cluster analysis
DESCRIPTION
Cluster Analysis. Mark Stamp. Cluster Analysis. Grouping objects in meaningful way Clustered data fits together in some way Can help to make sense of (big) data Useful technique in many fields Many different clustering strategies Overview, then details on 2 methods - PowerPoint PPT PresentationTRANSCRIPT

1
Cluster Analysis
Cluster Analysis
Mark Stamp

2
Cluster Analysis
Grouping objects in meaningful wayo Clustered data fits together in some
wayo Can help to make sense of (big) datao Useful analysis technique in many
fields Many different clustering strategies Overview, then details on 2
methodso K-means simple and can be effectiveo EM clustering not as simple
Cluster Analysis

3
Intrinsic vs Extrinsic
Intrinsic clustering relies on unsupervised learningo No predetermined labels on objectso Apply analysis directly to data
Extrinsic relies on category labels o Requires pre-processing of datao Can be viewed as a form of supervised
learning
Cluster Analysis

4
Agglomerative vs Divisive
Agglomerative o Each object starts in its own clustero Clustering merges existing clusterso A “bottom up” approach
Divisiveo All objects start in one clustero Clustering process splits existing
clusterso A “top down” approach
Cluster Analysis

5
Hierarchical vs Partitional
Hierarchical clusteringo “Child” and “parent” clusterso Can be viewed as dendrograms
Partitional clusteringo Partition objects into disjoint clusterso No hierarchical relationship
We consider K-means and EM in detailo These are both partitional
Cluster Analysis

6
Hierarchical Clustering
Example of a hierarchical approach...
1. start: Every point is its own cluster2. while number of clusters exceeds 1
o Find 2 nearest clusters and merge
3. end while OK, but no real theoretical basis
o And some find that “disconcerting”o Even K-means has some theory behind
itCluster Analysis

7
Dendrogram
Example Obtained by
hierarchical clusteringo Maybe…
Cluster Analysis

8
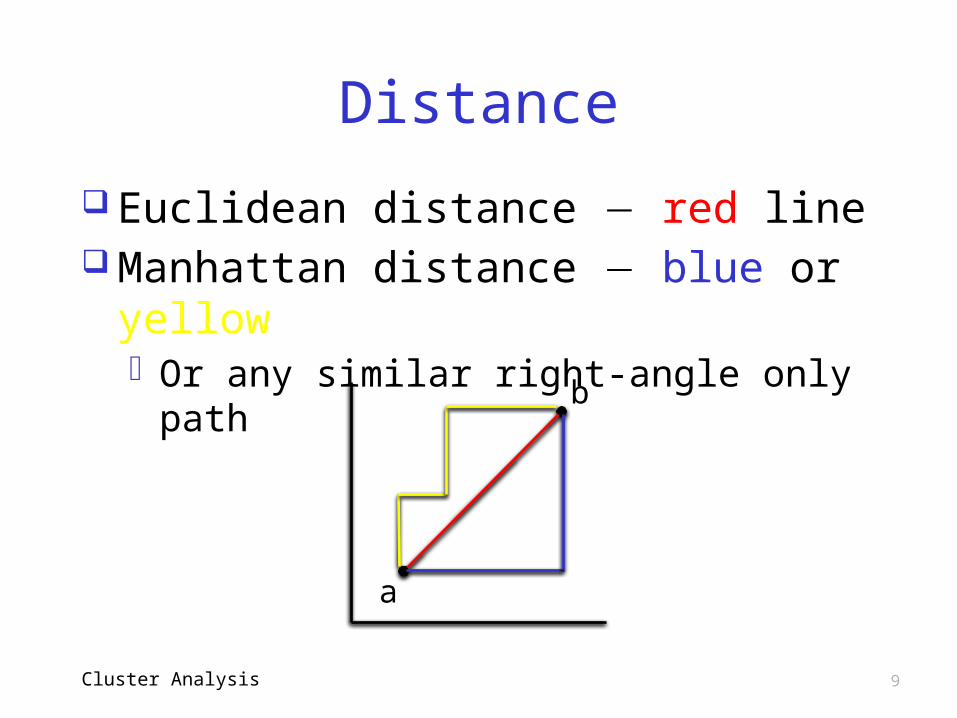
Distance
Distance between data points? Suppose
x = (x1,x2,…,xn) and y = (y1,y2,…,yn)
where each xi and yi are real numbers
Euclidean distance isd(x,y) = sqrt((x1-y1)2+(x2-y2)2+…+(xn-yn)2)
Manhattan (taxicab) distance isd(x,y) = |x1-y1| + |x2-y2| + … + |xn-yn|
Cluster Analysis
9
Distance
Euclidean distance red line Manhattan distance blue or yellow
o Or any similar right-angle only path
Cluster Analysis
a
b

