performance comparison of dynamic policies for remote caching
TRANSCRIPT

CONCURRENCY: PRACTICE AND EXPERIENCE, VOL. 5(4). 239-256 (JUNE 1993)
Performance comparison of dynamic policies for remote caching CALMN PU,' DANILO FLORISSI' AND PATRICIA SOARES? Departmeni of Computer Science Columbia University P.O. Box 704 New York, NY 10027, USA
KUN-LUNG WU AND PHIUP S. W IBM T. J. W&on Rucorcli Center
Yorktonm Heighrs, NY 10598, USA
SUMMARY In a distributed system, data servers (file systems and databases) can easily become bottlenecks. We propose an approach to offloading data access requests from overloaded data servers to nodes that are Idle o r less busy. This approach Is referred to as remore ruching, and the idle or less busy nodes are callcd muacol servers as they help out the busy server nodes on data accesses. In addition to server and cllent local caches, frequently accessed data are cached in the main memory of mutual Servers, thus Improving the data access time in the systcm. We evaluate several data propagation strategies among data Servers and mutual servers. These Include policies in which senders are actlvelpassive and receivers are activdpassive in initiating data propagation. For example, an active sender takes the initiative to offload data onto a passive rcccivcr. Simulation results show that the active-sendcrlpassive- receiver policy Is the method of choice in most cases. Active-Sender policies are best able to exploit the main memory of other idle nodes in the expected normal condition where some nodes are overloaded and others are Icss loaded. A11 active policlcs perform far better than the policy without remote caching even In the dcgencrated case where each node Is equally loaded.
1. INTRODUCTION
In a large distributed system, many computers are linked together providing an abundance of hardware resources. One of the key issues in distributed system research has been the better exploitation of these resources. The fundamental assumption is that in a sufficiently large system running independent applications, the statistical nature of job submission will always overburden some nodes, while others stay idle. The idle nodes provide an opportunity to improve the overall system performance. One example of using the idle nodes is CPU load sharing and balancing, which improve response time by moving jobs from busy nodes to idle nodes, alleviating CPU bottlenecks.
In this paper we study an alternative to improving system performance by alleviating another important system bottleneck, namely data access. We call this research area remole caching. The idea of remote caching is to offload data access requests from
' A significant portion of this work was done while C a l m F'u was visiting IBM TJ. Watson Research Center. This research was partially supported by National Science Foundation and Oki Electric. Calton Pu is now with the Department of Computer Science and Engineering, Oregon Graduate Insti~~te, Beavermn, OR 97006. 'Partially supported by the Brazilian Research Council (CNPq).
1040-3108193/040239-18$14.00 01993 by John Wiley & Sons. Ltd.
Received 24 September 1992 Accepted 17 Februoty 1993

240 c PU ma.
overburdened data servers to idle nodes (called mutwl-seruers) that replicate and cache useful data to answer data access requests. Remote caching is analogous to load sharing in its use of idle nodes to alleviate performance bottlenecks. However, the two techniques differ in that load sharing divides the work through process migration while remote caching multiplies the resources through data replication and caching.
Today’s distributed computing environment consists of a low-latency, high-bandwidth network (e.g. Ethernet and FDDI) connecting powerful workstations (e.g. Sparcstations and IBM RS/aooOs) and their data servers (with dozens of MIPS CPU power, dozens of megabytes real memory, and gigabytes of disk storing files and databases). Data servers may become a bottleneck in two ways. First, disk accesses may be required for servicing most of the data requests because the server cache is not large enough. Hence, disk speed starts to dominate in the response time of a data access request. Remote caching may help since it caches frequently accessed data (called hor set) in remote memory (the main memory of other mutual servers), which at network latency of a few milliseconds[ll is much faster than a typical disk access. Second, the bottleneck in file servers in some cases may turn out to be the CPU[2]. So, replicating data and distributing data accesses can decrease queueing delays on the CPU.
The focus of this paper is on remote caching policies. Remote caching policies decide where to replicate data objects (simply called objects from now on), and these policies are analogous to load-sharing algorithms that decide where to distribute jobs. We present and evaluate four policies: passive-sender/passive-receiver, passive-sendedactive- receiver, active-sendedpassive-receiver, and active-sender/active-receiver. We compare these policies under different load conditions and show that remote caching obtains significant performance gains when compared to a pure clienvserver system that only uses client and server caches. In general, the active-sender/passive-receiver policy is the method of choice. Active-sender policies generally perform we11 under normal conditions where some nodes are overloaded and others are less loaded-the ideal environments for remote caching. However. when both senders and receivers are active (i.e. active- sendedactive-receiver), the improvement is only marginal in the normal condition. When the load condition degenerates in such a way that each node is equally and heavily loaded, then the passive-sendedactive-receiver policy may perform slightly better. Overall, all the active policies perform far better than the one without remote caching even in the degenerated case.
The paper is organized as follows. Section 2 summarizes related work. Section 3 describes the remote caching idea and architecture, including the data propagation policies. Section 4 analyzes the results of our performance study. Section 5 concludes the paper.
2. RELATED WORK
2.1. Load sharing
Although remote caching and load sharing use different resources to deal with completely different bottlenecks, there is a strong analogy between them. Load sharing and remote caching make the same assumptions about their physical distributed system environment: a large network of powerful computers, where none of the components is a permanent bottleneck. In other words, the system is reasonably balanced, with good network

DYNAMIC POLICIES FOR REMOTE CACHING 241
bandwidth and local execution on average. The existence of busy nodes give us the problem, and idle nodes an opportunity for solution. Another aspect of the analogy concerns the information exchanged between the clients and mutual-servers. In load sharing, there are reasons for the system information (node idleness) to be sent from either job originators or job receivers [3]. Similarly, we see reasons for system information (node idleness and data location) to be sent from either the original data servers or mutual- servers.
The main difference between load sharing and remote caching is their goal. In load sharing, we have idle CPUs helping to alleviate CPU bottlenecks. In remote caching, idle machines (mutual-servers) help alleviate disk bottlenecks, in addition to the CPU bottlenecks of overloaded servers. A second distinction between them is in the mechanisms that implement remote caching. For remote caching, the mechanism of &fa propagation combines data migration and replication.
2.2. File assignment problem
Another related research area is the file assignment problem (FAP)[4], also known as the file allocation problem. FAP studies the optimal location of files in a distributed system to improve performance. FAP divides data in the same way load sharing divides jobs in a distributed system. Their common goal is to optimize the division according to a certain criterion, such as minimizing the response time or maximizing the throughput. One major difficulty of FAP is the complexity of general optimization problems. Many FAP papers make simplifying assumptions to obtain more tractable but less realistic problems.
