evolutionary induction of stochastic context free grammars
TRANSCRIPT

Pattern Recognition 38 (2005) 1393–1406www.elsevier.com/locate/patcog
Evolutionary induction of stochastic context free grammars
Bill Keller, Rudi Lutz∗Department of Informatics, The University of Sussex, Falmer, Brighton BN1 9QH, UK
Received 17 March 2004; accepted 17 March 2004
Abstract
This paper describes an evolutionary approach to the problem of inferring stochastic context-free grammars from finitelanguage samples. The approach employs a distributed, steady-state genetic algorithm, with a fitness function incorporatinga prior over the space of possible grammars. Our choice of prior is designed to bias learning towards structurally simplergrammars. Solutions to the inference problem are evolved by optimizing the parameters of a covering grammar for a givenlanguage sample. Full details are given of our genetic algorithm (GA) and of our fitness function for grammars. We present theresults of a number of experiments in learning grammars for a range of formal languages. Finally we compare the grammarsinduced using the GA-based approach with those found using the inside–outside algorithm. We find that our approach learnsgrammars that are both compact and fit the corpus data well.� 2005 Pattern Recognition Society. Published by Elsevier Ltd. All rights reserved.
Keywords:Grammatical inference; Grammar induction; Genetic algorithm; Stochastic context-free grammar; Language modeling
1. Introduction
Grammatical inference[1] is an important problem ofmachine learning, with key applications in many fields, in-cluding speech recognition[2], natural language processing[3,4], bioinformatics[5] and structural pattern recognition[6]. Although a wide variety of techniques for automatedgrammatical inference have been devised (for surveys seeRefs.[7–9]) most are subject to limitations that severely re-strict their range of application. For example, inference maybe limited to grammars for the regular languages[10,11],require access to both positive (grammatical) and negative(ungrammatical) instances of the target language[12], relyon bracketed data[13,14] or involve application-specifictechniques[15]. A goal of the present work has been to pro-vide a robust method for inferring a wide class of stochastic
∗ Corresponding author. Tel.: +44 1273 678 855;fax: +44 1273 671 320.
E-mail address:[email protected](R. Lutz).
0031-3203/$30.00� 2005 Pattern Recognition Society. Published by Elsevier Ltd. All rights reserved.doi:10.1016/j.patcog.2004.03.022
grammars on the basis of just frequency data about stringsin the target language.
Genetic algorithms (GAs)[16] are a family of probabilis-tic optimization techniques that offer advantages over spe-cialized procedures for automated grammatical inference. Anumber of researchers have already described applicationsof GAs to language identification problems with some suc-cess[12,17–30]. However, most of these researchers havenot addressed the problem of learningstochasticlanguagemodels. This is surprising in view of the many practicalapplications of such models to tasks such as speech recog-nition, part-of-speech tagging, optical character recognitionand robust parsing. While Schwem and Ost[25] do recog-nize the importance of the stochastic inference problem, theyrestrict their attention to the inference of stochastic regulargrammars. A GA-based approach to the problem of induc-ing stochastic context-free grammars is described by Kam-meyer and Belew[28]. However, their approach relies on theuse of the inside–outside (IO) algorithm[31] as a means oftuning production probabilities during evolution, and theyreport on only two simple language-learning experiments.

1394 B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406
The present work tackles the problem of inferring stochas-tic grammars for the class of context-free languages. A pre-liminary account of our general approach was presented inRef. [32]. Starting with a large covering grammar (i.e. a fi-nite set of rules which is guaranteed to generateat leasttheavailable example sentences), we use a GA to find a sub-set of the rules together with their parameters, which bothmodels the distribution of the sample sentences well, andgeneralizes appropriately. If the parameters of those rules inthe covering grammar that have been “rejected” are takento be zero, then this reduces to the problem of finding ap-propriate parameters for the rules in the covering grammar.Grammatical inference can therefore be regarded as a kindof optimization problem.
The standard approach to optimizing the parameters of astochastic context-free grammar given a language sample isto use the IO algorithm[31], an instance of the expectationmaximization[33,34] technique. IO estimation is an itera-tive procedure that searches for a (local) maximum in theparameter space. From the perspective of grammatical infer-ence however, there are well-known limitations to this ap-proach. In particular, there is no pressure to eliminate modelparameters, and the resulting grammars are usually complexand hard to interpret meaningfully. In addition, good perfor-mance of the IO algorithm is highly dependent on good ini-tial estimates for the rule parameters[35]. A poor choice ofinitial parameter estimates adversely affects both the speedwith which the algorithm converges, and the quality of thesolution that is found.
The structure of the remainder of this paper is as follows.In the next section we provide a brief overview of stochasticcontext-free grammar (SCFG) and the problem of corpus-based grammatical inference. Rather than inducing SCFGsdirectly, we find it more convenient to work with an al-ternative formalism that we call biased weighted grammar(BWG). The BWG formalism is introduced in Section 3 andin Section 4 we define a prior over BWGs that is designedto bias learning towards smaller, simpler grammar. A briefconsideration of the relationship between our prior and de-scription length is provided in Section 5. Section 6 describesour GA-based search procedure in detail, including discus-sion of our representation for grammars and the genetic op-erators that we employ. Then, in Section 7 we describe ourexperimental set-up and in Section 8 we report on the resultsof a number of language learning experiments. A compari-son of our approach with the IO algorithm is presented inSection 9. This is followed by a discussion and conclusion.
2. Corpus-based inference of stochastic CFGs
The SCFG formalism is a variant of context-free grammarin which each grammar rule is associated with a probabil-ity, a real number in the range [0,1]. The set of productionprobabilities may be referred to as theparametersof theSCFG. For a SCFGG, the languageL(G) generated byG
Fig. 1. SCFG for the languageanbn (n�1).
comprises the set of all strings of terminal symbols deriv-able from the start symbol of the grammar. In addition, therule parameters provide for the assignment of a (non-zero)probabilityPG(�) to each string� in L(G). The probabilityof a parse tree for a string� in L(G) is defined as the prod-uct of the probabilities of all the grammar rules involvedin its construction. The probabilityPG(�) of the string� isthen given as the sum of the probabilities of all of its parses.
An example of a simple SCFG is shown inFig. 1, with theprobability associated with each production given in paren-theses. The SCFG generates the language{anbn|n�1},wherePG(ab)= 0.6, PG(aabb)= 0.24, and so on.
For a SCFGG, it is normal to require that the probabilitiesassociated with all rules expanding the same non-terminalsymbol must sum to one. In this case,G is said to beproper.Also,G is said to beconsistentjust in case∑�∈L(G)
PG(�)= 1.
In what follows we will require that SCFGs are proper. Wewill also assume consistency, although nothing crucial de-pends on this. For a discussion of the conditions under whichSCFGs are consistent the reader is referred to Gonzalez andThomason[36].
A corpusC for a languageL is a finite set of strings drawnfromL, where each string� ∈ C is associated with an integerf (�) representing itsfrequency of occurrence. ThesizeNCof the corpus is defined as the sum of the frequencies of theindividual strings inC:
NC =∑�∈C
f (�).
The relative frequencyp(�) of a string� ∈ C is defined asp(�)= f (�)/NC . An example of a corpus for the language{anbn|n�1} is shown inFig. 2. The frequency of the stringab is 595, the frequency ofaabb is 238, and so on. Thetotal size of the corpus is 998. The relative frequencies ofthe stringsabandaabbare given byp(ab)= 0.596192 andp(aabb)= 0.238477.
Given a corpusC as training data, the inference problemis to identify a SCFG that (a) models the corpus as accu-rately as possible, and (b) generalizes appropriately to thewider language from which the corpus was drawn. A natu-ral and commonly used measure of accuracy or “goodness”

B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406 1395
Fig. 2. A corpus for the languageanbn.
for stochastic language models is the probability of the cor-pus data given the model. According to this measure, thebest we can do is to choose a grammarG maximizing thelikelihood functionP(C|G). That is,
G= argmaxG
P(C|G), (1)
whereP(C|G) may be defined as
P(C|G)= NC !∏�∈Cf (�)!
