optimisation of a simulated-annealing-based heuristic for single row machine layout problem by...
TRANSCRIPT

Pergamon
Int. Trana. Opl Res. Vol. 3, No. 1, pp. 37--49, 1996 Copyright © 1996 IFORS. Published by Elsevier Science Ltd.
Printed in Great Britain. All rights reserved S0969--6016(96)00006--8 0969-6016/96 .$15.00 + 0.00
Optimisation of a Simulated-Annealing-based Heuristic for Single Row Machine Layout Problem
by Genetic Algorithm MARCELLO BRAGLIA
Universita' di Brescia, Italy
We discuss a procedure to determine the optimal set of parameters relevant to heuristics based on the Simulated Annealing technique, an algorithm which is widely applied to combinatorial problems in the field of manufacturing systems. We consider the search for the best set as a second optimisation problem that we solve by a Genetic Algorithm. The performance of our approach is tested in the particular case of backtracking minimisation in a single row machine layout problem for flexible manufacturing systems. Copyright © 1996 IFORS. Published by Elsevier Science Ltd.
Key words: Genetic Algorithm, machine layout, Simulated Annealing
I. INTRODUCTION
Manufacturing Systems are the 'kingdom' of combinatorial problems (de Werra, 1987): scheduling, assembly line balancing, machine cells and part families formation, optimal layout, etc. Such problems are not trivial. On the contrary, when the complexity grows, the computation time required to find the optimal solution often becomes too long and not acceptable in practical cases. For this reason, one uses heuristics that are capable of producing good, but generally not optimal, solutions in reasonable response times.
In the last several years, a particular heuristic has emerged, the Simulated Annealing (SA) (Kirkpatrick et al., 1983), which is inspired by principles of physical science. It can be classified as a randomised (stochastic) heuristic and it is characterised by some main properties: (i) it accepts (even if with certain restrictions) transitions leading to an increase of the cost function value; (ii) it is independent of the problem; (iii) it is effective and robust (that is, independent of initial-solution and cost-function); (iv) it permits obtaining good performance, and, finally, (v) it is easy to use and to understand. Generally SA out-performs other 'classical' heuristics such as neighbourhood search procedures, greedy (construction) algorithms, etc.
The use of this particular heuristic, however, does have a major problem. In fact, the SA technique is characterised by a set of parameters whose values must be selected by the user. Unfortunately, as well know, even if in theory the parameters are not dependent on the problem, in practice the performance is strongly dependent on the particular choice by the user. In other words, the set of control parameters must be property determined in order to obtain high quality solutions in an efficient way. This question becomes critical in Manufacturing System problems as, for practical necessity, the computation times which are permitted are particularly short. For this reason, when dealing with SA heuristics, special attention is generally given just to this question. It is worth noting that similar considerations can be extended to other (parametric) techniques such as Tabu Search (TS) and Genetic Algorithms (GAs) often used to treat Manufacturing System problems.
Generally, the choice of reasonable parameters is empirically determined after an extensive experimentation with different values (e.g., Ogbu and Smith, 1990) or through a sensitivity analysis (e.g., Kouvelis and Chiang, 1992). A more efficient approach to find the optimal set of parameters, is to perform an experimental design (2 k or 2 k-p factorial design) with an associated statistical analysis, e.g. an analysis of variance (ANOVA). Good examples may be found in Brusco and Jacobs (1993), Gupta et al. (1993) (a GA application) and Logendran et al. (1993) (a TS application). However, the approach meets with a number of questions:
Correspondence: Marcello Braglia, Dipartimento di lngegneria Meccanica, Universita' di Brescia, Via Branze 38, 25123 Brescia, Italy

38 M. Braglia--Optimisation of a Simulated-Annealing-based Heuristic
(i) the performances of any technique must be evaluated both in terms ofcost-function and in terms of response time, which may require duplicating the above analysis with final indications which will not necessarily converge;
(ii) two kinds of information must be considered, numerical values (e.g., the initial temperature of the SA) and decisional variables which select a particular variant of the heuristic (e.g., the choice of a given permutation scheme of the SA algorithm). These decisional variables can create problems during the statistical analysis;
(iii) the optimal choice of the parameters depends on the particular problem and its dimension, with the risk that one is forced to repeat various analyses for different levels of complexity;
(iv) the analysis is complex and requires a non-negligible familiarity with statistics; (v) the technique of successive improvements which is eventually adopted (e.g., the Evolutionary
Operation (EVOP) technique can be a good candidate) is fundamentally based on the gradient concept and, as a consequence, encounters the problem of local minima;
(vi) as the heuristic answer is statistical in nature, the gradient technique suffers from the same problem as simulation analyses, namely the gradient can only be estimated (Law and Kelton, 1990).
The difficulty of applying this technique appears evident from various papers of different authors. In fact, the conclusions often concern the effects of a given parameter (for instance, the slow cooling schedule for good performances of a given SA, or the correlation between population size and dimension of the problem in a GA) instead of the development of a real optimisation program.
Recently, Freisleben et al. (1993) adopted an interesting approach to determine the optimal GA for a given problem (i.e., type of genetic operators and parameter settings). The approach is based on the use of a second GA with gene strings which encode the relevant information on the original GA. The technique is simple and able to overcome the problem of local minima. It permits treating an objective function which takes into account both the cost function of the original GA and the response time. Moreover, it is able to overcome possible estimation errors. It does not require any familiarity with advanced statistical methods and the search may be repeated easily for any dimension of the problem.
