web 3.0: integración de la web semántica y la web 2.0
TRANSCRIPT

Web 3.0: integración de la Web Semántica y la Web 2.0
Redes Sociales y Web 2.0
Alberto Los Santos Aransay Martha Xóchitl Nava Bautista Diego Alberto Godoy
Febrero 2009

Web 3.0: integración de la Web Semántica y la Web 2.0
INDICE
1. Introducción ........................................................................................................................ 1
2. ¿Qué es la Web 3.0? Conceptos. ........................................................................................ 4
2.1. ¿Cuál es la opinión de los expertos sobre los términos Web 1.0, Web 2.0 y Web 3.0? ....... 7
2.2. Opinión del grupo sobre los términos Web 1.0, 2.0 y 3.0 ................................................ 8
3. Integración de las ideas de la Web Semántica y la Web 2.0............................................. 10
3.1. Aportaciones de la Web Semántica a las aplicaciones insignia de la Web 2.0 .................. 14
3.2. Ejemplos de aplicaciones que actualmente combinen estas dos estrategias y que se puedan considerar Web 3.0 ........................................................................................................ 17
4. ¿Cómo podría integrarse el concepto de personalización en este ámbito? .................... 20
4.1. Ejemplo de extensión de las capacidades de personalización de las futuras aplicaciones. 23
5. Tendencias futuras ............................................................................................................ 24
5.1. Debilidades y riesgos del futuro de la Web 3.0 ............................................................. 27
5.2. Evolución de este campo según los expertos ............................................................... 28
5.3. Evolución según el grupo ........................................................................................... 30
5.4. Ideas del grupo para nuevos servicios ......................................................................... 31
6. Conclusiones ..................................................................................................................... 32
Bibliografía ................................................................................................................................ 33

Web 3.0: integración de la Web Semántica y la Web 2.01
1. Introducción
Actualmente se manejan diversas versiones de la World Wide Web (Web 1.0, Web 2.0, Web 3.0). Parece confuso, pero son simplemente términos que se le han dado de acuerdo a su evolución, en un afán de marcar una diferencia entre el antes y el después.
Previo al tema principal que nos interesa, la Web 3.0, es conveniente explicar qué son la Web 1.0 y la Web 2.0, a fin de darle un mayor sentido y contexto histórico. La figura 1, muestra un tanto la evolución de Web 1.0, 2.0 hasta llegar a la Web 3.0.
Fig. 1: El cambio de la Web de 1.0 a 3.0 [1] .
Web 1.0 es un término que se refiere a un estado de la World Wide Web, y cualquier página Web diseñada con un estilo anterior al fenómeno de la Web 2.0. Comenzó en los años 60’s, de la forma más básica que existe, con navegadores de sólo texto, como ELISA, bastante rápidos. Después surgió el HTML (Hyper Text Transfer Protocol) que hizo las páginas Web más agradables a la vista y los primeros navegadores visuales como IE, Netscape, etc. La Web 1.0 se componía de páginas de sólo lectura, el usuario no podía interactuar con el contenido (nada de comentarios, respuestas, citas, etc.). Estando el contenido totalmente limitado a lo que el Webmaster decidía alojar en la página Web [2] .
En la Web 1.0, el lenguaje de programación en base a marcas HTML era el utilizado para desarrollar las páginas Web mediante un estilo un tanto formateado, que le permitía al usuario leer tanto texto como imágenes. La información se podía visualizar a pesar de que el usuario se encontrara en una máquina distinta a la que almacenaba la información. Cualquier persona podía leer, pero sólo los desarrolladores que conocían el lenguaje HTML podían crear y editar las páginas web, ya que este lenguaje no era fácilmente entendible. Este hecho suponía una gran limitante porque las empresas que contrataban el servicio de página web estaban a merced de que los desarrolladores actualizaran la misma, aunque claro, según sus indicaciones. Además, se debía contar con un servidor donde alojar los datos, el cual podía ser propio o contratar un espacio con alguna empresa dedicada a ello. Posteriormente la programación se convirtió en dinámica y las páginas web dejaron de ser estáticas, logrando que el usuario pudiera visualizar contenidos diferentes en función de las acciones realizadas.

Web 3.0: integración de la Web Semántica y la Web 2.02
Enseguida surgió la Web 2.0 que marcó un avance en la forma de usar Internet. Este término de Web 2.0 fue acuñado por Tim O'Reilly [3] en 2004 para referirse a una segunda generación en la historia de la Web basada en comunidades de usuarios y una gama especial de servicios, como las redes sociales, los blogs, los wikis o las folksonomías, que fomentan la colaboración y el intercambio ágil de información entre los usuarios [4] .
La idea era presentarle al usuario una vista más sencilla, en la que se le permitiera modificar los contenidos de las páginas web sin tener que utilizar la programación de algún lenguaje. Ya no era sólo el desarrollador, quien es conocedor de los lenguajes de programación, el que podía editar la información. Se siguió haciendo uso de los servidores para alojar las páginas, pero varias empresas ofrecían espacios en sus servidores a más bajo costo e incluso algunas de forma gratuita.
La combinación de los nuevos conceptos de programación y gestión de páginas (CSS, XHTML, XML, SOAP, REST, JAVA, AJAX, P2P, RSS, widgets, etc.) y la masiva gratuidad de hardware en los servidores supuso – esta vez sí‐ una pequeña revolución en el uso de la Web. Usuarios que de otro modo nunca hubiesen tenido los medios para “subir” contenidos a la red, ahora podían hacerlo fácilmente. Esto generó las redes sociales, los blogs, las bases de datos de fotografías, etc. Y, aportó, conceptos como la Wikipedia y la creación colaborativa. Otra aplicación potencial muy interesante es el mashup (unión de varias aplicaciones aunándolas en una nueva con contenidos diferentes) [5] . En la figura 2 se muestran los conceptos asociados a la Web 2.0.
Fig. 2: Diagrama de conceptos que se asocian a Web 2.0 [6] .
Entonces, tenemos que la Web 1.0 se trató de la época en que el usuario normal (no el desarrollador de la página, sino el que hace uso de ella) únicamente se dedicaba a leer. La Web 2.0 le permitió al usuario, además de leer, también escribir e interactuar un poco más. A partir de ella surgió la Web 3.0, que no sólo permite leer y escribir, sino que incorpora conceptos tales como Web Semántica e inteligencia artificial, y la cual será nuestro objeto de estudio en los siguientes capítulos.
En el capítulo 2 explicaremos el concepto de la Web 3.0, y lo que opinan los expertos y nosotros mismos acerca de los términos Web 1.0, Web 2.0 y Web 3.0. En el capítulo 3 trataremos sobre la integración de las ideas de la Web Semántica y la Web 2.0, así como las aportaciones de la Web Semántica a las aplicaciones insignia de la Web 2.0 (wikis, blogs, folksonomías, etc.) y señalaremos algunos ejemplos de aplicaciones que actualmente combinen estas dos estrategias y que se puedan considerar Web 3.0. En el capítulo 4

Web 3.0: integración de la Web Semántica y la Web 2.03
hablaremos de cómo podría integrarse el concepto de personalización. Después, en el capítulo 5 expondremos las tendencias futuras, la evolución y nuestras ideas para nuevos servicios. Finalmente, en el capítulo 6 presentamos nuestras conclusiones.

Web 3.0: integración de la Web Semántica y la Web 2.04
2. ¿Qué es la Web 3.0? Conceptos.
La definición más utilizada para Web 3.0 es la ofrecida por Wikipedia, en la que se dice que se trata de un neologismo que es utilizado para describir la evolución del uso y la interacción en la red a través de diferentes caminos. Ello incluye, la transformación de la red en una base de datos, un movimiento hacia ofrecer los contenidos accesibles por múltiples aplicaciones non‐browser, el empuje de las tecnologías de inteligencia artificial, la Web Semántica, la Web Geoespacial, o la Web 3D. Frecuentemente es utilizado por el mercado para promocionar las mejoras respecto a la Web 2.0. El término Web 3.0 apareció por primera vez en el 2006 en un artículo de Jeffrey Zeldman, crítico de la Web 2.0 y asociado a tecnologías como AJAX. Actualmente existe un debate considerable en torno a lo que significa Web 3.0, y cuál es la definición acertada [7] .
Otra definición es la que realiza Jason Calacanis [8] , creador de Weblogs Inc, define la Web 3.0 como la creación de contenido y de servicios de alta calidad producidos por individuos usando la tecnología Web 2.0 como plataforma.
Existen diversos conceptos relacionados con la Web 3.0, tales como Web Semántica, inteligencia artificial, microformatos, personalización, Web 3D, etc., los cuales intentaremos explicar a continuación, y algunos de ellos los analizaremos con mayor profundidad en los capítulos posteriores. La figura 3 identifica algunas de las características que conforman la Web 3.0.
Fig. 3: Conceptos asociados a la Web 3.0 [9] .
El término de Web 3.0 es asociado comúnmente con el de Web Semántica. Se pretende dar una mejor estructura a los contenidos de las páginas Web para que puedan ser entendidos por los ordenadores. Actualmente, cuando un usuario realiza una búsqueda, es muy probable que recorra varios enlaces antes de dar con la información que realmente requiere. Esto se debe a que se buscan coincidencias con las palabras, pero los ordenadores no entienden cual es el contexto, sólo las personas lo saben. Entonces, mediante una mejor estructuración de la información y utilizando técnicas de inteligencia artificial, los ordenadores podrían mejorar los resultados.
El ejemplo clásico de Web Semántica sería aquella que permitiría que se formularan consultas como “busco un lugar para pasar las vacaciones con mi mujer y mis dos hijos de 5 y 2 años, que sea cálido y con un presupuesto máximo de 2000 euros”. El sistema devolvería un paquete de vacaciones tan detallado como los que vende una agencia de viajes pero sin la necesidad de que el usuario pase horas y horas localizando ofertas en Internet [10] .

Web 3.0: integración de la Web Semántica y la Web 2.05
En esta versión de la Web, los sitios, los vínculos, los medios y las bases de datos, son “más inteligentes” y capaces de trasmitir automáticamente más significados que los actuales. Por ejemplo, Berners‐Lee dijo que un portal que anuncie una conferencia incorporaría también una cantidad de información relacionada. Un usuario podría pulsar un vínculo y transferir inmediatamente la hora y la fecha de la conferencia a su calendario electrónico. La ubicación (dirección, latitud, longitud, hasta quizás la altura) podría ser enviada a su equipo GPS y los nombres y biografías de los otros invitados podría mandarse a un listado de mensajes instantáneo. En otras palabras, el lenguaje de acceso de cada página web podría ser referido a otras innumerables bases de datos, una vez que los diseñadores se pongan de acuerdo en un conjunto común de definiciones [11] .
Como ya mencionamos antes, los microformatos son uno de los conceptos asociados a la Web 3.0. Surgen del trabajo de la comunidad de desarrolladores de Technorati [12] , uno de los sitios Web 2.0 “de referencia”. Su objetivo es estandarizar un conjunto de formatos en los que almacenar conocimiento básico, como la información de contacto de una persona (microformato hCard), una cita (microformato hCalendar), una opinión (microformato hReview), una relación en una red social (microformato XFN) y así hasta un total de 9 especificaciones concluidas y 11 en proceso de definición. Aún cuando ya se están utilizando, su mayor inconveniente es el que se requiere de un microformáto específico y por ello distinto para cada caso. En la figura 4, se muestra la propuesta de implantación de los microformatos en Firefox [9] .
Fig. 4: Propuesta de implantación de los microformatos en Firefox [10] .
Por otro lado, en cuanto a los servicios online, lo que se busca lograr es un grado de homogeneidad. De esta forma, los usuarios no tendrían que aprender a utilizar cada uno de los servicios, sino que todos tendrían más o menos las mismas funcionalidades y bastaría con aprender a utilizar uno de ellos.
Un ejemplo de este tipo de desarrollos es el proyecto Parakey [13] , liderado por Blake Ross, uno de los desarrolladores clave de Firefox. Ross lo describe como un proyecto de código abierto que pretende crear una especie de sistema operativo web que permita a un usuario hacer lo mismo que haría con un sistema operativo tradicional. El propósito es hacer más fácil la transferencia entre los usuarios de imágenes, videos y textos. En Julio del 2007 Parakey fue adquirido por facebook [14] .

