architetture parallele -...
TRANSCRIPT

ARCHITETTUREPARALLELE

1 Parallelismo inerente e decomposizione dei problemi in grani di computazione
I problemi presentati ai calcolatori sono dotati di un parallelismo inerente che viene spesso oscurato dalla architettura di calcolatore.
Per concepire architetture che sfruttino il parallelismo inerente, è necessario che siano soddisfatte due condizioni. La prima è che i problemi siano suddivisibili in computazioni il più possibile indipendenti fra loro. La seconda è che esista un flusso di istruzioni o di dati che sia in grado di sfruttare adeguatamente, cioè di alimentare con continuità ed il più a lungo possibile, l’architettura parallela che ne deriva.
La dimensione di una computazione, chiamata grano, è determinata dalla quantità dicomunicazione fra le computazioni, che deve essere la più piccola possibile.
Grani di computazione sui quali sviluppare il parallelismo possono essere:
- Stadi corrispondenti alle varie fasi del ciclo d’istruzione ( pipeline di istruzioni), - Stadi corrispondenti ad operazioni all’interno della fase execute (pipeline di dati), - Elementi di elaborazione che operano parallelamente su vettori (array processor), - Processori (multiprocessori), - Computer (multicomputer).

2 Modelli di computazioneLa definizione di ogni tipo di architettura si basa su di un differente modello computazionale che deve precisare un insieme di meccanismi:
Meccanismo di controllo, che stabilisce come passare da una o più istruzioni ad un’altra o più istruzioni.Meccanismo di memorizzazione dei dati, che può consistere in:- memoria locale, con:
- replica dei dati in più copie, - canali di comunicazione in cui è determinato l’ordine di accesso, - rispetto automatico delle relazioni di dipendenza;
- memoria condivisa, con: - una sola copia dei dati, - introduzione del concetto di stato e suo cambiamento, - rispetto delle relazioni di dipendenza non implicito.
Meccanismo di selezione delle prossime istruzioni da eseguire fra quelle pronte ad essere eseguite (es. modelli “imperativi”).
Ogni problema può essere espresso mediante un grafo diretto, il grafo di problema, in cui i nodi rappresentano le istruzioni da eseguire e gli archi le relazioni di dipendenza. Al grafo rappresentante il problema si contrappone un altro grafo (grafo di controllo),che esprime non più le relazioni di dipendenza ma il modo in cui il controllo fluisce attraverso i nodi. Il grafo di controllo dipende dal numero di processori e dalla topologia di rete dell’architettura.

3 Tassonomia di FlynnSchema di classificazione per architetture parallele basato sul meccanismo di controllo.
In senso generale, in una architettura, una sequenza di istruzioni o Instruction stream (I) manipola una sequenza di operandi o Data stream (D).
Gli Instruction stream ed i Data stream possono essere singoli (S) o multipli (M), creando insieme quattro possibili combinazioni: SISD, SIMD, MISD, MIMD.
Di queste, MISD non sembra riferirsi a nessun tipo di architettura realistica.
SISD (Single Instruction stream, Single Data stream) non è un’architettura parallela, ma rappresenta i sistemi con CPU singola (uniprocessori) con eventuali coprocessori.
Elaborazione concorrente permessa: Instruction prefetching, Pipeline di istruzioni.

SIMD (Single Instruction stream, Multiple Data stream) Array processor.
Uno stream di istruzioni è trasmesso in broadcast da una unità di controllo ad un insieme di elementi di elaborazione (processing element o PE) che sono molto semplici, essenzialmente delle ALU.
Tutti i PE attivi eseguono la stessa istruzione in modo sincrono, ma su elementi differenti di array (Multiple Data stream), ognuno dei quali è memorizzato localmente ad ogni PE.
MIMD (Multiple Instruction stream, Multiple Data stream) Multiprocessori e Multicomputer.
Gli elementi di elaborazione sono processori, ognuno dei quali può eseguire indipendentemente dall’altro un differente programma su un differente insieme di dati. Quindi sono architetture asincrone.
La comunicazione tra i processori è effettuata o mediante uso di:
message passing, se i processori accedono a spazi di indirizzi separati,
o attraverso memoria condivisa.

4 Pipeline di datiDecomponendo la fase execute di una istruzione in sottoperazioni ed organizzando tali sottoperazioni a pipeline, si ottiene una pipeline di dati, a cui si applicano tutte le considerazioni fatte per le pipeline di istruzioni.
Le pipeline di dati sono di solito utilizzate per operazioni in floating point.
Un processore pipelened può costituire esso stesso l’elemento base di un’architettura sequenziale o parallela di altro tipo.
Il modello di computazione è tale che il flusso di controllo sia rigidamente sequenziale, esattamente come nel modello di von Neumann. La differenza con quest’ultimo sta nel fatto che non uno ma più processori, tanti quanti sono gli stadi della pipeline, possono lavorare contemporaneamente.
Un altro modo di vedere il matching fra il grafo di problema ed il grafo dell’architettura pipeline è la sua trasformazione in più grafi di controllo sequenziali sovrapposti e scalati di una unità l’uno dall’altro.
Una pipeline ha bisogno di essere alimentata da uno stream di oggetti.
Nel caso di pipeline di istruzioni, la pipeline viene attraversata da uno stream di istruzioni, mentre, nel caso di pipeline di dati, la pipeline viene attraversata da uno stream di elementi vettoriali.
Le unità delle pipeline di dati sono di tipo funzionale.

