a quality assurance workflow for ontologies based on semantic regularities
TRANSCRIPT

A Quality Assurance Workflow for Ontologiesbased on Semantic Regularities
Eleni Mikroyannidi1, Manuel Quesada-Martınez2, Dmitry Tsarkov1, JesualdoTomas Fernandez Breis2, Robert Stevens1, Ignazio Palmisano1
1 University of Manchester, Oxford Road, Manchester M13 9PL{mikroyannidi,tsarkov,stevens, palmisano}@cs.manchester.ac.uk
2 Universidad de Murcia, IMIB-Arrixaca, CP 30100 Murcia{manuel.quesada,jfernand}@um.es
Abstract. Syntactic regularities or syntactic patterns are sets of axiomsin an OWL ontology with a regular structure. Detecting these patternsand reporting them in human readable form should help the understand-ing the authoring style of an ontology and is therefore useful in itself.However, pattern detection is sensitive to syntactic variations in the as-sertions; axioms that are semantically equivalent but syntactically dif-ferent can reduce the effectiveness of the technique. Semantic regularityanalysis focuses on the knowledge encoded in the ontology, rather thanhow it is spelled out, which is the focus of syntactic regularity analysis.Cluster analysis of the information provided by an OWL DL reasonermitigates this sensitivity, providing measurable benefits over purely syn-tactic patterns - an example being patterns that are instantiated onlyin the entailments of an ontology. In this paper, we demonstrate, us-ing SNOMED-CT, how the detection of semantic regularities in entailedaxioms can be used in ontology quality assurance, in combination withlexical techniques. We also show how the detection of irregularities, i.e.,deviations from a pattern, are useful for the same purpose. We evaluateand discuss the results of performing a semantic pattern inspection andwe compare them against existing work on syntactic regularity detec-tion. Systematic extraction of lexical, syntactic and semantic patterns isused and a quality assurance workflow that combines these patterns ispresented.
1 Introduction
In ontology engineering (in this paper, ontology stands for Web Ontology Lan-guage ontology, or OWL ontology), the use and recognition of patterns is im-portant during authoring as it facilitates ontology understanding, verificationof compliance with coding guidelines, best practices and mandated axiom pat-terns [1]. A regular ontology, i.e., an ontology with regular structure, showscoherent organisation of the knowledge. For example, biomedical ontologies likeSNOMED-CT3 [19] or FMA4 [16,17] mandate regular design for similar con-cepts such as symmetrical parts of the body or description of diseases. A regular
3 http://goo.gl/aOSJm4 http://goo.gl/mbvama

design should ease the maintenance and extension of the ontology and is thus adesirable quality of an ontology.
We call a set of axioms with reoccurring (regular) syntactic structure a syn-tactic regularity or syntactic pattern [9]. The terms regularity and pattern willbe used interchangeably in the remainder of this paper.
A regularity can be expressed with a generalisation, or generalised axiom. Ageneralisation is an axiom in which some of the entities are replaced with vari-ables. An instantiation is an axiom, occurring in an ontology, where all variablesare bound to actual entities or expressions.
An example generalisation and one of its instantiations, found in SNOMED-CT, are shown in Figure 1. In Figure 1 the link between generalisation andinstantiation is in the variable bindings (e.g. ?C is bound to ‘Chronic kidney diseasestage 3 (disorder)’. The RoleGroup property is used syntactically to group togetherclosely related characteristics like morphologies, disorders etc [18]. Clusteringbased methods for detecting such syntactic regularities using the RegularityInspector for Ontologies (RIO) framework and their use for quality assuranceare described in [9,10].
Regularity:
?C v ?D u ∃RoleGroup.(∃’Clinical course (attribute)’.’Chronic (qualifier value)’)
Bindings:
?C = ‘Chronic kidney disease stage 3 (disorder)’,
?D = ‘Chronic renal impairment (disorder)’
Example Instantiation:
‘Chronic kidney disease stage 3 (disorder)’ v ‘Chronic renal impairment (disorder)’
u (∃RoleGroup(∃‘Clinical course (attribute)’.‘Chronic (qualifier value)’))
Fig. 1: Example regularity and axiom instantiation found in SNOMED-CT.
SNOMED-CT is the official clinical terminology in many countries, and isinternationally considered to be key for the achievement of semantic interoper-ability in healthcare [4,24]. Previous work on quality assurance for SNOMED-CT, with respect to its patterns, has been done with manual inspection of itsasserted axioms and the formulation of queries to detect irregularities, such asmissing restrictions [15,14].
Such quality assurance is usually guided through lexical patterns in the labelsof an ontology’s components. We call a lexical pattern a set of classes whose labelsshare a common group of consecutive words [12].
For example, the documentation for SNOMED-CT states that terms havingthe keyword “Chronic” in their label should instantiate the following documentedpattern:
?Chronic class v ?Findings u ∃RoleGroup.‘Chronic (qualifier value)’
In this documented pattern, the variable ?Chronic class holds all entities fromthe ontology that have the keyword “chronic” in their label while the variable?Finding holds entities which are defined as ‘findings’ in the ontology, related

