color image segmentation using a weighted kernel-based fuzzy c-means algorithm
TRANSCRIPT

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
132
Color Image Segmentation Using a Weighted kernel-based Fuzzy C-Means Algorithm
Siavash Alipour 1, Mousa Nazari 2, Jamshid Shanbehzadeh 3
1,2student with Department of Computer Engineering Kharazmi University
1 [email protected], [email protected]
3Associate Professor with Department of Computer Engineering Kharazmi University,
Abstract: Color image segmentation plays an important role in computer vision and image processing applications. Kernel-based fuzzy C-means (KFCM) is well known and powerful methods used in image segmentation.
Moreover, an appropriate assigning weight to features can improve its performance. This paper focuses on improving the image segmentation capabilities of KFCM based on feature weighting. It employs Entropy concept to measure the weight of features based on statistical variations viewpoint in KFCM. We compare the segmentation results of the proposed method with the well know algorithms along the same line that used weight selection procedure in FCM algorithm. Our simulation results reveal that the proposed algorithm provides greater segmentation performance for color image segmentation according to cluster validity function.
Keywords: kernel-based fuzzy C-means; Entropy; FCM; weight selection; Variation; Color image segmentation
1. Introduction
Color image segmentation plays an important role in computer vision and image processing applications. Segmentation is to partition an image into regions that are homogeneous according to a criterion, such as intensity, color, tone, texture and, etc [1]and, it is considered as one of the most difficult tasks in image processing and affects the quality of the final results of an image processing or machine vision system. Generally, the gray level image segmentation techniques can be divided into four categories, thresholding, clustering, edge detection,
and region extraction [2]. At present, these techniques can be extended to color images expressed in different color spaces. These spaces are obtained by using the linear and non-linear transformations of the RGB color space. Many different techniques of color image segmentation have been developed and detailed in the literature [3].
Nowadays, the clustering methods [4, 5] are considered as one type of fundamental tool for image segmentation. In clustering methods where clustering numbers are known in prior, fuzzy C-Means (FCM) algorithm is one of the most widely used methods due to its flexibility in clustering pixels of segmented

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
133
image [6, 7]. Compared with crisp and hard image segmentation methods, FCM improves partition performance and reveals the classification of data more reasonably [8, 9]. Basically, FCM clustering depends on the measure of distance between samples. In most situations, FCM employs the traditional distance measurement that supposes similar weight to each feature. This assumption affects its performance, since, in the real world problems, features of data have different affects in the overall clustering performance. Wang et al. [10] employed Iris data (Fisher,1936 [11]) to show that the different feature weight could improve the performance of FCM.
Although weighted fuzzy C-Means (WFCM) has become the most well-known and powerful tool in clustering analysis, it suffers from employing the squared-norm in similarity measurement. This can be effective in clustering “spherical” clusters. Zhang et al. [12] proposed a novel Kernelized Fuzzy C-means (KFCM) to address this problem. A new kernel-induced metric in the data space is adopted in KFCM to replace the original Euclidean norm metric employed in FCM. By replacing the inner product with an appropriate “kernel” function, one can implicitly perform a nonlinear mapping to a higher dimensional feature space without increasing the number of parameters. Sap et al. (2008) employed Weighted Kernel Fuzzy C-Means (WKFCM) in different types of datasets and showed good performance in comparison to other similar clustering methods. Wang et al. [10] demonstrated that the performance of FCM was affected by different feature weight, but if the feature weights were improperly chosen, the algorithm had performed poorly. Therefore it is important to select suitable feature weights to ensure the proper performance of FCM and KFCM.
This paper proposes a novel weighted kernelized Fuzzy c-means (WKFCM) algorithm that automatically assigns weights to variables based on
statistical variations viewpoint. We used Shannon entropy approach [13] to select the feature weight. The rest of paper is organized as follows. Section II is the background of this paper and it describes feature-weighting methods and KFCM clustering algorithms. Section III presents the novel weighted kernelized Fuzzy c-means (WKFCM) algorithm in detail. Section IV presents the experimental image segmentation results and, Section V concludes this paper.