4.1 Somma vettoriale in floating point con pipeline di datiIn un calcolatore seriale, la somma in floating point è decomponibile in quattro sottoperazioni:
confronto degli esponenti, allineamento, somma delle mantisse e normalizzazione del risultato
Nel caso di una somma vettoriale in floating point, in un calcolatore seriale tutte queste operazioni devono essere completate sulla prima coppia di elementi, prima che la successiva coppia possa essere presa in considerazione.
Invece, in un sistema pipelened a 4 stadi, corrispondenti ognuno ad una delle quattro sottoperazioni, ogni coppia di elementi può entrare nel primo stadio non appena la coppia precedente passa al secondo stadio.

γα = numero di stadi
= durata di ogni stadion = numero di elementi
dello stream
αγ γ
α
αγ αγ αγ
αγ (n-1) γ
αγ n
+ (n-1)
Il tempo richiesto per eseguire un’operazione su vettori di lunghezza n, in un calcolatore seriale, è uguale a n volte il tempo per portare a termine l’operazione su ogni singola coppia di elementi vettoriali, cioè n volte il prodotto del numero di sottoperazioni per il tempo richiesto da ognuna di esse (supposto uguale per tutte).
In un sistema organizzato a pipeline, tale tempo si riduce al tempo richiesto per ottenere il primo risultato più n – 1 cicli di pipeline.
Il ciclo della pipeline coincide sensibilmente con la durata di una sottoperazione. Di fatto è leggermente superiore per rendere conto delle interfacce fra gli stadi.
Tscalare =
Tpipeline =

La presenza di unità funzionali vettoriali differenti può essere sfruttata per aumentare il parallelismo, mediante una tecnica denominata chaining, che consiste nel concatenare due unità funzionali in modo che ogni risultato prodotto dalla prima possa essere inserito direttamente nella seconda, senza dover passare dai registri vettoriali.
L’effetto che si ottiene è quello di una pipeline estesa, con un numero di stadi equivalente alla somma degli stadi delle singole unità concatenate.
Tale caratteristica è utile quando si devono eseguire sequenze di istruzioni vettoriali che riutilizzano dei risultati parziali. Per es., l’esecuzione della sequenza:
Z = X + YA = Z x B
può essere accelerata con il chaining dell’unità di prodotto e dell’unità di somma.
Infatti, trascorso il tempo per riempire la pipeline del sommatore con i primi elementi di X e Y, è generato il primo risultato da memorizzare in Z. Ma, poiché Z è il primo operando dell’istruzione successiva (che richiede l’utilizzo del moltiplicatore), il risultato della prima pipeline viene direttamente fornito al moltiplicatore, realizzando quindi una pipeline multifunzione. Il tempo complessivo si riduce di n – 1 cicli di pipeline.

5 Array processor
Queste architetture sono esattamente l’equivalente del modello di von Neumann, applicato però ad operazioni vettoriali invece che ad operazioni scalari. Come nel modello di von Neumann, Il controllo è rigidamente sequenziale. Nel grafo di controllo, i nodi rappresentano operazioni vettoriali e gli archi convogliano vettori. Al nodo raggiunto dal controllo sono assegnati n elementi di elaborazione (PE), che operano parallelamente su n elementi o coppie di elementi di uno o due vettori. Il grafo di controllo è equivalente ad n grafi di controllo identici ed indipendenti, ognuno dei quali corrispondente al modello sequenziale, che eseguono di volta in volta la stessa istruzione scalare su un diverso elemento o coppia di elementi. Gli n nodi che eseguono la stessa istruzione sono raggiunti contemporaneamente dal controllo. Un’unità di controllo centrale trasmette in broadcast istruzioni ai PE multipli.Il modello dei dati prevede, per ogni PE, memoria locale sufficiente a contenere uno o due elementi di array nei successivi stadi della loro elaborazione. Esso elimina, cioè, i frequenti fetch e store dei dati, che sono così onerosi nelle grosse strutture di informazione. In generale, il risultato di un PE è funzione di dati appartenenti alla sua memoria locale e a quella di altri PE. Per questa ragione, i PE sono interconnessi con i loro vicini in strutture lineari o bidimensionali (mesh).
Broadcast del
controlloParallel
I/O
Array processorControllo
Switch

