wise: a web-interface for spelling error recognition for ... · pdf fileror tags in detail,...
TRANSCRIPT

Proceedings of the Int. Conference of the German Society for Computational Linguistics and Language Technology,pages 87–96, University of Duisburg-Essen, Germany, Sep 30–Oct 2 2015.
WISE: A Web-Interface for Spelling Error Recognition for German:A Description and Evaluation of the Underlying Algorithm
Kay BerklingCooperative State University
Karlsruhe, [email protected]
Rémi LavalleyCooperative State University
Karlsruhe, [email protected]
Abstract
This paper evaluates an automatic spellingerror tagger that is available via web in-terface. After explaining the existing er-ror tags in detail, the accuracy of the toolis validated against a publicly availabledatabase containing around 1700 writtentexts ranging from first grade to eighthgrade. The precision of the tool rangesfrom 83% to 100%. Some basic statisticsabout spelling errors in the existing dataset are given to demonstrate potential re-search areas. The site can be used to fur-ther explore this data. In addition, newdata can be donated and explored. Thisprocess will be described in detail.
1 Introduction
This paper evaluates an automatic spelling errortagger. The annotation and study of spelling er-rors represents one dimension towards gaining adeeper understanding about children’s writing ac-quisition. A database with 1701 spontaneouslywritten texts from grades 1-8, including Grund-schule, Hauptschule and Realschule is used forevaluation. This corpus is described separately in(Berkling et al., 2014; Lavalley et al., 2015). Thealgorithm’s evaluation is reported in this paper.The described website offers other researchers thepossibility of browsing through this data and therespective error annotations. For a given com-bination of features, the user is able to obtain alist of words from spellers matching that feature.Thus, one can compare girls’ vs. boys’ spellingsor study the development of the ability to capital-ize correctly from second grade until eighth grade.As examples of how to use the website, we willpresent some of the spelling errors in this databasealong with information about the precision of theautomatically tagged data.
The rest of the paper is structured as follows.After a brief review of the data collection in Sec-tion 2, Section 3 and Section 4 provide details andresults on the quality of the automatic spelling er-ror annotation of the data. Section 5 presents someof the statistics obtained when using the website.Section 6 describes the use of the GUI. Section 7concludes this paper.
2 Evaluation Data
This section briefly describes the collected dataand the data transcription and annotation methods.The data described in this paper was collected dur-ing the years 2011–2013 by the University of Ed-ucation, Karlsruhe (Berkling et al., 2014). Textwritten by children of various ages was collectedat schools in and around Karlsruhe, at elemen-tary schools (Grundschule) and two types of sec-ondary schools, (Hauptschule1 and Realschule2).The data was then prepared for automated process-ing (Lavalley et al., 2015) of orthographic errorclassification (Berkling et al., 2011).
2.1 Text Elicitation
In order to collect data, children were asked towrite as verbose a text as possible.
Grades 1 to 4: Either the picture book "Derkultivierte Wolf" (The Cultivated Wolf (Bloomand Biet, 2008) about a wolf that learns how toread) or "Stimmen im Park" (Voices in the Park(Browne, 1998) about children playing in the park)was read to the students. Afterwards the studentswere asked to continue the story or write their ownstory on that topic. This resulted in spontaneouslywritten texts.
Grades 5 to 8: The instruction to the writ-ing task was simply given as either :"Imagine the
1Hauptschule: Grades 5-9, offering lower secondary edu-cation for anyone.
2Realschule: Grades 5-10, offering medium secondaryeducation designated for apprenticeship.
87

Category/Level ExplanationWord Sentence DependenciesGrS missed capitalizationGrS_S beginning of sentenceGrS_other within sentenceKS missed decapitalizationKS_WA beginning of wordKS_WI within wordMorpheme Morpheme EndingsKA error due to devoicing:_AV <b>,<d>,<g> for /p/,/t/,/k/_G <g> for /ç/ after /I/_S <s> for /z/Syllable short vs. long vowelsV_KV (short) missing silent consonantV_ie (norm) incorrect usage of <ie> for /i:/V_i (exception) incorrect usage of <i> for /i:/V_ih (few, frequent) incorrect usage of <ih> for /i:/V_LV_h wrong <ah>,<eh>,<oh>,<uh>V_LV_aa wrong <aa>,<ee>,<oo>
Table 1: Spelling Error Categories.
world in 20 years. What has changed? How doyou envision your life in 20 years? How, whereand with whom do you live? Write a text as de-tailed as possible, so we can understand you andyour ideas."; or "A day with ..." followed by thestudent’s chosen favorite star.
