vturbo: accelerating virtual machine i/o processing using designated turbo-sliced core embedded lab....
TRANSCRIPT

vTurbo: Accelerating Virtual Machine I/O Processing Using Designated Turbo-Sliced
Core
Embedded Lab.Kim Sewoog
Cong Xu, Sahan Gamage, Hui Lu, Ramana Kompella, Dongyan Xu2013 USENIX Annual Technical Conference

Pay-as-you-go: Server Consolidation Save cost in running application and operational expenditure
Multiple VMs sharing the same core CPU access latency
Motivation
VM1 VM2 VM3 VM4
Hypervisor(or VMM)
Low I/OThroughput

Two basic stages Device interrupts are processed synchronously in the kernel Application asynchronously copies the data in kernel buffer
I/O Processing
VM1 VM2 VM3
CPU
Time
< Effect of CPU Sharing on I/O Processing >
IRQ Pro-cessing
Kernel Buf-fer
Application
IRQ processing delay
< I/O Processing Workflow >

Effect of CPU Sharing on TCP Receive
TCP Client
Hypervisor Shared Buffer
ScheduledVMs
DATA
DATA
VM1
VM2
VM3
DATA
ACK
ACK
ACK
IRQProcessing
Delay
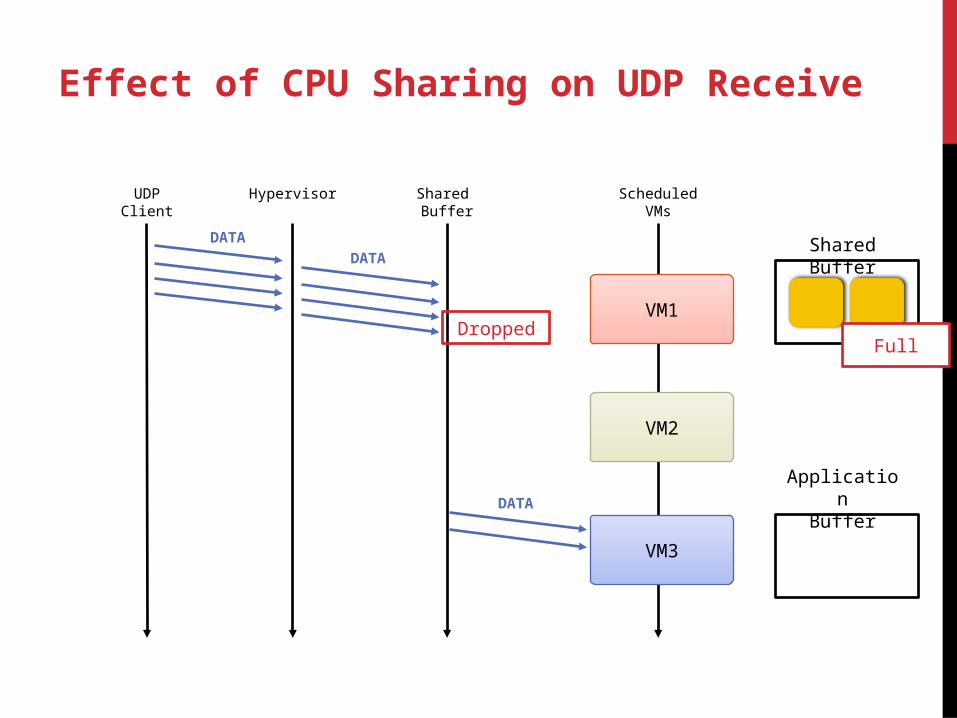
Effect of CPU Sharing on UDP Receive
UDPClient
Hypervisor Shared Buffer
ScheduledVMs
VM1
VM2
VM3
DATA
DATAShared Buffer
FullDropped
ApplicationBufferDATA
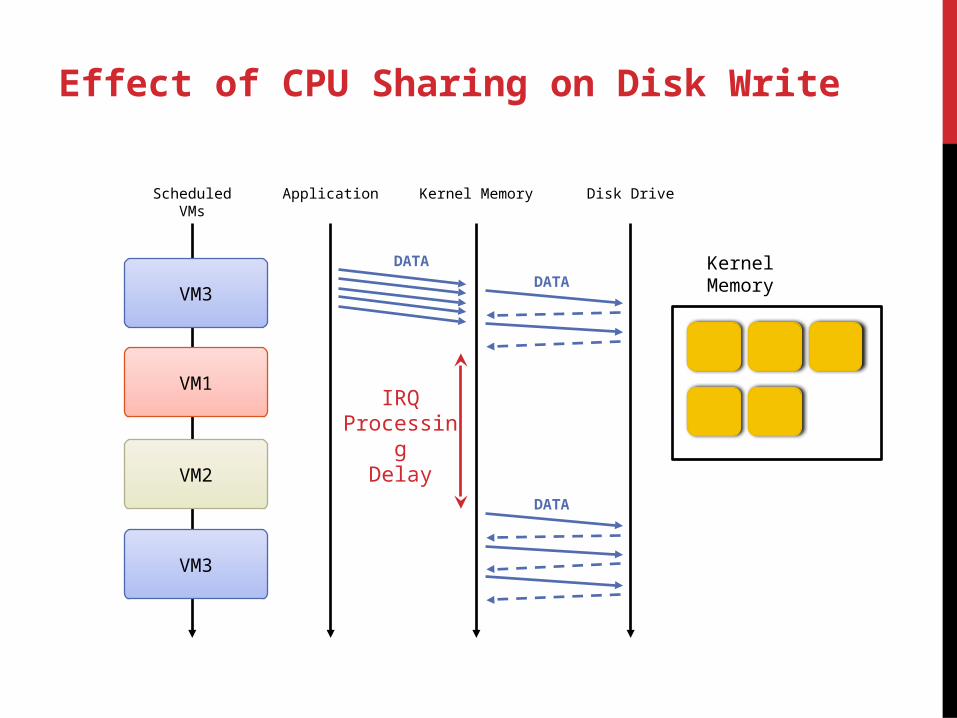
Effect of CPU Sharing on Disk Write
Application Kernel Memory Disk DriveScheduledVMs
VM1
VM2
VM3
DATA Kernel Mem-oryVM3
DATA
DATA
IRQProcessing
Delay