Remote caching differs from FAP in two main points. The first is architectural. We are concerned with the dynamic propagation of a large number of small objects (typically the size of a page or a network message) resident in volatile main memory while FAP studies the static allocation of a small number of large objects on disk. The second difference is in resource allocation. We want remote caching to adapt to current, actual UO load, while most of FAP work assumes some access patterns and optimizes on the average. Although some FAP algorithms[5] are adaptive and more recent work combines FAP, load balancing and partial replication[6], they have the usual restrictions of optimization algorithms (e.g. feasible for only a small number of files).
2.3. Other kinds of remote caching In addition to the remote caching presented in this paper, accessing data from remote memory instead of local disk can also improve the system response time for other applications. For example, data can be accessed from the cache of a remote workstation in a distributed file system (e.g. Reference 7) and a client/server database system (e.g. References 8-10). However, studies of caching in client/server systems generally focus on the coherency control among different copies of cached data. Moreover, although remote accesses are provided, a client workstation does not cache a local copy unless the data are needed by a process that runs on that workstation. In contrast, data can be propagated to any idle workstation in the remote caching of this paper.
Another application that exploits remote memory in a distributed system is the notion of distributed virtual memory[l1-13]. However, studies of distributed virtual memory apply the idea of remote caching to a more restricted domain of virtual memory pages.

242 c. PU ETAL.
Similar to the caching in client/ser databases, the emphasis of caching in shared virtual memory is also more on the coherency control of different cached copies; and caching on a remote workstation occurs only when a page is needed by a process running on that workstation. In addition, since data can be propagated from a busy server to any idle workstation in the remote caching schemes discussed in this paper, the structure of remote caching of this paper is clearly closer to that used in replication than in distributed virtual memory.
The performance potential of caching objects at remote memory has also been investigated in References 14-17. However, the problems addressed in these studies were focused on finding better replication strategies to minimize the access time for 8 given set of static parameters. In conmt, based on dynamically changing workloads, we study the different data propagation policies through which data servers and mutual servers communicate.
3. REMOTE CACHING
3.1. The basic architecture
The hardware base of remote caching systems is a network of workstations and servers. We assume that data requests come from a client workstation to a data server, For simplicity we do not consider replication at the disk level. In other words. each object (for example, files and relations) resides on one data server. So far our architecture is the same as the traditional clientherver model for distributed computing. Indeed, from the client point of view, they are the same. Remote caching changes the system structure only on the server side.
Our architecture may store data in the main memory of mutual-servers, in addition to the server buffer. Mutual-servers can be any node in the system, client or server, which happens to be idle or have a low load. However, in our simulation, we only consider the idle or lightly loaded data servers as mutual-servers. In general, data servers store their objects on disk (permanent data) and mutual-servers replicate and cache objects in their main memory (volatile data). When data servers get busy, lightly loaded mutual- servers step in and help cache data to alleviate the busy data servers. A mutual-server that contains both permanent and volatile data will give priority to requests in its permanent data, both in terms of servicing and buffer management.
3.2. The simulation model
We have developed a simulation program based on the SMPL package[l8] to model and analyze remote caching in a local area network (LAN). The simulation model has a fixed skeleton, which is a typical model of LAN connecting processing nodes, and four movable parts: the replica location algorithm and the replica consistency algorithm (Section 3.3), the replacement algorithm-valued redundancy-(Section 3.4) and the data propagation policy (Section 3.5).
The simulation models a network of data servers (CPUs and disks). Each resource (network, CPU and disk) has its own FIFO queue. Software costs such as cache access and maintenance are computed in terms of CPU service time and the number of network messages. In the simulation. there is only one broadcast network (modeling an Ethernet).

DYNAMIC POLICES FOR REMOTE CACHING 243
There are ten nodes each with its own CPU. a variable amount of main memory dedicated to object cache, and disk storage to contain 500 objects. Since objects are not replicated on disk, there is a total of SO00 distinct objects in the system, labeled by numbers from 1 to 5OOo.
During simulation, data requests (for single objects) are generated, an execution node is selected. and the request is sent to that node. The execution node fetches the object, processes it for some time (10 ms in this study), and terminates. A data ques t can be either read or write, and arrives at time intervals with an exponential distribution. The execution node is chosen uniformly or with skew (see Section 4 for more details). The object access pattern contains a small hot set, with the overall access generated as a discretized, normalized exponential distribution with mean 0.5. Objects labeled by small numbers are in the hot set and the number of accesses quickly decline as the object number increases.
To find an object, a cache access takes 1 ms, while objects are read from disk in 50 ms and written in 55 ms. Each request takes 10 ms to be processed at the execution node. An RPC (or broadcast) to locate objects consumes 3 ms of CPU time and each network transmission takes 0.5 ms. Additional simulations showed that the performance results are very robust with respect to these parameters. Changing them does not change the shape of the curves unless one of the resources (CPU, memory, and disk) becomes saturated. The simulation parameters are summarized in Table 1.
Table 1. Parameters of the simulation program
Number of server nodes 10 Number of networks 1 Cache capacity (objects) up to 2000 Disk storage per node 500 Processing time per request (ms) 10 Network transmission time (ms) 0.5 Cost of cache access (ms) 1 Cost of local disk read (ms) 50 Cost of local disk Write (ms) 55 RPC processing overhead (ms) 3 Mean request interarrival time (ms) 6 and 20
The experimental results from our simulation are derived using the parameters summarized in Table 1. Note that in this study, no single resource is saturated, even at the highest load case considered (request interarrival time of 6 ms). In particular, the network is not a bottleneck. The purpose of this study is to focus on the comparison of data propagation policies.
33. Data propagation mechanisms
The function of an object-locating method is to map the name of an object into its physical copies. To simplify this problem in our simulated LAN environment, we have adopted broadcast as the communications primitive. The request for any object is simply broadcast to the network, and all the server/mutual-servers listen to the network for relevant messages, both requests and replies.

244 c. PU ETAL.
