reinforcement learning for standards design - arxiv
TRANSCRIPT

Reinforcement Learning for Standards DesignShahrukh Khan KasiAI4Networks Center
University of OklahomaTulsa, OK, USA
Sayandev MukherjeeNext-Generation Systems
CableLabsSanta Clara, CA, USA
Lin ChengNext-Generation Systems
CableLabsLouisville, CO, USA
Bernardo A. HubermanNext-Generation Systems
CableLabsSanta Clara, CA, USA
Abstract—Communications standards are designed via com-mittees of humans holding repeated meetings over months oreven years until consensus is achieved. This includes decisionsregarding the modulation and coding schemes to be supportedover an air interface. We propose a way to “automate” theselection of the set of modulation and coding schemes to besupported over a given air interface and thereby streamlineboth the standards design process and the ease of extendingthe standard to support new modulation schemes applicable tonew higher-level applications and services. Our scheme involvesmachine learning, whereby a constructor entity submits proposalsto an evaluator entity, which returns a score for the proposal.The constructor employs reinforcement learning to iterate on itssubmitted proposals until a score is achieved that was previouslyagreed upon by both constructor and evaluator to be indicativeof satisfying the required design criteria (including performancemetrics for transmissions over the interface).
Index Terms—reinforcement learning, MCS selection
I. INTRODUCTION
The design of the physical layer (PHY) interface for acommunications standard is usually done by a standards com-mittee, comprising delegates from many member companies,institutions, and organizations. Consensus is achieved on theelements of the PHY design only after repeated meetingsstretching over months or even years. Moreover, the committeeto decide on the specifics of the PHY layer is different fromthe committee to decide on the applications and services tobe supported and prioritized by the communications standard.Thus, if a new application or service becomes popular and thecommunications standards organization wishes to support it,then the PHY layer committee may need to re-initiate theirextensive and exhausting meeting schedule in order to finalizethe selection of modulation and coding schemes (MCSs) thatwill allow for this application to be supported at the desiredlevel of performance.
Machine learning (ML) methods offer the potential toautomate many activities that consume vast amounts of timefrom large numbers of humans. In this work, we investigatethe use of ML to automate the selection of MCS sets forcommunication across a given interface. The goal is to allowMCS selection to happen given only the desired performancespecification across the PHY layer that is required by the nextlevel (say the MAC layer, or higher) of the communicationstack.
In the present work, we illustrate the applicability of ML-based standards design by showing how a selection of MCS
sets to fulfill certain desired criteria can emerge automaticallyfrom Reinforcement Learning (RL) applied to a “game” playedby two ML model entities, one called the constructor and theother the evaluator. The constructor proposes an MCS set tothe evaluator, which evaluates the proposal on a set of criteriathat is not revealed to the constructor. The evaluator returnsa score to the constructor that describes the quality of theproposed MCS set. This score is then treated by the constructorlike the reward in RL and used by the constructor to proposeand submit a revised MCS set to the evaluator, and so on. Thegame ends when the evaluator returns a score that is higherthan some threshold that the evaluator and constructor haveboth agreed upon earlier as implying satisfactory performanceof the proposed MCS set. The MCS set that achieves this scoreis then adopted for the standard.
Note that the threshold score could incorporate not onlythe performance requirements of the next higher (say MAC)layer in the communications stack, but also other criteria likewhich codecs are available to use royalty-free. Note also thatalthough we will restrict ourselves to studying the proposedscheme on the PHY layer, it is equally applicable to the MAClayer with requirements for satisfactory performance comingdown from, say, the Network layer, and so on. Thus, it ispossible to conceive that standards design could be completelyautomated in a top-down methodology just by imposing a setof requirements at the highest (i.e., application) layer, andpercolating the appropriate requirements and constraints downone layer at a time to a pair of constructor-evaluator MLmodels at each layer that together design the elements of thestandard that satisfy the requirements for that layer.
In Sec. II we describe the MCS selection problem in aPHY layer defined by an air interface. For concreteness, weassume that we can select from amongst all MCS selectionsallowed by the LTE-A standard. In Sec. III we propose our RL-based solution employing the game between a constructor andan evaluator. We define the format of constructor’s proposaland the criterion that the evaluator uses to compute the scorefor a submitted proposal. The constructor then receives thescore from the evaluator for its proposal. In Sec. IV wedescribe the RL scheme whereby the constructor iterates on itsproposal and generates an updated MCS set to propose to theconstructor, and so on. Finally, in Sec. V, we show the resultsof simulations for a constructor-evaluator pair and discuss ourconclusions in Sec. VI.
arX
iv:2
110.
