williamson thesis - our archive home
TRANSCRIPT

A Lightweight Data Integration
Architecture
David William Williamson
a thesis submitted for the degree of
Master of Science
at the University of Otago, Dunedin,
New Zealand.
12 June 2006

Abstract
Content syndication specifications such as Atom have become a popular
mechanism to disseminate information across the Internet, with many sites
providing Atom feeds for users to subscribe to and consume. Such a scenario
typifies the originally intended use of Atom; however, our research has ex-
plored an alternative domain for this syndication technology. This research
has evaluated Atom for its potential as a lightweight platform to support
data integration from a set of data sources to a single target database.
The implementation of the Atom-based architecture that we developed for
this research combines freely available server-side scripting technology with
the simplified asynchronous connection scheme that content syndication
technology offers. We use several use cases each with different degrees of
complexity, yet sharing common requirements, as a guide in the develop-
ment of our prototype.
In order to evaluate our Atom-based architecture, our experimental design
required the construction of an evaluation framework that measured the
prototype’s impact upon the network and computation resources it con-
sumed. These measurements were compared with observations of response
time requirements between operational and analytical processing systems.
The experiments carried out to evaluate the Atom-based data integration
architecture have shown that the architecture has potential in facilitating
a lightweight data integration solution. Our research has shown that an
Atom-based architecture is capable of operating within a range of condi-
tions and environments, and with further development, would be capable
of greater processing efficiency and wider compatibility with other types of
data structures.
ii

Acknowledgements
I would like to take this opportunity express my gratitude to all those people
who have supported me during this research, and in particular:
My supervisor Dr. Nigel Stanger, who suggested the idea that would be-
come the core of my work, and who has been invaluable in every step of
the project.
To Dr. Noria Foukia, Dr. Colin Aldridge and Dr. Tony Moore, for giving
their own time to proof-read and critique various parts of my thesis.
Graham & Co. of the Technical Services Group, thanks guys for providing
support and resources that enabled me to complete my experiments.
My colleagues and office-mates past and present: Prajesh, Christian, Heiko,
Dr. Xin, Matt, (soon to be Dr.) Grant, Ahmad and Jacqui, thanks for some
hilarious moments, lively debate on anything and for creating a fantastic
working environment. It has been a privilege to work alongside you all and
it is my hope that we can remain friends for a long time to come.
To my family, though you weren’t always sure what on earth it was I was
doing, you supported me nonetheless, thank you.
Lastly but certainly not least, my dear Sabine, you have been a pillar
of strength to me throughout this project, although we live in an age of
sophisticated communications technology, the other side of the world is still
a great distance. Completing this thesis has meant spending considerable
time apart; I sincerely thank you for your support.
iii

Contents
1 Introduction 11.1 Purpose of Study . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Research Scope . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.1 Objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2.2 Delimitations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Structure of Thesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Related Work 52.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 The Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1 Semantic Web Principles . . . . . . . . . . . . . . . . . . . . . . 72.2.2 Resource Description Framework (RDF) . . . . . . . . . . . . . 82.2.3 PRISM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.4 RSS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.5 Atom . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.2.6 Recent Developments . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Data Integration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.4 Publish/Subscribe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.5 Update Propagation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.6 Data Streaming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.7 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3 System Design 313.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 313.2 Use Cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.2.1 Movie Timetable e-Catalogue . . . . . . . . . . . . . . . . . . . 323.2.2 MP3 Music Retail System . . . . . . . . . . . . . . . . . . . . . 323.2.3 Electronics Retailer Data Warehouse . . . . . . . . . . . . . . . 33
3.3 Requirements Summary . . . . . . . . . . . . . . . . . . . . . . . . . . 343.4 Development . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.4.1 The Development Environment . . . . . . . . . . . . . . . . . . 343.4.2 Implementation Rationale . . . . . . . . . . . . . . . . . . . . . 353.4.3 The Feed Builder Module . . . . . . . . . . . . . . . . . . . . . 363.4.4 The Feed Consumer Module . . . . . . . . . . . . . . . . . . . . 413.4.5 System Configuration . . . . . . . . . . . . . . . . . . . . . . . . 43
iv

3.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443.6 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4 Experimental Design 484.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 484.2 Experiment Rationale . . . . . . . . . . . . . . . . . . . . . . . . . . . 494.3 Evaluation Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.3.1 The Load Test . . . . . . . . . . . . . . . . . . . . . . . . . . . 514.3.2 The Operational Test . . . . . . . . . . . . . . . . . . . . . . . . 524.3.3 The Latency Test . . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.4 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5 Results 565.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.2 Findings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.2.1 The Load Test . . . . . . . . . . . . . . . . . . . . . . . . . . . 565.2.2 The Operational Test . . . . . . . . . . . . . . . . . . . . . . . . 595.2.3 The Latency Test . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.3 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
6 Conclusion 626.1 Discussion of Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . 626.2 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 656.3 Recommendations and Conclusions . . . . . . . . . . . . . . . . . . . . 67
References 69
A Music Kiosk Use Case 76A.1 MP3 Kiosk Project Documentation . . . . . . . . . . . . . . . . . . . . 76A.2 Schemas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
A.2.1 Kiosk Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88A.2.2 Source Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
B Experiment Data Sets 91B.1 Load Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91B.2 Operational Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92B.3 Latency Test Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
C Example RSS Feed 93
v

List of Figures
2.1 A simple, single entry Atom feed document (Nottingham and Sayre, 2005). 112.2 Prototypical Architecture of a Data Integration System (Levy, 2000). . 152.3 Wiederhold’s (1993) three tier integration architecture “I3” utilising me-
diators. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.4 Inputs and Outputs of Data Integration (Batini, Lenzerini and Navathe,
1986). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.5 Interfacing Strategies (Pascoe and Penny, 1990). . . . . . . . . . . . . . 192.6 A data integration framework using publish/subscribe (Vargas, Bacon
and Moody, 2005). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.7 Golab and Ozsu’s (2003a) DSMS architecture. . . . . . . . . . . . . . . 272.8 Apama financial analysis system (Progress Software, 2006). . . . . . . . 29
3.1 Overview of the basic architecture . . . . . . . . . . . . . . . . . . . . . 373.2 Flow chart of Atom feed builder . . . . . . . . . . . . . . . . . . . . . . 383.3 Example Atom entry from the MP3 kiosk use case. . . . . . . . . . . . 403.4 Flow chart of Atom feed consumer . . . . . . . . . . . . . . . . . . . . 42
5.1 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575.2 Comparison of Outputs . . . . . . . . . . . . . . . . . . . . . . . . . . . 585.3 Network Traffic Generated by Atom Prototype . . . . . . . . . . . . . . 585.4 Packets Generated by Atom Prototype . . . . . . . . . . . . . . . . . . 605.5 Update latency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
vi

Chapter 1
Introduction
1.1 Purpose of Study
Atom is a content syndication specification intended to provide a simple means to read
and write information on the World Wide Web (WWW). The benefit of a specification
like Atom is that it allows users to easily remain up to date with the latest informa-
tion from many web sites, as well as easily publishing their own content for others to
consume (AtomEnabled, 2005).
This research has observed Atom in a context slightly removed from its web-centric
content origins; Atom has been evaluated for its potential as a lightweight platform
to support data integration, by means of asynchronous update propagation, between
relational databases. An asynchronous approach is easily scalable because of its general,
simplified support infrastructure; allowing connections between objects to be decoupled
in terms of synchronization, space and time.
Syndication presents a further simplified asynchronous framework that removes ad-
ditional infrastructure, like that found in publish/subscribe systems, between objects.
However, syndication technology retains the advantages of scalability associated with
asynchronous connection schemes. We have combined this simplified asynchrony with
the low cost, platform independent technology Hypertext Preprocessor (PHP).
The collective advantages of the scalability of an asynchronous approach, the sim-
plified infrastructure afforded by syndication technology such as Atom, and the feature-
rich technology of PHP, give rise to an avenue to create a data integration solution that
is lightweight in terms of the extent of impact on organisation’s available resources.
1

1.2 Research Scope
1.2.1 Objectives
As mentioned previously, the purpose of this research was to evaluate Atom for its
potential to facilitate data integration. In order to achieve this, the objective was
further abstracted and defined into two sub-goals:
1. To investigate the degree of potential an Atom-based approach has as a data
integration architecture that is lightweight in terms of tangible (network and
computational) resource requirements.
2. To infer from the degree of potential exposed by the prototype whether it is
worthwhile pursuing the use of syndication technology such as Atom in the do-
main of database integration.
In order to achieve these objectives, the following sub-goals were defined:
1. Identify appropriate technologies that are readily available and capable of deliv-
ering the features needed in the prototype Atom-based architecture.
2. Construct an appropriate framework to evaluate and examine the behaviour of
an implementation of Atom-based architecture under various loading conditions,
configurations and use cases.
3. Incorporate suitable use cases into the framework, i.e., identify scenarios within
the scope of usage the Atom-based architecture is intended for.
1.2.2 Delimitations
The scope of the research was narrowed primarily in regards to the schema and data
types used when evaluating the Atom-based architecture:
1. The research did not look at security features such as authentication or encryp-
tion.
2. The structure of data sources used in testing was restricted to relational type
schemas.
3. Data types used in both the data sources and the target were restricted to al-
phanumeric text.
2

4. The direction or flow of information is one-way, that is the focus has been on
propagating data from a source to a target and not back the other way.
1.3 Structure of Thesis
The content of this thesis has been organised into six chapters. Related work is covered
initially before details specific to this research are presented. The thesis concludes with
a discussion of the implications of the results obtained from this research.
Chapter 2 presents a series of topics from related work to illustrate and discuss
where both this research and the Atom specification are positioned. Initially precur-
sor technologies to the Atom specification are presented (the Semantic Web) before
the related fields of data integration, update propagation and the publish/subscribe
paradigm are discussed. The final section presents data streaming to illustrate a con-
trasting technology.
Chapter 3 details the implementation of the Atom-based architecture that we de-
veloped for this research. We combined the freely available, feature rich technology
PHP with the simplified asynchronous connection scheme that content syndication
technology offers to create our data integration prototype.
Chapter 4 describes the experimental design, which required the construction of
an evaluation framework that measured the prototype’s impact upon the network and
computation resources it consumed. These measurements were used in conjunction
with observations of response time differences between operational and analytical pro-
cessing systems.
Chapter 5 presents the results of the three different experiments carried out to eval-
uate the prototype implementation of the Atom-based data integration architecture.
The experiments focussed on obtaining data pertaining to the responsiveness (latency)
of the system and its impact on the network and computational resources available in
its immediate environment.
Chapter 6 concludes our work by summarising and discussing the results of our
research and its implications, before suggesting recommendations and directions for
further investigation.
3

1.4 Summary
The purpose of this research was to evaluate the Atom content syndication specification
for its potential as a platform to facilitate lightweight data integration architecture. The
term lightweight was defined in terms of impact on network and computing resources.
The extent of potential was used to infer if pursuing an Atom-based architecture beyond
a prototypical status was worthwhile.
The scope of the evaluation restricted the prototype Atom-based architecture to
focus on integrating data of alphanumeric text between source and target relational
databases, and has not addressed data security issues. The next chapter will present
topics from research work related to the Atom specification and data integration.
4

Chapter 2
Related Work
2.1 Introduction
This review of related work has been organised into five main subject areas. The
first presented in Section 2.2 discusses the Semantic Web, its core design principles
and the technology that is intended to implement it; namely Resource Description
Framework (RDF). This discussion is presented to give some background to the Atom
specification (Section 2.2.5), which has been built on Semantic Web technology and
plays an important part in this research activity.
Section 2.3 introduces the topic of data integration, which is the domain that the
Atom specification has been adapted for in this research. Data integration refers to
the problem of trying to provide a user with a unified view of data that may be stored
in multiple locations and in differing formats. This research activity has attempted to
evaluate Atom for its potential as a lightweight platform to support data integration
by means of asynchronous update propagation from a series of data sources to a single
target database.
Publish/subscribe is then discussed in Section 2.4, which is a paradigm that has
received significant attention recently for its claimed ability to provide a flexible and
highly scalable framework for large distributed information systems. The publish/sub-
scribe architecture uses a common framework that subscribers use to register their
interest in the occurrence of specific events.
The next topic is update propagation introduced in Section 2.5. Update propagation
refers to the problem of updating copies of an object and is commonly associated with
distributed systems. The problem is centred on the need to ensure that if a change
is made to an object (e.g., a row is updated in a table) then that change must be
disseminated to all other copies of that object in the system.
5

Data streaming is the final topic to be discussed in Section 2.6. A significant area
of research in its own right, information systems increasingly have to be able to process
types of data that are highly dynamic and transient.
2.2 The Semantic Web
The World Wide Web (WWW) as it stands today is comprised mostly of documents in-
tended for humans to read, which allows minimal opportunity for computers to perform
additional interpretation or processing on them (Koivunen and Miller, 2001; Berners-
Lee and Fischetti, 1999). In essence, computers in use on the Web today are primar-
ily concerned with the parsing of elementary layout information, for example head-
ers, graphics or text, or user input form processing (Berners-Lee, Hendler and Las-
sila, 2001).
There are few means by which computers can perform more meaningful processing
on web resources (Berners-Lee et al., 2001; Fensel, Hendler, Lieberman and Wahlster,
2003) most often because the additional meaning (semantics) required does not exist
or is not in a form that can be interpreted by them (Koivunen and Miller, 2001).
The motivation for the adoption of semantics can be made evident simply by using
a contemporary search engine to look for an address. This search will likely return
a variety of results ranging from street addresses, email addresses to public addresses
made by important individuals through the ages.
This kind of scenario is one of the reasons for the World Wide Web Consortium’s
(W3C) Semantic Web project (Koivunen and Miller, 2001). In the words of its creator,
Tim Berners-Lee, its goal is to:
“. . . develop enabling standards and technologies designed to help machines
understand more information on the Web so that they can support richer
discovery, data integration, navigation and automation of tasks. With Se-
mantic web we not only receive more exact results when searching for in-
formation, but also know when we can integrate information from different
sources, know what information to compare, and can provide all kinds of au-
tomated services in different domains from future home and digital libraries
to electronic business and health services.” (Koivunen and Miller, 2001, p.
27).
In other words, the Semantic Web will provide a mechanism in which more intelli-
gent searching and processing of information will be possible by further extending the
existing capabilities of the World Wide Web (WWW).
6

2.2.1 Semantic Web Principles
The W3C have outlined several assumptions that form the basis for how the Seman-
tic Web will operate; firstly that any (physical or abstract) object or concept can in
some way be referred to through the use of Uniform Resource Identifiers (URI’s). One
common example of a URI is the Uniform Resource Locator (URL) of a web page.
Closely aligned to this principle is the premise that resources and the links between
them can have types, for example, currently the Web is comprised of hyperlinks and
resources, and often the resources are documents which are oriented more toward hu-
man interaction (i.e. for reading by a user). Documents like those just described often
lack any additional data that machines could use to derive what kind of document it is
or what its relationship may be with other documents or resources. The Semantic Web
will remedy this situation by providing the capability to append additional metadata
providing computers with a means to perform further automation of tasks.
Like the contemporary WWW, the Semantic Web is unbounded with the possibility
of any number of different types of links between differing resources. Also, like the
WWW, links to resources may change, be used for something else or disappear entirely,
thus the Semantic Web must be able to tolerate volatility of the data that are held
within it.
Trustworthiness of a resource can be scrutinized by the application that intends
to process that resource’s information. Applications evaluate the trustworthiness of a
resource by looking at statements or assertions made about that resource. For example,
who has said what, when it was said and what authority allows such a statement to
be made by that particular entity about that resource.
The descriptive conventions used by the Semantic Web allow the creation of vo-
cabularies that can grow to accommodate the ever-expanding breadth of human un-
derstanding. In addition, a vocabulary used by one party can be combined with other
vocabularies (Berners-Lee, Connolly and Swick, 1999) in order to alleviate ambiguity
or inconsistency between parties.
The final principle outlines the W3C’s intention to standardise only what is deemed
necessary, allowing the Semantic Web to evolve and grow freely.
These principles are implemented through the use of specific web technologies and
standards developed by the W3C. The rest of this section will outline the relationships
of these components to the Semantic Web.
7

