pipelined cpus
TRANSCRIPT

Pipelined CPUs
(Second Edition: Sections 6.1-6.3 Fourth Edition: Sections 4.5-4.6) from Dr. Andrea Di Blas’ notes

CMPE 110 – Spring 2011 – J. Ferguson
Outline
• Pipeline Principles • Pipelined datapath • Pipelined control
8 - 2
CMPE 110 – Spring 2011 – J. Ferguson
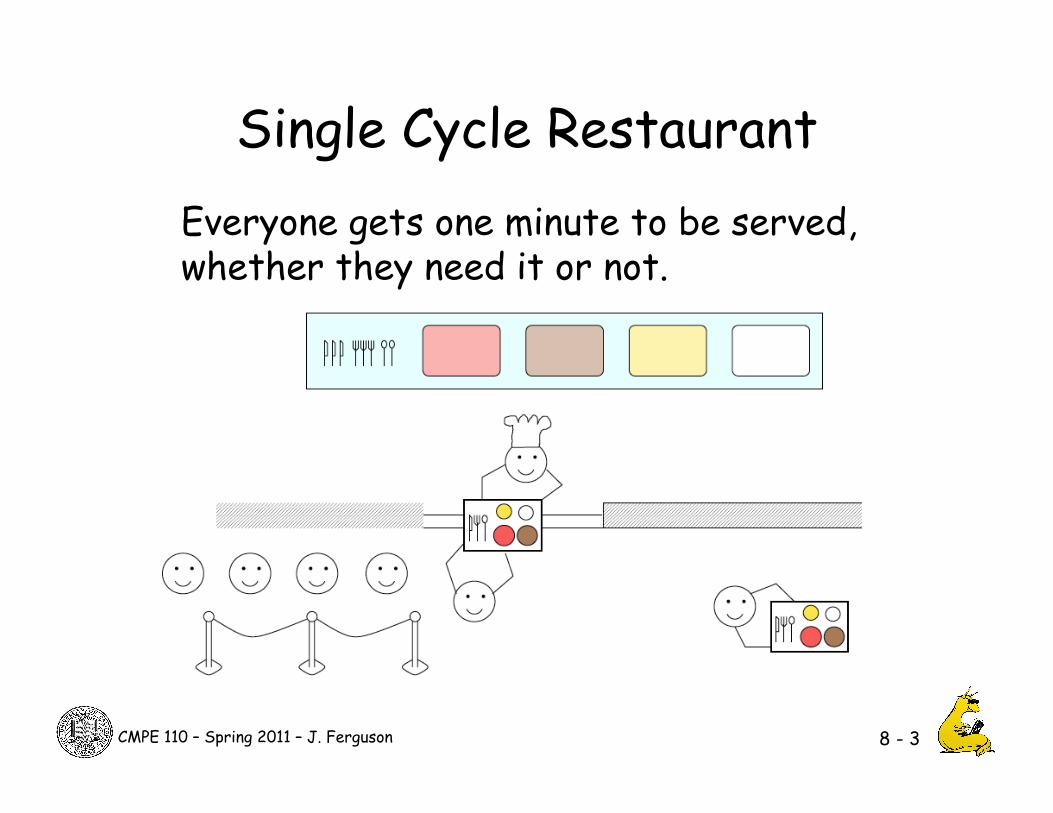
Single Cycle Restaurant
8 - 3
Everyone gets one minute to be served, whether they need it or not.
CMPE 110 – Spring 2011 – J. Ferguson 8 - 4
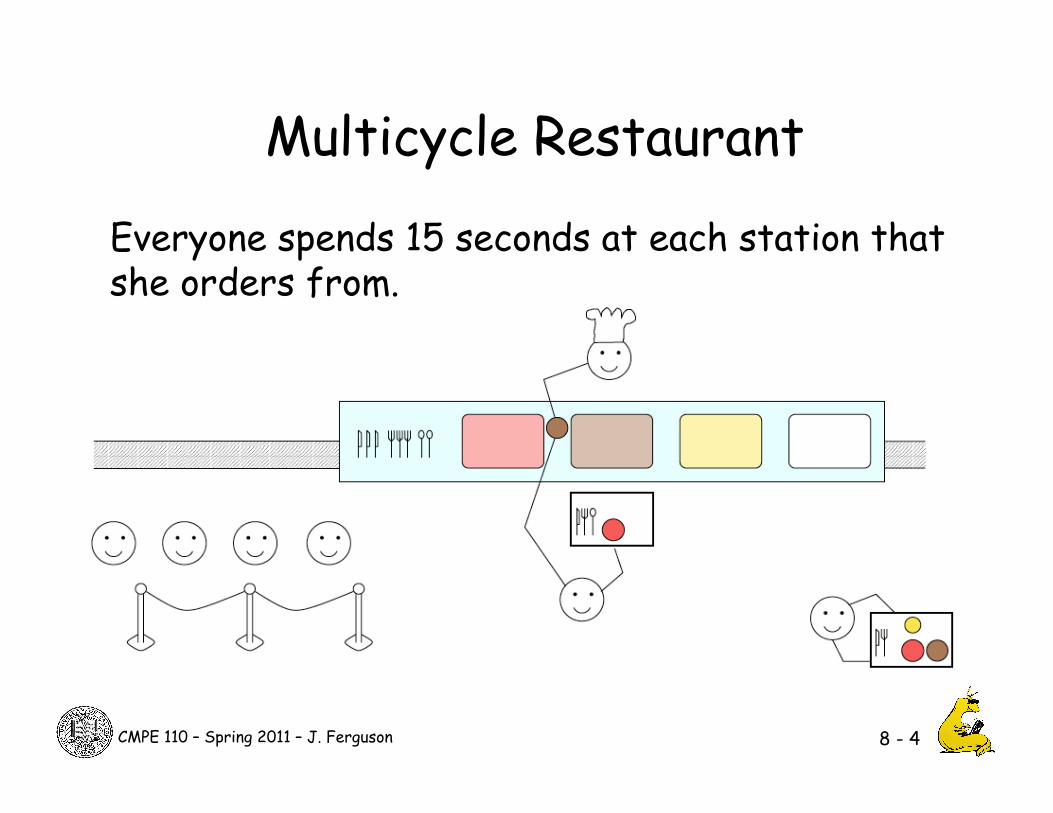
Multicycle Restaurant
Everyone spends 15 seconds at each station that she orders from.
