binarization of degraded document image based on feature space partitioning and classification
TRANSCRIPT

IJDAR (2012) 15:57–69DOI 10.1007/s10032-010-0142-4
ORIGINAL PAPER
Binarization of degraded document image based on featurespace partitioning and classification
Morteza Valizadeh · Ehsanollah Kabir
Received: 29 November 2009 / Revised: 21 November 2010 / Accepted: 2 December 2010 / Published online: 30 December 2010© Springer-Verlag 2010
Abstract In this paper, we propose a new algorithm forthe binarization of degraded document images. We map theimage into a 2D feature space in which the text and back-ground pixels are separable, and then we partition this featurespace into small regions. These regions are labeled as text orbackground using the result of a basic binarization algorithmapplied on the original image. Finally, each pixel of the imageis classified as either text or background based on the label ofits corresponding region in the feature space. Our algorithmsplits the feature space into text and background regions with-out using any training dataset. In addition, this algorithm doesnot need any parameter setting by the user and is appropriatefor various types of degraded document images. The pro-posed algorithm demonstrated superior performance againstsix well-known algorithms on three datasets.
Keywords Degraded document · Binarization ·Mode association clustering · Structural contrast ·Feature space partitioning
1 Introduction
Document image analysis is an important field of imageprocessing and pattern recognition. It consists of imagecapturing, binarization, layout analysis, and character recog-nition. Image binarization aims to convert a gray-scale imageinto binary and its quality affects the overall performance ofdocument analysis systems. Although various thresholding
M. Valizadeh (B) · E. KabirDepartment of Electrical Engineering, Tarbiat Modares University,Tehran, Irane-mail: [email protected]; [email protected]
E. Kabire-mail: [email protected]
algorithms have been developed, binarization of documentimages with poor and variable contrast, shadow, smudge,and variable foreground and background intensities is still achallenging problem.
The binarization methods reported in the literature aregenerally global or local. Global methods find a single thresh-old value by using some criteria based on the gray levels ofthe image. These methods compare the gray level of eachpixel with this threshold and classify it as a text or back-ground pixel. Global thresholding based on clustering [1],entropy minimization [2], and valley seeking in the intensityhistogram [3] as well as feature-based [4] and model-based[5] methods has been proposed. These methods are efficientfor the images in which the gray levels of the text and back-ground pixels are separable. If histogram of the text overlapswith that of the background, they result in improper binaryimages.
To overcome the disadvantages of global methods, vari-ous local binarization methods have been presented. Thesemethods use local information around a pixel to classify itas either text or background. We classify local binarizationmethods into two categories. The methods in the first cate-gory use the gray level of each pixel and its neighborhoodand examine some predetermined rules to binarize the imagelocally [6–13]. The second category contains the methodsthat use local information to extract local features and applya thresholding algorithm on them to obtain the binary image[14–17]. Finding appropriate threshold is an important stageof these methods.
Recently, some binarization algorithms have been pre-sented that work based on the classification methods. Thesealgorithms use some training samples to improve the binari-zation results [11,18,19]. The main limitation of these algo-rithms is that they are efficient exclusively for the specifictypes of images included in the training set.
123

58 M. Valizadeh, E. Kabir
Finding a proper boundary or threshold for separating textand background pixels in the feature space is a challengingproblem in binarization algorithms. Some methods minimizea global criterion to find a threshold [14,15,17], while thealgorithm [16] uses two global attributes of the text and back-ground pixels, labeled using another binarization algorithm,to calculate an adaptive threshold. When the features of thetext and background pixels are highly variable in differentregions of the image, thresholding based on global criteria orglobal attributes leads to some errors.
In this paper, we use the mode-association clustering algo-rithm based on hill climbing to partition a 2D feature spaceinto small regions. In this way, the feature space is parti-tioned in such a way that almost only the instances from eithertext or background pixels occupy a region, hence resultingmany pure regions. Then, we employ the result of Niblack’salgorithm to classify these regions into text or background.Classifying a region in feature space instead of classifyingits points individually makes our method robust against theerrors of Niblack’s algorithm. Each pixel is then classifiedas either text or background according to its correspondingregion in the feature space. Our algorithm is applicable forvarious types of degraded document images.
The rest of this paper is organized as follows. Section 2briefly reviews some related works on local binarizationmethods and their drawbacks. Section 3 describes the pro-posed binarization algorithm. Experimental results and com-parison with some well-known algorithms are discussed inSect. 4, and conclusions are given in Sect. 5.
2 Survey of local binarization algorithms
In general, document image binarization algorithms are cat-egorized into global and local. Since local algorithms yieldbetter results for degraded images, we concentrate on them.
Niblack proposed a dynamic thresholding algorithm thatcalculates a separate threshold for each pixel by shifting awindow across the image [6]. The threshold T (x, y) for thecenter of window is computed using local information.
T (x, y) = m(x, y) + ks(x, y) (1)
where m(x, y) and s(x, y) are local mean and standard devia-tion in the window centered on pixel (x, y). The window sizeand k are the predetermined parameters of this algorithm. Thevalue of k is set into −0.2. This method can separate text frombackground in the areas around the text, but wherever there isno text inside the local window, some parts of the backgroundare regarded as text and background noise is magnified.
Sauvola solved the problems of Niblack’s method assum-ing that the text and background pixels have gray valuesclose to 0 and 255, respectively [13]. He proposed a threshold
criterion as follows:
T (x, y) = m(x, y) [1 − k(1 − s(x, y)/R))] (2)
where R is a constant set to 128 for an image with 256 graylevels and k is set into 0.5. This procedure gives satisfac-tory binary image in the case of high contrast between fore-ground and background. However, the optimal values of Rand k are proportional to the contrast of the text. For poor-contrast images, if the parameters are not set properly, thetexts regions are missed.