2.2 Text TranscriptionAll texts were transcribed and anonymized as de-scribed in Lavalley et al. (2015). They are avail-able as target text (child’s intended text) andachieved text (child’s actual writing, including allspelling errors). This combination serves as thefoundation for tagging the spelling errors automat-ically.
2.3 Meta DataMeta data will serve as a way of indexing the datafor statistical analysis on the website. This in-cludes (school type, grade, age, gender, and lan-guages spoken at home) as shown in Figure 8.
3 Definition of Algorithms
After a brief description of the error categories ona theoretical level, the algorithm will be defined.
3.1 Error CategoriesAll texts are automatically annotated with a num-ber of defined spelling error categories listed in Ta-ble 1. The error categories are used as defined in(Fay, 2010; Scholze-Stubenrecht, 2004).
Spelling errors for the German language can bedefined based on the level at which rules about lan-
guage are applied when choosing a grapheme. Ta-ble 1 distinguishes word, morpheme and syllable-level spelling issues for the categories that areevaluated in this paper.
Capitalization: Capitalization in German de-pends on the grammatical function of the wordwithin a sentence. Both incorrect capitalization aswell as incorrect non-capitalization are tracked asspelling errors at this level.
Devoicing: At the end of syllables and mor-phemes, devoicing, Auslautverhärtung (AV), oc-curs in German pronunciation for most dialects.Here are some examples for this category:
• "Gans" is not pronounced with a soft /z/,which is the normal pronunciation of thegrapheme <s>. Because it is pronounced as/s/ it can lead to misspellings like "Ganz" or"Gants".
• "Gras" follows the typical pattern of <ß>used after long vowel to create the /s/ sound,which could lead writers to misspell this pat-tern as "Grass" or "Graß".
• "Hand" is pronounced as hant /hant/ andtherefore often misspelled with a final <t>.
• "lustig" <g> after /I/ is often pronounced as/ç/ and therefore mistakenly spelled as <ch>.
Vowel Length: The short/lax vowels in Ger-man are <a>, <e>, <i>, <o>, and <u> whilethe long/tense vowels in German are <a>, <e>,<ie>, <o>, and <u>. The information of lengthis not carried in the vowel grapheme except forthe case of <ie> vs <i>. Yet, vowel length issemantically discriminative. In analogy to the En-glish "silent <e>" ("cut" vs. "cute"), German or-thography makes use of a "silent consonant". Bydoubling the consonant letter after the vowel, thelength of the preceding vowel phoneme is short-ened. (For example, "Hüte" vs. "Hütte" changes/y:/ to /y/. This happens in the German bi-syllabicstructure called Trochee (stressed, unstressed: ¯ ˘),where the second syllable contains an <e> pro-nounced as /@/. The convention is maintained withchanges at the morpheme boundary (for example:können vs. könnt).
Exceptions to the system of denoting long vow-els vary. /i:/ can be marked as <ie> (default), <i>(exception), <ih> (mostly pronouns, like "ihn"or "ihr"). All other vowels, <a>, <e>, <o>,
88

and <u> can be be followed by <h> in certaincomplex syllable endings to mark length. Fur-thermore, <a>, <e> and <o> can be doubled(<aa>, <ee> and <oo>) to mark length. Thisform is rare.
For each of the words in the corpus the specificerror types are annotated with Basis (base rate)indicating whether the error could have theoreti-cally occurred. In addition, the Error rate denot-ing an actual occurrence of the error. This differ-entiation supports error normalization across textsand students.
3.2 Annotation Algorithm
The speech synthesis system MARY (Schröderand Trouvain, 2003) is used to obtain the pronun-ciation of both target and achieved texts. Fromthere, a simultaneous grapheme and phonemesegmentation and alignment is performed as de-scribed in (Berkling et al., 2011). Together withinformation about syllable boundaries, syllablestress and morpheme boundaries obtained fromBALLOON (Reichel, 2012), spelling errors areautomatically identified using a rule-based system.