We have applied a similar approach to the backtracking minimisation in a single row machine layout problem, that we have treated with a particular SA proposed by Kouvelis and Chiang (1992) and Kouvelis et al. (1992). The single row machine layout problem concerns the optimal placement of a set of facilities along a linear material handling track so that the total backtracking distance (i.e. the upstream flow) for a given set of jobs is minimised. In this paper it is shown how an appropriate GA is able to determine a good series of values for all the parameters. In particular, in the following section we dwell briefly on the basic theory of the SA approach and the variant adopted here. In Section 3 we present our particular version of GA. Section 4 contains the results obtained for a single row machine layout problem with backtracking minimisation. The last section presents the conclusions.
2. THE SIMULATED ANNEALING
The SA technique is a heuristic stochastic optimisation procedure based on the iterative improvement of the solution. It derives from a natural analogy with a stochastic relaxation technique developed by Metropolis et al. (1953) in the statistical mechanics of condensed matter physics. Several applications of this technique have been published in recent years and a number of classical combinatorial problems relevant to manufacturing systems have been considered. The basic idea is simple. During the search of a neighbourhood (generated by different possible random perturbation schemes), a better solution is always accepted while a worse solutions is accepted with a certain probability P, generally given by exp( - A/T), where A is the increase of the objective function value, and T is a control temperature (Metropolis criterion). The value of Tstarts at an initial temperature T o and is slowly reduced to a final value T~ according to a coolin 9 schedule based on a given coolin9 ratio a < 1 (i.e., Tk+ ~ = aTk). As a consequence, the probability of accepting uphill moves decreases with successive stages. A given SA may iterate for a number (L) of times at each temperature (L is generally called Markov chain length). The general scheme of a simulated annealing coded in psuedo-PASCAL

International Transactions in Operational Research Vol. 3, No. I 39
Procedure SEMULATED ANNEALING;
begin
INITIALIZE;
k:=0;
repeat
begin
L:=0;
repeat
PERTURBATION (solution S ---) S'; A = f(S')-f(S));
i ra _< 0 then
S = S '
else
if exp(-A/'Tk) > random uniform [0,1] then
S= S';
L:=L+ 1;
if f(S) _< f(BEST_S) then BEST_S:=S;
until EQUILIBRIUM_TEST is true; {for example, L = Markov chain length}
end;
k: =k+ 1;
until STOP_CRITERION is true; {for example, T k = Tf~: }
end.
Fig. [. Description of a general simulated annealing procedure in pseudo-PASCAL.
is shown in Fig. 1. For a fuller account on the subject, the reader may refer to Aarts and Korst (1990), van Laarhoven and Aarts (1992), and Reeves (1993).
The most important (theoretical) advantages of the SA technique are the following:
(i) the algorithm is effective and robust: it finds high-quality solutions which do not depend strongly on the choice of the initial solution (Aarts and Korst, 1990);
(ii) it converges asymptotically, with probability I, to the set of globally optimal solutions (e.g., van Laarhoven et al., 1992);
(iii) it is easily implemented; (iv) it is generally applicable (that is, independent of the problem).
Unfortunately the SAs suffer from a main disadvantage. As reported in van Laarhoven et al. (1992), the asymptotic convergence requires a number of conditions (e.g., Markov chains of infinite length) that cannot be satisfied in practice. In other words, the SA technique requires a very slow cooling schedule (i.e., high L and a ~ 1) to guarantee good performances. But in the field of Manufacturing Systems the CPU response time is a critical problem and, for this reason, one must adopt 'fast' SA versions. The performance of a finite-time implementation deeply depends on the choice of a set of critical values of the parameters. Moreover, generally we loose advantage (i) (i.e., a good initial solutions can influence the SA performances) and advantage (iv) (i.e., different parameter sets are needed for different problems and/or different sizes of the sam problem). While in the first case the problem is overcome, when possible, by using an initial solution generated by another heuristic, specific to the problem (e,g., Kouvelis and Chiang, 1992; Heragu and Alfa, 1992; Sridhar and Rajendran, 1993), in the second case the problem of the choice of the parameters is still waiting for a solution. In particular, the parameters that we have to choose carefully in a finite-time implementa- tion are:
(i) the initial temperature that defines the initial acceptance probability (or vice versa); (ii) a rule (or a value) to define the number L of iterations at each temperature (stage);

40 M. Braglia--Optimisation of a Simulated-Annealing-based Heuristic
(iii) the acceptance probability rule; (iv) a cooling schedule for T; (v) a stop criterion, that is a rule to define the number of stages;
(vi) a neighbourhood generation scheme.
For each one of these points, various authors have proposed different rules, i.e. modifications to the original Metropolis scheme in an attempt to provide near-optimal solutions in more and more reasonable response times. For this reason we may speak of a family of simulated-annealing-based heuristics (Kuik and Salomon, 1990).