CMPE 110 – Spring 2011 – J. Ferguson 8 - 5
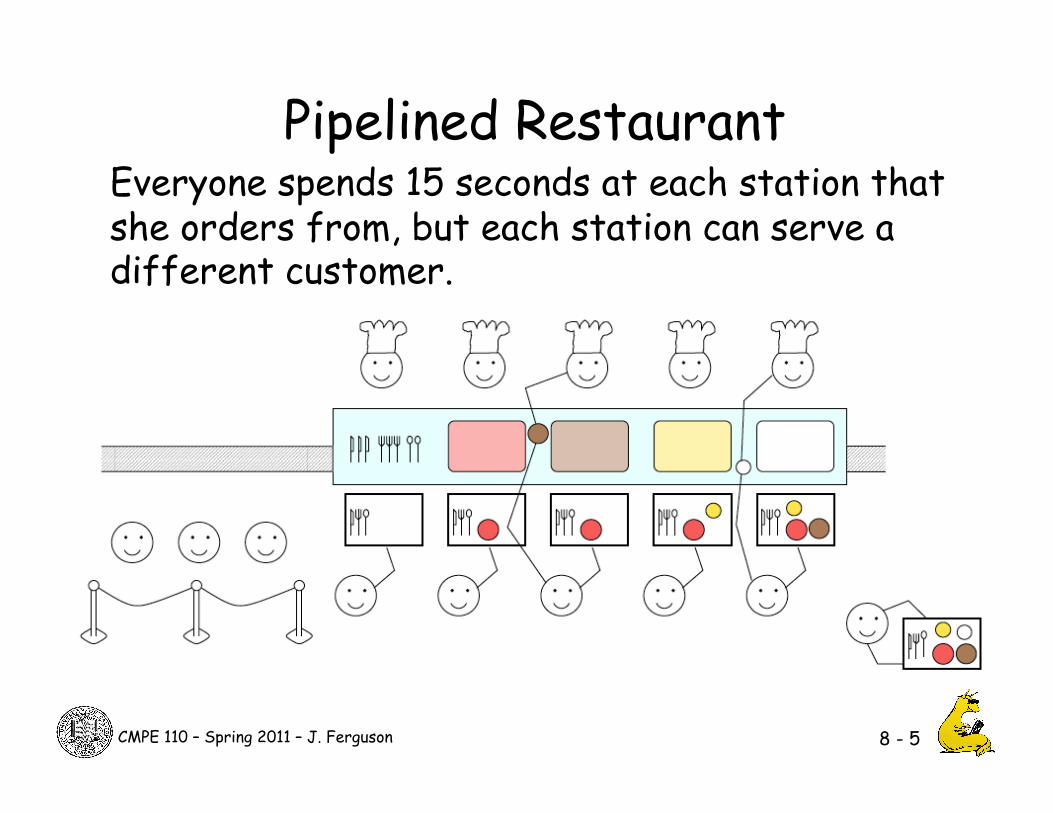
Pipelined Restaurant Everyone spends 15 seconds at each station that she orders from, but each station can serve a different customer.

CMPE 110 – Spring 2011 – J. Ferguson
Pipelined Datapath
• Just like with multicycle implementation there are stages,
• but each stage executes concurrently. • A new instruction begins execution every clock
cycle.
8 - 6
CMPE 110 – Spring 2011 – J. Ferguson
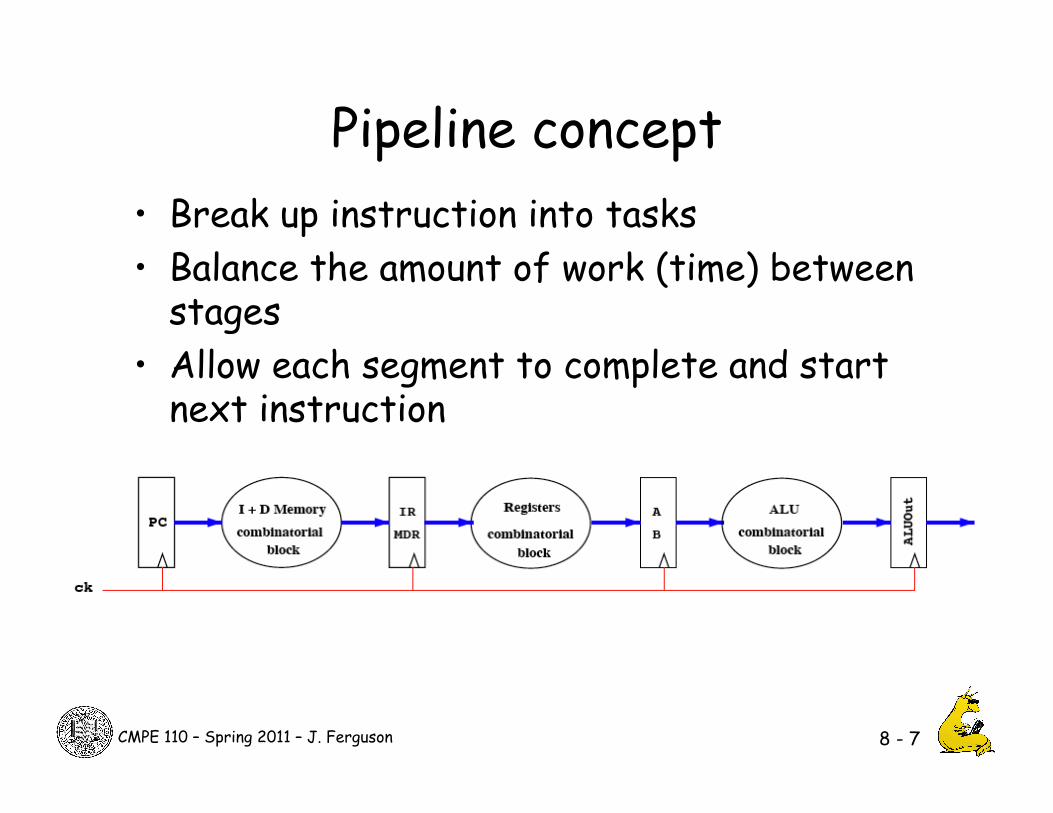
Pipeline concept
8 - 7
• Break up instruction into tasks • Balance the amount of work (time) between
stages • Allow each segment to complete and start
next instruction

CMPE 110 – Spring 2011 – J. Ferguson
Properties of Pipelines
• Latency: the time it takes for a single instruction to execute. Pipelining makes latency slightly worse.
• Throughput: number of instructions executed per unit time. Pipelining improves throughput.
• Five stages in classical pipeline: IF, ID, EX, MEM, WB. Just like our multicycle pipeline.
• Clock is constrained by slowest stage of pipeline. • Pipelining isn’t free: complexities in design and
additional resources (more later).
