automated semantic knowledge acquisition from sensor data
TRANSCRIPT

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
IEEE SYSTEMS JOURNAL 1
Automated Semantic KnowledgeAcquisition From Sensor Data
Frieder Ganz, Payam Barnaghi, and Francois Carrez
Abstract—The gathering of real-world data is facilitated bymany pervasive data sources such as sensor devices and smart-phones. The abundance of the sensory data raises the need to makethe data easily available and understandable for the potential usersand applications. Using semantic enhancements is one approachto structure and organize the data and to make it processable andinteroperable by machines. In particular, ontologies are used torepresent information and their relations in machine interpretableforms. In this context, a significant amount of work has beendone to create real-world data description ontologies and datadescription models; however, little effort has been done in creat-ing and constructing meaningful topical ontologies from a vastamount of sensory data by automated processes. Topical ontologiesrepresent the knowledge from a certain domain providing a basicunderstanding of the concepts that serve as building blocks forfurther processing. There is a lack of solution that construct thestructure and relations of ontologies based on real-world data.To address this challenge, we introduce a knowledge acquisitionmethod that processes real-world data to automatically create andevolve topical ontologies based on rules that are automaticallyextracted from external sources. We use an extended k-meansclustering method and apply a statistic model to extract and linkrelevant concepts from the raw sensor data and represent themin the form of a topical ontology. We use a rule-based system tolabel the concepts and make them understandable for the humanuser or semantic analysis and reasoning tools and software. Theevaluation of our work shows that the construction of a topologicalontology from raw sensor data is achievable with only smallconstruction errors.
Index Terms—Cybernetics, intelligent sensors computationaland artificial intelligence, machine intelligence, pattern analysissystems, man, and cybernetics, sensors.
I. INTRODUCTION
THERE is an emerging trend to use network-enabled de-vices that observe and measure the physical world to
communicate the sensory data over the Internet. This growingtrend toward integrating the real-world data into the Inter-net, which is supported by wireless sensor networks, radio-frequency identification tags, smartphones, Global PositioningSystem device, and many other sensory sources that capture andcommunicate the real-world data is referred to as Internet of
Manuscript received September 24, 2013; revised January 9, 2014,February 26, 2014, and May 13, 2014; accepted June 28, 2014. This paperdescribes work undertaken in the context of the EU ICT Iot.est project(http://www.Ict-Iotest.eu) contract number: 288385 and EU FP7 CityPulseproject (http://www.Ict-citypulse.eu) contract number: 609035.
The authors are with the Centre for Communication Systems Research, Uni-versity of Surrey, Guildford GU2 7XH, U.K. (e-mail: [email protected]).
Color versions of one or more of the figures in this paper are available onlineat http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/JSYST.2014.2345843
things (IoT). IoT defines a framework, where billions of devicesproduce and exchange data related to real-world objects (i.e.,things).
In IoT and other research domains such as pervasive andubiquitous computing, sensor devices are often used to obtainnew insights about our surrounding world and to facilitatethe interaction with it. However, the increasing use of data-producing devices leads to a deluge of sensory data that requiresnew methods to structure and represent the information and tomake the data accessible and processable for the applicationand services that use these data.
The semantic technologies have been used in recent years asone of the key solutions to provide formalized representationsof the real-world data [1]. The advantage of applying semantictechnologies to sensor data is conceptualization and abstractrepresentation of the raw data and making them machine in-terpretable and interlinking the data with existing resources onthe Web.
For instance, instead of communicating and representing rawnumerical values of a measurement of a weather condition, it ismore desirable to use semantic concepts and properties suchas BlizzardCondition, isHighWindCondition, or isFreezing-Condition measured and conceptualized by meteorologicalsensors.
Nevertheless, how the relationship between the raw data andits intended concept and/or relationship is established, still re-mains one of the biggest challenges in the IoT domain [2]. Thisissue is usually referred to as the symbol grounding problem[3], which describes the fundamental challenge of definingconcepts from numerical sensor data that is not grounded inmeaningful real-world information.
The real-world data is commonly gathered as numericalvalues that cannot easily be related to meaningful informationwithout knowing the context of the data such as observationtime and location. The data also underlies a natural volatilityand its meaning can change over time or it can be dependent onother external factors. For instance, 30 ◦C in summer can be anormal condition; however, in winter, it could be an error or anoutlier condition.
In order to overcome the grounding problem, we introducea rule-based system that designates the relationships betweendiscretized symbolized data and semantic concepts. We providean automated approach for a real-world data-driven topicalontology construction that represents the perceptual view of thecollected data and relationships between different concepts. Wehave developed a k-means clustering algorithm to group similardiscretized patterns that later represent named concepts in ourontology.
1932-8184 © 2014 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
2 IEEE SYSTEMS JOURNAL
Fig. 1. From raw data to semantics.
To discover relations between related concepts, we use aMarkov chain model approach to find the most frequent tem-poral occurrences between patterns and name them after theiroccurrence. To label unknown concepts and properties, weuse predefined rules. However, in order to have an automatedsystem, we need an independent rule system that mines rulesand applies them automatically to the concepts. To demonstratethe feasibility of our model, we introduce an approach that isable to automatically extract rules from existing resources onthe Web for the construction of new semantic concepts by usingthe raw sensory data.
We have implemented the aforementioned features and ap-plied our solution to a real-world data set with more than250 000 samples gathered from different sensors over one-month period. We show that it is possible to create a topicalontology that represents basic concepts that can be used as abuilding block for further processing and enhancements. Weevaluate the approach in terms of reconstruction error rate andshow excerpts of the automatically constructed ontology.
The remainder of this paper is organized as follows.Section II describes the concepts of real-world sensory data andsemantic representation of the data. The knowledge acquisitionprocess is presented in Section III. We have shown the feasi-bility of our solution by implementing a prototype and providethe evaluation results in Section IV. Section V describes therelated work. Section VI concludes this paper and describes thefuture work.
