ripple down rules: turning knowledge acquisition into knowledge maintenance
TRANSCRIPT

Arrificial Intelligence in Medicine 4 (1992) 463-475 Elsevier 463
Ripple down rules: Turning knowledge
acquisition into knowledge maintenance*
Paul Compton a, Glenn Edwards b, Byeong Kang a, Leslie Lazarus b, Ron Malor b, Phil Preston a and Ashwin Srinivasan bq c
a School of Computer Science and Engineering, University of New South Wales, PO. Box 1, Kensington,
NSW 2033, Australia
b Department of Chemical Pathology, St. I¢s Hospital, Dartinghurst, NSW 2010, Australia
’ The Turing Institute, George House, 36 North Hanover Street, Glasgow Gl2AD, UK
Received January 1992 Revised May 1992
Abstract
Compton, P., G. Edwards, B. Rang, L. Lazarus, R. Malor, P. Preston and A. Srinivasan, Ripple down rules: Turning knowledge acquisition into knowledge maintenance, Artificial Intelligence in Medicine 4 (1992) 463-475.
The most successful applications of medical expert systems Seem to be in the interpretation of laboratory data. However, even in this domain, knowledge acquisition and maintenance are major problems. We have developed a knowledge acquisition technique (‘ripple down rules’) based on using knowledge only in the context in which it is acquired. The method also guides the expert to enter rules that are valid. This method trivialises knowledge acquisition so that building a pathology expert system becomes the minor daily task for the expert of correcting wrong interpretations and tuning the knowledge base to current expertise. A major expert system based on this technique, PEIRS (Pathology Expert Interpretative Reporting System), is now in use. The current limitations of the technique are that the underlying tree structure of the knowledge base may require the expert to reenter some knowledge and that multiple diseasesare handled as composite diseases.
Keywords. Knowledge acquisition; knowledge engineering; context; medical expert systems; ripple down rules.
1 Introduction
Knowledge acquisition and engineering remain major problems for expert systems, particu- larly medical expert systems [14]. A particular aspect of knowledge engineering that little attention is paid to, is knowledge maintenance. Reports on the best known maintained system, XCON/Rl [l, 251 indicate that the major part of acquisition occurs during maintenance.
* ‘Es work was supported in part by the Australian Research Council Grant No. AC9031495 Correspondence to: Paul Compton, School of Computer Science and Engineering, University of New South
Wales, P.O. Box 1, Kensington, NSW 2033, Australia, email: [email protected]
Q93_3-3657p2f.mS.O @ 1992 - H sevier Science Publishers B.V. All rights reserved

P. Compton et al.
XCON is an example of a constantly changing domain as Digital introduces new computers into its product line which require configuring. Another maintained system is GARVAN-ESl, a medical expert system that was in routine use from mid 1984 to mid 1990. It was used to provide clinical interpretations of data from thyroid tests so that diagnostic reports issued by the laboratory included an expert interpretation of the data [S, 151. Thyroid interpretation has now been taken over by the PEIRS (Pathology Expert Interpretative Reporting System) described below. The design of PEIRS was based on the GARVAN-ES1 maintenance experience. The important contrast with XCON/Rl is that the domain of GARVAN-ES1 underwent only minor changes in six years of routine use, however it was continuously maintained in this time. The basis of this maintenance was that all reports issued by the laboratory were checked and signed. This was general policy as reports other than the thyroid reports handled by GARVAN-ES1 still required human comments and there was some initial doubt as to how the expert system would perform. This checking of reports and the consequent detection of errors and omissions in GARVAN-ESl’s knowledge base provided a unique opportunity to study the maintenance problems of an expert system [5, 10, 151.
The most obvious feature of this maintenance was that although the system was 96% correct when introduced into routine use [15], the knowledge base doubled in size before it reached 99.7% acceptance of its interpretations by experts. Secondly, experts did not get any better at providing ‘ready to use’ rules. The rules always had to be engineered to make them work correctly and validated by running test cases [S, lo]. Because the knowledge base was in use and was being maintained and the maintenance documented, it provided an attractive experimental domain. Experiments have been conducted using this knowledge base in the areas of machine learning [22, 231, the application of data dictionary technology to expert systems [ 16-181, the ripple down rule knowledge acquisition methodology described below [4,7,24] and related studies [9, 11,12,20,21].
The inductive learning approach was highly successful in building knowledge bases for the domain for fairly broad classes of classification. However, there are some 60 classifications in the thyroid domain alone. Some of these are extremely rare and there are also some extremely rare data profiles for more common classifications. Experts are often well able to deal with these exceptional situations, but the error pruning normally required with inductive learning techniques removes these rare cases making the techniques unsuitable for maintenance. Ways to produce error free data so that pruning is not required, will be discussed below.