0690
9v1
[st
at.M
L]
13
Oct
202
1
II. MCS SELECTION AND SIR DISTRIBUTION
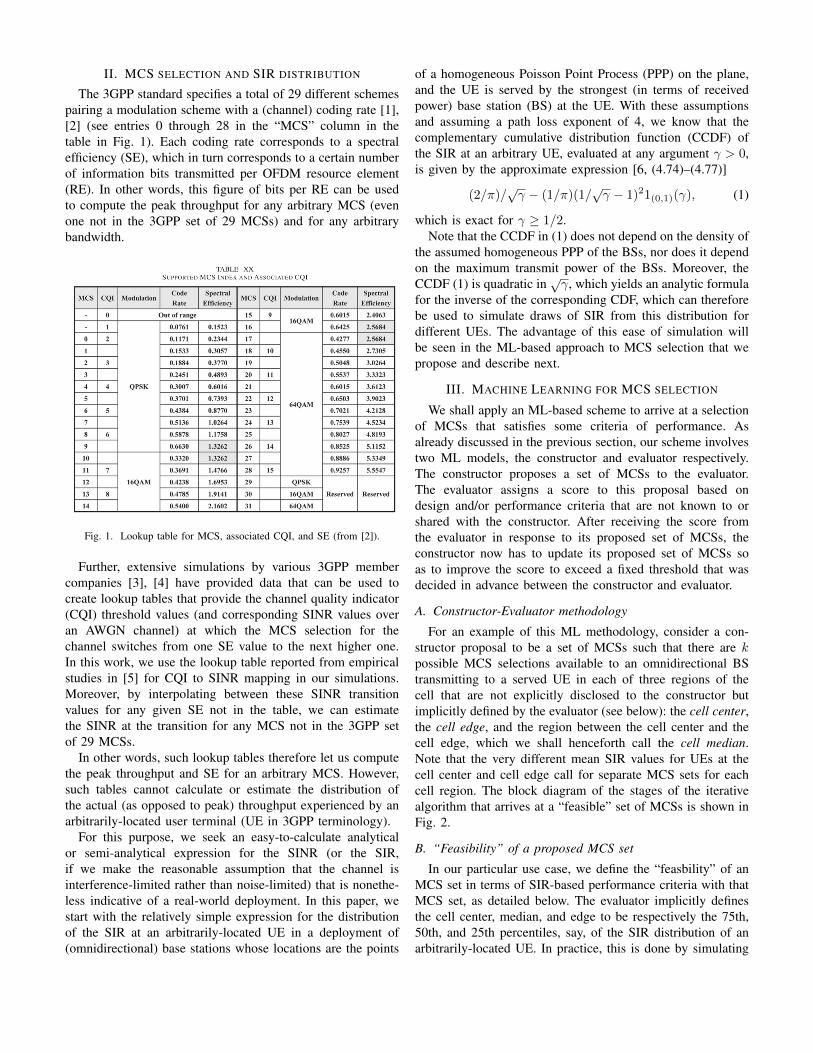
The 3GPP standard specifies a total of 29 different schemespairing a modulation scheme with a (channel) coding rate [1],[2] (see entries 0 through 28 in the “MCS” column in thetable in Fig. 1). Each coding rate corresponds to a spectralefficiency (SE), which in turn corresponds to a certain numberof information bits transmitted per OFDM resource element(RE). In other words, this figure of bits per RE can be usedto compute the peak throughput for any arbitrary MCS (evenone not in the 3GPP set of 29 MCSs) and for any arbitrarybandwidth.
Fig. 1. Lookup table for MCS, associated CQI, and SE (from [2]).
Further, extensive simulations by various 3GPP membercompanies [3], [4] have provided data that can be used tocreate lookup tables that provide the channel quality indicator(CQI) threshold values (and corresponding SINR values overan AWGN channel) at which the MCS selection for thechannel switches from one SE value to the next higher one.In this work, we use the lookup table reported from empiricalstudies in [5] for CQI to SINR mapping in our simulations.Moreover, by interpolating between these SINR transitionvalues for any given SE not in the table, we can estimatethe SINR at the transition for any MCS not in the 3GPP setof 29 MCSs.