Web 3.0: integración de la Web Semántica y la Web 2.06
Otros ejemplos del nuevo tipo de servicios son el servicio Mechanical Turk y el Google Image Labeler. El servicio Mechanical Turk [15] de Amazon permite a los desarrolladores dirigir hacia un grupo de participantes (voluntarios y remunerados), aquellas partes de un servicio que requieran de intervención humana, es decir, aquellas tareas que la computadora no puede realizar por sí misma, de manera muy similar al modo en el que se desarrollan aplicaciones distribuidas en Internet.
En el experimento de Google en modo de juego llamado Google Image Labeler, durante un periodo de 90 segundos, dos participantes en el juego, elegidos al azar por el sistema, tienen que etiquetar un conjunto de imágenes con tantos términos como les sea posible. De esta forma los usuarios obtienen diversión mientras que Google obtiene miles de imágenes clasificadas con etiquetas relevantes.
En cuanto a las redes sociales que forman parte de la Web 2.0, una de las aportaciones que realiza la Web 3.0, es el hecho de permitir buscar personas por su nombre o sus intereses y encontrar todas las redes sociales a las que pertenece. Algunas compañías que ofrecen estos servicios son: Explode, Spock, The Gorb, Orangeply. En la figura 5 se muestra la imagen del sitio Explode, el cual tiene como finalidad el buscar personas por nombres o intereses sin importar a que red social pertenezca.
Fig. 5: Sitio Explode.
Finalmente quedan otras características como la movilidad, es decir, acceder a la Web dónde y cuando sea necesario, la personalización, o sea configurar cualquier aplicación según nuestras necesidades y por último el concepto de Web 3D, que como su nombre indica se refiere a acceder a páginas en tercera dimensión, permitiéndonos un mayor realismo.

Web 3.0: integración de la Web Semántica y la Web 2.07
2.1. ¿Cuál es la opinión de los expertos sobre los términos Web 1.0, Web 2.0 y Web 3.0?
Existen opiniones encontradas entre los diversos expertos en lo que se refiere a los términos Web 1.0, Web 2.0 y Web 3.0. Intentaremos exponer algunas de sus ideas en esta sección.
El principal promotor de la Web 2.0 es Tim O’Reilly, quien hizo la primera diferenciación entre lo que es Web 1.0 y Web 2.0 mediante una lluvia de ideas para desarrollar una conferencia junto con un representante de la empresa MediaLive en Octubre del 2004. En la Tabla 1, se detalla la clasificación que hicieron de las aplicaciones web dependiendo de si se consideran Web 1.0 o Web 2.0.
Tabla 1: Comparativa de las aplicaciones correspondientes a la Web 1.0 y la Web 2.0 [3] .
Web 1.0 Web 2.0
DoubleClick ‐‐> Google AdSense
Ofoto ‐‐> Flickr
Akamai ‐‐> BitTorrent
mp3.com ‐‐> Napster
Enciclopedia online ‐‐> Wikipedia
Webs personales ‐‐> Blogs
evite ‐‐> upcoming.org y EVDB
Especulación de dominios ‐‐> Optimización de buscadores
Páginas vistas ‐‐> Coste por clicks
Raspado de pantalla (a través de HMTL)
‐‐> Web Services
Publicación de contenidos ‐‐> Participación
Sistemas de gestión de contenidos
‐‐> Wikis
Directorios (taxonomías) ‐‐> Marcado (Folksonomías)
Retorno de las visitas ‐‐> Subscripción
Sin embargo, otros expertos afirman que la Web 2.0 no significó una gran revolución, sino que fue una estrategia de marketing tecnológica, y como lo menciona Nova Spivack [16] de Radar Networks, en realidad se trata de la misma Web.
De hecho, el mismo creador de la Web, Tim Berners Lee [17] , defendió que no hay Web 2.0, porque la "antigua" (la 1.0 podríamos decir) ya implicaba un afán de colaboración y participación entre los usuarios. Berners Lee agregó que si uno creía que la Web 2.0 estaba compuesta de blogs y wikis, entonces eso en realidad quería decir que había sido creada “por” y “para” las personas. Y en realidad la Web fue creada con ese mismo propósito. Sin embargo, aunque Berners Lee no quiere emplear el término Web 2.0, reconoce el gran cambio que se originó en la red.

Web 3.0: integración de la Web Semántica y la Web 2.08
Parece ser que a pesar de los detractores de utilizar el término Web 2.0, éste se ha seguido utilizando y no sólo eso, sino que ahora ha surgido el término Web 3.0, el cual también ha generado controversia.
Los analistas de Gartner [18] están evitando dar la etiqueta de Web 3.0 a las nuevas tecnologías emergentes tales como la Web Semántica, alegando que no han marcado un cambio tan impactante como el que generaron los blogs, wikis y redes sociales de la Web 2.0.
Por otro lado, Berners‐Lee ve sólo dos versiones distintivas de su Web: la Web de los documentos, que surgió en la década de 1990, y la Web de los datos, que será el resultado de los lenguajes de programación semántica. “La gente sigue preguntando qué es la Web 3.0. Creo que la Web Semántica será profunda. Con el tiempo, será tan obvia como obvia nos parece hoy la Web”, dijo.
Steve Spalding [19] , autor del blog “How To Split An Atom”, pero más específicamente, autor del artículo titulado “Web 3.0 Defined”, en una entrevista [20] realizada en Octubre del 2007, menciona que no cree que la Web esté formada de diferentes versiones (1.0, 2.0, 3.0). Dice que lo que se pretende es encontrar un mejor lenguaje para describir los principales hitos en su progresión.
Nova Spivack en [21] , por su parte, cree que aunque no se necesite otra etiqueta para catalogar la Web, es menos intimidante usar el término Web 3.0 que el de Web Semántica. Aún así, entiende el porqué ocurre la confusión al hablar de términos como Web X.0. En su opinión, Web 3.0, es más bien la tercera década de la Web (2010 ‐ 2020), tiempo durante el cual varias tecnologías clave serán ampliamente utilizadas. Entre ellas RDF y las tecnologías emergentes de la Web Semántica. Si bien la Web 3.0 no es sinónimo de la Web Semántica (habrá otros importantes cambios tecnológicos en ese período), se caracterizará en gran medida por la semántica en general.
Por el contrario, Tim O'Reilly en [22] opina que, hay definitivamente algo nuevo, pero prefiere llamarlo de forma distinta a Web 3.0. Y es que cada vez se incrementan más los avances tecnológicos y es muy probable que la computación llegue a ser muy distinta de lo que conocemos hoy. O’Reilly agrega, que debemos llamar a la Web Semántica simplemente Web Semántica, y no tratar de enturbiar el agua tratándola de llamar Web 3.0. Especialmente cuando los puntos distintivos son en realidad los mismos puntos que él utilizó para distinguir a la Web 2.0 de la Web 1.5.
Los expertos difieren en si utilizar o no los términos Web 1.0, Web 2.0 y Web 3.0. Cada uno ofrece sus propios argumentos para apoyar o rechazar estos términos. Pero en lo que sí parecen estar de acuerdo es que la red ya no es la misma que antes, en que ésta ha evolucionado vertiginosamente en la forma de presentarse e interactuar con el usuario.
2.2. Opinión del grupo sobre los términos Web 1.0, 2.0 y 3.0 Los términos Web X.0 denotan un cambio de paradigma en cada una de las etapas de
la Web, pero a veces es difícil catalogar una aplicación en concreto dentro de una de las etiquetas.
Estamos de acuerdo con algunos de los expertos, en que es posible distinguir la Web 1.0 de la Web 2.0 debido al salto que se dio en el uso de la misma. La Web 1.0 como ya se ha dicho, está representada por páginas básicas hasta HTML (a veces con flash) bajo el control del webmaster. En la Web 2.0 los usuarios normales pueden interactuar con el contenido, incluyendo comentarios, y hasta compartiendo opiniones con otros usuarios, formando comunidades, foros, etc. Además aparecieron los blogs, con los que cualquier usuario podía tener su sitio web sin necesidad de poseer conocimientos técnicos. A nivel tecnológico

Web 3.0: integración de la Web Semántica y la Web 2.09
también supuso un cambio, con páginas más dinámicas, aparecieron términos como RSS, mashups, etc.
Entre la Web 2.0 y 3.0 creemos que es complicado hacer una separación, ya que ni siquiera hay acuerdo entre los gurús. Nuestra opinión es que, si fuese necesaria una clasificación, ésta debería estar organizada y regulada por estándares de entidades reconocidas como W3C. Podría ser interesante tener una clasificación de acuerdo al nivel de “madurez” que una aplicación posee, de acuerdo a las tecnologías, herramientas y formas de uso, algo similar a la figura 1.
Por tanto, respecto a la Web 3.0, es difícil en este momento hacer una distinción clara, puesto que no se ha visto un verdadero impacto como el que significaron las aplicaciones de la Web 2.0. Consideramos que aún estamos inmersos en la Web 2.0, evolucionando hacia la Web 3.0, la cual podría caracterizarse por la Web 3D y la inteligencia artificial. Tenemos una visión futurista de la Web con una interfaz novedosa, dinámica y mucho más automática, facilitando su uso al usuario.

Web 3.0: integración de la Web Semántica y la Web 2.010
3. Integración de las ideas de la Web Semántica y la Web 2.0
Como ya se señaló en la sección 1 Tim Berners‐Lee pensó originalmente en una Web de lectura/escritura, aunque luego la Web se utilizó como un medio de sólo lectura para la mayoría de los usuarios. En década de los 90 era muy similar a la combinación de una agenda telefónica y las páginas amarillas (una mezcla de los distintos anuncios y catálogos de empresas) y, a pesar del poder de conexión de los hipervínculos, existía poco sentido de comunidad entre los usuarios. Esta actitud pasiva hacia la Web se quebró cuando se realizaron una serie de cambios en los patrones de uso de la tecnología, que derivaron en lo que ahora se conoce como la Web 2.0, una palabra acuñada por Tim O'Reilly.
Los cambios que condujeron al actual nivel de compromiso social en línea, no han sido radicales o individualmente significativos, lo que explica que el término Web 2.0 se ha creado en gran medida después de los hechos, sin embargo, este conjunto de innovaciones en la arquitectura y los patrones de uso de la Web ha dado lugar a un papel totalmente diferente del mundo en línea como plataforma para la comunicación y la interacción social. El consiguiente aumento de la capacidad para obtener información y colaboración social en línea puede ser cuantificado [23] .
Una encuesta [24] realizada en 2006 en Estados Unidos basada en entrevistas a 2.200 personas demuestra que Internet mejora significativamente la capacidad de mantener redes sociales, a pesar de que al principio se temía por los efectos que podría tener la disminución de contacto en la vida real. La encuesta confirma que las redes no sólo son mantenidas y ampliadas en línea, sino que también son usadas con éxito en situaciones de la vida cotidiana, por ejemplo para obtener ayuda en caso de una enfermedad grave, búsquedas laborales, informar sobre eventos, etc.
La primera oleada de la socialización en la Web fue gracias a la aparición de los blogs, las wikis y otras formas de comunicación y colaboración basadas en la Web. Los Blogs y las wikis obtuvieron una masiva popularidad alrededor del año 2003 (véase la Fig. 6). Ambas herramientas tienen en común la facilidad para añadir contenido a la Web, ya que para la edición de los blogs y las wikis no se requiere ningún conocimiento de HTML o algún otro lenguaje de programación. Estas herramientas permiten a las personas o grupos tener su propio espacio personal en la Web y agregar contenido con facilidad. A pesar de que los weblogs en sus inicios fueron utilizados puramente para publicar cosas personales (como si fuera un diario), hoy en día BlogSphere [25] es ampliamente reconocida como una red social interconectada a través de la cual las noticias, ideas e influencias se transmiten rápidamente haciendo referencia o un comentario sobre lo publicado en otros blogs.
Aunque la Wikipedia es un ejemplo excelente, tanto las wikis grandes como pequeñas son utilizadas por grupos de distintos tamaños como una herramienta efectiva para gestionar los conocimientos almacenados y desarrollar ideas conjuntamente.

