qur'anic words stemming
TRANSCRIPT

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
December 2010 The Arabian Journal for Science and Engineering, Volume 35, Number 2C 37
QUR'ANIC WORDS STEMMING
Raja Jamilah Raja Yusof*, Roziati Zainuddin, Mohd. Sapiyan Baba Faculty of Computer Science and Information Technology
University of Malaya, 50603 Kuala Lumpur, Malaysia
and Zulkifli Mohd. Yusoff Academy of Islamic Studies
University of Malaya, 50603 Kuala Lumpur, Malaysia
:الخالصةه . لديها ترآيب صرفي معقد ةمن المعروف ان الكلمات العربي تقاقات من جذور الكلم ه او اش تج أنماط آلمات مختلف تحاول . إن الترآيب المختلف ين
.هذه الورقه التعرف إلى أنماط الكلمه المختلفه التي تنشا من جذور الكلمه
ل . لثالثين من القران الكريم ، وتم تحديد تسع حاالت اختبار للكلمات في هذا الجزء وقد تمت مقارنة أنماط الكلمة بالكلمات في الجزء ا وقد أظهر التحليذ محرك . أن استئصال األسماء والجزئيات تقود إلى أقل نسبة خطا بالمقارنه مع األبجديات العشر التي يمكن أن تضاف الى ملحقات جذر الكلمه آما تم تنفي
.11.7ms آلمه1000 ومتوسط الزمن الالزم إلنجاز %62.5 و آانت الدقه الناشئة قد حققت (RSE)قائم على قواعد أساسيه
ل ا مث ائج بغيره ة النت ة دق ت مقارن د تم صرفي, Khojaوق ل ال ي ) Buckwalter )BAMAالمحل ذور الثالث تخراج الج ة اس ) TRE(وخوارزمي .Votingوخوارزميه
_____________________ *Corrresponding Author: E-mail: [email protected]
Paper Received July 2, 2010; Paper Revised December 22, 2010; Paper Accepted December 29, 2010

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
The Arabian Journal for Science and Engineering, Volume 35, Number 2C December 2010 38
ABSTRACT
Arabic words are known to have complex morphological structure. The different structures produce various word patterns or derivatives from a root word. This paper attempts to identify various word patterns that originate from a root word. These word patterns are compared to the words in the 30th part of the Qur'an. Nine stemming test cases were outlined for words in the 30th part of the Qur’an. Analysis showed that stemming nouns and particles leads to a lower percentage error compared to stemming the 10 alphabets that can be added as affixes in a root word. A rule-based stemming engine (RSE) was also implemented and the stemming accuracy achieved was 62.5% and the average time taken to stem 1000 word tokens was 11.7ms. The accuracy of the results was comparable to other stemming engines such as the Khoja stemmer, Buckwalter Morphological Analyzer (BAMA), Tri-literal Root Extraction (TRE) algorithm, and Voting algorithm.
Key words: Arabic stemming, Qur’an, rule-based algorithm, Arabic word morphology

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
December 2010 The Arabian Journal for Science and Engineering, Volume 35, Number 2C 39
QUR'ANIC WORDS STEMMING
1. INTRODUCTION
Arabic natural language processing (ANLP) is strongly associated with the Arabic word morphology identification problem since the complexity of Arabic word structure is greater than a language such as English. The current research in progress includes building an Arabic Treebank [1–4], Arabic morphological analyzer [5], Arabic word stemming [6–9], and Arabic Diacritizer systems [10–12]. However, all of these fields of study can be considered to be parts of Arabic stemming research. Stemming is a process of inflecting a derivative word to a stem word or to its root. There are many approaches in stemming. However, according to Kharashi and Sughaiyer [13], there are several types of stemmers: table lookup, linguistic, combinatorial, and pattern-base. In the table lookup, Arabic words are stored in alphabetical order with their morphological information (information on stem, root, and affixation). One need only search through this table for word information. The combinatorial approach is based on algorithms that take a word and then compare it to lists of roots, patterns, particles, and affixes, while the linguistic approach analyses a word according to the Arabic word morphological system similar to a linguist. Lastly, the pattern-base approach uses a fast surface morphological analysis and a ruled-based parser algorithm to enhance the performance of the stemming engine.
One of the main goals of ANLP is effective document retrieval. For example, if query is input through a search engine, the relevant document retrieved must be based on either the root or the stem of the word. Therefore, the goals of most Arabic morphological analyzers and stemming engines are to extract the root and/or stem of a word. However, the intent of this paper is to analyze the effectiveness of stemming engines/algorithms to identify root words in the Holy Qur’an. The importance of this is that the Qur’an contains many classical words and the writing style is very different from modern standard Arabic. It is especially important to preserve the correctness of words in this sacred book of the Muslims. Even though there are no clear benefits, stemming algorithms purely for the Qur’an may open new doors both for the scientific community and scholars of the Qur’an, consequently, benefitting the general public. For example, an effective stemming algorithm for the Qur’an may help to support a more efficient method for data mining and visualization, leading to new strategies for teaching words of the Qur’an or faster retrieval of certain related concepts written in the Qur’an. In this paper, the Arabic word morphology will also be discussed apart from outlining our own experimentation on stemming Qur’anic words.
1.1. Related Work
The Khoja stemmer and BAMA can be considered as the two most frequently cited Arabic stemmer engines. The Khoja stemmer extracts roots from a word based on a prepared list of function words by a straightforward pattern matching procedure. BAMA [3] also includes a prepared list of several types: the lexicon of prefix, the suffix, and the stem on which word entries are checked upon. It deals with word stems rather than roots. The work of Al-Shammari and Lin [9], Taghva, Elkhoury, and Coombs [6], Yagi and Yaghi [7], Larkey, Ballesteros, and Connell [8] addresses issues related to Arabic stemming. Mainly, discussions are related to algorithms that can give the most accurate result when searching or retrieving Arabic words. The literature reveals that the most common algorithm on stemming includes
i) removing diacritics in Arabic words; ii) removing the suffixes and prefixes which may be particles or added alphabets; iii) normalization of the vowels (concerning the spelling variation representing a few Arabic letters to another to
ease the deduction of roots from word stems or tokens); iv) and comparing word entries to pre-existing lists or lexicons of stems, roots, prefixes, or suffixes.