Key Components
The following list is taken from The OWL Web Ontology Language Overview (McGuin-
ness and van Harmelen, 2004), and provides a description of the technologies and
standards that are to be used to implement the Semantic Web:
• XML provides a surface syntax for structured documents, but imposes no seman-
tic constraints on the meaning of these documents.
• RDF is a data model for objects (“resources”) and relations between them, it
provides a simple semantics for this data model, and these data models can be
represented in XML syntax.
• RDF Schema is a vocabulary for describing properties and classes of RDF re-
sources, with a semantics for generalization-hierarchies of such properties and
classes.
• OWL is the Web Ontology Language. Though not directly related to this re-
search, it is an important component of the Semantic Web and is intended to be
used when information contained in documents needs to be processed by applica-
tions rather than having the documents’ content presented in human-consumable
form.
2.2.2 Resource Description Framework (RDF)
RDF is a technology that is an integral part of the W3C Semantic Web initiative,
as the following excerpt from the W3C Semantic Web activity statement, by Powers
(2003), will attest:
“The Resource Description Framework (RDF) is a language designed to
support the Semantic Web, in much the same way that HTML is the lan-
guage that helped initiate the original Web. RDF is a framework for sup-
porting resource description, or metadata (data about data), for the Web.
RDF provides common structure that can be used for interoperable XML
data exchange” (Powers, 2003, p. 1).
What RDF does in the context of the Semantic Web is to provide the capability
of recording data in a way that can be interpreted easily by machines, which in turn
8

provides an avenue to “. . .more efficient and sophisticated data interchange, searching,
cataloguing, navigation, classification and so on. . . ” (Powers, 2003, p. 14).
The concept forming the basis for RDF model structure is that an entity being
described will have properties, and those properties will have values associated with
them. To formalise this concept, the RDF description statements consist of triples,
namely the subject, the predicate and the object. The subject part holds data about
what sort of entity this description is about (e.g. a document, a person etc.). The
predicate part contains a property of the subject (date created, name etc.) and the
object contains a value for the property (Manola, Miller and McBride, 2004).
PRISM and RSS 1.0 are two examples of applications resulting from RDF since
RDF’s inception in the late 1990’s.
2.2.3 PRISM
Publishing Requirements for Industry Standard Metadata (PRISM) is a metadata spec-
ification developed in the publishing industry. The specification was intended to help
publishers easily use their content in different ways and therefore improve the return on
the initial investment of creating the content to start with (IDEAlliance, 2006; Manola
et al., 2004).
2.2.4 RSS
RDF Site Summary (RSS) is an XML application, of which versions 0.90, 1.0 and
1.1 conform to the W3C’s RDF specification and is a format intended for metadata
description and content syndication (Manola et al., 2004). Originally developed by
Netscape as a means to syndicate content from multiple sources onto one page (Powers,
2003), RSS has been embraced by other individuals and organisations resulting in the
creation of multiple versions.
As a consequence, there are now two branches of the RSS standard. Versions 0.90,
1.0, 1.1 constitute the first branch. The second branch contains versions 0.91 - 0.94
and 2.0.1, commonly referred to as RSS 2.0, copyrighted by Harvard University and is
considered frozen.
At its most simple, the information provided in an RSS document consists of the
description of a channel (that could be on a specific topic such as current events, sport
or the weather, etc. ) consisting of items (e.g. a news headline) linked to other resources
(e.g. the related news article). Each item is comprised of a title, a link to the actual
9

content and a brief description or abstract. Appendix C contains an example RSS
document taken from the W3C website. Because of the proliferation of differing RSS
standards and associated problems with compatibility, a group of service providers,
tool vendors and independent developers have initiated the development of a separate
syndication standard called Atom.
2.2.5 Atom
The Atom specification is an XML-based document format that has been designed to
describe lists of related information (Nottingham and Sayre, 2005). These lists have
a URL and are accessed via HyperText Transfer Protocol (HTTP), i.e. over the Web,
and are known as feeds. Feeds are made up of multiple items, known as entries; each
entry can have an extensible set of attached metadata (Nottingham and Sayre, 2005).
Figure 2.1 shows an example of a simple, single-entry Atom feed document.
Atom as a technology comprises four key related components: a conceptual model
of a resource, a well defined syntax for this model, the actual Atom feed format and
an editing protocol. Both the feed format and the editing protocol make use of the
aforementioned syntax.
The latest specification of Atom (1.0) is a successor to the initial version (0.3),
which at the time of writing, was still in draft form, and states the main purpose that
Atom is intended to address is “. . . the syndication of Web content such as weblogs
and news headlines to Web sites as well as directly to user agents” (Nottingham and
Sayre, 2005). The specification also suggests that Atom should not be limited to just
web based content syndication but in fact may be adopted for other uses or content
types. A detailed comparison of the Atom and RSS 2.0 specifications can be accessed
from the official Atom website1.
2.2.6 Recent Developments
Recently both Google Inc. and Microsoft Corp. announced the release of APIs and
specifications that are based on content syndication technologies (Atom and RSS re-
spectively) to support the dissemination of data via the WWW.
Microsoft released the draft specification for SSE (Simple Sharing Extensions) ver-
sion 0.9 in November 2005, followed by version 0.91 in January 2006. SSE is a set
of extensions to the RSS 2.0 and Outline Processor Markup Language (OPML) 1.0
1http://www.atomenabled.org
10

<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Example Feed</title>
<link href="http://example.org/"/>
<updated>2003-12-13T18:30:02Z</updated>
<author>
<name>John Doe</name>
</author>
<id>urn:uuid:60a76c80-d399-11d9-b93C-0003939e0af6</id>
<entry>
<title>Atom-Powered Robots Run Amok</title>
<link href="http://example.org/2003/12/13/atom03"/>
<id>urn:uuid:1225c695-cfb8-4ebb-aaaa-80da344efa6a</id>
<updated>2003-12-13T18:30:02Z</updated>
<summary>Some text.</summary>
</entry>
</feed>
Figure 2.1: A simple, single entry Atom feed document (Nottingham
and Sayre, 2005).
11

specifications (Ozzie, Moromisato and Suthar, 2005). The goal of SSE is to provide
a basic, minimum set of extensions “. . . to support loosely-cooperating apps [applica-
tions]” (Ozzie et al., 2005, p. 1).
The proposed model of usage is very simple; the SSE website (Ozzie et al., 2005)
provides an example of a usage model comprising two nodes (the term “endpoints”
rather than “nodes” is used by Microsoft). Both nodes in the scenario wish to share
data with the other; to do this, each node publishes an RSS 2.0 feed containing those
data, along with the SSE mark-up. The SSE data contains information that is used
to by the nodes to synchronise each others’ items. The framework to facilitate the
synchronisation is created simply by each node subscribing to the other node’s feed.
Google released their GData protocol in April 2006 with an API that is currently
in a beta stage of development (Google, 2006). Unlike Microsoft’s SSE, the GData
protocol is based upon both Atom 1.0 and RSS 2.0, and also makes use of the Atom
specification’s publication protocol (Google, 2006). The GData protocol also provides
basic querying functionality.
Interestingly, both the GData and SSE documentation use calendar data synchroni-
sation scenarios as example uses of the technologies (Ozzie et al., 2005; Google, 2006).
More importantly however, the example scenarios represent a move away from more
conventional uses of syndication technologies; the calendar scenarios show the use of
Atom and RSS based technology to disseminate data bi-directionally between appli-
cation systems, rather than the more usual unidirectional publication of data as seen
with a news feed or personal web log.
Additionally, the fact that two of arguably the world’s most high profile technology
companies have developed similar enhanced syndication specifications and protocols
further emphasizes the growing focus on the use of content syndication technologies as
a model to disseminate data.
A possible use of such technologies is in the area of data integration, which is
discussed in the next section, and this is the domain to which the Atom specification
has been applied in this research.
2.3 Data Integration
Data integration is a term used to describe the act of combining data from different
sources in order to provide the user with a unified view of those data (Batini et al., 1986;
Yu and Popa, 2004; Lenzerini, 2002). The main advantage of a data integration system
12

is that it enables a unified interface (Levy, 2000; Friedman, Levy and Millstein, 1999)
to the user of disparate data sets, which in turn allows simpler querying of the data.
In this context, simpler querying means that there is less cognitive workload placed
upon the user. This workload reduction is achieved by the fact that the user no longer
has to deal with the issue of knowing where the data are and how to get them; rather
they can focus on what they actually want to retrieve. This activity is becoming
increasingly important to modern business operations, as more organizations become
reliant on systems to support staff in making important business decisions. These
systems and applications often require the assimilation of diverse sets of data (Yu and
Popa, 2004; Calvanese, Giacomo, Lenzerini, Nardi and Rosati, 1998; Wiederhold, 1995).
The research domain of data integration has been an active topic for some time (Beck,
Weitzal and Konig, 2002; Wiederhold, 1993; Ullman, 1997); today this domain is of
no less significance with many organizations requiring the aggregation of data from
multiple and often heterogeneous sources, for a wide variety of applications (Haas,
Miller, Niswonger, Roth, Schwarz and Wimmers, 1999).
A simple example of data integration at work is a searchable electronic library
catalogue2. Often such systems will also search through other remote sources such
as other library catalogues or journal article databases. The search results from each
source are then be integrated and presented to the user on their computer monitor.
Inmon (1993) also discusses how data integration is a necessity in the functionality
of a data warehouse. Data coming into a data warehouse need to be put through
an integration process to ensure that they can be inserted into the data warehouse,
thus allowing the data to be used for the purposes they are now intended for, such as
decision support.
These two examples also illustrate two distinct design philosophies towards data
integration architecture in terms of a temporal aspect. The library catalogue is pur-
posely built to be a responsive “on-demand” system where the user can perform ad-hoc
searches for book references and retrieve a result in real-time. In the data warehouse
environment, however, various operations and requests (e.g., insertion of new records,
querying the data etc) would happen at a much lower frequency, e.g., generating a
monthly sales report. Although both these approaches differ in temporal context, they
are both similar in terms of how they can be implemented; presently a common method
to facilitate data integration is with a “mediated” approach (Wiederhold, 1993; Widom,
1995).
2An example library catalogue system is at: http://otago.lconz.ac.nz/
13

Lenzerini (2002) formally defines a mediated schema-based data integration system
I as: I = (G, S, M) where G = Global Schema, S = Source Schema and M = Mapping
between G and S.
This approach uses a mediator that is placed between the source data and the global
schema. The mediator can help provide a mapping between the source and target
schemas that specifies where and what to extract from the source, and a description
of the rules that need to be followed in order to perform a valid transformation of
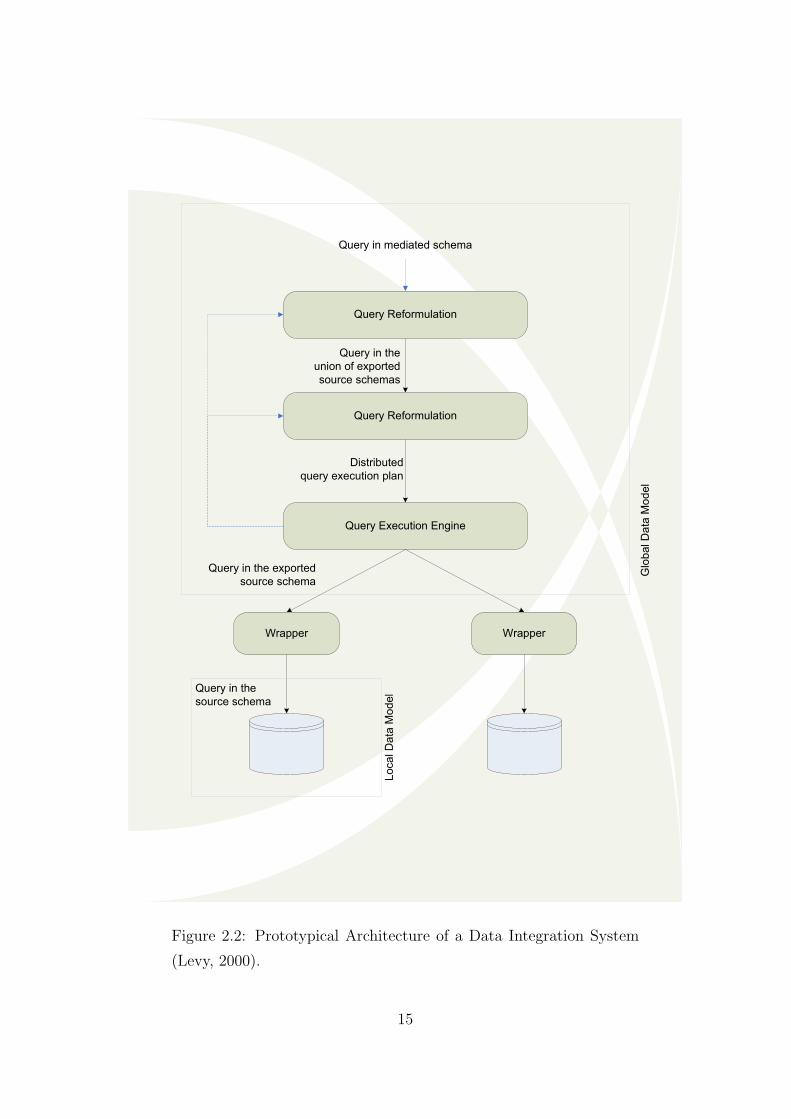
the data. Figure 2.2 provides an example of prototypical mediated data integration
architecture; it summarises techniques that have been previously illustrated by other
authors such as the “I3” architecture of Wiederhold (1993) shown in Figure 2.3.
Even earlier, traces of mediator based architecture can be found within work from
Batini et al. (1986), as shown in Figure 2.4. From these examples, a pattern starts to
emerge in regard to the structure of a data integration architecture. Three phases or
layers comprise a generic data integration architecture:
1. The data sources
2. The mediator framework
3. The global schema
The way a mapping between a source and a global schema is specified is very
important as it will determine how the source/s can be queried and what kind of data
can actually be collected (Lenzerini, 2002). As a consequence, the ability to model a
mapping specification receives significant attention within the data integration research
community.
Two common approaches mentioned in the literature for specifying mappings are
the Global-As-View (GAV) and Local-As-View (LAV) methods. A GAV approach
specifies the global (mediated) schema in direct reference to the data sources (Duschka,
Genesereth and Levy, 2000). Specifically, each item that constitutes the global schema
is associated with a particular view over the data sources (Cali, Calvanese, De Gia-
como and Lenzerini, 2002). For additional examples of GAV see the work of Adali,
Candan, Papakonstantinou and Subrahmanian (1996); Goh, Bressan, Madnick and
Siegel (1999); Tomasic, Raschid and Valduriez (1998); and Chawathe, Garcia-Molina,
Hammer, Ireland, Papakonstantinou, Ullman and Widom (1994).
The LAV approach conversely specifies the relationships between the global schema
and the data sources relative to the global schema itself, i.e. rather than constructing
14
Wrapper Wrapper
Query Execution Engine
Query Reformulation
Query Reformulation
Query in the
source schema
Query in mediated schema
Local Data Model
Global Data Model
Query in the
union of exported
source schemas
Distributed
query execution plan
Query in the exported
source schema
Figure 2.2: Prototypical Architecture of a Data Integration System
(Levy, 2000).
15

Layer 3 Independent applications on workstations - managed by
decision makers
Layer 2 Multiple mediators - managed by decision makers
Layer 1 Multiple databases - managed by decision makers
Result → decision making
Input ← Real world changes
Network services and information
Network services and information
Figure 2.3: Wiederhold’s (1993) three tier integration architecture
“I3” utilising mediators.
16

Database Integration
A Global Database
Schema
Data Mapping
from Global
to Local Databases
Mapping of
queries/transactions
from global to
local databases
Local Database
Schemas
Local Database
Queries/Transactions
Figure 2.4: Inputs and Outputs of Data Integration (Batini et al.,
1986).
17

a global schema from the data sources, a global schema is previously defined then the
sources are described as views over the global schema. Cali, Calvanese, Giacomo and
Lenzerini (2002) give a detailed formal description of LAV.
The discussion by Levy (2000) of the comparison between the LAV and GAV ap-
proaches is typical of that found in other works such as that of Lenzerini (2002); Cali,
Calvanese, De Giacomo and Lenzerini (2002); Ullman (1997); and Cali, Calvanese,
Giacomo and Lenzerini (2002). Regarding GAV, the main advantage of this approach
is that query reformulation over the participating sources is very simple (Levy, 2000).
However, there is a disadvantage to this approach in terms of the difficulties of scaling
a system to include additional data sources. This is because for each source a specifi-
cation needs to be built that shows all the possible combinations that the source can
be used in in reference to all the other relations in the mediated schema. This issue
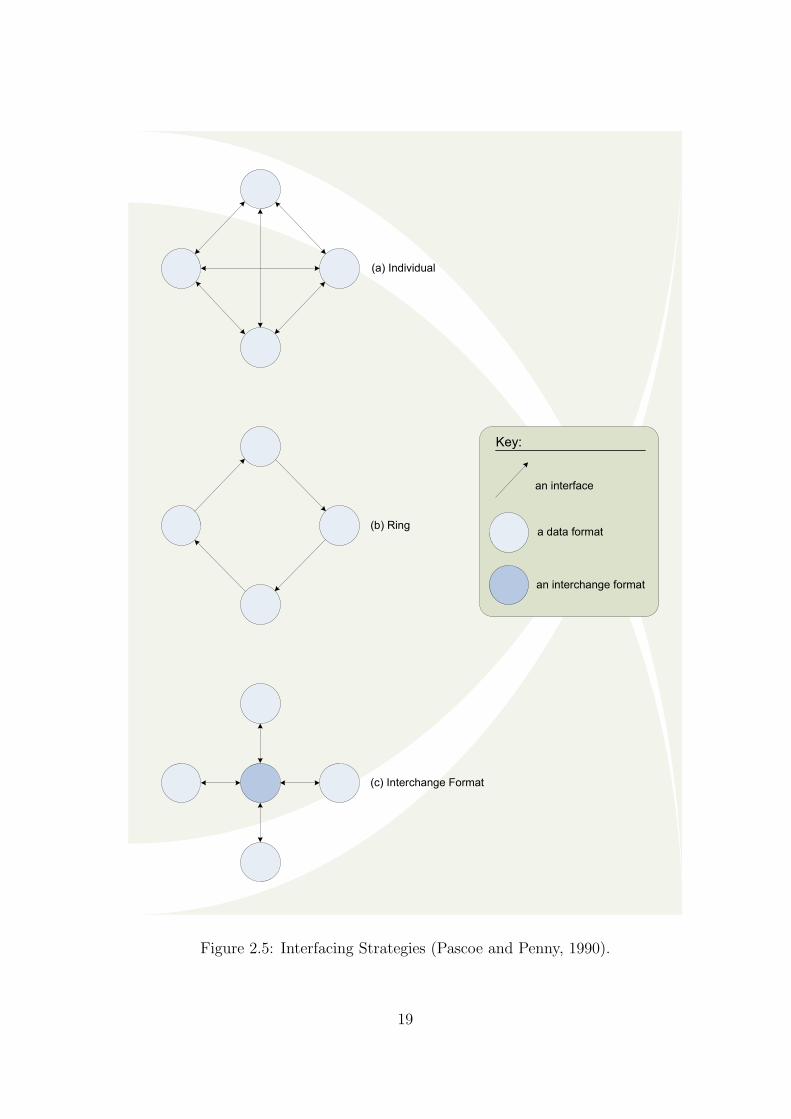
has been further quantified in the literature; Pascoe and Penny (1990) illustrated prob-
lems associated with various interfacing strategies used for performing data translation.
Their work identified three possible interfacing strategies which resemble several of the
patterns already discussed in regards to schema mapping and transformation. Figure
2.5 illustrates those three identified strategies.
The “Individual” strategy can be compared to the GAV approach in which each
source has a specification that dictates interaction with other sources in order to con-
struct a global schema. It is this particular example of the individual strategy that
highlights the scalability issues associated with a pure GAV approach. Here, we can
see that in the individual strategy a total of N(N − 1) individual interfaces need to be
constructed in order for the strategy to work correctly.
In the LAV approach the integration system is charged with the responsibility
of defining how each of the data sources interacts with each other; therefore there
is no need to manually specify those interactions as in GAV. This greatly improves
the potential of a LAV-based approach to scale easily. The disadvantage of the LAV
approach is that unlike GAV, query reformulation is a more complicated exercise. This
is because in an LAV setting the only information about the underlying data held
in the global schema are the views used to represent each source (Lenzerini, 2002).
The views can only provide some information about the data source. This situation
therefore often dictates the need to perform additional queries to obtain information
on how to actually use the sources to acquire an answer to the query posed. Referring
back to Figure 2.5, an LAV approach can be compared with the “Interchange Format”
strategy. This comparison is made evident if the central node can be interpreted as the
18
(a) Individual
(b) Ring
(c) Interchange Format
a data format
an interface
an interchange format
Key:
Figure 2.5: Interfacing Strategies (Pascoe and Penny, 1990).
19