I PE che fanno parte dell’array sono tutti identici e, come già detto, eseguono la stessa istruzione estratta da un’unica unità di controllo. L’unico allontanamento da questa regola consiste nella possibilità di rendere condizionale l’esecuzione dell’istruzione, in modo da permettere l’elaborazione di sottoinsiemi dell’array.Si fa notare come l’array processor sia il duale del pipelining, dove non sono i dati ad essere precaricati bensì gli stadi di escuzione delle istruzioni. In un caso, il parallelismo è realizzato nei confronti della struttura dati, nell’altro è diretto verso la struttura computazionale. Corrispondentemente, il tempo di calcolo dipende, nel caso degli array processor, soltanto dalla profondità computazionaledell’algoritmo e non dal numero degli elementi, mentre, nelle architetture pipeline, dipende linearmente dal numero degli elementi e non dalla profondità computazionale.
Un esempio delle potenzialità degli array processor nell’eseguire operazioni parallele è fornito dal calcolo del prodotto scalare A x B. L’ordine del tempo di esecuzione di tale calcolo su di un calcolatore scalare è di tipo lineare, cioè è proporzionale al numero n degli elementi dei due vettori (sono richiesti n prodotti ed n – 1 somme). Se si esamina il grafo del problema del prodotto scalare ottenuto col metodo delle somme parziali in cascata, detto anche di riduzione ciclica, ci si accorge che esiste un parallelismo inerente molto alto, che potrebbe essere utilmente sfruttato impiegando una opportuna architettura parallela.
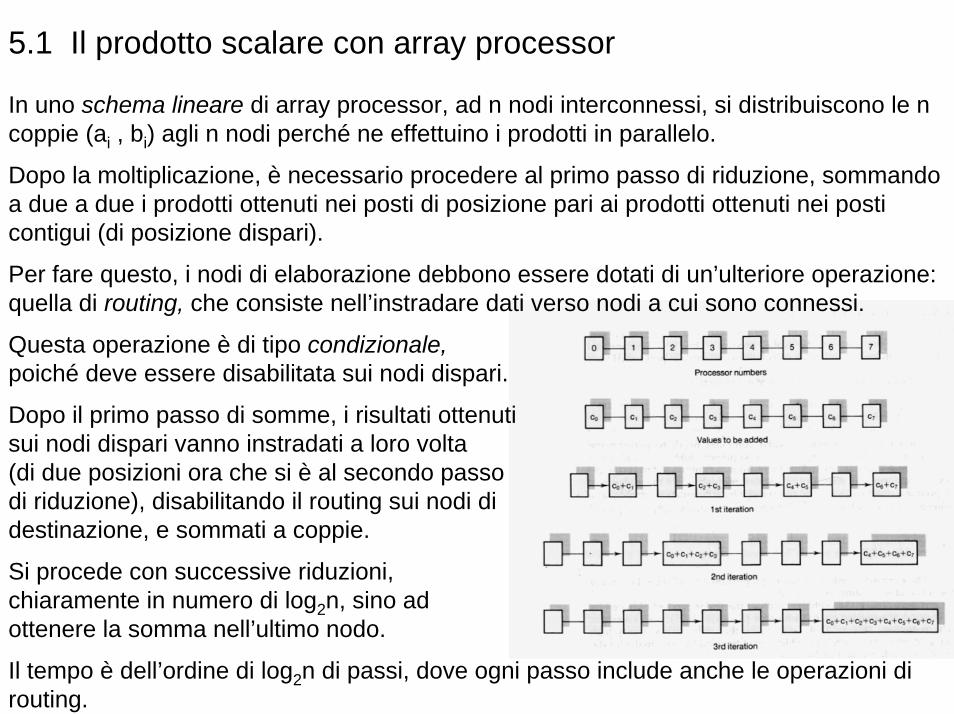
5.1 Il prodotto scalare con array processor
In uno schema lineare di array processor, ad n nodi interconnessi, si distribuiscono le n coppie (ai , bi) agli n nodi perché ne effettuino i prodotti in parallelo.
Dopo la moltiplicazione, è necessario procedere al primo passo di riduzione, sommando a due a due i prodotti ottenuti nei posti di posizione pari ai prodotti ottenuti nei posti contigui (di posizione dispari).
Per fare questo, i nodi di elaborazione debbono essere dotati di un’ulteriore operazione: quella di routing, che consiste nell’instradare dati verso nodi a cui sono connessi.
Questa operazione è di tipo condizionale, poiché deve essere disabilitata sui nodi dispari.
Dopo il primo passo di somme, i risultati ottenuti sui nodi dispari vanno instradati a loro volta (di due posizioni ora che si è al secondo passo di riduzione), disabilitando il routing sui nodi di destinazione, e sommati a coppie.
Si procede con successive riduzioni, chiaramente in numero di log2n, sino ad ottenere la somma nell’ultimo nodo.
Il tempo è dell’ordine di log2n di passi, dove ogni passo include anche le operazioni di routing.
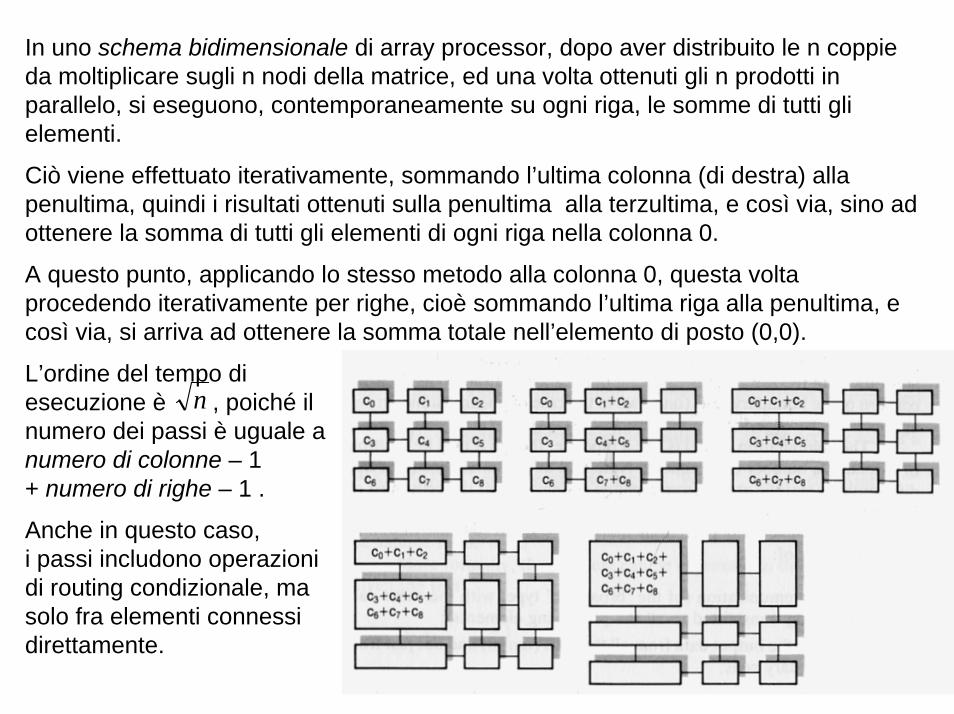
In uno schema bidimensionale di array processor, dopo aver distribuito le n coppie da moltiplicare sugli n nodi della matrice, ed una volta ottenuti gli n prodotti in parallelo, si eseguono, contemporaneamente su ogni riga, le somme di tutti gli elementi.
Ciò viene effettuato iterativamente, sommando l’ultima colonna (di destra) alla penultima, quindi i risultati ottenuti sulla penultima alla terzultima, e così via, sino ad ottenere la somma di tutti gli elementi di ogni riga nella colonna 0.
A questo punto, applicando lo stesso metodo alla colonna 0, questa volta procedendo iterativamente per righe, cioè sommando l’ultima riga alla penultima, e così via, si arriva ad ottenere la somma totale nell’elemento di posto (0,0).
L’ordine del tempo di esecuzione è , poiché il numero dei passi è uguale a numero di colonne – 1 + numero di righe – 1 .
Anche in questo caso, i passi includono operazioni di routing condizionale, ma solo fra elementi connessi direttamente.
n

