conference of European Institute of Retailing and ServicesStudies (EIRASS), pp. 411–422.
11. Tajima, M. (2007) Strategic value of RFID in supply chainmanagement.Journal of Purchas-ing and Supply Management, 13, 261–273.
12. Jones, P., Clarke-Hill, C., Shears, P., Comfort, D., andHillier, D. (2004) Radio frequencyidentification in the UK: opportunities and challenges.International Journal of Retail & Dis-tribution Management, 32, 164–171.
13. Angeles, R. (2005) RFID technologies: supply-chain applications and implementation issues.Information Systems Management, 22, 51–65.
14. Traub, K., et al. (2005) EPCglobal Architecture Framework. Tech. rep., EPCglobal.15. Sellitto, C., Burgess, S., and Hawking, P. (2007) Information quality attributes associated with
RFID-derived benefits in the retail supply chain.International Journal of Retail & DistributionManagement, 35, 69–87.
16. Bai, Y., Wang, F., and Liu, P. (2006) Efficiently filteringRFID data streams.CleanDB Work-shop, pp. 50–57.
17. Bai, Y., Wang, F., Liu, P., Zaniolo, C., and Liu, S. (2007)RFID data processing with a datastream query language.Proceedings of the 23nd International Conference on Data Engineer-ing, ICDE, pp. 1184–1193.
18. Wang, F., Liu, S., Liu, P., and Bai, Y. (2006) Bridging physical and virtual worlds: complexevent processing for RFID data streams.Lecture Notes in Computer Science, 3896, 588.
19. Jeffery, S., Garofalakis, M., and Franklin, M. (2006) Adaptive cleaning for RFID data streams.Proceedings of the 32nd international conference on Very large data bases, pp. 163–174,VLDB Endowment.
20. Wang, F. and Liu, P. (2005) Temporal management of RFID data. Proceedings of the 31stinternational conference on Very large data bases, pp. 1128–1139, VLDB Endowment.
21. Ban, C., Hong, B., and Kim, D. (2005) Time Parameterized Interval R-Tree for Tracing Tagsin RFID Systems.Lecture notes in computer science, 3588, 503.

30 Roberto De Virgilio et al
22. Gonzalez, H., Han, J., Li, X., and Klabjan, D. (2006) Warehousing and analyzing massiveRFID data sets.Proceedings of the 22nd International Conference on Data Engineering, p. 83,IEEE Computer Society Washington, DC, USA.
23. Maass, W. and Filler, A. (2006) Towards an infrastructure for semantically annotated physicalproducts.Informatik, 94, 544–549.
24. Romer, K., Schoch, T., Mattern, F., and Dubendorfer, T. (2004) Smart Identification Frame-works for Ubiquitous Computing Applications.Wireless Networks, 10, 689–700.
25. Marcus, D. A. A., Madden, S., and Hollenbach, K. (2007) Scalable semantic web data manage-ment using vertical partitioning.VLDB ’07: Proceedings of the 33rd international conferenceon Very large data bases, pp. 411–422, VLDB Endowment.
26. Bechhofer, S., Moller, R., and Crowther, P. (2003) The DIG Description Logic Interface.Pro-ceedings of the 16th International Workshop on DescriptionLogics (DL’03), Rome, Italy,September, vol. 81 ofCEUR Workshop Proceedings.
27. Baader, F., Calvanese, D., Mc Guinness, D., Nardi, D., and Patel-Schneider, P. (2002)TheDescription Logic Handbook. Cambridge University Press.
28. Brachman, R. and Levesque, H. (1984) The Tractability ofSubsumption in Frame-based De-scription Languages.4th National Conference on Artificial Intelligence (AAAI-84), pp. 34–37,Morgan Kaufmann.
29. Berners-Lee, T., Hendler, J., and Lassila, O. (2001) Thesemantic Web.Scientific American,284, 28–37.
30. Baader, F., Horrocks, I., and Sattler, U. (2003) Description Logics as Ontology Languages forthe Semantic Web.Festschrift in honor of Jorg Siekmann, Lecture Notes in Artificial Intelli-gence. Springer-Verlag.