Chen proposed an algorithm for locally setting the binari-zation parameters [11]. This algorithm is implemented in twostages. In the first stage, a feature representing the region con-trast is extracted, and using this feature, the original image isdecomposed into sub-regions. In the second stage, three fea-tures are extracted from each sub-region. These features areused to examine the sub-regions and classify them into fourclasses: background, faint strokes, heavy strokes, and heavyand faint strokes. For each sub-region, appropriate parame-ters are set according to its class.
T (x, y) = wm(x, y) + kG N (x, y)
where
⎧⎪⎪⎨
⎪⎪⎩
if background, w = 0, k = 0if faint stroke, w = 0.5, k = −1.1if heavy stroke, w = 0.7, k = −0.8if heavy with faint strokes, w = 0.7, k = −1.1
(3)
G N (x, y) represents the mean-gradient value of the sub-region in the direction of stroke slant. The parameters w andk are set experimentally and are not applicable to differenttypes of images. Logical level thresholding technique usesnot only the image gray level values but also the stroke widthof the characters to improve the binarization quality [9]. Thisalgorithm is based on the idea of comparing the gray levelof each pixel with some local averages in its neighborhood.These comparisons need a threshold to produce some logicalvalues, which are utilized to generate binary images. Yang[12] proposed an adaptive threshold calculation method toimprove the logical-level technique, but this threshold is pro-portional to a predetermined parameter, so the quality of thefinal binary image depends on the parameter setting by theuser.
Gatos estimated the background surface for the documentimage and compared the differences between the originalgray levels and this surface with an adaptive threshold tolabel each pixel as either text or background [16]. To esti-mate the background surface, he used Sauvola’s binariza-tion algorithm to roughly extract the text pixels and for themcalculated the background surface by interpolation of neigh-boring background pixels intensities. For other pixels, back-ground surface is set to the gray level of original image. Inthis algorithm, the average distance between foreground and
123

Binarization of degraded document image based on feature space partitioning and classification 59
Fig. 1 Block diagram of theproposed binarization algorithm
I (x,y) Feature
extraction Feature space partitioning
Partition classification
B(x,y)Pixel
classification
Niblack’s adaptive
thresholding
background, the average background values of backgroundsurface and three predetermined parameter are utilized to cal-culate the adaptive threshold. It yields satisfactory results forvarious types of degraded images. However, for documentimages with uneven background, the parameters should beadapted to obtain better performance.
A stroke-model-based method uses the two attributes of atext pixel to extract characters [14]: (i) its gray level is lowerthan that of its neighbors and (ii) it belongs to a thin con-nected component with a width less than the stroke width.Based on these two attributes, the gray-scale image is mappedinto a double-edge feature image. This mapping increases theseparation of text and background pixels and a global thres-holding followed by a reliable post-processing extracts thetext. In the double-edge image, the separability of the text andbackground depends on the contrast of the text in the originalimage. Global thresholding of double-edge image is not suit-able for the images with variable foreground and backgroundintensities where the low-contrast texts are missed.
3 Proposed binarization algorithm
The diagram of the proposed binarization algorithm is illus-trated in Fig. 1. This algorithm consists of feature extrac-tion, feature space partitioning, partition classification, andfinally pixel classification stages. The details of each stageare described in this section.
3.1 Feature extraction
Feature extraction is one of the most important steps inpattern recognition applications. Mapping the objects intoappropriate feature space leads to simple and accurate clas-sification or clustering algorithms. Therefore, we try to mapthe document image into a feature space in which the text andbackground pixels are separable. We propose a new featurenamed structural contrast and use it together with gray levelin this application.
For document binarization, the most powerful features arethose that take into account the structural characteristics ofthe characters. The stroke width is an important structuralcharacteristic that helps us to extract reliable features. In log-ical-level technique [9], based on the stroke width and gray
4 0( )p p′
3 7( )p p′
6 2( )p p′5 1( )p p′
1p
4 0( )p p′
3p2p
0 0( , )x y
SW
Fig. 2 The neighboring pixels utilized to extract structural contrast
level of the image, for each pixel, eight logical values aregenerated. These values are placed in a logical rule to clas-sify each pixel as either text or background. In this work, wemodify the logical-level technique to extract the structuralcontrast. Since this feature takes into account the structuralcharacteristics of the text, it increases the discrimination ofthe text and non-text pixels. Suppose we want to extract thestructural contrast, SC, at pixel (x0, y0) shown in Fig. 2. It isdefined as follows:
SC(x0, y0) = 3maxk=0
{min(MSW (pk), MSW (pk+1),
MSW (p′k)), MSW (p′
k+1)} − G(x0, y0)
MSW(pk) =(∑SW
i=−SW∑SW
j=−SW G(pkx − i, pky − j)
(2 × SW + 1)2
)
(4)
where G(x0,y0) represents the gray level of pixel (x0,y0),
pkx, pky are the coordinates of pk, p′i = p(i+4)mode 8, and SW
denotes the stroke width of the characters determined auto-matically.
We use the structural contrast as the first feature in ourapplication. Figure 3 shows a degraded image and its corre-sponding structural contrast feature.
In the conventional histogram based binarization algo-rithms, the gray level of each pixel is utilized as feature.Although, in degraded document images, this feature alonecannot separate the text and background pixels, it containsvaluable information and using it beside structural contrastmakes the text pixel more separable from background. There-fore, we use the gray level as the second feature in this work.The pixel (x, y) is mapped into feature space, f = [ f1, f2],where f1 = SC(x, y) and f2 = G(x, y)
123
60 M. Valizadeh, E. Kabir
Fig. 3 a Original image, b structural contrast feature image
10 20 30 40 50 60 700
50
100
150
200
250
Structural contrast
Gra
y le
vel
Text pixelsBackground pixels
(a) (b)
Fig. 4 a A typical degraded image, b some pixels of the image mapped into the 2D feature space
3.1.1 Finding the stroke width
Stroke width, SW, is a useful characteristic of the text. It isused to extract the feature SC. We used our previous method[20] to find SW automatically. This method computes the his-togram of the distances between two successive edge pixels inthe horizontal scan. Suppose that h(d) is a one-dimensionalarray, denoting the distance histogram and d ∈ {2, . . . , L}where L is the maximum distance to be counted. The SW isdefined as the distance, d, with the highest value in h(d). Thismethod finds the SW in degraded images more accuratelythan needed and satisfies our requirements. Experimentalresults showed that the tolerance of this method in finding SWis less than 20%, whereas we experimentally observed thatour binarization algorithm works efficiently if SW is foundwith 40% tolerance. The details of this experiment are citedin Appendix 1.
