ap statistics chapters 1 & 7 semester 1 project
DESCRIPTION
AP Statistics Chapters 1 & 7 Semester 1 Project. By: Bernadine De La Rosa Jennifer Hoang Nancy Le Christine Madamba Christina Nguyen Period 2. Chapter 1 Exploring Data. Introduction Any set of data contains information about some group of individuals - PowerPoint PPT PresentationTRANSCRIPT

AP StatisticsChapters 1 & 7Semester 1 Project
By:
Bernadine De La Rosa
Jennifer Hoang
Nancy Le
Christine Madamba
Christina Nguyen
Period 2

Chapter 1Exploring Data

Section 1.1 – Displaying Distributions with Graphs
Introduction0 Any set of data contains information about some group of
individuals0 Individuals- the objects described by a set of data0 Variable- any characteristic of an individual0 Variables can be divided into two sections: categorical and
quantitative 0 Categorical- places into categories0 Quantitative- Numerical value0 Lets try! 0 A political scientist selects a large sample of registered voters.
For each voter, she records gender, age, and household income. Which variables are quantitative and which are categorical?
• Gender: Categorical• Age: Quantitative• Household income: Quantitative

0 Distribution of a variable tells us what values the variable takes and how often it takes these values
0 Exploratory data analysis examines and describes the data’s main features
0 Two basic strategies:1. Examine each variable by itself, then connect it to the other one2. Make a graph. Add specific aspects of numerical summaries
Distribution

0 Bar graphs help the audience grasp the distribution quickly0 To construct a bar graph:
1. Label your axes and title your graph
2. Scale your axes. Use the counts in each category to help you scale your vertical axis
3.Draw a vertical bar above each category name to a height that corresponds to the count in that category
Determine which color students prefer to wear to class:Red- 5Green- 2Blue- 5Black- 3
Color Preference
Red Green Blue Black
Bar Graphs

Pie Charts0 Pie charts help us see what part of the whole each group forms0 How to construct a pie chart:* Tip: Recommended to use statistical software package
1. Change any numerical values into percents2. Estimate how much space the category will cover
depending on the data given3. All percents must add up to a total of 1
Red- 5 = .33 = 33%Green- 2 = .14 = 14%Blue- 5 = .33 = 33%Black- 3 = .20 = 20%

Dotplot0 Helps display quantitative data0 How to construct:
Data:8 1’s6 2’s 6 3’s9 4’s7 5’s14 6’s
1. Draw one horizontal line going across2. Label the axis3. Scale the axis4. Put a dot in the correct place for every value that appears in the data
You roll a die 50 times and record the numbers that you got. Using the data provided, construct a dotplot for this observation.

0 To describe overall pattern of a distribution1. Give the center and the spread2. See if the distribution has a simple shape that you can describe
0 Center is the value that divides the observations in half
0 Spread is giving by the smallest and largest value0 An outlier in any graph of data is an observation that
falls outside the overall pattern of the graph
Overall Pattern of a Distribution

Stemplot0 Stemplots are used when the values of a variable are too
spread out for us to make a reasonable dotplot0 How to construct a stemplot:
4. Title your graph and add a key describing what the stems and leaves represent
40 26 39 14 42 18 25 43 46 27 19 47 19 26 35 34 15 44 40 38 31 46 52 59
Given these values, construct a stemplot.
1. Separate each observation into a stem consisting of all but the rightmost digit and a leaf, the final digit2. Write the stems vertically in increasing order from top to bottom, and draw a vertical line to the right of the stems.3. Write the stems again, and rearrange the leaves in increasing order out from the stem
12345
4 5 8 9 95 6 6 72 4 5 8 90 0 2 3 4 6 72 9
Key: 5 2 = 52

