codage paramétrique de la parole en vue de sa transmission ... · huffman code pour comprimer de...
TRANSCRIPT

République Algérienne Démocratique et Populaire Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université D’Oran - Es-Senia - Faculté des Sciences
Département d’Informatique
Mémoire En vue de l’obtention du diplôme de Magistère
Spécialité : Informatique
Option : CAO
Intitulé
Codage paramétrique de la parole en vue de sa transmission sur Internet
Présenté par Mr LACHACHI Nour-Eddine
Encadreur : Mr BENHAMAMOUCH Djillali (M.C, Es-Senia) Co-Encadreur : Mr AMRAOUI Aek (M.C, ITO) Soutenu devant le jury : Président : Mr RAHMOUNI M.K (Prof, Es-Senia) Examinateur : Mr BENYETTOU Aek (Prof, USTO) Examinateur : Mr TEMMAR Aek (M.C, ITO) Examinateur : Mr OUALI Mohamed Farid (M.C, Es-Senia)
Octobre 2006

Résumé Le codage de la parole exige la description pertinente et l'extraction
précise d'informations du signal. Cela ne peut se faire qu'avec l'aide de théories et de techniques puissantes développées en traitement du signal dont la maîtrise requiert des connaissances très spécialisées. Par ailleurs, la grande complexité de la parole nécessite des traitements particuliers liés à sa production et à sa perception. Le signal de parole étant porteur d'une information spécifique pour la communication entre le locuteur et l'auditeur, le mécanisme de celle-ci ne doit pas être ignoré lors de la réduction de débit.
Le but principal de notre étude ne devait pas principalement développer des nouvelles techniques de codage, mais plutôt gagner la compréhension théorique dans les avantages et les inconvénients des techniques de codage et de trouver un motivation pour une approche permettant l’obtention d’une meilleure compréhension des étapes séparées d'un codeur de parole.
Les sons de parole sont produits soit par les vibrations des cordes vocales (source de voisement), soit par l'écoulement turbulent de l'air dans le conduit vocal, où soit lors du relâchement d'une occlusion de ce conduit (source de bruit).
On modélise un conduit vocal par une succession de tubes acoustiques de sections diverses qui peuvent être représenté par un filtre linéaire à paramètre variable dans le temps.
Le signal vocal est numérisé à l’aide d’un convertisseur analogique/numérique. Comme la voix humaine est constituée d’une multitude de sons, souvent répétitifs, le signal peut être compressé pour réduire le temps de transmission, ainsi on parle de système de codage.
Un système de codage de la parole comprend deux parties, un codeur et un décodeur. Le codeur analyse le signal pour en extraire un nombre réduit de paramètres pertinents qui sont représentés par un nombre restreint de bits pour archivage ou transmission. Le décodeur utilise ces paramètres pour reconstruire un signal de parole synthétique.

Remerciement J’exprime ma reconnaissance à Monsieur RAHMOUNI Kamel, Professeur à l’Université d’Oran département informatique, d’avoir accepté de présider le jury de thèse. Mes plus sincères remerciements sont adressés à Monsieur TEMAR Abdelkader, Maître de conférence à l’Institut de Télécommunication d’Oran, Monsieur BENYETTOU Abdelkader, Professeur à l’Université des Sciences et de la Technologie, et à Monsieur OUALI, Maître de conférence à l’Université d’Oran département informatique, pour avoir accepté d’être examinateur de cette thèse et dont je tiens à avoir de leurs part des critiques constructives. Merci à Messieurs BENHAMAMOUCHE Djillali, Maître de conférence à l’Université d’Oran département informatique, et AMRAOUI Abdelkader, Maître de conférence à l’Institut de Télécommunication d’Oran, pour leur encadrement, leurs nombreux conseils et suggestions qu’ils m’ont donnés tout au long de mes travaux. Mes remerciements vont également à l’ensemble des personnes qui m’ont accompagnée, de près ou de loin, et qui ont contribué, directement ou non, à l’aboutissement de ce travail.
i

Glossaire de termes et d’acronymes
Les termes les plus couramment utilisés dans cette thèse et dans le traitement de la parole en général sont :
A A-Law Standard Européen PCM de la téléphonie ACELP Algebraic Code Excited Linear Prediction ACR Absolute Category Rating ADM Adaptive Delta Modulation ADPCM Adaptive Differential Pulse Code Modulation ADSP Analogical/Digital Signal Processor ADxyM Adaptive Delta X Y Modulation APC Adaptive Predictive Coding APCM Adaptive Pulse Code Modulation A/N Analogique / Numérique ASIC Application Specific Integrated Circuit ASPEC Format Allemand de codage ASSP Acoustics Speech and Signal Processing ATC Adaptive Transform Coding
B Bandwidth Largeur de bande bps bits per seconde BCELP Binary Codebook Excited Linear Prediction
C CAN Convertisseur Analogique Numérique CCITT Comité Consultative International de la Téléphonie et la
Télégraphie CCR Comparison Category Rating CIF Common Intermediate Format CMOS Comparison Mean Opinion Score CELP Code-book Excited Linear Prediction Cepstre SPECtre inverse (logarithmique) CNA Convertisseur Numérique Analogique Codage Processus de mettre certains valeurs univoquement dans autres CODEC CODer / DECoder device Codebook Tableau pour trouver les correspondance entre codes et valeurs,
ou dictionnaire COMPAND COMPress / exPAND Compression Processus de codage pour réduire le débit de stockage ou
transmission CS-ACELP Conjugate Structure - Algebraic Code Excited Linear Prediction
ii

D dB decibelles DCT Discrete Cosine Transform Débit Taux d’information par unité de temps DFT Discrete Fourier Transform DLL Dynamic Link Library DOLBY Système Réducteur de bruits DPCM Differential Pulse Code Modulation DSP Digital Signal Processor DTW Dynamic Time Warping
E e-mail Electronic Mail (courir électronique) EasyWin Applications simplifiées pour WINDOWS ERASMUS Programme d’interchanges d’établissement européens
F FAQ Frequently Asked Questions FFT Fast Fourier Transform FIR Finite Impulse Response (Filtres RIF) Full-duplex Communication synchrone bidirectionnelle
H HIDM High Information Delta Modulation Huffman Code pour comprimer de données profitant des redondances hz Hertz
I iDFT Inverse DFT iFFT Inverse FFT IIR Infinite Impulse Response (Filtres RII) ISO International Standards Organization ITU-T International Telecommunications Union – Telecom Sector
K kbps kilo-bits par second Khz kilo-hertz Kbit Kilo-bit Koctets Kilo-octet
iii

L
LD-CELP Low Delay CELP LogPCM Logarithmic Pulse Code Modulation Lossy Avec perte LP Linear Prediction LPC Linear Predictive Coding LSP Linear Spectrum Pairs LSI Low Scale Integration LSB Least Significant Bit LVQ Learned Vector Quantisation LVQ Linear Vector Quantization LZ77 Lempel & Ziv 1977 Compression LZ78 Lempel & Ziv 1978 Compression LZW Lempel Ziv & Welch Compression
M Mhz Mega-Hertz MIPS Millions d’Instructions Par Seconde Modulation Processus de modification de la dimension où l’information est
transmise. MOS Mean Opinion Score MP-MLQ MultiPulse - Maximum Likelihood Quantization MSB Most Significant Bit
N N/A Numérique / Analogique NR Noise Reduction ns Nano-Seconds Numérisation Processus de convertir à un format discret
O Object Windows
Librairie de Borland orienté objets pour WINDOWS
P PCM Pulse Code Modulation Pitch Fréquence du fondamental, couramment connu comme timbre de
la parole PSI-CELP Pitch Synchronous Innovation - Code Excited Linear Prediction PSVQ Predictive Split Vector Quantizer
iv

Q QCELP Qualcomm Code Excited Linear Prediction QCIF Quarter Common Intermediate Format Quantification Processus de approcher une valeur continue à un nombre réduit
de bits
R RIFF Format Multimédia de Microsoft RPE-LTP Regular Pulse Excitation - Long Term Prediction RT Real Time
S SBC SubBand Coding SNR Signal to Noise Ratio SNRq SNR eQuivalent SNRseg SNR SEGmental Sonagramme Représentation du spectre respecte du temps Spectre Représentation de l’amplitude selon les fréquence
T TDHS Time Domain Harmonic Scaling TFR Transformée de Fourier Rapide
V VCELP Vector Code Excited Linear Prediction VoIP Voice over IP VQ Vector Quantization VOCODER VOice CODER
W WAV Extension du format de son de Microsoft WAVE Format de son de Microsoft WHT Walsh-Hadamard Transform
Z ZIP Format de compression très utilisé pour les ordinateurs µ-Law Standard Européen PCM de la téléphonie
v

SOMMAIRE
Introduction ………………………………………………..………..……………….. 1
Chapitre 1 Transmission de la voix sur Internet
1.1 Généralités sur la téléphonies IP ……………………………..…………………...……..…. 3 1.1.1 Techniques de transmissions ………………….………………………………..... 3
1.2 Principe de fonctionnement ………….………..………………………………………....…. 5 1.2.1 Architecture IP …………………………….…………………………………….. 5 1.2.2 Protocoles de signalisations ……………….…………………………………...... 7
1.3 SIP – Session Initiation Protocol ………………..……….………………………………..... 7 1.3.1 Architecture de SIP …………………………………………………………..…. 7
1.3.1.1 Agents utilisateurs (User Agent) …………………………………….... 8 1.3.1.2 Serveur SIP …….…………………………………………………..….. 8
1.4 Protocoles associés …………………………………….………..………………................. 10 1.4.1 Protocoles RTP et RTCP ………………………………………………....…..... 11 1.4.2 Protocoles TCP et UDP ……………………………………………….……...... 12 1.4.3 Protocole IP ………………………………………………………….……….....13
1.5 Conclusion ………………………..……………..……………………………….……........ 14
Chapitre 2 Numérisation des signaux de parole
2.1 Introduction ……………………………………………………………………………........ 15 2.2 La conversion analogique / numérique (A/N) ……………………..………..……………... 15
2.2.1 Principe de l’échantillonnage ……………………….…………………..……….16 2.3 La quantification d’un signal échantillonné ……………………..………………………….18
2.3.1 La quantification uniforme …………………………………..………....…….... 18 2.3.2 La quantification non uniforme ………………………………..…...………..… 20
2.4. Le codage PCM ……………….…………………..…………………………………….... 22 2.4.1 Le codage PCM uniforme …………………………………………..………..… 22 2.4.2 Le codage PCM logarithmique ……………………………………………….... 22
2.5 Conversion Numérique/Analogique …………………………..…………………………... 25 2.6 Conclusion …………………………..………………………….…………………….….... 25
vi

Chapitre 3 La production de la parole et son traitement numérique
3.1 Introduction ........................................................................................................................... 26 3.2 La production des sons de la parole humaine ……………..………………………………. 26
3.2.1 Le phonation …………………………………………………………………..... 28 3.2.2 Les formants …………………………………………………………………..... 28
3.3 Le son vue comme variation de la pression atmosphérique ..………….…………………... 29 3.3.1 Les sons purs et les sons complexes …….…………………………………….... 30
3.4 Modes de représentation graphique du son …….…..……………………………………… 30 3.4.1 Le domaine temporel …………………………………………………………... 30 3.4.2 Le domaine fréquentiel ………………………………………………………… 31
3.5 L’analyse du signal vocal ………….…….……………….………………………………... 32 3.6 L’audition et la perception ……….……….….………….…………………………………. 33 3.7 Modélisation acoustique de la parole …….………….…………….………………………. 34 3.8 Conclusion ………………………….…….……………………....….…………………….. 36
Chapitre 4 Analyse paramétrique du signal de parole
4.1 Introduction ………………………………………………………………………………. 37 4.2 Les fondements en traitement numérique du signal ………....…………………….…..… 37
4.2.1 Les systèmes numériques ……………… ……………………..…………..…... 37 4.2.2 Systèmes récursifs – Systèmes non récursifs ………..… …………………...... 38
4.2.2.1 Réponse impulsionnelle …………………….……………………........ 39 4.2.3 Modèle autorégressifs ……………… …… ……………………………..…… 40 4.2.4 Algorithme de Levinson ………… …… …… ……………………………....... 41 4.2.5 Algorithme de Schur-Cohn …………… …… ……… ……………...…........… 43
4.2.6 Filtre en treillis ………………………………………………………...……...… 44 4.2.7 Equivalence des algorithmes de Levinson et de Schur Cohn ……………….….. 45
4.3 Application de la prédiction linéaire à la parole …………………..……………..……… 46 4.3.1 Les principes de bases ………………………………………………………….. 46 4.3.2 Détermination des coefficients LP …………………………………..………..... 48
4.3.2.1 La méthode d’Autocorrelation ………… …………………..………… 48 4.3.2.2 La méthode de Covariance …………………………………..…..….... 51
4.3.3 Les différentes formes de paramètres LP ……………………………..…….... 52 4.3.3.1 Paramètres Cepstraux ………………………… …………………...... 53 4.3.3.2 Paramètres LAR ( Log Array Ratio ) …………………………..…….. 53
vii

4.3.3.4 Paires de Raies Spectrales (LSP) ………………………………..….. 54 4.4 Conclusion …………………………………………..…………………………………… 55
Chapitre 5 Quantification des signaux de parole
5.1 Introduction et principe …………………………..………………………..………………. 56 5.2 Notion de base ………….………………………………….....……..……………….…….. 57
5.2.1 Critère d’optimalité ……………………………………………………………… 57 5.3 La quantification scalaire ………………………………..…………….….………………... 57
5.3.1 La quantification uniforme …………………………………………………….... 58 5.3.2 La quantification non uniforme …………………………………………………. 58 5.3.3 Principe de la quantification scalaire ……………………………………………. 59 5.3.4 Méthodes de la quantification scalaire ………..… …………………………........ 60
5.4 La quantification vectorielle ……………………………………….………...…………….. 60 5.4.1 Principes de la quantification vectorielle ……………………………………….. 60 5.4.2 Description d'un quantificateur vectoriel ………………………………….……. 62
5.4.2.1 Le codeur …………………………..………………………………….. 62 5.4.2.2 Le décodeur …………………………………..……………………….. 62
5.4.3 Elaboration du dictionnaire ……………………………………………………... 63 5.4.3.1 Les algorithmes de construction d’un quantificateur …………..…….. 63
5.5 Conclusion …………………………………………………………………………..……. 67
Chapitre 6 Codage de la parole
6.1 Introduction …………………………………………….……..……………………………. 69 6.2 Techniques de codage ……………………………………………..….……………………. 70
6.2.1 Les codeurs temporels …………………………………………………………... 70 6.2.2 Les codeurs paramétriques ……………………………………………………… 71 6.2.3 Les codeurs hybrides ……………………………………………………………. 71
6.3 Segmentation du signal de parole ………………………………………………………….. 72 6.4 Le codage prédictif et analyse par synthèse ………….……………………………………. 73 6.5 Le codage prédictif linéaire bas débit …………………………….....…………….………. 74
6.5.1. Principe de la prédiction à court terme ………………………………………… 75 6.5.2. Principe de la prédiction à long terme …………………………….…………… 80 6.5.3. Estimation des paramètres prédicteurs ………………………………………… 82
viii

6.6 Signal d’excitation ………………………………….…………………….…..………….… 84 6.7 Pondération perceptive …………………………….….………………….……………...… 86 6.8 Le codeur CELP ……………………………………………..….…………….…………… 87 6.9 Modélisation du signal d’excitation …………………………….…………….…………… 89
6.9.1. Dictionnaire adaptatif …………………….….…………………….…………… 90 6.9.1.1 Analyse en boucle ouverte ………..……………………………………92 6.9.1.2 Analyse en boucle fermé …………….…………………………..….... 93 6.9.1.3 Recherche du pitch fractionnaire …….……………………..………… 93
6.9.2. Dictionnaire stochastique ……………………………………………..……..… 94 6.10 Conclusion …………………..…………………...…………………………..…………... 95
Chapitre 7 Implantations
A – Implantation du codeur CELP Basé sur le standard FS1016
7.1 La structure du codeur CELP basé FS1016 ………..………….……………………….…... 96 7.2 Analyse par prédiction à court terme …………………….…….………….…………….…. 97 7.3 Recherche du pitch dans le dictionnaire adaptatif ………….….………………...………… 99
7.3.1 Le retard fractionnaire ………………………………………………..…….…. 100 7.4 Recherche dans le dictionnaire fixe ou stochastique ……..………………….…..……….. 102
7.4.1 Exploration du dictionnaire stochastique ……………………………..…...….. 102 7.5 Le codeur CELP Basé FS1016 …………………………………..………….……...…….. 103
B- Implantation du Codeur/Décodeur LD-CELP
7.6 Structure du Codeur/Décodeur LD-CELP ………….….……………….………….…… 105 7.7 Le codeur LD-CELP …………………………….…………………….…………….…… 106 7.8 Le décodeur LD-CELP …………………………..………………………………….……. 108
Conclusion …………………………………………………………………………… 110
Annexe A Distance et mesure de distance …………………………………..……. 112
Bibliographies ……………………………………………………….……………... 115
ix

Liste des figures
Chapitre 1 Transmiss ion de la voix sur Internet
Fig. 1.1 Principe de la transmission de la voix par paquets ……………………………………. 4 Fig. 1.2 Réseau Internet …………………………………………….…………….…………..... 6 Fig. 1.3 Exemple d’acheminements de paquets ………………………………………………... 6 Fig. 1.4 Établissement et terminaison d’une session SIP entre deux agents utilisateurs ………….... 8 Fig. 1.5 Établissement d’une session SIP avec l’utilisation d’un serveur proxy SIP ………………. 8 Fig. 1.6 Établissement d’une session SIP avec l’utilisation d’un serveur de redirection SIP …….… 9 Fig. 1.7 Enregistrement de la localisation d’un usager auprès d’un serveur de redirection SIP …..... 9 Fig. 1.8 Opération SIP ………………………………………………………………………… 10 Fig. 1.9 Mise en paquet de l’information ……………………………………………………… 10 Fig. 1.10 Architecture RTP …………………………………………………………..………... 11
Chapitre 2 Numérisation des signaux de parole
Fig. 2.1 Enregistrement numérique d’un signal de parole ……………………………….…... 16 Fig. 2.2 Exemple d’échantillonnage d’un signal ………………………………………….…. 17 Fig. 2.3 Elaboration d'un signal vocal …………………………………………………….…. 17 Fig. 2.4 La quantification ……………………………………………………………………. 18 Fig. 2.5 Illustration de la quantification uniforme ………………….………………………... 19 Fig. 2.6 Résultats de la quantification d’un signal sur différent niveaux ……………………. 19 Fig. 2.7 Tracé de la loi de compression ………………………………………………….…... 21 Fig. 2.8 Tracé des deux lois de quantification logarithmique (A et µ) …………………….… 23 Fig. 2.9 Courbe caractéristique à 13 segments ……………………………………….……… 24 Fig. 2.10 Codification d’un échantillon ………………………………………….................... 25
Chapitre 3 La production de la parole et son traitement numérique
Fig. 3.1 Appareil phonatoire ………………………………………………………………… 26 Fig. 3.2 Les segments non voisé et voisé d’un signal de parole …………………………….. 27 Fig. 3.3 Spectres de la parole ………………………………………………………………… 27
x

Fig. 3.4 Pics formantiques de différentes voyelles …………………………………………… 29 Fig. 3.5 Son = Variation de la pression de l’air dans le temps ……….………………………. 30 Fig. 3.6 Représentation graphique de deux signaux …………………………………………... 31 Fig. 3.7 Représentation spectrale tri-dimensionnelle ………………………………………….. 32 Fig. 3.8 Spectre obtenu par Transformée Rapide de Fourier (FFT) ……………….................. 32 Fig. 3.9 Spectre lissé obtenu par prédiction linéaire (LPC) …………………………………... 33 Fig. 3.10 Empreinte d’un signal de parole ………………………………………..................... 33 Fig. 3.11 Modélisation de la parole …………………………………………………………….35 Fig. 3.12 Synthèse de la parole à 2 états d’excitation ………………………………................. 35 Fig. 3.13 Synthèse d’un signal de parole par prédiction linéaire ……………………………… 36
Chapitre 4 Analyse paramétrique du signal de parole
Fig. 4.1 Système numérique …………………………………………………………………... 37 Fig. 4.2 Système numérique linéaire et invariant ……………………………………………... 38 Fig. 4.3 Exemple de structure d’un filtre numérique récursif …………………….................... 39 Fig. 4.4 Réponse impulsionnelle ………………………………………………….................... 39 Fig. 4.5 Structure du filtre non récursif en treillis …………………………………………….. 44 Fig. 4.6 Structure du filtre récursif en treillis ……………………………………..................... 45 Fig. 4.7 diagramme d’un modèle simplifié pour la production de la parole ………………….. 47
Chapitre 5 Quantification des signaux de parole
Fig. 5.1 Quantificateur Scalaire ………………………….…………………………………... 58 Fig. 5.2 Partition uniforme d’un intervalle …………………………….…………………….. 58 Fig. 5.3 Quantificateur scalaire non uniforme ……………………….………………………. 59 Fig. 5.4 Quantification scalaire …………………………………….….……………………... 59 Fig. 5.5 Codes vecteur dans un espace 2-dimensionnel ……………………………………... 61 Fig. 5.6 La transmission d'un signal par quantification vectorielle ……………....................... 62
Chapitre 6 Codage de la parole
Fig. 6.1 Performances des codeurs temporels, paramétriques et hybrides ……………………. 72 Fig. 6.2 Diagramme du codeur LPAS ………………………………...………………………. 74
xi

Fig. 6.3 Modélisation de production de la parole ……………………….…………………….. 75 Fig. 6.4 Analyse et synthèse LP ………………………………………………………………. 77 Fig. 6.5 Gain en fonction de l’ordre de prédiction ……………………………………………. 78 Fig. 6.6 Modélisation LPC d’une voix ……..……………………………………..................... 78 Fig. 6.7 Signal source et signal résiduel après prédiction à court terme ……………………… 79 Fig. 6.8 Signal non-stationnaire : région de transition ……………………………................... 80 Fig. 6.9 Model d’analyse pour estimation de paramètres prédicteurs à court et à long terme ... 82 Fig. 6.10 Excitation simple du filtre de synthèse …………………………………................... 85 Fig. 6.11 Distribution des amplitudes du signal d’erreur …………………………................... 85 Fig. 6.12 Codeur LPAS avec pondération perceptive ………………………………………… 87 Fig. 6.13 Le codeur CELP …………………………………………………………………….. 87 Fig. 6.14 Synthèse de codeur CELP avec dictionnaires fixe et adaptatif ……………………... 89 Fig. 6.15 Dictionnaire adaptatif avant sélection de l’excitation ………………………………. 91 Fig. 6.16 Procédure de mise à jour du dictionnaire adaptatif …………………………………. 91 Fig. 6.17 Sélection de l’excitation pour T > L ………………………………………………… 93 Fig. 6.18 Sélection de l’excitation pour T < L ………………………………………………… 93
Chapitre 7 Implantations
Fig. 7.1 La structure du codeur CELP basé FS-1016 ……………...………………………….. 96 Fig. 7.2 Interpolation des LSPs selon la norme FS1016 ……………………………………… 98 Fig. 7.3 Structure du codeur LD-CELP ……………………………………………………… 105 Fig. 7.4 Structure du décodeur LD-CELP …………………………………………………… 106
xii

Introduction
Le développement de l’Internet et l’utilisation croissante des réseaux fondés sur le protocole Internet (Internet Protocol : IP) pour les services de communications, y compris pour des applications telle que la téléphonie, sont devenus des domaines importants pour l’industrie des télécommunications. La possibilité d’acheminer du trafic vocal sur des réseaux IP et les avantages offerts, notamment au niveau de l’intégration voix et données constituent un point de convergence entre deux technologies : la commutation de circuits telle que utilisée actuellement dans les réseaux classiques de téléphonie et la commutation de paquets pour la transmission de données (fichiers, images …).
Cependant, malgré toutes les avancées technologiques pour la radiodiffusion de médias, la conversation téléphonique n'est pas toujours déployée avec succès dans le réseau Internet. Ceci est dû aux faits que l’information à transmettre doit être réalisée en temps réel.
Par l’Internet on peut transférer des fichiers de taille importante de quelques giga octets, mais le problème réside dans le cas d’un transfert en temps réel.
Notre travail a un lien avec ce problème, car on veut transmettre de la parole à travers Internet de telle sorte que deux locuteurs puissent communiquer confortablement. Deux locuteurs peuvent être en des point différent dans le monde, et on sait que par Internet la transmission se fait par paquets, où ces derniers peuvent prendre plusieurs chemins à travers les routeurs du réseau, et à l’arrivée il faut que ces paquets soit ordonnées selon l’ordre de leurs émission.
Il faut surtout ne pas négliger la contrainte de perception auditive chez l’être humain qui ne doit pas dépasser les 200 ms, sinon le locuteur perçoit des sons peu confortables avec retour d’écho.
Or comme nous allons le voir au chapitre 3, la taille universelle utilisée en standard téléphonique est de 64000 octets par seconde, donc pour transférer un message parlé de 200 ms au plus, il faut transférer 12800 octet (12.5 Ko) en moins de 200 ms en tenant compte aussi du temps de transfert et des octets ajoutés aux paquets.
On voit que les volumes nécessaires à une transcription numérique de qualité d'un signal sonore rendent son transport difficile sur Internet, ce qui à une contrainte drastique de réduction de débit.
La largeur de bande citée ci-dessus (64000 octets) ne serait pas appropriée pour un utilisateur lié à l'Internet. Pour des utilisateurs de largeur de bande à flot audio si bas exigeraient une réduction du nombre de bits audio, ainsi on utilise la compression pour diminuer le nombre de bits nécessaires à la quantification de l'information.
Ainsi il faut élaborer des systèmes de codage de haute qualité avec un débit de plus en plus faible : un véritable défi a été lancé aux chercheurs au début des années 80.
Le codage de la parole exige la description pertinente et l'extraction précise d'informations du signal. Cela ne peut se faire qu'avec l'aide de théories et de techniques puissantes développées en traitement numérique du signal dont la maîtrise requiert des connaissances très spécialisées. Par
1

ailleurs, la grande complexité de la parole nécessite des traitements particuliers liés à sa production et à sa perception. En effet, le signal de parole étant porteur d'une information spécifique pour la communication entre le locuteur et l'auditeur, le mécanisme de celle-ci ne doit pas être ignoré lors de la réduction de débit.
Le but principal de notre étude n’a pas pour objectif principal de développer des nouvelles techniques de codage, mais plutôt d’acquérir la compréhension théorique dans les avantages et les inconvénients de techniques existantes et de trouver une motivation pour une approche permettant l’obtention d’une meilleure compréhension des étapes séparées d'un codeur de parole.
Cette thèse est organisée comme suit.
Dans le premier chapitre, on définit les bases de la transmission de la voix à travers Internet, et de là on comprend la nécessité du codage de la parole pour pouvoir assurer une fluidité d’une conversation téléphonique sur IP.
Le chapitre 2 présente comment la parole est produite par le système phonatoire de l’être humain, et on montre que le signal de parole est complexe, car sa structure résulte de l’interaction entre la production des sons et leur perception par l’oreille, avec comme objectif la transmission d’un message.
Le chapitre 3 présente de manière approfondie les caractéristiques du signal de parole et l’élaboration de traitements adéquats, en appliquant les théories et les techniques du traitement numérique du signal.
Au chapitre 4 on étudie en détail la techniques de codage de la voix par la prédiction linéaire de la parole. Dans cette technique, l'échantillon de parole courant est prédit par les échantillons de paroles passés dans une tranche donnée d’une durée moyenne de 20 msec.
Les techniques de traitement du signal mises en œuvre se différencient suivant la qualité de la parole transmise souhaitée. Pour une forte réduction de débit et une qualité téléphonique standard, le codage fait largement appel aux outils de modélisation et aux techniques de quantification qui sont présenté dans le chapitre 5 associées aux méthodes d’analyse par synthèse et au codage de la parole pour la téléphonie utilisant un réseau IP dont il font l’objet du chapitre 6.
Le chapitre 7 présente l’implantation de deux codeurs représentant le codage CELP (Code Excited Linear Predictive), le premier est le codeur CELP FS1016 à 4,8 Kbs et le deuxième Le Codeur LD-CELP (Low Delay Code Excited Prediction) à 16 Kbs, correspondant à des techniques de codage hybrides utilisant des méthodes de codage de la forme d'onde et prenant en compte certaines propriétés de la parole ou de la perception auditive.
2

Chapitre 1 Transmission de la voix sur Internet Les communications téléphoniques via le réseau Internet représentent à l’évidence un
phénomène en forte croissance dans le domaine des nouveaux moyens de communication. Plus récemment, il est apparu que la transmission de la voix sur Internet pouvait se développer à grande échelle. Avec l’augmentation continue de la vitesse des microprocesseurs et le développement des techniques de traitement du signal, il est devenu réaliste de faire transiter de la voix, au même titre que des données informatiques, sur le réseau Internet. La volonté de transporter de la voix a été une première étape vers l’objectif d’avoir un réseau unique permettant l’interconnexion de tous les supports et acceptant les contraintes temps réel du multimédia. De là, de nombreux acteurs se sont engagés sur des applications de téléphonie I P (Internet Protocol), qui disposent d’un potentiel important de nouvelles fonctionnalités. La téléphonie sur Internet apparaît donc comme une des évolutions majeures dans le domaine des télécommunications.
1.1 Généralités sur la téléphonie I P
Tout d’abord, i l convient de préciser que le terme téléphonie sur Internet ou téléphonie I P correspond à la téléphonie utilisant la communication par paquets et les technologies liées à l’Internet, que le réseau soit Internet, Intranet ou Extranet.
Indépendamment des aspects liés aux tarifs pratiqués dans les domaines de la téléphonie traditionnelle et d’Internet, quelques raisons objectives existent pour que les communications sur I P soient moins coûteuses que les communications sur réseau téléphonique commuté classique. La principale raison est inhérente à la mise en oeuvre de la transmission de la voix par paquets qui utilise mieux les liaisons de télécommunications que la technique de commutation de circuits qui dédie un circuit de bout en bout à chaque communication téléphonique sans tenir compte des temps morts de la conversation. Une des contraintes en téléphonie sur IP es t l a compression de l’information numérique, qui fait passer la voix numérisée d’un débit standard de 64 kbits/s à un débit de moins de 10 kbits/s en général, afin de réduire l’occupation spectrale du réseau.
Des constructeurs et des opérateurs ont mis en place des passerelles entre Internet et le réseau téléphonique classique et offrent une téléphonie sur Internet concurrente du service habituel. Cependant, la téléphonie sur Internet est encore loin de satisfaire aux exigences de qualité de service attendue. En effet, la voix sur I P , qui ne se résume pas à la capacité à établir une connexion vocale entre deux téléphones, peut offrir beaucoup de possibilités en ajoutant de nouveaux services à ceux habituellement fournis par le réseau téléphonique classique. L’idée est d’unifier le transport des informations, voix et/ou données, autour du protocole IP . Etant donné l’engouement actuel pour Internet et les investissements des opérateurs et des fournisseurs d’accès, la téléphonie I P apparaît bien comme une alternative aux réseaux téléphoniques classiques.
1.1.1 Techniques de transmissions
En téléphonie classique, la transmission pose peu de problèmes grâce à la commutation de
3

circuit. Un canal est réservé aux deux locuteurs et la qualité du signal est constante. Sur Internet, rien de tel, la réservation de ressources n’existe pas. C’est un réseau à commutation de paquets, dit asynchrone et fonctionnant en best-effort, sur lequel tous les trafics ont la même priorité. En apparence, toutes ces contraintes ne sont pas vraiment compatibles avec la téléphonie. Pour qu’un bon flux soit envisageable, il faut élaborer des algorithmes de compression capables d’adapter l’information au canal de transmission restreint et capricieux qu’est Internet.
Pour transmettre de la voix sur réseau téléphonique commuté, le signal analogique est numérisé par un codage PCM (Pulse Code Modulation), 8000 échantillons par seconde quantifiés sur 8 bits, conforme à la recommandation G.711 de l’Union Internationale des Télécommunications (UIT). Par conséquent, le signal en téléphonie sur réseau commuté correspond à un débit de 64 kbits/s. Les délais de codage et de transit nécessaires à ces opérations étant peu perceptibles par les utilisateurs, les conversations demeurent fluides et sans interruption.
La transmission de la voix sur réseau Internet ne peut pas s’effectuer par la même procédure car les caractéristiques d’une transmission par paquets sont totalement différentes de celles du réseau commuté. Internet mutualise les artères de communication entre tous les utilisateurs sans aucune hiérarchisation. Ainsi, i l est impossible de gérer les délais de transmission et donc la fluidité du trafic. I l existe seulement quelques mécanismes pour décongestionner un noeud du réseau saturé ce qui n’offre aucune garantie de débit. Envisager de faire de la téléphonie, qui nécessite des transmissions en temps réel, est donc en théorie difficile.
Fig. 1.1 Principe de la transmission de la voix par paquets
Le principe de base de la transmission de la voix sur les réseaux Internet consiste en :
1 - La voix à transmettre est échantillonnée et numérisée par un convertisseur analogique numérique.
2 - Le signal numérique obtenu est comprimé et encodé grâce à des algorithmes de compression spécifiques afin de diminuer le débit nécessaire et économiser des ressources fréquentielles rares.
3 - Le signal est découpé en paquets.
4 - Les paquets sont transmis à travers le réseau Internet
4