global schema and the outlying nodes as the views of the data sources that the schema
would interact with.
Additional derivatives of the GAV and LAV approaches have been presented in the
literature. Global and Local As View (GLAV) is a generalised combination of both the
GAV and LAV approaches (Madhavan and Halevy, 2003); furthermore, Levy provides
a good explanation and discussion of this derivative: “it combines the expressive power
of GAV and LAV, and the query reformulation is the same as LAV ” (Levy, 2000,
p. 582). The Both-As-View (BAV) approach (McBrien and Poulovassilis, 2003) has
been described as “a pathway of primitive transformation steps applied in sequence”
(Boyd, Kittivoravitkul, Lazantis, McBrien and Rizopoulos, 2004, p. 83) in which the
transformation process is built up in a series of discrete steps. At each step, a schema
construct is altered in some manner, e.g. by renaming or deleting it. Alongside each
change is a new query that specifies the extent of that change relative to the rest of
the schema.
The amount of research targeting how to model the mapping between sources is
indicative of the importance of this step in the integration process. The integration
systems that these methods are used in can be further classified; Batini et al. (1986)
illustrated three types of data integration:
1. Homogeneous, where all the sources of data share the same schema.
2. Heterogeneous, where data must be integrated from sources that may use dif-
ferent schemas or platforms (e.g., a combination of relational and hierarchical
databases).
3. Federated, where integration is facilitated by the use of a common export schema
over all data sources (i.e. the mediated approach).
The prototype system built and tested as part of this study (which will be discussed
in more depth in Chapter 3) falls under the homogeneous umbrella because all the data
sources used in testing had the exact same schema, albeit populated with different
content. Further to Batini’s classification of data integration scenarios, the prototype
exhibits traits of a federated approach where a common export schema, facilitated via
an Atom feed, is used to expose data from the sources for the target to consume. In
other words the Atom feed acts as a mediator between the data sources and the target.
Mediation is effected via two autonomous processes: an Atom feed builder that is used
to construct an Atom feed from source data, and a feed consumer used at the target
20

end to extract the source data and map it to the targets’ schema. It should also be
noted that mediation in this instance is only in one direction flowing from the source
to the target data. This reflects the nature of the publish/subscribe architecture that
the Atom standard was originally intended for and which will be discussed next.
2.4 Publish/Subscribe
The publish/subscribe architecture, also known as implicit invocation in software en-
gineering circles (Campailla, Chaki, Clarke, Jha and Helmut, 2001), has received sig-
nificant attention recently for its claimed ability to provide a flexible and highly scal-
able framework for large distributed information systems (Eugster, Felber, Guerraoui
and Kermarrec, 2003; Vargas et al., 2005; Wang, Jin and Li, 2004; Farooq, Parsons
and Majumdar, 2004; Gupta, S., Agrawal and El Abbadi, 2004; Ge, Ji, Kurose and
Towsley, 2003). The architecture uses a common framework, not unlike the mediator
approach mentioned in Section 2.3, that subscribers use to register their interest in the
occurrence of specific events.
Publishers provide notification to the framework when a new event has occurred.
The framework itself manages tasks associated with matching the descriptions pro-
vided by the subscribers to the content being made available by the publishers. These
tasks can be undertaken by using broker agents like the systems SIENA and Gryphon
mentioned by Baldoni, Contenti and Virgillito (2003). As described by Eugster et al.
(2003), a publish/subscribe system can provide a high level of scalability because it
can decouple objects participating within the system on three different dimensions:
Time: Objects do not need to be active within the system at the same time in order to
interact with the other participating objects. For example a publisher object may
publish something while a subscriber object is offline. Conversely, a subscriber
can receive publication event notifications when the publisher is offline.
Space: Objects interacting through the system do not need knowledge of the other
objects’ existence. This is because the participating objects (publishers and sub-
scribers) don’t interact with each other directly but rather through the event
service provided by the publish/subscribe architecture. Therefore, the event ser-
vice is a mediator that can manage the publication and dissemination of events
and data.
21

Synchronisation: This dimension regards how objects interact with each other. A
publishing object does not become unavailable whilst it elicits an event. In ad-
dition, consumers (subscribers) can receive notification of an event at any time
after that event was posted. Thus events and data are propagated and processed
in a completely asynchronous manner.
The loose event propagation afforded by the publish/subscribe paradigm is ideal
for large distributed systems, as it removes the costly overhead involved in maintaining
synchrony of distributed objects attempting to interact with each other.
Publish/subscribe systems fall into three main categories (Eugster et al., 2003):
Topic Based: A topic based system organises information through a set of predefined
subjects (topics) where each subject represents a distinct information channel.
Therefore a subscriber would look for and subscribe to a particular channel or
channels that would best fit their information requirements.
Content Based: A content based approach as the name suggests relates the sub-
scription definitions directly to the content of the exchange information itself.
Therefore channels are not formally structured or defined like a topic based ap-
proach, but instead have a dynamic logical representation.
Type Based: Eugster et al. (2003) suggested the type based approach as a potential
substitute for a topic based system. A type based system looks at the actual
structure of the event or information being passed, then groups items according
to the structures it identifies.
Vargas et al. (2005) describe a novel application of the publish/subscribe paradigm
that is particularly relevant to this research, as it adapts the publish/subscribe para-
digm to the data integration domain.
Figure 2.6 illustrates an architecture developed by Vargas et al. (2005) to inte-
grate several PostgreSQL databases. The system makes use of an Active Predicate
Store which stores and maintains definitions of conditions that are of interest, what
possible actions to take when a condition is met, and finally what notifications to
publish through to the database’s Hermes adapter. Hermes is the publish/subscribe
infrastructure used to facilitate the data integration functionality.
For example, when a change in state of the database occurs (e.g. an update), a
trigger is fired which in turn is associated with one (or possibly more) predicates held in
22

Hermes Adapter
Message Queue
Active Predicate Management
Database Storage
Notification Builder
Cache ManagerCondition EvaluatorNotification
Evaluator
Dynamic reactive behaviour
Triggers Functions
Active predicate storeUser Tables
Publisher Node
Figure 2.6: A data integration framework using publish/subscribe
(Vargas et al., 2005).
23

the Active Predicate Store. If the condition matches that defined within the predicate
then any actions associated with that predicate are executed. The final step is the
publication of notification messages which are sent to the Hermes system indicating
the details of the change that occurred in the database.
The approach uses (Event-Condition-Action) rules to describe the state change
situations to be monitored. It also provides space for additional conditions to be
evaluated when an event is detected and possible actions to take if the condition is
met. These rule definitions are housed within the Active Predicate Store, which is
located at the database storage level; they are essentially a set of specialist tables used
to maintain the event monitoring definitions for a particular database.
Above this is an Active Predicate Management layer which manages triggers asso-
ciated with the database, as well as features to evaluate a rule’s conditions in the event
of a trigger being activated. This layer also manages the creation of publish notification
messages that are sent to the Hermes adapter. A message queue is placed between the
Active Predicate Management layer and the Hermes adapter to facilitate exactly-once
delivery of notification messages from the Active Predicate management layer. The
notification messages themselves are XML based, which potentially means that the
messages could also be sent to systems other than Hermes. The Hermes adapter is
responsible for transforming the notification messages coming from the database into
a format appropriate for the Hermes system to use. This then enables the notifications
to be disseminated to subscribers of that particular information.
To summarise, the Hermes-based system described by Vargas et al. (2005) provides
an asynchronous, event-based system that pushes notification messages from a database
to the Hermes system for subscribers to consume. Hermes itself is classed as a content
based publish/subscribe system, which means the subscribers can describe their specific
information requirements with respect to the content of interest.
This section has discussed the publish/subscribe paradigm and has used the Her-
mes-based data integration system presented by Vargas et al. (2005) to provide a perti-
nent example of the publish/subscribe paradigm put to use within the domain of data
integration. To recap, a publish/subscribe architecture makes use of a common frame-
work that is used by subscribers to register their interest in the occurrence of events
with. Publishers provide notification to the framework when a new event has occurred.
The framework itself manages tasks associated with matching the descriptions provided
by the subscribers to the content being made available by the publishers.
A comparison of the Hermes-based system and the Atom prototype will be presented
24

later in Chapter 3. Both share the common feature that they facilitate data integration
by means of asynchronous update propagation. Update propagation in itself provides
its own unique challenges and forms the basis of discussion of the following section.
2.5 Update Propagation
Update propagation refers to the problem of updating copies of an object (Date, 2004)
and is commonly associated with distributed systems. The problem is centred on the
need to ensure that if a change is made to an object (e.g., a row is updated in a table)
then that change must somehow be disseminated to all other copies of that object in
the system (Date, 2004; Silberschatz, Korth and Sudarshan, 2006). This behaviour
ensures that data remain consistent at all sites. Within a distributed context, Ozsu
and Valduriez (1999) refer to this situation as “mutual consistency”, which they define
as “the condition that requires all the values of multiple copies of every data item to
converge to the same value” (Ozsu and Valduriez, 1999, p. 21).
The methods used to implement update propagation can be classified into two types:
synchronous or asynchronous, sometimes also referred to as eager or lazy approaches
respectively (Breitbart, Komondoor, Rastogi, Seshadri and Silberschatz, 1999).
The main advantage of a synchronous approach is that it can implement real-
time data consistency throughout the entire system. This is due to the fact that
a synchronous approach will use a two phase commit transaction protocol to apply
changes to all targets within the system as one transaction (Buretta, 1997). In this
situation latency (the time between when an update is made and when its effects
have been dispersed throughout the system, e.g., updating replicas in a distributed
database) is effectively zero because all the distributed copies are updated in one atomic
transaction. A disadvantage to this approach is that it is not particularly scalable
in terms of supported transaction volume, due to the increase in the probability of
deadlocks occurring as the number of transactions taking place increases (Gray, Homan,
Korth and Obermarck, 1981). This means that as the number of transactions performed
within the system increases, so does the probability of the system becoming unavailable
to users due to resource contention (i.e., deadlocks). However, techniques like two phase
locking used to prevent, avoid and recover from deadlocks as described by Silberschatz
et al. (2006); O’Neil and O’Neil (2001); Connolly and Begg (2005); and Atzeni, Ceri,
Paraboschi and Torlone (1999) can be adapted for use in a distributed setting.
In contrast an asynchronous approach can provide loose consistency (Buretta,
25

1997). Latency is always greater than zero, so there is a higher degree of lag be-
tween when the original update was executed and when the effects of that update have
been propagated throughout the various parts of the system. Unlike a synchronous
approach, an asynchronous approach does not adhere to a two phase locking protocol
and can be implemented in several different ways. One method performs regular re-
freshing of all the distributed sites; this can be done by either using a complete or an
incremental refresh.
A complete refresh is achieved when updates to the primary data sources are queued
up and executed as a batch resulting in a blanket update of everything within the
system. An incremental refresh works in much the same way as a complete refresh
except that only changes that have been made since the last refresh occurred are
processed. A disadvantage with complete or incremental refreshing is that it strips
the transactional features or granularity from the updates when they become queued
in the data staging area. Unlike the synchronous approach, where updates would be
propagated at or very near to the time they eventuated, an asynchronous approach may
distribute updates as a batch. This means it is more difficult to provide serialization
to transactions which in turn makes it more difficult to roll back the database to a
previous consistent state in the event of some error or failure.
However, if a system does not need constant real-time data consistency, an asyn-
chronous approach will allow for a flexible implementation. Another disadvantage,
caused by the increased latency between updating the original and updating the copies
is the issue of how to deal with conflicting updates that may have been executed later
or from another site.
2.6 Data Streaming
So far the discussions and examples presented have dealt primarily with data that
resides in more “traditional” data management systems. Recently, however, new com-
mercial/societal environments have led to systems having to deal with data not stored
in a static conventional space but that are instead coming from dynamic sources. Such
sources can be referred to as streams of data. Data streaming refers to models or
systems where the data in use or in demand are not conducive to being housed in a
conventional relational structure; rather the data arrive as a continuous, transient flow
or “stream” of data (Golab and Ozsu, 2003b; Babcock, Babu, Mayur, Motwani and
Widom, 2002).
26

Query
ProcessorInput Buffer Output Buffer
Working
Storage
Static Storage
Summary
Storage
Query
RepositoryStreaming
InputsStreaming
Outputs
Streaming
Inputs
User
Queries
Figure 2.7: Golab and Ozsu’s (2003a) DSMS architecture.
Figure 2.7 depicts an example of a generalisation of a data streaming management
system architecture (Golab and Ozsu, 2003a). The approach to querying such a data
source is also different to that of a persistent relational source. A query posed over
a conventional relational schema will produce an accurate result set based upon a
snapshot in time of the data being queried; an RDBMS will produce a query result
based upon the state of the data it is holding at the time the query was executed. This
type of querying is difficult to do when the data source in question is in fact a stream of
transient data in which its state is subject to constant change. The practical difficulty
arises due to the inordinate demands on a system’s finite memory resources (Golab
and Ozsu, 2003b; Babcock et al., 2002; Golab and Ozsu, 2003a; Xu, 2001; Madden and
Franklin, 2002). Therefore the type of querying often performed in a data streaming
scenario can be classified as continuous (Arasu, Babu and Widom, 2004) and often the
results are more approximate in nature.
Examples of current applications that use or generate data streams can be found
in areas such as sensor monitoring, finance, medicine and asset management, among
others. The following three systems are examples of applications from these areas.
27

• Ethereal (Ethereal, 2005) is a network monitoring and analysis tool that can
capture live data from a computer network, such as traffic levels, packet data
etc., summarise it and display that summary to the user or allow the user to
perform more sophisticated analysis.
• LifeShirt (Vivometrics, 2005) is a new product that enables non-invasive moni-
toring of a human patient’s vital signs e.g. pulse, CO2 levels or blood pressure.
The domestic version sends data to a Palm PC-like device for doctors to view.
A military version of the system is being investigated (Vivometrics, 2006), which
would also stream patient data back to a central point to help in planning medical
evacuations or personnel deployment.
• Apama (Progress Software, 2006). Figure 2.8 illustrates the architecture of the
Apama financial analysis tool. It accepts data streams coming from sources which
can be used in combination with other data sets to generate financial analysis
information for the user.
Data streaming has become a significant area of research in its own right. Due to
changes in commercial and societal conditions, information systems of various forms
more frequently have to deal with data coming from sources that are highly dynamic
and transient. In response to this challenge, Data Stream Management Systems like
that illustrated in Figure 2.7 are being developed to allow users to derive meaningful
information from these data streams. An Atom feed can be considered a type of data
stream, the feed is potentially a transient collection of data as it can have new entries
added to it at any given time.
2.7 Summary
This review has presented a series of topics from the recent body of work in the fields
of data integration and data management to illustrate and discuss where both this
research and the Atom specification are positioned. The Semantic Web was addressed
initially in order to provide background and context to the Atom content syndication
format. Atom has been developed in response to perceived issues regarding RSS,
the content syndication standard written in RDF, which is the language for building
applications for the Semantic Web.
Data integration looks at the problem of trying to portray a unified view to a user
of data sets that might not only be located in different places but also structured in
28

Open APIsSystem
Monitoring
Integration Adaptor Framework
GUIs
Other
Remote
Calculators
External
Libraries
Run Time
Dashboards
Graphical
Scenario
Development
Apama
Adapted from original graphic located at
http://www.progress.com
Figure 2.8: Apama financial analysis system (Progress Software,
2006).
29

a variety of different formats. We evaluated Atom for its potential as a lightweight
platform to support data integration by means of asynchronous update propagation
from a series of data sources to a single target database.
The publish/subscribe paradigm was discussed next to show an environment in
which Atom could be used. Additionally, a pertinent piece of research that used the
Hermes publish/subscribe infrastructure as a novel platform for data integration was
discussed. A feature that both the system presented in this thesis and the Hermes based
system presented by Vargas et al. (2005) share is that they facilitate data integration
by means of asynchronous update propagation.
Update propagation refers to the concept of ensuring distribution of updates to all
other copies of that object in the system.
Data streaming and the Atom feed can be considered to share similar characteristics.
A significant area of research in its own right, information systems increasingly have
to be able to process this kind of data that are highly dynamic and transient; however,
this is beyond the scope of this work.
In the next chapter, we will discuss the prototype implementation of the Atom-
based data integration architecture built for the purposes of this research.
30

Chapter 3
System Design
3.1 Introduction
This section discusses how an implementation of the Atom-based data integration
architecture was created for the purposes of this research. First Section 3.2 summarises
a series of use cases that were used to give guidance in development of the Atom
prototype. In order to evaluate the concept of using Atom for data integration, it
was decided to undertake a series of implementations based on use cases derived from
previously completed projects. Three use cases were identified as candidates, with each
one having a degree of complexity and scale slightly greater than that of its predecessor.
The first was the implementation of a prototype as an infrastructure for a movie
timetable e-catalogue system. This was considered the most elementary of the three
cases. The second case was to provide query propagation functionality to a digital
music (e.g. MP3) retail system; this system, in essence, extends the functionality of
the movie timetable system, by providing the capability to not only add and delete
records, but also to update them. The third and final use case was a data warehouse
solution for an electronics supplier. However, an implementation based on this case
was not completed due to time and resource constraints.
Due to the evolutionary nature of the development of the prototypes for each case,
each implementation consisted of a very similar architecture whereby data was exported
as an Atom feed from the source database(s), after which the feeds were consumed by
an integration module, then applied to the target database.
In Section 3.4 a brief description of the development environment and implementa-
tion rationale is presented, followed by a more in-depth look at the various components
of the implemented architecture. Section 3.5 discusses a comparison between our im-
plemented architecture and that of Vargas et al. (2005).
31