Histograms0 The most common graph of the distribution of one quantitative variable is a
histogram0 How to construct a histogram:
3.Draw a bar that represents the count in each class. The base of a bar should cover its class, and the bar height is the class count
6 12 2 4 17 4 6 10 3 9 13 9 15 14 6 18 1 9 6 6 11 24 14 14 5 17 17 5 13 22 20 3 5
Construct a histogram for this distribution:
1. Divide the range of the data into classes of equal width. Count the number of observations in each class2. Label and scale your axes and title your graph. Vertical axis contains the scale of counts
1 – 5 = 9 6 – 10 = 911 – 15 = 816 – 20 = 521 – 25 = 2
The data below is the number of unprovoked attacks by alligators on people in Florida each year for a 33- year period
Number of Unprovoked Attacks
F r equency 1-5 6-10 11- 15 16- 20
21-25
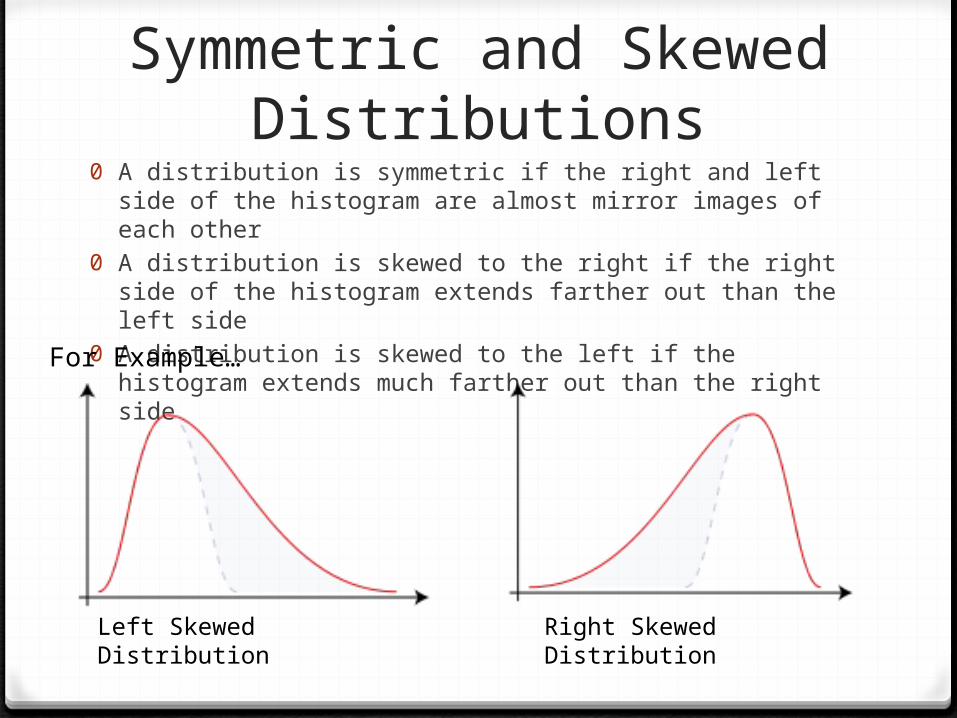
0 A distribution is symmetric if the right and left side of the histogram are almost mirror images of each other
0 A distribution is skewed to the right if the right side of the histogram extends farther out than the left side
0 A distribution is skewed to the left if the histogram extends much farther out than the right side
Left Skewed Distribution
Right Skewed Distribution
For Example…
Symmetric and Skewed Distributions

Symmetric and Skewed Distributions (Cont’d)
Symmetric Distribution

Percentile0 The pth percentile of a distribution is the value such
that p percent of the observation fall at or below it
0 For example:You may have received a standardized test score report that said you were in the 80th percentile. This means that 80% of the people who took the test earned scores that were less than or equal to your score. The remaining 20% are students that earned a higher score than you
Tip: Think of it like your SAT scores, if you are in the 60th percentile, you did better than 60% of the students that also took the SAT.

2. Label and scale your axes and title your graph3.Plot a point corresponding to the relative cumulative frequency in each class interval at the left endpoint of the next class interval
1. Decide on class intervals and make a frequency table, just as in making a histogram. Add three columns to your frequency table: relative, cumulative, and relative cumulative frequency
Ogive0 Also known as a culimative relative frequency0 Helps us understand the relative standing of an
individual observation0 How to construct an Ogive:

Ogive (Cont’d)
Twenty- nine female raccoons were observed and the number of male partners during the time the female was accepting partners (generally 1 to 4 days each year) was recorded for each female
Example:Construct an ogive with the data provided
1 3 2 1 1 4 2 4 1 1 1 3 1 1 1 1 2 2 1 1 4 1 1 2 1 1 1 1 3
0 To get the values for the relative frequency, count the number of times the value appears
0 To fill in the cumulative frequency column, find the % of the data0 For relative cumulative frequency column, add the %’s together