∏�∈C
PG(�)f (�).
The above formula requires some comment. Disregardingthe multinomial term for the moment, the product overstrings inC yields the probability (according toG) of aparticular sequence of strings, where each string� occursexactlyf (�) times. But, in general there are many such se-quences, differing only in the order in which the variousstrings occur. The probability of the corpus dataC given thegrammarG is therefore the sum of the probabilities of allof these sequences, of which there are exactly the numbergiven by the multinomial expression.
Unfortunately, there is no guarantee that simply maximiz-ing the probability of the corpus data according to Eq. (1)above will meet the further requirement ofgeneralization.To see this, note that the best grammar we could find fora finite corpus is one that generates the corpus exactly andassigns to each string its correct relative frequency. In otherwords, the most accurate grammar willover-fit the trainingdata. Intuitively, what we actually require is a grammar thatis most probable given the training data. That is, we wishto find G such that
G= argmaxG
P(G|C). (2)
The problem now is that it is not clear how to calculateP(G|C) directly. From Bayes rule we have
P(G|C)= P(G)× P(C|G)P (C)
.
Disregarding P(C), which is a constant, maximizingP(G|C) just corresponds to maximizing the product ofP(C|G), which we can calculate directly, andP(G), theprior probability of the grammarG. Of course, this posesthe problem of fixing an appropriate prior probabilitydistribution over grammars.
In principle there are many different priors that could bechosen, but it seems reasonable to assume that we shouldprefer smaller or simpler grammars to larger, more complexones. In fact, there are several, distinct reasons why thismay be so. First, smaller grammars with fewer parametersshould help to avoid the problem of over-fitting and lead tobetter generalization performance. Second, structurally sim-pler grammars are likely to be easier to comprehend and tointerpret. Third, since the time complexity of context-freeparsing is related to grammar size, compact grammars mayyield useful reductions in parse-time. Our choice of prioris therefore designed to give greater probability to compactgrammars. Essentially, we first fix a prior probability distri-bution over grammar rules, such that shorter rules are moreprobable than longer rules. The prior probability of a gram-mar is then defined in terms of the product of the prior prob-abilities of all of its rules. The details of this approach areexplained in the following sections.
3. Biased weighted grammars
There are a number of problems with the SCFG formal-ism from the perspective of grammatical inference. First,it is necessary for the learning algorithm to manipulate theprobabilities associated with the rules, and these are not in-dependent quantities. Additionally, there is no explicit mech-anism within the SCFG formalism that might allow us toexpress preferences for some types of rule over others. Ac-cordingly, rather than attempting to learn SCFGs directly, itturns out to be more convenient to deal with a related for-malism which we call BWG.
BWG is similar to SCFG in that grammar rules haveassociated numerical parameters. In a BWG however, eachgrammar rule is associated with two parameter values ratherthan just one: a real-valuedbias, and an integerweight.Both the biases and the weights are positive; also, the setof rule biases is required to sum to 1 (the biases define aprobability distribution over the set of all grammar rules).The cardinality of a BWGG is defined as the sum of therule weights and denoted byWG. The biases may be usedto code preferences for particular rules, while the weightscan be understood as integer rule counts (and therefore maybe manipulated independently of one another).
One way of thinking about a BWG is to imagine thatfor each non-terminal symbol in the grammar there is acorresponding, many-sided dice. For a given non-terminalX, each side of the correspondingX-dice is labeled by agrammar rule that expands it, and for each such rulerj therearewj faces labeled by that rule. Now, whenever we wishto rewrite a non-terminal symbolX during a derivation wecan throw theX-dice and use whichever rule comes up todo the rewriting. However, the dice is not a fair one: theprobability of landing on arj face is biased by the factorbj ,so that even if all the weights are identical, the probabilitiesof the various rules may still be different.

1396 B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406
It is not difficult to see that any BWGG can be convertedto an equivalent SCFGG′. Let Rj denote the set of rulesin G that expand the same non-terminal symbol as rulerj .Then, for each rulerj inG, with biasbj and weightwj thereis an identical rulerj in G′, with associated probabilitypjgiven by
pj = bjwj∑ri∈Rj biwi
.
We define the language generated by a BWGG to beL(G′):the language generated by the equivalent SCFGG′ and withthe same associated probability distribution over its sen-tences.
Weighted grammar[37] can be considered a special caseof BWG where all of the biases are set to the same value. Itshould be noted that any BWG is equivalent to some unbi-ased grammar. However, this does not mean that specifyingthe biases is pointless. It turns out that it is easier to learna BWG than the corresponding unbiased grammar, becausethe biases enable us to specify a preference for certain typesof rule. In particular, we fix a prior over grammars whichreflects a preference for simpler rules over more complexones.
4. A prior over biased weighted grammars
Given an initial covering grammar (a finite set of context-free grammar rulesR) our approach to grammar inductioninvolves a search for a suitable subset ofR, together witha set of associated parameters that models the target lan-guage accurately and generalizes appropriately. Rather thanattempting to infer an SCFG directly however, we tackle theproblem of grammar learning by trying to identify a suitableBWG with the required properties, and take its equivalentSCFG as the one learned by our system.
In the following we define a prior probability distributionover the space of all possible BWGs that may be obtainedfrom the covering rule set. Let us first assume the existenceof two probability distributions: a priorPR over the rulesin R, and a priorPN over the (positive, non-zero) integers.Now consider the following process for generating a BWGG. We begin by choosing an integerk >0 as the cardinalityof the grammar being generated. Next, we draw rules fromthe covering rule setR at random, with probability givenby the prior distributionPR . This draw is carried out withreplacement, so that the same rule may be selected repeat-edly, and the draw is terminated once we have made exactlyk selections. The derived BWGG has a rule set given byR, where each rulerj has a biasbj = PR(rj ) and an inte-ger weightwj equal to the number of times the rulerj wasselected in the draw. Note that the sum of thebj is 1 andthe cardinalityWG of G is equal tok (i.e. the sum of allthewj ). Accordingly, the probability of drawing the gram-marG (givenR, PR andPN ) is defined by the following
formula:
P(G)= WG!∏rj∈R wj !
∏rj∈R
bwjjPN(WG). (3)
We take Eq. (3) to be our prior probability distribution overgrammars. Note that the explanation for the appearance ofthe multinomial term is quite analogous to that given for itsuse in the definition of a corpus provided in Section 2.
In order to apply the definition in Eq. (3), it remains to fixa suitable prior distributionPR over the rules of the coveringgrammar and also a prior distributionPN over the integers.For the latter, we choose one of a family of priors due toRisannen, and induced by prefix codes for the integers (seeRef. [38] for more details). For the encoding we adopt, anintegern is coded with approximately
L(n)= log2(n)+ 2 log2(log2(n+ 1))+ 1
bits.1 The prior probabilityPN(n) of an integern is thenproportional to 2−L(n).
A natural way of computing the prior probability of eachrule rj is to look at the probabilities of the symbols thatoccur at each position in the rules of the covering rule setR. In particular, we consider the set of symbols allowedat a particular position in the rules,given the precedingsymbols. If we assume that all the symbols occurring ata given position are equiprobable, then we can computePR(rj ) in the following manner.
LetN be the set of non-terminal symbols that occur in thecovering rule setR and letn be the length of the right-handside of the longest rule. Now write each rulerj = sj0 →sj1 . . . sjm in the formsj0 → sj1 . . . sjmsjm+1 . . . sjn whereeach of thesjm+1 . . . sjn is a special “blank” symbol. Foreachk (0�k�n) defineSj,k to be that set of symbols givenby
Sj,k ={N if k = 0,{sik |ri ∈ R andsil = sjl (0� l < k)} otherwise.