3.2 Use Cases
3.2.1 Movie Timetable e-Catalogue
Case Scenario
The first, least technically demanding of the scenarios, was to create a system to
integrate movie timetable data from multiple cinemas. In this scenario the Atom
architecture uses movie timetable databases located at cinemas as data sources. The
target is a database holding content for a dynamic data-driven website.
The purpose of the website is to allow users to browse currently screening and
soon to be screened movies to find out what cinemas are showing which movies, the
screening times of the movies and to compare ticket prices between cinemas showing
the same movie. Such an application relieves users from the task of remembering all
the possible cinemas they could attend and allows them to focus on actually finding
out the information they need about the movie that is of interest to them.
System updates are infrequent; as this reflects the period during which a movie
would be shown at a cinema which is commonly several weeks.
Design Goals
The main goal in this scenario is to provide an infrastructure to integrate movie
timetable data from different cinema databases. The system is geared toward a light-
weight environment with source data updates occurring at a low frequency (such as
weekly). All previous data is overwritten by the latest.
Assumptions
The system is not intended to provide an archival service; it will provide users with
current timetable information for movies currently playing or movies that are to begin
screening very shortly. No update functionality is available in this system, so changes
require the entire Atom feed for that particular cinema data source to be refreshed.
3.2.2 MP3 Music Retail System
Case Scenario
With the initial movie catalogue implemented, the following use case scenario was
implemented to extend the functionality of the prototype. The system documentation
32

for the music kiosk project has been provided in Appendix A. The scenario for this
case is that a kiosk has been designed to sell music in digital format to consumers. The
kiosks are placed in high foot-traffic areas like shopping centres, or leased to businesses
such as music shops to complement their existing trading.
The system provides an interface to the user allowing them to search the databases
of music suppliers (record labels, for example Sony or EMI) for the specific albums or
tracks that they are looking for. Once the user has selected the tracks they want, they
use their credit card, EFTPOS card or mobile phone to pay for the tracks, which are
then downloaded to their portable storage device such as a portable hard disk or MP3
player, or written to a blank CD.
Design Goals
What was needed was an architecture that could act as a mediator between the mu-
sic supplier’s databases and the database within each of the music kiosks. Another
requirement was that the implementation should not interfere in any way with the
supplier’s data sources. The architecture needed to be able to provide the ability to
insert, delete or update records stored in the kiosk database, reflecting changes to the
stock of digital music stored at each of the participating music supplier’s databases.
In addition, due to the fact that changes to the source data are sporadic, the system
had to be highly responsive to ensure the data housed in the kiosk are kept up to date.
Assumptions
No music files are stored on the kiosk itself; rather each kiosk has its own database
which stores the locations of the music files, and thus the only type of data stored
would be essentially alphanumeric text.
3.2.3 Electronics Retailer Data Warehouse
Case Scenario
The final case to be developed was that of an architecture to support a data warehouse
for an electronics retailer. In this scenario, data from the retailer’s outlets throughout
New Zealand are transformed and inserted into an Atom feed ready to be consumed
by the data warehouse.
33

Design Goals
The goal of this implementation was to extend further developments from the previous
use cases to provide a means to send query requests between the retail outlet databases
and the company headquarters where the data warehouse is located. This would pro-
duce a prototype that could provide full data manipulation capability to heterogeneous
data sources. Due to time constraints, this implementation was not able to be com-
pleted, however it does show the direction that the development of the prototype was
taking.
3.3 Requirements Summary
There are several requirements shared by all the use cases presented. The implemented
system needed to be lightweight in terms of network and computational resource con-
sumption. Furthermore, it had to provide a non-invasive means of exposing source
data, i.e., it is strictly a mediator between the source and target objects. Finally, the
system should also be platform independent to reflect the diversity of environments it
could reside in.
3.4 Development
3.4.1 The Development Environment
The criteria for the selection of technologies to develop the prototype in were derived
from three considerations:
1. The technical abilities of the researcher.
2. The goals of the use case scenarios.
3. The resources that were accessible from the University of Otago Information
Science Department.
The development environment consisted of a single Dell Optiplex GX280 computer
with a single 2.8GHz CPU and 1 GB of RAM that had been issued to the author at the
commencement of this research. The computer had installations of the IIS 5 web server,
PHP 5, MySQL 4, the Firefox web browser and Windows XP Professional operating
system. In addition there was access to PostgreSQL and SQL Server instances via the
34

University of Otago campus network. Development of PHP scripts was undertaken
with a simple text editor.
The IIS 5 web server was used initially because it was already installed and con-
figured on the computer. PHP is a scripting language for Web based application
development; PHP 5 was chosen because of the authors’ familiarity with the language
and for its support of multiple operating systems, databases and other technologies.
MySQL was chosen for similar reasons to PHP, while the Firefox browser was selected
because it was available in both PC and Apple versions, which was useful as the testing
environment was located on a network of Apple computers (see Section 4.3).
3.4.2 Implementation Rationale
As mentioned in Section 3.2, the goal of the research was to identify the potential of an
Atom-based lightweight architecture for facilitating a data integration solution suitable
for general small scale scenarios, for example for SME’s.
The design for the prototype data integration architecture uses an Atom feed as a
mediator between a data source and the target. Furthermore, the architecture design
comprised two layers: the data export layer and a feed processing (mediation) layer,
as shown in Figure 3.1. An Atom feed generator is located within the data export
layer and is responsible for exposing new data from the source and sending it to the
Atom feed. Within the feed processing layer an Atom feed consumer is responsible for
reading the Atom feed and applying the updates to the data target. The prototype
makes use of a predefined hard-coded mapping written specifically for the schemas used
in the experiments and implemented in PHP. The prototype makes use of a predefined
hard-coded mapping written specifically for the schemas used in the experiments and
implemented in PHP.
Altering the means by which the feed generator, the Atom feed and the feed con-
sumer interact with each other enables different configurations of the data integration
architecture to be implemented. Figure 3.1 presents three suggested configurations
named “Pull”, “Push” and “Push + Pull” respectively. Pull represents the most simple
configuration in that the Atom feed generator/builder and the feed consumer operate
completely independently of one another, therefore the flow of information to the tar-
get is governed by the feed consumer. The Push method controls the consumption of
Atom feed data on the basis of change in state of the source data.
The Push + Pull method is more complicated than the previous implementations by
enabling the feed generators and consumers to message one another when new data is
35

available and also potentially allows flow of data back to the data source. Flow back to
the data source could also be theoretically implemented in the previous configurations
by providing a feed consumer to the original data source and a feed generator to the
original data target.
Further discussion on the Push and Pull configurations can be found in section
3.4.5; in addition, it should be noted that the mappings from the data source to the
Atom feed and from the Atom feed to the data target have been explicitly specified
i.e. hard-coded.
The decision was made to build a prototype system that implements the theoretical
Atom-based architecture. This option was adopted because this would provide direct
feedback as to the effectiveness of such an approach to data integration.
The prototype was implemented using PHP 5, as this technology requires little
overhead to set up, is platform independent and from a pragmatic standing, provides
an opportunity to explore implementation related issues and testing.
The prototype can work with MySQL, PostgreSQL and SQL Server database servers
(testing was carried out using MySQL database servers) and exhibits some degree of
platform independence by being capable of running on both a Windows XP operating
system (the development environment) and a Mac OS X operating system (the testing
environment). As Mac OS X is UNIX based, this indicates the system should also run
on other UNIX/Linux derivatives.
The following sections illustrate the key components of Atom based architecture
and the options available regarding how the components could be configured to create
different forms of the architecture presented in Figure 3.1. Essentially, the architecture
works by routinely checking the state of the data against a previous copy of it. When a
change is detected, a new Atom entry containing the information regarding the change
is created and appended to the Atom feed. The change is applied to the target when
the targets Atom feed consumer parses the feed and processes the new entry. Section
3.4.5 describes two particular configurations of the system that we investigated.
3.4.3 The Feed Builder Module
Figure 3.2 presents a flow chart of the Atom feed builder module implemented in this
prototype architecture. It is a completely self-contained unit, consisting of two key
components:
1. The staging database, used to capture update data for the atom feed.
36

Feed Processing Layer
Data Export Layer
Data Source Data Source Data Source
Atom Feed
Generator
Atom Feed
Generator
Atom Feed
Generator
Atom Feed Atom Feed Atom Feed
Atom Feed
Consumer
Atom Feed
Consumer
Atom Feed
Consumer
Target
Database
Staging
Database
Staging
Database
Staging
Database
“Pull” “Push” “Push+Pull”
Figure 3.1: Overview of the basic architecture
37

End.
Wait X Seconds.
Copy Source Data
to Staging
Database.
Data Source Content is Different
to Previous Copy?
Update Atom Feed.
Reset Staging
Database Tables.
True
Start
Shutdown Builder?True
False
False
Figure 3.2: Flow chart of Atom feed builder
38

2. A library of functions and object classes that implement the functionality of the
feed builder itself.
The reason for using a staging database as part of the prototype architecture is a
direct response to requirements set down in the use case scenario. As mentioned in
Section 3.3, the data integration architecture must not in any way interfere with or
require intrusive alterations to the systems used to store and manage the source data.
The staging database constructed for this implementation consists of two identically
structured tables. The structure of these tables is, in essence, a specialised denormalised
form of the source data schema. Each column within the staging database tables
represents a corresponding column from the data source, which was chosen based on
the data requirements of the target. The term “column” has been used, as the target
in the prototype environment was a relational database, however, there is no reason
from a theoretical standing why the target, or data source for that matter, cannot be
some other form of data model or structure.
The feed generator queries or “polls” its corresponding data source at regular in-
tervals and compares that query result (snapshot) to a previous snapshot, also stored
in the staging database. The comparison query set consists of three separate queries;
one that checks for newly inserted data, one for deleted data and one that looks for
data that have been updated. Data that have remained unchanged since the last time
the data source was polled are ignored.
If the latest query results differ from the previous snapshot, then updates have oc-
curred in the data source, and new entries corresponding to these source data changes
are created. Figure 3.3 illustrates an example entry for an album record that is to be
inserted into the target database. To create the entry items, the feed builder first col-
lects all the data required for the update from the columns within the staging database.
Then using pre-defined functions from the library, the feed builder transforms these
data into an Atom 0.3 draft standard entry item. Each column in the staging database
has a corresponding element within the Atom entry. For example, a column name
“track title” in the staging database would have an entry item element resembling:
<track_title>Take Five</track_title>
The new entries are then appended to the existing Atom feed in order of occurrence,
thus creating a succinct and sequential series of updates that can be parsed and pro-
cessed by the data target’s Atom feed consumer. A benefit of appending entries in this
way is that it allows for safe concurrent updates to be applied to the target even when
39

<entry>
<content>
<title>Soultrane</title>
<link rel="alternate" type="text/html" href="http://www.url.com"/>
<cmd>ADD</cmd>
<artist>John Coltrane</artist>
<genre>jazz</genre>
<cover-path>cover.jpg</cover-path>
<release-date>1958</release-date>
<track title="title1" length="0:12:08" location="pth1" size="16.6" track_no="1"/>
<track title="title2" length="0:10:55" location="pth2" size="15.0" track_no="2"/>
<track title="title3" length="0:06:17" location="pth5" size="5.21" track_no="3"/>
<track title="title4" length="0:04:56" location="pth4" size="5.26" track_no="4"/>
<track title="title5" length="0:05:34" location="pth3" size="15.0" track_no="5"/>
<modified>7-1-2006:21:56:21</modified>
</content>
</entry>
Figure 3.3: Example Atom entry from the MP3 kiosk use case.
the target’s feed consumer has been offline for a length of time (e.g. due to a network
connection failure). However, one trade-off apparent in the current implementation is a
situation where the feed size is ever increasing, which could lead to performance prob-
lems after some time. This problem could be reduced by implementing some form of
archival system where a chain of files would be created over time instead that logically
represented the Atom feed as a whole.
Once the Atom feed has been “refreshed” by the feed builder appending the new
feed entries, the query result from which those new updates were garnered replaces the
previous snapshot. This is done by truncating (emptying) the table and inserting the
new data. At this point, the process is finished and a countdown until the next time
the data source should be polled is resumed.
To summarise the features of the feed builder module, it is a completely self-
contained and autonomous process. It polls the data source at a regular, predetermined
time interval to compare the state of the source data with how it was the previous time
the module checked it. Updates occur when changes are discovered in the source data.
New Atom format entries are appended to the end of the Atom feed file.
40

3.4.4 The Feed Consumer Module
From an architectural viewpoint, the Atom feed consumer module is very similar to
that of the feed builder. The consumer comprises two components:
1. A timestamp item; which stores a timestamp of the last time the consumer
applied an update to the target.
2. A library of functions and object classes implementing the feed consumer func-
tionality.
The flow of data is the converse to that of the feed builder, i.e., from the Atom feed
to the target, rather than from the source to the Atom feed, as illustrated in Figure
3.1.
Figure 3.4 presents a flow chart of the prototypical Atom feed consumer. The feed
consumer works by polling the Atom feed, parsing the feed, and then comparing the
feed’s <modified> or <updated> element content1 with the timestamp it has stored in
its repository. If the two timestamps are different, and the timestamp in the Atom feed
is “newer” than that of the consumers, then the Atom feed must have been updated
recently, therefore the feed consumer module initiates the update process.
The update process involves the feed consumer iterating through the list of en-
tries currently contained in the Atom feed. When the consumer finds an entry whose
timestamp (located in the entry’s own <modified> element) is newer than that of
the consumer, it processes that entry. In the music kiosk system use case, the feed
consumer processes an entry by using a pre-defined mapping stored in its library to
construct a transaction that is in the correct language and syntax (in this instance
SQL) and maps the entry’s elements to a corresponding field in the target database2.
Once the feed consumer has reached the end of the Atom feed, the update pro-
cess is completed by updating the consumer’s timestamp repository and it restarts its
countdown for polling the Atom feed once more.
1In this case the modified element content is compared as the current prototype only has support
for the draft 0.3 Atom specification.2One obvious improvement would be to enable direct alteration or creation of a mapping by the
user through some kind of GUI, similar in concept to Altova’s “MapForce” product (Altova, 2005).
The rules could be housed within a native data structure of the consumer module and enforced through
a generic mapping core.
41

End.
Wait X Seconds.
Parse Atom Feed.
Consumer and Atom feed
Timestamps are Different?
Apply Updates to
Target.
Overwrite
Consumer
Timestamp with
Atom Timestamp.
True
Start
Shutdown Consumer?True
False
False
Figure 3.4: Flow chart of Atom feed consumer
42

3.4.5 System Configuration
The advantages of PHP with its platform independence features and the modularity of
the prototype components lend themselves to a variety of system configuration options,
both in terms of the location of various components and the means by which they
interact. For the purposes of this research, two methods of configuring the architecture
were investigated; classified as “Push” and “Pull” respectively.
Push
With the push method, the consumption of feed information is governed predominantly
by changes in state of the source data, i.e., when the feed generator detects a change in
state of the source data (for example when a record is updated) the feed is regenerated
(see Figure 3.1) and the consumer module is called immediately to apply the new
information to the target schema. The majority of this activity takes place at or
near the source data location, however, in practice, the location of each component is
not important as they are web-based. The current prototype partially supports the
push method; its functionality is limited due to some issues outstanding that restrict
its performance; in particular the efficiency of managing the influx of updates to the
target needs improvement.
An initial criticism of this approach is that it can cause resource contention or a
“stampede-like” effect when multiple updates from multiple sources are pushed simul-
taneously to the target. This could be alleviated by adding an input staging area at
the target, or adding more intelligence to the consumer modules in the form of a cache
that would store updates and pass them to the target at the next window of oppor-
tunity. These additional layers of complexity however may make the push method a
less appealing option than other configurations, as the implementation of such features
could detract from the original goal of a “lightweight”, agile system.
Pull
The pull method differs from the push approach on two key points. First, the feed
consumer modules operate independently of, and are therefore not directly influenced
by, the feed generator component. Secondly, the flow of feed information to the target
schema is governed by the consumer module itself (see Figure 3.1); that is, the consumer
module will regularly check or “poll” the Atom feed to see if it has changed. This is
done by simply checking the Atom feed’s <modified> element. Hence, rather than
43

forcing or pushing feed data, it is instead “pulled” down to the target.
The pull approach uses only one feed consumer module for all of the Atom feed files,
unlike the push method, where each feed has a dedicated consumer. This approach
has a distinct advantage; it enables a constant stream of sequential transactions to be
passed to the target database without the need for additional layers of complexity to
manage such a feature. This means an avenue to implement a simple consumer module
is established and problems of resource contention and/or congestion between different
feeds and the target are alleviated as each feed is processed in an orderly manner.
There are however some potential disadvantages associated with this approach.
Firstly, as implemented in the prototype, the updates for one feed need to be processed
and completed before the next feed can be parsed and checked for updates. This issue
may create performance problems in situations where many updates occur at a high
frequency. Therefore a more efficient approach in terms of implementation would be to
break down the consumer module into two distinct processes run in parallel: 1) parsing
the feed and extracting the update data, while 2) applying updates to the target.
3.5 Discussion
Although the system of Vargas et al. (2005, discussed in Section 2.4) is at a more ad-
vanced stage of development than the Atom-based prototype, a comparison of the two
approaches still yields some interesting points. First at a broad level both approaches
deliver update notification data asynchronously and they both use an XML-based spec-
ification to format those messages. However, the underlying methods by which the two
approaches do this are quite different. For instance, the Hermes-based system makes
extensive use of triggers and has developed additional features that enrich the source
relations with more reactive behaviour. In contrast to this, the Atom prototype makes
use of a staging area to routinely compare the current sate of the database with a
previous “snapshot” to infer any changes. Therefore the Hermes approach represents
a more reactive and ad-hoc behaviour in comparison to the Atom prototype which is
regulated and more akin to a batch process.
Obviously, the Atom prototype’s data staging approach is rather simplistic and is
not overly efficient, as it relies on using additional copies of the data of interest to infer
if any changes have taken place. However, one particular advantage of this approach is
that it is potentially easier to port to other database platforms as it only requires two
additional tables to be created and some minor changes to a handful of SQL queries in
44

order to be set in place. The Hermes-based approach however, because it is specifically
designed with PostgreSQL in mind, would require a significantly larger amount of work
to port its equivalent reactive relation behaviour to other database platforms because
of the additional extensions it makes to the database’s relations.
Another key difference is the means by which updates are actually propagated to
targets/subscribers. The Hermes-based system actively posts notification messages
as soon as a specific event trigger has been detected. When a subscriber (target)
becomes active it receives the publish notifications from Hermes. However, in the
Atom “pull” approach the target is not directly notified of changes. Instead, like the
data staging area, the target routinely polls the Atom feed to see if any changes have
in fact occurred. Compared to the active push of notification information by Hermes,
the Atom consumers only find out if new information is available when they poll the
Atom feed.
With regard to the Atom feed, it has features found in both the Hermes publisher
messages queue and the Hermes infrastructure. This assertion is based on two ob-
servations. First, the Atom prototype appends newly created update messages to the
existing list or “queue” in the Atom feed. Second, the feed itself represents the interme-
diary between data sources and targets, which is analogous to the Hermes infrastructure
role, albeit in a far more passive manner.
The comparison of the two systems can be condensed down to the following findings:
the Hermes system utilises the publish/subscribe paradigm to create an event-driven
asynchronous data integration framework, whereas the Atom prototype system adopts
a technique of asynchronously sampling the source data at a fixed frequency to infer
if new changes have occurred. The overriding theme of this comparison is that both
prototypes represent two approaches to data integration by means of asynchronous
update propagation.
The author’s Atom prototype architecture, when in the pull configuration, does
lend itself to providing a platform to facilitate update propagation. In fact, the re-
sulting architecture uses an asynchronous propagation approach to provide a means of
integrating data from a source to multiple targets, providing those targets all have an
Atom feed consumer module. In the architecture there are behaviours that can be used
to support this assertion. First, in its current configuration, the architecture makes
use of batch processing to carry out tasks. This can be seen in two areas:
1. The feed builder polls the data source at regular pre-defined intervals. If a change
in the database has been detected then the Atom feed is updated.
45

