web data collection - web mining...
TRANSCRIPT

Web Data Collection
Department of Communication PhD Student Workshop Web Mining for Communication Research
April 22-25, 2014
http://weblab.com.cityu.edu.hk/blog/project/workshops
Hai Liang

Copy and paste
Save as
…
2

Outline
I. Introduction to web data sources
II. Basic terms and procedures
III. Hands-on tutorial
– Collecting web data using NodeXL
– Collecting web data using Visual Web Ripper
– Collecting web data via APIs
– Collecting web data via scraping
3

SOURCES
4

Relevant Web Apps
Raw Processed
Media generated
• News website
• News sharing website
• Media outlet
User generated
• Social media
• Discussion groups
• Tweets corpus • HERMES
• Obama Win Corpus (OWC)
• blog corpus
5

PROCEDURES
6
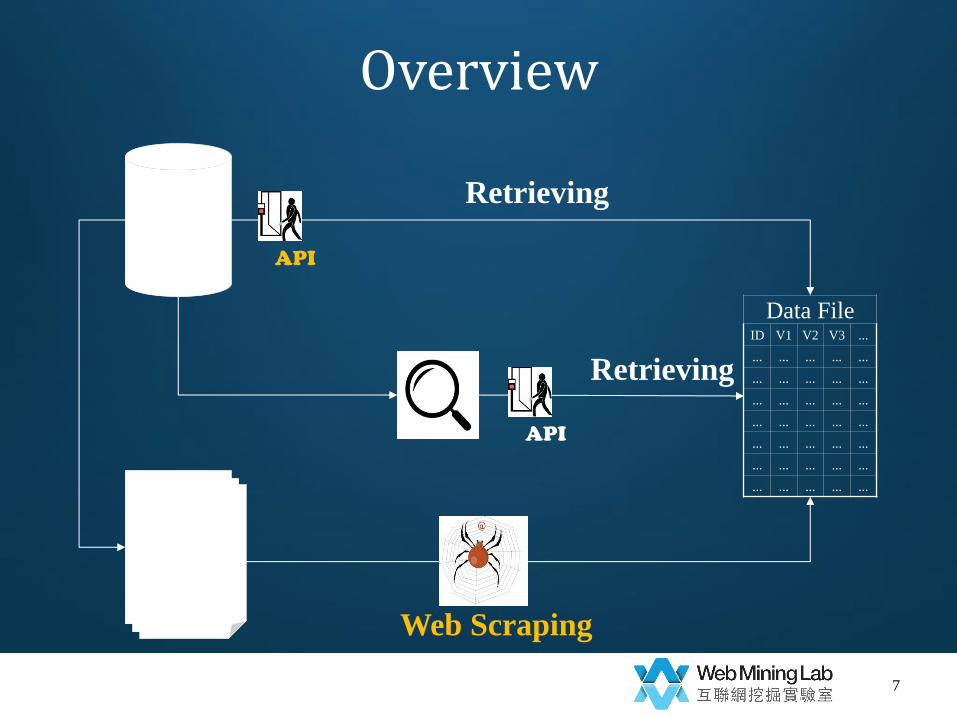
Overview
Data File ID V1 V2 V3 ...
... ... ... ... ...
... ... ... ... ...
... ... ... ... ...
... ... ... ... ...
... ... ... ... ...
... ... ... ... ...
... ... ... ... ...
Web
Pages
Web
Database
Web
Pages
Web
Pages
API
API
Web Scraping
Retrieving
Retrieving
7

Retrieving through API What is API:
• API (Application Programming Interface) is a small script file (i.e., program) written by users, following the rules specified by the web owner, to download data from its database (rather than webpages)
An API script usually contains:
• Login information (if required by the owner)
• Name of the data source requested
• Name of the fields (i.e., variables) requested
• Range of date/time
• Other information requested
• Format of the output data
• etc.
8