Reduce time-slice of each VM Causes significant context switch overhead
Intuitive Solution

Our Solution: vTurbo

IRQ processing offloaded to a dedicated turbo core Turbo core : Any physical core with micro-slicing (e.g., 0.1 ms)
Expose turbo core as a special vCPU to the VM Turbo vCPU runs on a turbo core Regular vCPUs run on regular cores
Pin IRQ context of guest OS to turbo vCPU
Benefits Improved I/O throughput (TCP/UDP, Disk) Self-adaptive system
Our Solution: vTurbo

vTurbo Design

vTurbo Design
VM1 VM2 VM3
Regular Core
VM3VM1 VM2 VM3VM1 VM2
Turbo Core
IRQIRQ
BufBuf
Application
TimeData Data

vTurbot’s Impact on Disk Write
Application Kernel Memory vTurboRegularCore
VM1
VM2
Kernel MemoryVM3
Disk Drive
DATA
VM1VM2
VM3
VM1VM2
VM3
VM1VM2
VM3
VM1VM2
VM3
VM1VM2
VM3
Kernel Buffer
Application Buffer
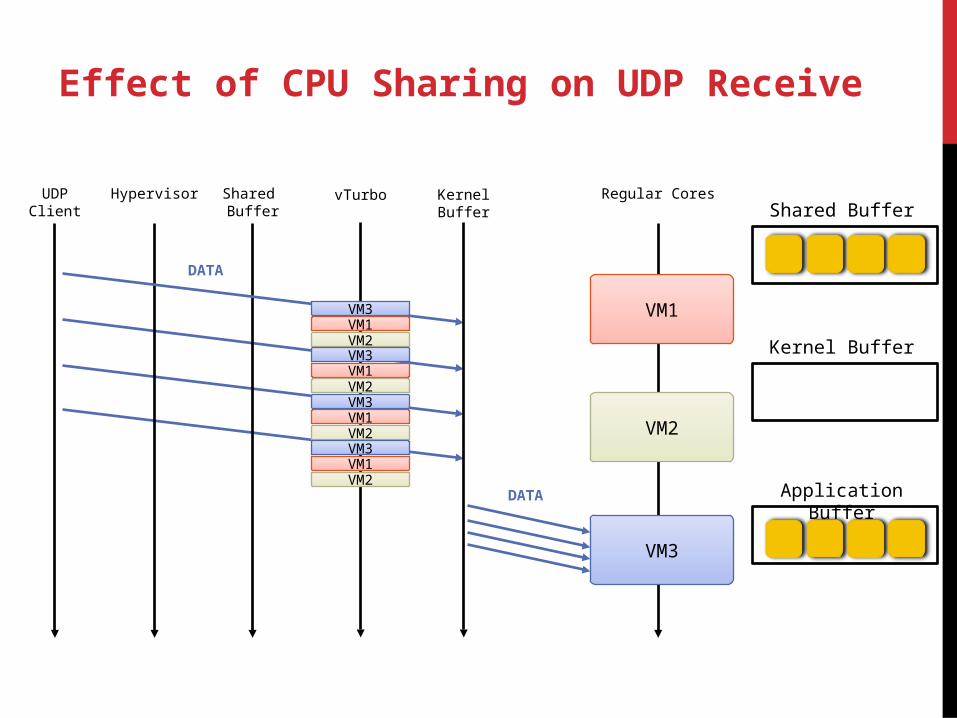
Effect of CPU Sharing on UDP Receive
UDPClient
Hypervisor Shared Buffer
Regular Cores
VM1
VM2
VM3
DATA
Shared BuffervTurbo
VM1VM2
VM3
VM1VM2
VM3
VM1VM2
VM3
VM1VM2
VM3
KernelBuffer
DATA

DATA
ACK
Effect of CPU Sharing on TCP Receive
TCP Client
Hypervisor Shared Buffer
Regular Cores
VM1
VM2
VM3
vTurbo
VM1VM2
VM3
VM1VM2
VM3
VM1VM2
VM3
VM1VM2
VM3
KernelBuffer
Backlog Queue
Receive Queue
Application Buffer
Locked
DATA

Turbo cores are not free
Maintain CPU fair-share among VMs Calculate the credits on both regular and turbo cores Guarantee the CPU allocation on turbo cores Deduct I/O intensive VMs’ credits on regular cores Allocate the deduction to non-IO intensive VMs
VM Scheduling Policy for Fairness
< total capacity among the regular and turbo cores >
< total capacity >
< each VM’s fair share of CPU >
< each VMs’ turbo core fair share >
< actual usage of the turbo core >

VM hosts 3.2 GHz Intel Xeon Quad-cores CPU, 16GB RAM Assign an independent core to driver domain(dom0) Xen 4.1.2 Linux 3.2 Choose 1 core as Turbo core
Gigabit Ethernet switch(10Gbps for 2 experiments)
Evaluation

File Read/Write Throughput: Micro-Benchmark
regular core <-> turbo core

TCP/UDP Throughput : Micro-Bench-mark

NFS/SCP Throughput : Application Benchmark

Apache Olio : Application Benchmark
3 components a web server to process user requests a MySQL database server to store user profiles and event information an NFS server to store images and documents specific to events

Conclusions
Problem : CPU sharing affects I/O throughput
Solution : vTurbo Offload IRQ processing to a turbo-sliced dedicated core
Results : Improve UDP throughput up to 4x Improve TCP throughput up to 3x Improve Disk write up to 2x Improve NFS’ throughput up to 3x Improve Olio’s throughput by up to 38.7%

Reference
CHENG, L., AND WANG, C.-L. “vbalance: Using interrupt load balance to improve i/o performance for smp virtual machine”, In ACM SoCC (2012)
DONG, Y., YU, Z., AND ROSE, G. “SR-IOV networking in Xen: archi-tecture, design and implementation”, In WIOV (2008).
GORDON, A., AMIT, N., HAR’EL, N., BEN-YEHUDA, M., LANDAU, A., SCHUSTER, A., AND TSAFRIR, D. “ELI: baremetal performance for I/O virtualization”, In ACM ASPLOS(2012).

THANK YOU !