2. The feed consumer at the target end mimics this process by polling the generated
Atom feed to check for new updates.
Secondly, the architecture makes use of a data staging area to compare the current
instance of the source data with a recent copy to discover any new changes. At that
point these changes are prepared for, and appended to, the Atom feed.
The third and most compelling trait is that the updates coming from the Atom
feed for the targets to consume are not processed in real time relative to the time of
the originating event in the source. This observed behaviour means that the latency
between a target and its source is always going to be greater than zero, which is
consistent with the definition of an asynchronous method.
Sections 2.4 and 2.5 explained that an asynchronous approach is easily scalable
because of its general, simplified support infrastructure; allowing connections between
objects to be decoupled in terms of synchrony, space and time. However, publish/sub-
scribe systems like Hermes still make use of an intermediary infrastructure to manage
the delivery of notifications and data. Syndication technologies like Atom do not rely
on notification mechanisms; rather, the consumer is responsible for checking for new
updates.
Syndication thus represents a further simplified asynchronous framework that re-
moves additional infrastructure between objects, yet still retains the advantages of
scalability associated with asynchronous connection schemes. We have combined this
further benefit of simplified asynchrony with the low cost, platform independent tech-
nology PHP.
The collective advantages of the scalability potential of an asynchronous approach,
the simplified implementation afforded by Atom and the feature rich technology of PHP
display an avenue to create a data integration solution that is lightweight in terms of
impact on an organisation’s available resources.
The Atom-based architecture design resulting from this research activity resembles,
but is not totally identical to, a data streaming model such as the one described by
Babcock et al. (2002). The key difference is in the time and usage domains that the
Atom architecture and a data streaming architecture reside in. This difference is found
primarily in the Atom system’s feed consumer behaviour; the current configuration of
the prototype Atom implementation polls the Atom data feed at a regular, predefined
time interval to check for newly appended data elements. This behaviour is compara-
ble to a standard RSS feed aggregator such as NewsGator3 that routinely checks for
3http://www.newsgator.com
46

updates to the news feeds a user has subscribed to. However this behaviour is in stark
contrast to a system operating a data streaming architecture, in which the stream of
data may be monitored constantly, or in a more “on demand” method, such as the
network monitoring example mentioned in Section 2.6.
This key point of difference in many respects is only evident when a system using
the Atom-based architecture adopts the polling method mentioned above. If, for ex-
ample, the Atom feed was treated as a data stream4, and the Atom based system was
configured so that it reacted or was triggered as soon as the feed was updated, then the
architecture may in fact begin to appear more similar to the data streaming model. An
implementation of this particular configuration was attempted by the author, albeit
with the source being a relational database within a simulated operational production
environment. However, due to time constraints and technical issues regarding web
browser incompatibility between the development and test environments, it was not
possible to conduct thorough testing and data gathering.
3.6 Summary
This chapter has explained the means by which our Atom-based architecture was imple-
mented. Section 3.2 presented a series of use cases used to give guidance in development
of the prototype system. Features common to all the use cases were that the prototype
be lightweight, non-invasive and platform independent as discussed in Section 3.3.
Section 3.4 presented details specific to the actual development of the prototype.
Overviews of the development environment and implementation rationale were pro-
vided before a more in-depth discussion of key components of the architecture. The
perceived advantages of scalability, simplicity and low cost in relation to features as-
sociated with asynchronous connection schemes, Atom and PHP, highlight a potential
means to implement a lightweight data integration architecture.
Finally Section 3.5 compared the implementation of the Atom-based architecture
that we built to the Hermes-based system of Vargas et al. (2005). The following chapter
will describe the experimental design that was used to evaluate the Atom prototype
implementation.
4As it can meet the requirements of a data stream as defined by Babcock et al. (2002); Madden
and Franklin (2002); Arasu et al. (2004); and Carney, Cetinternel, Cherniack, Convey, Lee, Siedman,
Stonebraker, Tatbul and Zdonik (2002)
47

Chapter 4
Experimental Design
4.1 Introduction
This chapter will outline the design of the experiments that were used to evaluate the
Atom prototype’s potential to facilitate data integration by means of update propaga-
tion. Three different tests were designed to evaluate the system’s ability to perform
under various loading conditions, the demands it would place upon the networking
and computation resources supporting the architecture, and the response time of the
system under different configurations.
It was intended originally to test both the push and pull configurations of the
prototype implementation of the architecture. However due to technical issues result-
ing from differences in the development and testing environments, data sufficient for
analysis was only captured for the pull configuration.
The pull configuration test consisted of altering the frequency by which the feed
consumer would poll the Atom feed to observe the pull configuration’s behaviour at
different frequencies. Two frequencies were tested; additional frequencies were intended
to be tested but were not carried out due to time constraints on the availability of
the testing equipment. The first set of test runs were conducted with the Atom feed
consumer set to poll the feed at 15 second intervals, the second set of test runs increased
this interval to 30 seconds.
The expectation for the testing was that if the polling frequency was low then the
response time would also be low enough to accommodate the demands of an opera-
tional processing system. However, this expectation must be balanced in reality if the
system is to progress further than its current prototypical stage in that it also must not
encroach negatively on the network and processing resources that comprise the system
48

operating environment. In other words, if it is found that the system is able to provide
low latency times (the time between when an update originates and when it is applied
to the target) between updates due to a low polling frequency, it may be at the cost
of too high a demand on networking or computing resources.
4.2 Experiment Rationale
The experiments were designed to be capable of generating the type of data needed
to conduct the Atom prototype evaluation. What was needed was a means to ob-
serve and record the prototype’s performance under conditions that could arise within
the use case scenarios. First we needed to define what was meant by performance;
in this context performance has been narrowly defined and further divided into two
classifications:
1. Responsiveness: Specifically this is the latency of the system, i.e., the time the
system takes to carry out a task like propagating an update from the data source
to the target.
2. Impact: This classification embraces features pertaining to the demands the sys-
tem places upon the resources available within the environment the system resides
in, i.e., the computer network.
In other words, any experiments to be used would need to be able to capture data
that would expose information regarding the system’s temporal responsiveness and the
impact the system places on its environment.
The element immediately identified to provide data about the system’s responsive-
ness was that of time; the requirement for any experiment of this type was to be able
to accurately record the time of events occurring within the system.
In terms of impact, the first task was to identify what could be recorded for mea-
suring the system’s impact on its environment. The obvious parameters to focus on
for this feature were the system’s outputs, i.e., the volume of data that the system was
generating and consuming.
However, in addition to performance, another parameter that had to be taken into
consideration was the requirements of the use case scenarios. The requirements provide
a means to compare the performance of the system relative to realistic scenarios.
This additional information enriches the raw performance data with greater mean-
ing. Therefore the experiments designed for this evaluation needed not only to be able
49

to record the performance of the Atom prototype architecture as previously defined,
but also needed to reflect the requirements set out in the use cases. It is important
to note that the principal use case scenario used to conduct the testing was the MP3
kiosk prototype described in section 3.2.2; this scenario was used because the Movie
timetable scenario was deemed too limited in scope to provide useful information, and
the data warehouse scenario was not available for testing. The experiments designed
in response to these requirements are presented next.
4.3 Evaluation Methodology
Response times differ significantly between systems involved in day-to-day operational
processing and analytical/data warehousing systems (Inmon, 1993; Atzeni et al., 1999;
Silberschatz et al., 2006). Inmon (1993) is one of the few to have actually put a
quantitative figure on this difference:
“Analytical response time is measured from 30 minutes to 24 hours. Re-
sponse times measured in this range for operational processing would be an
unmitigated disaster” (Inmon, 1993, preface p. x ).
This difference in response time requirements results from the kind of processing carried
out by these two distinct scenarios. An operational system deals with the day-to-day,
real-time demands of an organisation and as such requires low response times in order
for users to carry out their tasks; queries posed in this situation tend to be sporadic
and ad-hoc in nature with users needing quick access and retrieval of relevant data.
Conversely, a data warehouse often deals with large volumes of data in a manner akin
to batch processing, for example, performing queries for sales analysis at the end of a
company’s financial year. Thus the ability to process large volumes of data at often pre-
determined intervals is more of a factor in systems such as data warehouses compared
to operational processing.
This initial observation of the differences in response times between these two pro-
cessing paradigms forms the basis upon which the evaluation framework for testing the
Atom prototype has been built. The demands the prototype places on network, com-
putation resources and the system’s response time (latency) are cross-referenced with
Inmon’s (1993) observation, along with the requirements of the use cases presented in
Chapter 3, to infer whether the prototype has potential for further development in an
operational environment, an analytical environment, both or is simply not suitable in
50

its current state. The use of response time as an indicator of a systems performance
is a common approach, as mentioned in many of the approaches discussed by Nicola
and Jarke (2000) who surveyed performance modelling techniques for distributed and
replicated databases over the last 20 years.
The evaluation methodology consisted of three approaches in order to test the sys-
tem’s performance and efficiency. The goal of the methodology was to extract meaning-
ful data to infer the performance and scalability potential of the prototype architecture
relative to the observations outlined above, and to observe an implementation of the
architecture under various loading conditions and configurations. As the architecture
is intended for smaller-scale lightweight implementations the testing should serve to
elicit information that would support or reject this intention. The resources for the
testing environments (hardware) where chosen on the basis of what was available on a
scale sufficient to support the testing we had designed and within the time frame that
the testing had be completed in. As a result the load test and operational tests were
carried out on very similar platforms, while the latency testing was run within a differ-
ent environment, as it was undertaken at a later date than the previous experiments.
The three experiments that were created to acquire the data needed to investigate this
problem will now be described.
4.3.1 The Load Test
Description
This test was designed to explore the performance capabilities of the architecture under
various loading conditions. Data captured from the test included:
• Atom feed output size (bytes).
• Source data size, i.e., the size in bytes of the SQL representation of the source
data.
• Feed consumer output (bytes).
• The elapsed time (latency) from when the update process was started until it
was finished.
The loading changes were represented by using different sets of sample data of varying
sizes. The data sets used for this experiment can be found in Appendix B.
51

Environment
The testing environment for the load test comprised five Apple Power Macintosh G5
computers with dual 1.8GHz CPUs and 1GB of RAM each. The computers were con-
nected via an isolated full duplex gigabit Ethernet switch. Installed on each computer
were the Apache 1.3 web server, PHP 5, MySQL 4, the Firefox web browser and Mac
OS X operating system version 10.4. Four of the computers were used as data sources
while the fifth was used as the target.
Procedure
The experiment procedure involved 4 sets of 15 test runs, with each set having another
data source added to the system. Thus, the first set of test runs used one data source;
the second used two sources and so on.
To initiate a new test run, the Atom feed consumer was first shut down if it was
still running. Copies of the consumer’s data capture files were then made before the
originals were emptied in preparation for the next test run. At this point attention
was shifted to the feed builder (or builders, depending on how many data sources were
being used). The generated Atom feed and the feed builders’ data capture files were
copied before the content of the files were deleted. Next, the target database and
source data staging tables were emptied, by using the standard SQL “TRUNCATE”
command.
With all the system elements now reset, the feed builders were restarted to regener-
ate the initially empty Atom feeds, after which as a precautionary measure, a network
ping from the machines housing the Atom feeds to the target was made to ensure there
was nothing wrong with the network. With Atom feeds now regenerated and the net-
work connection checked, the only task left to do was to start the feed consumer to
begin the test run.
4.3.2 The Operational Test
Description
This test was predominantly focused on observing the impact of the Atom prototype
on its host network. A query generator was built, also in PHP 5, that would apply a
set of update queries to the data source at randomly chosen time intervals between 0
and 10 seconds. This was an attempt to represent a realistic production environment
that the source data could likely reside in. As the principal data being collected in
52

this experiment focused on network performance, the network monitoring software
Ethereal (Ethereal, 2005) was used to collect all network activity that occurred while
the Atom prototype was running. Ethereal also has a comprehensive set of analysis
tools that enabled network performance data relating to packets, protocols and traffic
to be collected. Specific data captured from this test included:
• Packet information: the total number of packets that traversed the network dur-
ing a test run, and of that total, how many packets contained HTTP data. Pack-
ets containing HTTP data was important as this was the protocol used by the
Atom prototype to read the Atom feed.
• The total amount of data that traversed the network (bytes).
Environment
The operational test used the same hardware as the load test with the exception of the
network switch, which was replaced with a slower 100Base-T network hub. This change
was necessary in order for the Ethereal monitoring software to be able to collect data.
This difference is attributed to differences in how a network hub and switch operate, i.e.,
a switch establishes a direct point-to-point connection between two nodes, which means
that the Ethereal software cannot monitor the network traffic, unless it is running on
one of those nodes, but this could potentially compromise the test environment. A
network using a hub however results in network data being broadcast, which then
allows Ethereal to view what is happening.
Procedure
Several series of test runs were initiated with each series testing the Atom prototype
in a different configuration. The first stage was to populate the target and refresh the
Atom feeds; this was in essence the same procedure used in the load test. At this point
the feed builders and consumer were temporarily shut down, so the Ethereal network
monitoring software could be initialised to capture network traffic. The feed builders
were then restarted, followed by the feed consumer, and finally the query generators
(one for each data source) were initialised. Each test run lasted for 2 hours.
At the conclusion of each run, the data from that run was collected and the system
reconfigured and prepared for the next test. The reconfiguration consisted of changing
the frequency of either the consumer or the feed builder depending on the architecture in
use, i.e., the consumer polling frequency was altered when the testing involved a “pull”
53

configuration while the feed builder frequency was altered when a “push” architecture
was in use.
Monitoring the various parameters mentioned above provided a means to view the
demands the system placed on the infrastructure it was using, with particular emphasis
on the network resources consumed and time taken for the data transformation and
processing itself.
4.3.3 The Latency Test
Description
This test was designed to gather data about the responsiveness of the system, in terms
of the system’s update propagation latency when operating at different polling fre-
quencies. The query generator was employed once more, however the ad-hoc firing of
queries was disabled, resulting in queries being fired at uniform intervals. A single feed
builder and consumer were set up, as well as a third machine that acted as a time
keeper. As soon as an update was made to the source data a message was sent to
the time keeper and the time of the event was logged. The same action occurred at
the consumer end when the update was applied to the target thus providing a means
to calculate the elapsed time (latency) from when an initial update occurred on the
source to when that update was propagated to the target.
Environment
The latency testing environment was different because the earlier environment was no
longer available; it consisted of: one Dell Latitude CPi laptop with a Pentium 2 300
MHz processor and 128MB of RAM (used for the time server); one Dell Latitude CPx
laptop Pentium 3 500 MHz, 256MB of RAM which housed the target database and
Atom feed consumer; and one Dell Latitude X300 laptop with a Pentium M 1.2 GHz
processor and 1 GB of RAM, which housed the source database, Atom feed builder
and query generator. All the laptops were running the Windows XP operating system,
Apache 2.0.55 web server, PHP version 5.0.4 and the source and target databases were
run on a MySQL version 4.1.11 server. The machines were networked via a Lantronix
LMR8T-2 10Base-T hub.
54