-Reddit API
• http://www.reddit.com/user/TheInvaderZim/comments/
• https://twitter.com/search?src=typd&q=%23tcot
• http://www.reddit.com/user/TheInvaderZim/comments/.json
• https://api.twitter.com/1.1/search/tweets.json?src=typd&q=%23tcot
9
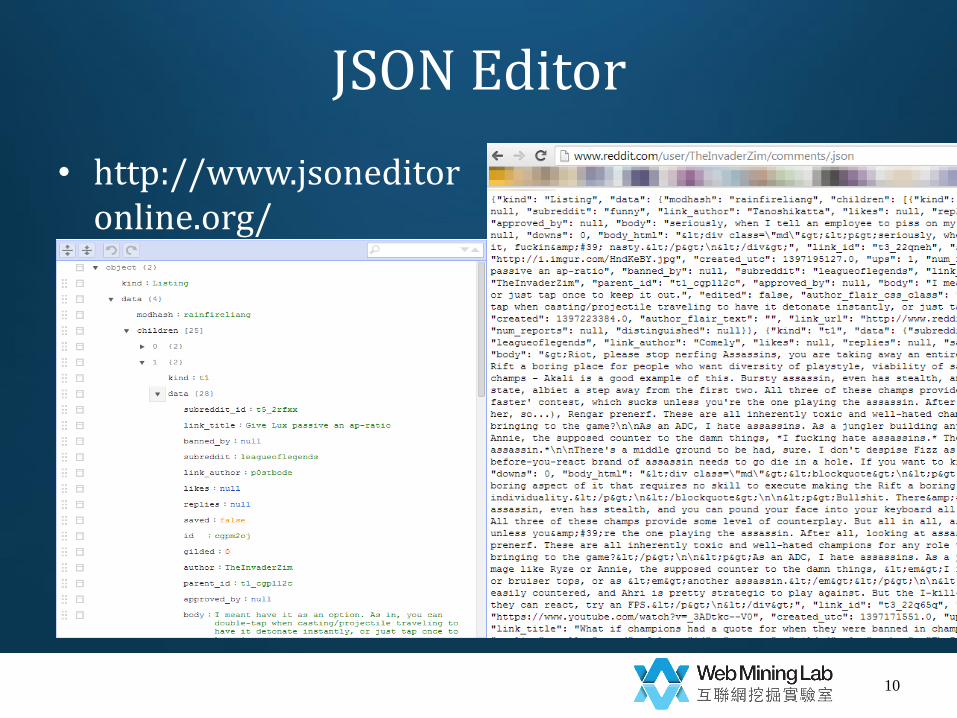
JSON Editor
• http://www.jsoneditoronline.org/
10

Web Scraping
Identify
Seeds
• hyperlinks
on a page
• list of web
URLs
• etc.
sampling
and/or prior
knowledge
is required
Crawl
Webpages
Parse
Tags
Save to
Data Files
• download
pages
matching
the seeds;
• scheduled
based on
crawling
policy of
target
sites.
• extract
tagged
elements
(e.g.,
URLs,
paragraphs,
tables, lists,
images,
etc.)
• save the
results in
tabular
format,
delineated
by tabs;
• readable
by Excel,
SPSS, etc.
11

Reddit: Seeds
URLs as seeds
12

Reddit: Parsing
13

HANDS-ON
14

NodeXL
I. http://nodexl.codeplex.com/
II. Twitter search network
III. Twitter user network
IV. Twitter list network
15