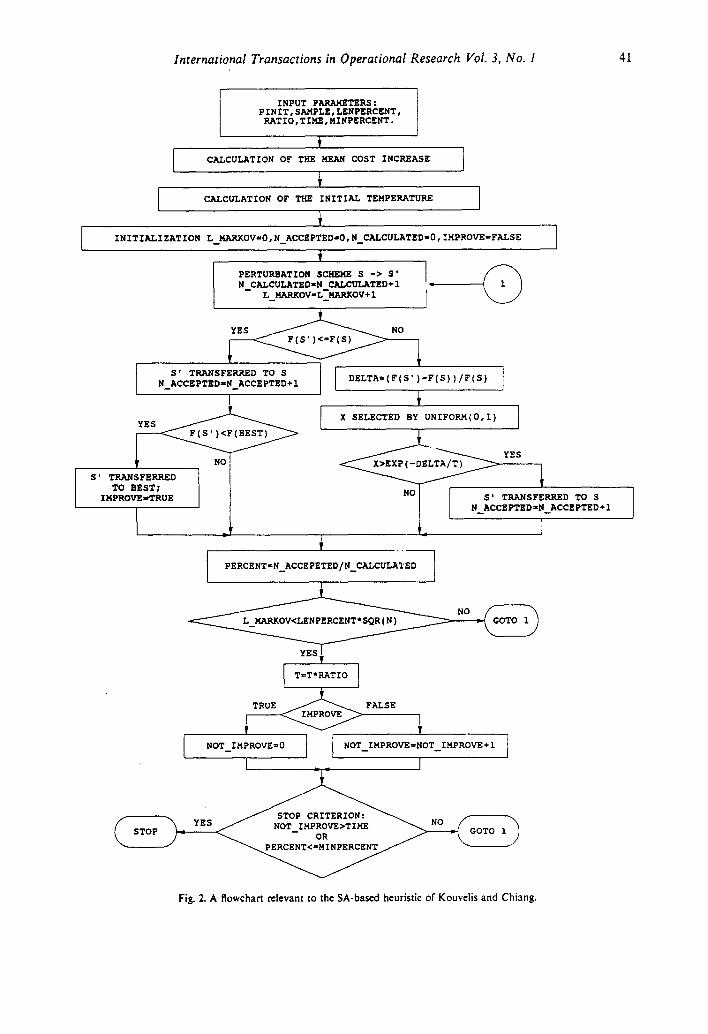
A recent example of these heuristics is the SA defined in Kouvelis and Chiang (1992), and Kouvelis et al. (1992). It is used here as a case study. The Kouvelis and Chiang SA-based heuristic (SA_KC) is defined as follows:
(1) the SA starts with an initial acceptance probability Po (say, PINIT) from which the initial temperature T o is calculated according to the Metropolis criterion exp(TX/To) ~- Po where ~ is the mean cost increase as calculated by a number (SAMPLE) of transitions;
(2) at each temperature the length of the Markov chain is taken to be equal to a percentage (LENPERCENT) of the total neighbourhood size (approx. N 2 in their case);
(3) the cooling schedule is given by the condition T k = rT~ + ~, k = 1,2 ..... r being a constant (RATIO) less than 1;
(4) the stop criterion is based on a double condition. The first condition stops the SA if the optimal configuration remains unchanged for a given number of temperature reduction stages (TIME). The second condition stops the SA if the total number of accepted transitions is less than a fraction (MINPERCENT) of the total attempted transitions.
A flow chart relevant to the SA_KC heuristic is shown in Fig. 2.
3. THE GENETIC ALGORITHM
GAs from a class of adaptive heuristics based on principles derived from the dynamics of population genetics (Holland, 1975). The searching process simulates the natural evolution of biological creatures and turns out to be an intelligent exploitation of a random search. A candidate solution is represented by an appropriate sequence of numbers, also known as a chromosome. In many applications the chromosome is simply a binary string of '0' and '1'. In the scheduling case a non-binary coding is adopted: a chromosome is a possible sequence of jobs. The quality of a chromosome is determined by the values of its fitness function, which evaluates the chromosome with respect to the objective (cost)function of the optimisation problem. An initially selected population of solutions (chromosomes), evolves by employing mechanisms modelled after those currently believed to apply in genetics. Generally, the mechanisms consist of three fundamental operators: reproduction, crossover and mutation. Reproduction is a weighted selection of copies of solutions from the population according to their fitness values to create one or more offspring. Crossover defines how the selected chromosomes (the parents) are recombined to create new structures (the offspring) for possible inclusion in the population. Mutation is a random modification of a randomly selected chromosome. Its function is to guarantee the possibility of exploring the space of solutions for any initial population and to permit the freeing from any zone of local minimum. Generally, the decision of the possible inclusion of offspring is governed by an appropriate filtering system. Both crossover and mutation occur at every cycle, with a given probability. As a rule, the crossover rate is between 0.7 and 1, whereas the mutation rate assumes values around 0.2 and 0.3. The aim of the three operations is to produce a sequence of populations that, on the average, tend to improve. In this evolution, the population should contain both the individuals that have been found as most valuable in the previous search and those ones that should be able to direct the search to even better solutions in the future. For a fuller account on this subject, the reader may refer to Goldberg (1989), Davis (1987, 1991) and Reeves (1993).
International Transactions in Operational Research Vol. 3, No. 1 41
INPUT PARAMZTERS: PINIT,SAMPLE,LENPERCENT, RATIO,TIME,MINPERCENT.
