1 alae: accelerating local alignment with affine gap exactly in biosequence databases xiaochun yang,...
TRANSCRIPT

1
ALAE: Accelerating Local Alignment with Affine Gap Exactly in Biosequence Databases
Xiaochun Yang, Honglei Liu, Bin Wang
Northeastern University, China

2
Local Alignment
Similar over short conserved regions Dissimilar over remaining regions
Applications Comparing long stretches of anonymous DNA Searching for unknown domains or motifs within proteins
from different families …

3
Related Work
Smith-Waterman algorithm (1981) An exact approach but very slow Not used for search
BLAST: an efficient but approximate approach OASIS: an exact approach and efficient only for short
query sequences (less than 60 characters) BWT-SW: an exact approach but inefficient
Our target An efficient and exact approach: ALAE (Accelerating Local
Alignment with affine gap Exactly)
4
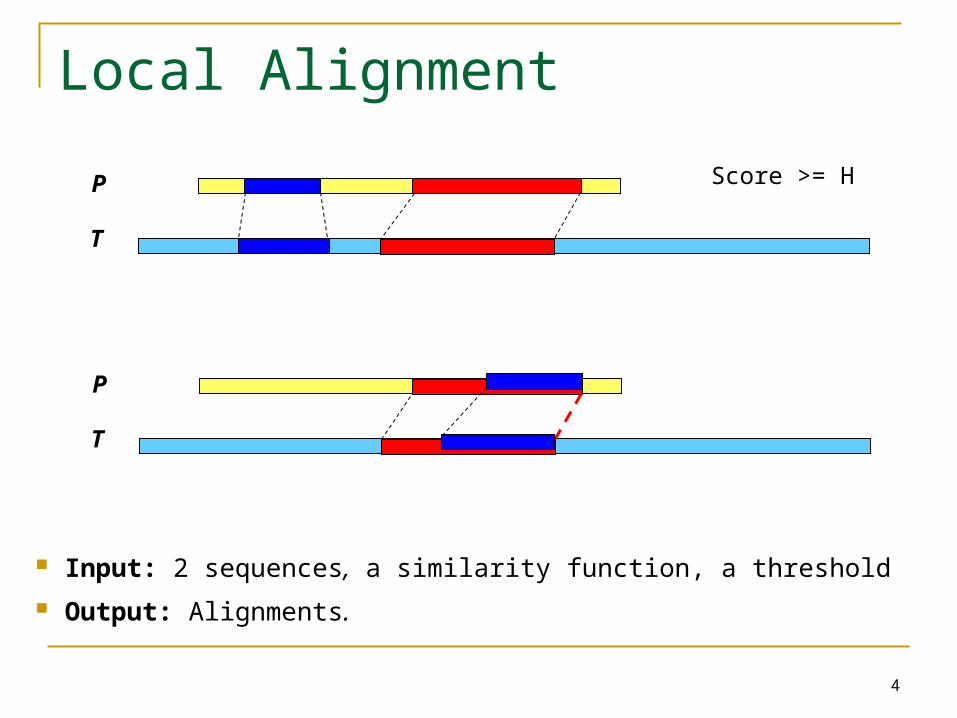
Local Alignment
Input: 2 sequences, a similarity function, a threshold
Output: Alignments.
T
P Score >= H
T
P

5
Measure Similarity Scoring scheme <sa, sb, sg, ss>
An identical mapping: positive score sa
A mismatch: negative score sb
Gap: negative score sg + r×ss
TGCGC-ATGGATTGACCGATGCGCCATTGAT--ACCGA
sim(S1,S2) = 15×1 + (-3) + (-2-1) + (-2 + 2 ×(-1)) = 5
S1:
S2:
Scoring scheme: <1, -3, -2, -1>
Gap opening penalty Gap extension penalty