Twitter Search network
• Demo 1
– Given a list of key words, e.g., {#tcot, #teaparty, #p2}
– Get the most recent N tweets containing the key words (including time stamps)
– Get all user information (name, time zone…)
– Get user relationships ∈ {follow, replies-to, mention}
16
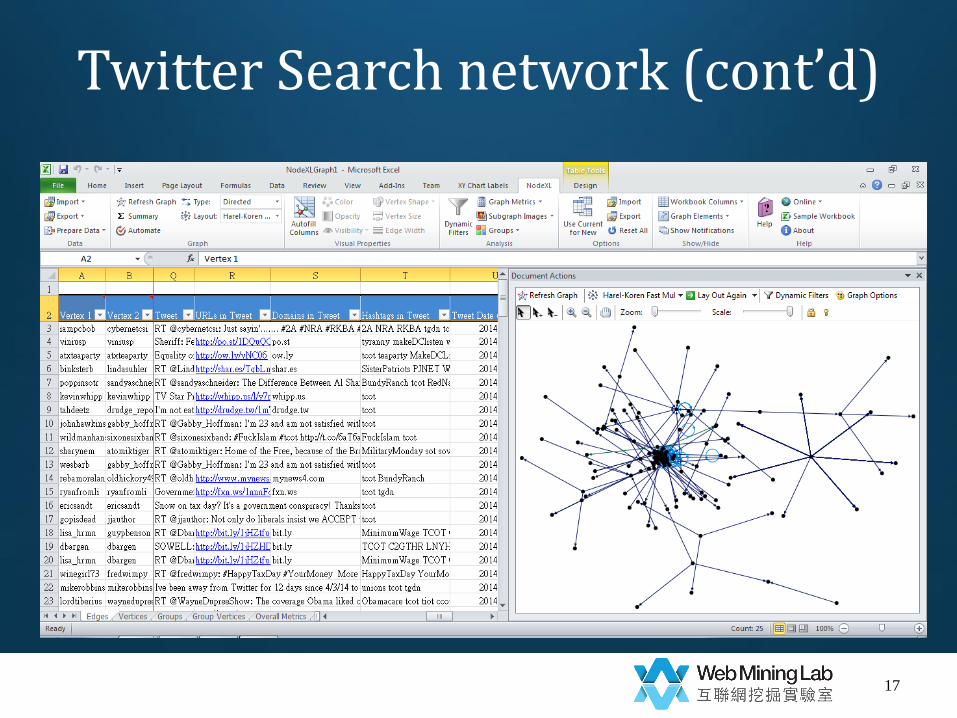
Twitter Search network (cont’d)
17

Twitter user network
• Demo 2
– Given a username, e.g., ‘cityu_lianghai’
– Get 100 most recent tweets
• Replies-to network
• Mentions network
• All users’ information (name, time zone, …)
• Text, url, location, time,…
18
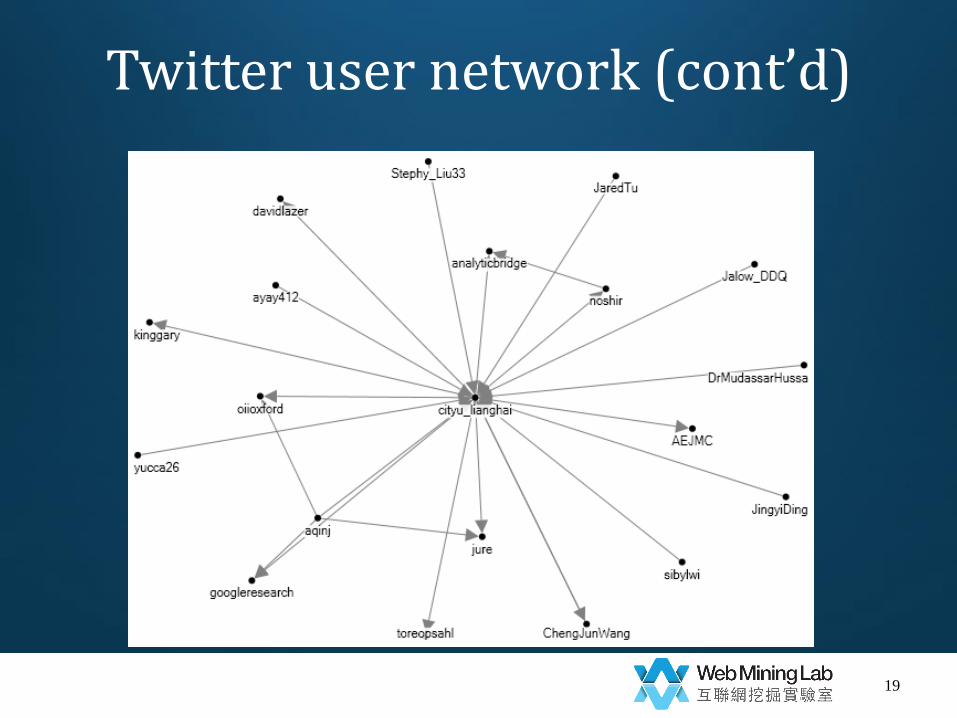
Twitter user network (cont’d)
19