CALCULATION OF THE MEAN COST INCREASE
PERTURBATION SCHEME S -> S' N CALCULATED=N CALCULATED+I -- L MARKOV=L--MARKOV+I
S' TRANSFERRED TO S N_ACCEPTED=NACCEPTED+I
IMPROT=TRUE [
IN ITIALI ZATION L_MARKOV=O, N ACCEPTED=O, N CALCULATED=O, IMPROVE=FALSE
,- @
STOP
I ELTA=(F(S' ) -F(S)) /F(S) I
X SELECTED BY UNIFORm(O,1)
~ ' ~ Y E S
"°1 I s, T ~ S , E ' ~ D TO S I [ N ACCEPTED=N ACCEPTED+I
L I
1 PERCENT=N ACCEPETED/N CALCULA~'ED 1
I T'T'~TIO I
,ALsE I I I
~ .... - .... o~ ....... ~----~GOTO
Fig. 2. A flowchart relevant to the SA-based heuristic of Kouvelis and Chiang.

42 M. Braglia--Optimisation of a Simulated-Annealing-based Heuristic
ASSIGN THE VALUATION RESULT
TO THE CHROMOSOME VALUE
3.1. Our genetic algorithm
_1 GENETIC ALGORITHM} r I ITERATION
TEST THE PERFORMANCES OF THE SIMULATED ANNEALING USING THE PARAMETERS DEFINED
IN THE CHROMOSOME
Fig. 3. Scheme of GA and SA interaction.
] CHROMOSOME
TO BE EVALUATED
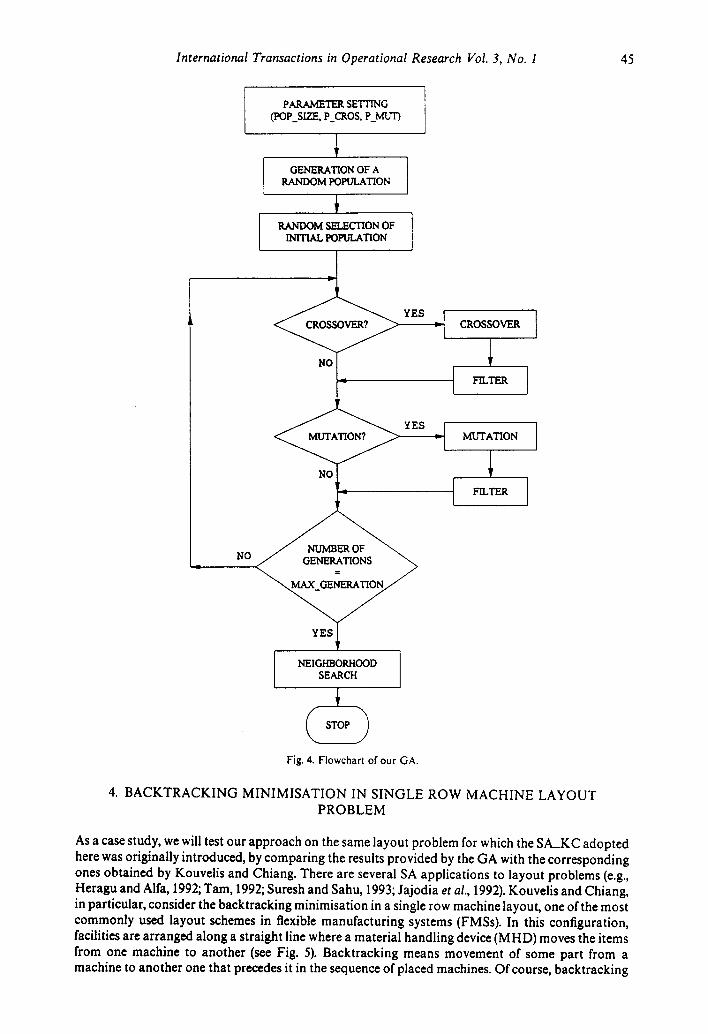
In this section, we describe the basic structure of the GA we adopted for the optimisation of the SA control parameters. How GA and SA interact with each other is shown in Fig. 3.
As regards the GA, we made the following choices:
(i) Representation First of all, we must decide how to encode the information relevant to the SA in the gene strings. As mentioned, there are two kinds of information of quite different nature that need to be represented. First, we must define the numerical values of parameters such as, for example, the initial and final temperatures. Second, we must select the perturbation operator, that is the random perturbation scheme. The coding scheme adopted in this paper is similar to that of Freisleben et al. (1993). Below, the two types of information will be referred to as parameters and decisions, respectively. In other words, a decision is a variable (gene) whose integer value implies the adoption of a particular random perturbation structure. A parameter is a variable (gene) which specifies the really coded value that is associated with the selected variant. The value is treated as a decimal number and is not codified as a binary number. In Table 1 we show the information, relevant to the SA__KC algorithm, represented by the individual genes in the strings (chromosomes) of the population. In our case, the perturbation scheme (or neighbourhood generation scheme) is the only decision information. The (random) perturbation schemes that we want to test in this paper are the following:
(a) Random interchange scheme: two positions are randomly selected in the machine sequence and the corresponding machines are interchanged;
(b) Insertion scheme: two numbers i andj are randomly selected and machine i is moved in positionj of the sequence;
(c) Adjacent interchange scheme: a positionj is selected and the corresponding machine is moved in position j + 1 or j - 1, randomly;
(d) Double random interchange scheme: a random interchange scheme is executed twice.