A dependable aspect of Arabic stemming systems is the Arabic text data used for testing. Many opt for the Penn Arabic Treebank [2,10–12,14–15], while discretely, other text data from sources such as the Holy Qur’an [4,16], Zad Corpus [5], and TREC Collection [23] are used and most of the time extracted from the LDC (Linguistic Data Consortium) website. In this paper, we present work on stemming Arabic text through pattern detection using a ruled-based approach. Our stemming engine is similar to [17] and [9] but we concentrate on using the data set from the Qur’an. The dataset is from the Qur’an Corpus by [4], which is partly based on the automatic annotation using the Buckwalter Arabic Morphological Analyzer (BAMA) [5]. Our evaluation of the engine is compared to the evaluation done by Sawalha and Atwell [18].
One practice lacking in the field of Arabic stemming is the comparative study using the same set of data but with different stemmer engines. For example, the work done by Kharashi and Sughaiyer [17] tested their engine using their own set of data. The stemmer consists of three parts, dealing with prefixes, suffixes, and stems. The final output is an extraction of a word’s morphological component. It was reported that it shows 80% accuracy on identifying stems. Similarly, Thabet [16] developed a light stemmer for the Qur’an that tested the data using the seven long
Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
The Arabian Journal for Science and Engineering, Volume 35, Number 2C December 2010 40
suras of the Qur’an. Since it is a light stemmer, the result reported is only based on the removal of prefixes (which achieved 99.6% accuracy) and suffixes (which achieved 97% accuracy). Darwish and Oard [5] developed the Sebawai engine which estimates the probabilities of templates, prefixes, and suffixes and which is constructed from the word-root pairs extracted from an Arabic corpus. The corpus they used was from the religious book called Zad Al-Me’ad (ZAD list) and from the Linguistic Data Consortium (LDC) Arabic corpus containing AFP newswire stories. Sebawai achieved 86.4% accuracy from the ZAD list and 43.9% from the LDC–fail list. Also, a different stemmer engine by (Altantawy, Habash, Ranbow and Saleh) called MAGEAD [14], which is a functional morphological analyzer and generator, achieved between 72.3–99.7% accuracy using the Penn Arabic Treebank data set. These few examples are further justified from the comprehensive study done by Kharashi and Sughaiyer [13]. Stemmer engines based on linguistic approaches achieved between 84–99.8% accuracy, while combinatorial achieved between 19–97% accuracy, and the rule-based approach achieved 80% accuracy. All of these used various types of datasets such as described earlier in the previous section.
Taghva, Elkhoury, and Coombs [6] developed a stemming engine called ISRI based on Arabic patterns and roots, and the evaluation of the engine was compared with ISRI, Khoja, and Light stemmer. The algorithm analyzes the length of words and the word pattern before which the removal of diacritics, prefixes, suffixes, and normalization process occurs. However, the stemmer was evaluated based on the effectiveness of document retrieval from the Arabic TREC collection consisting of 383,872 Arabic news stories. The three stemmer engines were found to be equally effective in document retrieval.
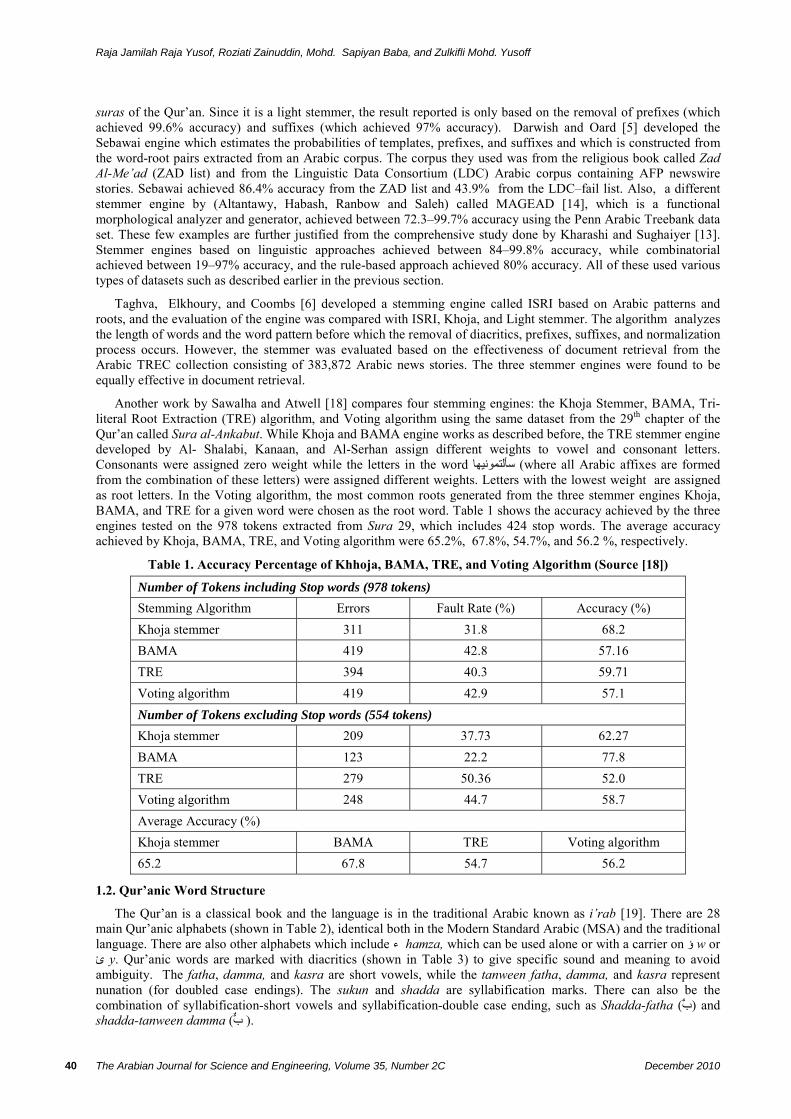
Another work by Sawalha and Atwell [18] compares four stemming engines: the Khoja Stemmer, BAMA, Tri-literal Root Extraction (TRE) algorithm, and Voting algorithm using the same dataset from the 29th chapter of the Qur’an called Sura al-Ankabut. While Khoja and BAMA engine works as described before, the TRE stemmer engine developed by Al- Shalabi, Kanaan, and Al-Serhan assign different weights to vowel and consonant letters. Consonants were assigned zero weight while the letters in the word سألتمونيها (where all Arabic affixes are formed from the combination of these letters) were assigned different weights. Letters with the lowest weight are assigned as root letters. In the Voting algorithm, the most common roots generated from the three stemmer engines Khoja, BAMA, and TRE for a given word were chosen as the root word. Table 1 shows the accuracy achieved by the three engines tested on the 978 tokens extracted from Sura 29, which includes 424 stop words. The average accuracy achieved by Khoja, BAMA, TRE, and Voting algorithm were 65.2%, 67.8%, 54.7%, and 56.2 %, respectively.