The probabilityPj,k with which symbolsjk occurs at posi-tion k of rule rj is then defined as
Pj,k = 1
|Sj,k | .
Finally, the prior probabilityPR(rj ) of rule rj is defined asthe product of the probabilities of the symbols that make itup:
PR(rj )=∏
0�k�nPj,k .
Note that this scheme generally assigns greater probabilitymass to shorter rules.
1 The n + 1 in the second term of this formula is simply toensure that the formula is well-defined for all integersn>1.

B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406 1397
5. A note on the prior and the MDL principle
The problem of grammatical inference from a corpus canbe viewed as an instance of a much more general problem,that of finding a suitable theory to account for some data.For any given set of data there are always many theoriesthat can account for it, and one is left with the task of tryingto choose amongst the competing alternatives. A principlethat is often appealed to in this context is that ofOccam’srazor, which states, roughly speaking, that given a choiceof theories, the simplest is preferable. There are two aspectsto this notion of simplicity however. On the one hand thereis the issue of how simply the theory describes the data,and on the other hand, how simple is the description ofthe theory itself. The tradeoff between these two aspectsof simplicity was formalized by Risannen[39] within thecontext of algorithmic information theory as theminimumdescription length(MDL) principle. Given some data setD,MDL claims that we should pick that theoryTminimizing:
L(T )+ L(D|T ),whereL(T ) is the number of bits needed to minimally en-code the theoryT, andL(D|T ) is the number of bits neededto minimally encode the dataD given the theoryT.
Shannon’s information theory[40] tells us that if we havea discrete setX of items with a probability distributionP(x)defined over it, then in the limit, to identifyx ∈ X we needto useL(x)= −log2P(x) bits.2 In other words,
P(x)= 2−L(x).This enables us to interpret the MDL principle in Bayesianterms: minimizingL(T ) + L(D|T ) corresponds to maxi-mizing P(T )× P(D|T ) and henceP(T |D).
In our case, given a corpusC, we wish to identify agrammarG minimizing the quantity
L(G)+ L(C|G), (4)
whereL(G) = −log2P(G) is the description length of thegrammar, andL(C|G) = −log2P(C|G) is the descriptionlength of the corpus given the grammar. It is interesting toconsider the interpretation of our prior over grammars inmore detail. From the definition of the prior,L(G) is givenby
L(G)= − log2
(WG!∏rj∈Rwj !
)
−∑
rj∈Rwj log2 bj − log2PN(WG). (5)
The final expression in Eq. (5) is just the number of bitsneeded to encode the integer cardinality of the grammar
2 The Kraft Inequality (see Ref.[41] for details), also impliesthe converse i.e. if we have a set of prefix codes for the elementsof X, then the length of these codewords can be used to define aprobability distribution overX by settingP(x) ∝ 2−L(x).
G, as explained previously in Section 4. The second termcan be understood as the number of bits needed to send asequence of messages describing the grammar rules ofG,using a code that is optimally efficient when the rules occurin proportion to the rule biases. It is initially harder to find aninterpretation of the first expression in terms of descriptionlength. However, for reasonably largewj it can be shown toapproximate the (negative) number of bits needed to describethe grammar rules ofG, but now assuming that the rulesoccur in exact proportion to their integer weights, rather thanthe biases.3 Consequently, minimizing (5) can be seen tohave two effects. On the one hand, description length willgenerally be shorter for grammars with lower cardinalityWG. This in turn implies a preference for grammars withsmaller rules sets, although it is perhaps more correct to viewit as a preference for lower precision in the specification ofthe rule parameters. On the other hand, for a fixed choiceof cardinality, description length will be minimized whenthe rule weights are in exact proportion to the rule biases,which in our case ensures a preference for shorter rules.
While information theory can be used to provide an in-sight into the prior in terms of description length, a num-ber of researchers have made more direct use of the MDLprinciple in grammatical inference. Stolcke[43] describesa corpus-based approach to learning probabilistic languagemodels based on merging and chunking of non-terminals.Starting from an overly specific covering grammar, the op-erators are applied to incrementally generalize the gram-mar, with a description length prior used to select the mostpromising operator to apply at each stage. Using increas-ingly sophisticated search strategies he reports success inlearning SCFGs for a number of formal languages. Chen[11] employs greedy heuristic search to look for a grammarmaximizing a function of the form of Eq. (4) above. He usesdescription length arguments to define a prior over stochas-tic context-free grammars, although for technical reasonshis approach is actually restricted to learning regular gram-mars. Both Grunwald[44] and Hong and Clark[15] applygrammar transformation techniques to learn (non-stochastic)grammars from an initial covering grammar. Grunwald’s ap-proach can be viewed as an implementation and extension ofmuch earlier work due to Solomonoff[45], while Hong andClark use an MDL-based measure originally due to Cook etal. [46]. In more recent work, Osborne[47] has explored theuse of MDL for extending an existing, manually constructeddefinite clause grammar. Clark[3] describes the use of MDLin an incremental approach to the induction of SCFGs thatis based on distributional clustering of sequences.
3 This follows from Stirling’s approximation (see e.g. Ref.[42]). For suitably large values ofn we have logn! ≈ n logn− n,whence it is possible to show that
−log2
(WG!∏rj∈Rwj !
)≈∑rj∈R
wj log2wj
WG.

1398 B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406
6. An evolutionary approach to grammar induction
A GA [16,48,49] is a stochastic optimization techniquethat often works well in difficult search landscapes. Inspiredby ideas taken from biology and natural evolution, a GAmaintains a population of individuals, each of which encodesa candidate solution to a given problem. In outline, a GAworks by repeatedly carrying out the following steps.
Select individuals from the population, based on an objec-tive measure of their ‘fitness’ as solutions to the targetproblem.
Breed one or more ‘children’ from the chosen individualsusing operations of recombination and mutation to mixfeatures of the ‘parents’, and to introduce some randomvariation.
Replace one or more members of the original populationby one or more of the resulting children.
This process has been shown to improve the fitness of thepopulation over time, under a wide range of selection andreplacement policies, and choice of recombination and mu-tation operators[48,49]. To adapt the technique to the prob-lem of corpus-based induction of grammars, we begin byconstructing a covering grammar that generates the corpusas a (proper) subset. Next, we set up a (randomly initial-ized) population of individuals encoding parameter settingsfor the rules of the covering grammar. We then apply a GAto improve the population of grammar encodings, and iter-ate until an appropriate stopping condition is met (e.g. thepopulation has converged). Finally, we take the grammarcorresponding to the fittest individual produced by the GAto be that learned by the system. In the following sectionswe describe the genetic algorithm employed by our systemfor grammar induction in more detail.
6.1. Selection and replacement
In the GA literature, a distinction is drawn between astandard, generational GA and what has come to be knownas a distributed, steady-state GA[50]. For the generationalGA, at each iteration an entirely new population is createdfrom some set of fit individuals chosen from the currentpopulation. Once complete, the new population replaces theold population in one go. For a distributed, steady-state GA,the population is spatially organized (typically over a two-dimensional grid) and individuals only breed with thosein some local neighborhood. Additionally, children are putback into the population immediately they are produced,rather than after an entire, new population of individualshas been completed. In many domains, distributed, steady-state GAs outperform the classical GA (see for exampleRef. [51]). This appears to be due to the selection and re-placement policy, which allows for rival solutions to emergeat different locations, and discourages too fast a spread ofsuccessful genetic information throughout the whole pop-
ulation. This in turn helps to avoid the risk of “prematureconvergence”, whereby the population as a whole rapidlyhomes in on some sub-optimal solution to the target prob-lem.
