1 atanasoff–berry computer, built by professor john vincent atanasoff and grad student clifford...
Post on 21-Dec-2015
218 views
TRANSCRIPT

1
Atanasoff–Berry Computer, built by Atanasoff–Berry Computer, built by Professor John Vincent Atanasoff and Professor John Vincent Atanasoff and grad student Clifford Berry in the grad student Clifford Berry in the basement of the physics building at Iowa basement of the physics building at Iowa State College during 1939–42. Binary State College during 1939–42. Binary digits, electronic computation. Clock digits, electronic computation. Clock frequency 60 Hz. (Wikipedia).frequency 60 Hz. (Wikipedia).
See info on ENIAC patent fight.See info on ENIAC patent fight.

2
Homework 1Homework 1 On website later todayOn website later today Due Thu, Feb 12, beginning of classDue Thu, Feb 12, beginning of class

3
COMP 740:COMP 740:Computer Architecture and Computer Architecture and ImplementationImplementation
Montek SinghMontek Singh
Tue, Feb 3, 2009Tue, Feb 3, 2009
Pipelining I: BasicsPipelining I: Basics

4
Reading: Appendix A (HP4)
Lecture OverviewLecture Overview Pipelining Basics Pipelining Basics
Introduction to the concept of pipelined processorIntroduction to the concept of pipelined processor Basic 5-stage pipeliningBasic 5-stage pipelining
What occurs at each stage?What occurs at each stage?Pipeline registersPipeline registersPipelining Load instructionPipelining Load instructionPipelining register-type instructionPipelining register-type instructionPipelining store instructionPipelining store instructionPipelining a branchPipelining a branch

