feature extractions with geometric algebra for classification of objects
TRANSCRIPT

Feature Extractions with Geometric Algebra for Classification ofObjects
Minh Tuan Pham, Kanta Tachibana, Eckhard Hitzer, Sven Buchholz, Tomohiro Yoshikawa, Takeshi Furuhashi
Abstract— Most conventional methods of feature extractiondo not pay much attention to the geometric properties of data,even in cases where the data have spatial features. In this studywe introduce geometric algebra to undertake various kinds offeature extraction from spatial data. Geometric algebra is ageneralization of complex numbers and of quaternions, and itis able to describe spatial objects and relations between them.This paper proposes to use geometric algebra to systematicallyextract geometric features from data given in a vector space. Weshow the results of classification of hand-written digits, whichwere classified by feature extraction with the proposed method.
I. I NTRODUCTION
Because nowadays, enormous amounts of data are avail-able in various fields, data mining which analyzes datato reveal interesting information becomes more and morenecessary. But so far most conventional methods of featureextraction ignore the geometric properties of data even in thecase where the data have spatial features. For example, whenm vectors are measured from an object in three-dimensionalspace, conventional methods represent the object byx ∈ R3m
which is the vector made by arrangingm groups of 3coordinates of each vector in a row. However, because thesecoordinate values depend on the definition of the coordinatesystem, inference or classification becomes remarkably bad,when objects are measured in a coordinate system differentfrom the one used for learning. Furthermore, spatial infor-mation of the object in three-dimensional space is lost wheneach elementx ∈ R3m is, for example, normalized. Someconventional methods may extract corrdinate-free features,but whether such features arise and are adopted depends onthe experience of the model builder.
In this study, we use geometric algebra (GA) whichcan describe spatial vectors and higher order subspace re-lations between them [1],[2],[3], to systematically under-take various kinds of feature extractions, and to improveprecision and robustness in classification problems. Thereare already many successful examples of its use in imageprocessing, signal processing, colored image processing, ormulti-dimensional time-series signal processing with com-plex numbers or quaternions, which are low dimensional GAs[4],[5],[6],[7],[8],[9],[10]. In addition, GA-valued neural net-work learning methods for learning input-output relationships[11] are well studied.
In our proposed method, geometric features extracted withGA can also be used for learning a data distribution. In thisstudy, we use geometric features to learn a Gaussian mixture
model (GMM) with the expectation maximization (EM)algorithm [12], and apply this to a classification problem.Because each feature extraction derived by the proposedmethod has its own advantages and disadvantages, we applya plural mixture of GMMs for the classification problem. Asan example of multi-class classification of geometric data, weuse a hand-written digit dataset of the UCI Machine LearningRepository [13]. When classifying new hand-written digits inpractice with the learning model, it is natural to expect thatthe coordinate system in a real new environment differs fromthe one used for obtaining the learning dataset. Therefore,in this paper, we evaluate the classification performance forrandomly rotated test data.
II. M ETHOD
A. Feature extraction with GA
GA is also called Clifford algebra. An orthonormal basis{e1, e2, . . . , en} can be chosen for a real vector spaceRn. The GA of Rn, denoted byGn, is constructed by anassociative and bilinear product of vectors, the geometricproduct, which is defined by
eiej ={
1 (i = j) ,−ejei (i 6= j) .
(1)
GAs are also defined for negative squarese2i = −1 of
some or all basis vectors. Such GAs have many applicationsin computer graphics, robotics, virtual reality, etc [3]. Butfor our purposes definition (1) will be sufficient.
Now we consider two vectors{al =∑
i aliei, l = 1, 2}in Rn. Their geometric product is
a1a2 =n∑
i=1
a1ia2i +n−1∑
i=1
n∑
j=i+1
(a1ia2j − a1ja2i) eij , (2)
where the abbreviationeij = eiej is adopted in the fol-lowing. The first term is the commutative inner producta1 · a2 = a2 · a1.The second term is the anti-commutativeouter producta1 ∧ a2 = −a2 ∧ a1. The second term iscalled a 2-blade.Linear combinations of 2-blades are calledbivectors, expressed by
∑I∈I2
wIeI , wI ∈ R, whereI2 ={i1i2 | 1 ≤ i1 < i2 ≤ n} is the ordered combination set oftwo different elements from{1, . . . , n}.For parallel vectorsa1 = κa2, κ ∈ R, and the second term becomes 0.