3.1.2 Discrimination power of the 2D feature space
To illustrate the discrimination power of the proposed fea-tures, we map some randomly chosen pixels of a typicaldegraded image shown in Fig. 4a into the 2D feature spaceand show them in Fig. 4b.
3.2 Feature space partitioning
In pattern recognition applications, clustering algorithms areutilized to group similar objects. In our work, we encounterlarge number of objects. For example, an image of 2,000 ×3,000 pixels contains 6,000,000 objects in the feature space.Clustering such a large number of objects is not a trivial taskand is very time consuming. Instead of clustering the objects,we partition the feature space using the mode-associationclustering technique [21]. Our partitioning algorithm con-sists of the following stages.
Histogram estimation: the feature space is divided intobins of equal size and the number of objects inside each binis counted. In the 2D feature space, we define a 1 × 1 squareas a bin.
Mode association clustering: starting from any point inthe feature space, we use hill climbing algorithm to findthe local maxima of the histogram. Those points that climbto the same local maximum are grouped into one partitionor region. This algorithm partitions the feature space intoN small regions in such a way that R = ⋃N
i=1 Ri whereR = { f |H( f ) > 0}, Ri = { f | f climbs to ith local max-imum} and H( f ) denotes the number of pixels in bin f .Figure 5 shows an example of the resulting regions in thefeature space.
123

Binarization of degraded document image based on feature space partitioning and classification 61
0 20 40 60 80 100 120 140 1600
50
100
150
200
250
Structural Contrast
Gra
y L
evel
Fig. 5 Partitioning of feature space into small regions
3.2.1 Purity of the regions
In the proposed binarization algorithm, we partition the fea-ture space into many small regions and classify those regions.Text and background pixels inside a wrong region are incor-rectly classified in the final binarization stage. Therefore,the purity of regions is important in our application. Likeother clustering algorithms, the mode-associated clusteringdoes not guarantee that all the objects assigned to the specificcluster belong to the same class. However, because of the fol-lowing reasons, it results in relatively pure regions. (i) Textand background pixels are dense in the regions of the featurespace associated with related classes while become sparse inthe regions that lie between these classes. In most cases, thereare clear gaps between text and background classes in the fea-ture space. During clustering, each point gradually climbs toa local maximum of the correct class and does not jump thegaps to an incorrect region. (ii) In this clustering algorithm,the number of clusters is not predetermined; instead, it isdetermined according to the distribution of the pixels in thefeature space. This leads to a large number of small regionswith high purity.
To examine our algorithm, we used 30 document imagesfrom three datasets and their ground truth to measure thepurity of the regions experimentally. We first partitioned thefeature space of each image into small regions and thencounted the number of text and background pixels in eachregion. The purities of text and background regions are mea-sured as follows:
PTR =∑
i∈text regions Nt (i)∑
i∈text regions Nt (i) + Nb(i)× 100
PBR =∑
i∈background regions Nb(i)∑
i∈background regions Nt (i) + Nb(i)× 100 (5)
where Nt (i) and Nb(i) denote the number of text and back-ground pixels inside the ith region. PTR and PBR representthe purities of text and background regions, respectively. Thisexperiment yielded PTR = 95.7% and PBR = 99.2%, showingacceptable purity. Since manual labeling of the boundary pix-els of the text is subjective, some differences between groundtruth and the results of our algorithm are negligible.
3.2.2 Complexity of clustering
In our method, the complexity of clustering algorithmdepends on the size of the feature space rather than the num-ber of pixels. To give a measure of complexity, we brieflyexplain the implementation of the clustering algorithm.
We start the algorithm from an arbitrary point in the fea-ture space and place a 5 × 5 window at this point. The max-imum value of histogram inside this window is found, andthe searching window is moved to it. This process contin-ues until a local maximum is reached. The starting point, thelocal maximum, and all points in the path between them arelabeled and are considered as a group. Then, we repeat thisprocess starting from another point not labeled yet. However,we terminate the maximum search process when we reacheither a new local maximum or a previously labeled point. Ifreaching a labeled point, the starting and all points in the pathto the destination point are labeled same as the destinationpoint. Otherwise, the starting point, the new local maximum,and the points in the path between them are labeled as a newgroup. This process continues until all points in the featurespace are labeled.
Using this method, the searching window is placed oneach point only once. We need 25 comparisons to find themaximum point inside each searching window and one com-parison to determine whether the central point is previouslylabeled or not. Our feature space has 256×256 points. So, thenumber of comparisons is 256×256×26. For an image with2000 × 3000 resolution, the number of comparisons neededis 0.28 per pixel. Feature space partitioning consumes onlya small portion of time needed for binarization of an image.