5
A B C D
Pipelining: It’s Natural!Pipelining: It’s Natural!Laundry Example:Laundry Example:
Ann, Brian, Cathy, Dave Ann, Brian, Cathy, Dave each have one load of clothes each have one load of clothes to wash, dry, and foldto wash, dry, and fold
Washer takes 30 minutesWasher takes 30 minutes
Dryer takes 40 minutesDryer takes 40 minutes
Folding takes 20 minutesFolding takes 20 minutes
6
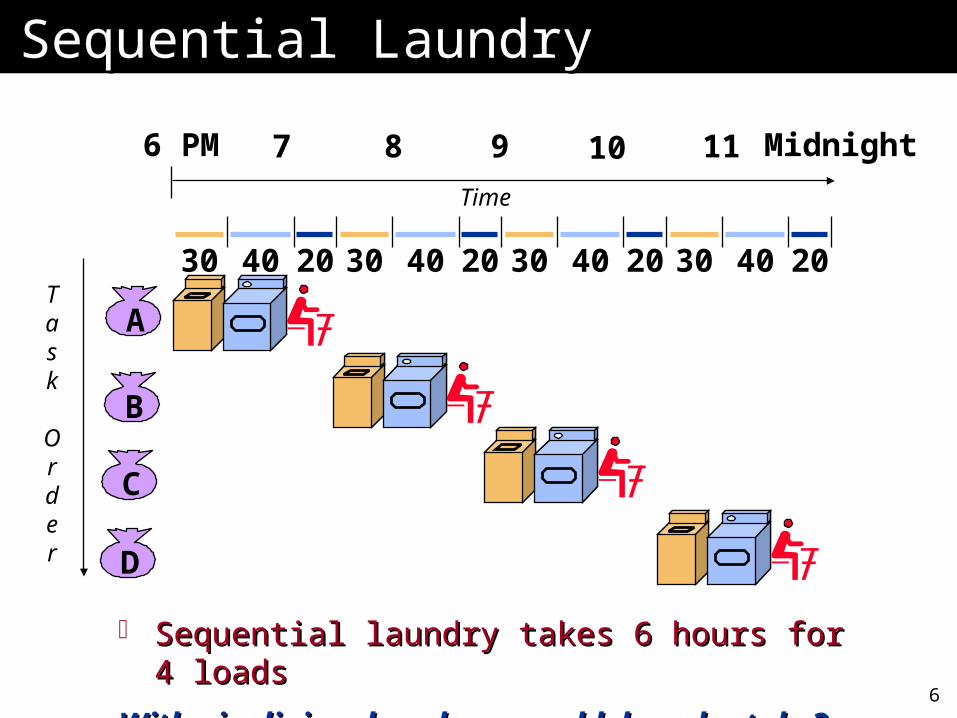
Sequential laundry takes 6 hours for 4 loadsSequential laundry takes 6 hours for 4 loads
With pipelining, how long would laundry With pipelining, how long would laundry take?take?
A
B
C
D
30 40 20 30 40 20 30 40 20 30 40 20
6 PM 7 8 9 10 11 Midnight
Task
Order
Time
Sequential LaundrySequential Laundry
7
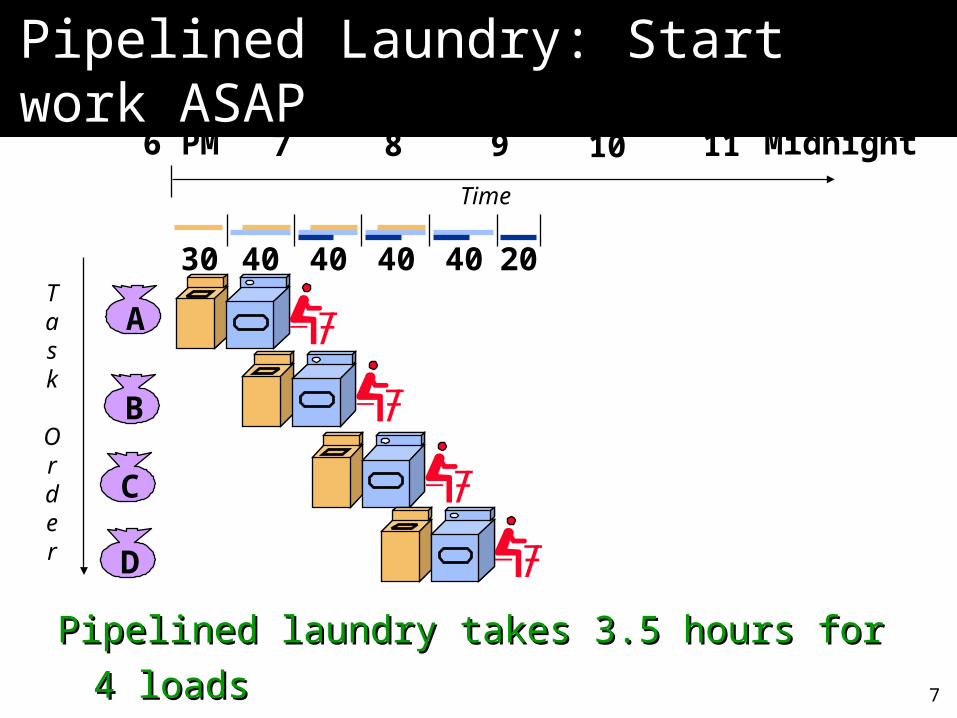
Pipelined laundry takes 3.5 hours for 4 loadsPipelined laundry takes 3.5 hours for 4 loads
A
B
C
D
6 PM 7 8 9 10 11 Midnight
Task
Order
Time
30 40 40 40 40 20
Pipelined Laundry: Start work Pipelined Laundry: Start work ASAPASAP

8
A
B
C
D
6 PM 7 8 9
Task
Order
Time
30 40 40 40 40 20
Pipelining PrinciplesPipelining Principles Pipelining doesn’t help Pipelining doesn’t help
latencylatency of single task, it of single task, it helps helps throughputthroughput of entire of entire workloadworkload
Pipeline rate limited by Pipeline rate limited by slowestslowest pipeline stage pipeline stage
Multiple tasks operating Multiple tasks operating simultaneouslysimultaneously
Potential speedup = Potential speedup = Number pipe stagesNumber pipe stages
Unbalanced lengths of Unbalanced lengths of pipe stages reduces pipe stages reduces speedupspeedup
Time to “fill” pipeline and Time to “fill” pipeline and time to “drain” it reduces time to “drain” it reduces speedupspeedup

9
IfetchIfetch: Instruction Fetch: Instruction Fetch Fetch the instruction from the Instruction MemoryFetch the instruction from the Instruction Memory
Reg/DecReg/Dec: Registers Fetch and Instruction : Registers Fetch and Instruction DecodeDecode
ExecExec: Calculate the memory address: Calculate the memory address MemMem: Read the data from the Data Memory: Read the data from the Data Memory WrBWrB: Write the data back to the register file: Write the data back to the register file
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5
Ifetch Reg/Dec Exec Mem WrBLoad
The Five Stages of a RISC The Five Stages of a RISC InstructionInstruction