In this work we have chosen to make use of a distributed,steady-state GA. The population of our GA is organizedas a two-dimensional grid, with opposing sides of the grididentified (i.e. members of the population inhabit the surfaceof a torus). Each grid location contains exactly one memberof the population, and each member of the population hasexactly eight adjacent neighbors with which it is allowed tobreed. A member of the population represents a BWG interms of a set of rule weights associated with the rules ofthe covering grammar. For a corpus C, an individual in thepopulation representing a BWGG is evaluated according tothe following fitness function:
fGA(G)= KC
L(G)+ L(C|G) . (6)
In Eq. (6), the numeratorKC is a corpus-dependentconstant bringing fitness values into the range[0,1].Maximizing this fitness function therefore minimizes thecombined description length of the corpus and the gram-mar (see Section 5). The algorithm proceeds as follows:
repeat until ( stopping condition is met )p1 = select an individual at random from the population;p2 = select the fittest of the eight neighbors ofp1;c1, c2 = breed two children fromp1 andp2;mutatec1 andc2;replace the least fit ofp1 and p2 by the fittest ofc1 andc2;endrepeat
Note that both selection and replacement are carried outwithin a small, local population. In addition, the fitter of thetwo children replaces the weaker of the two selected parents.This policy ensures that relatively unfit individuals may geta chance at breeding (thereby maintaining genetic diversityin the population) while useful genetic material from theweakest parent can still survive through the fittest child.
For later convenience in reporting experimental results,we will define a “generation” of the GA to beM iterationsof the basic select-breed-replace loop shown above, whereM is the size of the population. To complete the descriptionof the GA it remains to describe the representation of gram-mars and the genetic operators used for recombination andmutation.
6.2. The genomic representation of grammars
In order to represent a grammar, it is necessary to encodethe set of integer weights associated with the rules of thecovering rule set. Note that there is no need to representthe rule biases, as these are the same for every individualin the population and are determined in advance according

B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406 1399
to the prior probability distributionPR over grammar rules.Suppose that we fix some ordering on the rulesR of thecovering grammar. A simple scheme for representing the setof weights for a BWGG with rule setR is to encode eachweight as a fixed length bit-string. These encodings can thenbe concatenated in the prescribed order to form the genomerepresentation ofG.
A drawback to this simple approach however, is that thecovering grammar will generally have many more rules thanthe target grammar. As it stands, the encoding makes it rel-atively hard for the random processes of recombination andmutation to “turn a rule off” (i.e. to set all of the weight bitsto zero). In order to overcome this problem, we thereforeadapt the parameter representation by adding a small num-ber of initial bits to each of the bit strings encoding an inte-ger weight. Now, if each of these initial bits is set to 1, thenthe remaining bits are decoded to obtain the rule weight,and otherwise the weight is taken to be zero. In this way,the number of initial bits can be used to control the amountof bias in favor of zero weight, while the number of remain-ing bits controls the maximum size of the weights (and thusthe maximum precision with which the rule parameters canbe represented). In practice we have found that using justone initial bit combined with a block of seven bits encod-ing the integer weight works well. This combination is usedfor all of the language-learning experiments reported in thesubsequent sections.
A notable characteristic of our chosen representation isthat the probability of any given rule does not depend solelyon local properties of the genome (i.e. the state of the rele-vantn-bit block). In general, it will also depend on all of theweight encodings associated with rules expanding the samenon-terminal symbol. Further, the fitness of a given individ-ual may be crucially dependent on the state of weight en-codings that are widely separated within the genome. Thatis to say, our representation is one that exhibits high epista-sis and where global properties of the genome are in manyways more important than local properties. This presents aproblem, because such global dependencies are likely to bedisrupted during recombination.
6.3. Recombination and mutation
A variety of recombination or “crossover” operators havebeen proposed in the GA literature. The classical recombi-nation operator,one-point crossover, works by first breakingeach parent into two parts at some randomly chosen pointalong the genome. The parts that follow the crossover pointare then exchanged to produce two children that combinegenetic material from both of the parents. This ensures thatthe children are similar to their parents, whilst permitting theintroduction of novel differences that may afford some evo-lutionary advantage. An apparent problem with one-pointcrossover from our point of view however, is that depen-dencies between widely separated parts of the genome areunlikely to be preserved. This may make it hard for the GA
to discover fit individuals, and in the worst case, the popu-lation may simply fail to improve beyond a certain point.
We have experimented with several alternatives to theone-point crossover operator. These are, namely:two-pointcrossover, uniform crossover(see Ref.[49] for further de-tails) and a novel operator that we callrandomized and/orcrossover(RAOC). As its name suggests, the two-pointcrossover operator is similar to one-point crossover, but twocrossover points are chosen instead of one and each parentis broken into three parts. Two children are produced byexchanging the middle parts of the parents’ genomes. Theuniform crossover operator works in a rather different way.Instead of recombining genetic material from the parents inwhole chunks, uniform crossover effectively moves alongthe parents’ genomes one bit at a time, randomly decidingwhether to swap over bit values.
There are many problems where the performance of a GAis greatly enhanced by the use of domain specific operators.In the context of grammatical inference, operations such asintersection and union of rule sets seem to be good candi-dates for recombination operators. It seems plausible thatif two grammars each cover a corpus, but are overly gen-eral, then the intersection of their rule sets may still coverthe corpus, but be less general. Similarly, if two grammarseach cover a different subset of the corpus, then the unionof their two rule sets will cover both subsets. It may benoted that the set-theoretic operations of intersection andunion on rules sets can be approximated at the level of thegenome by the boolean operations of logicalandand log-ical or on grammar encodings. This has led us to define anovel crossover operator which we term RAOC. Like uni-form crossover, RAOC works along the parents’ genomesone bit at a time, creating two children as it goes. However,RAOC is defined so that, with probability�, at each bit po-sition the first child gets the logicalandof the correspond-ing bits of the parents, while the second gets the logicalor.Conversely, with probability(1 − �) the first child gets thelogicalor and the second gets the logicaland. The operatoris randomizedin the sense that the probability� is randomlychosen at the start of each breeding phase (see Appendix Afor a more formal account).
