zależności funkcyjne
DESCRIPTION
Zależności funkcyjne. Schemat semantyczny. Warunki integralności stanowią zbiór ograniczeń narzuconych na dane. Definicja 1 . Niech W oznacza zbiór warunków integralności dotyczących relacji R o schemacie SCH. Para = (SCH, W) jest definiowana jako schemat semantyczny relacji. - PowerPoint PPT PresentationTRANSCRIPT

Zależności funkcyjne

Schemat semantyczny
Warunki integralności stanowią zbiór ograniczeń
narzuconych na dane.
Definicja 1.
Niech W oznacza zbiór warunków integralności
dotyczących relacji R o schemacie SCH.
Para = (SCH, W) jest definiowana jako schemat
semantyczny relacji.

Schemat semantyczny
Definicja 2.
Niech będzie dany zbiór schematów semantycznych
relacji: = {1, 2, …, 2} . Niech oznacza
zbiór zależności semantycznych dotyczących więcej
niż jednego schematu.
Para = {, } jest definiowana jako schemat
semantyczny bazy danych.

Zależności funkcyjne
Zależności funkcyjne między atrybutami są rodzajem
warunków integralności.
Definicja 3. Niech będzie dany zbiór atrybutów
SCH oraz jego podzbiory X i Y. Mówimy, że Y jest
funkcyjnie zależny od X, co zapisujemy X Y, wtedy
i tylko wtedy, gdy dla każdej relacji R rozpiętej na
schemacie SCH i dla każdych dwóch krotek t1, t2 R
jest spełniony warunek:
t1(X) = t2(X) t1(Y) = t2(Y).

Zależności funkcyjne
Dla zależności funkcyjnych sformułowano zbiór reguł
wnioskowania, które pozwalają na wyprowadzenie
nowych zależności na podstawie istniejących.
Nazywamy je aksjomatami Armstronga.

AKSJOMATY ARMSTRONGA
A1. Y X X Y (zwrotność)
A2. X Y Z W XW YZ (powiększenie)
A3. X Y Y Z X Z (przechodniość)

AKSJOMATY ARMSTRONGA
Dowód
A1.
t1 (X) = t2 (X) Y X t1 (Y) = t2 (Y)
Zależności wynikające z aksjomatu zwrotności są
często nazywane trywialnymi.

AKSJOMATY ARMSTRONGA
A2.Dowód przez zaprzeczenie.
Załóżmy, że : t1 (XW) = t2 (XW) t1 (YZ) t2 (YZ).
t1 (XW) = t2 (XW) Z W t1 (XZ) = t2 (XZ)
t1 (X) = t2 (X) t1 (Z) = t2 (Z)
t1 (Z) = t2 (Z) t1 (YZ) t2 (YZ) t1 (Y) t2 (Y)
Otrzymaliśmy: t1 (X) = t2 (X) t1 (Y) t2 (Y) , co jest sprzeczne z założeniem.

AKSJOMATY ARMSTRONGA
A3.
( t1 (X) = t2 (X) t1 (Y) = t2 (Y))
(t1 (Y) = t2 (Y) t1 (Z) = t2 (Z))
(t1 (X) = t2 (X) t1 (Z) = t2 (Z))

REGUŁY ARMSTRONGA
Z aksjomatów Armstronga wynikają następujące
reguły:
D1. X Y X Z X YZ (suma)
D2. X Y WY Z XW Z (pseudoprzechodniość)
D3. X Y Z Y X Z (rozkład)

REGUŁY ARMSTRONGA
Dowód
D1.
X Y X YX (aksjomat A2)
X Z XY ZY (aksjomat A2)
X YX XY ZY X YZ (aksjomat A3)

REGUŁY ARMSTRONGA
Dowód
D2.
X Y XW YW (aksjomat A2)
XW YW YW Z XW Z (aksjomat A3)

REGUŁY ARMSTRONGA
Dowód
D3.
Z Y Y Z (aksjomat A1)
X Y Y Z X Z (aksjomat A3)

REGUŁY ARMSTRONGA
Zbiór reguł wnioskowania jest zupełny (sound)
i kompletny (complete). Oznacza to, że wszystkie
wyprowadzone zależności są poprawne oraz że można
wyprowadzić wszystkie zależności istniejące
w danym schemacie relacji.