with the chronic entity. The syntactic regularity in Figure 1, detected by RIO,conforms to this pattern.
It has been observed in [10] that intended design patterns, like “Chronic”, arenot fully revealed by syntactic analysis, as they can be only partially instantiatedin the asserted axioms, while portions of them only appear in the ontologyentailments [10]. As a result, these regularities revealed by inference are invisibleto analysis of syntatic patterns. The inclusion of entailments in the detection istherefore required to gain a better overview of the ontology structure in termsof its regularities or irregularities.
Moreover, syntactic variations without semantic consequences can influencethe detection of syntactic regularities, while the ontology entailments are notaffected by such changes. This syntactic sensitivity is likely to cause ontologyengineers to spend more effort to understand the underlying patterns.
Similar to a syntactic regularity, a semantic regularity abstracts over a set ofentailments with the same repetitive structure. The concepts of generalisationand instantiation are extended to cover semantic regularities as well as syntacticregularities.
The contribution of this paper is as follows: (1) We present an extension toRIO for dealing with entailments and use it detect semantic regularities. Wepresent the Knowledge Explorer Graph (KE), which is a tool for entailment ex-traction. (2) We describe a new Ontology Quality Assurance Workflow (QAW)by combining the existing approach in RIO with the detection of semantic regu-larities, guided by lexical pattern analysis. (3) We extend the analysis in [10] toother parts of SNOMED-CT and highlight benefits in terms of isolating irregu-larities by using semantic patterns.
We show that , by detecting patterns that escape syntactic analysis, semanticpattern analysis gives a better overview of the structure of an ontology thanthe syntactic patterns alone; this is demonstrated by presenting cases in whichentities share semantic patterns but not syntactic ones.
1.1 Related Work
Related work on the detection of patterns in ontologies has mainly focused onthe supervised detection of regularities. The method for matching axioms withontology design patterns described in [8] cannot detect knowledge patterns [2]and only detects patterns included in the Ontology Design Pattern catalogue.TEIRESIAS [3] supports the exploration of structural patterns, but the processis guided by the user. In the same context, supervised methods for mining pat-terns from ontologies with DL-safe rules [7] and through SPARQL queries [20]have been proposed. The methods presented in this paper are unsupervised andare not limited to identifying the patterns existing in a catalogue. In terms oflexical pattern detection, the authors in [22] formalized the concept of simpleand complex labels, and use them to define and detect “defining axioms”.
2 Pattern-based Ontology Quality Assurance Workflow
Figure 2 shows our Quality Assurance Workflow (QAW), which couples lexi-cal pattern detection with semantic and syntactic pattern detection. This QAW

(Figure 2) is based on the notion of “lexically suggest and logically define” [14].This means that terms that appear to have regularities in their names should in-stantiate a corresponding pattern in their axioms (e.g. terms with the “Chronic”keyword in their label should instantiate a pattern with the ‘Chronic (qualifiervalue)’).
Fig. 2: The pattern-based Quality Assurance Workflow (QAW) for an ontology.
First, we use the OntoEnrich tool [12] for detecting entities in the ontologymatching a particular lexical pattern.
Second, we extract asserted axioms (for detecting syntactic regularities) andentailed axioms (for detecting semantic regularities) that reference these entities.
Third, we apply RIO on the extracted axioms to compute syntactic [9] andsemantic regularities respectively. For the computation of semantic regularities,we first perform clustering on the signature of the extracted entailments to findgroups of similar entities with respect to their usage in the entailments. After,we rewrite the semantic regularities as generalisations.
Lastly, we evaluate the patterns obtained, inspecting and comparing the syn-tactic and semantic regularities. We also evaluate these regularities with respectto an expected group of patterns, which are documented or suggested by theontology developers. This can help isolate irregularities; for example, spottingentities that have a common lexical pattern but are missing a correspondingaxiomatic pattern.
3 Detection of Lexical Patterns in an Ontology
The details for the automatic extraction of lexical patterns are described in [13].Our method initially processes the ontology with O and extracts the labels,which are split into tokens using any white space character as a delimiter. Then,we create a graph using the label tokens. Each token is represented as a node in

a graph, and two tokens that appear consecutively and in consistent order in alabel are linked through an edge in the graph. Finding a lexical pattern of lengthN tokens requires navigation through N edges starting from an initial node. Wecan obtain the whole set of lexical patterns within an ontology by repeating theprocess in all the nodes of the graph.
A coverage threshold is used by our method to guide the lexical patterndetection, enabling filtering out of less frequent lexical patterns. For example,lexical patterns that appear in two labels might be considered insignificant. InSNOMED-CT, the most frequent lexical patterns are disorder (22.3%) and pro-cedure (17.09%), but they are also very general. In this work, an initial analysisof SNOMED-CT will be performed at different coverage thresholds to selectthe lexical patterns that will form the input to the next steps of the workflow.Examples of a multi-word lexical pattern are benign neoplasm of or biopsy of,which are found in 632 and 988 labels respectively.
4 Generation of Entailments with the KnowledgeExplorer
The axioms entailed by an ontology are extracted with the Knowledge Explorer(KE); an API for providing a graph of the TBox entailments, based on thecompletion graph generated by the FaCT++ tableaux reasoner [23]. For theentailment generation, we use KE with the whole ontology as input and then weextract the entailments referencing entities within a lexical pattern.
KE is an extension of the OWLAPI OWLReasoner: it is a Java interface thatallows client code to explore the completion tree built by a tableaux reasoner.The interface and documentation of KE are available on the OWLAPI website5. The KE provides convenient methods for the computation of entailmentsoccurring between complex classes. The entailments obtained through KE havethe same characteristics of soundness and completeness of the implementingreasoner; the advantage over using a plain reasoner is that KE allows fasteraccess to the completion graph, not available through OWLReasoner.
Conceptually, KE represents a graph based on the exploration of a singlemodel that a reasoner builds while it checks the TBox consistency. More formally,
Definition 1 (Completion graph). The completion graph is a directed graphG = 〈V,E,L〉, where V is a nonempty set of nodes, E ⊆ V ×V is a set of edges,and L maps every v ∈ V to a set of classes, and every e ∈ E to a set of properties.
Such a completion graph is produced by a tableaux-based reasoner duringsatisfiability check. A completion graph corresponding to a satisfiability checkfor a class A w.r.t. ontology O (whether or not O |= A v ⊥) has the features [6]:
1. There is a root node r ∈ V such that A ∈ L(r)2. For every class B ∈ L(r), O |= A v B, where A and B are classes.3. Every edge in the graph corresponds to a ∃R.C or ≥ nR.C class in a label6
of its starting nodes.
5 http://goo.gl/VqEaU26 The label here is different from the label of Section 3.