6
A Basic Approach
T
P
X …
i
The best alignment score of X[1,i] and any substring of P ending at position j.
j

7
A DP Algorithm

8
An Example of a DP MatrixP = GCTAG, T = AAAGCTA. Scoring scheme = <1,-3,-5,-2>
Ga
Gb
-2-5-2
-2 -5-2

9
A Basic Approach
P
> H
Suffix of T
t2 j
i2
T i = i1+t1 = i2+t2
P
> H
Suffi x o f T
j
i1
Tt1
> Hi
jP
4
66
T
P
i
j

10
Challenges Speed
Each matrix contains m ~ m×n entries n matrixes How to avoid calculating most of entries
without impairing the accuracy of the alignment results?
In-memory algorithm Long sequences: both T and P are long

11
Contributions Speed
Prune unnecessary calculations Avoid duplicate calculations
In-memory algorithm Use compressed suffix array
Mathematical analysis

12
Outline
Local filterings Global filtering Reusing calculations A hybrid algorithm

13
Local filterings Length Filtering
P
> H
Suffix of T
j
i1
Tt1
Pruned

14
Local filterings Score Filtering
P
> H
Suffix of T
j
i1
Tt1
Pruned

15
Local filterings q-Prefix Filtering
PrunedPruned
Simpler function

16
Comparison of Calculating One MatrixP=G1C2T3A4A5G6C7T8A9A10G11C12T13G14C15
X=G1C2T3A4A5G6C7T8A9G10T11Scoring scheme <1, -3, -5, -2>H=3
P
G C T A A G C T A A G C T G C
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
G -7 1 -3 -3 -3 -3 1 -3 -3 -3 -3 1 -3 -3 1 -3
C -9 -6 2 -5 -6 -6 -6 2 -5 -6 -6 -6 2 -5 -6 2
T -11 -8 -5 3 -4 -6 -8 -5 3 -4 -6 -8 -5 3 -4 -5
A -13 -10 -7 -4 4 -3 -5 -7 -4 4 -3 -5 -7 -4 0 -7
A -15 -12 -9 -6 -3 5 -2 -4 -6 -3 5 -2 -4 -6 -7 -3
X G -17 -14 -11 -8 -5 -2 6 -1 -3 -5 -2 6 -1 -3 -5 -7
C -19 -16 -13 -10 -7 -4 -1 7 0 -2 -4 -1 7 0 -2 -4
T -21 -18 -15 -12 -9 -6 -3 0 8 1 -1 -3 0 8 1 -1
A -23 -20 -17 -14 -11 -8 -5 -2 1 9 2 0 -2 1 5 -2
G -25 -22 -19 -16 -13 -10 -7 -4 -1 2 6 3 -3 -1 2 2
T -27 -24 -21 -18 -15 -12 -9 -6 -3 0 -1 3 0 -2 -4 -1

17
Comparison of Calculating One MatrixP=G1C2T3A4A5G6C7T8A9A10G11C12T13G14C15
X=G1C2T3A4A5G6C7T8A9G10T11Scoring scheme <1, -3, -5, -2>H=3
P
G C T A A G C T A A G C T G C
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
G -∞ 1 -∞ -∞ -∞ -∞ 1 -∞ -∞ -∞ -∞ 1 -∞ -∞ 1 -∞
C -∞ -∞ 2 -∞ -∞ -∞ -∞ 2 -∞ -∞ -∞ -∞ 2 -∞ -∞ 2
T -∞ -∞ -∞ 3 -∞ -∞ -∞ -∞ 3 -∞ -∞ -∞ -∞ 3 -∞ -∞
A -∞ -∞ -∞ -∞ 4 -∞ -∞ -∞ -∞ 4 -∞ -∞ -∞ -∞ -∞ -∞
A -∞ -∞ -∞ -∞ -∞ 5 -∞ -∞ -∞ -∞ 5 -∞ -∞ -∞ -∞ -∞
X G -∞ -∞ -∞ -∞ -∞ -∞ 6 -∞ -∞ -∞ -∞ 6 -∞ -∞ -∞ -∞
C -∞ -∞ -∞ -∞ -∞ -∞ -∞ 7 -∞ -∞ -∞ -∞ 7 -∞ -∞ -∞
T -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ 8 1 -∞ -∞ -∞ 8 -∞ -∞
A -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ 1 9 2 -∞ -∞ 1 5 -∞
G -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ 2 6 3 -∞ -∞ 2 -∞
T -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ -∞ 3 -∞ -∞ -∞ -∞

