validación de modelos - isa.cie.uva.esprada/validacion.pdf · de procesos obtenidas a partir de un...
TRANSCRIPT


Indice
Modelado Estimación de parámetros Validación de modelos

Modelos Representación aproximada de la realidad Abstracción: Incluimos solo aquellos aspectos y
relaciones que son de interés. Usos de los modelos: diseño, entrenamiento, que
pasa si…., decisiones,... Distintos modelos de un proceso para distintas
aplicaciones ¿Como generarlos, resolverlos, utilizarlos, validarlos?
Depende del proceso, de la aplicación, de las herramientas y datos disponibles,…

¿Qué es un modelo matemático?
Conjunto de ecuaciones que relacionan las variables de interés del proceso y representan adecuadamente su comportamiento
Distintas formulaciones para distintos objetivos y tipos de procesos
Obtenidas a partir de un conjunto de hipótesis y suposiciones
Compromiso entre facilidad de uso en una aplicación y la exactitud de la representación del mundo real

Representación adecuada
Proceso
u
tiempo
y
tiempo
Modelo
ym
tiempo + adecuación y facilidad de uso en la aplicación

¿Como obtener modelos?
Mediante razonamientos, usando leyes físicas, químicas, etc
Mediante experimentación y análisis de datos

Modelos de conocimiento
Se obtienen mediante razonamientos y la aplicación de principios de conservación de masa, energía, momento, etc. y otras leyes particulares del dominio de aplicación
Basados en un conjunto de hipótesis Tienen validez general si se cumplen las
hipótesis de partida Requieren conocimiento profundo del proceso
y de las leyes fisico-químicas

Identificación
El modelo se obtiene a partir de datos experimentales de entrada-salida del proceso
t t
Y U U
Y
Proceso
Modelo

Modelos
+
Un modelo siempre es una mezcla de conocimiento y de experimentación
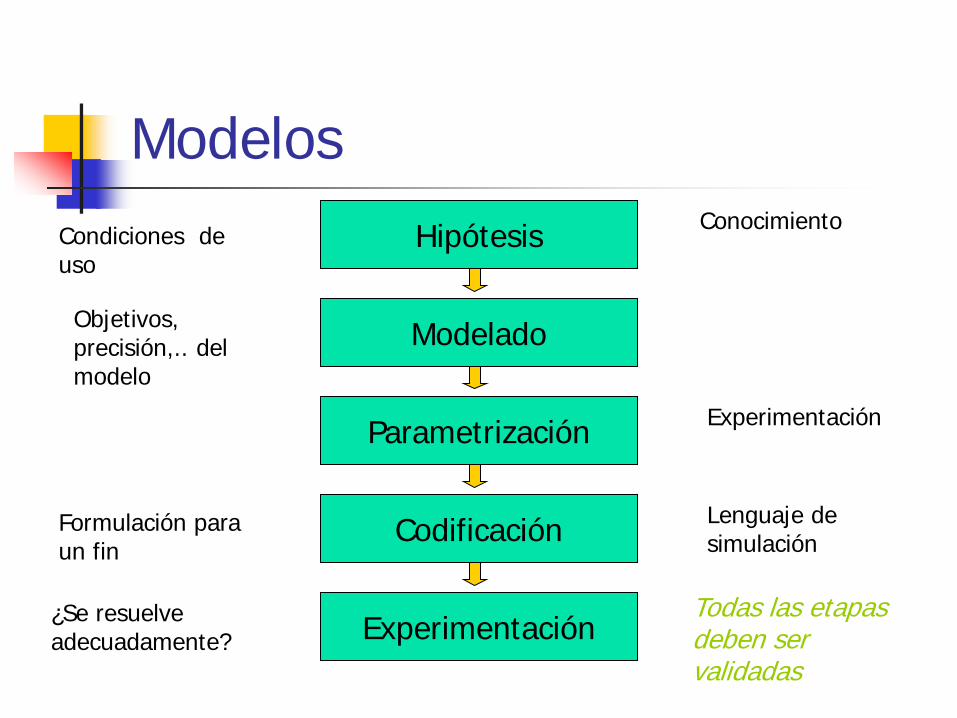
Modelos Hipótesis
Modelado
Parametrización
Codificación
Experimentación
Lenguaje de simulación
Conocimiento
Experimentación
Formulación para un fin
¿Se resuelve adecuadamente?
Condiciones de uso
Objetivos, precisión,.. del modelo
Todas las etapas deben ser validadas

Hipótesis
q
h
F
q
h
F
ci
c
Fcqctd
Vcdi −=
Mezcla perfecta Flujo pistón
)FVt(c)
AvAht(c)
vht(c)t(c iii −=−=−=

Ejemplo: Depósito Conservación de masa Acumulación= flujo entrada q - flujo salida F
m masa en el depósito A sección del depósito ρ densidad, k constante
q
h
F
Ecuación diferencial no-lineal
AhV hkqtdhdA
hkF hAm
Fqtdmd
=−=
=ρ=
ρ−ρ=
Ecuación algebraica
Parámetros

Modelos en variables de estado
)t),t(u,x(g)t(y
)t,p),t(u),t(x(fdt
)t(xd
=
=
Variables manipuladas y perturbaciones
Respuestas observables
u y x
x Estados
p parámetros

Modelado
)t),t(u,x(g)t(y
)t,p),t(u),t(x(fdt
)t(xd
=
=Determinación de la estructura del modelo
Determinación del valor de sus parámetros
Normalmente siempre aparecen alternativas en la formulación del modelo y es necesario escoger entre distintas estructuras
En la etapa de validación pueden aplicarse distintos test para elegir que elección fue mas adecuada

Parametrización
Los parámetros p del modelo pueden obtenerse mediante bibliografía, documentación, etc. pero siempre hay parámetros cuyo valor no se puede determinar de forma sencilla y precisa y que deben ser estimados
)t),t(u,x(g)t(y
)t,p),t(u),t(x(fdt
)t(xd
=
=

Ejemplo: reactor químico
Vd cd t
Fc Fc Vke cAAi A
ERT
A= − − −
Vd cd t
Fc Vke cBB
ERT
A= − + −
V cd Td t
F c T F c T UA T Tr r err
r r e ri r r er r rrρ ρ ρ= − + −( )
V cd Td t
F c T F c T Vke c H UA T Te e i e
ERT
A rρ ρ ρ= − + − −− ∆ ( )
Reactor
TT
AT
Refrigerante
Producto
A A→B