Table 1. Accuracy Percentage of Khhoja, BAMA, TRE, and Voting Algorithm (Source [18])
Number of Tokens including Stop words (978 tokens) Stemming Algorithm Errors Fault Rate (%) Accuracy (%) Khoja stemmer 311 31.8 68.2 BAMA 419 42.8 57.16 TRE 394 40.3 59.71 Voting algorithm 419 42.9 57.1 Number of Tokens excluding Stop words (554 tokens) Khoja stemmer 209 37.73 62.27 BAMA 123 22.2 77.8 TRE 279 50.36 52.0 Voting algorithm 248 44.7 58.7 Average Accuracy (%) Khoja stemmer BAMA TRE Voting algorithm 65.2 67.8 54.7 56.2
1.2. Qur’anic Word Structure
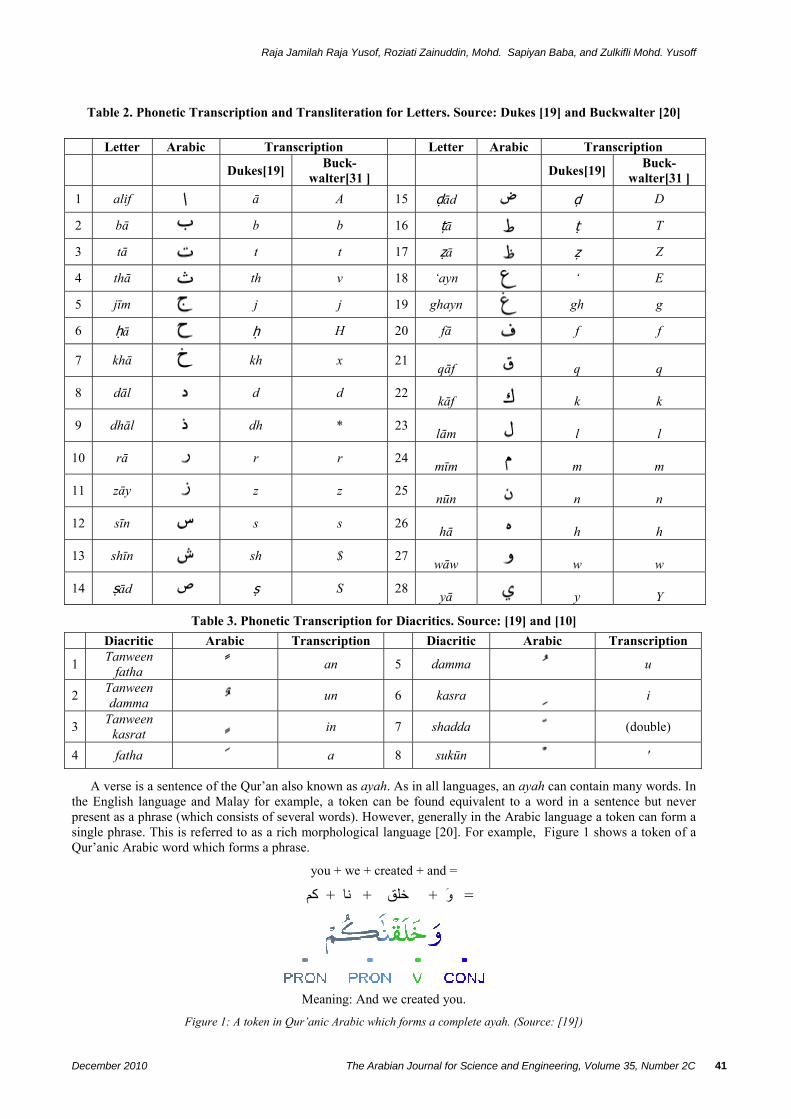
The Qur’an is a classical book and the language is in the traditional Arabic known as i’rab [19]. There are 28 main Qur’anic alphabets (shown in Table 2), identical both in the Modern Standard Arabic (MSA) and the traditional language. There are also other alphabets which include ء hamza, which can be used alone or with a carrier on ؤ w or y. Qur’anic words are marked with diacritics (shown in Table 3) to give specific sound and meaning to avoid ئambiguity. The fatha, damma, and kasra are short vowels, while the tanween fatha, damma, and kasra represent nunation (for doubled case endings). The sukun and shadda are syllabification marks. There can also be the combination of syllabification-short vowels and syllabification-double case ending, such as Shadda-fatha (ب) and shadda-tanween damma (ب ).
Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
December 2010 The Arabian Journal for Science and Engineering, Volume 35, Number 2C 41
Table 2. Phonetic Transcription and Transliteration for Letters. Source: Dukes [19] and Buckwalter [20]
Letter Arabic Transcription Letter Arabic Transcription
Dukes[19] Buck-walter[31 ] Dukes[19] Buck-
walter[31 ] 1 alif ā A 15 ḍād ḍ D
2 bā b b 16 ṭā ṭ T
3 tā t t 17 ẓā ẓ Z
4 thā th v 18 ‘ayn ‘ E
5 jīm j j 19 ghayn gh g
6 ḥā ḥ H 20 fā f f
7 khā kh x 21 qāf q q
8 dāl d d 22 kāf k k
9 dhāl dh * 23 lām l l
10 rā r r 24 mīm m m
11 zāy z z 25 nūn n n
12 sīn s s 26 hā h h
13 shīn sh $ 27 wāw w w
14 ṣād ṣ S 28 yā y Y
Table 3. Phonetic Transcription for Diacritics. Source: [19] and [10] Diacritic Arabic Transcription Diacritic Arabic Transcription
1 Tanween fatha an 5 damma u
2 Tanween damma un 6 kasra i
3 Tanween kasrat in 7 shadda (double)
4 fatha a 8 sukūn '
A verse is a sentence of the Qur’an also known as ayah. As in all languages, an ayah can contain many words. In the English language and Malay for example, a token can be found equivalent to a word in a sentence but never present as a phrase (which consists of several words). However, generally in the Arabic language a token can form a single phrase. This is referred to as a rich morphological language [20]. For example, Figure 1 shows a token of a Qur’anic Arabic word which forms a phrase.
you + we + created + and =
= و + خلق + نا + آم
Meaning: And we created you.