II. REAL-WORLD DATA PROCESSING FRAMEWORK
The main objective of this paper is to represent meaningfulrelations and extracted concepts from large amounts of sensorydata from the real-world data in a human and or machineinterpretable format. As shown in Fig. 1, real-world phenomenaare observed by collecting measurements from sensors and theraw data (mostly numerical) is sent to a user or a gateway, wherethe data is further processed and represented in a meaningfulsemantic representation.
We provide a framework that infers knowledge from thedata and constructs a topical ontology representation fromthe concepts that are extracted from the raw data. Here, weintroduce some background knowledge about sensor data anddiscuss semantic representation frameworks.
A. Real-World Data
Real-world data is commonly reported through observationand measurement data obtained from sensory devices. Sensordata is often communicated as raw time-series data that canconsist of a time stamp stating the time of measurement, deviceID, and the values sensed by the sensor that is on board of thesensor nodes, i.e., temperature, light, sound, presence, and otherrelevant metadata.
The number of sensor nodes that are reporting data is con-stantly increasing. On the one hand, the price for hardware hasfallen, and on the other hand, day-to-day devices and appliancesare equipped with more capable hardware. Due to the largenumber of sensor nodes and high sampling rates of sensor data,the amount of data is not bearable for many data processingalgorithms. The deluge of data requires a variety of differentefforts such as real-time reporting, spatial distribution, and thevariety of sensors and various qualities of the data for effec-tive processing. Therefore, dimension reduction techniques areusually used to reduce the number of features from a high-dimensional space to a low-dimensional representation [4].
Most commonly used techniques are the discrete fast Fouriertransformation (FFT), transforming the time-based data intothe frequency domain to remove unwanted frequencies beforetransforming it back to the time domain. The principal com-ponent analysis (PCA), extracting a new orthogonal base torepresent the original data by calculating the covariance orthe singular value decomposition (SVD), and the piecewiseaggregate approximation (PAA) and its symbolic representa-tion, which uses averaged windows, utilized in this paper. Weevaluate and discuss some of these techniques in the evaluationsection.
To abstract from numerical values and to create higher levelconcepts from the large amount of data produced by sensordevices, we use the symbolic aggregate approximation (SAX)dimensionality reduction mechanism [5]. SAX discretizes thedata and generates symbolic words representing patterns fromthe sensor data.
Data discretization serves as a building block for many pat-tern and event detection algorithms. It enables to map reoccur-ring patterns to events even if there is variance, time shifting, ordifferent means in the data [6]–[9]. In the current work, we usethe symbolic approximate aggregation to transform time-seriesdata into symbolized words, as shown and explained in Fig. 2.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
GANZ et al.: AUTOMATED SEMANTIC KNOWLEDGE ACQUISITION FROM SENSOR DATA 3
Fig. 2. Dimensionality reduction process of SAX. (a) (Blue line) One hundred data points of a sine curve. (Green dotted line) Curve after normalization. (b) Thenormalized curve is divided into nine windows. Each window represents the mean of 100/9 datapoints from the original data. This leads to a compression rate ofn/N, which is 9/100. (c) The output windows of the mean windows from (b) are vertically divided, according to a Gaussian distribution. Each segment is assignedto a letter. The segment in which the curve is in per window forms the SAX word; in this case, it is CDDCBAAAB.
Using SAX representations, we can detect similar patternsfrom different sensor sources. SAX divides a window intoequal segments and then creates a string representation for eachsegment. The SAX symbolic patterns are represented as stringwords; the string size and letters are adjustable in SAX (formore information refer to [8]).
For instance, a time-series sensor data, as shown in Fig. 2,is transformed into the SAX word “CDDCBAAAB”; similarpatterns will have resemblance to this symbolic representation.The string similarity between patterns in SAX helps to indexand compare different patterns by reducing the amount of datathat has to be processed and allows to associate rules to compareand/or process the SAX words.
To illustrate the symbolic data aggregation, we use an ex-ample, i.e., the word “CDDCBAAAB”, which is a pattern con-structed from sensor data obtained from an accelerometer thathas been attached to a door and measured over 5 s. This couldlead to the semantic concept “doorClosed” or “doorOpened”that can be stored and represented in an ontology. In thispaper, we use an extended version of the SAX algorithm, calledSensorSAX.
SensorSAX is optimized for sensor data and is describedin our earlier work presented in [10]. SensorSAX exploits avariable encoding rate instead of a constant rate based on theactivity in the streaming data and allows higher compressionand fewer errors in reconstructing the original raw data by onlytransmitting SAX words in case there is activity in the sensordata. In this paper, we focus on creating a topical ontology usingthe patterns that are extracted from the SensorSAX patterns.
B. Semantic Representation of Real-World Data
The key idea behind using semantic description for sensordata is to enable representation, formalization, and enhancedinteroperability of sensor data. Ontologies can be used to storesemantic concepts that represent phenomena and attributesfrom the real world that are understandable for the human userand also interpretable for machines due to the standardized datarepresentation.
The concepts can be linked together through relationshipsthat express interactions and dependencies between the con-cepts. The W3C Semantic Sensor Network Incubator Group has
introduced the semantic sensor network (SSN) ontology [11]that provides a model to annotate sensors and their metadataand gathered data. The SSN ontology uses semantic concepts tomodel the physical attributes of sensor networks such as “sensordevice,” “temperature sensor,” and “radio link.” Properties inthe SSN model the relationship between concepts such as“occurredAt”, “observedBy” to relate sensor data annotationsto domain models.
Zhao and Meersman [12] introduced the concept of topicalontologies that represent a basic knowledge structure of acertain domain that can be used as a building block for furtherenhancement. Topical ontologies include the main concepts(topics) that appear in a certain domain but unlike a taxonomyalso provide basic relations between the fundamental concepts.
We use the SSN ontology as a starting point for our methodand extend the ontology by extracting new insights from theraw sensor data to construct a topical ontology representing aextract of the observed domain. The following describes ourapproach to bridge the gap between raw data and the requiredsemantic concepts.
C. Overview of the Framework
In Fig. 3, an overview of the proposed framework to processthe raw sensory data and construct topical ontology is shown.The framework consists of three main components, i.e., datapreprocessing, ontology construction, and rule-based labeling.The raw sensor data serves as the input for the framework. Ak-means clustering mechanism is used to group the data intoclusters that form the unlabeled concepts. A Markov model isused to create temporal relations between the newly createdconcepts.
