zhiguo ge, weng-fai wong, and hock-beng lim proceedings of the design, automation, and test in...
TRANSCRIPT

Zhiguo Ge, Weng-Fai Wong, and Hock-Beng LimProceedings of the Design, Automation, and Test in Europe
Conference, 2007 (DATE’07)April 2007
112/04/18

Power consumption is of crucial importance to embedded systems. In such systems, the instruction memory hierarchy consumes a large portion of the total energy consumption. A well designed instruction memory hierarchy can greatly decrease the energy consumption and increase performance. The performance of the instruction memory hierarchy is largely determined by the specific application. Different applications achieve better energy-performance with different configurations of the instruction memory hierarchy.
Moreover, applications often exhibit different phases during execution, each exacting different demands on the processor and in particular the instruction memory hierarchy. For a given hardware resource budget, an even better energy-performance may be achievable if the memory hierarchy can be reconfigured before each of these phases.
AbstractAbstract
- 2 -

In this paper, we propose a new dynamically reconfigurable instruction memory hierarchy to take advantage of these two characteristics so as to achieve significant energy-performance improvement. Our proposed instruction memory hierarchy, which we called DRIM, consists of four banks of on-chip instruction buffers. Each of these can be configured to function as a cache or as a scratchpad memory (SPM) according to the needs of an application and its execution phases. Our experimental results using six benchmarks from the MediaBench and the MiBench suites show that DRIM can achieve significant energy reduction.
Abstract – Cont.Abstract – Cont.
- 3 -

The instruction delivery system constitutes a significant portion of the processor energy consumption As instructions are fetched almost every cycle
Scratchpad Memory (SPM) is energy efficient than cache However, the existing works on instruction SPM
。Not consider the phased behavior of applications during execution
What’s the ProblemWhat’s the Problem
- 4 -

Related WorksRelated Works
- 5 -
Reduce energy consumption in I-caches
Reduce energy consumption in I-caches
Use pure SPM or hybrid SPM and cache
architecture
Use pure SPM or hybrid SPM and cache
architecture
Reconfigure cache that adapts to application [18,
1]
Reconfigure cache that adapts to application [18,
1]
Dynamically reconfigurable instruction memory with $ and
SPM
Dynamically reconfigurable instruction memory with $ and
SPMThis Paper:
Reduce energy and instruction conflictsReduce energy and instruction conflicts
Shut down cache ways
Shut down cache ways
Static mapping instructions into
SPM [16, 9]
Static mapping instructions into
SPM [16, 9]
Dynamic instruction replacement for SPM [7, 4, 14]
Dynamic instruction replacement for SPM [7, 4, 14]
Reconfigure memory hierarchy ($/SPM) for a given application[11,
15]
Reconfigure memory hierarchy ($/SPM) for a given application[11,
15]Static architecture
with static mappingStatic architecture with
dynamic instr. replacemntStatic architecture exploration
with static mapping
Dynamically reconfigurable data memory with $ and SPM [6]
Dynamically reconfigurable data memory with $ and SPM [6]
Dynamic architecture tuning (phases during
execution)
Dynamic architecture tuning (phases during
execution)Reconfiguration
management algorithmReconfiguration
management algorithm

Reconfigure instruction memory architecture at runtime
Idea of the Dynamically Reconfigurable Idea of the Dynamically Reconfigurable Instruction Memory (DRIM)Instruction Memory (DRIM)
- 6 -
Exploit the different requirement between
phases within an application
Exploit the different requirement between
phases within an application
The four banks can be
dynamically reconfigured as cache or SPM

Base on a four way associative cache Configure four banks dynamically as cache or SPM
DRIM Architecture – Part 1DRIM Architecture – Part 1
- 7 -
a7…a0
11
22
Set ci to 1 when used as a SPM
Tag Bank will be gated
when configured as
a SPM
Tag Bank will be gated
when configured as
a SPM
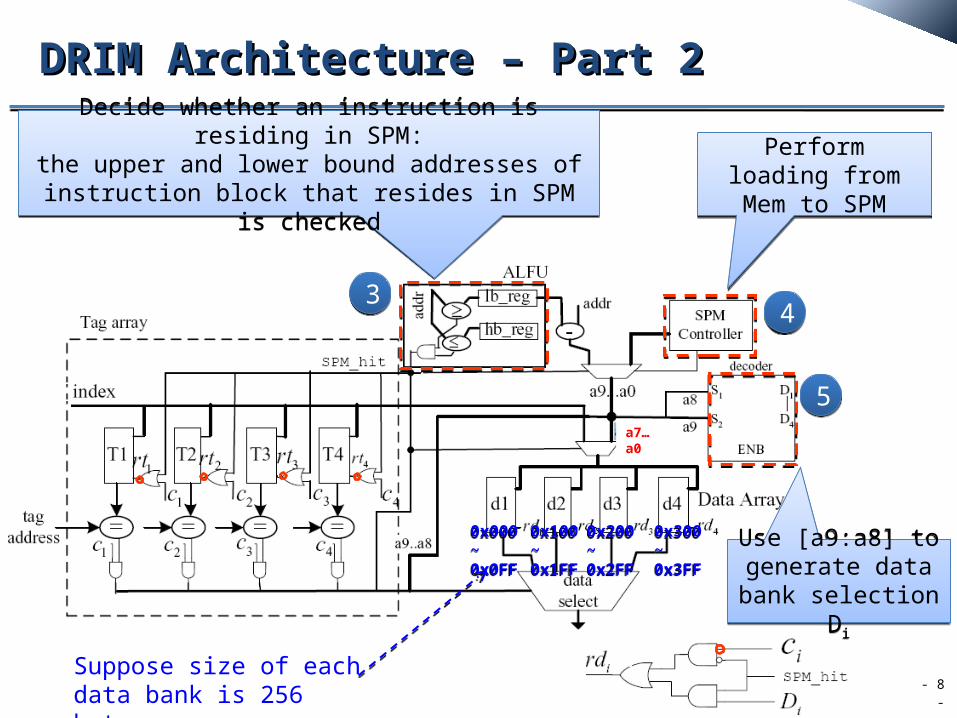
DRIM Architecture – Part 2DRIM Architecture – Part 2
- 8 -
a7…a0
3344
Decide whether an instruction is residing in SPM:
the upper and lower bound addresses of instruction block that resides in SPM is checked
Decide whether an instruction is residing in SPM:
the upper and lower bound addresses of instruction block that resides in SPM is checked
Perform loading from Mem to SPMPerform loading
from Mem to SPM
55
0x000~0x0FF0x000~0x0FF
0x100~0x1FF0x100~0x1FF
0x200~0x2FF0x200~0x2FF
0x300~0x3FF0x300~0x3FF
Use [a9:a8] to generate data bank selection
Di
Use [a9:a8] to generate data bank selection
Di
Suppose size of each data bank is 256 bytes

The SPM_hit controls the gating of the tag and data banks
DRIM Architecture – Part 3DRIM Architecture – Part 3
- 9 -
a7…a0
Data banki enable signal1: enable; 0: disable
if (SPM_hit) then all tag banks will be gated;else only the tag banks configured as cache will be searched;
if (SPM_hit) then all tag banks will be gated;else only the tag banks configured as cache will be searched;
if (SPM_hit) then the SPM bank will be selected by Di
else only the data banks configured as cache will be searched;
if (SPM_hit) then the SPM bank will be selected by Di
else only the data banks configured as cache will be searched;

Compiler Support for Dynamic Compiler Support for Dynamic Reconfiguration & Instruction LoadReconfiguration & Instruction Load
- 10 -
Get the required execution statistics:- Execution counts of edge of CFG- # of procedure invocations
Get the required execution statistics:- Execution counts of edge of CFG- # of procedure invocations
Optimize inst. layout within each procedure:- Bring the frequently executed basic blocks together
Optimize inst. layout within each procedure:- Bring the frequently executed basic blocks together
Determine the architectural configuration for different phases:- When & what - Instruction allocation to SPM
Determine the architectural configuration for different phases:- When & what - Instruction allocation to SPMGenerate code chunk & load into
SPM:- Group instruction blocks to SPM- Insert inst. for reconfiguration- Insert inst. for trace loading
Generate code chunk & load into SPM:
- Group instruction blocks to SPM- Insert inst. for reconfiguration- Insert inst. for trace loading
With an optimized inst. layout

Loop Procedure Hierarchy Graph (LPHG) to represent a program Capture all loops, procedure calls, and their relations
Suppose most of energy consumed by inst. fetch occurs inside loop If (Loop iterations > threshold), then it is beneficial to use SPM The deeper loop in LPHG has higher execution frequency
。Start from leaf loops to their parent loops If (Loop > SPM size), then cache is used to buffer rest of loop
Preface of Reconfiguration and Instruction Preface of Reconfiguration and Instruction AllocationAllocation
- 11 -

Algorithm for Reconfiguration and Algorithm for Reconfiguration and Instruction AllocationInstruction Allocation
- 12 -
Leaf node
Internal node
Whether it is beneficial to allocate more SPM
space from the free_banks
Whether it is beneficial to allocate more SPM
space from the free_banks
Allocate frequently executed inst. inside
loop to SPM
Allocate frequently executed inst. inside
loop to SPM
Delete all reconfig. points inserted in child loops and add a new
reconfig. point to entry of loop
Delete all reconfig. points inserted in child loops and add a new
reconfig. point to entry of loop
Since only one code chunk can reside in
SPM

The evaluation function Consider it is beneficial
。When reduce cache size does not severely increase the I-cache miss
Example of How to Evaluate ConflictsExample of How to Evaluate Conflicts
- 13 -
# inside circle: Loop Iterations# beside circle: Loop size
$$ $$$$$$
1. Try to configure one bank as SPM and allocate it to loop E:
1. Try to configure one bank as SPM and allocate it to loop E:
E
Total size of remaining
banks (64x3) > each of B, C, D
Total size of remaining
banks (64x3) > each of B, C, D
No Conflict -> Safe
Total size of remaining
banks (64x2) > each of B, C
Total size of remaining
banks (64x2) > each of B, C
Severe $ Conflict
D
2. Configure one more bank as SPM and move loop D:
2. Configure one more bank as SPM and move loop D:
3. Configure one more bank as SPM and move loop B:
3. Configure one more bank as SPM and move loop B:
Total size of remaining
banks (64x1) < C
Total size of remaining
banks (64x1) < C
SPM
SPM
SPM
SPM

Goal: reduce the number of reconfiguration If a loop does not have any sibling loops
。Hoist the reconfiguration point from inner loop to outer loop
Optimization: Hoist Reconfiguration PositionOptimization: Hoist Reconfiguration Position
- 14 -
Reconfiguration at entry of loop B
Reconfiguration at entry of loop B
Load code chunk into SPM whenever execute
the child loop
Load code chunk into SPM whenever execute
the child loop
Decide reconfig. points & inst allocated to
SPM
OriginalOriginal OptimizedOptimized

The DRIM is based on a 4-way associative I-cache Each bank is size of 256 bytes
Model energy consumption using CACTI for 0.13μm technology The logic that performs address checking and SPM control is
also included
Experimental SetupExperimental Setup
- 15 -
Energy Consumption Per Access
Energy of the cache portion when DRIM is configured as 1, 2, 3, 4 banks cache
and SPM
Energy of the cache portion when DRIM is configured as 1, 2, 3, 4 banks cache
and SPM
Energy for one data bank + energy overhead for
accessing SPM
Energy for one data bank + energy overhead for
accessing SPM

The average improvement 15.6% in I-cache miss rate 10.2% in execution time
The improvement comes from The frequently executed instructions of important loops are mapped into SPM
Performance ImprovementPerformance Improvement
- 16 -

The reduction in energy consumption by DRIM Range from 14.3% to 65.2% The average reduction is 41%
The reduction comes from The I-cache miss rate is improved
。Fewer SDRAM accesses The energy consumption per access of SPM is lower than that of
cache
Energy SavingEnergy Saving
- 17 -
There is actually energy savings even there is no miss rate
reduction
There is actually energy savings even there is no miss rate
reduction

This paper proposed a low power Dynamically Reconfigurable Instruction Memory (DRIM) The I-cache can be configured as SPM for
。Different applications as well as different phases of application’s execution
Compilation flow to support DRIM。Determine reconfiguration point and instructions allocated to SPM
Experimental results show that DRIM Reduce energy consumption up to 65.2%
ConclusionsConclusions
- 18 -

The DRIM architecture is clear and easy to understand It also shows that the tag bank is not utilized when configured as
SPM
The complex compiler framework makes it hard to migrate to other Instruction Set Architecture (ISA)
Comment for This PaperComment for This Paper
- 19 -