2. Background
This paper uses feature-weighting method based on statistical variations viewpoint and KFCM clustering for color image segmentation. Next part presents feature weighting methods. The second part explains KFCM.
2.1 Feature-weighting methods
This section introduces two simple data-based computational approaches based on variation viewpoint. One is a coefficient of variation (CV) approach and another is Shannon entropy approach that proposed by Hung et al [13, 14]. Measure of variation describes how spread out or scattered a set of data. It is also known as measures of dispersion or measures of spread. Let us start from scratching and devising a measure of variability that uses a random sample of size �,{��, . . . , ��} ⊂ �, where � is an n dimensional Euclidean space. Then, it would logically indicate what our construction should be able to measure how the data vary from average. The sample standard deviation, �, is a normal measure of variability, defined as:
� = �∑ (�� − �)�����
� − 1 , � =
1�
� ��
�
���
(1)

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
134
In practice, Karl Pearson’s coefficient of variation (CV) has been used extensively, defined by:
�� =�� (2)
On the other hand, if we have a random sample � ={��, … , ��} ⊂ ��, where �� is the d-dimensional Euclidean space and �� = ���,�, … , ��,�� represents the kth sample, then the coefficient of variation (CV) of the jth feature is defined as:
��� = �∑ ���,� − �������� (� − 1)�
�� , ��
=1�
� ��,�
�
���
(3)
From the experimental results obtained by Huang et al. [13, 14], we know that features with small variations provide more reliable information about clustering analysis than those with large variations. Therefore, the feature weight is inversely related to its variation. It means that a feature that has a large variation receives less weight than another feature that has a smaller variation. Thus the weight of the jth feature ( �� ) is proportional to 1/���, i.e.
�� =1 ���⁄
∑ 1 ���⁄����
, � = 1, … , � (4)
Information theory is a branch of applied mathematics, electrical engineering, and computer science involving the quantification of information and is based on probability theory and statistics. Entropy is a means to measure information of a random variable, and mutual information between two random variables. In entropy context, the term usually refers to the Shannon entropy, which quantifies the expected value of the information contained in a message. The second approach that they used to measure the information is explained next.
With the same notation as above, let �.� = ∑ ��,�����
and define as:
��,� =��,�
�.�, � = 1, … �; � = 1, … , �. (5)
The ∑ ��,� = 1���� . It means that (��,�, . . . , ��,�) may
be regarded as a probability distribution. Thus, Equation six presents the Shannon entropy about the jth coefficient (feature or attribute).
�� = − � ��,� ln ��,�
�
���
(6)
Equation 7 shows the entropy of the jth feature.
− �1�
ln �1�
� = ln (�)�
���
,
(7)
Equation 8 shows the normalized entropy.
�� =��
ln(�) = −∀ ���,� ln ��,�
ln(�)
�
���
,
� = 1, … , �
(8)
Where 0 ≤ �� ≤ 1. Apparently, the value �1 − ��� can measure the degree of variation of the jth feature. If this variation is large (small) then the value of �1 − ��� is also large (small). Since the feature weight is inversely related to its variation, the weight of the jth feature can be defined as:
�� =1 �1 − ���⁄
∑ 1 �1 − ���⁄����
, � = 1, … , �
(9)
2.2 KFCM clustering
Kernel-Based Fuzzy C-Means clustering (KFCM) algorithm has been proposed by Zhang et al [12]. KFCM is obtained by replacing a new kernel-based metric in the original Euclidean norm metric of FCM. It partitions a dataset X =�x�, x�, … , x�� ⊂ R�, where is the dimension, into c

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
135
fuzzy subsets by minimizing the following objective function:
��(�, �) = � � ����
�
���
�
���
�∅(��) − ∅(��)�2 (10)
Where c is the number of clusters and determined by a prior knowledge; N is the number of data points; ��� is the fuzzy membership of �� in class �; � is a weighting exponent on each fuzzy membership; � is the set of cluster and is an implicit nonlinear map where :
‖∅(��) − ∅(��)‖�
= �(��, ��) + �(��, ��)− 2�(��, ��)
(11)
Where, �(�, �) = ∅(�)�∅(�) is an inner product of the kernel function. If we use the Gaussian function
as a kernel function, �(�, �) = exp (− ‖���‖�
��� ), then �(�, �) = 1. According to Equation (10), Equation (11) can be rewritten as :
��(�, �) = 2 � � ����
�
���
�
���
�1 − �(��, ��)� (12)
Minimizing Equation (12) under the constraint of, ���, � > 1. We have
��� =�1 − �(��, ��)���/(���)
∑ �1 − �(��, ��)���/(���)����
(13)
�� =∑ ���
��(��, ��)������
∑ �����(��, ��)�
��� (14)
The full explanation of KFCM algorithm is as follows:
Step 1: Fix c, ���� (iteration times), m=2, and � > 0 for some positive constants;
Step 2: Initialize the membership matrix ����;
Step 3: For t=1 to ���� do:
a) Update all prototype ��� with �� =
∑ �����(��,��)��
����∑ �����(��,��)�
���
b) Update all memberships ���� with
��� = ����(��,��)���/(���)
∑ ����(��,��)���/(���)�
���
c) Compute �� = ����,�|���� − ���
���|, if ≤ �, stop;
End;
3. A novel weighted kernelized Fuzzy c-means (WKFCM) algorithm
Appropriate assigning weights to features can improve the performance of fuzzy type algorithms. This paper proposes a new kernel-based FCM type algorithm called WKFCM that select initial weight variables based on statistical variations viewpoint. We add a new step before the KFCM algorithm to select the initial weights based on the Shannon entropy approach according to the discussion in Section ΙΙ.
Let W= [��, ��, … , ��] be the feature-weight vector and β be a parameter for the weight of feature �� , we modify (12) as follows:
��(�, �, �) = 2 � � � ���� ��
��
���
�
���
�
���
�1
− �����, �����
(15)
Similar to solving (12), we can minimize (15), so we have :
���
=∑ ��
� �1 − �����, �������/(���)�
���
∑ ∑ ��� �1 − �����, �����
��/(���)����
����
(16)
�� =∑ ���
�(∑ ����
��� �(��, ��))������
∑ ����((∑ ��
����� �(��, ��)�
��� )
(17)

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
136
Thus, the following steps can describe the proposed WFCM algorithm.
Step 1: Select initial weights � = (��, ��, … , ��) by Equation (9)
Step 2: Fix c, ���� (iteration times), m=2, � = 2 and � > 0 for some positive constants;
Step 3: Initialize the membership matrix ���� ;
Step 4: For t=1 to ���� do:
a) Update all prototype ��� by Equation(17)
b) Update all memberships ���� by
Equation (16) c) Compute �� = ����,�|���
� − ������|, if
≤ �, stop؛
End؛
4. Experimental Result
This section presents several results of the simulations on the segmentation of medical and famous public Berkeley segmentation dataset (Fig.1). These results illustrate the ideas presented in the previous section. Four color images shown in Fig.1: airplanes that consists two objects (c =2): sky and airplane from [15, 16] and medical cells images of cancer disease (which is a challenging problem in this field) with two objects (c =2): cells and background from [17]. The originally images are stored in RGB color space. We consider the R, G, and B component of each pixel as the feature. Therefore we have (R,G,B) as a feature vector for each image pixel. Each primitive color (Red, Green and Blue) takes 8 bits and has the intensity range from 0 to 255. We have to cluster these pixels by our new algorithm and compare the result with KFCM [12] and WFCM methods by Wang [10] and Hung [18] on color image segmentation. The parameters in all methods were set as follows: (i) the weighting exponent m=2; (ii) the termination criteria ε=0.01; (iii) Gaussian RBF kernel width σ = 150 since it has shown better results than other values[12].