10
Example: Load InstructionExample: Load Instruction lw $1, -70($2)lw $1, -70($2)
lw $5, 100($0)lw $5, 100($0)
First field is destination registerFirst field is destination register Last field is source register for computing Last field is source register for computing
addressaddress memory address = register value + offsetmemory address = register value + offset
Note that register 0 is always 0Note that register 0 is always 0

11
Pipelining the LOAD InstructionPipelining the LOAD Instruction
The five independent pipeline stages are:The five independent pipeline stages are: Read next instruction: The Ifetch stageRead next instruction: The Ifetch stage Decode instruction and fetch register values: The Reg/Dec stageDecode instruction and fetch register values: The Reg/Dec stage Execute the operation: The Exec stageExecute the operation: The Exec stage Access data memory: The Mem stageAccess data memory: The Mem stage Write data to destination register: The WrB stageWrite data to destination register: The WrB stage
One instruction enters the pipeline every cycleOne instruction enters the pipeline every cycle The The latencylatency of a single load is still 5 cycles of a single load is still 5 cycles The throughput is much higherThe throughput is much higher
The “effective” CPI for 3 instructions is 7/3 (tends to 1)The “effective” CPI for 3 instructions is 7/3 (tends to 1) Cycle time is ~1/5th the cycle time of unpipelined implementationCycle time is ~1/5th the cycle time of unpipelined implementation One instruction comes out of the pipeline (completed) every cycleOne instruction comes out of the pipeline (completed) every cycle
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7
Ifetch Reg/Dec Exec Mem WrB1st lw
Ifetch Reg/Dec Exec Mem WrB2nd lw
Ifetch Reg/Dec Exec Mem WrB3rd lw

12
Load, Pipelined and NotLoad, Pipelined and Not

13
A Pipelined MIPS DatapathA Pipelined MIPS Datapath
Review: Let’s look at the types of blocksReview: Let’s look at the types of blocks

14
Load, Fetch StageLoad, Fetch Stage
Instruction fetched, PC <- PC+4, new PC savedInstruction fetched, PC <- PC+4, new PC saved

15
lw $1, 0x100 ($2)
PC
= 12
“8”A
dd
er
InstructionMemory
“4”
Instruction
Address
Clk
Ifetch
You are here!
Reg/DecP
C+
4
32
Detailed View Detailed View
Location 8: lw $1, 0x100($2)Location 8: lw $1, 0x100($2)

16
Load, Decode StageLoad, Decode Stage
Immediate field sign extended, regs fetchedImmediate field sign extended, regs fetched
17
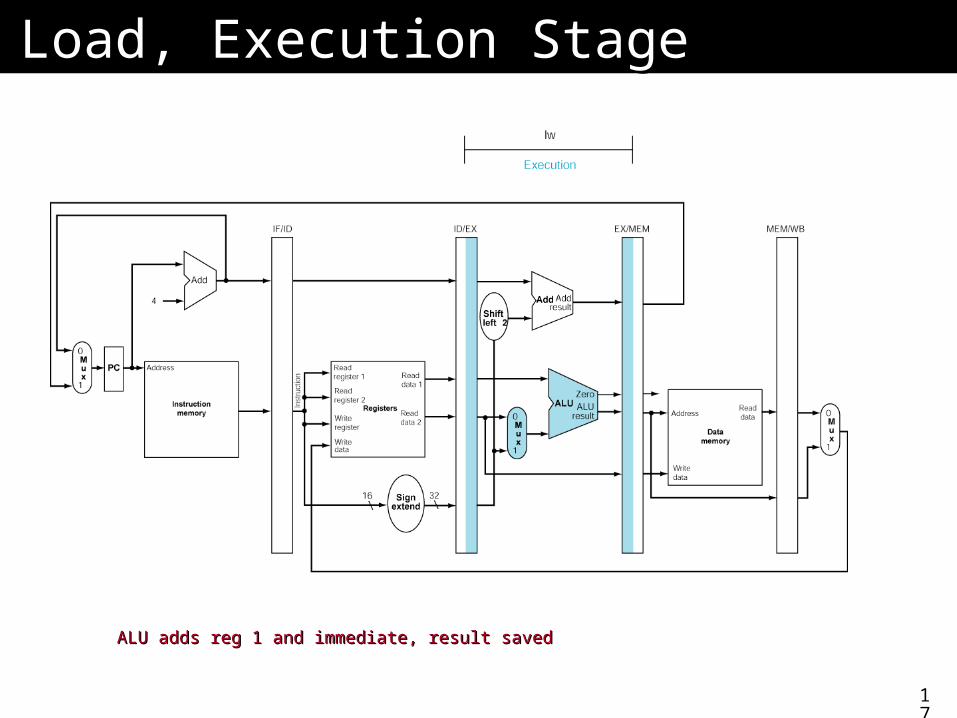
Load, Execution StageLoad, Execution Stage
ALU adds reg 1 and immediate, result savedALU adds reg 1 and immediate, result saved