The current object-location algorithm has three steps. First, it looks into the server local cache. If this fails, the node broadcasts a request to the network. At every remote site, the object request interrupts any local processing (to emulate an 0s support). All sites with a copy of the requested object in their caches queue for the network and reply; the requesting node discards all replies after the first. There may be some wasted competitive parallel processing on the same request, but the fastest server or mutual-server will reply with the object quickly. The answer to a request nullifies the request at the server and other slower mutual-servers, much the same way anti-messages annihilate! messages in Time-Warp systems[l9]. Timeout indicates that the object is not cached in any remote node; the object must then be fetched from the disk. A table look-up determines which site has the object and starts the appropriate disk operation assuming that objects are statically assigned to different data servers. In summary, when we need a copy of an object we traverse the memory hierarchy looking at local cache, remote cache and disks in turn.
The current simulation uses broadcast to propagate new versions of objects across the system. This is a read-oney'write-all strategy for maintaining replica contro1[20,21]. Each object is read in a single message or written as a block in a broadcast; thus time-stamping the update message suffices to maintain copy consistency. Almost all of the work using replication for performance adopts some variant of read-ondwrite-all strategy.
Since updates may introduce significant overhead in a system with replicated data, unrestrained replication is undesirable. Our solution is to use valued redundancy[22,23] (to be explained next) to avoid replicating objects that are updated often. This directly alleviates the update overhead problem. In the simulation we run experiments with varied percentages of reads and writes. The updates decrease the amount of performance improvement somewhat, but consistently maintain the trend.
3.4. Data propagation policies
We have developed the idea of valued redundancy[22231 for management of redundant data in distributed systems. An object's value increases with its usefulness in the system and decreases with its maintenance cost. By replicating only the most valuable objects (the cheapest objects that improve system performance and availability the most) we maximize the cost/performance ratio of redundant data.
There are several reasons valued redundancy is important for remote caching. First, we need to manage the real memory in mutual-servers for extended periods of time. Virtual memory page replacement and cache replacement policies emphasize low overhead in collecting information, so the amount of information they maintain is relatively small (a few bits per object). For relatively long-term management of objects, we need better information. As we will see in this Section, object values are more flexible and general than existing replacement schemes.
Second, data propagation differs from process migration primarily because of the number and granularity of objects we have to manage. Data objects are much smaller and more numerous than process states (by several orders of magnitude). Since we are passing data between the original data server and mutual-servers, we need some way to communicate the management information. In remote caching, objects carry their values for this purpose.

DYNAMIC FQLICIES FOR REMOTE CACHING 245
In our simulation. each object has two associated values. One is the global value, which is locally maintained and measures the worth of the object to the overall system. The other is the local value that measures the importance of the object for the specific node where the object is located in main memory. Different replicas of an object have different global and local values depending on where they reside.
The local value Lv is calculated simply by increasing it each time the object is accessed locally. The global value Gv is increased each time remote nodes request access to it; Gv is set to zero when it is updated. The combined object value is given by their linear combination:
V = Wla x Lv+ Wra x Gv (1)
where Wla is the weight of local accesses, and Wra is the weight of remote accesses. In the simulation, Wla is calculated as the percentage of local access and Wra the percentage of remote access. At local replacement, the object value V is used to decide which one is to be swapped out. When a node volunteers to cache an object for remote caching, both V and Gv are used to ensure that it is globally active.
3.5. Remote caching algorithms
Given objects carrying reasonably accurate values, we are ready to design data propagation policies. Currently, we are investigating methods analogous to some load-sharing work. We call them active-sender and active-receiver algorithms, which respectively correspond to the sender-initiated and receiver-initiated load sharing algorithms[3]. Both the active-sender and the active-receiver algorithms are handshake algorithms that guarantee data transfer at some communications cost.
33.1. Passive-senderipassive-receiver (PSIPR)
The first example is passive-sender/passive-receiver. This strategy uses a minimal amount of communication. The sender does not actively hand over any object. When it needs to throw away something at replacement, it simply broadcasts it to the network. If some mutual-server happens to be listening, the object might be picked up, otherwise it is dropped. Similarly, the receiver makes no efforts to fill its buffer. A mutual-server merely listens to the network. If some valuable object comes along, it is picked up. Otherwise the mutual-server stays idle. The advantage here is the small communication overhead and the avoidance of making wrong decisions based on stale state information. The disadvantage is that some object may be dropped, while others are replicated too many times.
Concretely, the passive-sender uses the replacement policy to find the least valuable object, which is broadcast to the network, along with its Gv. The other nodes (passive- receivers) might be listening to the network or not. The nodes listening, if any, will compare the Gv of the incoming object with the minimum value of objects in their caches. The decision to keep an object or not is entirely local. When a node is executing some requests. it stops listening to the network. When it becomes idle, it switches to being a mutual server.

246 c. PU ET AL.
33.2. Active-senderfpassive-receiver (ASIPR)
In the active-sender algorithm, a data server or mutual-server trying to get rid of some valuable object takes the initiative to hand over the object to another mutual-server. The idea of active-sender is that the sender knows more about objects being moved, so it should take the lead in the data propagation protocol.
The abstract active-sender algorithm is analogous to the sender-initiated load-sharing algorithm. When an active-sender node observes that it is a bottleneck (its CPU utilization approaches a threshold), it sends a broadcast message asking for idle or less loaded nodes to store its most globally valuable objects. From the fast-responding mutual- servers, the sender chooses one and hands over the object. The protocol ends with an acknowledgement from the receiver and only then it deletes the element from its cache. In this way, copies of the object do not proliferate or get lost. If the active-sender has to replace some low valuable element due to a miss, it behaves as a passive-sender.
3 5.3. Passive-senderlactive-receiver (PSIAR)
In the active-receiver algorithm, an idle mutual-server takes the initiative to obtain globally valuable objects from data servers and overflowing mutual-servers. As in load sharing, the justification for this smtegy is that busy nodes (senders) should be spared from additional load, so the idle nodes should pick up as much work as they can.
When an active-receiver node is idle, it sends a broadcast message asking to store in its main memory globally valuable objects from other nodes. As busy data servers and mutual-servers discover the existence of willing receivers, they answer by sending the willing receivers their most globally valuable object along with its Gv value. The idle nodes then decide which objects to store and finish the communication by sending an acknowledgement to the respective nodes. When a node receives this acknowledgement, it deletes the copied object from its cache, reclaiming the memory if needed.
One advantage of handshake protocols such as active-sender and active-receiver is the exactly-once object transfer semantics. The system knows that an object has moved from one location to another. This tends to reduce the number of copies in the system for each object.