Table 1: The initial weights using the proposed approaches on these four images. Images Shannon Entropy (R,G,B)
(0.2 ,0.1 ,0.7 )
(0.25 ,0.2 ,0.55)
(0.8 ,0.15 ,0.05 )
(0.35 ,0.3 ,0.35)
Table 1 shows the initial weights using the proposed approach for the four images. Fig.2 presents the simulation results of four images. The first three rows
are generated by WKFCM with random weights. The other rows are generated by Standard KFCM [12], WFCM [10], WFCM [18], the proposed WKFCM

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
137
respectively. The first and the second column of Fig.2 are the experimental results of two airplanes. The pixels that belong to the airplane class are shown with black color. We can see that KFCM [12] method that give the same weight to each feature, failed to segment airplane correctly, also some pixels are incorrectly segmented in the left bottom side of the image. Moreover, in Fig. 2 at the last row, the first and second column, we can see that proposed method provide better segmentation result than those of other feature-weight approaches by Wang [10] and Hung [18].
In the third and forth column of Fig.2, the target is to find a segmentation to present the cells, in order to give a schema of the points really forming part of the cells and, the number of cells. The problem of the incorrectly segmentation is also illustrated in Fig.2 in column 3 rows one to three, the resulting image has six cells, while in the fourth to sixth rows of the same column, we can see four cells. Moreover, as shown in the last row, the cells are better recognized by the proposed approach than WFCM by Wang [10] and
Hung [18]. In the last column, we can see that the cells are much better segmented than its counterparts in the same column.
In Fig.3, it is desired to segment vessels of retina as are shown with black color. Knowledge about the location of the vessels can be used as screening of diabetic retinopathy, e.g., to reduce the number of false positives in detecting microaneurysms [19], to serve as a means to register images taken at different time instants or at different locations of the retina [20]. From Fig.3, we can see that each vessel branch is identified better than other fuzzy type approaches by the proposed method.
According to the above results, it can be found that the performance of KFCM is affected by different weight features, and if the feature weights are not properly chosen for KFCM, the algorithm performs poorly. The simulation results reveal that, it can be seen that the proposed method which utilizes the KFCM algorithm combined with initial feature weights performed better than the randomly generated weights.
Fig.1: Data set used in the experiment
To evaluate the results of color image segmentation, it is necessary to make an objective evaluation of different feature-weights in the fuzzy type algorithms. The comparisons are illustrated using the cluster validity functions [21].The main idea of fuzzy partition validity functions is the equality of less fuzziness of the partition to the better the performance. The representative functions for this type are partition coefficient ��� [22] and partition