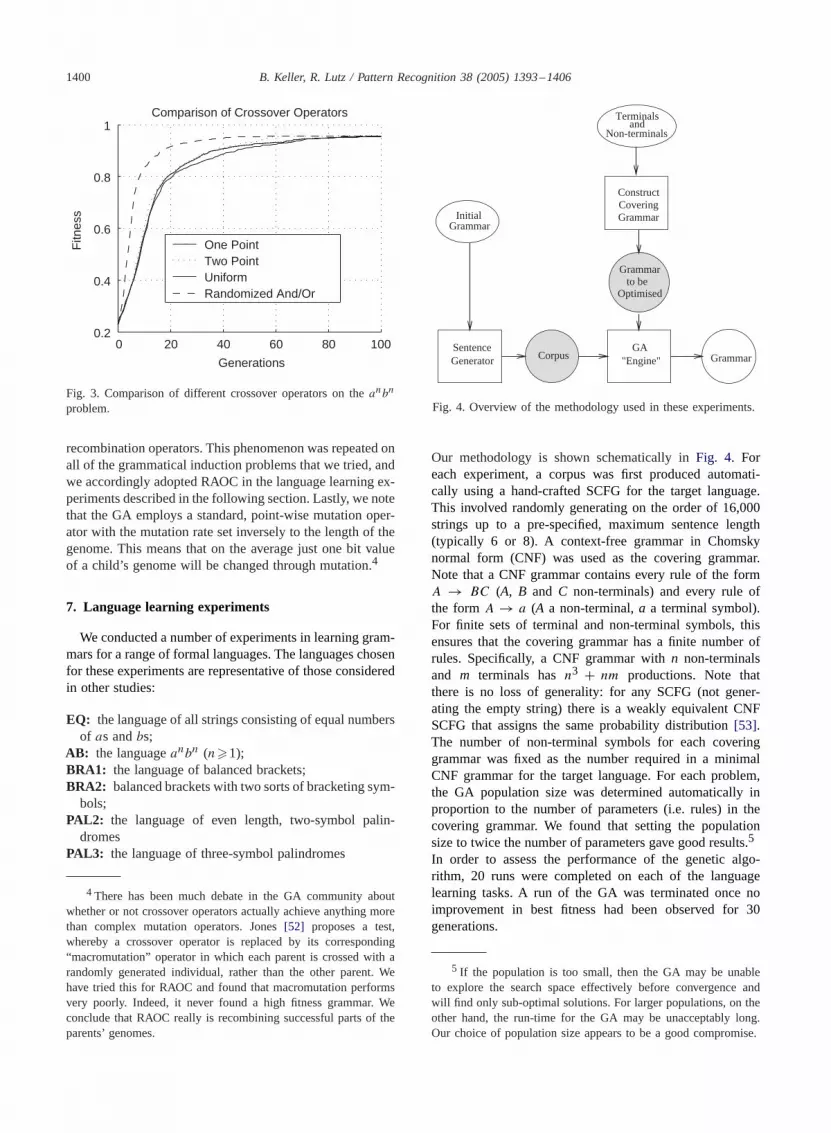
To evaluate the effectiveness of the different operators,we compared their performance on a number of languagelearning tasks (see Section 7 for details of each of thelearning tasks).Fig. 3 provides a comparison of the per-formance of each of the operators on one of our learningtasks (the languageanbn) and is typical of the results ob-served for the other problems. For each operator, the graphshows the fitness of the best individual in the population(averaged over 10 runs) against the number of generations.Clearly, by around 100 generations, fitness in the popula-tion has reached the same point regardless of which of thefour crossover operators was employed by the GA. In thissense, the different crossover operators may be regarded asequivalent. However, it is also clear that RAOC helps theGA to find good solutions far more quickly than the other
1400 B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406
0 20 40 60 80 1000.2
0.4
0.6
0.8
1Comparison of Crossover Operators
Generations
Fitn
ess
One PointTwo PointUniformRandomized And/Or
Fig. 3. Comparison of different crossover operators on theanbn
problem.
recombination operators. This phenomenon was repeated onall of the grammatical induction problems that we tried, andwe accordingly adopted RAOC in the language learning ex-periments described in the following section. Lastly, we notethat the GA employs a standard, point-wise mutation oper-ator with the mutation rate set inversely to the length of thegenome. This means that on the average just one bit valueof a child’s genome will be changed through mutation.4
7. Language learning experiments
We conducted a number of experiments in learning gram-mars for a range of formal languages. The languages chosenfor these experiments are representative of those consideredin other studies:
EQ: the language of all strings consisting of equal numbersof as andbs;
AB: the languageanbn (n�1);BRA1: the language of balanced brackets;BRA2: balanced brackets with two sorts of bracketing sym-
bols;PAL2: the language of even length, two-symbol palin-
dromesPAL3: the language of three-symbol palindromes
4 There has been much debate in the GA community aboutwhether or not crossover operators actually achieve anything morethan complex mutation operators. Jones[52] proposes a test,whereby a crossover operator is replaced by its corresponding“macromutation” operator in which each parent is crossed with arandomly generated individual, rather than the other parent. Wehave tried this for RAOC and found that macromutation performsvery poorly. Indeed, it never found a high fitness grammar. Weconclude that RAOC really is recombining successful parts of theparents’ genomes.
InitialGrammar
SentenceGenerator
GA"Engine"
Non-terminalsand
Terminals
GrammarCorpus
to beGrammar
Optimised
ConstructCoveringGrammar
Fig. 4. Overview of the methodology used in these experiments.
Our methodology is shown schematically inFig. 4. Foreach experiment, a corpus was first produced automati-cally using a hand-crafted SCFG for the target language.This involved randomly generating on the order of 16,000strings up to a pre-specified, maximum sentence length(typically 6 or 8). A context-free grammar in Chomskynormal form (CNF) was used as the covering grammar.Note that a CNF grammar contains every rule of the formA → BC (A, B andC non-terminals) and every rule ofthe formA → a (A a non-terminal,a a terminal symbol).For finite sets of terminal and non-terminal symbols, thisensures that the covering grammar has a finite number ofrules. Specifically, a CNF grammar withn non-terminalsand m terminals hasn3 + nm productions. Note thatthere is no loss of generality: for any SCFG (not gener-ating the empty string) there is a weakly equivalent CNFSCFG that assigns the same probability distribution[53].The number of non-terminal symbols for each coveringgrammar was fixed as the number required in a minimalCNF grammar for the target language. For each problem,the GA population size was determined automatically inproportion to the number of parameters (i.e. rules) in thecovering grammar. We found that setting the populationsize to twice the number of parameters gave good results.5
In order to assess the performance of the genetic algo-rithm, 20 runs were completed on each of the languagelearning tasks. A run of the GA was terminated once noimprovement in best fitness had been observed for 30generations.
5 If the population is too small, then the GA may be unableto explore the search space effectively before convergence andwill find only sub-optimal solutions. For larger populations, on theother hand, the run-time for the GA may be unacceptably long.Our choice of population size appears to be a good compromise.

B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406 1401
As explained in Section 4, our approach to grammar in-duction uses a prior probability distributionPR over gram-mar rules in order to fix the biases of a BWG. The biasesthen reflect prior assumptions about preferences for certainkinds of grammar rules (in our case, roughly speaking, thatshorter rules are preferable). As an alternative, we have alsoconsidered the case where no special assumptions are madeabout the grammar rules. Note that this is equivalent to us-ing a “flat” rule prior, so that all of the biases are uniformlyset to 1/|R|. In order to compare these alternatives we re-peated each of the language learning experiments exactly asbefore, but with uniform biases.
Finally, we note that a potential criticism of our languagelearning experiments is that we specify in advance the cor-rect number of non-terminals to be used in the coveringgrammar. While it is necessary on our approach to providea finite covering grammar, and therefore to specify somefixed, finite set of non-terminals, it is perhaps possible thatby providing a minimal set we are making the inductiontask too easy. To test this, we carried out a further 20 runsfor one of our language learning tasks (the language of two-symbol palindromes,PAL2) but using an expanded set ofnon-terminal symbols.
8. Experimental results
The main results of the language learning experi-ments are summarized in the table given inFig. 5. Foreach learning task, the table shows the target language,the number of non-terminals|N | used to construct thecovering grammar and the number of parameters|R|to be optimized. Two sets of results are presented: thefirst is for our prior as described in Section 4 (biasesfixed according to the probability distributionPR) andthe second is for the case of uniform biases. For bothsets of results, on each task the table shows what per-centage of the 20 runs that were carried out succeededin finding a correct grammar, as well as the maxi-mum fitness value found on the best and worst runs ofthe GA.
A run of the GA is counted as an unequivocal successif the learned grammar is correct in the sense that it
Fig. 5. Results on a number of language learning tasks.
Fig. 6. Near-miss grammar forPAL2.
generates the target language exactly.6 Occasionally how-ever, a grammar that would otherwise be counted as correctcontains one or a small number of additional, spurious ruleswith near zero probability. An example of such a grammarfor the languagePAL2 is shown inFig. 6. Aside from thepresence of one extra production, A→ SA, which has arelatively low associated probability (0.019737), the gram-mar is correct. Runs of the GA that return such “near miss”grammars are counted as successes in the table ofFig. 5.Our justification for including these grammars is twofold.First, near miss grammars are able to model the corpus ac-curately and therefore attain fitness values comparable tocorrect grammars. Conversely, grammars that do not evencontain a correct core rule set fail to achieve high fitness.Second, as the spurious rules often result in an increase ingrammar size for little or no gain in accuracy, it is possi-ble that they would be trimmed automatically given furtherGA generations. In the table, the contribution of near missgrammars to the overall success rate is made clear where ap-propriate, by reporting the success rate excluding near missgrammars in parentheses.