Parametrización (calibración)
Reactor
TT
AT
Refrigerante
Producto
A
t
u
y pa
Modelo u y
p
La respuesta del modelo ante las mismas entradas depende del valor de los parámetros
pb
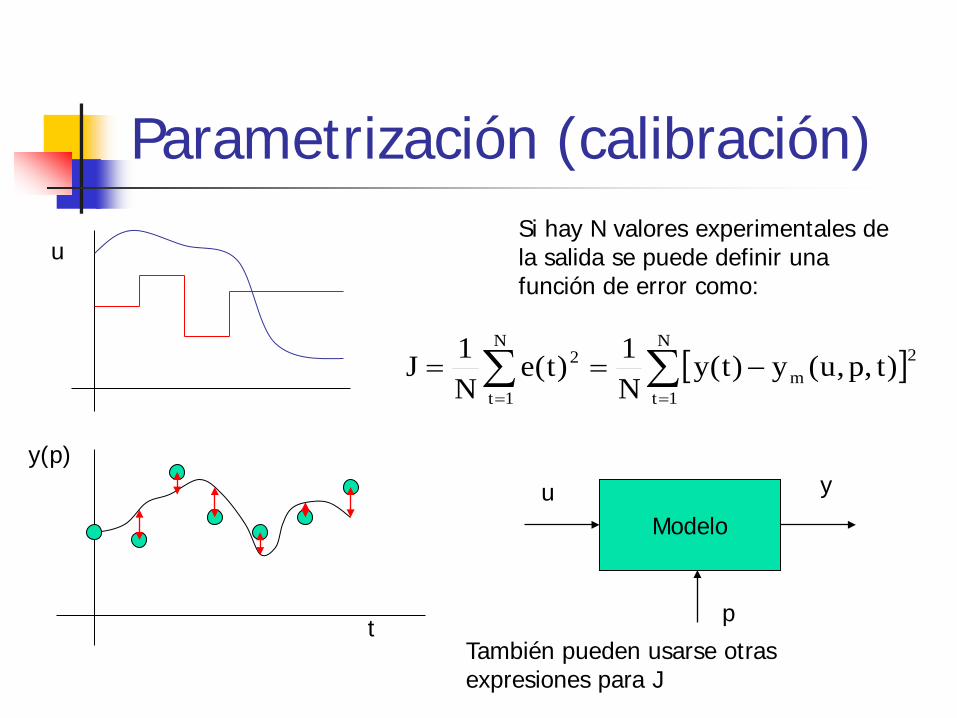
Parametrización (calibración)
t
u
y(p)
Modelo u y
p
Si hay N valores experimentales de la salida se puede definir una función de error como:
[ ]∑∑==
−==N
1t
2m
N
1t
2 )t,p,u(y)t(yN1)t(e
N1J
También pueden usarse otras expresiones para J
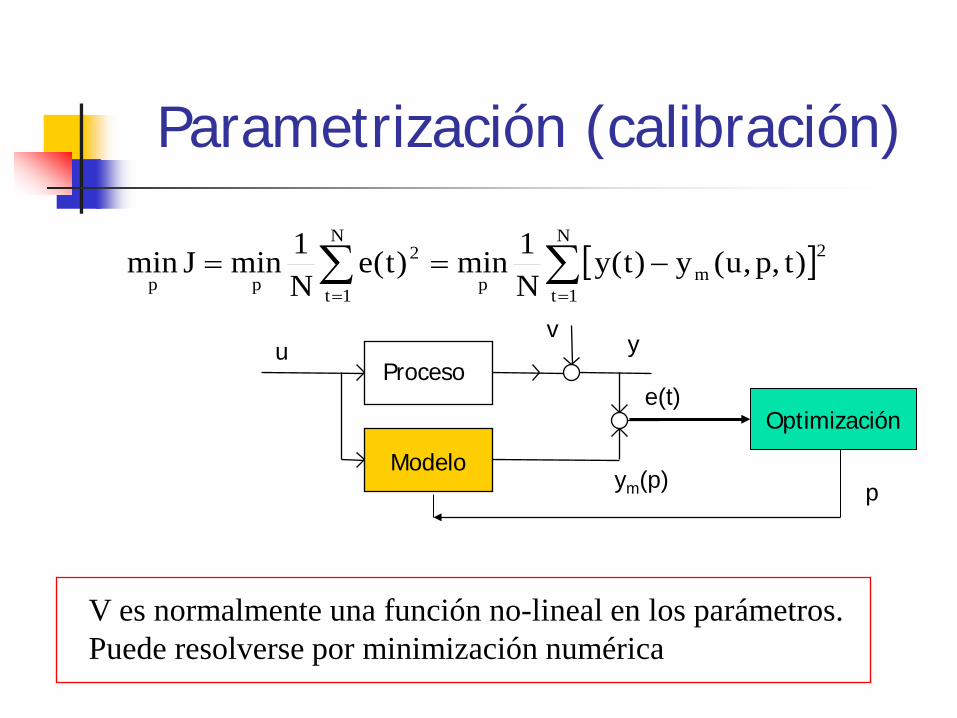
Parametrización (calibración)
[ ]∑∑==
−==N
1t
2mp
N
1t
2
pp)t,p,u(y)t(y
N1min)t(e
N1minJmin
V es normalmente una función no-lineal en los parámetros. Puede resolverse por minimización numérica
Optimización
u v
ym(p)
y
e(t)
p Modelo
Proceso

Parametrización por optimización
[ ]
pppu(t))g(x(t),(t)y ))t(u),t(x(f)t(x
)t,u,p(y)t(yminJmin
m
N
1t
2mpp
≤≤==
−= ∑=
Problema de optimización dinámica con restricciones
Entre los parámetros a estimar pueden incluirse también, junto a los parámetros del modelo, estados iniciales desconocidos o entradas no medidas (constantes o parametrizables)
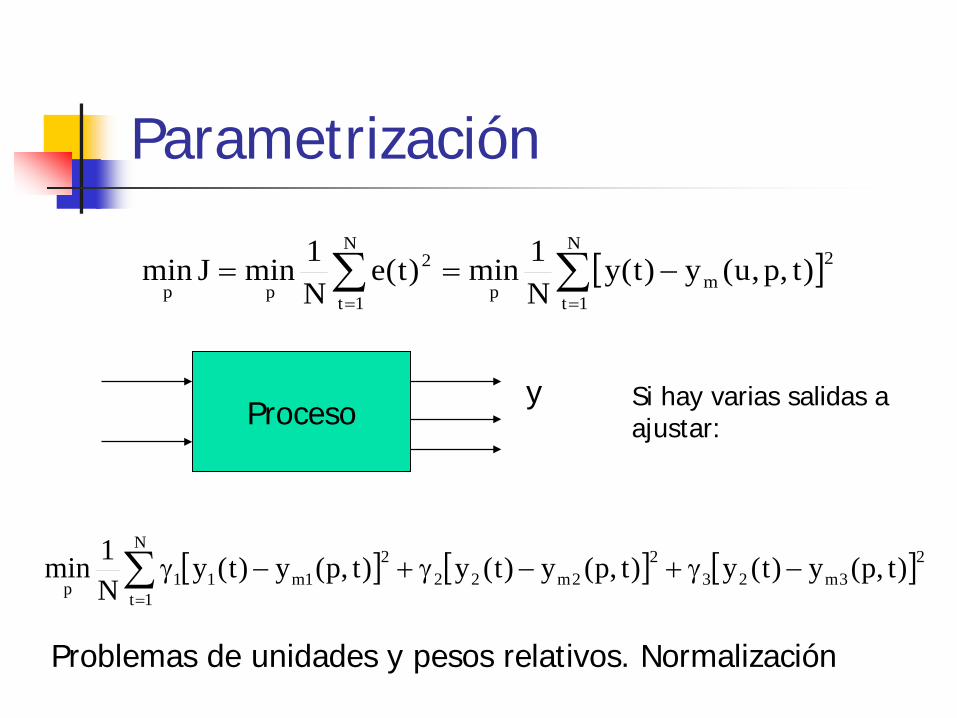
Parametrización
[ ]∑∑==
−==N
1t
2mp
N
1t
2
pp)t,p,u(y)t(y
N1min)t(e
N1minJmin
Proceso y
[ ] [ ] [ ]∑=
−γ+−γ+−γN
1t
23m23
22m22
21m11p
)t,p(y)t(y)t,p(y)t(y)t,p(y)t(yN1min
Problemas de unidades y pesos relativos. Normalización
Si hay varias salidas a ajustar:

Qué parámetros estimar
u
y p1
Es posible que, para un mismo experimento, la respuesta del modelo con dos valores diferentes p1 y p2 de un parámetro, sea muy o poco diferente
Solo debería escogerse un parámetro p para la optimización si la salida presenta una sensibilidad razonable ante cambios en p
p2

Sensibilidad de las salidas Sensibilidad del índice J
[ ]
u(t))g(x(t),(t)y ))t(u),t(x(f)t(x
)t,u,p(y)t(yJ
m
N
1t
2m
==
−= ∑=
j
miij p
)t(y)t(S∂
∂=
jpJ
∂∂
Sensibilidad de la salida i del modelo respecto al parámetro j en relación a un experimento dado. Es función del tiempo
Sensibilidad del índice J respecto al parámetro j en relación a un experimento dado.
Resume el efecto durante todo el tiempo del experimento

Sensibilidades
j
iij p
)t(y)t(S∂
∂= Dificultad para comparar
sensibilidades debido a la diferencia de unidades de cada Sij. Deben usarse factores de escala
j
i
i
jij p
)t(yyp
)t(s∂
∂=
md2m1m
d22221
d11211
sss
ssssss
La norma de cada columna j de la matriz de sensibilidades da una idea de la importancia del parámetro pj en el valor de las salidas

Cálculo de las sensibilidades
[ ]
u(t))g(x(t),(t)y ))t(u),t(x(f)t(x
)t,u,p(y)t(yJ
m
N
1t
2m
==
−= ∑=
[ ]
pg
px
xg
py
pf
px
xf
px
dtd
px
py)t,u,p(y)t(y2
pJ
m
mN
1tm
∂∂
+∂∂
∂∂
=∂
∂∂∂
+∂∂
∂∂
=∂∂
=∂∂
∂∂
−=∂∂ ∑
=
Pueden obtenerse mediante cocientes de incrementos o analíticamente
Integrando esta ecuación junto a las del modelo, es posible obtener la evolución de ∂x/∂p y por tanto las sensibilidades

Cálculo de las sensibilidades
Mediante cociente de incrementos, realizando simulaciones del modelo
p)t,p(y)t,pp(y
p)t(y)t(S ii
j
iij ∆
−∆+≈
∂∂
=
Las sensibilidades dependen, lógicamente, del punto p en que son evaluadas, y del experimento (a través de las entradas) que se considera

Identificabilidad
Independientemente del valor de la sensibilidad, puede ocurrir que el efecto sobre la salida de un cambio en un parámetro se anule por un cambio en otro parámetro hecho simultáneamente. Se dice entonces que hay un grado de co-linealidad en las sensibilidades frente a los parámetros, lo que dificulta la identificación
La identificabilidad es una propiedad estructural que depende de cómo los parámetros aparecen en el modelo, pero también de las medidas disponibles

Identificabilidad
Vd cd t
Fc Vke cBB
ERT
A= − + −Si E y R fueran desconocidas, con medida de temperatura se podría identificar el cociente E/R pero no los términos individuales
Ejemplo: En un reactor, sin medida de temperatura, los parámetros k y E, no pueden ser estimados independientemente
sKsm
+µ En el modelo de Monod, con datos limitados a
sustratos s pequeños, no es posible identificar sino el cociente µm/K

Identificabilidad Examinando la matriz de sensibilidades, puede verse si hay un cierto grado de co-linealidad a través del rango de (sub-bloques) de la misma
t
sij
sik
La co-linealidad dificulta la identificación
md2m1m
d22221
d11211
sss
ssssss

Re-parametrización
A veces solo es posible identificar combinaciones de parámetros, o se pueden hacer cambios de variables para obtener una estructura mas sencilla de identificar.
Si se ha hecho una transformación de los parámetros a estimar, o se han hecho cambios de variable para facilitar la identificabilidad o linealidad del modelo, debe tenerse en cuenta que:
Las características estadísticas de las nuevas variables son diferentes a las de los datos
Las regiones de confianza de los nuevos parámetros son diferentes de las de los originales
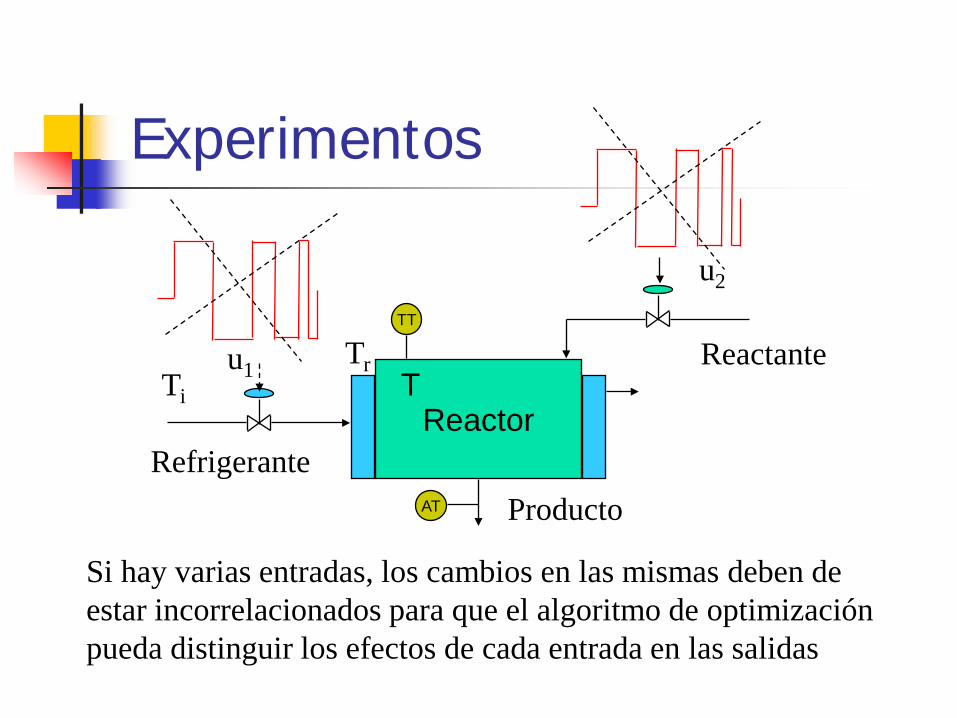
Experimentos
Reactor
TT
T
Refrigerante Producto
u1 Ti Reactante Tr
u2
AT
Si hay varias entradas, los cambios en las mismas deben de estar incorrelacionados para que el algoritmo de optimización pueda distinguir los efectos de cada entrada en las salidas

