adaptive quality of service-based routing approaches: development of neuro-dynamic state-dependent...
TRANSCRIPT

INTERNATIONAL JOURNAL OF COMMUNICATION SYSTEMSInt. J. Commun. Syst. 2007; 20:1113–1130Published online 15 November 2006 in Wiley InterScience (www.interscience.wiley.com). DOI: 10.1002/dac.858
Adaptive quality of service-based routing approaches:development of neuro-dynamic state-dependent reinforcement
learning algorithms
Abdelhamid Mellouk*,y, Saıd Hoceıni and Yacine Amirat
LISSI/SCTIC IUT Creteil-Vitry University Paris XII, 122 rue Paul Armangot Vitry sur Seine 94400, France
SUMMARY
In this paper, we propose two adaptive routing algorithms based on reinforcement learning. In the firstalgorithm, we have used a neural network to approximate the reinforcement signal, allowing the learner totake into account various parameters such as local queue size, for distance estimation. Moreover, eachrouter uses an online learning module to optimize the path in terms of average packet delivery time, bytaking into account the waiting queue states of neighbouring routers. In the second algorithm, theexploration of paths is limited to N-best non-loop paths in terms of hops number (number of routers in apath), leading to a substantial reduction of convergence time. The performances of the proposedalgorithms are evaluated experimentally with OPNET simulator for different levels of traffic’s load andcompared with standard shortest-path and Q-routing algorithms. Our approach proves superior toclassical algorithms and is able to route efficiently even when the network load varies in an irregularmanner. We also tested our approach on a large network topology to proof its scalability and adaptability.Copyright # 2006 John Wiley & Sons, Ltd.
Received 14 September 2005; Revised 22 June 2006; Accepted 7 September 2006
KEY WORDS: shortest-path routing; flow-based routing; N-best paths; neural networks; adaptive routing;neuro-dynamic state-dependent; reinforcement learning; traffic engineering
1. INTRODUCTION
Internet has become the most important communication infrastructure of today’s humansociety. It enables the worldwide users (individual, group and organizational) to access andexchange remote information scattered over the world. Currently, due to the growing needs intelecommunications (VoD, video conference, VoIP, etc.) and the diversity of transported flows,Internet network does not meet the requirements of the future integrated service networks that
*Correspondence to: Abdelhamid Mellouk, LISSI/SCTIC IUT Creteil-Vitry University Paris XII, 122 rue PaulArmangot Vitry sur Seine 94400, France.yE-mail: [email protected]
Copyright # 2006 John Wiley & Sons, Ltd.

carry multimedia data traffic with a high quality of service (QoS). The main aspects that have tobe taken into account for the evolution of the Internet are: a continuous growth of thebandwidth requests, the promise of cost improvements and finally the possibility of increasingprofits by offering new services. However, Internet does not support resource reservation, whichis primordial to guarantee an end-to-end QoS (bounded delay, bounded delay jitter and/orbounded loss ratio). Moreover, a data packet may be subjected to an unpredictable delayleading to an exceeded delivery deadline. Such a situation is undesirable for continuous real-time media. In this context and for optimizing the financial investment on their networks,operators must use the same support for transporting any kind of data flows. Therefore, it isnecessary to develop a high-quality control mechanism to check the network traffic load andensure QoS requirements.
Different definitions and parameters have been proposed to define the concept of QoS. TheITU-T E.800 recommendation defines QoS as ‘the collective effect of service performance whichdetermines the degree of satisfaction of a user of the service’. This definition is supplemented bythe I.350 ITU-T recommendation which defines more precisely the differences between QoS andnetwork performance. QoS concept in the Internet is focused on a packet-based end-to-end,edge-to-edge or end-to-edge communication. Several QoS parameters can be considered:availability, bandwidth, delay, jitter and loss ratio. It is clear that the integration of theseparameters into network control increases the complexity of the used algorithms. Anyway, therewill be QoS relevant technological challenges in the emerging hybrid networks mixing severaldifferent types of networks (wireless, broadcast, mobile, fixed, etc.).
Various techniques have been proposed to take into account QoS requirements [1]. Thesetechniques may be classified as follows: congestion control (slow start, weighted random earlydetection [2]), traffic shaping (leaky bucket, token bucket [3]), integrated services architecture(resource reservation protocol (RSVP) [4]), differentiated services (DiffServ [4]) and QoS-basedrouting. In this paper, we focus on QoS routing policies.
2. ROUTING ALGORITHMS IN NETWORK TELECOMMUNICATION
2.1. Classical routing algorithms
A routing algorithm is based on the hop-by-hop shortest-path paradigm. The source of a packetspecifies the address of the destination, and each router along the route forwards the packet to aneighbour located ‘closest’ to the destination. The best optimal path is chosen according to agiven criteria. When the network is heavily loaded, some routers may introduce an excessivedelay while others are under used. In some cases, this non-optimized usage of network resourcesmay lead not only to excessive delays but also to high packets loss rates. Among routingalgorithms extensively employed in the same autonomous system, one can enumerate: distancevector algorithm such as Routing Internet Protocol (RIP) and the link-state algorithm such asOSPF [5]. This kind of algorithm takes into account variations of loads leading to limitedperformances.