6 Array sistolici
A differenza degli array processor, che rispecchiano la struttura dei dati, gli array sistolici, come le architetture pipeline, realizzano direttamente la struttura degli algoritmi.
Essi sono formati da array (lineari o bidimensionali) di elementi di elaborazione identici connessi a maglia. Così ogni cella comunica soltanto con le sue vicine.
La comunicazione con l’esterno è assicurata dalle celle di confine (soltanto due per array sistolici lineari; tutte quelle del perimetro per array bidimensionali).
Il modello di computazione è di tipo pipeline, eventualmente multiplo e propagantesi in più direzioni.
Si osservi che un vincolo essenziale, che differenzia gli array sistolici dai sistemi pipeline, è che le celle siano tutte identiche.
Il risultato viene ottenuto facendo sì che ogni cella utilizzi come almeno uno dei suoi input l’output della cella precedente. Così, il risultato viene costruito ricorsivamente attraverso le varie celle e prelevato dall’ultima cella.

E’ possibile uscire dallo schema ‘puro-sistolico’ mediante:
a) la comunicazione globale (di tipo ‘broadcast’) di uno stesso dato dall’esterno a tutti gli elementi di elaborazione;
b) la raccolta dei dati di output da tutte le celle (‘fan-in’) e non soltanto dalle celle di confine;
c) la possibilità di inviare un’istruzione (un’unica istruzione alla volta) a tutti gli elementi di elaborazione. In quest’ultimo caso, la cella è un elemento sistolico programmabile.
Il grafo di controllo può essere considerato la sovrapposizione di più grafi sequenziali ricorsivi, sfasati di una o più unità l’uno dall’altro,
La sovrapposizione può essere realizzata non soltanto su grafi separati ma anche sullo stesso grafo (per la caratteristica di ricorsività).
In questo modo, la dimensione dell’array non ha influenza su quella del grafo di problema, poiché quest’ultimo può essere reiterato ritornando sugli stessi elementi anche più volte. Si può, così, bilanciare il parallelismo spaziale con quello temporale.
Il grafo di controllo è, dunque, in generale, un insieme di uno o più grafi ricorsivi parzialmente o totalmente “srotolati”, in sovrapposizione con altri identici grafi scalati di una o più unità.

6.1 Il problema del “pattern matching” con array sistoliciUn particolare tipo di computazione, nella quale gli array sistolici sono diffusamente sfruttati, è la soluzione del problema del pattern matching. Esso consiste nel determinare le posizioni delle occorrenze di una stringa campione in un testo dato.
Esempio: Testo: WXAYWXBYStringa campione: WX*YRisultato: 100001
Ogni 1 indica la posizione iniziale nel testo di una occorrenza del campione.

Una possibile soluzione prevede l’uso di un array semisistolico nel quale sia precaricata la stringa campionedegli m elementi.
I risultati parziali yk , inizialmente posti uguali ad 1, si muovono sistolicamenteverso destra, ed i caratteri del testo sisono trasmessi globalmente a tutte le celle, uno per ogni ciclo, per consentire, di volta in volta, di effettuare in parallelo i confronti di tutti i caratteri del campione con lo stesso carattere di testo.
array semisistolico
cella base e funzione di trasferimento

y1,out
y2,out
y3,out
y4,out
y5,out
_
_
_
Successione dei cicli per effettuare il pattern matching di una stringa di 4 caratteri con un testo lungo 8 caratteri.
Il primo risultato si ottiene al 4° ciclo dalla cella più a destra.

7 MultiprocessoriNei multiprocessori, i nodi sono costituiti da processori, quindi da:elementi di elaborazione + controllo.
La componente di memoria è condivisa (SAS - Shared Address Space).
Le architetture multiprocessore sono asincrone per la presenza del controllo nei nodi.
Per la mancanza del vincolo del sincronismo, i modelli computazionali sono più generali.
D’altra parte, è necessario comunque introdurre dei meccanismi di sincronizzazione(code e semafori), poiché i nodi cooperano alla risoluzione di uno stesso problema o competono per l’uso di risorse condivise.
Si ha necessità di decomporre i problemi da risolvere in sottoproblemi il più indipendenti possibile per ridurre al minimo l’overhead dei meccanismi di sincronizzazione.
(c)

La componente memoria può essere:
- concentrata tightly coupled (anche UMA - Uniform Memory Access o SMP - symmetric multiprocessor) (a),
- distribuita in moduli locali ai processori ma comunque accessibili dagli altri processori in modo remoto loosely coupled (anche NUMA - Non-Uniform Memory Access) (b), e quindi sempre condivisa da tutti i processori.
Esiste una terza possibilità:
- sistemi ibridi, con memorie locali a due porte.
In questo modo, ogni processore può comunicaredirettamente con la propria memoria locale e, tramite switch, con la memoria locale di altri processori.