Experimentos
)t(u)MM()t(uM)t(uM)t(y 2212211 +α=+=
Si se aplican señales proporcionales a las entradas, u1=αu2, simultaneamente, hay muchas combinaciones de los modelos M1 y M2 que se ajustan a las mismas parejas de entradas y salidas
Por otro lado, los experimentos deben cubrir el rango en amplitud y frecuencia adecuado para excitar las dinámicas fundamentales del proceso, y los valores de las sensibilidades de J antes los parámetros a estimar deben presentar unos valores razonables.
En caso contrario debe repetirse el experimento
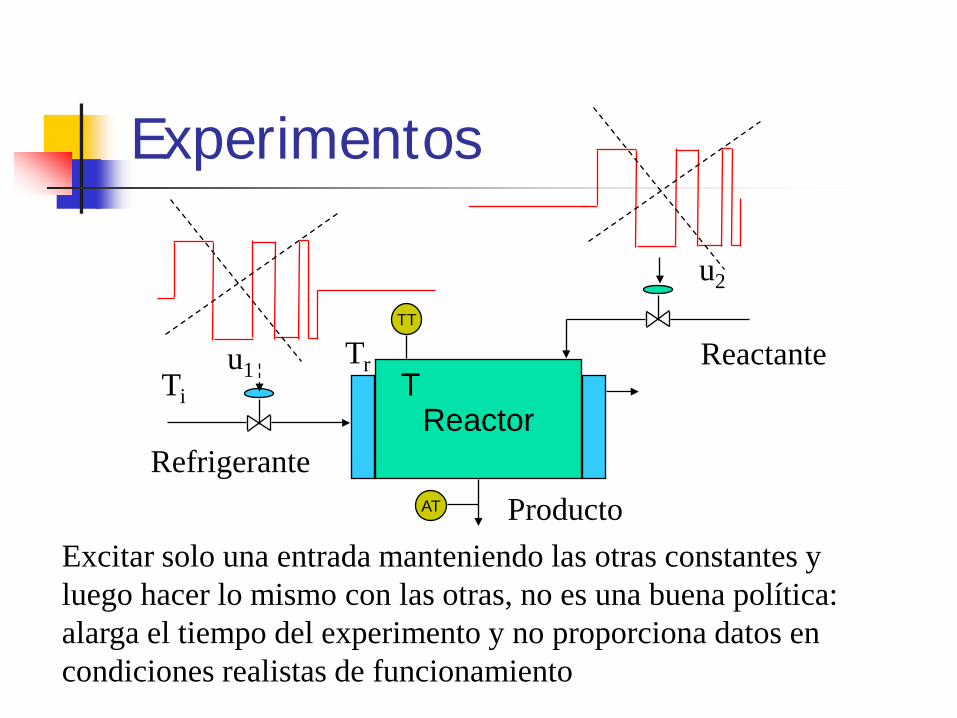
Experimentos
Reactor
TT
T
Refrigerante Producto
u1 Ti Reactante Tr
u2
AT
Excitar solo una entrada manteniendo las otras constantes y luego hacer lo mismo con las otras, no es una buena política: alarga el tiempo del experimento y no proporciona datos en condiciones realistas de funcionamiento

Diseño de experimentos
Cabe preguntarse cual es el experimento que mejor facilita la estimación de los parámetros de un modelo
[ ] [ ])t,u,p(y)t(yQ')t,u,p(y)t(yJ m
N
1tm −−= ∑
=
{ } ∑∑==
+δ
∂
∂
∂
∂δ≈δ+
N
1t
N
1t
m'
m* )CQ(trpp
)t(yQp
)t(y'p )pJ(pE
Contexto Multivariable
Si se hace un desarrollo de 2º orden de J en torno al valor óptimo p* de los parámetros (para cuyo valor ∂J/∂p=0)
Con C la matriz de covarianza del ruido de las medidas. Se suele escoger Q=C-1

Diseño de experimentos
Para facilitar la estimación, interesa que J(p*+δp) sea lo mayor posible, de modo que unos parámetros distintos del óptimo den un valor de J significativamente mayor
Para ello puede diseñarse un experimento que maximice la matriz de Información de Fisher (o alguna norma o función asociada):
∂
∂
∂
∂∑=
N
1t
m'
m
p)t(yQ
p)t(y
{ } ∑∑==
+δ
∂
∂
∂
∂δ≈δ+
N
1t
N
1t
m'
m* )CQ(trpp
)t(yQp
)t(y'p )pJ(pE

FIM
Si no hay dependencia lineal entre las sensibilidades, la matriz de información de Fisher debe ser de rango completo.
El cociente entre el máximo y mínimo valor propio de la FIM de por tanto una medida de la identificabilidad de los parámetros de un modelo con un experimento dado.
∂
∂
∂
∂∑=
N
1t
m'
m
p)t(yQ
p)t(y

Parametrización por optimización
[ ]
pppu(t))g(x(t),(t)y ))t(u),t(x(f)t(x
)t,u,p(y)t(yJmin
m
N
1t
2m
p
≤≤==
−= ∑=
Elección del tipo de índice J
Problemas de resolución numérica
•Simulación
•Resolución directa
Problemas de estimación de estados

Otras funciones objetivo J
Maximum Likelihood (ML) Para un valor de los parámetros p, ¿cual es la probabilidad de que los resultados del modelo coincidan con los datos experimentales? Se plantea la estimación como encontrar p de modo que se maximice esa probabilidad
)p|)N(y)N(y),....,1(y)1(y),0(y)0(y(Pmax mmmp===
Se suele formular como
))p|)N(y)N(y),....,1(y)1(y),0(y)0(y(Pln(min mmmp===−

Mínimos cuadrados ponderados (WLS)
Si los datos experimentales están distribuidos de forma normal en torno a las predicciones del modelo y son independientes, la probabilidad de obtener como salida del modelo los datos experimentales es:
σ
−−
σπ=
===
∑∏==
N
1t
2m
N
1t
mm
)t()p,y(y)t(y
21exp
)t(21
)p|)N(y)N(y),...,1(y)1(y(L
Tomando neperianos, maximizar esta función equivale a
( )∑=
−σ
N
1t
2m2p
)p,t(y)t(y)t(
1min σ2 varianza del error de medida

WLS
( )∑=
−σ
=N
1t
2m2p
)p,t(y)t(y)t(
1min)p(J
Si los errores son independientes y están de verdad distribuidos normalmente, J(p) debe seguir una distribución χ2 con N-d grados de libertad
Puede usarse como un test de las hipótesis anteriores o de la bondad del modelo

Otras funciones objetivo
∑=
−N
1tmp
)p,t(y)t(ymin Norma 1 Pesa por igual todos los errores
)p,t(y)t(ymaxmin mtp− Norma ∞
minimiza el mayor de los errores