2.2. QoS-based routing algorithms
Several studies have been conducted to propose an alternative paradigm that addresses theintegration of QoS criteria into routing algorithms. The most popular formulation of the
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1114
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

optimal distributed routing problem in a data network is based on a multicommodity flowoptimization whereby a separable objective function is minimized with respect to the type offlow subject to multicommodity flow constraints [6,7]. However, due their complexity, increasedprocessing burden, few proposed routing algorithms are appropriated for the internet likeQOSPF [8], MPLS [3,4], traffic engineering (TE) [1,2,9] or Wang–Crowcroft algorithm [10].
2.3. QoS-based state-dependent routing algorithms
For a network node to be able to make an optimal routing decision, according to relevantperformance criteria, it requires not only up-to-date and complete knowledge of the state of theentire network but also an accurate prediction of the network dynamics during propagation ofthe data packet through the network. This, however, is impossible unless the routing algorithmis capable of adapting to the network state changes in almost real time. So, it is necessary todevelop a new intelligent and adaptive optimizing routing algorithm. This problem is naturallyformulated as a dynamic programming problem, which, however, is too complex to be solvedexactly.
In our approach, we use the methodology of reinforcement learning (RL) introduced bySutton [11] to approximate the value function of dynamic programming. One of pioneeringworks related to this kind of approaches concerns Q-routing algorithm [12] based on Q-learningtechnique [13].
* Q-routing approach. In this technique [12], each node makes its routing decision based onthe local routing information, represented as a table of Q values which estimate the qualityof the alternative routes. These values are updated each time when the node sends a packetto one of its neighbours. However, when a Q value is not updated for a long time, it doesnot necessarily reflect the current state of the network and hence a routing decision basedon such an unreliable Q value will not be accurate. The update rule in Q-routing does nottake into account the reliability of the estimated or updated Q value because it depends onthe traffic pattern, and load levels. In fact, most of the Q values in the network areunreliable. For this purpose, other algorithms have been proposed like confidence-basedQ-routing (CQ-routing) [14] or confidence-based dual reinforcement Q-routing (DRQ-routing) [15].
All these routing algorithms use a table to estimate Q values. However, the size of the tabledepends on the number of destination nodes. Thus, this approach is not well suited when we areconcerned with a state space of high dimensionality.
* Ants-routing approach. Inspired by dynamics of how ant colonies learn the shortest route tofood source using very little state and computation, Ants routing algorithms proposedinitially by Subramanian et al. [16] are described as follows: instead of having fixed next-hop value, the routing table will have multiple next-hop choices for a destination, with eachcandidate associated with a possibility, which indicates the goodness of choosing this hopas the next hop in favour to form the shortest path [16]. These possibility values are initiallyequal and will be updated according to the ant packets pass by. Given a specified sourcenode and destination node, the source node will send out some kind of ant packets basedon the possibility entries on its own routing table. Those ants will explore the routes in thenetwork. They can memorize the hops they have passed. When an ant packet reachesat the destination node, the ant packet returns to the source node along the same route.
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1115
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

On the way back to the destination node, the ant packet will change the routing table forevery node it passes by. The rule of updating the routing tables is: increasing the possibilityof the hop it comes from while decreasing the possibilities of other candidates.
Ants approach is immune to the sub-optimal route problem since it explores, all the times, allthe paths of the network. However, the traffic generated by ant algorithms is more importantthan the traffic of the concurrent approaches.
In this paper, we propose two adaptive routing algorithms based on RL, optimizing theaverage packet delivery time. The first algorithm, presented and evaluated in Section 3, is basedon a neural network (NN) ensuring the prediction of routing parameters depending on trafficvariations. Compared with the approaches based on Q-tables, the Q-value is approximated by aRL-based NN of a fixed size, allowing the learner to incorporate various parameters such aslocal queue size and time of day, into distance estimation. Indeed, a NN allows the modelling ofcomplex functions with a good precision along with a discriminating training and taking intoaccount the context of the network. Moreover, it can be used to predict non-stationary orirregular traffics. The second algorithm called N-best Q-routing algorithm is presented andevaluated in Section 4. It addresses the exploration problem encountered in standard Q-routingalgorithms by reducing the search space to N-best no loop paths in terms of hops number. Infact, these algorithms explore the entire network and do not take into account the loop problemin a way leading to a large convergence time. In order to proof their scalability and adaptability,the algorithms we proposed have been tested on a large network topology.
3. Q-NEURAL ROUTING APPROACH
In this section, we present an adaptive routing algorithm based on the Q-learning approach, theQ-function is approximated by a RL-based NN. First, we formulate the RL process.
3.1. Reinforcement learning
The RL algorithm, called reactive approach, consists of endowing an autonomous agent with acorrectness behaviour guaranteeing the fulfilment of a desired task in a dynamic environment.The behaviour must be specified in terms of perception–decision–action loop (Figure 1). Eachvariation of the environment induces stimuli received by the agent, leading to the determinationof an appropriate action. The reaction is then considered as a punishment or performancefunction, also called, reinforcement signal. Thus, the agent must integrate this function tomodify its future actions in order to reach an optimal performance. In other words, a RLalgorithm is a finite-state machine that interacts with a stochastic environment, trying to learnthe optimal action the environment offers through a learning process. At any iteration theautomaton chooses an action, according to a probability vector, using an output function. Thisfunction stimulates the environment, which responds with an answer (reward or penalty). Theautomaton takes into account this answer and jumps, if necessary, to a new state using atransition function.