In other words, such lookup tables therefore let us computethe peak throughput and SE for an arbitrary MCS. However,such tables cannot calculate or estimate the distribution ofthe actual (as opposed to peak) throughput experienced by anarbitrarily-located user terminal (UE in 3GPP terminology).
For this purpose, we seek an easy-to-calculate analyticalor semi-analytical expression for the SINR (or the SIR,if we make the reasonable assumption that the channel isinterference-limited rather than noise-limited) that is nonethe-less indicative of a real-world deployment. In this paper, westart with the relatively simple expression for the distributionof the SIR at an arbitrarily-located UE in a deployment of(omnidirectional) base stations whose locations are the points
of a homogeneous Poisson Point Process (PPP) on the plane,and the UE is served by the strongest (in terms of receivedpower) base station (BS) at the UE. With these assumptionsand assuming a path loss exponent of 4, we know that thecomplementary cumulative distribution function (CCDF) ofthe SIR at an arbitrary UE, evaluated at any argument γ > 0,is given by the approximate expression [6, (4.74)–(4.77)]
(2/π)/√γ − (1/π)(1/
√γ − 1)21(0,1)(γ), (1)
which is exact for γ ≥ 1/2.Note that the CCDF in (1) does not depend on the density of
the assumed homogeneous PPP of the BSs, nor does it dependon the maximum transmit power of the BSs. Moreover, theCCDF (1) is quadratic in
√γ, which yields an analytic formula
for the inverse of the corresponding CDF, which can thereforebe used to simulate draws of SIR from this distribution fordifferent UEs. The advantage of this ease of simulation willbe seen in the ML-based approach to MCS selection that wepropose and describe next.
III. MACHINE LEARNING FOR MCS SELECTION
We shall apply an ML-based scheme to arrive at a selectionof MCSs that satisfies some criteria of performance. Asalready discussed in the previous section, our scheme involvestwo ML models, the constructor and evaluator respectively.The constructor proposes a set of MCSs to the evaluator.The evaluator assigns a score to this proposal based ondesign and/or performance criteria that are not known to orshared with the constructor. After receiving the score fromthe evaluator in response to its proposed set of MCSs, theconstructor now has to update its proposed set of MCSs soas to improve the score to exceed a fixed threshold that wasdecided in advance between the constructor and evaluator.
A. Constructor-Evaluator methodology
For an example of this ML methodology, consider a con-structor proposal to be a set of MCSs such that there are kpossible MCS selections available to an omnidirectional BStransmitting to a served UE in each of three regions of thecell that are not explicitly disclosed to the constructor butimplicitly defined by the evaluator (see below): the cell center,the cell edge, and the region between the cell center and thecell edge, which we shall henceforth call the cell median.Note that the very different mean SIR values for UEs at thecell center and cell edge call for separate MCS sets for eachcell region. The block diagram of the stages of the iterativealgorithm that arrives at a “feasible” set of MCSs is shown inFig. 2.
B. “Feasibility” of a proposed MCS set
In our particular use case, we define the “feasbility” of anMCS set in terms of SIR-based performance criteria with thatMCS set, as detailed below. The evaluator implicitly definesthe cell center, median, and edge to be respectively the 75th,50th, and 25th percentiles, say, of the SIR distribution of anarbitrarily-located UE. In practice, this is done by simulating

Fig. 2. Functional block diagram of the stages of the iterative algorithm with a constructor-evaluator pair whose outcome is a set of k feasible MCSs foreach of 3 cell regions: center, median, and edge.
n draws (for some large n) from the SIR distribution givenby (1), corresponding to n independent identically distributed(iid) UEs located uniformly in the cell, and computing theempirical 25th/50th/75th percentiles of these n draws.
The game between the constructor and evaluator beginswith the evaluator sending these 3 percentile values to theconstructor (see Block 1 in Fig. 2), signifying the challenge tothe constructor to propose (a) a set of k MCSs for a UE whoseSIR is each of these percentile values, that (b) achieves a score(given by the evaluator) exceeding some fixed threshold. Wenext discuss how the evaluator assigns a score to an MCS set.
C. Score assignment by the evaluatorFor each SIR value set by the evaluator (i.e., the SIR
corresponding to a UE located in the cell center, median, oredge respectively), the constructor sends (see Block 3 in Fig. 2)a 15-bit sequence that is just the concatenation of three 5-bitbinary strings representing the index (from 0 to 28) of theMCS in the table in Fig. 1. As discussed earlier, knowing theMCS allows the evaluator to use lookup tables like the onein [5] to compute the peak throughput, bits per RE, spectralefficiency, and the minimum SNR for viable use of that MCSon that link (see Block 4 in Fig. 2).