À la réception, les paquets sont réassemblés, le signal de données ainsi obtenu est décomprimé puis converti en signal analogique sonore.
Pour une communication en VoIP, le signal vocal doit être compressé à l’aide d’algorithmes beaucoup plus élaborés qu’en téléphonie classique. Ensuite, l’information à transmettre est découpée par une procédure de paquetisation, à raison de 20 à 30 millisecondes de parole par paquet, avant l’envoi sur le réseau IP . Les paquets d’informations, qui circulent sur Internet, empruntent des chemins différents et arrivent fréquemment dans le désordre. Les paquets sont alors stockés dans des mémoires tampons, ou buffer, pour être re-séquencés et permettre la décompression de l’information et sa transformation en signal sonore.
1.2 Principe de fonctionnement
De manière générale, le principe de la téléphonie sur réseau par paquets consiste, à partir d’une numérisation de la voix, à comprimer le signal, à le découper en paquets de données et à les transmettre sur le réseau. A l’arrivée, les paquets transmis sont réassemblés, le signal de données obtenu est décompressé puis converti en signal analogique pour restituer le signal sonore à l’utilisateur.
En téléphonie traditionnelle, les opérations de numérisation de la voix et de conversion en signal analogique existent déjà. La technique de compression/décompression est également disponible mais n’est utilisée, jusqu’à présent, que sur des communications à grande distance. La technologie du réseau utilisée actuellement est essentiellement celle de la commutation de circuits, qui implique l’établissement d’une liaison entre deux abonnés pendant toute la durée de la communication.
Dans un système de téléphonie sur réseau de données par paquets, deux types de connexion peuvent être distingués :
• la première consiste à mettre en oeuvre un réseau de transmission par paquets à liaison permanente de type ATM (Asynchronous Transfer Mode), qui permet de garantir la réception de l’intégralité des paquets et ceci dans l’ordre d’émission.
• la deuxième utilise un réseau de type Internet, basé sur le protocole I P , sur lequel les paquets d’informations sont acheminés par les noeuds du réseau constitués de routeurs. Les paquets arrivent alors à destination dans un ordre pouvant être différent de celui de l’émission. A la réception, les durées de transmission variables devront être compensées pour reconstituer le signal numérique. C’est le principe même de la transmission de la voix via le réseau Internet (VoIP). La téléphonie sur I P , qui est l’objet de notre étude, utilise un système de transmission de ce type.
1.2 .1 Architecture I P
Comme nous l’avons déjà dit, les réseaux téléphoniques classiques font appel aux techniques de commutation de circuits. L’arrivée des premières solutions de téléphonie sur I P a considérablement modifié l’éventail de solutions et de services mis à disposition des systèmes de communication, principalement dans le cadre de l’interconnexion avec le système d’information.
5

Fig. 1.2 Réseau Internet
Le réseau Internet global est formé en fait de réseaux d’interconnexion et d’accès appartenant à des opérateurs publics ou privés et de réseaux I P d’utilisateurs. Ces réseaux, qui peuvent être de types différents (réseau I P ou Public Switched Telephone Network) ou adopter des protocoles de communications distincts, sont interconnectés par des routeurs ou passerelles (figure 1.2). La passerelle accomplit en effet la traduction des protocoles pour l’établissement des appels ou des connexions multimédias, en gérant les différents formats rencontrés et en transportant l’information entre les différents réseaux qui lui sont connectés. Outre le transcodage, diverses fonctions sont assurées au niveau des routeurs, notamment la mise en paquets des données, le codage/décodage de la voix ou l’annulation d’échos. Précisons ici que seul le système de codage/décodage qui doit être intégré dans la passerelle a fait l’objet de notre étude.
Compte tenu de l’architecture du réseau Internet plusieurs routes peuvent être utilisées pour relier deux réseaux source/destination. Le trafic atteindra alors sa destination après avoir traversé plusieurs réseaux intermédiaires (figure 1.3). Le rôle décisif que joue le routage et l’interconnexion des réseaux font de la conception des protocoles de routage un défi majeur. Cependant, la partie réseau ne fait pas l’objet de notre étude. Notons juste, pour information, qu’il convient d’établir une distinction entre le routage proprement dit et les protocoles de routage qui lui sont associés.
Fig. 1.3 Exemple d’acheminements de paquets
En effet, tous les systèmes acheminant des données n’exécutent pas forcément des protocoles de routage. Ces protocoles créent des tables qui définissent le trajet optimal vers le récepteur, grâce à l’analyse des entêtes de paquets I P , en considérant plusieurs facteurs tels que la durée moyenne de transmission, la charge du réseau ou la longueur totale du message. Le routage consiste
6

seulement à transférer les paquets I P , appelés aussi datagrammes, en fonction des informations contenues dans la table de routage.
1.2.2 Protocoles de s ignal isat ions
Les services multimédia sur I P sont gérés par des protocoles de signalisation assurant l’établissement, le contrôle et la rupture d’une connexion temps réel. Cette signalisation doit définir des procédures communes entre les différents fournisseurs de produits. Malheureusement, comme souvent, i l n’est pas sûr que tous les systèmes puissent interfonctionner. En effet, plusieurs approches de normalisation existent actuellement, pour fixer une qualité de service de téléphonie sur I P et permettre l’inter-opérabilité des applications et des équipements, telles que le standard H.323 adopté par l ’UIT en 1996 qui est issu de la norme H.320 sur la visiophonie sur réseau numérique, le Session Initiation Protocol (SIP) de l ’ IETF (Internet Engineering Task Force) ou encore le protocole GLP (Gateway Location Protocol) qui détermine aussi les passerelles les plus proches d’un correspondant. Cependant, la convergence semble se faire actuellement sur le protocole SIP qui est réputé être plus souple et plus facile à appréhender et que nous allons détailler par la suite.
1.3 SIP - Session Initiation Protocol
(SIP) est un protocole standard qui permet l’établissement, la terminaison et le changement de session au niveau poste à poste et client/serveur. I l est présentement l ’ u n des protocoles les plus prometteurs a f i n d ’ o f f r i r les nouveaux services en émergence par son mécanisme de localisation des utilisateurs et son extensibilité.
SIP permet de localiser des utilisateurs au sein d ’ u n réseau étant donné que son fonctionnement est basé sur l’enregistrement d ’ u n usager auprès d ’ u n serveur SIP qui est en mesure de localiser l’usager. Par exemple, un usager ([email protected]) s’enregistre à un serveur SIP en effectuant une requête. Celui-ci va être en mesure de déterminer l’adresse du poste où l’utilisateur se situe (poste.gel.usherb.ca). La localisation de l’usager étant connue ([email protected]), différentes sessions offrant divers services pourront être ouvertes avec cet usager. En effet, SIP permet à un usager ([email protected]), indépendamment de sa localisation d’être accessible (dans ce cas, à l’adresse [email protected]) dans un réseau.
SIP est un protocole qui a la caractéristique d’être extensible. Cette extensibilité lui permet de transporter une charge utile arbitraire. En effet, SIP peut être combiné à d’autres protocoles de communication, codecs ou encore formats de fichiers afin d ’ o f f r i r des nouveaux services au travers de sessions SIP. Par exemple, deux usagers peuvent bavarder pour ensuite décider d’ouvrir une session téléphonique IP a f i n de converser ensemble. Lors de cette conversation, des fichiers ou des photos peuvent être échangés en temps réel. En conséquence, SIP, par son architecture extensible, permet une interaction intégrée de plusieurs médias entre usagers distants.
1 .3 .1 Arch i t ec ture de SIP
L’architecture de SIP comporte deux entités principales : les agents SIP et les
7

serveurs SIP. Ces entités interagissent entres elles a f i n de localiser un usager au sein d ’ u n réseau et permettre des services qui sont dénis dans les extensions de SIP.
1.3.1.1 Agents utilisateurs (User agents)
I l existe plusieurs types d’agents utilisateurs. Ceux-ci peuvent être des périphériques ou encore des logiciels interagissant ensemble a f i n de fournir des services tels que la vidéoconférence, la téléphonie IP, les jeux interactifs ou encore les échanges de fichiers. Ces agents utilisateurs (User Agents (UA)) sont dénommés UA client ou UA serveur selon qu’ils effectuent ou qu’ils reçoivent une requête d’ouverture de session. Lors d’une ouverture d’une session, une requête est effectuée du UA client au UA serveur (voir figure 1.4). Une session poste à poste peut donc être ouverte entre deux utilisateurs utilisant SIP.
Fig. 1.4 Établissement et terminaison d’une session SIP entre deux agents utilisateurs.
1.3.1.2 Serveur SIP
I l existe quelques types de serveur SIP : Serveur Proxy SIP, serveur de redirection SIP et serveur d’enregistrement. Ces trois types de serveur effectuent diverses tâches au sein d’un réseau.
Fig. 1.5 Établissement d’une session SIP avec l’utilisation d’un serveur proxy SIP.
8

Serveur Proxy SIP est un élément qui transfère les requêtes SIP à un agent utilisateur serveur et les réponses SIP à un agent utilisateur client (Fig 1.5). Une requête peut traverser quelques serveurs Proxy SIP afin d’être acheminé vers un client. Chacun de ces serveurs va appliquer les règles de routage et effectuer les modifications nécessaires aux diverses requêtes avant de le transférer au prochain élément. Les réponses vont être réacheminer au travers des divers éléments suivant le chemin inverse de la requête.
Fig. 1.6 Établissement d’une session SIP avec l’utilisation d’un serveur de redirection SIP.
Serveur de redirection SIP est un serveur qui transfère vers le client l’information concernant le routage de la requête (Fig. 1.6) afin que celui-ci effectue les requêtes sans passer par le serveur. En faisant de sorte, le serveur n’est plus impliqué dans les échanges futur de messages entre un agent utilisateur client et serveur.
Serveur d’enregistrement est un serveur qui traite les requêtes d’enregistrement (REGISTRER) afin de mettre à jour la localisation de l’usager dans la base de données, grâce aux informations fournies lors de la requête (Fig 1.7).
Fig. 1.7 Enregistrement de la localisation d’un usager auprès d’un serveur de redirection SIP.
9

La figure suivante nous montre la procédure de connexion d’un client à un autre de façon générale.
SIP Client (User Agent Server)
Fig. 1.8 Opération SIP
1.4 Protocoles associés
Le transfert de données sur Internet s’effectue par paquets de données. Cette structure repose sur l’utilisation de protocoles TCP/IP (Transport Control Protocol/ Internet Protocol).
Chaque document, qu’il s’agisse de texte, image ou voix, est numérisé puis réparti en paquets. Chacun de ces paquets est alors envoyé sur Internet indépendamment des autres et essaie de prendre le chemin le plus rapide pour parvenir à sa destination. Ceci est réalisé en fonction de l’encombrement d’une partie ou de l’autre du réseau au moment où le paquet est expédié. La segmentation de l’information permet une plus grande flexibilité dans l’utilisation des ressources puisque la communication ne monopolise pas une ligne donnée.
Fig. 1.9 Mise en paquet de l’information
10

Pour assurer une communication Internet, chaque équipement d’interconnexion impliqué devra posséder le module TCP/IP. Le Protocole Internet, chargé de l’acheminement de données, encapsule les paquets TCP ou UDP (User Datagram Protocol). A l’arrivée dans un routeur, le paquet I P transmis est décapsulé et analysé. Ses informations sont examinées pour savoir vers quel réseau le paquet doit être acheminé et un nouveau paquet I P est constitué selon le réseau désigné puis transmis. Le module d’arrivée extrait le datagramme de niveau supérieur et passe à la couche TCP qui indique les paramètres de service tels que la priorité du paquet ou le codage de sécurité du paquet.
1.4 .1 Protocoles R T P et RTCP
Le protocole de transport en temps réel RTP a été développé en 1993 par IETF et standardisé en 1996, dont le but est de transmettre sur Internet des données qui ont des propriétés temps réel (audio, vidéo …). C’est un protocole de la couche application du modèle OSI et utilise les protocoles de transport TCP ou UDP, mais, généralement, il utilise UDP qui est mieux approprié à ce genre de transmission.
Environnement et Application Multimédia Temps-Réel
RTCP
RTP
UDP AAL5
IP ATM Other protocols
Fig. 1.10 Architecture RTP
Le rôle principal de RTP consiste à mettre en œuvre des numéros de séquences de paquets IP et des mécanismes d’horodatages (timestamp) pour permettre de reconstituer les informations de voix ou vidéo. Plus généralement, RTP permet ·
- D’identifier le type de l’information transportée;
- D’ajouter des indicateurs de temps (horodater) et des numéros de séquence à l’information transportée; Ce standard inclut en effet un horodateur (Timestamp) des paquets permettant au destinataire d’utiliser la numérotation des séquences pour reconstituer l’ordre original des paquets et de détecter les paquets perdus.
- De contrôler l’arrivée à destination des paquets.
RTCP (Real Time Control Protocol,) est un protocole de contrôle utilisé conjointement avec RTP pour contrôler les flux de données et la gestion de la bande passante. RTCP permet de contrôler le flux RTP, et de véhiculer périodiquement des informations de bout en bout pour renseigner sur la qualité de service de la session de chaque participant à la session. Il est le protocole sous -jacent (UDP par exemple) qui permet grâce à des numéros de ports différents et consécutifs le multiplexage des paquets de données RTP et des paquets de contrôle RTCP. Le protocole RTCP remplit trois fonctions :
11

- L’information sur la qualité de service : RTCP fournit, en rétroaction des informations sur la qualité de réception des données transmises dans les paquets RTP. Cette information est utilisée par la source émettrice pour adapter le type de codage au niveau des ressources disponibles.
- L’identification permanente : RTCP transporte un identificateur original de la source RTP c’est à dire la provenance du flux, appelé CNAME (Canonical name). Cet identificateur permet une identification permanente de chacun des flux multimédia entrants.
- Le calibrage de la fréquence d’émission : La réception des feed-back et la connaissance du nom permanent servent à ajuster la fréquence d’envoi des paquets à la bande passante mise à la disposition de l’utilisateur situé à l’autre extrémité.
Le protocole RTP est adapté aux applications présentant des propriétés temps réel. I l permet ainsi de reconstituer la base de temps des flux (horodatage des paquets et possibilité de re-synchronisation des flux par le récepteur), de détecter les pertes de paquets et d’en informer la source ou encore d’identifier le contenu des données pour leur associer un transport sécurisé. Bien qu’autonome, le RTP peut être complété par le RTCP. Ce dernier apporte à la source un retour d’informations sur la transmission et sur les éléments destinataires. Par exemple, un rapport peut regrouper des statistiques concernant la transmission telles que le pourcentage de perte, le nombre cumulé de paquets perdus ou la variation de délai de transmission, appelée gigue.
Ces deux protocoles sont adaptés pour la transmission de données temps réel. Pour le transport de la voix, ils permettent une transmission correcte sur des réseaux bien ciblés tels que les réseaux ATM qui fournissent une qualité de service adaptée. Des réseaux bien dimensionnés, comme un Intranet, pourront aussi être adéquats. En revanche, les protocoles RTP et RTCP ne permettent pas d’obtenir des transmissions temps réel d’assez bonne qualité pour la VoIP. En effet, RTP ne procure pas de réservation de ressources sur le réseau, de fiabilisation des échanges (pas de retransmission automatique et de régulation automatique du débit) ou de garantie dans le délai de livraison (seules les couches de niveau inférieur le peuvent) et de continuité du flux temps réel.
1 .4 .2 Protoco les T C P e t U D P
Le protocole TCP est un protocole de contrôle de transmission, qui assure un circuit virtuel entre les applications utilisateurs. Le protocole TCP établit un mécanisme d’acquittement et de re-émission de paquets manquants. Ainsi, lorsqu’un paquet se perd et ne parvient pas au destinataire, TCP permet de prévenir l’expéditeur et lui réclame de renvoyer les informations non parvenues. Il assure d’autre part un contrôle de flux en gérant une fenêtre de congestion qui module le débit d’émission des paquets. Il permet donc de garantir une certaine fiabilité des transmissions. TCP assure un service fiable et est orienté connexion, cependant il ne convient pas à des applications temps réel à cause des longs délais engendrés par le mécanisme d’acquittement et de retransmission
Le protocole UDP est le protocole de transport sans confirmation, qui permet aux applications d’échanger des datagrammes sans accusé de réception ni remise garantie. Le traitement des erreurs et la retransmission doivent être effectués par d’autres protocoles. UDP n’utilise ni fenêtrage, ni accusés de réception, il ne reséquence pas les messages, et ne met en place aucun contrôle de flux. Par conséquent, la fiabilité doit être assurée par les protocoles de
12

couche application. Les messages UDP peuvent être perdus, dupliqués, remis hors séquence ou arriver trop tôt pour être traiter lors de leurs réception. UDP est un protocole particulièrement simple conçu pour des applications qui n’ont pas à assembler des séquences de segments. Son avantage est un temps d’exécution court qui permet de tenir compte des contraintes de temps réel ou de limitation d’espace mémoire sur un processeur, contraintes qui ne permettent pas l’implantation de protocoles beaucoup plus lourds comme TCP. Dans des applications temps-réel, UDP est le plus approprié, cependant il présente des faiblesses dues au manque de fiabilité.
Les protocoles Transport Control Protocol (TCP) et User Datagram Protocol (UDP) doivent pouvoir supporter la transmission de données sur une large gamme de réseaux, depuis les liaisons filaires câblées jusqu’aux réseaux commutés. Ils s’intègrent dans une architecture multicouche de protocoles, supportant le fonctionnement de réseaux hétérogènes et supposent que les couches inférieures de communication, sur lesquelles ils s’appuient, leur procurent un service de transmission par paquet. Ces protocoles s’interfacent donc juste au dessus du protocole I P et fournissent un service de transfert de segments de données ou de voix, encapsulés dans un paquet Internet.
Les applications nécessitant une transmission fiabilisée et ordonnée d’un flux de données utiliseront de préférence le protocole TCP. Lorsque deux processus désirent communiquer, leurs TCP respectifs négocient et établissent la connexion. Le protocole met ensuite en forme les données à transmettre afin de les transférer au protocole I P , qui les acheminera vers le TCP distant. Ce protocole doit bien sûr inclure les informations nécessaires à la reconstruction des données originales. Pour cela le TCP effectue un contrôle d’erreurs et traite les cas de données perdues, erronées, dupliquées ou arrivées dans le désordre à l’autre bout de la liaison Internet. I l fournit aussi au destinataire un moyen de contrôler le flux de données envoyé par l’émetteur.
Dans le cas d’une transmission de la voix, le protocole TCP sera remplacé par le User Datagram Protocol (UDP), beaucoup plus simple à gérer étant donné qu’il ne fournit pas de contrôle d’erreurs. En effet, le protocole UDP n’opère pas de contrôle de transmission des données, contrairement au TCP, lors d’une communication établie entre deux machines. I l s’agit d’un mode dans lequel la machine émettrice envoie des données sans prévenir la machine réceptrice, qui reçoit les données sans envoyer d’avis de réception à la première. Ce protocole, plus adapté au transport temps réel et donc à la VoIP, ne garantit alors ni la délivrance du message ni son éventuelle réémission. La plus grande rapidité de restitution de l’information se fera au détriment de la qualité de transmission.
1.4.3 Protocole I P
Le protocole IP est au centre du fonctionnement de l’Internet. Il fait partie de la couche Internet de la suite de protocoles TCP/IP. Il assure sans connexion un service non fiable de délivrance de paquets IP. Le service est non fiable car il n’existe aucune garantie pour que les paquets IP arrivent à destination. Certains paquets peuvent être perdus, dupliqués ou remis en désordre. On parle de remise au mieux. Le protocole IP permet aux paquets de se déplacer sur le réseau Internet, indépendamment les uns des autres, sans liaison dédiée. Chacun d’entre eux, envoyé sur le réseau, se voit attribuer une adresse IP. Cette dernière est un en-tête accolé à chaque paquet et contenant certaines informations, notamment, l’adresse destinataire, sa durée de
13

vie, le type de service désiré, etc. Le protocole IP actuellement utilisé en est à la version 4 et la nouvelle version Ipv6 est déjà prête à prendre le relais.
Le protocole I P (Internet Protocol) a été conçu pour permettre les communications entre systèmes informatiques. Sa principale fonction est d’acheminer les paquets I P à travers l’ensemble des réseaux interconnectés, selon l’interprétation d’une adresse identifiant les équipements. Il va assurer le traitement individuel et la transmission des paquets I P entre deux modules Internet, en fournissant un entête propre à chaque datagramme, considéré alors comme une entité indépendante. Cet entête contiendra l’ensemble des informations nécessaires à leur transfert, et disposera de mécanismes permettant l’adressage des services TCP/UDP quelle que soit leur position dans le réseau.
En plus de l’adressage et de l’acheminement en best effort des paquets, la couche I P réalise le multiplexage de protocoles ainsi que la destruction des datagrammes ayant transité trop longtemps sur le réseau. Cependant, le protocole I P ne garantit pas la réussite de l’acheminement, le contrôle d’erreur et de flux, ainsi que le séquencement des données.
1.5 Conclusion
La voix sur IP procure des avantages certains aux entreprises et aux utilisateurs. Un seul réseau est utilisé pour la voix, la vidéo et les données, ce qui a pour conséquence de réduire les frais d’exploitations. D’autre part, les utilisateurs peuvent éviter les frais dus aux appels interurbains et payer uniquement les frais de connexions locales. D’autres applications de la voix et la vidéo sur IP permettent la tenue de réunions et de conférences multimédia.
Dans ce chapitre, nous avons présenté le principe de la téléphonie sur IP et nous avons étudié les protocoles qui permettent ce genre d’applications. Parmi ces protocoles, nous avons présenté les protocoles de transports et de contrôles en temps réel RTP et RTCP qui utilisent le protocole UDP pour le transport de la voix et de la vidéo.
La transmission de la voix sur réseau Internet doit être fluide pour permettre une conversation sans interruption. Notre travail s’est porté sur le codage de la parole, pour élaborer des algorithmes de compression de paroles en tenant compte des délais de codage afin d’adapter l’information au canal de transmission restreint et capricieux qu’est Internet
14

Chapitre 2
Numérisation des signaux de parole
2.1 Introduction
La parole est la manière naturelle et, en conséquence, la forme la plus commune de communication humaine. À la différence d’autres moyens électroniques de communication, les systèmes utilisant la parole offrent à l’utilisateur non entraîné un accès simple et naturel. Il semble improbable que, dans l’avenir, même l’impact de la technologie des ordinateurs et de réseaux numériques (fax, e-mail et autres) ne puisse changer la préférence des gens pour la parole comme moyen fondamental de communication entre eux.
Les travaux sur le traitement de la parole ont une histoire de plus de cinquante ans : en 1939, pour la première fois, un chercheur des laboratoires Bell aux États- Unis, M. Dudley, proposa un appareil nommé Vocoder (« Voice Coder » ou « codeur de voix ») visant à coder électriquement le signal vocal selon des paramètres limités, puis à le transmettre avec un débit d’informations réduit et à le reproduire enfin dans un système de synthèse effectuant l’opération réciproque du Vocoder. Plus tard, le même chercheur réalisa un autre système de synthèse électrique de la parole, actionné par un clavier. Enfin apparut, en 1947, le sonagraphe, premier analyseur de la composition du signe vocal en fréquence et en amplitude.
Depuis lors, un dénombrement de tous les événements et développements de produits seraient fastidieux puisque des avances ont été très importantes depuis cette date, fondamentalement, dans le domaine des télécommunications.
Le traitement de la parole suppose toujours en premier lieu une analyse du signal vocal acoustique converti au préalable en signal électrique par un microphone. Puisque les ordinateurs ne peuvent pas manipuler des sources analogiques, on doit convertir les signaux au format numérique avec un convertisseur analogique/numérique (conv. A/N ou ADC pour Analog Digital Converter). Le processus inverse sera fait par le convertisseur numérique/analogique (conv. N/A). Le développement rapide des ordinateurs et des circuits intégrés en conjonction avec la croissance des communications numériques a encouragé l’application des techniques numériques au traitement du signal.
2.2 La conversion analogique / numérique (A/N)
La conversion analogique numérique implique d’abord un échantillonnage qui consiste à représenter un signal continûment variable par une séquence discrète de valeurs, suivie d'une opération de quantification qui consiste à remplacer la valeur exacte analogique de l'échantillon par la plus proche valeur approximative extraite d’un ensemble fini de valeurs discrètes. Cette valeur est comprise entre deux valeurs limites qui fixent la plage de conversion.
Chaque nombre xk, représente un ensemble de valeurs analogiques contenues dans une intervalle de largeur Dk appelé pas de quantification. Lorsque la plage de conversion est subdivisée en pas
15

de quantification égaux, on parle de quantification uniforme.
Un signal analogique est une fonction x(t) d'amplitudes continues, définit sur t continue.
Un signal numérique est une tableau x(n) d'amplitudes discrètes définit pour n valeurs discrètes. Le passage de x(t) à x(n) ajout un bruit : le bruit de quantification mesuré par son énergie.
Fig. 2.1 Enregistrement numérique d’un signal de parole.
La figure ci-dessus montre que le son émis par le locuteur, il est capté par un microphone. Le signal vocal est ensuite numérisé à l’aide d’un convertisseur analogique-numérique, en définissant la fréquence de coupure du filtre de garde, la fréquence d’échantillonnage, le nombre de bits et le pas de quantification.
2.2.1 Principe de l’échantillonnage
L'échantillonnage, première étape d'une conversion analogique-numérique, est défini par sa fréquence : la fréquence d'échantillonnage (exprimée en Hertz : Hz) fe qui est l'inverse de l'intervalle de temps entre chaque prélèvement sur le signal analogique.
Le théorème de l'échantillonnage du mathématicien Shannon stipule que la fréquence d'échantillonnage doit être au moins égale au double de la fréquence la plus élevée du signal à transmettre. Donc pouvoir représenter numériquement un signal de fréquence maximale fmax, on doit l'échantillonner à un taux qui vaut au moins le double de cette fréquence:
fe > 2 fmax
Cette fréquence d'échantillonnage a été déterminée à 8000 Hz par l'UIT (Union International des Télécommunications) pour la transmission d'un signal vocal à travers le réseau téléphonique limité à une bande de 300-3400 Hz.
x
16

Fig. 2.2 Exemple d’échantillonnage d’un signal.
fA = 8000 Hz signifie que le signal de fréquence vocale est exploré 8000 fois par seconde. L'intervalle entre deux échantillons successifs du même signal de fréquence vocale (période échantillonnage = TA) se calcul comme suit :
sHzfTA
A µ125800011 ===
La conversion du signal vocal se fait par l'intermédiaire d'un filtre passe-bas et d'un commutateur électronique. Le filtre passe-bas limite la bande de fréquences qui doit être transmise, il élimine les fréquences dont les valeurs sont plus élevées que la moitié de la fréquence d'échantillonnage. Chaque 125 us, le commutateur électronique mesure la valeur du signal de fréquence vocal (échantillon).
Fig. 2.3 Elaboration d'un signal vocal.
17

2.3 La quantification d’un signal échantillonné Chacun des échantillons prélevés peut prendre en principe une infinité de valeurs du fait de la nature analogique du signal. Toutefois, la précision avec laquelle ces amplitudes doivent et peuvent être connues est nécessairement limitée par toutes sortes de considérations pratiques. On est amené à remplacer la valeur exacte de l'échantillon par la plus proche valeur approximative tirée d'un assortiment fini de valeurs discrètes: il y a quantification.
La quantification permet de donner une valeur approximative à un signal instantané exacte par la valeur la plus voisine triée d'un assortiment fini de q éléments entiers (valeurs discrètes).
Fig. 2.4 La quantification
La représentation numérique d'un échantillon utilise un nombre fini de bits. Avec n bits, on peut représenter 2n valeurs différentes.
La quantification a pour effet d'arrondir l'amplitude de chaque échantillon à l'une de ces 2n valeurs. Ainsi on peut dire que le nombre de bits de quantification détermine donc la précision en amplitude ou la dynamique de la conversion, alors que la fréquence d'échantillonnage détermine la précision temporelle de la conversion.
2.3.1 La quantification uniforme
La quantification fait correspondre à chaque amplitude mesurée un nombre entier codé en binaire. Pour la quantification uniforme on prend une plage de valeurs à quantifier s'étendant sur L volts, avec un pas de quantification de S = L/2n.
Pour que le signal soit fidèlement reproduit, on doit non seulement l'échantillonner à un taux suffisant mais aussi avec un nombre suffisant de bits pour pouvoir rendre l'amplitude de chaque valeur la plus précise possible. Si les valeurs sont représentées dans un ambitus trop faible, les valeurs quantifiées diffèrent significativement des valeurs échantillonnées et le signal est entaché d'un bruit de quantification, comme illustré sur la figure ci-dessous.
18

Fig. 2.5 Illustration de la quantification uniforme
On réalise facilement que si le nombre de niveaux de quantification est élevé, alors le signal codé ressemble au signal non codé. Le codage s'appelle, en terme technique, la quantification du signal, et l'erreur sur le signal le bruit de quantification. Le bruit de quantification est inversement proportionnel au nombre de pas de quantification du codeur / décodeur.
La solution à ce problème est évidemment de s'assurer que les signaux sont échantillonnés avec un nombre suffisant de bits pour chaque prélèvement mais ceci au prix d’une augmentation du débit.
Fig. 2.6 Résultats de la quantification d’un signal sur différent niveaux
19

Le signal quantifié n'est pas exactement égal au signal échantillonné. La différence entre les deux peut être vue comme un bruit qui s'ajoute au signal lors du processus de quantification. La puissance de ce bruit dépend évidemment du pas de quantification. Plutôt que la puissance absolue du bruit, on évalue généralement le rapport signal sur bruit de quantification. Dans le cas d'une quantification uniforme à n bits, ce rapport (en décibel) est donné par (S/N)n = 4.8+6n
Le signal de parole présente théoriquement une densité de probabilité proche d’une loi de probabilité gaussienne, ainsi la valeur moyenne des échantillons est voisine de zéro et les faibles valeurs sont prédominantes.
De là on conclu que la quantification uniforme mal adaptée aux signaux de faible amplitude, le signal quantifié sera tronqué (très grande perte d’information).
Or, une bonne distribution des niveaux (quantification non uniforme) favorise les signaux de faibles amplitudes, le signal quantifié se rapprochera mieux du signal original.
2.3.2 La quantification non uniforme
Le but de cette méthode est de déterminer la loi optimale de quantification qui rend le rapport signal/bruit indépendant de l’amplitude du signal. Autrement dit, de réduire ou d’éliminer la dépendance entre l’amplitude du signal et le bruit qui en résulte. Sachant que c’est la densité de probabilité qui définit l’amplitude.
Pour remédier à l'inconvénient représenté par la quantification uniforme, le système logarithmique rend le rapport signal/bruit totalement indépendant de l'amplitude du signal émis (l'intensité sonore de la voix du locuteur), et cela en éliminant carrément la densité de probabilité du rapport signal/bruit.
Pour déterminer la loi optimale de quantification qui rend le rapport signal sur bruit indépendant de l’amplitude du signal, on considère f une loi de transformation du signal d’entrée tel que y=f(x) ou y sera finalement quantifié linéairement. Alors, pour exprimer la loi f, on peut écrire :
( ) 2y dy f x avec yx dx N
∆= = ∆
∆=
Où N est le nombre d’intervalles. On peut alors exprimer chacune des longueurs ∆i des intervalles qui sont associés par la loi f à la longueur ∆ des intervalles de quantification linéaire :
( )2 /
/iy Nx
f x dy dx∆
∆ = ∆ = =
La puissance totale du bruit (ou l’erreur) de quantification de cette loi s’écrit alors, en approchant la somme discrète par une somme continue :
20

( ) ( )2 2
, 12 12
mm
m m
XXi i
b totX X
P p e p x dx− −
∆ ∆= ≈∑ ∫
Il vient alors pour le rapport «signal/bruit» dBRSB avec 2nmX = ∆ :
( )
( )
( )
( )
2
2
2
22
1 212
1 2
12
m
m
m
m
m
m
m
m
X
XsdB
Xb
X
X
X
X
X
x p x dxPRSBP dx p x dx
N dy
x p x dx
dx p x dxN dy
−
−
−
−
= =⎛ ⎞⎜ ⎟⎝ ⎠
=⎛ ⎞⎛ ⎞
⎜ ⎟ ⎜ ⎟⎝ ⎠ ⎝ ⎠
∫
∫
∫
∫
Finalement, pour que RSBdB soit indépendant de l’amplitude du signal, il suffit d’écrire:
( )2
2,
dxp x x k avec kdy
dxsoit x kdy
⎛ ⎞∀ = ⎜ ⎟
⎝ ⎠
=
∈ℜ
La solution de cette équation différentielle va s’écrire :
00
00
ln 0
ln 0
xy y k pour xx
xy y k pour xx
− = >
−− = <
Soit, pour tout x, y = 1 + k ln |x| : on trouve une loi logarithmique.
Fig. 2.7 Tracé de la loi de compression
21