Next,we consider the geometric product ofa1a2 =a2 · a1 + a2 ∧ a1 with a third vectora3.First,becausea1 · a2 ∈ R,(a1 · a2)a3 is a vector.Next, (a1 ∧ a2)a3 =
(∑I∈I2
wIeI
) ∑i a3iei. For a certainI = i1i2,
eIei = ei1ei2ei =
ei1 (i = i2) ,−ei2 (i = i1) ,ei1i2i (i1 6= i 6= i2) .
(3)
Therefore(a1 ∧ a2)a3 can be separated into a vector, i.e.the sum of terms corresponding to the first two lines ofeq. (3), and a 3-bladea1 ∧ a2 ∧ a3, i.e. the sum of termscorresponding to the bottom line of (3). A linear combinationof 3-blades is called a trivector which can be represented by∑
I∈I3wIeI , whereI3 = {i1i2i3 | 1 ≤ i1 < i2 < i3 ≤ n}
is the combinatorial set of three different elements from{1, . . . , n}.
In the same way the geometric producta1 . . .ak, (k ≤ n)of linear independent vectorsa1, . . . ,ak has as its maximumgrade term thek-bladea1∧ . . .∧ak. Linear combinations ofk-blades are calledk-vectors, represented by
∑I∈Ik
wIeI ,where Ik = {i1 . . . ik | 1 ≤ i1 < . . . < ik ≤ n}is the combination set ofk elements from{1, . . . , n}. 1-blades are vectors withI1 = {i1 | 1 ≤ i1 ≤ n}.0-blades are scalars withI0 = {∅}. For the unit realscalar, many authors simply writee∅ = 1. For Gn,
∧k Rn
denotes the set of allk-blades andGkn denotes set ofk-
vectors. The relationship betweenk-blades andk-vectors is∧k Rn = {A ∈ Gkn | ∃{b1, . . . ,bk}, A = b1 ∧ . . . ∧ bk}.
The most general element ofGn is A =∑
I∈I wIeI ,where I =
⋃nk=0 Ik = P ({1, . . . , n}), andP (·) denotes
the power set. Concrete examples are the general elementsof G2 which are linear combinations of{1, e1, e2, e12};and general elements ofG3 which are linear combinationsof {1, e1, e2, e3, e12, e13, e23, e123}. A general element ofGn can always be represented byA =
∑nk=0〈A〉k with
〈A〉k =∑
I∈IkwIeI , where 〈·〉k inclicates an operator
which extracts thek-vector part. The operator that selectsthe scalar part is abbreviated as〈·〉 = 〈·〉0.
The geometric product ofk (1 ≤ k ≤ n) vectors yields
a1 ∈ G1n = Rn =
1∧Rn,
a1a2 ∈ G0n ⊕
2∧Rn,
a1a2a3 ∈ G1n ⊕
3∧Rn,
...
a1 . . .ak ∈{G1
n ⊕ . . .⊕ Gk−2n ⊕∧k Rn (odd k) ,
G0n ⊕ . . .⊕ Gk−2
n ⊕∧k Rn (evenk) .(4)
Now we propose a systematic derivation of feature ex-tractions from a set or a series of spatial vectorsξ ={pl ∈ Rn, l = 1, . . . ,m}. Our method is to extractk-vectorsof different gradesk; which encode the variations of thefeatures. Scalars which appeared in eq. (4) in the case ofk = 2 can also be extracted.
First, assumingξ is a series ofn-dimensional vectors,n′+1 feature extractions are derived wheren′ = min{n,m}. For
k = 1, . . . , n′, we write k′ = k − 1,
fk (ξ) = {〈pl . . .pl+k′e−1I 〉, I ∈ Ik, l = 1, . . . , n′ − k′}
∈ R(m−k′)|Ik|, (5)
where, |Ik| is the number of combinations ofk elementsfrom n elements, ande−1
I is the inverse ofeI . For I =i1 . . . ik, e−1
I = eik. . . ei2ei1 . We further define
f0 (ξ) = {〈plpl+1〉, l = 1, . . . , n′ − 1} ∈ Rm−1. (6)
Next, assuming thatξ is a set of vectors,n′ + 1 featureextractions can also be derived in the same way
fk (ξ) = {〈pl1 · · ·plke−1I 〉, I ∈ Ik} ∈ R(mCk)|Ik|, (7)
f0 (ξ) = {〈pl1pl2〉} ∈ RmC2 , (8)
wheremCk is the number of combinations when we choosek elements fromm elements. The dimension of the featurespace becomes different from the case whereξ is a series.