Web 3.0: integración de la Web Semántica y la Web 2.011
Fig. 6: Desarrollo de la red social [23] . La proporción de páginas con los términos blogs, wiki en
el tiempo se muestra en el eje izquierdo. La proporción de sitios con los términos folksonomy, XmlHttpRequest y mashup se mide en el eje derecho.
Sin importar el objetivo, la propiedad colectiva de una Wiki da sentido de comunidad (o al contrario revela una falta de cohesión del grupo) a través de discusiones que se generan sobre contenidos compartidos. Es así como las primeras redes sociales en línea nacieron al mismo tiempo que comenzó el auge de los blogs y las wikis.
En el año 2003, Friendster [26] atrajo a más de cinco millones de usuarios que se registraron en el lapso de unos pocos meses [27] , después Google y Microsoft pusieron en marcha servicios similares.
Aunque estos sitios tienen características parecidas a los que aparecen en las páginas webs personales, a diferencia de éstos, proporcionan un punto central de acceso y una estructura para el proceso de compartir información personal en línea y para la socialización. Después de registrarse, estos sitios, permiten a los usuarios publicar un perfil con información básica, invitar a otros amigos a registrarse y vincular su perfil a los de sus amigos, también permite, visualizar y navegar por la red de vínculos de amistad, con el fin de descubrir los amigos en común, amigos con los que se perdió el contacto o posibles nuevos amigos basados en intereses comunes. Es así como estos sistemas tan populares permiten mantener grandes redes de contactos personales, y proveen un medio adecuado para alcanzar diferentes objetivos.
Por ejemplo, existen servicios que usan los perfiles de usuarios y las redes para estimular diferentes tipos de intercambio, como puede ser Flickr [28] para intercambio de fotos o Del.icio.us para el intercambio de páginas favoritas. Muchos de estos sistemas se basan en el etiquetado colaborativo (folksonomías) para conectar a los usuarios con contenidos y otros usuarios interesados en temas similares. Al igual que las wikis, este nuevo tipo de sitios tienen como objetivo dar un rol activo a la comunidad de usuarios en la creación, mantenimiento y organización del contenido. Los perfiles explícitos de los usuarios permiten a estos sistemas introducir mecanismos de calificación (ratings) en donde los usuarios o sus contribuciones son puestas en una tabla de posiciones (ranking) de acuerdo a su pertinencia o veracidad. Las tablas son formas explicitas de capital social que regulan los intercambios en las comunidades en línea de la misma manera que la reputación en el mundo real. Por ejemplo, en la plataforma de noticias Digg [29] los usuarios dan pulgares hacia arriba o hacia abajo para puntuar las noticias publicadas por otros usuarios. Además este sistema ofrece la posibilidad a

Web 3.0: integración de la Web Semántica y la Web 2.012
los usuarios de ver lo que otros usuarios están haciendo en tiempo real, dando la sensación de estar aún más conectado, con los miembros en línea en ese momento.
Así como las redes sociales, otro estandarte de la Web 2.0 es el diseño e implementación de aplicaciones web, que han evolucionado para mejorar la experiencia del usuario de interactuar con esta de una forma fluida y amigable [30] . En términos de diseño, los nuevos sitios web ponen énfasis en una interfaz de apariencia clara, accesible y atractiva que interfiera lo menos posible en la funcionalidad de la aplicación. En términos de implementación, los nuevos sitios web se basan en novedosas formas de aplicar algunas de las tecnologías preexistentes (JavaScript asíncrono y XML, también conocido como AJAX). En consonancia con la facilidad de uso, se puede observar también una preferencia por formatos, lenguajes y protocolos que son fáciles de utilizar y desarrollar. Es el caso de lenguajes como JSON ("JavaScript Object Notation", es un formato ligero para el intercambio de datos) y protocolos como REST (Representational State Transfer, REST es una técnica de arquitectura software para sistemas hipermedia). Esto da como resultado que se pueda acelerar el desarrollo de prototipos y aplicaciones, también ayuda la ideología del movimiento de software de código abierto, posibilitando que las aplicaciones Web 2.0 provean libremente sus datos y servicios para que los usuarios puedan experimentar con ellos. Por ejemplo Google, Yahoo y un sinnúmero de sitios web dan a conocer la forma de utilizar sus servicios a través APIs, mientras que los proveedores de contenidos hacen lo mismo con la información en forma de feeds RSS. El resultado de la experimentación de los usuarios con combinaciones de estas tecnologías son los denominados mashups, es decir sitios basados en mezclas de los datos y los servicios proporcionados por terceros. El mejor ejemplo de esta evolución son los mashups basados en el servicio de cartografía de Google, como Panoramio [31] .
¿Pero cómo se relaciona la Web Semántica con la Web 2.0? Para algunos suele ser una percepción común que la Web 2.0 y la Web Semántica son visiones contrastadas que compiten por el futuro de la Web. En este sentido la Web Semántica es un esfuerzo de la W3C para desarrollar una Web con tecnología semántica. En la práctica las ideas de Web 2.0 y de Web Semántica no son excluyentes: mientras la Web 2.0 pone énfasis sobre todo en cómo los usuarios interactúan con la Web, la Web Semántica abre nuevas oportunidades tecnológicas para los desarrolladores a la hora de combinar datos y servicios de diversas fuentes. Por ejemplo, una premisa básica de la Web 2.0 es que los usuarios están dispuestos a proporcionar contenidos y metadatos. Estos contenidos pueden tomar forma de artículos y hechos organizados en tablas y categorías como en Wikipedia, fotos organizadas en álbumes de acuerdo a tags como en Flickr o información estructurada embebida en páginas principales y blogs en forma de microformatos [32] .
Mientras estas cuestiones ya están superadas en la Web 2.0, para la comunidad de la Web Semántica es una prioridad conocer si los usuarios estarían dispuestos a proporcionar metadatos para enlazar contenidos en la Web Semántica. Desde una perspectiva histórica es interesante conocer que en los inicios de la Web Semántica se esperaba que los usuarios pudieran taggear contenidos de la Web, describiendo sus páginas principales y el contenido multimedia. Las primeras implementaciones de RDF embebido en HTML, como SHOE [33] no tuvieron éxito debido a que no era práctico para los usuarios comunes utilizar una codificación tan intrincada para describir los metadatos. Aunque hoy día sigue siendo dudoso que los usuarios comunes pudieran dominar la Web Semántica y lenguajes tales como RDF y OWL, está claro que muchos quieren proporcionar información en forma estructurada y a través de un interfaz de uso fácil que oculte la complejidad de la representación subyacente. Los microformatos, ya descritos anteriormente en el documento, han demostrado ser muy populares debido a su facilidad de uso y la posibilidad de “embeberlos” en el HTML. Además, las páginas webs creadas automáticamente a partir de una base de datos (tal como las páginas de los blogs o páginas personales) pueden codificar metadatos en microformatos sin que el

Web 3.0: integración de la Web Semántica y la Web 2.013
usuario se entere necesariamente. Al mismo tiempo, los microformatos conservan todas las ventajas de RDF en términos de comprensión por parte de las computadoras. Por ejemplo, el motor de búsqueda de un blog puede proporcionar una búsqueda sobre las propiedades del autor o de la publicación. Tomando como base los microformatos, la idea de proporcionar una manera de codificar RDF en las páginas del HTML ha vuelto a surgir como RDF/A [34] . En una línea similar, por un lado, hay trabajos avanzados para extender el software de MediaWiki (que es software de base para la Wikipedia) para permitir que los usuarios codifiquen hechos en el texto de los artículos mientras los escriben. El proyecto se llama Semantic Wikimedia [35] . Este marcado adicional de los hechos procesables por las máquinas, permitiría extraer, preguntar y agregar fácilmente conocimiento a la Wikipedia. Por otro lado existen trabajos similares sobre herramientas para Wikis completamente nuevas, que combinan la libre escritura de texto y la edición colaborativa de información estructurada [36] .
Otra premisa de la Web 2.0 es que debido a la extensiva colaboración en línea, muchas aplicaciones tienen acceso a muchos metadatos sobre los usuarios. Información sobre las opciones, las preferencias, el gusto y las redes sociales de usuarios significa para las nuevas aplicaciones la posibilidad de construir perfiles mucho más ricos de un usuario. Claramente, la tecnología semántica puede ayudar a encontrar usuarios con las mismas preferencias, como así también contenido disponible relacionado, sin embargo, la semántica no es suficiente, ya que hay una componente de confianza que está más allá de las inferencias que se pueden hacer basadas en los perfiles [37] . Por lo tanto los sistemas semántico‐sociales pueden proporcionar recomendaciones basadas tanto en las redes sociales de usuarios y sus perfiles personales, como en mecanismos basados puramente en redes de confianza.
Por otra parte lo que la tecnología de la Web Semántica puede ofrecer a la comunidad del Web 2.0 es una infraestructura estándar para construir combinaciones creativas de datos y de servicios. Los formatos estándares para el intercambio de datos y esquemas de información, ayudan a la integración de los datos, así también, los lenguajes de consulta y protocolos estandarizados, para acceder a las fuentes de datos remotos, proporcionan una plataforma para el fácil desarrollo de mashups. Por ejemplo, FreeBase [38] es una base de datos abierta que contiene información acerca del mundo, y permite que los usuarios compartan, enlacen, y corrijan conjuntamente ontologías y datos estructurados a través de una interfaz web. Una API pública permite que los desarrolladores construyan aplicaciones usando el conocimiento combinado de FreeBase.
A esta combinación de visiones y tecnologías es a la que los expertos han denominado Web 3.0. La figura 7 muestra como la aplicación de las tecnologías de la Web Semántica extienden a la bien conocida Web 2.0, éstas en conjunto forman lo que hoy se conoce como Web 3.0.
Fig. 7: La Web 3.0 extiende a la Web 2.0 usando tecnologías de la Web Semántica [39] .

Web 3.0: integración de la Web Semántica y la Web 2.014
3.1. Aportaciones de la Web Semántica a las aplicaciones insignia de la Web 2.0
Basado en la integración de las ideas de la Web Semántica y la Web 2.0 se presentan a continuación los aportes que puede realizar la primera en cuanto a dos de las aplicaciones más conocidas de la segunda.
Folksonomías aumentadas con Ontologías: Describir los recursos por medio de un conjunto de palabras clave es una forma muy común de organizar el contenido para su uso futuro, como en la búsqueda y la navegación. Es una forma de colaboración en el proceso de compartir recursos basados en la Web, llamado "marcado", o "etiquetado/anotación social", el cual ha ido ganando popularidad entre los usuarios de la Web. A la luz de la filosofía Web 2.0, los distintos sistemas de etiquetado social disponibles hoy en día permiten a los usuarios describir sus recursos (páginas web, imágenes, vídeos, etc.) con un conjunto de palabras llamadas "etiquetas", que los mismos usuarios creen pertinente para caracterizar los recursos de acuerdo a sus propias necesidades y sin depender de un vocabulario controlado o de una estructura previamente definida. El objetivo principal de estas etiquetas es facilitar el acceso y compartir tanto los recursos como sus anotaciones, así mismo, sirven como enlaces a recursos etiquetados por sus propietarios o por otros usuarios, lo cual permite el surgimiento de un compromiso y la evolución de la estructura de clasificación, que a veces se denomina "folksonomía", es decir, una taxonomía popular, o de una ligera estructura conceptual y creada por los usuarios. En ese sentido, una de las mayores fortalezas de los sistemas de etiquetado social, es el hecho de que no se supone un vocabulario predefinido, pero a su vez es una debilidad, ya que conduce a una serie de limitaciones y deficiencias en lo que se refiere a la utilización de las etiquetas para recuperar el contenido.
Los principales problemas de los sistemas de etiquetados sociales incluyen la ambigüedad, los sinónimos y discrepancias en la granularidad. Por ejemplo, una palabra ambigua como apple, puede hacer referencia a una manzana en inglés o a la empresa que fabrica dispositivos electrónicos, lo cual puede hacer que el usuario obtenga resultados no deseados en una consulta. Sinónimos como coche, auto, automóvil o carro, o la falta de coherencia entre los usuarios en la elección de etiquetas para recursos similares, por ejemplo, la ciudad de Buenos Aires y Baires, hace que sea imposible para el usuario recuperar todos los recursos a menos que este conozca todas las posibles variantes de las etiquetas que se hayan podido utilizar. Los diferentes niveles de granularidad en las etiquetas puede ser también un problema, por ejemplo los documentos etiquetados “Java” pueden ser significativos solo para algunos usuarios, pero los documentos etiquetados con “programación” pueden ser demasiado generales para otros. Para tratar estos problemas en [40] se presenta un método para minimizarlos, haciendo explícita la semántica que hay detrás del etiquetado social en los sistemas de anotación.
Este método consiste en una serie de procesos que incluyen una limpieza, el análisis de concurrencia, la agrupación y por último, la clasificación de etiquetas en grupos de elementos (conceptos, propiedades o instancias) dentro de las ontologías y la extracción de las relaciones semánticas entre ellas. Como resultado de este método se obtienen grupos de etiquetas muy relacionadas que corresponden a elementos de las ontologías y que están estructurados de acuerdo con las ocurrencias de las relaciones entre esos elementos, que pueden ser vistos como ontologías facetadas, es decir, ontologías parciales que conceptualizan aspectos específicos del conocimiento, todo esto, en contraste con las tradicionales ontologías "monolíticas". Las ontologías resultantes son construidas juntando fragmentos derivados de múltiples ontologías. Después, estas ontologías resultantes pueden ser usadas para varias tareas en los sistemas de etiquetado. Por ejemplo, pueden ser usadas en consultas para eliminar ambigüedades u ofrecer etiquetas relacionadas al usuario para hacer más específica y extendida la búsqueda. Las agrupaciones de las etiquetas (y las relaciones entre ellas) pueden