Procedure
The time server was first initialised followed by the feed builder, the query generator
and finally the feed consumer. The query generator was set to execute 100 separate
updates on the source database. Each time an update was executed, an event notice
was sent to the time server along with the content of the update statement. The time
server would attach a timestamp when it received the event notification.
A similar process happened when the feed consumer applied an update from the
Atom feed to the target; as soon as the consumer had an update it would send an event
notification to the timeserver along with the contents of the update it had generated.
Thus every event that occurred in both the feed builder and consumer could be logged,
which meant it was possible to calculate the elapsed time from when an update was
initially applied to the source until it was finally applied to the target.
This procedure was repeated twice, the first run with the feed consumer set to poll
at 15 seconds whilst the second had the consumer polling at 30 seconds. The end result
was elapsed times for 200 separate update events being captured for analysis.
4.4 Summary
The methodology for evaluating the Atom prototype has been presented. The evalua-
tion framework measured the prototype’s impact upon the network and computation
resources it consumed and compared these to observations of response time differences
between operational and analytical processing systems.
The testing observed the system to see if it could operate in a stable yet respon-
sive manner, and at the same time place relatively low demand/loading on its support
infrastructure. If the system can achieve this then the prototype Atom-based archi-
tecture will have potential to be developed further for use in smaller scale commercial
data integration solutions. If however, the system places high to excessive demands
on the resources that it requires, this could imply one of two things: either that the
architecture does not have the potential to facilitate a lightweight data integration so-
lution, or that it may in fact be more suitable to processing tasks that occur at slower
frequencies. The results from conducting this evaluation are presented in the next
chapter.
55

Chapter 5
Results
5.1 Introduction
The following results pertain to the pull configuration of the Atom prototype as a suf-
ficient amount of data suitable for analysis was not collected for the push configuration
due to technical issues mentioned earlier in Section 4.1. In addition, although 30 test
runs were carried out for the operational test, only 18 were used for actual analysis.
This is attributed to the fact that some of the capture files were over a gigabyte in size
which may have caused problems when the data was written to DVD media. Section
5.2 outlines the results for each of the three tests conducted to provide data for eval-
uating the implementation of the Atom-based architecture. First the load test results
are presented in Section 5.2.1, followed by the operational test in Section 5.2.2 and
finally the latency test in Section 5.2.3. The chapter concludes with a summary of the
results in Section 5.3.
5.2 Findings
5.2.1 The Load Test
Figure 5.1 summarises the performance of the Atom prototype in terms of average
elapsed time under different loading conditions. The elapsed time was calculated by
adding the time taken by the feed builder modules to update the Atom feed to the time
taken by the feed consumer module to parse the Atom feed and apply the updates to
the target.
A total of 60 test runs were completed, comprising four sets with each set having a
different number of data sources connected. The first set of test runs were conducted
56

Average Time for Update Propagation
0.0
5.0
10.0
15.0
20.0
25.0
0 1 2 3 4 5
Number of Sources
Tim
e (M
inu
tes)
Figure 5.1: Performance
with one data source, and yielded an average elapsed processing time of 00:04:46,
ranging from 00:04:32 to 00:05:16. With two sources connected, the system completed
processing in 00:09:47 on average, ranging from 00:09:01 to 00:11:25 while this time
increased to 00:16:58 on average with three data sources and ranged from 00:16:04 to
00:18:53. The final set of test runs required the Atom prototype to process data from
4 different data sources, this task on average was completed within 00:23:02 with the
shortest time of the set being 00:22:30 and the longest 00:23:27.
In addition to processing time performance, other data acquired recorded the size of
the Atom feed and output SQL generated in relation to the size of the SQL representa-
tion of the original source data, as shown in Figure 5.2. The sizes of the various outputs
being measured were calculated using the PHP function filesize()which returns the
size in bytes of the file in question.
With one data source, the size of the source data SQL representation was 0.498
MB, the Atom feed measured 0.744 MB and the feed consumer output was 1.208 MB.
With two data sources the source SQL representation doubled to 0.996 MB, the Atom
feed was 1.488 MB and the consumer output 2.432 MB. The third set of test runs used
three data sources and increased the source SQL representation size to 1.494 MB, the
Atom feed size to 3.647 MB and the consumer output SQL to 2.232 MB. The final test
of four sources yielded a source SQL representation size of 1.992 MB, an Atom feed
size of 2.976 MB with consumer output SQL measuring 4.866 MB.
57

Source SQL Representation, Atom feed and SQL code size comparison
0
1
2
3
4
5
6
1 2 3 4
Number of Sources
Ou
tpu
t S
ize
(meg
abyt
es)
Initial Source SQLAtom FeedConsumer SQL Size
Figure 5.2: Comparison of Outputs
Atom Generated Network Traffic (Bytes)
0
1
2
3
4
5
6
0 60 120 180 240 300 360 420 480 540 600 660 720 780 840 900 960 1020
Bytes (millions)
Tes
t R
un
s
15 Seconds30 Seconds
Figure 5.3: Network Traffic Generated by Atom Prototype
58

5.2.2 The Operational Test
As mentioned in Chapter 4, the operational test was designed to observe the prototype
system within the confines of a semi-realistic environment. The data captured from
this test included all network traffic that was generated immediately prior to, during
and immediately after the prototype was in operation. The number of data sources
that the system had to deal with was fixed at four. Figure 5.3 shows the distribution of
test runs in relation to the amount of network traffic generated. A total of 30 test runs
were completed with 15 test runs performed with the consumer polling frequency set
at 15 seconds, and the second set of tests had the consumer operating with a 30 second
polling frequency. Only 18 were used for analysis; this was necessary as a portion of
the network capture files were corrupted and with time constraints placed on the test
equipment, there were no alternatives other than to continue on to analysis with a
smaller sample than what was originally anticipated.
Results from the non-corrupted operational test data show that the average total
amount of data that traversed the network when the consumer was polling at 15 seconds
was 584 MB and ranged from 335.482 MB to 953.235 MB. The average amount of data
to traverse the network when the consumer was set to poll at 30 seconds was 380.322
MB, ranging from 201.334 MB to 683.729 MB.
In addition to the amount of data being generated and sent across the network,
data pertaining to the kinds of packets being sent and received were also collected. Of
particular significance were packets containing HTTP data, as this was the protocol
used by the prototype to send and receive data from the Atom feed. Figure 5.4 shows
the distribution of test runs relative to HTTP packet content. With the system set
to poll at 15 seconds, the average total number of packets containing HTTP data was
605860 and ranged from 348678 to 988018 as seen in Figure 5.4. Conversely, with
the feed consumer set to poll at 30 second intervals the average number of packets
containing HTTP data was 394458, ranging from 240711 to 708744. The average
difference in total HTTP packets between the two configurations was 211402.
5.2.3 The Latency Test
With the consumer set to poll the Atom feed at 15 second intervals, the mean elapsed
time for an update to be propagated to the target was 33 seconds with a variance of 22.3
seconds. However, with the consumer set to poll the Atom feed at 30 seconds, the mean
update propagation time increased to 66 seconds. The resulting doubling in length
59
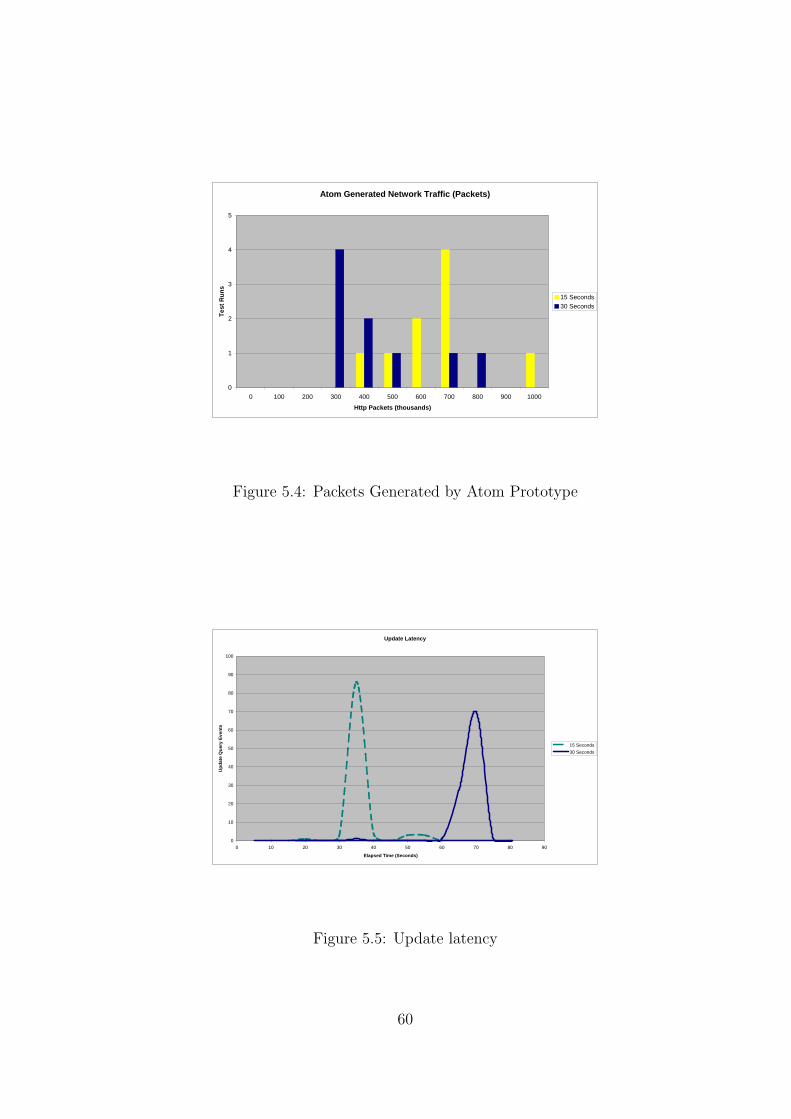
Atom Generated Network Traffic (Packets)
0
1
2
3
4
5
0 100 200 300 400 500 600 700 800 900 1000
Http Packets (thousands)
Tes
t R
un
s
15 Seconds30 Seconds
Figure 5.4: Packets Generated by Atom Prototype
Update Latency
0
10
20
30
40
50
60
70
80
90
100
0 10 20 30 40 50 60 70 80 90
Elapsed Time (Seconds)
Up
dat
e Q
uer
y E
ven
ts
15 Seconds
30 Seconds
Figure 5.5: Update latency
60

of the polling frequency led to an equally proportional increase to the mean update
propagation latency; it would be interesting in future to conduct tests at additional
polling frequencies to see if this trend continues. Figure 5.5 illustrates a comparison
of the distribution of elapsed times between the two different configurations of the
system tested. The mean difference of update propagation times between the two
configurations was 33 seconds.
5.3 Summary
This chapter has presented the results of the three different experiments carried out to
evaluate the prototype implementation of the Atom based data integration architecture.
The results presented are all associated with the pull configuration of the prototype.
The load test results in Section 5.2.1 show that the average elapsed times for the
prototype system to completely propagate the contents of the data source ranged from
00:04:46 to 00:23:02 depending on how many data sources were connected to the system.
The operational test results in Section 5.2.2 present the impact the prototype system
had on the network resources the testing was conducted on, however the results from
this particular test may not be as compelling as they could have been as the amount
of data captured was less than what was originally intended. Section 5.2.3 presented
results from the latency test which compared update latency between two different
feed consumer polling frequencies. More in depth discussion of these results will be
presented in the next chapter.
61

Chapter 6
Conclusion
6.1 Discussion of Results
Observations of response time differences between operational and analytical processing
systems, as identified by Inmon (1993) and Silberschatz et al. (2006) amongst others,
were used as a measure. The tests that were developed, described in Section 4.3,
recorded data pertaining to response time (latency) of the system, as well as the size
of various inputs and outputs of the system, such as the size of the Atom feed itself.
The results of the experiments were then presented in Chapter 5.
Results from the latency test (see Figure 5.5 on page 60) showed that the proto-
type system is capable of delivering response times low enough to fall within the range
deemed suitable for operational processing environments by Inmon (1993). Further-
more, results from the load testing (see Figure 5.1 on page 57) indicated that the system
in its current form is capable of accurately processing large data sets in a timely fash-
ion. The extent to which these results can be related to each other is limited slightly
as both sets of testing were performed on platforms that varied greatly in terms of
processing performance, as noted in Sections 4.3.3 and 4.3.1 respectively.
However, these results should still be looked at in contrast to what was found with
the operational testing (see Figures 5.3 and 5.4 on page 58). In one particular opera-
tional testing run, it was found that nearly one gigabyte of data eventually traversed
the network, with the system averaging between 380 MB to 584 MB depending on the
polling frequency being used. When looking back at the load test results, the average
size Atom representation for the entire contents of one data source was only 0.744 MB.
What can be drawn from these results is that although the prototype can perform
with a level of latency low enough to support an operational processing environment,
62

it does so at a cost of placing a substantial demand on the supporting environment’s
network resources, in relation to the size of the Atom feed that it generates.
An initial reaction to this observation is the system would be more suitable to an
analytical processing environment, where responsiveness (low latency) is not so much
of an issue; rather, the ability to process large volumes of data accurately has greater
emphasis. In such an environment the polling frequency would be set much lower,
resulting in a much lower impact on network resources.
However, it would be premature to draw such a conclusion from these observa-
tions. We must remember that all the testing conducted for this evaluation has been
performed on a prototype system which, in this case, means that some functionality,
or the means by which the functionality has been implemented, is sub-optimal. For
example, on closer inspection of how the prototype actually works (see Section 3.4.2),
the feed consumer must download the entire Atom feed and parse it to infer whether
any new updates have been appended to the feed.
An immediate, disadvantage to this approach can be seen: when the consumer is
polling the feed at a high frequency, it is essentially downloading the entire Atom feed
at a high frequency, which can result in the generation of a large amount of unnecessary
network traffic. The Atom feed is not overwritten; rather new data are appended to
the end of the feed (see Section 3.4.3), which adds to the initial issue by having an ever-
increasing amount of old or stale data traversing the network. The main advantage of
not overwriting the Atom feed is that it provides a simple mechanism for maintaining
a serialised copy of all the data generated so far.
The SSE specification briefly mentioned in Section 2.2.6 contains a method where
two feeds are created; one is used in a production context, called the partial feed, which
contains the latest updates. The other, named the complete feed, is more of an archival
service; and is useful for initial synchronisation when new feed consumers come online.
This has the advantage that the partial feed can be limited to a certain size to limit
network usage, while at the same time the complete feed can be used to keep data
serialised and be used to initialise new feed consumers or synchronise consumers who
have been offline for some time.
Another important issue, relating once more to the system’s prototype status, arises
from the way the mapping between the data source and target has been created; the
prototype made use of a predefined, hard-coded mapping, written specifically for the
schemas used in the experiments. In many ways this is the reason why the prototype
performed well in terms of accuracy, as the mapping was completely optimised for that
63

one particular case. This is a problem because before the system can be tested further,
or used with differing data sources and schemas, a new hard-coded mapping has to be
written and the prototype’s code base adapted to suit.
This situation may be bearable in simple situations where there are only a few
items to map and programmers are readily available to code the mapping. Realistically
however, this simply defeats the purpose of using the data integration architecture, as
there would be no real difference between using the Atom-based system and building
a solution from scratch. In other words, the prototype in its current form cannot be
generalised to other scenarios very easily.
To summarise so far, interpreting the data at face value may lead us prematurely
to believe that the system would be best suited to an analytical processing context.
However, it is really far too early to consider such an idea when the underlying details
of the prototype’s state of implementation are also examined. When developmental
status of the system is actually taken into account, we find the system requires, initially,
three specific refinements:
1. Addressing the issue of network resource consumption at high polling frequencies.
2. Managing of the size of the Atom feed itself; this is partly related to the previous
issue.
3. Enabling the system to be generalised to other scenarios by improving the means
by which mappings between source and target schemas are specified. This could
be achieved by incorporating an appropriate mapping specification (like those
mentioned in Section 2.3 on page 14) into the architecture, as well as investigating
the use of an ontology specification to construct semantic mappings between
participating objects.
The prototype can really be considered to be at an “alpha” stage of development;
testing has revealed that it, and therefore an Atom-based architecture, is capable of
facilitating data integration between relational databases to an extent. However, to
continue down this path the implementation of a more refined version would need to
be undertaken, followed by additional testing to compare with the initial results of this
research.
When the results are compared with the state of the prototype, it is found that the
system is really at a point where the decision whether to continue further development
work or not needs to be made.
64