Utilisée effectivement en télécommunications, cette loi est définie de façon différente en Europe (Loi A) et aux Etats-Unis (Loi µ), ce qu’on va définir par la suite.
2.4 Le codage PCM
Le codage par modulation d’amplitude (Pulse Coded Modulation) appelé Modulation d’Impulsion et Codage (MIC) en français réalise une quantification de chaque échantillon du signal sur un certain nombre de bits. Le nombre de niveaux de quantification est une puissance de 2 de sorte que toutes les valeurs sont codées par un mot binaire chacun.
Différentes lois de quantification sont utilisées. Une loi uniforme est utilisée pour coder la musique, tandis que une loi logarithmique est utilisée pour coder la parole.
2.4.1 Le codage PCM uniforme
Le codage PCM uniforme sert de référence pour évaluer les gains de compression des autres types de codeurs du fait qu’il se contente de coder le signal sans le compresser. Il est utilisé dans le codage des CD de manière à couvrir les exigences de l’oreille humaine. Ainsi, la bande passante de l’oreille est [20Hz, 20kHz] et sa dynamique est de 120 dB. Le codage haute fidélité des CD est basé sur ces résultats, il a pour fréquence d’échantillonnage 44.1kHz et une dynamique de 96dB, les mots binaires font 16 bits sachant q’un bit augmente la dynamique de 6dB.
2.4.2 Le codage PCM Logarithmique
Le PCM logarithmique est basé sur un échantillonnage préalable, suivi d'une quantification non uniforme privilégiant les amplitudes faibles relativement aux grandes amplitudes, respectant ainsi la distribution gaussienne du signal de parole.
Un codage selon une loi uniforme entraîne une quantification à 12 bits (ou 4096 niveaux). En relation avec la fréquence d'échantillonnage nécessaire, qui est de 8 kHz, ceci entraîne un débit de 96 kbit/s pour une simple conversation téléphonique; ceci est jugé excessif. Le codage non uniforme utilisé par PCM permet de réduire ce débit à 64 kbit/s, et corollairement, se contente de 8 bit (ou 256 niveaux) pour le codage.
L'Union Internationale des Télécommunications a défini deux lois de quantification:
- La loi µ, utilisée aux Etats-Unis et au Japon. - La loi A, utilisée en Europe.
La loi A est postérieure à la loi µ, et est légèrement plus facile à implémenter. La loi µ en revanche est légèrement meilleure au niveau du rapport signal/bruit pour les faibles amplitudes. Ces deux lois qui peuvent sembler identique sont incompatibles: il n'est pas possible de coder selon la loi A et de décoder selon la loi µ. Ceci interdit toute compatibilité directe entre les systèmes européens et américains.
La loi de compression en usage aux USA est la loi µ, définie par :
22

( ) ( ) ( )maxmax
ln 1 sgn
ln 1 255
xµ
xF x x x
µpour µ
⎛ ⎞+⎜ ⎟
⎝ ⎠=+
=
La loi A, utilisée en Europe est définie par :
( )( ) ( )
( )
max
maxmax
max
1 01 ln A
1 ln1 1
1 ln A
Avec A 87.56
A x A xsign x
A xF x A x
x A xx
A x
⎧≤ ≤⎪ +⎪
⎪= ⎛ ⎞⎨+ ⎜ ⎟⎪
⎝ ⎠⎪ ≤ ≤⎪ +⎩
=
Fig. 2.8 Tracé des deux lois de quantification logarithmique (A et mu)
En pratique, on réalise une approximation de la loi logarithmique, cette dernier dite « méthode des treize segments ». Pour cela, on découpe la courbe y = f(x) en segments comme suit :
– On coupe horizontalement l’intervalle en 16 intervalles de même longueur. – On coupe verticalement l’intervalle en 7 intervalles de longueur croissants en puissance de deux. – On relie par une courbe les points d’intersection coupes (horizontale et verticale) pour former 6 segments positifs et 6 négatifs en plus du segment initial (zero).
– La construction est bien entendue symétrique par rapport à l’origine.
On obtient finalement une approximation par morceau comportant 13 segments, compte tenu de la construction à proximité de l’origine.
23

Fig. 2.9 Courbe caractéristique à 13 segments.
Les 128 intervalles de quantification positifs et les 128 intervalles négatifs (128+128=256=28) sont représentés à l'aide d'un code binaire à 8 positions ; les mots de code ont donc 8 bits. Le bit n°1 (poids fort) de tous les mots de code à 8 bits qui représentent les intervalles de quantification positifs est toujours à "1" ; le bit n°1 de tous les signaux de caractère qui représentent les intervalles de quantification négatifs étant toujours à "0". Selon les recommandations de l'UIT G.711 et G.713, les bits n°2, 4, 6 et 8 de chaque mot de code à 8 bits doivent être inversés avant d'être transmis (code ninini, n = non inversé, i = inversé) afin d'éviter une longue suite de zéros.
24

Fig. 2.10 Codification d’un échantillon
2.5 Conversion Numérique/Analogique
Le processus inverse de la conversion A/N doit être réalisé dans la conversion N/A. Un filtre pas-bas suivra le convertisseur. Les mêmes relations doivent être vérifiées (fréquence de coupure plus petite que la moitié de la fréquence d’échantillonnage).
2.6 Conclusion
Les conversions A/N et N/A concernent des procédures bien étudiées et populaires. Aucune avance significative ne s’est produite à part l’amélioration et l’économie des composants électroniques et l’augmentation de la fréquence. À cet égard, on peut noter de nouvelles techniques qui sont apparues pour la reconstruction de signaux de bande limitée.
25

Chapitre 3
La production de la parole et son traitement numérique
3.1 Introduction
La parole peut être décrite comme le résultat de l’action volontaire et coordonnée d’un certain nombre de muscles. Cette action se déroule sous le contrôle du système nerveux central qui reçoit en permanence des informations par rétroaction auditive.
Aussi il est difficile de décrire les phénomènes liés aux sons, et à leur propagation, sans évoquer le fonctionnement de nos propres organes qui nous permettent d’émettre et d’entendre des sons. Il s’agit bien sûr d’une description globale, mais qui met en évidence notre perception sonore.
En effet, quelque soit les démonstrations théoriques et techniques, notre perception sonore s’accompagne de critères, comme aigu - grave, fort - faible, harmonieux, etc….
3.2 La production des sons de la parole humaine
L’appareil de production de la parole humaine, premier outil de communication, est composé de plusieurs organes qui fonctionnent en même temps pour produire des sons.
Fig. 3.1 Appareil phonatoire
L'appareil respiratoire fournit l'énergie nécessaire lorsque l'air est expiré par la trachée-artère. Au sommet de celle-ci se trouve le larynx où la pression de l'air est modulée avant d'être expulsé par le conduit vocal qui s'étend du pharynx jusqu'aux lèvres. Le larynx est un ensemble de muscles et de cartilages mobiles qui entourent une cavité située à la partie supérieure de la trachée. Les cordes vocales sont en fait deux lèvres symétriques placées en travers du larynx ; ces lèvres
26

peuvent fermer complètement le larynx et, en s'écartant, déterminer une ouverture triangulaire appelée glotte. L'air y passe librement pendant la respiration, pendant la voix chuchotée, et aussi pendant la phonation des sons sourds ou non voisés.
Les sons voisés résultent au contraire d'une vibration périodique des cordes vocales; des impulsions périodiques de pression sont ainsi appliquées au conduit vocal qui est un ensemble de cavités situées entre la glotte et les lèvres. Il peut être considéré comme une succession de tubes ou cavités acoustiques de sections diverses. Les sons voisés résultent donc de l'excitation du conduit vocal par des impulsions périodiques de pression liées aux oscillations des cordes vocales.
Fig. 3.2 Les segments non voisé et voisé d’un signal de parole
De là on considère que la voix humaine est le résultat d'une modification continuelle par le conduit vocal du signal émis par trois types de sources sonores:
Une source voisée, qui correspond à la vibration des cordes vocales et se présente sous la forme d'un signal quasi-périodique, une source fricative, qui correspond aux turbulences engendrées par les rétrécissements en certains points du conduit buccal (lèvres, langue-palais, glotte), et une source plosive qui correspond au bruit d'explosion engendré par la fermeture puis l'ouverture brusque du conduit buccal avec les lèvres ou la langue.
Fig. 3.3 Spectres de la parole
27

Sur la figure ci-dessus, on peut observer le spectre de l'onde émise par les cordes vocales avant et après filtrage par le conduit vocal.
La parole se distingue des autres sons par des caractéristiques acoustiques ayant leurs origines dans les mécanismes de production. Les sons de parole sont produits soit par les vibrations des cordes vocales (source de voisement), soit par l'écoulement turbulent de l'air dans le conduit vocal, où soit lors du relâchement d'une occlusion de ce conduit (source de bruit).
3.2.1 La phonation
Dans le processus de communication parlée, pour une langue donnée, les sons permettent de distinguer les différentes unités de signification du langage. L'unité élémentaire d'un son permettant la distinction des différents mots est le phonème.
La notion de phonème ne tient compte que des caractéristiques acoustiques qui permettent une distinction entre des mots. On ne tient pas compte des phénomènes physiques de production du son, tant que la différence d'articulation (fonction du dialecte, de la cadence d'élocution, du contexte) ne permet pas de distinguer des mots différents.
Il est intéressant de grouper les sons de parole en classes phonétiques, en fonction de leur mode articulatoire. On distingue généralement trois classes principales : les voyelles, les consonnes, les semi-voyelles et les liquides.
Les voyelles diffèrent de tous les autres sons par le degré d’ouverture du conduit vocal. Si le conduit vocal est suffisamment ouvert pour que l’air poussé par les poumons le traverse sans obstacle, il y a production d’une voyelle. Le rôle de la bouche se réduit alors à une modification du timbre vocalique.
Si, au contraire, le passage se rétrécit par endroit, ou même s’il se ferme temporairement, le passage forcé de l’air donne naissance à un bruit : une consonne est produite. La bouche est dans ce cas un organe de production à part entière. Exemple de fermeture par les lèvres pour [b] et [p], par les dents pour [t] ou [d] ou bien par le palais pour [k] ou [g].
D'autres aspects de la parole permettent de distinguer les différentes significations. Des phénomènes comme la prosodie, la durée ou l'intensité des phonèmes, et le timbre de la voix permettent à l'auditeur d'identifier le locuteur ou de se faire une idée sur son attitude.
Cette multiplication des informations complique le traitement de la parole, mais l'être humain en tire sans doute des avantages pour percevoir le message, particulièrement lorsque le signal acoustique est bruité.
3.2.2 Les formants
Un formant est un « pic » d’amplitude dans le spectre d’un son composé de fréquences harmoniques, inharmoniques et/ou du bruit. Ci-contre est représenté un formant centré sur la fréquence 1 kHz.
28

Fig. 3.4 Pics formantiques de différentes voyelles
Les pics formantiques sont caractéristiques des sons vocaux voisés (voyelles chantées, parlées ou murmurées) et de plusieurs instruments de musique.
Une voyelle est produite en imposant une position particulière aux différentes articulateurs (lèvres, langue, ...).
Le conduit vocal présente des fréquences de résonance, ce qui se manifeste dans le spectre en l'apparition de pics formantiques.
La position des formants est indépendante de la hauteur (fréquence fondamentale) et est caractéristique d'une voyelle particulière, comme l'illustre la figure ci-dessus donnant le spectre de trois sons voisés ("I", "A", "OU"). Mais il faut aussi préciser que la position des formants pour une même voyelle peut différer d'un locuteur (ou chanteur) à l'autre.
Les analyses spectrales rapportent aussi que de quatre à cinq formants importants sont présents dans tous les spectres de voix.
3.3 Le son vue comme variation de la pression atmosphérique:
Le son est un phénomène perceptuel qui se produit lorsqu’un objet entre en vibration mécanique et cause une variation de la pression atmosphérique dans l’air entourant cet objet. Les variations de pression se propagent dans l’air (à la vitesse du son) et, le cas échéant, atteignent l’oreille de l’auditeur.
29

Fig. 3.5 Son = Variation de la pression de l’air dans le temps
La nature de ces vibrations peut être périodique ou non-périodique, ou encore une combinaison de ces deux natures. Les variations périodiques suivent un motif particulier qui se répète dans le temps et donnent, en général, une sensation de hauteur (son voisé) alors que les variations non-périodiques donnent une sensation de bruit (son non voisé). Il est a noter que les sons naturels sont presque toujours semi-périodiques, c’est-à-dire qu’ils correspondent à une combinaison de variations périodiques et non-périodiques. Ces variations se nomment communément forme d’onde. La durée du motif récurrent de la forme d’onde est la période. Le nombre de fois que cette période se répète en une seconde nous donne sa fréquence fondamentale. Lorsque le nombre de périodes par seconde décroît, la sensation de hauteur du son baisse et vice-versa. L’amplitude (ou l’ambitus) de la variation de la pression atmosphérique donne la sensation de volume (ou intensité, force) au son.
3.3.1 Les sons purs et les sons complexes
L’intensité du son est liée a la pression de l’air en amont du larynx; sa hauteur est fixé par la fréquence de vibration des cordes vocales, appelée fréquence du fondamental ou pitch.
La fréquence du fondamental peut varier:
- De 80 à 200 Hz (5 ms. à 12.5 ms.) pour une voix masculine. - De 150 à 450 Hz (2.22 ms. à 6.66 ms.) pour une voix féminine. - De 200 à 600 Hz (1.66 ms. à 5 ms.) pour une voix d’enfant.
Si un son ne contient qu'une seule fréquence, on le dit sinusoïdal ou son pur. En général, les sons acoustiques contiennent des fréquences autres que la fréquence fondamentale. Celles-ci s'additionnent à la fréquence fondamentale pour former un son complexe, ce qui donne lieu à la perception du timbre d'un son. Les fréquences additionnelles sont appelées harmoniques ou partiels selon qu'elles sont des multiples entiers de la fréquence fondamentale ou pas.
3.4 Modes de représentation graphique du son
3.4.1 Le domaine temporel
La figure 3.5 ci-dessus montre une représentation d'un son semi-périodique dans le domaine temporel. Lorsque la ligne de la fonction est en haut du graphique, la pression atmosphérique est à son maximum (compression) et lorsqu'elle est au bas du graphique, elle est au minimum (raréfaction). L'amplitude de la forme d'onde est donc la quantité de variation de la
30

pression atmosphérique. En général, l'amplitude se calcule à partir de l'axe 0 (position d'équilibre ou valeur moyenne des variations) jusqu'au point d'amplitude maximum de la forme d'onde.
3.4.2 Le domaine fréquentiel
La représentation fréquentielle permet d'afficher les caractéristiques spectrales d'un signal audio. Les figures ci-dessous donnent les représentations temporelle (forme d'onde) et fréquentielle (spectre) d'une onde sinusoïdale et d'une onde en dent de scie.
Fig. 3.6 Représentation graphique de deux signaux
Dans les deux cas, comme la variation est périodique, on obtient un spectre de raies. La représentation fréquentielle permet de voir le contenu fréquentiel de la forme d'onde (pour une période de cette forme d'onde). Dans cette représentation, l'amplitude de chaque raie indique l'amplitude de chacune des fréquences présentes dans le signal. La forme d'onde sinusoïdale ne contient qu'une seule fréquence, alors que l'onde en dent de scie en contient un très grand nombre.
La représentation spectrale tri-dimensionnelle (amplitude/fréquence/temps) est une expansion de la représentation fréquentielle qui permet de montrer le profil de l'évolution dans le temps de l'amplitude de chacune des composantes fréquentielles du signal.
31

Fig. 3.7 Représentation spectrale tri-dimensionnelle
(Amplitude - Fréquence - Temps)
On peut dire qu’un signal vocal met en évidence des traits acoustiques qui sont : sa fréquence fondamental, son énergie, et son spectre. Chaque trait acoustique est lui même lié à une grandeur percéptuelle : pitch, intensité, et timbre.
3.5 L’analyse du signal vocal
Le signal vocal est numérisé à l’aide d’un convertisseur analogique/numérique (voir chapitre 2). Comme la voix humaine est constituée d’une multitude de sons, souvent répétitifs, le signal peut être compressé pour réduire le temps de transmissions par un canal quelconque.
On présente deux groupes de méthodes.
Un premier groupe de méthodes est constitué par les méthodes spectrales. Elles sont fondées sur la décomposition fréquentielle du signal sans connaissance a priori de sa structure fine. La plus utilisée est celle utilisant la transformée de Fourier rapide (Fast Fourier Transform - FFT). Tout son est la superposition de plusieurs ondes sinusoïdales. Grâce à la transformée de Fourier rapide, on peut isoler les différentes fréquences qui le composent. On obtient ainsi une répartition spectrale du signal (Fig. 3.8).
Fig. 3.8 Spectre obtenu par Transformée Rapide de Fourier (FFT)
32

En appliquant la transformée de Fourier rapide à un son complexe et en la répétant de nombreuses fois, on dresse un graphique donnant l’évolution de l’amplitude et de la fréquence en fonction du temps. On obtient ainsi une empreinte caractéristique du son.
Un deuxième groupe de méthodes est constitué par les méthodes d’identification. Elles sont fondées sur une connaissance des mécanismes de production (ex : le conduit vocal). La plus utilisée est celle basée sur le codage prédictif linéaire (appelée LPC). L’hypothèse de base est que le canal buccal est constitué d’un tube cylindrique de section variable. L’ajustement des paramètres de ce modèle permet de déterminer à tout instant sa fonction de transfert. Cette dernière fournit une approximation de l’enveloppe du spectre du signal à l’instant d’analyse.
Fig. 3.9 Spectre lissé obtenu par prédiction linéaire (LPC)
On repère alors aisément les fréquences formantiques, c’est-à-dire les fréquences de résonance du conduit vocal. En effet, elles correspondent au maximum d’énergie dans le spectre. En répétant cette méthode plusieurs fois, on obtient l’empreinte du signal, comme le montre la figure ci-dessous.
Fig. 3.10 Empreinte d’un signal de parole
3.6 L’audition et la perception
Dans le cadre du traitement de la parole, une bonne connaissance des mécanismes de l’audition et des propriétés perceptuelles de l’oreille est aussi importante qu’une maîtrise des mécanismes de production. En effet, tout ce qui peut être mesuré acoustiquement ou observé par la phonétique articulatoire n’est pas nécessairement perçu.
Notre système d’audition présente des performances remarquables. Nous sommes capables d’entendre des sons ayant une plage de fréquences allants de 20Hz à 20kHz environ.
Les ondes sonores sont recueillies par l’appareil auditif, ce qui provoque les sensations auditives. Ces ondes de pression sont analysées dans l’oreille interne qui envoie au cerveau l’influx
33

nerveux qui en résulte; le phénomène physique induit ainsi un phénomène psychique grâce à un mécanisme physiologique complexe.
Des vibrations acoustiques en dehors de la zone audible sont également repérables. Il s’agit :
Des infrasons : qui sont des sons de fréquences inférieures aux fréquences dites audibles.
Des ultrasons : qui sont des vibrations trop rapides pour pouvoir être perceptibles par notre système auditif.
Des micro sons :qui sont des sons de fréquences audibles mais d'intensité trop faible pour être perçu par notre cerveau.
Remarquons pour terminer que ce qui est perçu n’est pas nécessairement compris. Une connaissance de la langue interfère naturellement avec les propriétés psychoacoustiques de l’oreille. En effet, les sons ne sont jamais prononcés isolément, et le contexte phonétique dans lequel ils apparaissent est lui aussi mis à contribution par le cerveau pour la compréhension du message. Ainsi, certains sons portent plus d’information que d’autres, dans la mesure où leur probabilité d’apparition à un endroit de la chaîne parlée est plus faible, de sorte qu’ils réduisent l’espace de recherche pour les sons voisins. Les sons sont organisés en unités plus larges, comme les mots, qui obéissent eux-mêmes à une syntaxe et constituent une phrase porteuse de sens. Par conséquent, c’est tout notre savoir linguistique qui est mis à contribution lors du décodage acoustico-phonétique.
3.7 Modélisation acoustique de la parole
Pour réduire le débit tout en conservant une qualité suffisante ou pour améliorer la qualité pour un débit imposé, il faut chercher les paramètres pertinents qui constituent le signal de parole. Pour cela un modèle simplifié du système phonatoire ne retenant que les paramètres les plus significatifs du signal est recherché
Une modélisation précise du conduit vocal et de la source d’excitation est nécessaire pour produire respectivement un signal intelligible et naturel. Des études menées dans le but de définir un modèle produisant un signal proche du signal de parole ont permis de décrire un modèle de production linéaire.
Réaliser un modèle exploitable de production de la parole humaine au niveau du canal vocal, est le premier pas d’une analyse du signal de parole. De l’étude acoustique, on peut déduire que le signal de parole est produit par l’excitation du canal vocal humain composé du conduit buccal, nasal, ainsi que du pharynx.
On modélise un conduit vocal par une succession de tubes acoustiques de sections diverses qui peuvent être représenté par un filtre linéaire à paramètre variable dans le temps.
34

Fig 3.11 Modélisation de la parole
Dans une grande majorité de codeurs, la production de parole est modélisée par une opération de filtrage, où une source sonore excite un filtre censé représenter le conduit vocal. Physiologiquement la source et le filtre ne sont pas séparés. Cependant, ils seront considérés comme tels lors de l’analyse des signaux de parole.
Durant la production de signaux voisés, le canal vocal est excité par une série d’impulsions glottales quasi périodique générées par les cordes vocales. L’excitation pour des signaux non-voisés est un bruit blanc aléatoire. Ces hypothèses, vérifiées en pratiques conduisent à une modélisation simple mais efficace du mécanisme de production de la parole.
Fig. 3.12 Synthèse de la parole à 2 états d’excitation
Un outil particulièrement adapté à l’investigation de ce type de modélisation est l’analyse spectrale à court terme du signal.
A partir de ce modèle de production de parole, une technique de synthèse a été décomposée en trois éléments (Fig. 3.13) : un signal d’excitation, un filtre de corrélation court terme (LPC : Linear Predictive Coding) dont la fonction est de modéliser l’enveloppe spectrale du signal et un
35

filtre de corrélation long terme (LTP : Long Term Predictor) dont la fonction est de générer la périodicité des sons voisés.
Fig. 3.13 Synthèse d’un signal de parole par prédiction linéaire
3.8 Conclusion
La parole est représenté par un signal vocal qui met en évidence des traits acoustiques qui sont : sa fréquence fondamental, son énergie, et son spectre. Chaque trait acoustique est lui même lié à une grandeur percéptuelle : pitch, intensité, et timbre.
De là on définit la constitution de la parole par des sons qui sont produits soit par les vibrations des cordes vocales (source de voisement), soit par l'écoulement turbulent de l'air dans le conduit vocal.
Donc on peut dire l’être humain émis des sons voisés et non voisés. Les sons voisés se constituent par des impulsions périodiques de pression liées aux oscillations des cordes vocales, par contre les sons non voisés sont dû à une phonation des sons sourds, ou chuchotés (source de bruit).
Si on veut traiter de la parole, une modélisation précise du conduit vocal et de la source d’excitation est nécessaire pour produire respectivement un signal intelligible et naturel.
On modélise un conduit vocal par une succession de tubes acoustiques de sections diverses qui peuvent être représenté par un filtre linéaire à paramètre variable dans le temps
Dans une grande majorité de codeurs, la production de parole est modélisée par une opération de filtrage, où une source sonore excite un filtre censé représenter le conduit vocal.
36

Chapitre 4
Analyse paramétrique du signal de parole
4.1 Introduction
Dans ce chapitre on présentera une base sur la paramétrisation du signal de parole : c’est l'analyse par prédiction linéaire. Comme la prédiction linéaire se réfère à une variété des formulations du problème pour modéliser les formes d'onde de parole, on détaillera les formulations de base d'analyse par prédiction linéaire et on examinera les ressemblances et les différences parmi elles.
4.2 Les fondements en traitement numérique du signal
4.2.1 Les systèmes numériques
Un système numérique (Fig. 4.1) reçoit en entrée une séquence de nombres x0, x1, x2, …, notée plus simplement x(n), et produit en sortie une séquence de nombres y(n) obtenue à partir de l’entrée après application d’un algorithme. On dit que le système est stable si, lorsqu’on lui présente une entrée finie, il produit une sortie finie.
Fig. 4.1 Système numérique
Les caractéristiques les plus importantes d’un système numérique sont la linéarité et l'invariance dans le temps.
Un système est linéaire si :
• l'entrée x(t) produit une sortie y(t), alors quand on applique une entrée k.x(t), la sortie sera k.y(t). Si deux entrées x1(t) et x2(t) engendrent deux sorties y1(t) et y2(t), alors αx1(t)+ βx2(t) engendrera αy1(t)+ βy2(t).
Un système est invariant dans le temps si :
• une translation de l'entrée ( x(t) → x(t-t0) ) se traduira par une même translation dans le temps de la sortie ( y(t) → y(t- t0) ).
37

Fig. 4.2 Système numérique linéaire et invariant
4.2.2 Systèmes récursifs – Systèmes non récursifs
D’une manière générale, les systèmes numériques linéaires et invariants (SLI) peuvent être décrits par des équations aux différences finies, linéaires et à coefficients constants, de la forme :
1 0( ) ( ) ( )
N M
i ii i
y t y t i x t ia b= =
+ =− −∑ ∑ (1)
Une telle équation exprime le fait que la valeur de la sortie y(t) à l’instant courant est une combinaison linéaire des N sorties précédentes, de l’entrée courante, et des M entrées précédentes.
De tels systèmes sont dits récursifs étant donnée le caractère récursif de l’équation correspondante : il faut avoir déjà calculé toutes les sorties précédentes pour pouvoir calculer la sortie courante.
Un cas particulier est celui des systèmes dont les valeurs de sortie ne dépendent que de l’entrée courante, et des M entrées précédentes :
0( ) ( )
M
ii
y t x t ib=
= −∑ (2)
De tels systèmes sont dits non récursifs.
L’ordre d’un SLI numérique est donné par le degré de la récursivité de l’équation aux différences finies associée : N.
On appelle filtre numérique un système numérique linéaire et invariant. On parlera donc dans la suite de filtre récursif et de filtre non récursif.
Il est possible de visualiser l’équation de récurrence associée à un filtre numérique, sous la forme d’une structure (ou graphe de fluence) faisant apparaître les éléments de base suivants :
La structure associée est donnée à la figure 4.3 :
38

Fig. 4.3 Exemple de structure d’un filtre numérique récursif
On constate que le caractère récursif ou non récursif d’un filtre numérique est lié à la présence ou à l’absence de boucles dans sa structure.
4.2.2.1 Réponse impulsionnelle
Si les hypothèses de linéarité et d'invariance temporelle sont vérifiées, on peut caractériser le système par sa réponse impulsionnelle soit h(t). C'est le signal qu'on obtient en sortie si on applique en entrée l’impulsion ``de Dirac'' δ(t).
(δ(t) =1 pour t=0 et nulle partout ailleurs)
δ(t) h(t) SLI numérique
Fig. 4.4 Réponse impulsionnelle
Le calcul de la réponse impulsionnelle d’un SLI numérique est immédiat : il suffit d’effectuer la récurrence numérique sous-jacente. De là, on constate que la réponse impulsionnelle d’un filtre récursif est une séquence illimitée de valeurs non identiquement nulles (même si le filtre est stable), puisque chaque valeur de sortie dépend des valeurs de sorties précédentes. Par contre, la réponse impulsionnelle d’un filtre non récursif est donnée par la suite de ses coefficients, et constitue donc une séquence qui s’annule après un nombre fini de valeurs. Il s’ensuit que les filtres récursifs sont appelés filtres à réponse impulsionnelle infinie (RII) et que les filtres non récursifs sont dits à réponse impulsionnelle finie (RIF).
39

4.2.3 Modèle autorégressifs
Soit un signal x(t), qu'on suppose être stationnaire et de moyenne nulle. On en calcule les coefficients de corrélation pour τ = 0,…,p:
( ) ( ) ( )r E x t x tτ τ= + (3)
Dans le cas de l'analyse du signal de parole, cette hypothèse de stationnarité n'est pas vérifiée et on considère que x(t) est connu sur un intervalle de temps [0,…,T-1] et que x(t) est nul en dehors de cet intervalle. On calcule alors les coefficients de corrélation r(τ) de la manière suivante
∑−
=
+=1
0)()()(
T
ttxtxr ττ (4)
On cherche à trouver les coefficients ai d'un filtre non récursif de degré p, dont la fonction de transfert Ap(z) est donnée par :
( )
0( )
pp i
p ii
z aA z −
=
= ∑ (5)
Où a0(p) = 1 dont l'entrée est x(t) et la sortie εp(t). On cherche à minimiser la variance de εp(t)
qu'on nommera σ2(p)
⎪⎭
⎪⎬
⎫
⎪⎩
⎪⎨
⎧
== ⎥⎦
⎤⎢⎣⎡∑ −
p
i
pi itxaEp
0
)( )(2
2
)(σ (6)
εp(t) peut être interprétée comme l'erreur de prédiction entre le signal x(t) et sa prédiction linéaire calculée à partir des échantillons précédents.
∑=
= −p
ip
i itxatx0
)( )()(ˆ (7)
En développant le carré
⎥⎦
⎤⎢⎣
⎡−−= ∑∑
==
p
k
p
k
p
i
p
ipktxitxEaa
0
)(
0
)(2
)()()(σ (8)
∑ ⎥⎦⎤
⎢⎣⎡∑ −=
= =
p
i
p
i
pkp kira
0 0
)(2)( )(σ (9)
En dérivant cette forme quadratique par rapport aux paramètres recherchés a1(p),…,ap
(p), on obtient le minimum lorsque sont satisfaites les p équations suivantes, écrites sous une forme matricielle
40

⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
−−
−−
0...00
)0(...)2()1()(...............
)2(...)0()1()2()1(...)1()0()1(
)(
)(
1
)(
0
...a
aa
p
p
p
p
rprprpr
prrrrprrrr
(10)
Lorsque ces p équations sont vérifiées, la formule (9) donnant la valeur de la variance se simplifie : lorsque i # k
0)(0
)( =∑ −=
p
kkira p
k (11)
et
σ 2)(
)(0
)( pp
k
p
kkira =∑ −
=
(12)
En combinant cette équation avec l'équation matricielle (10), on obtient
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−−
−−
0
00
...)0()2()1()(
)2()0()1()2()1()1()0()1(
)()2()1()0(
...
2)(
)(
)(2
)(1
)(0
...
...............
...
...
...σ p
pp
p
p
p
a
aaa
rprprpr
prrrrprrrrprrrr
(13)
Ces équations sont connues sous le nom d'équations de Yule Walker. La matrice des coefficients d'autocorrélation, Rp qui y apparaît a une forme bien particulière : tous ses éléments situés sur des parallèles à la diagonale principale sont identique, on dit que c'est une matrice de Toeplitz. Elle est de plus symétrique.
Remarque : l'application d'une matrice de Toeplitz à un vecteur s'interprète comme la convolution de la séquence associée à ce vecteur avec la séquence permettant d'engendrer la matrice.
4.2.4 Algorithme de Levinson
De cette structure très particulière de la matrice se déduit une méthode itérative de résolution très simple : Supposons qu'on connaisse la solution à l'ordre (p-1) de la formule (13), soit
( 1) ( 1) ( 1) ( 1)0 1 2 1, , ,......., ,
Tp p p ppa a a a− − − −
−⎡ ⎤⎣ ⎦
Si on complète ce vecteur par une pième coordonnée égale à zéro et qu'on lui applique la matrice Rp on obtient
41

⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
=
−
−
=
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−−
−
−
−
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
∑ −
−−−−−
−−−−
−
1
0
)1(
...
2)1(
)1(1
)1(2
)1(1
)1(0
...
...
..................
...
...
...
)(
0
0
0
0
...
)0()1()2()1()()1()0()3()2()1(
)2()3()0()1()2()1()2()1()0()1(
)()1()2()1()0(
p
i
pi
p
pp
p
p
p
kpra
a
a
a
a
rrprprprrrprprpr
prprrrrprprrrrprprrrr
σ
14)
On peut appliquer la matrice Rp au vecteur
( 1) ( 1) ( 1) ( 1)2 1 01 , ,......., , ,,0
Tp p p pppa a a a
− − − −−−
⎡ ⎤⎣ ⎦
Comme Rp est centro-symétrique, on obtient :
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
∑ −
=
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
−
−−
−−
⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
=−
−−−−−
−−−−
−
σ2)1(
...
)1(
)1(0
)1(1
...
)1(2
)1(1
...
...
..................
...
...
...
0
0
0
)(0
)0()1()2()1()()1()0()3()2()1(
)1()3()0()1()2()1()2()1()0()1(
)()1()2()1()0(
1
0
p
pk
p
p
pp
pp
p
kkpra
a
a
a
a
rrprprprrrprprpr
prprrrrprprrrrprprrrr
(15)
Les deux membres de droite de (15) et de (16) ont toutes leurs composantes nulles sauf la première et la dernière. On cherche une solution de (13) telle que toutes les composantes du vecteur de droite sont nulles. On peut l'obtenir en effectuant une combinaison linéaire de
( 1) ( 1) ( 1) ( 1)0 1 2 1, , ,.......,
Tp p p ppa a a a− − − −
−⎡ ⎤⎣ ⎦
et de
( 1) ( 1) ( 1) ( 1)2 1 01 , ,......., ,,0
Tp p p pppa a a a
− − − −−−
⎡ ⎤⎣ ⎦
soit
42