Below we show several feature extractions for the caseof hand-written digit data of the UCI Repository [13]. Eachof the digit data is given by 8 pointsξ = {p1, . . . ,p8},measured by dividing the hand-written curves in equally longcurve segments. A 2-dimensional point is given bypl =xle1+yle2 with
∑8l=1 xl =
∑8l=1 yl = 0. Using GA, various
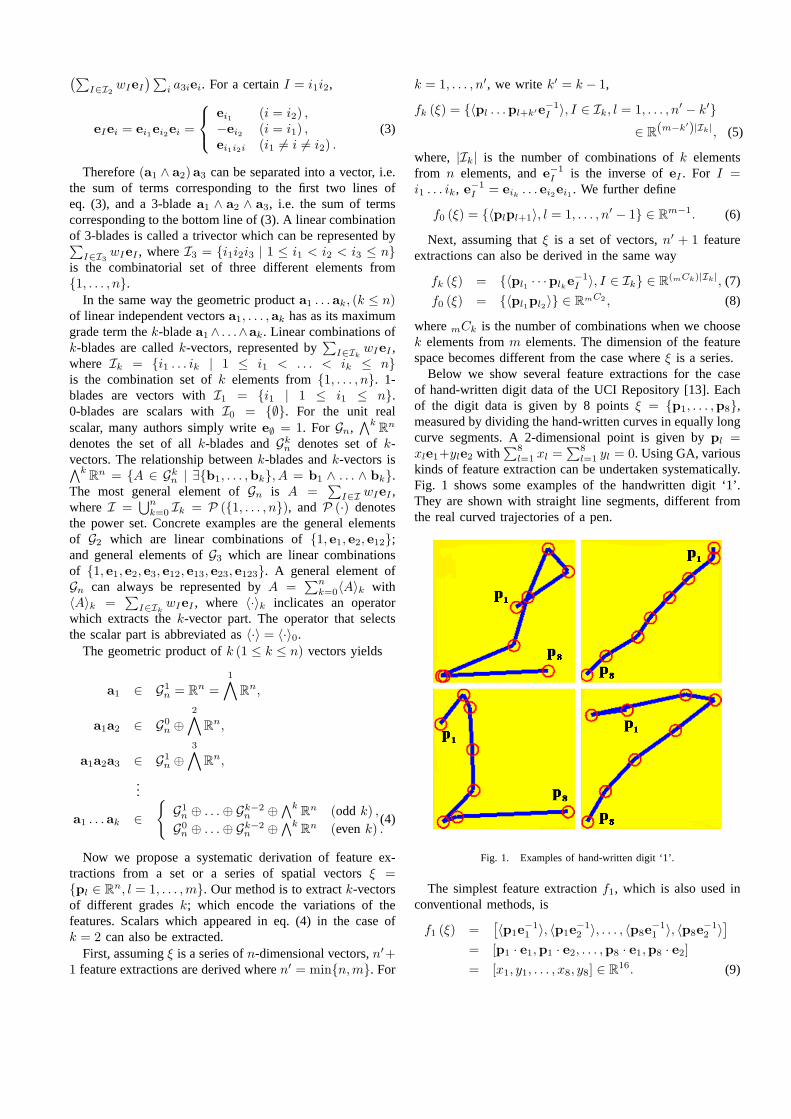
kinds of feature extraction can be undertaken systematically.Fig. 1 shows some examples of the handwritten digit ‘1’.They are shown with straight line segments, different fromthe real curved trajectories of a pen.
Fig. 1. Examples of hand-written digit ‘1’.
The simplest feature extractionf1, which is also used inconventional methods, is
f1 (ξ) =[〈p1e−1
1 〉, 〈p1e−12 〉, . . . , 〈p8e−1
1 〉, 〈p8e−12 〉]
= [p1 · e1,p1 · e2, . . . ,p8 · e1,p8 · e2]= [x1, y1, . . . , x8, y8] ∈ R16. (9)

A second feature extractionf2 uses the directed magni-tudes of outer products of consecutive points,
f2 (ξ) =[〈p1p2e−1
12 〉, . . . , 〈p7p8e−112 〉
]
= [x1y2 − x2y1, . . . , x7y8 − x8y7] ∈ R7. (10)
A third feature extractionf0 uses the inner product ofconsecutive points
f0 (ξ) = [〈p1p2〉, . . . , 〈p7p8〉] (11)
= [x1x2 + y1y2, . . . , x7x8 + y7y8] ∈ R7.