It is necessary for the agent to gather useful experience about the possible system states,actions, transitions and rewards actively to act optimally. Another difference from supervisedlearning is that online performance is important: the evaluation of the system is often concurrentwith learning.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1116
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

A RL system thus involves the following elements: an agent (sensors), an environment, areinforcement function, an action, a state and a value function, which is obtained from thereinforcement function, and a policy. In order to obtain a network routing useful model, it ispossible to associate the network’s elements to the basic elements of a RL system, as shown inTable I.
RL algorithms [11] face the same issues as traditional distributed algorithms, with someadditional particularities for routing. First, the behaviour of a network (i.e. environment) likeInternet is quite complex and often stochastic (especially links, link costs, traffic andcongestion), therefore, routing algorithms must take into account the dynamic nature of thenetwork, for which no explicit and reliable model is available. This means that RL algorithmshave to sample, estimate and perhaps build pertinent models of the network behaviour.Secondly, RL algorithms, unlike other machine-learning algorithms, do not have an explicitlearning phase followed by evaluation. Since there is no training signal for a direct evaluationof the policy’s performance before the packet has reached its final destination, it is difficultto apply supervised learning techniques for this kind of problem [17]. In addition, it isdifficult to determine to what extent a routing decision that has been made on a single node mayinfluence the network’s overall performance. This fact fits into the temporal credit assignmentproblem [17].
Table I. Correspondences between a RL system and network elements.
Networks elements RL system
Network Environment }Each network node Agent }Delay in links and nodes Reinforcement function TEstimate of total delay Value function Qðs; y; dÞAction of sending a packet Action a(s1)Node through which the packet passes in time t State in time t s1Local routing decision Policy p
Figure 1. Reinforcement learning model.
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1117
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

3.2. Q-learning algorithm for routing
In our routing algorithm, the objective is to minimize the average packet delivery time.Consequently, the reinforcement signal which is chosen corresponds to the estimated time totransfer a packet to its destination. Typically, the packet delivery time includes three variables:the packet transmission time, the packet treatment time in the router and the latency in thewaiting queue. In our case, the packet transmission time is not taken into account. In fact, thisparameter can be neglected in comparison with the other ones and has no effect on the routingprocess.
The reinforcement signal T employed in the Q-learning algorithm can be defined as minimumof the sum of the estimated Qðy;x; dÞ sent by the router x neighbour of router y and the latencyin waiting queue qy corresponding to router y.
T ¼ minx2neighbour of y
fqy þQðy;x; dÞg ð1Þ
where Qðs; y; dÞ denotes the estimated time by the router s so that the packet p reaches itsdestination d through the router y. This parameter does not include the latency in the waitingqueue of the router s. The packet is sent to the router y which determines the optimal path tosend this packet [18].
Once the choice of the next router made, the router y puts the packet in the waiting queue,and sends back the value T as a reinforcement signal to the router s. It can therefore update itsreinforcement function as:
DQðs; y; dÞ ¼ Zðaþ T �Qðs; y; dÞÞ ð2Þ
So, the new estimation Q0ðs; y; dÞ can be written as follows (Figure 2):
Q0ðs; y; dÞ ¼ Qðs; y; dÞð1� ZÞ þ ZðT þ aÞ ð3Þ
a and Z are, respectively, the packet transmission time between s and y, and the learning rate.
3.3. Neural net architecture
The NN proposed in our study is a multi layers perceptron (MLP) with eight (08) inputs andfour (04) outputs (Figure 3). One hidden layer is used with 80 neurons.
Figure 2. Updating the reinforcement signal.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1118
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

The first four inputs correspond to the destination address d and the four others to the waitingqueue states. The outputs are the estimated packet transfer times passing through theneighbours of the considered router. The algorithm derived from this architecture is calledQ-neural routing.
In general, the topology of the NN must be fixed before the training phase. The only variablesbeing able to be modified are the values of the weights of connections. The specification of thisarchitecture, the number of cells of each layer and of connections, remains a crucial problem. Ifthis number is insufficient, the model will not be able to take into account all data. On thecontrary, if it is too significant, the training will be perfect but the recognition will be poor. Thisproblem is known under the name of ‘overfitting’. The model learns the data of the training byheart. However, here it is about the online training, for which the number of examples is notdefined a priori. For this purpose, we propose an empirical study based on pruning technique tofind a compromise between a satisfactory estimate of the function Q and an acceptablecomputing time.
As illustrated in Figure 4, the best result is obtained for a NN with a hidden layer of 150neurons.
Figure 3. Neural net architecture.
Figure 4. Empirical pruning study for choosing the number of hidden cells over the time of convergence.
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1119
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

3.4. Implementation and simulation results
To show the efficiency and evaluate the performances of our approach, an implementation hasbeen performed on OPNET software of MIL3 Company [19]. The proposed approach has beencompared with that based on standard Q-routing [12] and shortest-path routing policy.
OPNET constitutes for telecommunication networks an appropriate modelling, schedulingand simulation tool. It allows the visualization of a physical topology of a local, metropolitan,distant or on board network. The protocol specification language is based on a formaldescription of a finite-state automaton.