3.3 Region classification
After partitioning the feature space into small regions, we usethe result of an auxiliary binarization algorithm to classifyeach region as either text or background. In this way, an aux-iliary binary image is produced to generate the primary labelsof pixels. To classify region Ri,, the text and background pix-els of the auxiliary binary image, which their feature vectorslie in Ri , are counted. Suppose Nab(Ri ) and Nat (Ri ) are thenumber of pixels in Ri labeled as background and text in the
123

62 M. Valizadeh, E. Kabir
0 50 100 1500.4
0.5
0.6
0.7
0.8
0.9
1
1.1
Region index
TN
0 100 200 300 400 500 600 700
0.7
0.8
0.9
1
1.1
Region index
TP
(a) (b)
Fig. 6 a Percentage of background pixels in the regions labeled as background, b percentage of text pixels in the regions labeled as text
auxiliary image, respectively. Ri is classified as follows:
Class(Ri ) ={
text if Nat (Ri ) > Nab(Ri )
background otherwise(6)
where Class(Ri ) represents the class of Ri . Although thismethod accurately classifies the partitions, using it for classi-fying the single points in the feature space leads to some clas-sification errors because there are some errors in the primarylabels. This is the reason why we first partition the featurespace and then classify the resulting regions instead of clas-sifying all single points in the feature space.
3.3.1 Choosing the auxiliary binarization algorithm
Our region classification method performs well when we usean auxiliary binarization algorithm that correctly labels morethan 50% of the pixels inside each region. We found thatNiblack’s method is appropriate for this application. As men-tioned in Sect. 1, Niblack’s algorithm extracts the text objectseffectively but it classifies some parts of the background astext. The classification result of background pixels dependson the following conditions.
1. Both background and text pixels inside the sliding win-dow are utilized to compute a local threshold.
2. Only the background pixels exist inside the sliding win-dow.
In the first condition, almost all of the background pix-els inside the sliding window are classified correctly. In thesecond condition, in most cases, the number of correctly clas-sified background pixels is larger than the number of back-ground pixels classified falsely. Therefore, more than 50%of background pixels inside a small area in the image areclassified correctly. The background pixels inside each smallarea are almost similar and are expected to map into the sameregion in the feature space. Therefore, it is likely that morethan 50% of the pixels inside each region in the feature spaceare classified correctly if the sliding window is small enough
to maintain the local attributes of the image. To justify this,we carried out the following experiment.
We applied our partitioning algorithm over 30 documentimages and classified the small regions in the feature spacemanually. Then, we measured the percentage of correctlyclassified pixels using Niblack’s algorithm in each region asfollows:
TP = Nat (Ri )
Nat (Ri ) + Nab(Ri )class(Ri ) = text
TN = Nab(Ri )
Nat (Ri ) + Nab(Ri )class(Ri ) = background
(7)
where TP and TN are calculated for the text and backgroundregions, respectively. The results of this experiment showedthat Niblack’s algorithm correctly classifies more than 50%of the pixels, which lie in the same region (Fig. 6). Therefore,this algorithm satisfies our requirement. In our work, usinga very large window for implementing Niblack’s algorithmleads to not eliminating some smudges, while a very smallwindow may miss some large characters. We used a 60 × 60sliding window, which is appropriate for a wide range ofcharacter size.
We use the Niblack’s algorithm to generate the primarylabels and apply our region classification algorithm to sepa-rate the regions into text and background. Figure 7 illustratesthe result of our region classification algorithm applied to theregions in Fig. 5.
3.4 Final binarization
We use the classification results of regions to binarize thedocument image. Suppose G(x, y) is mapped into [ f1, f2]in the feature space where [ f1, f2] ∈ Ri . The binary image,B(x, y), is obtained as follows:
B(x, y) ={
0 if class(Ri ) = text1 if class(Ri ) = background
(8)
In this way, we obtain a binarization algorithm that can dealwith document images suffering from uneven background,shadows, non-uniform illumination, and low contrast.
123

Binarization of degraded document image based on feature space partitioning and classification 63
0 50 100 1500
50
100
150
200
250
Structural Contrast
Gra
y L
evel
Backgroundregion
Text region
Fig. 7 Feature space classification result for Fig. 5
Fig. 8 Result of our algorithm applied to the image shown in Fig. 4a
Partitioning the feature space into small regions and clas-sifying them rather than directly dividing the feature spaceinto text and background regions are the main reason forthe success of our algorithm. The binarization result of ouralgorithm applied to the image in Fig. 4a is shown in Fig. 8.
4 Experimental result
We carried out a comparative study to evaluate the perfor-mance of our algorithm. In this experiment, Otsu’s globalthresholding [1], Niblack’s local binarization [6], Sauvola’slocal binarization [13], Oh’s algorithm [15], Ye’s algorithm[14], and Gatos’ method [16] were implemented, and theresults obtained were utilized as benchmarks. For Sauvola’salgorithm, as recommended in [22] we set the parameter kinto 0.34. Using this value yields better results in our exper-iments. Both visual and quantitative criteria were used inour evaluation. We used three datasets of document images.Each dataset corresponds to the specific degradations anddemonstrates the efficiency of different algorithms dealingwith those degradations. Dataset I is ICDAR 2009 Dataset
[23], which includes 10 historical document images sufferingfrom the degradations such as smear, smudge, variable fore-ground and background intensities, and bleeding through. Inthis dataset, most of the degradations are due to aging. Data-set II includes 10 document images selected from the MediaTeam Dataset [24]. The images of this dataset have degra-dations such as textured background, shadow through, vari-able foreground and background intensities, and low-contrasttext. These images are not severely degraded, and most ofbinarization algorithms can binarize them with small errors.Dataset III involves 10 document images we captured underbadly illumination conditions. The images in this dataset suf-fer from severely variable foreground and background inten-sities and low contrast due to image acquisition conditions.Binarization of these images is not a trivial task, and mostalgorithms fail to binarize them properly.
4.1 Visual evaluation
We applied the binarization algorithms to document imagesof different datasets and visually compared the results. Theseexperiments showed that, compared with six well-knownalgorithms, our algorithm yields superior performance onmost of document images.
