ajuste teórico del semivariograma - bienvenidos estimacion... · yseav la matriz de covarianza de...
TRANSCRIPT

Ajuste teórico del semivariograma
1. Mínimos cuadrados2. Métodos basados en la función de
verosimilitud3. Ajuste a Sentimiento

1. Mínimos CuadradosSe toman los valores del semivariograma empírico como variablerespuesta, en función de la distancia h.
h1 h2 . . . hk
h1 h2 . . . hk
∑i1
khi − hi ;2
Requiere :No correlación y homocedasticidad →No se satisfacen
Aunque h presenta menor correlación que h

2. Mínimos cuadrados generalizadosSean h h1 , . . . , hk
′ y
h; h1;, . . . ,hk ,
y sea V la matriz de covarianza de h
La cantidad a minimizar
h − h; ′V−1h − h;
Desventaja: Determinación de V

Propuesta para V asumiendo normalidad
omo 2h ∑i1
nhzsh−zs 2
nh
para cada h y s zs h − Zs2 2 h 12
Diagonal de la matriz U 12
Var zs hj − Zs2 Var2hjU
42hVarU 82hj

CorrZs1 h1 − Zs12;Zs2 h2 − Zs22
CorrZs1 h1 − Zs1;Zs2 h2 − Zs 22
s1−s2h1 s1−s2−h2 −s1−s2h1−h2 −s1−s22h1 .2h2
Nota: Si X1,X2 N20; , donde
82h1 8h1h2
8h1 h2 82h2
entonces CorrX12,X2
2 2

Mínimos Cuadrados ponderadosV DiagVar2hi Diag 82hi;
nhi
De donde la expresión a minimizar queda
2 − 2 ′V−12 − 2
∑i1
knhi
hi hi;
− 12

Máxima Verosimilitud
Supone el conocimiento de la densidadEstimadores sesgados de la varianza y el objetivo en este caso particular son justamente parámetros de ésta.Muestra grandeRequiere inversas de matrices muy grandes (nxn)

De forma general, supongamos que ( )( ),nN X β θΖ ∑∼ , donde
X es una matriz n x (k+1) de rango k+1 < n
( )θ∑ es una matriz n x n tal que ( ) ( ) ( )( )cov ,i jz s z sθ ⎡ ⎤=∑ ⎣ ⎦
que depende de θ a través del modelo que describe la dependencia espacial, ( )2 ;hγ θ , C(h), ρ(h).

Ejemplo: Supongamos que la variable Z es georeferenciada en2 , si x i,yi ;y que su media se puede explicar usando las coordenadas geográficasX, Y y una covariable T. Entonces las matrices necesarias para ajustar elrespectivo modelo de regresión Z X son :
Z
zs1
.
.
.
zsi
.
.
.
zsn
; X
1 x 1 y1 t1
. . . .
. . . .
. . . .
1 x i yi t i
. . . .
. . . .
. . . .
1 x n yn tn
0
1
2
3

La función de Verosimilitud → L, queda
12
n/2 1||
1/2exp − 1
2 Z − XT−1Z − X
La función logverosimilitud → L, queda
− n2 log2 − 1
2 log| | − 12 Z − XT−1Z − X
El negativo de la función logverosimilitud → L, queda
n2 log2 1
2 log| | 12 Z − XT−1Z − X

REMLAplicar Método de Máxima Verosimilitud a A′Z en lugar de Z,donde A es una matriz de contraste de errores.
Ejemplo: Sean
Z
Zs1
Zs2
Zs3
y A
1 0−1 10 −1
A′Z 1 −1 00 1 −1
Zs1
Zs2
Zs3
Zs1 − Zs2
Zs2 − Zs3

A es una matriz de la siguiente forma:
A aij es una matriz n − 1 n con los siguienteselementos
aij
1 para i j, j 1, . . . ,n − 1
−1 para i j 1, j 1, . . . ,n0 en cualquier otra parte
EA′Z 0 y
VarA′Z A′VarZA A′A