4. For every node x and class C, the reasons for C ∈ L(x) include:– There is a class B: B ∈ L(x) and O |= B v C;– There is a node y: (y, x) ∈ E and R ∈ L(y, x) and either ∃R.C ∈ L(y)
or ∀R.C ∈ L(y)
Entailments considered: The entailments that are extracted from KE areof the form A v B and A ≡ B, where A is always an atomic class and Bcan be an atomic or complex class. Both trivial (i.e., asserted) entailments andnon-trivial entailments are included in the set of extracted entailments.
The grammar for B is:
B → >|A|B uB|∃R.B
This grammar leads to infinite instantiations, which is due to the possibilityof an infinite number of non-trivial entailments. For example, we can have entail-ments of the form A v ∃R.A, A v ∃R.R.A and so on. In order to extract a finiteset of entailments and to ensure the termination of exploration in KE, we rely onthe reasoner. The models of a concept expression must be tree-like. They mighthave infinite branches, which can be unrolled cycles or infinitely long branches.In such cases, the reasoner uses blocking techniques to ensure termination [5].Thus, the KE provides only the part of a branch up to its first repetition. Thiscover both infinitely long branches and unrolled cycles.
There are also implementation restrictions: at the time of writing, the fol-lowing cannot be directly extracted from the KE: (1) expressions containingnon-simple properties, e.g. O |= A v ∃R.C, where R is a non-simple property7.These expressions are not explored further and they are skipped. (2) in Defini-tion 1, for ∃R.C ∈ L(y) or ∀R.C ∈ L(y), R is always an object property. Theselimitations are dependent on the current FaCT++ implementation, not on theKE interface itself.
Computation of entailments: Algorithm 1 computes a set of entailmentsS from the KE. To achieve this, it uses the recursive Algorithm 2 (getFillers(R))to explore all descendant nodes to the RootNode. Algorithm 1 in step 10 callsthe function checkEntailments (Algorithm 3) to check if the created axiomsα, β are entailed by the ontology O. This guarantees that extracted entailmentsfrom the KE are always valid. In addition, KE provides several methods to ac-cess the graph, namely: (1) getRootNode(A) returns the root node of a graphfor a class A; (2) getLabel(x) returns a set {B : B ∈ L(x)} (3) getProp-erties(x) returns {R : ∃y, (x, y) ∈ E,R ∈ L(x, y)}; (4) getNeighbours(x,R)returns {y : (x, y) ∈ E,R ∈ L(x, y)};
Algorithm 1 can be used with any consistent OWL-DL ontology as it doesnot add any constraints on the reasoning process.
5 Semantic Pattern Detection
We use a pattern detection process similar to the knowledge discovery pro-cess [21].The main steps for the computation of semantic regularities are: (1)extraction of a set of entailments n from the KE; (2) computation of pairwise
7 Non-simple property is defined in [11]

Algorithm 1 ComputeKnowledgeExplorationAxioms(O)
Input: O an ontologyOutput: A set of entailments S, such that O |= S;1: S ← ∅2: for all A ∈ Sig(O) that O 6|= A v⊥ do3: R← getRootNode(A)4: for all p ∈ getProperties(R) do5: F ← ∅ . p-fillers6: for all N ∈ getNeighbours(R, p) do7: F ← F ∪ getFillers(N)8: end for9: end for10: S ← S ∪ checkEntailments(A, p, F )11: end for12: return S
Algorithm 2 getFillers (R)
Input: A node ROutput: A set of complex classes Fillers;1: Fillers← getLabel(R) ∪ {>}2: for all p ∈ getProperties(R) do3: for all N ∈ getNeighbours(R, p) do4: for all C ∈ getFillers(N) do5: Fillers ← Fillers ∪{∃p.C}6: end for7: end for8: end for9: return Fillers
similarity distances for all the entities in the Sig(n); (3) computation of clustersof similar entities in the Sig(n); (4) formulation of generalisations that describeclusters of similar entities. Steps (2)-(4) are similar to the detection of syntacticregularities described in [9], thus we do not show details on these steps but justan outline. The main difference is that the detection of syntactic regularities isdone on the basis of asserted axioms while the detection of semantic regularitiesis done on the basis of entailments.
To demonstrate the main points for the semantic pattern computation wewill use a simplified example from SNOMED-CT with three classes, e1 =Chronickidney disease stage 3 (disorder), e2 =Chronic lung disease (disorder), e3 =Chronic eczema(disorder). A subset of their extracted entailments based on KE is shown in Ta-ble 1.
Entity Pairwise Similarity Distance. In order to decide the variable inour patterns (e.g. ?chronic class variable that holds all chronic entities or entitieswith similar content) we perform clustering in the signature of the entailments.The clusters of similar entities are represented with variables in the generalisa-tions.
In clustering, the distance measure defines the shape of clusters. In RIO,the distance between two entities is defined with respect to their usage in theentailments. For its computation we use a replacement function for abstractingthe entailments. That is:
Replacement function φ. Given an ontology O, and a set of entailmentsS for O, we define Φ={ ?class, ?objectProperty, ?dataProperty, ?star } a set of foursymbols that do not appear in the Sig(O). A placeholder replacement is a func-