The unnamed concepts (i.e., clustered SAX patterns) andtemporal relations are used to create the initial topical ontology.After the initial ontology construction, the concepts are labeledusing a rule-based reasoning mechanism. The rule-based engineprocesses the context of the data and tries to name the unlabeledconcepts and properties. The process is shown in Fig. 4 and thedetailed description is found in Section III-C.
1) Data Preprocessing: In a first step, the raw data is stan-dardized to a mean of 0 and a standard deviation of 1to ensure an even distribution of the data over the whole

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
4 IEEE SYSTEMS JOURNAL
Fig. 3. Framework overview.
Fig. 4. Clustering the patterns into concepts.
processing period and allow comparison of differentlydistributed signals. Afterward, the data is transformed tothe SAX patterns. This allows the mapping of symbol-ized descriptions to semantic concepts in the ontologyconstruction and also reduces the size of data commu-nication. The dimensionality of the data is reduced by theaggregation algorithm in SAX.
This step can be performed on the sensing devices.In case the devices are not able to perform the task duelimited processing capabilities, the process can be movedto a node with higher processing capabilities (e.g., agateway).
2) Ontology Construction: The structure creation processdefines the outline of the ontology construction. A prelim-inary ontology structure is created by extracting conceptsand properties using a clustering algorithm and a statis-tical model. We follow a conceptual clustering approach[13] to create semantic concepts without labeling them.
The clusters are formed based on the similarity ofthe attributes: symbolic representation and the metadatasuch as sensor type and time range of the measurement.Each cluster is formalized as an unnamed concept inthe ontology structure. To model the properties in ourcurrent implementation, we use a Markov model to findthe temporal relations such as “occursAfter” between theconcepts.
3) Rule-Based Labeling: In order to name the concepts andthe properties, we utilize a rule-based mechanism. Therule system is based on the Semantic Web Rule Language(SWRL). It accepts symbolized SAX patterns and adds aname tag to the unlabeled concepts.
We introduce a system that is able to extract rules basedon the meta-information and external data sources toautomatically define the labels (this process is explainedin Section III-C).
III. REAL-WORLD DATA-DRIVEN
ONTOLOGY CONSTRUCTION
The following three methods are introduced to develop asolution that automatically constructs an ontology depictinga perceptual view of the sensed environment: clustering thesymbolic patterns, creating properties via a Markov model, andnaming the unlabeled concepts via a rule-based method.
A. Clustering for Concept Construction
In order to reduce the amount of data that has to be processed,we use the SAX algorithm to create compressed symbolicrepresentations of the data. SAX introduces a distance functionthat allows comparing generated words such as “ABBA” and“ABBC” and stating a similarity between 0 and 1. Commondistance measurements and string similarity functions such asLevenshtein- or Hamming-distance cannot be used on the SAXwords due to nonuniform distribution of the letters in the mainSAX algorithm.
The sole comparison of the words is not sufficient, as wordscan be similar but measured by different types of sensors thatare not related to each other. The words are also dependent onthe observation time. We introduce a set of information thatis needed to cluster the data into different groups based ontheir different attributes. We define a triple set A = [P, t, T ],where P is a SAX word, t is the observation type and T theobservation time. In addition, we define a distance function[shown as (2)] to compare the similarity of two triple sets
saxDist(P,Q) =
√n
w
√√√√ w∑i=1
(dist(pi, qi)2 (1)
distance(A1, A2) = saxDist(P1, P2) ∗ timeDiff(t1, t2)
∗ typeDiff(T1, T2). (2)

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
GANZ et al.: AUTOMATED SEMANTIC KNOWLEDGE ACQUISITION FROM SENSOR DATA 5
In (1), saxDist(P,Q) returns the distance between twowords P1 and P1 according to the distance function in [8].The original saxDist function is depicted in (1), where n is thelength of the SAX word, w the alphabet size of letters used inthe discretization process and the function dist(pi, q1) referringto a precalculated lookup table for the particular alphabet sizew. We extend the first equation by adding a factor to comparethe time difference and type difference between two triples.timeDiff returns a value between ]0,1] according to thetemporal distance of two triples and typeDiff returning either0 or 1, matching the type of the triples. Comparing functionvalues from the Euclidean and non-Euclidean space can leadto wrong results as the space dimensions are not equal. Thealternatives are the use of nonlinear dimensionality reductiontechniques and the kernel trick to map them into a commonspace; however, the complexity for sensor networks to performthis step is too high. In the evaluation section, we show thefeasibility of this approach.
The extracted triples from the data are fed into a k-meansclustering method [14] that uses the previous defined distancefunction. Each cluster is transferred to an unlabeled concept thatis later labeled through the rule-based mechanism. We extendthe commonly used k-means algorithm for non-numerical SAXbased patterns. The extended k-means algorithm is described inAlgorithm 1 for two clusters.
In normal k-means, clusters are formed by calculating thedistance in an Euclidean space between different sample sets.However, our sample sets consist of the non-Euclidean mem-bers: pattern, type and time. Therefore, we use the distancefunction shown in (2) to measure the distances between differ-ent triples.
Algorithm 1 Modified K-means clustering method
function CLUSTERING(c1,c2)
for pi ∈ TriplesP dod1 = distance(c1, pi)d2 = distance(c2, pi)if d1 < d2 then
cluster1.add(pi)else
cluster2.add(pi)end if
end forreturn cluster1, cluster2
end functionc1 = random(P )c2 = random(P )cluster1, cluster2 = clustering(c1, c2)while ε ≤ 0.1 do
c1 = average(cluster1);c2 = average(cluster2);cluster1, cluster2 = clustering(c1, c2)newC1 = average(cluster1)newC2 = average(cluster1)ε = (c1− newC1) + (c2− newC2)
end while
We start with choosing two triples randomly from the datawhich serve as the initial centroids for two different clusters.The distances of the other triples from the centroids are cal-culated according to the distance function shown in (2). Thetriples are then clustered respectively according to their distanceto the centroid. The average of each cluster is then calculatedwith the help of the distance function, and the centroids areshifted according to the average distances to the centroids. Theprocess is iteratively repeated until both centroids converge to acertain point.