8 - 8
CMPE 110 – Spring 2011 – J. Ferguson
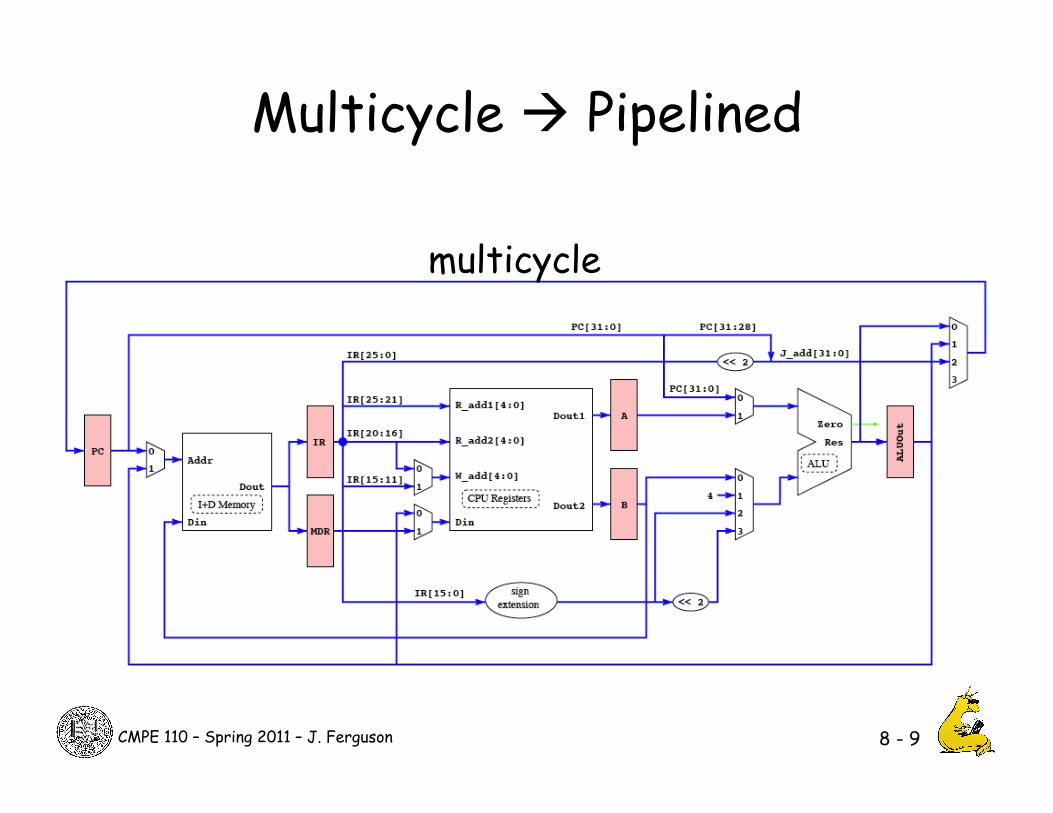
Multicycle Pipelined
8 - 9
multicycle
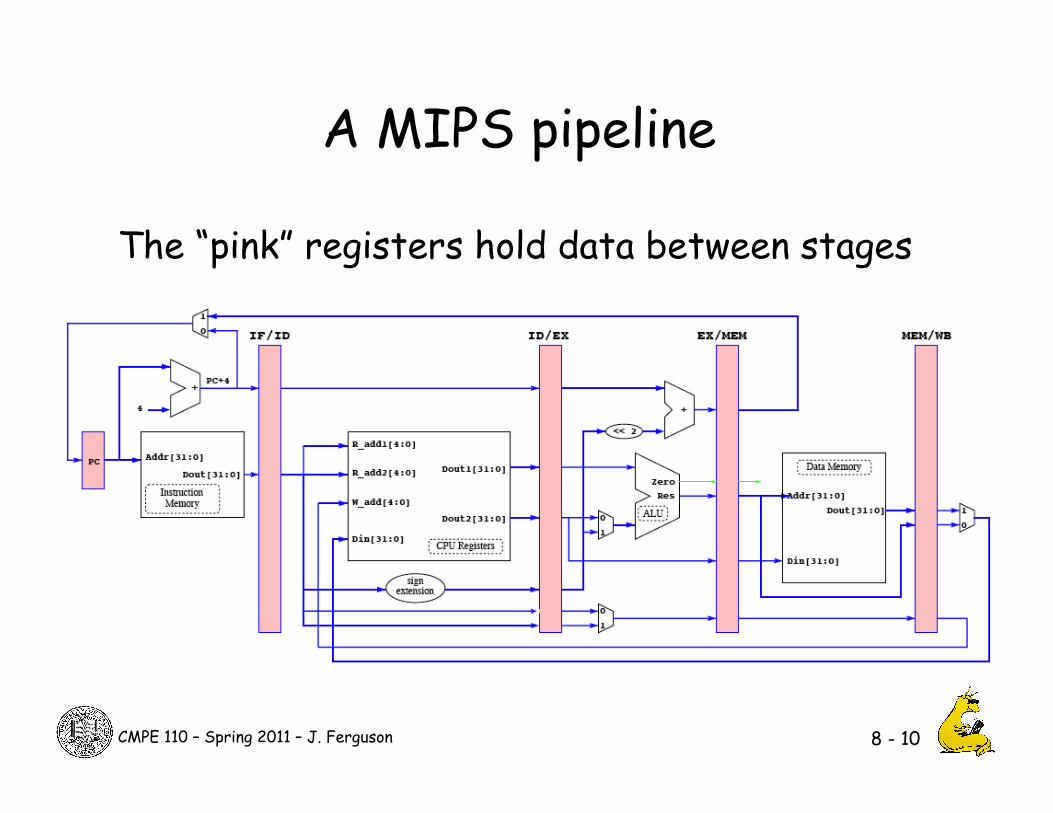
CMPE 110 – Spring 2011 – J. Ferguson
A MIPS pipeline
8 - 10
The “pink” registers hold data between stages

CMPE 110 – Spring 2011 – J. Ferguson
Pipeline Performance
• If all instructions took N Cycles, and • each of N pipeline stages did 1/Nth of the work,
and • the clock speed didn’t change, • the pipeline implementation’s “throughput” would be
N times faster than the multicycle implementation. • Because an instruction would be finished every clock
cycle.