Twitter list network
• Demo 3
– Given a list of user names, e.g., {cityu_lianghai, aqinj, ChengJunWang, cityu_jzhu, wzzjasmine, StephanieDurr, marc_smith, toreopsahl}. N=8
– To find the relationships between any two users
• 8*7=56 pairs (directed)
• Relationship∈{follow, replies-to, mention}
20
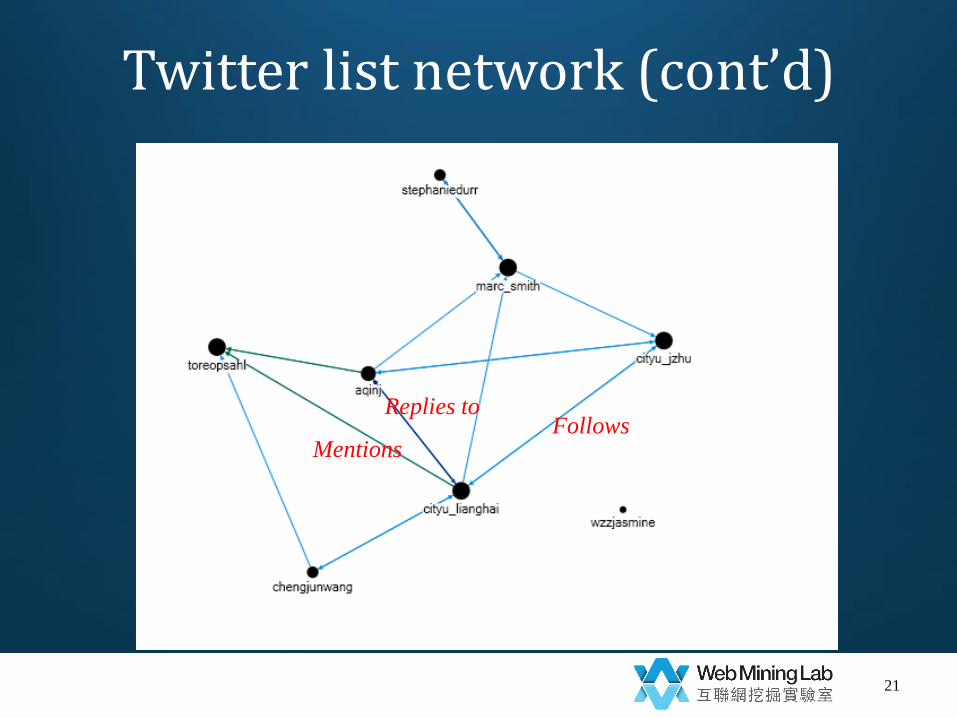
Twitter list network (cont’d)
Follows Replies to
Mentions
21