B. Data Distribution Learning for Multi-class Classification
A GMM is useful to approximate a data distribution ina data space. A GMM is charecterized by parametersΘ ={βj , µj ,Σj}, whereβj,µj andΣj are the mixture ratio, themean vector, and the variance covariance matrix of thej-thGaussian, respectively. The output is
p (ξ | Θ) =M∑
j=1
βjNd (f (ξ)− µj ; Σj), (12)
whereNd (·; ·) is the d-dimensional Gaussian distributionfunction whose center is fixed at the origin.
To train M Gaussians with given incomplete dataX ={xi = f(ξi) | 1 ≤ i ≤ N}, the EM algorithm [12]is often utilized. The algorithm identifies both parametersΘ and latent variablesZ = {zij ∈ {0, 1} | 1 ≤ j ≤M}. The zij are random variables, which forzij = 1indicate that the individual datumxi belongs thej-th ofM Gaussian distributions. Thus
∑Mj=1 P (zij) = 1.The
EM algorithm repeats the E-step and the M-step untilP (Z)and Θ converge. The E-step updates the probabilities ofZaccording to Bayes’ theoremP (Z | X, Θ) ∝ p (X | Z, Θ).The M-step updates the parametersΘ of the Gaussians tomaximize the likelyhoodl (Θ, X, Z) = p (X | Z, Θ).
A major drawback of the GMM is its large number offree parameters whose order isO
(Md2
). Moreover when
the correlation between any pair of features is close to 1,the calculation of the inverse matrix is numerically unsta-ble. So, the GMM becomes unable to compute the correctprobability distribution. To remedy this, Tipping and Bishop[14] proposed to use only the eigencomponents with thelargestq eigenvalues, whereq is a preset value of a Gaussiandistribution. But the number of free parameters is not nec-essarily the same for different Gaussian distributions. Withfixed q therefore the GMM produces a bad approximationof a probability distribution. To improve this, Meinicke andRitter [15] proposed to use only the eigencomponents ofGaussian distributions which are larger than a certain cutoff.The cutoff eigenvalue is set atλ− = αλmax, whereα ∈ (0, 1]is a hyper parameter andλmax is the largest eigenvalue of thevariance covariance matrix of incomplete dataX. It means
Fig. 2. Flow of multi-class classfication. The top diagram shows thetraining of the GMM for classC ∈ {‘0’ , . . . , ‘9’ }. The D1C denotesa subset of training samples whose label isC. The f : ξ 7→ x showsfeature extraction. Either of{f1, f2, f0} is chosen asf . The bottomdiagram shows estimation by the learned GMMs. The samef chosen fortraining is used here. The GMMC outputsp (ξ | C). The final estimation isC∗ = arg maxC p (ξ | C) P (C), whereP (C) is the prior distribution.The setD3 consists of independent test data.
that we develop eq. (12)
p (x | Θ) =M∑
j=1
βj
d∏
k=1
N1 ((x− µj) · vk; λk)
≈M∑
j=1
βj
{qj∏
k=1
N1 ((x− µj) · vk;λk)
}
×{N1
((x− µj)− ; λ−
)}d−qj
, (13)
where,λk is thek-th largest eigenvalue of thej-th Gausiandistribution. Thevk is the corresponding eigenvector.Be-causek ≤ qj ⇔ λk > λ−, the bracket(x− µj)− is thelength of the component, which is perpendicular to theqj
eigenvectors with the largest eigenvalues.The flow of training and estimation of hand-written digit
classification, as an example of multi-class classsification, isshown in Fig. 2. TheM andα for each GMM are decidedby validation with datasetD2.
C. Mixture of Experts
Each feature extraction derived with GA has advantagesand disadvantages.A big merit of adopting learning ofdistributions rather than learning of input-output relationsis that the learned distributions allow us to obtain reliableinference by mixing plural weak learners. In this study, wetherefore use a mixture of GMMs. Inferences are mixed as
p (ξ | C) =2∏
k=0
p (fk(ξ) | C) . (14)
Fig. 3 shows the mixture of different GMMs. Inferencesvia different feature extractions are mixed to produce theoutputp (ξ | C).
