what i learned from translation of the sre ryuji tamagawa
TRANSCRIPT

SRE サイトリライアビリティエ
ンジニアリングの翻訳から学
んだこと
2017/10/28
玉川竜司@翻訳者

簡単に自己紹介
• Sky株式会社の開発チーム所属です
• 本業とは別に、オライリージャパンからコンピュータ関係の技術書を翻訳出版しています
• 8月出版の最新刊が「サイトリライアビリティエンジニアリング」

既刊

今年の予定

本日の内容
• The SRE Bookの出版と日本での動き
• Site Reliability Engineerとは?
• 速度と信頼性、そしてデータに基づく業務判断
• 技術の話
• 育成・採用の話
• Google SREと一緒に翻訳をしてみて学んだこと

はじめにご承知おきいただきたいこと
• 本日お話しすることは、ほぼすべて出版される書籍に書かれていることです
• 私自身がSRE的なポジションで実際に働いているわけではないので、お話でおきるこ
とはほぼすべて「伝聞」のようなものです
• とはいえ、SREという役割が生まれた背景や解決しようとする課題は、ソフトウェア
の開発やサービス、運用にかかわる方なら十分理解できる(というか身につまされ
る)ことであり、今日のお話、そしてSRE本からお持ち帰りいただけることもたくさ
んあると考えています
• 質問は随時していただいて結構です

The SRE Bookの出版と日本での動き

‘The SRE Book’
「Google の社員たちは彼らがたどってきたプロセスを、つまずきも含めて
本書で明らかにしてくれている。Google のサービスが巨大な規模と素晴ら
しい信頼性を共に実現できたのは、このプロセスによるものだ。統合され
たサービス群を生み出し、それらをスケールさせたいと考えている方々に
は、本書を読むことを強くおすすめする。本書は、メンテナンス性の高い
サービスを構築するための、現場の方々に向けたガイドである」
- Rik Farrow, USENIX
「Gmail のような大規模なサービスを書くのは難しいことだ。高い信頼性の
下でそれらを動作させるのはさらに難しいことであり、ましてやそれが
日々変化するのであればなおさらだ。包括的な「レシピ本」である本書は、
Google がそれをどう成し遂げているのかを教えてくれる。
読者の皆さんは、自分で間違いを犯すよりも、私たちの間違いから学ぶ方
が負担が少ないことに気づくだろう」
- Urs Hölzle, SVP テクニカルインフラストラクチャ、Google

日本でも続々誕生
• メルカリ
http://tech.mercari.com/entry/2015/11/18/153421
• スマートニュース
https://www.slideshare.net/NobutoshiOgata/introducing-inhouse-paas-in-
smartnews
• サイボウズ
http://blog.cybozu.io/entry/2016/09/01/080000

日本語版ではサブタイトルを変更
•英語版:How Google runs production systems
(Googleはどのようにプロダクションシステムを動作させているか)
• 日本語版:

ぜひ読んでいただきたい「監訳者前書き」
本書はあらゆる規模のサービスの運用にさまざまな形で関わるすべての人に向けて書か
れています。大規模で多数のユーザーがいるサービスの運用者はもちろんのこと、まだ
信頼性が第一のフォーカスでないようなサービスの運用にあたっても手間やコストを下
げてより開発の速度を上げるのに役立つ情報が得られるでしょう。個人でサービスを開
発や運営されている方にも実践できる内容が数多くあります。
また、普段運用に直接は関わる機会の少ない方々にもぜひ読んでいただきたく思ってい
ます。ソフトウェア開発者にも、SRE の視点を得ることで設計や実装に活かせる新しい
発見が数多くあることでしょう。サービスの運用コストはその設計や実装に大きく依存
していますし、サービスの運用と開発の協調もSRE の重要なポイントの1 つです。SRE
チームのマネージャーや、新しくSRE組織を立ち上げたいと考えているCTO にも、SRE の
コアバリューについての理解を深める一助となることでしょう。

見るべきは、技術論よりも組織論
• なぜGoogleは次々と信頼性の高いサービスを投入・運用できるのか?
• Googleのスーパーなインフラがあるからなのか?
• 部分的にはYesだが、それは一部に過ぎない
• 組織としての考え方(SREの原則)と、それに基づく地道な改善が大きい
• 本書に出てくる様々な取り組みから学び、それぞれの現場で活用できる
ことはたくさんある