The proposed algorithm has been compared with that based on standard Q-routing andshortest-path routing policies (such as RIP). The topology of the network employed here forsimulations, which is used in many papers (such as [12,14]), includes 33 interconnected nodes, asshown in Figure 5. Two kinds of traffic have been studied: low load and high load of thenetwork. In the first case, a low rate flow is sent to node destination-1, from nodes source-1 andsource-4. From the previous case, we have created conditions of congestion of the network.Thus, a high rate flow is generated by nodes source-2 and source-3. Figure 5 shows the twopossible ways R-1 (router-29 and router-30) and R-2 (router-21 and router-22) to route thepackets between the left part and the right part of the network.
Performances of algorithms are evaluated in terms of average packet delivery time. Figures 6and 7 illustrate the obtained results when source-2 and source-3 send information packetsduring 10min.
From Figure 7, one can see, clearly that after an initialization period, the Q-routing andQ-neural routing algorithms, exhibit better performances than RIP. Thus, packet averagepacket delivery time obtained by Q-routing algorithm and Q-neural routing algorithm isreduced by respectively, 23.6% and 27.3% compared with RIP routing policy (Table II).
Figure 5. Network topology for simulation.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1120
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac
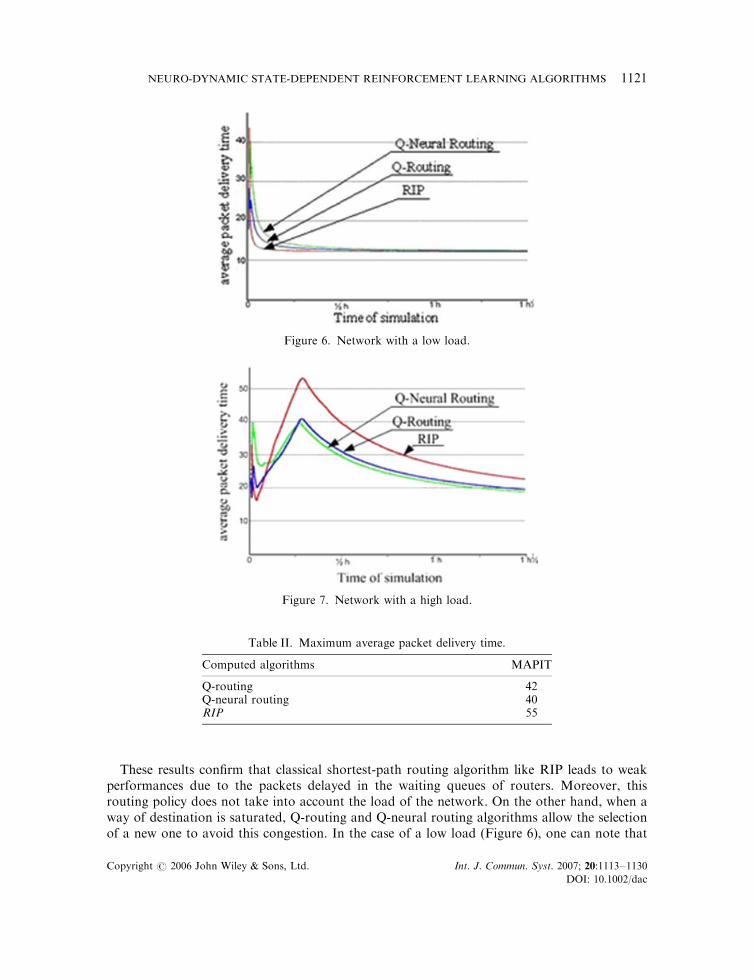
These results confirm that classical shortest-path routing algorithm like RIP leads to weakperformances due to the packets delayed in the waiting queues of routers. Moreover, thisrouting policy does not take into account the load of the network. On the other hand, when away of destination is saturated, Q-routing and Q-neural routing algorithms allow the selectionof a new one to avoid this congestion. In the case of a low load (Figure 6), one can note that
Figure 6. Network with a low load.
Figure 7. Network with a high load.
Table II. Maximum average packet delivery time.
Computed algorithms MAPIT
Q-routing 42Q-neural routing 40RIP 55
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1121
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

after a period of initialization, performances of these algorithms are approximately the same asthose obtained with RIP routing policy.
Figure 8 illustrates the average packet delivery time obtained when a congestion of thenetwork is generated during 60min. Thus, in the case where the number of packets is moreimportant, the Q-neural routing algorithm gives better results compared with the Q-routingalgorithm. For example, after 2 h of simulation, Q-neural routing exhibits a performance of20% better than that of Q-routing. Indeed, the utilization of waiting queue state of theneighbouring routers in the decision of routing allows anticipation of routers congestion.
4. N-BEST OPTIMAL PATHS Q-ROUTING APPROACH
A Q-neural routing needs a rather large computational time and memory space. In the goal ofreducing the complexity of our algorithm, we propose a hybrid approach using NNs andreducing the search space to N-best no loop paths in terms of hops number reduction. Thisapproach requires each router to maintain a link state database, which is essentially a map of thenetwork topology. When a network link changes its state (i.e. goes up or down, or its utilizationis increased or decreased), the network is flooded with a link state advertisement (LSA) message[20]. This message can be issued periodically or when the actual link state change exceeds acertain relative or absolute threshold [21,22]. Obviously, there is tradeoff between the frequencyof state updates (the accuracy of the link state database) and the cost of performing thoseupdates. In our approach, the link state information is updated when the actual link statechange. Once the link state database at each router is updated, the router computes the N-bestoptimal paths and determines the best one from Q-routing algorithm.