Web 3.0: integración de la Web Semántica y la Web 2.015
ser representadas gráficamente (en forma de las tan conocidas nubes) para facilitar una mejor comprensión sobre la forma en que el sistema usa las etiquetas en las búsquedas, y también se pueden utilizar para eliminar la ambigüedad.
En este sentido se puede decir que evidentemente las folksonomías y las ontologías deberían coexistir ya que se puede aprovechar la flexibilidad que ofrecen las folksonomías para proveer un mecanismo sencillo para que los usuarios de la web etiqueten recursos o hechos y utilizando internamente ontologías para modelar y mapear (Fig. 8) el conocimiento, de manera que toda la complejidad del modelo nunca sea expuesta a los usuarios.
Fig. 8: Folksonomías mapeadas a Ontologías [41] .
Mashups Semánticos: En [42] se presenta un prototipo de mashup con aplicación de tecnologías semánticas para el manejo de emergencias, en la que los distintos organismos de planificación han de colaborar y compartir datos, así como información sobre las acciones que están realizando. Sin embargo, muchos servicios de emergencia no están disponibles a través la red. Por lo tanto, las interacciones entre los organismos o cuerpos de emergencia por lo general se producen de forma personal o telefónica y el sistema resultante es de alcance limitado y lento para dar respuestas a tiempo. Esto es totalmente contrario a la naturaleza de la necesidad de acceso a la información en una situación de emergencia.
Por ello se ha desarrollado una arquitectura sobre la base de un framework de Semantic GIS [43] (Sistema de Información Geográfica semántico). En este framework los servicios y los datos son compartidos a través de Web Services (WS), que permiten acceso a base de datos distribuidas de manera transparente y provee de operaciones básicas de consulta. La información que proveen los WS a veces debe ser adaptada a la particularidad del dominio de los SIG para poder ser semánticamente descritos por ontologías. El corazón del sistema es una plataforma de ejecución de Servicios Web Semánticos (SWS), que se encarga de alojamiento, descubrimiento y selección de servicios que satisfagan los objetivos, además, los organiza para que trabajen juntos, se encarga de la mediación y por último los ejecuta, y devuelve los resultados. Estos resultados son accesibles para los usuarios a través de la aplicación Web EMS que también utiliza datos de Google Maps. Para mejorar la comunicación también se utiliza Buddyspace [44] , un cliente de mensajería instantánea basado en el protocolo Jabber, en donde cada usuario especifica su contexto mediante un archivo FOAF/RDF, el cual contiene un punto GPS definido con la latitud y longitud. En caso de ser relevante este punto se muestra en el mapa, según las especificaciones de las ontologías.
Wikis Semánticas: Una wiki semántica es un sistema de colaboración para crear y editar contenido para la Web Semántica basado en las bien conocidas wikis. Proporciona un

Web 3.0: integración de la Web Semántica y la Web 2.016
sistema donde los usuarios anónimos en Internet pueden colaborar entre sí para construir un sitio basado en Web Semántica. En contraste con los wikis tradicionales, no es fácil para los usuarios finales crear o editar contenido con semántica a partir de cero, sin conocimiento de la compleja sintaxis de RDF / OWL y la semántica de las ontologías para compartir información. Debido a lo expuesto existen actualmente tres enfoques que intentan resolver estos problemas.
1) Generación Automatizada de metadatos RDF: Estos datos se generan automáticamente para los metadatos facilitados por los usuarios en las páginas de la Wiki. Muchas Wikis convencionales como PukiWiki [45] o PHPWiki [46] ya incluyen esta funcionalidad. Aunque los usuarios no necesitan saber acerca de la sintaxis RDF, estos sistemas proveen la generación automática de datos RDF, a partir de metadatos definidos por el usuario. Desafortunadamente las descripciones RDF proporcionadas por estos sistemas se limitan a metadatos de las páginas de la wiki, tales como el título, la fecha y hora de actualización de los enlaces, etc.
2) Generación automatizada de RDF a partir de representaciones intermedias: Los datos se generan automáticamente a través de las etiquetas y los comandos especiales insertados por los usuarios en el contenido. PeriPeri [47] y Rhizome [48] Wiki son ejemplos de esta categoría. Los usuarios tienen que insertar etiquetas semánticas especiales o marcas equivalentes. Esto requiere que los usuarios tengan que aprender antes a utilizar estas etiquetas, y ello puede requerir una curva de aprendizaje importante.
3) Anotaciones RDF generadas por el Usuario: Los datos RDF son provistos directamente por los usuarios en formato crudo. Platypus [49] Wiki es un ejemplo de esta categoría. Los usuarios tienen que insertar por sí mismos datos RDF XML en bruto, por lo que el sistema puede ser visto como un editor RDF en un navegador Web. Por supuesto, este método depende de que los usuarios estén familiarizados con la sintaxis RDF, que exige una curva de aprendizaje mayor que la de caso anterior, por lo que es muy difícil para el usuario final, en general, realizar este tipo de anotaciones.
Una mejora a estos enfoques es la que se propone en [50] , allí se presenta una nueva wiki semántica denominada "KawaWiki" en la que expertos y usuarios finales pueden colaborar para crear un sitio basado en Web Semántica. KawaWiki genera páginas RDF y Wiki basadas en plantillas RDF y valida su coherencia con la descripciones en RDFS. Estas descripciones se crean a partir de la importación de ontologías disponibles en la red. KawaWiki tiene por objeto proporcionar una arquitectura donde los usuarios finales, expertos y ontologistas puedan colaborar para publicar de una manera semánticamente coherente páginas RDF y Wiki como se haría en una wiki de hoy día. Para ello se ha desarrollado un sistema de plantillas RDF con el fin de ocultar la compleja sintaxis de este lenguaje a los usuarios finales y un mecanismo de comprobación y validación para garantizar la coherencia de datos.

Web 3.0: integración de la Web Semántica y la Web 2.017
3.2. Ejemplos de aplicaciones que actualmente combinen estas dos estrategias y que se puedan considerar Web 3.0
En esta sección se presentan dos ejemplos emblemáticos de aplicaciones Web 3.0. En primer lugar Twine, como red social abierta y después WEASEL, una red social corporativa.
EL caso Twine:
Desde el lanzamiento de su versión beta, los usuarios de Twine [51] han mantenido sesiones de una duración media de 6 minutos al día, y recientemente ha aumentado a 12 minutos superando a MySpace y casi alcanzando los tiempos de 15 minutos de los usuarios del popular Facebook, toda una proeza para una red social que ha sido presentada al público hace tan sólo unos días por Radar Networks. Lo que justifica este temprano y anticipado éxito de Twine, así como la expectación que ha suscitado su anunciado lanzamiento, no es tan sólo el hecho de que sea un eficaz buscador y un innovador gestor de contenidos, sino la incorporación de tecnologías semánticas en las que se sustenta. Esta plataforma pertenece a una nueva etapa en el desarrollo de la Web y es una de las primeras aplicaciones de la Web Semántica.
Twine utiliza el lenguaje de descripción de contenidos RDF. La Web se adentra en una nueva era comenzando a implementarse en ella recursos como el procesamiento de lenguaje natural, hasta ahora restringidos al campo de la inteligencia artificial. Con la inclusión de RDF los gestores de contenido artificiales serán capaces no sólo de clasificar y etiquetar automáticamente los contenidos, sino de interpretar los datos. Estas aplicaciones y herramientas semánticas llevan a nuevo nivel de evolución a la interacción hombre‐máquina y también la comunicación entre las propias máquinas. La generación automática de etiquetas, descripciones y sumarios para las páginas web marcadas según los intereses del usuario es una herramienta ideal para la recopilación, el intercambio y la gestión del conocimiento.
Twine se diferencia de otras redes sociales, porque lo principal no es el "con quién", sino el "qué", es decir, las relaciones están al servicio del crecimiento y el enriquecimiento de los contenidos de interés para el usuario. Según Nova Spivack, fundador de Radar Networks y máximo responsable de Twine, lo que se debe tener claro al usar esta herramienta es el "para qué" se está usando, ya que las ventajas de las tecnologías semánticas no son obvias a primera vista. También al usar Twine por primera vez podemos tener la sensación de estar manejando una aplicación de redes sociales tradicionales, sólo cuando el contenido creado en base a nuestros intereses crece y se enriquece, será el momento en que el usuario comenzará a recibir mucho más de lo que ha aportado. Recibir más de lo que se ha aportado en lo que respecta a los contenidos de interés para el usuario será algo habitual cuando se esté interactuando con las redes de nueva generación. En este tipo de redes no se trata de multiplicar el contenido porque sí, sino más bien de descartar lo irrelevante y seleccionar lo fundamental, y eso es lo que en principio es capaz de hacer la Web Semántica. "Es fácil crear información, pero es difícil reducirla".
Para aprovechar realmente y sacar el máximo partido de las tecnologías semánticas es necesario involucrarse en twines de contenido públicos e interactuar con otros usuarios. Los twines son como madejas de información que tienen como núcleo los intereses del usuario y alrededor de los cuales se van tejiendo los hilos de contenido relacionados con ellos. Las madejas pueden ser públicas o privadas, puede ser documentos, vídeos, fotos, marcadores, mensajes, recomendaciones de otros usuarios, etc. Esta herramienta ya está disponible para cualquier usuario, como se puede ver en la figura 9, pudiendo comenzar a utilizarla y probarla para organizar desde ella su vida en línea.

Web 3.0: integración de la Web Semántica y la Web 2.018
Fig. 9: Pantalla Inicial de Twine.
El Caso de Vodafone y su Web Semántica Corporativa de I+D
La compañía Vodafone es el mayor operador de telefonía celular en el mundo, da servicio a cientos de millones de clientes. En su rápida evolución y el entorno altamente competitivo, la innovación es un elemento clave para mantener el liderazgo. El departamento de I+D de Vodafone es una organización mundial encargada de proveer a las empresas con nuevas tecnologías, productos y servicios. Toda la información sobre las actividades del grupo de I+D de Vodafone es publicada por sus empleados en su sitio web corporativo con el objetivo de fomentar la creación y el mantenimiento de los conocimientos tecnológicos dentro de la empresa y también el descubrimiento de las redes sociales emergentes en torno a los diferentes ámbitos de especialización. Sin embargo, la publicación de esa información en una web corporativa accesible para todo el grupo de I+D no garantizaba que los empleados conocieran de su existencia. Además, los empleados eran libres de subir todo lo que pudieran considerar interesante o digno de una referencia futura, sin las limitaciones de estructura o formatos, por ejemplo PDF, DOC, vídeos MPEG, etc. Otro factor negativo era que cada usuario podía almacenar la información en donde quisiera en el sitio web corporativo, lo que hacía muy difícil recuperar información útil y también hacer referencias de un recurso a otro. Estas dificultades constituían un verdadero problema para la empresa.
Este escenario incluye una serie heterogénea de páginas web y bases de datos no estructuradas relacionadas, pero físicamente disociadas, que contienen la información corporativa (en general bases de datos relacionales, como las estándar actuales, sin información semántica). Dicha información debe ser representada de manera unificada, y debe estar disponible para que cualquier empleado de Vodafone la pueda encontrar de una manera intuitiva y natural. La solución fue el proyecto WEASEL [52] , que se basa en utilizar la anotación semántica automática vía ontologías (Fig. 10) para facilitar la agregación de información de diferentes fuentes, de forma que se muestre información agregada y estructurada de forma comprensible a lo largo de toda la web corporativa. La tecnología de anotación explota las fuentes textuales y anota las fuentes multimedia a través de sus descripciones. El uso de ontologías también permite sistemas de recuperación de información más sofisticados, para ello se han desarrollado dos interfaces de recuperación:
La primera permite la explotación de la estructura de la ontología como mecanismo de navegación.

