architetture parallele - univecalpar/2_architetture.pdf · calcolo ad alte prestazioni- s. orlando...
TRANSCRIPT

1 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Architetture Parallele
Salvatore Orlando

2 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Scope of Parallelism
• Conventional architectures coarsely comprise of – processor, memory system, and the datapath.
• Each of these components present significant performance bottlenecks. • Parallelism addresses each of these components in significant ways.
• Different applications utilize different aspects of parallelism - e.g., – data itensive applications utilize high aggregate throughput, – server applications utilize high aggregate network bandwidth, and – scientific applications typically utilize high processing and memory
system performance. • It is important to understand each of these performance bottlenecks.

3 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Implicit Parallelism: Trends in Microprocessor Architectures
• Microprocessor clock speeds have posted impressive gains over the past two decades (two to three orders of magnitude).
• Higher levels of device integration have made available a large number of transistors.
• The question of how best to utilize these resources is an important one.
• Single-core processors use these resources in multiple functional units and execute multiple instructions in the same cycle.
• The precise manner in which these instructions are selected and executed provides impressive diversity in architectures.

4 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Pipelining and Superscalar Execution
• Pipelining overlaps various stages of instruction execution to achieve performance.
• At a high level of abstraction, an instruction can be executed while the next one is being decoded and the next one is being fetched.
• This is akin to an assembly line for manufacture of cars.

5 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Pipelining and Superscalar Execution
• Pipelining, however, has several limitations.
• The speed of a pipeline is eventually limited by the slowest stage. • For this reason, conventional processors rely on very deep
pipelines (20 stage pipelines in state-of-the-art Pentium processors).
• However, in typical program traces, every 5-6th instruction is a conditional jump! This requires very accurate branch prediction.
• The penalty of a misprediction grows with the depth of the pipeline, since a larger number of instructions will have to be flushed.
• One simple way of alleviating these bottlenecks is to use multiple pipelines.
• The question then becomes one of selecting these instructions.

6 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Superscalar Execution: An Example of two-way execution

7 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Superscalar Execution: An Example
• In the above example, there is some wastage of resources due to data dependencies.
• The example also illustrates that different instruction mixes with identical semantics can take significantly different execution time.

8 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Superscalar Execution
• Scheduling of instructions is determined by a number of factors: – True Data Dependency: The result of one operation is an input
to the next. – Resource Dependency: Two operations require the same
resource. – Branch Dependency: Scheduling instructions across conditional
branch statements cannot be done deterministically a-priori.
– The scheduler, a piece of hardware, looks at a large number of instructions in an instruction queue and selects appropriate number of instructions to execute concurrently based on these factors.
– The complexity of this hardware is an important constraint on superscalar processors.

9 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Superscalar Execution: Issue Mechanisms
• In the simpler model, instructions can be issued only in the order in which they are encountered. – That is, if the second instruction cannot be issued because it
has a data dependency with the first, only one instruction is issued in the cycle. This is called in-order issue.
• In a more aggressive model, instructions can be issued out-of-order. – In this case, if the second instruction has data dependencies
with the first, but the third instruction does not, the first and third instructions can be co-scheduled. This is also called dynamic issue.
• Performance of in-order issue is generally limited.

10 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Superscalar Execution: Efficiency Considerations
• Not all functional units can be kept busy at all times. • If during a cycle, no functional units are utilized, this is referred to
as vertical waste. • If during a cycle, only some of the functional units are utilized, this
is referred to as horizontal waste.
• Due to limited parallelism in typical instruction traces, dependencies, or the inability of the scheduler to extract parallelism, the performance of superscalar processors is eventually limited.
• Conventional microprocessors typically support four-way superscalar execution.

11 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Very Long Instruction Word (VLIW) Processors
• The hardware cost and complexity of the superscalar scheduler is a major consideration in processor design.
• To address this issues, VLIW processors rely on compile time analysis to identify and bundle together instructions that can be executed concurrently.
• These instructions are packed and dispatched together, and thus the name very long instruction word.
• This concept was used with some commercial success in the Multiflow Trace machine (circa 1984).
• Variants of this concept are employed in the Intel IA64 processors.

12 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
VLIW Processors: Considerations
• Issue hardware is simpler. • Compiler has a bigger context from which to select co-scheduled
instructions. • Compilers, however, do not have runtime information such as
cache misses or branch taken. • Scheduling must be based on sophisticated static predictions to
pack independent instructutions in each VLIW – may result inherently conservative.
• VLIW performance is highly dependent on the compiler. A number of techniques such as loop unrolling, speculative execution, branch prediction are critical.
• Typical VLIW processors are limited to 4-way to 8-way parallelism.

13 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Limitations of Memory System Performance
• Memory system, and not processor speed, is often the bottleneck for many applications.
• Memory system performance is largely captured by two parameters, latency and bandwidth.
• Latency is the time from the issue of a memory request to the time the data is available at the processor.
• Bandwidth is the rate at which data can be pumped to the processor by the memory system.

14 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Memory System Performance: Bandwidth and Latency
• It is very important to understand the difference between latency and bandwidth.
• Consider the example of a fire-hose. – If the water comes out of the hose two seconds after the hydrant
is turned on, the latency of the system is two seconds. – Once the water starts flowing, if the hydrant delivers water at the
rate of 5 gallons/second, the bandwidth of the system is 5 gallons/second.
• If you want immediate response from the hydrant, it is important to reduce latency.
• If you want to fight big fires, you want high bandwidth.

15 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Memory Latency: An Example
• Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns (no caches). Assume that the processor has two multiply-add units and is capable of executing four instructions in each cycle of 1 ns. The following observations follow: – The peak processor rating is 4 GFLOPS. – Since the memory latency is equal to 100 cycles and block size
is one word, every time a memory request is made, the processor must wait 100 cycles before it can process the data.

16 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Memory Latency: An Example
• On the above architecture, consider the problem of computing a dot-product of two vectors. – A dot-product computation performs one multiply-add on a
single pair of vector elements, i.e., each floating point operation requires one data fetch.
– It follows that the peak speed of this computation is limited to two floating point ops (one multiply-add) every pair fetch (200 ns) ….. or
• one floating point operation every 100 ns, or • a speed of 10 MFLOPS, a very small fraction of the peak processor
rating!

17 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Improving Effective Memory Latency Using Caches
• Caches are small and fast memory elements between the processor and DRAM.
• This memory acts as a low-latency high-bandwidth storage. • If a piece of data is repeatedly used, the effective latency of this
memory system can be reduced by the cache.
• The fraction of data references satisfied by the cache is called the cache hit ratio of the computation on the system.
• Cache hit ratio achieved by a code on a memory system often determines its performance.

18 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Caches: Example
• Consider the architecture from the previous example. In this case, we introduce a cache of size 32 KB with a latency of 1 ns or one cycle.
• We use this setup to multiply two matrices A and B of dimensions 32 × 32. We have carefully chosen these numbers so that the cache is large enough to store matrices A and B, as well as the result matrix C.

19 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Caches: Example (continued)
• The following observations can be made about the problem: – Fetching the two matrices into the cache corresponds to
fetching 2K words, which takes approximately 200 µs. – Multiplying two n × n matrices takes 2n3 operations. For
our problem, this corresponds to 64K operations, which can be performed in 16K cycles (or 16 µs) at four instructions per cycle.
– The total time for the computation is therefore approximately the sum of time for load/store operations and the time for the computation itself, i.e., 200 + 16 µs.
– This corresponds to a peak computation rate of 64K/216 or 303 MFLOPS.

20 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Caches
• Repeated references to the same data item correspond to temporal locality.
• In our example, we had O(n2) data accesses and O(n3) computation. This asymptotic difference makes the above example particularly desirable for caches.
• Data reuse is critical for cache performance.

21 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Memory Bandwidth
• Memory bandwidth is determined by the bandwidth of the memory bus as well as the memory units.
• Memory bandwidth can be improved by increasing the size of memory blocks.
• The underlying system takes l time units (where l is the latency of the system) to deliver b units of data (where b is the block size).

22 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Memory Bandwidth: Example
• Consider the same setup as before, except in this case, the block size is 4 words instead of 1 word. We repeat the dot-product computation in this scenario: – Assuming that the vectors are laid out linearly in memory, eight
FLOPs (four multiply-adds) can be performed in 200 cycles. – This is because a single memory access fetches four
consecutive words in the vector. – Therefore, two accesses can fetch four elements of each of the
vectors ⇒ 200 cycles = 200 ns • 8 ops (performed in 2 ns) overlapped with the load of the next block
– This corresponds to a FLOP every 25 ns, for a peak speed of 40 MFLOPS.
• spatial locality

23 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Memory Bandwidth
• It is important to note that increasing block size does not change latency of the system. – Physically, the scenario illustrated here can be viewed as a wide
data bus (4 words or 128 bits) connected to multiple memory banks.
– In practice, such wide buses are expensive to construct. – In a more practical system, consecutive words are sent on the
memory bus on subsequent bus cycles after the first word is retrieved.

24 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Memory Bandwidth
• The above examples clearly illustrate how increased bandwidth results in higher peak computation rates.
• The data layouts were assumed to be such that consecutive data words in memory were used by successive instructions (spatial locality of reference).
• If we take a data-layout centric view, computations must be reordered to enhance spatial locality of reference.

25 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Memory Bandwidth: Example
Consider the following code fragment: for (i = 0; i < 1000; i++)
column_sum[i] = 0.0; for (j = 0; j < 1000; j++) column_sum[i] += b[j][i];
The code fragment sums columns of the matrix b into a vector column_sum.

26 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impact of Memory Bandwidth: Example
• Vector column_sum is small and easily fits into the cache • Matrix b is accessed in a column order, but is stored in row-order. • The strided access results in very poor performance.
We can fix the above code as follows: for (i = 0; i < 1000; i++)
column_sum[i] = 0.0; for (j = 0; j < 1000; j++)
for (i = 0; i < 1000; i++) column_sum[i] += b[j][i];
• In this case, the matrix is traversed in a row-order and performance can be expected to be significantly better.

27 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Memory System Performance: Summary
• The series of examples presented in this section illustrate the following concepts: – Exploiting spatial and temporal locality in applications is critical for
amortizing memory latency and increasing effective memory bandwidth.
– Memory layouts and organizing computation appropriately can make a significant impact on the spatial and temporal locality.
– The ratio of the number of operations to number of memory accesses is a good indicator of anticipated tolerance to memory bandwidth.

28 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Alternative Approaches for Hiding Memory Latency
• Consider the problem of browsing the web on a very slow network connection. We deal with the problem in one of three possible ways: 1. we anticipate which pages we are going to browse ahead of time
and issue requests for them in advance; 2. we open multiple browsers and access different pages in each
browser, thus while we are waiting for one page to load, we could be reading others; or
3. we access a whole bunch of pages in one go - amortizing the latency across various accesses.
• The first approach is called prefetching, the second multithreading, and the third one corresponds to spatial locality (increasing the memory block) in accessing memory words.

29 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multithreading for Latency Hiding
• A thread is a single stream of control in the flow of a program. • We illustrate threads with a simple example:
for (i = 0; i < n; i++) c[i] = dot_product(get_row(a, i), b);
• Each dot-product is independent of the other, and therefore represents a concurrent unit of execution.
• We can safely rewrite the above code segment as:
for (i = 0; i < n; i++) c[i] = create_thread(dot_product,get_row(a, i), b);

30 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multithreading for Latency Hiding: Example
• In the code, the first instance of this function accesses a pair of vector elements and waits for them.
• In the meantime, the second instance of this function can access two other vector elements in the next cycle, and so on.
• After l units of time, where l is the latency of the memory system, the first function instance gets the requested data from memory and can perform the required computation.
• In the next cycle, the data items for the next function instance arrive, and so on.
• In this way, in every clock cycle, we can perform a computation.

31 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multithreading for Latency Hiding
• The execution schedule in the previous example is predicated upon two assumptions: – the memory system is capable of servicing multiple outstanding
requests, and – the processor is capable of switching threads at every cycle.
• It also requires the program to have an explicit specification of concurrency in the form of threads.
• Machines such as the HEP and Tera rely on multithreaded processors that can switch the context of execution in every cycle. Consequently, they are able to hide latency effectively.

32 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Prefetching for Latency Hiding
• Misses on loads cause programs to stall. • Why not advance the loads so that by the time the data is actually
needed, it is already there! • The only drawback is that you might need more space to store
advanced loads. • However, if the advanced loads are overwritten, we are no worse
than before! • Unfortunately, if you prefetch in the cache, you can introduce
pollution in the cache, by removing blocks to be used in the next future

33 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Tradeoffs of Multithreading and Prefetching
• Multithreading and prefetching are critically impacted by the memory bandwidth. Consider the following example: – Consider a computation running on a machine with a 1 GHz
clock, 4-word cache line, single cycle access to the cache, and 100 ns latency to DRAM.
– The computation has a cache hit ratio at 1 KB of 25% (miss 75%) and at 32 KB of 90% (miss 10%).
– Consider two cases: first, a single threaded execution in which the entire cache is available to the serial context, and second, a multithreaded execution with 32 threads where each thread has a cache residency of 1 KB.
– If the computation makes one data request in every cycle of 1 ns (4 GB/s), you may notice that the first scenario requires 400MB/s of memory bandwidth and the second 3GB/s.