4.1. Constructing N-best paths
Several papers discuss the algorithms for finding N-best paths [22–24]. Our solution is based ona label-setting algorithm (based on the optimality principle and being a generalization of
Figure 8. Very high load network.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1122
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

Dijkstra’s algorithm) [23]. The space complexity is O(Nm), where K is the number of paths andm, the number of edges. By using a pertinent data structure, the time complexity can be keptat the same level O(Nm). We modify the algorithm to find the N-best non-loop pathsas follows:
Let a DAG (N; A) denote a network with n nodes and m edges, where K ¼ f1 . . . kg; andA ¼ faBijB=j; i 2 Kg: The problem is to find the top N paths from source s to all the other nodes.
Let us define a label set X and a one-to-many projection h: K!X, meaning that each node,i 2 K corresponds to a set of labels h(i), each element of which represents a path from s to i.
/* S the source node* K –set of nodes in network* X – the label set* Counti – Number of paths determined from S to I* elm – Affected number to assigned label* P – Paths list from S to destination (D)* N – paths number to compute* h – corresponding between node and affected label number*//* Initialization */counti=0 /* for all i 2 N*/elem=1h(elem)=sh�1(s)={elem}distanceelem=0X={elem}PN=0While (countt5N and X !={ })
begin/* find a label lb from X, such thatdistancelb5=distancelb1, 8lb12X*/X=X – {lb}i=h(lb)counti=counti+1if (i==D) then /* if the node I is the destination node D */
beginp=chemin de 1 a lb
PN=PN U {h(p)}end
if (counti 5=N) thenbegin
for each arc(i,j)EAbegin/* Verify if new label does not result in loop */v=lbWhile (h(v) !=s)
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1123
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac
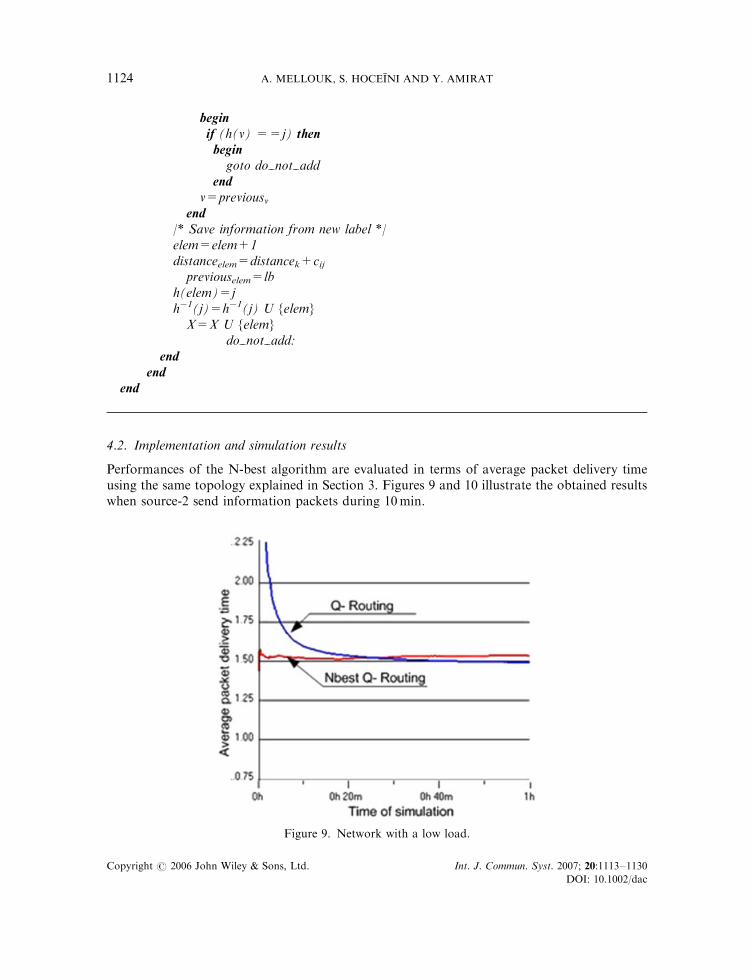
beginif (h(v) ==j) thenbegin
goto do not addend
v=previousvend
/* Save information from new label */elem=elem+1distanceelem=distancek+cij
previouselem=lbh(elem)=jh�1(j)=h�1(j) U {elem}
X=X U {elem}do not add:
endend
end
4.2. Implementation and simulation results
Performances of the N-best algorithm are evaluated in terms of average packet delivery timeusing the same topology explained in Section 3. Figures 9 and 10 illustrate the obtained resultswhen source-2 send information packets during 10min.