10
Distance
Lots and lots more distance measures
Other examples includeo Mahalanobis distance takes mean
and covariance into accounto Simple substitution distance
measure of “decryption” distance o Chi-squared distance statistical o Or just about anything you can think
of…Cluster Analysis

11
One Clustering Approach
Given data points x1,x2,x3,…,xm Want to partition into K clusters
o I.e., each point in exactly one cluster A centroid specified for each
clustero Let c1,c2,…,cK denote current centroids
Each xi associated with one centroido Let centroid(xi) be centroid for xi
o If cj = centroid(xi), then xi is in cluster j
Cluster Analysis

12
Clustering
Two crucial questions1. How to determine centroids, cj?
2. How to determine clusters, that is, how to assign xi to centroids?
But first, what makes a cluster “good”?o For now, focus on one individual clustero Relationship between clusters later…
What do you think?Cluster Analysis

13
Distortion
Intuitively, “compact” clusters goodo Depends on data and K, which are giveno And depends on centroids and
assignment of xi to clusters, which we can control
How to measure “goodness”? Define distortion = Σ
d(xi,centroid(xi))o Where d(x,y) is a distance measure
Given K, let’s try to minimize distortion
Cluster Analysis

14
Distortion
Consider this 2-d datao Choose K = 3 clusters
Same data for botho Which has smaller
distortion? How to minimize
distortion?o Good question…
Cluster Analysis

15
Distortion
Note, distortion depends on Ko So, should probably write distortionK
Problem we want to solve…o Given: K and x1,x2,x3,…,xm
o Minimize: distortionK
Best choice of K is a different issueo Briefly considered later
For now, assume K is given and fixedCluster Analysis

16
How to Minimize Distortion?
Given m data points and K Minimize distortion via exhaustive
search?o Try all “m choose K” different cases? o Too much work for realistic size data set
An approximate solution will have to doo Exact solution is NP-complete problem
Important Observation: For min distortion…o Each xi grouped with nearest centroido Centroid must be center of its groupCluster Analysis

17
K-Means Previous slide implies that we can
improve suboptimal cluster by either…1. Re-assign each xi to nearest centroid
2. Re-compute centroids so they’re centers
No improvement from applying either 1 or 2 more than once in succession
But alternating might be usefulo In fact, that is the K-means algorithm
Cluster Analysis

18
K-Means Algorithm Given dataset…1. Select a value for K (how?)2. Select initial centroids (how?)3. Group data by nearest centroid4. Recompute centroids (cluster
centers)5. If “significant” change, then goto 3;
else stop
Cluster Analysis

19
K-Means Animation
Very good animation herehttp://shabal.in/visuals/kmeans/2.html
Nice animations of movement of centroids in different cases here
http://www.ccs.neu.edu/home/kenb/db/examples/059.html
(near bottom of web page) Other?
Cluster Analysis

20
K-Means
Are we assured of optimal solution?o Definitely not
Why not?o For one, initial centroid locations criticalo There is a (sensitive) dependence on
initial conditionso This is a common issue in iterative
processes (HMM training, is an example)
Cluster Analysis

21
K-Means Initialization
Recall, K is the number of clusters How to choose K? No obvious “best” way to do so But K-means is fast
o So trial and error may be OKo That is, experiment with different K o Similar to choosing N in HMM
Is there a better way to choose K?
Cluster Analysis

22
Optimal K?
Even for trial and error, we need a way to measure “goodness” of results
Choosing optimal K is tricky Most intuitive measures will tend to
improve for larger K But K “too big” may overfit data So, when is K “big enough”?
o But not too big…Cluster Analysis

23
Schwarz Criterion Choose K that minimizes
f(K) = distortionK + λdK log mo Where d is the dimension, m is the number of
data points, and λ is ??? Recall that distortion depends on K
o Tends to decrease as K increaseso Essentially, adding a penalty as K increases
Related to Bayes Information Criterion (BIC)o And some other similar things
Consider choice of K in more detail later…Cluster Analysis
K
f(K)

24
K-Means Initialization
How to choose initial centroids? Again, no best way to do this
o Counterexamples to any “best” approach
Often just choose at random Or uniform/maximum spacing
o Or some variation on this idea Other?
Cluster Analysis

25
K-Means Initialization
In practice, we might do following Try several different choices of K
o For each K, test several initial centroids
Select the result that is besto How to measure “best”?o We look at that next
May not be very scientifico But often it’s good enough
Cluster Analysis

26
K-Means Variations One variation is K-mediods
o Centroids point must be actual data point
Fuzzy K-meanso In K-means, any data point is in one
cluster and not in any othero In fuzzy case, data point can be partly
in several different clusters o “Degree of membership” vs distance
Many other variations…Cluster Analysis

27
Measuring Cluster Quality
How can we judge clustering results?o In general, that is, not just for K-
means Compare to typical
training/scoring…o Suppose we test new scoring methodo E.g., score malware and benign fileso Compute ROC curves, AUC, etc.o Many tools to measure
success/accuracy Clustering is different (Why? How?)
Cluster Analysis