34 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Tradeoffs of Multithreading and Prefetching
• Bandwidth requirements of a multithreaded system may increase very significantly because of the smaller cache residency of each thread.
• Multithreaded systems become bandwidth bound instead of latency bound.
• Multithreading and prefetching only address the latency problem and may often exacerbate the bandwidth problem.
• Multithreading and prefetching also require significantly more hardware resources in the form of storage.

35 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Explicitly parallel platforms
• An explicitly parallel program must specify concurrency and interaction between concurrent subtasks.
• The former is sometimes also referred to as the control structure and the latter as the cooperation/communication model.
• Parallelism can be expressed at various levels of granularity – from instruction level to processes. – between these extremes exist a range of models, along with
corresponding architectural support.
• Single control vs multiple control – SIMD vs MIMD
• Cooperation and data exchange between parallel tasks – accessing a shared data space (SM) and exchanging messages (DM). – multiprocessors vs multicomputers.
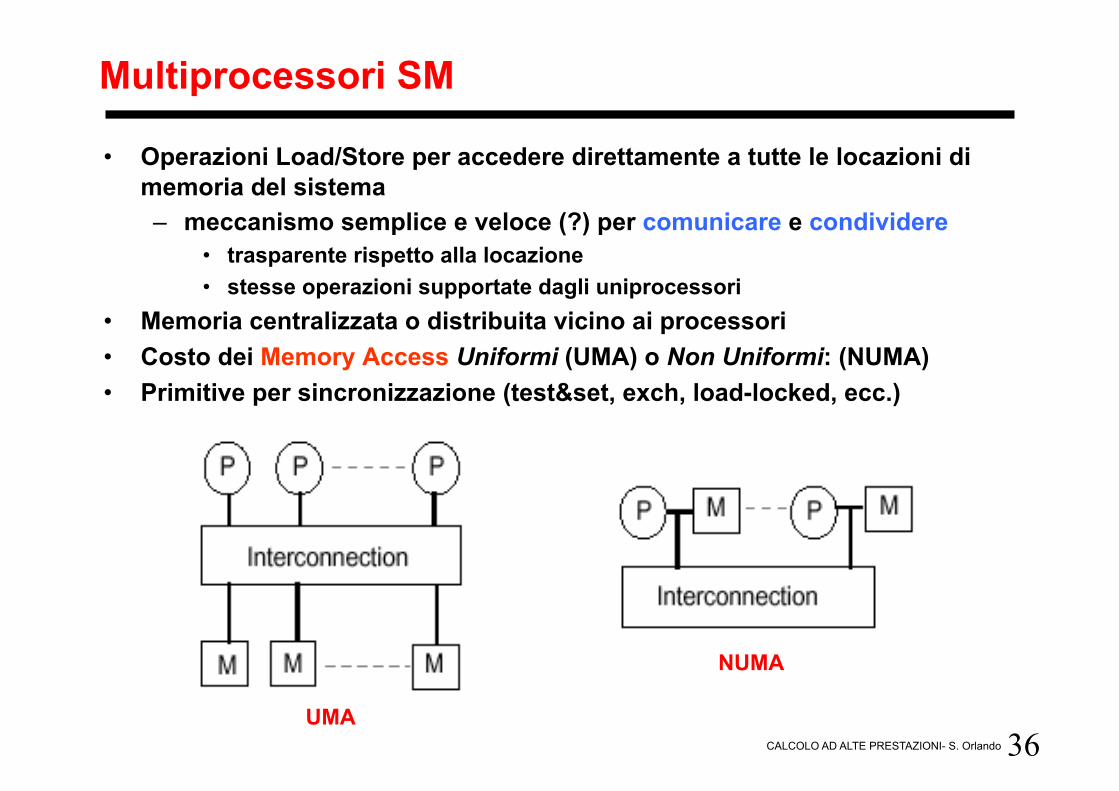
36 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multiprocessori SM
• Operazioni Load/Store per accedere direttamente a tutte le locazioni di memoria del sistema – meccanismo semplice e veloce (?) per comunicare e condividere
• trasparente rispetto alla locazione • stesse operazioni supportate dagli uniprocessori
• Memoria centralizzata o distribuita vicino ai processori • Costo dei Memory Access Uniformi (UMA) o Non Uniformi: (NUMA) • Primitive per sincronizzazione (test&set, exch, load-locked, ecc.)
UMA
NUMA

37 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Modello di memoria per SM
Spazio Virtuale Spazio Fisico

38 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multiprocessori SM UMA e reti di interconnessione
• Bus: Usato da molti degli attuali Multiprocessori simmetrici (SMP) con limitato paralellismo – poco costoso e espandibile – approccio poco scalabile causa banda limitata del bus – le cache (coerenti) alleviano il problema del bus condiviso
• Per SMPs a più alto parallelismo – Crossbar: Costoso e poco espandibile – Multistage: Meno costoso del crossbar, aumenta latenza, banda
aggregata ridotta
MEM MEM MEM MEM
$ P
$ P
C C
I/O I/O Crossbar
MEM MEM MEM MEM
$ P
$ P
C C
I/O I/O
Multistage
MEM MEM MEM MEM
$ P
$ P
C C
I/O I/O
Bus

39 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multiprocessori SM NUMA
• Architettura simile a quella MP (Private Memory), con memoria distribuita – convergenza delle architetture parallele scalabili
• Concetto memoria locale e remota esposta al programmatore – costo d’accesso ai moduli di memoria remoti molto maggiore del costo
per accedere ai moduli di memoria locali – Le macchine NUMA richiedono località da parte degli algoritmi per
ottenere alte prestazioni • Accessi alla memoria globale vengono trasformati in
– in accessi alla memoria locale, oppure – in messaggi inviati a controllori di memoria remoti
• read-request read-response
Rete Scalabile
$ P
MEM $ P
MEM $ P
MEM

40 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multiprocessori SM NUMA
• Alternativa 1 (SGI/Cray T3E): – Modello memoria locale/remota esposta al programmatore, il cui
compito è quello di diminuire la frequenza degli accessi remoti – Il controllore della memoria genera messaggi di richiesta per load/store
non-locali – Non abbiamo meccanismi hardware per la coerenza
• Se i dati sono replicati su moduli di memoria diversi, la coerenza tra repliche è sotto responsabilità del programmatore
• La cache locale mantiene solo repliche di dati contenuti nel modulo di memoria locale
• Alternativa 2 (SGI Origin) – Stessa organizzazione a memoria distribuita – Cache locali che permettono di replicare anche porzioni di dati remoti – Meccanismo di cache coherence scalabile (non bus-based),
implementato in hardware (come per gli SMP)

41 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Multicomputer DM (MP)
• Memoria e cache privata per ogni nodo • Nodi collegati da una rete di interconnessione • Processi su nodi diversi possono scambiare dati privati tramite primitive di
scambio messaggi (MP) • Send + Matching Recv forniscono un metodo per copiare da memoria a
memoria, più un evento di sincronizzazione tra i processi

42 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Prestazioni dello scambio di messaggi
• Latenza di startup – È la quantità di tempo che impiega un generico comando per
iniziare ad avere effetto – La latenza di startup dell’invio di un messaggio è la quantità di
tempo per inviare un messaggio di lunghezza zero => overhead • Il tempo tra quando il primo bit lascia il computer mittente, e
quando lo stesso bit arriva al computer ricevente • Bandwidth (Larghezza di banda)
– Bits/second che possono attraversare una connessione • Semplice modello di prestazioni per MP
– tempo necessario per inviare e consegnare un messaggio di N Bytes Time = latency + N / bandwidth

43 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Prestazioni dello scambio di messaggi
• Overhead HW/SW su sender/receiver • L’invio di un messaggio è un’operazione costosa di I/O:
– impacchettamento/spacchettamento (protocollo) – copiare i dati dal buffer della rete (kernel space) allo user space (e
viceversa) – invio dei dati sulla rete – ricezione dei dati nei buffer

44 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Prestazioni dello scambio di messaggi
• Modello più accurato di prestazioni: tiene conto – degli overhead su sender/receiver – della topologia della rete – della strategia di routing
• per evitare possibili conflitti e/o ridurre i link attraversati – della strategia di switching
• Circuit/Packet/CutThrough switching – del controllo del flusso
• quando un msg (o una sua porzione) attraversa un certo cammino di instradamento? Per risolvere conflitti nel’uso delle risorse.

45 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Alcuni concetti di networking
• Topologia – reti (network) permettono di condividere cammini/linee tra device differenti – “Quali sono i cammini possibili per i pacchetti per raggiungere la destinazione?”
• Routing – insieme di operazioni per calcolare un cammino valido da sorgente e destinazione – “Quale tra i cammini possibili sono permessi per trasmettere il pacchetto?” – Funzione da eseguire sul sorgente (intero path), oppure al volo sui device intermedi
• Arbitraggio e controllo del flusso – Più pacchetti possono richiedere l’uso della stessa risorsa contemporaneamente:
conflitto – “Quando un dato cammino sarà disponibile per un pacchetto?”
• Switching – Riguarda il singolo pacchetto – Una volta che le risorse sono state concesse, queste sono switched per fornire il
cammino tra sorgente e destinazione – “Come sono allocati i cammini ai pacchetti?” – Prima dell’arrivo del pacchetto: circuit switching – Una volta ricevuto l’intero pacchetto: store-and-forward packet switching – Una volta ricevuto una porzione del pacchetto: cut-through (wormhole) packet
switching

46 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Evoluzione delle Architetture MP • Switch e reti specializzate • La topologia nelle reti di prima generazione era più importante perché:
– venivano usati strategie di switching store&forward, con costo di comunicazione dipendente linearmente da numero di hops × dimensione del pacchetto
• I router moderni adottano strategie di switching che trasmettono in pipeline i pacchetti (wormhole) – più link lavorano in parallelo per trasportare pezzetti (flit=flow units)
dello stesso pacchetto, che seguono lo stesso cammino fissato dalla testa del verme
– diminuisce l’importanza della distanza tra processori (in termini di hops) come misura del costo di comunicazione
• costo dipende da numero di hops + dimensione del pacchetto
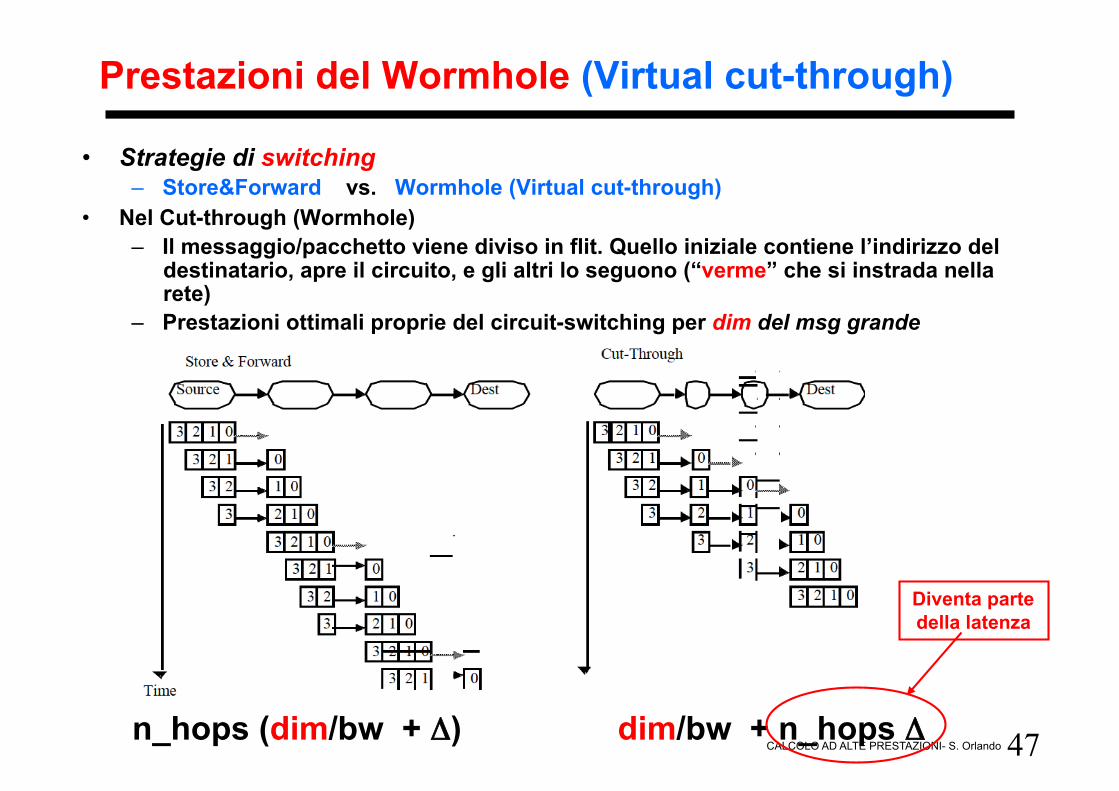
47 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Prestazioni del Wormhole (Virtual cut-through)
• Strategie di switching – Store&Forward vs. Wormhole (Virtual cut-through)
• Nel Cut-through (Wormhole) – Il messaggio/pacchetto viene diviso in flit. Quello iniziale contiene l’indirizzo del
destinatario, apre il circuito, e gli altri lo seguono (“verme” che si instrada nella rete)
– Prestazioni ottimali proprie del circuit-switching per dim del msg grande
n_hops (dim/bw + Δ) dim/bw + n_hops Δ
Diventa parte della latenza