( ) ( 1)0 0
( 1)( ) ( 1)11 1
( ) ( 1)( 1)2 22
1
( ) ( 1) ( 1)1 1 1
( ) ( 1)
0
... ... ...
0
0
p p
pp pp
p ppp
p
p p pp pp p
p
a aaa a
a aa ka a aa a
−
−−
−
−−−
−
− −− −
−
⎛ ⎞ ⎛ ⎞⎛ ⎞⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎜⎜ ⎟
= +⎜ ⎟ ⎜⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎝ ⎠ ⎝ ⎠⎝ ⎠
⎟⎟ (16)
En appliquant Rp
⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛ −
+
⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
=
⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
−
=
−
−
−
=
−
−
−
∑
∑ σ
σ
2
)1(
1
0
)1(
1
1
0
)1(
2
)1(
)(
)(
1
)(
)(
1
)(
0
0...00
)(
)(0...00
...
p
p
k
p
k
p
p
k
p
k
p
p
p
p
p
p
p
p
p
kpr
kpr
a
k
aaa
aaa
R (17)
On choisit kp-1 de manière à annuler le dernier élément du vecteur de droite, et
σ 2
)1(
1
0
)1(
1
)(
−
−
=
−
−
∑ −−=
p
p
k
p
kp
kprak (18)
kp-1 s'appelle souvent "coefficient de corrélation partielle" ou "Parcor". On remarque que le premier élément du vecteur de droite est σ2
(p) et que par conséquent
∑ −−
=
−
−−+=
1
0
)1(
1
2
)1(
2
)( )(p
k
p
kppp kprakσσ (19)
En remplaçant ∑ par sa valeur donnée par l'équation (12) écrite à l'ordre p-1 −−
=
−1
0
)1( )(p
k
p
k kpra
σ2
)1(1
1
0
)1( )( −−
−
=
− −=∑ − pp
p
k
p
k kkpra (20)
[ ]k ppp
2
1
2
)1(
2
)(1
−−−=σσ (21)
4.2.5 Algorithme de Schur-Cohn (Analyse de la stabilité du filtre récursif)
Pour savoir si un filtre récursif est stable ou non, il faut compter le nombre de racines de son dénominateur zPA(z) à l'extérieur du cercle de rayon 1. Nous présentons ici un algorithme classique qui permet de savoir si ce nombre est nul. On se donne un polynôme zPA(z) de degré p (a(0)=1)
)()1(...)1()0()( 1 pazpazazazAz ppp
p ++++= −− (22)
On construit un polynôme dont les coefficients sont ceux de zpAp(z) pris en sens inverse
)0()1(...)1()()( 1* azazpazpazAz ppp
p ++++= −− (23)
43

Où encore
)()( 1*
zAzAz ppp −= (24)
On construit ensuite un polynôme de degré p-1 et dont le coefficient du terme de plus haut degré vaut 1:
)1()2(...)1()0()( 11
2
1
1
111 −− −−
−
−
−
−−
− ++++= pazpazazazAz pp
p
p
p
ppp (25)
On pose
ak pp=
−1 (26)
En effectuant une combinaison linéaire des polynômes zpA(z) et zpA*(z), et on calcule le polynôme de degré p-1 tel que le coefficient de son terme de plus haut degré ap-1(0) soit égal à un :
[ ])()(1
)( *
12
1
1
11 zzz AzkAzk
zAz pp
ppp
pp
p
−
−
−
−
− −−
= (27)
Le facteur z-1 traduit la réduction de degré. On réitère cette opération jusqu'à ce que le degré du polynôme A0(z) soit nul. On obtient ainsi une séquence kp-1,…,k0. Alors le polynôme zpA(z) a toutes ses racines strictement inférieures à un en module si et seulement si tous les coefficients k0,k1,…,kp-1 sont compris entre -1 et +1. Si un des coefficients km a un module égal à 1, zpAp(z) a au moins une racine à l'extérieur du cercle de rayon un, le filtre récursif 1/Ap(z) est un filtre instable.
4.2.6 Filtre en treillis
Une autre structure intéressante, en particulier lorsqu'on souhaite contrôler précisément la stabilité d'un filtre est la structure en ``treillis'' qui fait intervenir les coefficients parcors ki de l'algorithme de Schur-Cohn de test de stabilité.
Fig. 4.5 Structure du filtre non récursif en treillis
Dans cette structure les calculs récursifs sont les suivants
44

up(t) = x(t) (entrée)
m =p-1,…,0 : um(t) = um+1(t) – kmvm(t-1)
: vm+1(t) = vm(t-1) + kmum+1(t)
V0(t) = u0(t) (bouclage à droite)
y(t) = vp(t) (sortie) (28)
Notez que le bouclage respecte bien la causalité: en effet dans chaque boucle il y a une mémorisation z-1 (donc un retard). Cette structure de filtre permet de garantir la stabilité du filtre réalisé. Cette propriété est utilisée en particulier lors de l'analyse/synthèse de la parole par la méthode dite de ``prédiction linéaire''.
Fig. 4.6 Structure du filtre récursif en treillis
4.2.7 Equivalence des algorithmes de Levinson et de Schur Cohn
Comme les variances sont des réels positifs, on en déduit que kp-1 est un nombre compris entre -1 et +1. Or, on remarque que la récurrence de Levinson est exactement la même que celle qu'on a développée dans le cas du filtre en treillis à partir de l'algorithme de Schur-Cohn. Voici l'écriture de l'algorithme de Levinson (16).
⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
+
⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
=
⎟⎟⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
−
−
−
−
−
−
−
−
−
−
−
−
aa
aa
ka
aaa
aa
aaa
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
)1(
0
)1(
1
)1(
2
)1(
1
1
)1(
1
)1(
2
)1(
1
)1(
0
)(
)(
1
)(
2
)(
1
)(
0
.........
0
0
(29)
L'écriture correspondante de l'algorithme de Schur-Cohn
45

⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−−
⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−=
⎟⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜⎜
⎝
⎛
−
−
−
−−−
−
−
−
aa
aa
kk
aa
aa
ka
aa
p
p
p
p
p
p
p
p
p
p
p
p
p
p
pp
p
p
p
)(
0
)(
1
)(
1
)(
2
1
1
)(
)(
1
)(
1
)(
0
2
1)1(
1
)1(
1
)1(
0
......... 111
0
(30)
L'écriture en termes de combinaisons de vecteurs peut se traduire en termes de combinaisons de polynômes. Dans les équations qui suivent, on associe toujours au vecteur
( ) ( ) ( ) ( ) ( )0 1 2 1, , ,......., ,
Tp p p p pppa a a a a−⎡⎣ ⎦⎤
(31)
le polynôme en z-1 Ap(z) et au vecteur
( ) ( ) ( ) ( )( )1 2 1 0, , ,......., ,
Tp p p ppp p pa a a a a− −⎡ ⎤⎣ ⎦
(32)
le polynôme en z-1 [z-p Ap(z-1)].
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−⎟⎟
⎠
⎞
⎜⎜
⎝
⎛=
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−−
+−
−
−
−
−
−− )(
)()(
)(1
11
11
1
1
1
1
11
zAzzA
zkzk
zAzzA
pp
p
p
p
p
p (33)
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
−−
−−=
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
− −
−−
−
−
−
−
−
+−
−
−
−
)()(
.)()(
1
11
111
12
1
2
1
1
2
1
12
1
11
1
zAzzA
kkk
kk
kzAz
zAp
p
p
pp
p
p
p
p
pp
p
zz (34)
L'écriture correspondante de l'algorithme de Schur-Cohn
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
−−
−−
−
−=
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
− −
−−
−
−
−
−
−
+−
−
)()(
)()(
1
11
111
1 1
2
1
2
1
1
2
1
12
1
11
1
zAzzA
kkk
kk
kzAz
zAp
p
pp
p
p
p
p
pp
p
zz (35)
Les matrices apparaissant dans les équations (33) et (34) sont inverses l'une de l'autre. On en déduit donc que le polynôme zpAp(z) a toutes ses racines à l'intérieur du disque de rayon 1 et que le filtre 1/Ap(z) est stable.
4.3 Application de la prédiction linéaire à la parole
4.3.1 Les principes de bases
On peut voir le diagramme du modèle de base pour la production de paroles, appropriée à l'analyse de prédiction linéaire dans la figure 4.7 ci-dessous.
46

Fig. 4.7 diagramme d’un modèle simplifié pour la production de la parole
Dans ce modèle, le système vocal et l'excitation glottale sont représentés par un filtre numérique variant dans le temps dont la fonction du système d’état stable est de la forme :
∑=
−−= p
k
k
k zaGzH
11
)( (36)
Le système peut être excité soit par un train d'impulsion pour la parole voisée, soit par une séquence aléatoire pour la parole non voisée. On peut donner les échantillons de paroles s(n) utilisant l'équation de différence simple :
1( ) ( ) ( )
p
kk
s n s n k Gu nα=
= +−∑ (37)
Le prédicteur linéaire avec des coefficients de prédiction αk et d'ordre p est défini comme un système dont la sortie est :
1ˆ( ) ( )
p
kk
s n s n ka=
= −∑ (38)
La fonction du système de ce prédicteur linéaire est :
1( )
pk
kk
P z a z −
=
= ∑ (39)
L'erreur de prédiction est définie comme :
ˆ( ) ( ) ( )e n s n s n= − (40)
1( ) ( ) ( )
p
kk
e n s n s n ka=
= − −∑ (41)
Ainsi le filtre d'erreur de prédiction est la sortie du système dont la fonction de transfert est :
1( ) 1
pk
kk
A z a z −
=
= − ∑ (42)
47

La comparaison des équations (37) et (40) suggère que si αk = ak, donc e(n) = G.u(n) et dans une telle condition, le filtre d'erreur de prédiction A(z) sera un filtre inverse pour le système H(z).
)()( zAGzH = (43)
Le problème de base de prédiction linéaire est de déterminer un ensemble de coefficients de prédiction ak directement du signal de paroles et de cette façon on obtient une bonne estimation des propriétés spectrales de signal de parole à l'aide de l'équation (43).
Donc le but est de minimiser l’erreur de prédiction e(n), entre le signal de parole s(n) et son estimation ˆ( )s n , en adaptant les coefficients ak k=0...p pour chaque trame de N échantillons. Pour cela le critère des moindres carrés est utilisé :
12
0min( )( )
N
nne
−
=∑
4.3.2 Détermination des coefficients LP
Il y a deux méthodes largement utilisées pour l’estimation des coefficients LP:
- Autocorrélation
- Covariance
4.3.2.1 La méthode d’Autocorrélation
A cause de la contrainte de l’utilisation des trames de N échantillons , il est important dans la méthode d'autocorrélation d'appliquer une fenêtre. Normalement, une fenêtre de Hamming est employée. L’application de la fenêtre élimine les problèmes causés par des changements rapides du signal aux bords de la fenêtre, qui assure une transition lisse d’un bloc à un autre des paramètres estimés dans l'analyse.
Les paramètres optimaux ak k=0...p, avec a0 = 1, sont obtenus en annulant la dérivée de l’équation
12
0min( )( )
N
nne
−
=∑ (44)
par rapport aux coefficients aj :
1 2 10
0
( )( )( ) ( )2N Nn
nj j
e nne e na a
δδδ δ
− −= =
=
∑ ∑ (45)
,1
0
( ) ( )( )2
N
n j j
s n nse na a
δ δδ δ
−=
=
⎡ ⎤−∑ ⎢ ⎥
⎣ ⎦
48

1 1
0
( )( )2
pN kk
n j
s n kae na
δδ
− ===
−∑∑
1
0( ) ( )2
N
ne n s n j
−=
=−∑
1,
0( ) ( ) ( )2
N
ns n n s n js
−=
=⎡ ⎤− −∑ ⎣ ⎦
1 1 ,
0 0( ) ( ) ( ) ( )2 2
N N
n ns n s n j s n s n j
− −= −
= =− −∑ ∑
1 1
0 0 1( ) ( )2 2 ( )( )
N pNk
n n ks n s n j s n js n ka
− −= −
= = =−∑ −−∑ ∑
En posant les coefficients d’autocorrélation r j j=0...p obtenus par :
1
00,....,( ) ( )
Nj
navec j ps n s n jr
−=
==−∑ (46)
L’annulation de l’équation (45) permet alors d’obtenir les équations de Yule-Walker :
10,....,(| |) 0
pkj
kavec j pr j kar
=− = =−∑ (47)
Ces équations peuvent être mises sous forme matricielle :
0 1 1 11
1 0 2 2
1 2 0
...
............ ... ... ...
...
p
p
ppp p
r r r a rar r r r
a rr r r
−
−
− −
⎡ ⎤ ⎡ ⎤
2
⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥=⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦⎣ ⎦
(48)
Or
Ra = r Cette matrice symétrique, dont les éléments d’une même diagonale sont égaux, est dite de Toeplitz.
Le vecteur des coefficients LP ak k = 0….p est obtenu par l’inversion de la matrice de corrélation :
1
11
22
0 1 1
1 0 2......
1 2 0
...
...... ... ... ...
... pp
p
p
p p
r r ra r
r r ra r
a rr r r
−
−⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥−⎢ ⎥ ⎢ ⎥=⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦
− −
⎡ ⎤⎢⎢⎢ ⎥⎢ ⎥⎣ ⎦
⎥⎥ (49)
49

Méthode numérique : Algorithme de Levinson-Durbin
Soit le km
ka ième coefficients pour une trame particulière dans la mième itération.
L’algorithme récursive de Levinson résous les équations ordonnées suivantes récursivement pour m = 1,2,…,p
11
1
mm
mm kk
k ar−
−
m kr −=
= − ∑ .
m
ma k=m
.
( )2
11m mkE mE −= − (50)
Ou initialement E0=r0 et a0=1. A chaque itération le mième coefficient pour k=1,2,…,m, décrit l’ordre optimal m
m
maième de prédiction, et l’erreur minimal Em est réduit par un facteur
de ( . Ainsi E)21 mk− m n’est jamais négative |km| < 1.
Le détail de cet algorithme est :
Entrée : Ordre de prediction p , coefficients d’autocorrelation ro,r1,…,rp
Sortie : Coefficient LP , ,…, ( )
1 1
pa a= ( )
2 2
pa a= ( )p
p pa a=
0 0E r=
Pour i = 1 à p faire 1 ( 1)
1
1
i i
i ikki
i
ar rk E
− −
−=
−
+= − ∑ k
j
( )i
i ia k=
Pour j = 1 à i-1 faire ( ) ( 1) ( 1)i i i
j j i ia a k a− −
−= +
Fin pour j ( )2
11i iikE E −= −
Fin Pour i Fin de l’algorithme
On sait que le modèle de signal, qui est en réalité l'inverse de A( z):
)()( zAGzH = (51)
Où G est le gain du modèle et donné par : 2
01
. (1p
ii
pEG kr=
= = −∏ ) (52)
Le terme de gain permet au spectre du modèle LP d'être vérifié au spectre du signal de parole original.
50

Les observations importantes obtenu par l'utilisation de cette forme de solution LP sont comme suit :
(1) Les variables intermédiaires ki, appelé les coefficients de réflexion ou coefficients de Parcor sont limitées :
-1 ≤ ki ≤ +1
Ce résultat est extrêmement utile pour le stockage et les applications de compression impliquant des modèles LP, comme pour le système de reconnaissance de la parole qui stocke les grands numéros de modèles d'identification.
(2) Dans le processus de résolution des coefficients de prédiction d'ordre p utilisant cette méthode itérative, les solutions pour les coefficients de prédiction ainsi que l'erreur de prédiction de tous les ordres moins que p ont été obtenues. C'est commode pour les applications de traitement du signal qui exigent l'évaluation de l'ordre du modèle comme une partie de la tâche.
(3) Le modèle convenable devient mieux avec l'augmentation de l'ordre de prédiction linéaire. Ce fait peut facilement être vérifié employant l'équation (50). E0>E1>...>Ep.
(4) le plus haut ordre du prédicteur linéaire représente facilement les détails plus excellents dans le spectre, tandis que plus bas ordre représente seulement la tendance du spectre.
4.3.2.2 La méthode de Covariance
La méthode de covariance est très similaire à la méthode d’autocorrélation. La différence de base est la longueur de fenêtrage d’analyse. La méthode de covariance applique un fenêtrage sur l’erreur de prédiction au lieu du signal original.
Etant donné un signal, s(n), nous cherchons à modéliser le signal comme une combinaison linéaire de ses échantillons précédents. L'erreur de prédiction moyenne à court terme est définie comme :
2( )n
neE = ∑ (53)
2
ˆ( ) ( )n
s n s nE = −⎡ ⎤∑⎣ ⎦ (54)
2
1( ) ( )
n
pk
ks n s n kE a=
=
⎡ ⎤− −∑ ∑⎢ ⎥⎣ ⎦ (55)
Nous minimisons l'erreur de prédiction moyenne à court terme, dans l’ordre de trouver les valeurs de ak Cela peut être fait en mettant :
10i
E i pa=∂ ≤ ≤
∂ (56)
51

La différentiation donne
1( ) ( ) ( ) ( )
p
kn n k
s n s n k s n k s n ia−
⎡ ⎤= ⎢ ⎥
⎣ ⎦− − −∑ ∑ ∑ (57)
Si nous définissons
( , ) ( ) ( )n
ni k s n i s n kφ = − −∑ (58)
Alors l'équation (57) peut être écrite de façon compacte comme
11, ...,( , ) ( ,0)
p
k n nk
i pi k ia φ φ=
= =∑ (59)
On connaît cela sous le nom de l’équation de prédiction linéaire (Yule-Walker).
L’équation peut être représenté sous forme de matrice
1
2
(1,1) (1,2) ... (1, ) (1)(2,1) (2,2) ... (2, ) (2)
...... ... ... ... ...( ,1) ( , 2) ... ( , ) ( )p
pp
p p p p
aa
a
φ φ φ ϕφ φ φ ϕ
φ φ φ ϕ
⎡ ⎤⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥ =⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦ ⎣ ⎦ p
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
(60)
Où ϕ(i) = φ(i,0) pour i = 1,..,p
Or
φa = ϕ La matrice φ n’est pas une matrice de Toeplitz, mais elle est symétrique et positive. L’algorithme de Levinson Durbin ne peut pas être utilisé pour résoudre ces équations, pour cela on utilise la méthode de décomposition de Cholesky.
L'erreur de prédiction moyenne à court terme peut être écrite comme
1(0,0) (0, )
p
kn nk
kE φ φα=
= − ∑ (61)
4.3.3 Les différentes formes de paramètres LP
On a montré que les paramètres LP sont les zéro du dénominateur de la fonction de transfert H(z).
1
1 1( )( ) 1
pi
ii
H zA z a z −
=
= =− ∑
(62)
Où [a0,a1,a2,…,ap]T sont les paramètres du filtres ou bien par les paramètres de Parcor [k0,k1,k2,…,kp-1]T .après transformation Ces deux ensembles de paramètre sont équivalent aux p
52

premiers coefficients d’autocorrélation représentant l’ordre du filtre auxquels ils sont dérivés. Suivant l’application, une forme de paramètres peut être préférés à une autre. Les paragraphes suivant présentent une brève description de ces divers paramètres.
4.3.3.1 Paramètres Cépstraux
Un autre ensemble de paramètres utilises pour représenter les paramètres LP résulte de l’analyse homomorphique. Celles-ci consiste à réaliser successivement une transformation de Fourier, un logarithme de la norme de chaque composante et une transformation de Fourier inverse. Cette analyse possède la propriété de transformer la corrélation dans le domaine temporel en une somme dans le domaine spectrale. Ce type d’analyse peut être applique au signal synthétique résultant du modèle autorégressif.
)0()0(0 φ== Ec
ac 111=−
acac kki
i
kii i
ki−
−
=∑ −−−=
1
1 pour i = 2,…,p
acc kki
p
ki i
ki−
=∑ −−=
1 pour i = p+1,…..
De ces équations, on constate que les p premiers coefficient cépstraux sont liés, et donc équivalent en information aux coefficients LP du filtre. La première composante c0, est l’énergie contenue dans la fenêtre d’analyse. Cependant, ils possèdent la même sensibilité aux erreurs de quantification que les paramètres LP. Pour cette raison, ils ne sont pas utilises pour le codage. Leur principal intérêt est qu’ils permettent de calculer de manière efficace la distorsion spectrale d’un signal de parole, entre deux filtres autorégressifs par une distance euclidienne. Cette dernière remarque justifie l’utilisation de ces paramètres reconnaissance de parole.
4.3.3.2 Paramètres LAR ( Log Array Ratio )
Les propriétés des paramètres de parcor sont excellentes pour transmettre l’information contenue dans le filtre autorégressif. Cependant l’expérimentation montre que la fonction de transfert du filtre LPC est très sensible aux erreurs de quantification lorsque les coefficients parcor approchent les frontières +1 et –1, de leurs domaines d’évolution. Viswanathan et Makhoul ont introduit une transformation non linéaire qui uniformise la sensibilité de la fonction de transfert du filtre LPC sur l’ensemble du domaine d'évolution. Cette transformation définit les paramètres LAR par la relation suivante :
kkLAR
i
ii −
+=
11log10
i = 1,…,p
Ces paramètres sont un excellent choix pour la représentation de la fonction de transfert du filtres LPC pour les système fonctionnant avec un débit binaire d’information supérieur a 4800 bits/sec. Cependant en transmission de la parole, ils sont de plus en plus remplaces par de nouveaux paramètres qui possèdent des propriétés encore plus intéressantes.
53

4.3.3.4 Paires de Raies Spectrales (LSP)
Les formes dérivées des coefficients parcors permettent d’obtenir d’excellents résultats, si l’on accepte d’utiliser un débit d’information binaire d’environ 2000 bits/sec (40 bits/50 tranches de 20 msec) pour le codage des paramètres LP. Lorsque l’on désire obtenir un débit binaire de transmission de plus faible, il faut augmenter encore le taux de compression et la qualité obtenue se dégrade très rapidement. Il y a deux raisons principales à ces altérations. D'abord il faut au moins 4 bits pour un codage correct d’un coefficient parcor. Ensuite, la distorsion spectrale due à l’interpolation augmente rapidement lorsque la période de rafraîchissement est augmentée. Là on décrit une autre forme de coefficients LPC qui possèdent des propriétés de quantification et d'interpolabilité temporelle encore meilleurs grâce aux conséquences de leur interprétation dans le domaine fréquentiel.
Si l’on définit des filtres autorégressifs d’ordre j croissant et de formes ci-dessus, les polynômes Aj(z) élabores satisfont aux récurrences suivantes:
,1)()()( 11 zAzkzAzA jj
jjj−+=
−
−
− =1,…,p
1)(0 =zA
Où [k1,k2,…,kp]T sont les coefficient de Parcors
On peut étendre l’ordre du filtre a (p+1) sans introduire aucune nouvelle information en choisissant le (p+1)ème coefficient Parcor a leur valeurs +1 ou –1. L’équation ci-dessus devient alors respectivement pour les deux valeurs de kp+1 :
)()()()( 1)1(1 zAzzAzAzP p
ppp
−== +−
+ + (kp+1 = 1)
)()()()( 1)1(1 zAzzAzAzQ p
ppp
−== +−
+ − (kp+1 = -1)
Cette transformation est intéressante. En effet, les polynômes P(z) et Q(z) sont respectivement symétrique car ils satisfont aux relations suivantes:
)()( 11
zPzzP p −= +
)()( 1)1(
zQzzQ p −−= +−
Ces polynômes possèdent des propriétés utiles résumées ci-dessous :
- tous les zéros de P(z) et Q(z) sont sur le cercles unité
- les zéros de P(z) et Q(z) sont alternés sur ce même cercle unité
La première propriété permet d’exprimer ces zéros par:
0)( 1 =eP jω 0)( 2 =eQ jω
54

0)( 3 =eP jω 0)( 4 =eQ jω
……..
0)( 1 =−eP pjω 0)( =eQ pjω
La seconde permet de les ordonner. On a en effet :
0<ω1<ω2<…<ωp<π Par définition, les paires de raies spectrales (Line Spectrum Pairs en anglais et LSP en abrégé) sont les racines de ces polynômes regroupés dans vecteur défini comme suit:
[ω1,ω2,…,ωp]T Vecteurs LSP en Radians
Ce vecteur caractérise bien un filtre autorégressif car il existe toujours une relation biunivoque entre le vecteur LSP et le vecteur des coefficients de prédictions ai.
L’intérêt des paramètres LSP pour la modélisation du filtre de synthèse résulte des excellentes propriétés de quantification de ces paramètres par rapport aux coefficients de Parcor permettant ainsi d’atteindre de plus grand taux de compression.
4.4 Conclusion
La méthode de prédiction linéaire fournit une méthode robuste, fiable et précise pour estimer les paramètres qui caractérisent le système linéaire variant dans le temps. C'est un outil très important dans le traitement du signal digital parce qu'il est utilisé dans différent domaine comme le traitement de signal de paroles, traitement d'image etc.
Dans ce chapitre on a mis l'accent sur la prédiction linéaire appliquée à la parole et quelques propriétés sur les extensions des mathématiques de prédiction linéaires de base ont été discutées.
La prédiction linéaire est devenu la technique prédominante pour estimer les paramètres de parole de base comme le pitch, les formants et les spectres. L'importance dans la prédiction linéaire est la capacité de fournir des évaluations très précises de paramètres de parole aussi bien que la vitesse relative de calcul.
En utilisant la prédiction linéaire nous sommes capables de fournir un filtre tout-pôle au modèle du système vocale. Dans cette technique, la technique de minimisation des moindre carrée est utilisée pour estimer des valeurs de données inconnues en termes de valeurs passées et futures. De telles approches peuvent mener à l'extraction de pitch plus précis (voir chapitre 6) dans l'interpolation entre des échantillons de données et peuvent avoir des applications dans la compréhension des caractéristiques de phase non-minima de parole.
Des différentes formes des paramètres du filtres de ce modèle autorégressif, il s’avère que les paramètres LSP sont les plus adéquats aux applications de codage de la parole bas débit. Il y a peu, ils étaient remplacés par les paramètres de parcors à cause de la trop grande complexité de la recherche des paramètres LSP. Maintenant, les générations de processeurs spécialisés de traitement de signal étant ce qu’elles sont, les meilleures propriétés de quantification et les conséquences de l’interprétation fréquentielle des paramètres LSP font que ces derniers remplacent avantageusement les paramètres parcors dans les applications de codage de parole à bas débit.
55

Chapitre 5
Quantification des signaux de parole
5.1 Introduction et principe
En général, la quantification apparaît dans un processus de compression, pour réduire la quantité d’information, de manière souvent irréversible, car elle introduit une distorsion et il faudra minimiser cette dernière lors de la conception d’un quantificateur.
Au cours du traitement numérique du signal de parole, toutes les données sont représentées sur un certain nombre d’éléments binaires avec une précision finie. Pour cette opération on doit représenter les amplitudes du signal analogique, à des instants discrets du temps, par une valeur choisie parmi un ensemble fini. Outre la nécessité de la quantification pour numériser les données.
Le taux de compression augmentera lorsque le nombre d’intervalles de quantification diminuera. Par exemple, dans un schéma de compression, la première étape consiste à représenter la parole dans un domaine, où l’information est moins corrélée que dans l’espace initial. Ainsi, une quantification est utilisée pour simplifier cette représentation, tout en préservant l’information la plus pertinente. On remplace ainsi les valeurs initiales par un ensemble fini d’éléments qui donneront des résultats acceptables lors de la phase de décompression.
La quantification est une opération non linéaire, et vise à réduire la variété des échantillons, donc d’améliorer le débit.
1 valeur d’entrée → 1 valeur quantifiée : Quantification scalaire
n valeurs d’entrée → 1 valeur quantifiée : Quantification vectorielle
Le problème de la quantification est de définir la fonction associant configurations d’entrée aux nouvelles valeurs.
En théorie la quantification vectorielle est plus performante et elle a la propriété de prendre en compte la corrélation entre les échantillons successifs du signal. Sa mise en oeuvre est toutefois délicate.
Précisons que les ordres de grandeurs des débits de transmission, précisés dans cette notre étude, correspondent à une fréquence d’échantillonnage du signal à quantifier égale à 8 kHz. Selon le débit recherché en sortie d’un codeur, une quantification scalaire (QS) qui traite chaque échantillon indépendamment des précédents (débit > 32 kbits/s) ou une quantification multidimensionnelle ou vectorielle (QV) (débit < 16 kbits/s) est utilisée. Les deux types de quantificateur présentant le même formalisme, le choix se fera de manière à obtenir une distorsion entre les signaux, initial et quantifié, la plus faible possible.
56

5.2 Notion de base
Un quantificateur réalise une discrétisation de l’espace. Cela signifie qu’un vecteur de l’espace Rp est mis en correspondance avec un dictionnaire C. Le nombre d’éléments N de ce dictionnaire est fini et appelé taille du dictionnaire. Si p = 1, le quantificateur est dit scalaire ; si p > 1 il est dit vectoriel.
Ainsi pour chaque élément yi, i = 1,...,N du dictionnaire C, il existe une région Ri, appelée région de Voronoi, qui est l’ensemble des X ∈ Rp quantifiées en yi.
5.2.1 Critère d’optimalité
Il y a deux conditions nécessaires pour assurer l’optimalité d’un quantificateur.
1. La première condition est connue sous le nom de règle du plus proche voisin. Elle signifie qu’un vecteur x est quantifié en son plus proche correspondant dans le dictionnaire, soit x est quantifié en yi si et seulement si d(x; yi) ≤· d(x; yj) ∀ j≠ i, ou d est une mesure de distance.
2. La deuxième condition est connue sous le nom de règle du centroïde. Elle spécifie le calcul de yi pour une région de Voronoi Ri. yi doit minimiser la distorsion moyenne dans Ri, soit Di = E d(x; yi) / x ∈ Ri.
5.3 La quantification scalaire
La quantification scalaire porte sur la grandeur physique associée à l’information au niveau de la parole. L’objet de la quantification est de diviser la gamme dynamique ou dynamique de la grandeur physique en un nombre fini d’intervalles, et d’attribuer à toutes les valeurs du même intervalle une seule valeur, dite valeur quantifiée.
Trois questions se posent alors :
– trouver la gamme dynamique ;
– choisir le nombre d’intervalles ;
– et répartir ces intervalles.
Ces questions renvoient à des considérations physiques liées aux propriétés acoustiques. Le système auditif humain intervient aussi de manière importante dans ces considérations, mais à un niveau subjectif.
Posons S le paramètre à quantifier pouvant représenter tout paramètre extrait du signal de parole, tel que l’amplitude du signal échantillonné. Notons fS(s) la densité de probabilité de la variable S et b sa résolution, c’est à dire le nombre de bits pour la représenter. L’opération de quantification consiste à discrétiser le paramètre S pour obtenir une représentation numérique i(n) de l’information qu’il représente. Son domaine de définition est alors partitionné en L = 2b
intervalles distincts et un représentant est défini pour chacun de ces intervalles.
57

Fig. 5.1 Quantificateur Scalaire
La procédure d’encodage Q décide à quel intervalle appartient le paramètre s(n) et lui associe le numéro i(n) ∈ 1...L correspondant (Fig. 5.1). C’est ce numéro d’intervalle qu’il faudra transmettre au processus de décodage Q-1 qui effectuera la procédure inverse en associant à i(n) son représentant . L’opération de quantification apportera toujours des dégradations irréversibles par rapport au signal d’origine qui se traduisent par une erreur, ou bruit, de quantification e(n) :
)(ˆ ns
)(ˆ)()( nsnsne i−=
où )(ˆ nsi1≤ i ≤ L est l’ensemble des représentants, appelé dictionnaire.
5.3.1 La quantification uniforme
Le processus de quantification uniforme est tout à fait irréaliste mais permet de présenter de façon simple la quantification scalaire. Cette technique consiste à partitionner l’intervalle [-A, A], où le signal à temps discret s(n) prend ses valeurs, avec une loi uniforme en L intervalles distincts P1, ..., PL de même longueur ∆= 2A/L
Fig. 5.2 Partition uniforme d’un intervalle
Le représentant si(n) est défini généralement par le milieu de l’intervalle (Fig. 5.2) pour répondre, au mieux, au critère de minimisation de l’erreur quadratique moyenne σ2
s :
)(ˆ)(2
2 nsnsE is −=σ
Un critère de maximisation du rapport signal sur bruit de quantification peut aussi être choisi.
5.3.2 La quantification non uniforme
Les hypothèses précédentes sont très mal adaptées à un processus réel, tel que le signal de parole, dont les propriétés statistiques ne sont pas stationnaire. Leur loi de probabilité n’étant pas uniforme, le quantificateur précédent n’est plus optimal.
La partition P1, ..., PL ne pourra plus être composée d’éléments de longueur constante. La longueur de chaque intervalle devra être d’autant plus petite que la densité de probabilité fS(s) correspondante sera grande (Fig. 5.3). De plus, les représentants ne seront plus )(ˆ nsi
58

forcément les milieux des intervalles mais seront déterminés par la moyenne de la variable aléatoire S sur l’intervalle considéré.
Fig. 5.3 Quantificateur scalaire non uniforme
Dans la pratique, on ne connaît pas la densité de probabilité. Pour construire un quantificateur, des données empiriques sont utilisées en associant à chaque échantillon le même poids. La base d’apprentissage devra être composée d’un grand nombre d’échantillons représentatifs de la source. L’algorithme de Lloyd-Max permet ainsi de construire un quantificateur optimal.
5.3.3 Principe de la quantification scalaire
1. Diviser l’intervalle d’entrées [a,b] en Nd sous-intervalles [di , di+1[, i ∈ 0 … Nd-1. di= seuils de décision.
2. Associer à chaque sous-intervalle [di , di+1[ une valeur ri (niveau de reconstruction).
3. on code une donnée d de S par ri si d ∈ [di , di+1[. En pratique, on envoie l’indice de l’intervalle. Le décodeur doit connaître le niveau de reconstruction.
Le taux de compression possible est de Card(E(S))/Nd
La quantification peut être uniforme (seuils de décisions équidistants) ou non.
Si on connaît la statistique de la source, on peut définir un quantificateur optimal. Pour cela, on cherche l’ensemble seuil de décision – niveau de reconstruction qui minimise l’erreur quadratique moyenne du signal reconstruit.
Fig. 5.4 Quantification Scalaire
59