目次1. イントロダクション
2. SRE の観点から見たGoogle のプロダクション環境
3. リスクの受容
4. サービスレベル目標
5. トイルの撲滅
6. 分散システムのモニタリング
7. Google における自動化の進化
8. リリースエンジニアリング
9. 単純さ
10. 時系列データからの実践的なアラート
11. オンコール対応
12. 効果的なトラブルシューティング
13. 緊急対応
14. インシデント管理
15. ポストモーテムの文化:失敗からの学び
16. サービス障害の追跡
17. 信頼性のためのテスト
18. SRE におけるソフトウェアエンジニアリング
19. フロントエンドにおけるロードバランシング
20. データセンターでのロードバランシング
21. 過負荷への対応
22. カスケード障害への対応
23. クリティカルな状態の管理: 信頼性のための分散合意
24. cronによる分散定期スケジューリング
25. データ処理のパイプライン
26. データの完全性
27. 大規模なプロダクトのローンチにおける信頼性
28. SRE の成長を加速する方法
29. 割り込みへの対処
30. SRE の投入による運用過負荷からのリカバリ
31. SRE におけるコミュニケーションとコラボレーション
32. 進化するSRE のエンゲージメントモデル
33. 他の業界からの教訓
34. まとめ

Site Reliability Engineerとは?

本から抜粋
SRE とは、ソフトウェアエンジニアに運用チームの設計を依頼したと
きにできあがるものです。私が2003 年にGoogle に入社し、7 人のエン
ジニアで構成される"Production Team" を受け持ったとき、私はそれま
での人生のすべてをソフトウェアエンジニアとして過ごしてきました。
そのため、私はそのグループを自分自身がSRE として働くと仮定した
場合の理想の形に設計し、管理したのです。それ以来、グループは成
熟し、今日のGoogle のSRE チームとなりました。そしてチームは依然
として、生涯にわたるソフトウェアエンジニアだった私が思い描いた、
その出発点に忠実であり続けています。
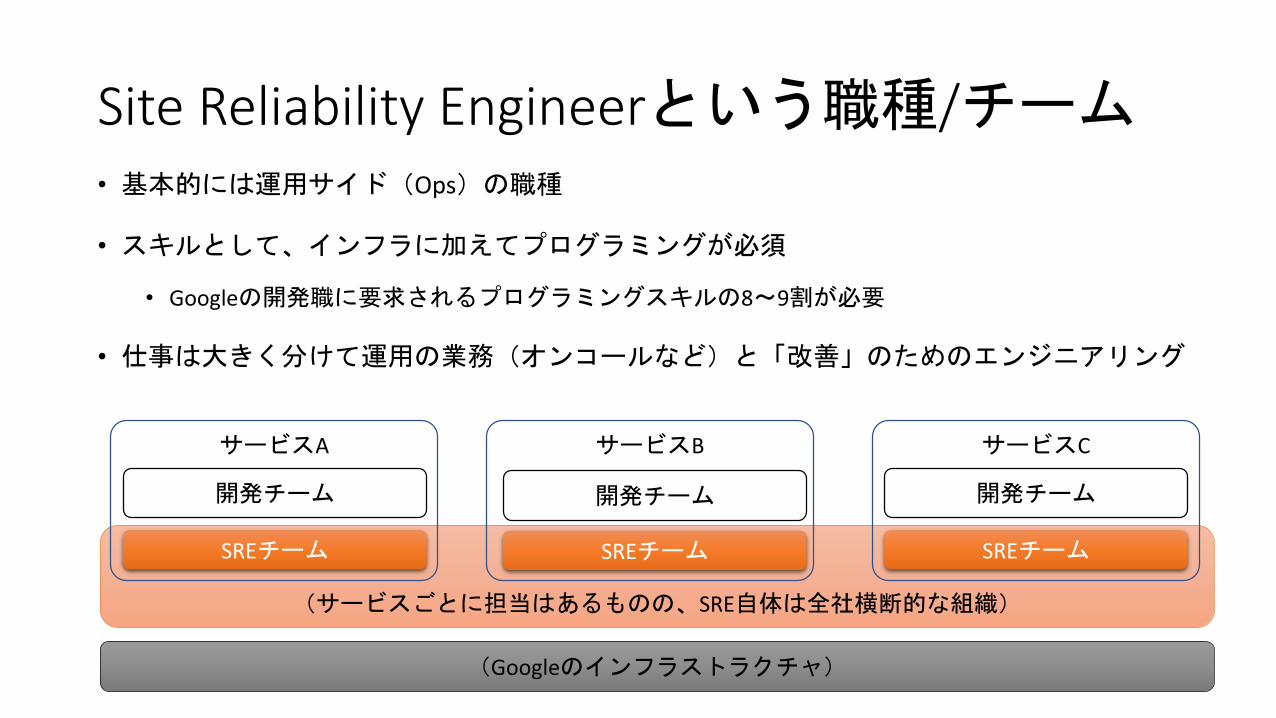
Site Reliability Engineerという職種/チーム• 基本的には運用サイド(Ops)の職種
• スキルとして、インフラに加えてプログラミングが必須
• Googleの開発職に要求されるプログラミングスキルの8~9割が必要
• 仕事は大きく分けて運用の業務(オンコールなど)と「改善」のためのエンジニアリング
(Googleのインフラストラクチャ)
(サービスごとに担当はあるものの、SRE自体は全社横断的な組織)
開発チーム 開発チーム 開発チーム
SREチーム SREチーム SREチーム
サービスA サービスB サービスC