Konsekwencja logiczna
Oznaczmy przez F zbiór zależności funkcyjnych
między atrybutami schematu SCH.
Zależność funkcyjna f jest konsekwencją logiczną F,
co zapisujemy F = f, jeśli f jest spełnione dla
wszystkich relacji o schemacie SCH.

Domknięcie zbioru zależności funkcyjnych F+
Jest to zbiór zależności funkcyjnych będących
konsekwencjami logicznymi F

Nasycenie atrybutu X+
Zbiór F+ zawiera zazwyczaj wiele elementów, nawet
jeśli F nie jest zbiorem dużym. Za pomocą reguł
wnioskowania można bowiem wyprowadzić wiele
zależności. Wyznaczanie F+ jest więc procesem
czasochłonnym. Znacznie łatwiej można wyznaczyć
nasycenie atrybutu X+ .

Nasycenie atrybutu X+
Jest to zbiór atrybutów prostych A takich, że zależność
XA można wyprowadzić zgodnie z regułami
wnioskowania.

Twierdzenie 1
Zależność XY można otrzymać na podstawie reguł
wnioskowania Y X+

Twierdzenie 1
Dowód
Załóżmy, że Y = {Ai, A2, …, An}
1. Y X+.
Zgodnie z definicją X+ jest zbiorem atrybutów Ai,
takich, że prawdziwa jest zależność X Ai. Na
podstawie reguły sumy X X+.
Y X+ X+ Y (aksjomat A1
X X+ X+ Y X Y (aksjomat A3)

2. X Y
X Y X Ai. (D6)
Oznacza to, że Ai X+ Y X+
Twierdzenie 1

1. Przyjmujemy X0 = X
2. W każdym następnym kroku powiększamy Xi ,
Xi+1 = Xi S, o atrybuty należące do następującego
zbioru S: S = {A: Y Z Y Xi A Z}.
Ze względu na to, że Xi Xi+1 … U wnioskujemy,
że metoda jest zbieżna.
Proces wyznaczania X+ kończymy, gdy Xi = Xi+1 .
WYZNACZANIE NASYCENIA ATRYBUTU
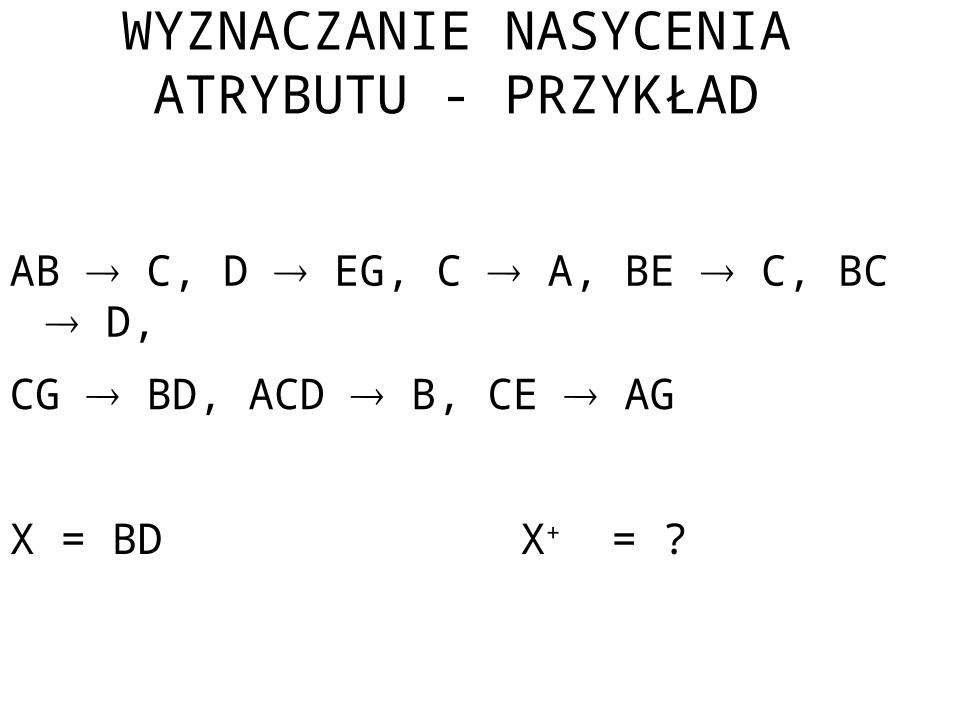
AB C, D EG, C A, BE C, BC D,
CG BD, ACD B, CE AG
X = BD X+ = ?
WYZNACZANIE NASYCENIA ATRYBUTU - PRZYKŁAD