5.3.4 Méthodes de la quantification scalaire
Les méthodes de quantification scalaire inclus la Modulation par Impulsion de Code (MIC – Pulse Code Modulation ou PCM, voir chapitre 2), le Différentiel PCM (DPCM) et la Modulation de Delta (DM).
L'uniforme PCM est un processus sans mémoire qui quantifie des amplitudes en arrondissant chaque échantillon à un jeu de valeurs discrètes. La différence entre des niveaux de quantification adjacents, c'est-à-dire, la taille et le pas, est constante dans le MIC uniforme non-adaptatif.
Une autre classe de MIC non uniforme compte sur des quantificateurs logarithmiques, appelé loi µ et loi A. Ceux-ci sont tout à fait communs dans des applications de paroles. Un quantificateur logarithmique à 7 bits pour la parole réalise la performance d'un quantificateur à 12 bits uniforme. Des variations de gamme dynamiques en MIC uniforme ou non uniforme peuvent être traitées en employant une taille et un pas adaptatif.
5.4 La quantification vectorielle
Contrairement à la quantification scalaire (QS) qui traite chaque échantillon indépendamment des précédents, le quantificateur vectoriel permet de prendre en compte la dépendance entre les différentes composantes du signal. La propriété fondamentale de ce quantificateur est la recherche de la corrélation qui peut exister entre les échantillons successifs du signal.
Lorsque le débit devient inférieur ou égal à 16 kbits/s, soit 2 bits par échantillon, il devient nécessaire de les regrouper pour former un vecteur et de quantifier l’ensemble. Le schéma de principe est le même que celui donné en Fig. 5.1. Les scalaires et apparaissant à l’instant n sont simplement remplacés par des vecteurs. La quantification vectorielle choisit les représentants des vecteurs de données à quantifier dans un ensemble de vecteurs prédéterminés, de même dimension, stockés dans une table ou un dictionnaire.
)(ns )(ˆ ns
5.4.1 Principes de la quantification vectorielle
La quantification vectorielle dans son sens le plus général est l'approximation d'un signal d'amplitude continue par un signal d'amplitude discrète. Dans le cadre de notre application, elle consiste à représenter tout vecteur x de dimension k par un vecteur y de même dimension appartenant à un ensemble fini appelé dictionnaire.
D'un point de vue mathématique, nous pouvons définir notre quantificateur vectoriel de cette manière: Soit I l'ensemble des indices correspondant au dictionnaire Y et yi∈I l'ensemble des vecteurs de Y.
I=1,…,N Le processus de codage est défini par:
C : R → I
X → C(x)
60

Le processus de décodage étant quant à lui défini par:
D : I → Y
I → yi
Donc un quantificateur vectoriel dresse la carte de vecteurs k-dimensions dans l'espace de vecteur Rk dans un jeu fini de vecteurs Y = yi : i = 1, 2 ,..., N. Chaque vecteur yi est appelé un vecteur de code. Et le jeu de tous les vecteurs de code est appelé un dictionnaire. Associé à chaque vecteur de code, yi est l'une plus proche région voisine appelée la région de Voronoi et il est défini par :
pour tout ,: ijyxyxRxV jik
i ≠−≤−∈=
Le jeu de régions Voronoi divise l'espace entier Rk tel que :
ΥN
i
ki RV
1=
= et pour tout i ≠ j ΙN
iiV
1=
= φ
La figure ci-dessous (Fig. 5.5) montre quelques vecteurs dans l'espace. A chaque groupe de vecteurs est associé un vecteur de code représentatif. Chaque vecteur de code réside dans sa propre région Voronoi. Ces régions sont séparées avec des lignes imaginaires. Etant donné un vecteur d'entrée, le vecteur de code qui est choisi pour le représenter est celui dans la même région Voronoi.
Fig. 5.5 Codes vecteur dans un espace 2-dimensionnel.
Les vecteurs d'entrée sont marqués avec un x, les codes vecteurs sont marqués avec des cercles
et les régions Voronoi sont séparées avec des frontières.
61

Le vecteur de code représentatif est déterminé pour être le plus proche dans la distance Euclidien du vecteur d'entrée. La distance Euclidien est définie par :
∑=
−=k
jijji yxyxd
1
2)(),(
Où xj est le composant jème du vecteur d'entrée et yij est le jème est composant du code vecteur yi.
5.4.2 Description d'un quantificateur vectoriel
Un Quantificateur Vectoriel se décompose donc généralement en deux applications:
- Un codeur
- Un décodeur
5.4.2.1 Le codeur
Le rôle du codeur consiste, pour tout vecteur y du signal en entrée, à rechercher dans le dictionnaire D le code-vecteur yj le plus "proche" du vecteur source y. La notion de proximité a été modélisée dans notre mise en œuvre par la distance euclidienne entre vecteurs. C'est uniquement l'adresse I(i) du code-vecteur yj ainsi sélectionné qui sera transmise, c'est donc à ce niveau que s'effectue la compression. Dans le cadre de notre étude, le dictionnaire est tout simplement représenté par un tableau et l'adresse du code-vecteur correspond à son indice dans le tableau.
5.4.2.2 Le décodeur
Le décodeur dispose d'une réplique du dictionnaire et consulte celui-ci pour fournir le code-vecteur d'indice correspondant à l'adresse reçue. Le décodeur réalise donc l'opération de décompression.
Fig. 5.6 La transmission d'un signal par quantification vectorielle.
A travers ce schéma, il est aisé de se rendre compte de l'importance primordiale du dictionnaire utilisé lors des opérations de codage et de décodage.
62

5.4.3 Elaboration du dictionnaire
Concevoir un dictionnaire qui représente le mieux un jeu de vecteurs d'entrée est NP-Complet. L'élaboration de ce dernier se fait à partir d'une séquence d'apprentissage. Les vecteurs constituant cette séquence correspondent à des blocs du signal de parole où a un ensemble de coefficients si l'on se situe dans un espace transformé comme nous le verrons par la suite. Cela signifie qu'il exige une recherche complète des meilleurs vecteurs possibles dans l'espace
Un dictionnaire, indépendamment de son mode de construction et du système de recherche employé est défini par deux paramètres principaux:
- son nombre de vecteurs représentants: N.
- la dimension de l'espace vectoriel → dimension des vecteurs représentants: k.
Comme nous le verrons par la suite, nous travaillerons toujours dans un espace transformé et notre espace vectoriel sera un sous-ensemble de R
k avec k ∈ 20,21,23 ,…,2n. Les vecteurs de
cet espace représenteront des blocs du domaine transformé.
Ces deux paramètres apparaissent étroitement liés et c'est en essayant d'ajuster au mieux la valeur de ces paramètres qu'il sera possible de construire un bon dictionnaire. Avant de chercher quelle paraît être la meilleure composition de ces paramètres, il apparaît primordial de fixer un ordre de grandeur quant à leur taille.
5.4.3.1 Les algorithmes de construction d’un quantificateur
Les algorithmes de construction des quantificateurs permettent de trouver les dictionnaires et les régions de Voronoi qui minimisent la distorsion moyenne globale.
On peut citer les algorithmes ci-dessous.
A - Algorithme des nuées dynamiques ou K-moyennes (K-MEANS)
Pour cet algorithme on choisi un ensemble initial de K vecteurs références. L'ensemble des vecteurs est classé par la règle du plus proche voisin. Pour chaque sous ensemble de vecteurs, on calcul le centroïde correspondant aux vecteurs d'apprentissage appartenant à cette classe de vecteurs. Si les variations des centroïdes n'évoluent plus c'est à dire que la distorsion est jugée minimale, on arrête la procédure sinon on réitère l'algorithme.
Plus précisément, cet algorithme a pour but de déterminer sur l'ensemble E à classer une partition en k classe satisfaisant un critère global de qualité. Il se sert au départ d'un dictionnaire donné (des noyaux). Des séries de dictionnaire de même taille seront construites et la distorsion globale sera réduite à chaque itération.
Il est difficile de construire un dictionnaire C optimal lorsqu’on ne connaît pas les densités de probabilité des éléments à quantifier. C’est pourquoi on utilise souvent une base d’apprentissage T=x1, …, xP pour construire un quantificateur. Cette base d’apprentissage peut provenir d’une base de données importante.
63

L’algorithme des K-moyennes est itératif, et repose sur les 2 conditions d’optimalité énoncées plus haut (paragraphe 5.2). A chaque nouvelle itération, la base d’apprentissage est quantifiée et les K éléments du dictionnaire sont positionnés au centre de gravité des nouvelles régions (d’où le terme < K-moyennes >). La difficulté de cet algorithme consiste à initialiser le dictionnaire C.
On dispose d’une base d’apprentissage de P vecteurs x1, …, xP. On cherche à calculer un dictionnaire C = c1, …, cK. On note Cm = c1
m, …, cKm le dictionnaire obtenu à la mème
itération.
Etape 01 :
Initialisation : Soit k = 0. On fixe un dictionnaire initial C0 et on calcule la distorsion totale D0.
Dans le cas d’un quantificateur scalaire, le dictionnaire composé des K valeurs uniformément espacées sur la dynamique est acceptable.
Dans le cas d’un quantificateur vectoriel, le dictionnaire peut être composé de K vecteurs de la base d’apprentissage.
Etape 02:
Boucle de calcul : Soit K = K + 1
(a) On classe chaque vecteur de la base d’apprentissage :
xn ∈ Rj ⇔ || xn - cj || ≤·|| xn – cj || ∀ l = 1, 2,…, K, l ≠ j
(b) Mise à jour du dictionnaire
1n
jnj
kj
x RC N ∈
= ∑ x pour j = 1, 2,…, K
Où Nj est le nombre de vecteurs de la séquence d’apprentissage appartenant à Rj.
(c) Calcul de la distorsion totale :
1
kktot j
jD D
=
= ∑ avec 2
1−
jnj
kn j
x Rx CD
∈= −∑ , j = 1, 2,…,k
Etape 03 :
Test de sortie
- si > seuil alors retourner à l’( )( )1 /k k ktot tot totD D D− − étape 02.
- sinon l’entraînement est terminé, le dictionnaire final est C = Ck et la distorsion totale sera . k
totD
64

B - Algorithme LBG
Cet algorithme proposé par Linde, Buzo et Gray correspond à une extension de l'algorithme de Lloyd-Max utilisé pour l'élaboration de dictionnaires dans le cas de la quantification scalaire. Son rôle est pour un dictionnaire initial donné d'essayer d'optimiser le codeur et le décodeur.
Etape 01 : initialisation
Déterminez le nombre de vecteurs code, N, ou la taille du dictionnaire.
Sélectionner N vecteurs code aléatoirement et laissez-le être le dictionnaire initial. Les vecteurs code initiaux peuvent être aléatoirement choisis du jeu de vecteurs d'entrée.
Fixer
- un dictionnaire initial C(0)
de taille N
-un seuil δ >0
- un nombre maximum d'itérations p
- une source de vecteurs x de distribution connue
Initialiser
- D(-1) = ∝ - m = 0
Etape 02 :
L'utilisation de la distance Euclidien groupe les vecteurs autour de chaque vecteur code. Ceci est fait en prenant chaque vecteur d'entrée et en essaye de trouver la distance Euclidien entre ce dernier et chaque vecteur code. Le vecteur d'entrée appartient au groupe du vecteur code qui rapporte la distance minimal.
- Pour le dictionnaire courant C(m)
= ci
(m) i= 1, ..., N, trouver la partition optimale
R(m)
= Ri(m) i= 1, ..., N qui minimise la distorsion moyenne soit:
x ∈ Ri(m) si d( x;ci
(m) ) < d( x;cj(m) ) ∀ j ≠ i
- Calculer la distorsion moyenne
[ ]∑ ∈==
N
i
m
RxcxdED mmi1
)( )(/),(
Etape 03 :
- Si ( D(m-1) – D(m) )/ D(m) ≤ δ où m = p
- stopper : le QV final est décrit par R(m)
et C(m).
65

- Sinon
- continuer
Etape 04 :
- Pour la partition R(m)
, calculer le dictionnaire optimal C(m+1) = ci
(m+1) i=1,…,N avec
ci(m) = cent(Ri
(m)).
- Incrémenter m.
- Retourner à l'étape 02.
L'abréviation cent utilisée dans l'algorithme correspond au centroïde. Le centroïde ci d'une région Ri est dans le cas de la distance euclidienne défini par:
ci=cent(Ri)=E[x/x ∈ Ri]. Cet algorithme d'optimisation itératif travaille à partir d'un dictionnaire initial. Le problème est donc reporté sur le choix de ce dictionnaire initial dont l'expérience a prouvé qu'il contribuait fortement aux performances de l'algorithme LBG. En effet, chaque itération ne provoquant qu'un changement local du dictionnaire, l'algorithme converge vers le minimum local le plus proche du dictionnaire initial.
Cet algorithme est aussi le plus populaire et c'est dû à sa simplicité. Bien que ce soit localement optimal, encore il est très lent. La raison de cette lenteur est parce que pour chaque itération, on doit déterminer dans chaque groupe, exige que chaque vecteur d'entrée soit comparé avec tous les vecteurs code dans le dictionnaire.
C – Algorithme utilisant la méthode par dichotomie vectorielle
Cette méthode a été proposée dans la version initiale de l'algorithme de LBG sous le nom de "splitting". On procède de la manière suivante.
Le centroïde, définissant la moyenne de tous les vecteurs de la séquence d’apprentissage, est calculé. Le vecteur résultant est divisé en deux, en rajoutant et retranchant la même quantité au vecteur. L’algorithme LBG est ensuite appliqué pour construire le dictionnaire optimal de taille 2. Le processus est itéré pour construire successivement le dictionnaire optimal de taille 22,23,…, et enfin N
Un débit R=log2(N) entier est alors exigé. Dans ce cas, une succession de QV ayant des débits croissants de 0 à R est générée. Le procédé de construction est le suivant:
Etape 01 : initialisation
- Initialiser le dictionnaire C en prenant C[0]=c0 où c0 est le centroïde de la séquence d'apprentissage prise dans son ensemble.
- Noter u le vecteur de Rk ayant toutes ses composantes égales à 1.
- Fixer une perturbation scalaire ε.
66

- Fixer le débit R.
- Fixer un seuil de distorsion∇.
- Prendre r=0.
Etape 02 :
Perturber le dictionnaire courant C=ci i=0,…,2r-1 ⎧ C[2i+1]=C[i] - εu ∀ i=0,…,2r-1 ⎨ ⎩ C[2i]=C[i] + εu Incrémenter r
Etape 03 :
- Considérer le nouveau dictionnaire C=ci i=0,…,2r-1
- Exécuter l'algorithme de LBG sur le dictionnaire C.
- Si ( r/k = R ou D(r) < ∇ )
- Arrêter en retenant c(r) .
- Sinon
- Retourner à l'étape 02.
Cet algorithme a été mis en œuvre lors de la conception de notre logiciel de quantification vectorielle. La charge en calculs engendrée par la construction du dictionnaire est très importante mais n'est pas considérée comme un handicap prépondérant étant donné qu'un dictionnaire est construit une fois pour toutes.
5.5 Conclusion
Dans ce chapitre on a présenté deux types de quantification scalaire et vectorielle.
La première porte sur la grandeur physique associée à l’information au niveau de la parole en essayant de trouver la dynamique de la grandeur physique en un nombre fini d’intervalles, et d’attribuer à toutes les valeurs du même intervalle une seule valeur.
Par contre la deuxième permet de prendre en compte la dépendance entre les différentes composantes du signal de parole. La propriété fondamentale à prendre en considération dans la quantification vectorielle est la recherche de la corrélation qui peut exister entre les échantillons successifs du signal de parole. De là, on peut dire que la quantification vectorielle est une opération irréversible. Dans cette opération, il y a perte de l'information et le signal original ne pourra plus être restitué.
La quantification vectorielle permet d’atteindre de meilleures performances que la quantification scalaire. Les techniques de quantification vectorielle procurent des algorithmes permettant la détermination de dictionnaires quasi-optimaux, tel que l’algorithme de LBG et montrent que l’on
67

peut obtenir, pour une résolution donnée (nombre de bits disponibles par échantillon), une distorsion très proche des limites théoriques entre les signaux original et quantifié.
Toutefois, les résultats théoriques ne sont pas applicables directement. Les capacités de mémorisation des dictionnaires et de calcul, permises par les microprocesseurs de traitement du signal disponibles actuellement, sont inférieures aux performances réclamées et posent des problèmes pour un traitement efficace surtout en temps réel.
Des solutions existent mais non traitées dans ce chapitre pour faire face à cette complexité de calcul accrue. Les quantifications vectorielles prédictives et multi-étapes sont deux réponses possibles :
• Dans le cas de la quantification vectorielle prédictive, le processus cherche à décorréler le plus possible les vecteurs entre eux en enlevant la partie prédictive puis quantifie le vecteur résiduel.
• Dans le cas de la quantification vectorielle de type multi-étapes on procède par approximations successives. Une quantification vectorielle grossière est réalisée. Ensuite, une deuxième porte sur l’erreur de quantification commise par la première et ainsi de suite. Le codeur CS ACELP recommandé par la norme G.729 de l’UIT, fait appel à ce type de quantification.
68

Chapitre 6
Codage de la parole
6.1 Introduction
L’accroissement des demandes au niveau des réseaux de communications numériques a provoqué d’importantes recherches. Des méthodes de traitement du signal sont apparues dans le but de réduire le nombre de bits nécessaires à la représentation du signal de parole et à la transmission des informations tout en maintenant un niveau de qualité suffisant et une complexité de calcul raisonnable.
Le développement de calculateurs de plus en plus performants a offert la possibilité de traiter numériquement le signal en remplacement du traitement analogique et a rendu possible la mise en oeuvre d’algorithmes de plus en plus sophistiqués pour la compression du signal de parole. Avant tout algorithme, il est maintenant nécessaire de numériser les signaux. Le débit binaire du signal numérisé est alors égal au produit de la fréquence d’échantillonnage par le nombre d’éléments binaires nécessaire à la représentation de toutes les valeurs discrètes du signal. Pour réduire ce débit, des algorithmes vont permettre de supprimer les redondances inutiles du signal, nécessitant ainsi un système de codage.
Un système de codage de la parole comprend 2 parties : un codeur et un décodeur. Le codeur analyse le signal pour en extraire un nombre réduit de paramètres pertinents qui sont représentés par un nombre restreint de bits pour archivage ou transmission. Le décodeur utilise ces paramètres pour reconstruire un signal de parole synthétique.
Les caractéristiques principales d’un codeur sont :
• Le débit binaire: fixe ou variable,
• La qualité de parole reconstruite,
• La complexité de calcul et mémoire requise,
• Le délai
• La sensibilité aux erreurs dues au canal de transmission et,
• La largeur de bande du signal.
La plupart des algorithmes de codage mettent à profit un modèle linéaire simple de production de la parole. Ce modèle sépare la source d'excitation, qui peut être quasi-périodique pour les sons voisés ou de type bruit pour les sons fricatifs ou plosifs, du canal vocal qui est considéré comme un résonateur acoustique.
69

Quand un signal de parole numérisé est transmis, la bande passante requise est fonction du débit binaire, de là on peut parler de compression, d’où son but est de produire une représentation compacte des sons de parole de sorte que lorsqu’ils seront reconstruit, ils soient perçus comme très proches de l’original. Les deux mesures principales de «proches» sont l’intelligibilité et le naturel. Le point de référence standard est la qualité de Toll qui est celle utilisé sur des lignes téléphoniques.
De là on peut dire que le rôle de tous les systèmes de codage de parole est de transmettre la parole avec une bonne qualité en employant la capacité de canal la plus petite possible. En général, il y a une corrélation positive entre l'efficacité du débit du codeur et la complexité algorithmique exigée pour le réaliser. Plus un algorithme est complexe, plus le coût du traitement et de mise en œuvre sera élevé.
6.2 Techniques de codage
De nombreux travaux relatifs aux algorithmes de codage tendent à maximiser le compromis entre l’efficacité, le coût et la qualité de transmission des systèmes de communication en fonction des débits disponibles.
Les algorithmes de codage de parole peuvent être divisés en trois classes distinctes : les codeurs temporels ou de forme d’onde, les codeurs paramétriques, et les codeurs hybrides.
6.2.1 Les codeurs temporels
Les codeurs temporels, très simples à mettre en oeuvre, utilisent des techniques de codage qui cherchent avant tout à préserver l’allure temporelle du signal de parole, ce qui les rend robustes aux différents types d’entrée. Le signal reconstruit avec ce type de codeur converge vers le signal original avec l’augmentation du débit de transmission. La qualité du signal synthétisé obtenue est excellente pour un débit relativement élevé. Les premiers codeurs temporels de type PCM (Pulse Code Modulation) ou MIC (Modulatation par Impulsion Codée), qui reposent exclusivement sur le théorème d’échantillonnage de Shannon et une quantification fixe, sont apparus dans les années 60. Etant donnée la distribution d’amplitudes des échantillons de parole, un quantificateur non-uniforme apporterait une meilleure qualité pour le même débit. Ainsi, l’Union Internationale des Télécommunications a normalisé le codeur G.711 en 1972, un codeur logarithmique de parole de type PCM pour la transmission téléphonique avec un débit de 64 kbits/s. Ce type de codage échantillonne le signal de parole à une fréquence de 8 kHz et opère une quantification sur 8 bits du signal de parole dans la bande de fréquences [300, 3400] Hz. Avec une complexité plus élevée, le codage de parole peut être obtenu avec des débits inférieurs. Ensuite, une technique, dont le principe est de quantifier non plus la valeur d’un échantillon à un instant donné mais la différence avec une valeur prédite à partir d’échantillons précédents, a été introduite. Le signal à coder se limitant aux coefficients d’un filtre, le nombre de bits nécessaires à sa quantification est diminué. Cette technique dite ADPCM (Adaptive Differential Pulse Code Modulation) émerge au début des années 80 et permet de réduire le débit de moitié par rapport à la loi PCM sans détériorer la qualité de parole et des services annexes (télécopie, télégraphie, transmission de données). Le codeur G.721, normalisé par l’UIT depuis 1984, est un exemple de système ADPCM qui fonctionne à 32 kbits/s.
70

6.2.2 Les codeurs paramétriques
Des systèmes de codage paramétriques, basés sur des connaissances théoriques de production de parole, vont permettre des transmissions à moyen et bas débit (entre 5 et 16 kbits/s). La technique consiste à extraire du signal de parole les paramètres les plus pertinents permettant au décodeur de le synthétiser. Les performances des codeurs paramétriques, également connus sous le nom de vocoders, dépendent de la précision des modèles de production de parole. Ces codeurs ont été conçus pour des applications à bas débit et sont principalement prévus pour maintenir l’intelligibilité du signal vocal. La plupart des codeurs paramétriques sont basés sur le codage prédictif linéaire (LPC), détaillé plus loin dans ce chapitre. Atal et Schroeder proposent en 1970 une technique de codage, appelée APC (Adaptive Predictive Coding), dont le principe est d’extraire les redondances du signal de parole, à l’aide d’un modèle de prédiction linéaire, et de quantifier le signal d’erreur résiduel. La qualité de cette classe de codeurs est limitée par la reconstruction synthétique du signal. Cependant, ces codeurs fournissent, à faibles débits, des performances supérieures à celles des codeurs temporels. Un codage efficace peut actuellement être réalisé à des débits inférieurs à 2 kbits/s avec des vocoders basés sur l’analyse LPC.
6.2.3 Les codeurs hybrides
L’utilisation des techniques temporelles conduit à une excellente qualité de parole mais induit un débit assez élevé. La fréquence d’échantillonnage étant fixée, la réduction de débit des codeurs temporels fait chuter rapidement la qualité d’écoute pour des débits inférieurs à 16 kbits/s. Une meilleure qualité pourra être observée pour des vocoders jusqu’à des débits de 4 kbits/s. Mais ses applications restent réduites à cause d’une complexité accrue. Des codeurs hybrides utilisent alors les deux méthodes temporelle et paramétrique de façon complémentaire, ce qui permet un codage de parole de bonne qualité à des débits moyens. Ces codeurs sont basés sur des techniques de codage temporel auxquelles des modèles de production de parole sont associés pour améliorer leur efficacité. Cependant, ce type de codage nécessitera des coûts de calculs plus importants. Tous les codeurs hybrides s’appuient, eux aussi, sur une analyse LPC pour obtenir les modèles de synthèse de parole. Les deux techniques paramétrique et temporelle modélisent respectivement le conduit vocal et le signal d’erreur résiduel. En 1982, Atal et Remde utilisent le principe d’analyse par synthèse et modélisent le signal d’erreur à partir d’excitations multi-impulsionnelles. Ce n’est qu’en 1985, qu’Atal et Schroeder définissent le codeur CELP (Code Excited Linear Prediction), qui détermine une forme d’onde optimale du signal d’erreur en utilisant l’analyse par synthèse. Récemment, les codeurs CELP ont suscité beaucoup d’attention et servent de base à la plupart des algorithmes de codage de la parole. Un codeur LD-CELP (Low Delay-CELP) ciblant un faible délai de codage/décodage a été donné par la recommandation G.728 de l’UIT où ce dernier a fait objet de notre étude et implantation.
71

Table 6.1 Récapitulatif des contraintes des différentes techniques de codage
Codage
Normes
Débit
(kbits/s)
Qualité (MOS)
Délai de Codage
(ms)
Complexité
(MIPS)
temporel PCM
MICDA
G.711
G.726
64
32
4.2
4.0
0.13
0.3
0.1
12.0
paramétrique LPC 2.4 2.3 50 7.0
analyse et synthèse
CELP
LD-CELP
CS-ACELP
G.728
G.729
4.8
16
8
3.5
3.9
4.0
50
3
30
16.0
33.0
20.0
La table 6.1 récapitule tous ces différents types de codage et fournit leurs caractéristiques principales : le débit, le délai de codage, la qualité estimée par une note subjective MOS (Mean Opinion Score) et la complexité de calcul exprimée en Million d’Instructions Par Seconde (MIPS).
Fig. 6.1 Performances des codeurs temporels, paramétriques et hybrides
6.3 Segmentation du signal de parole
La parole est généralement produit en exhalant l'air par la glotte et le conduit vocal. L’air venant des poumons, est modulé par les vibrations des cordes vocales et le conduit vocal ce qui provoque un son des langages parlés.
72

On sait que les caractéristiques du filtre du conduit vocal (voir chapitre 2) et de la parole évoluent avec le temps, et donnent un signal vocal non-stationnaire. Le signal étant généralement considéré comme quasi-stationnaire sur de faibles périodes de l’ordre de quelques dizaines de millisecondes (entre 5 et 20ms), une segmentation est effectuée par déplacement d’une fenêtre d’analyse sur le signal numérisé. Ainsi on peut avoir les caractéristiques spectrales du signal de parole pendant l’analyse (stationnarité locale).Des recouvrements temporels sont pris en compte lors de la segmentation pour atténuer les effets de bord et conserver les caractéristiques fréquentielles du signal. Chaque segment de parole échantillonnée est appelé trame.
Pour atténuer les changements brusque du signal d’une trame à une autre, on utilise des fenêtres d’analyse symétriques et centrées sur la trame à traiter, telles que les fenêtres de Hamming ou de Hanning. Mais pour répondre à la contrainte de délai pour le codage temps réel de la parole, des fenêtres asymétriques peuvent être employées.
6.4 Le codage prédictif et analyse par synthèse
La relative simplicité de calcul et la bonne estimation des paramètres de la technique de prédiction linéaire en font une des méthodes les plus utilisées dans les processus de traitement de parole (voir chapitre 4).
La plupart des méthodes actuelles permettant des taux de compression significatifs et cherchent à exploiter la redondance propre du signal. Il suffira alors de ne transmettre au décodeur que l’information non prédictible.
On présente un modèle de synthèse, qui va permettre de donner la structure d’un codeur de parole basé sur le codage prédictif et l’analyse par synthèse (LPAS : Linear Prediction Analysis by Synthesis). Dans le codage LPAS (Fig. 6.2), le signal d’entrée est analysé et un signal d’excitation est déterminé. La fonction du codage prédictif consiste à définir les coefficients du filtre de prédiction tandis que le signal d’excitation est modélisé par l’analyse par synthèse. L’erreur entre le signal d’entrée et celui mis en forme par le filtre de synthèse, reproduisant les résonances (formants) du conduit vocal, est alors minimisée par le critère des moindres carrés (MMSE : Minimum Mean Square Error) pour choisir le meilleur signal d’excitation.
De par leur construction, les codeurs prédictifs ne sont plus des codeurs temporels. En effet, les données à transmettre ne sont plus des valeurs du signal échantillonné mais des paramètres résultant de la prédiction linéaire et du codage du signal d’excitation. Ces opérations effectuées pour le calcul des différents paramètres sont répétées à toutes les trames, voire plusieurs fois par trame. Les paramètres correspondants sont alors transmis au décodeur qui reconstruira le signal de parole grâce à la même structure de synthèse.
73

Fig. 6.2 Diagramme du codeur LPAS
Une des raisons du succès du codage LPAS est la possibilité d’incorporer dans sa structure une fonction qui prend en compte la perception de l’appareil auditif humain. Ce principe a pour but de minimiser un critère d’erreur plus subjectif entre le signal de parole réel et sa modélisation paramétrique. Ceci est réalisé par pondération des fréquences perceptuelles sur le signal d’erreur pendant la sélection du meilleur signal d’excitation.
6.5 Le codage prédictif linéaire bas débit
Le codage de parole à bas débit exige des représentations compactes et précises du filtre du conduit vocal et de la source d’excitation. C’est pourquoi la prédiction linéaire (LP : Linear Prediction), qui exploite les redondances du signal de parole en le modélisant par un nombre restreint de paramètres sous la forme d’un filtre linéaire, est un des outils les plus importants de l’analyse de parole.
L’idée de base du Codage Prédictif Linéaire (LPC : Linear Predictive Coding) est de considérer que tout échantillon de parole peut être exprimé comme une combinaison linéaire d’échantillons antérieurs. Un ensemble unique de coefficients prédicteurs peut alors être déterminé et utilisé pour supprimer les redondances à court terme du signal.
Lors d’une analyse à court terme, la redondance proche entre les échantillons du signal de parole est supprimée par le filtre d’analyse LP, représentant le conduit vocal. Ce filtre permet d’extraire la structure des formants du signal d’entrée et d’obtenir un signal de sortie de faible énergie, correspondant à l’erreur de prédiction appelée signal résiduel ou signal d’excitation. Le filtre inverse d’analyse est le filtre de synthèse LP, dont la fonction de transfert décrit l’enveloppe spectrale du signal de parole.
Un raffinement et un meilleur codage du signal de parole peuvent être obtenu en utilisant un prédicteur à long terme qui prendra en compte la corrélation entre des échantillons éloignés de ce signal de parole. Dans ce cas un autre filtre LP peut être employé appelé filtre prédicteur du pitch et
74

exploite la périodicité du signal, et l’extraction de cette périodicité est obtenue par estimation du pitch. L'inverse de ce filtre est appelé le filtre de pitch, qui modélise l'effet de la glotte et sa fonction de transfert décrit la structure harmonique du signal de parole.
Notons que cette analyse n’aura aucun effet sur les sons non-voisés de la parole puisque l'excitation non voisée est aléatoire, donne un bruit blanc et son spectre est plat.
6.5.1. Principe de la prédiction à court terme
La prédiction linéaire est un des outils les plus importants dans l'analyse de parole. Sa simplicité relative de calcul et sa capacité de fournir des évaluations précises sur des paramètres de parole, rend cette méthode prédominante dans le codage bas débit de parole, la synthèse ou la reconnaissance vocale.
Fig. 6.3 Modélisation de production de la parole
Le système LP (Fig. 6.3) modélise le conduit vocal qui caractérise la production de la voix. Le modèle H(z) le plus utilisé pour représenter le conduit vocal est un modèle pôle-zéro ou AutoRégressif à Moyenne Ajustée (ARMA : Auto Régressive Moving Average). Le signal s(n) est alors une combinaison linéaire de ses échantillons antérieurs et du signal d’excitation du système u(n) :
0 1( ) ( ) ( )
q p
l kl k
s n u n l s n kG b a= =
= −− −∑ ∑ (1)
Où le gain G et les coefficients ak et bl du filtre LP sont les paramètres du système avec b0 = 1. Les p échantillons passés étant considérés, p est l’ordre de prédiction linéaire. La fonction de transfert du système H(z)ARMA, dont les pôles du filtre représentent les formants du spectre est donnée par :
1
1
1( )
1
ql
llpARMA k
kk
b zH z G
a z
−
=
−
=
+=
+
∑
∑ (2)
Le facteur de gain G est généralement égal à 1. Deux cas particuliers sont alors possibles pour ce filtre :
• Si ak = 0 pour k = 1, ..., p, H(z)ARMA devient un modèle tout-zéro ou à Moyenne Ajustée (MA : Moving Average). Ce filtre H(z)MA permet de modéliser parfaitement les segments du
75

signal dont le spectre tend vers zéro. Cependant, les zéros qui transcrivent les sons non-voisés sont difficiles à déterminer car un ensemble d’équations non-linéaires doit être résolu.
Le signal s(n) en régime temporelle est représenté par:
0( ) ( )
q
ll
s n u n lb=
= −∑ avec b0 = 1 (3)
Et la fonction en z est représenté par :
1( ) 1MA
ql
ll
H z b z−==
+∑ (4)
• Si bl = 0 pour l = 1, ..., q, H(z)ARMA est réduit à un modèle tout-pôle appelé modèle Auto-Régressif (AR). Le modèle AR, qui représente parfaitement les résonances spectrales des sons voisés, est souvent utilisé pour sa simplicité et son efficacité dans des systèmes temps réel. La fonction de transfert du conduit vocal est alors approximée par le modèle tout-pôle H(z)AR :
1
1( )1
pAR k
kk
H za z −
=
=+ ∑
(5)
Pour obtenir le filtre H(z)AR = 1/A(z) avec le polynôme A(z) dont les paramètres ak sont appelés coefficients LP.
1( ) 1
pk
kk
A z a z −
=
= + ∑ (6)
Basé sur le modèle tout-pôle, l'échantillon de parole courant est prédit par une combinaison linéaire de p échantillons passés
1ˆ( ) ( )
p
kk
s n s n ka=
= − −∑ avec a0 = 1 (7)
Le modèle de tout-pôle est préféré pour la plupart des applications parce que c'est plus efficace en calcul et adapte le modèle des tubes acoustiques pour la production de parole (voir chapitre 3), et il fournis une très bonne représentation des effets du conduit vocal des sons de voyelles qui sont résonants du point de vue acoustique.
On peut dire que ce modèle est une approximation pour des classes de phonème nasal et fricatives qui contient des spectres nuls qui sont bien modelés par les zéros de la fonction de transfert du conduit vocale. Néanmoins, l'oreille humaine est plus sensible aux spectres des pôles que les zéro.
Les coefficients LP sont déterminés, à l’aide de différentes techniques telles que les méthodes d’autocorrélation, de covariance ou de Burg (voir chapitre 4), à partir d’un système à p équations et p inconnues de telle sorte que le signal reconstitué soit le plus proche possible du signal original.
76