Figure 9. Network with a low load.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1124
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac
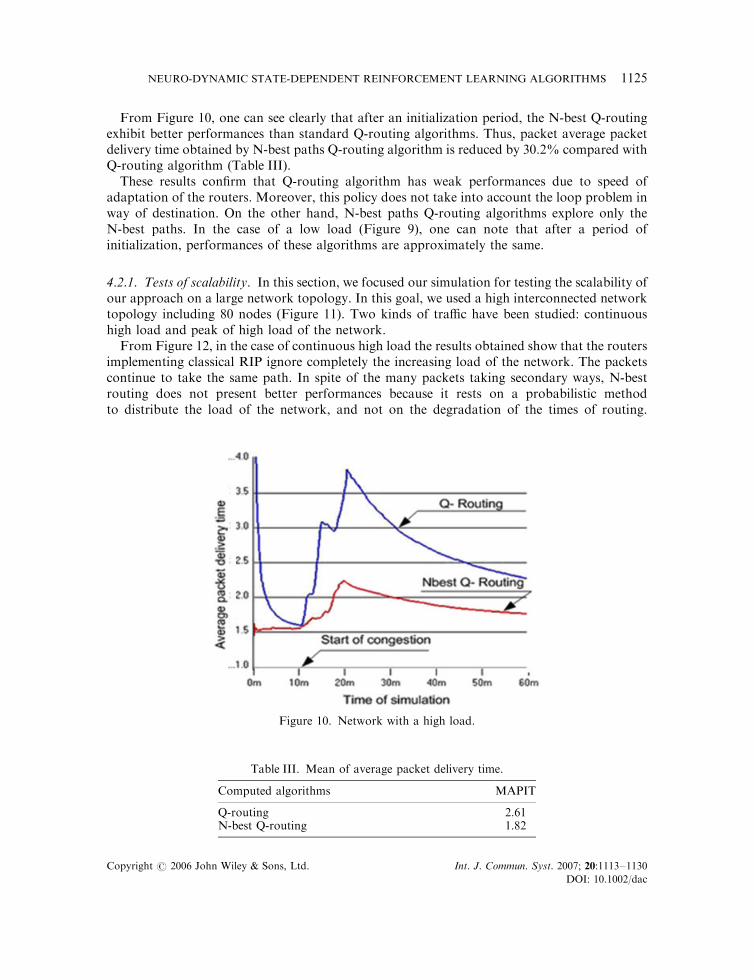
From Figure 10, one can see clearly that after an initialization period, the N-best Q-routingexhibit better performances than standard Q-routing algorithms. Thus, packet average packetdelivery time obtained by N-best paths Q-routing algorithm is reduced by 30.2% compared withQ-routing algorithm (Table III).
These results confirm that Q-routing algorithm has weak performances due to speed ofadaptation of the routers. Moreover, this policy does not take into account the loop problem inway of destination. On the other hand, N-best paths Q-routing algorithms explore only theN-best paths. In the case of a low load (Figure 9), one can note that after a period ofinitialization, performances of these algorithms are approximately the same.
4.2.1. Tests of scalability. In this section, we focused our simulation for testing the scalability ofour approach on a large network topology. In this goal, we used a high interconnected networktopology including 80 nodes (Figure 11). Two kinds of traffic have been studied: continuoushigh load and peak of high load of the network.
From Figure 12, in the case of continuous high load the results obtained show that the routersimplementing classical RIP ignore completely the increasing load of the network. The packetscontinue to take the same path. In spite of the many packets taking secondary ways, N-bestrouting does not present better performances because it rests on a probabilistic methodto distribute the load of the network, and not on the degradation of the times of routing.
Figure 10. Network with a high load.
Table III. Mean of average packet delivery time.
Computed algorithms MAPIT
Q-routing 2.61N-best Q-routing 1.82
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1125
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

The N-best Q-routing presents best performances than standard Q-routing algorithms clearly.Indeed, after one period of adaptation, the times are lower than the times induced by the othermethods. Thus, the mean of average packet delivery time obtained by N-best Q-routingalgorithm is reduced by 25% compared with Q-routing algorithm.
These results confirm that Q-routing algorithm has weak performances due to speed ofadaptation of the routers. Moreover, this policy does not take into account the loop problem in
Figure 11. Network topology for scalability simulation.