Algorithm 3 checkEntailments (A, p, Fillers)
Input: a class A, objectProperty p, a set of classes Fillers;Output: A set of entailments S, such that O |= S
1: S ← ∅2: for all C ∈ Fillers do3: Axiom α← A v ∃p.C ∪A ≡ ∃p.C4: if O |= α then S ← S ∪ {α}5: end if6: Axiom β ← A v ∀p.C ∪A ≡ ∀p.C7: if O |= β then S ← S ∪ {β}8: end if9: end for10: return S
tion φ : Sig(O) → Sig(O) ∪ Φ which, when applied to an entity e ∈ Sig(S),returns: (1) one of e, ?star or ?class if e is a class name; (2) one of e, ?star or?objectProperty if e is an object property name; (3) one of e, ?star or ?dataPropertyif e is a data property name; (4) one of e, ?star or ?individual if e is an individualname. Thus, the φ decides whether or not to replace an entity e with a symbolbased on some decision criteria. Since the set of entailments S we extract con-tains only class names and object property names, only cases (1) and (2) arerelevant in this work. Then, the pairwise distance between two entities is definedas:
Definition 2 (Distance). Let O be an ontology, S a set of entailments for O,σi and σj two entities from Sig(S), Σ and φ a placeholder replacement function.We denote Ai the set {φ(Ax(α)), α ∈ S, σi ∈ Sig(α)}, i.e: the set of placeholderreplacements for the entailments in S that reference σi.We define the distance between the two entities, (σi,σj) ∈ ΣxΣ as:
d(σi, σj)←|Ai ∪ Aj | − |Ai ∩ Aj |
|Ai ∪ Aj |The distance between two entities e1, e2 is computed as an overlap between
their referencing entailments that have been transformed into more abstractforms by the placeholder function φ. The defined distance is always in the interval[0,1], where 0 means that the two entities are identical and 1 that they have nosimilarity.
φ is used to enable comparison between the referencing entailments of e1 ande2. Different decision criteria can be used for φ; Here we use a popularity basedreplacement function, which has been used previously in [9] and determines ourdistance as follows: When computing d(e1, e2), for each entailment a where eitheroccurs, the function replaces e1 or e2 with ?star and decides whether to replacethe other entities with a placeholder depending on their popularity across all theentailments that have the same structure as a
The application of φ in the entailments of e1, e2, e38 when computing thepairwise distances will result in the abstracted entailments of Table 2. Thus, thedistances are computed as an overlap of the entailments from Table 2 and ared(e1, e2)=0.5, d(e1, e3)=0, d(e2, e3)=0.5.
8 For simplicity, we consider only the entailments of Table 1 as referencing entailmentsof e1, e2, e3

Table 1: Example entailments of three SNOMED-CT ‘Chronic’ classes.a1 = ‘Chronic kidney disease stage 3’ v ‘Disease’
a2 = ‘Chronic kidney disease stage 3’ v ‘Chronic renal impairment’
a3 = ‘Chronic kidney disease stage 3’ v ∃RoleGroup.(∃‘Clinical course’.
(‘SNOMED CT Concept’ u ‘Descriptor’ u ‘Time patterns’
u ‘Special atomic mapping values’ u ‘Courses’
u ‘Special disorder atoms’ u ‘Qualifier value’ u Chronic)b1 = ‘Chronic lung disease’ v Disease
b2 = ‘Chronic lung disease’ v Disorder of body system
b3 = ‘Chronic lung disease’ v ∃RoleGroup.(∃‘Clinical course’.
(‘SNOMED CT Concept’ u ‘Descriptor’ u ‘Time patterns’
u ‘Special atomic mapping values’ u ‘Courses’
u ‘Special disorder atoms’ u ‘Qualifier value’ u Chronic)c1 = ‘Chronic eczema’ v Disease
c2 = ‘Chronic eczema’ v Disorder of integument
c3 = ‘Chronic eczema’ v ∃RoleGroup.(∃‘Clinical course’.
(‘SNOMED CT Concept’ u ‘Descriptor’ u ‘Time patterns’
u ‘Special atomic mapping values’ u ‘Courses’
u ‘Special disorder atoms’ u ‘Qualifier value’ u Chronic)
Clustering and Generalised Entailments We use agglomerative hierar-chical clustering (AHC); it is a common solution to unsupervised detection ofclusters, and we use it in favor of other algorithms like k-means as we do nothave a predetermined number of clusters.
An AHC algorithm takes as input a proximity matrix that holds all pairwisedistances for the entities in the Sig(S), where S is the set of entailments inwhich we are interested in finding patterns. AHC initialises every cluster with asingle entity and merges clusters as long as all pairwise distances between thetwo clusters are less than 1 (maximal distance). In every agglomeration step theproximity matrix is updated according to the Lance-Williams formula [21].
After the computation of clusters, the generalisations (semantic patterns)are formed with respect to these clusters. In particular, the entailments thatreference entities in a cluster are rewritten by replacing such entities with itscorresponding cluster variable. In our example, the entities e1, e2, e3 end up inthe same cluster (cluster 1), while ‘Disease’ ends up in cluster 18 along with another15 classes. Thus, the generalisation ?c 1 v ?c 18 has a1 from Table 1 as instan-tiation. The final generalisation should not be confused with the intermediateabstractions of Table 2 used for computing the pairwise distances.
Variable naming: Having an informative name for a variable of a clustershould facilitate the inspection of the generalisations by ontology engineers. Thename of a variable is selected to be the name of the least common subsumer ofthe entities in the corresponding cluster. If the least common subsumer is the> (owl:Thing) entity, then a generic name is selected as the name of the clustervariable (e.g. c i, where i denotes the sequence of the cluster like ?c 15 to denote