Recall that there are n UEs scattered over the cell, andeach UE has a (simulated) SIR value. For each cell region,the evaluator now compares the minimum SNR requirementfor each of the k MCSs proposed by the constructor withthe (simulated) SIR of each UE in that cell region. For eachproposed MCS for that cell region, we count the number ofUEs in that cell region whose SIR exceeds the minimumSNR requirement for viable use of that MCS. The averageof this number of UEs across all k proposed MCSs for thatcell region is called the MCS Suitability Score (MSS) anddefines the score assigned by the evaluator (and returned to
the constructor) to the set of k proposed MCSs for that cellregion (see Block 5 in Fig. 2). Note that the MSS is alwaysbetween 0 and 1.
IV. REINFORCEMENT LEARNING SOLUTION
We now describe and evaluate an RL solution whereby theconstructor can update its set of k MCSs (for each cell region)so as to eventually exceed a fixed threshold for the MSS forthat cell region. Note that we are actually training not one butthree RL agents at the constructor, one for each cell region.
We begin by defining the state for each of the RL agents atthe constructor. Although it may be surprising, we will use aquantized version of the MSS for the most recent proposal asthe current state.
Next, we consider the action space of each of these RLagents. If there are M possible MCS choices for a given cellregion, then there are
(Mk
)actions possible for the RL agent
for that cell region, each action being a proposal of a set ofk MCSs submitted to the evaluator. In other words, this RLagent has an action space of size
(Mk
). If we allow the full 29
choices for MCS in each cell region (M = 29) with k = 3,say, then
(Mk
)= 3654, which is impractically large and also
unrealistic because, e.g., a UE at the cell edge cannot use thelargest MCSs anyway. Therefore the action space will need tobe restricted in some way, as discussed below.
Lastly, we define the reward corresponding to an action(defined by proposing a set of k MCSs) as some function ofMSS and SE , where SE is the average across all UEs inthis cell region of the highest spectral efficiency achievable ateach UE from amongst the proposed k MCSs. We may furthernormalize this SE by the maximum spectral efficiency overall (29) MCSs in order to get an SE between 0 and 1.
The RL approach is illustrated in Fig. 3.
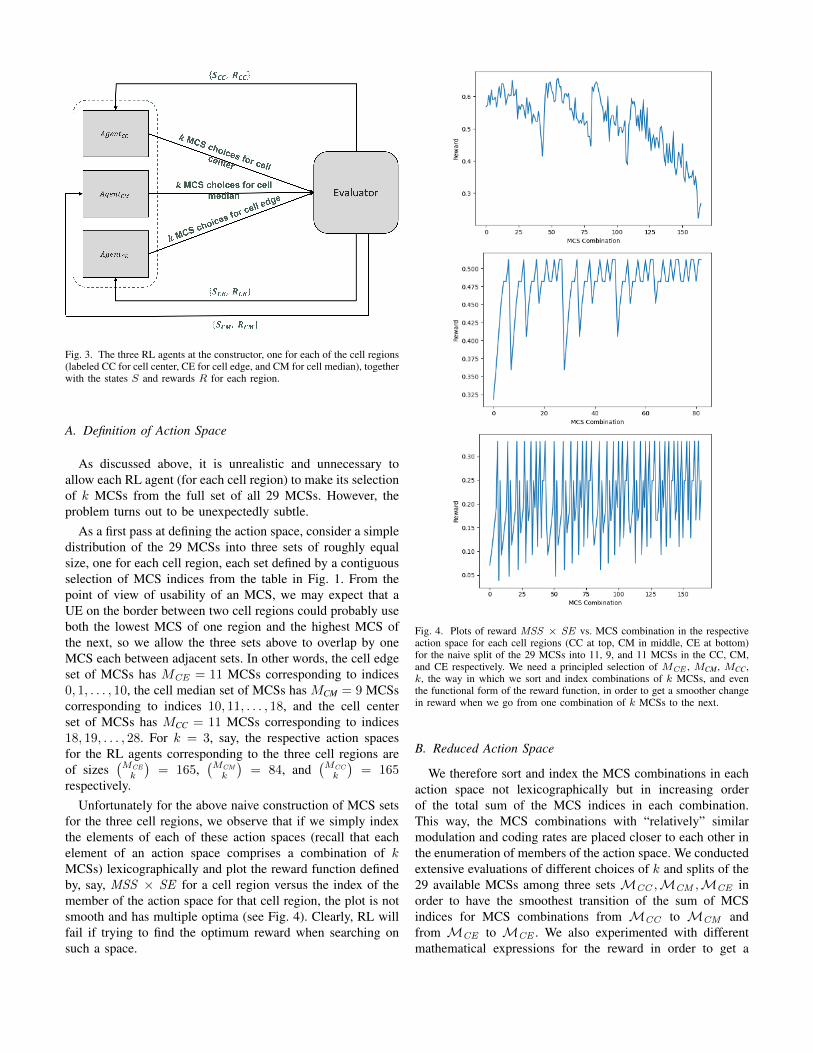
Fig. 3. The three RL agents at the constructor, one for each of the cell regions(labeled CC for cell center, CE for cell edge, and CM for cell median), togetherwith the states S and rewards R for each region.