Capitalization: Capitalization and de-capitalization is performed by comparing theachieved and target grapheme. If the target iscapitalized then the Basis is tagged. If theachieved grapheme is not, then the Error istagged. If this happens at the beginning of asentence, then the subcategory GrS_S is used.For all other words, the subcategory GrS_other isused. If the target is de-capitalized then the Basisfor KS_WA category is tagged. If the achievedgrapheme is capitalized then the Error is tagged.For a letter that is wrongly capitalized withinword the Error for KS_WI is tagged ("Haus"misspelled as "haus"). Bases = 1 for KS_WIif there is at least one de-capitalized letter in theword.
Devoicing: Devoicing appears at the end of syl-lables and morpheme boundaries for certain con-sonants. The Basis of each KA_AV is tagged forgraphemes consonants <b>, <d>, <g>, <ng>,<v>, <w> unless these appear before a vowel orglottal stop. The Error is tagged if these are mis-spelled as <p>, <t>, <k>, <n>, <f> ("Hant"instead of "Hand"). The Basis of each KA_Sis tagged for grapheme <s> pronounced /s/ un-less part of an inflectional morpheme in an un-stressed syllable preceded by /@/ or as a "Fugen-
s" (Geburt.s.tag). The Error is tagged if mis-spelled as <tz>, <ts>, <z>, <ß>, or <ss>("Gans" misspelled as "Ganz"). In the current ver-sion a Basis is not marked after voiceless con-sonants because the devoicing remains even if thewords are followed by a vowel.3 The Basis ofeach KA_G is tagged for graphemes <g> if pro-nounced /ç/ or /x/ and preceded by /I/. The Erroris tagged if the misspelling is <ch> ("lustig" mis-spelled as "lustich").
Vowel Length: The Basis of each V_KVis tagged when there are double consonantgraphemes: <bb>, <dd>, <ff>, <gg>, <ll>,<mm>, <nn>, <pp>, <rr>, <ss>, <tt>,<ck>, or <tz>. The preceding phoneme must bea short vowel and the double consonant must beat the end of a morpheme boundary. The Erroris tagged if the grapheme is not correct ("rennen"misspelled as "renen").
Each of V_ie V_i V_ih V_LV_aa iseasy to identify. If there is a grapheme<ie>,<i>,<ih> corresponding to the phoneme/i:/ or <aa>,<ee>,<oo> in the target thenthe Basis is tagged. If the achieved graphemedoes not match the target then the Error forthe corresponding category is tagged. V_LV_hworks similarly, except that there may not bea morpheme boundary within the graphemes<ah>,<eh>,<oh>,<uh>,<äh>,<öh>,<üh>.These graphemes are then tagged with Basis. Ifachieved and target graphemes do not match, anError is tagged.
4 Evaluation of Error Annotations
The correctness of the tool was measured by man-ually checking 2000 randomly chosen achieved-target pairs from the corpus, about 10% of the en-tire word count. The results are given in Table 2.
4.1 Human-Machine Agreement
Regarding the (de-)capitalization errors, the ma-chine can always detect lower and upper case mis-matches correctly assuming that correct sentenceboundaries are given as input in the case of GrS_S.Therefore, no human agreement is reported. Theother categories perform as listed in Table 2.
For each of the categories, the table reports pos-itive (the Basis or Error count for the spellingcategory > 0) and negative (the Basis or Errorcount for the spelling category = 0) tags. (Note
3Devoiced Consonants are: p t k pf ts tS f s S C x
89

Category Basis ErrorKA_AV true(false) true(false)positive 209 (0) P=1 17(1) P=.94negative 1798 (3) R=.98 1981(1) R=.94
KA_G true(false) true(false)positive 28 (0) P=1 3(0) P=1negative 1972 (0) R=1 1997(0) R=1
KA_S true(false) true(false)positive 65 (4) P=.94 7(0) P=1negative 1917 (14) R=.82 1993(0) R=1
KV true(false) true(false)positive 388 (7) P=.98 115 (5) P=.96negative 1596 (17) R=.96 1878 (2) R=.98
ie true(false) true(false)positive 186 (1) P= .99 49 (3) P=.94negative 1809 (6) R= .96 1945 (4) R=.92
i true(false) true(false)positive 55 (11) P=.83 9(0) P=1negative 1939 (2) R=.96 1991(0) R=1
aa,ee,... true(false) true(false)positive 9(0) P=1 3(0) P=1negative 1991(0) R=1 1997(0) R=1
ah,eh,oh,uh true(false) true(false)positive 74(0) P=1 11(1) P=.91negative 1928(0) R=1 1988(0) R=1
ih true(false) true(false)positive 4(0) P=1 1(0) P=1negative 1996(0) R=1 1999(0) R=1
Table 2: Machine performance on Basis andError as evaluated by human expert on 10% ofdata set (2000 randomly chosen words). Precision:P = tp/(tp + fp), Recall: R = tp/(tp + fn)
that a particular error category can appear morethan once in a word, like "Affenmutter", whichexplains why some numbers do not add up to2000.) The human rater then sorts both positiveand negative tags into true (correctly identified)and false (incorrectly identified). The results arelisted along with precision (class is correctly pre-dicted) and recall (ability to select instances ofclass from data).