4.1.1 Experiment 1
In this experiment, the evaluation is carried out on the imagesof Dataset I. Figure 9 shows two examples of this exper-iment. The evaluation results are summarized as follows.Otsu’s algorithm regards some background regions as textand misses some texts. It yields the worst results. Niblack’salgorithm retains all texts but labels large number of noisyblobs as text. Oh’s algorithms miss the low-contrast texts.Sauvola’s algorithm labels some parts of background as text.Gatos’ and Ye’s algorithms result in binary images withsmall degradations. Our algorithm yields the best binaryimages in most cases. Only in the cases of severely bleeding-through degradation, our algorithm does not eliminate somebleeding-through texts and Sauvola’s algorithm outperformsours. The binarization results of our binarization algorithmfor 8 remaining images of Dataset I are given in Appendix 2.
4.1.2 Experiment 2
In this experiment, Dataset II is utilized for evaluation.The images in this dataset are not highly degraded. There-fore, most of binarization algorithms can produce cleanimages with small degradations. We visually compared theresults. Figure 10 shows a document image with shadow-through degradation and the binarization results. Niblack’sand Oh’s algorithms are not efficient dealing with this deg-radation and label many noisy blobs as text. Although other
123

64 M. Valizadeh, E. Kabir
Fig. 9 Binarization results of two typical historical images a Original images; b Otsu; c Sauvola; d Niblack; e Oh; f Ye; g Gatos; h our method
evaluated algorithms correct the shadow-through, they misssome details. For example, they fill the small holes of char-acters ‘a’ and ‘e’ in the word “Telefax”, magnified for bettervisualization. Our algorithm corrects this degradation whileretaining the details.
4.1.3 Experiment 3
In this experiment, we used the images of Dataset III. Thereare degradations such as blurring, low-contrast text, andseverely variable foreground and background intensities inthese images. Figure 11 shows a low-contrast and blurredimage and the binarization results of different algorithms.Using Otsu’s algorithm, the text is properly extracted fromthe background. However, it yields broken and touching char-acters in some parts of the image. Sauvola’s algorithm gives abinary image in which many characters are missed and someare broken. Niblack’s algorithm extracts many backgroundblobs as text. In addition, this algorithm leads to highestamount of touching characters. Oh’s and Gatos’s algorithmsresult in similar binary images that have large number of bro-ken characters. Ye’s and our algorithms result in clean binaryimages.
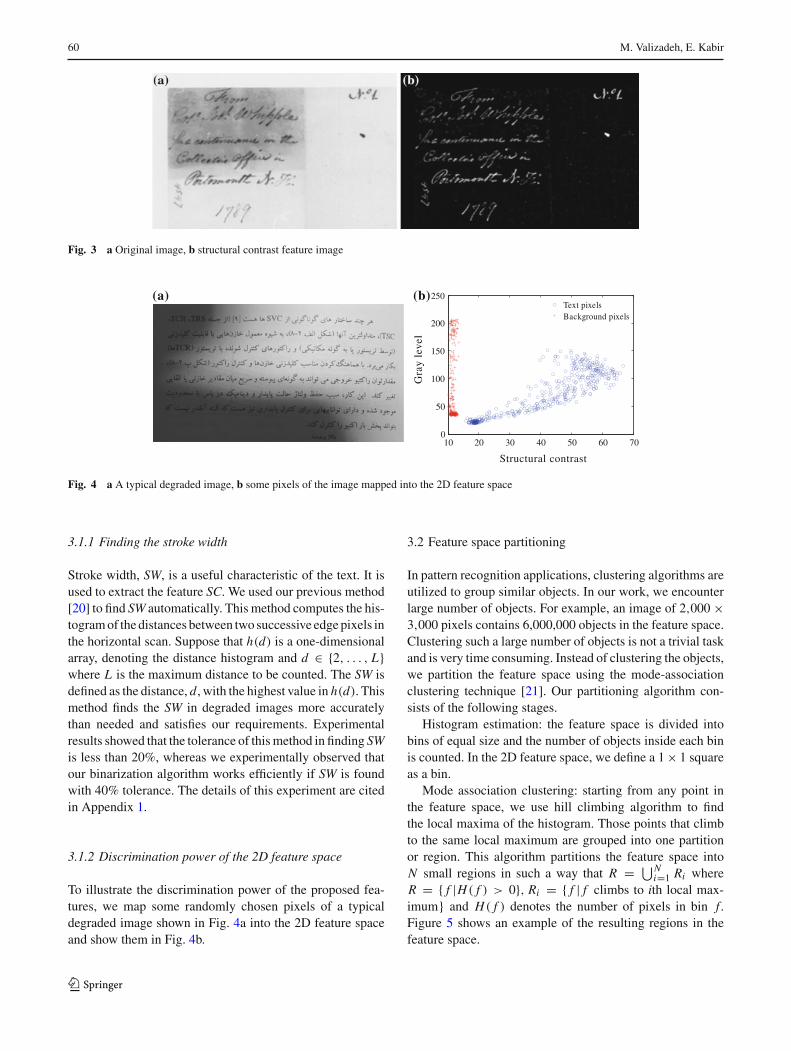
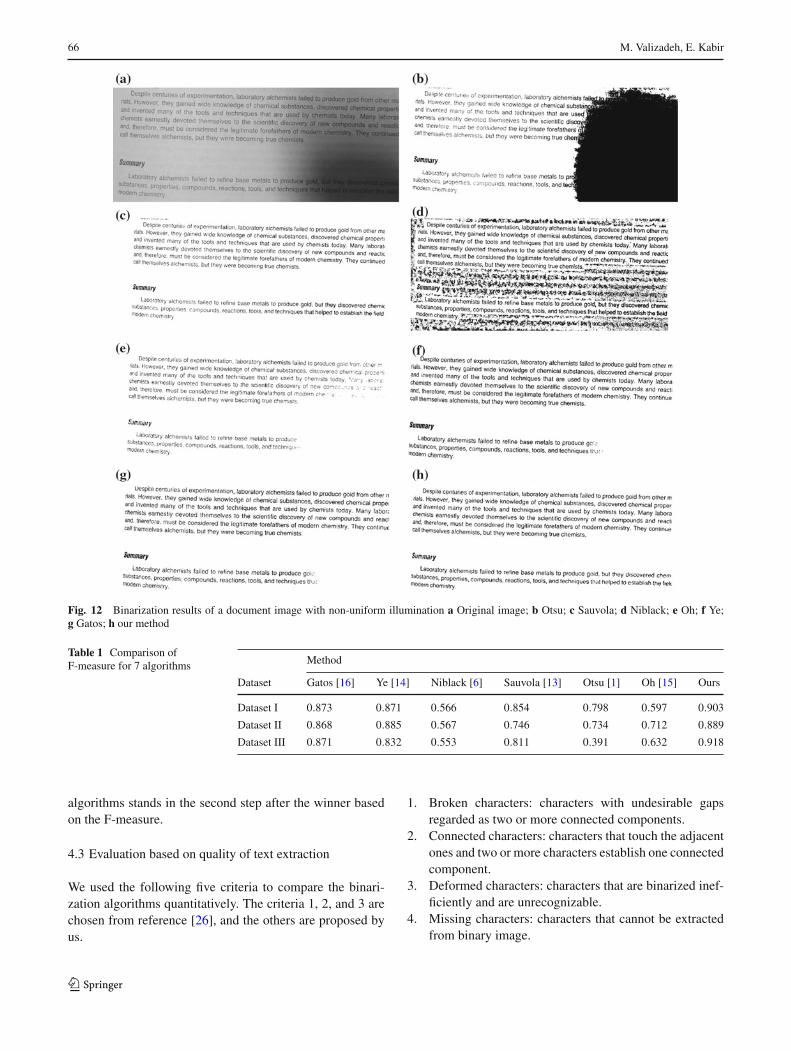
Figure 12 shows a document image with non-uniform illu-mination and the binarization results of different algorithms.Otsu’s algorithm cannot extract the text from background,because the gray-level values of the text overlaps with thoseof the background. Sauvola’s algorithm assumes that the graylevels of text and background are close to 0 and 255, respec-tively. Low-contrast texts with gray levels close to 255 donot satisfy this assumption and are missed or broken up.Niblack’s algorithm labels many background blobs as text.Oh’s, Ye’s and Gatos’ algorithms miss the text in the shadowarea. Our algorithm results in a clean binary image. Dealingwith document images captured with camera, our algorithmextremely outperforms other algorithms evaluated.