31. Paolucci, M., Kawamura, T., Payne, T., and Sycara, K. (2002) Semantic Matching of WebServices Capabilities.The Semantic Web - ISWC 2002, pp. 333–347, no. 2342.
32. Li, L. and Horrocks, I. (2004) A Software Framework for Matchmaking Based on SemanticWeb Technology.International Journal of Electronic Commerce, 8, 39–60.
33. Colucci, S., Di Noia, T., Di Sciascio, E., Donini, F., andM.Mongiello (2003) Concept abduc-tion and contraction in description logics.16th International Workshop on Description Logics(DL’03), September, vol. 81 ofCEUR Workshop Proceedings.
34. Gardenfors, P. (1988)Knowledge in Flux: Modeling the Dynamics of Epistemic States. Brad-ford Books, MIT Press.
35. Di Noia, T., Di Sciascio, E., Donini, F., and Mongiello, M. (2003) Abductive matchmakingusing description logics.IJCAI ’03, pp. 337–342.
36. Lee, C.-H. and Chung, C.-W. (2008) Efficient storage scheme and query processing for supplychain management using rfid.Proceedings of the ACM SIGMOD International Conference onManagement of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008, pp. 291–302, ACM.
37. Ban, C., Hong, B., and Kim, D. (2005) Time parameterized interval r-tree for tracing tagsin rfid systems.Database and Expert Systems Applications, 16th International Conference,DEXA 2005, Copenhagen, Denmark, August 22-26, 2005, Proceedings, vol. 3588 ofLectureNotes in Computer Science, pp. 503–513, Springer.
38. Gonzalez, H., Han, J., Li, X., and Klabjan, D. (2006) Warehousing and analyzing massiverfid data sets.Proceedings of the 22nd International Conference on Data Engineering, ICDE2006, 3-8 April 2006, Atlanta, GA, USA, p. 83, IEEE Computer Society.
39. De Virgilio, R., Sugamiele, P., and Torlone, R. (2009) Incremental aggregation of RFID data.Proceedings of the 2009 International Database Engineering & Applications Symposium, pp.194–205, ACM.
40. Di Noia, T., Di Sciascio, E., Donini, F., Ruta, M., Scioscia, F., and Tinelli, E. (2008) Semantic-based Bluetooth-RFID interaction for advanced resource discovery in pervasive contexts.In-ternational Journal on Semantic Web and Information Systems (IJSWIS), 4, 50–74.
41. Ruta, M., Di Noia, T., Di Sciascio, E., Scioscia, F., and Piscitelli, G. (2007) If objects couldtalk: A novel resource discovery approach for pervasive environments.International Journalof Internet and Protocol Technology (IJIPT), 2, 199–217.

Semantic-based RFID Data Management 31
42. Ruta, M., Di Noia, T., Di Sciascio, E., and Donini, F. (2006) Semantic-Enhanced BluetoothDiscovery Protocol for M-Commerce Applications.International Journal of Web and GridServices, 2, 424–452.
43. EPCglobal Ratified Specification (October, 4, 2005) Object Naming Service (ONS - ver. 1.0),http://www.epcglobalinc.org.
44. Beckmann, J. L., Halverson, A., Krishnamurthy, R., and Naughton, J. F. (2006) Extendingrdbmss to support sparse datasets using an interpreted attribute storage format.Proceedings ofthe 22nd International Conference on Data Engineering, ICDE 2006, 3-8 April 2006, Atlanta,GA, USA, p. 58, IEEE Computer Society.
45. Ruta, M., Di Noia, T., Di Sciascio, E., Piscitelli, G., and Scioscia, F. (2008) Semantic-basedmobile registry for dynamic RFID-based logistics support.10th International Conference onElectronic Commerce, ICEC 08, ACM Press, to appear.
46. Chamberlain, J., Blanchard, C., Burlingame, S., andE. Forestier, S. C., Griffith, G., Mazzara,M., Musti, S., S.-Y.Son, Stump, G., and Weiss, C. (2006)IBM WebSphere RFID Handbook:A Solution Guide. IBM International Technical Support Organization.
47. Kawakita, Y. and Mistugi, J. (2006) Anti-collision performance of Gen2 air protocol in randomerror communication link.Proceedings of the International Symposium on Applications andthe Internet Workshops - SAINT 2006, pp. 68–71.