Web 3.0: integración de la Web Semántica y la Web 2.019
La segunda está basada en lenguaje natural y permite que los usuarios introduzcan preguntas libres donde el resultado se acompaña de una explicación.
Fig. 10: Parte de la Ontología Usada en WEASEL [52] .
Las ventajas que ha obtenido Vodafone con WEASEL son:
1) La información previamente dispersa se ha transformado en información consistente a lo largo de toda la Web corporativa.
2) Las anotaciones se actualizan automáticamente.
3) Los sistemas de búsqueda dan respuestas concretas en vez de listados de documentos.
4) La tecnología semántica y la estructura de la ontología facilitan la navegación por la información.
5) La interfaz de lenguaje natural (en inglés) permite que los empleados realicen consultas utilizando expresiones naturales.
6) Las respuestas que ofrece el interfaz de lenguaje natural se explican de forma simple y comprensible con lenguaje natural.
Web 3.0: integración de la Web Semántica y la Web 2.020
4. ¿Cómo podría integrarse el concepto de personalización en este ámbito?
Después de haber revisado los diversos conceptos que surgen alrededor de la Web 2.0, Web 3.0 y Web Semántica, nos preguntamos, ¿cómo se puede lograr la integración de la personalización en la futura Web? Realmente la personalización va implícita en la Web 3.0, partiendo de que ésta es una evolución de la Web 2.0 unida a la Web Semántica. En la Web 2.0 los contenidos son totalmente adaptables según la información que se pueda obtener del usuario y de su entorno, y considerando también que uno de los objetivos de la Web Semántica es el poder ofrecer a las máquinas mayor control sobre los contenidos de la Web, para así facilitar las tareas a los usuarios, entendemos que el propósito final es proponer información más concreta a los usuarios de forma más eficiente (como se ha detallado anteriormente en el ejemplo del buscador semántico, ofreciendo directamente un paquete vacacional), por tanto personalizar los contenidos.
Fig. 11: Evolución de la Web y el uso de la colaboración en ella [53] .
A partir de la figura 11, podemos ver cómo ha evolucionado la Web en cuanto a la forma en que interactúan todos los actores y el contenido. En la Web Semántica, la colaboración entre usuarios y la información extra, puede ser usada para personalizar los contenidos.
Aunque haya multitud de definiciones para la Web 3.0, vamos a incluir otra más, primero porque creemos que es novedosa y segundo porque recoge el término que estamos tratando ahora, la personalización:
Web 3.0 = (4C + P + VS) [54]
Donde:

Web 3.0: integración de la Web Semántica y la Web 2.021
3C = Contenido, Comercio, Comunidad
4th C = Contexto P = Personalización
VS = Búsqueda vertical
Hasta ahora la personalización ha estado muy limitada, aunque se hayan involucrado muchos esfuerzos en mejorar los algoritmos, existía un vacío de partida, la falta de contexto de la información. Después de realizar una búsqueda en un buscador podríamos obtener multitud de recursos multimedia emergiendo de la pantalla totalmente descentrados de nuestro interés.
Por refrescar el concepto, ¿qué es la personalización (en el entorno tecnológico)? La personalización es la adaptación de un servicio o contenido al usuario, en función de sus características, preferencias personales o información previa que proporciona. Este proceso tiene varios pasos:
a) La recolección de los datos
b) La categorización de los datos recopilados (fase de pre‐procesamiento)
c) El análisis de los datos recolectados
d) La definición de las acciones a ejecutar (p.ej. presentar recomendaciones al usuario).
Se puede observar que a través de estas tareas, la necesidad de la semántica en la personalización es obvia. Pero, para facilitar la comprensión de estas ideas, ¿de qué aplicaciones estamos hablando? Existen multitud de campos donde son aplicables las tecnologías web semánticas. Veamos una clasificación de las aplicaciones según su función [10] :
• Aplicaciones de búsqueda. Las tecnologías de Web Semántica permiten desarrollar buscadores avanzados aplicados a distintos dominios. Los buscadores disponibles en la actualidad (de segunda generación) llevan a cabo el proceso de búsqueda utilizando técnicas clásicas de recuperación de información (IR, Information Retrieval) basadas en la ocurrencia de determinadas palabras clave en las páginas (búsqueda sintáctica), combinado con mecanismos de sinonimia denominados genéricamente tesauros. En el caso de los buscadores web, estas técnicas se complementan con algoritmos de relevancia basados en el número de enlaces entre páginas (pagerank). Las tecnologías de Web Semántica van a permitir construir buscadores de tercera generación (buscadores semánticos). Estos buscadores van a complementar las soluciones de búsqueda tradicionales, haciéndolas mucho más ricas, ya que no sólo se buscará en el universo web la ocurrencia de ciertas palabras clave, sino que también se buscará atendiendo al significado (semántica) de dichas palabras clave en un contexto.
Es el caso, por ejemplo, de una persona que puede estar interesada en buscar libros que hablen sobre la vida y obra de un determinado escritor. En un buscador de segunda generación se encontrarán muchas entradas correspondientes a libros escritos por ese escritor, pero no se encontrarán fácilmente aquellos libros que realmente buscaba el usuario. Esto se debe a que la búsqueda se realiza por la ocurrencia de palabras y no por su significado.
• Aplicaciones de asistencia al usuario. Estas aplicaciones están relacionadas con los agentes personales de usuario que permiten realizar búsquedas avanzadas en Internet, descubrimiento de servicios, composición de servicios, etc.

Web 3.0: integración de la Web Semántica y la Web 2.022
• Aplicaciones de integración de fuentes de datos heterogéneas. Estas aplicaciones permiten obtener, agrupar y correlacionar información dispersa en Internet sobre un dominio, como, por ejemplo, deportes o noticias.
• Aplicaciones de anotación semántica de contenidos multimedia. Estas aplicaciones permiten catalogar los contenidos multimedia de forma semántica, pudiéndose realizar catálogos de contenidos personalizados para los usuarios, así como el descubrimiento de nuevos recursos multimedia de interés para el usuario, etc.
• Aplicaciones de adaptación automática de contenidos en base a la anotación semántica de los mismos. La idea que subyace en estas aplicaciones es que los contenidos web sean adaptados dinámicamente teniendo en cuenta su semántica y la personalización asociada al usuario. Actualmente existen mecanismos automáticos de adaptación de contenidos, pero basados únicamente en aspectos sintácticos de las páginas.
• Aplicaciones para las empresas. Bajo este punto aparecen todas aquellas aplicaciones de la Web Semántica encaminadas a mejorar los mecanismos actuales de gestión de las empresas, explotando al máximo el nuevo abanico de posibilidades que ofrecen las tecnologías y plataformas de Web Semántica.
Todas las categorías tienen distintas características entre sí, y por supuesto también tienen cosas comunes, una de ellas es la personalización. Para resultar más efectivas y útiles, todas ellas hacen uso de la información del contenido y de los usuarios para hacer un tratamiento u otro de los datos.
¿Dónde encontrar la personalización en estas herramientas? En la aplicaciones de búsqueda, asistencia al usuario y adaptación automática de contenidos, los procesos filtran la información que debe ser presentada al usuario en base a información previamente almacenada del mismo (a través de formularios, sitios previamente visitados, o forma de actuar en la Web); de forma similar, entre las aplicaciones citadas anteriormente la información ofrecida se personaliza cuando se ofrecen contenidos multimedia o en las aplicaciones empresariales, donde en base a los usos previos, se pueden caracterizar las diferentes pantallas o secuencias. Además en la Web actual y futura, la personalización aparece alrededor de las redes sociales, y a través de las nuevas interfaces, surgen nuevos conceptos como Folksonomías y Ontologías, etc.
¿Y cómo favorece la futura Web la personalización? El esqueleto de la Web Semántica se compondrá de metadatos asociados a los documentos y archivos de la Web actual, y metalenguajes. Mediante el uso de las nuevas tecnologías como XML, XML Schema, RDF, RDF Schema y OWL, se aportará sintaxis, estructura, dependencias y propiedades de los datos, aumentando las posibilidades de la Web gracias a:
a) Los documentos etiquetados con información semántica podrá ser interpretada por el ordenador con una capacidad comparable a la del lector humano.
b) Vocabularios comunes de metadatos y mapas entre vocabularios que permitan a quienes elaboran los documentos disponer de nociones claras sobre cómo deben etiquetarlos.
c) Agentes automáticos que realicen tareas para los usuarios de estos metadatos de la Web Semántica
d) Servicios Web que provean de información a los agentes.
A partir de la metainformación, y la Inteligencia Artificial, las futuras aplicaciones serán capaces de ofrecer resultados concretos, facilitando a los usuarios su interacción con la red.

Web 3.0: integración de la Web Semántica y la Web 2.023
4.1. Ejemplo de extensión de las capacidades de personalización de las futuras aplicaciones
En esta sección vamos a intentar explicar a través de un ejemplo, el grado actual de integración de la personalización y las posibilidades que ofrecerá la Web Semántica alrededor de ella.
Imaginemos un blog personal sobre viajes, los metadatos de uso corriente que podemos encontrar hoy son: Título de la página que aparece en el índice de un buscador, palabras clave sobre el sitio, idioma de la página, autor, copyright del contenido, etc. Éstos se incluyen en las cabeceras de una página web.
A partir de una barra de herramientas, tipo barra de Alexa o barra de Google (las cuales generan estadísticas propias según la actividad del usuario), se puede recopilar más información: Links relacionados con esa página, valoración de la misma por parte de sus visitantes, velocidad promedio de descarga del sitio, propietario del dominio, etc.
Posibles ejemplos de nuevos metadatos que introducen las tecnologías en desarrollo son los FOAF (“Friend of a Friend”), metadatos con información personal sobre el autor del documento. Este tipo de datos, se incluyen en un fichero escrito en XML y cuya extensión es “.rdf” (Resource Description Framework). Un FOAF puede ser simple (ID, Login o Nick y nombre) o muy complejo y llegar a incluir datos como página personal, agenda de contactos, proyectos en los que trabaja, etc.
El FOAF fue pensado en un principio para hacer algo parecido a www.Friendstser.com pero en código libre (de ahí lo de Friend of a Friend) y crear automáticamente una red de contactos. Pero ha ido convirtiéndose poco a poco en el formato de metadato utilizado para la información personal.
Los buscadores actuales, nos llevarían al blog sobre viajes según las palabras clave del sitio y el título del mismo, y opcionalmente, también podrían usar los datos generados por las barras de navegación, pero los futuros metadatos darían la opción de ofrecer al usuario resultados más precisos o de partida más interesantes, ya que podrían buscar sitios que hayan visitado otros amigos u otros usuarios con los mismos gustos, mismos autores, etc. De todas formas la Web Semántica no está basada en simples metadatos, sino en estructuras más o menos organizadas de ellos, por lo que el grado de posibilidades para encontrar resultados precisos y mejorar la usabilidad, precisión y personalización aumenta.

Web 3.0: integración de la Web Semántica y la Web 2.024
5. Tendencias futuras
Aunque es difícil poder aventurar cuál es el futuro de la Web, puesto que todo lo referente a la tecnología evoluciona de forma muy rápida y en direcciones que no se pueden predecir, intentaremos recoger qué tendencias existen en relación a la Web 3.0 y la Web Semántica.
Las tecnologías de la Web 3.0, en su uso de datos semánticos; se han implementado y usado a pequeña escala, principalmente en compañías para conseguir una manipulación de datos más eficiente, aunque como se ha citado en el trabajo, poco a poco van apareciendo nuevos servicios apoyados sobre la base semántica, y la tecnología va evolucionando. En los últimos años, se ha potenciado el desarrollo para trasladar estas tecnologías de inteligencia semántica al público general, pero como ya se ha dicho, es difícil predecir si tendrá éxito o la Web Semántica será posible.
El primer paso hacia la "Web 3.0" es el nacimiento de la "Data Web", ya que los formatos en que se publica la información en Internet son dispares, como XML, RDF y microformatos; el reciente crecimiento de la tecnología SPARQL, permite un lenguaje estandarizado y una API para la búsqueda a través de bases de datos en la red. La "Data Web" permite un nuevo nivel de integración de datos y aplicación inter‐operable, haciendo los datos tan accesibles y enlazables como las páginas web. La "Data Web" es el primer paso hacia la completa “Web Semántica”. En la fase “Data Web”, el objetivo es principalmente, hacer que los datos estructurados sean accesibles utilizando RDF. El escenario de la "Web Semántica" ampliará su alcance en tanto que los datos estructurados e incluso, lo que tradicionalmente se ha denominado contenido semi‐estructurado (como páginas web, documentos, etc.), estén disponibles en los formatos semánticos de RDF y OWL.
Web 3.0 también ha sido utilizada para describir el camino evolutivo de la red que conduce a la inteligencia artificial. Algunos escépticos lo ven como una visión inalcanzable. Sin embargo, compañías como IBM y Google están implementando nuevas tecnologías que cosechan información sorprendente, como el hecho de hacer predicciones de canciones que serán un éxito, tomando como base información de otras webs de música. Existe también un debate sobre si la fuerza conductora tras Web 3.0 serán los sistemas inteligentes, o si la inteligencia vendrá de una forma más orgánica, es decir, de sistemas de inteligencia humana, a través de servicios colaborativos como del.icio.us, Flickr y Digg, que extraen el sentido y el orden de la red existente y cómo la gente interactúa con ella.
En relación con la dirección de la inteligencia artificial, la Web 3.0 podría ser la realización y extensión del concepto de la “Web Semántica”. Las investigaciones académicas están dirigidas a desarrollar programas que puedan razonar, basados en descripciones lógicas y agentes inteligentes. Dichas aplicaciones, pueden llevar a cabo razonamientos lógicos utilizando reglas que expresan relaciones lógicas entre conceptos y datos en la red. Sramana Mitra difiere con la idea de que la "Web Semántica" será la esencia de la nueva generación de Internet y propone la fórmula para encapsular Web 3.0 que ya se ha presentado antes [54] .
Otro posible camino para la Web 3.0 es la dirección hacia la visión 3D, liderada por el Web 3D Consortium. Esto implicaría la transformación de la Web en una serie de espacios 3D, llevando más lejos el concepto propuesto por Second Life [55] . Esto podría abrir nuevas formas de conectar y colaborar, utilizando espacios tridimensionales.
De todas formas, la Web Semántica en parte se encuentra mucho más cerca de lo que pensamos. De hecho, algunas de sus aplicaciones ya están incorporadas desde hace tiempo en nuestra vida internauta cotidiana. Un buen ejemplo de ello son los ficheros RSS. Se trata de formatos RDF basados en XML que permiten organizar y distribuir información según las