35.4. Active-senderlactive-receiver (ASIAR)
Finally, we also tested the active-sendedactive-receiver algorithm. This strategy combines the active roles of sender and receiver, possibly combining the benefits of both. In this policy, all nodes are both active-sender and active-receiver. When they are idle, they volunteer to store other nodes’ most globally valuable objects. When they become a bottleneck, they ask other nodes to store their most valuable objects.
4. PERFORMANCE ANALYSIS
4.1. The main scenarios
There are two main parameters in our performance comparison: load distribution and object access pattern. Load distribution decides how requests are distributed among the

DYNAMIC POLICIES FOR REMOTE CACHING 247
nodes for execution. There are two ways each request selects a node in which it executes. First, the node selection uses a skewed probabilistic distribution, ensuring that some nodes are busy and others are idle. We expect this to be the normal case, and use a discretized. normalized exponential distribution with mean 5. In this case the gains in remote caching are more obvious and stable. Second. the node selection uses a uniform distribution, i.e. all the nodes are equally likely to be chosen. This represents the degenerated case. This scenario tends to even out the load on the nodes, reducing the advantages of remote caching.
The second parameter is the object access pattern. There are two ways each request chooses an object to access. First, each node has the same access distribution pattern (we use a discretized, normalized exponential distribution to model a combination of a small hot set and a cold majority). The choice of the same hot set for each node tends to enhance the effectiveness of remote caching, since objects cached in the mutual servers are more likely to be of interest to other nodes. Second, each node has a different set of hot objects for the requests executed at that node. In the simulation, node one has the peak starting at object 1, and node 2’s peak starts at object 501, etc. The choice of distinct hot sets will reduce the effectiveness of remote caching, since each node is in principle busy with its own hot set and objects cached in mutual servers are less likely to be of interest to other nodes.
We consider two levels of load conditions in the system. The system is considered to be lightly loaded when the request interarrival time is 20 ms, with typical utilization of less than 20% for CPU, disk and network. On the other hand. an interarrival time of 6 ms represents a heavy load, with typical utilization of 60% to 80% for those resources.
In our study, there are four combinations of load distribution and object access pattern: (1) skewed load and same hot set (skewWsame), (2) skewed load and distinct hot set (skewed/distinct), (3) equal load and same hot set (equaVsame), and (4) equal load and distinct hot set (equalldistinct). Of the four combinations, skewdsame favors remote caching the most while equal/distinct favors it the least. For each combination we compare the four data propagation policies: (a) passive-sender and passive-receiver (PSPR), (b) active-sender and passive-receiver (ASPR), (c) passive-sender and active- receiver (PS/AR), and (d) active-sender and active-receiver (AS/AR).
In the study, ‘idle’ and ‘busy’ are defined by constant thresholds. When the workloads among the nodes are skewed, the thresholds are 20% and 40% CPU utilization, respectively; namely, a node is considered to be idle when the CPU utilization is below 20% and busy when above 40%. However, when the nodes are equally loaded, the thresholds for idle and busy are 10% and 30% CPU utilization, respectively. The timeout is defined as 2.5 x 2x (network transmission time + cache access time).
4.2. Skewed load, same hot set (skewedlsame)
The first experiment uses an exponentially decreasing distribution for node selection. Some nodes will be overloaded with requests arriving at them and others will be almost idle. In addition, each node accessed the same hot set. The availability of idle nodes and the choice of same hot set both enhance the effectiveness of remote caching.
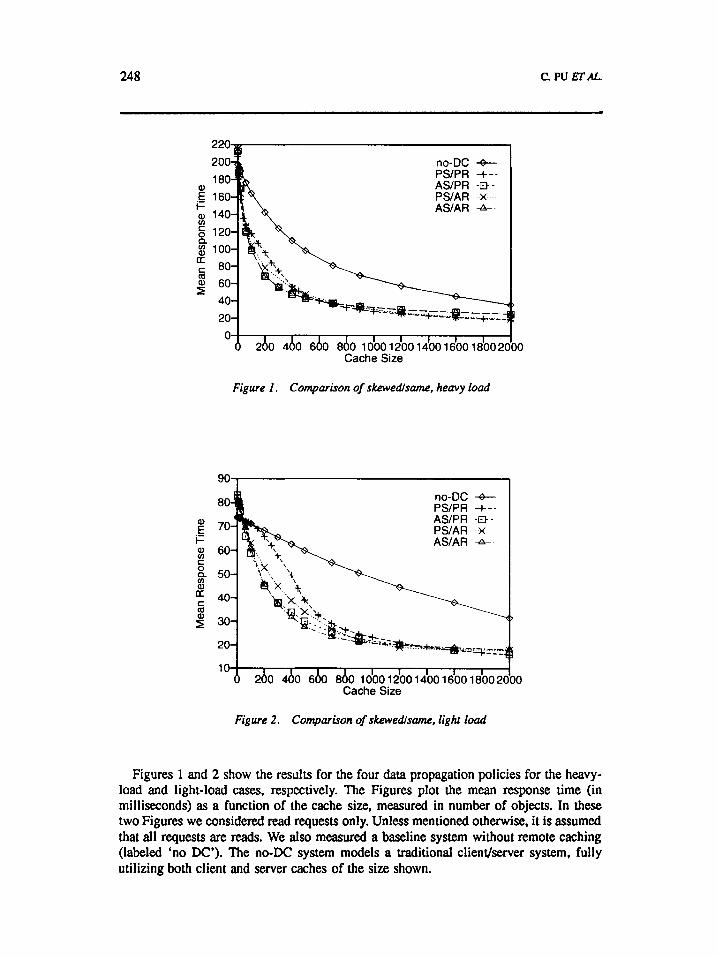
248 c. PU ETAL..
--- m 200 180
E" 160 i--
no-DC +- PSIPR +-- ASPR -D- PSIAR X ASIAR 4-
[r
m c 80- 60- 40- 20- 0 ' 6 260 460 660 860 1dOO 1dOO 1200 Id00 1dOO 21
Cache Size
Figure 1 . Comparison of skewedlsame. heavy load
no-DC + PSIPR +-- ASIPR -0- PSIAR ..X.--- ASIAR A-.
*~.*-+.R+.~q- --- ._ lo ' 6 260 460 660 860 Id00 1dOO 1400 Id00 1dOO2
Cache Size
>
1
Do
Figure 2 . Comparison of skewedlsame, light load
Figures 1 and 2 show the results for the four data propagation policies for the heavy- load and light-load cases, respectively. The Figures plot the mean response time (in milliseconds) as a function of the cache size, measured in number of objects. In these two Figures we considered read requests only. Unless mentioned otherwise, it is assumed that all requests are reads. We also measured a baseline system without remote caching (labeled 'no DC'). The no-DC system models a traditional client/server system, fully utilizing both client and server caches of the size shown.