Table 2: Abstracted entailments of e1, e2, e3 for the computation of their pairwisedistances.
Entailments of e1 for computing distances d(e1, e2) and d(e1, e3)
φ(a1) = ?star v ‘Disease’
φ(a2) = ?star v ?class
φ(a3) = ?star v ∃RoleGroup.(∃?objectProperty.
(‘SNOMED CT Concept’ u ‘Descriptor’ u ‘Time patterns’
u ?class u ‘Courses’ u ?class u ‘Qualifier value’ u Chronic)Entailments of e2 for computing distances d(e2, e1) and d(e2, e3)
φ(b1) = ?star v ‘Disease’
φ(b2) = ?star v Disorder of body system
φ(b3) = ?star v ∃RoleGroup.(∃?objectProperty.
(‘SNOMED CT Concept’ u ‘Descriptor’ u ‘Time patterns’
u ?class u ‘Courses’ u ?class u ‘Qualifier value’ u Chronic)Entailments of e3 for computing distances d(e3, e1) and d(e3, e2)
φ(c1) = ?star v Disease
φ(c2) = ?star v ?class
φ(c3) = ?star v ∃RoleGroup.(∃?objectProperty.
(‘SNOMED CT Concept’ u ‘Descriptor’ u ‘Time patterns’
u ?class u ‘Courses’ u ?class u ‘Qualifier value’ u Chronic)
cluster number 15). With this approach we try, when possible, to give variablesa name that indicates the type of entities it holds.
Measuring Regularity: For checking the impact of regularities we definethe following metric: Given a set of G generalisations (patterns), instantiatedby A entailments, then the mean instantiations per generalisations (MIPG) is
MIPG = |A||G| . Other metrics for assessing the patterns is the combination of
number of clusters with the number of generalisations and mean instantiationsper generalisation. For example, having many clusters, shows that RIO detectedmore deviations from a regularity. This can be verified by the number of gen-eralisations which is high and the MIPG value which in that case is low. Thatmeans, that the user has to inspect many more regularities in order to get anintuition about the construction of the corresponding clustered entities.
6 Application of the QAW in SNOMED-CT
Our analysis consists of the following main steps: (1) Detection of entities witha particular lexical pattern. (2) Extraction of referencing asserted axioms (fordetecting syntactic regularities) or entailments (for detecting semantic regulari-ties) of these entities. (3) Application of RIO to the extracted axioms or entail-ments for the computation of syntactic and semantic regularities respectively.(4) Comparison of the syntactic and semantic regularities. (5) Verification ofdominant regularities with expected patterns. (6) Isolation of irregularities. Theirregularities we are dealing with are (a) missing descriptions with respect to adocumented pattern, (b) lexical irregularities.