18
Load, MemoryLoad, Memory
Use address and get data from memoryUse address and get data from memory
19
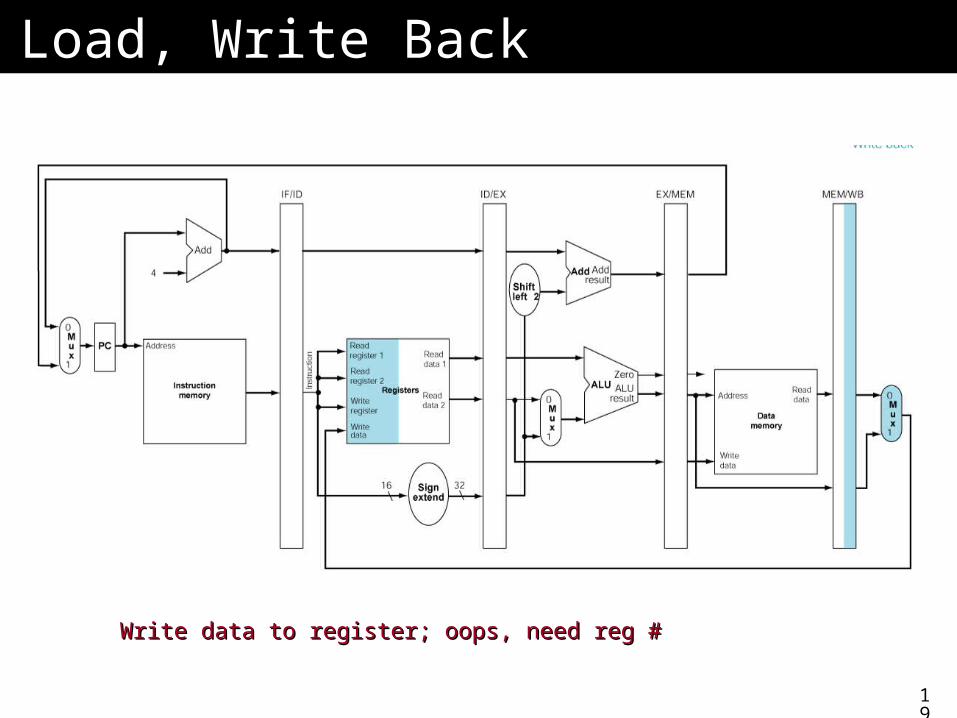
Load, Write BackLoad, Write Back
Write data to register; oops, need reg #Write data to register; oops, need reg #

20
Corrected PipelineCorrected Pipeline

21
e.g.:e.g.: add R1, R2, R3add R1, R2, R3
IfetchIfetch: Instruction fetch: Instruction fetch Fetch the instruction from the instruction memoryFetch the instruction from the instruction memory
Reg/DecReg/Dec: Registers fetch and instruction decode: Registers fetch and instruction decode ExecExec: ALU operates on the two register operands: ALU operates on the two register operands WrBWrB: Write the ALU output back to the register file: Write the ALU output back to the register file
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec WrBR-type
The Four Stages of R-typeThe Four Stages of R-type

22
We have a problem called We have a problem called pipeline conflictpipeline conflict or or hazardhazard 2 instructions try to write to the register file at the same 2 instructions try to write to the register file at the same
time!time! ““Contention for a shared resource” (in OS terminology)Contention for a shared resource” (in OS terminology)
It is no longer meaningful to talk about the execution of It is no longer meaningful to talk about the execution of a single instruction in isolationa single instruction in isolation Execution is inherently concurrent; need to achieve Execution is inherently concurrent; need to achieve
serializabilityserializability
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec Mem WrLoad
Ifetch Reg/Dec Exec WrR-type
Ifetch Reg/Dec Exec WrR-type
OOPS! We have a problem!
Pipelining the R-type and Load Pipelining the R-type and Load InstructionsInstructions