18
Outline
Local filterings Global filtering Reusing calculations A hybrid algorithm

19
Global Filtering
P
> H
Suffix of T
t2 j
i2
T
i = i1+t1 = i2+t2
P
> H
Suffi x o f T
j
i1
Tt1
> Hi
jP4
6
6
Pruned

20
Global Filtering
Pruned fork areas
Using X’: Alignment score >= Sa
It is unnecessary to calculate the fork area in the matrix of X and P
Question:Safely avoid calculating based on calculated matrixes?

21
Global Filtering
X’
Update and check unnecessary calculations on-the-fly
Scoring scheme<1, -3, -5, -2>
Boolean matrix
X
(1) Space consuming: m×n space(2) Calculation order

22
Global Filtering
X’ X
q-prefix domination
X’ dominates X

23
Global Filtering
X’ X
q-prefix domination
X’ dominates X
Text T Constructing dominations offline in O(n) time
Query P Check useless calculations on-the-fly
t
Calculation order is unnecessary.

24
Outline
Local filterings Global filtering Reusing calculations A hybrid algorithm
25
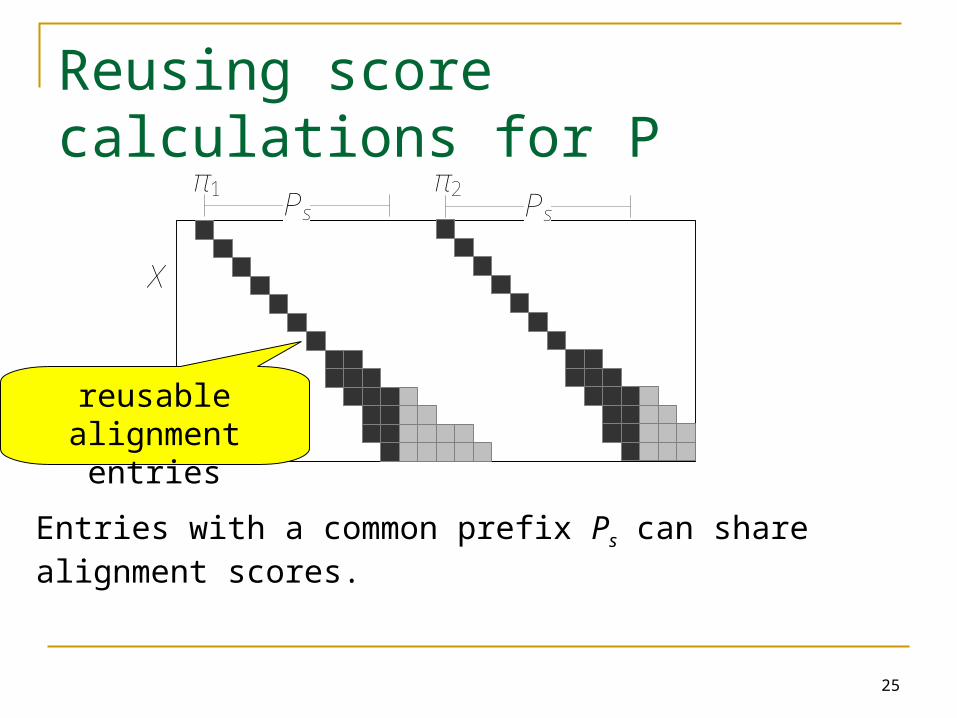
Reusing score calculations for P
π1Ps
π2Ps
X
Entries with a common prefix Ps can share alignment scores.
reusable alignment entries

26
Reusing score calculations for P
j1Ps
j2Ps
XFGOE FGOE
i
π1 π2
reusable alignment entries
If two forks have equivalent scores for their FGOEs, their entries with common substring Ps can share alignment scores.