The analysis is divided into two parts: (a) a qualitative analysis performedwith six sets of entities extracted from SNOMED-CT for which we can checkpatterns with SNOMED-CT’s documentation and with prior work on qualityassurance for SNOMED-CT; and (b) a quantitative analysis performed with alarger set of 308 lexical patterns and extracted entities for which we describesyntactic and semantic regularities and show how the workflow we suggest forquality assurance can be generalised for different sets of entities that instantiatea lexical pattern.
For the analysis we used the January 2013 release of SNOMED-CT. Thisversion consists of 296 529 axioms and is in the EL profile. The statistical analysisalong with the files containing the regularities can be found online9.
6.1 Qualitative analysis
An analysis similar to the one performed in [14,10] is done on six cases whoselabel should comply with their axiomatic description. These six patterns referto (1) classes whose name includes the word “chronic” in the beginning or inthe middle of their label and are expected to be subclasses of ∃RoleGroup.Chronic(qualifier value); (2) classes whose name includes the word “acute” in the be-ginning or in the middle of their label and are expected to be subclasses of∃RoleGroup. Sudden onset AND/OR short duration (qualifier value), (3) classes whosename includes the word “present” and are expected to be subclasses of the∃RoleGroup.Present (qualifier value), (4) classes whose name includes the word “ab-sent” and are expected to be subclasses of the ∃RoleGroup.Absent (qualifier value),(5) classes that have the keywords “right” or (6) “left” in their names andare expected to be subclasses of ∃Laterality (attribute).Right (qualifier value) and∃Laterality (attribute).Left (qualifier value) respectively. We will call these sets ofentities target entities. In [10] pattern inspection was carried out on syntacticpatterns only.
Table 3 shows the analysis of semantic patterns for the target entities. Fig-ure 3 shows the semantic patterns expected to be found for chronic and acuteentities along with one example instantiation. For the remaining cases, the re-sults are similar.
Comparison of syntactic and semantic regularities: As shown in Ta-ble 3, there is a difference between syntactic and semantic regularities. Semanticregularities are more uniform; that is because the entities with lexical patternsare distributed in fewer clusters and the expected patterns are better formedin most cases; we have fewer variations in the generalisations that refer to anexpected pattern. Also, because we consider the entailments, we do not miss anyinformation on the instantiation of the expected pattern. Therefore, semanticregularities do not suffer from syntactic variations.
Semantic irregularities We compare the results with existing work onquality assurance for “chronic”, “acute” in [14]. Although this analysis useson an older version of SNOMED-CT (May 2010), the discrepancies still exist.Our analysis also highlighted additional discrepancies. In particular, 14% of thechronic classes do not instantiate the documented pattern, i.e., do not conformto it; this includes the irregular classes reported in [14]. Only 2% of the chronic
9 http://goo.gl/RvvNL
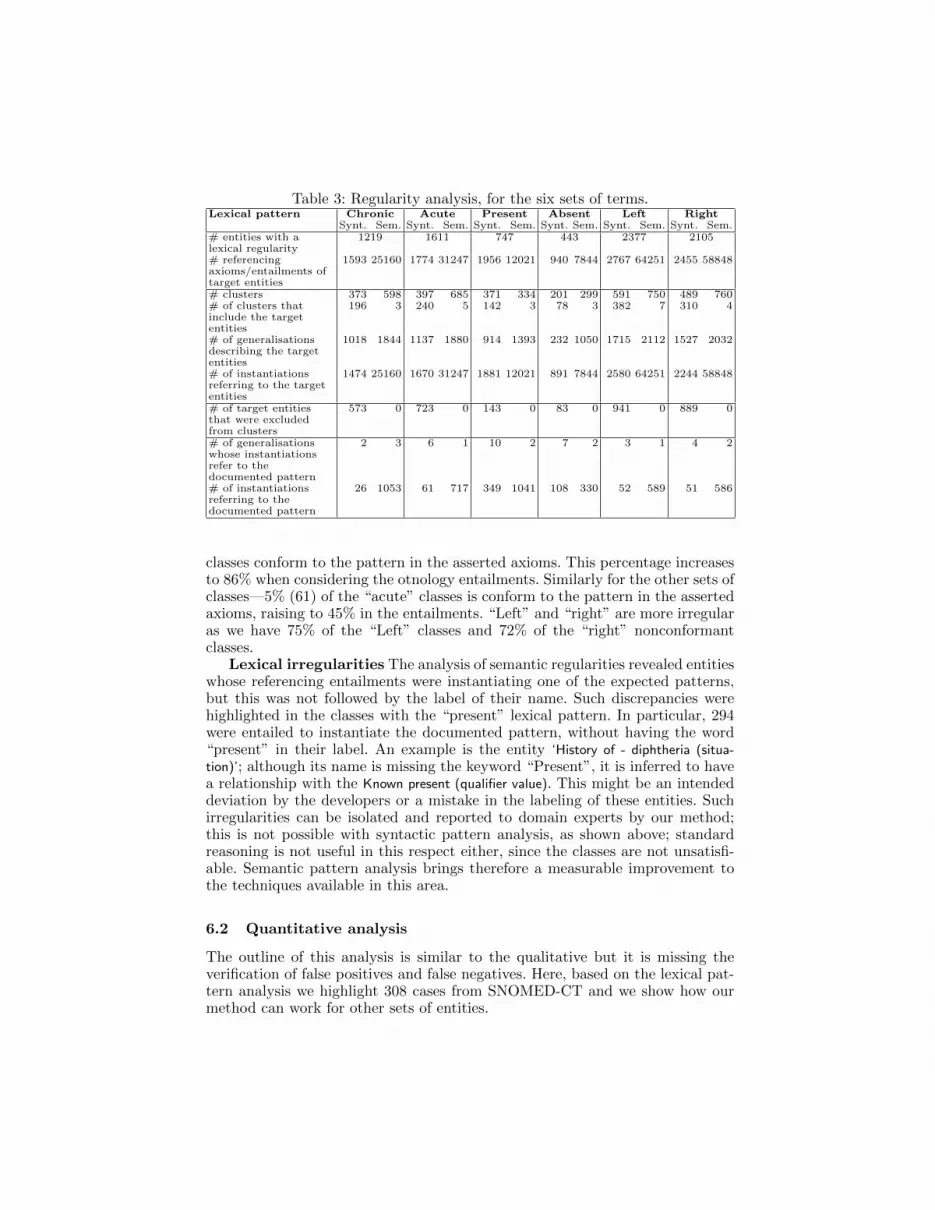
Table 3: Regularity analysis, for the six sets of terms.Lexical pattern Chronic Acute Present Absent Left Right
Synt. Sem. Synt. Sem. Synt. Sem. Synt. Sem. Synt. Sem. Synt. Sem.# entities with alexical regularity
1219 1611 747 443 2377 2105
# referencingaxioms/entailments oftarget entities
1593 25160 1774 31247 1956 12021 940 7844 2767 64251 2455 58848
# clusters 373 598 397 685 371 334 201 299 591 750 489 760# of clusters thatinclude the targetentities
196 3 240 5 142 3 78 3 382 7 310 4
# of generalisationsdescribing the targetentities
1018 1844 1137 1880 914 1393 232 1050 1715 2112 1527 2032
# of instantiationsreferring to the targetentities
1474 25160 1670 31247 1881 12021 891 7844 2580 64251 2244 58848
# of target entitiesthat were excludedfrom clusters
573 0 723 0 143 0 83 0 941 0 889 0
# of generalisationswhose instantiationsrefer to thedocumented pattern
2 3 6 1 10 2 7 2 3 1 4 2
# of instantiationsreferring to thedocumented pattern
26 1053 61 717 349 1041 108 330 52 589 51 586
classes conform to the pattern in the asserted axioms. This percentage increasesto 86% when considering the otnology entailments. Similarly for the other sets ofclasses—5% (61) of the “acute” classes is conform to the pattern in the assertedaxioms, raising to 45% in the entailments. “Left” and “right” are more irregularas we have 75% of the “Left” classes and 72% of the “right” nonconformantclasses.
Lexical irregularities The analysis of semantic regularities revealed entitieswhose referencing entailments were instantiating one of the expected patterns,but this was not followed by the label of their name. Such discrepancies werehighlighted in the classes with the “present” lexical pattern. In particular, 294were entailed to instantiate the documented pattern, without having the word“present” in their label. An example is the entity ‘History of - diphtheria (situa-tion)’; although its name is missing the keyword “Present”, it is inferred to havea relationship with the Known present (qualifier value). This might be an intendeddeviation by the developers or a mistake in the labeling of these entities. Suchirregularities can be isolated and reported to domain experts by our method;this is not possible with syntactic pattern analysis, as shown above; standardreasoning is not useful in this respect either, since the classes are not unsatisfi-able. Semantic pattern analysis brings therefore a measurable improvement tothe techniques available in this area.
6.2 Quantitative analysis
The outline of this analysis is similar to the qualitative but it is missing theverification of false positives and false negatives. Here, based on the lexical pat-tern analysis we highlight 308 cases from SNOMED-CT and we show how ourmethod can work for other sets of entities.