Considering the amount of work currently going into the already large body of
data integration research (as discussed in Section 2.3), and that there are already com-
mercially available products such as Altova’s MapForce (Altova, 2005), the immediate
decision could be not to continue further development.
However, with the recent announcements of the SSE and GData specifications (see
Section 2.2.6), there are signs that there is a growing community investigating the
extended usage of content syndication technologies. Therefore, rather than shelving
the project because there is already much work, both academic and commercial, going
on in the field of data integration, an alternative option is to open further development
up to the open source community.
This option would have the advantages of being able to expose the prototype to
others investigating extended use of syndication technologies, gain access to a large
talent pool of developers and in general present the prototype and the ideas behind it
to further scrutiny and debate from a large diverse audience.
6.2 Summary
We have evaluated Atom for its potential as a lightweight architecture to support data
integration. Data integration looks at the problem of trying to portray a unified view to
a user of data sets that could not only be located in different places but also structured
in a variety of different ways.
A series of topics from related work were presented in Chapter 2 to illustrate and
discuss where both this research and the Atom specification are positioned. Atom is
a content syndication specification, and has been developed in response to perceived
issues regarding RSS, especially to address the proliferation of differing versions of
the RSS specification. Furthermore, it provides an avenue for further development
in light of the fact that RSS 2.0 is copyrighted by Harvard university and considered
frozen, that is, further development of that particular branch of the specification will
not continue.
The publish/subscribe paradigm was discussed next to show an environment in
which Atom is used. Additionally a pertinent piece of research that used the Hermes
publish/subscribe infrastructure as a novel platform for data integration was discussed,
in part to illustrate the domain this research wanted to investigate the Atom specifi-
cation within. A feature that both the Atom prototype we developed and the Hermes-
based system of Vargas et al. (2005) shared is that they facilitate data integration by
65

means of asynchronous update propagation, which refers to the problem of updating
copies of an object and is commonly associated with distributed systems. However,
how the Atom-based and the Hermes-based systems do this is quite different.
Data streaming contrasts with the asynchronous behaviour of the Atom-based pro-
totype that we developed. A significant area of research in its own right, information
systems increasingly have to be able to process these kinds of data that are highly
dynamic and transient.
Chapter 3 then presented an implementation of the Atom-based architecture that
we developed for this research. The prototype has been developed in PHP, in part
due to our familiarity with the technology, and also as this enabled a prototype to
be developed that would be ported easily to different platforms. This was of initial
pragmatic importance as both the development and testing environments were located
on different platforms. Furthermore PHP is freely available, which means that it is
a suitable candidate to base an affordable production grade version of the system on.
We combined the freely available, feature rich technology PHP with the simplified
asynchronous connection scheme content syndication technology offers to create our
data integration prototype.
Two particular configuration types of the architecture were presented, namely
“push” and “pull”. Within the push method, the consumption of feed information
is governed predominantly by changes in state of the source data, i.e., when the feed
generator detects a change in state of the source data the feed is regenerated and the
consumer module is called immediately to apply the new information to the target
schema. The pull method differs from the push approach on two key points. First,
the feed consumer modules operate independently of, and are therefore not directly
influenced by, the feed generator component. Secondly, the flow of feed information to
the target schema is governed by the consumer module itself.
Three use cases were presented (see Section 3.2 on page 32) that were used to
give guidance in development of the Atom prototype. Each use case had a degree of
complexity and scale slightly greater than that of its predecessor, however, all the use
cases share some common requirements. The first of these requirements was that the
architecture has a non-intrusive nature; that is, the architecture should act strictly as a
mediatory framework between the sources and target. Furthermore, the implemented
architecture should be lightweight in terms of the network and computational resources
it consumes and it should also be platform independent.
Chapter 3 discussed the key components of the Atom-based architecture, namely
66

the feed generator and feed consumer, before a comparison of the Atom prototype to the
publish/subscribe data integration architecture of Vargas et al. (2005) was presented
in Section 3.5.
Chapter 4 described the experimental design used to evaluate the prototype. The
evaluation framework measured the prototype’s impact upon network and computation
resources when operating in specific use cases presented earlier in Chapter 3, specifically
the MP3 kiosk case.
Chapter 5 presented the results of the three experiments used to evaluate the im-
plemented Atom based data integration architecture. The results presented are all
associated with the pull configuration of the prototype.
6.3 Recommendations and Conclusions
Some initial recommendations of features that should be provided by any further de-
velopment of the Atom-based architecture were identified earlier in this chapter, prin-
cipally enabling the system to be generalised to scenarios outside those found within
this research. Another interesting feature would be to investigate the ability to prop-
agate schemas as well as data. This would enable a means to deploy data sets on
platforms different to what the schema was originally created on without needing to
first manually specify an equivalence mapping. For example, a vendor whose develop-
ment environment is different to that of its client could still develop a data structure
and then use the Atom system to transfer and transform that structure to the client
ready for deployment. Another useful scenario would be when initially establishing a
mapping between a data source and a target; the source’s schema specification could
be sent and the Atom consumer could then derive a mapping solution to the target for
verification by the user.
It would also be worth considering looking at the SSE and GData APIs as a basis for
the development of a future prototype. Both technologies are backed by organisations
with substantial resources, and already have resources for the developer community set
in place. Furthermore, it may be an opportune time to survey the extent of research
regarding the emerging use of content syndication technology, like Atom, outside of its
conventional context.
In conclusion, the architecture presented in this thesis has potential in facilitating a
lightweight data integration solution and can exhibit a non-intrusive behaviour toward
the data objects interacting through it. Our research has shown that an Atom-based
67

architecture is capable of operating within a range of conditions and environments and
with further development, would be capable of greater processing efficiency and wider
compatibility with other types of data structures.
68

References
Adali, S., Candan, K. S., Papakonstantinou, Y. and Subrahmanian, V. S. (1996).
Query caching and optimization in distributed mediator systems, The 1996 ACM
SIGMOD International Conference on Management of Data, ACM Press, New
York, NY, USA, pp. 137–146.
Altova (2005). Altova mapforce database mapping. http://www.altova.com/
products/mapforce/xml to db database mapping.html, accessed 7 October
2005.
Arasu, A., Babu, S. and Widom, J. (2004). CQL: A Language for Continuous
Queries over Streams and Relations, Lecture Notes in Computer Science, 2921
edn, Springer.
AtomEnabled (2005). AtomEnabled. http://www.atomenabled.org, accessed 9
February 2005.
Atzeni, P., Ceri, S., Paraboschi, S. and Torlone, R. (1999). Database Systems: Con-
cepts, Languages & Architectures, McGraw-Hill, London.
Babcock, B., Babu, S., Mayur, D., Motwani, R. and Widom, J. (2002). Models and
issues in data stream systems, ACM Principles Of Database Systems (PODS),
ACM Press, Madison, Wisconsin, USA, pp. 1–16.
Baldoni, R., Contenti, M. and Virgillito, A. (2003). The evolution of publish/subscribe
communication systems, Future Directions of Distributed Computing, Vol. 2584,
Springer Verlag.
Batini, C., Lenzerini, M. and Navathe, S. B. (1986). A comparative analysis of method-
ologies for database schema integration, ACM Computing Surveys 18(4): 323–364.
Beck, R., Weitzal, T. and Konig, W. (2002). Promises and pitfalls of sme integration,
The 15th Bled Electronic Commerce Conference, Bled, Slovenia, pp. 567–583.
69

Berners-Lee, T., Connolly, D. and Swick, R. R. (1999). Web architecture: Describing
and exchanging data. http://www.w3.org/1999/04/WebData.
Berners-Lee, T. and Fischetti, M. (1999). Weaving the Web, Orion Business, London.
Berners-Lee, T., Hendler, J. and Lassila, O. (2001). The Semantic Web, Sci-
entific American . http//www.scientificamerican.com/2001/0501issue/
0501berners-lee.html.
Boyd, M., Kittivoravitkul, S., Lazantis, C., McBrien, P. and Rizopoulos, N. (2004).
AutoMed: A BAV data integration system for heterogeneous data sources, Lecture
Notes in Computer Science, Springer-Verlag, pp. 82–97.
Breitbart, Y., Komondoor, R., Rastogi, R., Seshadri, S. and Silberschatz, A. (1999).
Update propagation protocols for replicated databases, Proceedings of the 1999
ACM SIGMOD International Conference on Management of Data, ACM Press,
Philadelphia, Pennsylvania, United States, pp. 97–108.
Buretta, M. (1997). Data Replication Tools and Techniques for Managing Distributed
Information, John Wiley & Sons, New York.
Cali, A., Calvanese, D., De Giacomo, G. and Lenzerini, M. (2002). Data Integration
under Integrity Constraints, number 2348 in Lecture Notes in Computer Science,
Springer.
Cali, A., Calvanese, D., Giacomo, G. D. and Lenzerini, M. (2002). On the Expressive
Power of Data Integration Systems, number 2503 in Lecture Notes in Computer
Science, Springer.
Calvanese, D., Giacomo, G. D., Lenzerini, M., Nardi, D. and Rosati, R. (1998). Infor-
mation integration: Conceptual modelling and reasoning support, The 3rd IFCIS
International Conference on Cooperative Information Systems (CoopIS’98), IEEE
Computer Society Press, New York, NY, pp. 280–291.
Campailla, A., Chaki, S., Clarke, E., Jha, S. and Helmut, V. (2001). Efficient filtering in
publish-subscribe systems using binary decision diagrams, The 23rd International
Conference on Software Engineering (ICSE’01), IEEE Computer Society, Toronto,
Canada, pp. 04–43.
70

Carney, D., Cetinternel, M., Cherniack, C., Convey, C., Lee, S., Siedman, G., Stone-
braker, M., Tatbul, N. and Zdonik, S. (2002). Monitoring streams - a new class
of data management applications, The 28th Very Large Databases (VLDB) Con-
ference, Hong Kong, China, pp. 215–226.
Chawathe, S., Garcia-Molina, H., Hammer, J., Ireland, K., Papakonstantinou, Y.,
Ullman, J. and Widom, J. (1994). The TSIMMIS project: Integration of hetero-
geneous information sources, The Information Processing Society of Japan (IPSJ)
Conference 1994, Tokyo, Japan.
Connolly, T. M. and Begg, C. E. (2005). Database Systems: A Practical Approach to
Design, Implementation, and Management, Addison-Wesley, Essex, UK.
Date, C. J. (2004). An Introduction to Database Systems, eighth edn, Addison-Wesley,
New York.
Duschka, O. M., Genesereth, M. R. and Levy, A. Y. (2000). Recursive query plans for
data integration, The Journal of Logic Programming 43(1): 49–73.
Ethereal (2005). Ethereal: A network protocol analyser. http://www.ethereal.com,
accessed 7 October 2005.
Eugster, P. T., Felber, P. A., Guerraoui, R. and Kermarrec, A. (2003). The many faces
of publish/subscribe, ACM Computing Surveys 35(2): 114–131.
Farooq, U., Parsons, E. W. and Majumdar, S. (2004). Performance of publish/subscribe
middleware in mobile wireless networks, WOSP ’04: Proceedings of the 4th In-
ternational Workshop on Software and Performance, ACM Press, New York, NY,
USA, pp. 278–289.
Fensel, D., Hendler, J., Lieberman, H. and Wahlster, W. (eds) (2003). Spinning the
Semantic Web, MIT Press, Cambridge, MA.
Friedman, M., Levy, A. and Millstein, T. (1999). Navigational plans for data in-
tegration, 16th National Conference on Artificial Intelligence (AAAI’99), AAAI
Press/The MIT Press, pp. 67–73.
Ge, Z., Ji, P., Kurose, J. and Towsley, D. (2003). Matchmaker: Signalling for dynamic
publish/subscribe applications, The 11th IEEE International Conference on Net-
work Protocols (ICNP’03), IEEE Computer Society, Los Alamitos, CA, p. 222.
71

Goh, C. H., Bressan, S., Madnick, S. and Siegel, M. (1999). Context interchange:
new features and formalisms for the intelligent integration of information, ACM
Transactions on Information Systems 17(3): 270–293.
Golab, L. and Ozsu, M. T. (2003a). Issues in data stream management, SIGMOD
Record 32(2): 5–14.
Golab, L. and Ozsu, M. T. (2003b). Processing sliding window multi-joins in continuous
queries, The 2003 International Conference on Very Large Databases, Morgan
Kaufmann, pp. 500–511.
Google (2006). Google Data APIs Overview. http://code.google.com/apis/gdata/
overview.html, accessed 24 May 2006.
Gray, J., Homan, P., Korth, H. F. and Obermarck, R. (1981). A strawman analysis of
the probability of wait and deadlock, IBM Technical Report RJ3066 .
Gupta, A., S., O. D., Agrawal, D. and El Abbadi, A. (2004). Meghdoot: Content-based
publish/subscribe over P2P networks, in H. A. Jacobsen (ed.), Middleware 2004,
International Federation of Information Processing (IFIP), pp. 254–273.
Haas, L. M., Miller, R. J., Niswonger, B., Roth, M. T., Schwarz, P. M. and Wimmers,
E. L. (1999). Transforming heterogeneous data with database middleware: Beyond
integration, IEEE Data Engineering Bulletin 22(1): 31–36.
IDEAlliance (2006). About PRISM. http://www.prismstandard.org/about/, ac-
cessed 05 November 2006.
Inmon, W. H. (1993). Building the Data Warehouse, John Wiley & Sons, New York.
Koivunen, M. and Miller, E. (2001). W3C Semantic Web activity, Semantic Web
Kick-Off in Finland: Vision, Technologies, Research and Applications, HIIT Pub-
lications, Helsinki, Finland, pp. 27–43.
Lenzerini, M. (2002). Data integration: A theoretical perspective, ACM Principles Of
Database Systems (PODS), ACM, Madison, Wisconsin, USA, pp. 233–246.
Levy, A. Y. (2000). Logic-based techniques in data integration, in J. Minker (ed.),
Logic Based Artificial Intelligence, Kluwer Academic, Dordrecht, pp. 575–595.
72

Madden, S. and Franklin, M. J. (2002). Fjording the stream: An architecture for
queries over streaming sensor data, The 18th International Conference on Data
Engineering (ICDE’02), IEEE, p. 0555.
Madhavan, J. and Halevy, A. Y. (2003). Composing mappings among data sources,
The 29th Very Large Databases (VLDB) Conference, Berlin, pp. 572–583.
Manola, F., Miller, E. and McBride, B. (2004). RDF Primer. W3C Recommendation.
http://www.w3.org/TR/rdf-primer/.
McBrien, P. and Poulovassilis, A. (2003). Data integration by bi-directional schema
transformation rules, The 19th International Conference on Data Engineering
(ICDE’03), IEEE, pp. 227–238.
McGuinness, D. L. and van Harmelen, F. (2004). OWL Web Ontology Language.
http://www.w3.org/TR/owl-features/.
Nicola, M. and Jarke, M. (2000). Performance modelling of distributed and replicated
databases, IEEE Transactions on Knowledge and Data Engineering 12(4): 645–
672.
Nottingham, M. and Sayre, R. (2005). The Atom Syndication Format, 2005. http:
//tools.ietf.org/html/rfc4287.
O’Neil, P. and O’Neil, E. (2001). Database: Principles, Programming, Performance,
Morgan Kaufmann, San Francisco, CA.
Ozsu, M. T. and Valduriez, P. (1999). Principles of Distributed Databases, 2nd edn,
Prentice Hall, New Jersey.
Ozzie, J., Moromisato, G. and Suthar, P. (2005). XML developer center: Simple
sharing extensions for RSS and OPML. http://msdn.microsoft.com/xml/rss/
sse, accessed 24 May 2006.
Pascoe, R. T. and Penny, J. P. (1990). Construction of interfaces for the exchange
of geographic data, International Journal of Geographical Information Systems
4(2): 147–156.
Powers, S. (2003). Practical RDF, O’Reilly, Sebastopol, CA.
Progress Software (2006). Progress Apama algorithmic trading platform. http://www.
progress.com/realtime/products/apama/index.ssp, accessed 10 April 2006.
73

Silberschatz, A., Korth, H. F. and Sudarshan, S. (2006). Database System Concepts,
fifth edn, McGraw-Hill, New York.
Tomasic, A., Raschid, L. and Valduriez, P. (1998). Scaling access to heterogeneous data
sources with DISCO, IEEE Transactions on Knowledge and Data Engineering
pp. 808–823.
Ullman, J. D. (1997). Information integration using logical views, Database Theory -
ICDT ’97. 6th International Conference Proceedings pp. 19–40.
Vargas, L., Bacon, J. and Moody, K. (2005). Integrating databases with pub-
lish/subscribe, The 25th International Conference on Distributed Computing Sys-
tems Workshops (ICDCSW’05), IEEE Computer Society, pp. 392–397.
Vivometrics (2005). Vivometrics technology backgrounder. http:
//www.vivometrics.com/site/pdfs/find.php?file=VivoMetrics
TechnologyBackground, accessed 15 April 2006.
Vivometrics (2006). Advanced real-time monitoring ensemble for first respon-
ders deployed by U.S. military. http://www.vivometrics.com/site/press
pr20060411.html, accessed 15 April 2006.
Wang, J., Jin, B. and Li, J. (2004). An Ontology-Based Publish/Subscribe System,
number 3231 in Lecture Notes in Computer Science, Springer.
Widom, J. (1995). Research problems in data warehousing, CIKM ’95: Proceedings of
the fourth international conference on Information and knowledge management,
ACM, pp. 25–30.
Wiederhold, G. (1993). Intelligent information integration, Proceedings of the 1993
ACM SIGMOD International Conference on Management of Data (SIGMOD ’93),
ACM Press, New York, NY, pp. 434–437.
Wiederhold, G. (1995). Mediation in information systems, ACM Computing Surveys
27(2): 265–267.
Xu, L. (2001). Efficient and scalable on-demand data streaming using UEP codes,
Proceedings of the Ninth ACM International Conference on Multimedia, ACM
Press, New York, NY, pp. 70–78.
74

Yu, C. and Popa, L. (2004). Constraint based XML query rewriting for data integration,
Proceedings of the 2004 ACM SIGMOD International Conference on Management
of Data (SIGMOD ’04), ACM Press, New York, NY, pp. 371–382.
75

Appendix A
Music Kiosk Use Case
A.1 MP3 Kiosk Project Documentation
76

Digital Music Kiosk
Development Team:
Stefan Bryce
Prajesh Chhannabhai
David Williamson
77

Executive Summary
Since the rise in popularity of digital audio, the music industry has sought to make music
available in a manner that is convenient for the consumer in order to continue to obtain
revenue from copyrighted works. Having had several iterations, there appears to be no
serious progress that meets the needs of the mobile consumer.
The latest positive progress has been the advent of paid music content delivered across the
Internet. However, the delivery of music to a person’s home is only a partial solution, and
assumes access to a PC with reasonable Internet access – not a given in many parts of the
world. Instead, high speed easily accessible avenues of delivery are required.
This document outlines a possible solutions taking advantage of available hardware and
the creation of leading edge interfaces to provide what the consumer wants – high-speed
delivery of digital media.
78

1 Introduction ...................................................................................................................... 4
2 Background....................................................................................................................... 4
2.1 Justification of System ................................................................................................. 4
2.2 Existing Product Evaluation ........................................................................................ 5
KIS Company Details........................................................................................................ 5
OverDrive Company Details ............................................................................................. 5
3 Problem Identification ..................................................................................................... 9
3.1 Identified problems and proposed solutions:............................................................... 9
3.2 Future Work................................................................................................................. 9
4 Scope and Objectives...................................................................................................... 10
4.1 Scope...................................................................................................................... 10
4.2 Objectives............................................................................................................... 10
5 Proposed Solution........................................................................................................... 11
5.1 System overview ....................................................................................................... 11
79

1 Introduction
This project proposes the development of a digital music retail kiosk.
A growing trend in the adoption of portable MP3 players and a slowing of CD purchases from traditional music retail channels has emerged1. Many vendors have tried to implement a solution to complement the growing popularity of the MP3 file format, but have not been as effective as originally envisaged. This project attempts to alleviate the shortfalls identified in previous efforts by producing a prototype that may be developed into a commercially viable product.
The purpose of this document is to: Outline the justification of the proposed solution Identify the validity of our solution Confirm the scope and objectives for the project
2 Background
2.1 Justification of System
Due to a trend of consumers moving towards digital audio, rather than traditional, a new niche has been created in the e-commerce industry to satisfy consumer demands. Some key players in the music industry, for example Sony, have attempted to implement their own solutions to fill this void.
We propose a solution that addresses past failures and attempts to cater towards modern consumer needs. Our proposed solution will allow consumers the opportunity to customize their music purchase by means of creating custom music compilations. To make the systems more flexible, the kiosk will have provision for a wide variety of modern high speed storage devices.
It is intended that it will connect to multiple music databases, although this is out of the scope of this prototype.
A system that contains a wide variety of music, with speed, it is anticipated consumers will take to in a positive manner. This will also offer music distributors a legitimate and easy way to distribute legal digital audio.
80