Some of the errors that the tool misses are ex-plained in more detail below.Morpheme: Devoicing - KA
KA_AV reported a false error in this pairof (target achieved) (see Section 2): (entschiedentschid). In the pair (gesagt gesat) both basisand error at grapheme <g> were missed. "Angst","kriegst" did not get tagged correctly as basis. Inthe latter case <g> at end of a morpheme bound-
ary should have been tagged with a consonant de-voicing. In the case of "Angst", <g> is not lo-cated at a morpheme boundary, so it can be de-bated whether this case falls into this particularcategory.
KA_G made no mistakes in identifying basis orerror tags correctly.
KA_S missed a number of words: "etwas","Applaus", "ausleiht", "Auspuff", "beste", "es","Gäste", "heraus", "Krebs". Others were falselyidentified: "anstrengend", "bisschen".Syllable: Silent Consonant - KV
The following pairs were tagged as KV but arenot strictly speaking a KV pattern because thedouble consonant did not appear within a trochee("rennen") nor at the end of a morpheme boundary(as in "rennt"). It is therefore debatable whetherthis item is falsly tagged: (allein alein). Otherwords are imported: (Gorilla Goriler), (HorrorHorer), (Installateur Instalatör), (intelligenten in-teligenten), (Tickets Tickets) and can be arguednot to fall under regular spelling patterns. It shouldbe possible, however, to identify these as non KVbecause there is neither a morpheme boundary nora reduced syllable containing an <e> followingthe double consonant. Another exception is thewrongly tagged (Hartz Hartz) which should not beidentified as KV as the preceding r-colored vowelis long (<ar> a6) and therefore does not followthe KV pattern.
The following list of words was missed bythe algorithm: "Auspuff", "ertappten", "gestoppt","gezockt", "hockte", "Lego§sammler", "Mucks","öffnet", "reinlassen", "rockten", "selbstbewusst","Truppe", "wussten", "Zigaretten", "Zocken","frisst", "höllische".Syllable: Regular /i:/ <ie>
Missed words include: "Dienstag§mittag, "die","Dienerinnen", and "Fernbedienung". "Fossilien"was mistakenly tagged. (sieht siet) and (zieht ziet)were mistakenly tagged with errors as the missing<h> does not belong to the <ie> error category.Syllable: Irregular /i:/ <i>
The following were badly annotated as allthese <i> are pronounced /I/: "Automechaniker","Chemielaborantin", "direkten", "finanziellen","Gitarre", "Grafiker", "Mechatroniker", "Navi","Plastikindustrie". One mistake identifieda transcription error on the achieved side:"Abteiliungsleiter", correctly spelled without the<i> in the center as "Abteilungsleiter".
90

Syllable: Irregular /i:/ <ih>
There were no mistakes in this category.Syllable: Irregular long vowel (<aa>, ...)
There were no mistakes in this category.Syllable: Irregular long vowel (ah, ...)
One word was mistakenly identified as an er-ror for this category: (Rutschbahn Rudschbahn),which is a mis-alignment problem due to thespelling error of <dsch>.
The next step is to diagnose the cause for theabove listed problems. Causes for these kinds oferrors can usually be removed and usually belongto one or the other of the following category ofproblems:
• In some of these cases the morpheme bound-ary or the pronunciation was not returned cor-rectly by the underlying tool. (These arefixed by providing the correct pronunciationthrough an amended pronunciation file andreporting the problem to the research groupfor the underlying morpheme tagging system,which usually fixes the problem.)
• The rules of the algorithm may need to be re-fined.
• Foreign words did not get tagged correctly.
5 Data Exploration
A broad overview of results for the spelling erroranalysis on the entire data set are given in this sec-tion. Depicted for each error category is the nor-malized value of the fraction of correctly spelledwords of that category as given by Equation 1.