III. E XPERIMENTAL RESULTS AND DISCUSSION
A. Classification of Hand-written Digits
We used the Pen-Based Recognition of Hand-written Dig-its dataset (Pendigits dataset in the following) of the UCIRepository [13] as an example application for multi-class
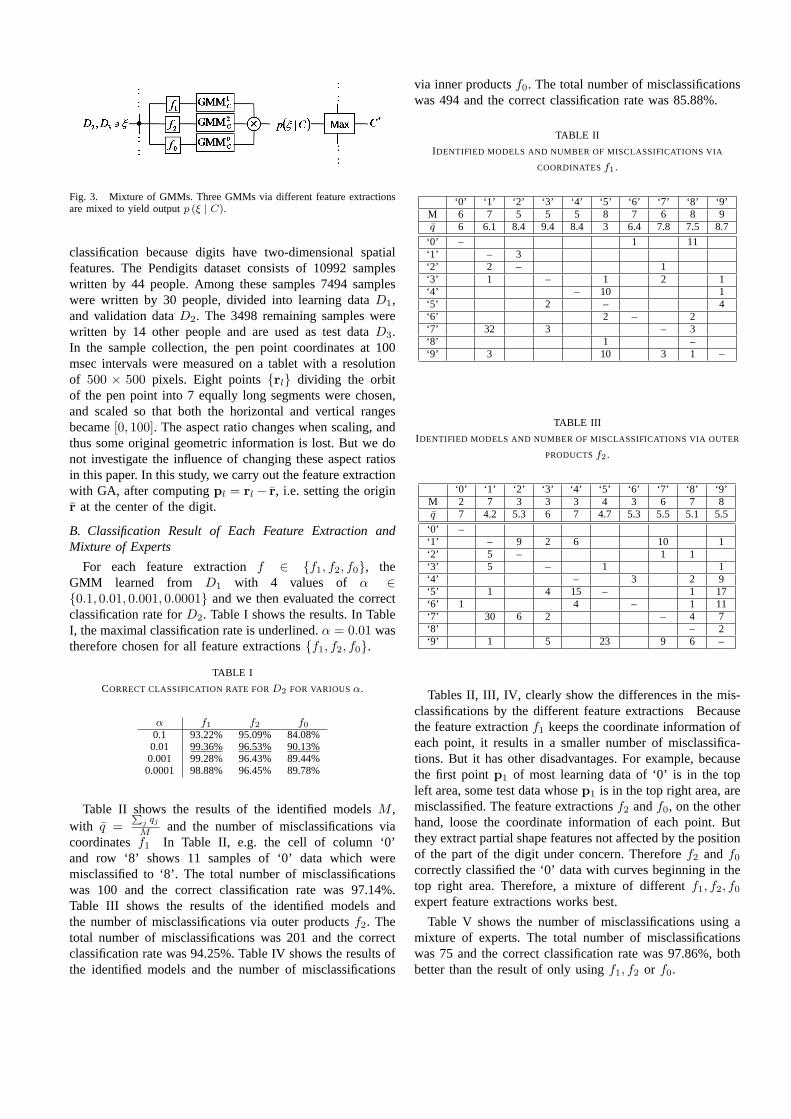
Fig. 3. Mixture of GMMs. Three GMMs via different feature extractionsare mixed to yield outputp (ξ | C).
classification because digits have two-dimensional spatialfeatures. The Pendigits dataset consists of 10992 sampleswritten by 44 people. Among these samples 7494 sampleswere written by 30 people, divided into learning dataD1,and validation dataD2. The 3498 remaining samples werewritten by 14 other people and are used as test dataD3.In the sample collection, the pen point coordinates at 100msec intervals were measured on a tablet with a resolutionof 500 × 500 pixels. Eight points{rl} dividing the orbitof the pen point into 7 equally long segments were chosen,and scaled so that both the horizontal and vertical rangesbecame[0, 100]. The aspect ratio changes when scaling, andthus some original geometric information is lost. But we donot investigate the influence of changing these aspect ratiosin this paper. In this study, we carry out the feature extractionwith GA, after computingpl = rl− r̄, i.e. setting the originr̄ at the center of the digit.