48 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Prestazioni del Wormhole (Virtual cut-through)
• Virtual cut-through – In presenza di conflitti (output link busy), i flit del pacchetto vengono
raccolti e memorizzati sullo switch – Avendo a disposizione molta memoria, in presenza di conflitti le
prestazioni possono diventare simili al packet switching (s&f) • Wormhole
– Non abbiamo buffer sui nodi per memorizzare pacchetti • Tecnologia più semplice, e quindi adottata più largamente
– In presenza di conflitti (output link busy), il “verme” composto dai flit che costituiscono il pacchetto rimane bloccato “in place ”
Verme bloccato (wormhole) Verme raccolto e
bufferizzato (cut-through)

49 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempio: impatto di pattern di comunicazione differenti
• Le reti di interconessione tra i processori – possono avere topologie ricche, e i pacchetti dei messaggi possono
attraversare contemporaneamente più connessioni
• Bisection bandwidth (misura aggregata per valutare le topologie) – La Bisezione (Bisection) è il minimo numero di link da tagliare per
dividere una rete (grafo) in due parti uguali – La Bisection bandwidth è la banda totale attraverso la bisezione, e
modella la potenzialità della rete nel trasmettere msg multipli – Misura pessimistica

50 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempio: impatto di pattern di comunicazione differenti
• Poiché Δ è trascurabile, per trasferire un msg: – ts + dim/bw, dove ts è
il tempo di inizializzazione/latenza • Mesh di p × p nodi • Se ogni nodo comunica con un suo
vicino, come previsto tutte le comunicazioni possono essere completate in un tempo ts + dim/bw
• Se ogni nodo comunica con un partner random – (p×p)/2 comunicazioni finiranno per attraversare l’equipartizione della
rete (bisezione) – Se i link sono bidirezionali, la bisezione attraversa 2 p fili
• ogni filo attraversato da ((p×p)/2) / 2p = p/4 messaggi, per un size totale di p/4 × dim/bw
– I p/4 messaggi dovranno essere serializzati (conflitto + controllo flusso)
– Tempo totale ts + p/4 × dim/bw
p link

51 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Evoluzione delle Architetture MP
• Diverse tecniche per “attaccare” la rete al nodo di elaborazione • Scopo dell’evoluzione è ridurre la latenza di trasmissione, in particolare gli
overhead per copiare messaggi, impacchettarli, passare tra modalità utente/kerkel
• Tecniche hw/sw adottabili – DMA + processore specializzato – primitive user-level con meno copie – integrazione del sottosistema di comunicazione sul bus processore-
memoria

52 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Evoluzione delle Architetture MP
• Rete statica diretta, con link solo verso gli altri computer con cui è possibile comunicare Routing SW
• Evoluzione: computer attaccati a switch, che si occupano di instradare dinamicamente i messaggi e di fornire una interconnessione completa virtuale ai livelli SW di comunicazione Routing HW

53 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Evoluzione delle Architetture MP
• Prime architetture MP con meccanismi di comunicazione di basso livello – ogni nodo collegato da link bidirezionali con un numero fisso di vicini
(ipercubi o mesh) – ogni link associato con un coda FIFO corta (poca memoria) – primitive sincrone per garantire lo svuotamento della coda – Modello di Programmazione primitivo, molto vicino all’HW
• estrema importanza del mapping dei processi e dei canali di comunicazione • multiplexing dei link FIFO (ad esempio quando più processi cooperanti sono
mappati su nodi interconnessi) a carico del SW utente • Topologie delle reti erano importanti:
– esposte al programmatore – algoritmi specializzati rispetto alle topologia

54 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Altre architetture parallele
• Negli anni 80 abbiamo assistito ad un grande proliferare di architetture parallele – SIMD hanno avuto il maggior successo commerciale
• concetti ripresi largamente dalle architetture specializzate, ma programmabili, come le GPU (Graphic Processing Unit)
– Architetture dataflow hanno avuto soprattutto ricadute accademiche
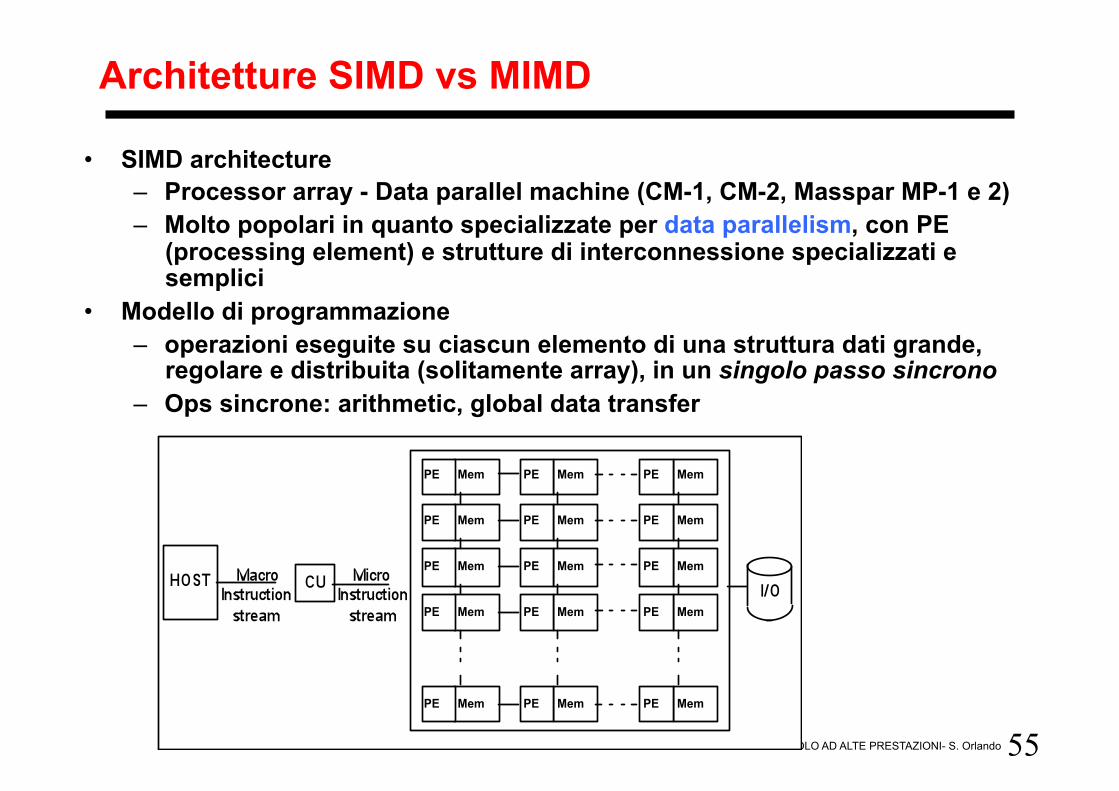
55 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Architetture SIMD vs MIMD
• SIMD architecture – Processor array - Data parallel machine (CM-1, CM-2, Masspar MP-1 e 2) – Molto popolari in quanto specializzate per data parallelism, con PE
(processing element) e strutture di interconnessione specializzati e semplici
• Modello di programmazione – operazioni eseguite su ciascun elemento di una struttura dati grande,
regolare e distribuita (solitamente array), in un singolo passo sincrono – Ops sincrone: arithmetic, global data transfer

56 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Programmare un SIMD array processor
• Il modello SIMD fa affidamento sulla struttura regolare della computazione (es., image processing).
• E’ però spesso necessario spegnere dei processori per impedire aggiornamenti di dati non voluti – i paradigmi di
programmazione SIMD forniscono un’ ”activity mask”, che determina se un processore deve o meno partecipare nella computazione
– poca flessibilità del modello

57 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Architetture SIMD vs MIMD
• Le motivazioni di costo nell’avere un unico controllo non sono più vere dalla metà degli anni 80, con l’avvento dei microprocessori – diventa economico costruire macchine MIMD, con processori
commodity • Calcoli data parallel semplici e regolari hanno di solito buona località
– realizzabili efficientemente su macchine SM o MP con compilatori efficienti
– granularità della computazione associata a ogni processore MIMD molto maggiore di quella tipica associata a ogni PE della macchina SIMD
– può ancora essere necessario avere implementazioni efficienti di operazioni per la sincronizzazione globale (barriere)
– il modello di programmazione per computazioni data parallel regolari converge verso l’SPMD
• Varianti del concetto di architettura SIMD è alla base dei co-processori multimediali (come l’MMX dei microprocessori Intel)
• Revival del concetto grazie all’avvento di GPU con unità SIMD

58 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Architetture pipelined-SIMD
• Macchine vettoriali = Supercalcolatori anni 70-80 (Cray) • Capaci di eseguire “in maniera pipeline” operazioni data parallel su vettori
(+, -, *, /) • Trasformazione da data-parallel in pipeline
– Istruzioni vettoriali = operazione data-parallel – Singola operazione = scomposta in un pipeline di n stadi – Operazioni identiche e indipendenti possono essere eseguite in pipeline
Es.: mult C,A,B con C, A e B registri vettoriali di n elementi
A[1] B[1] A[2] B[2] A[n] B[n]
C[1] C[2] C[n]
* * * A[n] … A[1]
B[n] … B[1]
C[1] … C[n] * k
* 1 ⇒
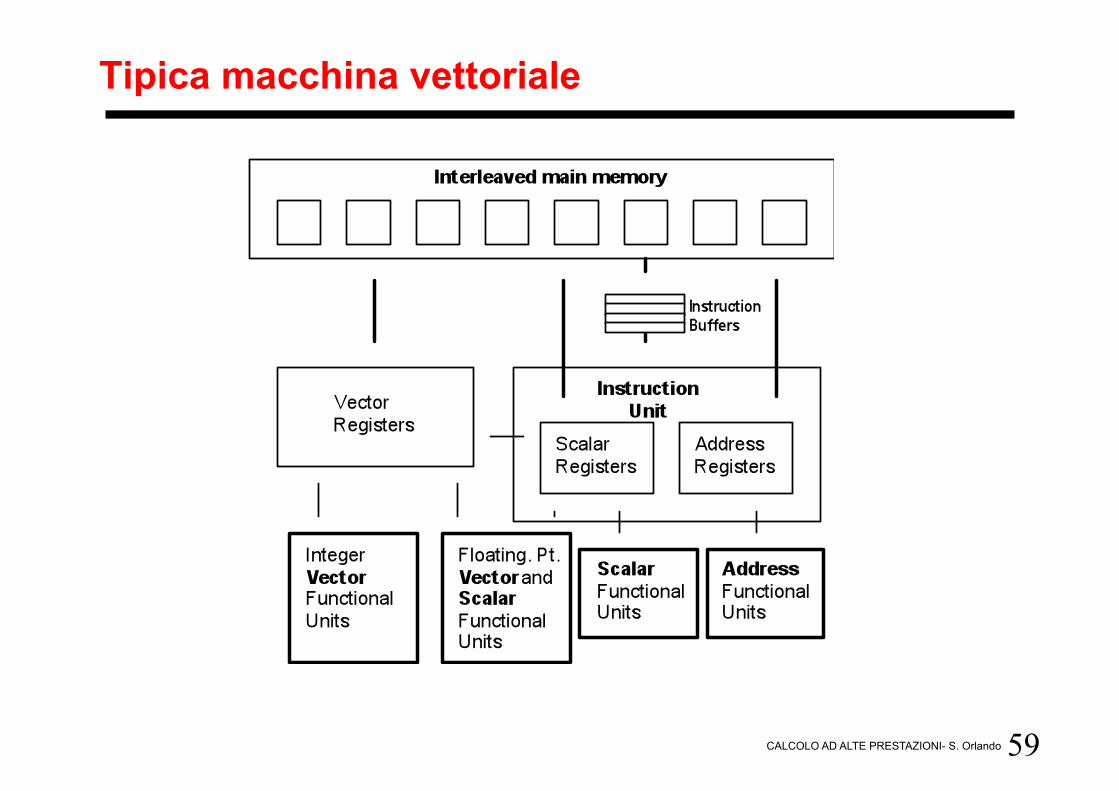
59 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Tipica macchina vettoriale
60 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
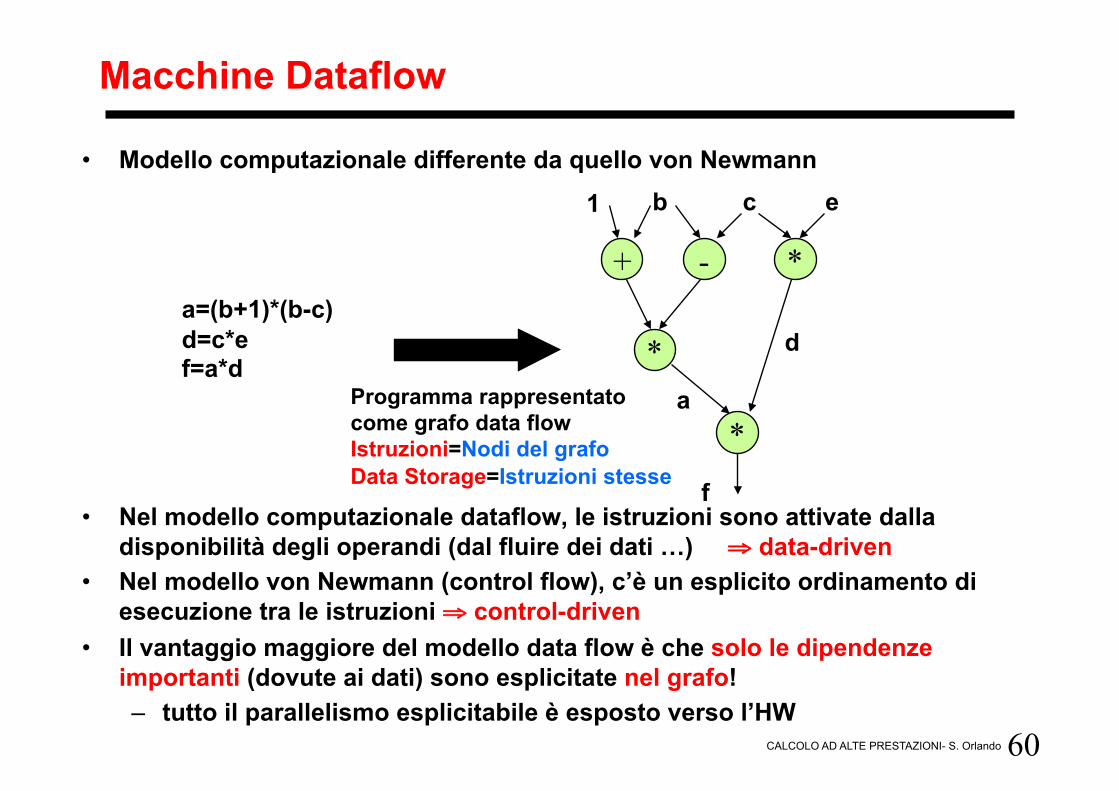
Macchine Dataflow
• Modello computazionale differente da quello von Newmann
• Nel modello computazionale dataflow, le istruzioni sono attivate dalla disponibilità degli operandi (dal fluire dei dati …) ⇒ data-driven
• Nel modello von Newmann (control flow), c’è un esplicito ordinamento di esecuzione tra le istruzioni ⇒ control-driven
• Il vantaggio maggiore del modello data flow è che solo le dipendenze importanti (dovute ai dati) sono esplicitate nel grafo! – tutto il parallelismo esplicitabile è esposto verso l’HW
a=(b+1)*(b-c) d=c*e f=a*d
+ - *
*
*
b 1 c e
d
a
f
Programma rappresentato come grafo data flow Istruzioni=Nodi del grafo Data Storage=Istruzioni stesse