x data dictionary in a conventional system is used as the central repository of design information concerning the system. All the objects in the system and their interrelationships are defined within the dictionary. From the dictionary one should be able to find all the usages of a given object in the system, which greatly simplifies maintenance. Experiments have been carried out on improving the maintenance of expert systems by applying this conventional software maintenance technique to knowledge bases [M&18]. The result of this work was a ‘knowledge dictionary’, an extension of a conventional data dictionary so that knowledge could be broken down into its constituent parts and stored in the dictionary. For example, a rule in this approach is made up of a set of relationships which are stored separately. This greatly increases one’s ability to browse and search the knowledge base; for example, it becomes a trivial matter to find which rules include certain conditions. Techniques were also developed whereby inferencing could be carried out in the database. However, improved browsing alone does not resolve the knowledge acquisition problem. It is still necessary to validate rules by checking them against test cases, and often the expert will be required to

Ripple dam rules 465
correct the first draft of the rule [6,9]. It is customary to blame knowledge acquisition problems on the difficulty experts have in
reporting on their mental processes so that knowledge acquisition research normally focuses on helping the experts bring out their knowledge. These approaches are and will remain very valuable, but observation of experts during the knowledge maintenance of GARVAN-ES1 has suggested a different approach [5, lo]. It seems that experts never report on their knowledge, rather they justify why a particular judgement is correct. These justifications are necessarily dependent on the context in which they are made. For example, for the same case, the justification an expert provides for a conclusion may change depending on whether it is being made to a peer, a lay-person, or a knowledge engineer. These justifications vary with the context and can be considered as knowledge constructed on the run to deal with the particular situation rather than knowledge recalled. It seems that we necessarily arrive at justifications in context for expert judgement because of the nature of knowledge, rather than the inability of experts to report on their mental processes [3, lo]. This viewpoint is similar to some of the ‘situated cognition’ approaches to knowledge, e.g. [2]. We suggest that conventional knowledge acquisition techniques are hampered by the expectation that if one only digs deep enough ‘true’ knowledge is found. If one assumes that there is no underlying knowledge to be found but rather justifications that the expert constructs for the present context, one approaches knowledge acquisition in a different way.
This model has formed the basis for developing a ripple-down organisation for the rules comprising the knowledge-base [6, 71. Essentially, this method (described further below) records the context in which knowledge is acquired from the expert and only allows this knowledge to be used again in the same context. This method has been used in an expert system for the clinical interpretation of chemical pathology reports.
2 Chemical Pathology report interpretation
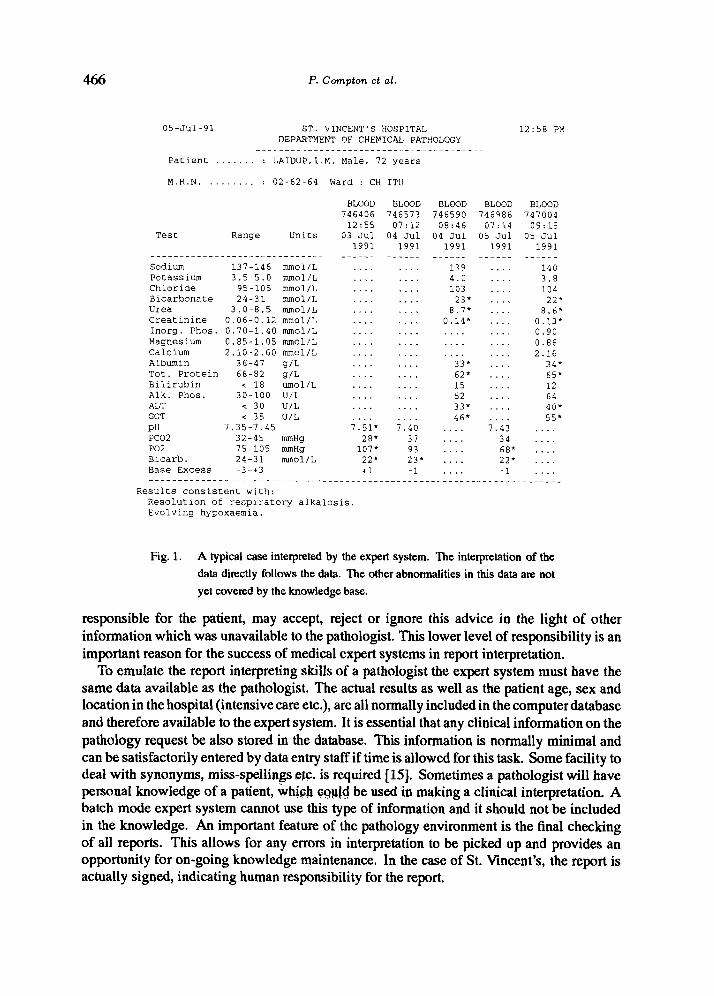
Chemical Pathology reports are now extremely complex. A report from the Department of Chemical Pathology at St. Vincent’s Hospital may contain results from up to 200 dif- ferent biochemical tests with the normal report containing results from about 20 different tests. A single page of a report will indicate results from 5 consecutive blood samples and some reports extend over a number of pages (Fig. I). Traditionally, pathologists provided an interpretative comment for a report but this has become increasingly difficult with the large number of reports now generated by laboratories (500 per day at Chemical Pathology, St. Vincent’s). St. Vincent’s reports are still checked by hand and signed and some reports put aside for a pathologist’s interpretation. This is only possible manually with a small number of reports. Figure I illustrates a standard pathology report with a clinical interpretation. In this case the interpretation was provided by the expert system. The aim of a pathology report interpretation expert system is to provide expert interpretations for all reports issued by the laboratory. Note that this task is not the same as diagnosis. Diagnosis is carried out by the clinician responsible for the patient. A clinical interpretation of a report merely presents the clinician with further information about the results that the pathologist thinks may be relevant to the patient’s diagnosis or management. The interpretation may include information as to the most likely clinical cause of the results, information about drug interactions resulting in a possibly spurious result or suggest further tests to resolve an ambiguity, etc. The clinician
05-Jul-91 ST. VINCENT'S HOSPITAL DEPARTMENT OF CHEMICAL PATHOLOGY
12:58 PM
Patient
M.R.N.