8 - 11
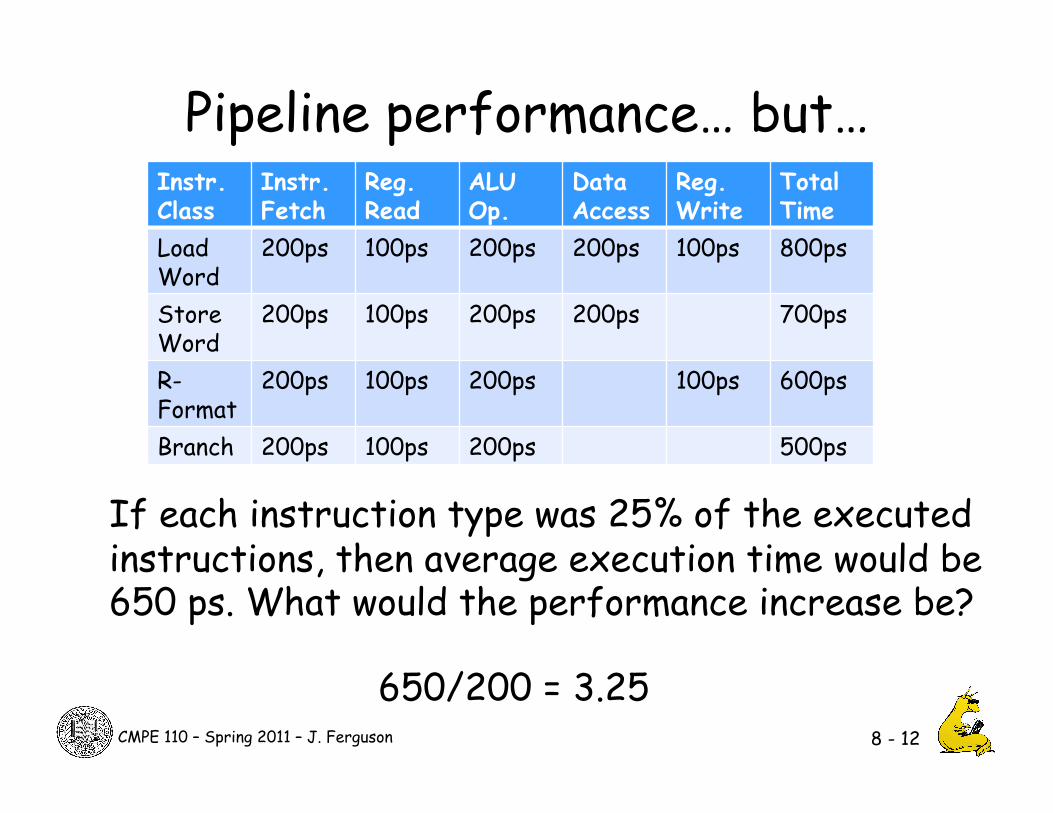
CMPE 110 – Spring 2011 – J. Ferguson
Pipeline performance… but…
8 - 12
Instr. Class
Instr. Fetch
Reg. Read
ALU Op.
Data Access
Reg. Write
Total Time
Load Word
200ps 100ps 200ps 200ps 100ps 800ps
Store Word
200ps 100ps 200ps 200ps 700ps
R-Format
200ps 100ps 200ps 100ps 600ps
Branch 200ps 100ps 200ps 500ps