A. Definition of Action Space
As discussed above, it is unrealistic and unnecessary toallow each RL agent (for each cell region) to make its selectionof k MCSs from the full set of all 29 MCSs. However, theproblem turns out to be unexpectedly subtle.
As a first pass at defining the action space, consider a simpledistribution of the 29 MCSs into three sets of roughly equalsize, one for each cell region, each set defined by a contiguousselection of MCS indices from the table in Fig. 1. From thepoint of view of usability of an MCS, we may expect that aUE on the border between two cell regions could probably useboth the lowest MCS of one region and the highest MCS ofthe next, so we allow the three sets above to overlap by oneMCS each between adjacent sets. In other words, the cell edgeset of MCSs has MCE = 11 MCSs corresponding to indices0, 1, . . . , 10, the cell median set of MCSs has MCM = 9 MCSscorresponding to indices 10, 11, . . . , 18, and the cell centerset of MCSs has MCC = 11 MCSs corresponding to indices18, 19, . . . , 28. For k = 3, say, the respective action spacesfor the RL agents corresponding to the three cell regions areof sizes
(MCE
k
)= 165,
(MCM
k
)= 84, and
(MCC
k
)= 165
respectively.Unfortunately for the above naive construction of MCS sets
for the three cell regions, we observe that if we simply indexthe elements of each of these action spaces (recall that eachelement of an action space comprises a combination of kMCSs) lexicographically and plot the reward function definedby, say, MSS × SE for a cell region versus the index of themember of the action space for that cell region, the plot is notsmooth and has multiple optima (see Fig. 4). Clearly, RL willfail if trying to find the optimum reward when searching onsuch a space.
Fig. 4. Plots of reward MSS × SE vs. MCS combination in the respectiveaction space for each cell regions (CC at top, CM in middle, CE at bottom)for the naive split of the 29 MCSs into 11, 9, and 11 MCSs in the CC, CM,and CE respectively. We need a principled selection of MCE , MCM, MCC,k, the way in which we sort and index combinations of k MCSs, and eventhe functional form of the reward function, in order to get a smoother changein reward when we go from one combination of k MCSs to the next.
B. Reduced Action Space
We therefore sort and index the MCS combinations in eachaction space not lexicographically but in increasing orderof the total sum of the MCS indices in each combination.This way, the MCS combinations with “relatively” similarmodulation and coding rates are placed closer to each other inthe enumeration of members of the action space. We conductedextensive evaluations of different choices of k and splits of the29 available MCSs among three sets MCC ,MCM ,MCE inorder to have the smoothest transition of the sum of MCSindices for MCS combinations from MCC to MCM andfrom MCE to MCE . We also experimented with differentmathematical expressions for the reward in order to get a

reward vs. MCS combination plot that is as smooth as possible.Finally, we settled on the following: k = 4 and MCC =
MCM = MCE = 12. Depending on the typical SIR rangesof each cell region and SINR sensitivity levels from [5],the MCS choices for cell-edge are restricted to MCS indicesMCE = {0, 1, . . . , 11}, cell-median are restricted to MCSindices MCM = {6, 7, . . . , 17}, and cell-center are restrictedto MCS indices MCC = {17, 18, . . . , 28}.