DYNAMIC POLICIES FOR REMOTE CACHING 249
In these two Figures all four policies demonstrate the superior performance advantages over the no-DC case for almost the entire set of cache sizes up to 2000 objects? Active- sender policies, including ASPR and AS/AR, have better performance than passive- sender ones, including PSPR and PS/AR. However, when both senders and receivers are active (AS/AR), performance improvement over ASPR is only marginal in the light-load case.
All four policies perform almost comparably for all cache sizes under the heavy-load condition (see Figure 1). However, in Figure 2, for small cache sizes, the passive-sender policies do not show significant performance improvements over the no-DC case as the active-sender policies under the light-load condition. Particularly, the PS/PR policy shows the least improvements for small cache sizes. This is because in PSPR when a passive sender broadcasts its least valuable object at replacement, many passive receivers may simultaneously store a copy of it, wasting memory space that can store other locally valuable objects. In other words, the local caches of passive receivers are contaminated by the globally valuable objects thrown away by the passive senders. Since the workload is skewed, if the system is heavily loaded. only the caches of the supposedly ‘idle’ nodes can be contaminated. These nodes will stay idle most of the time, so no significant performance degradation can be seen. However, if the system is lightly loaded, even the more loaded nodes may become ‘idle’ temporarily and have their local caches contaminated. When these nodes become busy again, their performance suffers because of the cache contamination. Cache contamination results in local cache misses, especially when the cache size is small. However, if the cache size is large enough to contain both the majority of locally accessed objects and other globally valuable objects, providing remote caching for other nodes has little effect on the local cache hits, as shown in Figure 2 for cache sizes greater than 800 objects. As a result, all four remote caching algorithms perform almost equally well for cache sizes greater than 800 objects.
Figures 3 and 4 show the results when the requests are 50% reads and SO% writes, which represent a case with high update rates (other researchers typically use a lower update r a t e f o r example 25%[24]). Both Figures also demonstrate the advantages of the three active policies compared to no remote caching. The PSPR policy is less efficient than the active policies for a wide range of cache sizes because of multiple redundant copies for each object being maintained in the mutual servers. The gap between the three active policies becomes closer compared to Figures 1 and 2. This is because remote caching is effective only when a request is a read; when a request is a write, the presence of extra copies in mutual servers incurs overhead for update propagation. The clustering of the three active policies with a high update ratio is also observed in the other experiments studied. To better distinguish the three active policies, from now on we only show the 100% read figures.
To illustrate the effectiveness of the active-sender policy, we show the hit ratio of local memory, remote memory and disk in Figures 5 and 6 for the PSPR and ASPR cases. For a cache size of 400 objects and high request rates, the AS/PR policy reduces the number of disk accesses by almost 50% when compared to the PSPR policy. The local
In Figures 1 and 2. no-DC is better than remote caching for very small cache sizes (less than 40 objects). Obviously, wen local =quests cannot be effectively supported with a very small cache, not to mention supporting remote requests in mote caching. Therefore, we ignore in our study the cases where the cache sizes are very small.
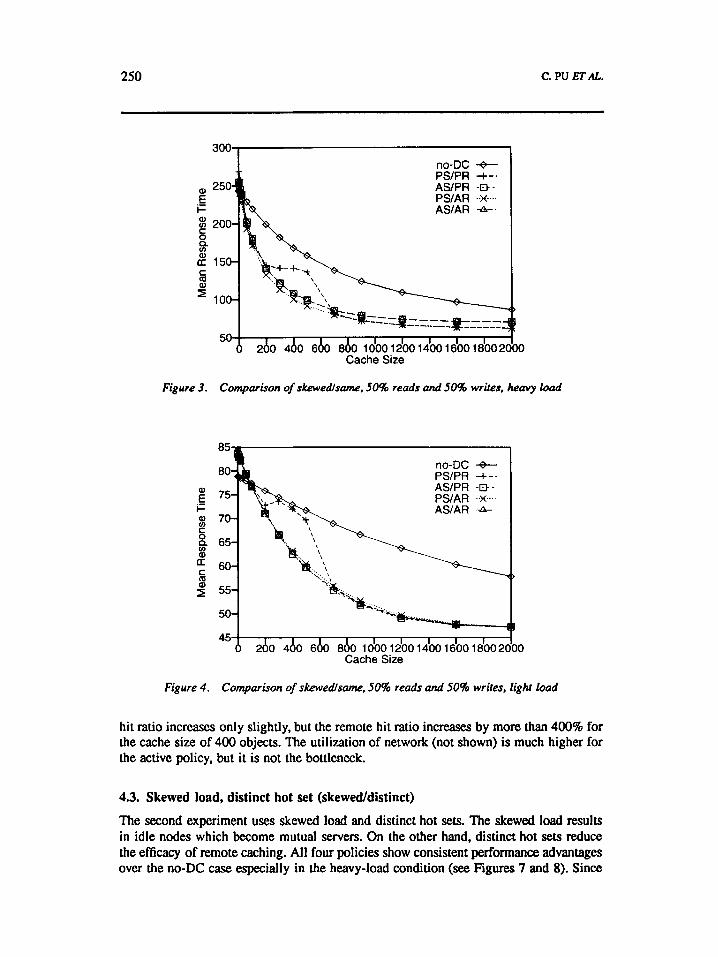
250 c. PU ma.
no-DC -3- PSIPR -t--
a, 250 ASIPR -0- PSIAR ..X-... ASIAR a-.
E F
50 6 260 460 6bO 860 100012001400160018002 I I I I I
Cache Size
>
P DO
Figure 3. Comparison of skewedlsame. 50% reads and 50% writes, heavy load
45 ' b 260 460 660 8bO 1000 1200 1400 1600 180021 I I I I I
Cache Size
I
30
Figure 4 . Comparison of skewedlsame, 50% reads and 50% writes, light load
hit ratio increases only slightly, but the remote hit ratio increases by more than 400% for the cache size of 400 objects. The utilization of network (not shown) is much higher for the active policy, but it is not the bottleneck.