The clustering process groups similar SAX words (i.e pat-terns) in clusters. Each cluster is then represented as an un-named concept. We use the clusters instead of the patterns,because small deviations in the raw data produce different pat-terns. Using large number of patterns with small deviations tocreate our topical ontology will then produce a huge number ofconcepts and relations that provide little information. Instead,we group the similar patterns and use representative concepts(i.e., clusters).
B. Statistics-Based Property Extraction
We use the frequency of unnamed concepts and their tem-poral occurrence to construct a Markov chain that representsthe likelihood of temporal relations between unnamed concepts.The model is able to detect and represent relations betweenconcepts through temporal properties such as occursAfter,occursBefore, and occursSame.
We provide two options to use the extracted likelihoods. Incase that the ontology supports fuzzy relations, or weightedproperties as provided for instance by fuzzy OWL 2 [15], thelikelihoods are noted in the semantic representation and can beused by a fuzzy reasoner [16]. If the underlying ontology orreasoner does not support fuzzy relations and only crisp andwell-defined properties can be accepted, we define a thresholdthat has to be met to transfer the observed temporal dependencyto a semantic representation. The threshold defines the level thatan uncertain relation should be accepted and included in theontology.
It is clear that by decreasing the threshold level, more re-lations will be included in the ontology; however, the lowerthreshold level will also decrease the accuracy of the propertydefinition in the ontology. The threshold level definition isapplication and domain dependent and the extent of relationsversus accuracy can be used to define this. The threshold can bedefined using heuristics or it can be defined manually.
In this paper, and in the evaluation section, we showhow different threshold levels affects the ontology construc-tion. We use a heuristic defined threshold of 0.8 to filterunwanted relations. In the example shown in Fig. 5, using0.8 as the threshold level leads to defining two properties,namely, 〈Concept 2, “occursAfter”,Concept 2〉, 〈Concept 3,“occursAfter”,Concept 1〉 (the direction of arrows in Fig. 5represents the temporal presents of the concepts).
C. Rule-Based Concept and Property Naming
We use the SWRL [17] to label the unnamed conceptsand properties that have been extracted through the clustering

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
6 IEEE SYSTEMS JOURNAL
Fig. 5. Temporal relation based on pattern frequency.
process. The rules defined in SWRL follow the syntax form:antecedent ⇒ consequent, where the consequent is the antic-ipated name to be used to label the concepts and properties andto fulfill the antecedent rules. The following shows an exampleof a SWRL rule:
isTemperatureSensor(?tmp)
&lessThanOrEqual(?tval, 8)
⇒ coldTemperature.
The rules can be used to label a concept as “coldTempera-ture” in case that the antecedent conditions, “originated froma temperature sensor” and “the value of the measurement isbelow 8”, are satisfied. In our implementation, we initiallydefine the rules manually by considering available sensor typesand possible states that can result from these types or theircombination.
However, in large-scale data processing scenarios, manualannotation is not a feasible approach and can hinder extensi-bility and scalability of the solutions. There is a need to definemechanisms that can automatically extract rules. We define aminimum set of information needed to define the rules by usingsensor type, mathematical operator and location. The target isto find the labels that can be used to describe the unnamedsemantic concepts. Sensor type and location information canbe obtained by the sensor description that is usually availablein a machine-readable format.
Based on the sensor type, we can infer possible attributes thatcan be applied as label. For this purpose, we use the commonsense semantic ontology “conceptNet” [18]. For instance, wecan obtain the possible labels via the sensor type tempera-ture. Querying ConceptNet with temperature will lead to theresult set “warm,” “cold,” “hot,” and “cool.” By knowing thelocation of the sensor, we can query the ConceptNet entitiesand extract related attributes and causal rules relevant to aparticular type (e.g., temperature, light). In Table I, we showan excerpt of extracted properties that serve as basis for the rulegeneration.
TABLE IAUTOMATICALLY EXTRACTED PROPERTIES FOR RULE CREATION
D. Discussion
The current work allows to create a topical ontology fromraw sensor data. The created ontology can be used as a baselinefor further improvements creating richer ontologies. Our ap-proach is divided into three steps: data preprocessing, ontologyConstruction, and rule-Based labeling.
We have attempted to propose an automated framework;however, there are certain parameters during each step that varythe outcome. In the following, we describe the parameters ineach step and discuss their impact. The used SAX algorithmto transform the raw numerical sensor data into string repre-sentations to reduce the dimensionality and easy comparabilitytakes a window of samples with a specified window length andturns it into a reduced vector with a smaller length. The choiceof the reduced vector length can have an impact on the nextprocessing steps. In case a very small vector length has beenchosen, important data, such as outliers or certain patterns, canbe lost. In case the reduced vector length is chosen high, theeffect of reducing the amount of data is decreased and eithertoo many noise is passed onto the next algorithm or the amountof data is not suitable for the processing intensive clusteringprocess.
Aside from parameter n, to control the reduced vector outputlength, parameter a has to be set to control the size of thedictionary that is used when transforming to a string represen-tation. The larger the dictionary, the more fine grain will be theresolution of the discretized representation. We have conductedsome research that chooses the right parameters based on thevariance of the data [19]. This is useful when interesting eventsoccur outside the mean of a data window. Other possibletechniques for the dimensionality reduction are PCA and thediscrete Fourier transformation. The different techniques arebenchmarked in the evaluation section.