Twitter list network (cont’d)
22
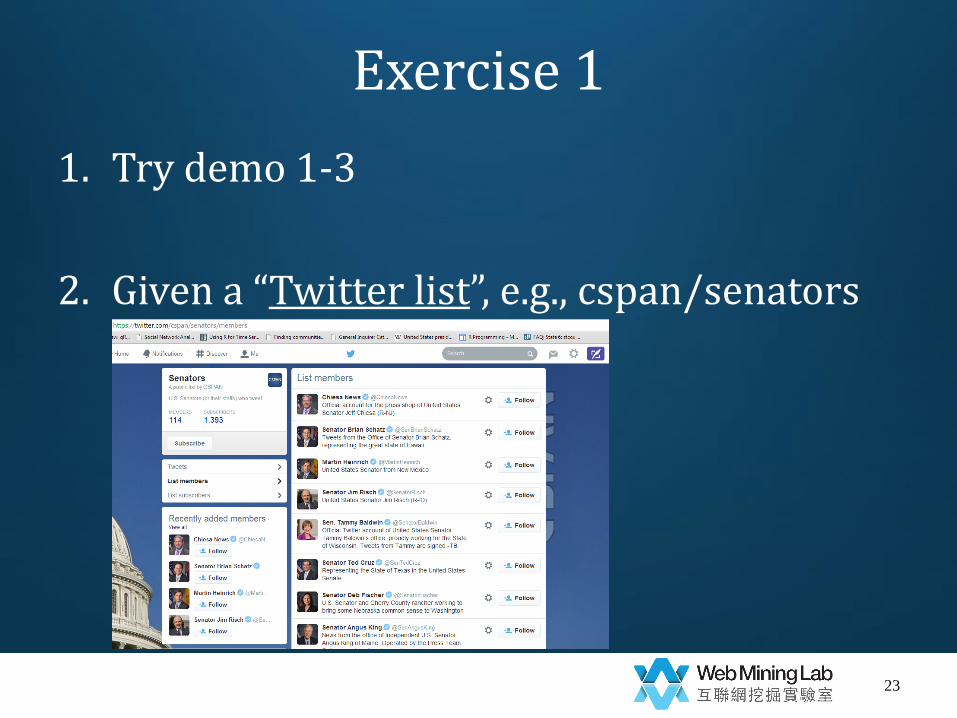
Exercise 1
1. Try demo 1-3
2. Given a “Twitter list”, e.g., cspan/senators
23
Visual Web Ripper
24

Visual Web Ripper (cont’d)
I. Demo 4
I. Given a “Twitter list”, e.g., cspan/senators (exercise 1)
II. Get all member names and their tweets (NodeXL can extract part of the members and tweets)
25

APIs-Python
I. Install Active python
II. Start -> type “cmd”
III. Type
I. “pip install json”
II. “pip install requests”
III. “pip install beautifulsoup4”
26

APIs (reddit.com)
I. Demo 5
I. Given a username, e.g., ‘TheInvaderZim’
II. Get comments by the user
II. Demo 6
I. Given the URL of the front page
II. Get the most controversial posts. Extract titles and “ups”
27

APIs (reddit.com) (cont’d)
# Import the modules
import requests
import json
# Demo5: Get a user's Comments
user = "TheInvaderZim"
r = requests.get("http://www.reddit.com/user/"+user+"/comments/.json")
# r.text
# Convert it to a Python dictionary
data = json.loads(r.text)
for item in data['data']['children']:
#output_file = open('Demo5.txt', 'a')
body = item['data']['body']
#output_file.write(body+"\r\n")
print body
#output_file.close()
# Demo6: Get controversial posts r2 = requests.get("http://www.reddit.com/controversial/.json") data2 = json.loads(r2.text) for item in data2['data']['children']: #output_file = open('Demo6.txt', 'a') title = item['data']['title'] domain = item['data']['domain'] sub = item['data']['subreddit'] ups = item['data']['ups'] #output_file.write(str(title)+'\t'+str(domain)+'\t'+str(sub)+'\t'+str(ups)+"\r\n") print str(title)+'\t'+str(domain)+'\t'+str(sub)+'\t'+str(ups)+"\r\n" #output_file.close()
28

Exercise 2
• Try demo 5-6
• Get 100 news titles on a topic of your interest (e.g., politics)
– Author
– Time stamp
– Url
– Ups/downs
– Number of comments
29

Exercise 2 (cont’d)
30

Scraping
I. Demo 7 (similar to demo 6)
I. Given the URL of the front page (No API this time)
II. Get the most controversial posts. Extract titles and “ups”
31

Scraping (cont’d)
32

Exercise 3
• Please visit debatepolitic.com (http://www.debatepolitics.com/)
• Using scraping method to get the following table (N>30 threads)
Thread Title Author Time Number of views Number of replies
xx xx xx xx xx
xx xx xx xx xx
33

Exercise 3 (cont’d)
34

TOOLS
35

Frequently Used Tools for Data Collection
Operation Open Source Commercial
Pull-down
menus
• NodeXL (SNSs)
• VOSON (hyperlinks)
• IssueCrawler (pages)
• Visual Web Ripper
• Web Data Extractor
Program-
mining-based
• Python APIs
• Python Beautiful
Soup
• Twitter Firehose API
36