For the GA using the prior of Section 4 the first fourlearning tasks (EQ, AB, BRA1 andBRA2) presented littledifficulty. Only one unsuccessful run of the GA occurred(for the languageanbn). The relatively low fitness valueattained in this case shows the presence of a local maxi-mum around which the population has converged. The palin-drome problems,PAL2 andPAL3, provided the GA witha rather harder test, although the overall success rate re-mained high. Perhaps surprisingly, a slightly higher successrate was returned for thePAL3 learning task than forPAL2.As the figures in parentheses indicate however, near missgrammars contributed increasingly to the total number ofsuccesses.
Using uniform rule biases, very similar results wereachieved by the GA on the first three learning tasks. How-ever, for the languageBRA2 the success rate fell to just25%. Results on the palindrome languages were also mixed,with the GA achieving 85% on thePAL2 task, but just50% forPAL3 (although there were no near misses). This
6 Note that we do not require that the grammar assign exactlythe same probability distribution over strings as the SCFG usedto generate the corpus. However, for a grammar that is correct,parameter optimization invariably results in a close match to theactual distribution and the fitness of the learned grammar is high.

1402 B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406
Fig. 7. Learning with redundant non-terminal symbols.
suggests that using the biases to encode preferences forshorter or simpler rules does make a positive contributionto the performance of the GA. The differences are mostmarked in the comparative success rates achieved for thelearning tasksBRA2 and PAL3. This is also interestinggiven our choice of CNF for the initial covering grammar,as for CNF it might seem that a preference for shorter ruleswould have little or no effect.
Results for the furtherPAL2 learning task using an ex-panded set of non-terminal symbols are presented in thetable shown inFig. 7. For ease of comparison, the tablealso shows the earlier results using a minimal set of non-terminals. For this learning task, the covering grammar wasconstructed using 8 non-terminal symbols, rather than 5, re-sulting in a total of 528 rule parameters to be optimized bythe GA. As the table shows, the GA (biases set accordingto PR) achieved a 100% success rate, with no near missgrammars. This compares with the figure of 85% (75% with-out near misses) achieved using the minimal set of 5 non-terminals. Contrary to what might be expected therefore, itappears that constructing the covering grammar from a min-imal set of non-terminal symbols may actually make thingsharder rather than easier for the GA.
The final column of the table shows the average sizes ofthe best grammars found by the GA on each learning task.The grammars found by the GA using a covering grammarconstructed from 8 non-terminal symbols are on averagesome 50% larger than those found previously. Note that thisincrease in size is not due to the inclusion of spurious rulesof the sort observed for near miss grammars, as all of thegrammars found were correct. This may suggest that ourprior is not sufficiently punishing of redundancy in the rulesets of the grammars.
9. A comparison with the inside–outside algorithm
Our evolutionary approach to grammar induction turnsthe problem of language learning into one of functionoptimization. It is of interest to see how the gram-mars found by the GA compare with those found us-ing the standard technique for optimizing the param-eters of a SCFG—the IO algorithm[31]. We carriedout a number of experiments using the IO algorithmto infer grammars for the language learning tasks de-scribed in the previous section. With the exceptionof the PAL3 task, 50 runs of the IO algorithm were
Fig. 8. Comparison of grammars found using the IO algorithmwith those found by the GA.
carried out for each of our problems, where a runwas terminated once the change in grammar fitnessfrom one iteration to the next had fallen to less than10−5. In the case ofPAL3 it was possible to com-plete only 35 runs owing to the very long run-timeinvolved.
The results of the experiments with the IO algorithm areshown in Fig. 8. Figures for the GA on the same learn-ing task are also provided, but it is important to note thatsome care must be taken in comparing the results. First,it is not possible to simply compare grammar fitness ascomputed by the GA with fitness as given by the IO al-gorithm. This is because the fitness function for the GAtrades off grammar complexity against the ability to modelthe corpus accurately, whereas the IO algorithm simply op-timizes the latter quantity. For this reason, the fitness val-ues shown in the “best” and “worst” columns for both theIO algorithm and the GA are computed in terms of thefunction:
fEM(G)= −KCL(C|G) (7)
even though the GA is actually optimizing the function:
fGA(G)= −KCL(C|G)+ L(G) . (8)
This would seem to favor the IO algorithm, because under(8) the GA is paying a penalty to keep grammars small.We might therefore expect the grammars found by the GAto achieve rather lower fitness values according to (7) thanthose found by IO algorithm. In fact, the figures show thatthe GA actually finds grammars with comparable (oftenslightly better) fitness values than the IO algorithm, whilesimultaneously finding smaller grammars. Indeed, the aver-age grammar sizes reported in the table for the IO algorithmare for trimmed grammars. Very low probability rules wereremoved from the rule sets of the grammars returned bythe IO estimation procedure. Without this step, the gram-mar sizes would clearly be much larger. For example, theaveragenumber of rules with non-zero probabilities in the

B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406 1403
(untrimmed) grammars found by the IO algorithm for thePAL3 learning task was 362.7
Success rates for the IO algorithm are shown as percent-ages over 50 runs (or 35 forPAL3), where the criterion forsuccess is the same as that employed for the experiments us-ing the GA. Even with trimming, all of the grammars foundon successful runs of the IO algorithm were actually near-misses in the sense discussed in Section 8. As the learningtasks become more difficult, the success rate for the IO al-gorithm drops off quite sharply. For thePAL3 learning task,the success rate is less than one in ten. Again, however, itwould be misleading to compare these figures directly withthose for the GA. In particular, if we consider the numberof grammar evaluations carried out (where each evaluationinvolves a complete parsing of the corpus) the IO algorithmappears to be doing less work than the GA in order to find asolution to the learning task. Against this, the GA is manag-ing to find small and accurate grammars very consistently.
10. Discussion
The evolutionary approach to grammar induction de-scribed in this paper differs from most previous work usingGAs in addressing the problem of corpus-based inferenceof SCFGs. This makes direct comparison of our results withthose of other researchers difficult. However, the target lan-guages chosen for the experiments that we have conductedare typical of those in other studies, and the results reportedin this paper appear promising. The only other GA-basedapproach to the induction of SCFGs that we are aware ofis that of Kammeyer and Belew[28]. They report successin learning the languageBRA1 over five runs of their al-gorithm. The only other learning task that they consider issimilar to ourEQ, and to learn this their approach requiressome local search using the IO algorithm to improve param-eter values after each breed phase. We have also comparedour GA-based approach with the standard technique for theestimation of SCFGs, the IO algorithm, and shown that theGA succeeds in finding small and accurate grammars.
The main limitation of our approach is the cost involvedin evaluating the fitness of each candidate solution, which re-quires parsing every string in the corpus in all possible ways.Although inference can be performed very quickly for smallcovering grammars, the computational effort increases withthe number of non-terminals used to construct the coveringgrammar. Our current GA implementation caches the insideprobabilities used to evaluate grammar fitness, as these maybe used many times during parsing of a corpus. For the lan-guages studied in this paper, this results in very significantsavings. Coupled with the fact that the grammars being eval-
7 This figure is not quite the number of rules in the originalcovering grammar, as limitations in the precision of floating pointarithmetic mean that a rule occasionally get its probability set tozero.
uated by the GA are generally small in comparison to thecovering rule set, the result is that run-times for the GA arequite comparable with those of the IO algorithm.8 Never-theless, the computational cost is prohibitive for CNF cov-ering grammars with more than about a dozen non-terminalsymbols. For larger scale problems (e.g. grammars for natu-ral language fragments) an interesting possibility would beto move to a massively parallel implementation of our al-gorithm.