The ontology construction step uses a modified k-meansclustering algorithm that groups similar samples based on theirdistance. The algorithm requires two parameters, i.e., the pre-dicted number of clusters K and a distance function. Com-monly, the Euclidean distance is used to calculate similaritybetween data points; however, here we use a modified distance
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
GANZ et al.: AUTOMATED SEMANTIC KNOWLEDGE ACQUISITION FROM SENSOR DATA 7
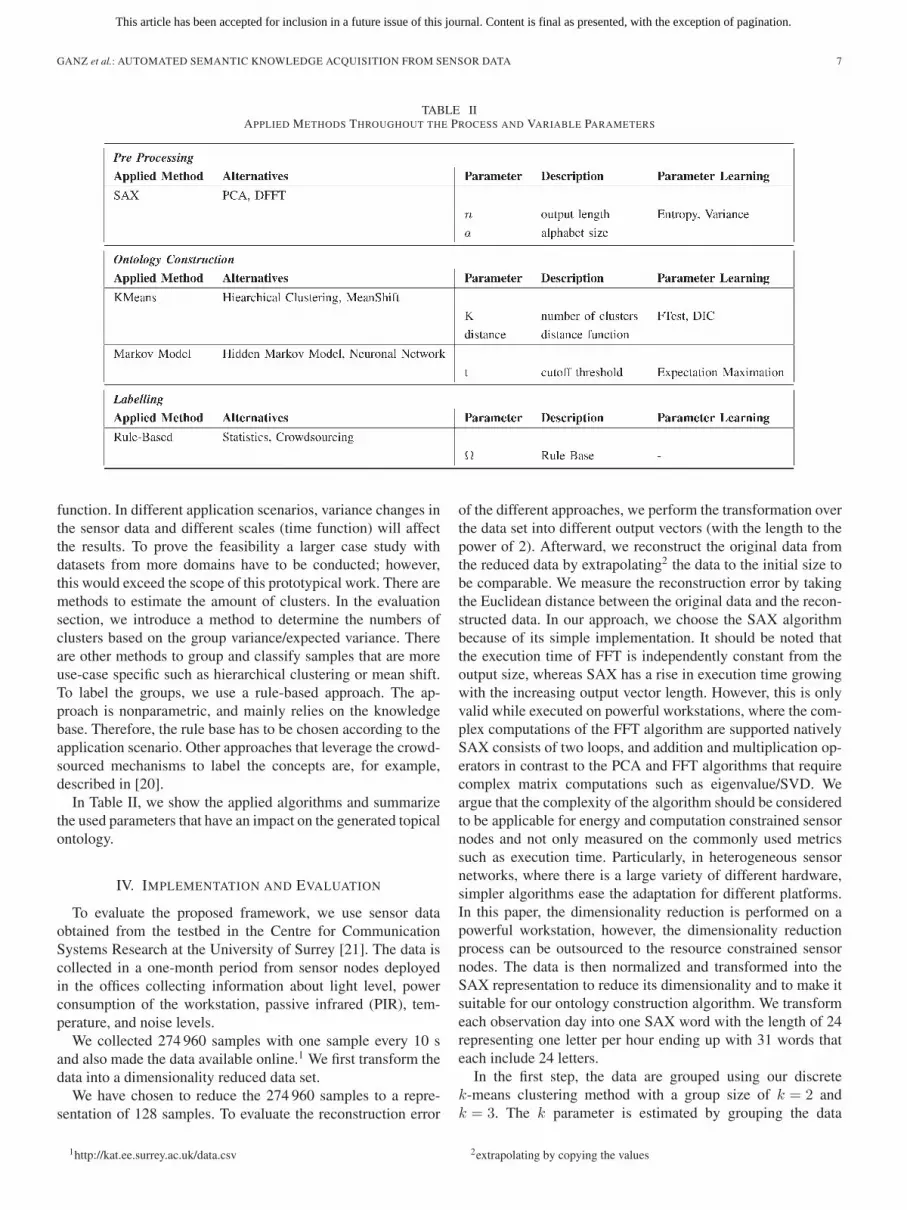
TABLE IIAPPLIED METHODS THROUGHOUT THE PROCESS AND VARIABLE PARAMETERS
function. In different application scenarios, variance changes inthe sensor data and different scales (time function) will affectthe results. To prove the feasibility a larger case study withdatasets from more domains have to be conducted; however,this would exceed the scope of this prototypical work. There aremethods to estimate the amount of clusters. In the evaluationsection, we introduce a method to determine the numbers ofclusters based on the group variance/expected variance. Thereare other methods to group and classify samples that are moreuse-case specific such as hierarchical clustering or mean shift.To label the groups, we use a rule-based approach. The ap-proach is nonparametric, and mainly relies on the knowledgebase. Therefore, the rule base has to be chosen according to theapplication scenario. Other approaches that leverage the crowd-sourced mechanisms to label the concepts are, for example,described in [20].
In Table II, we show the applied algorithms and summarizethe used parameters that have an impact on the generated topicalontology.
IV. IMPLEMENTATION AND EVALUATION
To evaluate the proposed framework, we use sensor dataobtained from the testbed in the Centre for CommunicationSystems Research at the University of Surrey [21]. The data iscollected in a one-month period from sensor nodes deployedin the offices collecting information about light level, powerconsumption of the workstation, passive infrared (PIR), tem-perature, and noise levels.
We collected 274 960 samples with one sample every 10 sand also made the data available online.1 We first transform thedata into a dimensionality reduced data set.
We have chosen to reduce the 274 960 samples to a repre-sentation of 128 samples. To evaluate the reconstruction error
1http://kat.ee.surrey.ac.uk/data.csv
of the different approaches, we perform the transformation overthe data set into different output vectors (with the length to thepower of 2). Afterward, we reconstruct the original data fromthe reduced data by extrapolating2 the data to the initial size tobe comparable. We measure the reconstruction error by takingthe Euclidean distance between the original data and the recon-structed data. In our approach, we choose the SAX algorithmbecause of its simple implementation. It should be noted thatthe execution time of FFT is independently constant from theoutput size, whereas SAX has a rise in execution time growingwith the increasing output vector length. However, this is onlyvalid while executed on powerful workstations, where the com-plex computations of the FFT algorithm are supported nativelySAX consists of two loops, and addition and multiplication op-erators in contrast to the PCA and FFT algorithms that requirecomplex matrix computations such as eigenvalue/SVD. Weargue that the complexity of the algorithm should be consideredto be applicable for energy and computation constrained sensornodes and not only measured on the commonly used metricssuch as execution time. Particularly, in heterogeneous sensornetworks, where there is a large variety of different hardware,simpler algorithms ease the adaptation for different platforms.In this paper, the dimensionality reduction is performed on apowerful workstation, however, the dimensionality reductionprocess can be outsourced to the resource constrained sensornodes. The data is then normalized and transformed into theSAX representation to reduce its dimensionality and to make itsuitable for our ontology construction algorithm. We transformeach observation day into one SAX word with the length of 24representing one letter per hour ending up with 31 words thateach include 24 letters.