: LAIDUP,I.M. Male, 72 years
. . . . . . : 02-62-64 Ward : CH ITU
BLOOD BLOOD 746406 746573
Test
BLOOD BLOOD BLOOD 746590 746986 747004
12:55 07:12 08:46 07:14 09:15 Range Units 03 Jul 04 Jul 04 Jul 05 JUl 05 Jul
1991 1991 1991 1991 1991 ---_-_-_-_--_---__ ______ ______ _-_-__
137-146 mmol/L . . . . . . . . 139 . . . . 140 3.5-5.0 mmOl/L . . . . . . . 4.0 . 3.8 95-105 mmOl/L . . . . . 103 I... 104 24-31 mmOl/L ........ 23* . . 22*
3.0-8.5 mmol/L ........ 8.7* . .._ 8.6" 0.06-0.12 mmOl/L . . . . . . . . 0.14* . . . . 0.13* 0.70-1.40 mmOl/L . . . . . . . . 0.90 0.85-1.05 nunol/L . . . . ._.. . . . . . . 0.86 2.10-2.60 mmol/L ........ . . . 2.16
36-47 g/L ........ 33' . . . . 34' 66-82 g/L . . . . . . 62' . . . . 65' < 18 umOl/L . . . . . . . 15 . . . . 12 30-100 U/L . . . . . . . . 52 . . . . 64 < 30 U/L . . . . . . 33* . . . . 40' < 35 U/L . . . . . . . . 46* . . . . 55'
1.35-7.45 7.51* 7.40 . . . . 7.43 . . . 32-45 mmHg 28* 37 . . . . 34 . . . . 75-105 mmHg 107* 93 68' . . . 24-31 mmOl/L 22* 23' . . . 22' . . . -3-+3 +1 -1 . . . -1 . . . .
_________________________-_____-_-_-~_~______-----_--_-_-_-__-__________ Results consistent with:
Resolution of respiratory alkalosis. Evolving hypoxaemia.
_____-_-_-_
Sodium Potassium Chloride Bicarbonate Urea Creatinine Inorg. Phos. Magnesium Calcium Albumin Tot. Protein Bilirubin Alk. Phos. ALT GGT PH PC02 PO2 Blcarb. Base Excess
P. compton et al.
Fig. 1. A typical case interpreted by the expert system. The interpretation of the
data directly follows the data. ‘Ihe other abnormalities in this data are not
yet covered by the knowledge base.
responsible for the patient, may accept, reject or ignore this advice in the light of other information which was unavailable to the pathologist. This lower level of responsibility is an important reason for the success of medical expert systems in report interpretation.
To emulate the report interpreting skills of a pathologist the expert system must have the same data available as the pathologist. The actual results as well as the patient age, sex and location in the hospital (intensive care etc.), are all normally included in the computer database and therefore available to the expert system. It is essential that any clinical information on the pathology request be also stored in the database. This information is normally minimal and can be satisfactorily entered by data entry staff if time is allowed for this task. Some facility to deal with synonyms, miss-spellings etc. is required [ 15). Sometimes a pathologist will have personal knowledge of a patient, which could be used in making a clinical interpretation. A batch mode expert system cannot use this type of information and it should not be included in the knowledge. An important feature of the pathology environment is the final checking of all reports. This allows for any errors in interpretation to be picked up and provides an opportunity for on-going knowledge maintenance. In the case of St. Vincent’s, the report is
actually signed, indicating human responsibility for the report.

Ripple down rules 467
1: ruie false
67 rules fall to fire
301: rule false 314: true CURR(BLOOD_PH) 1s NORMAL
AND CURR(BLOOD_PO2) > 59.00
AND CURR(BLOOD_PO2j is LOW 370: rule false 397: rule false 485: true MIN(BLOOD_PC02) < NORMAL
Fig. 2. The rule trace for the case in Fig. 1. This rule trace was provided by the main-
tenance module, the batch in time system produces only the interpretation.
This feature of the maintenance module is not normally used in arriving at
a new rule. Two rules tired on this case with the interpretation provided by
the last rule that fired rule 485. The CURR timction returns the value for
the most recent measurement for that analyte. For the analytes in Fig. I this
is the 7 : 14 sample on the 5th July. The minimum BLOODPCOZ is the
first result. Notice that the expert has chosen to specify that BLOODPOZ
is low but above a certain value.