61 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Data flow
• Caratteristiche positive – Parallelismo esplicito, scheduling dinamico delle istruzioni
• Problemi – Copia dei dati (anche di strutture dati complesse come gli array) – Poco sfruttamento della località
• ops connesse hanno località tra di loro, e quindi sarebbe utile raggrupparle assieme per localizzare (o evitare) le comunicazioni e le copie
– Troppo parallelismo in eccesso rispetto alle unità hw (?) • Il macro data flow è un’implementazione SW su macchine convenzionali
del modello data flow – In questo caso le ops data flow hanno granularità maggiore (thread) – Supporto deve essere capace di mappare dinamicamente molti thread
sui processori disponibili – Sfruttamento dello indirizzamento comune (evita di copiare dati)
• Ricadute del modello data-flow: – Analisi data flow utilizzata dai compilatori, e dai processori in grado di
schedulare dinamicamente le istr. (esecuzione out-of-order)

62 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Convergenza delle architetture HW/SW
• Il SW ha ridotto le barriere tra architetture diverse, permettendo di emulare modelli di programmazione non nativi – Send/Recv supportati da macchine SM via buffer e sincronizzazione – E’ possibile construire uno spazio di indirizzamento globale (Virtual
SM) su una macchina MP ( Global Addr -> Proc Id | Local Addr ) • Page-based (o finer-grained) shared virtual memory
• Hardware sta convergendo – Hardware delle macchine SM basate su
• distribuzione della memoria • scambi di msg a basso livello per implementare accessi remoti e politiche di
cache coherence (directory based) – Integrazione stretta della Network Interface sui bus processore
memoria anche su macchine MP (send/receive con low-latency, high-bandwidth)
• Anche i clusters di WS/SMP sono ormai considerati sistemi paralleli – equipaggiati con System Area Networks (SAN) veloci, costruite con la
stessa tecnologia di reti specializzate per MPP

63 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Architettura parallela scalabile
• Nodo: processore(i), sistema di memoria, più communication assist – CA più vicino possibile al bus processore-memoria
• Rete scalabile • La convergenza permette la convergenza di sforzi di ricerca
– molte innovazioni, soprattutto per quanto riguarda l’integrazione del CA con il nodo, le operazioni supportate, l’efficienza richiesta (latenza vs banda), ecc.

64 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Convergenza delle architetture HW/SW
SIMD
Message Passing
Shared Memory
Dataflow
Systolic Arrays Generic
Scalable Architecture
I modelli architetturale sono distinti, ma l’organizzazione fisica converge

65 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Reti di interconnessione
• Negli scorsi anni i corsi di calcolo parallelo erano fortemente incentrati sulle proprietà delle reti di interconnessione
• Il programmatore era infatti costretto a considerare le caratteristiche della topologia per sviluppare algoritmi efficienti
• Ad esempio, esistono interi libri di algoritmi per mesh o ipercubi • Oggi, grazie allo sviluppo di reti switched, è possibile astrarre gli algoritmi
dalla rete grazie – al routing gestito in hw/fw – alle tecniche di switching, grazie alle quali le prestazioni della rete sono meno
legate al numero di link attraversata dai pacchetti (n. di hops) • Il programmatore può fare riferimento a parametri più generali della
topologia per catturare le caratteristiche salienti della rete, e quindi il loro impatto sui costi del programma parallelo
• Bisogna anche considerare che, con lo sviluppo della tecnologia dei microprocessori e l’uso di componenti commodity per la costruzione di macchine parallele
– è purtroppo aumentato il gap tra il costo della computazione locale su un’unità di dati (con dati in cache), e il costo di comunicazione
– è diventato più importante NON comunicare, invece di cercare di farlo efficientemente

66 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Reti di interconnessione (Crossbar e bus)
• Crossbar. Abbiamo un numero di interruttori uguali a p2
• La rete è molto performante (collegamenti diretti) ma non è facilmente espandibile
• Costo elevato rispetto alla espandibilità
• Bus. E’ molto espandibile, ma non è scalabile. Costituisce un collo di bottiglia all’aumentare dei nodi

67 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Reti di interconnessione
• Sono state progettate reti che cercano un compromesso tra crossbar e bus
• Reti dirette/statiche – ogni elemento (processore, modulo di memoria, computer) è collegato
direttamente e staticamente tramite dei link ad un numero finito di altri nodi
• Rete indiretta/dinamica – il collegamento tra gli elementi passa attraverso un insieme di switch
che instradano i pacchetti

68 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Reti di interconnessione
• La definizione precedente di rete diretta non è precisa – Esistono le versioni dinamiche delle topologie dirette
• Rete diretta “dinamica” – c’è uno switch per ogni elemento, e quelli che erano i collegamenti
diretti tra elementi diventano collegamenti diretti tra i “corrispondenti” switch
– Collegamenti diretti tra nodi, dove: Nodo = Elemento+switch • Rete indiretta multistage
– il numero di switch è differente dal numero di elementi

69 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Direct vs Indirect Static network Indirect network
Switching elementProcessing node
Network interface/switch
P
P P P
P
P
PP
Classification of interconnection networks: (a) a static network; and (b) a dynamic network.
Uno switch per ogni PE

70 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Switch
• Gli Switch mappano – Un numero fisso di porte di input su un numero fisso di porte di output
• Il numero di porte dello switch è detto degree dello switch : d – Il costo di uno switch cresce solitamente come d2 se realizzato al suo
interno come crossbar
• Gli switching possono fornire supporto per il routing, multicast, buffering

71 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempio di rete indiretta
• Un esempio di rete indiretta è quella multistage, dove ogni stage è solitamente implementato come una batteria di switch (tanti switch box)
• In questo esempio, i nodi collegati sono processori & memorie (SM-MIMD UMA), ma la stessa rete può essere usata per un multicomputer

72 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Rete omega • log p stage, con ogni stage costituito da p/2 piccoli switch box • ogni switch box è un piccolo crossbar 2x2 (4 interruttori), capace di effettuare 2
operazioni: pass-through e cross-over • in totale un numero di interruttori 2 p lop p invece di p2 nel caso del crossbar • Routing semplice, confrontando allo stage i i bit i-esimi della rapresentazione
binaria degli ID di sender/receiver: – se diversi: cross-over se uguali: pass-through
Pass-through
Cross-over

73 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Rete Omega: Interconnessione tra stage
• Perfect shuffle: da 8 input a 8 output
• Ad ogni stage, l’input i è connesso all’output j se:

74 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Rete Omega: blocking
• Un esempio di blocco per conflitto
Uno dei due messaggi, 010 →111 oppure 110 →100, è bloccato sul link AB

75 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempi di rete dirette
• 2-D mesh, 2D-torus, 3D-mesh – Versioni sia statiche e sia dinamiche

76 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Valutazioni topologie
• Bisection Width, BW – minimo numero di link che collegano due partizioni della rete – ogni partizione contiene circa la metà dei nodi – BW = numero di link che attraversano la linea immaginaria che
bi-seziona la topologia – Bisection Bandwidth, BB, è uguale a BW x link bandwidth
• Degree, d – Numero di link incidenti per nodo
• Diameter, D – Il più lungo cammino minimo tra ogni coppia di nodi
• Simmetria – topologia isomorfa a sé stessa, tutti i nodi possono essere etichettati in
modo da diventare il nodo origine • Dimensionalità della topologia e lunghezza dei fili
– ha a che fare con il packaging della rete, che deve forzatamente avvenire sulle 3 dimensioni fisiche
– ci sono reti a molte dimensioni con fili molto lunghi

77 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Valutazioni topologie
• Reti dove il Degree d non aumenta all’aumentare del numero di nodi sono espandibili (e scalabili ?)
• La Bisection Width BW tiene conto della quantità di traffico massimo che può attraversare le due partizioni di nodi – è una misura pessimistica, nel caso in cui tutto il traffico fosse
soprattutto tra nodi appartenenti a partizioni diverse – essendo una misura pessimistica, la linea di bi-sezione deve essere
scelta in modo da minimizzare il numero di link che l’attraversano • Il Diameter D è una misura importante se l’instardamento dei pacchetti
avviene in modalità store&forward – anch’essa è però una misura pessimistica

78 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Famiglia di reti dirette
• k-ary n-cube – n: numero dimensioni – k: radix (base) usata per la numerazione dei nodi
• Versioni sia statiche e sia dinamiche (in questo caso, uno switch per nodo) • Numero di nodi N = kn
• In dettaglio – k nodi in ciascuna dimensione – ogni nodo può essere etichettato con un numero di n cifre in radix
(base) k – ogni nodo è connesso a ciascun altro nodo che ha un’etichetta che
differisce • per una sola cifra e per una quantità unitaria (mod k)
• Un k-ary n-cube può essere costruito ricorsivamente – connettendo assieme un numero k di k-ary (n-1)-cubes – necessario connettere nodi con la stessa etichetta nei vari k-ary (n-1)-
cubes originali
• Esiste un modello analogo, k-ary n-fly, per le reti multistage

79 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Alcuni k-ary n-cube
• k-ary 1-cube – 1D mesh – in figura k=4 – limited degree : d=2 – D=k-1 – N=kn=k
• k-ary 2-cube – 2D-mesh – in figura, k=4 – degree limitato : d=4 – D=2(k-1) – N=kn=k2
• Esistono i corrispondenti tori – link wrap-around
0 1 2 3
00 01 02 03
10 11 12 13
20 21 22 23
30 31 32 33