28
Clustering Quality
Clustering is a fishing expeditiono Not sure what we are looking foro Hoping to find structure, “data
discovery”o If we know answer, no point to
clustering Might find something that’s not
thereo Even random data can be clustered
Some things to consider on next slideso Relative to the data to be clustered
Cluster Analysis

29
Cluster-ability?
Clustering tendencyo How suitable is dataset for clustering?o Which dataset below is cluster-
friendly?o We can always apply clustering…o …but expect better results in some
cases
Cluster Analysis

30
Validation
External validationo Compare clusters based on data
labelso Similar to usual training/scoring
scenarioo Good idea if know something about
data Internal validation
o Determine quality based only on clusters
o E.g., spacing between and within clusters
o Harder to do, but always applicable
Cluster Analysis

31
It’s All Relative
Comparing clustering resultso That is, compare one clustering result
with others for same dataseto Can be very useful in practiceo Often, lots of trial and erroro Could enable us to “hill climb” to
better clustering results…o …but still need a way to quantify
things
Cluster Analysis

32
How Many Clusters?
Optimal number of clusters?o Already mentioned this wrt K-meanso But what about the general case?o I.e., not dependent on cluster
techniqueo Can the data tell us how many
clusters?o Or the topology of the clusters?
Next, we consider relevant measuresCluster Analysis

33
Internal Validation
Direct measurement of clusterso Might call it “topological” validation
We’ll consider the followingo Cluster correlationo Similarity matrixo Sum of squares erroro Cohesion and separationo Silhouette coefficient
Cluster Analysis

34
Correlation Coefficient
For X=(x1,x2,…,xn) and Y=(y1,y2,…,yn) Correlation coefficient rXY is
Can show -1 ≤ rXY ≤ 1o If rXY > 0 then positive cor (and vice
versa)o Magnitude is strength of correlationCluster Analysis

35
Examples of rXY in 2-d
Cluster Analysis

36
Cluster Correlation
Given data x1,x2,…,xm, and clusters, define 2 matrices
Distance matrix D = {dij} o Where dij is distance between xi and xj
Adjacency matrix A = {aij} o Where aij is 1 if xi and xj in same
clustero And aij is 0 otherwise
Now what?Cluster Analysis

37
Cluster Correlation
Compute correlation between D and A
High inverse correlation implies nearby things clustered togethero Why inverse?
Cluster Analysis

38
Correlation
Correlation examples
Cluster Analysis

39
Similarity Matrix
Form “similarity matrix”o Could be based on just about anythingo Typically, distance matrix D = {dij},
where dij = d(xi,xj)
Group rows and columns by cluster Heat map for resulting matrix
o Provides visual representation of similarity within clusters (so look at it…)
Cluster Analysis

40
Similarity Matrix Same examples as above
Cluster Analysis
Corresponding heat maps on next slide

41
Heat Maps
Cluster Analysis

42
Residual Sum of Squares
Residual Sum of Squares (RSS)o Aka Sum of Squared Errors (SSE)o RSS is squared sum of “error” termso Definition of error depends on
problem What is “error” when clustering?
o Distance from centroid?o Then it’s the same as distortiono But, could use other measures instead
Cluster Analysis

43
Cohesion and Separation
Cluster cohesiono How “tightly packed” is a clustero The more cohesive a cluster, the
better Cluster separation
o Distance between clusterso The more separation, the better
Can we measure these things?o Yes, easily
Cluster Analysis

44
Notation
Same notation as K-meansoLet ci, for i=1,2,…,K, be centroids
oLet x1,x2,…,xm be data points
oLet centroid(xi) be centroid of xi oClusters determined by centroids
Following results apply generallyoNot just for K-means
Cluster Analysis

45
Cohesion
Lots of measures of cohesiono Previously defined distortion is usefulo Recall, distortion = Σ d(xi,centroid(xi))
Or, could use distance between all pairs
Cluster Analysis

46
Separation Again, many ways to measure this
o Here, using distances to other centroids
Or distances between all points in clusters Or distance from centroids to a
“midpoint” Or distance between centroids, or…Cluster Analysis

47
Silhouette Coefficient
Essentially, combines cohesion and separation into a single number
Let Ci be the cluster that xi belongs to o Let a be average of d(xi,y) for all y in Ci
o For Cj ≠ Ci, let bj be avg d(xi,y) for y in Cj
o Let b be minimum of bj
Then let S(xi) = (b – a) / max(a,b)o What the … ?
Cluster Analysis

48
Silhouette Coefficient
The idea...
Cluster Analysis
xi avg
avg
b=min
a=avg
Usually, S(xi) = 1 - a/b
Ci
Cj
Ck

49
Silhouette Coefficient For given point xi …
o Let a be avg distance to points in its clustero Let b be dist to nearest other cluster (in a
sense) Usually, a < b and hence S(xi) = 1 – a/b If a is a lot less than b, then S(xi) ≈ 1
o Points inside cluster much closer together than nearest other cluster (this is good)
If a is almost same as b, then S(xi) ≈ 0o Some other cluster is almost as close as
things inside cluster (this is bad)Cluster Analysis