Figure 1: A token in Qur’anic Arabic which forms a complete ayah. (Source: [19])

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
The Arabian Journal for Science and Engineering, Volume 35, Number 2C December 2010 42
Qur’anic words can be categorized into sets of nominals called ism’, verbs called fi’il, and particles called harf. Nouns, pronouns, adjectives, and adverbs are all in the nominal category while prepositions, conjunctions, interrogatives, and others are in the category of particle. The verbs are derived from a root word with 3, 4, or 5 consonants. The root word meaning is changed by inserting 10 affixed alphabets (10AL) which are سألتمونيها s’ltmwnyhA. These can be added in front (as prefix), in the middle (as infix), or the end (as suffix) of the root word forming another word with related meaning. For example, consider a root word آتب (from 3 consonants ب b, ت t, ك k) which means “write”. Adding one or a few of the 10AL to the root forms a stem that has different but related meanings: “writing", "book", "author", "library", or "office”. Nouns, proper nouns, and adjectives have roots while particles have none. The meaning of particles usually remains the same and no derivatives are formed from them. Consider the three consonant word فعل (with 3 consonant letters ل, ع, ف ). Let ف f be the first consonant word, ع E the second consonant word, and ل l the third consonant word. There are also particles and pronouns that are concatenated to noun and verb tokens. These are added as suffixes or prefixes. Table 4 shows the related prefixes and suffixes common in the Qur’an.
Table 5 shows the different word forms that can be produced by adding one or a few of the 10AL. These words were taken from two main sources: [21] and [22]. The latter source is a very old book on Arabic grammar so that the grammar discussed would be close to the verses of the Qur’an, and the former is a more recent source yet at the same time it adopted a traditional approach to Arabic grammar.
Table 4. Particle and Pronouns Prefixes and Suffixes Particles as prefixes Particles/pronouns as suffixes Word token Prefix Word token Suffix +أل الكتب Al+ ك+ آتبك +k +لل للكتب ll+ آم+ أبنآءآم +km +ب بكتب b+ هم+ أنفسهم +hm +ل لكتب l+ ه+ تجدوه +h +ف فما f+ تم+ أقررتم +tm +و وعلى w+ عدنا و نا+ +nA +أ أفلا A+ وا+ وعملوا +wA +لن لندخلنهم ln+ ها+ جعلنها +hA Others forms of the above تم+ ٱتخذتم +tm + Al ٱل + ٱلناس
Let X represent the 10AL added to the Arabic root word فعل fEl as either prefix (Pre), suffix (Suf), or infix (In). The three main word pattern / word forms are as follows:
• Root words with one to three added prefixes:
o فعل +X3X2X1 Pre1Pre2Pre3+fEl
o فعل + X2X1 Pre1Pre2 +fEl
o فعل + X1 Pre1+fEl
• Root words with one to three added suffixes. However, the most common have up to a maximum of two added suffixes:
o X3 X2 X1+فعل fEl+Suf1Suf2 Suf3
o X2 X1+فعل fEl+Suf1Suf2
• Root words with one to two added infixes between the consonant alphabets. However, the most common type adds only one infix between each consonant:
o ل +X2 ع+X1+ ف f+ In1+E+In2+ l
o عل+ X1+ ف f+In1+ El
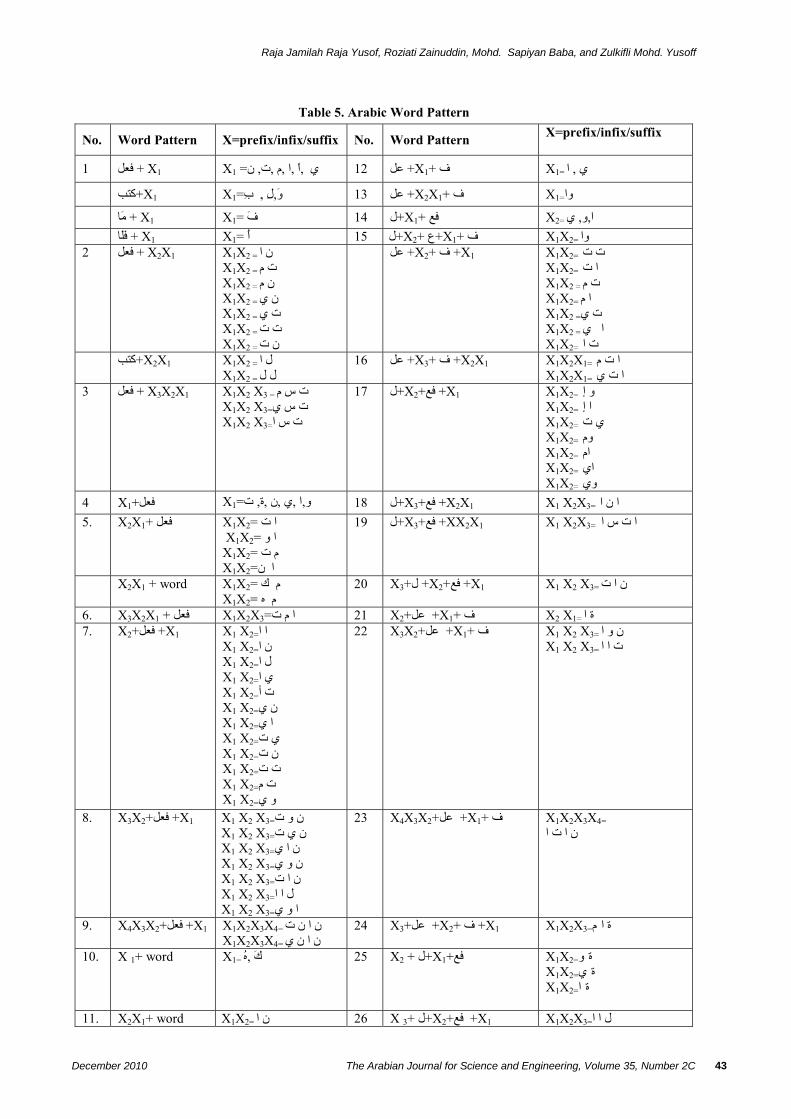
Lastly, the combinations of the three main word forms above are also possible. Table 5 shows 29 Arabic word patterns identified through literature. These will be used for constructing stemming algorithm.
Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
December 2010 The Arabian Journal for Science and Engineering, Volume 35, Number 2C 43
Table 5. Arabic Word Pattern
No. Word Pattern X=prefix/infix/suffix No. Word Pattern X=prefix/infix/suffix
X1 X1 + فعل 1 = ن ي , ا =X1 ف +X1+ عل 12 ي ,ا ,ا ,م ,ت,
آتب+ X1 X1=عل 13 و,ل , ب +X2X1+ ف X1=وا
ما+ X1 X1= ل 14 ف+X1+ فع X2= ا,و, ي فلا+ X1 X1= ل 15 أ+X2+ ع+X1+ ف X1X2= وا ن ا = X2X1 X1X2 + فعل 2
X1X2 = ت م X1X2 = ن م X1X2 = ن ي X1X2 = ت ي X1X2 = ت ت X1X2 = ن ت
ت ت =X1 X1X2+ ف +X2+ عل X1X2= ا ت X1X2 = ت م X1X2= ا م X1X2 =ت ي X1X2 = ا ي X1X2= ت ا
آتب+ X2X1 X1X2 = ل ا X1X2 = ل ل
ا ت م =X2X1 X1X2X1+ ف +X3+ عل 16X1X2X1= ا ت ي
ت س م = X3X2X1 X1X2 X3 + فعل 3X1X2 X3=ت س ي X1X2 X3=ت س ا
و إ =X1 X1X2+ فع+X2+ل 17X1X2= ا إ X1X2= ي ت X1X2= وم X1X2= ام X1X2= اي X1X2= وي
4 X1+فعل X1= ت, ة ا ن ا =X2X1 X1 X2X3+ فع+X3+ل 18 و,ا ,ي ,ن ,5. X2X1+ فعل X1X2= ا ت
X1X2= ا و X1X2= م ت X1X2=ا ن
ا ت س ا =XX2X1 X1 X2X3+ فع+X3+ل 19
X2X1 + word X1X2= م ك X1X2= م ه
20 X3+ل +X2+فع +X1 X1 X2 X3= ن ا ت
6. X3X2X1 + فعل X1X2X3=21 ا م ت X2+عل +X1+ ف X2 X1= ة ا 7. X2+فعل +X1 X1 X2=ا ا
X1 X2=ن ا X1 X2=ل ا X1 X2=ي ا X1 X2=ت أ X1 X2=ن ي X1 X2=ا ي X1 X2=ي ت X1 X2=ن ت X1 X2=ت ت X1 X2=ت م X1 X2=و ي
22 X3X2+عل +X1+ ف X1 X2 X3= ن و ا X1 X2 X3= ت ا ا
8. X3X2+فعل +X1 X1 X2 X3=ن و ت X1 X2 X3=ن ي ت X1 X2 X3=ن ا ي X1 X2 X3=ن و ي X1 X2 X3=ن ا ت X1 X2 X3=ل ا ا X1 X2 X3=ا و ي
23 X4X3X2+عل +X1+ ف X1X2X3X4= ن ا ت ا
9. X4X3X2+فعل +X1 X1X2X3X4= ن ا ن ت X1X2X3X4= ن ا ن ي
24 X3+عل +X2+ ف +X1 X1X2X3=ة ا م
10. X 1+ word X1= 25 ك ,ه X2 + ل+X1+فع X1X2=ة و X1X2=ة ي X1X2=ة ا
11. X2X1+ word X1X2= 26 ن ا X 3+ ل+X2+فع +X1 X1X2X3=ل ا ا

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
The Arabian Journal for Science and Engineering, Volume 35, Number 2C December 2010 44
X1X2=ن و X1X2=ن ي
X1X2X3=ن ا ي X1X2X3 =ة و م
27 X4X3 +ل+X2+فع +X1 X1X2X3 X4=ن و و م X1X2X3 X4=ن ا و م X1X2X3 X4=ت ا و م
28 X5X4X3 +ل+X2+فع +X1 X1X2X3X4 X5= ن ا ت و م
29 X3 + ل+X2+ ع+X1+ فعل ف X1X2X3 = ن ا ا
2. EXPERIMENTAL METHOD
There are two outlined experiments in the following sections. The first is a case study on the 30th part of the Qur’an (Juz Amma). The second is an actual implemented algorithm based on the word patterns identified in Table 5. All experiments were done on a dual 2.4-GHz processor with 2.99 GB of memory.
2.1. Case Study on Juz Amma
The case study was conducted using Juz Amma consisting of short suras from chapters 78 to 114 of the Qur’an. There are approximately 3000 words or 2000 over word tokens in Juz Amma which were taken as the dataset to conduct the case study. These words were stored in a MySQL database and queries on the related tables were made base on the test cases below using Regression Expression to find the percentage of correctness in removing prefixes and suffixes.
The tested cases were divided into 2 categories, i.e., removing one of 10AL and pronoun/ particle:
i. Prefixes of only one or two alphabets
a. + ي y+, + ت t+, +م m+ (in the category of 10AL)
b. + ل ل ll+, + ف f+ (in the category of particles)
ii. Suffixes of one or two alphabets
a. ا ن + +An, و ن + +wn, + ي ن +yn (in the category of 10AL)
b. م+ +tm, ك م + +km and ك + +k (in the category of pronouns)
2.2. Implementing Word Pattern Identifier
The word pattern identifier algorithm was implemented using our Rule-based Stemming Engine (RSE). The stemming process is to determine the root word of the input token from Dukes’s [19] Qur’an Corpus. The corpus consists of the word tokens listed according to word and ayah number with tagset for each word token. RSE consists of several methods implemented using Java language, JDK1.6.0_02 in the Eclipse IDE version 3.3.2. It is 1400 lines of codes and the size is 40K. The Qur’anic words were taken from sura 29 by Dukes [1]. This contains the Arabic Qur’anic words, the word information (word, ayah and sura number) and the part-of-speech tagset which is written in Roman scripts. The Arabic words and the part-of-speech tagset were extracted and put into two separate lists. The stemmed word tokens from the Arabic word list were later on compared to the part-of-speech tagset list. The tagset list contains information of each root of the Arabic word (if relevant, since some words have no root). Our algorithm only caters to three-letter root words.
The algorithm is as follows:
i) Get word tokens from the corpus.
a. Separate word token from word tagset into two vector lists:
i. Qur’an word list (Arabic script)
ii. Part-of-speech tagset list (Roman script)
ii) Remove particle prefixes ( +ل l+, + ف f+ , + ب b+ , و+ w+,+ٱ A+)
iii) Remove diacritization from all word tokens
iv) Remove prefixes (the prefixes in Table 4 excluding the ones in ii)
v) Remove suffixes (the suffixes in Table 4)
vi) Determine length of word, stem the words by removing one of 10AL as in Table 5 and put them into a new vector list
a. If word length = 1, 2, 3 or >8, return the word without stemming

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
December 2010 The Arabian Journal for Science and Engineering, Volume 35, Number 2C 45
b. If word length = 4, use algorithm to detect word pattern of length 4
i. Delete one of 10AL
ii. return the three-letter root
c. If word length = 5, use algorithm to detect word pattern of length 5
i. Delete two of 10AL
ii. return the three-letter root
d. If word length = 6, use algorithm to detect word pattern of length 6
i. Delete three of 10AL
ii. return the three-letter root
e. If word length = 7, use algorithm to detect word pattern of length 7
i. Delete four of 10AL
ii. return the three-letter root
f. If word length = 8, use algorithm to detect word pattern of length 8
i. Delete five of 10AL
ii. return the three-letter root
vii) In a stemmed word of length three, replace middle vowel letters to و (w)1
viii) Transliterate generated root words after stemming and compare to tagset
a. Take the new list containing the stemmed Arabic words
b. Transliterate the list above so that the comparison of the root words written in Roman script from the other list (described in i-a) can be done
ix) Compute accuracy of RSE
In this second experimentation, we started with inputting word tokens, including the tagset into RSE. The word tokens from sura 29 were first fed into RSE to find out the accuracy percentage and the time taken to stem all the word tokens. Then, the procedures were repeated using the 30th part of the Qur’an called Juz Amma, sura 2, sura 3 to 5, sura 6 to 12, and the whole Qur’an.