Time Plot
0 A time plot of a variable plots each observation against the time at which it was measured. Always mark the time scale on the horizontal axis and the variable of interest on the vertical axis
0 When examining a time plot, look once again for an overall pattern and for strong deviations form the pattern
0 Trend- a long-term upward or downward movement over time
0 Seasonal variation- a pattern that repeats itself at regular time intervals
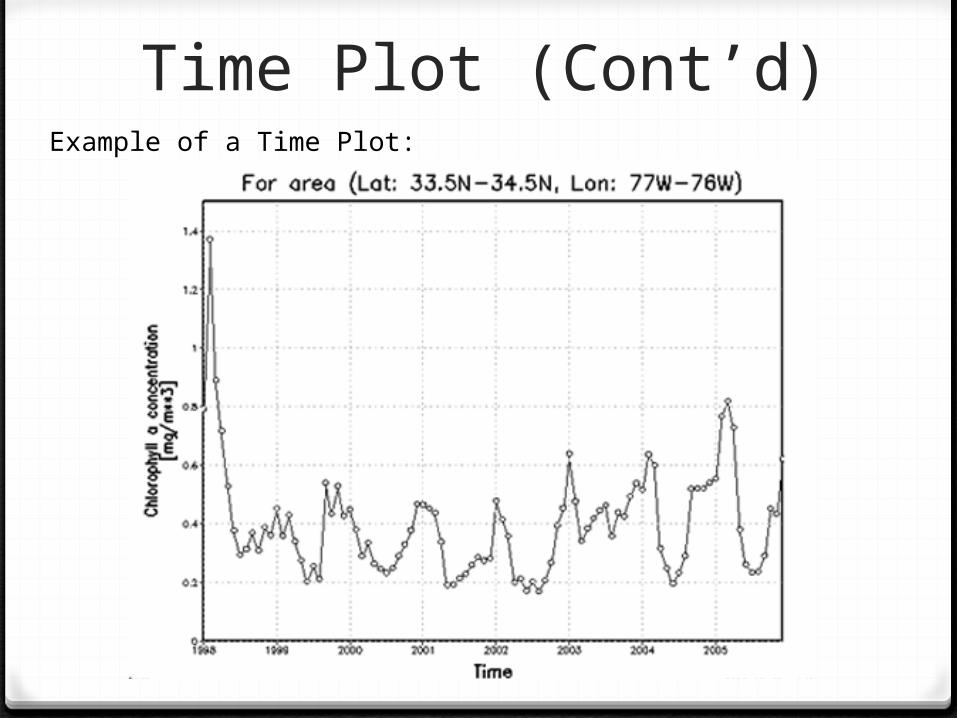
Time Plot (Cont’d)Example of a Time Plot:

Section 1.2 – Describing Distributions with Numbers0 Mean
0 Average of observations0 Median
0 Midpoint of values (Center)0 Inter Quartile Range (IQR)
0 IQR= Q3 – Q10 Outlier
0 Less than Q1 – 1.5 x IQR0 More than Q3 + 1.5 x IQR

The Five Number Summary0 Overall description of a distribution:
0 Min0 Q10 M0 Q30 Max
Example:
22 25 34 |35| 41 41 46 |46| 46 47 49 |54| 54 59 60 Min Q1= 35 M= 46 Q3= 54 Max

IQR and Outlier0 IQR= Q3 – Q1= 54 – 35= 19
0 Finding OutlierQ1 – 1.5 x IQR
35 – 1.5 x 19= -28.5 (Lower cutoff)
Q3 + 1.5 x IQR54 + 1.5 x 19= 82.5 (Upper cutoff)
0 There are no outliers.

Chapter 7Random Variables

Section 7.1 – Discrete and Continuous Random Variables
0 Random variable - a variable whose value is a numerical outcome of a random phenomenon
0 Discrete random variables0 The outcome probabilities must be between 0 and 1 and
have a sum of 1.0 When the outcomes are numerical, they are values of a
random variable.

0 A discrete random variable X has a countable number of possible values.
0 The probability distribution of X lists the values and their probabilities.
Value of X: x₁ x₂ x₃… xk
Probability: p ₁ p ₂ p₃… pk
0 pi has two requirements.
1) The probability of pi has to be a number between 0 and 1.
2) p₁ + p ₂ + … + pk = 1.
Find the probability of any even by adding the probabilities pi of the particular values x that make up the event.