23
Each functional unit can only be used once per Each functional unit can only be used once per instrinstr
Each functional unit must be used at the same Each functional unit must be used at the same stage for all instructionsstage for all instructions Load uses Register File’s Write Port during its 5th Load uses Register File’s Write Port during its 5th
stagestage
R-type uses Register File’s Write Port during its 4th R-type uses Register File’s Write Port during its 4th
stagestage
Ifetch Reg/Dec Exec Mem WrBLoad
1 2 3 4 5
Ifetch Reg/Dec Exec WrBR-type
1 2 3 4
How to resolve this pipeline hazard?
Important ObservationsImportant Observations

24
Clock
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9
Ifetch Reg/Dec Mem WrBR-type
Ifetch Reg/Dec Mem WrBR-type
Ifetch Reg/Dec Exec Mem WrBLoad
Ifetch Reg/Dec Mem WrBR-type
Ifetch Reg/Dec Mem WrBR-type
Exec
Exec
Exec
Exec
Ifetch Reg/Dec Exec WrR-type Mem
1 2 3 4 5
Solution: Delay R-type’s Write by 1 Solution: Delay R-type’s Write by 1 CycleCycle Delay R-type’s register write by one cycle:Delay R-type’s register write by one cycle:
Now R-type instrs also use Reg File’s write port at Now R-type instrs also use Reg File’s write port at Stage 5Stage 5
Mem stage is a NO-OP stage: nothing is being doneMem stage is a NO-OP stage: nothing is being done

25
IfetchIfetch: Instruction fetch: Instruction fetch Fetch the instruction from the instruction memoryFetch the instruction from the instruction memory
Reg/DecReg/Dec: Registers fetch and instruction : Registers fetch and instruction decodedecode
ExecExec: Calculate the memory address: Calculate the memory address MemMem: Write the data into the data memory: Write the data into the data memory
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec MemStore WrB
The Four Stages of StoreThe Four Stages of Store

26
Third Stage of StoreThird Stage of Store
Very similar to load, save reg contents to be written to memVery similar to load, save reg contents to be written to mem

27
(NOTE: This is a slow/unoptimized branch; will cover faster branching later)(NOTE: This is a slow/unoptimized branch; will cover faster branching later)
IfetchIfetch: Instruction fetch: Instruction fetch Fetch the instruction from the instruction memoryFetch the instruction from the instruction memory
Reg/DecReg/Dec: Registers fetch and instruction decode: Registers fetch and instruction decode ExecExec: ALU compares the two register operands: ALU compares the two register operands
Adder calculates the branch target addressAdder calculates the branch target address MemMem: If the registers compared in Exec stage are : If the registers compared in Exec stage are
equalequal Write the branch target address into the PCWrite the branch target address into the PC
Cycle 1 Cycle 2 Cycle 3 Cycle 4
Ifetch Reg/Dec Exec MemBeq WrB
The Four Stages of BeqThe Four Stages of Beq

28
Each instruction has 5 stages: Each instruction has 5 stages:
Five independent functional units to work on each stageFive independent functional units to work on each stage
Each functional unit is used only once!Each functional unit is used only once! A second instr can start doing Ifetch as soon as the first A second instr can start doing Ifetch as soon as the first
finishes its Ifetch stagefinishes its Ifetch stage Each instr still takes five cycles to completeEach instr still takes five cycles to complete
The The latencylatency of a single instr is still 5 cycles of a single instr is still 5 cycles The The throughputthroughput is much higher is much higher
CPI approaches 1 CPI approaches 1 Cycle time is ~1/5th the cycle time of the single-cycle Cycle time is ~1/5th the cycle time of the single-cycle
implementationimplementation Instructions start executing before previous instructions Instructions start executing before previous instructions
complete executioncomplete execution
Ifetch Reg/Dec Exec Mem WrB
Key Ideas Behind Instruction Key Ideas Behind Instruction PipeliningPipelining
CPI Cycle time

29
Next TimeNext Time HazardsHazards
Complications that arise due to dependencies Complications that arise due to dependencies between instructions, or disruptions to linear flow of between instructions, or disruptions to linear flow of executionexecution

30
Readings/ReferencesReadings/References The undergrad book by Patterson and The undergrad book by Patterson and
Hennessy (Computer Organization and Design) Hennessy (Computer Organization and Design) has a detailed description of pipelininghas a detailed description of pipelining