4.2 Quantitative evaluation by F-measure
In this experiment, we used F-measure to compare the per-formance of binarization algorithms. This criterion is utilizedin the first document image binarization contest [25]. It isdefined as follows:
F-measure = 2 × Recall × Precision
Recall + Precision(9)
123

Binarization of degraded document image based on feature space partitioning and classification 65
Fig. 10 Binarization results ofa document image withshadow-through degradationa Original image; b Otsu;c Sauvola; d Niblack; e Oh;f Ye; g Gatos; h our method.The word “Telefax” is magnifiedfor better visualization
Fig. 11 Binarization results of a low-contrast and blurred image a Original image; b Otsu; c Sauvola; d Niblack; e Oh; f Ye; g Gatos; h our method
where Recall = TPTP+FN , Precision = TP
TP+FP and TP, FPand FN denote true-positive, false-positive, and false-nega-tive values, respectively. We used all three datasets for eval-uation. The ground truth of Dataset I is available from [23],and the ground truths of two other datasets were manually
generated. The comparison of 7 algorithms are given inTable 1. Our algorithm yields the best results for all data-sets.
Comparing the results of our algorithm on Dataset I withthe algorithms participated in DIBCO 2009 shows that our
123
66 M. Valizadeh, E. Kabir
Fig. 12 Binarization results of a document image with non-uniform illumination a Original image; b Otsu; c Sauvola; d Niblack; e Oh; f Ye;g Gatos; h our method
Table 1 Comparison ofF-measure for 7 algorithms Method
Dataset Gatos [16] Ye [14] Niblack [6] Sauvola [13] Otsu [1] Oh [15] Ours
Dataset I 0.873 0.871 0.566 0.854 0.798 0.597 0.903
Dataset II 0.868 0.885 0.567 0.746 0.734 0.712 0.889
Dataset III 0.871 0.832 0.553 0.811 0.391 0.632 0.918
algorithms stands in the second step after the winner basedon the F-measure.
4.3 Evaluation based on quality of text extraction
We used the following five criteria to compare the binari-zation algorithms quantitatively. The criteria 1, 2, and 3 arechosen from reference [26], and the others are proposed byus.
1. Broken characters: characters with undesirable gapsregarded as two or more connected components.
2. Connected characters: characters that touch the adjacentones and two or more characters establish one connectedcomponent.
3. Deformed characters: characters that are binarized inef-ficiently and are unrecognizable.
4. Missing characters: characters that cannot be extractedfrom binary image.
123

Binarization of degraded document image based on feature space partitioning and classification 67
Table 2 Evaluation results ofbinarization algorithms based onfive criteria
Gatos [16] Ye [14] Niblack [6] Sauvola [13] Otsu [1] Oh [15] Ours
Broken characters 209 148 0 347 198 346 69
Connected characters 19 57 613 85 97 43 73
Deformed characters 216 218 84 245 136 142 49
Missing characters 519 617 0 674 2117 384 8
Blobs in background region 4 0 Too many 35 24 0 5
5. Blob in background region: False object extracted as text.
We applied different binarization algorithms to the imagesof Dataset III and measured these criteria manually. In thisexperiment, the test images have 6,304 characters in total.The results are given in Table 2.