#Basis(CAT )−#Errors(CAT )#Basis(CAT )
(1)
Figure 1 shows that correct (de-)capitalizationimproves with each grade. However, correct capi-talization is still misspelled at a rate of 10% evenin eighth grade. Capitalization is difficult withinsentence, as German has more complex rules thanmost other languages. But even at the beginning ofa sentence, trivial capitalization is not mastered.
Figure 2 depicts the development of spellingerrors for the category of devoiced consonantsat the ends of morpheme or syllable boundariesexplained in Section 3. The devoiced <s> isthe most difficult but all three categories improverapidly after third grade. Both <ig> (average of
Figure 1: % Correct for capitalization in generaland at sentence start. % Correct decapitalization.
.3 occurrences per text in Grade 8) and <s> (aver-age of 3 occurrences per text in Grade 8) are muchmore rare than AV (average of 10 occurrences pertext in Grade 8). This may in part explain the out-lier in Grade 2 for /s/.
Figure 2: % Correct at morpheme and syllableendings for "Auslautverhärtung" - devoicing ofvoiced consonants in general (AV) for <s> as /s/and <ig>.
Figure 3 shows the statistical distribution of er-rors for the example of V_KV. There is a verylarge variance in occurrence frequency of bothbase and errors. Mean and variance for % correctfor this category show that there is need for furtheranalysis that is beyond the scope of this paper.
Figure 4 shows the development of spelling er-rors regarding the marking of long vowels. Theseinclude the various ways of denoting long /i:/ as<ih>, <i>, <ie> (default). The marking of <i>is mastered most quickly (3 occurrences per texton average in Grade 8). Further it is surprising
91
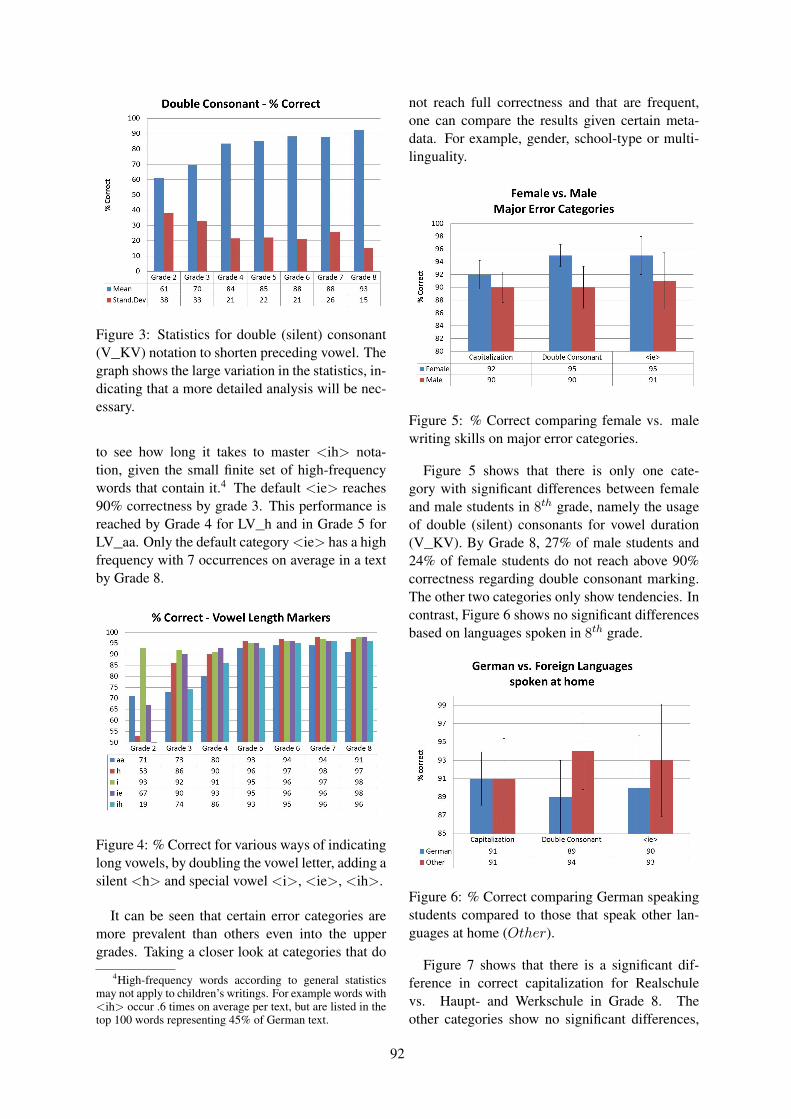
Figure 3: Statistics for double (silent) consonant(V_KV) notation to shorten preceding vowel. Thegraph shows the large variation in the statistics, in-dicating that a more detailed analysis will be nec-essary.