27
Outline
Local filterings Global filtering Reusing calculations A hybrid algorithm
28
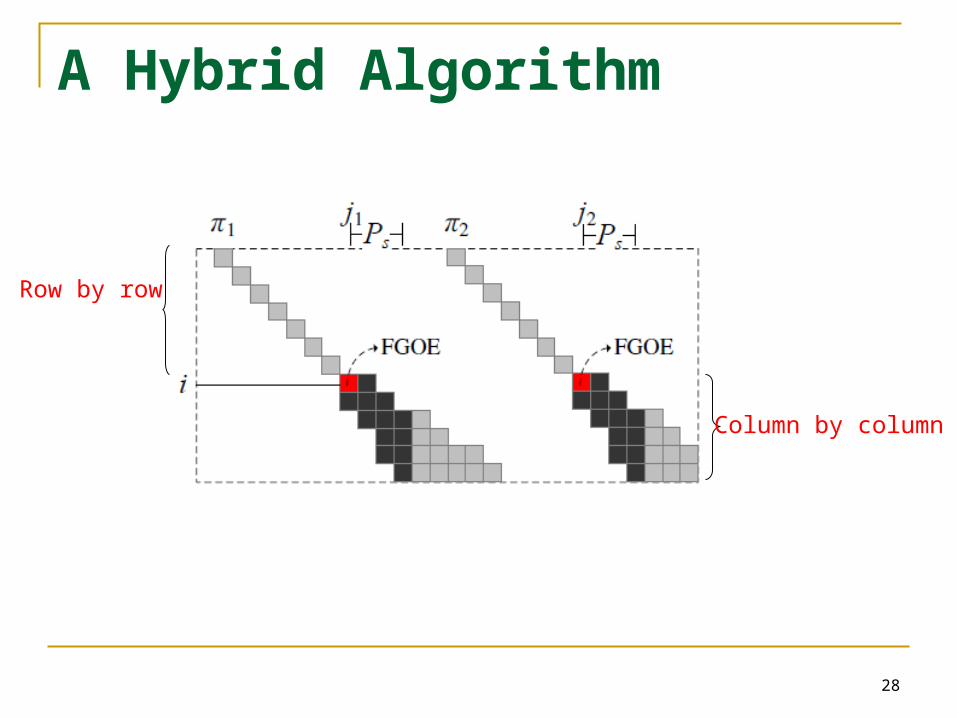
A Hybrid Algorithm
Row by row
Column by column

29
Mathematical Analysis
Upper bound on the number of calculated entries for representative scoring schemes specified by BLAST ( http://blast.ncbi.nlm.nih.gov/Blast.cgi) DNA: 4.50mn0.520 ~ 9.05mn0.896
Proteins: 8.28mn0.364 ~ 7.49mn0.723