Fig. 6.4 Analyse et synthèse LP
La modélisation complète peut maintenant être décomposée en deux parties (Fig. 6.4):
• Une partie analyse qui filtre le signal d’entrée avec la fonction de transfert A(z). Ce filtre tout-zéro est défini comme le filtre d’analyse LP et permet d’extraire l’information prédictible du signal et de définir un signal d’erreur résiduel entre le signal de parole d’entrée s(n) et son estimation : )(ˆ ns
• Une partie synthèse qui effectue un filtrage de fonction de transfert H(z)AR. Ce filtre tout-pôle, connu sous le nom de filtre de synthèse LP, permet de reconstruire, à l’aide d’un signal d’excitation approprié, un signal de parole artificiel.
1( ) ( ) ( ) ( )
p
res kk
s n s n s n s n ke=
= − = + a −∑) (8)
Le signal résiduel eres est l’excitation idéale du modèle LPC du conduit vocal HAR(z). Une modélisation précise de ce signal permet d’obtenir un signal reconstruit naturel. Or l’estimation des paramètres LP du modèle vocal entraîne une approximation du signal d’excitation. A mesure que l’ordre du modèle LPC augmente, un meilleur ajustement au spectre de la voix est obtenu.
Cependant, plus l’ordre p sera élevé, plus le nombre de paramètres à transmettre augmentera. Ainsi on peut dire que l’ordre doit résulter d’un compromis entre une bonne représentation de la structure formantique du signal de parole, la complexité de calcul et le débit de transmission. En général, deux pôles sont nécessaires pour représenter chaque formant et jusqu’à quatre autres sont employés pour approximer les vallées du spectre.
La figure 6.5 montre la variation du gain de prédiction Gp, exprimé en dB, en fonction de l’ordre du filtre d’analyse.
77
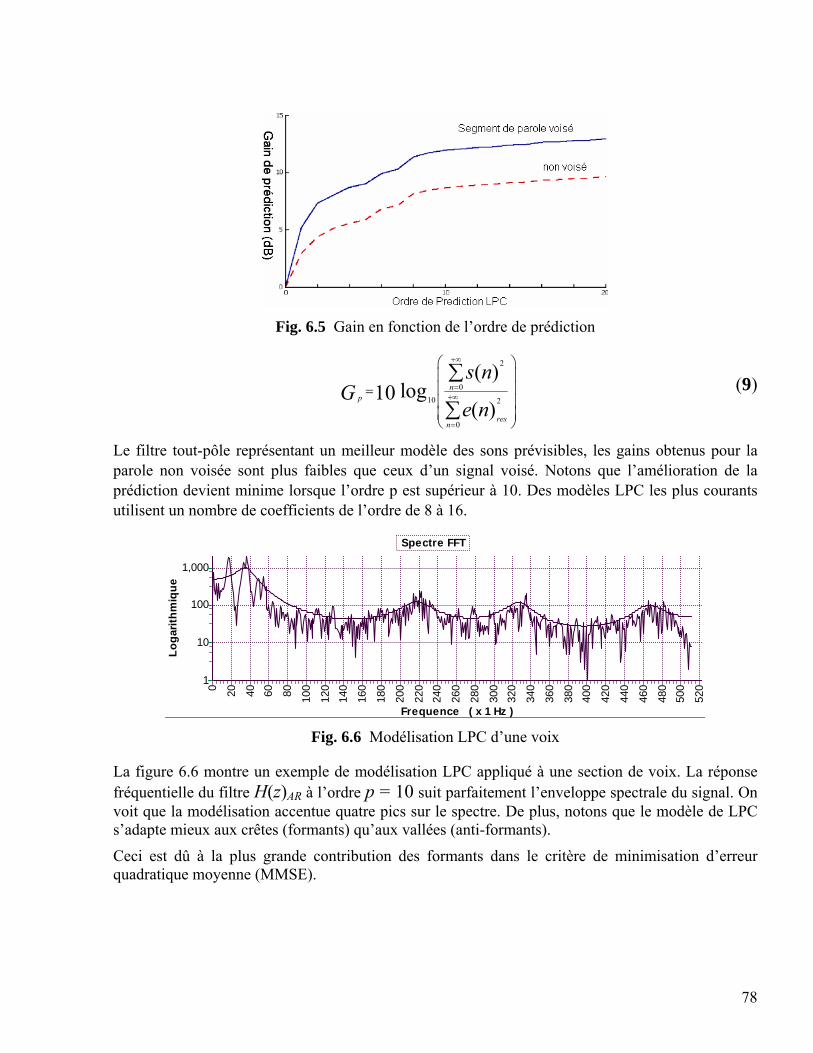
Fig. 6.5 Gain en fonction de l’ordre de prédiction
2
010 2
0
( )log10
( )n
p
resn
s nG
e n
+∞
=+∞
=
⎛ ⎞⎜⎜=⎜ ⎟⎜ ⎟⎝ ⎠
∑
∑
⎟⎟ (9)
Le filtre tout-pôle représentant un meilleur modèle des sons prévisibles, les gains obtenus pour la parole non voisée sont plus faibles que ceux d’un signal voisé. Notons que l’amélioration de la prédiction devient minime lorsque l’ordre p est supérieur à 10. Des modèles LPC les plus courants utilisent un nombre de coefficients de l’ordre de 8 à 16.
Spectre FFT
Frequence ( x 1 Hz )52
0
500
480
460
440
420
400
380
360
340
320
300
280
260
240
220
200
180
160
140
120
100806040200
Loga
rithm
ique
1
10
100
1,000
Fig. 6.6 Modélisation LPC d’une voix
La figure 6.6 montre un exemple de modélisation LPC appliqué à une section de voix. La réponse fréquentielle du filtre H(z)AR à l’ordre p = 10 suit parfaitement l’enveloppe spectrale du signal. On voit que la modélisation accentue quatre pics sur le spectre. De plus, notons que le modèle de LPC s’adapte mieux aux crêtes (formants) qu’aux vallées (anti-formants).
Ceci est dû à la plus grande contribution des formants dans le critère de minimisation d’erreur quadratique moyenne (MMSE).
78

Signaux
Temps ( x 0,1 ms ) 10,0
00
9,50
0
9,00
0
8,50
0
8,00
0
7,50
0
7,00
0
6,50
0
6,00
0
5,50
0
5,00
0
4,50
0
4,00
0
3,50
0
3,00
0
2,50
0
2,00
0
1,50
0
1,00
0
5000
Am
plitu
de
30,00020,00010,000
0-10,000-20,000-30,000
Signaux
Temps ( x 0,1 ms ) 10,0
00
9,50
0
9,00
0
8,50
0
8,00
0
7,50
0
7,00
0
6,50
0
6,00
0
5,50
0
5,00
0
4,50
0
4,00
0
3,50
0
3,00
0
2,50
0
2,00
0
1,50
0
1,00
0
5000
Am
plitu
de
30,00020,00010,000
0-10,000-20,000-30,000
Fig. 6.7 (a) signal source, (b) signal résiduel après prédiction à court terme
Un second exemple d’analyse LPC, effectuée toutes les 1024 millisecondes sur un signal de parole échantillonné à 8 kHz, est donné (Fig. 6.7). Après avoir déterminé les coefficients du filtre d’analyse, le signal d’erreur e(n)res est extrait (Fig. 6.7 (b) ). Ce signal devient l’excitation du filtre de synthèse qui fournira une estimation du signal de parole s(n). )(ˆ ns
On peut calculé le gain de prédiction linéaire Gpseg pour chaque trame de signal de N échantillons et fait ressortir les caractéristiques de l’analyse à court terme.
1 2
0110 2
0
( )( ) log10
( )
N
nNPseg
resn
s n kNG k
e n kN
−
=−
=
⎛ ⎞⎜ ⎟⎜=⎜ ⎟⎜ ⎟⎝ ⎠
+∑
+∑⎟ (10)
Où k ≥ 0, est le numéro de la trame.
On note que la modélisation à court terme d’un signal de parole est généralement plus médiocre lorsque le signal est fortement non stationnaire. Et pour être complet qu’analogiquement à la quantification prédictive, la prédiction linéaire peut être classée, soit en tant que forward adaptive, dans le cas d’une prédiction basée sur des échantillons de parole du signal d’entrée où les coefficients LP doivent être transmis au récepteur, soit en tant que backward adaptive où la prédiction est basée sur des échantillons du signal reconstruit. La plupart des codeurs à bas débit utilisent la prédiction forward adaptive.
79

6.5.2. Principe de la prédiction à long terme
La mise en oeuvre d’une Prédiction à Long Terme (LTP : Long Term Prediction), lors d’un codage par prédiction linéaire, est un moyen efficace de représenter la périodicité du signal de parole.
Cette analyse n’a pas d’effet sur des trames de parole non voisée qui n’ont pas de structure harmonique. En effet, elle a pour but de modéliser les vibrations des cordes vocales produisant les sons voisés qui possèdent des corrélations à long terme et se traduisent au niveau du signal de parole par une fréquence fondamentale F0 ou hauteur de voix. Le nombre pi d’échantillons, appelé pitch, contenus dans l’intervalle entre deux écartements successifs des cordes vocales, peut être exprimé par :
pi = Fe/F0
Où Fe est la fréquence d’échantillonnage. La fréquence fondamentale varie en fonction de chaque individu. En général, la variation s’étend de 80 à 200 Hz pour une voix masculine (voix grave), de 150 à 450 Hz pour une voix féminine et de 200 à 600 Hz pour une voix d’enfant (voix aiguës).
Notons que dans le cas où la fréquence fondamentale F0 n’est pas un diviseur de la fréquence d’échantillonnage Fe, la valeur de pi n’est pas un nombre entier. Ainsi l’estimation du pitch est un des problèmes les plus difficiles de l’analyse de la parole. Elle est également un des plus importants, car l’oreille est plus sensible aux changements de fréquence F0 qu’à n’importe quel autre paramètre.
Fig. 6.8 Signal non stationnaire : région de transition
Mais l’identification de la fréquence fondamentale est rendue difficile par plusieurs facteurs :
• Le signal, considéré comme stationnaire sur une trame de courte durée (10 à 30 ms), présente souvent des cassures. Dans les régions de transition, les caractéristiques de la parole peuvent changer rapidement (Fig. 6.8)
• Le filtrage d’analyse LPC a pour effet de modifier les harmoniques. Certains seront amplifiés (1er formant), d’autres atténués
• Les transmissions étant à bande limitée [300, 3400] Hz, les premiers harmoniques sont souvent perdus (voix d’homme)
80

• L’éventail des fréquences fondamentales possibles est assez large. L’intervalle classique des valeurs de pitch de 20 à 160 échantillons correspond à un intervalle pour F0 de 50 à 400 Hz
• La possibilité d’une présence simultanée d’une excitation voisée et non-voisée
• La présence de bruit ambiant.
Le pitch modélise la période fondamentale du signal et représente le nombre d’échantillons de retard qu’il est nécessaire de prendre pour retrouver une portion de signal similaire. La prédiction à long terme symbolise ainsi la mémoire du système. La redondance à long terme peut être modélisée en utilisant un filtre linéaire P(z) du premier ordre. Le filtre d’analyse de pitch est donné par :
( ) 1 piP z zβ= − (11)
Où β est le coefficient prédicteur, correspondant au degré de périodicité avec 0 ≤ β < 1 et pi l’estimation en nombre d’échantillons de la période fondamentale.
Dans le domaine temporel, le filtre d’analyse de pitch soustrait un échantillon de parole retardé d’un délai estimé à partir des échantillons de la trame courante. Dans le domaine fréquentiel, le filtre d’analyse de prédiction à long terme enlève la structure harmonique du signal d’entrée. Ces paramètres, calculés en général 50 à 200 fois par seconde, sont déterminés également de manière à optimiser le signal de parole synthétisé.
La méthode, dite en boucle ouverte, fournit un signal résiduel e(n)res par le filtrage du signal de parole s(n) par P(z).
(( ) ( )ress n )pie n s n β= − − (12)
Pour un signal voisé, on a un critère CLTP:
( )2
2
( ) ( )( )
nLTP
n
s n s n piC s n pi
=−∑
−∑ (13)
Ce dernier possède un maximum local pour les valeurs de pi correspondant à la fréquence fondamentale ou à ses multiples. Dans ce cas, la valeur de β est proche de 1. Pour un signal non voisé ou transitoire, qui n’a pas de structure périodique marquée où possède une période pi trop importante pour qu’elle soit prise en compte, il n’existe pas de pic identifiable. La valeur de pi est alors généralement aléatoire et la valeur du gain optimal est donnée par β ≅ 0.
On conclus que la prédiction à long terme modélise au mieux les signaux stationnaires fortement périodiques, ainsi une multiplication par deux de Fe entraîne une amélioration de 6 dB sur le gain de prédiction, c’est à dire une division par 4 de l’erreur de prédiction.
81

Puisqu’il n’y a pas de relation entre la fréquence d’échantillonnage et la fréquence fondamentale, la période de pitch n’est pas nécessairement un nombre entier. Un filtre prédicteur du premier ordre n’est donc pas toujours suffisant pour déterminer exactement la périodicité du signal. Pour une meilleure représentation du pitch, une solution consiste à augmenter la résolution du signal. Kroon et Atal proposent alors un filtre d’analyse P(z) d’ordre supérieur. Ce filtre fournit une interpolation des échantillons et permet d’approximer le signal de parole, à une fréquence d’échantillonnage plus importante, par une combinaison linéaire de ses échantillons antérieurs :
1
1( ) 1 k
k
pi kP z zβ −
=−
+= − ∑ (14)
L’utilisation d’une prédiction à coefficients multiples permet d’obtenir de meilleurs résultats et d’affiner le gain de prédiction. Toutefois ce traitement augmente la complexité des calculs et le nombre de coefficients du filtre, ce qui peut entraîner des problèmes d’instabilité. Un filtre de prédiction du pitch d’ordre 3 (Equation 14) est un bon compromis entre la qualité du signal de parole synthétisée et le coût des opérations supplémentaires mises en oeuvre. Une autre méthode, pour améliorer l’efficacité de prédiction, est d’employer un pitch de meilleure résolution temporelle. Cette période, appelée pitch fractionnaire, pourra prendre des valeurs non entières.
Notons cette notion de pitch fractionnaire sera utilisé lors de la conception de notre codeurs basé FS1016 dans le chapitre suivant.
6.5.2. Estimation des paramètres prédicteurs
Dans cette partie on présente une formulation générale pour déterminer les coefficients de prédiction à court et à long terme.
Basé sur le model montré dans la figure ci-dessous, le signal d'erreur ew[n] fenêtré est donné comme suit :
Fig 6.9 Model d’analyse pour estimation
des paramètres prédicteurs à court et à long terme
( ) ( ) ( )w en n ee w= n (15)
1( ) ( ) ( ) ( ) ( )
L
w e w e k wk
kn n n n ne w s w c s D=
= − −∑ (16)
Où s(n) est le signal d’entrée, wd(n) et we(n) sont les fenêtres donnée et d’erreur respectivement
82

Les valeurs entières de Dk sont arbitraire mais distincts correspondant aux retards du signal d'entrée pondéré s(n).
L’énergie de l’erreur ou l’erreur quadratique moyenne est donnée par
2( )w neξ+∞
−∞
= ∑ (17)
Les coefficients ck sont calculés en réduisant au minimum ξ. C'est fait en prenant la dérivée partielle de l’équation ci-dessus, en respectant chacun des coefficients ck, pour k = 1,...,L et mettant chacune des L équations résultantes à zéro. Cela mène à un système linéaire des équations qui peuvent être écrites dans une forme matricielle (Φ c= a):
...1 1 1 2 1 11
...2 1 2 2 2 22...... ... ... ... ...
...1 2
[ , ] [ , ] [ , ] [ , ]0[ , ] [ , ] [ , ] [ , ]0
[ , ] [ , ] [ , ] [ , ]0
L
L
L L L L L L
D D D D D D DccD D D D D D D
cD D D D D D D
φ φ φ φφ φ φ φ
φ φ φ φ
⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ =⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥⎣ ⎦⎣ ⎦
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
(18)
Où 2[ , ] ( ) ( ) ( )e w w
ni j n n i n jw s sφ
+∞
=−∞
= − −∑ (19)
La matrice φ est positive et symétrique, elle est aussi une matrice Toeplitz si les retards des intercoefficients sont égaux. Selon φ est Toeplitz ou non, la récursion de Levinson ou la décomposition de Cholesky peut être employée pour résoudre le système d'équations.
Pour un prédicteur de formant Dk = k pour k = 1,…,p et pour un prédicteur de pitch d’ordre Np Dk = D + k pour k = 0,…,Np-1.
Si we(n) = 1 ∀ n, la formulation ci-dessus résulte la méthode d’autocorrélation, et si wd(n) = 1 ∀ n, la formulation résulte la méthode de covariance.
Pour la prédiction de formant ou la prédiction à court terme, il a été montré que la méthode d'autocorrélation donne une phase minimal du filtre d’analyse LP, tandis que le filtre de synthèse LP résultant a partir de la méthode covariance pourrait être instable.
Dans le cas de prédiction du pitch, la méthode d'autocorrélation (sauf le cas d'un seul prédicteur de pitch) et la méthode de covariance pourraient aboutir à un filtre de synthèse du pitch instable. Cependant, l'instabilité est souvent utile pour modéliser l’augmentation des amplitudes dans le signal d'excitation. Comme la méthode covariance donne des gains de prédiction de valeur hausse, elle est ainsi préférée pour la prédiction du pitch. Chaque fois que le filtre de synthèse du pitch devient instable, des arrangements de stabilisation efficaces peut être employé pour limiter l'instabilité à des limites désirables.
83

Jusqu'ici nous avons supposé que l'on connaît la période du pitch D. Souvent un filtre de pitch d’un seul prédicteur est employé et D est déterminé séparément du coefficient de pitch en utilisant la méthode covariance, dans ce cas, l’erreur quadratique moyenne, peu être écrite dans la forme matricielle, ξ= φ[0,0]-2cTa+cTΦ c, et étant donné que l'on donne les coefficients optimales par c=Φ-1a, l’erreur quadratique moyenne sera :
ξ= φ[0,0]-cTa. (20) Pour un seul prédicteur du pitch on aura :
φ[D, D]c1=φ[0,D] (21)
et le coefficient optimale βopt est donné par
1
[0, ][ , ]opt
Dc D D
φβ φ= = (22)
Donc l’erreur quadratique moyenne se réduit à 2[0, ][0,0] [ , ]
DD D
φξ φ φ= − (23)
L’erreur quadratique moyenne est minimisé en maximisant φ2[0,D]/φ[D,D]. Cette fonction est calculé sur toute les valeur possibles de D, et sont maximum indique le meilleurs choix pour la période du pitch D. Le rang des valeurs sur lequel la période du pitch est recherché est typiquement entre 20 et 143 échantillons (pour la parole échantillonnés à 8 Khz) qui couvre les valeurs du pitch les plus rencontrés dans la parole humaine.
6.6 Signal d’excitation
L’analyse LPC fournit une technique efficace pour coder les informations du filtre de conduit vocal (Fig. 6.4). Le filtre A(z) enlève les redondances des échantillons proches du signal de parole. Cependant, les trames de parole voisée contiennent une corrélation qui reste présente dans le signal résiduel à court terme. Les segments voisés étant les plus importants pour la perception globale d’un signal de parole, la plupart des codeurs se concentrent sur l’efficacité de codage des signaux d’excitation quasi-périodiques en utilisant une analyse de prédiction à long terme la plus efficace possible.
La parole synthétisée est obtenue en excitant un filtre de synthèse LP avec un signal d’excitation périodique, qui se compose d’une suite d’impulsions d’une période égale à l’estimation du pitch ou d’un bruit blanc pour produire respectivement des sons voisés ou non, auxquels est associé un gain approprié (Fig. 6.10). L’inconvénient principal de ce type de synthèse est que le signal de parole reconstruit garde une qualité mécanique, en raison du modèle simple de l’excitation. Le signal d’excitation à coder et à transmettre au décodeur demandera donc une évaluation plus précise de ses paramètres pour obtenir une parole synthétisée plus naturelle.
84

Fig. 6.10 Excitation simple du filtre de synthèse
Notons que pour un signal stationnaire et périodique, le signal résiduel ressort faible et totalement décorrélé alors que les périodes non stationnaires du signal sont faiblement prédites. De plus, les analyses à court et long terme n’étant pas complémentaires, le gain de prédiction cumulé à l’issue des deux analyses n’est pas égal à la somme des gains de prédiction dissociés. Enfin remarquons que ces deux analyses ne sont pas capables de modéliser certaines particularités du signal de parole telles que les variations brusques d’amplitude. Cette difficulté à modéliser les non stationnarités était attendue car le principe de l’analyse prédictive repose sur l’analyse de signaux stationnaires alors que le signal de parole ne l’est pas. Les hypothèses de départ n’étant pas strictement vérifiées, il est logique que les résultats soient eux aussi quelque peu faussés.
Le signal d’excitation obtenu après prédiction à court et long terme est un signal blanchi présentant théoriquement une densité de probabilité proche d’une loi de probabilité gaussienne. Cette approximation peut être faite si les périodes de silence et de transitions, entre sons voisés ou non, ne sont pas prises en compte.
Fig. 6.11 Distribution des amplitudes du signal d’erreur
85

Notons que cette distribution se rapproche plus d’une loi de Laplace que d’une loi gaussienne. La valeur moyenne des échantillons est voisine de zéro et les faibles valeurs sont prédominantes.
6.7 Pondération perceptive
Le principe de l’analyse par synthèse, utilisée pour déterminer le signal d’excitation, est de minimiser un critère d’erreur entre une séquence du signal de parole s(n) et sa modélisation paramétrique )(ˆ ns (Fig. 6.2). L’excitation optimale sera par exemple établie par minimisation de
l’erreur quadratique moyenne, définie comme l’espérance mathématique
(⎭⎬⎫
⎩⎨⎧
− )(ˆ)(2
nsnsE ) (24)
Cependant, ce critère n’étant pas bien adapté à notre système auditif, une correction peut être intégrée pour pallier cet inconvénient. Dans de nombreux cas, le critère d’erreur est modifié par une pondération perceptive dont le but est de contrôler la répartition fréquentielle du bruit, qui s’étend généralement sur tout le spectre.
Le caractère physiologique de l’oreille possède la propriété intéressante d’enregistrer les sons d’une manière fréquentielle. De cette propriété découle la pondération perceptive qui a pour fonction de répartir la puissance du bruit d’une fréquence à une autre. Cette répartition est efficace lorsque la distribution de la puissance du bruit est augmentée au niveau des formants.
Dans ce cas, le bruit est masqué par la puissance du signal et l’écoute sera plus agréable. Le nouveau critère, appelé critère d’erreur subjectif, est défini comme la minimisation de l’erreur quadratique donnée par
( )2
( )( ) ( )( )
A zs z s zzAγ
⎡ ⎤−⎢ ⎥
⎣ ⎦
) (25)
Où le filtre de pondération perceptive est donné par :
1
1
1( )( ) 1
pk
kk
p k k
kk
a zA zzA a zγ γ
−
=
−
=
+=
+
∑
∑ (26)
Le filtre de pondération est construit à partir du filtre de prédiction à court terme A(z). Ce choix rend la répartition spectrale du bruit proportionnelle à celle du signal de parole. Toutefois le système auditif ne réagissant pas avec la même sensibilité pour toutes les fréquences, il est nécessaire d’introduire un coefficient γ pour contrôler au mieux la répartition de la puissance du bruit.
86

Fig. 6.12 Codeur LPAS avec pondération perceptive
6.8 Le codeur CELP
Le but du codage est de diminuer le débit nécessaire à la transmission des informations de synthétisation de la parole. Pour ce faire, des méthodes efficaces ont été proposées pour réduire le nombre de bits nécessaires pour coder le signal d’excitation. Les premiers codeurs prédictifs furent obtenus en quantifiant les échantillons du signal d’erreur de prédiction sur 2 ou 3 bits. Ce type de codage présentant un fort bruit de quantification, le débit n’a pu être réduit au-delà de 16 kbits/s sans une perte de qualité importante.
Après la prédiction à court et à long terme, le signal résiduel résultant est très proche à bruit avec une normalisation de gain approprié qui suit une distribution presque Gaussienne. Ceci nous motive à l'utilisation d'un dictionnaire de formes d'onde généré aléatoirement selon une loi Gaussienne. En raison de leur nature aléatoire, ces formes d'onde sont aussi appelées stochastiques et le dictionnaire de formes d'onde est généralement mentionné comme dictionnaire stochastique. Les codeurs CELP ne transmettent pas le signal résiduel après la prédiction. Au lieu de cela, un index à une forme d'onde stockée dans le dictionnaire stochastique avec un facteur de gain est envoyé.
Fig. 6.13 Le codeur CELP
87

Les codeurs de type CELP (Code Excited Linear Predictive), dont le modèle est donné par la figure ci-dessus (Fig.6.13), forment un sous-ensemble de la classe plus générale des codeurs LPAS (Linear Prediction Analysis by Synthesis). Ce type de codeur hybride utilise de façon complémentaire les avantages des techniques de codage temporelles et paramétriques pour permettre un codage efficace du signal de parole.
Le principe des codeurs CELP étant basé sur la prédiction linéaire et l’analyse par synthèse, l’innovation ne réside que dans le codage du signal d’erreur. Une analyse de prédiction linéaire standard (calcul à l’ordre p des coefficients akp
k=1 du filtre LP) et une modélisation du pitch (détermination des paramètres pi et β ) sont utilisées dans cet ordre pour déterminer, en tenant compte d’une pondération perceptive, l’excitation idéale du filtre de synthèse et les paramètres de reconstruction de la parole. Ce signal d’erreur résiduelle est ensuite représenté à partir de trames de signal prédéfinies, contenues dans un ou plusieurs dictionnaires. Cette technique de codage sélectionne, en parcourant les dictionnaires, la forme d’onde du signal d’excitation qui minimise l’erreur quadratique moyenne entre le signal de parole et sa modélisation paramétrique. Notons que le signal d’excitation étant choisi par bloc, le choix de la meilleure forme d’onde peut être regardé comme une quantification vectorielle des échantillons et la différence entre le signal résiduel et la forme d’onde choisie considérée comme une erreur de quantification.
Les dictionnaires ont des structures particulières et sont caractérisés selon leur méthode de construction. Le signal d’excitation possédant une densité de probabilité proche d’une gaussienne, Schroeder et Atal ont proposé un dictionnaire de mots de code constitué d’échantillons aléatoires gaussiens. D’autres types de dictionnaires ont été envisagés dans le but de réduire la complexité des algorithmes de sélection de la forme d’onde optimale ou le nombre de bits nécessaires pour son codage.
Les formes d’ondes permettront de bien modéliser l’excitation non-voisée et le filtre de synthèse de prédiction à long terme fournira la périodicité désirée au signal reconstruit. Les mots de code étant normalisés à l’unité, un gain leur est généralement associé de manière à modéliser au mieux le signal résiduel. Les paramètres à transmettre ne sont alors plus que l’index correspondant à la position du meilleur mot de code dans le dictionnaire, son gain associé et les coefficients des filtres d’analyse. Le dictionnaire étant connu du décodeur, l’index et le gain sont alors utilisés pour exciter les filtres de synthèse et donc reconstruire le signal de parole.
L’utilisation d’un codeur CELP pour le codage de la parole tend à donner de bons résultats pour des débits assez bas, compris entre 4 et 16 kbits/s, dont 75% est assigné au codage des paramètres liés aux dictionnaires. Au-dessous de 4 kbits/s, la qualité se dégrade brusquement car il n’y a plus assez de bits disponibles pour représenter en juste proportion l’excitation. Cependant, les performances obtenues dépendent pour beaucoup du dictionnaire choisi. Ce sont généralement les applications liées au codeur qui vont dicter le type de dictionnaire à utiliser. En effet, pour une application temps réel, l’utilisation d’un dictionnaire gaussien ou stochastique est pratiquement impossible du fait de la charge de calcul nécessaire pour déterminer les formes d’onde optimales. L’utilisation d’un dictionnaire algébrique est alors plus souvent privilégiée.
88

Notons pour la suite de notre étude (chapitre 7) que le filtre de synthèse de pitch est souvent remplacé par une recherche dans un dictionnaire adaptatif, dont le contenu est mis à jour à l’aide de l’excitation codée passée. Les systèmes utilisant ce type de dictionnaires représentent l’excitation courante par une version antérieure et modulé de celle-ci, à l’aide généralement d’une période de pitch fractionnelle. Pendant cette recherche, une gamme de valeurs de chaque paramètre est testée et celle qui fournit la synthétisation la plus précise est choisie. Ce processus qui choisit, à partir du signal résiduel LP, les paramètres d’un dictionnaire de manière à optimiser la qualité du signal reconstruit, est désigné sous le nom de recherche en boucle fermée et fait suite à l’analyse LPC, dite en boucle ouverte, qui détermine les paramètres en analysant directement le signal d’entrée. Toutes ces notions sont reprises, dans le chapitre 7, lors de la présentation détaillée du codeur basé FS1016 implanté pour cette étude.
6.9 Modélisation du signal d’excitation
Le filtre de synthèse de prédiction linéaire modélise la périodicité à court terme du signal. Dans de nombreux codeurs récents, le filtre de synthèse de pitch est considéré comme une recherche dans un dictionnaire adaptatif dont le contenu est mis à jour à l’aide de l’excitation passée. Dans les systèmes utilisant ce type de dictionnaire, la périodicité à long terme est ainsi modélisée en représentant l’excitation courante par une version passée et modulée de celle-ci. Le dictionnaire adaptatif, dans un dispositif CELP (Fig. 6.14), tend à fournir une bonne approximation de la forme d’onde d’excitation et plus particulièrement pour les segments continus de parole voisée. Le dictionnaire stochastique aura alors pour objectif de modéliser les composants aléatoires restants et les segments non-voisés du signal d’excitation.
Fig. 6.14 Synthèse de codeur CELP avec dictionnaires fixe et adaptatif
Pour la détermination de ces paramètres d’excitation, il existe différentes méthodes dont la complexité de calcul et les performances varient. Dans les codeurs de type CELP, une recherche exhaustive dans les dictionnaires adaptatif et stochastique est effectuée pour déterminer l’excitation u(n) qui est une combinaison linéaire de la contribution des dictionnaires :
( ) ( ) ( )u n v n c nGβ= + avec n = 1, … ,L-1 (27)
89

Où les formes d’onde c, v et les gains associés G, β des dictionnaires fixe et adaptatif représentent les paramètres d’excitation possible qui cherchent à minimiser l’erreur quadratique moyenne entre les sous-trames de parole originales et celles reconstruites par le filtre de synthèse LP. Remarquons pour la suite que le signal à modéliser n’étant pas le signal de parole d’entrée s(n) mais en fait le signal perceptuel sw(n) :
0( ) ( ) ( )
L
w wk
n k s ns h=
= k−∑ (28)
le signal d’excitation à rechercher aura pour expression :
1 1
0 0( ) ( ) ( ) ( ) ( ) ( ) ( )
L L
w w wk k
u n k v n k k c n k n nh G h v Gβ β− −
= =
= + = +− −∑ ∑ wc (29)
Avec n = 0, … ,L-1
Où L et hw représentent respectivement le nombre d’échantillons contenus dans une sous-trame et la réponse impulsionnelle du filtre de pondération perceptive. Les deux dictionnaires étant habituellement explorés séquentiellement, le vecteur d’excitation optimal vopt et son gain βopt pour le répertoire adaptatif sont déterminés dans un premier temps. Ensuite, l’entrée du dictionnaire stochastique copt et son gain Gopt sont choisis. L’ordre se justifie par le fait que le dictionnaire adaptatif fournit normalement la plus grande contribution à l’excitation globale u(n).
Il est largement accepté que le signal de parole, reconstruit par un codeur CELP, souffre d’une légère dégradation de qualité. Une première dégradation, due à une capacité limitée à retranscrire la périodicité des sons voisés, tend à s’accentuer pour des valeurs de pitch élevées correspondant à des fréquences fondamentales de la gamme [200, 400] Hz. Une seconde provient de l’utilisation d’un bruit comme excitation stochastique, ce qui augmente le niveau sonore du bruit de fond perçu dans le signal synthétisé. Afin d’améliorer la modélisation de l’excitation tout en maintenant une complexité de calcul raisonnable, différentes techniques ont été proposées.
6.9.1. Dictionnaire adaptatif
Bien que les coefficients du filtre de synthèse LP soient mis à jour à chaque trame, les paramètres d’excitation comprenant les gains et les index des dictionnaires seront déterminés à chaque sous-trame pour obtenir une meilleure modélisation de l’excitation et réduire les dimensions des dictionnaires.
Le pitch p optimal étant estimé en comparant le signal traité à des segments d’excitation passée, le dictionnaire adaptatif, noté U, doit mémoriser à chaque sous-trame les échantillons 1
0 ( )L
nu n −
= de
l’excitation courante. Pour des délais inférieurs à la longueur L d’une sous-trame, les échantillons 1
0 ( )L
nu n −
= nécessaires à l’exploration du dictionnaire n’étant pas encore connus, le signal résiduel de
prédiction linéaire 1
0 ( )L
nres ne−
= est copié sur cet intervalle (Fig. 6.15).
90