La función de Verosimilitud → L, queda
12
n−1/2 1|A ′A |
1/2exp − 1
2 A′Z ′A′A−1A′Z
La función logverosimilitud → L, queda
− n−12 log2 − 1
2 log|A′A| − 12 A
′Z′A′ A−1A′Z
El negativo de la función logverosimilitud → L, queda
n−12 log2 1
2 log|A′A| 12 Z ′AA′A−1A′Z

Verosimilitud Compuesta (pseudoverosimilitud)
Sean Zs1,Zs2, . . . ,Zsn variables aleatorias cuyasdistribuciones marginales son conocidas fZsi ;excepto por .
∑i1
nlnfZsi ; → Verosimilitud Compuesta
CSk ;y∑i1
n∂ lnfZsi;
∂k→Función score compuesta

CS para estimar el semivariogramaVerosimilitud compuesta (pseudoverosimilitud)
Uij Zsi − Zsj → nn−12
Si Zsi N;2 Uij N0;2si − sj;
CS;U ∑i1
n−1∑ji
n∂si−sj;
∂1
42si−sj ;uij
2 − 2si − sj;

Desempeño del método de verosimilitud compuesta
Por no ser una verosimilitud en general, no es eficiente, sin embargo,No hay que invertir matrices de tamaño nxnLas matrices que hay que invertir serán cuadradas y el orden dependerá del número de parámetros del modelo propuesto de semivariogramaProvee muchos datos. Ejemplo si n=100, existirán n(n-1)/2=4950 pares posibles

Método Geoestadístico
Técnicas exploratoriasEstimación de la función media o uso del ajuste de medianasModelar la estructura de dependencia espacial con los residuosPredecir el atributo de interés en ubicaciones no observadas y calcular la media cuadrada de los residuos de la predicción

Predicción Espacial y Kriging
El valor del fenómeno en estudio en cada ubicación s es una variable aleatoriaZ(s) o E[Z(s)]Los métodos de kriging generan predicciones óptimas teniendo en cuenta la estructura de dependencia espacialEl fenómeno varía continuamente en la región, pero se tienen solo n observaciones.

Modelos para datos geoestadísticos
Zs Xs s
EZs Xs
VarZs
Parámetros de la media
Parámetros de dependencia espacial