Given the existence of penalized variants of expectationmaximization algorithms[55] it is natural to wonder whetherwe might incorporate our prior directly into the IO algo-rithm. Brand [56] has reported some success in learningstructurally simple hidden Markov models (HMMs) usinga variant of the forwards–backwards algorithm that incor-porates an “entropic” prior. In other work, we have foundthat simple Dirichlet priors over emission probabilities canimprove learning for HMMs[57]. The IO algorithm mightbe similarly adapted by modifying the update rule on eachiteration to take account of a penalty term on the parame-ter space. However, theL(G) penalty term that we use isactually a function over integer rule weights, and as suchis non-differentiable. This presents a problem for a simple,penalized variant of the IO algorithm, because in order toderive the update rule it is necessary to take derivatives.While it may be feasible to generalize our prior to somedifferentiable function over real-valued parameters, it seemsthat search-based optimization techniques like the GA canoffer an advantage in permitting penalty terms that imposearbitrary structural constraints.
11. Summary and conclusion
We have demonstrated that a genetic algorithm, makinguse of a prior over grammars can successfully learn SCFGsfrom corpora. Our approach employs a distributed, steady-state GA to optimize the parameters of a large coveringgrammar. Good results are obtained on a range of formallanguages using a prior that is designed to prefer simplergrammars. We have compared our GA-based approach withthe inside–outside algorithm, currently the standard proce-dure for estimating the parameters of a SCFG. Althoughthe GA optimizes a function that trades-off accuracy againstgrammar size, it turns out that the grammars found by theGA are both smallandaccurate in comparison to those pro-duced by the IO algorithm.
8 Our current implementation of the IO algorithm is based onthat due to Stolcke[54], which has an asymptotic time complexityof O(|G|2n3). On thePAL2 task, using a 2 GHz Pentium 4 pro-cessor, a single run of the GA takes about 10 min, while a singlerun of the IO algorithm takes around 1 h.

1404 B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406
Appendix A. Definition of randomized and/or crossover
A.1. �-and/or crossover
To define RAOC we begin by defining a crossover opera-tor we refer to as�-and/or crossover. This is really a familyof operators, one for each� ∈ [0,1]. Each such operatortakes two genomesp1 andp2 and produces two offspringc1 and c2. Let pij denote thej th bit of genomepi (andsimilarly for ci ). LetXi be 1 with probability�, and 0 withprobability(1− �), then�-and/or crossover can then be de-fined by:
c1i ={p1i ∧ p2i if Xi = 1,p2i ∨ p2i otherwise
and
c2i ={p1i ∨ p2i if Xi = 1,p1i ∧ p2i otherwise,
where∧ and∨ are the Boolean operatorsand andor, re-spectively.
A.2. Randomized and/or crossover (RAOC)
This is defined in terms of the family of�-and/or opera-tors. Each time two parents are chosen to reproduce, pick avalue of� at random (uniform distribution) and then carryout �-and/or crossover. Note that� varies with each mating.
References
[1] E.M. Gold, Language identification in the limit, Inf. Control10 (1978) 447–474.
[2] Y. Wang, A. Acero, Evaluation of spoken language grammarlearning in the ATIS domain, in: Proceedings of theInternational Conference on Acoustics, Speech and SignalProcessing, Orlando, Florida, 2001, pp. 41–44.
[3] A. Clark, Unsupervised induction of stochastic context-freegrammars using distributional clustering, in: W. Daelemans, R.Zajac (Eds.), Proceedings of CoNLL-2001, Toulouse, France,2001, pp. 105–112.
[4] D. Klein, C.D. Manning, Distributional phrase structureinduction, in: W. Daelemans, R. Zajac (Eds.), Proceedings ofCoNLL-2001, Toulouse, France, 2001, pp. 113–120.
[5] I. Salvador, J.-M. Benedi, RNA modeling by combiningstochastic context-free grammars andn-gram models,International J. Pattern Recogn. Artif. Intell. 16 (3) (2002)309–316.
[6] L. Miclet, Structural Methods in Pattern Recognition,Chapman & Hall, New York, 1986.
[7] D. Angluin, C. Smith, Inductive inference: theory andmethods, Comput. Surv. 15 (3) (1983) 237–269.
[8] K.S. Fu, T.L. Booth, Grammatical inference: introduction andsurvey, IEEE Trans. Pattern Anal. Mach. Intell. 8 (1986)343–375.
[9] Y. Sakakibara, Recent advances of grammatical inference,Theor. Comput. Sci. 185 (1997) 15–45.
[10] R. Carrasco, J. Oncina, Learning stochastic regular grammarsby means of a state merging method, Proceedings of theSecond International Colloquium on Grammatical Inference,ICGI’94, Lecture Notes in Artificial Intelligence, vol. 862,Springer, Berlin, 1994, pp. 139–150.
[11] S.F. Chen, Bayesian grammar induction for languagemodeling, Proceedings of the 33rd Annual Meeting ofthe Association for Computational Linguistics, 1995, pp.228–235.
[12] P. Dupont, Regular grammatical inference from positiveand negative samples by genetic search: the GIG method,Grammatical Inference and Applications, ICGI’94, LectureNotes in Artificial Intelligence, vol. 862, Springer, Berlin,1994, pp. 236–245.
[13] S. Crespi-Reghizzi, An effective model for grammaticalinference, Inf. Process. 71 (1971) 524–529.
[14] Y. Sakakibara, Learning context-free grammars from structuraldata in polynomial time, Theor. Comput. Sci. 76 (1992)223–242.
[15] T.W. Hong, K.L. Clark, Using grammatical inference toautomate information extraction from the web, Proceedings ofthe Fifth European Conference on Principles of Data Miningand Knowledge Discovery, PKDD 2001, Lecture Notes inComputer Science, vol. 2168, 2001, pp. 216–227.
[16] J.H. Holland, Adaptation in Natural and Artificial Systems,University of Michigan Press, 1975.
[17] H. Zhou, J.J. Grefenstette, Induction of finite automata bygenetic algorithms, Proceedings of the IEEE InternationalConference on Systems, Man and Cybernetics, Atlanta, GA,1986, pp. 170–174.
[18] P. Wyard, Context-free grammar induction using geneticalgorithms, in: R. Belew, L.B. Booker (Eds.), Proceedings ofthe Fourth International Conference on Genetic Algorithms,ICGA-91, Morgan Kaufmann, CA, 1991, pp. 514–519.
[19] S. Sen, J. Janakiraman, Learning to construct pushdownautomata for accepting deterministic context-free languages,in: G. Biswas (Ed.), Applications of Artificial IntelligenceX: Knowledge-Based Systems, vol. 1707, SPIE, 1992, pp.207–213.
[20] P.J. Angeline, G.M. Saunders, J.B. Pollack, An evolutionaryalgorithm that constructs neural networks, IEEE Trans. NeuralNetworks 5 (1) (1994) 54–65.
[21] W.-O. Huijsen, Genetic grammatical inference: inductionof pushdown automata and context-free grammars fromexamples using genetic algorithms, Master’s Thesis,Department of Computer Science, University of Twente,Enschede, The Netherlands, 1993.
[22] S. Lucas, Structuring chromosomes for context-free grammarevolution, in: Proceedings of the IEEE Conference onEvolutionary Computation, IEEE World Congress onComputational Intelligence, 1994, pp. 130–135.
[23] M.M. Lankhorst, Grammatical inference with a geneticalgorithm, in: L. Dekker, W. Smit, J.C.A. Zuidervaart (Eds.),Proceedings of the 1994 EUROSIM Conference on MassivelyParallel Processing Applications and Development, Delft, TheNetherlands, 1994, pp. 423–430.