30
Experiments Data sets
Human genome data set Length of a text: 50 million ~ 1 billion.
Mouse genome data set Length of each query: 1 thousand ~ 1 million.
Protein data set Length of a text: 10 million ~ 50 million. Length of each query: 200 ~ 100,000.
E-value: threshold Scoring scheme: the same parameters as BLAST
Environment:GNU C++, Intel 2.93GHz Quad Core CPUi7 and 8GB memory with a 500GB disk, running a Ubuntu (Linux) operating system.
31
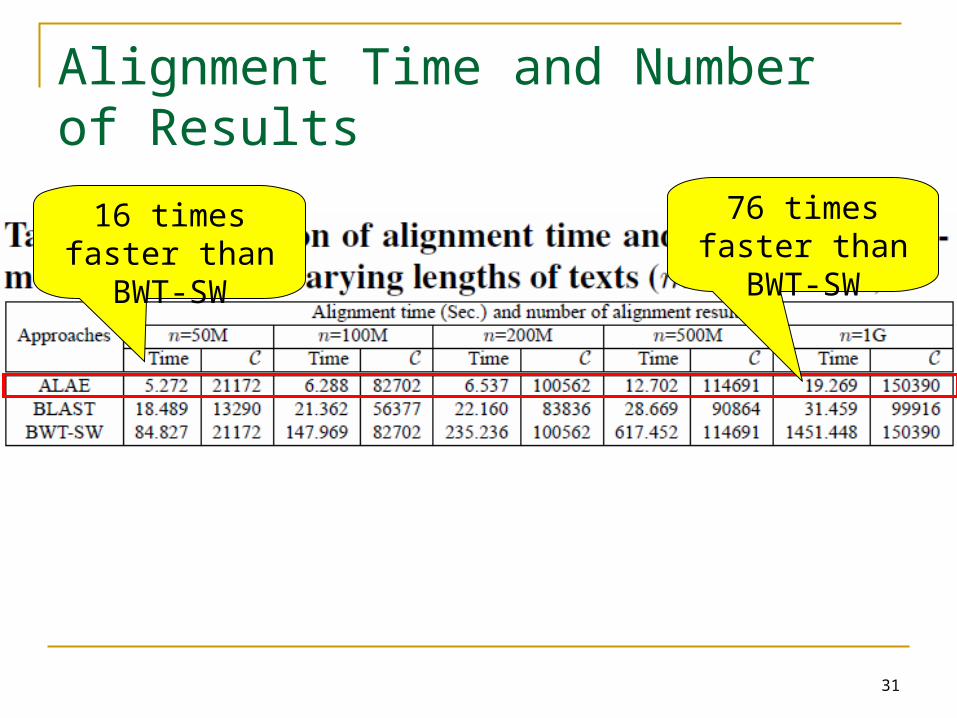
Alignment Time and Number of Results
76 times faster than BWT-SW
16 times faster than BWT-SW

32
Filtering Ratio

33
Reusing Ratio

34
Index Size

35
Conclusions
High efficiency of ALAE Improves BWT-SW significantly Accelerates BLAST for most of the scoring schemes
In-memory approach using compressed suffix array
Mathematical analysis Upper bound on calculated entries

36
Thank you!
Source code to be available at http://faculty.neu.edu.cn/yangxc/project

37
Simulating Searches Using Compressed Suffix Array Match a q-length substring in text
Identify forks Find occurrences of a substring in text
Calculate end positions of alignments Get all suffixes with the same prefix as Xq

38
X = GC
Positions of GC in TSA[4] = 5SA[5] = 1
Review of Compressed Suffix ArrayT = G1C2T3A4G5C6
T’ = G1C2T3A4G5C6$7
Conceptual matrix
G C T A G C $C T A G C $ GT A G C $ G CA G C $ G C TG C $ G C T AC $ G C T A G$ G C T A G C
BTW = CTGGA$C
$ G C T A G CA G C $ G C TC $ G C T A GC T A G C $ GG C $ G C T AG C T A G C $T A G C $ G C
7462513
SA[0,6]

39
X = GC P-1 = CG
Positions of CG in T-1
SA[2] = 2SA[3] = 6
Therefore,Positions of GC in TSA[2]-|X|+1 = 1SA[3]-|X|+1= 5
Compressed Suffix Array – reverse T to T-1T = G1C2T3A4G5C6
T’ = $0G1C2T3A4G5C6
Conceptual matrix
C G A T C G $G A T C G $ CA T C G $ C GT C G $ C G AC G $ C G A TG $ C G A T C$ C G A T C G
BTW = GGT$CCA
$ C G A T C GA T C G $ C GC G $ C G A TC G A T C G $G $ C G A T CG A T C G $ CT C G $ C G A
0426153
SA[0,6]
T-1 = C6G5A4T3C2G1$0

40
Align Distinct Substring in T with P
T
P
X …
i v
j
v v

41
Alignment Time
T = 50 million characters P = 10 thousand characters
Smith-Waterman algorithm 7.7 hours
ALAE 25 ms