80 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
2-ary n-cube (ipercubi)
• 0-D ipercubo – 2-ary 0-cube
• 1-D ipercubo – 2-ary 1-cube
• 2-D ipercubo – 2-ary 2-cube
• 3-D ipercubo – 2-ary 3-cube
• 4-D ipercubo – 2-ary 4-cube
• Si noti la base binaria per etichettare i nodi
• Degree non limitato: d=log N = log kn = n
• D=n • N=kn=2n

81 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Parametri del k-ary n-cube
• N = kn BW = kn-1 D = n (k-1) d = 2 n
• k-ary 1-cube N=k BW=1 D=k-1 d=2n=2 • k-ary 2-cube N=k2 BW=k D=2(k-1) d=2n=4 • k-ary 3-cube N=k3 BW=k2 D=3(k-1) d=2n=6
• ….. • 2-ary n-cube N=kn=2n BW=2n-1 D=n d=n=log N

82 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Parametri del k-ary n-cube
• N = kn BW = kn-1 D = n (k-1) d = 2 n
• k-ary 1-cube N=k BW=1 D=N-1 d=2n=2 • k-ary 2-cube N=k2 BW=N1/2 D=2(N1/2-1) d=2n=4 • k-ary 3-cube N=k3 BW=N2/3 D=3(N1/3-1) d=2n=6
• ….. • 2-ary n-cube N=kn=2n BW=N/2 D=log N d=n=log N
• Nel progettare una rete, se il degree (d) degli switch è il fattore limitante per espandibilità, necessario diminuire (fissare) la dimensione n – reti con n e d fisso (a grado di interconnessione limitato)
• Se la distanza di routing (D) è un problema, o abbiamo bisogno di una BW alta, dobbiamo aumentare dimensionalità (valori di n alti)
• Topologie con n piccolo (e fisso) sono meno costose, e facili da fabbricare – problema del packaging dei fili su molte dimensioni
83 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
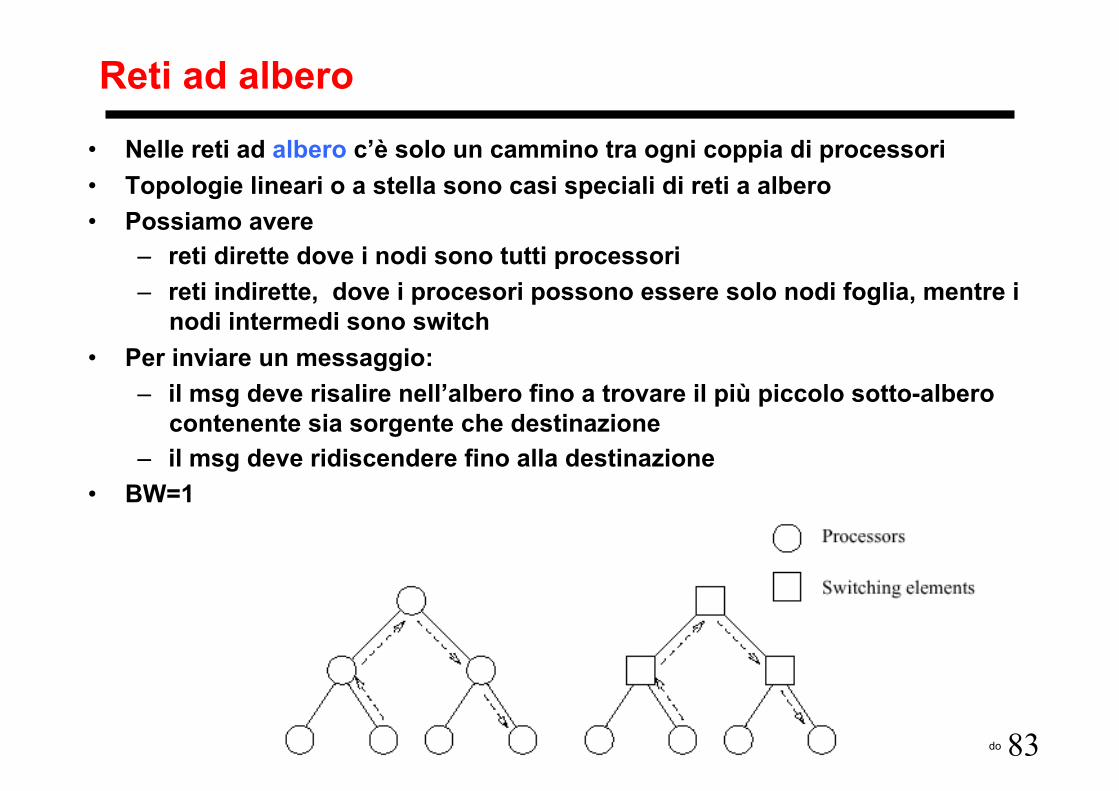
Reti ad albero
• Nelle reti ad albero c’è solo un cammino tra ogni coppia di processori • Topologie lineari o a stella sono casi speciali di reti a albero • Possiamo avere
– reti dirette dove i nodi sono tutti processori – reti indirette, dove i procesori possono essere solo nodi foglia, mentre i
nodi intermedi sono switch • Per inviare un messaggio:
– il msg deve risalire nell’albero fino a trovare il più piccolo sotto-albero contenente sia sorgente che destinazione
– il msg deve ridiscendere fino alla destinazione • BW=1

84 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Reti ad albero
• In queste reti c’è un bottleneck di comunicazione sui livelli più alti dell’albero – se molti processi a sinistra comunicano con i processori a destra, lo
switch sulla root deve gestire tutti i messagi. • Una soluzione è l’incremento del numero di link tra i nodi vicini alla root
– fat tree – Aumentiamo BW

85 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Fat tree
Realizzazione con switch box 2X2

86 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Misure relative ad altre topologie dirette
Degree d

87 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Misure relative ad altre topologie indirette
Degree d

88 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impatto del routing
• Come viene calcolato l’instradamento (routing) sulla rete dal sorgente alla destinazione? – Deterministico vs adattativo – Routing deve prevenire i deadlock
• dimension-ordered o e-cube routing (deterministico). – Routing deve evitare gli hot-spots
• two-step / two-phase routing • Messaggio mandato ad un processore intermedio scelto in modo random

89 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
E-cube routing
Routing di un msg da Ps (010) a Pd (111) in un ipercubo a 3-dimensioni
Ordine deterministico nell’instradamento sulle 3 dimensioni
Step 2 (110 111)Step 1 (010 110)
pdpdpd
pspsps
111110
101
011
100
010
001000
111110
101
011
100
010
001001000
010
101100
011
110 111
000

90 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Process-to-Processor Mapping vs. Routing
• Embedding di un pattern di comunicazione logico su una data topologia reale
• Ad esempio, se vogliamo portare un algoritmo progettato astrattamente per una data topologia di rete, su un’altra topologia
=> Mapping tra grafi: G(V,E) in G’(V’,E’)
• Metriche di mapping – Il max n. di archi in E mappati su un link in E’:
• Congestione del mapping – Il max n. di link in E’ su cui ogni singolo arco in E è stato mappato
• Dilatazione del mapping – Il rapporto tra i numeri di nodi in V’ e in V
• Espansione del mapping

91 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Embedding di topologie
• Mapping di processi su processori – Cosa succede se abbiamo un algoritmo progettato per una topologia
logica, ad esempio a mesh 3-D dove tutte le comunicazioni sono tra vicini, da mappare su una topologia fisica ad ipercubo?
• Di solito si può realizzare facilmente se la topologia fisica è più ricca di quella logica (sia nel numero di nodi e sia in quello degli archi) – Obiettivo: realizzare un mapping dove tutti i collegamenti tra processi
siano mappati su link diretti (congestione e dilatazione = 1)
• Purtroppo nelle macchine parallele attuali diventa difficile controllare il mapping – Molti ambienti di programmazione permettono di specificare solo il
grado di parallelismo – Topologia fisica non esportata verso il programmatore – Rete + Routing garantisce interconnessione logica completa – Costo trasmissione dipende sempre meno dal numero di hops – Purtroppo conflitti tra messaggi sono ancora da evitare per ottenere
buone prestazioni

92 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Impatto del mapping sulle prestazioni

93 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempio di embedding: array lineare su un ipercubo
• Un array lineare composto da 2d nodes (labeled 0 through 2d−1)
• Embedding semplice in un ipercubo d-dimensionale – mapping del nodo i dell’array lineare array – sul nodo G(i, d) dell’ipercubo
• Funzione G(i, d) definita come segue:
0

94 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempio di embedding: array lineare su un ipercubo
• G(0,3) = G(0,2) = G(0,1) = 0002
• G(1,3) = G(1,2) = G(1,1) = 0012
• G(2,3) = G(2,2) = 21 + G(22
-1-2, 1) = 21 + G(1, 1) = 21 + 1 = 0112
• G(3,3) = G(3,2) = 21 + G(21 -1-3, 1) = 21 + G(0, 1) = 21 + 0 = 0102
• G(4,3) = 22 + G(23 -1-4, 3) = 22 + G(3, 3) = 22 + 2 = 1102
• …..
95 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Embedding a Hypercube into a 2-D Mesh: Example

96 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Sistemi SM con cache coherence • Appartengono a questa classe molti multiprocessori a basso costo come gli
SMP (multiprocessori simmetrici) bus based – sistema di memoria che permette l’accesso uniforme (UMA) a processori multipli – usati per calcolo parallelo, ma anche per incrementare il throughput di job
multiprogrammati – accoppiamento stretto (permettono la condivisione a grana fine) – la comunicazione è implicita nelle store/load su indirizzi condivisi – copie automatiche per replicare coerentemente i dati nelle varie cache – sincronizzazione tramite operazioni su locazioni di memoria condivise
• Compito del programmatore (compilatore) – ridurre le sincronizzazioni – limitare gli spazi condivisi di memoria – allocare i dati in modo che il meccanismo di coerenza della cache non comunichi
inutilmente dati
I/O devices Mem
P 1
$ $
P n
Bus