SREの原則
• 信頼性にフォーカスを置く
• ソフトウェアエンジニアリングによって運用を自動化し、スケールできる
ようにする
• 手作業→ 自動化→ 自律化
• SREチームの規模はサービスの規模に比例してはならない(サービスの複雑さには影
響を受ける)
• 「トイル」の撲滅
• 英雄的な献身に頼るのではなく、組織としての仕組みづくりを重視する

トイルってなんだ• トイルとは、プロダクションサービスを動作させることに関係する作業で、手作業で繰り返し行われ、自動化することが可
能であり、戦術的で長期的な価値を持たず、作業量がサービスの成長に比例するといった傾向を持つもの」
• 手作業であること
• これは例えば、何らかのタスクを自動化するためのスクリプトを、手作業で実行するような作業が含まれます。
• 繰り返されること
• ある作業をするのが初めてであったり、あるいは2 回目程度なのであれば、その作業はトイルではありません。トイルとは、繰り返し何度
も何度も行われるものです。
• 自動化できること
• マシンが人間同様に行えるタスクや、そのタスクの必要性がなくなる仕組みが作れることであれば、その仕事はトイルです。そのタスク
に人間の判断が欠かせないのであれば、それはトイルとは言いがたいでしょう。
• 長期的な価値を持たないこと
• あるタスクを終えた後でも、サービスが同じ状態のままなのであれば、そのタスクはおそらくトイルです。例えば仮に、古いコードや設
定に踏み込んで整理するといった、つまらない作業が含まれていたとしても、そのタスクによってサービスに恒久的な改善が加えられた
ら、それはトイルではありません。
• サービスの成長に対してO(n) であること
• その作業に、サービスのサイズ、トラフィックの量、ユーザー数などに比例してスケールするようなタスクが含まれているなら、そのタ
スクはおそらくトイルです。

トイルの撲滅
• たとえばサーバーの稼働状況のモニタリング
• メトリクスの生成、収集、集計といったことは徹底して自動化する
• その自動化のための「開発」作業は(50%ルールに守られて)積極的に行う
• Googleの場合、サーバーにはすべて同じメトリクス収集(CPU負荷とかトラフィックとか
リクエスト数とか)の仕組みが組み込まれている(HTTPで値をとれる)
• その仕組みの上でモニタリングやアラートの仕組みを(SREが)作っている
• 最初から完成度の高い仕組みを作ったりはできない。これはGoogleでも同じ。継
続的にこういったソフトウェアエンジニアリングを行える組織体制・ルールを
つくり、着実に改善を積み重ねている

速度と信頼性、そしてデータに基づく業務判断

重要視していること:速度と信頼性
• ここでの「速度」は新しい機能やサービスを投入するペースのこと
• 「信頼性」は(主に)SLO(Service Level Objective)のこと
• 開発者(Devs)は速度を、運用者(Ops)は信頼性を重視する傾向
がある
開発チーム 運用チーム
新機能をリリースしたい
動いているものは変更したくない
緊張関係

計測されたデータに基づく業務判断
•エラーバジェット
• 50%ルール
以下はGoogleでの例ですが、あくまでこれは「Googleでは」こういう実施方法を取ってい
るということであって、肝心なのは
・品質を示すデータの定義
・定義されたデータの計測
・計測されたデータに基づいて業務判断をしていくこと
だと思います。

SLI / SLO / SLA
• SLI(サービスレベル指標):計測するデータの定義
• SLO(サービスレベル目標):SLIに対して設定された社内的な目標値
• Googleの場合は「完全に落ちる」ことはほぼないので、
成功したリクエスト数 / リクエスト数
などを指標としている
• SLA(サービスレベルアグリーメント):お客様との契約として守ること
を宣言した値
• 守れなかった場合にお客様との間で金銭のやりとりが生じるのがSLA