7.1 Unità di switching
Nei sistemi multiprocessore, la componente comunicazione è concentrata in un’unica unità di switching.
Gran parte dell’efficienza dipende da tale unità, che tende ad essere la parte più complessa di tali sistemi.
A volte la struttura di interconnessione è un semplice bus, ma questo, all’aumentare del numero dei processori, diventa ben presto un collo di bottiglia.
All’altro estremo c’è l’interconnessione completa, che, però, ha una complessità dell’ordine di n2 link e un grado uguale ad n link.
Per avere complessità minori, senza dover sacrificare il numero dei nodi connessi, si ricorre a schemi di interconnessione indiretta o dinamica, come:
- bus multipli, - crossbar switch, - connessioni multistadi.
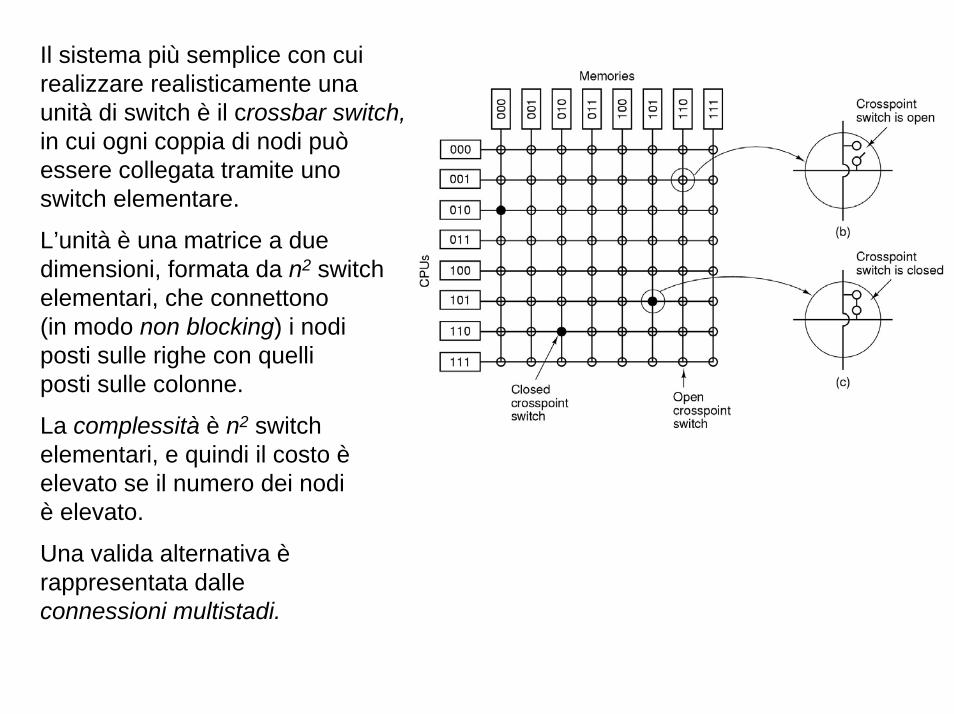
Il sistema più semplice con cui realizzare realisticamente una unità di switch è il crossbar switch, in cui ogni coppia di nodi può essere collegata tramite uno switch elementare.
L’unità è una matrice a due dimensioni, formata da n2 switch elementari, che connettono (in modo non blocking) i nodi posti sulle righe con quelli posti sulle colonne.
La complessità è n2 switch elementari, e quindi il costo è elevato se il numero dei nodi è elevato.
Una valida alternativa è rappresentata dalle connessioni multistadi.

7.1.1 Connessioni multistadiLe connessioni multistadi realizzano il collegamento fra i nodi attraverso un numero di switch superiore ad 1.
Ognuno di tali switch è esso stesso un crossbar switch elementare (tipicamente 2 x 2 o 4 x 4).
Se si vogliono connettere n nodi tra loro ( o con altri n nodi) usando dei crossbar switch M x M (M < n), si ottiene una rete a log M n stadi, in cui ogni stadio ha n / M switch.
Si ha, così, una riduzione notevole della complessità, da n2 a nlog M n, ottenuta al costo di un allungamento dei percorsi di comunicazione da 1 a log M n.
I ritardi sono più bassi all’aumentare di M, ovvero della complessità degli switch elementari, ma possono anche aumentare perché al crescere di M aumenta la probabilità di richiesta dello stesso switch.
All’aumentare di M si possono duplicare gli switch in modo da creare percorsi alternativi e per aumentare l’affidabilità.
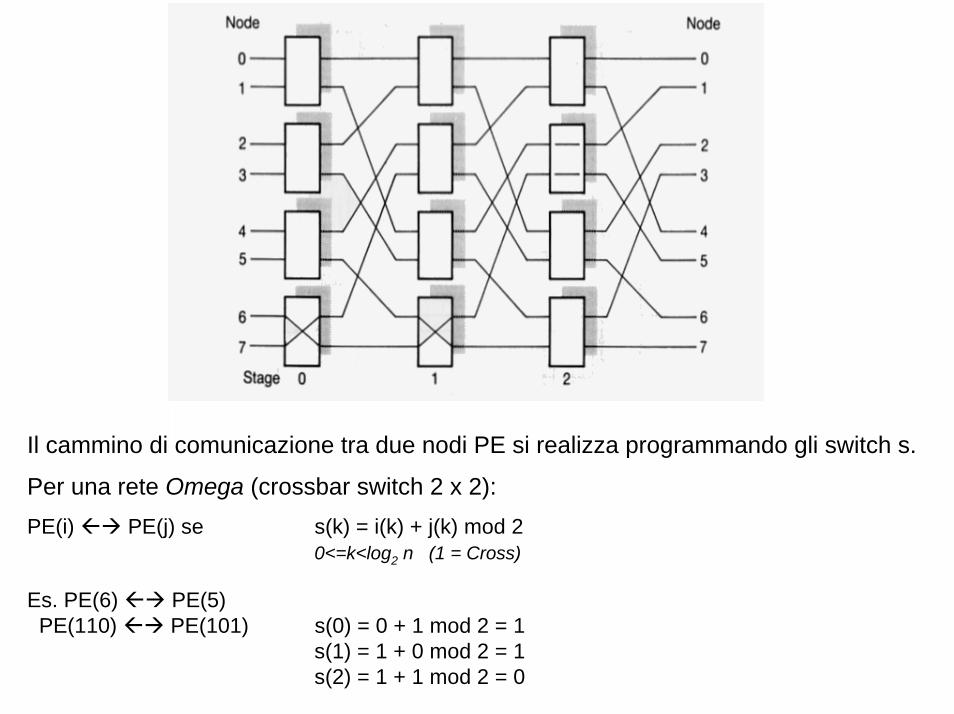
Il cammino di comunicazione tra due nodi PE si realizza programmando gli switch s.
Per una rete Omega (crossbar switch 2 x 2):PE(i) PE(j) se s(k) = i(k) + j(k) mod 2
0<=k<log2 n (1 = Cross)
Es. PE(6) PE(5)PE(110) PE(101) s(0) = 0 + 1 mod 2 = 1
s(1) = 1 + 0 mod 2 = 1s(2) = 1 + 1 mod 2 = 0