3 Ripple down rules
Knowledge is added to the system only in response to a report having an inadequate or incorrect interpretation. The crucial component of the context in this domain is that the knowledge the expert provides to deal with this case is a justification why their new interpretation is better than the interpretation given for the case (perhaps no interpretation). If the expert was justifying why their interpretation was better than another person’s, they would try to improve the justification in terms of what they assumed to be the other person’s beliefs and assumptions etc. If one considers the justifications provided to a patient versus a colleague who queries the expert’s interpretation of a report, this attempted guessing of the other person’s knowledge or reason for the query is obvious. In the case of the expert system, the knowledge behind the interpretation does not have to be guessed, it is all the knowledge in the knowledge base that has determined the interpretation provided by the expert system. This includes both rules that have actually been satisfied by the data, and rules that have been evaluated during the inference process but have not been satisfied by the data. In other words we want the new rule that is being added to be applied to a set of data only if the data is able to satisfy the rules that previously provided the wrong interpretation and if the data does not satisfy other evaluated rules also not satisfied in providing the earlier wrong interpretation.
To achieve this the expert system is built as a tree with a rule at each node. Each node then has two branches depending on whether or not the rule is satisfied by the data being considered. Any new rule that is added in response to a wrong interpretation, is attached to the branch at which the expert system terminated, thus making a new node. For example, in a one rule expert system, if the rule gives an interpretation which the expert thinks is wrong the new rule will be attached to the satisfied branch of the first rule. On the other

P. Complon et al.
hand if the one rule expert system fails to give an interpretation the new rule added will be attached to the unsatisfied branch. The tree then evolves over time as the expert corrects wrong interpretations. Note that each node of the tree is a rule of any desired complexity and that the interpretation produced from the tree is that from the last rule that was satisfied by the data (Fig. 3). Initial experiments rebuilding GARVAN-ES1 showed that knowledge can
be acquired 40 times faster than a conventional approach to knowledge acquisition [6,7].
7 8 .09 10
11
-c A
I__t
rule IKX satisfied 9 11 rule saa$ied
Fig. 3. (From [8].) A ripple down rule knowledge base. Each node in the tree
is a rule with any desired conjunction of conditions. Each node also has
a case associated with it, the case that prompted the inclusion of the rule.
In this example rules are numbered as are the leaves of the tree to indicate
which rule the classification comes from when a case traverses the tree. The
classification comes loom the last rule that was satisfied by the data. The
heavy line illustrates a path through the knowledge base for a case giving
interpretation 9. If this is the wrong interpretation and a rule has to be added
to give interpretation 11, it would be joined onto the unsatisfied branch of
rule 10 as shown, as this was the exit point from the knowledge base for that
particular case [S] .
Normally when rules are added or changed the expert system has to be validated by running it on test cases. One approach to this is to use ‘cornerstone cases’, cases for which the rules were previously changed [5, 151. One has to check all such cases; here this is unnecessary. The only cornerstone case that can be misinterpreted by the new rule is the case associated with the rule that last fired, the rule that gave the wrong interpretation, which the new rule is going to correct. Rather than check this case, the expert’s choice of conditions for the new rule can be restricted so that it must include at least one condition from a list of differences between the case for which the rule is added and the case associated with the last rule that fired giving the wrong interpretation. For example:

Ripple down rules 469
old case new case
TSH high TSH high T3 low T3 low FTI normal ‘IT4 high
The expert must choose either or both the conditions WI NOT normal’ and ‘TT4 high’ as conditions in the rule and can optionally chose any of the common conditions to make the rule intelligible. Such a rule is guaranteed to work on the new case but not the old case, so no further checking is required or relevant. The extra common conditions will not affect
the performance of the rule on the new or old case, but may improve its performance on yet unseen cases by narrowing the rule’s scope.
It should be noted that this method of differences relates to other knowledge acquisition methodologies based on personal construct theory, in turn based on the hypothesis that humans are better at identifying which features make objects different than enumerating the features of an object considered by itself [13]. This fits closely with the philosophical basis for ripple down rules. In practice these other methods ask the expert to think of a difference between two objects; here the expert has to identify which differences are important.
The simple differences in the example above assume that the numerical laboratory results have been preprocessed as high, low, normal etc. according to the reference range for each analyte. However, this is not always sufficient to discriminate between cases. Figure 2 illustrates a rule for which the PO2 is low but greater than 59. By allowing the use of numerical values in rules the system essentially allows ranges to be redefined in context. This avoids the use of fuzzy or probabilistic reasoning and corresponds to the simple way in which experts mentally adjust reference ranges in different contexts. The system also has a number of built in functions to allow experts to make up rules in terms of higher level features. For example:
Rule 410 IF TDIFF(CURR(BLOOD_TSH),MAX(BLOOD_TSH) < 30.00 THEN
This rule considers the time difference between the most recent TSH result and the maximum TSH. Other functions return average, nett change, minimum, the value of an attribute at the time of the maximum or minimum value of another attribute. These functions allow temporal patterns to be handled fairly simply. Again if the rule is not specific enough, it can
be refined in a later rule to provide a new context. It seems much simpler with temporal data to accept whatever rule the expert provides, but to allow this to be refined, than to try to obtain a good, generally correct temporal rule. Simple arithmetic operators can also be used in rules if required by the expert. It should be noted that this system is already in routine use and that the expert is not assisted by a knowledge engineer. These functions are all built-in so a programmer is required if further functions are to be added. The particular functions included were arrived at after a conventional knowledge acquisition exercise of discussing with experts what features they needed to identify in the data. With ripple down rules in their current development this is the only remaining task for a knowledge engineer: identifying and programming such functions.