50
Silhouette Coefficient
Silhouette coefficient is defined for each point
Avg silhouette coefficient for a clustero Measure of how “good” a cluster is
Avg silhouette coefficient for all pointso Measure of overall clustering
“goodness” Numerically, what is a good result?
o Rule of thumb on next slide
Cluster Analysis

51
Silhouette Coefficient
Average coefficient (to 2 decimal places)o 0.71 to 1.00 strong structure foundo 0.51 to 0.70 reasonable structure foundo 0.26 to 0.50 weak or artificial structureo 0.25 or less no significant structure
Bottom line on silhouette coefficiento Combine cohesion, separation in one
numbero A useful measures of cluster qualityCluster Analysis

52
External Validation
“External” implies that we measure quality based on data in clusterso Not relying on cluster topology
(“shape”) Suppose clustering data is of
several different typeso Say, different malware families
We can compute statistics on clusterso We only consider 2 stats hereCluster Analysis

53
Entropy and Purity
Entropyo Standard measure of uncertainty or
randomnesso High entropy implies clusters less
uniform Purity
o Another measure of uniformityo Ideally, cluster should be more “pure”,
that is, more uniform
Cluster Analysis

54
Entropy
Suppose total of m data elementso As usual, x1,x2,…,xm
Denote cluster j as Cj o Let mj be number of elements in Cj
o Let mij be count of type i in cluster Cj
Compute probabilities based on relative frequencieso That is, pij = mij / mj
Cluster Analysis

55
Entropy
Then entropy of cluster Cj is Ej = − Σ pij log pij, where sum is over i
Compute entropy Ej for each cluster Cj
Overall (weighted) entropy is thenE = Σ mj/m Ej, where sum is from 1 to K
and K is number of clusters Smaller E is better
o Implies clusters less uncertain/randomCluster Analysis

56
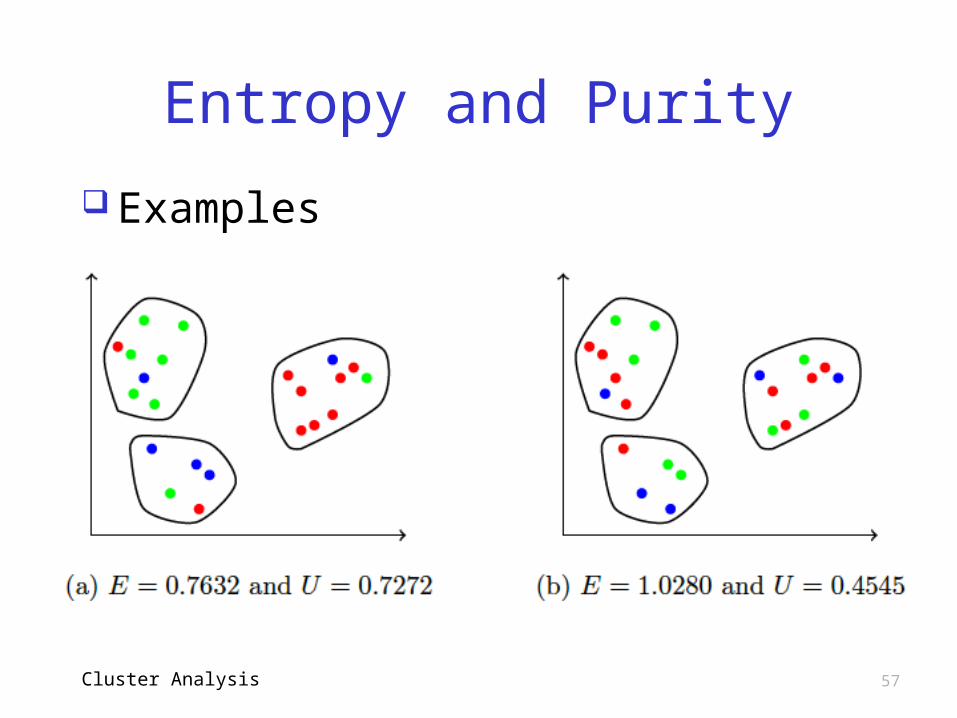
Purity
Ideally, each cluster is all one type Using same notation as in
entropy…o Purity of Cj defined as Uj = max pij o Where max is over i (different types)
If Uj is 1, then Cj all one type of datao If Uj is near 0, no dominant type
Overall (weighted) purity isU = Σ mj/m Uj, where sum is from 1 to KCluster Analysis
57
Entropy and Purity
Examples
Cluster Analysis