entropy ��� [23]. As a result, the best clustering is achieved when the value ��� is maximal or ��� is minimal. Both ��� and ��� possess a monotonic evolution tendency in respect to c. Modification of the ��� [21] can reduce the monotonic tendency. Table 2 is a brief summary of 3 selected cluster validity functions which will be used to evaluate the performance of WKFCM with KFCM [12], WFCM by Wang [10] and WFCM by Hung [18].

Global Journal of Science, Engineering and Technology (ISSN: 2322Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
Global Journal of Science, Engineering and Technology (ISSN: 2322-2441)
138
Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
139
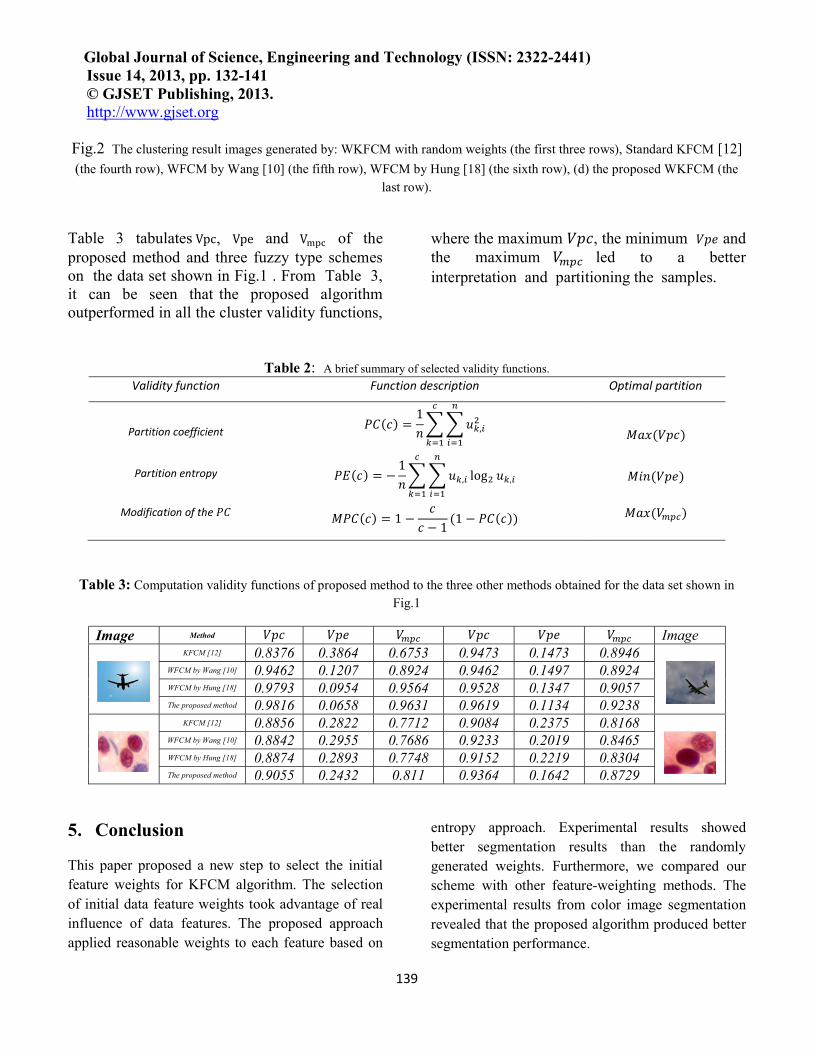
Fig.2 The clustering result images generated by: WKFCM with random weights (the first three rows), Standard KFCM [12] (the fourth row), WFCM by Wang [10] (the fifth row), WFCM by Hung [18] (the sixth row), (d) the proposed WKFCM (the
last row).
Table 3 tabulates Vpc, Vpe and V��� of the proposed method and three fuzzy type schemes on the data set shown in Fig.1 . From Table 3, it can be seen that the proposed algorithm outperformed in all the cluster validity functions,
where the maximum ���, the minimum ��� and the maximum ���� led to a better interpretation and partitioning the samples.
Table 2: A brief summary of selected validity functions. Validity function Function description Optimal partition
Partition coefficient ��(�) =1�
� � ��,��
�
���
�
���
���(���)
Partition entropy ��(�) = −1�
� � ��,�
�
���
log� ��,�
�
���
���(���)
Modification of the �� ���(�) = 1 −�
� − 1(1 − ��(�)) ���(����)
Table 3: Computation validity functions of proposed method to the three other methods obtained for the data set shown in Fig.1
Image Method ��� ��� ���� ��� ��� ���� Image
KFCM [12] 0.8376 0.3864 0.6753 0.9473 0.1473 0.8946
WFCM by Wang [10] 0.9462 0.1207 0.8924 0.9462 0.1497 0.8924 WFCM by Hung [18] 0.9793 0.0954 0.9564 0.9528 0.1347 0.9057 The proposed method 0.9816 0.0658 0.9631 0.9619 0.1134 0.9238
KFCM [12] 0.8856 0.2822 0.7712 0.9084 0.2375 0.8168
WFCM by Wang [10] 0.8842 0.2955 0.7686 0.9233 0.2019 0.8465 WFCM by Hung [18] 0.8874 0.2893 0.7748 0.9152 0.2219 0.8304 The proposed method 0.9055 0.2432 0.811 0.9364 0.1642 0.8729
5. Conclusion
This paper proposed a new step to select the initial feature weights for KFCM algorithm. The selection of initial data feature weights took advantage of real influence of data features. The proposed approach applied reasonable weights to each feature based on
entropy approach. Experimental results showed better segmentation results than the randomly generated weights. Furthermore, we compared our scheme with other feature-weighting methods. The experimental results from color image segmentation revealed that the proposed algorithm produced better segmentation performance.

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
140
[1] I. Bankman, Ed., Handbook of Medical Image Processing and Analysis (2nd Edition). Elsevier, 2009, p.^pp. Pages.
[2] R. Harrabi and E. Ben Braiek, "Color Image Segmentation Based on a Modified Fuzzy C-means Technique and Statistical Features," International Journal Of Computational Engineering, vol. 2, pp. 120-135, 2012.