Figure 12. Network with a continuous high load.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1126
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac
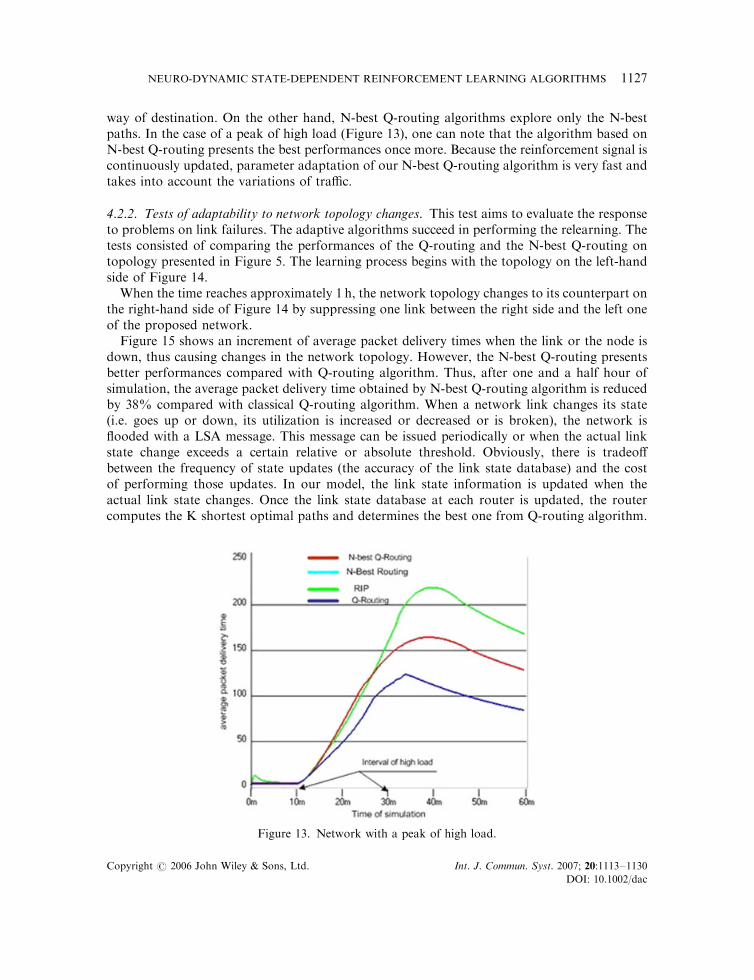
way of destination. On the other hand, N-best Q-routing algorithms explore only the N-bestpaths. In the case of a peak of high load (Figure 13), one can note that the algorithm based onN-best Q-routing presents the best performances once more. Because the reinforcement signal iscontinuously updated, parameter adaptation of our N-best Q-routing algorithm is very fast andtakes into account the variations of traffic.
4.2.2. Tests of adaptability to network topology changes. This test aims to evaluate the responseto problems on link failures. The adaptive algorithms succeed in performing the relearning. Thetests consisted of comparing the performances of the Q-routing and the N-best Q-routing ontopology presented in Figure 5. The learning process begins with the topology on the left-handside of Figure 14.
When the time reaches approximately 1 h, the network topology changes to its counterpart onthe right-hand side of Figure 14 by suppressing one link between the right side and the left oneof the proposed network.
Figure 15 shows an increment of average packet delivery times when the link or the node isdown, thus causing changes in the network topology. However, the N-best Q-routing presentsbetter performances compared with Q-routing algorithm. Thus, after one and a half hour ofsimulation, the average packet delivery time obtained by N-best Q-routing algorithm is reducedby 38% compared with classical Q-routing algorithm. When a network link changes its state(i.e. goes up or down, its utilization is increased or decreased or is broken), the network isflooded with a LSA message. This message can be issued periodically or when the actual linkstate change exceeds a certain relative or absolute threshold. Obviously, there is tradeoffbetween the frequency of state updates (the accuracy of the link state database) and the costof performing those updates. In our model, the link state information is updated when theactual link state changes. Once the link state database at each router is updated, the routercomputes the K shortest optimal paths and determines the best one from Q-routing algorithm.
Figure 13. Network with a peak of high load.
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1127
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

5. CONCLUSIONS
In this paper, we have proposed two adaptive routing algorithms based on the Q-routingalgorithm. The first one, called Q-neural routing, is based on a stochastic neural model, used forparameter estimation and updating in routing decision. This first approach offers advantagescompared with standard RIP routing policy and Q-routing algorithm, like the reduction of the
Figure 14. Link’s modification in the network topology.
Figure 15. Performance in the modifying topology.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1128
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

memory space required for the storage of secondary paths, and a reasonable computing time foralternative paths search.
In order to reduce the convergence time, a second approach is proposed: N-best Q-routing. Itis based on a multipath routing technique (finding N-best paths in terms of hops router)combined with the Q-routing algorithm for minimizing the average packet delivery time onthese paths. The exploration space is then reduced to the N-best paths.
The proposed algorithms have been implemented and evaluated on OPNET Simulator. Thesimulation results have shown their efficiency from adaptivity point of view. In fact, theproposed algorithms take into account the network state in a better way than the classicalapproaches do.
Finally, our work in progress consists on one hand, in using other metrics for finding theN-best optimal paths (residual bandwidth, loss ratio, waiting queue state, etc.) and on the otherhand, in proposing a conditioning technique of the neural model in order to take into accountother parameters like the information type of each packet (voice, video, data). We are alsoworking on the feasibility of the proposed algorithms in the context of mobile ad hoc networks.