58
EM Clustering Data might be from different
probability distributionso Then “distance” might be poor
measureo Maybe better to use mean and
variance Cluster on probability distributions?
o But distributions are unknown… Expectation Maximization (EM)
o Technique to determine unknown parameters of probability distributions
Cluster Analysis

59
EM Clustering Animation
Good animation on Wikipedia pagehttp://en.wikipedia.org/wiki/Expectation–maximization_algorithm
Another animation herehttp://www.cs.cmu.edu/~alad/em/
Probably others too…
Cluster Analysis
60
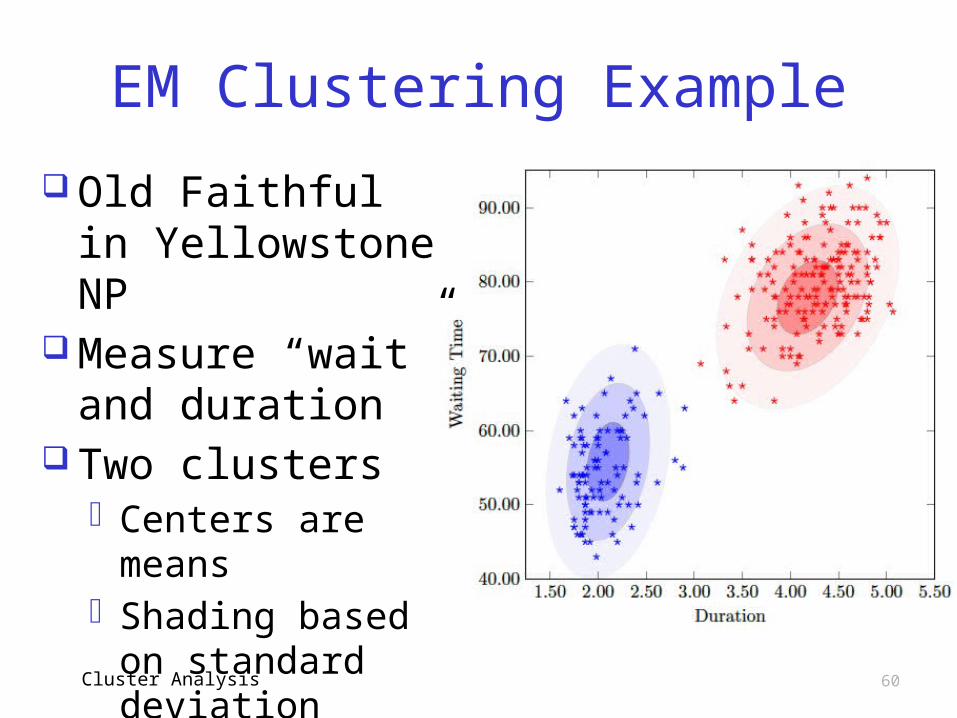
EM Clustering Example
Old Faithful in Yellowstone NP
Measure “wait” and duration
Two clusterso Centers are
meanso Shading based on
standard deviation
Cluster Analysis

61
Maximum Likelihood Estimator
Maximum Likelihood Estimator (MLE)
Suppose you flip a coin and obtainX = HHHHTHHHTT
What is most likely value of p = P(H)?
Coin flips follow binomial distribution:
Where p is prob of “success” (heads)
Cluster Analysis

62
MLE Suppose X = HHHHTHHHTT Maximum likelihood function for
X is
And log likelihood function is
Optimize log likelihood function
In this case, MLE is θ = P(H) = 0.7 Cluster Analysis

63
Coin Experiment
Given 2 biased coins, A and Bo Randomly select coin, then…o Flip selected coin 10 times, and…o Repeat 5 times, for 50 total coin flips
Can we determine P(H) for each coin?
Easy, if you know which coin selectedo For each coin, just divide number of
heads by number of flips of that coinCluster Analysis

64
Coin Example
For example, supposeCoin B: HTTTHHTHTH 5 H and 5 TCoin A: HHHHTHHHHH 9 H and 1 TCoin A: HTHHHHHTHH 8 H and 2 TCoin B: HTHTTTHHTT 4 H and 6 TCoin A: THHHTHHHTH 7 H and 3 T
Then maximum likelihood estimate isPA(H)=24/30=0.80 and PB(H)=9/20=0.45
Cluster Analysis

65
Coin Example
Suppose we have same data, but we don’t know which coin was selectedCoin ??: 5 H and 5 TCoin ??: 9 H and 1 TCoin ??: 8 H and 2 TCoin ??: 4 H and 6 TCoin ??: 7 H and 3 T
Can we estimate PA(H) and PB(H)?Cluster Analysis

66
Coin Example
We do not know which coin was flipped
So, there is “hidden” informationo This sounds familiar…
Train HMM on sequence of H and T ??o Using 2 hidden stateso Use resulting model to find most likely
hidden state sequence (HMM “problem 2”)
o Use sequence to estimate PA(H) and PB(H)
Cluster Analysis