Web 3.0: integración de la Web Semántica y la Web 2.025
preferencias de los usuarios. Los RSS contienen metadatos sobre fuentes de información suscritas que avisan a los usuarios que los recursos han cambiado y muestran los nuevos contenidos sin tener que acudir directamente a la página. Otras aplicaciones actuales son los buscadores semánticos, algunos ejemplos:
‐ AskWiki: Buscador para la Wikipedia [56] .
‐ Ayuntamiento de Zaragoza: Buscador de la web del Ayuntamiento de la ciudad [57] .
‐ Buscador del BOPA (Boletín Oficial del Principado de Asturias) [58] .
‐ Hakia: Buscador basado en ontologías semánticas [59] .
‐ Semantic web search [60] .
‐ Swoogle: Otro buscador web semántico [61] .
‐ PiggyBank: Navegador web semántico [62] .
‐ PowerAqua: Un sistema que ofrece respuestas a preguntas [63] .
Por tanto ya hay ejemplos operativos y el futuro de la Web es la semántica, ¿pero cuál es el futuro de la Web Semántica? Idealmente pretende ser un entorno más estructurado, con muchas más posibilidades para los ordenadores. Así, la Web Semántica parece estar siguiendo sus lentos pasos hacia la utopía de la información universal organizada.
Con estas bases, ¿qué proyectos de investigación se están llevando a cabo en relación a la Web Semántica?
Nepomuk [64]
El "Proyecto Nepomuk", que cuenta con el apoyo de la Unión Europea, tiene como objetivo "darle sentido" a la información que poseemos gracias a la creación de un escritorio semántico. Al mismo tiempo, este escritorio será social, ya que se podrá compartir información de forma sencilla, utilizando términos cotidianos para nosotros, pero que el ordenador podrá entender a la perfección. Éste es el inconveniente principal al que todos los proyectos basados en semántica se enfrentan. Tanto los ordenadores como la red poseen información, pero no pueden entenderla porque ésta sólo puede ser leída por humanos.
Al incorporar el aspecto semántico, los ordenadores y la futura Internet (en caso de que se alcance ese nivel) podrán entender esa información, alcanzando un nivel de precisión, exactitud y personalización impresionante en los resultados que arroje. Resultados, dicho sea de paso, que responderán a preguntas realizadas en el lenguaje cotidiano. A la pregunta, "¿Dónde está la panadería más cercana?", la Web Semántica nos debería responder con la dirección de la panadería más cercana, sin preguntarnos nada más. Incluso, debería poder saber qué tipo de pan nos gusta, en caso que haya dos panaderías cerca y deba escoger a cuál referirnos.
Web 3.0: integración de la Web Semántica y la Web 2.026
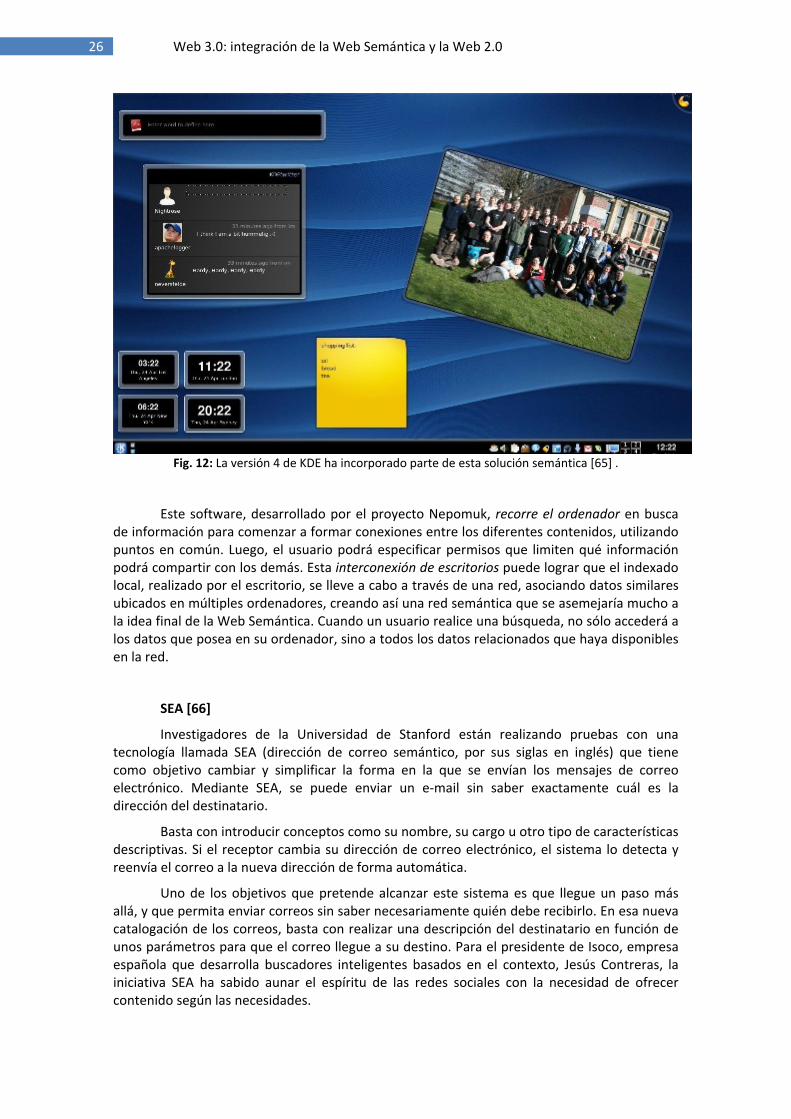
Fig. 12: La versión 4 de KDE ha incorporado parte de esta solución semántica [65] .
Este software, desarrollado por el proyecto Nepomuk, recorre el ordenador en busca de información para comenzar a formar conexiones entre los diferentes contenidos, utilizando puntos en común. Luego, el usuario podrá especificar permisos que limiten qué información podrá compartir con los demás. Esta interconexión de escritorios puede lograr que el indexado local, realizado por el escritorio, se lleve a cabo a través de una red, asociando datos similares ubicados en múltiples ordenadores, creando así una red semántica que se asemejaría mucho a la idea final de la Web Semántica. Cuando un usuario realice una búsqueda, no sólo accederá a los datos que posea en su ordenador, sino a todos los datos relacionados que haya disponibles en la red.
SEA [66]
Investigadores de la Universidad de Stanford están realizando pruebas con una tecnología llamada SEA (dirección de correo semántico, por sus siglas en inglés) que tiene como objetivo cambiar y simplificar la forma en la que se envían los mensajes de correo electrónico. Mediante SEA, se puede enviar un e‐mail sin saber exactamente cuál es la dirección del destinatario.
Basta con introducir conceptos como su nombre, su cargo u otro tipo de características descriptivas. Si el receptor cambia su dirección de correo electrónico, el sistema lo detecta y reenvía el correo a la nueva dirección de forma automática.
Uno de los objetivos que pretende alcanzar este sistema es que llegue un paso más allá, y que permita enviar correos sin saber necesariamente quién debe recibirlo. En esa nueva catalogación de los correos, basta con realizar una descripción del destinatario en función de unos parámetros para que el correo llegue a su destino. Para el presidente de Isoco, empresa española que desarrolla buscadores inteligentes basados en el contexto, Jesús Contreras, la iniciativa SEA ha sabido aunar el espíritu de las redes sociales con la necesidad de ofrecer contenido según las necesidades.

Web 3.0: integración de la Web Semántica y la Web 2.027
Las pruebas que se han realizado con este sistema han obtenido, según los investigadores, muy buena respuesta, pero se plantean dudas sobre el volumen de correo basura que se recibiría. Es ahí donde se debe poner en práctica el potencial de la Web semántica, para comprender el contenido del correo y eliminarlo si no es del interés del destinatario. "El que consiga comprender el significado del contenido on‐line y lo entregue a las personas que lo consideran interesante se convertirá en el nuevo Google", apunta Contreras.
5.1. Debilidades y riesgos del futuro de la Web 3.0 Aunque ya se hayan detectado aplicaciones y servicios basados en la Web Semántica,
la completa implantación de la misma está aún lejos. Este sistema, construido sobre ontologías, estructuras y metadatos, para la representación formal y común de las ideas/conceptos/términos utilizados en un campo específico, no es en absoluto trivial ni gratuito. Su coste repercute en una mayor complejidad de la propia estructuración del conocimiento y de los algoritmos que permiten su gestión, lo que implica también una reducción en la eficiencia. La propia evolución de los sistemas de cómputo seguramente permitirá que, a mediano plazo, estas implementaciones sean eficientes y constituyan una alternativa que, hoy no está tan clara.
En este sentido un paso intermedio es el uso de soluciones híbridas en las que se combinen formalismos (ontologías) con estructuras no‐formales (folksonomías). Estas estructuras de datos permitirían soluciones más eficientes, aunque menos versátiles.
Extrayendo de la wikipedia [7] una buena definición de lo que dicen que está por venir:
“El límite de la Web Semántica está dado no por las máquinas o sistemas biológicos que se pudieran usar, sino porque la lógica con que se intenta construir carece del uso del tiempo, ya que la lógica formal es puramente metonímica y carece de la metáfora, y eso es lo que marcan los teoremas de Gödel, la tautología final de toda construcción y /o lenguaje metonímico (matemático), que lleva a contradicciones.”
El problema está en que se pretende construir un sistema inteligente que sustituya nuestro pensamiento, al menos en las búsquedas de información, pero la particularidad de nuestro pensamiento es el uso del tiempo, el que permite terminar una acción, pero esto no puede ser reproducible en las máquinas.
Así que según se indica, todos los esfuerzos encaminados a la Web Semántica están destinados al fracaso a priori si lo que se pretende es prolongar nuestro pensamiento humano en las máquinas, ellas carecen de discurso metafórico, pues sólo son una construcción matemática, que siempre será tautológica y metonímica, ya que además carece del uso del tiempo que es lo que lleva al corte, la conclusión o problema de la parada.
Aún así, creemos que lo que se pretende con la introducción de la semántica en la Web no es reproducir totalmente el pensamiento humano, pero sí facilitar el uso de la Web a los usuarios y hacer los procesos de Internet más inteligentes. Sin embargo, estas líneas ofrecen un razonamiento negativo sobre consideraciones de ciertos investigadores.
Volviendo a las limitaciones que nos podemos encontrar, hay que recordar que en la red no todo el mundo aporta en el mismo sentido, y siempre hay personas que buscan el perjuicio de los demás. Con la aparición de nuevas tecnologías y propuestas, nacerán debilidades contra los que habrá que luchar, por ejemplo el SPAM semántico. ¿Quién puede asegurar que nadie intentará engañar a las futuras aplicaciones? ¿Se podrá crear una Web X.0 totalmente segura y confiable?

Web 3.0: integración de la Web Semántica y la Web 2.028
5.2. Evolución de este campo según los expertos La evolución de la Web ya se ha tratado en este trabajo, detallando los conceptos de
Web 1.0, Web 2.0, Web 3.0 y Web Semántica. En la siguiente figura se puede ver una línea de evolución tecnológica de acuerdo con Nova Spivack, miembro de la compañía americana Radar Networks. En ella se ilustra todo el trayecto desde la "prehistoria" de los ordenadores personales hasta la futura Web 4.0 (o WebOS).
Fig. 13: Evolución de la Web [67] .
Supuestamente hasta el 2020, la World Wide Web estará ingresando en una nueva fase evolutiva, la Web 3.0, una denominación seguida por cierto sector y rechazada por otro. No todos tienen claro dónde termina la Web 2.0; incluyendo a Sir Timothy Berners Lee, el propio "inventor" de la Internet y director del World Wide Web Consortium (W3C), el organismo que supervisa el desarrollo de la gran red y establece sus convenciones. Realmente no todos permiten llamar Web 3.0 al cambio que se aproxima.
Sir Berners‐Lee en una conferencia realizada en Marzo de 2006 [68] hablaba sobre la Web Semántica y las posibilidades que puede ofrecer a los futuros servicios. Un punto común en su discurso con otras muchas personas es la problemática para poder catalogar toda la información, y componer los metadatos para todos los recursos, más aún si son a través de ontologías estructuradas, puesto que requieren aún más esfuerzo. Aunque él, como impulsor de la idea, es optimista. Exponía además ciertos puntos sobre los que se fundamenta el futuro de la Web Semántica:
o Mayor poder de integración de la información, necesitando una conciencia más estricta y más transparencia en los servicios (“¿Por qué? ¿Cómo sabes eso?”).
o Mayor poder en el análisis de datos por parte de los ordenadores, que permitirá mayor estabilidad y nuevas oportunidades.
o Nuevas ideas, nuevos sistemas y por tanto, nuevas reglas.
o Un nuevo campo: La Web Science.