In the first step, the data are grouped using our discretek-means clustering method with a group size of k = 2 andk = 3. The k parameter is estimated by grouping the data
2extrapolating by copying the values

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
8 IEEE SYSTEMS JOURNAL
Fig. 6. Determining the numbers of clusters based on the cluster group variance.
Fig. 7. Clustering the triples into groups.
over different k, and for each k, the variance of each clustergroup is calculated. The goal is to keep the overall varianceper cluster as low as possible. In Fig. 6, we show the varianceover different values of k and eventually set the number ofclusters to two for the following steps. The variance is usedas a rule-of-thumb method. For future work, we examine usingprobability density functions and data distributions to determinethe number of clusters. The latter will eliminate the varianceanalysis and cluster number selection by using a predictivemechanism; however, the current experiment provides a betterindication of the behavior of clusters by applying differentvalues for k but will come at a cost of accuracy. Each data pointin Fig. 7 represents a triple (Sax Pattern, Time stamp, Sensortype) that is grouped into one particular group. The clusters arethen represented as a concept. We know from the data that twotrends can be observed, the data from the power meter, noiseand PIR sensors have high activity during workdays and remainsteady over the weekend. The goal is to automatically label theunnamed concepts as either workday or weekend and representthis knowledge in the ontology.
We evaluate the results of the clustering method with real cal-endar information shown in Fig. 8. The best case is to achievean error rate of 0, thus all triples of the data set have beencorrectly grouped into either the workday or weekend group.
Due to the fact that we choose random triples as startingpoint for our clustering method the results in each experimentcould be different. To show the performance of the algorithm indifferent experiments, we run the evaluation 100 times to get acomparable average, minimum and maximum of the error rate.The results are shown in Table III. In most cases the triplesare correctly categorized; however, sometimes an odd startingtriples is selected, and all triples including the ones from theweekend are categorized as weekdays, resulting in the highesterror rate of 8. The outcome of the clustering method alsohighly depends on the underlying data set. The Mic and PIRdata sets lead to the smallest error rate regardless of the initialcluster set. However, the selection of the initial centroids andthe cluster size has still place space for improvements and willbe addressed in future work.
The groups are then included in a baseline ontology asunnamed concepts. The temporal relation between the conceptsis extracted using the statistical model. In this scenario, itis more likely that one concept follows the same conceptp(group1|group1) = 0.7 and group 2 following after group 1p(group2|group1) = 0.2. This expresses that it is more likelythat a weekday follows another weekday. As stated earlier theamount of (temporal) relationships is dependent on cluster sizeand cutoff threshold.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
GANZ et al.: AUTOMATED SEMANTIC KNOWLEDGE ACQUISITION FROM SENSOR DATA 9
Fig. 8. Evaluating the clustered data from different sensors with real calendar information and showing the error rate over 100 random runs.
TABLE IIIERROR RATE IN DETECTING THE CORRECT GROUPS
FROM DIFFERENT SENSOR TYPES
Fig. 9. Number of relations based on the factors: cutoff threshold and clustersize.
In Fig. 9, we show the dependency between cluster size,threshold and resulting amount of relations that are eventuallyrepresented in the ontology. Currently, there is no automatedway to choose the right parameters and thus heuristics anddomain experience have to be considered while designing thesystem.
Fig. 10 shows an excerpt of the automatically constructedontology. Squares represent classes that can have individuals,instances from a certain domain and represented as circles inthe figure. On the left of the figure is the information that can begathered from the sensor devices itself. Meta-information suchas observation period, deployed devices and their capabilities
are represented as SSN concepts. The SAX words and theinferred information that is acquired through the framework areshown on the right. The gray highlighted concepts show thenovelty of the automated process. Fig. 11 shows a screenshot ofthe ontology visualized by an ontology visualization tool.3 Theframework can conclude the meaning of raw sensor data andrepresent it in an topological ontology. The created ontologycan be downloaded.4
V. RELATED WORK
Here, we provide an overview of related work on knowledgerepresentation and creating insights from unstructured data. Wealso describe the methods and techniques that are used in thispaper.
A. Similar Approaches
There are some notable work that learn and construct on-tologies and semantic representations of data from text docu-ments. Wei et al. [22] introduce an automatic learning approachto construct terminological ontologies based on different textdocuments. Common words that have a semantic similarity aregrouped together and represented as concepts in an ontology.The authors use probabilistic models similar to our work.However, the work of Wang et al. can be applied to only text-based data.
Lin et al. [23] introduced a learning approach that constructsan ontology automatically without the requiring training data.The approach is not only domain independent but also relies ontext data. The keyword only data allows using existing distancemetrics, such as cosine distance, to find similar concepts. Inour approach, we had to introduce a similarity function for thespecial domain of sensor data.
3http://semweb.salzburgresearch.at/apps/rdf-gravity4http://http://personal.ee.surrey.ac.uk/Personal/F.Ganz/onto.owl

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
10 IEEE SYSTEMS JOURNAL
Fig. 10. Schematic view of the constructed topological ontology.
Fig. 11. Excerpt of the automatically created topological ontology.
With the upcoming of the semantic sensor Web, severalworks have been conducted in providing sensor data withsemantic representations. Sheth et al. use semantics to representand structure real-world data in 2009 [1]. However, trans-forming the raw data into the semantic representation remainsa challenge, particularly with the deluge of data that is notfeasible to manage them using manual solutions.
Dietze and Domingue [24] described the problem of sym-bolic grounding and the semantic sensor Web and introduces anapproach that uses conceptual spaces to bridge the gap betweensensor measurements and symbolic ontologies in an automaticmanner. The authors state that finding the right distance func-tion remains as one of the challenges. In the current work, wedefine a distance function that includes the three main featuresof interest; pattern shape, type of measurement and observationperiod and provide a distance function.