to see how long it takes to master <ih> nota-tion, given the small finite set of high-frequencywords that contain it.4 The default <ie> reaches90% correctness by grade 3. This performance isreached by Grade 4 for LV_h and in Grade 5 forLV_aa. Only the default category <ie> has a highfrequency with 7 occurrences on average in a textby Grade 8.
Figure 4: % Correct for various ways of indicatinglong vowels, by doubling the vowel letter, adding asilent <h> and special vowel <i>, <ie>, <ih>.
It can be seen that certain error categories aremore prevalent than others even into the uppergrades. Taking a closer look at categories that do
4High-frequency words according to general statisticsmay not apply to children’s writings. For example words with<ih> occur .6 times on average per text, but are listed in thetop 100 words representing 45% of German text.
not reach full correctness and that are frequent,one can compare the results given certain meta-data. For example, gender, school-type or multi-linguality.
Figure 5: % Correct comparing female vs. malewriting skills on major error categories.
Figure 5 shows that there is only one cate-gory with significant differences between femaleand male students in 8th grade, namely the usageof double (silent) consonants for vowel duration(V_KV). By Grade 8, 27% of male students and24% of female students do not reach above 90%correctness regarding double consonant marking.The other two categories only show tendencies. Incontrast, Figure 6 shows no significant differencesbased on languages spoken in 8th grade.
Figure 6: % Correct comparing German speakingstudents compared to those that speak other lan-guages at home (Other).
Figure 7 shows that there is a significant dif-ference in correct capitalization for Realschulevs. Haupt- and Werkschule in Grade 8. Theother categories show no significant differences,
92

only tendencies. 37% of students in Werk- andHauptschule and 26% of students in Realschule donot reach 90% correct command of capitalization.
Figure 7: % Correct comparing Realschule vsHaupt- and Werkschule.
The above are some examples of the type ofpossible analyses that can be performed with re-spect to the meta data and provides a valuable re-source for researchers and perhaps teachers. De-pending on which spelling errors are of interest,the user interface provides a template of categoriesto select from as shown in Figure 9 in the Ap-pendix.
6 Accessibility of Algorithms
The website is available in English and Germanvia http://ktc.dh-karlsruhe.de/wise.php. The usersare able to either explore the Karlsruhe Databaseor upload their own file in order to have the textannotated with spelling errors.
6.1 Data Exploration
As presented in Figure 8, the Karlsruhe Databaseexploration can be performed by filtering the de-sired texts according to meta-data, returning theerrors committed by children of specific grades,kind of schools, ages, etc. Then the user canchoose the types of spelling errors he wants toanalyse (Figure 9). The result will be a tabulatedfile (csv) providing all the (non-unique) word pairsmatching the filtering criterion, with basis and er-ror values for each of the selected categories.
6.2 Data Input
If the user wants to perform an analysis on his owndata, he can choose the "Upload your own file"
option at the top of the web-page. The uploadedfile must be a text file with the following format:
The first lines, preceded by #, are used todeclare the meta-data. These metadata are:#Grade:number#Gender:F/M#Age:number#L1:languageSpokenAtHome[, anotherLanguage-SpokenAtHome]*#Schooltype:KindOfSchool (i.e., Grunschule,RealSchule, Hauptschule, Werkrealschule, ...)#Date:dd/mm/yyyy (date of the data collection)#Misc:free text (use this field for additionalinformation, e.g. dyslexic child can be indicatedhere as LRS)The rest of the file is used to provide the text toanalyse, one sentence per line; the format is:achieved (child) sentence 1target (corrected) sentence 1Am Tag danach ging er wieder_in die Schule.Am Tag danach ging er wieder_in die Schule.Die Kinder aus seinen{G} Klasse beo§bachten.Die Kinder aus seiner{G} Klasse beo§bachtenSie haben noch [§weiter] lesen geübt.Sie haben noch [§weiter] lesen geübt.Peter{N} war traurich.Peter{N} war traurig.Es gibt Hightek{F}=comuter{F}.Es gibt Hightech{F}=Computer{F}.