Our approach deals with only trilliteral root words as in TRE, while Khoja, BAMA, and the Voting algorithm deals with other root lengths. Pattern matching using data files are used by Khoja, BAMA, and the Voting algorithm, while RSE and TRE uses pattern matching based on the 10AL without data files. Lastly, normalization was not included in BAMA or our algorithm such as in Khoja.
Table 6. Comparison of Features Included in the Stemming Algorithm of Khoja, BAMA, TRE, Voting, and RSE
Algorithm Features
Khoja BAMA TRE Voting RSE
1 Deal with triliteral root words √ √ √ √ √
2 Deal with other length root words √ √ X √ X
3 Pattern matching using data files √ √ X √ X
4 Pattern matching using 10AL X X √ X √
5 Normalization √ X - √ X
1 This is not right in all cases; at this moment, this step results in a higher accuracy rate.
Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
The Arabian Journal for Science and Engineering, Volume 35, Number 2C December 2010 46
3. RESULTS AND DISCUSSION
3.1. Case Study Result and Discussion
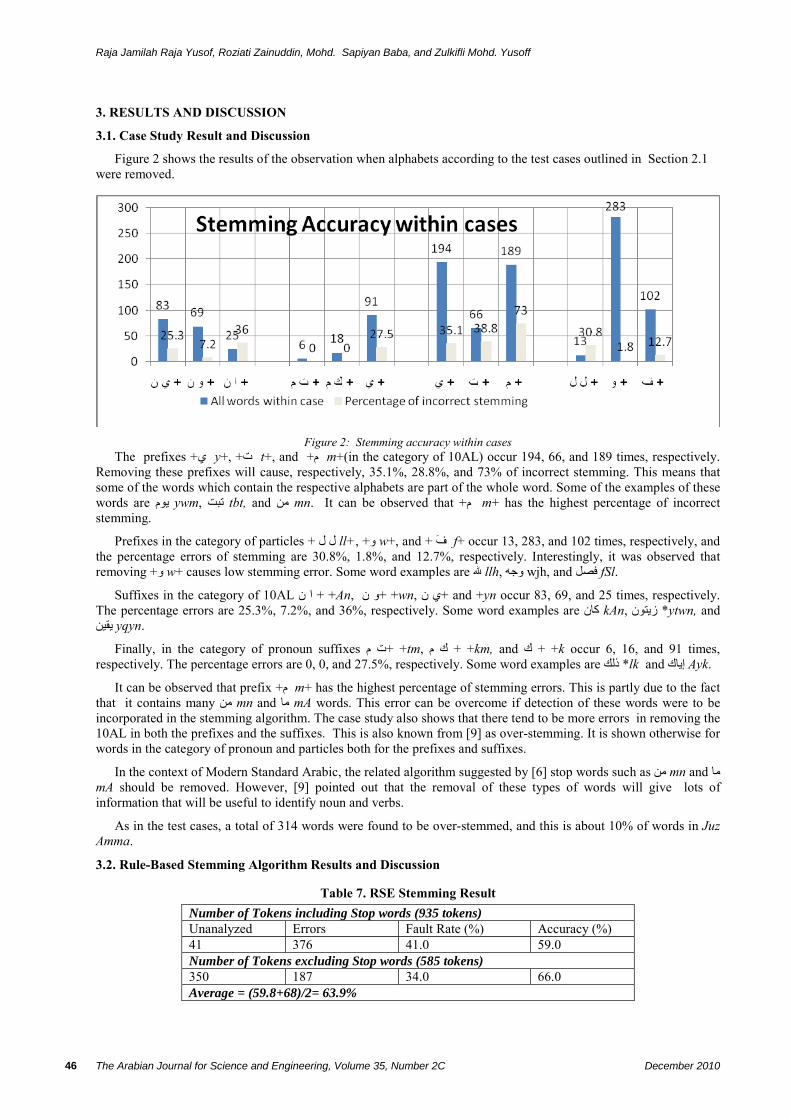
Figure 2 shows the results of the observation when alphabets according to the test cases outlined in Section 2.1 were removed.
Figure 2: Stemming accuracy within cases
The prefixes +ي y+, +ت t+, and +م m+(in the category of 10AL) occur 194, 66, and 189 times, respectively. Removing these prefixes will cause, respectively, 35.1%, 28.8%, and 73% of incorrect stemming. This means that some of the words which contain the respective alphabets are part of the whole word. Some of the examples of these words are يوم ywm, تبت tbt, and من mn. It can be observed that +م m+ has the highest percentage of incorrect stemming.
Prefixes in the category of particles + ل ل ll+, +و w+, and + ف f+ occur 13, 283, and 102 times, respectively, and the percentage errors of stemming are 30.8%, 1.8%, and 12.7%, respectively. Interestingly, it was observed that removing +و w+ causes low stemming error. Some word examples are هللا llh, وجه wjh, and فصل fSl.
Suffixes in the category of 10AL ا ن + +An, و ن + +wn, + ي ن and +yn occur 83, 69, and 25 times, respectively. The percentage errors are 25.3%, 7.2%, and 36%, respectively. Some word examples are آان kAn, زيتون *ytwn, and .yqyn يقين
Finally, in the category of pronoun suffixes ت م+ +tm, ك م + +km, and ك + +k occur 6, 16, and 91 times, respectively. The percentage errors are 0, 0, and 27.5%, respectively. Some word examples are ذلك *lk and إياك Ayk.
It can be observed that prefix +م m+ has the highest percentage of stemming errors. This is partly due to the fact that it contains many من mn and ما mA words. This error can be overcome if detection of these words were to be incorporated in the stemming algorithm. The case study also shows that there tend to be more errors in removing the 10AL in both the prefixes and the suffixes. This is also known from [9] as over-stemming. It is shown otherwise for words in the category of pronoun and particles both for the prefixes and suffixes.