2.2 Existing Product Evaluation
KIS Company Details
Name: Kiosk Information Systems, Inc. URL: http://www.kis-kiosk.com Products/Solutions Products: KIS 770 Kiosk
KIS 780 SNAPTRAX Kiosk Technologies: Based around Dell Optiplex Computer Critique:
The KIS kiosk products provide a wide range of content and services to the client. Deliverables consist of downloadable digital content for mobile phones, digital photo printing and photo CD creation, internet browsing services and digital music retail. The digital music component allows the user to create unique compilations and burn them to CD's or download to a laptop or MP3 player. Although these kiosks provide users with the ability to create music compilations, the range of music available to be purchased is somewhat limited.
OverDrive Company Details
Name: OverDrive, Inc. URL: http://www.overdrive.com Products/Services Product: Digital Rights Management (DRM) Technologies: Microsoft Digital Asset Server
Windows Media Adobe Content Server
Critique Although OverDrives DRM solution does provide a high level of customization at the design level, it does have two key factors limiting its usefulness as a platform for kiosk based music retailing. Firstly the digital audio format supported is limited to Windows Media (.WMA) files only. And secondly, the DRM solution is a generalized specification incorporating a patchwork of technologies. This is in part due to the solution's intended use as the building blocks for myriad digital content distribution applications. However, such architecture is not always suitable for a specialized digital music retail kiosk where responsiveness and flexibility are critical design considerations.
81

MMS Company Details Name: RedDotNet's Multimedia
Merchandising system URL: http://www.reddotnet.com/ Products/Solutions Products: Multimedia Merchandising System Technologies: Run on a windows NT/2000 Platform
Remotely controlled and updated
Critique:
This system is only a music preview system offering no method of burning or downloading the audio music, used only as a listening and searching post The system must be located inside a music retail shop, and only carries a database of the audio that the shop has available for purchase.
Soundbuzz Company Details Name: Soundbuzz URL: http://www.soundbuzz.com Products/Solutions Products: "CDBank" Kiosk Technologies: Customised CD Production Digital
Rights Management Touch Screen Interface
Critique:
The Soundbuzz CDBank kiosks are interactive, freestanding machines that allow a user to burn a custom or single track CD (CD-audio format) of their own choice from a pre-set track list. They also allow the user to take a digital picture and write a personal message that is printed on the CD itself. The machine takes regular cash/coins and cash cards and due to this - it has to be a secure, heavily locked-up machine. Using Microsoft's Windows Media Rights Management technology, music is protected as it is distributed around the Internet. Soundbuzz's in-house DRM solution, developed jointly with Microsoft, ensures media rights are protected and cleared and Soundbuzz's multi-currency payment cart allows users, even those with local currency credit cards, to make purchases online.
82

Charge Me Company Details Name: Charge Me URL: http://www.charge-me.co.uk/ Products/Solutions Product: Charge Me MK1 Technologies Pentium Based PC System Critique: The MK1 kiosk focuses on the delivery of mobile content, i.e. loading of logos, ring tones, images, topping up etc. It does make provision for downloading of music. Currently allows for mobile transfer as well as Memory card download channels, but plans to expand to Bluetooth as well. The kiosk has some of the hardware solutions, but as its target area is the mobile phone market, it has limited range on the music front. It does not allow for custom made compilations, or copying to media such as MP3 devices, or even CD's. It is a good solution for mobile technologies, but doesn't cover the music side of things in much depth. Syncor Systems Company Details Name: Syncor Systems URL: http://www.syncorsystems.com Products/Solutions Product: Swat Team Flexible Interactive Kiosk Critique: The kiosk provides a web-enabled, cross platform database driven tool, to search for music. It allows searches by number, brand and artist. The system is built with a graphical, multimedia, touch screen interface. However its shortfall is that it is basically an electronic listening and search post, hence it does not allow one to download or copy music to any forms of media.
83

Synergy Media Group Company Details Name: Synergy Media Group URL: http://www.touchstand.com Products/Solutions Product: TouchStand Media Kiosk Technologies Wireless Technology
Bar Code Scanning Listening Station Touch Screen Interface Apple computer platform running OS/X
Critique: Developed by Synergy Media Group, the TouchStand Kiosk is a web-enabled, in-store media kiosk that offers retailers and their customers digital audio clips from more than 3.2 million songs, retailer-defined top seller lists, in-depth content searches, consumer data mining, e-mail and mailing list management, labour-free point of sale, and automatic content updating in one integrated package that is branded with the retailer's marketing. Its music database comes from Muze2 Inc. The TouchStand Media Kiosk runs on an Apple with an OSX operating system and an eMac computer with a full colour 17" touch screen. TouchStand's wireless network connection to the internet is secured by SonicWALL's3 encryption technology. Problems identified with this kiosk are that it does not yet offer any copying of music; it currently only serves as an electronic catalogue for retailers, hence there is no ability for it to copy to any media as yet. Also, there is no ability for customers to create a customized search as it only looks for whole existing albums (i.e. not individual tracks
84

3 Problem Identification
3.1 Identified problems and proposed solutions:
Transfer Rate
Transfer rate was found to cause problems in previous projects due to the waiting time for the finished product. Our solution to this is using more advanced hardware than what was previously available, using modem data transfer methods.
Hardware Speed
Similar to the transfer speed, the processing speed of the system sometimes resulted in a hindered performance. With the use of the most modern hardware technology this will aid in increasing the responsiveness of the system.
Lack of Medium options
Previous systems were using only CD-ROM as the principle form of output. This restriction gave the consumer no choice in how they received their content and made the system susceptible to frequent maintenance, for example, reloading the machine with blank media.
Our solution addresses these issues by offering the latest in data transfer technology thus giving the consumer more flexibility in how they acquire their media.
3.2 Future Work
Variety of music
A lack of a wide variety of music that catered to different consumer demographics, restricted sales and usage of previous implementations.
Our solution to this problem will be to make the application adaptable to accept data from multiple distributed sources, therefore providing a more diverse and rich pool of content from which consumers can choose from.
Cash Security
Cash handling has made previous implementations cumbersome and vulnerable to threats such as theft and damage resulting in increased chances of downtime. The physical requirements of storing the cash within the kiosk further restricted the placement options available. It also incurred further overhead with the need for the cash to be collected on a regular basis.
85

4 Scope and Objectives
4.1 Scope
The system prototype will include: • Interactive Graphical User Interface. • Diverse range of hardware inputs/outputs.
Future work includes:
• The ability to connect to multiple databases. • Payment options like EFTPOS and Credit Card.
4.2 Objectives
The proposed system will offer: • Low maintenance system design. • Provision for efficient use through a well defined
Graphical User Interface. • Response by using high speed data transfer methods. • Ease of scalability for the system, both hardware and
software. • Provide a secure transaction environment for both user
and the owners.
86

5 Proposed Solution
5.1 System overview
Inputs User Specific
• Search Function • Browsing capability
System Specific • EFTPOS • Network
Functionality • GUI • Database
Outputs System Outputs
• User Connectivity • USB 2.0, Firewire, Wireless, Memory Cards • CD (Only if administered by local staff.)
Audio • Sample • Purchased Media • Digital file
87

A.2 Schemas
A.2.1 Kiosk Schema-- phpMyAdmin SQL Dump
-- version 2.6.2
-- http://www.phpmyadmin.net
--
-- Host: localhost
-- Generation Time: Apr 14, 2006 at 04:10 PM
-- Server version: 4.1.11
-- PHP Version: 5.0.4
--
-- Database: ‘kiosk_target‘
--
-- --------------------------------------------------------
--
-- Table structure for table ‘album‘
--
CREATE TABLE album (
album_id int(10) NOT NULL auto_increment,
artist_id int(10) NOT NULL default ’0’,
genre_id int(10) NOT NULL default ’0’,
release_date date NOT NULL default ’0000-00-00’,
total_songs int(10) NOT NULL default ’0’,
price_id int(10) NOT NULL default ’3’,
cover_path varchar(200) NOT NULL default ’’,
album_title varchar(50) NOT NULL default ’’,
album_size decimal(3,2) NOT NULL default ’0.00’,
discontinued enum(’Y’,’N’) NOT NULL default ’N’,
PRIMARY KEY (album_id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Table structure for table ‘artist‘
--
CREATE TABLE artist (
artist_id int(10) NOT NULL auto_increment,
artist_name varchar(50) NOT NULL default ’’,
PRIMARY KEY (artist_id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Table structure for table ‘genre‘
--
CREATE TABLE genre (
genre_id int(10) NOT NULL auto_increment,
genre_name varchar(50) NOT NULL default ’’,
PRIMARY KEY (genre_id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Table structure for table ‘price‘
--
CREATE TABLE price (
price_id int(10) NOT NULL auto_increment,
price decimal(3,2) NOT NULL default ’0.00’,
PRIMARY KEY (price_id)
88

) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Table structure for table ‘track‘
--
CREATE TABLE track (
track_id int(10) NOT NULL auto_increment,
track_title varchar(50) NOT NULL default ’’,
artist_id int(10) NOT NULL default ’0’,
album_id int(10) NOT NULL default ’0’,
track_no int(2) NOT NULL default ’0’,
track_length time NOT NULL default ’00:00:00’,
price_id int(10) NOT NULL default ’1’,
file_location varchar(200) NOT NULL default ’’,
track_size decimal(3,2) NOT NULL default ’0.00’,
discontinued enum(’Y’,’N’) NOT NULL default ’N’,
PRIMARY KEY (track_id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Table structure for table ‘transaction‘
--
CREATE TABLE ‘transaction‘ (
transaction_id int(10) NOT NULL auto_increment,
transaction_date date NOT NULL default ’0000-00-00’,
total_price decimal(4,2) NOT NULL default ’0.00’,
PRIMARY KEY (transaction_id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- Table structure for table ‘transaction_line‘
--
CREATE TABLE transaction_line (
line_id int(10) NOT NULL auto_increment,
transaction_id int(10) NOT NULL default ’0’,
track_id int(10) NOT NULL default ’0’,
album_id int(10) NOT NULL default ’0’,
PRIMARY KEY (line_id)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1 ;
A.2.2 Source Schema-- phpMyAdmin SQL Dump
-- version 2.6.2
-- http://www.phpmyadmin.net
--
-- Host: localhost
-- Generation Time: May 13, 2006 at 03:33 PM
-- Server version: 4.1.11
-- PHP Version: 5.0.4
--
-- Database: ‘atom_kiosk‘
--
-- --------------------------------------------------------
--
-- Table structure for table ‘album‘
--
89

CREATE TABLE album (
album_id int(10) NOT NULL auto_increment,
artist_id int(10) NOT NULL default ’0’,
genre_id int(10) NOT NULL default ’0’,
release_date date NOT NULL default ’0000-00-00’,
cover_path varchar(200) NOT NULL default ’’,
album_title varchar(50) NOT NULL default ’’,
PRIMARY KEY (album_id),
KEY release_date (release_date),
KEY cover_path (cover_path),
KEY album_title (album_title)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1;
-- --------------------------------------------------------
--
-- Table structure for table ‘artist‘
--
CREATE TABLE artist (
artist_id int(10) NOT NULL auto_increment,
artist_name varchar(50) NOT NULL default ’’,
PRIMARY KEY (artist_id),
KEY artist_name (artist_name)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1;
-- --------------------------------------------------------
--
-- Table structure for table ‘genre‘
--
CREATE TABLE genre (
genre_id int(10) NOT NULL auto_increment,
genre_name varchar(50) NOT NULL default ’’,
PRIMARY KEY (genre_id),
KEY genre_name (genre_name)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1;
-- --------------------------------------------------------
--
-- Table structure for table ‘track‘
--
CREATE TABLE track (
track_id int(10) NOT NULL auto_increment,
album_id int(10) NOT NULL default ’0’,
track_title varchar(50) NOT NULL default ’’,
track_length time NOT NULL default ’00:00:00’,
file_location varchar(200) NOT NULL default ’’,
track_size decimal(3,2) NOT NULL default ’0.00’,
PRIMARY KEY (track_id),
KEY track_title (track_title),
KEY file_location (file_location)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=1;
90

Appendix B
Experiment Data Sets
Rather than provide the raw SQL data for these tests, PHP scripts have been provided
which were used to generate the SQL data.
B.1 Load Test<?php
//The following script contains a set of simple for loops,
//one loop for each table, altering the number of iterations
//each loop performs will alter the number of SQL statements
//generated...
//initialse SQL string...
$sql="";
//genres...
for($i=1;$i<=5;$i++)
{
$sql.="INSERT INTO genre VALUES(".$i.", ’genre".$i."’); \n";
}
//artists...
for($i=1;$i<=100;$i++)
{
$sql.="INSERT INTO artist VALUES(".$i.", ’artist".$i."’); \n";
}
//albums...
$album_id = 1;
$g=1;
for($ar=1;$ar<=100;$ar++)
{
for($al=1;$al<=5;$al++)
{
$sql.="INSERT INTO album VALUES(".$album_id.", ".$ar.", ".$g.", ’".rand(1900, 2005)."-".rand(1,12)."-".rand(1,29)
."’, ’coverpath_for_album".$album_id."’, ’album_title".$album_id."’); \n";
$album_id++;
}
if($g==5)
{
$g=1;
}
else
{
$g++;
}
}
//tracks...
$track_id = 1;
91

for($al=1;$al<=500;$al++)
{
for($t=1;$t<=10;$t++)
{
$sql.="INSERT INTO track VALUES(".$track_id.", ".$al.", ’track_title".$track_id."’, ’00:".rand(2,10).":".rand(10,45)."’, ’"
."file_location".$track_id."’, ".rand(1,5).".".rand(0,99)."); \n";
$track_id++;
}
}
//location of output SQL file...
$fh = fopen("c:\source5605.sql", "w");
fwrite($fh, $sql);
fclose($fh);
echo("SQL script complete.");
?>
B.2 Operational Test<?php
//This PHP script generates SQL update commands
//in order to produce an SQL update script for the
//operational test.
$source_name="3019";
$sql="";
//tracks...
for($i=1;$i<=150;$i++)
{
$sql.="UPDATE track SET track_title = ’track_titleUPDATE_".$i."_".$source_name."’ WHERE track_id = ".$i."; \n";
}
//albums...
for($i=1;$i<=100;$i++)
{
$sql.="UPDATE album SET album_title = ’album_titleUPDATE_".$i."_".$source_name."’ WHERE album_id = ".$i."; \n";
}
//genres...
for($i=1;$i<=10;$i++)
{
$sql.="UPDATE genre SET genre_name = ’genreUPDATE_".$i."_".$source_name."’ WHERE genre_id = ".$i."; \n";
}
//artists...
for($i=1;$i<=100;$i++)
{
$sql.="UPDATE artist SET artist_name = ’artistUPDATE_".$i."_".$source_name."’ WHERE artist_id = ".$i."; \n";
}
$fh = fopen("../DB_SCRIPTS"."/".$source_name."_update.sql", "w");
fwrite($fh, $sql);
fclose($fh);
echo("SQL script complete.");
?>
B.3 Latency Test Data
The latency test data was generated using the same, PHP script as that used for the
operational test data, refer to Section B.2.
92

Appendix C
Example RSS Feed
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF xmlns="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<channel rdf:about="http://www.w3.org/2000/08/w3c-synd/home.rss">
<title>The World Wide Web Consortium</title>
<description>Leading the Web to its Full Potential...</description>
<link>http://www.w3.org/</link>
<dc:date>2002-10-28T08:07:21Z</dc:date>
<items>
<rdf:Seq>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item164"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item168"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item167"/>
</rdf:Seq>
</items>
</channel>
<item rdf:about="http://www.w3.org/News/2002#item164">
<title>User Agent Accessibility Guidelines Become a W3C
Proposed Recommendation</title>
<description>17 October 2002: W3C is pleased to announce the
advancement of User Agent Accessibility Guidelines 1.0 to
Proposed Recommendation. Comments are welcome through 14 November.
Written for developers of user agents, the guidelines lower
barriers to Web accessibility for people with disabilities
(visual, hearing, physical, cognitive, and neurological).
The companion Techniques Working Draft is updated. Read about
the Web Accessibility Initiative. (News archive)</description>
<link>http://www.w3.org/News/2002#item164</link>
<dc:date>2002-10-17</dc:date>
</item>
<item rdf:about="http://www.w3.org/News/2002#item168">
<title>Working Draft of Authoring Challenges for Device
Independence Published</title>
<description>25 October 2002: The Device Independence
Working Group has released the first public Working Draft of
Authoring Challenges for Device Independence. The draft describes
the considerations that Web authors face in supporting access to
their sites from a variety of different devices. It is written
for authors, language developers, device experts and developers
of Web applications and authoring systems. Read about the Device
Independence Activity (News archive)</description>
<link>http://www.w3.org/News/2002#item168</link>
<dc:date>2002-10-25</dc:date>
93

</item>
<item rdf:about="http://www.w3.org/News/2002#item167">
<title>CSS3 Last Call Working Drafts Published</title>
<description>24 October 2002: The CSS Working Group has
released two Last Call Working Drafts and welcomes comments
on them through 27 November. CSS3 module: text is a set of
text formatting properties and addresses international contexts.
CSS3 module: Ruby is properties for ruby, a short run of text
alongside base text typically used in East Asia. CSS3 module:
The box model for the layout of textual documents in visual
media is also updated. Cascading Style Sheets (CSS) is a
language used to render structured documents like HTML and
XML on screen, on paper, and in speech. Visit the CSS home
page. (News archive)</description>
<link>http://www.w3.org/News/2002#item167</link>
<dc:date>2002-10-24</dc:date>
</item>
</rdf:RDF>
94