This text can be annotated (grammar errors,foreign words, ...) according to the annotationscheme presented in Table 3 5. Words can be an-notated with qualifications such as grammatical er-ror ("gebte{G}" instead of "gab" which is clearlynot a spelling error). At the sentence level substi-tutions can be annotated such as [wo der] (using"wo" instead of "der"). In the latter case the stu-dent’s word will still be analyzed. Text is accom-panied by meta data that will support growing alarger indexed database of children texts.
6.3 Data Output
The output of the above input is a tabulated .csvfile with Tab as field separator, listing both Basisand Error for each of the corresponding selectederror categories.
The following statistics are computed on thewhole text and returned with the tagged file:
5Numbers are transcribed as they are; words like"Leeeooooooooooooonnn" also should not be corrected.
93

Letter- and Word-Level Annotations:* unreadable lettera_b a and b should have been written separatelya§b a and b should have been joineda=b missing hyphena∼b wrongly placed hyphena−−b denotes split of word at end of line (not hyphen)a{n} n repetitions of word aa{F} Foreign word defined by non-German graphemes,
foreign grapheme-phoneme correspondencea{I} incomplete worda{G} grammatical errors not to be analyzed for spellinga{A} abbreviations such as Etc.{A}a{N} Names, not analysed with the spell tagger
Sentence Level Annotations[§ fW] an unknown deletion[§ b] a known deletion b[a §] an insertion a[a b] substitution of a for b
a is corrected on target sideAchieved: [seinne ihre]Target: [seine ihre]
[a b_c] best guess of word boundary[a_b c] kanicht = ka[n nn_n]icht[a *] some combinations of letters make up word a
the real word can not be identified.a can include conventions from word-level annotationsFor example: [rtchen**gdsdfg *] [rtchen**gdsdfg *]or [a{G} b]
Table 3: Conventions for annotation of transcrip-tions as relevant to automatic spelling annotation.
Standard Method:Each selected category provides the sum of Basisand Error found in the text and their ratio(Quotient) of actual errors: total number ofErrors divided by total number of Basis.
However, these raw statistics may not be appro-priated in all cases. For example, consider thata child always misspells a specific word but doesnot generalize this to other words with similar pat-terns. In this case, it might be interesting to countpattern occurrences and not word occurrences. Toexpress other ratios, two additional normalizationmethods have been added to the output.Achieved-Target Pair Normalization:Basis counts each occurrence of the same pair(target;achieved) of words. This way, the same ex-act error, on the same word, repeated several timescounts only once towards the final sum and quo-tient.Target-Word Normalization:Each target word counts towards the Basis ex-actly once, regardless of how many differentspelling errors are committed. Errors on this par-ticular target word are then kept as a ratio (For
example, in Table 4 30% (.3) of the time, theword "Gott" is misspelled as "Got"). All the oc-currences of the same target word sum to 1. Inother words, each occurrence of this word countsas 1/nbOccTargetWord. With this measure, anisolated error on a word which is correctly writtenall the other times (could be a typo for instance)has a lower impact compared to the other count-ing methods. Conversely, if a word was spelledcorrectly once (by chance) out of ten times thisshould equally have a low impact (keeping the ra-tion at .9).
Table 4 compares these different measures com-puted for the V _KV error category. The exampletext contains 10 occurrences of the word "Affe"(monkey), misspelled as "Afe", which is a V _KVerror. This text also contains 2 correctly spelledoccurrences of "stellen" (place) and 1 occurrenceof "kann" (I can) both falling under KV rules. Nor-malizing differently will modulate the effect of theerrors in "Affe". Depending on the use case, allthe errors should be counted under the standard(std) normalization scheme. This is the case fordictation. Assuming the child principally knowsthe V _KV pattern, which seems to be the casewhen looking at the table. Unfortunately, the oneword the child is not able to generalize to is themost frequent one. Pair normalization takes thisinto account by looking at pairs of mistakes, de-emphasizing re-occurrence of particular mistakes.Supposing however, that it is important to reporton the ratio of types of errors committed on a pairpattern that occurs several times. In this case, thethird normalization takes into account the fractionof errors committed. This is shown in the tablewith the example of the word "Gott". In this case,the child is unsure about the orthography of "Gott"(god) and writes it correctly 4 times and incor-rectly twice. In the pairwise normalization theError would be reported as 50/50, counting eachpair only once, losing the frequency of each pair.In the target-word normalization the ratio wouldbe presented accurately.