(ii) lnitialisation We adopt a randomly-created population of 10 ( = POP_SIZE) chromosomes. The values of the different genes of each chromosome are randomly sampled from uniform distributions defined over appropriate intervals. For example, the cooling schedule parameter is sampled from the distribution U(0.50,0.99), while the type of permutation scheme is sampled from the distribution U(1,4), etc. Each chromosome is given a value of the objective (cost) function which corresponds to the mean value obtained with n replications of the SA algorithm, in correspondence of the same codified configuration of parameters. The corresponding fitness value for the i-th chromosome, is simply obtained as Fitness(i) = Cost_Function(i) with (normalised) selection probability

International Transactions in Operational Research Vol. 3, No. I 43
Table 1. Codification of chromosome genes
Num. Type Represented information
I Parameter Initial acceptance probability (PINIT)
2 Parameter Initial test dimension (SAMPLE)
3 Parameter Markov Chain Length (LENPERCENT)
4 Parameter Cooling schedule (RATIO)
5 Parameter First stop criterion condition (TIME)
6 Parameter Second stop criterion condition (MINPERCENT)
7 Decision Permutation scheme
P(i) =
POP_SIZE - 1 Fitness(i) I
1 - POe slz-i-z~--- | " k~=l F{tness(k)/
The best individuals are clearly characterised by a higher probability of sampling, i.e., in turn, of evolution. The choice of an appropriate cost function, and consequently of the probability P(i), is important for the performances of the GA. In fact, the choice must emphasize the performance differences of the various chromosomes, so that the best ones tend to prevail during the evolution of the GA. On the other hand, differences cannot be too great, otherwise a few chromosomes will 'dominate' all the others and the population of the GA will converge to a local minimum too rapidly. In our case, we have adopted the following cost function:
Cost_function(i) = BACK(i) + fl CALLS(i),
where BACK(i) is the backtracking value as obtained when using the parameters of the chromosome 'i', CALLS(i) is the total number of SA iterations, that is of calls to the function of backtracking evaluation, and fl is a parameter which weights the computation time with respect to the performances that are obtained. The value of the Cost__function is obtained as an average of the results produced by 5 replications of the SA with the set of parameters codified i the corresponding chromosome. This cost function permits simultaneous consideration of both the performance values and corresponding computation times (in terms of calls to the backtracking function). This solves one of the problems mentioned in the Introduction.
(iii) Reproduction Reproduction corresponds to the weighted selection (based on given fitness-dependent probabilities of the various chromosomes) of 10 sequences from the preceding population. Of course, it may be found that in the new population the same configuration is sampled several times. The resulting population is the initial (starting) population of the GA.
(iv) Recombination (crossover) Having selected a pair of chromosomes from the population according to the fitness values, two offspring are created by a crossover operator which changes the corresponding blocks in the two selected chromosomes (i.e., the parents). The operator proceeds as follows:
(1) It chooses an interval to be swapped. This is done by random sampling of two numbers, i and j, between 0 and 8.
(2) It exchanges the two intervals between the two parents.
To limit the exchange ofgenes from parent to parent the adopted conditions is [ i - J l ~< 4. Moreover, a filter is introduced which accepts the replacement of the parents only when the offspring are better. We adopt a crossover rate equal to 0.90.

44 M. Braglia--Optimisation of a Simulated-Annealing-based Heuristic
(v) Mutation The mutation operator randomly changes one of the genes of the chromosome, sampled by the population according to the fitness value. The mutation of the selected field consists of a random increment or decrement of the gene value of a given quantity. For example, the variation entity of the cooling parameter is _+ 0.05, the variation of the initial temperature is _+ 10, etc. Moreover, a filter is introduced which accepts the mutated chromosome in the population only if it is better than its parent. We adopt a mutation rate of 0.3
(vi) Neighbourhood structure By virtue of the crossover and mutation actions, the GA tends to make a given population of sequences evolve towards the region of global minimum of the objective function. Thus, it does not concentrate on the value of the single sequence of the single individual. For this reason, and mainly for problems of large dimensions, it is not certain that the optimal sequence will belong to the region of space where the population is concentrated by the evolution process. This can also be understood when considering the characteristic stepwise behaviour of the optimal value as a function of the generation ( = crossover + mutation) number. It is evident from such behaviour that a GA encounters difficulty in improving the optimum value after a certain point of the search, when the population ends in a minimum region of the solution space. To by-pass this problem, we introduce an improvement which permits overcoming an intrinsic weakness of 'classical' GAs. The basic idea of our approach is to associate the GA to a final neighbourhood search procedure to fine-tune the optimal gene, as also suggested by Grefenstette (in Davis, 1987) for the Travelling Salesperson Problem (TSP) and developed by Braglia and Gentili (1994) for the makespan minimisation in flowshop scheduling problems. In such a context, the function of the GA is that of pre-processor, whose aim is to lead the population to the region of global optimum (or sufficiently close to that region). Then, from the best chromosome of the final population a neighbourhood search is started for the minimum of the corresponding zone.