REFERENCES
1. Strassner J. Policy-Based Network Management: Solutions for the Next Generation. Morgan Kaufmann: Los Altos,CA, 2003.
2. Welzl M. Scalable Performance Signalling and Congestion Avoidance. Kluwer Academic Publishers: Dordrecht, 2003.3. Adamovic L, Collier M. A new traffic engineering approach for IP networks. Proceedings of CSNDSP, Newcastle,
U.K., 2004.4. Zhi L, Mohapatra P. QRON: QoS-aware routing in overlay networks. IEEE Journal on Selected Areas in
Communications 2004; 22(1):29–40.5. Grover WD. Mesh-based Survivable Transport Networks: Options and Strategies for Optical, MPLS, SONET and
ATM Networking. Prentice-Hall PTR: Englewood Cliffs, NJ, 2003.6. Gallager RG. A minimum delay routing algorithm using distributed computations. IEEE Transactions on
Communications 1977; 25(1):73–85.7. Ozdaglar AE, Bertsekas DP. Optimal solution of integer multicommodity flow problem with application in optical
networks. Proceedings of Symposium on Global Optimisation, Santorini, Greece, June 2003.8. Armitage GL. Revisiting IP QoS: why do we care, what we have learned? ACM SIGCOMM 2003 RIPQOS
Workshop Report. ACM/SIGCOMM Computer Communications Review 2003; 33:81–88.9. Pujolle G, Koner U, Perros H. Resource allocation in the new fixed and mobile internet generation. International
Journal of Network Management 2003; 13(3):181–185.10. Wang Z, Crowcroft J. QoS routing for supporting multimedia application. IEEE Journal on Selected Areas in
Communications 1996; 14(7):1228–1234.11. Sutton RS, Barto AG. Reinforcement Learning. MIT Press: Cambridge, MA, 1997.12. Boyan JA, Littman ML. Packet routing in dynamically changing networks: a reinforcement learning approach.
Advances in Neural Information Processing Systems, vol. 6. Morgan Kaufmann: San Francisco, CA, 1993; 671–678.13. Watkins CJ, Dayan P. Q-learning. Machine Learning Journal 1992; 8:279–292.14. Kumar S, Miikkualainen R. Confidence-based Q-routing: an on-line adaptive network routing algorithm.
Proceedings of Artificial Neural Networks in Engineering, St. Louis, Missouri, November 1998.15. Kumar S, Miikkualainen R. Confidence based dual reinforcement Q-routing: an adaptive online network routing
algorithm. Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence, IJCAI-99, Sweden,Stockholm. Kaufmann: San Francisco, CA, 1999; 758–763.
16. Dorigo M, Stuzle T. Ant Colony Optimization. MIT Press: Cambridge, MA, 2004.17. Haykin S. Neural Networks}A Comprehensive Foundation. Macmillan: New York, 1998.18. Hoceini S. Reinforcement learning techniques for an adaptive routing in telecommunication networks in the case of
irregular traffic. Ph.D. Thesis, Department of Computer Science and Robotics Lab}LISSI/SCTIC, The Universityof Paris XII-Val de Marne, November 2004.
19. OPNET Technologies Inc., http://www.mil3.com20. Hoceini S, Mellouk A, Amirat Y. Neural net based approach for adaptive routing policy in telecommunication
networks. IEEE HSNMC’04, Lecture Notes in Computer Science, vol. 3079, Springer: Berlin, 2004; 360–368.
NEURO-DYNAMIC STATE-DEPENDENT REINFORCEMENT LEARNING ALGORITHMS 1129
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac

21. Lin S, Ming-wei X, Ke X, Yong C, Youjian Z. Simple QoS path first protocol and modeling analysis. IEEE ICN’042004; 4:2122–2126.
22. Lin S, Yong C, Ming-wei X, Ke X. Quality of service routing network and performance evaluation. IEEE ICN’05,Lecture Notes in Computer Science, vol. 3421. Springer: Berlin, 2005; 202–209.
23. Eppstein D. Finding the K shortest paths. SIAM Journal of Computing 1999; 28:652–673.24. Martins EQV, Pascal MMB, Santos JLE. The K shortest paths problem. Research Report, CISUC, June 1998.
AUTHORS’ BIOGRAPHIES
Abdelhamid Mellouk received his MSc degree from University Es-Senia Oran Algeriain 1989, his PhD degree from University of Paris Sud Orsay, France in 1994. He is aHead of Telecommunication and Network’s (TN) Department since 1999 and VicePresident of French National Assembly of Heads of TN Depts since 2002. His mainresearch interests include: multimedia and high-speed communications; wireless andmobile communications; Routing in dynamic traffic network; quality of service;traffic engineering and shaping; networks policy-based management and real-timeapplication. He is Senior Member IEEE, a member of IEEE CommunicationsSociety, IEEE Computer Society and Internet Society. He served also as a TrackTPC Chairs, co-organizer chair, technical program committee member or chairingsessions for some 30 of 2005 and 2006 international conferences.
Saıd Hoceıni obtained his PhD degree from University of Paris XII, France in 2004.His research interests include dynamic routing, quality of service and securityvulnerability assessment.
Yacine Amirat received the MSc and PhD degrees in robotics and computer sciencefrom the University of Paris 6 (Pierre et Marie Curie), France, in 1986 and 1989,respectively. In 1990, he co-created the Computer Sciences and Robotics Laboratoryof Paris 12 University (LIIA), France. In 1996, he receives the Habilitation degreefrom the same university, where he is currently a professor. His research interestsinclude soft computing and control of complex systems, among them distributedsystems. He has published more than 80 papers in scientific journals, books andconference proceedings in these fields. He is scientific director of several researchprojects of the LISSI Laboratory of the University of Paris 12 and leader of theSCTIC research group. He also supervised 14 PhD theses and managed 17 researchprojects mainly related to control of systems and artificial intelligence. He has servedas Technical Committee Member, session Chair and session organizer of several
international conferences. He is also member of IEEE Computational Intelligence Society and IEEERobotics and Automation Society.
A. MELLOUK, S. HOCEINI AND Y. AMIRAT1130
Copyright # 2006 John Wiley & Sons, Ltd. Int. J. Commun. Syst. 2007; 20:1113–1130
DOI: 10.1002/dac