Web 3.0: integración de la Web Semántica y la Web 2.029
Este escepticismo sobre la integración de los metadatos es relatado por Lluis Codina en [69] . Indicando que las posibilidades a corto y medio plazo de la Web Semántica son reducidas. Citando textualmente:
“Si casi nadie usa metadatos ahora, ¿por qué razón, de pronto, todo el mundo va a poner metadatos en sus páginas? Peor aún, si los autores de páginas web han demostrado su incapacidad para usar una norma relativamente simple como era la primera versión de Dublin Core, ¿por qué van a hacerlo ahora que ha llevado su complejidad al límite de lo impracticable?
Por último, respecto a las ontologías y su explotación mediante motores de inferencia o sistemas expertos: si la inteligencia artificial suma ya varias décadas de fracasos, por lo menos en relación a la hipótesis fuerte, o sea en relación a su objetivo declarado a bombo y platillo de lograr que los ordenadores piensen, ¿por qué va a tener éxito ahora?
Por tanto, las posibilidades de que la Web Semántica sea una realidad tal como la presenta el W3 Consortium, sin que se produzca antes, al menos un cambio de paradigma de gran calado en las ciencias de la computación, son ridículas. Sin embargo, no nos engañemos: el objetivo de la Web Semántica es magnífico, producirá importantes avances en algunos o en todos los terrenos relacionados con la representación y el acceso al conocimiento y en mi opinión, desde las ciencias de la documentación, debería obtener todo nuestro apoyo. “
En la 5ta. Conferencia Internacional de la Web Semántica, realizada en noviembre de 2006, Tom Gruber [69] [70] señaló en su presentación que hay una falsa idea popular que tiende a considerar la Web Semántica y la Web Social como dos mundos con ideologías alternativas y en oposición sobre cómo debe ser la Web. Consideró que esto era absurdo, y que era hora de abrazar una idea unificada, suscribiendo a la visión del Web semántico como substrato para la inteligencia colectiva.
Al respecto, José Antonio del Moral [71] sostiene que en la Web 3.0 se produciría una unificación de las comunidades sociales, para lograr que el usuario tuviera una sola identidad en Internet.
¿Cuáles son los impedimentos para que el uso del modelo semántico, a corto plazo, se haga extensivo?, ¿existen alternativas a dicho modelo?
Más allá del optimismo expresado por Berners‐Lee, la Web Semántica ‐como explica en su tesis doctoral, María Jesús Lamarca [72] ‐ sin duda mejorará la accesibilidad de la información, pero el problema es que exige una completa marcación de la Web. Por tal motivo, agrega, otros investigadores han tomado un camino diferente para implementar la Web Semántica. En lugar de utilizar estándares y reformateos webs, están construyendo nuevos agentes para que puedan entender mejor la Web tal como está hoy en día. Las páginas web ya tienen información semántica, así que lo que hacen es que los agentes las entiendan tal como los humanos. No están haciendo las páginas más fáciles de leer, sino a los agentes más inteligentes.
Por tanto, todos o la mayoría, coinciden en que la Web Semántica es un objetivo que hay que perseguir y en el que hay que profundizar, pero quizás sea difícil que a corto plazo se cubran las necesidades que exige su despliegue. Será el futuro algún día, pero hoy esta filosofía tiene muchas limitaciones, por tanto hay que restringir mucho el campo de las aplicaciones que se hacen para que tengan algún éxito.
Actualmente la Web consigue la comunicación y entendimiento entre humanos y máquinas, pero para conseguir la comunicación y entendimiento entre máquinas, se tiene que

Web 3.0: integración de la Web Semántica y la Web 2.030
conseguir que la información introducida por los usuarios sea estructurada de forma que las máquinas puedan comprenderla, y este proceso no es inmediato.
Por tanto, en la actualidad esto sólo es posible si limitamos mucho el campo de la información que deseamos introducir, pero seguramente en un futuro se conseguirá solucionar este problema y entonces empezará a tener sentido pensar en la Web Semántica. Mientras tanto, seguirán apareciendo aplicaciones basadas en información muy concreta, pero no se podrán extrapolar a algo más global.
5.3. Evolución según el grupo No se puede predecir con certeza cuál será la evolución de la Web. Los equipos cada
vez son más potentes y la tecnología ofrece más posibilidades, pero es difícil saber qué ideas surgirán de las empresas y sus desarrolladores.
Realmente es difícil aventurar el éxito de una aplicación antes de su lanzamiento, en ocasiones un servicio puede marcar un antes y un después, debido a su popularidad, apareciendo multitud de aplicaciones entorno a la idea. Por ejemplo youtube, donde se pueden ver vídeos almacenados en servidores en Internet, ha sido un éxito. A partir de él han aparecido muchos complementos, aplicaciones que ofrecen películas completas, y en la actualidad ya existen programas que permiten ver la televisión en directo a través de streaming (las olimpiadas podían ser seguidas a través de la web de Televisión Española). ¿Será lo siguiente la Web 3D?
Sin embargo, sí nos atrevemos a señalar algunos caminos que podrían evolucionar de acuerdo a lo que hoy en día se ha comenzado a desarrollar:
‐ Internet evoluciona hacia una plataforma única de aplicaciones y servicios totalmente integrados, donde la reutilización automática de “cosas” será clave. Por tanto, tenderá a homogeneizarse.
‐ La eliminación de ambigüedades dará la posibilidad de realizar búsquedas más exactas.
‐ Las ontologías convergerán en una ontología global que estructurará datos de una gran base de datos mundial.
‐ Por su parte, cada vez está tomando más peso la geo‐localización de los contenidos, aplicaciones, etc., (por ejemplo, a partir de google maps).
Tampoco hay que olvidar las redes sociales que en estos momentos son las aplicaciones con mayor auge dada la magnitud de personas que participan en ellas. Podría suceder que la siguiente gran innovación surja en esta área. De hecho ya hay varios desarrollos dirigidos a llamar la atención de más personas, mejorando su experiencia en el uso de la Web y en la forma de relacionarse con los demás.
Sobre la movilidad, existe una tendencia hacia estar siempre conectado, por tanto, en un futuro no muy lejano quizás los dispositivos móviles permitan una navegación correcta y podamos llevarnos la oficina o Internet “en el bolsillo”, o en los ambientes donde mayor tiempo pasamos se integren equipos que nos permitan conectarnos (por ejemplo en los vehículos).
Finalmente, ¿Veremos algún día la Web Semántica totalmente implementada? Creemos que es difícil catalogar toda la información que hay en Internet, y una implementación parcial tal vez no cubra todas las expectativas. Deseamos que se logre y creemos en sus beneficios, y tal vez entonces tendrán razón los expertos que afirman que el

Web 3.0: integración de la Web Semántica y la Web 2.031
nuevo paso que dará lugar a la Web 3.0 será la Web Semántica, pero este avance lo vemos todavía lejano y difícil de concretarse en su totalidad.
5.4. Ideas del grupo para nuevos servicios El concepto de Hipermedia Física (HF) fue utilizado por primera vez en [73] y extendido
[74] y [75] para describir un tipo especial de aplicaciones en las que se combina la computación ubicua y la realidad aumentada con la hipermedia.
Los Sistemas basados en HF permiten “aumentar” los objetos del mundo real con información digital y links. De esta forma, se permite que un usuario móvil, equipado con un PDA, un Teléfono celular u otro dispositivo de computación móvil, pueda explorar un único espacio de navegación que contenga en su totalidad a objetos físicos del mundo real o una mezcla de objetos físicos y objetos digitales, siguiendo el bien conocido paradigma hipermedia. En este tipo de sistemas los usuarios verán como nodos de una red hipermedia a los objetos del mundo real que le son familiares. Al igual que en un sistema basado en hipermedia tradicional los usuarios a partir de estos nodos podrán seguir links para navegar los distintos objetos de la red, pero a diferencia de los sistemas tradicionales los links podrán ser de dos tipos, el primer tipo son los links físicos (wakeable links) en los cuales los usuarios tendrán que trasladarse físicamente de un objeto a otro siguiendo las instrucciones (por ejemplo un mapa) brindadas por el sistema para alcanzar el siguiente nodo de la red, el segundo tipo son los links de las aplicaciones hipermedia tradicionales, a los cuales se puede acceder a través del navegador web convencional. Por ello la HF nos permite que objetos del mundo real sean objetos de primera clase, es decir que el material físico tiene su contraparte digital.
Otro punto importante que se debe tener en cuenta en este tipo de aplicaciones son los servicios, contex‐aware [76] (sensibles al contexto) que prestan, los cuales permiten adaptar el comportamiento de la aplicación al contexto, dependiendo de diversos factores como ser: el usuario y sus preferencias, la ubicación de este, el historial de navegación, el clima, etc.
En tal sentido la Web 3.0 podría aportar ontologías para describir objetos físicos como nodos de redes hipermedia física, debido a los objetos toman distintos roles cuando uno utiliza este tipo de sistemas, por ejemplo (punto de inicio, punto de interés, punto intermedio, etc.) un buena ontología y sistemas de razonamiento podría ayudar a los usuarios a no perderse mientras camina, mostrar información de alerta automática, indicar que se ha perdido el rumbo mientras se camina, etc. Los “wakeables” podrían estar dotados de semántica con anotaciones por parte de usuarios del sistema y también podría haber una ontología para definirlos. Cualquier información de contexto como la ubicación, el clima, el mismo usuario y sus preferencias podría definirse como los microformatos y ser entendido por múltiples aplicaciones. Los puntos de interés podrían ser sugeridos con más acierto, logrando así que el navegado físico se haga en menor tiempo y con el menor gasto de energía. El historial compartido es muy importante ya que de ese historial dependerá la semántica de la navegación y los links o acciones que se pueda tomar en un determinado momento.

Web 3.0: integración de la Web Semántica y la Web 2.032
6. Conclusiones
El propósito de clasificar la Web 1.0, la Web 2.0 y la Web 3.0, no es más que un intento por marcar pautas en la evolución de la Web. Sin embargo, se debe ser cauteloso al asignar los términos Web X.X, para no caer en múltiples versiones que sólo podrían causar confusiones sin sentido.
En este trabajo, después de revisar las diversas definiciones de Web 1.0, Web 2.0, Web 3.0 y Web Semántica, nos hemos centrado en la Web 3.0 y la posible integración de la Web Semántica, intentando detallar sus características y rasgos más importantes.
Según lo indicado en el documento, ni siquiera los expertos se ponen de acuerdo sobre las definiciones de las sucesivas Webs, puesto que no es un hecho destacado que quede marcado concretamente en el tiempo. La evolución de la Web no es rupturista, sino que es gradual y en lo relativo al futuro podría seguir diversos caminos, aunque el camino marcado por muchos es el de la Web Semántica.
La Web Semántica es una Web para las máquinas, sin embargo la creación y mantenimiento de los contenidos es social. Mientras que en la actualidad la mayor parte del contenido en línea en el mundo sólo es comprensible por las personas, la Web Semántica podría proporcionar capas adicionales en la arquitectura web para la descripción de contenidos mediante el uso compartido de vocabularios llamado ontologías. Esto permitiría a los ordenadores poder conocer lo expresado en los recursos de la Web. Con ayuda de la semántica se podrá tomar y tratar la información de múltiples fuentes y llegar a conclusiones de manera similar al razonamiento humano. Si bien las maquinas son útiles para la manipulación de datos según reglas predefinidas, la componente humana es necesaria por tener la capacidad asociativa e interpretativa para la creación y mantenimiento de las ontologías.
La sinergia que se produce entre la Web 2.0 y la Web Semántica permitirá aplicaciones cada vez más personalizadas. En el documento se han enumerado aplicaciones actuales que basadas en la Web Semántica, y además se han detallado otras más novedosas, que podrían estar disponibles en fechas cercanas
Nuestra opinión es que aunque siempre son bienvenidas las mejoras, y la semántica en la web es una bastante importante, el poder introducir los cambios necesarios para implementar estas mejoras siempre es difícil. Catalogar toda la información que se dispone en Internet puede llegar a ser muy costoso, y por tanto creemos que el despliegue de esta solución aún está lejos, por lo que las posibles aplicaciones relacionadas aún tardarán en llegar a la mayoría de los usuarios.