If each instruction type was 25% of the executed instructions, then average execution time would be 650 ps. What would the performance increase be?
650/200 = 3.25
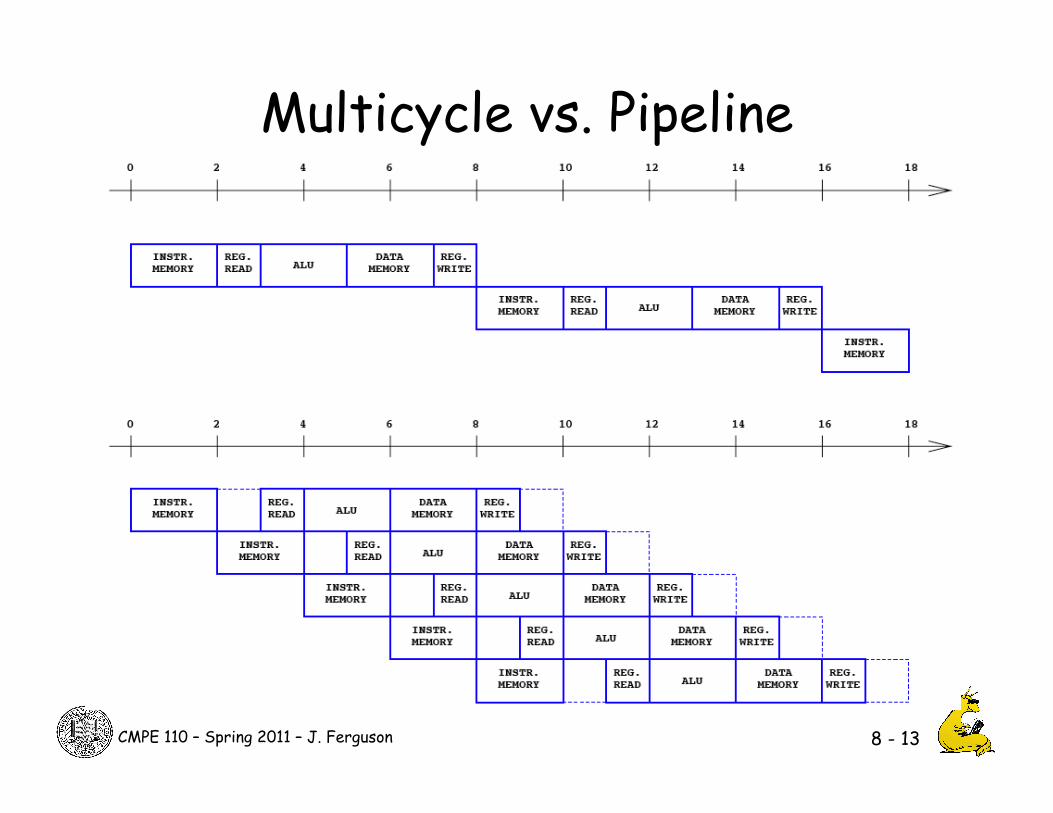
CMPE 110 – Spring 2011 – J. Ferguson
Multicycle vs. Pipeline
8 - 13

CMPE 110 – Spring 2011 – J. Ferguson
MIPS ISA and Pipelining
• All instructions are the same length • Few instruction formats (and similar as possible) • Memory operands only in load and store and simple
addressing mode • Operands are aligned in memory
8 - 14
CMPE 110 – Spring 2011 – J. Ferguson
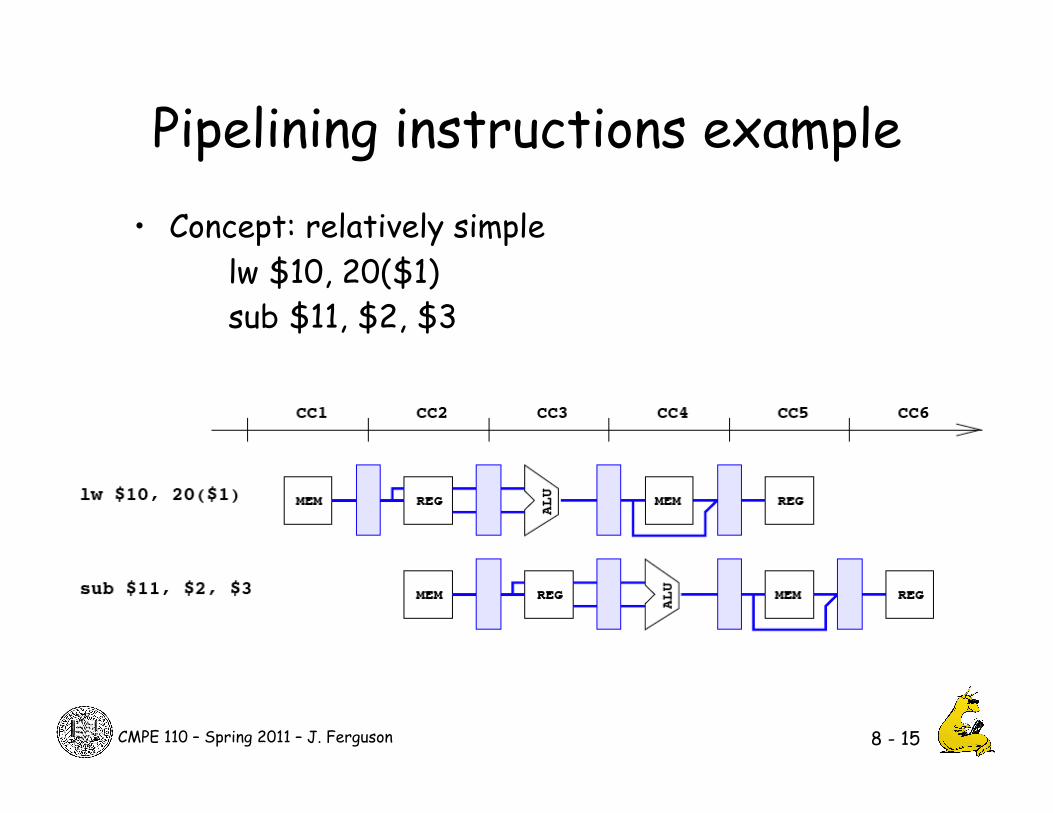
Pipelining instructions example • Concept: relatively simple
lw $10, 20($1) sub $11, $2, $3
8 - 15
CMPE 110 – Spring 2011 – J. Ferguson
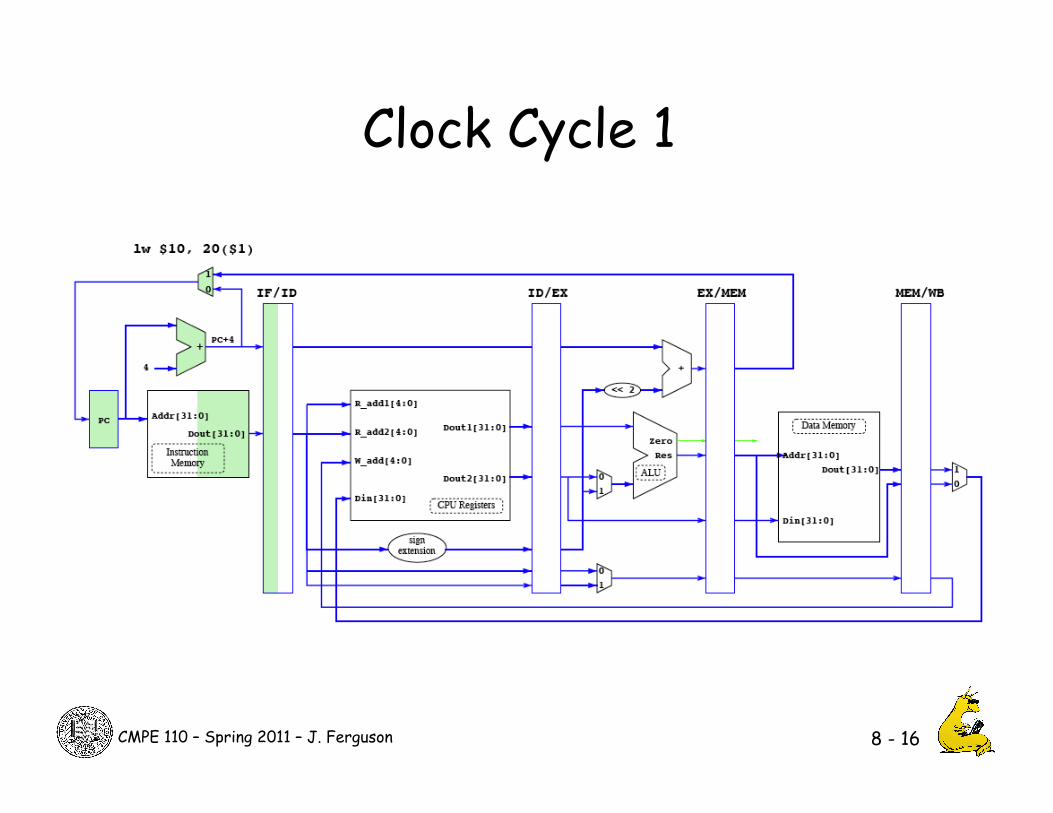