Resolución con simulación
Simulación desde 1 a N para calcular J(p)
Optimizador
p J
u(t), y(t)
[ ]
pppu(t))g(x(t),(t)y ))t(u),t(x(f)t(x
)t,u,p(y)t(yJmin
m
N
1t
2m
p
≤≤==
−= ∑=

Minimización de funciones
J(θ)
θ2
θ1
θ2
θk+1= θk+αdk θ1
Métodos iterativos
d dirección de búsqueda α longitud del paso
dk
Restricciones en p

Resolución por Discretización
[ ]
ppp.....
1)))))u(t2),g(x(t2)y(t ))2t(u),2t(x(f)3t(x1))u(t1),g(x(t1)y(t ))1t(u),1t(x(f)2t(x
u(t)g(x(t),y(t) ))t(u),t(x(f)1t(x
)t,u,p(y)t(yx,p
JminN
1j
2m
≤≤
++=+++=+++=+++=+
==+
−= ∑=
Se incrementa el número de variables de decisión con los estados
Es posible imponer restricciones sobre el estado
Resolución con SQP / IP
La discretización puede ser difícil

Optimización local / global
Muchos métodos de optimización conducen a soluciones locales que no proporcionan los mejores valores de los parámetros
Conviene utilizar métodos globales:
Estocasticos (algoritmos genéticos, etc.)
Deterministas (α-BB)

Varianza de las estimas
Una vez que se ha aplicado un procedimiento de optimización y se han obtenido unos parámetros óptimos p* , es importante determinar el grado de confianza en los mismos.
Matriz de covarianza
Regiones de confianza de los parámetros
Isodistancias
En el caso de estimación no lineal muchas de las medidas de la imprecisión son aproximadas

Covarianza del error
∂
∂
∂
∂= ∑
=
N
1t
m'
m
p)t(yQ
p)t(yF
La matriz de información de Fisher es la inversa de la matriz de covarianza del error de estimación de los parámetros, calculados con el mejor estimador lineal no sesgado.
Esta medida supone que los errores son solo de medida. Una expresión de la matriz de covarianza de los errores de estimación (para el caso de una sola salida en el ajuste) mas ajustada viene dada por:
1*
FdN)p(JV −
−=

Regiones de confianza
{ } ∑∑==
+δ
∂
∂
∂
∂δ≈δ+
N
1t
N
1t
m'
m* )CQ(trpp
)t(yQp
)t(y'p )pJ(pE
Conocida la matriz de Fisher, la expresión:
Permite el cálculo aproximado de regiones de confianza de los parámetros estimados que pueden dibujarse como “elipses” cuyos ejes coinciden on los vectores propios de la FIM

Intervalos de confianza
Estimada V, es posible determinar intervalos de confianza para cada parámetro, para un determinado nivel de confianza:
ii
ii
V035.3p
V147.2p
±
± 90%
99%
Aunque en un entorno multiparamétrico deben tomarse con cierta reserva, pues la región de confianza conjunta no equivale a la caja resultante de la individual de cada parámetro
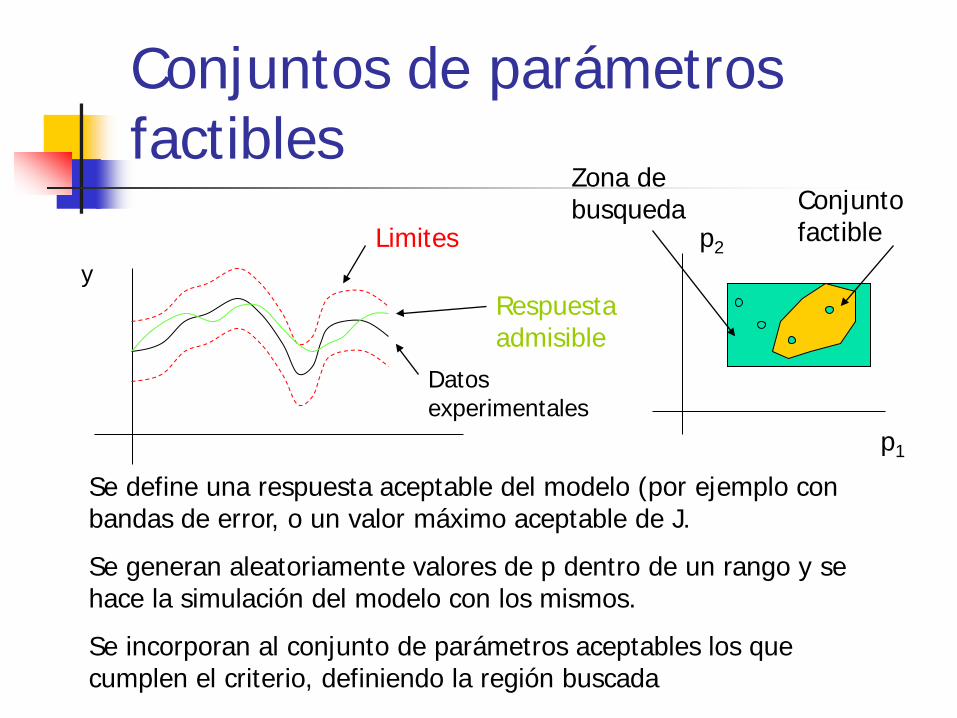
Conjuntos de parámetros factibles
y
Datos experimentales
Limites
Respuesta admisible
p2
p1
Se define una respuesta aceptable del modelo (por ejemplo con bandas de error, o un valor máximo aceptable de J.
Se generan aleatoriamente valores de p dentro de un rango y se hace la simulación del modelo con los mismos.
Se incorporan al conjunto de parámetros aceptables los que cumplen el criterio, definiendo la región buscada
Conjunto factible
Zona de busqueda

Identificación Global
[ ]∑∑==
θ−==N
1t
2m
N
1t
2 ),t(y)t(y(N1)t(e
N1J
Criterio de minimización del error :Dado un conjunto de datos experimentales u(t), y(t), buscar los parámetros θ que minimizan la función de coste J :
Procesou
v
Modeloy
y
m
e(t)
m