Ejemplos
Zij i j sisj eij; eij iid0,2
sisj remueve cualquier autocorrelación espacial
Zij i j ij;
ij correlacionados
Dependencia entre i y j es modeladacon el covariograma, correlograma o semivariograma.
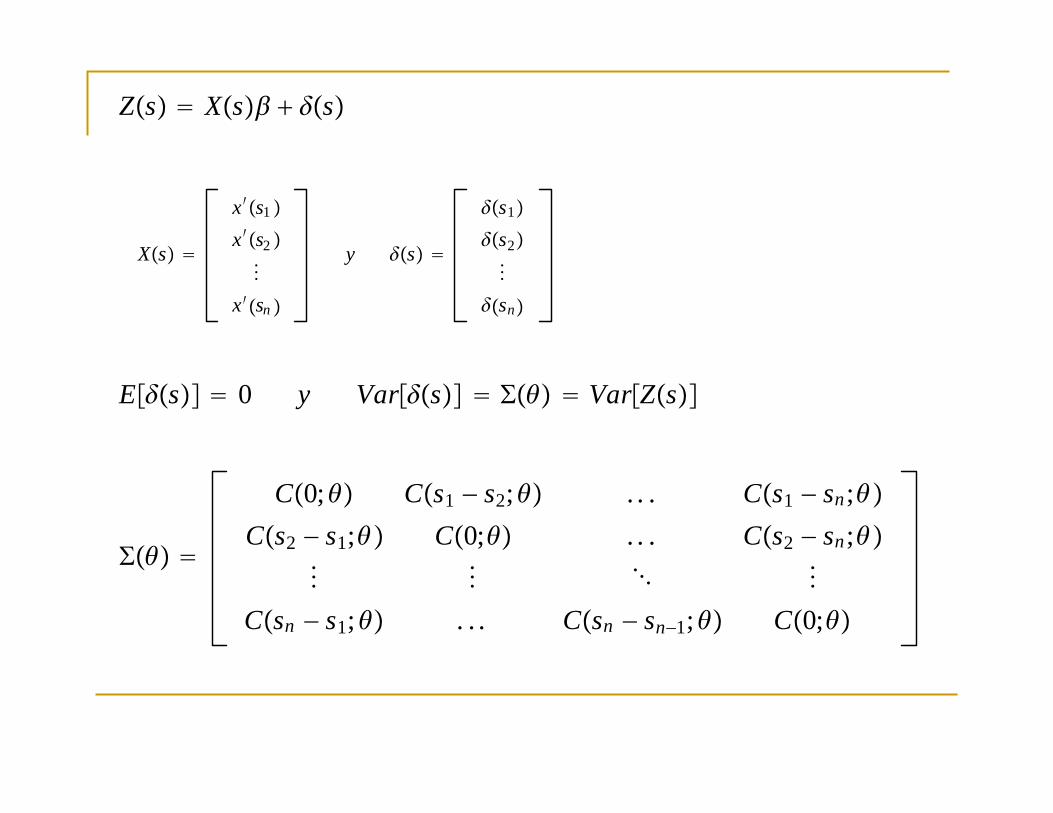
Zs Xs s
Xs
x′s1
x′s2
x′sn
y s
s1
s2
sn
Es 0 y Vars VarZs
C0; Cs1 − s2; . . . Cs1 − sn;Cs2 − s1; C0; . . . Cs2 − sn;
Csn − s1; . . . Csn − sn−1; C0;
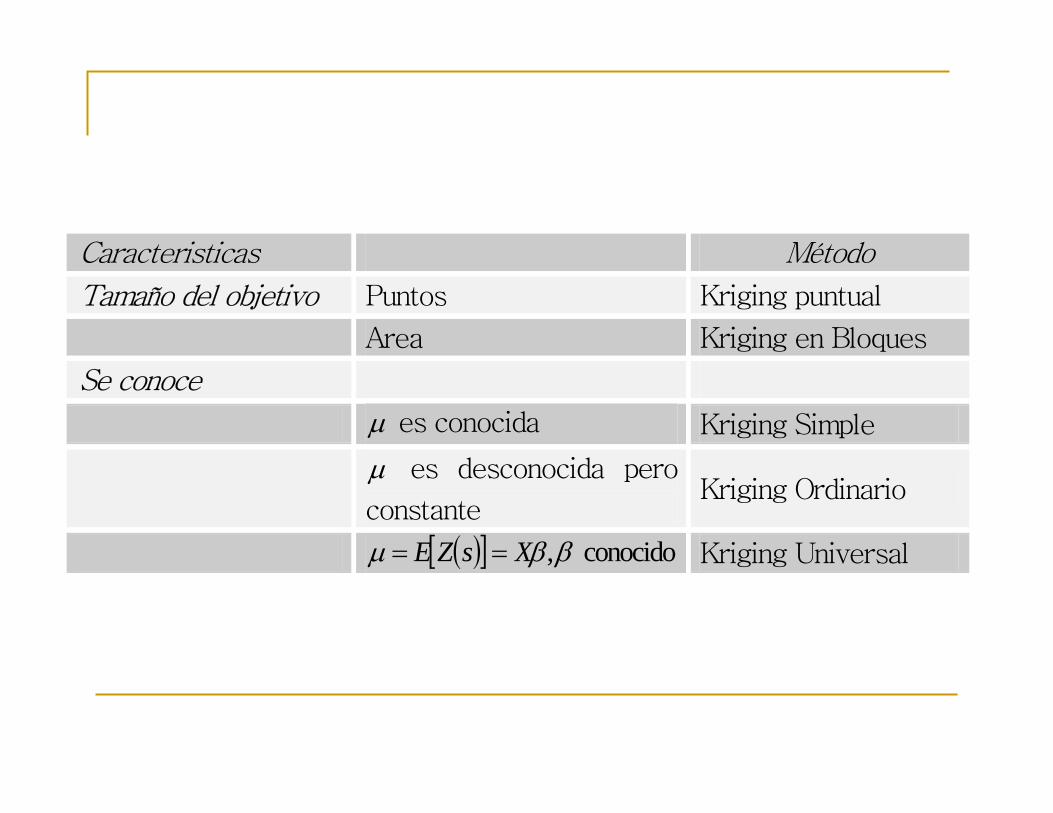
Caracteristicas Método
Tamaño del objetivo Puntos Kriging puntual
Area Kriging en Bloques
Se conoce
µ es conocida Kriging Simple
µ es desconocida pero
constante Kriging Ordinario
( )[ ] conocido ,ββµ XsZE == Kriging Universal