Generalisation:
?c 1 v ∃RoleGroup(∃Clinical course (attribute)(?c 1 u ?c 103 u ?c 143 u ?c 18))
Total Instantiations: 607
Example Bindings:
?c 103:CLASS = [Time patterns (qualifier value), Special disorder atoms (qualifier value),
Courses (qualifier value), Special atomic mapping values (qualifier value),
Qualifier value (qualifier value)]
?c 18:CLASS = [SNOMED CT Concept (SNOMED RT+CTV3)],
?c 143:CLASS = [Descriptor (qualifier value)],
?c 1:CLASS = [Chronic (qualifier value),Chronic renal failure syndrome (disorder)]
Example Instantiation:
’Chronic renal failure syndrome (disorder)’ v ∃RoleGroup.
(∃Clinical course (attribute).(SNOMED CT Concept (SNOMED RT+CTV3)
u Descriptor (qualifier value) u Time patterns (qualifier value)
u Special atomic mapping values (qualifier value) u Courses (qualifier value)
u Special disorder atoms (qualifier value) u Qualifier value (qualifier value)
u Chronic (qualifier value)))
(a) A semantic regularity describing the chronic pattern
Generalisation:
?c 1 v ∃RoleGroup.(∃Clinical course (attribute).(?c 157 u ?c 3 u ?c 35))
Total Instantiations: 736
Example Bindings
?c 35:CLASS = [Time patterns (qualifier value),Special disorder atoms (qualifier value),
Courses (qualifier value),Sudden onset AND/OR short duration (qualifier value),
Special atomic mapping values (qualifier value),Descriptor (qualifier value)]
?c 3:CLASS = [SNOMED CT Concept (SNOMED RT+CTV3)],
?c 157:CLASS = [Qualifier value (qualifier value)],
?c 1:CLASS = [Acute bacterial endocarditis (disorder)]
Example Instantiation:
Acute bacterial endocarditis (disorder) v ∃RoleGroup.(∃Clinical course (attribute)
(SNOMED CT Concept (SNOMED RT+CTV3) u Descriptor (qualifier value)
u Time patterns (qualifier value) u Special atomic mapping values (qualifier value)
u Courses (qualifier value) u Special disorder atoms (qualifier value)
u Qualifier value (qualifier value) u Sudden onset AND/OR short duration (qualifier value)))
(b) A semantic regularity describing the acute pattern
Fig. 3: Semantic regularities in SNOMED-CT describing (a) the “chronic” pat-tern and (b) the “acute” documented pattern respectively.

Detection of lexical patterns To narrow down the scope of our analysiswe pick lexical patterns that have the same coverage in the ontology as the oneswe picked for the qualitative analysis. The extraction of lexical patterns is basedon the methods presented in [13] and we used the OntoEnrich tool [12]. The sixlexical patterns of the qualitative analysis had a coverage between 0.1%–0.4%in the entities of the ontology. Thus, in the quantitative analysis we extract allclasses that appear to have a lexical pattern in 0.1%–0.4% of the entities of theontology. The intuition behind this is that this interval has more chances tocontain labels that are relatively more meaningful with respect to the content ofthe ontology.
Table 4 is similar to Table 3 and it shows the total mean values for thesyntactic and semantic regularities we generated for the 308 lexical patterns weprocessed according to the workflow of Figure 2.
Table 4: Average values of syntactic and semantic regularities for the 308cases(extracted based on lexical patterns).
Syntactic Semantic# entities with a lexical regularity (target entities) 521.2# referencing axioms/entailments of target entities 1086.57 10792.96# clusters 218.79 203.82# clusters that included the target entities 98.06 2.64# generalisations describing the target entities 714.11 602.37mean instantiations per generalisation 1.52 17.052# of target entities that were excluded from clusters 291.42 0
The results in Table 4 show that the semantic regularities for classes with alexical pattern are more uniform than syntactic regularities;the target entitiesare distributed in fewer clusters than in the syntactic regularities. Also althoughfor the computation of the semantic regularities, both trivial and non-trivialentailments are considered, these are described with fewer generalisations. Onthe contrary, on the computation of the syntactic regularities, RIO producesmore generalisations due to syntactic variations. The syntactic variations of theasserted axioms, also explain the fact that in the syntactic regularities many ofthe target entities are excluded from clusters and they do not have a detectableregularity. These results are comparable to the findings we get for the knowncases presented in Table 3.
7 Conclusions
We have presented a novel approach to unsupervised detection of semantic pat-terns in an ontology based on cluster analysis of entities with similar usage inentailments. We introduced the Knowledge Explorer (KE) and presented themethods for extracting a finite set of entailments with a specific grammar fromKE, that are used as an input to our algorithms for detecting semantic patterns.Future work will involve the inclusion of other types of entailments, such as classand property assertions and the comparison of alternative grammars.
We also presented a pattern based approach for quality assurance of largeand complex ontologies, like SNOMED-CT. The quality assurance method we