Fig. 6.15 Dictionnaire adaptatif avant sélection de l’excitation
Les éléments u du dictionnaire U correspondent aux échantillons de
ou de l’excitation passée :
1 1
0 0 ( ) ( )L L
n nres n ne r− −
= ==
max( ) (u n rd = )n+ (30)
max( ) (u p ud = )p− − (31)
avec n = 0, ..., L-1 et p = 1, ..., dmax, la valeur dmax étant le pitch maximal autorisé. Le dictionnaire adaptatif pouvant alors s’écrire sous la forme d’une structure Toeplitz, chaque vecteur du dictionnaire U représente l’excitation pour un délai spécifique.
...max max max min
...max max max min... ... ... ...
... min
... min
( ) ( 1) ( 1)( 1) ( ) ( 2
(1) (2) ( 1)(0) (1) ( )
u u u Ld d d du u u Ld d d d
Uu u u du u u d
⎡ ⎤⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥=⎢ ⎥⎢ ⎥⎢ ⎥⎢ ⎥⎣ ⎦
)+ − + −
− −
+
+ − (32)
Où dmin représente la valeur minimum utilisée dans la recherche du pitch. Notons que la capacité de stockage de modèles d’excitation du dictionnaire adaptatif contribue de manière significative à la qualité d’un codeur CELP. Cependant, pour un signal fortement bruité, cette mémoire de dmax échantillons contribuera également aux mauvaises performances du codeur.
Fig. 6.16 Procédure de mise à jour du dictionnaire adaptatif
91

Les coefficients des filtres de prédiction linéaire sont recalculés toutes les trames et entraînent une nouvelle opération de filtrage des dictionnaires d’excitation à chaque sous-trame comme indiquée par l’équation :
1 1
0 0( ) ( ) ( ) ( ) ( ) ( ) (
L L
w w wk k
u n k u n k k c n k n nh G h u Gβ β− −
= =
= + = +− −∑ ∑ )wc (33)
avec n = 0, … ,L-1
En effet, le dictionnaire adaptatif est actualisé, après détermination du pitch et sélection de l’excitation courante, mais seule L échantillons devront être filtrés, les autres ne subissant qu’une
translation de position (Fig. 6.16). Le décalage est réalisé après que l’excitation 1
0 ( )L
nu n −
= résultante des contributions des dictionnaires, fixe et adaptatif, soit copiée sur les échantillons
courants . Une nouvelle séquence du signal résiduel de prédiction linéaire
est ensuite introduite pour préparer la recherche du pitch de la sous-trame suivante.
1
0 ( )L
nu n −
=
1 1
0 ( ) ( )L L
nres n ne r− −
==
0n=
k
La procédure d’exploration du dictionnaire adaptatif contribuant à un large part de la complexité du codeur, beaucoup de techniques ont été proposées pour l’améliorer. La plus commune est basée sur la réduction du nombre de périodes de pitch à examiner en effectuant une procédure à deux étapes. Une analyse en boucle ouverte estime, dans un premier temps, une période de pitch par des valeurs entières et réduit l’intervalle possible sur lequel la recherche pourra être affinée. Le nouvel intervalle présélectionné est alors exploré par une procédure en boucle fermée pour déterminer, grâce à des valeurs non entières, une meilleure résolution du pitch.
6.9.1.1 Analyse en boucle ouverte
La complexité de la recherche en boucle fermée est réduite grâce à la réduction, par une analyse en boucle ouverte, de l’intervalle des valeurs de pitch possible autour d’une valeur optimale potentielle Tbo. L’estimation du pitch en boucle ouverte peut fournir généralement une ou plusieurs valeurs possibles du paramètre p pour chaque trame de longueur N. Dans une approche de type CELP, une fonction d’autocorrélation appliquée au signal de parole pondéré
0( ) ( ) ( )
L
w wk
n k s ns h=
= −∑ (34)
est communément utilisée pour extraire ces valeurs de pitch :
1
0( ) ( )
N
p w wn
n n ps sR−
=
= −∑ (35)
92

6.9.1.2 Analyse en boucle fermé Dans l’exploration en boucle fermée du répertoire adaptatif, le signal résiduel de prédiction
linéaire filtré par la pondération perceptive est utilisé en tant que signal d’excitation de référence
. Ce dernier est aussi appelé signal cible. La recherche de la valeur de pitch en boucle
fermée s’effectue alors par maximisation de la corrélation R
1
0 ( )L
nc nr−
=
T : 1 1 1
0 0 0( ) ( ) ( ) ( ) ( )
L L L
T c cwwn k n
k n k u n T n u n ThR r r− − −
= = =
⎛ ⎞= =⎜ ⎟
⎝ ⎠− − −∑ ∑ ∑ (36)
où rcw représente le signal cible filtré par la pondération perceptive et u l’excitation antérieure, contenue dans le dictionnaire adaptatif U, retardée par un délai T représentant les valeurs entières voisines de Tbo obtenu à partir de l’analyse en boucle ouverte. Le délai T, qui fournit la valeur maximale RTmax, sélectionne le signal d’excitation de la sous-trame courante (Fig. 6.16) et sera noté pour la suite T1 ou T2 selon l’ordre de la sous-trame. Notons que c’est cette étape qui demande la
copie du signal résiduel de prédiction linéaire 1
0 0 ( ) ( )L
n nres n ne r1L− −
= == dans le dictionnaire
adaptatif (Fig. 6.16) pour les échantillons 1
0 ( )L
nu n −
= qui ne sont pas connus mais nécessaires pour
les valeurs de pitch inférieures à L = 40 (Fig. 6.17).
Fig. 6.17 Sélection de l’excitation pour T > L
Fig. 6.18 Sélection de l’excitation pour T < L
Dans la première sous-trame, le retard T1 est trouvé en recherchant dans un intervalle de 6 valeurs entières Top - 3, Top + 3 autour du pitch en boucle ouverte Top. Pour la seconde, la recherche de pitch en boucle fermée est faite sur 9 entiers autour de la valeur T1.
6.9.1.3 Recherche du pitch fractionnaire La recherche du pitch dans le dictionnaire adaptatif a été jusqu’à présent limitée à des
multiples entiers de la période d’échantillonnage, ce qui peut affecter les performances du codeur. Un gain de prédiction à long terme plus élevé peut être envisagé en assouplissant cette restriction par
93

l’utilisation de valeurs de pitch fractionnaires. Une période de pitch non-entière pourra être exprimée comme un retard entier T à la fréquence d’échantillonnage Fe et une fraction t/fr, où t = 0, ..., fr-1 et fr est la résolution souhaitée pour la recherche du pitch. En effet, la valeur non-entière t à la fréquence fr d’échantillonnage Fe correspond à un retard entier t du signal échantillonné à frFe.
Une recherche de pitch fractionnaire de résolution 1/fr pourra alors être mise en oeuvre en
augmentant la fréquence Fe du signal 1
0 ( )L
nu n T −
=− par un facteur fr. Un signal interpolé
1
0 ( ) r
L
n
fru n T f −
=− sera ensuite retardé de t échantillons puis sous-échantillonné. Le signal
obtenu, dont la fréquence d’échantillonnage est de nouveau Fe, correspond au signal original retardé par un pitch non-entier T + t/fr .
Notons cette notion de recherche du pitch fractionnaire sera utilisé lors de la conception de notre codeurs basé FS1016 dans le chapitre suivant.
6.9.2. Dictionnaire stochastique
Bien que l’introduction d’un dictionnaire adaptatif sur-échantillonné améliore sensiblement la qualité du signal reconstruit, le bas débit du codeur, qui réduit le nombre de bits disponibles pour modéliser l’excitation et donc limiter la taille du dictionnaire stochastique, entraîne une dégradation inévitable de la parole synthétisée. Pendant une durée du signal de parole voisé, le dictionnaire adaptatif contribue à une grande part de l’excitation courante. Le but de l’excitation codée fixe est alors de fournir au mieux la partie restante. Dans beaucoup d’autres cas et en particulier lorsque la période de pitch est faible et inférieure à la longueur de sous-trame, le dictionnaire adaptatif offre très peu de chances de contenir une bonne représentation du signal résiduel et donc sa contribution est diminuée. Par conséquent un poids plus important est donné à la partie du dictionnaire stochastique dont le faible nombre d’impulsions différentes de zéro disponibles (en général 4 à 5 impulsions) ne peuvent pas modéliser de manière efficace l’excitation restante. Le vecteur choisi pourra augmenter le bruit de quantification ou même fausser la périodicité du signal d’excitation. Cette excitation dégradée et bruitée étant réintroduite dans le dictionnaire adaptatif, l’erreur de modélisation perturbera par la suite et durant plusieurs itérations la recherche du pitch. Pour parer à cet effet, plusieurs techniques ont été proposées pour réduire la présence du bruit entre les harmoniques et mettre en valeur la périodicité originale du signal, telles que l’implantation d’un filtre de synthèse, dit filtre de pitch adaptatif, immédiatement après la sélection de la contribution du dictionnaire fixe.
Pour une valeur de pitch entière le vecteur stochastique 1
0 ( )L
nc n −
= est modifié de telle sorte que : n
c(n)=c(n) pour n = 0, ..., T-1
c(n) = c(n) + βpc(n) pour n = T, ..., L-1
94

avec
βp = 0.2 si βopt(-1) < 0.2
βp = βopt(-1) si 0.2 ≤ βopt
(-1) ≤ 0.8
βp = 0.8 si βopt(-1) > 0.8
Où βopt(-1) représente le gain optimal de la contribution du dictionnaire adaptatif de la sous-trame
précédente.
L’exploration de ce dictionnaire sera traitée lors de la mise en œuvre de notre codeur basé FS1016 dans le chapitre 7.
6.10 Conclusion
Dans ce chapitre nous avons présenté les différents types de codeurs paroles et ne nous sommes intéressé aux codeurs hybrides qui utilisent de façon complémentaire les avantages des techniques de codage temporelles et paramétriques pour permettre un codage efficace du signal de parole. Le codeur CELP a été étudié, dont son principe est basé sur la prédiction linéaire et l’analyse par synthèse, son innovation ne réside que dans le codage du signal d’erreur. Dans ce contexte quelques méthodes d'analyse et représentations de l'excitation ont été discutées. Il a été désigné que l'excitation est souvent modélisée en deux parties. Une prédiction à court terme sur une tranche de parole suivie par une prédiction à long terme.
95

Chapitre 7
Implantations
A – Implantation du codeur CELP basé sur le standard FS1016
Le FS-1016 (Federal Standard 1016) est codeur vocal complexe, robuste et modéré, basé sur la technique CELP et présente un débit de 4,8 kbits/s. C’est un codeur qui a été conjointement développé par la défense nationale des Etats-Unis( DoD - Departement of Defense), et les laboratoires AT&T Bell, et est un point de référence de base dans la recherche d’algorithme des codeurs bas débit. Le FS-1016 fournit un codage de qualité suffisante pour beaucoup d’applications actuelles, mais il ne peut pas être approprié aux applications téléphoniques.
7.1 La structure du codeur CELP basé FS1016
La majorité des composants du codeur CELP basé FS-1016 ont été détaillées dans les chapitres précédents.
Fig. 7.1 La structure du codeur CELP basé FS-1016
Il est constitué de trois parties :
Analyse par prédiction à court terme
Recherche du pitch dans le dictionnaire adaptatif
Recherche dans le dictionnaire stochastique ou le dictionnaire Fixe
96

Le codeur basé CELP FS1016 utilise une fréquence d’échantillonnage de 8 Khz et une fenêtre d’analyse de 30 ms (soit 240 échantillons) divisée en quatre sous-fenêtres de 7.5 ms (soit 60 échantillons).
La parole est analysée en premier par la prédiction linéaire à court terme sur une fenêtre entière pour extraire les dix (10) coefficients de prédiction linéaire. Ensuite, la recherche dans le dictionnaire adaptatif et la recherche dans le dictionnaire stochastique sont appliquées consécutivement dans l'ordre à chacun des quatre sous-fenêtres, suivi par une pondération perceptive.
Les paramètres qui définissent ce modèle sont, l'index dictionnaire adaptatif et le gain, l'index dictionnaire stochastique et le gain, et les paramètres de prédiction LP à court terme. L'optimisation des paramètres de synthèse est basée sur la minimisation par le critère des moindres carrés (MMSE : Minimum Mean Square Error) pour choisir le meilleur signal résiduel ou d’excitation à partir des deux dictionnaire.
La pondération consiste en un filtre de pondération spectral sonore.
1
1
1( )
1
pk
kk
pk
kk
k
a zw z
a zγ
−
=
−
=
−=
−
∑
∑
(1)
Dont la tâche est de transférer les altérations de codage aux régions de haute énergie du spectre où ils sont moins audibles. Le codeur CELP basé FS-1016 est basé sur un codage de parole à bande étroite où la largeur de bande de la parole d'entrée est limitée à 3400 Hz.
7.2 Analyse par prédiction à court terme
Dans la prédiction linéaire à court terme, le signal de parole est supposé stationnaire dans la fenêtre d'analyse (défini à 30 ms). Un codage linéaire prédictive basé sur un filtre à réponse d’impulsion infinie (IIR) d'ordre dix (10) nommé filtre LPC, est employée pour adapter l'enveloppe de spectre du signal de parole original, qui imite l'effet de filtrage de l'étendue vocale. La formule du filtre LPC est :
1( )( )
F zA z
= (2)
Où 10
1( ) 1 i
ii
A z a z −
=
= − ∑ (3)
L’analyse par prédiction linéaire à court terme est réalisée une fois par fenêtre en boucle ouverte sur le signal de parole. Elle comporte l’estimation de 10 coefficients de prédiction ai par la méthode d’autocorrélation sur les fenêtres d’analyse de 30 ms (pondéré par la fenêtre de Hamming) et une expansion en largeur de bande de 15HZ. Cela consiste à remplacer les coefficients de prédiction ai par les coefficients a'i = γi.ai avec γ = 0.994.
Les coefficients du filtre LPC quantifiés ne garantissent en aucun cas la stabilité du filtre à réponse d’impulsion infinie (IIR). Pour amender les susdits problèmes, on remplace les coefficients LPC en Paires de Raies Spectrales (Line Spectral Pairs en abrégé LSP).
97

Les LSPs sont les racines d'une fonction du système et sont placés sur le cercle d'unité dans le domaine z (voir chapitre 4). Ainsi, ils ont la même amplitude et sont seulement différents dans leurs phases. La quantification appliquée au LSPs affecte seulement les phases résultantes. En conséquence, la stabilité du filtre est moins vulnérable par la quantification.
Les coefficients a'i sont convertis aux coefficients LSP (voir Annexe A) qui sont plus adaptés à la transmission.
Les valeurs des coefficients LSP, utilisés dans la détermination de l’excitation des sous-fenêtres, sont obtenues par interpolation linéaire de deux ensembles de coefficients LSP (calculés pour deux fenêtres successifs n et n+1) pour former un ensemble intermédiaire pour chacune des 4 sous-fenêtres de la fenêtre à coder.
Fig. 7.2 Interpolation des LSPs selon la norme FS1016
Les coefficients LPC calculé pour traiter la fenêtre courante (fenêtre n) et la fenêtre suivante (fenêtre n+1) sont transformées en leurs coefficients équivalent et
1 2, ,......,
n nlsp lsp lsp10
n101 2
11 1, ,......, nn nlsp lsp lsp ++ +
Ainsi les coefficients LSP des quatre sous fenêtre sont dérivés de la fenêtre courante comme suit:
Les LSPs de la sous fenêtre 1 = ( ) ( )7 / 8 1/8j j
nnlsp lsp+ for j = 1, . . ., 10.
Les LSPs de la sous fenêtre 2 = ( ) ( )1
5 / 8 3 / 8j
n nlsp lsp j
++ for j = 1, . . ., 10.
Les LSPs de la sous fenêtre 3 = ( ) ( )1
3 / 8 3/ 8j
n nlsp lsp j
++ for j = 1, . . ., 10.
Les LSPs de la sous fenêtre 4 = ( ) ( )1
1/ 8 7 / 8j
n nlsp lsp j
++ for j = 1, . . . , 10.
La parole de chaque sous-fenêtre est ensuite synthétisée sur la base des coefficients LSP interpolés.
Parmi les dix (10) coefficients, quatre (4) coefficients sont plus perceptuellement sensible aux oreilles humaines. En conséquence, on réserve 4 bits pour chacun de ces 4 coefficients LSP sensible et on met 3 bits pour chacun des 6 coefficients LSP restant. Cela additionne à 34 bits pour les 10 coefficients LSP, qui utilise une largeur de bande de 34 bits/30 msec = 1.133 Ko/s.
Après avoir trouvé les coefficients LSP, la recherche dans le dictionnaire adaptatif et stochastique seront alors activée séquentiellement pour une nouvelle minimisation du signal résiduel.
98

7.3 Recherche du pitch dans le dictionnaire adaptatif
A cause de la nature quasi-périodique de la parole, il y a présence d’une quantité d’information redondante, et cette redondance devient plus apparente si la taille des fenêtres diminue.
La redondance à long terme peut être modélisée en utilisant un filtre linéaire P(z) du premier ordre. Le filtre d’analyse de pitch est donné par :
( ) 1 MP z zβ −= − (4)
Où β est le coefficient prédicteur, et l’on appel aussi gain du pitch, correspondant au degré de périodicité avec 0 ≤ β < 1 et M l’estimation en nombre d’échantillons de la période fondamentale, et l’on appelle aussi période du pitch.
Dans le codeur CELP basé FS1016, le signal d'excitation glottal synthétique correspond à la période du pitch optimal pour chaque sous-fenêtre et il est choisi à partir d’un dictionnaire adaptatif à travers un schéma d’estimation en boucle fermé.
La procédure du dictionnaire adaptatif corrèle les M les échantillons de la nème fenêtre avec les M les échantillons de la parole précédemment synthétisé correspondant à la corrélation la plus haute qui sont transmis avec un paramètre de gain pour chaque pitch.
La procédure est adaptative à l'excitation précédente, qui est la production combinée de la recherche du dictionnaire stochastique et du dictionnaire adaptatif due aux fenêtres précédentes. La relation entre le prédicteur du pitch précédente et le prédicteur du pitch courant peut être caractérisé par le filtre de prédiction à long terme:
1 1( ) ( ) .1MzF P z zβ −= =
− (5)
Où M est la période du pitch ou retard du pitch (ou Lag en anglais) et β estimateur de la période du pitch est appelée prédicteur à long terme (LTP Long Term Predictor) ou simplement prédicteur du pitch ou gain du pitch.
Le dictionnaire adaptatif contient 147 éléments, procédant par décalage du registre de stockage qui est mis à jour au début de chaque sous-fenêtre. Initialement, il est mis au zéro, et après la première fenêtre, il sera constitué des échantillons d'excitations précédentes. L'ordre est tel que les premiers éléments d'excitation issue du filtre de prédiction linéaire sont les premiers chargés dans le dictionnaire adaptatif. Les éléments déjà dans le registre de stockage sont décalés pendant le processus de mise à jour. Cela signifie que les excitations initiales seront décalés vers l'haut par 60 échantillons c'est-à-dire, les 60 premiers échantillons seront enlevés et 60 nouveaux échantillons seront insérés à la fin du registre. Ces principes sont détaillés au chapitre 6 paragraphe 6.9.1.
Dans notre implantation, le dictionnaire adaptatif, modélise la périodicité du signal à long terme due au Pitch. Il est constitué d’une mémoire tampon composée de 256 vecteurs-codes correspondants aux excitations passées. On utilise 128 retards entiers et 128 retards fractionnaires allant de 20 à 147 échantillons.
99

De ces 147 échantillons, on considère 128 valeurs retard de pitch entier et 128 valeurs retard de pitch réelle à enchevaucher par 60 échantillons (longueur de la sous-fenêtre) dans le dictionnaire adaptatif, pour donner le meilleur index définissant le meilleur retard du pitch.
Dans le cas d’un retard de pitch entier la valeur du retard de pitch est prise entre 20 et 147 échantillons (128 valeurs d'entier). Les codes adaptatifs représentant les échantillons dans le dictionnaire adaptatif correspondent aux retards entre 60 et 147 sont composés d'éléments 0-59, 1-60..., 87-146, respectivement.
Le code adaptatif pour chaque retard fractionnaire est obtenu par la même méthode que dans le retard d'entier. La seule différence est que les excitations à l'intérieur du dictionnaire adaptatif doivent être retardées par une fraction d'échantillon avant le traitement. Dans la partie qui suit on explique le calcul du retard fraction qui a été prise en compte pour notre implantation et son principe pour la recherche du pitch optimale.
7.3.1 Le retard fractionnaire
Le retard d'entier m impose la restriction de la recherche du pitch optimale à cause de la résolution de prélèvement d'échantillons inhérente du signal. La recherche du pitch sera la plus efficace si nous pourrions considérer les excitations précédentes comme un signal continu tel que le meilleur retard mf (où mf est un nombre réel) qui donne la meilleure similitude entre la parole synthétique et la parole perceptuellement pondérée est choisie.
D'abord, nous convertissons x(n) en un signal continu par l'interpolation suivante:
sin( ( ) / )( ) ( ) ( ) /ck
t kT Tt x kx t kT Tπ
π+∞
=−∞
=−
∑ − (6)
Soit un filtre de phase linéaire pass-tout avec la fonction de transfert : ( )c jH Ω
( ) fc
j m rj eH Ω=Ω (7)
Notez que l’homologue de domaine digitale de ( )c jH Ω est ( / )( ) fc
j mj j TH eHe ωω ω −= = ,
qui est le filtre phase linéaire digital pass-tout. L’équation (1) implique que yc(t) est une version retardée de xc(t). Plus spécifiquement, nous avons :
(( ) cc ft Ty t mx= )− (8)
Substitution l’équation (6) dans l’équation (8) et l'utilisation du rapport y[n] =yc(nT), nous obtenons
sin[ ( ) / ]( )[ ] [ ] ( )c
k
ff
f
nT T kT TmnT Ty n x kmx nT T kT Tm /π
π+∞
=−∞
= =− −
− ∑ − − (9)
sin[ ( )][ ] [ ] ( )k
f
f
n kmy n x k n kmπ
π+∞
=−∞
=− −
∑ − − (10)
soit mf = m +f où m est un entier et f = 1/4 , 1/3, 1/2, 2/3, 3/4, y[n] peut être exprimé comme :
100

sin[ ( )] sin[ ( )][ ] [ ] [ ]* ( ) ( )k
n m f k m fy n x n xn m f k m f n kπ ππ π
+∞
=−∞
= =− − − −
−∑− − − − (11)
Où * est l'opérateur de convolution. Soit j =m-k, on peut utilisé l'égalité sin(-x) = -sin(x) et réarrangeons l'index d'addition pour obtenir
sin[ ( )][ ] [ ]( )j
j fy n x n m jj fπ
π−∞
=+∞
=− − − +∑ − −
(12)
sin[ ( )][ ] [ ]( )j
j fy n x n m jj fπ
π+∞
=−∞
=+ − +∑ +
(13)
sin[ ( )][ ] [ ]( )j
j fy n x n m jj fπ
π−∞
=+∞
=+ − +∑ +
(14)
y[n] ne peut pas être mis en oeuvre exactement sur des calculateurs numériques. Cependant, nous pouvons tronquer l'addition employant la technique de conception de filtre RIF (Réponse à Impulsion Finie), comme suit :
/ 2 1
/ 2
sin[ ( )][ ] ( ) ( )( )N
j N
j fy n h j f x n m jj fπ
π−
=−
=+ + − +∑ +
(15)
( ) cos0.54 0.46/ 2
kh kN
π= + (16)
Les équations ci-dessus peuvent être récrit comme suit :
/ 2 1
/ 2
sin[ ( )][ ] (12( )) ( )( )N
j N
j fy n h j f x n m jj fπ
π−
=−
=+ + − +∑ +
(17)
/ 2 1
/ 2[ ] [ ] ( )
N
fj N
y n j x n m jw−
=−
= − +∑ (18)
( ) cos0.54 0.466kh kNπ
= + (19)
7.4 Recherche dans le dictionnaire fixe ou stochastique
Après l'analyse LPC et la prédiction du pitch, le signal résiduel devient apériodique, qui est souvent vue comme un signal d'innovation. Ce signal d'innovation donne un bruit de fond malgré le manque d'information de la parole, qui ne peut pas être négligé. En son absence, la parole sonnera maladroite et artificiel.
Le dictionnaire stochastique est employer pour rapprocher le signal d’innovation et modélise le signal qui provient du filtre inverse A(z) (paragraphe 6.2) et auquel la structure périodique due au Pitch est soustraite. Ce signal présente une distribution d’échantillons similaire à celle d’une distribution Gaussienne. Le dictionnaire stochastique est un dictionnaire entrelacé (déplacement de 2 échantillons) dont les éléments sont quantifiés à 3 niveaux (-1, 0, 1) et distribués selon une distribution Gaussienne de moyenne nulle et de variance unitaire.
101

La recherche dans le dictionnaire stochastique est exécutée pour chaque sous-fenêtre par une opération en boucle fermée, en adoptant le critère de minimisation de l’erreur quadratique moyenne. Le dictionnaire stochastique est composé de 512 vecteurs-codes. Chaque vecteur code a son propre index. Pour faciliter la recherche dans le dictionnaire, les 512 vecteurs-codes sont placées dans un tableau unidimensionnel (de 1, 0,-1) avec approximativement zéros de 77 %.
7.4.1 Exploration du dictionnaire stochastique
Au chapitre précédent (paragraphe 6.9), on a dit que dans les codeurs de type CELP, une recherche exhaustive dans les dictionnaires adaptatif et stochastique est effectuée pour déterminer l’excitation u(n) qui est une combinaison linéaire de la contribution des deux dictionnaires :
( ) ( ) ( )u n v n c nGβ= + avec n = 1, … ,L-1 (20)
Où les formes d’onde c, v et les gains associés G, β des dictionnaires fixe et adaptatif représentent les paramètres d’excitation possible qui cherchent à minimiser l’erreur quadratique moyenne entre les sous-fenêtre de parole originales et celles reconstruites par le filtre de synthèse LP.
Considérant que le dictionnaire stochastique est constitué de Ms mots de codes de L échantillons
(pour notre implantation L=60). Chaque mot 1
0; 1,...,
L
ni si Mc−
== , indicé par sa position i
dans le dictionnaire, subira une pondération perceptive à chaque sous-fenêtre comme indiqué dans l’équation ( ) ( ) ( )w wu n n nv G cβ= + . Le filtrage d’un vecteur 1
0( )
L
ni nc−
=
pouvant
être caractérisé par l’expression matricielle ci-dessous, la structure de Toeplitz de Hp simplifie l’obtention de l’excitation stochastique pondérée
1
0
; 1,...,L
n
wi si Mc−
=
⎧ ⎫=⎨ ⎬
⎩ ⎭.
0
1 0
2 3 0
1 2 1 0
(0) (0)... (1) (1)
... ... ... ... ... ... ...... ( 2) ( 2)... ( 1) ( 1)
0 0 0 00 0
0
i i
i
pwi
L L i i
L L i i
L LL L
h ch h c c
c Hh h h c ch h h h c c
− −
− −
⎡ ⎤ ⎡ ⎤ ⎡ ⎤⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢⎢ ⎥ ⎢ ⎥ ⎢= =⎢ ⎥ ⎢ ⎥ ⎢ ⎥
− −⎢ ⎥ ⎢ ⎥ ⎢ ⎥⎢ ⎥ ⎢ ⎥ ⎢ ⎥− −⎣ ⎦ ⎣ ⎦ ⎣ ⎦
i
c⎥⎥
)
(21)
Connaissant les contributions du dictionnaire adaptatif vopt, βopt pour la sous-fenêtre courante, l’indice i ∈ 1, Ms du mot cwi et son facteur de gain associé Gi sont maintenant recherchés afin de minimiser la distorsion D.
( )21
0( ) ( ) ( )i
Lw opt i wiopt
nn n ns v G cD E β
−=
=
⎧ ⎫⎪ ⎪⎛ ⎞− −∑⎨ ⎬⎜ ⎟⎝ ⎠⎪ ⎪⎩ ⎭
(22)
(21
0( ) ( )i
Li wi
nd n nG cD E
−=
=
⎧ ⎫⎪ ⎪⎛ −∑ ⎞⎨ ⎬⎜ ⎟⎝ ⎠⎪ ⎪⎩ ⎭
(23)
102

En général pour optimiser en terme de coût de calcul la procédure d’exploration du dictionnaire stochastique, l’indice optimal i sera plutôt choisi tel qu’il maximise les rapports
2
,,
wi
wi wi
c dc c
où
,wic d est le produit scalaire des vecteurs 1
0; 1,...,
L
nwic si M−
== et 1
0( )
L
n
−
=
. Le gd n ain associé
au mot d’indice i sera alors déterminé par ,,i
wcG = e pour le filtrage des mots ci
wi wi
dc c
. Comm i,
l’introduction de la matrice triangulaire Hp permet la réécriture des différents produits scalaires et du rapport à maximiser :
, t tp pwi wi i i i ic c c c c cH H= = tΦ (24)
, t
pwi ic d d cH= (25)
( )22
,,
tp iwi
twi wi i i
d cHc dc c c c
=Φ
(26)
Où l’opérateur ( )t représente la transposition et Φ= HtpHp la matrice de covariance de Hp :
1
( , ) ( ) ( )L
n lk l h n k h n l
−
=
=Φ −∑ − (27)
avec k ∈ 0, L-1 et l ∈ k, L-1. Notons qu’une forte diminution de la charge de calculs peut encore être envisageable si les valeurs des ,wi wic c sont pré-calculées, cependant un coût de mémorisation supplémentaire des mots sera ajouté.
7.5 Le codeur CELP Basé FS1016
Le signal synthétique est obtenu par le passage d’un signal d’excitation à travers un filtre de prédiction linéaire 1/A(z). L’excitation est calculée par sous-fenêtre. Elle est le résultat de l’addition de deux excitations élémentaires: la première est un vecteur-code extrait du dictionnaire adaptatif à l’indice M et pondéré par un gain β. La deuxième est un vecteur-code extrait du dictionnaire stochastique à l’indice is et pondéré par un gain G. L’analyse du codeur CELP consiste à trouver les paramètres d’excitation (les indices et les gains) de manière à minimiser l’erreur quadratique moyenne perceptuelle entre le signal de parole originale et le signal synthétisé. L’analyse utilisée est dite en boucle fermée. Le codeur contient donc à la fois le module d’analyse et le module de synthèse.
Le codeur transmet, à chaque fenêtre de 30 ms, une trame de 144 bits (table 1) à travers le canal de transmission. Après décodage de cette trame, le décodeur CELP reconstruit le signal de parole synthétique en utilisant le même module de synthèse que celui du codeur. C’est-à-dire par passage de l’excitation à travers le filtre de prédiction linéaire. Finalement un post-filtrage adaptatif peut être ajouté pour améliorer le signal de parole synthétique de sortie.
103

Paramètres/fenêtre. Bits/fenêtre Débits 10 LSP 34
[3,4,4,4,4,3,3,3,3,3]1,13333
4 Indices adaptatifs 4 gains adaptatifs
8 + 6 + 8 + 6 4 x 5
1,600
4 Indices fixe 4 gains fixe
4 x 9 4 x 5
1,86667
Bit de synchronisation
1
Bits de correction d’erreur
4
0,2
Bit non utilisé 1 Débit total 144 4, 8
Kbits/s
Table 7.1 Allocation des bits du codeur CELP basé FS1016
La complexité du calcul du codeur CELP basé FS1016 a été estimée à 16 MIPS (pour une recherche des dictionnaires partielle) et le score MOS a donné 3,2.
104