Ripple down rules can be viewed as binary decision trees, but with each node a rule of any level of complexity (conjunctive conditions only). Each rule makes a classification, and the classification is passed down the tree but the final classification is from the last rule satisfied. Similarly ripple down rules can be seen as ordered rules with the addition that when a rule is

470 P. Compton et al.
satisfied it may lead to a further set of ordered rules which are refinements of the rule rather than a final conclusion. The important feature of ripple down rules is not their architecture per se, but that this architecture greatly simplifies knowledge acquisition. However, together with decision trees and ordered rules, ripple down rules can only provide a single classification for a case. Ways to handle this limitation will be discussed below.
4 Results
PEIRS (Pathology Expert Interpretative Report System) is an expert system using the method described above to produce automatic interpretation of pathology reports. It is in routine use in the Department of Chemical Pathology, St. Vincent’s Hospital Sydney. PEIRS is implemented in C and runs on a Vax under VMS. It has two modules, a batch mode version that runs automatically to append comments to reports and a maintenance version which shows the case differences and which the expert uses to add new rules. Other versions of ‘ripple down rules’ have been developed in Prolog, CLIPS and Hypercard and a term subsumption language and integrated into a wider knowledge acquisition environment [12].
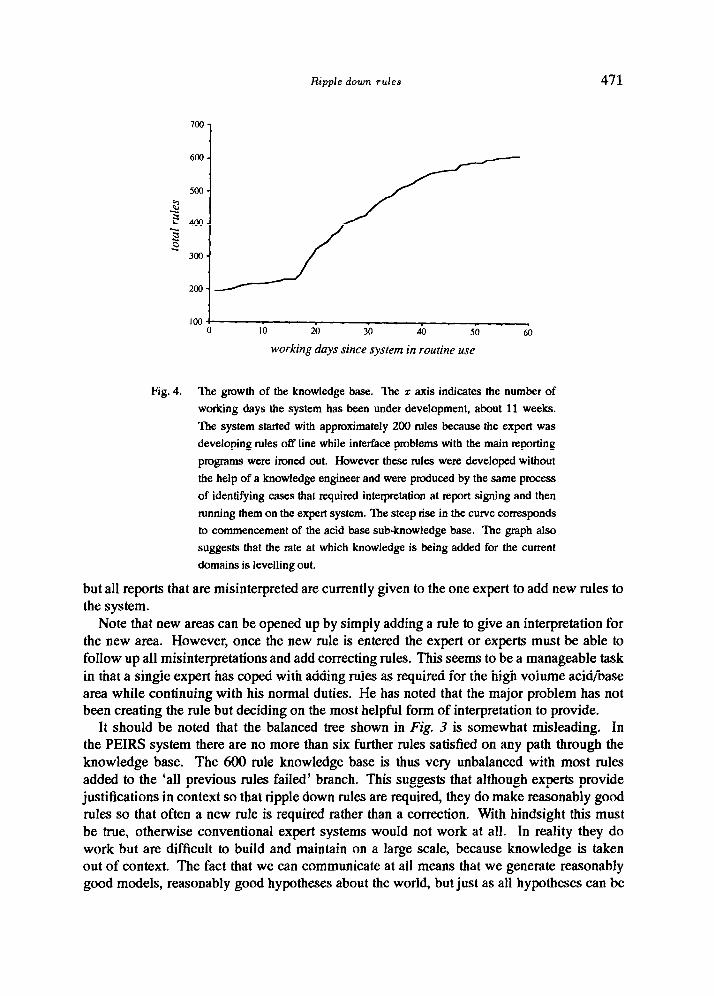
At the time of writing, this system has been in routine use for about eleven weeks and so far just over 600 rules have been added. Development commenced with thyroid data and is now mainly concerned with acid/base balance. The system also has some catecholamine and diabetes rules. The thyroid development was completely separate from the previous Garvan system to provide a further evaluation of the method. No knowledge from GARVAN-ES1 was used and the knowledge was added by an expert who was not involved in the original development (or any other expert system project). Figure 4 illustrates the rate of growth of the knowledge base. At about 230 rules the thyroid component of the system is about 95% correct which is consistent with earlier Garvan results and suggests that it will double in size [lo]. The Garvan system was 96% correct when introduced into routine use, however it doubled in size before reaching 99.7% acceptance by experts. In the redevelopment of GARVAN-ES1 as a ripple down rule system 550 rules were required to reach approximately 99% accuracy. The rate of thyroid knowledge acquisition has slowed down to a rule every few days, so that the system seems to be in the maintenance phase. Note that on Garvan archival data about 72% of the results are normal so that an interpretation level of over 95% represents a significant development.