Stocker et al. [25] described a system to detect and classifydifferent types of road vehicles passing a street with the help ofvibration sensors and machine learning algorithms. The workacquires knowledge represented as an ontology by using twoabstraction layers; the physical sensor layer and the sensor datalayer.
However, the approach requires user interaction and/ordomain-dependent training data to train the system to a certainenvironment. In our approach, we introduce an autonomoussystem that does not rely on training data.
B. Data Processing Mechanisms
The knowledge acquisition requires several processing steps.Due to the large volume of real-world data, techniques arerequired to lower the amount (or dimension) of the data in-put to make it manageable for processing algorithms such asclustering and statistical methods. In the domain of time-seriesanalysis there has been a large amount of dimension reductiontechniques such as FFT [26], discrete wavelete transformation[27], and PAA [28] and SAX. The comparative study byDing et al. [29] revealed that SAX performs best in preserv-ing the data features by remaining high dimension reduction(data compression).
To reduce the flood of real-world sensor data, we used theSAX method introduced by Lin et al. [8]. SAX transforms time-series data into aggregated words that can be used for patterndetection and indexing. However, SAX was not developed for

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
GANZ et al.: AUTOMATED SEMANTIC KNOWLEDGE ACQUISITION FROM SENSOR DATA 11
small constrained devices and we therefore introduce Sensor-SAX [10], a modified version that has less data transmission intimes of low activity in the sensor signal that is processed.
In order to group similar types of patterns and events, clus-tering mechanisms are used. Cluster mechanisms do not requiretraining data and can be unsupervised. However, the clusteringmethods rely on distance functions that map the data samples toa comparable space. The k-means clustering method providesfast computation of the groups even in large data sets. However,the biggest drawback is that the number of clusters (i.e., k) isan input parameter and therefore should be known beforehand.
In order to create the properties, we used a rule-miningapproach similar to Hu et al. [30]. The authors aim at creat-ing ontologies automatically by learning the logical rules toconstruct the ontology. In this paper, we use a rule learningapproach similar to the one of Hu et al. to label the unnamedconcepts in the ontology.
Overall, the concepts that are created using the clusteringalgorithm are named using a logical rule-mining approach. Thisallows the ontology construction method to insert new namedconcepts into the ontology and define the relations between theconcepts.
VI. CONCLUSION
In this paper, we have introduced an approach that auto-matically generates a semantic ontology from raw sensor datathat represents information and new insights gathered througha knowledge acquisition process. We have introduced threemechanisms, namely, a discrete k-means clustering method,a statistical method, and a rule-based system, to provide aframework that is able to construct a knowledge representationfor sensor data without requiring a preliminary training data.The proposed ontology learning solution will allow creating amachine-readable and machine-interpretable representation ofthe concepts (i.e., patterns) and their relations that are definedbased on spatiotemporal and thematic attributes of the streams.The constructed ontology can be used in control and monitoringapplications that use the sensory data to observe the status of anenvironment or a physical entity or it can be used to providean overall view of the changes and related occurrences over aperiod.
We evaluate our approach with the help of a prototypicalimplementation and real-world data gathered from sensorsdeployed in an office environment. We construct an ontologyrepresenting a work week in an office with a manual definedcluster size.
The results show an effective way in representing and nam-ing semantic concepts from sensor data. However, the currentexecution time does not reflect the requirements for real-timeprocessing; therefore, more investigation has to be made tomake this approach more suitable for learning and ontologyconstruction from real-time streaming data. The approach alsocreates properties between semantic concepts; however, weuse a predefined threshold to filter unwanted relationships.For the future work, we will investigate how to find the bestparameters for the framework in terms of window lengths forthe dimensionality reduction process, the cluster size (k) and
the threshold that selects the amount of relations created. Asidefrom the technical aspects, the approach can be exploited toautomatically model relationships between different users andtheir habits (assumed the rule base contains the right informa-tion), and therefore, the impact on privacy has to be considered.
REFERENCES
[1] A. Sheth, C. Henson, and S. S. Sahoo, “Semantic sensor web,” IEEEInternet Comput., vol. 12, no. 4, pp. 78–83, Jul./Aug. 2008.
[2] O. Corcho and R. García-Castro, “Five challenges for the semantic sensorweb,” Semantic Web, vol. 1, no. 1/2, pp. 121–125, Apr. 2010.
[3] A. M. Cregan, “Symbol grounding for the semantic web,” in The Seman-tic Web: Research and Applications. Berlin, Germany: Springer-Verlag,2007, pp. 429–442.
[4] Y. Pao, “Dimension reduction, feature extraction and interpretation ofdata with network computing,” in Studies in Pattern Recognition, vol. 25.Singapore: World Scientific, 1996, ser. Series in Machine Perception andArtificial Intelligence, pp. 131–146.
[5] J. Lin, E. Keogh, S. Lonardi, and B. Chiu, “A symbolic representationof time series, with implications for streaming algorithms,” in Proc. 8thACM SIGMOD Workshop Res. Issues DMKD, 2003, pp. 2–11.
[6] E. Keogh, J. Lin, and A. Fu, “HOT SAX: Efficiently finding the mostunusual time series subsequence,” in Proc. 5th IEEE Int. Conf. DataMining, 2005, pp. 1–8.
[7] Q. Yan, S. Xia, and Y. Shi, “An anomaly detection approach based onsymbolic similarity,” in Proc. CCDC, May 2010, pp. 3003–3008.
[8] J. Lin, E. Keogh, L. Wei, and S. Lonardi, “Experiencing SAX: A novelsymbolic representation of time series,” Data Mining Knowl. Discov.,vol. 15, no. 2, pp. 107–144, Oct. 2007.
[9] D. Minnen, C. Isbell, M. Essa, and T. Starner, “Detecting subdimensionalmotifs: An efficient algorithm for generalized multivariate pattern discov-ery,” in Proc. 7th IEEE ICDM, Oct. 2007, pp. 601–606.