97 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Vantaggi delle cache
• Le cache riducono il bottleneck costituito dal bus – molte load/store non hanno più
bisogno di transitare sul bus per accedere alla memoria
• Si riduce la latenza per accedere ai dati – accesso alla cache più veloce
rispetto alla memoria • Processori possono condividere dati in
sola lettura
• Cosa succede se dei dati replicati nelle cache vengono modificati da qualche processore ?
P P P
98 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
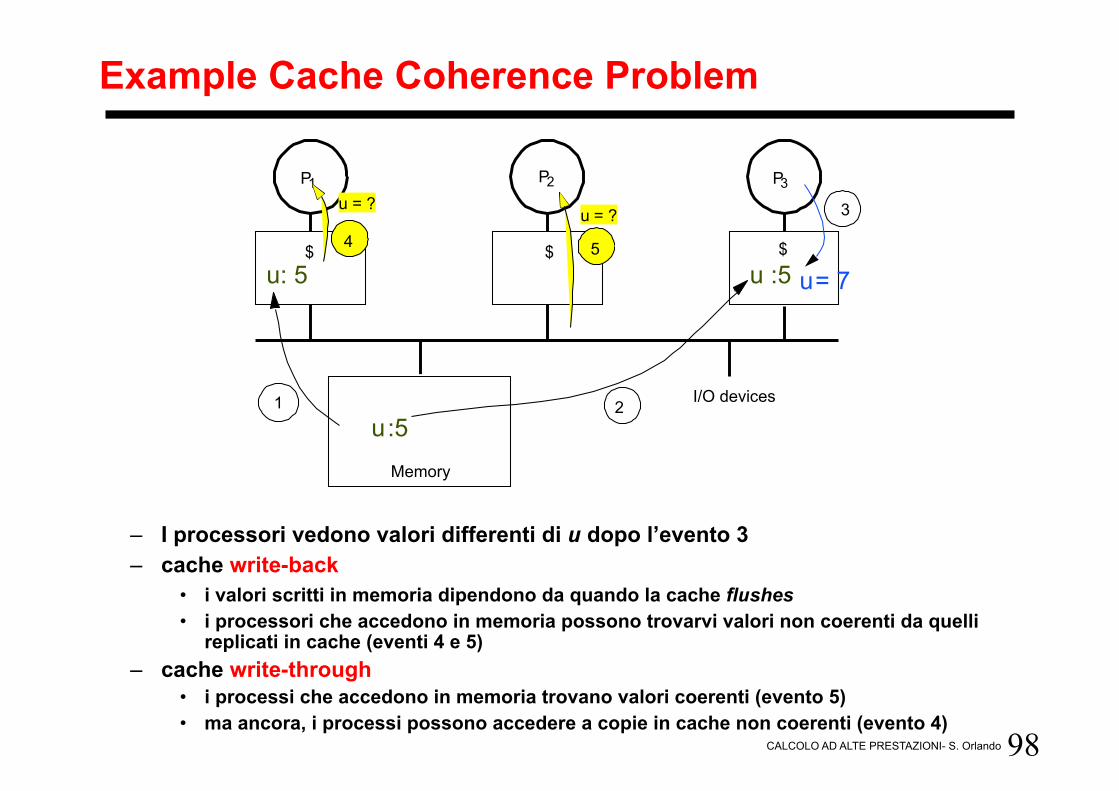
Example Cache Coherence Problem
– I processori vedono valori differenti di u dopo l’evento 3 – cache write-back
• i valori scritti in memoria dipendono da quando la cache flushes • i processori che accedono in memoria possono trovarvi valori non coerenti da quelli
replicati in cache (eventi 4 e 5) – cache write-through
• i processi che accedono in memoria trovano valori coerenti (evento 5) • ma ancora, i processi possono accedere a copie in cache non coerenti (evento 4)
I/O devices
Memory
P 1
$ $ $
P 2 P 3
5 u = ?
4
u = ?
u :5 1
u: 5
2
u :5
3
u = 7
99 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
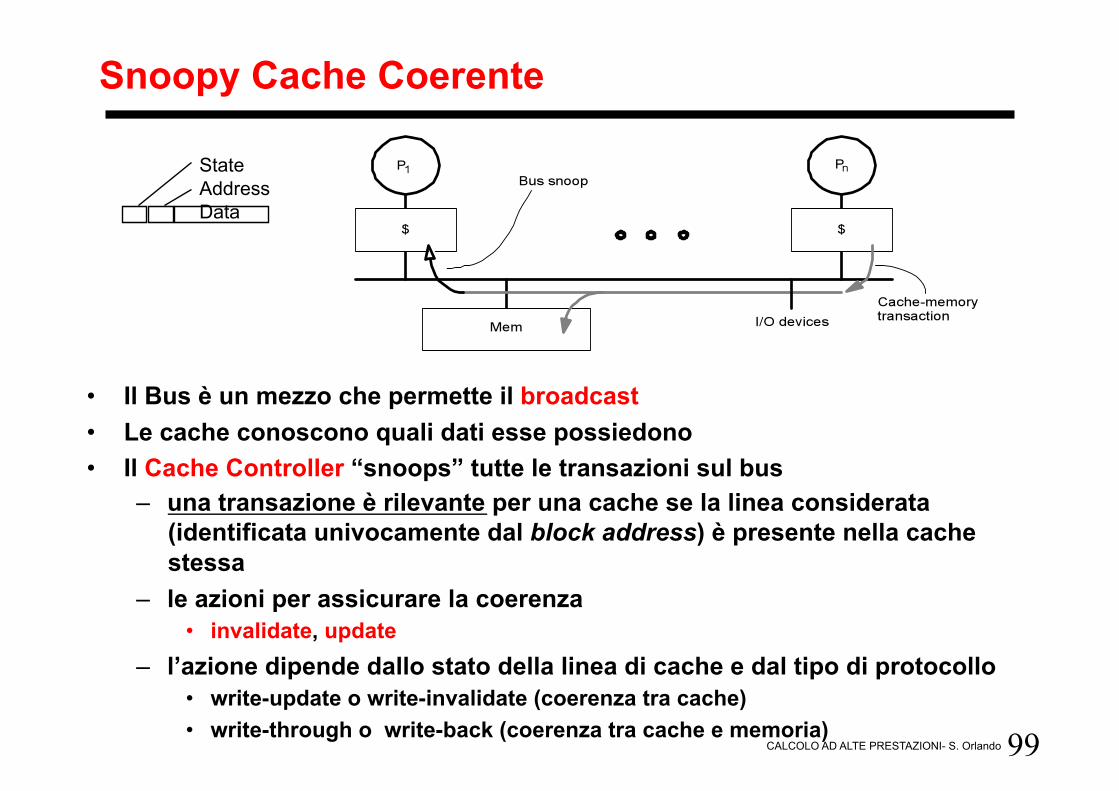
Snoopy Cache Coerente
• Il Bus è un mezzo che permette il broadcast • Le cache conoscono quali dati esse possiedono • Il Cache Controller “snoops” tutte le transazioni sul bus
– una transazione è rilevante per una cache se la linea considerata (identificata univocamente dal block address) è presente nella cache stessa
– le azioni per assicurare la coerenza • invalidate, update
– l’azione dipende dallo stato della linea di cache e dal tipo di protocollo • write-update o write-invalidate (coerenza tra cache) • write-through o write-back (coerenza tra cache e memoria)
State Address Data

100 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Invalidate vs Update
• Update – Invio una transazione sul bus per aggiornare tutte le copie
eventualmente replicate nelle cache – Transazione sul bus corrisponde alla trasmissione di
• Indirizzo • Blocco modificato
• Invalidate – Invio una transazione sul bus per invalidare tutte le copie
eventualmente replicate nelle cache – Transazione sul bus corrisponde alla trasmissione di
• Indirizzo

101 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Invalidate vs Update
• Update – contro: può sprecare la banda del bus inutilmente
• ad esempio, se un dato viene aggiornato in una cache remota, ma non viene più letto
• più scritture successive da parte di un processore provocano update multipli
– pro: copie multiple in R/W sono mantenute coerenti dopo una scrittura. Si evitano i miss su accessi in lettura successivi all’update (non è necessario andare sul bus)
• Invalidate – pro: le scritture multiple da parte di un processore non provocano
traffico addizionale sul bus – contro: una accesso successivo all’invalidation provoca un miss (è
necessario andare sul bus) => Pro e contro dei due approcci dipendono dai pattern di riferimento dei
programmi e dalla complessità hw per la loro realizzazione • Sistemi moderni usano
– write-back e write-invalidate per ridurre il traffico sul bus

102 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Size del blocco di cache e False sharing
• I Protocolli ragionano in termini di blocchi di cache, non di singole word • La dimensione del blocco gioca un ruolo importante per la gestione della
coerenza – protocolli che hanno a che fare con blocchi piccoli sono più efficienti,
dovendo trasmettere meno roba – blocchi grandi sono migliori per sfruttare la località spaziale
• False sharing – consideriamo due variabili scorrelate (ovvero private rispetto a due
thread, non condivise), che vengono poste nello stesso blocco – accessi in scrittura al blocco da parte di processori diversi vengono
considerate in conflitto dal protocollo di coerenza • anche se i processori accedono a word differenti del blocco
– necessario porre nello stesso blocco solo variabili correlate • e.g. private rispetto allo stesso processore • tecniche di compilazione • programmatore
103 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
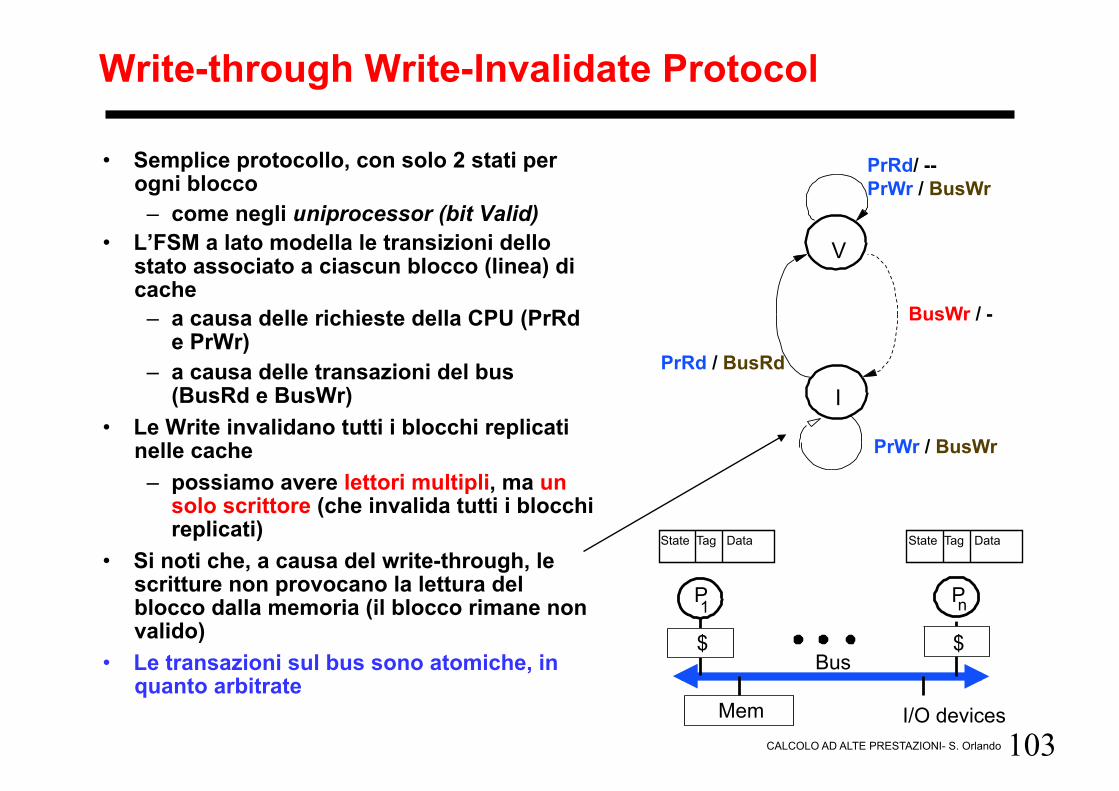
Write-through Write-Invalidate Protocol
• Semplice protocollo, con solo 2 stati per ogni blocco
– come negli uniprocessor (bit Valid) • L’FSM a lato modella le transizioni dello
stato associato a ciascun blocco (linea) di cache
– a causa delle richieste della CPU (PrRd e PrWr)
– a causa delle transazioni del bus (BusRd e BusWr)
• Le Write invalidano tutti i blocchi replicati nelle cache
– possiamo avere lettori multipli, ma un solo scrittore (che invalida tutti i blocchi replicati)
• Si noti che, a causa del write-through, le scritture non provocano la lettura del blocco dalla memoria (il blocco rimane non valido)
• Le transazioni sul bus sono atomiche, in quanto arbitrate
I
V
BusWr / -
PrRd/ -- PrWr / BusWr
PrWr / BusWr
PrRd / BusRd
State Tag Data
I/O devices Mem
P 1 $ $
P n
Bus
State Tag Data

104 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempio di Write-back Write-Invalidate
I/O devices
Memory
P 1
$ $ $
P 2 P 3
5 u = ?
4
u = ?
u :5 1
u :5
2
u :5
3
u = 7