Clock Cycle 1
8 - 16
CMPE 110 – Spring 2011 – J. Ferguson
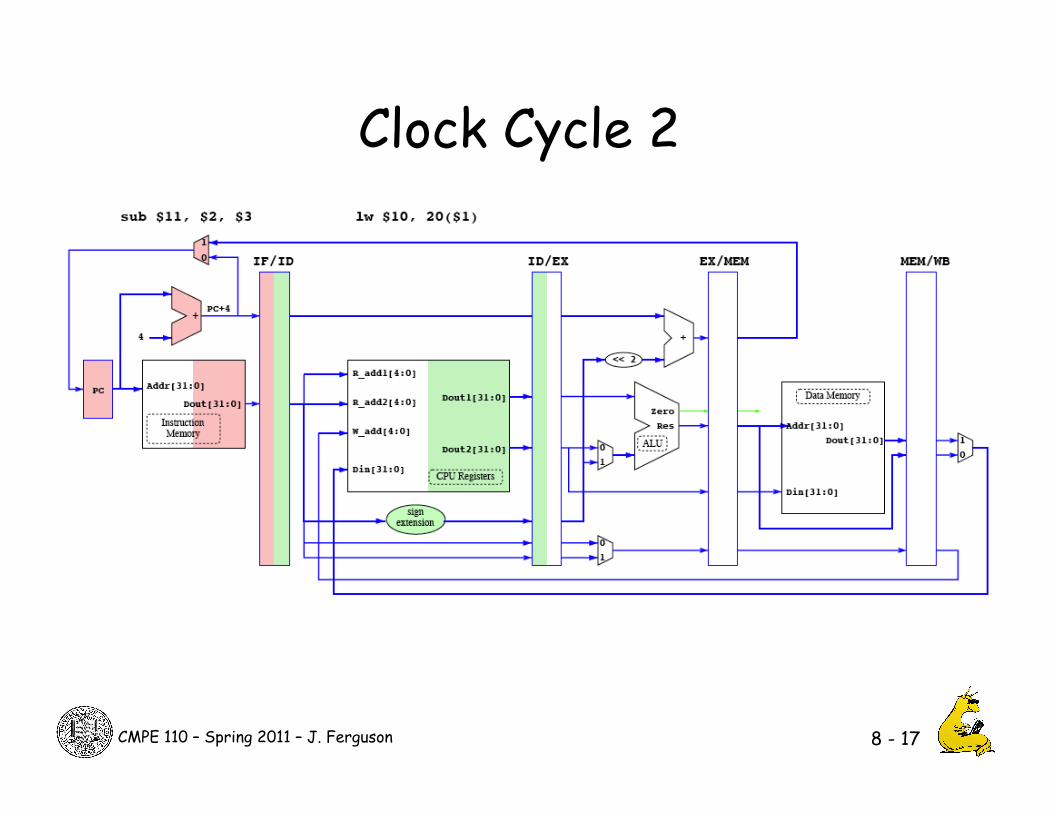
Clock Cycle 2
8 - 17
CMPE 110 – Spring 2011 – J. Ferguson
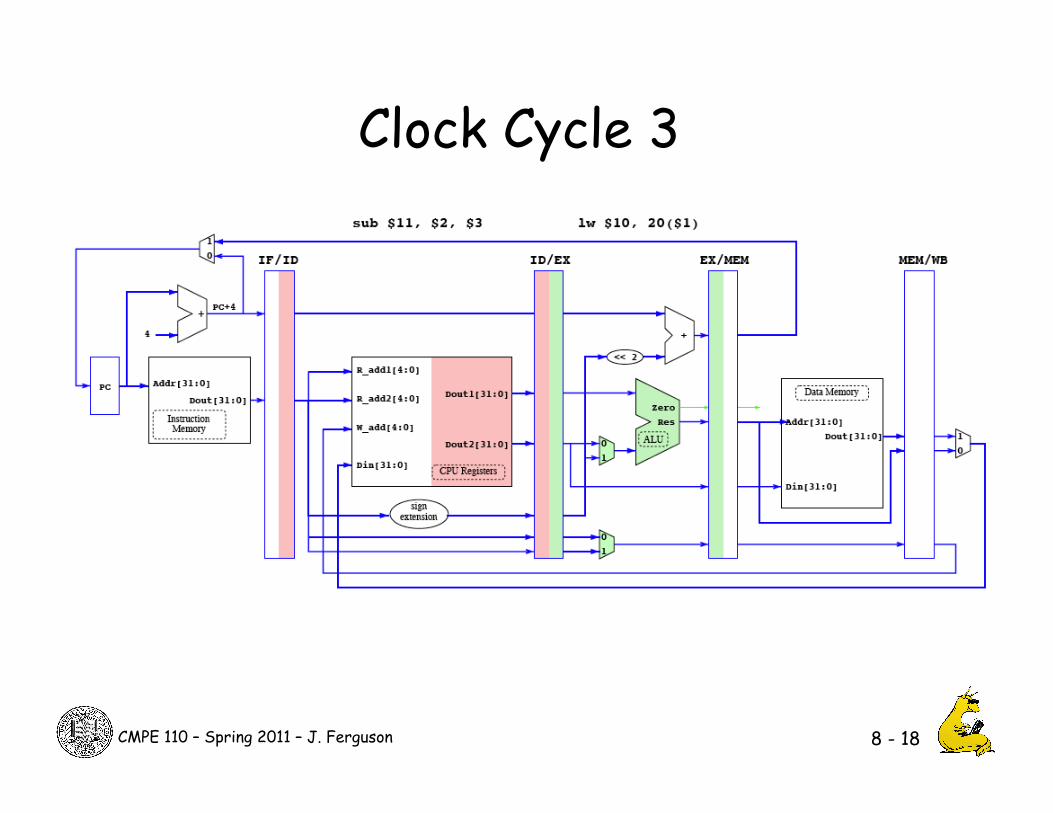
Clock Cycle 3
8 - 18
CMPE 110 – Spring 2011 – J. Ferguson
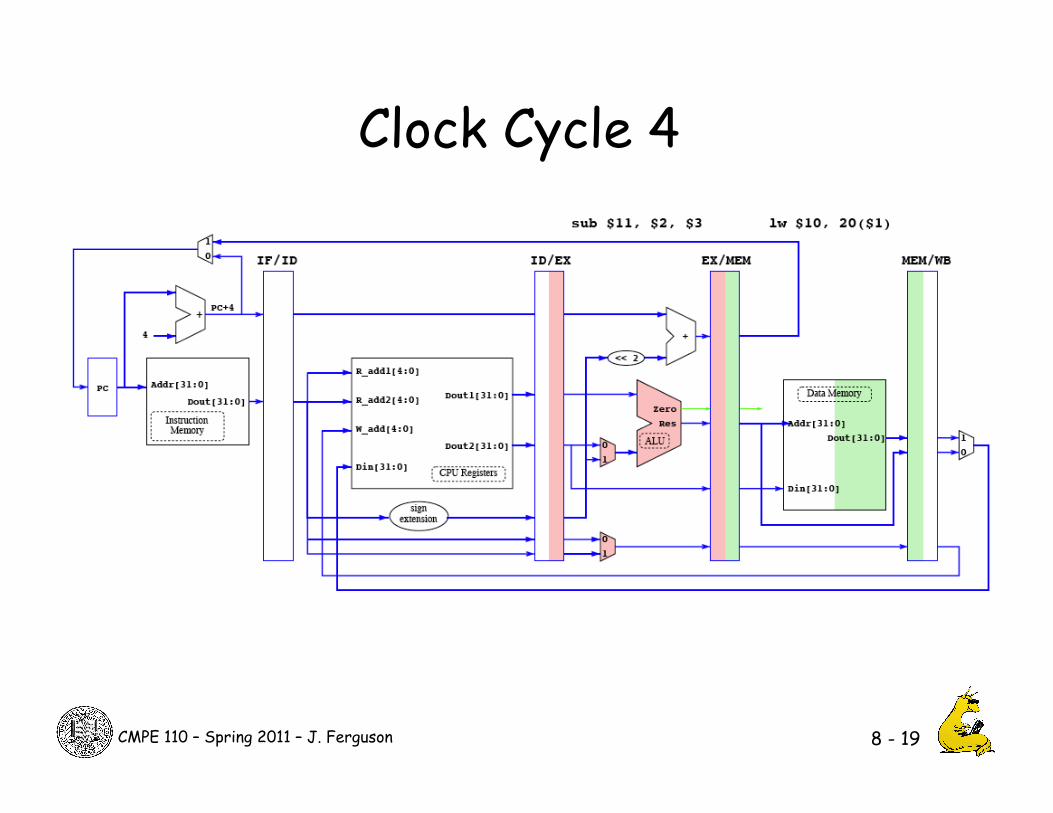
Clock Cycle 4
8 - 19
CMPE 110 – Spring 2011 – J. Ferguson