A neighbourhood search is a local heuristic which is based on a stepwise improvement of the value of the objective function only by exploration of the neighbourhood solutions of a given initial solution. For neighbourhood solutions we intend solutions which differ little from one another (e.g., just for the position of one element of a scheduling order). It is evident that using this kind of algorithm requires the definition of a starting solution, an objective function and a neighbourhood structure (that is, a rule which determines the neighbourhood solutions). In our analysis, neighbourhood solutions are defined as follows. Starting from the first gene of the best chromosome of the population (i.e., in our case, the initial temperature) the value is first incremented and then also reduced of a quantity equal to that used in the mutation process. In this way, two new sets of parameters are evaluated. If the best set is also better than the starting solution, the new set of parameters is recorded as best solution. Then, the second gene of this new solution is considered and so on. The process is repeated up to the last gene of the sequence. Thus, each step of the neighbourhood search requires the evaluation of 2 x n sets of parameters, where n is the number of genes (eight in our case). At the end, if an improvement is observed with respect to the starting configuration, the process is repeated starting again from the first gene. The algorithm terminates when no further improvement can be obtained.
One could object that even the performances of the GA depend, in turn, on the choice of the value/decision parameters. Thus, one may be led to conclude that if time and energies must be spent to optimise the GA, this could be done directly on the SA. Such an observation is meaningful, but an advantage generally exists with our procedure. In fact, even when adopting quite standard GAs for the optimisation of the value/decision parameters, the results are good, with values of the parameters of the SA that generally lead to better performances. In other words, the GAs turn out to have an excellent flexibility and robustness. For the choices that are made, the GA we adopted (the corresponding flowchart is shown in Fig. 4) may be considered rather standard. The only true novelty, rarely used, but recommended here, concerns the final neighbourhood search which often permits to obtain non-negligible improvements. Moreover, even a valid, but not as efficient GA, at the end provides a fairly good set of parameters from which successive ameliorative analyses can eventually be started.
International Transactions in Operational Research Vol. 3, No. 1 45
PARAMETER SETTING (POP_SIZE, P_CROS, P_MUT)
GENERATION OF A RANDOM POPULATION
RANDOM SELECTION OF INITIAL POPULATION
P
YES
~ ¥ES
0 q
NO
NEIGHBORHOOD SEARCH
Fig. 4. Flowchart of our GA.
_l CROSSOVER I
FILTER
_1 MtrrAalO ] -I
FILTER
4. BACKTRACKING MINIMISATION IN SINGLE ROW MACHINE LAYOUT PROBLEM
As a case study, we will test our approach on the same layout problem for which the SA_KC adopted here was originally introduced, by comparing the results provided by the GA with the corresponding ones obtained by Kouvelis and Chiang. There are several SA applications to layout problems (e.g., Heragu and Alfa, 1992; Tam, 1992; Suresh and Sahu, 1993; Jajodia et al., 1992). Kouvelis and Chiang, in particular, consider the backtracking minimisation in a single row machine layout, one of the most commonly used layout schemes in flexible manufacturing systems (FMSs). In this configuration, facilities are arranged along a straight line where a material handling device (MHD) moves the items from one machine to another (see Fig. 5). Backtracking means movement of some part from a machine to another one that precedes it in the sequence of placed machines. Of course, backtracking

46 M. Braglia--Optimisation of a Simulated-Annealing-based Heuristic
MACHINE 2 3
4 MACHINE 3
C) C)
M A C H I N E
1
Fig. 5. A s ingle row machine layout scheme.
adversely impacts the movement cost and productivity of a manufacturing facility as it causes the movement in the flow line to resemble the movement in a job shop layout. Moreover, different material handling devices from those in use may be required, and queues may appear. The study of the facility layout is important as increased machine flexibility and product diversification create additional complexity in scheduling and material handling. An excellent review on this subject can be found in Hassan (1994).
Rigorously, the mathematical formulation of the problem is the following (Sarker et al., 1994). Given a flow matrix F (generally called from-to chart), whose generic elementf~ i is the number of total parts moves from machine i to machine j, the model requires each of M unique machines to be assigned to one of M locations along a linear track in such a way that the total backtracking distance is minimised. Assume that machine locations and facilities are equally-spaced. Then, the general model may be stated as follows:
minimise
subject to
M M M M
cOO = E E E E i = I k = l j = l h = l
M
x i ,= 1, k = 1,2 ..... M i=1
M
xik = i, i= 1,2,...,M k = l
xik = 0 or 1, for all i,k.
The decision variable xik equals 1 if machine i is assigned to location k, and 0 otherwise. The distance parameter dikjh is given by
where
- - ~k-h i f h < k , i d = l , 2 ..... M 6kh =
0 otherwise.
The constraints ensure that each machine is assigned to one location and that each location has one machine assigned to it.