Identificación global
[ ]∑=
θ−=N
1t
2)t(u)(M)t(y(N1J
θ1
θ2 Isodistancia: Lugar geométrico de los puntos del espacio paramétrico con igual valor de J
Todos los modelos sobre una isodistancia tienen la misma validez respecto al criterio de suma de cuadrados de errores
.cteJ)(f ==θ
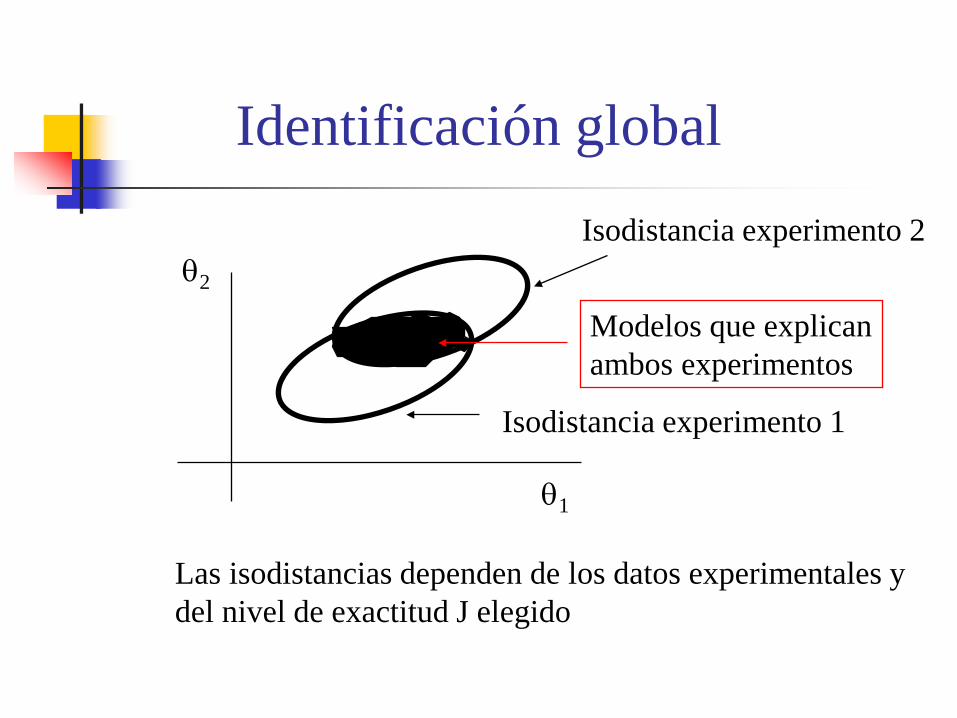
Identificación global
θ1
θ2
Isodistancia experimento 2
Isodistancia experimento 1
Modelos que explican ambos experimentos
Las isodistancias dependen de los datos experimentales y del nivel de exactitud J elegido

Isodistancias
θ1
θ2
Informan sobre la calidad de los parámetros, y el rediseño de experimentos
θ1
θ2
Exp 1
Exp 2
Nivel de calidad no compatible con los experimentos

Cálculo de Isodistancias Κ
∑=
−
−
+
−=N
1t
2
1
1
)t(uaq1
Kq)t(y(N1J
a
x
x Para cada valor de a se resuelve una ecuación de segundo grado para obtener el correspondiente valor de K
Ejemplo con un modelo sencillo de primer orden
Regiones de confianza
En un caso mas general, la construcción de isodistancias es compleja. Una forma de construir las curvas de un criterio dado, p.e. con un nivel de confianza del 100(1-α) %, o sea, los puntos para los que
)FdN
d1)(p(JJ dN,d,*
−α−+=
es establecer una región amplia y partiendo de puntos del contorno, optimizar hasta que J alcanza ese valor
F: distribución F con d y N-d grados de libertad y nivel α

Parametrización / Metodología Toma de datos experimentales (separar los de
calibración y validación) Análisis y depuración de los datos Selección de los parámetros a estimar
Identificabilidad estructural Cálculo de Sensibilidades
Posible reparametrización del modelo para linealizar la estimación
Estimas iniciales y rangos Elegir la función de costo Estimar los parámetros por optimización Estimar los residuos y la región de confianza de los
parámetros

Ejemplo en EcosimPro: Reactor de Van der Vusse
DA2CBA
→→→
Reactor altamente no lineal y difícil de controlar
Parámetros a estimar:
Volumen 10 l
Masa de refrigerante 5 Kg

Resolución con simulación
Simulación desde 1 a N para calcular J(p)
Optimizador
p J
u(t), y(t)
[ ]
pppu(t))g(x(t),(t)y ))t(u),t(x(f)t(x
)t,u,p(y)t(yJmin
m
N
1j
2m
p
≤≤==
−= ∑=
Proceso simulado resultado
p*
Reactor Van der Vusse

Validación
Validar un modelo es obtener un grado de confianza en el mismo para el fin al que se destina
No hay una “demostración” de la validez de un modelo, sino unos resultados positivos en un conjunto de test que nos dan esa confianza
La validez de un modelo puede perderse por un solo test negativo

Validación El conjunto de test positivos y negativos
permiten establecer el rango de validez del modelo
Distintas situaciones implican distintas técnicas: El proceso existe y se trata de construir un modelo
que reproduzca la realidad El proceso no existe aún y se trata de construir un
modelo para predecir su comportamiento y optimizarlo cara al diseño

Validación
Conjunto de pruebas de diferente naturaleza que ayudan a validar el modelo
La validación ha de hacerse a todos los niveles de construcción del modelo: Hipótesis Formulación Codificación Resolución numérica (verificación) Aplicación
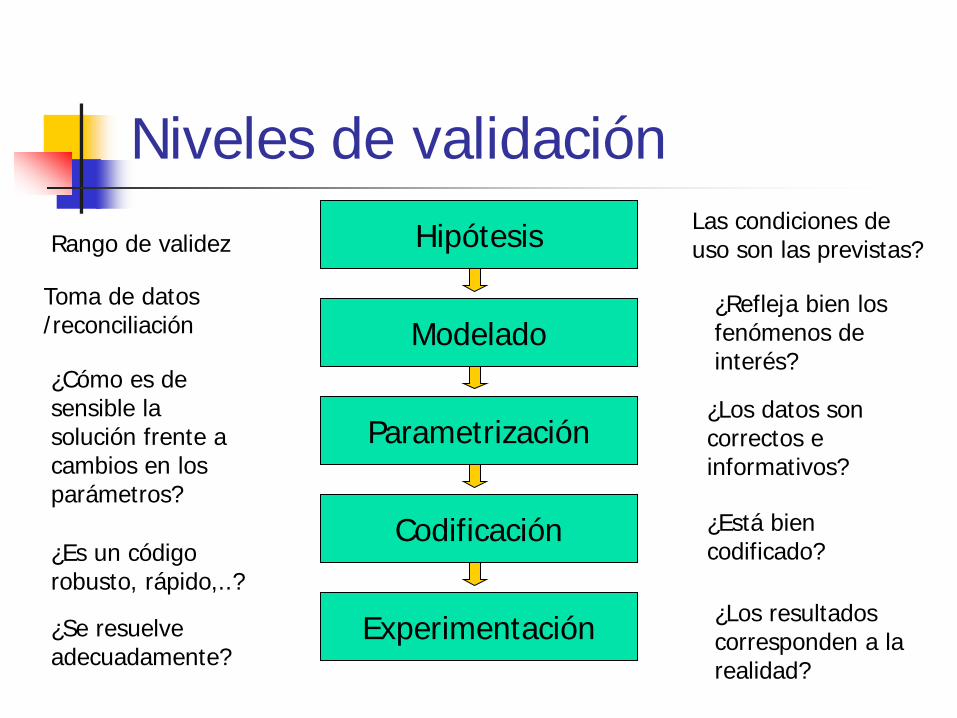
Niveles de validación Hipótesis
Modelado
Parametrización
Codificación
Experimentación
¿Está bien codificado?
Las condiciones de uso son las previstas?
¿Los datos son correctos e informativos?
¿Es un código robusto, rápido,..?
¿Se resuelve adecuadamente?
¿Los resultados corresponden a la realidad?
¿Refleja bien los fenómenos de interés?
Toma de datos /reconciliación
¿Cómo es de sensible la solución frente a cambios en los parámetros?
Rango de validez