43. Skewed load, distinct hot set (skeweddistinct)
The second experiment uses skewed load and distinct hot sets. The skewed load results in idle nodes which become mutual servers. On the other hand, distinct hot sets reduce the efficacy of remote caching. All four policies show consistent performance advantages over the no-DC case especially in the heavy-load condition (see Figures 7 and 8). Since
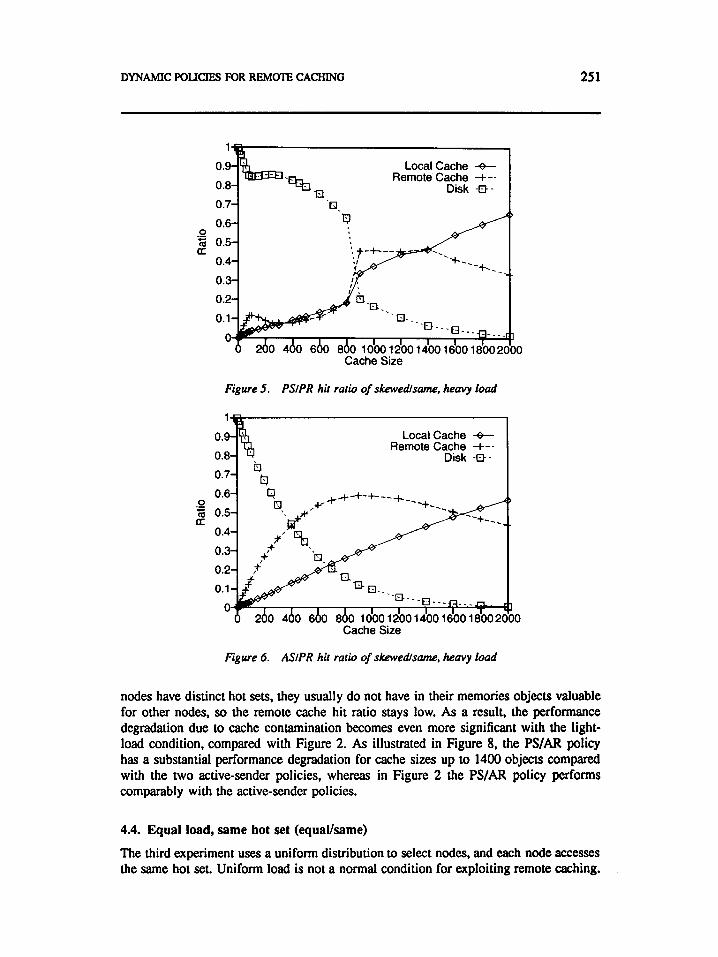
DYNAMIC POLICIES FOR REMOTE CACHING 25 1
0 Cache Size
Figure 5 . PSIPR hit ratio of skewedlsame, heavy load
Cache Size
Figure 6. ASIPR hit ratio of skewedlsame, heavy load
nodes have distinct hot sets, they usually do not have in their memories objects valuable for other nodes, so the remote cache hit ratio stays low. As a result, the performance degradation due to cache contamination becomes even more significant with the light- load condition. compared with Figure 2. As illustrated in Figure 8, the PS/AR policy has a substantial performance degradation for cache sizes up to 1400 objects compared with the two active-sender policies, whereas in Figure 2 the PS/AR policy performs comparably with the active-sender policies.
4.4. Equal load, same hot set (equalhame)
The third experiment uses a uniform distribution to select nodes, and each node accesses the same hot set. Uniform load is not a normal condition for exploiting remote caching.
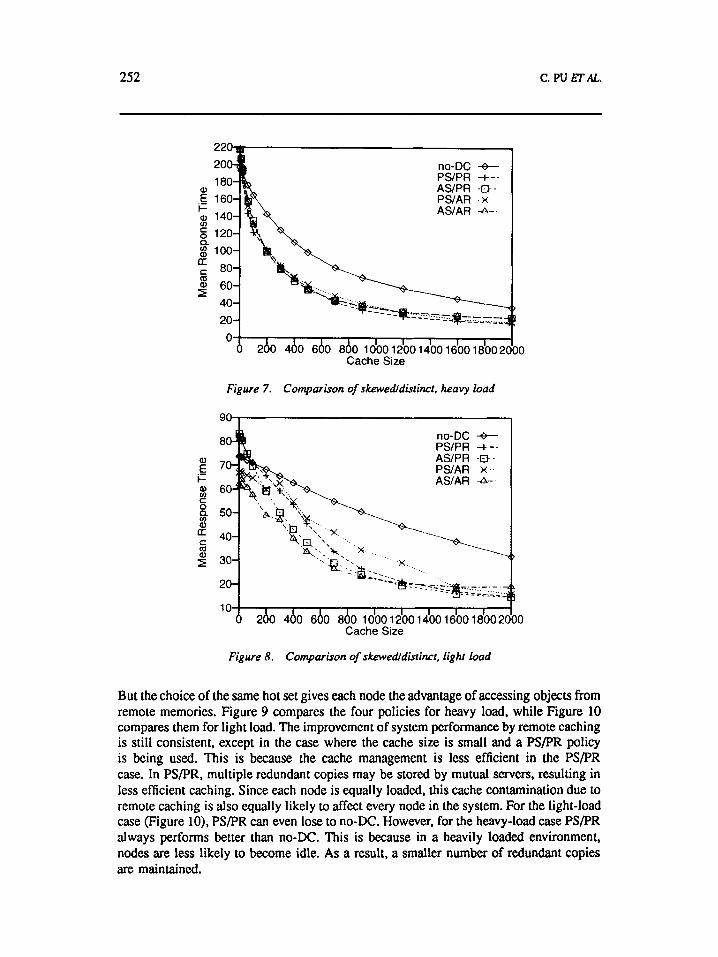
252 c. PU ETAL..