Concerning the optimal setting of the parameters, Kouvelis and Chiang pointed out that the SA technique is very sensitive to the values of the control parameters but, if the SA parameters are fine-tuned to the best level for the specific application, good configurations are provided. For this reason they propose an extensive and 'heavy' sensitivity analysis. Hassan himself notes that 'SA requires considerable computational time for determining suitable values for its parameters' and observes that 'studies on parameters of SA and its theoretical aspects in the context of machine layout

International Transactions in Operational Research Vol. 3, No. I 47
Table 2. Original values of Kouvelis and Chiang
Num. Represented information Best variant/value parameter
1 PINIT 0.5 SAMPLE 0.05
3 LENPERCENT 0.95 4 RATIO 0.88 5 TIME 50 6 MINPERCENT 0.01 7 Permutation scheme Random interchange
Table 3. Parameter values obtained by GA with a problem size of 17 machines
Num. Represented information Best variant/value parameter
l PINIT 0.83 2 SAMPLE 0.54 3 LENPERCENT 0.20 4 RATIO 0.90 5 TIME 47 6 MINPERCENT 0.41 7 Permutation scheme Random interchange
may be what is needed'. Then, the problem of setting the parameters is held in great consideration also in layout applications.
The parameters of the specific SA treated by Kouvelis and Chiang, in the particular case of 17 machines (and based on their computational experience relevant to more than 300 problems), are presented in Table 2. For the sake of comparison, below we will turn our attention to the case of random initial solution.
The general structure of the GA we have adopted is the one described in Section 3. The value offl is chosen equal to I0. The choice of this parameter is clearly important and generally will depend on the necessities and possibilities of the user. In our case the choice fl = 10 follows from the necessity of having computat ion times (in terms of calls to the evaluation function) comparable with those required by the choice proposed by Kouvelis and Chiang. In Table 3 we present the final result obtained with the parameters of our optimisation approach, at the end of a search whose behaviour is reported in Fig. 6. As in Kouvelis and Chiang, SAMPLE and L E N P E R C E N T give the percentage with respect to the neighbourhood size (equal to N 2 in their case). The GA always gives the values of the two parameters a percentage of N 2, even if the size of the adopted permutation scheme is different. This has been done to avoid having two gene values of the chromosome correlated with one another. Table 4 shows the performance values obtained with the two sets of parameters as averages of 10 experiments. As one can see, the GA leads to better performances than those provided by the Kouvelis and Chiang choice. Both in terms of backtracking and in terms of evaluated sequences (i.e., computat ion time).
34500
c -
o ° 1
==
d
34000
33500
33000
32500
32000
31500
\ "-x
I I I
0 10 20 30 40 50 60
GA gene rations
70
Fig. 6. Behaviour of the GA search (17 machines problem). ITOR l - I - C

48 M. Braglia--Optimisation of a Simulated-Annealing-based Heuristic
Table 4. Performance obtained with a problem size of 17 machines
Kouvelis and Chiang Genetic algorithm
Backtracking 3412 3236 Number of calls 7936 216
Table 5. Performance obtained with problem sizes of 7 and 11 machines
7 Machines 11 Machines
Kouvelis Genetic Kouvelis Genetic and Chiang algorithm and Chiang algorithm
Backtracking 197 204 806 804 Number of calls 2499 87 6167 158
In Table 5 we report the results obtained with the other problem dimensions (i.e., 7 and 11) considered by Kouvelis and Chiang. The SA is optimised by the GA proposed in Section 3. As one can see, the parameters of the SA obtained by GA permit reaching better results in the particular case of I 1 machines. Almost the same value of backtracking is reached with 7 machines, but it is obtained by very few iterations. Probably, in this case, the small dimension of the problem makes the weights given to the computational times too important with respect to the value of the objective function. For this reason, in the latter case, to have a better backtracking value, it is convenient perhaps to change the weight parameter fl in the GA cost function.
To better evaluate our results, we conclude with an economic observation on the considerable importance of the layout problem. As reported in Afentakis et al. (1990), Tompkins and Reed estimate that from 20 to 50% of the total manufacturing operating cost is due to the material handling system. As a consequence, even a small improvement of the performances of the heuristic (e.g., the 5.2% obtained in the case of 17 machines) must be considered interesting.
5. CONCLUDING REMARKS
We have presented an approach to determine the optimal set of parameters (type of operators and parameter settings) for Simulated-Annealing-based heuristics, applied to manufacturing system problems. The fundamental idea is to consider the search for the best set as another combinatorial optimisation problem which is solved by a Genetic Algorithm. The information on the stochastic technique is easily represented in strings of genes. Performance results obtained by the optimisation of a particular Simulated Annealing, in a single row machine layout problem with backtracking minimisation, demonstrate the validity of our approach. It turns out to be efficient and easier than a classical statistical analysis based on the construction of an experimental design. Despite the many variants one may adopt, the GA is found to be a robust algorithm and the results are always found good. Generally, better results are reached if the best chromosome of the final population of the GA is subjected to a local neighbourhood search for determining the minimum of the corresponding zone.
Future work may concern: (i) applications of our approach to various combinatorial problems (e.g., scheduling) and different parametric techniques (e.g., Tabu Search), (ii) the improvement of the GA structure and, in particular, (iii) the study of appropriate indicators (see, Freisleben et al., 1993) to take into account the impact of the different parameters on the performances of the heuristic which is under consideration, in order to guide better and better the 'evolution' (i.e., the search process) of the GA.
Acknowledgements - This work has been supported in part by INFM and CNR. The calculations have been made on a DIGITAL DEC 3000/600 Alpha computer of the Department of Physics, University of Parma.