7.1 - Example #10 The instructor of a large class gives 15% each of A’s and D’s,
each of B’s and C’s and 10% F’s. Choose a student at random from this class. To “chose a random” means to give every student the same chance to be chosen. The student’s grade on a four-point scale (A=4) is a random variable X.0 The value of X changes when we repeatedly choose students at
random, but it is always one of 0, 1, 2, 3, or 4.
This is the distribution of X:Grade: 0 1
2 3 4Probability: 0.10 0.15 0.30 0.30 0.15
0 The probability that the student got a B or better is the sum of the probabilities of an A and a B:P(grade is a 3 or 4) = P(X = 3) + P (X = 4)
= 0.30 + 0.15
= 0.45

Probability Histogram
0 We can use histograms to display probability distributions as well as distributions of data.0Probability histograms are used to compare the probability
model for random digits with the model given by Benford’s law (Chapter 6).
0 The height of each bar represent the probabilities.0 They all add to 1.
0 Using histograms help us quickly compare the two distributions.

Continuous Random Variables0 When we use the table of random digits to select a
digit between 0 and 9, the result is a discrete random variable.0 This is one way of assigning probabilities, by using the
random digits table.0However for certain events, it may be impossible because
there are infinitely many possible values.
0 A new way of assigning probabilities to events is to use areas under a density curve.0 The total area of a density curve is exactly 1 underneath
it, corresponding to a total of a probability of 1.0This is important way of assigning probabilities to events.

Continuous Random Variables (Cont’d)
0 A continuous random variable X takes all values in an interval of numbers.
0 The probability distribution of X is described by a density curve.
0 The probability of any event in the area under the density curve and above the values of X that make up the area.
0 The probability model for a continuous random variable assigns probabilities to intervals of outcomes rather than to individual outcome.0 All continuous probability distributions assign probability 0 to every
individual outcome.

Normal Distributions as Probability Distributions
0 Normal distributions are probability distributions.0 This is because density curves describe an assignment of
probabilities.
0 As we know, N(μ, σ), is the shorthand notation for normal distribution. In the language of random variables, if X has the N(μ, σ) distribution, then the standardized variable:
Z= X – μ
σ is a standard normal random variable having the
distribution, N(0, 1).

Section 7.2 – Means and Variances of Random Variables
0 Rules for Variances0 Two random variables X and Y are independent if
knowing that any event involving X alone did or did not occur tells us northing about the occurrence of an event involving Y alone.
0 When random variables are not independent, the variance of their sum depends on the correlation between them as well as on their individual variances.
0 We use ρ, the Greek letter rho, for the correlation between two random variables.
0 The correlation between two independent random variables is zero.

0 Rule 1. If X is a random variable and a and b are fixed numbers, then
σ² +bX = b²ₐ σ²ₓ0 Rule 2. If X and Y are independent ransom variables,
thenσ²x+y = σ²x+σ²yσ²x-y = σ²x+σ²y
0 This is the addition rule for variances of independent random variables.
0 Rule 3. If X and Y have correlation p, thenσ²x+y = σ²x+σ²y + 2ρσxσyσ²x-y = σ²x+σ²y - 2ρσxσy
0 This is the general addition rule for variances of random variables.

Combining Normal Random Variables
0 Any linear combination of independent normal random variables is also normally distributed. That is, if X and Y are independent normal random variables and a and b are any fixed numbers, aX + bY is also normally distributed. In particular, the sum or difference of independent normal random variables has a normal distribution.

7.2 - Example #10 A college uses SAT scores as one criterion for admission. Experience has
shown that the distribution of SAT scores among its entire population of applicants is such that
SAT Math score X µx = 625 σx = 90SAT Verbal score Y μy = 590 σy = 100
What are the mean and standard deviation of the total score X + Y among students applying to this college?
The mean overall SAT score isμx+y = μx + μy = 625 + 590 = 1215
The variance and standard deviation of the total cannot be computed from the information given. SAT verbal and math scores are not independent, because students who score high on one exam tend to score high on the other also. Therefore Rule 2 does not apply and we need to know ρ, the correlation between X and Y, to apply Rule 3.