1. X0 = BD
2. Tylko jedna zależność spełnia warunek Y Xi . Jest to D EG. Lewa strona tylko tej zależności jest podzbiorem X0 . Powiększamy X0 o {E,G}. Tak więc X1 = {BDEG}.
Postępując podobnie otrzymujemy w czwartym kroku X3 = {ABCDEG}, czyli zbiór wszystkich atrybutów.
WYZNACZANIE NASYCENIA ATRYBUTU - PRZYKŁAD

Zbiory zależności F i G są równoważne, jeśli F+ = G+.
Mówimy, że F pokrywa G ( i G pokrywa F).
Zbiory są równoważne każda zależność z F należy
do G+ i każda zależność z G należy do F+ .
Twierdzenie 2
Każdy zbiór zależności funkcyjnych F jest pokryty
zbiorem zależności G, w którym nie istnieje prawa
strona o więcej niż jednym atrybucie.
POKRYCIA ZBIORÓW ZALEŻNOŚCI

Dowód:
Niech X Y F, Y = {A1, A2 ,…, An}.
Niech G będzie zbiorem zależności postaci X Ai .
Atrybuty Ai odpowiadają zależnościom X Y F.
Na podstawie D6 X Y X Ai G F+ .
Na podstawie D4 X A1 X A2 … X An
X Y F G+
POKRYCIA ZBIORÓW ZALEŻNOŚCI

Wyznaczenie F+ nie jest konieczne. Wystarczy
wyznaczyć zbiór minimalny, czyli taki z którego
wynikają wszystkie zależności należące do F+ .
ZBIÓR MINIMALNY

Zbiór zależności F jest minimalny jeśli:
1. Prawa strona każdej zależności w F jest pojedynczym atrybutem
2. Zbiór F – {XA} nie jest równoważny F
3. Zbiór F – {XA} {ZA}, gdzie Z X
nie jest równoważny F.
ZBIÓR MINIMALNY

Warunek 2 oznacza, że zbiór F nie zawiera zależności
redundantnych.
Warunek 3 oznacza, że zbiór F nie zawiera zależności
z atrybutami nadmiarowymi po lewej stronie.
ZBIÓR MINIMALNY

AB, BA,
AC, CA,
BC
Co można wyeliminować?
ZBIÓR MINIMALNY - PRZYKŁAD

1. BA i AC
BC CA BA , AB BC AC
2. BC
BA AC BC
Nie można wyeliminować wszystkich trzech
zależności. Wynik zależy od kolejności analizowania
poszczególnych zależności
ZBIÓR MINIMALNY - PRZYKŁAD

ABC , AB, BA
Co można wyeliminować?
ZBIÓR MINIMALNY - PRZYKŁAD

ABC , AB, BA
AB ABC AC
BA ABC BC
Można wyeliminować A albo B. Nie można
wyeliminować A i B
Na wynik ma wpływ kolejność.
ZBIÓR MINIMALNY - PRZYKŁAD

AB C, D EG, C A, BE C, BC D,
CG BD, ACD B, CE AG
Wyznaczyć zbiór minimalny
ZBIÓR MINIMALNY - PRZYKŁAD

Na podstawie D6 otrzymujemy zależności z
pojedynczymi atrybutami po prawej stronie:
AB C, D E, D G
C A, BE C, BC D,
CG B, CG D ACD B,
CE A, CE G
ZBIÓR MINIMALNY - PRZYKŁAD

AB C, D E, D G
C A, BE C, BC D,
CG B, CG D ACD B,
CE A, CE G
1. C A CE A CE A do usunięcia
ZBIÓR MINIMALNY - PRZYKŁAD

1. C A ACD B CD B
do usunięcia A z ACD B
2. CG D CD B CG B
CG B do usunięcia
Rozwiązanie I
AB C, D E, D G,
C A, BE C, BC D,
CG D, CD B, CE G
ZBIÓR MINIMALNY – PRZYKŁAD – ROZWIĄZANIE I
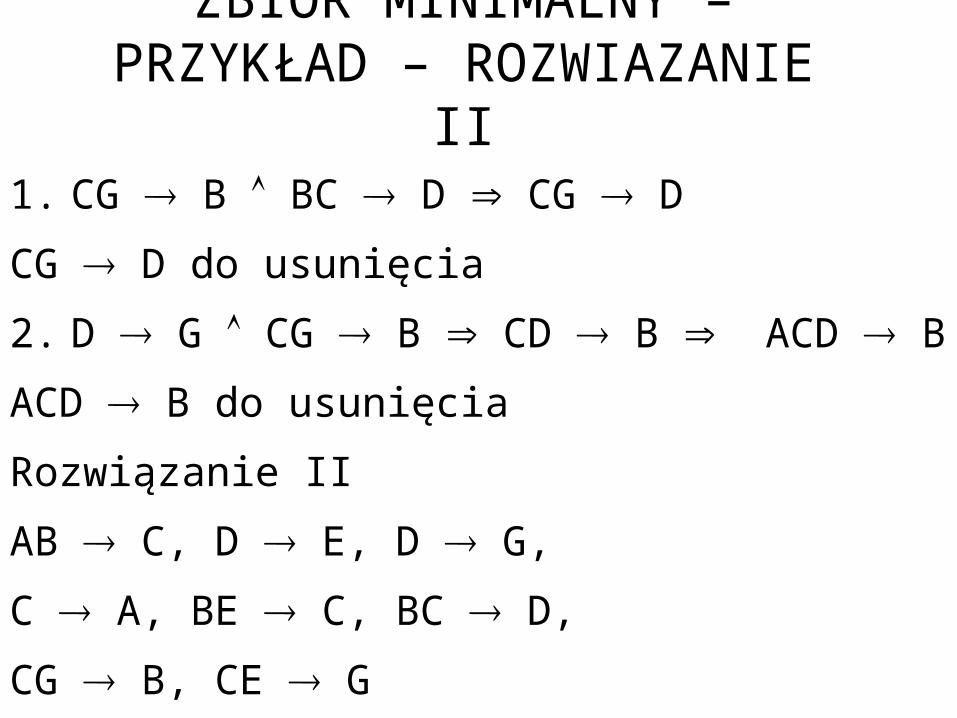
1. CG B BC D CG D
CG D do usunięcia
2. D G CG B CD B ACD B
ACD B do usunięcia
Rozwiązanie II
AB C, D E, D G,
C A, BE C, BC D,
CG B, CE G
ZBIÓR MINIMALNY – PRZYKŁAD – ROZWIAZANIE II

WYZNACZANIE KLUCZA
Twierdzenie 3
Niech R oznacza relację o schemacie SCH.
Niech F oznacza zbiór zależności funkcyjnych
między atrybutami schematu SCH.
X A F+ SCH – {A} SCH F+
Dowód:
(SCH – {A}) X (SCH – {A}) A F+ (aksjomat A2)

WYZNACZANIE KLUCZA
Przy wyznaczaniu klucza wykorzystujemy
twierdzenie 3. Jako pierwsze przybliżenie
przyjmujemy zbiór wszystkich atrybutów: K = SCH.
Następnie usuwamy poszczególne atrybuty
sprawdzając czy K – {A} SCH F+.
Algorytm kończy się, gdy nie istnieje możliwość
usunięcia żadnego atrybutu.
Otrzymany wynik zależy od kolejności w jakiej
rozpatrujemy poszczególne atrybuty.

WYZNACZANIE KLUCZA - PRZYKŁAD
P-profesor, G-godzina, N-sala, Y-klasa, T-przedmiot
Profesor P wykładający przedmiot T prowadzi zajecia
o godzinie G w sali N z klasą Y
Zbiór zależności:
F = {PT, PGY , GNP, GYN}

WYZNACZANIE KLUCZA - PRZYKŁAD
K = PGNYT
PT PGNYPGNYT K = PGNY
PGY PGNPGNY K = PGN
GNP GNPGN K = GN
Kluczem jest GN.
Można zauważyć, że nie jest to jedyny klucz.
Przy innej kolejności usuwania atrybutów
otrzymalibyśmy klucze PG lub GY.

WYZNACZANIE KLUCZA – UWAGI DODATKOWE
Przy wyznaczaniu kluczy można wykorzystać następujące
własności:
1. Każdy klucz kandydujący zawiera wszystkie atrybuty
występujące tylko po lewej stronie zależności funkcyjnych
2. Nie istnieje klucz kandydujący zawierający atrybuty
występujące tylko po prawej stronie zależności funkcyjnych
3. Jeżeli zbiór atrybutów występujących tylko po lewej stronie
zależności funkcyjnych identyfikuje pozostałe atrybuty,
to tworzy on jedyny klucz relacji.

WYZNACZANIE KLUCZA - PRZYKŁAD
Wyznaczmy klucz schematu R(K, G, N, S, U, O) z następującymi zależnościami:GUS, GSK, KN, KUO Atrybutami występującymi tylko po lewej stronie są Na podstawie reguł Armstronga otrzymujemy:GUS GSK GUK GUK KN GUN GUK KUO GUOGU identyfikuje pozostałe atrybuty, co oznacza, że jest to jedyny klucz schematu.

ROZKŁAD do 3NF
Algorytm zapewniający uzyskanie rozkładu
bezstratnego i zachowującego zależności do postaci
3NF.
1. Wyznaczyć zbiór minimalny zależności
2. Dla zależności postaci X Ai utworzyć schemat
{X, A1 , A2 , …, An }
3. Jeżeli żaden ze schematów nie zawiera klucza, utworzyć schemat, do którego należą atrybuty kluczowe

ROZKŁAD do 3NFPRZYKŁAD
Rozpatrzmy następujące rozkłady schematu
R(A, B, C, D) ze zbiorem zależności:
F = {A C, C B}
• R1(A, C), R3(A, B, D)
• R2(B, C), R4(A, C, D)
• R1(A, C), R2(B, C), R5(A, D)

PRZYKŁAD
1. R1(A, C), R3(A, B, D) –
brak zależności B C, rozkład odwracalny,
R1 w BCNF, R3 w 1NF
2. R2(B, C), R4(A, C, D) –
rozkład odwracalny, zależności zachowane,
R2 w BCNF, R4 w 1NF
3. R1(A, C), R2(B, C), R5(A, D) –
rozkład odwracalny, zależności zachowane,
relacje w BCNF

PRZYKŁAD
Zauważmy, że zbiór zależności F = {A C, C B}
jest zbiorem minimalnym oraz że kluczem schematu
jest AD.
Przedstawiony algorytm prowadzi do rozkładu
R1(A, C), R2(B, C), R5(A, D).