In the context of Modern Standard Arabic, the related algorithm suggested by [6] stop words such as من mn and ما mA should be removed. However, [9] pointed out that the removal of these types of words will give lots of information that will be useful to identify noun and verbs.
As in the test cases, a total of 314 words were found to be over-stemmed, and this is about 10% of words in Juz Amma.
3.2. Rule-Based Stemming Algorithm Results and Discussion
Table 7. RSE Stemming Result Number of Tokens including Stop words (935 tokens) Unanalyzed Errors Fault Rate (%) Accuracy (%) 41 376 41.0 59.0 Number of Tokens excluding Stop words (585 tokens) 350 187 34.0 66.0 Average = (59.8+68)/2= 63.9%
Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
December 2010 The Arabian Journal for Science and Engineering, Volume 35, Number 2C 47
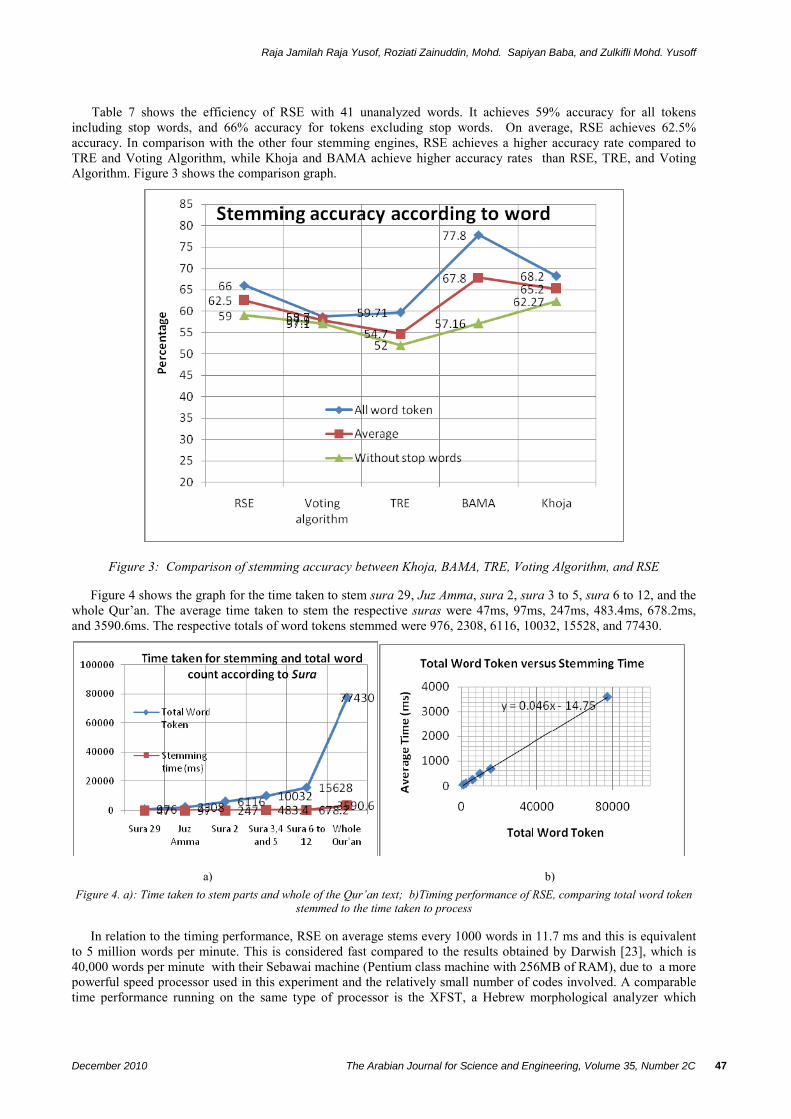
Table 7 shows the efficiency of RSE with 41 unanalyzed words. It achieves 59% accuracy for all tokens including stop words, and 66% accuracy for tokens excluding stop words. On average, RSE achieves 62.5% accuracy. In comparison with the other four stemming engines, RSE achieves a higher accuracy rate compared to TRE and Voting Algorithm, while Khoja and BAMA achieve higher accuracy rates than RSE, TRE, and Voting Algorithm. Figure 3 shows the comparison graph.
Figure 3: Comparison of stemming accuracy between Khoja, BAMA, TRE, Voting Algorithm, and RSE
Figure 4 shows the graph for the time taken to stem sura 29, Juz Amma, sura 2, sura 3 to 5, sura 6 to 12, and the whole Qur’an. The average time taken to stem the respective suras were 47ms, 97ms, 247ms, 483.4ms, 678.2ms, and 3590.6ms. The respective totals of word tokens stemmed were 976, 2308, 6116, 10032, 15528, and 77430.
Figure 4. a): Time taken to stem parts and whole of the Qur’an text; b)Timing performance of RSE, comparing total word token stemmed to the time taken to process
In relation to the timing performance, RSE on average stems every 1000 words in 11.7 ms and this is equivalent to 5 million words per minute. This is considered fast compared to the results obtained by Darwish [23], which is 40,000 words per minute with their Sebawai machine (Pentium class machine with 256MB of RAM), due to a more powerful speed processor used in this experiment and the relatively small number of codes involved. A comparable time performance running on the same type of processor is the XFST, a Hebrew morphological analyzer which
a) b)

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
The Arabian Journal for Science and Engineering, Volume 35, Number 2C December 2010 48
contains a huge network representation of the Hebrew language, approximately 2 million states and 2.2 million transitions. It can process up to 20,000 words per minute [24].
4. CONCLUSION
An algorithm can be constructed using an Arabic word pattern identified by expert views of the Arabic grammar. Although there are up to 900 [13] patterns in MSA, a reduced list (29 forms) for analyzing words in the Qur’an was used to test and implement the RSE. In the case study, it was interestingly discovered that particle and pronoun prefixes and suffixes showed very low over-stemming percentages. The result of RSE stemming accuracy was comparable to the Khoja and BAMA stemming engines, although it achieved a slightly lower accuracy rate of 62.5%. The time to stem a word token from the Qur’an dataset was on average 11.7 ms for each 1000 words, which is around 5 million words per minute. These are promising results since the algorithm involved was small, simple, and with limitations. Future studies of the implementation on a more extensive stemming algorithm can be conducted by adding a more rule-based pattern algorithm, a mechanism of deciding whether to use ا A, و w, or ي y for the middle letter of a three-letter root, and testing the algorithm against wide domains and a large test corpus using all possible test cases. Furthermore, future studies can also include comparing the improved algorithm against other stemming algorithms using the same data sets. Pure stemming algorithm without any type of lexicon may lead to many over-stemmed and even under-stemmed Arabic words. This was shown from the case study and RSE stemming accuracy. Therefore, it can be concluded that to identify root words, using RSE for the Qur’an is currently not suitable if close to 100% accuracy is required.