Esempio di incoerenza (1)
1. CPU0 read X dalla memoria: store X=0 nella sua cache
2. CPU1 read X dalla memoria: store X=0 nella sua cache
3. CPU0 write X=1: store X=1 nella sua cache
4. CPU0 write back la linea di cache: store X=1 in memoria
5. CPU1 read X dalla sua cache: load X=0 dalla sua cache
Valore incoerente per X su CPU1
Problema 1: CPU1 ha usato un vecchio valore che era già stato modificato da CPU0Soluzione: Invalidate tutte le copie prima di permettere che una write proceda
CPU0 CPU1
WT-Cache WT-Cache
Memory
X= X=
X=
Coerenza di cache.
Cache locali ai processori possono portare alla presenza di copie multiple per una stessa locazione di memoria (Modello di programmazione SAS: molte copie un nome). Coerenza delle cache è un meccanismo per mantenere copie aggiornate. Essa consiste nel localizzare tutte le copie di una locazione di memoria e nell’eliminare le copie vecchie.
Protocolli di coerenza di cacheBasati su snooping: Ogni blocco di cache è accompagnato dallo stato di condivisione di quel blocco:
Modified (M), Exclusive (E), Shared (S), Invalid (I).
Non utilizzabileInvalid (I)AggiornataNon modificateNon modificataShared (S)
AggiornataNoUnica e non modificata
Exclusive (E)
Non aggiornataNoUnica e modificataModified (M)Copia in memoriaCopie in altre cacheCopia nella cacheStato
11.1.1 Protocollo MESI (protocollo basato su snooping)

Esempio di incoerenza (1)
1. CPU0 read X dalla memoria: store X=0 nella sua cache
2. CPU1 read X dalla memoria: store X=0 nella sua cache
3. CPU0 write X=1: store X=1 nella sua cache
4. CPU0 write back la linea di cache: store X=1 in memoria
5. CPU1 read X dalla sua cache: load X=0 dalla sua cache
Valore incoerente per X su CPU1
CPU0 CPU1
WT-CacheS
WT-CacheS (X=1)
Memory
X=1 X=0
X=1
Problema 1: CPU1 ha usato un vecchio valore che era già stato modificato da CPU0Soluzione: Invalidate tutte le copie prima di permettere che una write proceda

Esempio di incoerenza (1)0 1I I
1. CPU0 read X dalla memoria: store X=0 nella sua cache E I
2. CPU1 read X dalla memoria: store X=0 nella sua cache S S
3. CPU0 write X=1: store X=1 nella sua cache M I
4. CPU0 write back la linea di cache: store X=1 in memoria E I
5. CPU1 read X dalla memoria: store X=1 nella sua cache S S
Valore coerente per X su CPU1
CPU0 CPU1
WT-CacheS
WT-CacheS
Memory
X=1 X=1
X=1
Problema 1: CPU1 ha usato un vecchio valore che era già stato modificato da CPU0Soluzione: Invalidate tutte le copie prima di permettere che una write proceda


1. CPU0 read X da memoria: store X=0 nella sua cache
2. CPU1 read X da memoria: store X=0 nella sua cache
3. CPU0 write X=1: store X=1 nella sua cache
4. CPU1 write X=2: store X=2 nella sua cache
5. CPU1 write back la linea di cache: store X=2 in memoria
6. CPU0 write back la linea di cache: store X=1 in memoria
Il valore in memoria dell’ultimo dato modificato in cache, X=2 da CPU1 , è andato perso
Esempio di incoerenza (2)
Problema 2: Incorretta sequenza di write back di linee di cache modificateSoluzione: Non consentire che ci sia più di una copia modificata.
CPU0 CPU1
WT-CacheI
WT-CacheE
Memory
X=1 X=2
X=1

1. CPU0 read X da memoria: store X=0 nella sua cache
2. CPU1 read X da memoria: store X=0 nella sua cache
3. CPU0 write X=1: store X=1 nella sua cache
4. CPU1 write X=2: store X=2 nella sua cache
5. CPU1 write back la linea di cache: store X=2 in memoria
6. CPU0 write back la linea di cache: store X=1 in memoria
Esempio di incoerenza (2)
CPU0 CPU1
WT-CacheI
WT-CacheE
Memory
X=1 X=2
X=1
Il valore in memoria dell’ultimo dato modificato in cache, X=2 da CPU1 , è andato perso
0 1I I
E I
S S
M I
I M
I E