105 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Protocollo W-back (W-invalidate) • Cerchiamo di estendere il controller della
cache Write-back degli uniprocessori • 2 tipi di richieste da parte della CPU (PrRd,
PrWr) con Replace in caso di miss/conflitto • 3 stati
– Invalid, Valid (clean), Modified (dirty) • in origine 2 transazioni sul bus:
– read (BusRd), write-back (BusWB) – si trasferiscono interi cache-block
Estensione multiprocessore (W-invalidate): => trattiamo Valid come “Shared” mentre
Modified diventa sinonimo di exclusive chi detiene un blocco in stato M lo deve W-back anche se arrivano richieste esterne per il blocco
=> necessario introdurre un nuovo tipo di transazione sul bus per invalidare
– read-exclusive: read per modificare (I -> M e V->M), così gli altri proc. sanno che il blocco è acquisito in scrittura e invalidano
PrRd/—
PrRd/— PrW r/BusRd
PrW r/—
V
M
I
Replace/BusWB
PrW
PrRd/BusRd
Replace/-
106 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
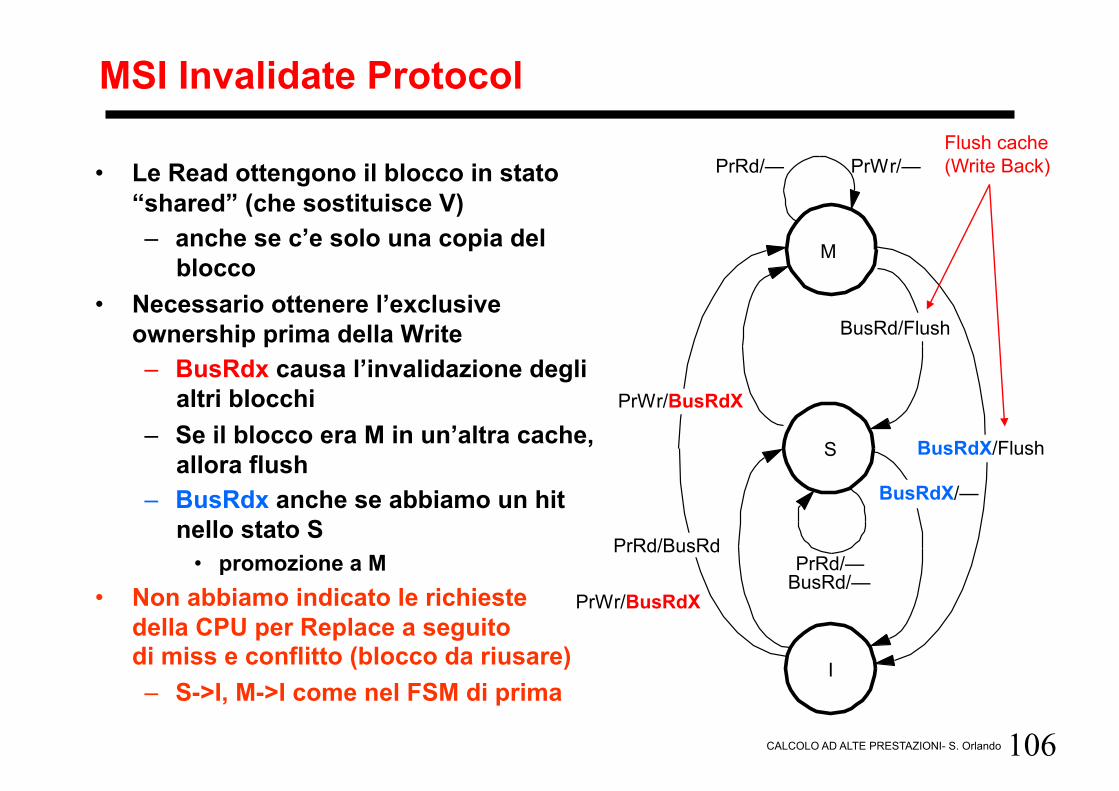
MSI Invalidate Protocol
• Le Read ottengono il blocco in stato “shared” (che sostituisce V) – anche se c’e solo una copia del
blocco • Necessario ottenere l’exclusive
ownership prima della Write – BusRdx causa l’invalidazione degli
altri blocchi – Se il blocco era M in un’altra cache,
allora flush – BusRdx anche se abbiamo un hit
nello stato S • promozione a M
• Non abbiamo indicato le richieste della CPU per Replace a seguito di miss e conflitto (blocco da riusare) – S->I, M->I come nel FSM di prima
PrRd/—
PrRd/—
PrW r/BusRdX BusRd/—
PrW r/—
S
M
I
BusRdX/Flush
BusRdX/—
BusRd/Flush
PrW r/BusRdX
PrRd/BusRd
Flush cache (Write Back)
107 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
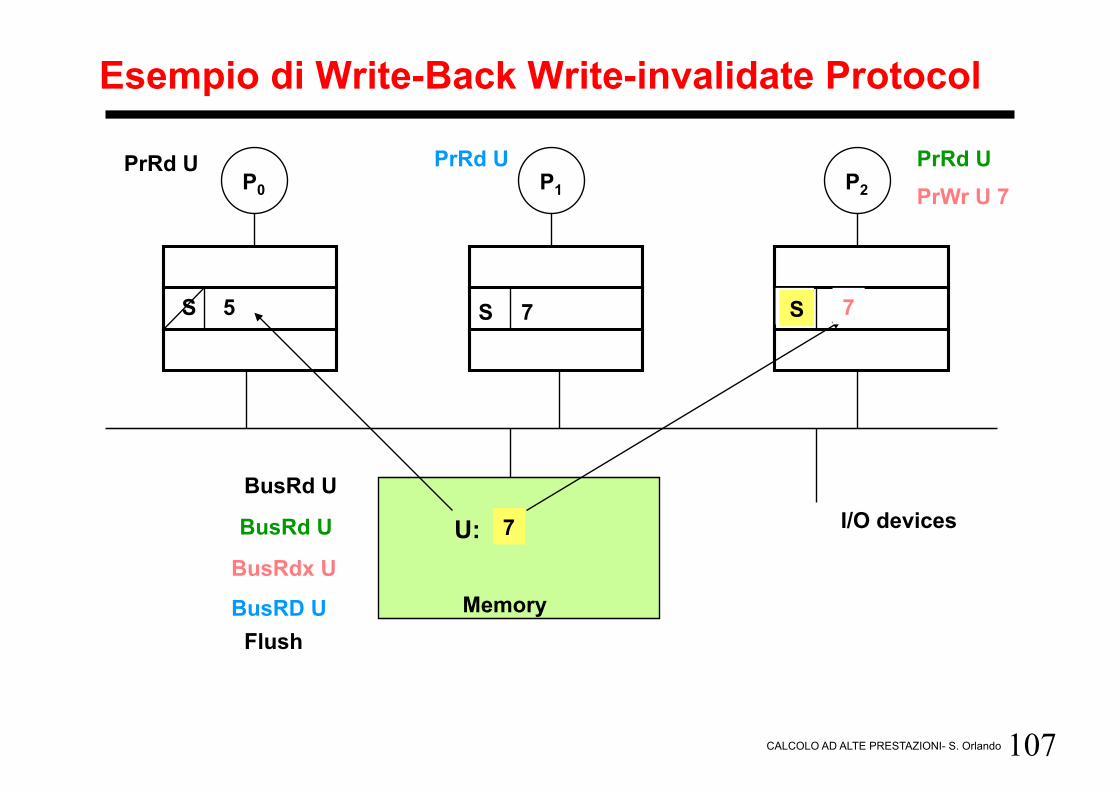
Esempio di Write-Back Write-invalidate Protocol
I/O devices
P0 P1 P2
Memory
U: 5
PrRd U
BusRd U
5 S
PrRd U
BusRd U
S 5
PrWr U 7
BusRdx U
7 M
PrRd U
BusRD U
7 S
Flush
7
S

108 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Esempio di esecuzione (3 state coherence protocol)
• M = D = dirty/modified
• I = invalid • S = Shared

109 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Protocollo MESI
• Il Pentium e il PowerPC adottano un protocollo chiamato MESI – Write-invalidate Write-back
• Rispetto all’MSI lo stato S in sola lettura è stato ulteriormente suddiviso – E (Exclusive) : il blocco è usato in lettura solo da un processore – S (Shared) : il blocco è usato in lettura da più processori
• Vantaggi: – la promozione E->M può essere fatta senza far viaggiare la richiesta sul
bus di BusRdx, per invalidare le eventuali copie replicate

110 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Meccanismi di sincronizzazione
• La sincronizzazione per accedere ad una risorsa avviene scrivendo in una locazione di memoria (lock, semaforo)
• Pensiamo ad una variabile di lock con 2 stati – 0: via libera – 1: stop
• Conosciamo il problema ….. – leggiamo la variabile, la troviamo uguale a 0, decidiamo di accedere, e
ci scriviamo 1 per segnalare l’accesso – tra la lettura e la scrittura potrebbe inserirsi un’altra scrittura (race
condition) => necessario effettuare la lettura e la scrittura in maniera atomica
• non possiamo garantire l’atomicità con la disabilitazione delle interruzioni, come negli uniprocessori – altri processori possono contemporaneamente fare lo stesso tipo di
accesso

111 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Meccanismi di sincronizzazione
• Architetture diverse hanno istruzioni speciali diverse – atomic exchange
• scambia i valori di un reg e di una locazione di mem – test-and-set (vecchio)
• testa il valore di una variabile in mem, e la setta solo se il test è ok – load locked & store conditional
• meccanismo recente presente in alcuni processori • prima effettuiamo una load locked • la prossima store conditional fallisce se il valore memorizzato nella
locazione di memoria è nel frattempo cambiato

112 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Meccanismi di sincronizzazione
• Vediamo un semplice spin-lock con atomic exchange li R3, #1
lockit: exch R3, 0(R1) ; scambiamo R3 con la cella di ; mem indirizzata da R1
bnez R3, lockit ; se R3!=0, e’ gia’ lockato
• Non è il massimo …. – le continue scritture provocate dallo exch, unito al meccanismo di
coerenza, possono generare molto traffico sul bus – un metodo più economico è continuare a loopare leggendo con semplici
read, che leggono copie locali alla cache, senza traffico sul bus
lockit: lw R3, 0(R1) ; leggiamo in R3 la cella di ; mem indirizzata da R1 bnez R3, lockit ; se R3!=0, e’ gia’ lockato li R3, #1 exch R3, 0(R1) ; scambiamo R3 con la cella di ; mem indirizzata da R1 bnez R3, lockit ; se R3!=0, e’ gia’ lockato

113 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Spin-lock e attesa attiva
• Attesa attiva (busy-waiting) – poiché i processi che competono per accedere ad una regione critica
tramite spin-lock rimangono in attesa attiva, evitiamo di usare i lock per accedere a regioni critiche molto grandi
– es.: usiamo le spin lock per rendere atomica l’operazione di P o V su un semaforo (piccola sezione critica)
Semaphore = Synchronization variable.
P(s): [ while (s == 0) wait(); s--; ] V(s): [ s++; ]
I programmatori usano P e V per creare operazioni atomiche più grandi: [ codice ] = P(s); …codice…; V(s)
P e V rese atomiche tramite spin_lock()
spin_lock(V); P(S); V = 0; // unlock(V)

114 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Consistenza sequenziale
• La coerenza della cache garantisce che processori multipli abbiano una vista consistente della memoria condivisa
• In particolare, abbiamo finora illustrato un tipo di consistenza detta consistenza sequenziale
– “A multiprocessor is sequentially consistent if the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.” [Lamport, 1979]
• Come se non ci fossero cache, e con una singola memoria
– Le operazioni di memoria inviate dai vari processori devono essere eseguite [issue, execute, complete] in modo atomico

115 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Consistenza sequenziale
• Esempio – Supponiamo che i processori 1 e 2 inviino la coppia di richieste
seguenti alla memoria in questo ordine:
(1a) A=1 (W) (2a) print B (R) (1b) B=2 (W) (2b) print A (R)
i possibili ordinamenti sequential consistent (SC) sono 1a-> 1b-> 2a-> 2b 1a-> 2a-> 1b-> 2b 1a-> 2a-> 2b-> 1b 2a-> 2b-> 1a-> 1b 2a-> 1a-> 2b-> 1b 2a-> 1a-> 1b-> 2b
• Se all’inizio A=0 e B=0 – Il processore 2 non può quindi leggere B=2 e A=0 – Per vedere A=0 dovrebbe essere necessario che 2b->1a
• 4^ ordinamento – Per vedere B=2 dovrebbe essere necessario che 1b->2a
• 1^ ordinamento

116 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Consistenza sequenziale e rilassata
• Implementazioni possibili della SC – Un processore ritarda il completamento di ogni accesso in memoria
fino a che tutte le invalidazioni/update sono state effettuate – Un processore ritarda l’inizio di una nuova operazione fino a quando le
precedenti non sono completate • Mantenere la consistenza SC può provocare problemi di performance
– Dobbiamo pagare le latenze di update / invalidate/ flush senza poter sovrapporre computazioni utili
– Non possiamo, ad esempio, mettere una scrittura in un write buffer in attesa del completamento, e continuare con altre computazioni
• Possibili soluzioni – Implementazioni che garantiscano la coerenza SC, in modo da
nascondere le alte latenze (difficile …. soprattutto su multiprocessori a larga scala)
– Implementazioni che realizzino un modello di consistenza meno restrittivo (relaxed), permettendo così un’implementazione più veloce

117 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Consistenza rilassata e vista del programmatore
• SC semplifica il modello di programmazione visto dal programmatore
• Modelli rilassati – rimuovono alcuni vincoli sulla sovrapposizione e il riordino delle
operazioni di memoria – permettendo così una più efficiente implementazione
• Solitamente i programmi a memoria condivisa sono sincronizzati – Il programmatore assume che il programma è corretto se accessi a dati
condivisi avvengono dopo opportune chiamate a primitive di sincronizzazione (sono i dati condivisi a dare problemi di coerenza…..)
• L’idea dei modelli rilassati è – di permettere in generale qualsiasi ordinamento delle operazioni di W/R – ma di forzare l’ordinamento solo tra operazioni che sono esplicitamente
ordinate da sincronizzazioni esplicite • Ad esempio, una lock prima di una R deve forzare la conclusione di una
precedente W (che di solito è seguita da una unlock) – il programma sincronizzato eseguito sul modello rilassato dovrebbe
avrebbe la stessa semantica del programma eseguito su un altro sistema basato su un modello SC

118 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Sistemi SM a larga scala (NUMA)
• Garantire la coerenza con un bus non scala – il bus assieme al protocollo di snooping costituisce un collo di bottiglia
• No cache coherence – T3E/T3D: macchine con spazio di indirizzamento globale, di tipo NUMA,
a parallelismo massiccio – Private Memory, ma con possibilità di accesso anche a memorie remote
(cioè memorie private ad altri processori) – possiamo costruirci sopra agevolmente operazioni di put/get – non abbiamo politiche di coerenza
• copie dei dati, e coerenza a carico del sw, ovvero del programmatore/compilatore
• cache locali, della memoria privata – le load remote non sono cacheable
– approccio perfetto per problemi regolari, un po’ meno per quelli irregolari, dove gli approcci sw finiscono per essere poco performanti
• per problemi irregolari diventa difficile partizionare i dati e assegnare le partizioni alle memorie locali dei vari processori
• approccio sw conservativo (poca performance): dati non distribuiti, ma centralizzati, con accessi remoti da parte dei vari processori

119 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Sistemi SM a larga scala (NUMA)
• Coerenza su sistemi a larga scala? – Rimpiazziamo il bus con una rete più scalabile – Rimpiazziamo il protocollo di snooping
• che richiede che tutti i cache controller possono avere accesso ad un mezzo di trasmissione condiviso (il bus), su cui vengono inviati in broadcast le richieste
– Usiamo un’architettura NUMA, con memoria distribuita