Web 3.0: integración de la Web Semántica y la Web 2.033
Bibliografía
[1] “Digital Rhetoric: Social Media and Persuasive Games (Class Twelve: Web 3.0”). [En línea]. 2006. Disponible en: http://www.digitalrhetoric.org/course/classtwelve.html
[2] Wikipedia. Web 1.0. [En línea]. Actualización: 27 de Enero del 2009. Disponible en: http://es.wikipedia.org/wiki/Web_1.0
[3] O'Reilly, Tim. “What Is Web 2.0”. [En línea]. O'Reilly Network. 2005. Disponible en: http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what‐is‐web‐20.html
[4] Wikipedia. Web 2.0. [En línea]. Actualización: 16 de Febrero del 2009. Disponible en: http://es.wikipedia.org/wiki/Web_2.0
[5] Ramírez, Félix. “Web 3.0 y literatura digital.” [En línea]. 2008. Disponible en: http://biblumliteraria.blogspot.com/2008/12/web‐30‐y‐literatura‐digital.html
[6] Angermeier, Markus. “Web 2.0.” [En línea]. Disponible en: http://nww.nerdwideweb.com/web20/es.png
[7] Wikipedia. Web 3.0. [En línea]. Actualización: 13 de Febrero del 2009. Disponible en: http://es.wikipedia.org/wiki/Web_3.0
[8] Calcanis, Jason. “Web 3.0, the “official” definition”. [En línea]. 2007. Disponible en: http://calacanis.com/2007/10/03/web‐3‐0‐the‐official‐definition/
[9] Ortiz Moreno, Rocio. “Web 2.0 y Web 3.0.” [En línea]. 2008. Disponible en: http://golden‐nature.blogspot.com/
[10] Pérez Crespo, Salvador. “Cómo será la Web 3.0.” [En línea]. Telefónica Investigación y Desarrollo para Telefónica España. 2007. Disponible en: http://sociedaddelainformacion.telefonica.es/jsp/articulos/detalle.jsp?elem=4215
[11] Shannon, Victoria. “El ciberespacio se moderniza: se viene la Web 3.0.” [En línea]. La nación. 2006. Disponible en: http://www.lanacion.cl/prontus_noticias/site/artic/20060530/pags/20060530185814.html
[12] Sitio para compartir fotos, videos, blogs, etc.: www.technorati.com
[13] Proyecto para facilitar la transferencia entre usuarios de fotos, videos, etc. http://www.parakey.com
[14] Sitio para compartir entre usuarios fotos, videos, etc. http://www.facebook.com
[15] Sitio de Amazon que promueve lo que llaman HITs (Human Intelligence Tasks). http://www. mturk.com
[16] Spivack, Nova. “Does the Semantic Web = Web 3.0?”. [En línea]. 2006. Disponible en: http://novaspivack.typepad.com/nova_spivacks_weblog/2006/11/does_the_semant.html
[17] Web 2.0 journal, SYS‐CON Media Inc. “Forget Web 2.0, says Berners‐Lee: 'Web 1.0 was already all about connecting people’.” [En línea]. 2006. Disponible en: http://web2.sys‐con.com/read/263602_p.htm
[18] Brodkin, Jon. “Gartner touts Web 2.0, scoffs at sequel.” [En línea]. Network World. 2007. Disponible en: http://www.networkworld.com/news/2007/092107‐gartner‐web‐20.html?page=3

Web 3.0: integración de la Web Semántica y la Web 2.034
[19] Spalding, Steve. “How To Define Web 3.0.” [En línea]. 2007. Disponible en: http://howtosplitanatom.com/news/how‐to‐define‐web‐30‐2
[20] Chandler, Jeff. “Interview With Steve Spalding.” [En línea]. 2007. Disponible en: http://www2.ub.edu/bid/consulta_articulos.php?fichero=17serra2.htm
[21] Spivack, Nova. “Web 3.0 ‐‐ The Best Official Definition Imaginable.” [En línea]. 2007. Disponible en: http://novaspivack.typepad.com/nova_spivacks_weblog/2007/10/web‐30‐‐‐‐the‐a.html
[22] O’Reilly, Tim. “Today's Web 3.0 Nonsense Blogstorm” [En línea]. 2007. Disponible en: http://radar.oreilly.com/archives/2007/10/todays‐web‐30‐nonsense‐blogsto.html
[23] Mika, Peter. “Social Networks and the SemanticWeb: Semantic Web and Beyond, Computing for Human Experience”. 2007. ISBN‐13: 978‐0‐387‐71000‐6 e‐ISBN‐13: 978‐0‐387‐71001‐3
[24] Boase, Jeffrey; Horrigan, John B.; Wellman, Barry; and Rainie, Lee. “The Strength of Internet Ties.” Technical report, Pew Internet &American Life Project, Enero 2006.
[25] Definición de BlogSphere en Wikipedia Disponible en: http://en.wikipedia.org/wiki/Blogspace
[26] Red social Friendster: http://www.friendster.com
[27] Kahney, Leander. “Making Friendsters in High Places.” Wired, Julio de 2003.
[28] Sitio para Compartir Fotos: http://www.flickr.com/
[29] Sitemas de Recomendaciones Basados en la Historia del Usuario http://digg.com/
[30] Berners‐Lee, Tim. “Semantic web and web 2.0”, conference presentation, International Semantic Web Conference. [En línea]. Noviembre del 2006. Disponible en: http://www.w3.org/2006/Talks/1108‐swui‐tbl/
[31] Sitio web que permite subir fotos y geo‐referenciarlas en Google Maps: http://www.panoramio.com/
[32] Sitio web de la Organización que impulsa los microformatos: http://www.microformats.org
[33] Heflin, Jeff and Hendler, James. “A Portrait of the Semantic Web in Action.” IEEE Intelligent Systems, 16(2):54–59, 2001
[34] Adida, Ben and Birbeck, Mark. “RDFa Primer 1.0”, Mayo de 2006.
[35] Völkel, Max ; Krötzsch, Markus; Vrandecic, Denny; Haller, Heiko and Studer, Rudi. “Semantic Wikipedia”. In Proceedings of the 15th International WorldWide Web Conference, pages 585–594, Edinburgh, United Kingdom, 2006.
[36] Auer, Sören; Dietzold, Sebastian and Riechert, Thomas. “OntoWiki A Tool for Social, Semantic Collaboration”. In Proceedings of the Fifth International SemanticWeb Conference (ISWC 2006), number 4373 in Lecture Notes in Computer Science (LNCS), pages 736–749. Springer‐Verlag, 2006.
[37] Golbeck, Jennifer and Hendler, James. “FilmTrust: Movie recommendations using trust in web‐based social networks.” In Proceedings of the IEEE Consumer Communications and Networking Conference, 2006
[38] Base de Datos social: http://www.freebase.com
[39] Hendler, J. “Web 3.0 emerging.” [En línea]. Computer, vol. 42, no. 1, pp. 111‐113, 2009. Disponible en: http://dx.doi.org/10.1109/MC.2009.30

Web 3.0: integración de la Web Semántica y la Web 2.035
[40] L. Specia and E. Motta, "Integrating folksonomies with the semantic web," 2007, pp. 624‐639. Available: http://dx.doi.org/10.1007/978‐3‐540‐72667‐8_44
[41] Fernández, Sergio; Rubiera, Emilio; Berrueta, Diego; Polo, Luis. “Integración de folksonomías y ontología.” [En línea] Morfeo‐EzWeb. 2008. Disponible en: http://forge.morfeo‐project.org/wiki/index.php/D.2.3_Integraci%C3%B3n_de_folksonom%C3%ADas_y_ontolog%C3%ADas
[42] Tanasescu, Vlad and Domingue, John. “A Semantic Google Maps Based Emergency Management Graphical User Interface”.
[43] Tanasescu, V. Toward. “User Oriented Semantic Geographical Information Systems”, 2nd AKT Doctoral Symposium, Aberdeen Univeristy, UK, 2006.
[44] Eisenstadt, M.; Komzak, J.; Dzbor, M. “Instant messaging + maps = powerful collaboration tools for distance learning.” In Proceedings of TelEduc03, Havana, Cuba, 2003.
[45] Sitio Web del Proyecto PukiWiki: http://pukiwiki.sourceforge.jp/?About%20PukiWiki
[46] Sitio Web del Proyecto PHPWiki: http://phpwiki.sourceforge.net/
[47] Sitio Web del Proyecto PeriPeri Wiki: http://c2.com/cgi/wiki?PeriPeri
[48] Sitio Web del Proyecto Gestor de Contenidos con RDF: http://www.liminalzone.org/Rhizome
[49] Sitio web de Platypus Wiki: http://platypuswiki.sourceforge.net/
[50] Kawamoto, Kensaku; Kitamura, Yasuhiko and Tijerino, Yuri. “KawaWiki: A Semantic Wiki Based on RDF Templates.” Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI‐IAT 2006 Workshops)(WI‐IATW06)
[51] Red Social que utiliza tecnología de la web semántica: http://www.twine.com/
[52] WEASEL, Vodafone R&D Corporate Semantic Web: http://www.w3.org/2001/sw/sweo/public/UseCases/Vodafone‐es/
[53] Imagen extraída de: http://blogs.nesta.org.uk/photos/uncategorized/2007/07/26/semantic_web_2.gif
[54] Sramana Mitra, “Web 3.0 = (4C + P + VS)”. [En línea]. Disponible en: http://www.sramanamitra.com/2007/02/14/web‐30‐4c‐p‐vs/
[55] Second Life: http://secondlife.com/
[56] Askwiki, un motor de búsqueda semántico: http://askwiki.com
[57] Buscador semántico de trámites en línea del Ayuntamiento de Zaragoza: http://www.zaragoza.es/tramites
[58] Boletín oficial del Principado de Asturias: http://bopa.fundacionctic.org
[59] Buscador semántico hakia: http://www.hakia.com
[60] Buscador web semántico: http://www.semanticwebsearch.com/query/
[61] Buscador web semántico swoogle: http://swoogle.umbc.edu
[62] Piggy Bank, plugin para Firefox: http://simile.mit.edu/piggy‐bank/

Web 3.0: integración de la Web Semántica y la Web 2.036
[63] Sistema de respuesta a preguntas basado en ontologías: http://technologies.kmi.open.ac.uk/poweraqua/
[64] Nepomuk, el escritorio semántico social: http://nepomuk.semanticdesktop.org/xwiki/bin/view/Main1/
[65] Extraída de: http://www.neoteo.com/Portals/0/imagenes/cache/5574x580y1000.jpg
[66] Kassof, M., Petrie, C., Zen, L. y Genesereth M. “Semantic Email AddressingThe Semantic Web Killer App?”. IEEE INTERNET COMPUTING, 2009.[En línea]. Disponible en: http://logic.stanford.edu/sharing/papers/sea‐ic.pdf
[67] Extraída de: http://www.radarnetworks.com
[68] Berners‐Lee. “Building beneficial weblike things.“ Presentación en el W3C, Marzo de 2006. [En línea]. Disponible en: http://www.w3.org/2006/Talks/0314‐ox‐tbl/
[69] Codina, L. “Internet invisible y web semántica: ¿el futuro de los sistemas de información en línea?”. Revista Tradumática, Noviembre de 2003. [EN línea]. Disponible en: http://bibliotecnica.upc.es/bustia/arxius/30094.pdf
[70] Gruber, T. “Where the Social Web Meets the Semantic Web”. ISWC 2006. [En línea] Disponible en: http://videolectures.net/iswc06_gruber_wswms/
[71] “La Web 3.0, ¿futura realidad o ficción?”. Diciembre de 2006. [En línea]. Disponible en: http://www.cincodias.com/articulo/empresas/Web‐futura‐realidad‐ficcion/20061201cdscdiemp_26/cdsemp/
[72] Lamarca, M. J. “Hacia la Web Semántica”. [En línea]. Disponible en: http://www.hipertexto.info/documentos/web_semantica.htm
[73] Gronbaek, K.; Kristensen, J.; Eriksen, M. “Physical Hypermedia:Organizing Collections of Mixed Physical and Digital Material.” Proceedings of the 14th. ACM International Conference of Hypertext and Hypermedia (Hypertext 2003).
[74] T., Gagach, J. “Integrating the Web and the World: Contextual Trails on the Move.” Proceedings of the 15th. ACM Internacional Conference of Hypertext and Hypermedia (Hypertext 2004), ACM Press. 2004.
[75] Harper, S., Goble, C., Pettitt, S. “ProXimity: Walking the Link. In Journal of Digital Information”, Volume 5, Issue 1, Article No 236, 2004‐04‐07. [En línea] Disponible en: http//jodi.ecs.soton.ac.uk/Articles/v05/i01/Harper/
[76] G. Rossi, S. Gordillo, C. Challiol, A. Fortier. “Context‐Aware Services for Physical Hypermedia Applications.” In Proceedings of the 2006 Workshop on Context‐Aware Mobile Systems (CAMS'06), Springer Verlag, LNCS, forthcoming.