7.2 - Example #1 (Cont’d)0 Nationally, the correlation between SAT Math and Verbal scores is about ρ = 0.7.
If this is true for these students,σ²x+y = σ²x+σ²y + 2ρσxσy
= (90)² + (100)² + (2)(0.7)(90)(100)= 30,700
The variance of the sum X + Y is greater than the sum of the variances σ²x+σ²y because of the positive correlation between SAT Math scores and SAT Verbal scores. That is, X and Y tend to move up together and down together, which increases the variability of their sum. We find the standard deviation from the variance,
σ²√30,700 = 175

7.2 - Example #20 Zadie has invested 20% of her funds in Treasury bills and 80% in an
“index fund” that represents all U.S. common stocks. The rate of return in an investment over a time period is the percent change in the price during the time period, plus any income received. If X is the annual return on T-bills and Y the annual return on stocks, the portfolio rate of return is
R = 0.2X +0.8YThe returns X and Y are random variables because they vary from year to year. Based on annual returns between 1950 and 2000, we have
X = annual return on T-bills μx = 5.2% σx = 2.9%Y = annual return on stocksμy = 13.3% σy = 17.0%Correlation between X and Y ρ = -0.1
Stocks had higher returns than T-bills on the average, but the standard deviations show that returns on stocks varied much more from year to year. That is, the risk of investing in stocks is greater than the risk for T-bills because their returns are less predictable.

7.2 - Example #2 (Cont’d)0 For the return R on Zadie’s portfolio of 20% T-bills and 80% stocks,
R = 0.2X + 0.8YμR = 0.2μx + 0.8μy = (0.2 x 5.2) + (0.8 x 13.3) = 11.68%
To find the variance of the portfolio return, combine Rule 1 and Rule 3:σ²R = σ²0.2X + σ²0.8Y + 2ρσ0.2Xσ0.8Y = (0.2)²σ²x + 0.8²σ²y + 2ρ(0.2σx)(0.8σy) = (0.2)²(2.9)² + (0.8)²(17.0)² + (2)(-0.1)(0.2 x 2.9)(0.8 x
17.0) = 183.719 σR = √183.719 = 13.55%
The portfolio has a smaller mean return than an all-stock portfolio, but it is also less risky. As a proportion of the all-stock values, the reduction in standard deviation is greater than the reduction in mean return. That’s why Zadie put some funds into Treasury bills.

7.2 Mean and Variances of Random Variables (Continued)
0 Mean x- bar: ordinary average0 Mean of random variable X: an average of possible
values of x.Example: taking X to be the amount your ticket pays you the
probability distribution of X is..
Pay off x: $0 $500
Probability: 0.999 0.001Long run average: $500 1 + $0.999 = $0.50
1000 1000
0 You will often find the mean of a random variable X called the expected value.

Mean of a Discrete Random Variable
The mean of a discrete random variable X is a weighted average of the possible values that the random variable can take. Unlike the sample mean of a group of observations, which gives each observation equal weight, the mean of a random variable weights each outcome xi according to its probability, pi. The common symbol for the mean (also known as the expected value of X) is , formally defined by
The mean of a random variable provides the long-run average of the variable, or the expected average outcome over many observations.
Example: Suppose an individual plays a gambling game where it is possible to lose $1.00, break even, win $3.00, or win $10.00 each time she plays. The probability distribution for each outcome is provided by the following table:
Outcome -$1.00 $0.00 $3.00 $5.00 Probability 0.30 0.40 0.20 0.10
The mean outcome for this game is calculated as follows: = (-1*.3) + (0*.4) + (3*.2) + (10*0.1) = -0.3 + 0.6 + 0.5 = 0.8. In the long run, then, the player can expect to win about 80 cents playing this game -- the odds are in her favor.

0 Continuous random variable X: described by a density curve; variance of a random variable.
0 Mean: A measure of the center of a distribution.0 The Variance of a random variable X is also denoted
by ;σ 2 but when sometimes can be written as Var(X).
0 Variance of a random variable can be defined as the expected value of the square of the difference between the random variable and the mean.
0 Given that the random variable X has a mean of μ, then the variance is expressed as:

Variance of a Discrete Random Variable
0 Discrete random variables are introduced here. The related concepts of mean, expected value, variance, and standard deviation are also discussed.
0 Let X be a numerically valued random variable with expectedvalue µ = E(X). Then the variance of X, denoted by V (X), is
V (X) = E((X − µ)^2)

• Law of a Large Number: Remarkable fact because it holds for any population, not just for some special class such as normal distribution.
• The mean μ of a random variable is the average value of the variable in two senses.
• μ is the average of the possible values, weighted by their probability of occurring.
0 RULE 1: If X is a random variable and A and B are fixed numbers, then
a+b xμ μ0 RULE 2: if X and Y are
random variables then x+y= μ x+yμ
Rules for Means: