word level language identification in code-switched texts
TRANSCRIPT

Word level language identification in
bilingual code-switched texts
PACLIC 2014 (12-14 December)
Harsh Jhamtani – IIT Roorkee / Adobe Research India
Suleep Kumar Bhogi - IIT Roorkee / Samsung Research
Dr. Vaskar Raychoudhury - IIT Roorkee
Contact: [email protected]
1

Introduction
Spanish-English
Tamil-French
Hopi-Tewa
Marta: Ana, if I leave her here would you send her upstairs when you leave?
Zentella: I’ll tell you exactly when I have to leave, at ten o’clock. Y son las nueve y
cuarto. ("And it’s nine fifteen.")
Selvamani: Parce que n’importe quand quand j’enregistre ma voix ça l’aire d’un garçon.
([in French] "Because whenever I record my voice I sound like a guy.")
Alors, TSÉ, je me ferrai pas poigné ("So, you know, I’m not going to be had.")
[laughter]
Selvamani: ennatā, ennatā, enna romba ciritā? ([in Tamil] "What, what, what's so
funny?")
Speaker A: Tututqaykit qanaanawakna. ([in Hopi] "Schools were not wanted.")
Speaker B: Wédít’ókánk’egena’adi imbí akhonidi. ( [in Tewa] "They didn’t want a
school on their land.")
2

Hinglish
An instance of Linguistic Code
Switching – HINGLISH
Why has Hinglish become popular?
Mingling of western culture into Indian culture.
Youth is mostly influenced.
More comfortable to express.
3

Main main temple ke pass hoon
4
मैं main temple पास ह ूँके
मैंमैं (H)
Means – “I am
near the main
temple”

Problem statement
Word level identification of language
- In case of Hindi words, identify the authentic script
5
Main main temple ke pass hoon
H E E H HH
Our system
मैं पास ह ूँके

Why to solve this problem?
How can analyzing such texts help?
Sentiment analysis
Opinion Mining
Information Retrieval – analyzing search
queries
Machine translation of such texts
6
125 million Indians know English in addition to their mother tongue
More than 50 million
Indians know both English
and Hindi
43 million Indians on facebook

Issue : Modeling and analyzing such language is
tough
Main Challenges faced
Inconsistent spelling usage
Ambiguous word usage
Current technology is not good enough
Simple English dictionary look up can not help
7

Language Identification
Written TextsSpoken Language
Document Level Word Level
Foreign-InclusionCode-Switched
Identifying LCS
points
Transliteration Similarity
Metric
Related work
8

King et al
• Character n-grams
• Full word
• Non-word characters between words
• Conditional Random Fields trained with Generalized Expectation Criteria
(Druck, et al., 2008)
• Semi- and weakly-supervised training method for CRFs
horse Unigrams
“h”, “o”,
“r”, “s”, “e”
Bigrams
“_h”, “ho”,
“or”, “rs”,
“se”, “e_”
Trigrams
“_ho”, “hor”,
“ors”, “rse”,
“se_”
4-grams
“_hor”,
“hors”,
“orse”, “rse_”
5-grams
“_hors”,
“horse”,
“orse_”
the horse, ‘94 bred Before
“space_present”
After
“comma_present”
“space_present”
“apostrophe_present”
“4_present”
Full Word
“horse”
9
Source: King Abney

Data sets
Data set 1: Hinglish Sentences: This is a dataset of 500 Hinglish sentences containing a total of 3,287 words. e.g. rupee\E ki\H=की value\E giri\H=गिरी
We evaluated on additional 1000 Hinglish sentences.
• Data set 2: Transliteration pairs: It has multiple transliterated forms of same Hindi words. tera, thera, teraa, teraaa : तेरा
• Data set 3: Hindi Dictionary: It is a Hindi word frequency list. e.g. लेने 2226
Data set 4: Transliterated Hindi Dictionary – We generated standard transliterated forms of all the words in the Dataset 3 using ITRANS rules.
Data set 5: English Dictionary – It is a standard dictionary of 207,824 English words along with their frequencies computed from a large news corpus.
10

Proposed solution
Classifier 1 Classifier 2
English Score
Modified Edit
Distance
Hindi Score
N-gramsFeatures
HINGLISH
SentencesP(E,w)
POS Tagger (English)
POS Tagger(Hindi)
POS-tagged HINGLISH Sentences
Identified Language of Words
FUNCTIONAL DIAGRAM
11

Common spelling substitutions
Edit
Distance
khushbu
khushboo
Dissimilarity
Score =2
Edit
Distance
khushbu
khushi
Dissimilarity
Score =2
Observation: People often tend to substitute, ‘u’ in place of ‘oo’ while writing
transliterated forms.
The Edit Distance algorithm does not capture this fact.
We call this type of substitutions as common spelling substitutions.
Same
word
Different
words
12

Classifier 1
• Modified Edit Distance
• English Score
• Hindi Score
• Ngram
13

Method to generate substitution pairs
Data set 2
– multiple
transliterati
on forms
Enumerate
substitution
pairs
Assign cost
for using a
substitution
pair
14

String dissimilarity feature
Cost for substitution s=c1(s)
Normal cost=c2
Cut-off threshold = subst_th
1. Get a list of possible spelling substitutions along with with frequency counts.
2. Extract those substitutions which occur more than subst_th times.
3. For each Hindi transliteration htavailable, calculate the cost of word wwith ht. The feature is the minimum cost over all ht. Also store the corresponding transliteration.
C1(s) = k/log(freq(s))
15

Classifier 1
• Modified Edit Distance
• English Score
• Hindi Score
• Ngram
16

English and Hindi scores
This feature is to address ambiguous word usage problem.
Example
द र – door
door - door
If we know that door(E) is a frequent word and द र is not a
frequent word, then “door” corresponds to door(E) with greater
probability.
Here we also tried to leverage an estimated language
distribution of words in test data.
17

Frequency of words as feature
For a given word w in the test data,
English Score:
eng_score(w) = score(w), if w ∈ English Dictionary
= 0, otherwise
score(w) = log(freq(w))/M
M=max(log(freq(w))) for all w ∈ English Dictionary
Hindi score: First the modified Edit Distance algorithm is used to identify
the closest matching Hindi word hw for a given word w in the test data.
hindi_score(w) = score(hw)
score(hw) = log(freq(hw))/M
M=max(log(freq(q))) for all q ∈ Hindi Dictionary
18

KDE graphs
19

Classifier 1
• Modified Edit Distance
• English Score
• Hindi Score
• Ngram
20

N-grams (sequence of characters)
Sequence of letters occurring more frequently is a characteristic feature
of a language.
Learn the most frequent bigrams, trigrams, 4-grams from the training
data set.
For any term t (N-gram) in word w, the Delta TF-IDF score V is
computed using formula
V=n(t,w) * log2(Ht/Et).
where, n (t, w) is the frequency count of term t in word w.
Ht and Et are the number of occurrences of term t in the English and
Hindi dictionaries.
21

Classifier 2
Classifier 1 Classifier 2
English Score
Modified Edit
Distance
Hindi Score
N-gramsFeatures
HINGLISH
SentencesP(E,w)
POS Tagger (English)
POS Tagger(Hindi)
POS-tagged HINGLISH Sentences
Identified Language of Words
FUNCTIONAL DIAGRAM
22

Parts-of-speech (POS)
All the previous features we have discussed focus on individual
words of a code-switched sentence.
Here we see that language usage of word follows certain pattern- POS
based patterns.
We did some analysis based on context based hypothesis on code
switched sentences to show that POS helps to find language usage of
words.
23

Few hypothesis
1. Words on the two sides of conjunctions ‘and’, ‘aur’, etc. are usually of same languages the conjunction
ready hai? editing and all done?
hello world ya kuch aur?
padmasana yoga technique and posture
2. Direct objects are switched very often
.. court ne election-commission...
3. Determiner and the corresponding noun/verb are of same language
You would rather say “ that chair ” instead of “that kursi”
4. Adjectives/adverbs are usually of the same language as that of noun/verb they modify
“Beta good boy banke dikha” and not “ .. good ladka ..“
80%
20%
FOLLOW HYPOTHESIS
DO NOT FOLLOW HYPOTHESIS
24

How to leverage this?
Identifier = Language_POS
e.g. English noun => E_NN
e.g. Hindi adjective => H_JJ
From the training data set tagged with POS, learn the most frequent bigrams and
trigrams of identifiers.
Results From Dataset
Most frequent bigram: H_JJ; E_NN -> 222
Most frequent trigram: H_NN; H_PSP; E_NN -> 61
25
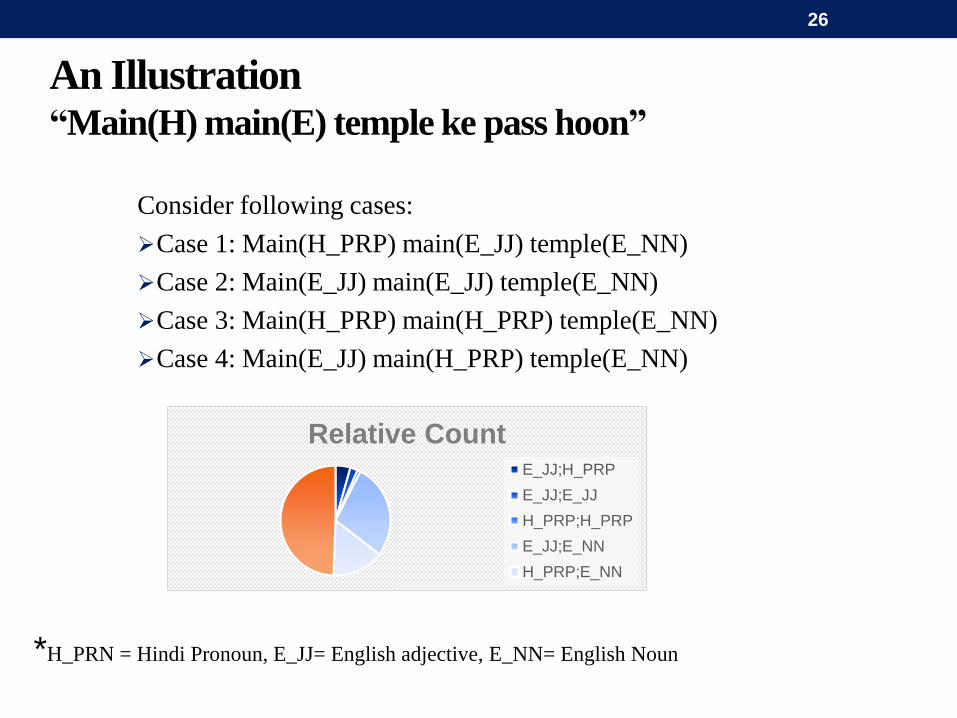
An Illustration“Main(H) main(E) temple ke pass hoon”
Consider following cases:
Case 1: Main(H_PRP) main(E_JJ) temple(E_NN)
Case 2: Main(E_JJ) main(E_JJ) temple(E_NN)
Case 3: Main(H_PRP) main(H_PRP) temple(E_NN)
Case 4: Main(E_JJ) main(H_PRP) temple(E_NN)
*H_PRN = Hindi Pronoun, E_JJ= English adjective, E_NN= English Noun
Relative CountE_JJ;H_PRP
E_JJ;E_JJ
H_PRP;H_PRP
E_JJ;E_NN
H_PRP;E_NN
26
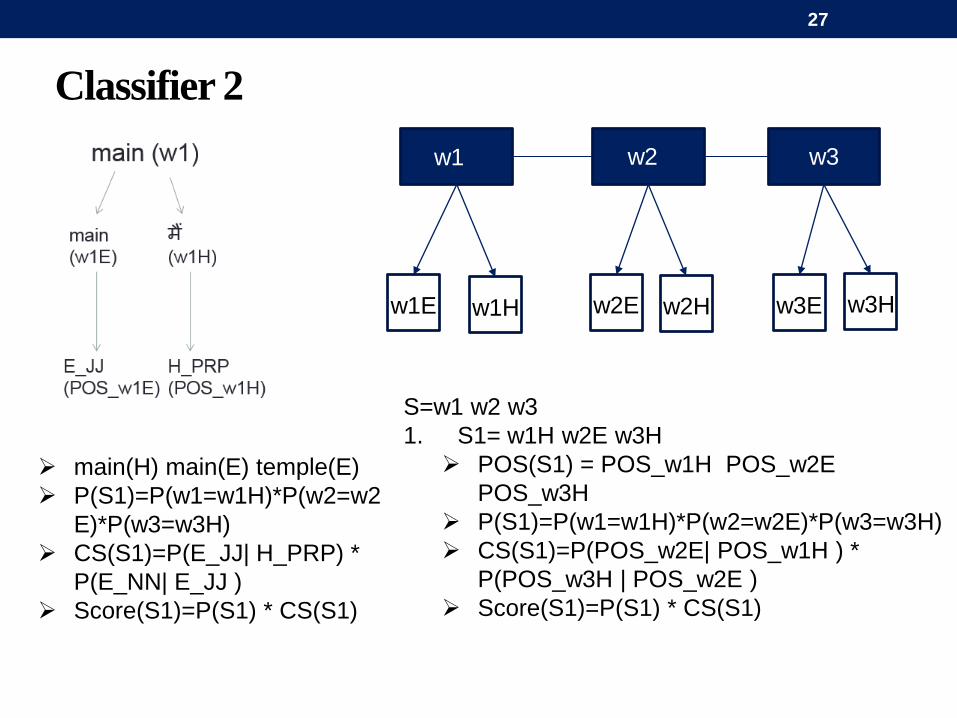
Classifier 2
w1E w1H w2E w2H w3E w3H
w1 w2 w3
S=w1 w2 w3
1. S1= w1H w2E w3H
POS(S1) = POS_w1H POS_w2E
POS_w3H
P(S1)=P(w1=w1H)*P(w2=w2E)*P(w3=w3H)
CS(S1)=P(POS_w2E| POS_w1H ) *
P(POS_w3H | POS_w2E )
Score(S1)=P(S1) * CS(S1)
main(H) main(E) temple(E)
P(S1)=P(w1=w1H)*P(w2=w2
E)*P(w3=w3H)
CS(S1)=P(E_JJ| H_PRP) *
P(E_NN| E_JJ )
Score(S1)=P(S1) * CS(S1)
27

RESULTS
28

Baseline: Presence in English dictionary
No. of words (K) HPRE HRE HF1 EPRE ERE EF1
Top 100 0.74 0.98 0.84 0.31 0.02 0.04
Top 500 0.76 0.96 0.85 0.59 0.15 0.24
Top 1000 0.79 0.95 0.86 0.69 0.28 0.40
Top 5000 0.85 0.93 0.89 0.75 0.55 0.64
Top 10000 0.87 0.86 0.87 0.63 0.64 0.63
ALL 0.92 0.39 0.55 0.35 0.91 0.50
HPRE = Precision for Hindi class , HRE = Recall for the Hindi class, HF1 = f1 score for the Hindi class
EPRE = Precision for English class , ERE = Recall for the English class, EF1 = f1 score for the English
class
29
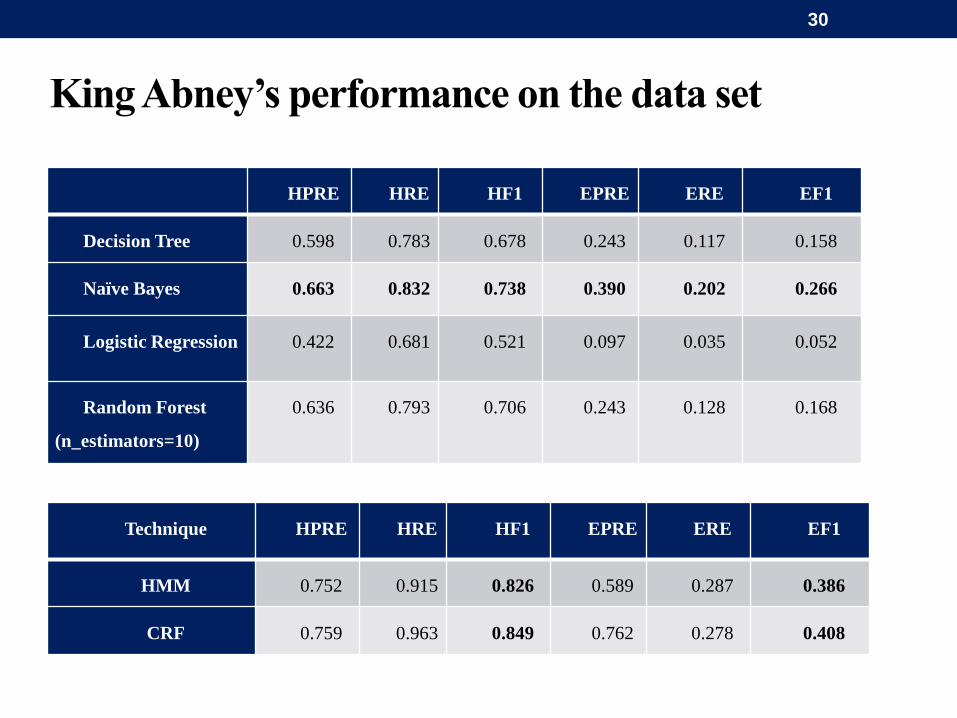
King Abney’s performance on the data set
HPRE HRE HF1 EPRE ERE EF1
Decision Tree 0.598 0.783 0.678 0.243 0.117 0.158
Naïve Bayes 0.663 0.832 0.738 0.390 0.202 0.266
Logistic Regression 0.422 0.681 0.521 0.097 0.035 0.052
Random Forest
(n_estimators=10)
0.636 0.793 0.706 0.243 0.128 0.168
Technique HPRE HRE HF1 EPRE ERE EF1
HMM 0.752 0.915 0.826 0.589 0.287 0.386
CRF 0.759 0.963 0.849 0.762 0.278 0.408
30

Classifier 1 - Using n-grams of characters, all
features
HPRE HRE HF1 EPRE ERE EF1
Decision Tree 0.848 0.799 0.823 0.466 0.552 0.505
Naïve Bayes 0.892 0.484 0.627 0.335 0.816 0.475
Logistic Regression 0.941 0.582 0.719 0.403 0.885 0.554
Random Forest 0.896 0.791 0.840 0.521 0.713 0.602
HPRE HRE HF1 EPRE ERE EF1
Decision Tree 0.959 0.934 0.946 0.809 0.874 0.840
Naïve Bayes 0.976 0.744 0.844 0.539 0.943 0.686
Logistic Regression 0.919 1.000 0.958 1.000 0.724 0.840
Random Forest 0.954 0.982 0.968 0.9379 0.851 0.892
31

Performance of Classifier 2
f1-score (Hindi class) f1-score (English class)
Identifier bi-grams 0.966 0.897
Identifier tri-grams 0.974 0.919
32

Error Analysis
Model NE* (% of total misclassified
words)
𝑪𝑭𝟏 = n-grams 10.76%
𝑪𝑭𝟐 =ngrams + eng_score + hindi_score +
dissimilarity_score
11.49%
𝑪𝑭𝟑 = 𝑪𝑭
𝟏 + 𝑪𝑭𝟐 27.00%
33
*NE -> Named entities

Performance of Modified Edit Distance
40
42
44
46
48
50
52
54
56
Percentage
Percentage correct
34

Comparing Four Methods to Create Substitution Pairs
Method 1 Method 2 Method 3 Method 4
k N P N P N P N P
0.1 1298 53.64 1305 53.93 1235 51.03 1050 43.39
0.5 1298 53.64 1305 53.93 1206 49.83 1073 44.34
1 1296 53.55 1307 54.01 1269 52.44 1139 47.07
1.5 1296 53.55 1309 54.09 1290 53.31 1197 49.46
35
40
45
50
55
60
0.1 0.5 1 1.5
Method 1
Method 2
Method 3
Method 3
35

Conclusions
Word level language identification is important to solve for
further analysis of such texts
We devised efficient techniques for word level language
identification and finding the authentic Hindi script.
We plan to test the work in other language pairs
And extend it further to cases with more than two languages switched in
the same text.
We plan to extend the work to incorporate sentence level
contextual features.
36