67
Coin Example
HMM is very “heavy artillery”o And HMM needs lots of data to
converge (or lots of different initializations)
o EM gives us info we need, less work/data
EM algorithm: Initial guess for params o Then alternate between these 2 steps:o Expectation: Recompute “expected
values”o Maximization: Recompute params via
MLEs
Cluster Analysis

68
EM for Coin Example
Start with a guess (initialization)o Say, PA(H) = 0.6 and PB(H) = 0.5
Compute expectations (E-step) First, from current PA(H) and PB(H) we find
5 H, 5 T P(A) = .45, P(B) = .55 9 H, 1 T P(A) = .80, P(B) = .20 8 H, 2 T P(A) = .73, P(B) = .27 4 H, 6 T P(A) = .35, P(B) = .65 7 H, 3 T P(A) = .65, P(B) = .35
Why? See next slide…
Cluster Analysis

69
EM for Coin Example
Suppose PA(H) = 0.6 and PB(H) = 0.5 o And in 10 flips of 1 coin, we find 8 H and
2 T Assuming coin A was flipped, we
havea = 0.68 × 0.42 = 0.0026874
Assuming coin B was flipped, we haveb = 0.58 × 0.52 = 0.0009766
Then by Bayes’ FormulaP(A) = a/(a + b) = 0.73 and P(B) = b/(a + b) =
0.27
Cluster Analysis

70
E-step for Coin Example
Assuming PA(H) = 0.6 and PB(H) = 0.5, we have5 H, 5 T P(A) = .45, P(B) = .55 9 H, 1 T P(A) = .80, P(B) = .20 8 H, 2 T P(A) = .73, P(B) = .27 4 H, 6 T P(A) = .35, P(B) = .65 7 H, 3 T P(A) = .65, P(B) = .35
Next, compute expected (weighted) H and T
For example, in 1st lineo For A we have 5 x .45 = 2.25 H and 2.25 To For B we have 5 x .55 = 2.75 H and 2.75 TCluster Analysis

71
E-step for Coin Example
Assuming PA(H) = 0.6 and PB(H) = 0.5, we have5 H, 5 T P(A) = .45, P(B) = .55 9 H, 1 T P(A) = .80, P(B) = .20 8 H, 2 T P(A) = .73, P(B) = .27 4 H, 6 T P(A) = .35, P(B) = .65 7 H, 3 T P(A) = .65, P(B) = .35
Compute expected (weighted) H and T For example, in 2nd line
o For A, we have 9 x .8 = 7.2 H and 1 x .8 = .8 To For B, we have 9 x .2 = 1.8 H and 1 x .2 = .2 T
Cluster Analysis

72
E-step for Coin Example
Rounded to nearest 0.1: Coin A Coin B5 H, 5 T P(A) = .45, P(B) = .55 2.2H 2.2T 2.8H
2.8T9 H, 1 T P(A) = .80, P(B) = .20 7.2H 0.8T 1.8H
0.2T8 H, 2 T P(A) = .73, P(B) = .27 5.9H 1.5T 2.1H
0.5T 4 H, 6 T P(A) = .35, P(B) = .65 1.4H 2.1T 2.6H
3.9T 7 H, 3 T P(A) = .65, P(B) = .35 4.5H 1.9T 2.5H
1.1T
expected 21.2H 8.5T 11.8H 8.5T
This completes the E-step We computed these expected values
based on current PA(H) and PB(H)
Cluster Analysis

73
M-step for Coin Example
M-step Re-estimate PA(H) and PB(H) using
results from E-step:PA(H) = 21.2/(21.2+8.5) ≈ 0.71
PB(H) = 11.8/(11.8+8.5) ≈ 0.58
Next? E-step with these PA(H), PA(H) o Then M-step, then E-step, then…o …until convergence (or we get tired)Cluster Analysis

74
EM for Clustering
How is EM relevant to clustering? Can use EM to obtain parameters of K “hidden” distributionso That is, means and variances, μi and σi
2
Then, use μi as centers of clusterso And σi (standard deviations) as “radii”o Often use Gaussian (normal)
distributions Is this better than K-means?Cluster Analysis

75
EM vs K-Means
Whether it is better or not, EM is obviously different than K-means…o …or is it?
Actually, K-means is special case of EMo Using “distance” instead of “probabilities”
In K-means, we re-assign points to centroidso Like “E” in EM, which “re-shapes” clusters
In K-means, we recompute centroidso Like “M” of EM, where we recompute
parametersCluster Analysis

76
EM Algorithm
Now, we give EM algorithm in generalo Eventually, consider a realistic example
For simplicity, we assume data is a mixture from 2 distributionso Easy to generalize to 3 or more
Choose probability distribution typeo Like choosing distance function in K-
means Then iterate EM to determine
params
Cluster Analysis