REFERENCES
[1] K. Dukes, E. Atwell, and A. M. Sharaf, “Syntactic Annotation Guidelines for the Quranic Arabic Treebank”, in The Seventh International Conference on Language Resources and Evaluation (LREC-2010), 2010.
[2] M. Maamouri, A. Bies, T. Buckwalter, and W. Mekki, “The Penn Arabic Treebank: Building a Large-Scale Annotated Arabic Corpus”, in Proc. of the Arabic Language Technologies and Resources Int’l. Conference; NEMLAR, 2004. http://papers.LDC.uPenn.edu/NEMLAR2004/Penn-Arabic-Treebank.pdf.
[3] T. Buckwalter, “Issues in Morphological Analysis”, in Arabic Computational Morphology. Eds. A. Soudi, A. van den Bosch, and G. Neumann. Springer, 2007, pp. 23–41.
[4] K. Dukes and N. Habash, “Morphological Annotation of Quranic Arabic”, in Proceeding of the Seventh International Conference on Language Resources and Evaluation (LREC-2010), 2010.
[5] K. Darwish and D. W. Oard, “Adapting Morphology for Arabic Information Retrieval”, in Arabic Computational Morphology. Eds. A. Soudi, A. van den Bosch, and G. Neumann. , Springer, 2007, pp. 245–162.
[6] K. Taghva, R. Elkhoury, and J. Coombs, “Arabic Stemming Without a Root Dictionary”, in Proc. of the International Conference on Information Technology: Coding and Computing (ITCC'05) - Volume I - Volume 01 (April 04 - 06, 2005). ITCC. IEEE Computer Society, Washington, DC, pp. 152–157. DOI= http://dx.doi.org/10.1109/ITCC.2005.90
[7] J. Yaghi and S. M. Yagi, “Systematic Verb Stem Generation for Arabic”, in Proc. of the Workshop on Computational Approaches to Arabic Script-Based Languages (Geneva, Switzerland, August 28 - 28, 2004). ACL Workshops. Association for Computational Linguistics, Morristown, NJ, pp. 23–30.
[8] L. S. Larkey, L. Ballesteros, and M. E. Connell, “Improving Stemming for Arabic Information Retrieval: Light Stemming and Co-occurrence Analysis”, in Proc. of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (Tampere, Finland, August 11 - 15, 2002). SIGIR '02. ACM, New York, NY, pp. 275–282.
[9] E. T. Al-Shammari and J. Lin, “Towards an Error-Free Arabic Stemming”, in Proceeding of the 2nd ACM Workshop on Improving Non English Web Searching (Napa Valley, California, USA, October 30 - 30, 2008). iNEWS '08. ACM, New York, NY, pp. 9–16.
[10] M. Rashwan, M. Al-Badrashiny, and M. A. Attia, “Stochastic Arabic Diacritizer Based on a Hybrid of Factorized and Un-factorized Textual Features”, IEEE Transactions on Audio, Speech, and Language Processing (TASLP), 19(2010), pp.166–175.
[11] N. Habash and O. Rambow, “Arabic Diacritization Through Full Morphological Tagging”, in Proc. of the 8th Meeting of the North American Chapter of the Association for Computational Linguistics (ACL); Human Language Technologies Conference (HLT-NAACL), 2007.
[12] I. Zitouni, J. S. Sorensen, and R. Sarikaya, “Maximum Entropy Based Restoration of Arabic Diacritics”, in Proc. of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics (ACL); Workshop on Computational Approaches to Semitic Languages; Sydney-Australia, July 2006; http://www.ACLweb.org/anthology/P/P06/P06-1073

Raja Jamilah Raja Yusof, Roziati Zainuddin, Mohd. Sapiyan Baba, and Zulkifli Mohd. Yusoff
December 2010 The Arabian Journal for Science and Engineering, Volume 35, Number 2C 49
[13] I. A. AlSughaiyer and I. A. AlKharashi, “Arabic Morphological Analysis Techniques: A Comprehensive Survey”, Journal of the American Society for Information Science and Technology, 55(2004), pp. 189–213.
[14] M. Altantawy, N. Habash, O. Rambow, and I. Saleh, “Morphological Analysis and Generation of Arabic Nouns: A Morphemic Functional Approach”, in Proc. of the Seventh International Conference on Language Resources and Evaluation (LREC), 2010.
[15] N. Habash, O. Ranbow, and G. Kiraz, “Morphological Analysis and Generation for Arabic Dialects”, in Proc. of the ACL Workshop on Computational Approaches to Semitic Languages, 2005, pp. 17–21.
[16] N. Thabet, “Stemming the Qur'an”, in Proc. of the Workshop on Computational Approaches to Arabic Script-based Languages, 2004, pp. 28–31.
[17] I. A. Al Kharashi and I. A. Al-Sughaiyer, “Rule Merging in a Ruled-Based Arabic Stemmer”, in Proc. of the 19th International Conference on Computational Linguistics, 2002.
[18] M. Sawalha and E. Atwell, “Comparative Evaluation of Arabic Language Morphological Analysers and Stemmers”, in Proc. of COLING 2008 22nd International Conference on Comptational Linguistics, 2008.
[19] A. Dukes, “Phonetic Transcription”, 2010, available at http://corpus.quran.com/documentation/phonetic.jsp. Last retrieved in June 2010.
[20] T. Buckwalter, “Arabic Transliteration”, Retrieved September 13, 2010, from Buckwalter Arabic Transliteration: http://www.qamus.org/transliteration.htm
[21] R. Ismail, Kosa Kata Bahasa Arab Mikro, Teknik dan Aspek [Micro Arabic Vocabulary, Techniques and Aspects]. Kota Bahru, Kelantan, Malaysia, 2008.
[22] D. Forbes, Grammar of the Arabic Language. London: WM H Allen & Co, 1868.
[23] K. Darwish, “Building a Shallow Arabic Morphological Analyzer in One Day”, in Proc. of the ACL-02 Workshop on Computational Approaches to Semitic Languages. Association for Computational Linguistics, Morristown, NJ, USA, 2002, pp.1–8.
[24] S. Wintner, “Strengths and Weaknesses of Finite-State Technology: A Case Study in Morphological Grammar Development”, Nat. Lang. Eng., 14(2008), pp. 457–469.