200 no-DC + 180 PS/PR +--
AS/PR -a- i= AS/AR 4- ? 160 PS/AR x 2 140 g 120 8 100 Q
I
U
0 ' 6 260 460 660 860 1 do0 12bO 1400 1dOO 1dOO 2( I
Cache Size
> e DO
Figure 7 . Comparison of skewedldistinct. heavy load
90 , I no-DC + PSlPR +-- AS/PR -0-
AS/AR -A-- PS/AR -X-- - -
10 ' b 2b0 460 600 8bO 10'00 1 do0 id00 1dOO Id00 2dOO Cache Size
Figure 8. Comparison of skewedldistinct, light load
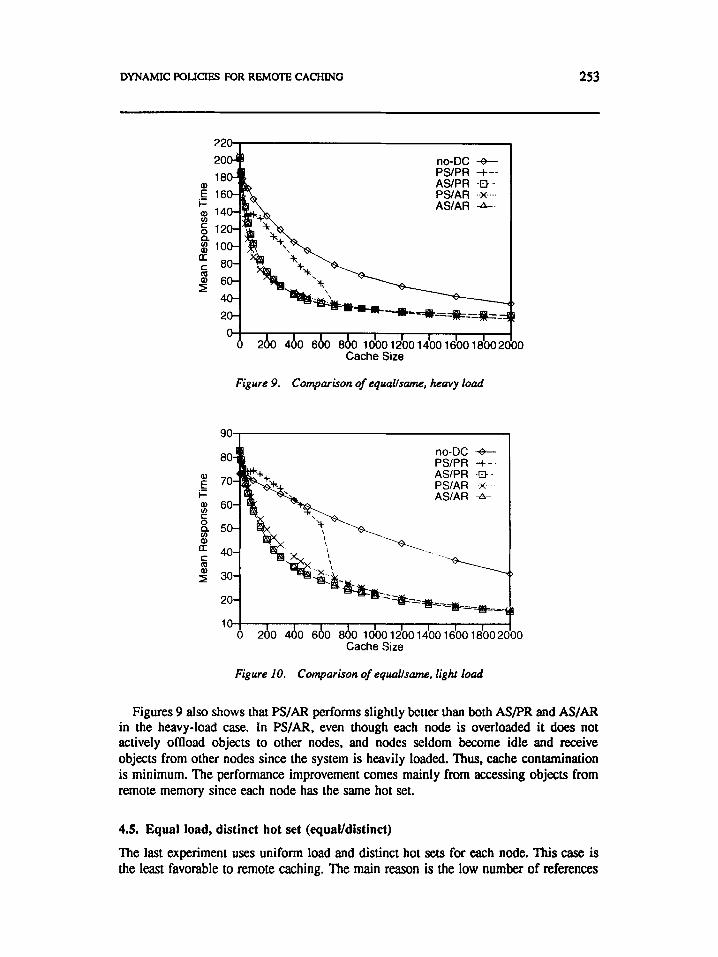
But the choice of the same hot set gives each node the advantage of accessing objects from remote memories. Figure 9 compares the four policies for heavy load, while Figure 10 compares them for light load. The improvement of system performance by remote caching is still consistent, except in the case where the cache size is small and a PSPR policy is being used. This is because the cache management is less efficient in the PSPR case. In PSPR, multiple redundant copies may be stored by mutual servers, resulting in less efficient caching. Since each node is equally loaded, this cache contamination due to remote caching is also equally likely to affect every node in the system. For the light-load case (Figure 10). PSPR can even lose to no-DC. However, for the heavy-load case PSPR always performs better than no-DC. This is because in a heavily loaded environment, nodes are less likely to become idle. As a result, a smaller number of redundant copies are maintained.
DYNAMIC POLICIES FOR REMOTE CACHING 253
220
200 no-DC 4-
160 F
0 ' 6 260 460 660 860 1000 1dOO Id00 1400 1dOO 21 1
Cache Size
Figure 9. Comparison of equdlsame, Iieavy load
no-DC +-- ASIPR D PS/AR X
80 PS/PR +-- 70
$ 60
8 50
40
30
20
I= ASIAR A-
C
Q,
c a
!
30
10 ' b 260 460 660 860 1000 1 do0 1 do0 1dOO 1 do0 2060 I
Cache Size
Figure 10. Comparison of equdlsame. light load
Figures 9 also shows that PS/AR performs slightly better than both ASPR and ASlAFt in the heavy-load case. In PS/AR, even though each node is overloaded it does not actively oMoad objects to other nodes, and nodes seldom become idle and receive objects from other nodes since the system is heavily loaded. Thus, cache contamination is minimum. The performance improvement comes mainly from accessing objects from remote memory since each node has the same hot set.
4.5. Equal load, distinct hot set (equavdistinct)
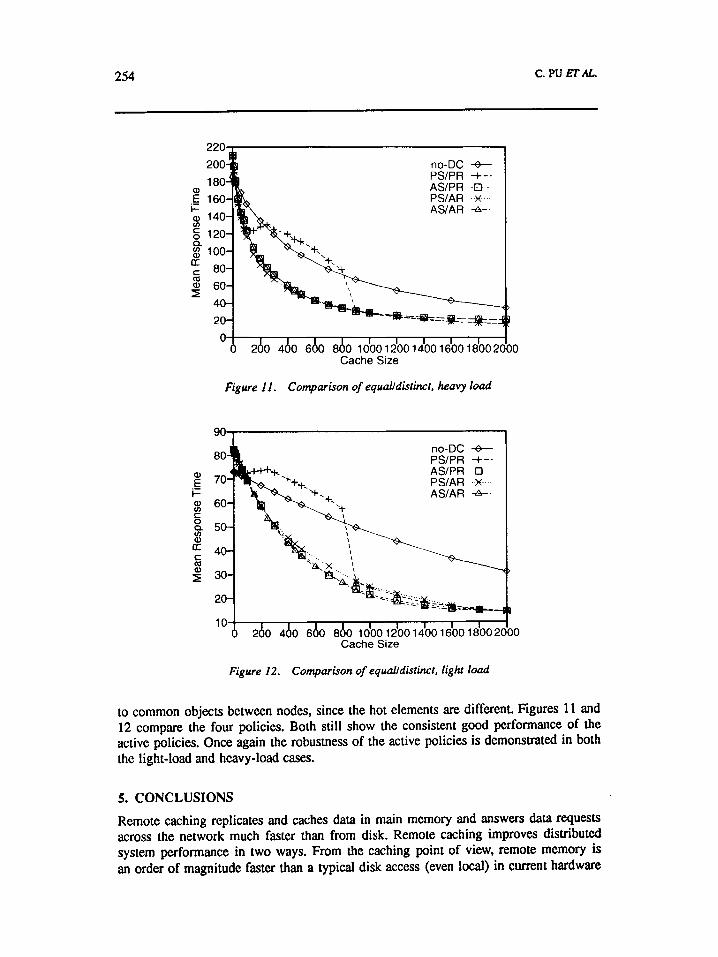
The last experiment uses uniform load and distinct hot sets for each node. This case is the least favorable to remote caching. The main reason is the low number of references
254 c. PU mu.