Distintos problemas asociados a un modelo
¿Que se supone conocido para estimar el resto? Reconciliación de datos Estimación de estados y perturbaciones Estimación de parámetros Verificación Validación
)t),t(u,x(g)t(y
)t,p),t(u),t(x(fdt
)t(xd
=
=

Reconciliación de datos
)t),t(u,x(g)t(y
)t,p),t(u),t(x(fdt
)t(xd
=
=
El modelo se supone perfecto y se trata de estimar las modificaciones en los datos experimentales que hacen que estos se ajusten exactamente al modelo
Suele plantearse en estado estacionario
Puede combinarse con estimación de parámetros

Estimación de estados con horizonte deslizante
t-N t
¿Qué estado inicial pasado en t-N y que mínimas perturbaciones v(t-i) harían evolucionar el sistema de la forma mas próxima a la que lo ha hecho al aplicarle los controles que le han sido aplicados?
t-N
t u
y
v
x
[ ]
Vv
N
0i
22mv,x
L)it(vL))t(u),t(x(g)t(y
))t(v),t(u),t(x(f)1t(x
)it(v)it(y)it(yminiNt
≤−≤=
=+
−γ+−−−∑=−
Con modelo perfecto

Verificación
¿El modelo de simulación representa adecuadamente al modelo conceptual? Codificación Errores tipo división por cero, etc. Métodos numéricos de solución Precisión
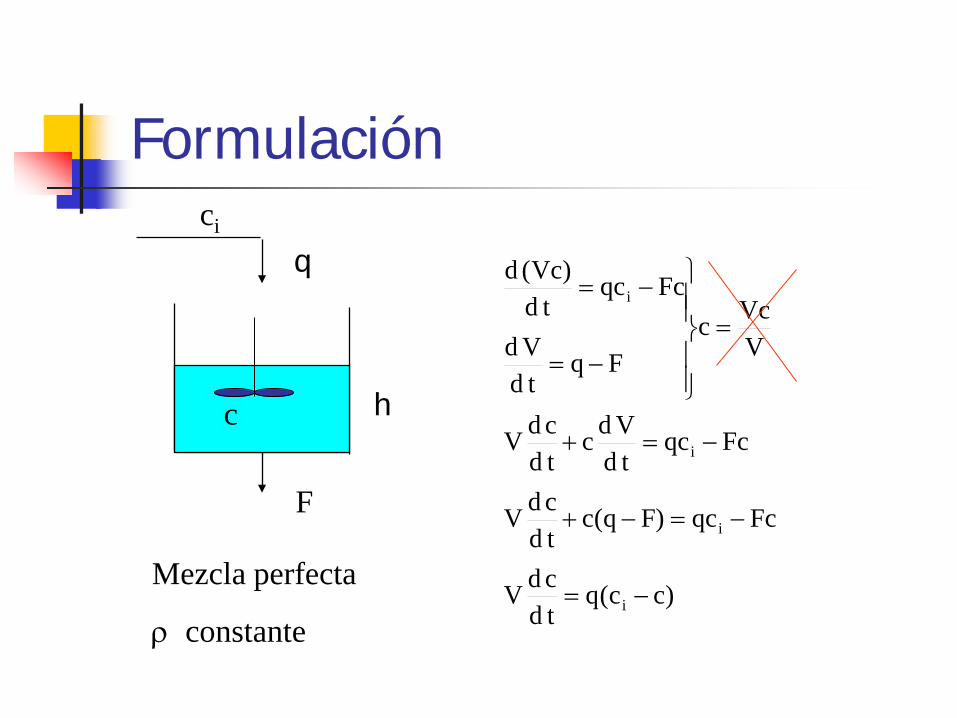
Formulación
q
h
F
ci
c
)cc(qtdcdV
Fcqc)Fq(ctdcdV
FcqctdVdc
tdcdV
VVcc
FqtdVd
Fcqctd
)Vc(d
i
i
i
i
−=
−=−+
−=+
=
−=
−=
Mezcla perfecta
ρ constante

Causalidad q
h
F Causalidad física
hkF
FqtdhdA
=
−=
Causalidad computacional
q h F
La causalidad fija el uso del modelo
¿Qué pasa si?
¿Qué debo hacer para?
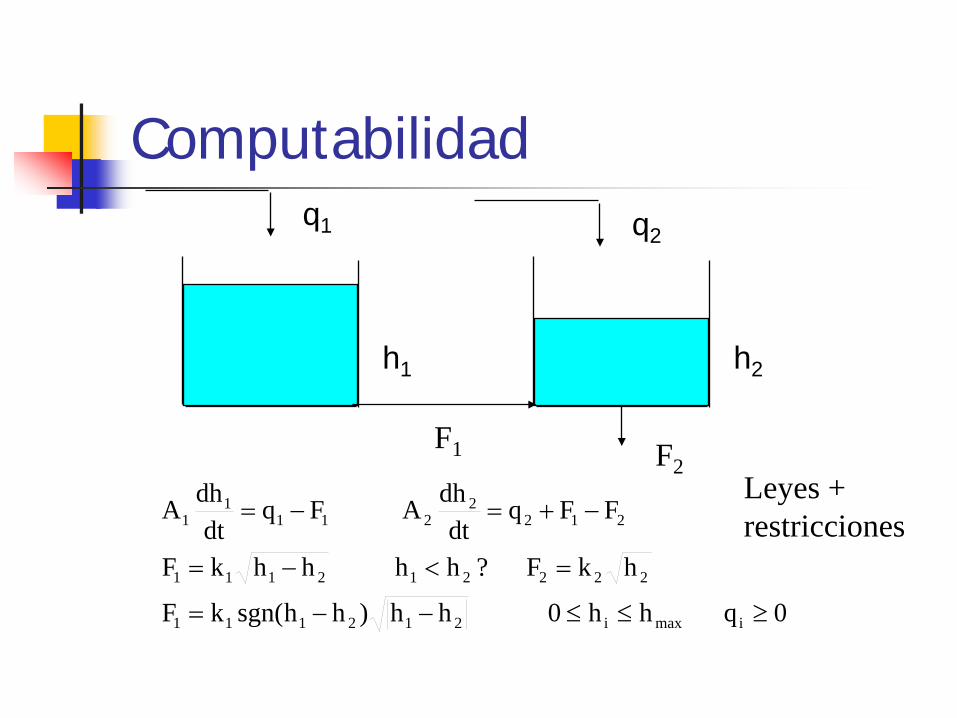
Computabilidad q1
h1
F1
h2
F2
0q hh0 hh)hhsgn(kF
hkF ?hh hhkF
FFqdt
dhA Fqdt
dhA
imaxi212111
222212111
2122
2111
1
≥≤≤−−=
=<−=
−+=−=
q2
Leyes + restricciones

Validación
Respuestas cualitativas del modelo Comprobación con datos
experimentales Test estadísticos Análisis de sensibilidad Capacidad de predicción del modelo Distorsión de parámetros

Respuestas cualitativas
Respuestas cualitativas del modelo a entradas tipo
u y Model
Discusión y evaluación de respuestas tipo del modelo con expertos en el proceso