The number of MCS combinations possible for each cellregion is then
(124
)= 495. This is too large a space to search
directly, so we further restrict the possible actions that can betaken by the RL agent at each state to be only one of thefollowing three actions: reuse the present MCS combination,use the preceding MCS combination, or use the succeedingMCS combination, where “preceding” and “succeeding” are interms of the indexing of MCS combinations as defined above.
V. RESULTS AND DISCUSSION
In addition to reducing the possible actions of the RL agentfor each cell region to just three at each state, we also definea quantized (into one of 20 bins) value of the MSS for thatregion as the state of the agent, and define the reward as R =(MSS + SE )/2 for a smoother reward vs. MCS combinationindex curve. Then we run standard Q-learning [7, Sec. 6.5] asdescribed in Algorithm 1.
Initialize:γ = 0.90αmin = 0.5, αdecay = 0.995εmin = 1.0, εdecay = 0.995α← αinit = 0.7, ε← εinit = 0.01Q(s, a) for all states s and all actions a arbitrarily
Loop for each episode:Initialize the new state SLoop for each step of episode:
Choose A from ε-greedy policy from QTake action A, get reward R, new state S′
Q(S,A)←Q(S,A)+α[R+γmaxaQ(S′, a)−Q(S,A)]S ← S′
α← max(αmin, ααdecay)ε← max(εmin, εεdecay)
until S is a terminal state
Algorithm 1: Q-learning for RL agent for one cell region
This reward function is smoothed using a moving averageover a rectangular window of width 50. As is clear from Fig. 5,the plot of the smoothed reward versus MCS combination isfairly smooth for each of the cell regions, thereby making itpossible to find a combination of k = 4 MCSs that maximizeaccumulated discounted reward.
Running the Q-learning algorithm shows that the algorithmdoes “converge” to a terminal state in the sense that it deliversMCS combination actions that yield values of the smoothedreward function close to its maximum. In Fig. 6, we plot
(bottom panel) the MCS combination actions that are selectedby the RL agent for the cell center during a single exam-ple episode of RL training between iterations (TTIs) 10000through 50000, after the training algorithm has converged inthe above sense. Comparing against the plot of the rewardfunction versus MCS combination index from Fig. 5 (upperpanel) shows that the selected MCS combinations are thosefor which the (smoothed) reward function is either at or verynear its maximum value.
These observations are further confirmed by plotting the(unsmoothed) normalized reward (see top plot in Fig. 7)corresponding to the same iterations (TTIs) as in the bottomplot in Fig. 6 for the cell center RL agent. We observe thatthe MCS combinations selected by the RL agent after aboutTTI 10000 are (near-) optimal for the normalized reward aswell, since the normalized reward has a maximum value of1.0. The same observations as in Fig. 6 and Fig. 7 also holdfor the RL agents for the cell median and cell edge regions(plots not shown here for reasons of space).
VI. CONCLUSIONS
We have proposed a scheme using a pair of constructor-evaluator ML models to automate the selection of MCS setsto satisfy pre-selected design criteria over an LTE-like airinterface. The constructor uses RL in order to train an agent tosubmit MCS set selections as proposals and iterate based onthe scores reported by the evaluator for a proposed submission.We showed how to design the state space, action space, andselect a reward function and demonstrated via simulation thatRL does allow the constructor to find an MCS that works.
In general, the selection of the reward function is important,and can be different from the semi-analytical representationwe generated here based on lookup table values. For morecomplex reward functions, we need a careful optimization ofthe hyperparameters of the RL algorithm (e.g., Q-learning).
This work shows the potential of ML to automate thetedious, slow and conflict-laden process of standards designin order to enable quick support for new applications.
REFERENCES
[1] Qualcomm Europe, “Conveying MCS and TB size via PDCCH”, 3GPPTSG-RAN WG1 #52bis R1-081483, April 2008.
[2] Gwanmo Ku and John MacLaren Walsh, “Resource allocation and linkadaptation in LTE and LTE advanced: A tutorial.” IEEE communicationssurveys & tutorials, vol. 17, no. 3, pp. 1605-1633, 2014.
[3] Teckchai Tiong, “Adaptive transceivers for mobile communications.” 4thIEEE International Conference on Artificial Intelligence with Applica-tions in Engineering and Technology, 2014.
[4] Yen-Wei Kuo and Li-Der Chou, “Power saving scheduling scheme forInternet of Things over LTE/LTE-advanced networks.” Mobile Informa-tion Systems 2015.