B. Classification Result of Each Feature Extraction andMixture of Experts
For each feature extractionf ∈ {f1, f2, f0}, theGMM learned from D1 with 4 values of α ∈{0.1, 0.01, 0.001, 0.0001} and we then evaluated the correctclassification rate forD2. Table I shows the results. In TableI, the maximal classification rate is underlined.α = 0.01 wastherefore chosen for all feature extractions{f1, f2, f0}.
TABLE I
CORRECT CLASSIFICATION RATE FORD2 FOR VARIOUSα.
α f1 f2 f0
0.1 93.22% 95.09% 84.08%0.01 99.36% 96.53% 90.13%0.001 99.28% 96.43% 89.44%0.0001 98.88% 96.45% 89.78%
Table II shows the results of the identified modelsM ,with q̄ =
Pj qj
M and the number of misclassifications viacoordinatesf1.In Table II, e.g. the cell of column ‘0’and row ‘8’ shows 11 samples of ‘0’ data which weremisclassified to ‘8’. The total number of misclassificationswas 100 and the correct classification rate was 97.14%.Table III shows the results of the identified models andthe number of misclassifications via outer productsf2. Thetotal number of misclassifications was 201 and the correctclassification rate was 94.25%. Table IV shows the results ofthe identified models and the number of misclassifications
via inner productsf0. The total number of misclassificationswas 494 and the correct classification rate was 85.88%.
TABLE II
IDENTIFIED MODELS AND NUMBER OF MISCLASSIFICATIONS VIA
COORDINATESf1 .
‘0’ ‘1’ ‘2’ ‘3’ ‘4’ ‘5’ ‘6’ ‘7’ ‘8’ ‘9’M 6 7 5 5 5 8 7 6 8 9q̄ 6 6.1 8.4 9.4 8.4 3 6.4 7.8 7.5 8.7
‘0’ – 1 11‘1’ – 3‘2’ 2 – 1‘3’ 1 – 1 2 1‘4’ – 10 1‘5’ 2 – 4‘6’ 2 – 2‘7’ 32 3 – 3‘8’ 1 –‘9’ 3 10 3 1 –
TABLE III
IDENTIFIED MODELS AND NUMBER OF MISCLASSIFICATIONS VIA OUTER
PRODUCTSf2 .
‘0’ ‘1’ ‘2’ ‘3’ ‘4’ ‘5’ ‘6’ ‘7’ ‘8’ ‘9’M 2 7 3 3 3 4 3 6 7 8q̄ 7 4.2 5.3 6 7 4.7 5.3 5.5 5.1 5.5
‘0’ –‘1’ – 9 2 6 10 1‘2’ 5 – 1 1‘3’ 5 – 1 1‘4’ – 3 2 9‘5’ 1 4 15 – 1 17‘6’ 1 4 – 1 11‘7’ 30 6 2 – 4 7‘8’ – 2‘9’ 1 5 23 9 6 –
Tables II, III, IV, clearly show the differences in the mis-classifications by the different feature extractions.Becausethe feature extractionf1 keeps the coordinate information ofeach point, it results in a smaller number of misclassifica-tions. But it has other disadvantages. For example, becausethe first pointp1 of most learning data of ‘0’ is in the topleft area, some test data whosep1 is in the top right area, aremisclassified. The feature extractionsf2 andf0, on the otherhand, loose the coordinate information of each point. Butthey extract partial shape features not affected by the positionof the part of the digit under concern. Thereforef2 and f0
correctly classified the ‘0’ data with curves beginning in thetop right area. Therefore, a mixture of differentf1, f2, f0
expert feature extractions works best.
Table V shows the number of misclassifications using amixture of experts. The total number of misclassificationswas 75 and the correct classification rate was 97.86%, bothbetter than the result of only usingf1, f2 or f0.