The rate at which acid/base rules are added also appears to be starting to slow down (Fig. 4). The expert at present is deciding what domain to tackle next. These are still very preliminary results, but it appears clear that the ripple down rule approach is viable in the lab environment and that such systems can be built by experts without knowledge engineering help. Since the system went into routine use there have been no queries to knowledge engineers and there have been no knowledge engineers available at St. Vincent’s. The only queries have been from knowledge engineers to the experts wondering how the system is progressing. It should also be noted that the expert has no particular computer skills or interest beyond using word processing, statistics and drawing packages as part of his normal chemical pathology work. The expert only has to respond to reports which have been identified as requiring a new interpretation, draft the new interpretation and select the conditions which require the new interpretation. It remains an expert task to sign all reports which are issued by the labora- tory, providing a perfect opportunity to check interpretations. A number of experts sign reports
Ripple down mules 471
700 -
600-
1001 0 10 20 30 40 50 60
working days since system in routine use
Fig. 4. The growth of the knowledge base. The z axis indicates the number of
working days the system has been under development, about 11 weeks.
The system started with approximately 200 rules because the expert was
developing rules off tine while interface problems with the main reporting
programs were ironed out. However these rules were developed without
the help of a knowledge engineer and were produced by the same process
of identifying cases that required interpretation at report signing and then
running them on the expert system. ‘Ihe steep rise in the curve corresponds
to commencement of the acid base sub-knowledge base. ‘Ihe graph also
suggests that the rate at which knowledge is being added for the current
domains is levelling out.
but all reports that are misinterpreted are currently given to the one expert to add new rules to the system.
Note that new areas can be opened up by simply adding a rule to give an interpretation for the new area. However, once the new rule is entered the expert or experts must be able to follow up all misinterpretations and add correcting rules. This seems to be a manageable task
in that a single expert has coped with adding rules as required for the high volume acid/base area while continuing with his normal duties. He has noted that the major problem has not been creating the rule but deciding on the most helpful form of interpretation to provide.
It should be noted that the balanced tree shown in Fig. 3 is somewhat misleading. In the PEIRS system there are no more than six further rules satisfied on any path through the
knowledge base. The 600 rule knowledge base is thus very unbalanced with most rules added to the ‘all previous rules failed’ branch. This suggests that although experts provide justifications in context so that ripple down rules are required, they do make reasonably good rules so that often a new rule is required rather than a correction. With hindsight this must be true, otherwise conventional expert systems would not work at all. In reality they do work but are difficult to build and maintain on a large scale, because knowledge is taken out of context. The fact that we can communicate at all means that we generate reasonably good models, reasonably good hypotheses about the world, but just as all hypotheses can be

472 P. Compton et al.
falsified because they are true only in a particular, albeit fairly general context, so too, rules no matter how apparently general require further refinement in context.
5 Limitations
The two obvious limitations of the ripple down rule approach are that knowledge may be repeated throughout the knowledge base and that the system arrives at a single leaf node and so provides a single classification of the data. It is the expert’s experience that repetition of the same or similar conditions in a rule leading to the same conclusion, is not a major problem. This is borne out by other experiments. In a previous study we have investigated machine learning methods such as ID3 since they should produce a more optimal tree with less repeated knowledge [21]. The knowledge bases produced by the inductive methods were a similar size to the ripple down rule knowledge base developed for the same cases, suggesting that repetition was not a problem. Ripple down rules also had the advantage of requiring fewer cases to provide a high level of performance.
In other sub-domains in chemical pathology, repeated knowledge may be more of a problem and may require a solution. We have attempted to reduce the ripple down rule tree to possible cases interpreted by the tree to provide a basis for using induction. This has been impossible because of the predominance of false branches which require the negation of conjunctive rules to be converted to disjunctions. More than 252 cases would be required to represent the knowledge base using this approach. In response to the studies noted above, Brian Gaines modified his Induct learning algorithm to directly produce ripple down rules from training cases [ 111, Using this strategy Gaines has been able to produce a threefold reduction in the size of the tree. With such a tool available one could commence building a ripple down rule base manually until the knowledge base was obviously in need of reducing. One would then run past cases (available in the Hospital database) through the expert system to produce a well classified set of training cases. Induct would then produce a new set of ripple down rules from these cases to which the expert would continue to add rules manually when required. One may ask why the necessity of using the manual method at all, why not just archived cases. From experience in accumulating the 9,500 cases above it is extremely difficult to get consistently classified cases where the cases are given sophisticated interpretations by hand. Secondly ripple down rules from correcting errors is a much quicker development path than waiting to accumulate sufficient cases for induction [21]. This strategy needs to be evaluated further because as will be outlined below, there are some advantages in maintaining the knowledge as originally provided by the expert.
The second and more important problem arises because ripple down rules were designed for reaching single conclusions about each case. The classification for a case may be XX or perhaps YY but it cannot be XX and YY. In the domains studied to date, multiple classifications have been handled by treating XX and YY as a single, specific conclusion. This works, and there are many instances where a specific composite interpretation is required, but could obviously lead to considerable knowledge repetition. If for example YY is a classification which is quite independent of the other classifications being made, many repeated rules will have to be added to the system to produce all the special single classifications where YY combines with other classifications. The experts see this as a much more serious problem and have avoided it so far by postponing adding knowledge for domains where multiple

Ripple down rules 473
interpretations are common. In the long term this may be a significant problem for a large general purpose pathology report expert system. The obvious solution of having separate trees for independent domains is not attractive because it is difficult to provide a clear cut separation of domains. It also requires making final decisions about where the different parts of the knowledge will go before this knowledge is included. This is contrary to the style of ripple down rules which are aimed at on-going refinement of the knowledge and which do not require knowledge engineering decisions from experts (with the exception that even avoiding multiple classification domains is an engineering decision, required because of the tool used). We have therefore attempted to find ways whereby multiple classifications could be incorporated directly into ripple down rules.