77
EM Algorithm
Assume 2 distributions (2 clusters)o Let θ1 be parameter(s) of 1st distribution
o Let θ2 be parameter(s) of 2nd distribution
For binomial, θ1 = PA(H), θ2 = PB(H) For Gaussian distribution, θi = (μi,σi
2) Also, mixture parameters, τ = (τ1,τ2)
o Fraction of samples from distribution i is
τi
o Since 2 distributions, we have τ1 + τ2 = 1
Cluster Analysis

78
EM Algorithm
Let f(xi,θj) be the probability function for distribution j o For now, assuming 2 distributions o And xi are “experiments” (data points)
Make initial guess for parameterso That is, θ = (θ1, θ2) and τ
Let pji be probability of xi assuming distribution j
Cluster Analysis

79
EM Algorithm
Initial guess for parameters θ and τ o If you know something, use ito If not, “random” may be OKo In any case, choose reasonable values
Next, apply E-step, then M-step…o …then E then M then E then M ….
So, what are E and M steps?o Want to state these for the general
caseCluster Analysis

80
E-Step
Using Bayes’ Formula, we compute
o Where j = 1,2 and i = 1,2,…,n o Assuming n data points and 2
distributions Then pji is prob. of xi is in cluster j
o Or the “part” of xi that’s in cluster j
Note p1i + p2i = 1 for i=1,2,…,n Cluster Analysis

81
M-Step
Use probabilities from E-step to re-estimate parameters θ and τ
Best estimate for τj given by
This simplifies to
Cluster Analysis

82
M Step
Parms θ and τ are funcs of μi and σi
2 o Depends on specific distributions used
Based on pji, we have…
Means:
Variances:Cluster Analysis

83
EM Example: Binomial
Mean of binomial is μ = Np o Where p = P(H) and N trials per
experiment Suppose N = 10, and 5 experiments:
x1: 8 H and 2 T
x2: 5 H and 5 T
x3: 9 H and 1 T
x4: 4 H and 6 T
x5: 7 H and 3 T
Assuming 2 coins, determine PA(H), PB(H)
Cluster Analysis

84
Binomial Example
Let X=(x1,x2,x3,x4,x5)=(8,5,9,4,7) o Have N = 10, and means are μ = Np o We want to determine p for both coins
Initial guesses for parameters:o Probabilities PA(H)=0.6 and PB(H)=0.5
o That is, θ = (θ1,θ2) = (0.6,0.5)
o Mixture params τ1 = 0.7 and τ2 = 0.3
o That is, τ = (τ1,τ2) = (0.7,0.3)
Cluster Analysis

85
Binomial Example: E Step
Compute pji using current guesses for parameters θ and τ
Cluster Analysis

86
Binomial Example: M Step
Recompute τ using the new pji
So, τ = (τ1,τ2) = (0.7593,0.2407)
Cluster Analysis

87
Binomial Example: M Step
Recompute θ = (θ1,θ2) First, compute means μ = (μ1,μ2)
Obtain μ = (μ1,μ2) = (6.9180,5.5969)
So, θ = (θ1,θ2) = (0.6918,0.5597)Cluster Analysis

88
Binomial Example: Convergence
Next E-step: o Compute new pji using the τ and θ
Next M-step: o Compute τ and θ using pji from E step
And so on… In this example, EM converges to
τ = (τ1,τ2) = (0.5228, 0.4772)
θ = (θ1,θ2) = (0.7934, 0.5139)Cluster Analysis

89
Gaussian Mixture Example
We’ll consider 2-d datao That is, each data point is of form
(x,y) Suppose we want 2 clusters
o That is, 2 distributions to determine We’ll assume Gaussian
distributionso Recall, Gaussian is normal distributiono Since 2-d data, bivariate Gaussian
Gaussian mixture problemCluster Analysis
90
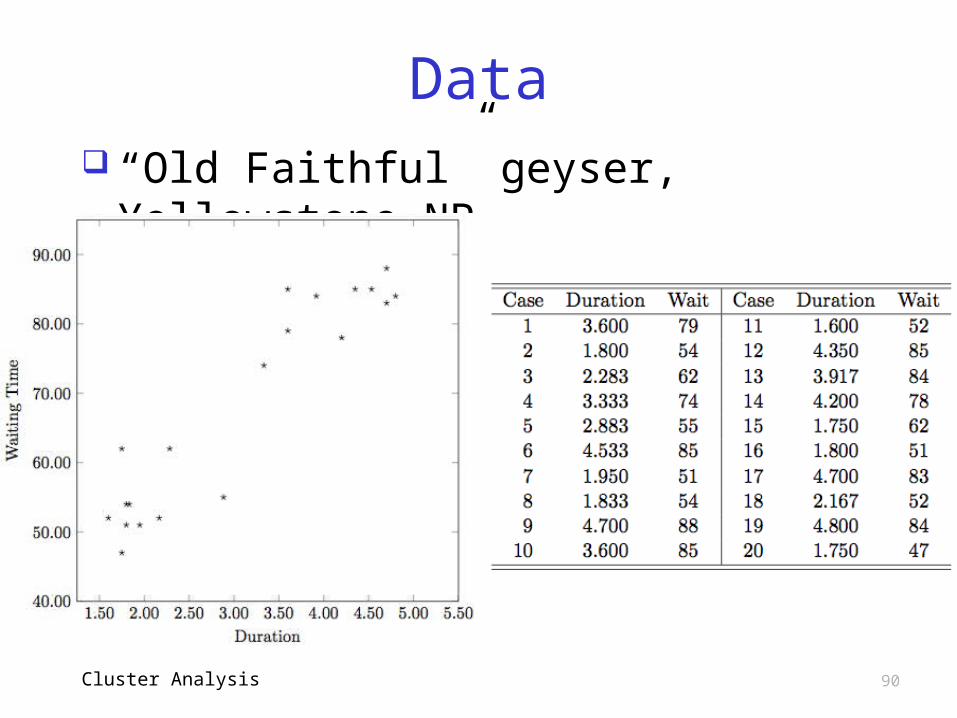
Data “Old Faithful” geyser, Yellowstone
NP
Cluster Analysis