Número de Atributos
Un único atributo Kriging
Múltiples atributos Cokriging
Linealidad
Predictor lineal en Z(s) Kriging
Predictor lineal en
funciones de Z(s) Kriging Disyuntivo

Otro modelo de efecto hueco
h Co Cs 1 − exp− ha Jo 2 h
El valor de controla la magnitud del efecto hueco.
Jo∙ es la función de Bessel de primera clase de
orden cero.
J0x ∑n0
−1n
22nn!Γn1x2n

Funciones de Bessel
Jvx ∑n0
−1n
22nvn!Γnv1x2nv

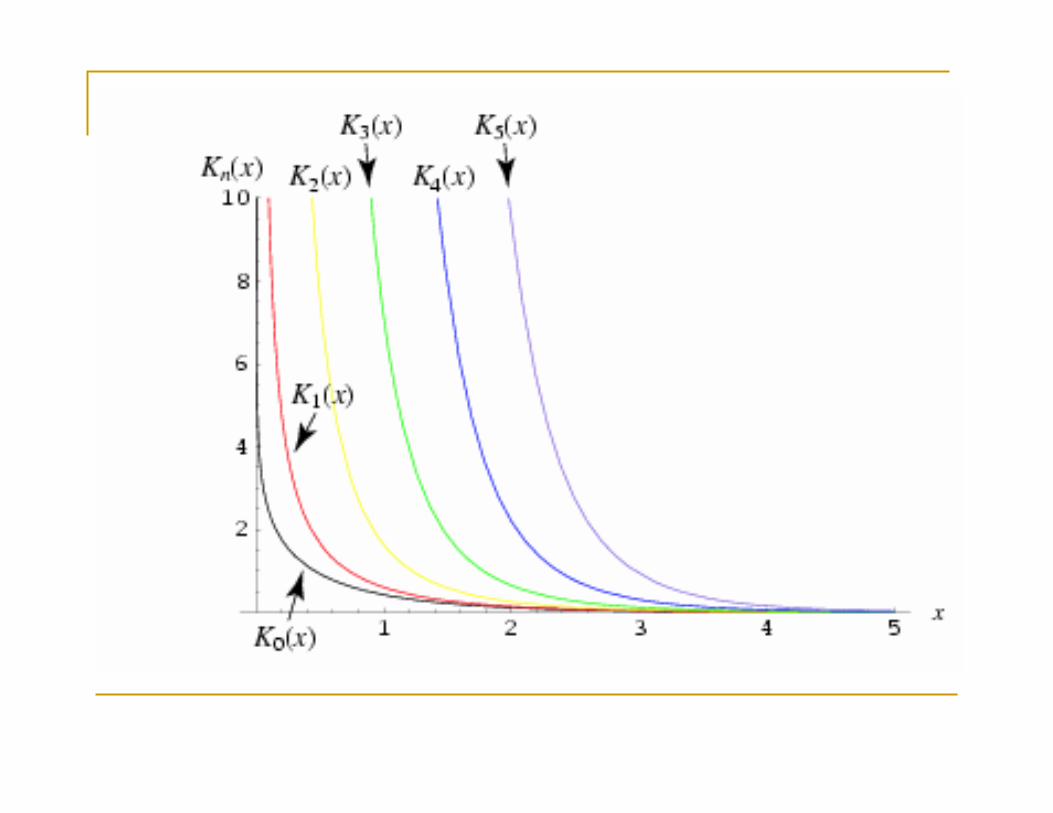
Familia de Correlación de Matérn
h;, 12−1Γ
h
K
h
Donde , son los parámetros y K∙
es la función de Bessel modificadade tercera clase de orden .

Función de Bessel modificada de tercer clase de orden