The simplest approach may be to allow the ripple down interpreter to backtrack and explore any false branches. This is a legitimate strategy because the false branches are don’t care rather than false. A rule is made up by the expert and automatically added to the false branch of the rule because the case failed to satisfy the rule. However, the expert is not aware of this, so that a rule made up and attached to a ‘false’ or ‘don’t care’ branch may be perfectly appropriate for some cases which satisfy the rule. This strategy is equivalent to having a number of independent trees, but avoids having to specify the scope of the tree. An important side effect of this approach is that particular sequences of rules being satisfied elsewhere in the tree may warn that the initial conclusion reached may be wrong. If the initial conclusion reached is 1, but there is another sequence of rules elsewhere in the tree which has been added to correct 1 to 2, then perhaps the first 1 is wrong. Preliminary studies indicate that these warnings may be used to make expert system performance less brittle and the expert system avoid some stupid errors [20]. These results suggest that an important feature of human expertise might be that we utilise the experience of how our knowledge has developed, while conventional expert systems have available only their current best knowledge.
The major question with the backtracking approach for multiple classifications is whether the slightly different knowledge acquisition task will be as easy for experts as at present. The changes occur because when an expert wants a report to provide a new interpretation, more than a single interpretation on the report may have to be removed, or replaced. The case difference list also becomes more complex as it may deal with a number of parts of the tree. The information about the tree remains hidden from the expert, who just has to deal with the difference list but the knowledge acquisition task will increase. Preliminary studies suggest that the maximum increase in the task would be 80% but perhaps considerably less [19]. Because of the ease of selecing differences from a list, we anticipate this increase will be acceptable to experts, particularly since it avoids the potentially far greater increase due to treating multiple classifications.
Another solution is to move away from the tree representation. We have proposed an approach whereby an ‘in context’ knowledge acquisition methodology may be applied to a flat expert system in which multiple rules could provide separate interpretations and help to reduce repetition knowledge problems [9]. In this approach rules can be modified, but each case for which a modification is made is kept, resulting in perhaps more than one case per rule. When a rule is narrowed to exclude a case a difference list can be produced from the intersection of all the cases connected to the rule compared to the new case. Generalising a rule is more complex in that all the other cornerstone cases have to be considered in arriving at a list of conditions which will allow the new case to fire on the rule but prevent any other case firing. It remains to be seen whether this task could be reduced to the simplicity of

474 P. c mpton et al.
difference selection in ripple down rules or the backtracking extension above.
6 Conclusion
The major result from this study is perhaps the attitude of the pathologists towards this type of expert system. They have decided that the expert system should never be finished. Since knowledge acquisition using the technique is such a minor task and is well integrated into their other duties, they perceive that the expert system should be used to track new developments in laboratory based knowledge. Knowledge in domains such as this obviously keeps on evolving, not only technical knowledge but the type of interpretation which may be appropriate for reports. The pathologists see PEIRS as an important tool by which they will be able to properly manage the product of the laboratory. This is in important contrast to most approaches to expert systems, where the goal is to relieve an expert of a task and building the expert system is approached as a once only task. This is an unrealistic approach in pathology and many other medical domains where knowledge is undergoing continual development. Ripple down rules provides a way of expert system development moving in parallel with knowledge development.
Ripple down rules is a first attempt at providing an expert system environment in which gradual and easy evolution is possible. It is possible that the total knowledge acquisition task for the ripple down rules and a conventional system is similar, but ripple down rules allow this to be spread over a long period of time and handled as part of normal laboratory activities and do not require a knowledge engineer or knowledge engineering skills. This does not prolong start up time because the expert system can be deployed immediately with errors used as the opportunity for further knowledge acquisition, as they occur. We have shown elsewhere that this sort of expert system rapidly reaches a fairly high level of performance [21].
The reason that ripple down rules have these attractive properties is because the knowledge is only used in the context in which it is required. This restriction also allows difficult tem- poral and probabilistic reasoning to be dealt with very easily. This restriction also results in the problem with the method of repeated knowledge acquisition, particularly in dealing with multiple independent diseases. Various solutions to this problem are under investigation, but it should be noted that despite this restriction PEIRS is actually in routine use dealing with problems not easily handled by other expert system strategies.
References
[l] J. Bachant and J. McDermott, Rl revisited: four years in the trenches,NMug. (Fall 1984) 21-32.
[2] W.J. Clancey, Book review of ‘The Invention of Memory’, Artificial intelligence 50 (2) (1991) 241-284.
[3] P. Compton, Insight and knowledge, in: J. Boose, W. Clancey, B. Gaines and A. Rappaport, eds., AAAK Spring Symp. Cognitive Aspects ofZCnowledge Acquisition (Stanford University, 1991) 51-63.
[4] P. Compton, G. Edwards, B. Rang, L. Lazarus, R. Malor, T. Menzies, P. Preston, A. Srinivasan and C. Sammut, Ripple down rules: Possibilities and limitations, in: J. Boose and B. Gaines, eds., 6th BunnfAAAI Knowledge Acquisition for Knowledge Based Systems Workshop, Banff (1991) 6.1-6.18.
[S] P. Compton, R. Horn, R. Quinlan and L. Lazarus, Maintaining an expert system, in: J.R. Quinlan, ed., Applications of Expert Systems (Addison Wesley, London, 1989) 366-385.

Ripple down rules 475
[6] P. Compton and R. Jansen, Knowledge in context: A strategy for expert system maintenance, in: C. Barter and M. Brooks, eds., Proc. AI 88 (Springer-Verlag, Berlin, 1990) 292306.
[7] P. Compton and P. Preston, A minimal context based knowledge acquisition, in Knowledge Acquisition: Practical Tools and TechniquesAAAl-90 Workshop, Boston (1990).
[8] P. Compton, A. Srinivasan, G. Edwards, R. Malor and L. Lazarus, Knowledge base maintenance without a knowledge engineer, in: J. Leibowitz, ed., Proc. World Congress on Expert System (Pergamon, Orlando, FL$1991)668-675.
[9] P. Compton, W. Yang, M. Lee and B. Jansen, Cornerstone cases in a dictionary approach to knowledge based systems, in: B. Jansen, B. Gaines, J. Carlis and J. Kontio, eds., LICAI-92 workhopon SoftwareEngineering for Knowledge-Based Systems, Sydney (1991).
[lo] P.J. Compton and R. Jansen, A philosophical basis for knowledge acquisition, Knowledge Acquisition 2 (1990) 241-257.
[I l] B. Gaines, Induction and visualization of rules with exceptions, in: J. Boose and B. Gaines, eds., 6th AAAI Knowledge Acquisition for Knowledge BasedSystems Workshop, Bannf (1991) 7.1-7.17.
[12] B. Gaines, Integrating rules in term subsumption knowledge representation servers, in: Proc. AAAZ-92 (1991) 458-463.
[13] B. Gaines and M. Shaw, Cognitive and logical foundations of knowledge acquisition,in: SthAAAIffiowledge Acquisition for Knowledge Based Systems Workshop, Bannf (1990) 9.1-9.25.
[14] D.A. Guise, N.B. Guise and R.A. Miller, Towards computer-assisted maintenance of medical knowledge bases, Artificial Intelligence in Med. 2 (1990) 21-33.
[15] K. Horn, P.J. Compton, L. Lazarusand J.R. Quinlan, An expert system for the interpretation of thyroid assays in a clinical laboratory,Aust. Comput. J. 17 (1985) 7-11.
(161 R. Jansen and P. Compton, The knowledge dictionary: An application of software engineering techniques to the design and maintenance of expert systems and performance systems, Proc. AAAI-88 Workshop on Integration of Knowledge Acquisition & Performance Systems (1988).
[17] R. Jansen and P. Compton, ‘Ihe knowledge dictionary: A data dictionary approach to the maintenance of expert systems, Knowledge BasedSyst. 2 (1) (1989) 14-26.
[18] R. Jansen and P. Compton, The knowledge dictionary: Storing different knowledge representations, Proc. 5th Aust. Conf on Appkations of Expert Systems (1989) 143-162.
[19] B. Kang and P. Compton, Knowledge acquisition in context: The multiple classification problem, in: Proc. 2nd Pacific Bim Internat. Conf on Artificial Intelligence, Seoul (1992) 847-854.
[20] B. Kang and P. Compton, Towards a process memory, in: J. Boose, W. Clancey, B. Gaines and A. Rappaport, eds.,AAAISpringSymp.: CognitiveAspectsofKnowledgeAcquisition, Stanford University (1991) 139-146.
[21] Y. Mansuri, P. Compton and C. Sammut, A comparison of a manual knowledge acquisition method and an inductive learning method, in: J. Boose, J. Debenham, B. Gaines and J. Quinlan, eds.,Australian Workshop on Knowledge Acqukition for Knowledge Based Systems, Pokolbin (1991) 114-132.
[22] J.R. Quinlan, Simplifying decision trees, Internat. J. Man-Machine&dies 27 (1987) 221-234.
[23] J.R. Quinlan, P.J. Compton, K.A. Horn and L. Lazarus, Inductive knowledge acquisition: A case study, in: J.R. Quinlan, ed., Applications of Expert Systems (Addison Wesley, London, 1987) 159-173.
(241 A. Srinivasan, P. Compton, R. Malor, G. Edwards and L. Lazarus, Knowledge Acquisition in Context for a Complex Domain, in: B. Wellinga, J. Boose and B. Gaines, eds., Proc. Fifrh European Knowledge Knowledge Acquisition Workshop (Pergamon, Oxford, 1992, in press).
[2S] A. van de Brug, J. Bachant and J. McDermott, The taming of Rl, IEEEExpert (Fall 1986) 34-38.