220 200 180
E 160 i= 8 140 g 120 $ 100 Q
a: C 8o m
60 40 20
5
0 ' 6 260 460 660 860 ld00 1 do0 1dOO 1dOO 1 do0 21 Cache Size
Figure 11. Comparison of equalidistinct, heavy load
"V
no-DC + 80 PStPR +--
ASIPR -0- E 70 PSIAR ..X.... i= ASIAR -A-- 8 60
50
40
8 30
20
C 0
C m
10 ' 6 260 460 660 860 1dOO 1dOO ld00 1dOO 18002 I
Cache Size
!
30
>
I
00
Figure 12. Comparison of equalidistinct, light load
to common objects between nodes, since the hot elements are different. Figures 11 and 12 compare the four policies. Both still show the consistent good performance of the active policies. Once again the robustness of the active policies is demonstrated in both the light-load and heavy-load cases.
5. CONCLUSIONS
Remote caching replicates and caches data in main memory and answers data requests across the network much faster than from disk. Remote caching improves distributed system performance in two ways. From the caching point of view. remote memory is an order of magnitude faster than a typical disk access (even local) in current hardware

DYNAMIC POLICIES FOR REMOTE CACHING 255
configurations. From the parallelism point of view, replicating data carefully alleviates the server bottleneck. Both factors contribute to better response time in answering data requests across the network.
We studied four data propagation policies under different load conditions and data access patterns. Remote caching performs the best with skewed load where there are some overloaded and some less loaded nodes, and when each node accesses the Same hot set. The four policies are the combinations of passive and active senders with passive and active receivers. For example, an active sender takes the initiative to ofHoad data on to a passive receiver. For a wide range of parameters under skewed load, all four policies show superior performance compared with the one without remote caching, which models a pure client/server system. In general, the activesender/passive-receiver is the method of choice under most conditions. The active-sender policies (including AS/AR and AS/PR) perform the best under skewed load, whether each node has the same hot set or not. The three active policies significantly outperform the one without remote caching even in the degenerated case where each node is equally loaded. In all the cases, active-sender/active- receiver shows only marginal improvement over active-sendedpassive-receiver.
REFERENCES
1. M. Schroeder and M. Burrows. 'Performance of Firefly RPC'. ACM Trans. Comput. Syst.,
2. 3. H. Howard et al., 'Scale and performance in a distributed file system', ACM Tram. Comput. Syst., 6(1). 51-81 (1988).
3. D. L. Eager, E. D. Lazowska and J. Zahorjan. 'A comparison of receiver-initiated and sender- initiated adaptive load sharing', Performance Evaluation. 6. 53-68 (1986).
4. L. W. Dowdy and D. V. Foster, 'Comparative models of the file assignment problem', ACM Computing Surveys, 14(2), 287-314 (1982).
5. C. T. Yu, M.-K. Siu, K. Lam and C. H. Chen, 'Adaptive file allocation in star computer network', IEEE Trans. on Sofr. Eng., SE-11(9), 959-965 (1985).
6. R. Mukkamala. S. C. Bruell and R. K. Shultz. 'Design of partially replicated distributed database systems: An integrated methodology', in Proc. of 1988 ACM SIGMETRICS, May
8(1), 1-17 (1990).
1988. pp. i87-196. 7. M. N. Nelson, B. B. Welch and J. K. Ousterhouf 'Caching in the sprite network file system',
ACM Tram. Computer System. 6(1). 134-154 (1988). 8. M. J. Carey, M. M.Franklin. M. Livny, and E. 1. Shekita. 'Data caching tradeoffs in cliendserver
DBMS architecture', in Proc. of 1991 ACM SIGMOD. 1991. pp. 357-366. 9. M. J. Franklin, M. J. Carey and M. Livny, 'Global memory management in client-server DBMS
architecture', in Proc. of 18th VLDB. 1992, pp. 596-609. 10. A. Dan and P. S. Yu, 'Performance analysis of coherency control policies through lock
retention', in Proc. of I992 ACM SIGMOD, 1992, pp. 114-123. 1 1 . D. Comer and J. Griffoen, 'A new design for distributed systems: The remote memory model',
in Proc. of the Summer I990 Usenix Symposium, 1990. 12. E. W. Felten and J. Zahorjan. 'Issues in the implementation of a remote memory paging
system', Technical Report TR 91-03-09, Dcpartment of Computer Science & Engineering, University of Washington, March 1991.
13. K. Li and P. Hudak, 'Memory coherence in shared virtual memory systems', ACM Truns.
14. A. Leff, P. S. Yu and J. L Wolf, 'Policies for efficient memory utilization in a remote caching architecture', in Proc. of the 1st lnt. Conference on Parallel and Distributed Information Systems, 1991. pp. 198-207.
Comput. S y ~ t . , 7(4), 321-359 (1989).

256 c. PU ETAL..
15. A. Lff. J. L. Wolf and P. S. Yu. ‘Distributed object replication algorithms for a remote caching architecture’. in Proc. of Int. Cot$ on Parallel Processing. 1992. pp. II-114-II-123.
16. A. Leff. J. L. Wolf and P. S. Yu, ‘LRU-based replication algorithms in a LAN remote caching architecture’, in Proc. of 17th Coqf on Local Computer Networks, Sept. 1992 pp. 244-253.
17. A. Leff. J. L. Wolf and P. S. Yu, ‘Replication algorithms in a remote caching architecture’. IEEE Trans. Parallel and Distributed Systemr, to be published.
18. M. H. MacDougall, Simulating Computer Systems, Computer Systems. MIT Ress. 1987. 19. D. R. Jefferson, ‘Virtual time’, ACM Tram. Prog. Lung. Syst., 7(3), 40442.5 (1985). 20. P. A. Bemstein and N. Goodman. ‘An algorithm for concurrency control and recovery in
replicated distributed databases’, ACM Trans. Database Systems, 9(4), 596-615 (1984). 21. C. Pu, J. D. Noe and A. Proudfoot. ‘Regeneration of replicated objects: A technique and its
Eden implementation’, IEEE Trans. on Sop. Eng., SE-14(7). 936-945 (1988). 22. A. Leff. C. Pu and F. Kon. ‘Cache performance in server-based and symmetric database
architectures’, in Proc. of the ISMM Int. Cot$ on Parallel and Distributed Computing, and Systems, 1990.
23. C. Pu, A. Leff, E Kon and S. W. Chen. ‘Valued redundancy’, in Proc. of the Workshop on Management of Replicated Data, 1990.
24. E. D. Lazowska. J. Zahorjan, D. Cheriton and W. Zwaenepoel. ‘File access performance of diskless workstations’, ACM Trans. Comput. Sysr.. 4(3). 238-268 (1986).