REFERENCES
Aarts, E. & Korst, J. (Ed.) (1990). Simulated Annealing and Boltzmann Machines. UK: Wiley. Afentakis, P., Millen, R.A. & Solomon, M.M. (1990). Dynamic layout strategies for flexible manufacturing systems.

International Transactions in Operational Research l,'ol. 3, No. I 49
International Journal of Production Research, Vol. 28, pp. 311-323. Braglia, M. & Gentili, E. (1994). An improved genetic algorithm for flow-shop scheduling problem. Proceedings of lOth
International Conference 'CARs & FOF'94" (pp. 137-142). Ottawa. Brusco, M. J. & Jacobs, L. W. (1993). A similated annealing approach to the cyclic staff-scheduling problem. Naval Research
Logisitics, Vol. 40, pp. 69-84. Davis, L. D. (Ed.) (1987). Genetic Algorithms and Simulated Annealing. London: Pitman Publishing. Davis, L. D. (Ed.) (1991). Handbook of Genetic Algorithms. N.Y.: Van Nostrand Reinhold. De Werra, D. (1987). Design and operation of flexible manufacturing systems: the kingdom of heuristic methods. RAIRO, Vot.
21, pp. 365-382. Freisleben, B. & Hartfelder, M. (1993). Optimization of genetic algorithms by genetic algorithms. Proceedings of Artificial
Neural Nets and Genetic Algorithms Conference (ANNGA) (pp. 392-399). Innsbruck. Goldberg, D.E. (Ed.) (1989). Genetic Algorithms in Search, Optimization, and Machine Learning. Reading, MA: Addison-
Wesley. Gupta, M.C., Gupta, Y.P. & Kumar, A. (1993). Minimizing flow time variance in a single machine system using genetic
algorithms. European Journal of Operational Research, Vol. 70, pp. 289-303. Hassan, M. M. D. (1994). Machine layout problem in modern manufacturing facilities. International Journal of Production
Research, Vol. 32, pp. 2559-2584. Heragu, S.S. & AIfa, A.S. (1992). Experimental analysis of simulated annealing based algorithms for the layout problem.
European Journal of Operational Research, Vol. 57, pp. 190-202. Holland, J. H. (Ed.) (1975). Adaptation in Natural and Artificial Systems. Ann Arbor, MI: University of Michigan Press. Kirkpatrick, S., Gelatt, C. D. Jr & Vecchi, M. P. (1983). Optimization by simulated annealing, Science, Vol. 220, pp. 671-680. Kouvelis, P. & Chiang, W.-C. (1992). A simulated annealing procedure for single row layout problems in flexible
manufacturing systems. International Journal of Production Research, Vol. 30, pp. 717-732. Kouvelis, P., Chiang, W.-C. & Fitzsimmons, J. (1992). Simulated Annealing for machine layout problems in the presence of
zoning constraints. European Journal of Operational Research, Vol. 57, pp. 203-223. Kuik, R. & Salomon, M. (1990). Multi-level lot-sizing problem:evaluation of a simulated annealing heuristic. European Journal
of Operational Research, Vol. 45, pp. 25-37. Jajodia, S., Minis, I., Harhalakis, G. & Proth, J. M. (1992). CLASS: Computerized LAyout Solution using Simulated annealing.
International Journal Production Research, Vol. 30, pp. 95-101. Law, A. M. & Kelton, W. D. (Ed.) (1991). Simulation Modeling & Analysis. USA: McGraw-Hill. Logendran, R., Ramakrishna, P. & Sriskandarajah, C. (1994). Tabu search-based heuristics for cellular manufacturing systems
in the presence of alternative process plans. International Journal Production Research, Vol. 32, pp. 273-297. Metropolis, N., Rosenbluth, A., Rosenbluth, M., Teller, A. & Teller, E. (1953). Equation ofstate calculations by fast computing
machines. Journal of Chemical Physics, Vol. 21, pp. 1087-1092. Ogbu, F.A. & Smith, D. K. (1990). The application of the simulated annealing algorithm to the solution of the n/m/Cmax
flowshop problem. Computers and Operations Research, Vol. 17, pp. 243-253. Reeves, C. R. (Ed.) (I 993). Modern Heuristic Techniques for Combinatorial Problems. Oxford: Blackwell Scientific Publications. Sarker, B.R., Wilhelm, W.E. & Hogg. G. L. (1994). Backtracking and its amoebic properties in one-dimensional machine
location problems. Journal of the Operational Research Society, Vol. 45, pp. 10242-1039. Sridhar, J. & Rajendran, C. (1993). Scheduling in a cellular manufacturing system: a simulated annealing approach.
International Journal of Production Research, Vol. 31, pp. 2927-2945. Suresh, G. & Sahu, S. (1993). Multi objective facility layout using simulated annealing. International Journal of Production
Economics, Vol. 32, pp. 239-254. Tam, K.Y. (1992). A simulated annealing algorithm for allocating space to manufacturing ceils. International Journal
Production Research, Vol. 30, pp. 63-87. van Laarhoven, P.J.M. & Aarts, E.H.L. (Ed.) (1992). Simulated Annealing: Theory and Applications. Dordrecht, The
Netherlands: Kluwer Academic Publishers. van Laarhoven, P.J.M. Aarts, E. H. L. & Lenstra, J. K. (1992). Job shop scheduling by simulated annealing. Operations
Research, Vol. 40, pp. 113-125.