ziip capacity planning
TRANSCRIPT


© 2015 IBM Corporation2
Abstract
zIIP Capacity Planning tends to be neglected - in favour of General-Purpose Engines (GCPs). With recent enhancements to DB2 allowing you to offload critical CPU to zIIPs, and to get the most out of zAAP-on-zIIP, it's time to take zIIP Capacity Planning seriously.
This presentation describes how to do zIIP Capacity Planning properly - with instrumentation and guidelines.

© 2015 IBM Corporation3
If You Only Remember 3 4 Things
Capacity Planning for zIIPs has become much more important
Pay especial attention to what % Busy represents “full”
Measure zIIP potential and usage down to the address space level
Consider LPAR configuration carefully for zIIPs

© 2015 IBM Corporation4
Why People Don't Do zIIP Capacity Planning
zIIPs are much cheaper than general purpose processors (GCPs)– Maintenance cost lower also
zIIPs don't attract a software bill
zIIP Utilization hasn't historically been all that high
zIIP-eligible work can spill to GCPs at a pinch
zIIPs are sometimes not the most carefully considered part of a purchase
Ignoring zIIPs, ICFs, IFLs, zAAPs simplifies things to a single processor pool

© 2015 IBM Corporation5
But consider
Spilling to a GCP costs money
Not spilling to a GCP can cost performance & scalability
zIIPs aren't free
Shoving another processor book in can be difficult or impossible– And at end of processor life upgrades become impossible
More software that exploits zIIP installed– Some more performance-critical than previous exploiters
New and modernised applications increasingly use zIIP
LPAR configuration for zIIPs affects their performance

© 2015 IBM Corporation6
Recent News
zAAP On zIIP– Even with zAAPs installed
New 2 : 1 zIIP : GCP configuration rule with z13, zEC12 and zBC12 processors
DB2 Version 10 Deferred Write and Prefetch Engines
DB2 Version 11 further exploiters
z13 zIIP SMT

© 2015 IBM Corporation7
DB2 Version 10 Deferred Write And Prefetch Engines
Substantial portion of DBM1 address space CPU– Changed by APAR PM30468 from MSTR address space
100% eligible for zIIP
Very stringent performance requirements– Must not be delayed– Latency to cross over to GCP generally too high
Substantially changes zIIP Capacity Planning rules
Treat DBM1 as a key address space and protect its access to CPU, including zIIP

© 2015 IBM Corporation8
Why Protect DB2 System Address Spaces From Being Pre-empted?
MSTR contains the DB2 system monitor task – Requires aggressive WLM goal to monitor CPU stalls & virtual storage constraints
DBM1 manages DB2 threads & critical for local DB2 latch & cross-system locking negotiation
– Any delay in negotiating a critical system or application resource (e.g. P-lock on a space map page) can lead to a slowdown of the whole DB2 data sharing group
DIST & WLM-managed stored procedure AS only run the DB2 service tasks– i.e. work performed for DB2 not attributable to a single user– Classification of incoming workload, scheduling of external stored procedures, etc.– Typically means these address spaces place a minimal CPU load on the system
• BUT… they do require minimal CPU delay to ensure good system wide performance– The higher CPU demands to run DDF and/or SP workloads are controlled by the WLM
service class definitions for the DDF enclave workloads or the other workloads calling the SP
• Clear separation between DB2 services which are long-running started tasks used to manage the environment and transaction workloads that run and use DB2 services

© 2015 IBM Corporation9

© 2015 IBM Corporation10
So Let's Take This Seriously...

© 2015 IBM Corporation11
Many Sources Of Information
From RMF:– SMF 70 – SMF 72-3
From z/OS:– SMF 30
From middleware:– SMF 101 DB2 Accounting Trace– SMF 110 CICS Statistics Trace

© 2015 IBM Corporation12
With RMF data you can ... see zIIP Pool Busy

© 2015 IBM Corporation13

© 2015 IBM Corporation14
...break down by LPAR

© 2015 IBM Corporation15

© 2015 IBM Corporation16
...drive down to the Service Class level
(Slide is for zIIP on GCP)
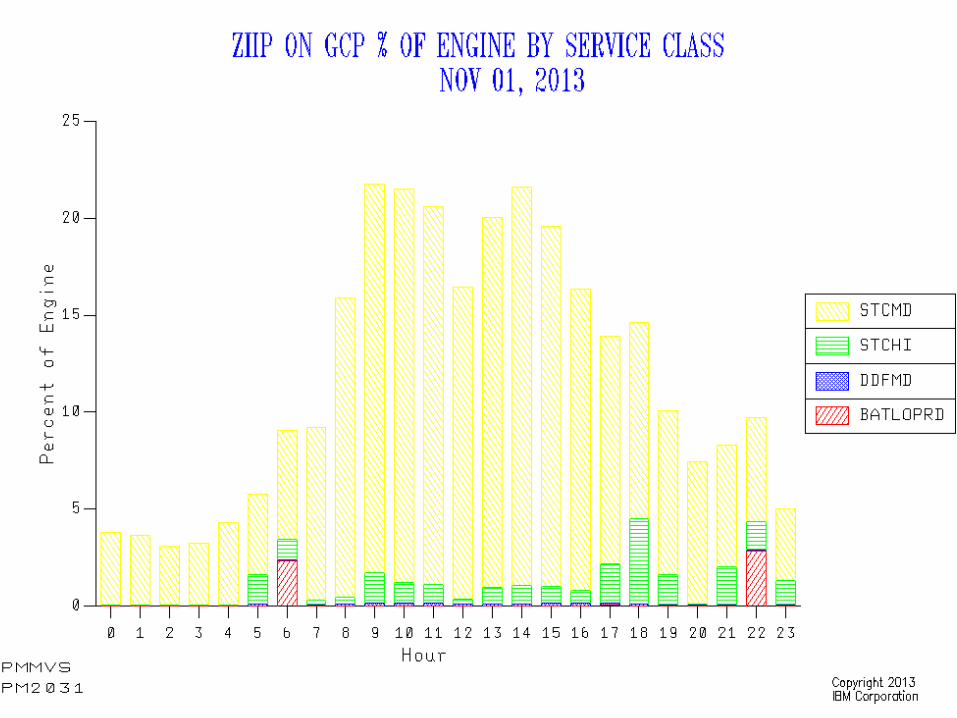
© 2015 IBM Corporation17

© 2015 IBM Corporation18
Service Class (Period) Information
For Velocity Goal service class periods you get samples...
For work that's not zIIP eligible you get e.g. Using and Delay samples for CPU and I/O– These are the sample counters that affect the velocity calculation:
Velocity % = 100 x Using / (Using + Delay)
With zIIP-eligible work you get better resolution – as you get Using and Delay samples specific to zIIP
Useful to correlate Delay for zIIP with % zIIP on GCP– Can explain behaviour

© 2015 IBM Corporation19

© 2015 IBM Corporation20
Understanding Your Exploiters
Exploiters come in different shapes and sizes– And leave “footprints” accordingly
Dependent Enclave– e.g. DBM1 Prefetch / Deferred Write
Independent Enclave– e.g. DDF
zAAP-on-zIIP– Formerly zAAP-eligible e.g. Java
e.g. Dependent Enclave for DBM1 Address Space is Performance Critical from DB2 Version 10

© 2015 IBM Corporation21
Understanding Your Exploiters ...
Table summarised over several hours. You probably need peak 15 – 30 mins
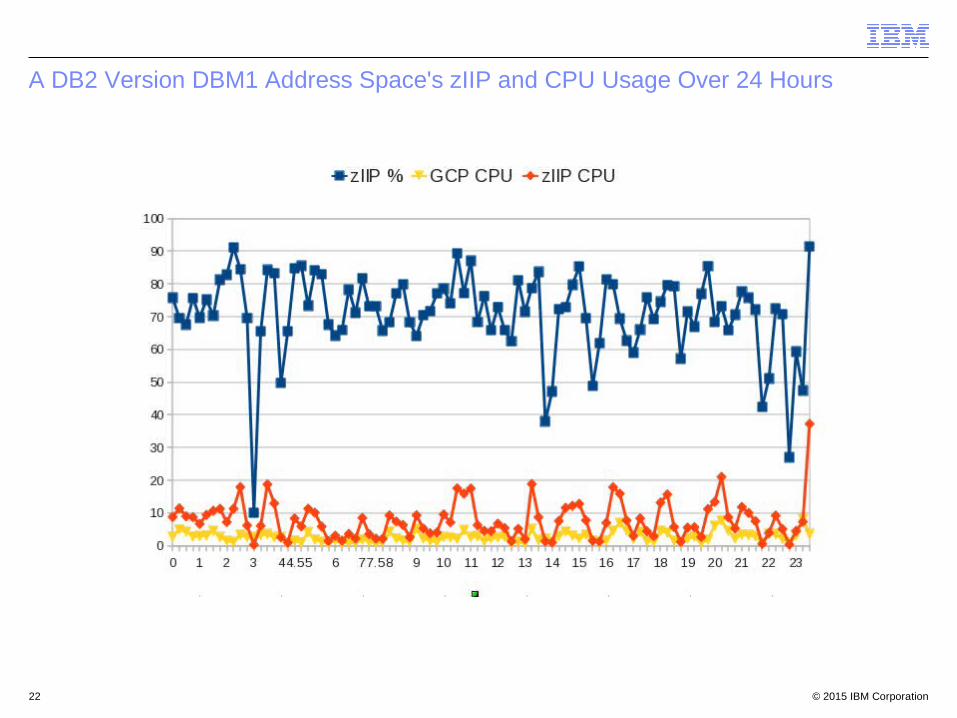
© 2015 IBM Corporation22
A DB2 Version DBM1 Address Space's zIIP and CPU Usage Over 24 Hours

© 2015 IBM Corporation23
Projections
Projecting Near-Term zIIP CPU Requirements:
– For existing workloads that don't run on a zIIP:• “Project CPU” reports how much CPU is zIIP-eligible via RMF• DB2 V9 Specific: Coarse Upper Bound on V10 zIIP-eligible is all DBM1 CPU
– For workloads that don't exist yet use any sizing guidelines you can get
– Some “adaptive exploiters” exist:• These only try to use zIIP if one configured• “Project CPU” will show zero
Projecting Into The Future– The same as standard CPU Capacity Planning

© 2015 IBM Corporation24
zIIP “Short Engine” Effect LPAR Configuration is important
LPARs with low zIIP usage sharing a zIIP– Especially with a low weight
Potential high latency in logical zIIP being dispatched– If other LPARs have the zIIP
In multiple zIIP case Hiperdispatch can help– “Corrals” work into fewer logical ( & physical) zIIPs– But e.g. 1-Way Queuing regime has unhelpful characteristics
Of especial concern:– Single zIIP LPAR with low weight and only “DBM1 Engines” exploiter– Consider not configuring the zIIP to the LPAR

© 2015 IBM Corporation25
zIIP To GCP Ratios
What's most important is how the zIIP performs
Extreme case 12 : 1 GCP : zIIP ratio especially unhelpful because of the “1”
An unscientific view is that somewhere in the region of 2 : 1 to 4 : 1 is rarely harmful
Consider both “in LPAR” and “across the machine” effects– Sometimes the answer will be “no zIIPs for this LPAR”

© 2015 IBM Corporation26
Subcapacity General Purpose Processors
zIIP runs at full speed– e.g. about twice as fast as a 6xx General Purpose Processor (GCP)
Good news:– zIIP higher capacity and faster than GCP
Not so good news:– zIIP-eligible work running on a GCP is worse– Variability in speed if some runs on zIIP and some not
• Not terribly different to DDF situation since PM12256
How this plays depends on numbers of threads and CPU-intensiveness
CPU Conversion Factor:– Use R723NFFS to convert zIIP CPU to GCP equivalent (and vice versa)
Consider configuring more zIIPs than the raw capacity requirement would suggest

© 2015 IBM Corporation27
And just when you thought it couldn't get any more complicated...
… Here are Horst Sinram's z13 zIIP SMT slides

Motivation for Simultaneous Multi Threading§ “Simultaneous multithreading (SMT) permits multiple independent threads of
execution to better utilize the resources provided by modern processor architectures.”*
§ With z13, SMT allows up to two instructions streams per core to run simultaneously to get better overall throughput
§ SMT is designed to make better use of processor hardware units
§ On z/OS, SMT is available for zIIP processing:● Two concurrent threads are available per core● Capacity (throughput) usually increases● Performance may be superior using single threading
*Wikipedia®
A/B
A
B
B
Load/Store (L1 Cache)
A A B
Execution Units (FXU/FPU)
instructions
A B A A
B A A
B
Shared Cache
A B A A
B A
BA
Cache
Thread-A
Thread-B
Use of Pipeline Stages in SMT
Both threads
Stage idle
* Statements regarding IBM future direction and intent are subject to change or withdrawal, and represent goals and objectives only.28

New terminology for SMT…■ z/OS logical processor (CPU) Thread
■ A thread implements (most of) the System z processor architecture■ z/OS dispatches work units on threads■ In MT mode two threads are mapped to a logical core
■ Processor core Core■ PR/SM dispatches logical core on a physical core
■ Thread density 1 (TD1) - when only a single thread runs on a core■ Thread density 2 (TD2) - when both threads run on a core
■ MT1 Equivalent Time (MT1ET)■ z/OS CPU times are normalized to the time it would have taken to run same
work in MT-1 mode on a CP■ ASCB, ASSB, …, SMF30, SMF32, SMF7x, …
■ You will usually not see the term MT1ET because it is implied
■ Several new metrics to describe how efficiently core resources could be utilized…
* Statements regarding IBM future direction and intent are subject to change or withdrawal, and represent goals and objectives only.29

…and several new metrics for SMT…■ New metrics:
■ WLM/RMF: Capacity Factor (CF), Maximum Capacity Factor (mCF) ■ RMF: Average Thread Density, Core busy time,
Productivity (PROD)
§How are the new metrics derived?Hardware provides metrics (counters) describing the efficiency of
processor (cache use/misses, number cycles when one or two threads were active…)
LPAR level counters are made available to the OS
MVS HIS component and supervisor collect LPAR level counters. HIS provides HISMT API to compute average metrics between “previous” HISMT invocation and “now” (current HISMT invocation)
HIS address space may be active but is not required to be active
System components (WLM/SRM, monitors such as RMF) retrieve metrics for management and reporting
* Statements regarding IBM future direction and intent are subject to change or withdrawal, and represent goals and objectives only.30

z/OS MT Capacity Factors - used by WLM/SRM■ Capacity Factor (CF)
How much work core actually completes for a given workload mix at current utilization - relative to single thread
Therefore, MT1 Capacity Factor is 1.0 (100%)
MT2 Capacity Factor is workload dependent
Describes the actual, current efficiency of MT2
Maximum Capacity Factor (mCF)
How much work a core can complete for a given workload mix at most relative to MT-1 mode
Used to estimate MT2 efficiency if the system was fully utilized
E.g., to derive WLM view of total system capacity or free capacity
Value range of CF and mCF is [0.5 … 2.0]
Expect CF in a range of 1.0 -1 .4 (100%-140%) for typical workloads
Untypical (“pathological”) workloads may see untypical/pathological CF/mCFs, such as <1
* Statements regarding IBM future direction and intent are subject to change or withdrawal, and represent goals and objectives only.31
% Used MT-2 Core Capacity during Core Busy Time
% Used MT-2 Core Capacity during Measurement Interval

Additional z/OS MT metrics reported by RMF
§ Core Busy Time– Time any thread on the core is executing instructions
when core is dispatched to physical core § Average Thread Density
– Average number of executing threads during Core Busy Time (Range: 1.0 - 2.0)
§ Productivity– Core Busy Time Utilization (percentage of
used capacity) for a given workload mix– Productivity represents capacity in use (CF) relative to
capacity total (mCF) during Core Busy Time.§ Core Utilization
– Capacity in use relative to capacity total over some time interval
– Calculated as Core Busy Time x Productivity
32

Processor samples may change when going to MT-2 mode
• In MT-2 mode we see less processor delays resulting in a higher execution velocity
* Statements regarding IBM future direction and intent are subject to change or withdrawal, and represent goals and objectives only.33
Synthetic, non-representative workload

Transitioning into MT2 mode: WLM considerations (1)
• Less overflow from zIIP to CPs may occur because• zIIP capacity increases, and • number of zIIP CPUs double
• CPU time and CPU service variability may increase, because• Threads which are running on a core at the same time influence
each other• Threads may be dispatched at TD1 or TD2
• Unlike other OS, z/OS attempts to dispatch threads densely
• Sysplex workload routing: routing recommendation may change because
• zIIP capacity will be adjusted with the mCF to reflect MT2 capacity• mCF may change as workload or workload mix changes
* Statements regarding IBM future direction and intent are subject to change or withdrawal, and represent goals and objectives only.34

Transitioning into MT2 mode: WLM Considerations (2)
• Goals should be verified for zIIP-intensive work, because
• The number of zIIP CPUs double and the achieved velocity may change
• “Chatty” (frequent dispatches) workloads may profit because there is a chance of more timely dispatching
• More capacity is available• Any single thread will effectively run at a reduced speed and the
achieved velocity will be lower.Affects processor speed bound work, such as single threaded Java batch
• MT-2 APPL% numbers can continue to be used to understand relative core utilization in a given interval, at times of comparable maxCFs.However, the maxCF needs to be considered when comparing APPL% across different workloads or times with different maxCF values.
* Statements regarding IBM future direction and intent are subject to change or withdrawal, and represent goals and objectives only.35

© 2015 IBM Corporation36
Conclusions

© 2015 IBM Corporation37
If You Only Remembered 3 4 Things I Hope They Were
Capacity Planning for zIIPs has become much more important
Pay especial attention to what % Busy represents “full”
Measure zIIP potential and usage down to the address space level
Consider LPAR configuration carefully for zIIPs

© 2015 IBM Corporation38
Burn Before Reading :-)
Date Version
13 Jan 2014 1 Original version
07 Feb 2014 2 Updated thanks to comments from Kathy Walsh and slide on DB2 address spaces from John Campbell. Also has abstract.
13 Apr 2014 3 Added slide on Subcapacity Models. Plus thoughts on V10 Estimation and on % of DBM1 work that is zIIP-eligible.
15 Apr 2015 4 Added Horst Sinram's z13 zIIP SMT slides