Comparing the three cases, 10 mispellings of"Affe" have a large impact on the standard ra-tio, with an error rate of 63% for V _KV (10 ofthe 12 V _KV errors are due to this word). Thepair normalized ratio tells us that 40% of the wordpairs raise a V _KV error: (Affe;Afe) counts asBase = Error = 1 such as the 2 occurrences of"Got" instead of "Gott". "Gott" correctly written
94

std pnorm tnormT A occ B E B E B EAffe Afe 10 10 10 1 1 1 1kann kann 1 1 0 1 0 1 0Gott Gott 4 4 0 1 0 0.7 0Gott Got 2 2 2 1 1 0.3 0.3stellen stellen 2 2 0 1 0 1 0
Sum 19 19 12 5 2 4 1.3Quot 0.6 0.4 0.3
Table 4: Example of different computations forSUMME and QUOTIENT in case of KV erroranalysis: standard (std), pair-normalized (pnorm)and targetword-normalized (tnorm). B: BaseE:Error T:target word, A: achieved word, occ:number of occurrences in the text.
also counts as Base = 1 but Error = 0. Targetnormalized ratio tells us that 33% of target wordsare wrong: (Affe;Afe) counts as 1, so Basis =Error = 1. "Gott" is misspelled 2 times out of 6,so the error ratio for this word is 0.33. Comparedto the previous measure, this one takes into con-sideration the fact that "Gott" has been correctlywritten 66% of the times, whereas with pair nor-malized ratio, we considered that there were twodifferent spellings and one was correct, leading to50% of correct spellings. An example of such anoutput and the three ways of data normalization isdepicted in Figure 10.
7 Conclusions
In this paper we evaluated a tool for automatic an-notation of spelling errors on a publicly availabledatabase. We introduced a website that allows re-searchers to explore the tagged corpus or uploadnew data in order to have it annotated and joinedto the data collection effort. This work is an im-portant contribution to the research about spellingacquisition.
Acknowledgments
The work leading to these results was in partfunded by a research grant from the German Re-search Foundation (BE 5158/1-1).
ReferencesKay Berkling, Johanna Fay, and Sebastian Stüker.
2011. Speech Technology-based Framework forQuantitative Analysis of German Spelling Errorsin Freely Composed Children’s Texts. In SLaTE,pages 65–68.
Kay Berkling, Johanna Fay, Masood Ghayoomi, Ka-trin Hein, Ludwig Linhuber, and Sebastian Stüker.2014. A Database of Freely Written Texts ofGerman School Students for the Purpose of Auto-matic Spelling Error Classification. In LanguageResources and Evaluation Conference LREC 2014,pages 1212–1217, Reykjavik and Iceland.
Becky Bloom and Pascal Biet. 2008. Der kul-tivierte Wolf. Lappan Verlag, Oldenburg. AndreaGrotelüsche, Translator.
Anthony Browne. 1998. Stimmen im Park. Lappan,Oldenburg. Peter Baumann, Translator.
Johanna Fay. 2010. Die Entwicklung derRechtschreibkompetenz beim Textschreiben. Eineempirische Untersuchung in Klassen 1 bis 4. PeterLang, Frankfurt.
Rémi Lavalley, Kay Berkling, and Sebastian Stüker.2015. Preparing children’s writing database for au-tomated processing. In Workshop on L1 Teaching,Learning and Technology (L1TLT), Leipzig, Ger-many, September.
Uwe Reichel. 2012. PermA and Balloon: Tools forstring alignment and text processing. In Proc. Inter-speech, pages 1874–1877, Portland and Oregon.
Werner Scholze-Stubenrecht. 2004. Duden - Diedeutsche Rechtschreibung: Auf der Grundlage derneuen amtlichen Rechtschreibregeln, volume 1 ofDer Duden in zwölf Bänden. Dudenverl, Mannheim[u.a.], 23 edition.
Marc Schröder and Jürgen Trouvain. 2003. The Ger-man Text-to-Speech Synthesis System MARY: ATool for Research, Development and Teaching. InInternational Journal of Speech Technology, pages365–377.
95

Figure 10: Example of tool output.
Figure 8: Meta data selection on Web interface. Figure 9: Selection of error categories to mark.
96