8 MulticomputerMentre i multiprocessori sono costituiti da processori che hanno accesso alla stessa memoria (sistemi con spazio di indirizzi singolo o condiviso), i multicomputer sono costituiti da calcolatori con spazi di indirizzi separati o distribuiti.
I computer possono essere connessi:
- direttamente solo ad alcuni dei computer (detti vicini), ed indirettamente, tramite questi, agli altri,
- indirettamente, tramite una rete di interconnessione.
Nel primo caso, ciò che contraddistingue il multicomputer è una topologia di retepiuttosto che un’unità di switching separata.
Le topologie seguono il più possibile la struttura dei grafi di problema.
Nei multicomputer, la decomposizione di un problema in sottoproblemi acquista un carattere di criticità più accentuata rispetto ai multiprocessori ed agli array processor a causa dei maggiori ritardi di comunicazione e della conseguente necessità di grani di computazione più grossi.

La tecnica di comunicazione, non essendoci registri o memoria condivisa, usa dei canali e message passing fra i processi comunicanti.
La comunicazione può essere sincrona, se il primo processo che è pronto per comunicare deve attendere che anche l’altro sia pronto, o asincrona, se i nodi hanno capacità di buffering dei dati.
Due processi, quando debbono comunicare, lo fanno inviando istruzioni di output e di input su di un canale (primitive send e receive a livello più alto).
Se il modello è di tipo sincrono, un processo che arriva alla sua istruzione di I/O deve attendere (cioè viene deschedulato) che anche l’altro raggiunga la sua istruzione di I/O (blocking send call), se invece è di tipo asincrono ritorna subito (non blocking send call).

Astrazione Message-Passing
ProcessP Process Q
AddressY
Address X
Send X, Q, t
Receive Y, P, tMatch
Local processaddress spaceLocal process
address space
– Send specifica il buffer che deve essere trasmesso ed il processo ricevente– Recv specifica il processo inviante e la memoria di applicazione in cui ricevere– Copia memoria a memoria, ma è necessario nominare processi– Tag opzionale su send e regola di matching su receive– Il processo utente nomina anche dati ed entità locali nello spazio di processo– Nella forma più semplice, il match send/recv ottiene un evento di
sincronizzazione a coppie– Molti overhead: copie, buffer management, protezione

Modelli di programmazione parallela
Modello di programmazione sequenziale
Modello di programmazione SAS (Shared Address Space)
Modello di programmazione MP (Message Passing)
1 Naming: Come ci si riferisce a dati e/o processi?
spazio di indirizzi lineare
un qualsiasi processo può nominare qualsiasi variabile nello spazio di indirizzi condiviso
I processi possono nominare dati privati direttamente, non c’è shared address space
2 Operazioni: Quali operazioni sono fornite per accedere a questi dati?
load/store load e store, più quelle necessarie per l’ordinamento
Comunicazione esplicita tramite send and receiveSend: dati da spazio di indirizzi privato ad un altro processoReceive: copie da un processo a spazio di indirizzi privatoDeve essere capace di nominare processiPuò costruire uno spazio di indirizzi globale sul top di MP, a livello di programma o mediante compilatore, librerie o OS
Modello di programmazione sequenziale
Modello di programmazione SAS (Shared Address Space)
Modello di programmazione MP (Message Passing)
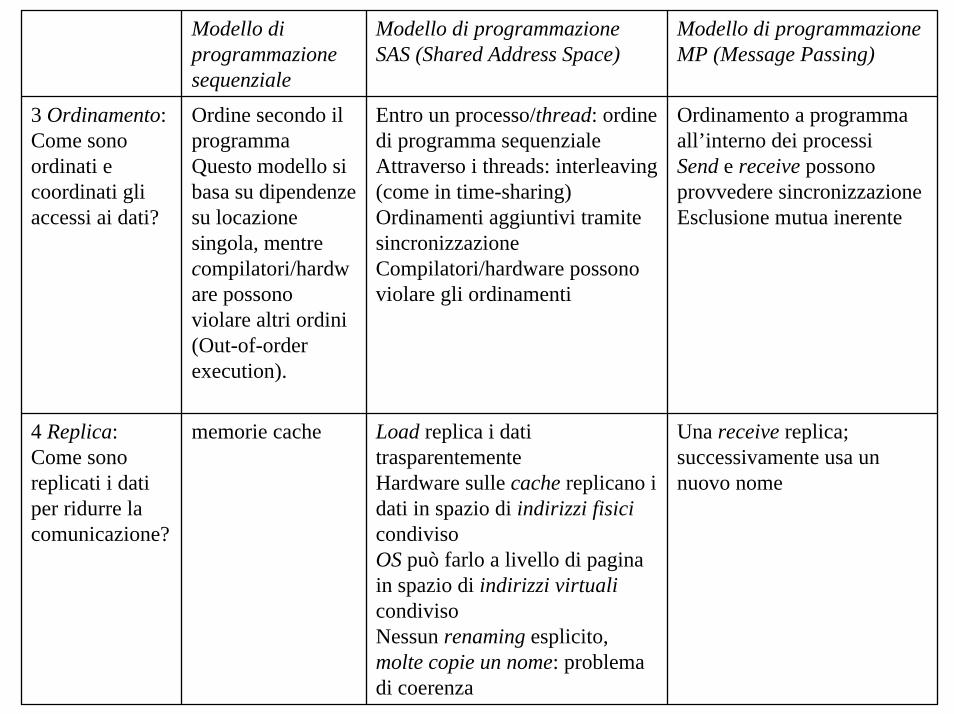
3 Ordinamento: Come sono ordinati e coordinati gli accessi ai dati?
Ordine secondo il programmaQuesto modello si basa su dipendenze su locazione singola, mentrecompilatori/hardware possono violare altri ordini (Out-of-order execution).
Entro un processo/thread: ordine di programma sequenzialeAttraverso i threads: interleaving (come in time-sharing)Ordinamenti aggiuntivi tramite sincronizzazioneCompilatori/hardware possono violare gli ordinamenti
Ordinamento a programma all’interno dei processiSend e receive possono provvedere sincronizzazione Esclusione mutua inerente
4 Replica: Come sono replicati i dati per ridurre la comunicazione?
memorie cache Load replica i dati trasparentementeHardware sulle cache replicano i dati in spazio di indirizzi fisicicondivisoOS può farlo a livello di pagina in spazio di indirizzi virtualicondivisoNessun renaming esplicito, molte copie un nome: problema di coerenza
Una receive replica; successivamente usa un nuovo nome