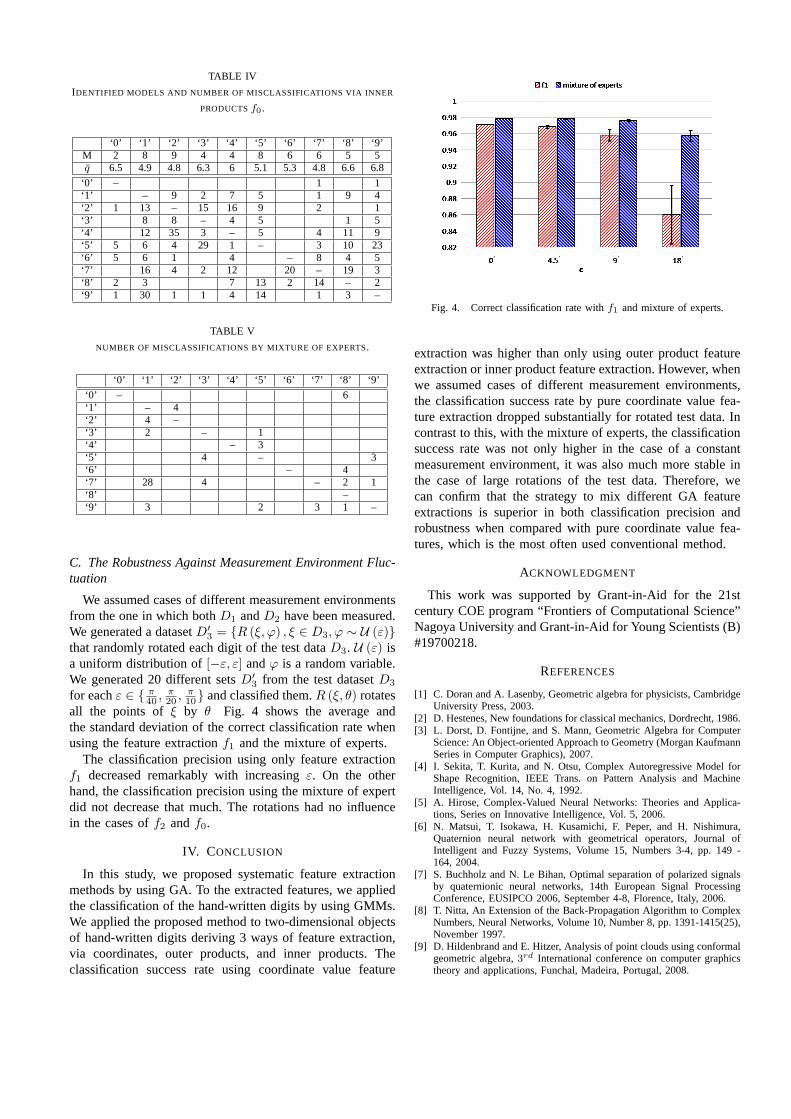
TABLE IV
IDENTIFIED MODELS AND NUMBER OF MISCLASSIFICATIONS VIA INNER
PRODUCTSf0 .
‘0’ ‘1’ ‘2’ ‘3’ ‘4’ ‘5’ ‘6’ ‘7’ ‘8’ ‘9’M 2 8 9 4 4 8 6 6 5 5q̄ 6.5 4.9 4.8 6.3 6 5.1 5.3 4.8 6.6 6.8
‘0’ – 1 1‘1’ – 9 2 7 5 1 9 4‘2’ 1 13 – 15 16 9 2 1‘3’ 8 8 – 4 5 1 5‘4’ 12 35 3 – 5 4 11 9‘5’ 5 6 4 29 1 – 3 10 23‘6’ 5 6 1 4 – 8 4 5‘7’ 16 4 2 12 20 – 19 3‘8’ 2 3 7 13 2 14 – 2‘9’ 1 30 1 1 4 14 1 3 –
TABLE V
NUMBER OF MISCLASSIFICATIONS BY MIXTURE OF EXPERTS.
‘0’ ‘1’ ‘2’ ‘3’ ‘4’ ‘5’ ‘6’ ‘7’ ‘8’ ‘9’
‘0’ – 6‘1’ – 4‘2’ 4 –‘3’ 2 – 1‘4’ – 3‘5’ 4 – 3‘6’ – 4‘7’ 28 4 – 2 1‘8’ –‘9’ 3 2 3 1 –
C. The Robustness Against Measurement Environment Fluc-tuation
We assumed cases of different measurement environmentsfrom the one in which bothD1 andD2 have been measured.We generated a datasetD′
3 = {R (ξ, ϕ) , ξ ∈ D3, ϕ ∼ U (ε)}that randomly rotated each digit of the test dataD3. U (ε) isa uniform distribution of[−ε, ε] andϕ is a random variable.We generated 20 different setsD′
3 from the test datasetD3
for eachε ∈ { π40 , π
20 , π10} and classified them.R (ξ, θ) rotates
all the points of ξ by θ.Fig. 4 shows the average andthe standard deviation of the correct classification rate whenusing the feature extractionf1 and the mixture of experts.