[10] F. Ganz, P. Barnaghi, and F. Carrez, “Information abstraction for heteroge-neous real world Internet data,” IEEE Sensors J., vol. 13, no. 10, pp. 3793–3805, Oct. 2013.
[11] M. Compton et al., The SSN ontology of the W3C semantic sensor networkincubator group. Amsterdam, The Netherlands: Elsevier, 2012.
[12] G. Zhao and R. Meersman, “Architecting ontology for scalability andversatility,” in On the Move to Meaningful Internet Systems 2005:CoopIS, DOA, ODBASE. Berlin, Germany: Springer-Verlag, 2005,pp. 1605–1614.
[13] D. H. Fisher, “Knowledge acquisition via incremental conceptual cluster-ing,” Mach. Learn., vol. 2, no. 2, pp. 139–172, Sep. 1987.
[14] J. A. Hartigan and M. A. Wong, “Algorithm as 136: A k-means clusteringalgorithm,” J. R. Stat. Soc. Ser. C, Appl. Stat., vol. 28, no. 1, pp. 100–108,1979.
[15] F. Bobillo and U. Straccia, “Fuzzy ontology representation using OWL 2,”Int. J. Approx. Reason., vol. 52, no. 7, pp. 1073–1094, Oct. 2011.
[16] A. Emrich, F. Ganz, D. Werth, and P. Loos, “Statistics-based graphicalmodeling support for ontologies,” in Proc. 7th Int. Conf. Adv. SEMAPROIARIA, P. Dini, Ed., Porto, Portugal, Sep. 29–Oct. 4, 2013, pp. 13–19.
[17] W3C Member Submission, I. Horrocks et al., SWRL: A Semantic WebRule Language Combining OWL and ruleML, vol. 21, p. 79 2004.
[18] H. Liu and P. Singh, “ConceptNet-A practical commonsense reasoningtool-kit,” BT Technol. J., vol. 22, no. 4, pp. 211–226, Oct. 2004.
[19] F. Ganz, P. Barnaghi, and F. Carrez, “Multi-resolution data communica-tion in wireless sensor networks,” in Proc. IEEE World Forum InternetThings, 2014, pp. 571–574.
[20] P. Viappiani, S. Zilles, H. J. Hamilton, and C. Boutilier, “Learningcomplex concepts using crowdsourcing: A Bayesian approach,” inAlgorithmic Decision Theory. Belin, Germany: Springer-Verlag, 2011,pp. 277–291.
[21] M. Nati, A. Gluhak, H. Abangar, and W. Headley, “SmartCampus: A user-centric testbed for Internet of things experimentation,” in Proc. 16th Int.Symp. Wireless Pers. Multimedia Commun., 2013, pp. 1–6.
[22] W. Wang, P. M. Barnaghi, and A. Bargiela, “Probabilistic topic modelsfor learning terminological ontologies,” IEEE Trans. Knowl. Data Eng.,vol. 22, no. 7, pp. 1028–1040, Jul. 2010.
[23] Z. Lin, R. Lu, Y. Xiong, and Y. Zhu, “Learning ontology automaticallyusing topic model,” in Proc. ICBEB, 2012, pp. 360–363.
[24] S. Dietze and J. Domingue, “Bridging between sensor measurementsand symbolic ontologies through conceptual spaces,” in Proc. 1st Int.Workshop Semantic Sensor Web, 2009, pp. 1–15.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
12 IEEE SYSTEMS JOURNAL
[25] M. Stocker, M. Rönkkö, and M. Kolehmainen, “Making sense of sensordata using ontology: A discussion for road vehicle classification,” in Proc.Int. Congr. iEMSs, 2012, pp. 1–8.
[26] C. Faloutsos, M. Ranganathan, and Y. Manolopoulos, “Fast subsequencematching in time-series databases,” ACM SIGMOD Rec., vol. 23, no. 2,pp. 419–429, Jun. 1994.
[27] K.-P. Chan and A. W.-C. Fu, “Efficient time series matching by wavelets,”in Proc. 15th Int. Conf. Data Eng., 1999, pp. 126–133.
[28] E. J. Keogh and M. J. Pazzani, “Scaling up dynamic time warping for datamining applications,” in Proc. 6th ACM SIGKDD Int. Conf. Mining, 2000,pp. 285–289.
[29] H. Ding, G. Trajcevski, P. Scheuermann, X. Wang, and E. Keogh, “Query-ing and mining of time series data: Experimental comparison of represen-tations and distance measures,” Proc. VLDB Endowment, vol. 1, no. 2,pp. 1542–1552, Aug. 2008.
[30] W. Hu, J. Chen, H. Zhang, and Y. Qu, “Learning complex mappingsbetween ontologies,” in The Semantic Web, vol. 7185, J. Pan, H. Chen,H.-G. Kim, J. Li, Z. Wu, I. Horrocks, R. Mizoguchi, and Z. Wu, Eds.Berlin, Germany: Springer-Verlag, 2012, ser. Lecture Notes in ComputerScience, pp. 350–357.
Frieder Ganz received the Ph.D. degree from theCentre for Communication Systems Research, Uni-versity of Surrey, Surrey, U.K., in 2014.
His research is focused on information abstrac-tion and extracting machine-interpretable knowledgefrom large volumes of sensory data using streamprocessing and machine learning techniques.
Payam Barnaghi is a Lecturer (Assistant Profes-sor) with the Centre for Communication SystemsResearch, University of Surrey, Surrey, U.K. Hisresearch interests include machine learning, Internetof Things, semantic Web, Web services, informa-tion centric networks, and information search andretrieval.
Francois Carrez received the Ph.D. degree in the-oretical computer science from the University ofNancy, Nancy, France, in 1991.
For 18 years, he worked with Alcatel ResearchCentre, Paris, in areas such as security, distributedartificial intelligence, ad hoc networking, and se-mantics. He joined the University of Surrey, Surrey,U.K., in 2006 and is currently a Senior ResearchFellow with the Centre for Communication SystemsResearch. His research interests include Internet ofThings (IoT), architecture design, and activity the-
ory. He is also the Secretary of the IoT International Forum.