I thread sono simili ai processi, nel senso che entrambi rappresentano una singola sequenza di istruzioni eseguita in parallelo con altre sequenze (mediante time slicing o multielaborazione).Un processo è caratterizzato, oltre che dal codice eseguibile, dall'insieme di tutte le informazioni che ne definiscono lo stato, come il contenuto della memoria indirizzata, i thread, i descrittori dei file e delle periferiche in uso.I thread condividono le medesime informazioni di stato, la memoria ed altre risorse di sistema.Multithreading è un modello di esecuzione e di programmazione popolare che permette che thread multipli esistano nel contesto di un singolo processo, condividendo le risorse del processo ma capaci di eseguire indipendentemente.
Processo: spazio di indirizzi virtuali più uno o più thread. Porzioni degli spazi di indirizzi dei processi sono condivise.La scrittura ad un indirizzo condiviso è visibile ad altri thread (anche in altri processi).E’ una estensione naturale del modello ad uniprocessore: operazioni convenzionali in memoria per comunicazione; operazioni atomiche speciali per sincronizzazione. OS usa la memoria condivisa per coordinare i processi.

Verso la convergenza delle architettureEvoluzione e ruolo del software hanno sfumato i confini fra le diverse architetture
– Send/recv supportate su macchine SAS mediante buffer– Si può costruire spazi di indirizzi globali su MP – Memoria virtuale condivisa basata su pagine (o grani più piccoli)
Anche l’organizzazione hardware converge– A livello più basso, anche l’ hardware SAS passa messaggi hardware
Anche cluster di workstation/SMP sono sistemi paralleli– Emergenza di veloci system area networks (SAN)
Modelli di programmazione distinti, ma organizzazioni convergenti.
I nodi sono connessi da reti generali e utilizzanocommunication assist (interfaccia di rete e controllore di comunicazione).Le reti sono scalabili.La convergenza orapermette l’introduzione di una quantità di innovazioni, tutte all’interno della struttura.
Mem
° ° °
Network
P
$
Communicationassist (CA)

p
9 Strutture di interconnessione per architetture paralleleGli switch elementari nell’unità di switching dei multiprocessori, i processing elementdegli array processor ed i computer dei multicomputer con interconnessione diretta, sono interconnessi secondo specifiche topologie di rete.
Le interconnessioni sono esprimibili tramite relazioni formali o trasformazioni.
Etichettiamo i nodi nella rete mediante una numerazione progressiva. Se p sono i nodi di una rete, essi saranno etichettati mediante un intero da 0 a p -1.
Nel caso di array bidimensionale, mediante due interi da 0 a -1.
Imponiamo, inoltre, la restrizione che il numero dei nodi sia una potenza di 2, cioè
p = 2k.
Allora l’intero che identifica un nodo può essere espresso mediante una rappresentazione binaria:

La trasformazione più immediata è quella di sommare 1 ad i, per esprimere la connessione tra due nodi contigui numericamente.
La connessione diventa ciclica o wrap-around se si esegue l’operazione mod p, nel caso bidimensionale mod
Le altre trasformazioni possono essere:
- il complemento di un bit nella stringa binaria,
- una rotazione a sinistra o a destra, e
- l’elisione del bit di ordine più basso ol’aggiunta di un 1 o uno 0 al bit di ordine più basso.
p

Le interconnessioni che si possono ottenere, applicando queste trasformazioni, sono elencate in figura.
Alcuni parametri:
Grado: massimo numero di link per switch.
Distanza: la distanza tra due nodi è il minimo numero di link richiesto per stabilire un percorso tra i due nodi.
Diametro: la minima distanza tra i due nodi più lontani. Stabilisce un limite inferiore alla complessità degli algoritmi con comunicazioni tra coppie arbitrarie di nodi.Si cerca di tenere bassi sia il grado che il diametro.

Grado = 2Diametro = p/2 = 2(k-1)
Grado = 4Diametro = 2k/2
i (i+1) mod p
(i,j) (i, (j+1) mod 2k/2)
(i ,j) ((i+1) mod 2k/2, j)
Cyclic shift lineare
Cyclic shift bidimensionale o maglia (mesh)

Grado = 3
i i(0)
i ik-2 … i1 i0 ik-1
i i0 ik-1 ik-2 … i1
Exchange
Shuffle
Unshuffle
Perfect shuffle
Necklace di una connessione shuffle

Grado = kDiametro = k
i i(b), b = 0, 1, 2
Cubo binario di dimensione 3
Grado = 3Diametro = 2(k-1)
i ik-1 ik-2 … i1i ik-1 ik-2 … i1 i0 0i ik-1 ik-2 … i1 i0 1
Albero binario