The classification precision using only feature extractionf1 decreased remarkably with increasingε. On the otherhand, the classification precision using the mixture of expertdid not decrease that much. The rotations had no influencein the cases off2 andf0.
IV. CONCLUSION
In this study, we proposed systematic feature extractionmethods by using GA. To the extracted features, we appliedthe classification of the hand-written digits by using GMMs.We applied the proposed method to two-dimensional objectsof hand-written digits deriving 3 ways of feature extraction,via coordinates, outer products, and inner products. Theclassification success rate using coordinate value feature
Fig. 4. Correct classification rate withf1 and mixture of experts.
extraction was higher than only using outer product featureextraction or inner product feature extraction. However, whenwe assumed cases of different measurement environments,the classification success rate by pure coordinate value fea-ture extraction dropped substantially for rotated test data. Incontrast to this, with the mixture of experts, the classificationsuccess rate was not only higher in the case of a constantmeasurement environment, it was also much more stable inthe case of large rotations of the test data. Therefore, wecan confirm that the strategy to mix different GA featureextractions is superior in both classification precision androbustness when compared with pure coordinate value fea-tures, which is the most often used conventional method.
ACKNOWLEDGMENT
This work was supported by Grant-in-Aid for the 21stcentury COE program “Frontiers of Computational Science”Nagoya University and Grant-in-Aid for Young Scientists (B)#19700218.
REFERENCES
[1] C. Doran and A. Lasenby, Geometric algebra for physicists, CambridgeUniversity Press, 2003.
[2] D. Hestenes, New foundations for classical mechanics, Dordrecht, 1986.[3] L. Dorst, D. Fontijne, and S. Mann, Geometric Algebra for Computer
Science: An Object-oriented Approach to Geometry (Morgan KaufmannSeries in Computer Graphics), 2007.
[4] I. Sekita, T. Kurita, and N. Otsu, Complex Autoregressive Model forShape Recognition, IEEE Trans. on Pattern Analysis and MachineIntelligence, Vol. 14, No. 4, 1992.
[5] A. Hirose, Complex-Valued Neural Networks: Theories and Applica-tions, Series on Innovative Intelligence, Vol. 5, 2006.
[6] N. Matsui, T. Isokawa, H. Kusamichi, F. Peper, and H. Nishimura,Quaternion neural network with geometrical operators, Journal ofIntelligent and Fuzzy Systems, Volume 15, Numbers 3-4, pp. 149 -164, 2004.
[7] S. Buchholz and N. Le Bihan, Optimal separation of polarized signalsby quaternionic neural networks, 14th European Signal ProcessingConference, EUSIPCO 2006, September 4-8, Florence, Italy, 2006.
[8] T. Nitta, An Extension of the Back-Propagation Algorithm to ComplexNumbers, Neural Networks, Volume 10, Number 8, pp. 1391-1415(25),November 1997.
[9] D. Hildenbrand and E. Hitzer, Analysis of point clouds using conformalgeometric algebra,3rd International conference on computer graphicstheory and applications, Funchal, Madeira, Portugal, 2008.

[10] E. Hitzer, Quaternion Fourier Transform on Quaternion Fields andGeneralizations, Advances in Applied Clifford Algebras, 17(3), pp. 497-517 (2007).
[11] G. Sommer, Geometric Computing with Clifford Algebras, Springer,2001.
[12] A. Dempster, N. Laird, and D. Rubin, Maximum likelihood fromincomplete data via the EM algorithm. Journal of the Royal StatisticalSociety Series B, Vol. 39, No. 1, pp. 1—38, 1977.
[13] A. Asuncion, and D. J. Newman, UCI Machine Learning Repository.Irvine, CA: University of California, School of Information and Com-puter Science, 2007.
[14] M. E. Tipping and C. M. Bishop, Mixtures of probabilistic principalcomponent analysers, Neural Computation, Vol. 11, pp. 443–482, 1999.
[15] P. Meinicke and H. Ritter, Resolution-Based Complexity Control forGaussian Mixture Models, Neural computation Vol. 13, Issue 2, pp.453—475, February 2001.