[3] M. B. Meenavathi and K. Rajesh, "Volterra Filter for Color Image Segmentation," International Journal of Electrical and Electronics Engineering, vol. 35, pp. 209-214, 2008.
[4] R. Xu and D. Wunsch, "Survey of clustering algorithms," IEEE Trans on Neural Networks, vol. 16, pp. 645-678, 2005.
[5] J. Yu, "General c-means clustering model," IEEE Trans on Pattern Analysis and Machine Intelligence, vol. 27, pp. 1197-1211, 2005.
[6] M. N. Ahmed, et al., "A modified fuzzy C-means algorithm for bias field estimation and segmentation of MRI data," IEEE Trans. Med. Imaging, vol. 21, pp. 193-199, 2002.
[7] W. Cai, et al., "Fast and robust fuzzy c-means clustering algorithms incorporating local information for image segmentation," Pattern Recognition, vol. 40, pp. 825–838, 2007.
[8] J. C. Bezdek, et al., "Review of MR image segmentation techniques usin pattern recognition," Medical Physics, vol. 20, pp. 1033-1048, 1993.
[9] D. L. Pham and J. L. Prince, "An adaptive fuzzy C-means algorithm for image segmentation in the presence of intensity inhomogeneities," Pattern Recognit, vol. 20, pp. 57-68, 1999.
[10] X. Z. Wang, et al., "Improving fuzzy c-means clustering based on feature-weight learning," Pattern Recognition Lett., vol. 25, pp. 1123–1132., 2004.
[11] R. Fisher, "The use of multiple measurements in taxonomic problems," Ann. Eugenics 7, pp. 179–188, 1936.
[12] D.-Q. Zhang and S.-C. Chen, "A novel kernelized fuzzy c-means algorithm with application in medical image segmentation," Artificial Intelligence in Medicine, vol. 32, pp. 37-50, 2004.
[13] W. L. Hung, et al., "Variation Approaches to Feature-Weight Selection and Application to Fuzzy Clustering," IEEE World Congress on Computational Intelligence, pp. 276-280, 2008.
[14] W. L. Hung, et al., "Weight selection in W-K-means algorithm with an application in color image segmentation," Computers and Mathematics with Applications, pp. 668–676, 2011.
[15] http://www.eecs.berkeley.edu/Research/Projects/CS/vision/bsds/BSDS300/html/dataset/images/color/3096.html.
[16] Shawn Lankton (author of ref. [13]) website: http://www.shawnlankton.com/.
[17] R. Harrabi and E. B. Braiek, "Colour image segmentation using the second order statistics and a modified fuzzy C-means technique," Scientific Research and Essays, vol. 7, pp. 1734-1745, 2012.
[18] W. L. Hung, et al., "Bootstrapping approach to feature-weight selection in fuzzy c -means algorithms with an application in color image segmentation," Pattern Recognition Letters 29, pp. 1317–1325, 2008.
[19] M. Larsen, et al., "Automated detection of fundus photographic red lesions in diabetic retinopathy," Investigat. Opht. Vis. Sci., vol. 44, pp. 761–766, 2003.
[20] F. Zana and J. C. Klein, "A multimodal registration algorithm of eye fundus images using vessels detection and Hough transform," IEEE Trans. Med. Imag, vol. 18, pp. 419–428, May 1999.
[21] M. Halkidi and M. Vazirgiannis, "Clustering validity assessment: Finding the optimal partitioning of a data set," Proceedings of the IEEE international conference on data mining, pp. 187-194, 2001.

Global Journal of Science, Engineering and Technology (ISSN: 2322-2441) Issue 14, 2013, pp. 132-141 © GJSET Publishing, 2013. http://www.gjset.org
141
[22] J. Bezdek, "Cluster validity with fuzzy sets. J Cybern," Journal of Cybernetics, vol. 3, pp. 58–73, 1974.
[23] J. Bezdek, "Mathematical models for systematic and taxonomy," proceedings of eigth international conference on numerical taxonomy, San Francisco, pp. 143–66, 1975.