SLOとエラーバジェット
• エラーバジェット = 1 – SLO
• (Googleでは通常四半期単位でデータを計測)
• エラーバジェットが残っている限り新機能をリリースできる(業務判断)
• エラーバジェットがなくなった場合、リセットがかかるまで(緊急のセ
キュリティ対応などを除き)新機能のリリースは禁止
データに基づいて業務判断を行うことをルール化することによって、
開発チームとSREチームが同じ方向を向いて業務に当たれるようにする

100%は目指さない
• たとえばコンシューマ向けのサービスであれば、99.99%の可用性と
99.999%の可用性の違いはユーザーにはほぼ分からない(デバイスの
故障、回線の問題など、他の要因で事実上マスクされる)
• この場合、0.009%の可用性向上のためのコストは無駄
• サービスの性格に応じたSLOの定義が非常に重要
• 「航空機やペースメーカーの信頼性の話はまったく異なる」

50%ルール
• SREはその作業時間(計測データの定義と計測)の50%以上をエンジニア
リング業務に当てなければならない
• SREが運用業務(含む障害対応)に当てる時間が50%を超えた場合、50%以
下に戻るまでは開発チームがSREの支援に時間を当てる(業務判断)
データに基づいて業務判断を行うことをルール化することによって、
開発チームとSREチームが同じ方向を向いて業務に当たれるようにする

技術の話

「魔法」の話はあまり出てきません
•本書に出てくるのはある意味で「地味」な話です
• Googleのインフラがなければ意味のない話なのか?→そんなこ
とはありません
•ソフトウェアでコントロールできる範囲の話であれば、学べる
ことはたくさんあります

計測と改善の仕組み作り
• 必要なメトリクスを得るための仕組みをインフラに作り込む
• 収集したメトリクスをモニタリングするための仕組みを作り込む
• 基本的なメトリクスの取得の仕組みがすべてのマシンに共通して組み込ま
れている
• たとえばPythonあたりでスクリプトが書けるなら、自分たちの環境でもで
きることは多いはず

徹底した自動化志向
•自動化のメリットは「複利」
•手動(トイル)→自動化→自律化
•マクロに見るとすごい(たとえばMySQLのマイグレーションの
自律化)ことも、ミクロに見れば当たり前の技術(シェル芸と
か)の積み重ね

採用・育成の話

SREの採用はたいへん
• Googleの開発エンジニアに求められるスキルの80-90%
•加えてインフラ周りの知識が必要
•基本的に需要に対して供給不足
(Googleのインフラストラクチャ)
(サービスごとに担当はあるものの、SRE自体は全社横断的な組織)
開発チーム
SREが開発したライブラリ
サービスSREという「人」ではなくSRE
のノウハウを詰め込んだライブラリを使ってもらう

教育とオンコール
• オンコール対応になることはキャリアの1つのマイルストーン
• そこに至るまでの教育システムもきちんと整備する
• 「千尋の谷に突き落とす」ようなやり方はしない
• P.412 表28-1 「SREの教育の方法」
• ドキュメント→ポストモーテム→シャドウ→オンコール

障害対応とトレーニング
•年に一度、全社的な障害対応のトレーニング
•「たまにしかやらないことは身につかない」ことを受け入れる
•障害対応時の手順を日常業務に組み込んでおく
• SLOを超えて「動いてしまう」システムをときどきあえて止めることで、
障害があってもあわてなくて済むようにした話
•できないことを精神論でかたづけない。徹底して理詰め

Google SREと一緒に翻訳をして
みて学んだこと

SREの皆さんの仕事っぷり
• Google Docsのヘビーな活用
•必要なドキュメントを非常に手早く、しかも適切な集計/自動化
を施して作成
•いわゆるOffice系ツールの活用能力もとても大事
(なお、最終の校正はdropboxでした…)
•どうしても生ずる泥臭い作業も、適切なツールで効率よくこなす
•こういったことも「SREの原則」の1つの表れだと感じました

翻訳のやり方が変わりました
•オンラインアプリケーション(Google Docs、dropbox)の進化
を実感
•監訳者、編集者の方々との共同作業のやりかたが変化
•なんといっても500ページ超の本の監訳対応をすべてオンライ
ンアプリでやったという経験と自信
•スマートフォンも十分に役立ちます

(余談)三人称単数の’They’
• Theyが単数形として使われている(動詞が三単現のs付き)文が
ある
•誤植かと思いきや…
• Gender neutralな表現として、性別を持たない「人」を表す代名
詞としてtheyが使われるようになっているとのこと

質問をどうぞ!