The results of our evaluation are described as follows:
• Otsu’s algorithm is not suitable for the images withuneven background (e.g. Fig. 12). Using this algorithm, alot of faint texts and those in dark background are missedand some of the faint characters become broken.
• Niblack’s method does not miss the text, but it yieldsa lot of touching characters in low-contrast images. Inaddition, it labels a large amount of background blobs astext.
• Sauvola’s method eliminates the background properly butbreaks up faint characters or removes them totally in low-contrast document images.
• Gatos’ algorithm uses three predetermined parametersand two global attributes of document image to calculatethe adaptive threshold. It misses some of the charactersor breaks them up in the badly illuminated images if itsparameters are not adapted for these types of images.
• Ye’s algorithm maps the original image into the double-edge feature image and uses global thresholding to sepa-rate text from background. Therefore, when the contrastof the text is variable in different parts of the images, thelow-contrast characters are missed.
• Oh’s algorithm uses a global threshold to extract regionsof interest, ROI, in which rain falls. Some ROIs aremissed, and the related texts are lost. In addition, whenthe variation of gray levels inside a character is high, thisalgorithm breaks it up. This algorithm is not appropriatefor the images with uneven background.
• Our algorithm maps the pixels into an appropriate featurespace and classifies this space using the result of Niblack’salgorithm. It results in clean binary images for the mostof test images. However, dealing with severely bleeding-through degradation, some of the spurious componentsare labeled as text.
5 Conclusion
In this paper, we proposed a new algorithm for the binari-zation of document images. We presented a novel feature,structural contrast, and mapped the document image into a2D feature space in which the text and background pixels areseparable. Then, we partitioned this space into small regions.These regions were classified to text and background usingthe result of Niblack’s algorithm. Each pixel is then classi-fied as either text or background based on its location in thefeature space. Our binarization algorithm does not need anyparameter setting by the user and is appropriate for varioustypes of degraded images. The main advantage of our algo-rithm against the previous classification-based algorithms isthat it does not need any training dataset and uses the resultof Niblack’s algorithm. In different experiments, the pro-posed algorithm demonstrated superior performance againstsix well-known algorithms on three datasets of degradedimages.
Acknowledgments This work was supported in part by Iran Tele-communication Research Center, ITRC, under contact T500-4683.
Appendix 1
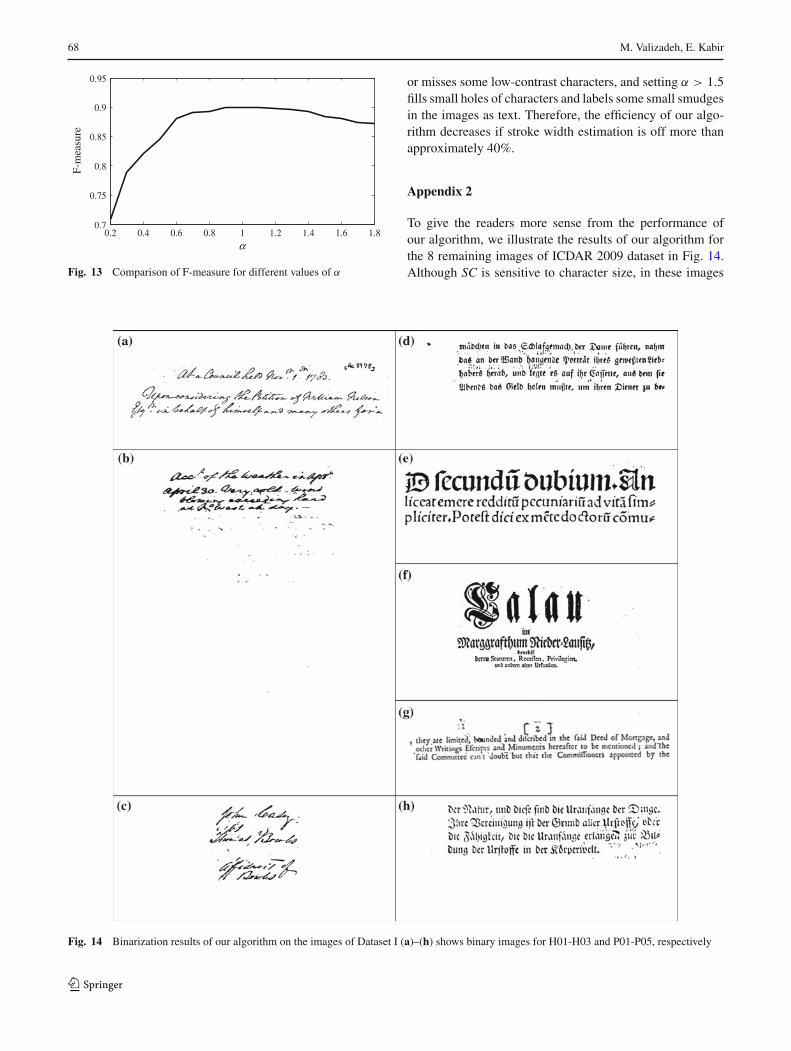
In our work, stroke width, SW, is used as a structural char-acteristic of the text, and the accuracy of its value affects theefficiency of the feature SC. It is important to determine thathow sensitive the binarization results are to the errors in theestimation of SW. We did the following experiment to mea-sure the quality of binarization algorithm for different valuesof error in the estimation of SW. We manually determined theSW of the text for 30 document images and used [α × SW ]in our binarization algorithm instead of automatic estimationof SW, where 0.2 ≤ α ≤ 1.8 and [A] denotes the roundedvalue of A. F-measure was calculated for different values ofα as shown in Fig. 13. F-measure has small variation whenα ≥ 0.6 and decreases rapidly for α < 0.6. Visual inspec-tion of resulting binary images verified this experiment, andwe observed that for 0.6 ≤ α ≤ 1.5, the binary imageshave almost same qualities. However, setting α < 0.6 breaks
123
68 M. Valizadeh, E. Kabir
α
F-m
easu
re
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.80.7
0.75
0.8
0.85
0.9
0.95
Fig. 13 Comparison of F-measure for different values of α
or misses some low-contrast characters, and setting α > 1.5fills small holes of characters and labels some small smudgesin the images as text. Therefore, the efficiency of our algo-rithm decreases if stroke width estimation is off more thanapproximately 40%.