91
Bivariate Gaussian
Gaussian (normal) dist. of 1 variable
Bivariate Gaussian distribution
o Where
o And ρ = cov(x,y)/σxσy
Cluster Analysis

92
Bivariate Gaussian: Matrix Form
Bivariate Gaussian can be written as
Where
And S is the covariance matrix and hence
Also and Cluster Analysis

93
Why Use Matrix Form?
Generalizes to multivariate Gaussian o Formulas for det(S) and S-1 changeo Can cluster data that’s more than 2-d
Re-estimation formulas in E and M steps have the same form as beforeo Simply replace scalars with vectors
In matrix form, params of (bivariate) Guassian: θ=(μ,S) where μ=(μx,μy)
Cluster Analysis

94
Old Faithful Data
Data is 2-d, so bivariate Gaussians Parameters of a bivariate Gaussian:
θ=(μ,S) where μ=(μx,μy)
We want 2 clusters, so must determineθ1=(μ1,S1) and θ2=(μ2,S2)
Where Si are 2x2 and μi are 2x1
Make initial guesses, then iterate EMo What to use as initial guesses?
Cluster Analysis

95
Old Faithful Example
Initial guesses? Recall that S is 2x2 and symmetric,
o Which implies that ρ = s12/sqrt(s11s22) o And must always have -1 ≤ ρ ≤ 1
This imposes restriction on S We’ll use mean and variance of x
and y components when initializing
Cluster Analysis

96
Old Faithful: Initialization
Want 2 clusters Initialize 2 bivariate Gaussians
For both Si, can verify that ρ = 0.5 Also, initialize τ = (τ1,τ2) = (0.6,
0.4) Cluster Analysis

97
Old Faithful: E-Step
First E-step yields
Cluster Analysis

98
Old Faithful: M-Step
First M-step yieldsτ = (τ1,τ2) = (0.5704, 0.4296)
And
Easy to verify that -1 ≤ ρ ≤ 1 o For both distributions
Cluster Analysis

99
Old Faithful: Convergence
After 100 iterations of EMτ = (τ1,τ2) = (0.5001, 0.4999)
With
And
Again, we have -1 ≤ ρ ≤ 1
Cluster Analysis

100
Old Faithful Clusters
Centroids are means: μ1, μ2
Shading is standard devs o Darker area is
within one σ o Lighter is two
standard dev’s
Cluster Analysis

101
EM Clustering
Clusters based on probabilitieso Each data point has a probability
related to each clustero Point is assigned to the cluster that
gives highest probability In K-means, uses distance, not
prob. But can view prob. as a “distance” So, K-means and EM not so
different…Cluster Analysis

102
Conclusion
Clustering is fun, entertaining, very usefulo Can explore mysterious data, and more…
And K-means is really simpleo EM is powerful and not that difficult either
Measuring success is not so easyo “Good” clusters? And useful information? o Or just random noise? Anything can be
clustered Clustering is often just a starting point
o Helps us decide if any “there” is thereCluster Analysis

103
References: K-Means A.W. Moore, K-means and hierarchical
clustering P.-N. Tan, M. Steinbach, and V. Kumar,
Introduction to Data Mining, Addison-Wesley, 2006, Chapter 8, Cluster analysis: Basic concepts and algorithms
R. Jin, Cluster validation M.J. Norusis, IBM SPSS Statistics 19
Statistical Procedures Companion, Chapter 17, Cluster analysis
Cluster Analysis

104
References: EM Clustering C.B. Do and S. Batzoglou, What is the
expectation maximization algorithm?, Nature Biotechnology, 26(8):897-899, 2008
J.A. Bilmes, A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov models, ICSI Report TR-97-021, 1998
Cluster Analysis