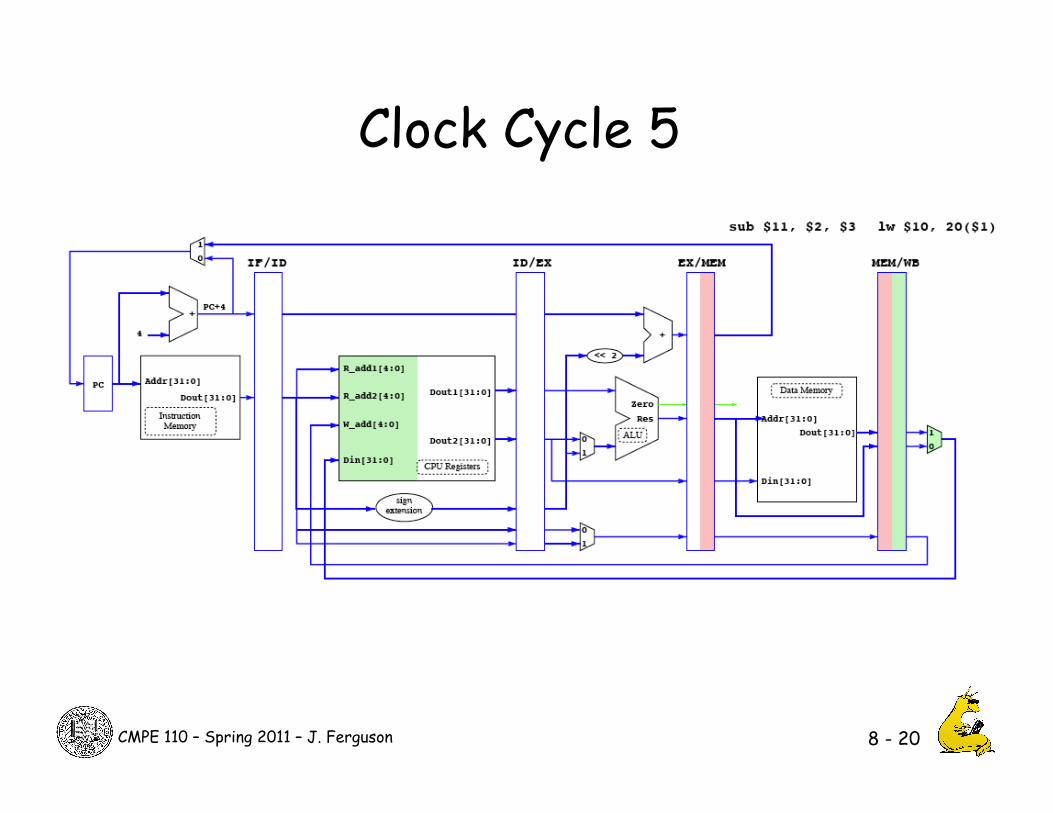
Clock Cycle 5
8 - 20
CMPE 110 – Spring 2011 – J. Ferguson
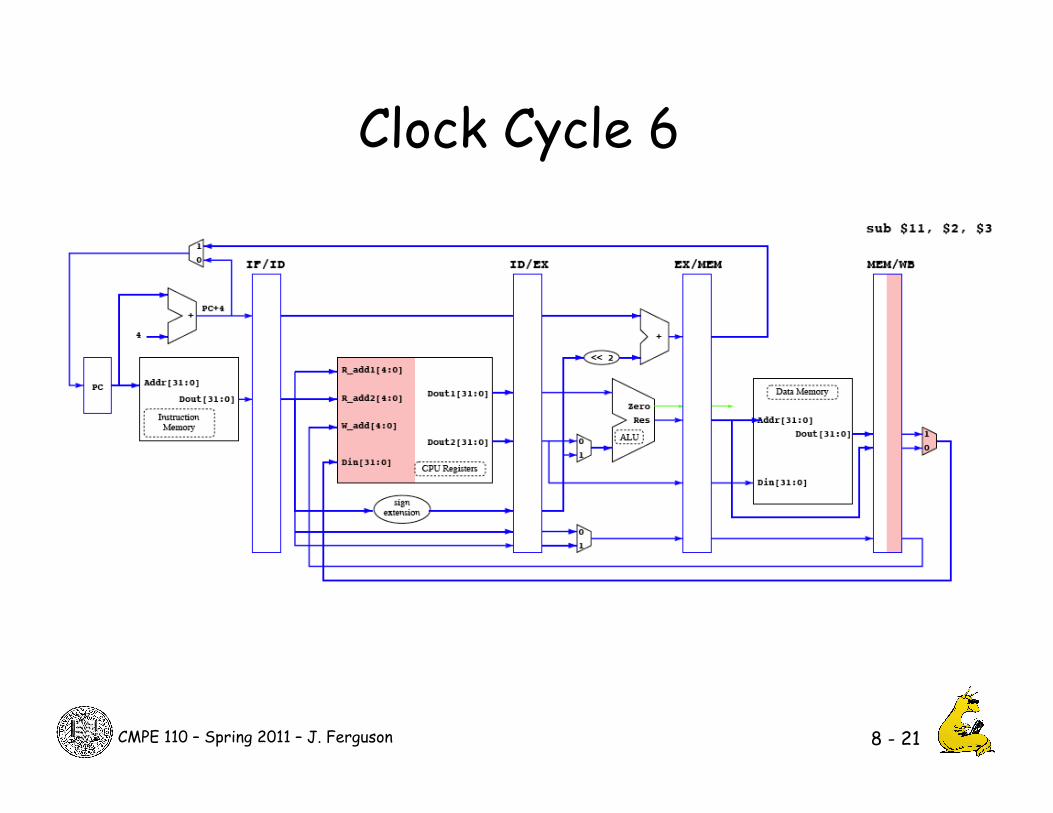
Clock Cycle 6
8 - 21
CMPE 110 – Spring 2011 – J. Ferguson
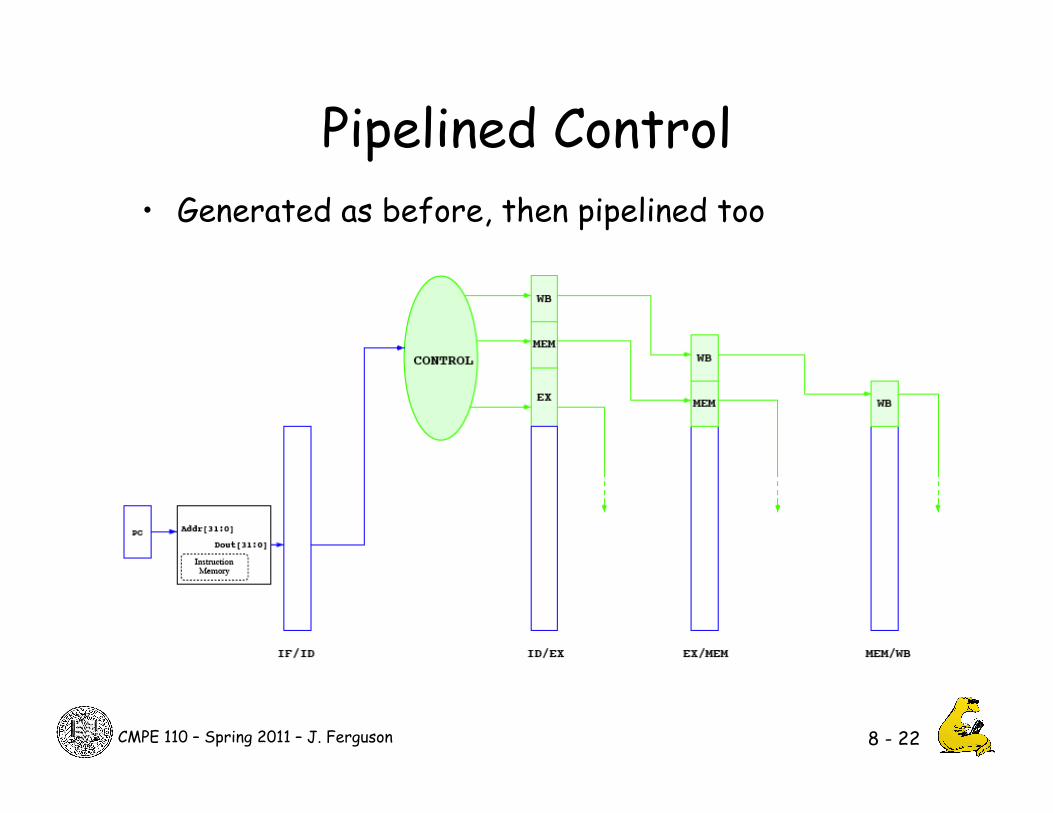
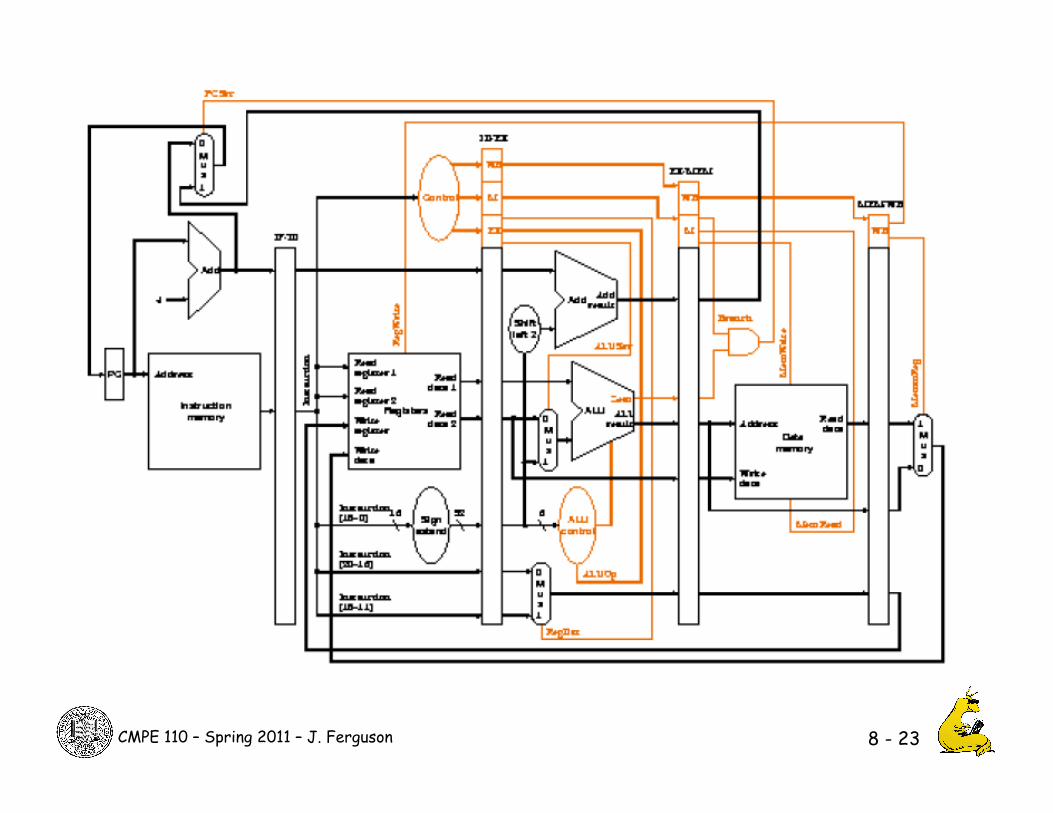
Pipelined Control • Generated as before, then pipelined too
8 - 22
CMPE 110 – Spring 2011 – J. Ferguson 8 - 23