[24] D. Dunay, F. Petry, B. Buckles, Regular language inductionwith genetic programming, Proceedings of the FirstInternational Conference on Evolutionary Computing, 1994,pp. 396–400.

B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406 1405
[25] M. Schwem, A. Ost, Inference of stochastic regular grammarsby massively parallel genetic algorithms, Proceedings of theSixth International Conference on Genetic Algorithms, ICGA-95, Morgan Kaufmann, CA, 1995, pp. 520–527.
[26] R. Losee, Learning syntactic rules and tags with geneticalgorithms for information retrieval and filtering: an empiricalbasis for grammatical rules, Inf. Process. Manage. 32 (1996)185–197.
[27] G. De Pauw, W. Daelemans, A short introduction to GRAEL:grammar adaptation, evolution, and learning, Proceedingsof the Third International Conference on the Evolution ofLanguage, 2000, pp. 72–76.
[28] T. Kammeyer, R. Belew, Stochastic context-free grammarinduction with a genetic algorithm using local search,in: R. Belew, M. Vose (Eds.), Foundations of GeneticAlgorithms, vol. 4, Morgan Kaufmann, Los Altos, CA, 1996,pp. 409–436.
[29] A. Belz, An approach to the automatic acquisition ofphonotactic constraints, in: M.T. Ellison (Ed.), Proceedingsof the Fourth Meeting of the ACL Special InterestGroup in Computational Phonology, SIGPHON ‘98, 1998,pp. 35–44.
[30] T.C. Smith, I.H. Witten, Learning language using geneticalgorithms, in: S. Wermter, E. Riloff, G. Scheler (Eds.),Connectionist, Statistical, and Symbolic Approaches toLearning for Natural Language Processing, Lecture Notes inArtificial Intelligence, vol. 1040, Springer, Berlin, 1996, pp.132–145.
[31] J.K. Baker, Trainable grammars for speech recognition, in:J.J. Wolf, D.H. Klatt (Eds.), Proceedings of the 97th Meetingof the Acoustical Society of America, Boston, MA, 1979, pp.547–550.
[32] B. Keller, R. Lutz, Learning SCFGs from corpora by a geneticalgorithm, in: G.D. Smith, N.C. Steele, R.F. Albrecht (Eds.),Proceedings of the International Conference on ArtificialNeural Networks and Genetic Algorithms, ICANNGA-97,Spring, Berlin, 1997, pp. 210–214.
[33] A.P. Dempster, N.M. Laird, D.B. Rubin, Maximum likelihoodfrom incomplete data via the EM algorithm (with discussion),J. R. Statist. Soc. B 39 (1977) 1–38.
[34] G.J. McLachlan, T. Krishnam, The EM Algorithm andExtensions, Wiley, New York, 1997.
[35] K. Lari, S.J. Young, The estimation of stochastic context-freegrammars using the inside-outside algorithm, Comput. SpeechLang. 5 (1990) 237–257.
[36] R.C. Gonzales, M.G. Thomason, Syntactic Pattern Recogni-tion: An Introduction, Addison-Wesley, Reading, MA, 1978.
[37] A. Salomaa, Probabilistic and weighted grammars, Inf. Control15 (1969) 529–544.
[38] J. Risannen, A universal prior for integers and estimationby minimum description length, Ann. Statist. 11 (2) (1983)416–431.
[39] J. Risannen, Modelling by shortest data description,Automatica 14 (1978) 465–471.
[40] C.E. Shannon, The mathematical theory of communication,Bell System Tech. J. 27 (1948) 379–423, 623–656.
[41] M. Li, P. Vitanyi, An Introduction to Kolmogorov Complexityand its Applications, second ed., Springer, New York, 1997.
[42] W. Feller, An Introduction to Probability and its Applications,vol. 1, third ed. Wiley, New York, 1968.
[43] A. Stolcke, Bayesian Learning of Probabilistic LanguageModels, Doctoral Dissertation, Department of ElectricalEngineering and Computer Science, University of Californiaat Berkeley, 1994.
[44] P. Grunwald, A minimum description length approachto grammar inference, in: G. Scheler, E. Riloff (Eds.),Connectionist, Statistical, and Symbolic Approaches toLearning for Natural Language Processing, Lecture Notes inArtificial Intelligence, vol. 1004, Springer, Berlin, 1994, pp.203–216.
[45] R.J. Solomonoff, A formal theory of inductive inference, Inf.Control 7 (1964) 1–22, 224–254.
[46] C.M. Cook, A. Rosenfeld, A.R. Aronson, Grammaticalinference by hill-climbing, Inf. Sci. 10 (1976) 59–80.
[47] M. Osborne, MDL-based DCG induction for NP identification,in: M. Osborne, E. Tjong, K. Sang (Eds.), Proceedings ofCoNLL-99, 1999, pp. 61–68.
[48] D.E. Goldberg, Genetic Algorithms in Search, Optimisation,and Machine Learning, Addison-Wesley, Reading, MA, 1989.
[49] M. Mitchell, An Introduction to Genetic Algorithms, MITPress, Cambridge, MA, 1996.
[50] R.J. Collins, D.R. Jefferson, Selection in massively parallelgenetic algorithms, in: R.K. Belew, L.B. Booker (Eds.),Proceedings of the Fourth International Conference on GeneticAlgorithms, ICGA-91, Morgan Kaufmann, San Mateo, CA,1991, pp. 249–256.
[51] M. McIlhagga, P. Husbands, R. Ives, A comparison ofsimulated annealing, dispatching rules and a coevolutionarydistributed genetic algorithm as optimisation techniquesfor various integrated manufacturing planning problems,Proceedings of PPSN IV, vol. I, Lecture Notes in ComputerScience, vol. 1141, Springer, Berlin, 1996, pp. 604–613.
[52] T. Jones, Crossover, macromutation, and population-basedsearch, Proceedings of the Sixth International Conference onGenetic Algorithms, Morgan Kaufmann, Los Altos, CA, 1995,pp. 73–80.
[53] B. Krenn, C. Samuelson, The Linguist’s Guide toStatistics, 1997; Available fromhttp://www.coli.uni-sb.de/∼krenn/edu.html
[54] A. Stolcke, An efficient probabilistic context-free parsingalgorithm that computes prefix probabilities, Comput.Linguist. 21 (2) (1995) 165–201.
[55] P.J. Green, On the use of the EM algorithm for penalizedlikelihood estimation, J. R. Stat. Soc. B 52 (1990) 443–452.
[56] M. Brand, Structure learning in conditional probability modelsvia an entropic prior and parameter extinction, Neural Comput.11 (5) (1999) 1155–1182.
[57] B. Keller, R. Lutz, Improved learning for hidden Markovmodels using penalized training, Proceedings of ArtificialIntelligence and Computer Science 2002, AICS-02, LectureNotes in Artificial Intelligence, vol. 2464, Springer, Berlin,2002, pp. 53–60.
About the Author—RUDI LUTZ obtained a degree in Mathematics from Warwick University in 1973, an M.Sc. in Computer Science fromthe Heriot-Watt University in 1976, and a Ph.D. in Artificial Intelligence from the Open University in 1993. His research interests includeapplying AI techniques to software engineering problems, machine learning, and statistical natural language processing. He has been alecturer in Artificial Intelligence at the University of Sussex since 1983.

1406 B. Keller, R. Lutz / Pattern Recognition 38 (2005) 1393–1406
About the Author—BILL KELLER graduated with a B.Sc. in Computer Science from the University of Warwick in 1983. He was awardedan MA in Cognitive Science from the University of Sussex in 1985 and a Ph.D. in Computational Linguistics, also from Sussex, in1991. Since 1989 he has lectured at Sussex in Computer Science and Artificial Intelligence, working currently within the Departmentof Informatics. His research interests include formal representation of grammatical knowledge, machine learning of natural language andstatistical approaches to language processing