Appendix 2
To give the readers more sense from the performance ofour algorithm, we illustrate the results of our algorithm forthe 8 remaining images of ICDAR 2009 dataset in Fig. 14.Although SC is sensitive to character size, in these images
Fig. 14 Binarization results of our algorithm on the images of Dataset I (a)–(h) shows binary images for H01-H03 and P01-P05, respectively
123

Binarization of degraded document image based on feature space partitioning and classification 69
our algorithm yields satisfactory results even for the docu-ments that have text with different font size, as in Fig. 14eand f. In these images, the gray level discriminates the textfrom background. Therefore, our algorithm can handle thesecases although SC is not a good feature for them.
References
1. Otsu, N.: A threshold selection method from grey level histo-gram. IEEE Trans. Syst. Man Cybernet. 9, 62–66 (1979)
2. Kapur, J.N., Sahoo, P.K., Wong, A.K.C.: A new method for graylevel picture thresholding using the entropy of the histogram.Comput. Vis. Graph. Image Process. 29, 273–285 (1985)
3. Weszka, J.S., Rosenfield, A.: Histogram modification for thresholdselection. IEEE Trans. Syst. Man Cybernet. 9, 38–52 (1979)
4. Dawoud, A., Kamel, M.S.: Iterative multimodel subimage binari-zation for handwritten character segmentation. IEEE Trans. ImageProcess. 13, 1223–1230 (2004)
5. Liu, Y., Srihari, S.N.: Document image binarization based on tex-ture features. IEEE Trans. Pattern Anal. Mach. Intell. 19, 540–544(1997)
6. Niblack, W.: An Introduction to Digital Image Processing. PrenticeHall, Englewood Cliffs, NJ, USA (1986)
7. White, J.M., Rohrer, G.D.: Imager segmentation for optical char-acter recognition and other applications requiring character imageextraction. IBM J. Res. Dev. 27, 400–411 (1983)
8. Parker, J.R.: Gray level thresholding in badly illuminatedimages. IEEE Trans. Pattern Anal. Mach. Intell. 13, 813–819(1991)
9. Kamel, M., Zhao, A.: Extraction of binary character/graphicsimages from grayscale document images. Graph. Models ImageProcess. 55, 203–217 (1993)
10. Bernsen, J.: Dynamic thresholding of grey-level images. In:Proceedings of the 8th International Conference on Pattern Rec-ognition, Paris, pp. 1251–1255 (1986)
11. Chen, Y., Leedham, G.: Decompose algorithm for thresholdingdegraded historical document images. IEE Proc. Vis. Image SignalProcess. 152, 702–714 (2005)
12. Yang, Y., Yan, H.: An adaptive logical method for binarization ofdegraded document images. Pattern Recognit. 33, 787–807 (2000)
13. Sauvola, J., Pietikainen, M.: Adaptive document image binariza-tion. Pattern Recognit. 33, 225–236 (2000)
14. Ye, X., Cheriet, M., Suen, C.Y.: Stroke-model-based characterextraction from gray-level document images. IEEE Trans. ImageProcess. 10, 1152–1161 (2001)
15. Oh, H.H., Lim, K.T., Hien, S.I.: An improved binarizationalgorithm based on a water flow model for document imagewith inhomogeneous backgrounds. Pattern Recognit. 38, 2612–2625 (2005)
16. Gatos, B., Pratikakis, I., Perantonis, S.J.: Adaptive degraded doc-ument image binarization. Pattern Recognit. 39, 317–327 (2006)
17. Lu, S., Tan, C.L.: Binarization of badly illuminated documentimages through shading estimation and compensation. In: 9thInternational Conference on Document Analysis and Recognition,Brazil, pp. 312–316 (2007)
18. Huang, S., Ahmadi, M., Sid-Ahmed, M.A.: A hidden Markovmodel-based character extraction method. Pattern Recognit. 41,2890–2900 (2008)
19. Chou, C.H., Lin, W.H., Chang, F.: A binarization method withlearning-built rules for document images produced by cameras.Pattern Recognit. 43, 1518–1530 (2010)
20. Valizadeh, M., Komeili, M., Armanfard, N., Kabir, E.: Degradeddocument image binarization based on combination of two com-plementary algorithms. In: International Conference in Advancesin Computer Tools for Engineering Applications, Lobanon,pp. 595–599 (2009)
21. Li, J., Ray, S., Lindsay, B.G.: A nonparametric statistical approachto clustering via mode identification. J. Mach. Learn. Res. 8, 1687–1723 (2007)
22. Badekas, E., Papamarkos, N.: Automatic evaluation of documentbinarization results. In: Proceedings of the 10th IberoamericanCongress on Pattern Recognition, pp. 1005–1014. Havana (2005)
23. First international document image binarization contest (http://users.iit.demokritos.gr/~bgat/DIBCO2009/benchmark/)
24. Media Team Oulu Document database (http://www.mediateam.oulu.fi/MTDB/)
25. Gatos, B., Ntirogiannis K., Pratikakis, I.: ICDAR 2009 documentimage binarization contest (DIBCO 2009). In: 10th InternationalConference on Document Analysis and Recognition, Spain, pp.1375–1382 (2009)
26. Solihin, Y., Leedham, C.G.: Integral ratio: A new class of globalthresholding techniques for handwriting images. IEEE Trans.Pattern Anal. Mach. Intell. 21, 761–768 (1999)
123