demonstrate checks the conformance with the pattern based construction of anontology. In particular, the methods we suggest are based on the detection of lex-ical patterns in the terms of an ontology and then the detection of correspondingsemantic regularities to verify conformance to an expected pattern. The work-flow is based on the intuition that terms with similar lexical description shouldalso have a common logical description.
We tested and evaluated this hypothesis with six cases from SNOMED-CT.The results show the ability to gain meaningful patterns from the inferences ofan ontology that can facilitate detection of quality assurance issues.
Our method highlighted entities that did not explicitly instantiate a patternin their asserted axioms, but were found to instantiate it in the entailmentsof the ontology; lexical irregularities in the entities were also revealed – suchcases could not be discovered by syntactic tools and could be only discoveredby an ontology engineer after querying the ontology in question. The quanti-tative analysis performed with 308 similar cases in SNOMED-CT showed thatthe combination of lexical patterns with the patterns that RIO can reveal canbe useful to inspect the construction of portions of the ontology, with strongimplications for quality assurance in ontologies. The qualitative analysis showedthat semantic patterns provide an improved picture of an intended pattern andthe deviations from that pattern.
Acknowledgments. Manuel Quesada-Martınez is funded by the Spanish Min-istry of Science and Innovation through TIN2010-21388-C02-02 and fellowshipBES-2011-046192.
References
1. E. Blomqvist and K. Sandkuhl. Patterns in ontology engineering: Classification ofontology patterns. ICEIS (3), pages 413–416, 2005.
2. P. Clark. Knowledge patterns. Knowledge Engineering: Practice and Patterns,pages 1–3, 2008.
3. R. Davis. Interactive transfer of expertise: Acquisition of new inference rules.Artificial Intelligence, 12(2):121 – 157, 1979.
4. European Commission. Semantic interoperability for better health and saferhealthcare. deployment and research roadmap for Europe. ISBN-13 : 978-92-79-11139-6, 2009.
5. B. Glimm, I. Horrocks, and B. Motik. Optimized Description Logic Reasoning viaCore Blocking. In J. Giesl and R. Hahnle, editors, Proc. of the Int. Joint Conf. onAutomated Reasoning (IJCAR 2010), volume 6173 of Lecture Notes in ArtificialIntelligence, pages 457–471. Springer, 2010.
6. I. Horrocks, O. Kutz, and U. Sattler. The even more irresistible SROIQ. InPrinciples of Knowledge Representation and Reasoning, pages 57–67, 2006.
7. J. Jozefowska, A. Lawrynowicz, and T. Lukaszewski. Towards discovery of frequentpatterns in description logics with rules. Rules and Rule Markup Languages forthe Semantic Web, pages 84–97, 2005.
8. M. T. Khan and E. Blomqvist. Ontology design pattern detection-initial methodand usage scenarios. In SEMAPRO 2010, The Fourth International Conference onAdvances in Semantic Processing, pages 19–24, 2010.
9. E. Mikroyannidi, L. Iannone, R. Stevens, and A. Rector. Inspecting regularities inontology design using clustering. The Semantic Web–ISWC 2011, pages 438–453,2011.

10. E. Mikroyannidi, R. Stevens, L. Iannone, and A. Rector. Analysing SyntacticRegularities and Irregularities in SNOMED-CT. Journal of biomedical semantics,3(1):8, 2012.
11. B. Motik, P. Patel-Schneider, B. Parsia, C. Bock, A. Fokoue, P. Haase, R. Hoekstra,I. Horrocks, A. Ruttenberg, U. Sattler, et al. OWL 2 Web Ontology Language:Structural Specification and Functional-Style Syntax (Second Edition). W3C Rec-ommendation, 11, 2012.
12. M. Quesada-Martınez, J. T. Fernandez-Breis, and R. Stevens. Enrichment of OWLontologies: a method for defining axioms from labels. In L. Moss and D. Slee-man, editors, Proceedings of the International Workshop on Capturing and Refin-ing Knowledge in the Medical Domain (KMED’2012), pages 5–10, Galway, Ireland,2012.
13. M. Quesada-Martınez, J. Fernandez-Breis, and R. Stevens. Lexical characteriza-tion and analysis of the bioportal ontologies. In N. Peek, R. Marın Morales, andM. Peleg, editors, Artificial Intelligence in Medicine, volume 7885 of Lecture Notesin Computer Science, pages 206–215. Springer Berlin Heidelberg, 2013.
14. A. Rector and L. Iannone. Lexically suggest, logically define: Quality assurance ofthe use of qualifiers and expected results of post-coordination in SNOMED CT.Journal of Biomedical Informatics, 45(2):199 – 209, 2012.
15. A. L. Rector, S. Brandt, and T. Schneider. Getting the foot out of the pelvis:modeling problems affecting use of SNOMED CT hierarchies in practical applica-tions. Journal of the American Medical Informatics Association, 18(4):432–440,July 2011.
16. C. Rosse, J. Mejino, et al. A reference ontology for biomedical informatics: theFoundational Model of Anatomy. Journal of biomedical informatics, 36(6):478–500, 2003.
17. C. Rosse and J. L. Mejino Jr. The foundational model of anatomy ontology. InAnatomy Ontologies for Bioinformatics, pages 59–117. Springer, 2008.
18. K. Spackman, R. Dionne, E. Mays, and J. Weis. Role grouping as an extensionto the description logic of ontylog, motivated by concept modeling in snomed. InProceedings of the AMIA Symposium, page 712. American Medical InformaticsAssociation, 2002.
19. K. A. Spackman, K. E. Campbell, and R. A. Cote. SNOMED RT: a referenceterminology for health care. In Proceedings of the AMIA annual fall symposium,page 640. American Medical Informatics Association, 1997.
20. O. Svab-Zamazal, F. Scharffe, and V. Svatek. Preliminary results of logical on-tology pattern detection using sparql and lexical heuristics. In Proceedings of theWorkshop on Ontology Patterns (WOP-2009), 2009.
21. P.-N. Tan, M. Steinbach, and V. Kumar. Introduction to Data Mining. Addison-Wesley, 2005.
22. A. Third. “Hidden semantics”: what can we learn from the names in an ontol-ogy? In Proceedings of the Seventh International Natural Language GenerationConference, Utica, IL, USA, May 2012.
23. D. Tsarkov and I. Horrocks. Fact++ description logic reasoner: system description.In Proceedings of the Third international joint conference on Automated Reasoning,IJCAR’06, pages 292–297, Berlin, Heidelberg, 2006. Springer-Verlag.
24. Y. Wang, M. Halper, H. Min, Y. Perl, Y. Chen, and K. Spackman. Structuralmethodologies for auditing snomed. Journal of Biomedical Informatics, 40(5):561–581, 2007.