120 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Cache-coherence basato su Directory
• Nelle snoopy cache, ogni richiesta legata al protocollo di coerenza è inviata a tutti i processori – Questa è una limitazione intrinseca del protocollo, anche se resa “poco
costosa” dall’esistenza del bus • Nota che il protocollo di snooping è completamente decentralizzato => non
abbiamo un singolo posto dove poter controllare se il dato è in memoria o è stato replicato/modificato in una qualche cache – Sfruttiamo le caratteristiche di broadcast del bus, e di snooping da
parte dei cache controller
• Per migliorare la scalabilità, è possibile mandare messaggi relativi alla coerenza solo ai processori/cache che devono essere notificati?
• Impieghiamo per questo un protocollo di Cache-coherence basato su Directory – Nel protocollo Directory-based, le informazioni sulla condivisione/
replicazione dei blocchi di memoria sono invece centralizzate nella directory
– La directory mantiene un bit-vector di presenza per ogni data item (cache line) assieme allo stato

121 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Cache-coherence basato su Directory
• Nella formulazione più semplice – una directory con una entry per ogni blocco – per ogni entry, informazioni rispetto a quali sono i processori, e in che
stato, hanno portato il blocco nelle loro cache – informazione della directory proporzionale a
• num. Proc × num. Blocchi
– esempi di stati associati ai blocchi nella directory • Shared (R), Uncached, Exclusive/Modified (W) • Il Proc. che possiede il blocco nello stato Modified diventa l’owner

122 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Cache-coherence basato su Directory
• La directory centralizzata evita il broadcast, ma tutti messaggi per accedere un nuovo blocco devono essere accodati (sequenzializzati) verso lo stesso punto di centralizzazione, anche se non c’è nessuna condivisione
• siamo passati da una soluzione completamente decentralizzata ad un una completamente centralizzata
⇒ soluzione: decentralizzare le directory per ciascun gruppo di memorie, introducendo il concetto di home node, ovvero il nodo dove sia la copia primaria del blocco e sia l’entry della directory risiedono
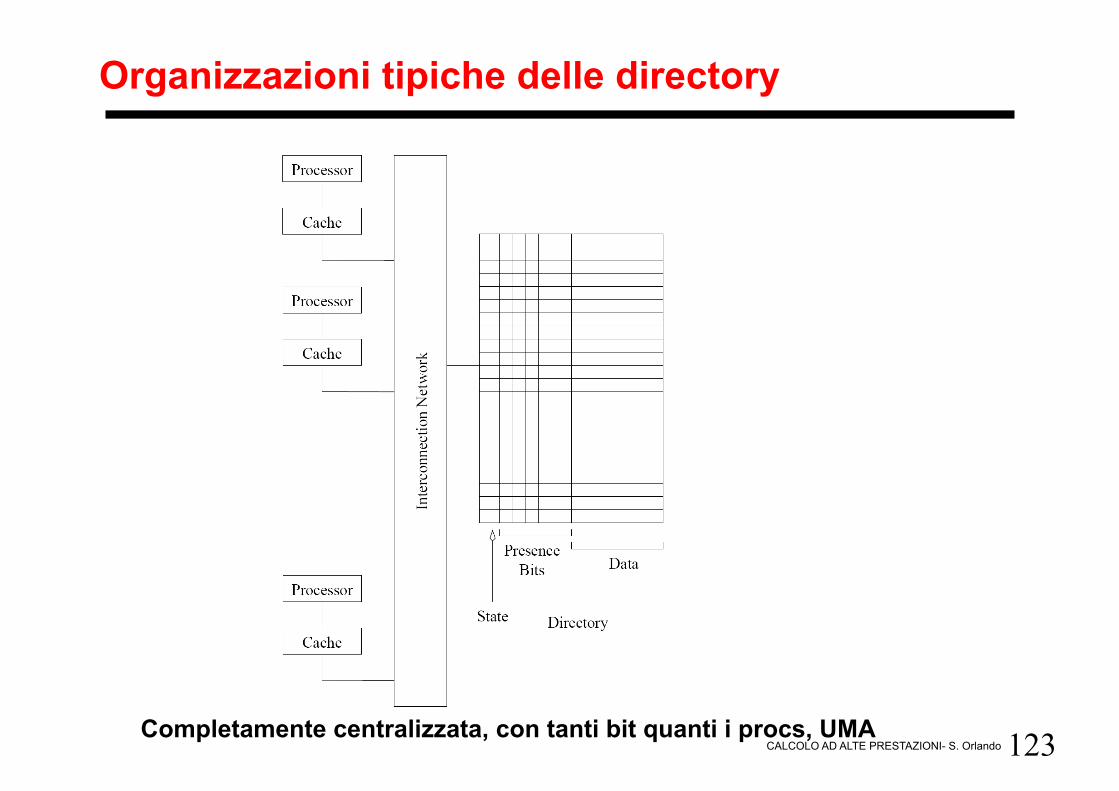
123 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Organizzazioni tipiche delle directory
Completamente centralizzata, con tanti bit quanti i procs, UMA

124 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Organizzazioni tipiche delle directory
• Completamente distribuita (NUMA), con tanti bit quanti i procs • Gerarchica (NUMA di SMP UMA), per ridurre la quantità di bit per entry
(bit per cluster invece che per proc)

125 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Protocollo Directory-based - Write-invalidation
• Per invalidare, come conseguenza di un write, vengono scambiati diversi messaggi – nodo che ha generato il write → directory
– directory → uno o più nodi per le invalidazioni (multicast) • Note che nel protocollo di snooping, i due passi sono combinati
– uso di broadcast a tutti i nodes
• Tipi di messaggi tra directory e nodi – local node : dove la richiesta è stata originata. – home node : node dove la locazione di memoria e la directory
entry risiede – Indirizzi fisici staticamente distribuiti
• dato un indirizzo fisico, in numero del nodo dove risiede il blocco di memoria e la directory entry relativa sono noti
• Es.: bit high-order dell’indirizzo usati come numero del nodo

126 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Protocollo Directory-based - Write-invalidation
• Operazione di Write miss – broadcast sul bus (o anche su altre reti) nello schema snooping – messaggi di data fetch e invalidate, inviati selettivamente dal controllore
della directory

127 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Protocollo Directory-based - Write-invalidation
• Come per il protocollo snooping – ogni blocco di cache deve essere in stato modified/exclusive se
scritto – un blocco in stato shared deve essere aggiornato in memoria
(deve quindi essere una copia read-only del blocco mantenuto in memoria)
• Nel protocollo directory-based, la directory costituisce l’altra metà del protocollo di coerenza, assieme ai cache controller – un messaggio inviato alla directory causa due azioni: – aggiornare lo stato della directory – inviare messaggi addizionali per soddisfare la richiesta

128 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Protocollo Directory-based - Write-invalidation
• Lato cache-controller
• In grigio gli eventi giunti dall’esterno (directory)
• Entrambi i msg – Read miss – Write miss
provocano un msg di Data value reply

129 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Protocollo Directory-based - Write-invalidation
• Lato directory-controller

130 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Cluster di WS
• Sono sempre più diffusi cluster di WS (uniprocessori, multicore, SMP, SMP di multicore) usati per il calcolo parallelo – Si noti che anche le macchine attualmente vendute come computer
paralleli adottano gli stessi processori “commodity” delle workstation – I cluster di SMP sono anche detti clumps (clusters of multprocessors)
• Le WS sono computer a basso costo, con reti locali, o con speciali reti (NIC PCI + switch esterni) che hanno il vantaggio di offrire un supporto per le comunicazioni efficienti in termini di latenza e banda
• Ogni WS è solitamente dotata di un SO general purpose, ed ha accesso all’I/O (dischi locali o server NSF) – I/O distribuito utile per risolvere problemi che operano su grosse moli
di dati (es. Data Mining) – Il kernel del SO può chiaramente essere modificato per specifici scopi

131 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Cluster di SMP (clump)

132 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
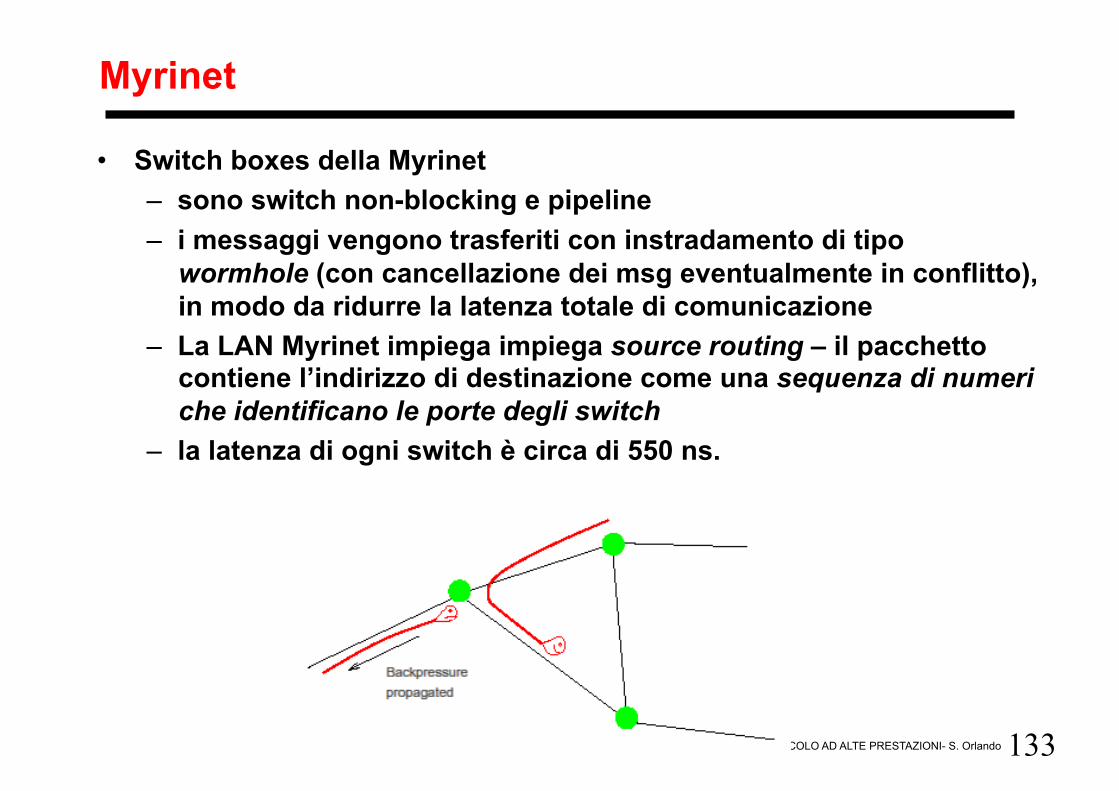
Myrinet
• Una rete veloce per cluster interessante e relativamente poco costosa è la Myrinet – i suoi switch box possono essere connessi a altri box o alle
singole porte di ogni host (NIC) • Internamente gli switch box sono realizzati tramite una topologia a
rete indiretta (Clos network) – i link bidirezionali supportano fino a 2+2 Gb/s – Myrinet permette di costruire topologie di rete regolari differenti – connettendo gli switch appropriatamente è possibile scalare
nelle prestazioni della rete
133 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Myrinet
• Switch boxes della Myrinet – sono switch non-blocking e pipeline – i messaggi vengono trasferiti con instradamento di tipo
wormhole (con cancellazione dei msg eventualmente in conflitto), in modo da ridurre la latenza totale di comunicazione
– La LAN Myrinet impiega impiega source routing – il pacchetto contiene l’indirizzo di destinazione come una sequenza di numeri che identificano le porte degli switch
– la latenza di ogni switch è circa di 550 ns.

134 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Myrinet
• I pacchetti possono avere qualsiasi lunghezza, e incapsulare altri pacchetti, anche IP
• Usando le API per accedere al Myricom's GM message-passing system possiamo sostenere bande one-way di – ~1. 96 Gbits/s tra processi utente UNIX su macchine diverse – latenze per msg corti di circa ~7µs – poca utilizzazione della CPU dell’host
• Esistono software di comunicazione come MPI, VIA, e TCP/IP che sono stati implementati efficientemente sul livello GM

135 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Myrinet strutturata a mesh
• Dimensional routing (e-cube) per evitare deadlock
• I pacchetti attraversano il mesh prima nella direzione x poi in quella y
• La testa del messaggio contiene info di routing
• Come il pacchetto arriva ad uno switch, questo determina il prossimo switch / host nel cammino

136 CALCOLO AD ALTE PRESTAZIONI- S. Orlando
Quadro di insieme delle architetture parallele
Architetture
SISD SIMD MIMD
Array Processor Vector Processor Multiprocessor Multicomputer
UMA CC-NUMA NC-NUMA MPP COW
Bus Switched Memoria Distribuita
Reti di interconnessione e meccanismi di basso livello di comunicazione sono simili
COMA