B- Implantation du Codeur/Décodeur LD-CELP Quand les algorithmes de codage de parole sont employés pour des systèmes de communication, le retard de codage peut devenir un problème. Le retard de codage est le temps qu’on prend pour faire un traitement de codage et de décodage pour une tranche de parole, aussi il faut prendre en compte des retards complémentaires en raison des considérations de transmission. Le codeur LD-CELP s'approche du problème de codage dans une façon significativement différente pour réduire son retard de codage à moins de 2 ms.
7.6 Structure du Codeur/Décodeur LD-CELP
Le principe des Codeurs/Décodeur CELP est d'effectuer une recherche par analyse et synthèse dans un répertoire de séquences codées (dictionnaire), exécute l'analyse de prédiction linéaire à court terme et transmet les coefficients LPC et l'information d'excitation au décodeur. Ce processus est mentionné comme processus adaptatif en avant.
Dans le LD-CELP, seulement l'excitation est transmise. Les coefficients de prédiction linéaire à court terme sont mis à jour au décodeur basé sur des échantillons de parole antérieurs décodé selon la prédiction adaptative arrière. Ainsi il utilise une adaptation séquentielle des prédicteurs et du gain pour avoir un retard de codage ou délai d'algorithme de 0,625 ms.
Les coefficients des prédicteurs sont mis à jour par analyse en codage prédictif linéaire (LPC) des signaux d'excitation (la parole en l'occurrence) qui sont préalablement quantifié.
Le gain est mis à jour au moyen des informations de gain incluses dans les séquences d'excitation préalablement quantifiées. La taille du bloc correspondant au vecteur d'excitation et à l'adaptation du gain ne dépasse pas 5 échantillons.
Un filtre de pondération perceptive est mis à jour par analyse LPC des signaux de parole non quantifiés.
Fig. 7.3 Structure du codeur LD-CELP
105

Fig. 7.4 Structure du décodeur LD-CELP
7.7 Le codeur LD-CELP
Le signal d'entrée est partitionné en blocs de cinq échantillons consécutif. Le codeur possède un répertoire d'excitation (ou dictionnaire) où sont stockés 1024 vecteurs de séquences codées (codage à quantification vectorielle). Une séquence codée y est repérée par un index sur 10 bits.
Le codeur considère uniquement des vecteurs : cinq échantillons de parole forment un vecteur de parole, cinq échantillons d'excitation forment un vecteur d'excitation, etc.
Pour chaque bloc, le codeur fait passer chacun des 1024 vecteurs possibles du répertoire des séquences codées par un module de normalisation du gain et par un filtre de synthèse. On obtient alors 1024 vecteurs quantifiés de signal possible. Le codeur choisit celui qui minimise l'erreur quadratique moyenne pondérée en fréquence par rapport au signal entrant. Le vecteur retenu est le " vecteur code ", c'est son seul index qui est passé au décodeur.
Le vecteur code sert à mettre à jour la mémoire du filtre pour le traitement du vecteur de signal suivant. Le gain et les coefficients du filtre de synthèse et les coefficients de filtre pondération perceptive sont également régulièrement mis à jour par adaptation en boucle basée sur le signal précédent quantifié et l'excitation normalisée.
Le gain d'excitation est mis à jour pour chaque vecteur, tandis que les coefficients de filtre de synthèse et les coefficients de filtre pondération perceptive sont mis à jour tous les quatre vecteurs (c'est-à-dire chaque 20 échantillons). Au décodeur on transmet l’index de 10 bits correspondant au meilleur vecteur code du dictionnaire représentant le vecteur du signal d’entrée quantifié.
La figure ci-dessous schématise en détail le codeur LD-CELP
106

7.7.1 Conversion du format de signal d’entrée MIC
Ce bloc convertit le signal d'entrée MIC loi A ou loi µ en signal MIC uniforme. Différentes représentations internes sont possibles pour le MIC uniforme, notamment du fait que les tables normalisées pour la loi A et la loi µ comprennent des parties fractionnaire. Cette représentation interne dépend du dispositif utilisé.
Dans cette recommandation, la gamme maximale supposée pour le signal d'entrée est de -4095 à + 4095, ce qui inclut la loi A comme la loi µ.
7.7.2 Tampon vectoriel
Le tampon vectoriel se charge de la construction des vecteurs de paroles de cinq échantillons consécutifs à partir des échantillons entrants. La petite taille de ce tampon autorise un délai dans un seul sens inférieur à 2 ms.
7.7.3 Adaptateur du filtre de pondération perceptive
L'adaptateur du filtre de pondération perceptive n'apparaît pas sur le schéma. Les coefficients du filtre de pondération perceptive sont recalculés sur la base d'une analyse par prédiction linéaire (LPC) des signaux de paroles non quantifiées.
Les coefficients sont obtenus par calcul des coefficients d'autocorrélation (fenêtrage hybride) du signal de parole, qui sont convertis en coefficients de prédiction (par un module de Levinson-Durbin après application d'un facteur de correction par bruit blanc (WNCF white noise correction factor) ), qui à leur tour sont utilisés pour déterminer les coefficients du filtre de pondération.
7.7.4 Filtre de pondération perceptive
Ce filtre transforme le vecteur de parole entrant actuel en vecteur de parole pondéré. Le filtre de pondération perceptive est un filtre à pôles et zéros du 10ème ordre. Il est à noter que pour les signaux non vocaux (signaux de modems par exemple), le CCITT indique qu'il est préférable de neutraliser le filtre de pondération perceptive.
107

7.7.5 Filtre de synthèse
Le filtre de synthèse est en réalité composé de deux filtres du 50ème ordre tout-pôle composés d'une boucle de rétroaction avec un prédicateur LPC du 50ème ordre dans la branche de rétroaction.
7.7.6 Calcul du vecteur cible VQ
Ce bloc calcule, par soustraction, le vecteur cible de recherche dans le répertoire de vecteurs d'excitation quantifiés.
7.7.7 Adaptateur en boucle du filtre de synthèse
Son rôle est de mettre à jour les coefficients du filtre de synthèse. Il fonctionnement de façon proche de celle de l'adaptateur du filtre de pondération perceptive.
7.7.8 Adaptateur en boucle du gain vectoriel
Le gain d'excitation est un facteur de pondération utilisé pour mettre à l'échelle le vecteur d'excitation choisi. L'adaptateur essaye de prédire le gain d'après les gains précédents par prédiction linéaire adaptative dans le domaine des gains logarithmiques.
7.7.9 Module de recherche dans le répertoire d’excitation
Il recherche dans le répertoire des 1024 vecteurs codes possibles et retient celui qui produit un vecteur de parole quantifié le plus proche possible du vecteur de parole d'entrée.
Pour faciliter la recherche dans le répertoire, ce dernier est en fait composé de deux répertoires plus petits :
• un répertoire de forme codé sur 7 bits (128 vecteurs codes indépendants)
• un répertoire de gain codé sur 3 bits (huit valeurs scalaires symétriques par rapport à zéro : 1 bit de signe et deux bits d'amplitude)
Un vecteur code retenu est composé du meilleur vecteurs code de forme et de la meilleure valeur de gain (7 + 3 = 10 bits).
7.8 Le décodeur LD-CELP
L'opération de décodage est aussi exécutée bloc par bloc. En recevant chaque index de 10 bits, le décodeur exécute une consultation du dictionnaire pour extraire le vecteur code excitation. Ce dernier passe par un module de normalisation du gain et par un filtre de synthèse pour produire le courant vecteur décodé du signal. Les coefficients de filtre de synthèse et le gain sont alors mis à jour de la même manière comme dans le codeur.
Ensuite on fait passé le vecteur de signal décodé par un post-filtre adaptatif pour augmenter la qualité perceptive. Les coefficients du post-filtre sont mis à jour périodiquement employant l'information disponible au décodeur.
108
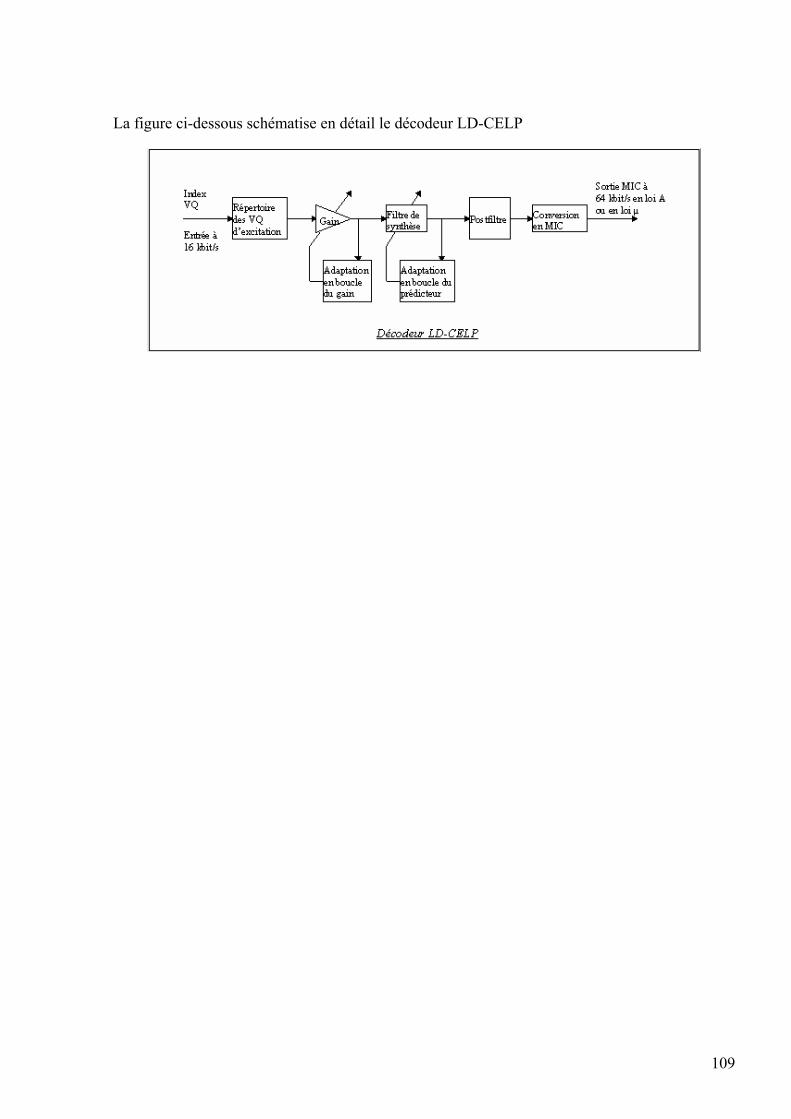
La figure ci-dessous schématise en détail le décodeur LD-CELP
109

Conclusion
Il nous a été demandé dans cette thèse de faire une étude sur le codage paramétrique de la parole en toute ses formes afin de palier à une compréhension globale sur la question de produire de la parole et de comprendre la modélisation mathématique de cette dernière pour extraire toute les informations nécessaire en vue de sa transmission, et de pouvoir utiliser ses informations en réception pour pouvoir faire une reconstruction du signal de parole, mettant en évidence, la compréhension des processus de production et de perception de la parole, le développement d’outil de traitement du signal, la définition de modèles paramétriques pertinents du signal, et la définition d’une architecture et des stratégies de contrôle adaptés pour l’organisation des connaissance et leurs interprétations.
En premier lieu on a vue comment se produit la parole utilisant l’anatomie humaine et on a montré qu’on modélise un conduit vocal par une suite de tube acoustiques qui peuvent être représenté par un filtre linéaire à paramètre variable dans le temps.
Les études de traitement de la parole pour la prise, la restitution et le codage des signaux ont toujours fait largement appel aux avancées en théorie du traitement du signal. Ces études on fait objet de deuxième chapitre.
L'une des premières étapes dans tout traitement de la parole est sa paramétrisation. A partir d'un signal numérisé, nous devons extraire un nombre limité de paramètres décrivant le signal, et qui conviennent au traitement de la parole. Ces paramètre sont les paramètres d'un filtre numérique représentant le conduit vocal qu’on appelle paramètres de prédiction linéaire (LP parameters), ou ces dernier sont convertis en d’autre paramètres moins corrélés que les paramètres LP, afin que le filtre numérique soit stable. De là, on peut dire que les paramètres de prédiction linéaire ne modélisent que l'enveloppe spectrale du signal parole. Il est cependant connu, que la fréquence fondamentale influence aussi cette enveloppe spectrale.
La quantification porte sur la grandeur physique associée à l’information au niveau de la parole, qu’on divise en gamme lui attribuant une seule valeur, dite valeur quantifiée.
En général, la quantification apparaît en deuxième lieu dans un processus de compression, pour réduire la quantité d’information, de manière souvent irréversible, puisqu’elle introduit inévitablement une distorsion. C’est cette distorsion qu’il faudra minimiser lors de la conception d’un quantificateur. Deux types de quantification ont été définis, la quantification scalaire et la quantification vectorielle qui se base sur la concentration des valeurs dans un espace vectoriel composé des vecteurs informations.
La plus part des codeurs sont basé sur la prédiction linéaire où la parole codé est synthétisé par l'excitation d'un filtre tout-pôle variant dans le temps qu’on appelle les codeurs CELP (Code Excited Linear Prediction). Les coefficients (ou paramètres) du filtre sont obtenus avec une méthode d'évaluation autorégressive et décrivent l'enveloppe spectrale du signal. On peut dire que la prédiction Linéaire forme le coeur de beaucoup de codeurs à divers débit.
110

La différence principale entre les différents codeurs est la méthode qui est employée pour coder l'excitation du filtre de synthèse de prédiction linéaire et en particulier le nombre de bits employés à cette fin (le débit). Tant que le débit diminue, l’évaluation précise, l'interpolation et la quantification des paramètres du modèle autorégressif devient de plus en plus importante, de là les erreurs ne peuvent pas être facilement compensé par l'excitation. Une représentation précise du modèle est très importante pour la qualité, car le modèle de prédiction linéaire est une partie si importante dans les codeurs.
La réalisation de systèmes de codage performants à divers débits, en particulier celle d'un codeur pour la parole de haute qualité doit mettre à profit les caractéristiques psychoacoustiques du système auditif.
Une partie significative de la mise en oeuvre de la Voix sur IP (VoIP) est le codeur/décodeur (Codec) bas débit, dont le taux de compression et la complexité de calcul peuvent parfois décider la douceur d'un appel IP.
En 1991, l'Administration de Services de Général des EU a publié la Norme Fédérale 1016 (FS1016), qui spécifie un codeur basé CELP à un débit de 4.8 Ko/s. Avec l'avantage de libres brevet d'invention, FS1016 a été choisi comme un Codec expérimental pour une recherche patronnée dans différent laboratoires sur un recouvrement de perte de paquet spécifiquement pour l'utilisation dans l'Internet public. Cependant couronné de succès, sa complexité massive informatique limite sa faisabilité pour des applications en temps réel IP de téléphone. Cela nous mène à la recherche d'améliorer sa complexité de calcul sans détérioration de sa qualité de voix.
La mesure de la qualité de la parole synthétisée se base sur une évaluation objective sur le débit et une évaluation subjective, sur un corpus de parole important, et était nécessaire sur l’expérimentation des codeurs qu’on a implanté (Les codeurs CELP basé FS1016 et LD-CELP).
La conception d’un codeur est un travail fastidieux qui nécessite des compétences diverses comme le traitement du signal, l’acoustique, l’algorithmique, et une bonne connaissance des évolutions incessantes de ce domaine. Aussi, l’optimisation de toutes les parties du codeur n’est pas envisageable car chaque partie peut à elle seule susciter un travail de recherche.
Les progrès rapides de technologies de traitement numérique et l’extension des réseaux numériques ont entraîné une explosion des domaines d’application dans le secteur des télécommunications. Pour les années futures, les besoins des communications avec les mobiles, la généralisation de nouveaux services multimédias associant la parole, les images et les données, l’augmentation des débits disponibles liée à l’extension des réseaux de télécommunication seront encore les moteurs principaux du développement des recherches en traitement du signal de parole.
111

Annexe A
Distance et mesure de distance
Dans toute approche de traitement numérique du signal, le choix de l’espace de représentation du signal est étroitement lié à celui de la distance définie dans cet espace. Les spectres ainsi que les coefficients de prédiction linéaire peuvent être assimilés à des vecteurs numériques de dimension d.
Il est possible d’utiliser toutes les distances classiques, en particulier les distances de Minkovski, parmi lesquelles, la classique distance euclidienne, et la distance de Mahalanobis qui normalise les coefficients par leur matrice de covariance.
1. Distances de Minkovski, Manhattan, et Euclidienne
Les distances de Minkovski Lτ entre deux vecteurs X=(x1,…, xd)t et Y=(y1,…,yd)t de dimension d s’expriment:
⎟⎠⎞⎜
⎝⎛ −∑
==
d
k kkr y
yxYXLr
r1
),(
Les distances les plus courantes sont les distances de Manhattan pour r=1 et la distance euclidienne de pour r=2. La distance euclidienne, en particulier peut aussi être définie vectoriellement comme:
dE(X,Y)²=(X-Y)T(X-Y)
2. Distance d’Itakura
Les distances usuelles ci-dessus ne sont pas nécessairement adaptées aux représentations choisies. Dans le cas de représentations paramétriques du signal de parole, le modèle utilisé permet parfois de déduire une mesure adaptée, comme par exemple la distance d’Itakura pour les coefficients LPC.
Si A=(1,a1,…,ap)t et B=(1,b1,…,bp)t sont des vecteurs contenant les coefficients de prédiction de deux modèles auto-régressifs d’ordre p, la distance d’Itakura est défini comme :
⎥⎥⎦
⎤
⎢⎢⎣
⎡=
BRBARABAd
bt
bt
log),(1
Ou Rb est la matrice d’autocorrélation du signal ayant servi à l’estimation du modèle B. La mesure fait le rapport de l’erreur de prédiction du signal par un modèle de référence A et de
112

l’erreur de prédiction par un modèle optimal calculé sur le signal lui-même. Ce rapport étant par définition plus grand que un, la mesure est positive, mais elle n’est pas symétriques.
3. Le rapport signal sur bruit segmental
Pour évaluer la qualité de la parole synthétisée, la mesure la plus couramment utilisée dans le domaine temporel est le rapport signal sur bruit segmental SNRseg. Le signal est découpé en NF segments de N échantillons chacun et on calcule une moyenne ( est le signal de parole
original et le signal synthétisé) :
)(ns)(ˆ ns
( )( )
∑∑ +−+
∑ +−
= ⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
= −
=
−
=1
0
11
0
2
1
0
2
10 )(ˆ)(log10
N
i ii
iSNRseg
F
N
j
N
j
F jNsjNs
jNsN
4. La distorsion spectrale
La distorsion spectrale est une autre mesure objective dans le domaine spectrale. La distorsion spectrale pour une trame i est définie par :
dfF
i
is
fSfS
FSDs
i ∫⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎟⎠
⎞⎜⎜⎝
⎛=
0
2
)(ˆ)(log10 10
1 (dB)
Où Fs est la fréquence d’échantillonnage, Si(f) et S^i(f) sont les densités spectrales LPC (estimées à partir des coefficients de prédiction) de la trame numéro i et sont donnés par :
)(1)(
/2 2
eAfS
F sfji
i π=
et
)(ˆ1)(ˆ
/2 2
eAfS F sfj
ii π
=
Où Ai(z) et Aˆi(z) sont les polynômes correspondants respectivement aux coefficients de
prédiction originaux et aux coefficients de prédictions quantifiés pour la ième trame de parole. En passant à la notation numérique, distorsion devient :
( )( )∑
−
⎥⎥
⎦
⎤
⎢⎢
⎣
⎡
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛
−=
=
11 1
0
/2
/2
1001 ˆlog10
n
nn eSeS
nnSD Nnj
i
Nnj
ii π
π
Les densités spectrales sont évaluées par DFT(Transformée de Fourier Discrète) en utilisant l’algorithme FFT. n0 et n1 correspondent respectivement à 0 et 97, si la distorsion SDi est calculée dans l’intervalle de fréquence allant de 0Hz à 3kHz (le signal est échantillonné à 8kHz et on utilise N=256 points pour le calcul de la DFT, la résolution entre deux points est donc de 8kHz/256 = 31,25 Hz).
113

5. La distance euclidienne pondérée pour LSF
La distance euclidienne pondérée est une mesure qui utilise les coefficients LSF. En effet les coefficients LSF ont une relation avec les formants et les valets de l’enveloppe spectrale calculée par l’équation ci dessous. Si et sont deux vecteurs composés chacun de P coefficients LSF originaux et quantifiés respectivement, alors leurs distance euclidienne pondérée et définie par:
f f
∑ −=
=p
iii ffwcffd ii
1
2
)ˆ()ˆ,(
wi est le poids assigné au ième coefficient LSF, est défini par:
)( fSw ir
i =
Où S(fi) est la densité spectrale LPC estimée à la fréquence fi et associée au vecteur à tester. r est une constante empirique qui contrôle le poids des différents coefficients LSF et est déterminée expérimentalement. La valeur 0.15 pour r est une valeur satisfaisante. Donc la pondération dépend de la valeur de la densité spectrale LPC à la fréquence du coefficient LSF considérée. L’oreille humaine est plus sensible aux basses fréquences qu’aux hautes fréquences. Pour exploiter cette caractéristique, on introduit un coefficients de pondération constant défini par :
Ci = 1.0 1≤ i ≤ 8
Ci = 0.8 i = 9
Ci = 0.4 i = 10
114

Bibliographies
Livres
[Rabiner 1975] Rabiner L.R and Gold B. « Theory and Application of Digital Signal Processing » Pretice Hall, 1975
[Boite 1987] Boite R, et Kunt M. « Traitement de la parole » Presses Polytechniques Romande,1987
[Paliwal 1995] Paliwal K. « Speech coding and synthesis » Elsevier 1995
[Rocwell 1996] Rocwell Telecomunication 1996 « Speech codec specification Digital Simltaneous Voice and Data » Document Rocwell
[Steven 1998] Steven A. Tretter « Introduction to Speech Digitization Techniques » October 1998
[Sridharan 1999] S. Sridharan, J. Leis, K. K. Paliwal « CHAPTER 4 : SPEECH CODING » Handbook of Neural Networks for Speech Processing (First edition) Ed. S. Katagiri 1999 Artech House
Thèses
[Victor 1985] Victor T.M. Lam « The Stability of Pitch Synthesis Filters in Speech Coding » Department of Electrical Engineering, McGill University Montreal, Canada, June 1985
[Vandana 1991] Vandana S.Rungta « Parallel vector quantization codebook generation » UTAH State University 1991
[Abboud 1992] Karim Abboud « WideBand CELP Coding » McGill, Université du Quebec Montreal Canada, November 1992
[Chahine 1993] Gabriel Chahine « Pitch Modelling for Speech Coding at 4,8 Kbits/s »
115

McGill, Université du Quebec Montreal Canada, July 1993
[Jose 1995] José Hernadez. « Algorithmes d’aquisition, compressions et restitution de la parole à vitesse variable. Etude et mise en place » ENSEA - Cerby-Pontoise (Paris) 1995
[Costantinos 1997] Costantinos PapaCostantinou « Improved Pitch Modelling For Low Bit Rate Speech Coders » Departement of Electrical Engineering. Mc Gill University Montreal Canada, 1997
[Alexis 1998] Alexis Bernard Pascal « Source Channel Coding of Speech » University of California Los Angeles 1998
[Grassi 1998] Sara Grassi « Optimized Implementation of Speech Processing Algorithms » Faculté des Sciences, Université de Neuchatel, Suisse, Fevrier 1998
[Rosenberg 1998] Jonathan Rosenberg and Henning Schulzrinne « Signaling for Internet Telephony » Department of Computer Science, Columbia University New York, USA, January 31, 1998
[Marcus 1999] Marcus Vaalgamaa « Moving average Vector Quantization in Speech Coding » Faculty of Electrical and Communication Engineering. Helsinki University of Technology, January 1999
[Kundan 2000] Kundan Singh and Henning Schulzrinne « Unified Messaging using SIP and RTSP » Department of Computer Science, Columbia University New York, USA, October 11, 2000
[Wesly 2001] Wesly Pereira « Modifying LPC Parameter Dynamics to Improve Speech Coder Efficiency » McGill, Université du Quebec Montreal Canada, September 2001
[Collen 2002] Patrice Collen. « Technique d’enrichissement de spectre des signaux audionumériques » Ecole National Supérieure de télécommunication 2002
[Kuang 2002] Chien-Kuang Lin « Low-Complexity CodeBook Searching Algorithms for FS1016 » Department of Communications Engineering National Chiao Tung University Hsinchu, Taiwan 300, R.O.C., June, 2002
[Zhijian 2003] Zhijian Yuan « The weighted Sum of Line Spectrum Pair for Noisy Speech » Laboratory of Acoustics and audio Signal Processing Departement of Electricel and Communication Engineering
116

Helsinki University of Technology
[Kim 2004] Jong Hwa Kim. « Lossles WideBand audio Compression : Prediction and Transform» Université Technique de Berlin
[Xiaotang 2004] Xiaotang Zhang and Henning Schulzrinne « Voice over TCP and UDP » Department of Computer Science, Columbia University New York, USA, September 28, 2004
Cours - Polycopies
[Laroche 1995] Jean Laroche « Traitement des Signaux Audio-Fréquence » Département Signal, Groupe Acoustique, TELECOM Paris, Février 1995
[Paliwal 1996] K.K. Paliwal and W.B. Kleijn « Quantization of LPC Parameters »
[Erkelens 1998] J.S. Erkelens «Autoregressive Modelling for Speech Coding: Estimation, Interpolation and Quantisation»
[Dutoit 2000] Dutoit T. « Introduction au Traitement Automatique de la Parole » Note de cours / DEC2 Faculté Polytechnique de Mons (Belgique) – TCTS Lab, 2000
[Mercier 2003] Grégoire Mecier, Christian Roux, Gilbert Martineau « Technologies du Multimédia » ENST Bretagne, dpt ITI, BP 832, 15 janvier 2003
[Besson 2003] Olivier Beson « Analyse Spectrale Paramétrique » ENSICA.
Articles & rapports
[Kabal 1986] Peter Kabal And Ravi Prakash Ramachadran « The Computation of Line Spectral Frequencies Using Chebyshev Polynomials » IEEE Transactions on Acoustics Speech and Signal Processing,Vol ASSP-34, n°6, December 1986
[Kabal 1987] P. Kabal « Code Excited Linear Prediction Coding of Speech at 4.8 kb/s » INRS-Communications McGill, Université du Quebec Montreal Rapport de Recherche
117

[Kabal 1988] Peter Kabal « High Quality 16 Kb/s Speech Coding For Network Application » INRS-Communications McGill, Université du Quebec Montreal Canada Proc. Speech Tech'88 (New York, NY), pp. 328-331, April 1988
[XYDEAS 1990] C.S. XYDEAS, M.A. IRETON and D.K. BAGHBADRANI « Theory and Real Time Implementation of a CELP Coder at 4.8 and 6.0 Kbits/s Using Ternary Code Excitation » Rapport
[Paliwal 1993] Paliwal K., B. Attal « Efficient Vector Quantization of LPC Parameters at 24 Bits/Frame » IEEE Trans. Speech and Audio Procesing, Vol. 1, n° 1, January 1993
[Patrick 1994] Patrick Fiche, Vincent Ricordel, Claude Labit « Etude d’Algorithmique de Quantification Vectorielle Arborescente » Rapport INRIA n° 2241 – Janvier 1994
[Cox 1996] Richard V. Cox, Peter Kroon « Low Bit Rate Speech Coders For Multimedia Communications » Speech Processing Software Technologies Research AT&T Labs Research November 1996
[Westall 1996] F A Westall, R D Johnston and A V Lewis « Speech technology for telecommunications » BT Technol J Vol 14 No 1 January 1996
[Wong 1996] W T K Wong, R M Mack, B M G Cheetham and X Q Sun « Low Rate Speech Coding for Telecommunications » BT Technol J Vol 14 n°01 January 1996
[Fang 1998] Fang Zheng, Zhanjiang Song, Ling Li, Wenjian Yu, Fengzhou Zheng, and Wenhu Wu «The Distance Measure For Line Spectrum Pairs Applied To Speech Recognition» Speech Laboratory, Department of Computer Science and Technology, Tsinghua University, Beijing, 100084, P. R. China International Conference on Spoken Language Processing (ICSLP-98)
[Gray 1998] Robert M. Gray, Fellow, IEEE, and David L. Neuhoff, Fellow, IEEE « Quantization » IEEE Transactions on Information Theory, Vol. 44, n° 6, October 1998
[Zhou 1998] Jin Zhou, Yair Shoham, Ali Akansu « Simple Fast Vector Quantization of the Line Spectral Frequencies » Electrical Engineering Department, New Jersey Institute of Technology Rapport de Recherche
[Badran 1999] M. Al-Akaidi, S. Badran, J. Blackledge « Real Time Speech Coder : CELP for Telecommunication » Faculty of Computing Sciences & Engineering, De Montfort University, Leicester Rapport de Recherche
118

[Gonon 1999] Gilles Gonon « Le codage audio et ses différents étapes » Laboratoire Informatique de l’Université de Maine Rapport bibliographique
[Kundan 1999] Kundan Singh and Henning Schulzrinne « Peer-to-Peer Internet Telephony using SIP » Department of Computer Science, Columbia University New York, USA, 1999
[Murat 1999] Marat Tartal « Comparaison of Speech Coding Algorithm : ADPCM, CELP and VSELP » Rapport bibliographique University of Texas Dallas
[Noll 1999] Peter Noll « Speech and Audio Coding for Multimedia Communications » Technish Universitat Berlin, Proceding Intelligent Communication Technologies and Application, Neuchatel, SCHWEIZ
[Sunil 1999] Sunil Arya, David M. Mount « Algorithms for Fast Vector Quantization » Department of Computer Science and Institute for Advanced Computer Studies University of Maryland, College Park, Maryland, USA Raport de Recherche
[Alexis 2000] Alexis Bernard Paksoy, Alan McCree and Erdal « Efficient Methods to Code and Search Fixed Codebook Excitations of Algebraic and Multi-Pulse CELP Coders » Electrical Engineering Department Center, University of California, Los Angeles Dallas, Texas Work performed during internship at TI in the summer of 2000
[Baudoin 2000] Geneviève Baudoin, Jan Cernocky, Philippe Gournay, Gérard Chollet « Codage de la parole à bas et très bas débits » rapport de recherche 2000 - 1634-Hermes/Telecom55•9/10
[Combescure 2000] P. Combescure , C. Sorin « Le Traitement du Signal Cocal » Rapport de recherche , 2000
[Harborg 2000] E.Harborg, J.E.Knudsen, A.Fuldseth and F.J.Johansen « A Real Time Wideband CELP Coder for a Videophone Application » Rapport bibliographique Sintef Delab n-7034 Norvegian Telecom Research
[Lyard 2000] E. Lyard « Compression MPEG, Transmission GSM et Reconnaissance Vocal » Rapport de recherche, 2000
[Mauc 2000] M. Mauc, G. Baudoin, and M. Jelinek « Complexity Reduction For FS-1016 With Multistage Search »
119

rapport de recherche 2000 – ESIEE Noisy Le Grand
[Riccardi 2000] G. Riccardi G.A. Mian « Analysis by Synthesis Algorithmes For Low Bit Rate Coding » Dipratimento Di Elettronica Ed Informatica Universite Di Padora
[Seung 2000] Sebastien Seung « Vector Quantization and Principal Component Analysis » Rapport de Recherche 2000
[Shivali 2000] Shivali Srivastava « Fundamentals of Linear Prediction » Departement of electrical and computer engineering, Mississipi State University Rapport de recherche
[Bhaskar 2001] Bhaskar D. Rao « Improved Modelling and Quantization Methods for Speech Coding » Departement of electrical and computer engineering University of California, San diego Final report 2001
[Barras 2001] Barras C. LIMSI-CNRS « Reconnaissance Automatique de la Parole : vers l’indexation automatique d’archives sonores » Orsay Info n°62 Janvier 2001
[Černock 2001] Jan Černock , Geneviève Baudoin, Dijana Petrovska-Delacrétaz et Gérard Chollet. « Vers une Analyse Acoustico-phonétique de la Parole indépendante de la langue, basée sur ALISP » Département Signaux et Télécommunications, ESIEE, Paris, France CNRS-LTCI, ENST, Paris, France
[Groupe 2001] Groupe d'Experts - Aspects Techniques « Téléphonie sur IP (IP Telephony) » Union Internationale des Télécommunications (UIT) Octobre 2001
[Baudoin 2002] Jan Černock , Geneviève Baudoin, Dijana Petrovska-Delacrétaz et Gérard Chollet. « Codage de la parole à bas et très bas débit » Département Signaux et Télécommunications, ESIEE, Paris, France CNRS-LTCI, ENST, Paris, France
[Dong 2002] Dong Lin and Benjamin W. Wah « LSP-Based Multiple-Description Coding For Real-Time Low Bit Rate Voice Transmissions » Department of Electrical and Computer Engineering and the Coordinated Science Laboratory University of Illinois, Urbana Proc. IEEE Int. Conf. on Multimedia & Expo, 2002.
[Maha 2002] Maha Elsabrouty, Martin Bouchard, Tyseer Aboulnasr « A New Hybrid Long-Term And Short-Term Prediction Algorithm For Packet Loss Erasure Over IP-Networks »
120

School of Information Technology and Engineering, University of Ottawa, 161 Louis-Pasteur, Ottawa (Ontario) Rapport de recherche
[Servetti 2002] Antonio Servetti, Carlos Di Martin « Perception-Based Partial Encryption of Compressed Speech » IEEE Transaction on speech and Audio procesing Vol 10 n°08 Novembre 2002
[Gonzalo 2003] Gonzalo Camarillo and Henning Schulzrinne « Signalling Transport Protocols » Department of Computer Science, Columbia University New York, USA, 2003
[Narasimha 2003] J. Narasimha « CELP Speech Coders » rapport de recherche 2003
[Dong 2005] Benjamin W. Wah, Fellow, IEEE, and Dong Lin « LSP-Based Multiple-Description Coding for Real-Time Low Bit-Rate Voice Over IP » IEEE Transactions on Multimedia, Vol. 7, n°01, February 2005
121