[5] Yi Hua Chen, Kai Jen Chen and Jyun Jhih Yang, “LTE MCS cell rangeand downlink throughput measurement and analysis in urban area,”Internet of Things, Smart Spaces, and Next Generation Networks andSystems. Springer, 2017.
[6] Sayandev Mukherjee, Analytical Modeling of Heterogeneous CellularNetworks: Geometry, Coverage, and Capacity. Cambridge, UK: Cam-bridge University Press, 2014.
[7] Richard S. Sutton and Andrew G. Barto, Reinforcement Learning: AnIntroduction, 2nd ed. Cambridge, MA: MIT Press, 2018.
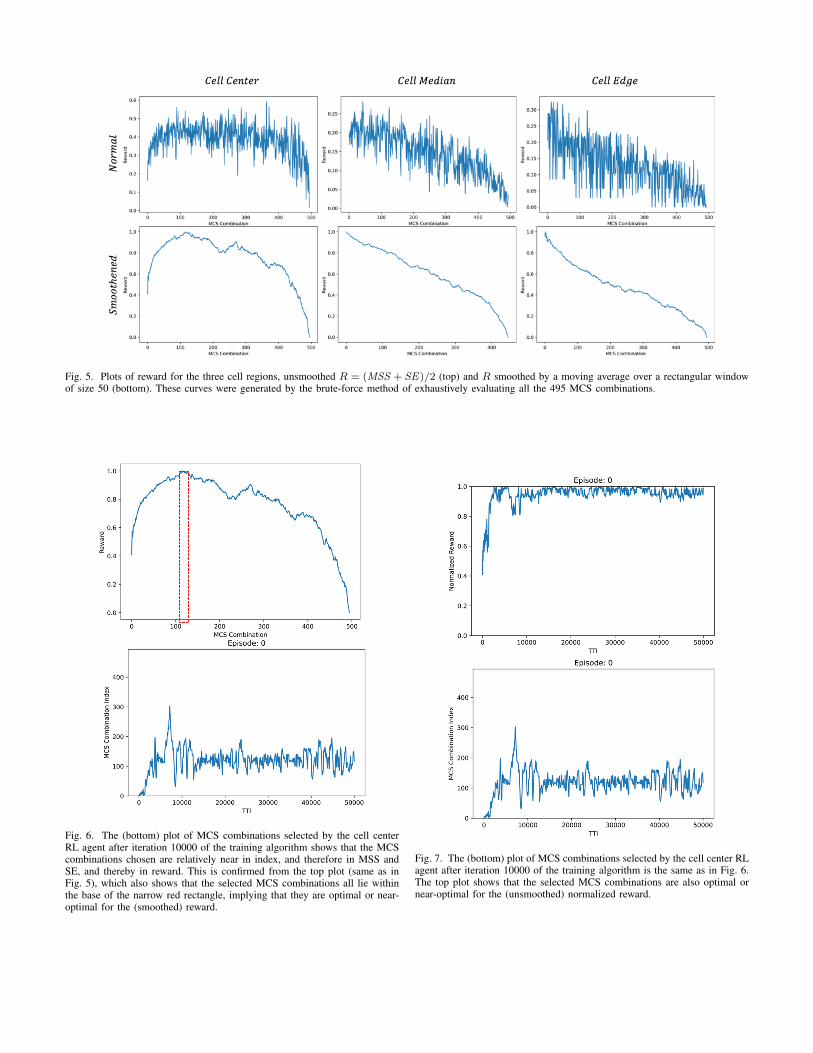
Fig. 5. Plots of reward for the three cell regions, unsmoothed R = (MSS + SE)/2 (top) and R smoothed by a moving average over a rectangular windowof size 50 (bottom). These curves were generated by the brute-force method of exhaustively evaluating all the 495 MCS combinations.
Fig. 6. The (bottom) plot of MCS combinations selected by the cell centerRL agent after iteration 10000 of the training algorithm shows that the MCScombinations chosen are relatively near in index, and therefore in MSS andSE, and thereby in reward. This is confirmed from the top plot (same as inFig. 5), which also shows that the selected MCS combinations all lie withinthe base of the narrow red rectangle, implying that they are optimal or near-optimal for the (smoothed) reward.
Fig. 7. The (bottom) plot of MCS combinations selected by the cell center RLagent after iteration 10000 of the training algorithm is the same as in Fig. 6.The top plot shows that the selected MCS combinations are also optimal ornear-optimal for the (unsmoothed) normalized reward.