Respuestas cualitativas
Respuestas cualitativas del modelo a entradas tipo

Respuestas cualitativas
Test de Turing: ¿Se puede discriminar una respuesta del modelo y de la realidad si se presentan en el mismo formato?
Trazas de la evolución de variables tipo flujo, etc. a través de los distintos componentes

Comprobación con datos experimentales
Comparación de las respuestas del modelo y datos experimentales distintos a los usados en la parametrización
( )∑=
−N
1t
2m )t(y)t(y
N1
Proceso u
v
Modelo(p) y
y
m
y
modelo
experimental
t condiciones iniciales
perturbaciones

Indices de error
( )∑=
−N
1t
2m )t(y)t(y
N1
y m
y
modelo
experimental
t
Medida numérica de las discrepancias entre la respuesta del modelo y los datos experimentales
Pueden usarse para comparar varios modelos de un proceso y decidir sobre cual es mas adecuado

Indices de error
Muchos índices ponderan la suma de los errores y el número de parámetros d en el modelo
∑=
−+N
1t
2m ))t(y)t(y()
Nd21(
∑=
−−+ N
1t
2m ))t(y)t(y()
Nd1Nd1(
N1
Akaike Information Criterion AIC
Final Prediction Error FPE
Estima de la varianza del error de predicción con los datos nuevos
d2N
))t(y)t(y(logN
N
1t
2m
+
−∑=

Indices de error
Bayesian Information Criterion BIC
∑=
−+N
1t
2m ))t(y)t(y()Nlog
Nd21(
Rissamen’s Minimal Description lenght
Penaliza mas la complejidad del modelo
)Nlog(dN
))t(y)t(y(logN
N
1t
2m
+
−∑=
Es consistente: La probabilidad de seleccionar un modelo erroneo tiende a cero con N

Indices de error Test F para ver si el modelo j (con mas parámetros) es significativamente mejor que el modelo i, con un nivel α de confianza
)dN/())t(y)t(y(
)dd/())t(y)t(y())t(y)t(y(
jjmod
N
1t
2m
ijjmod
N
1t
2m
imod
N
1t
2m
−
−
−
−−
−
∑
∑∑
=
==
Debe compararse con la distribución F(dj-di, N-dj) con el nivel α de confianza

Errores
Los errores de la estimación provienen de: Errores de medida de los datos. Idealmente se
suelen suponer independientes, de media cero y varianza constante. Para caracterizarlos pueden usarse datos de las salidas con entradas constantes.
Errores del modelo o la estima de parámetros. Si el modelo fuera perfecto, los residuos deberían tener las mismas características estadísticas que los errores de medida.

Test estadisticos
u v y
Modelo
Proceso
ym
e
Si el modelo es correcto los residuos no deben presentar una estructura “sistemática”, sino ser el resultado de las perturbaciones aleatorias que actuan sobre el proceso
Residuos e(t) = y(t) - ym(t)
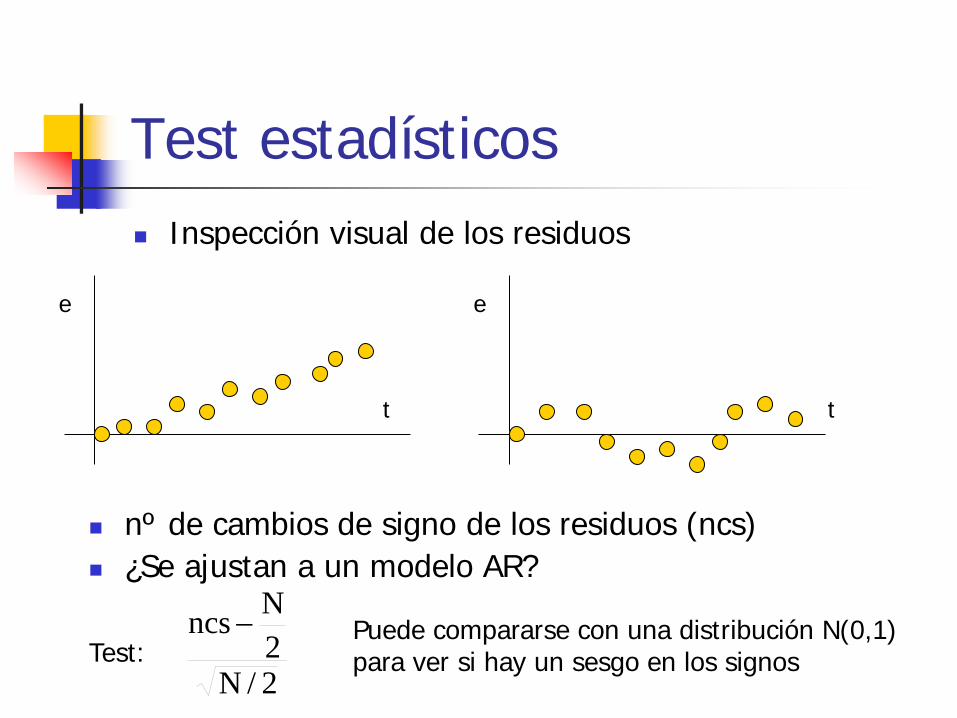
Test estadísticos Inspección visual de los residuos
e
t
e
t
nº de cambios de signo de los residuos (ncs) ¿Se ajustan a un modelo AR?
Test: 2/N2Nncs − Puede compararse con una distribución N(0,1)
para ver si hay un sesgo en los signos

Test estadísticos
Rue(k) Re(k)
2σ
2σk k
No correlación entre la entrada y los residuos: Los errores deben ser independientes de un experimento particular
Blancura de los residuos Lazo abierto, lazo cerrado

Varianza de los parámetros
Las regiones de confianza de los parámetros dan una medida de la calidad de la calibración y, por tanto, de la bondad el modelo.
=
2221
1211
vvvv
V
Los términos cruzados de la matriz de covarianza dan una idea de la independencia de los parámetros, pues deben estar incorrelacionados

Sensibilidad
¿ Cuanto varia J ante un cambio unidad en p ?
[ ]
pppu(t))g(x(t),(t)y ))t(u),t(x(f)t(x
)t,u,p(y)t(yJmin
m
N
1j
2m
p
≤≤==
−= ∑=
Puede obtenerse a partir del problema dual de optimización en ciertos casos

Validación
Capacidad de predicción del modelo Distorsiones de los parámetros Coherencia de las distintas representaciones Varianza de las estimaciones
{ }var ( , )( )( )
G e nN
ww
jwt v
u
θ ≅ΦΦ

Capacidad de predicción
y(t+j)
u(t+j) t
)jt(y +
En ciertos casos, se utilizan fórmulas de predicción de controladores predictivos tales como el DMC, GPC, etc.

Distorsión de parámetros
)t),t(u,x(g)t(y
)t,p),t(u),t(x(fdt
)t(xd
m =
=
Tras la estimación de parámetros se obtiene un valor de los mismos p* (constante) que ajusta lo mejor posible la respuesta del modelo a los datos experimentales
)t,p(y)t(y)t(e *m
* −=
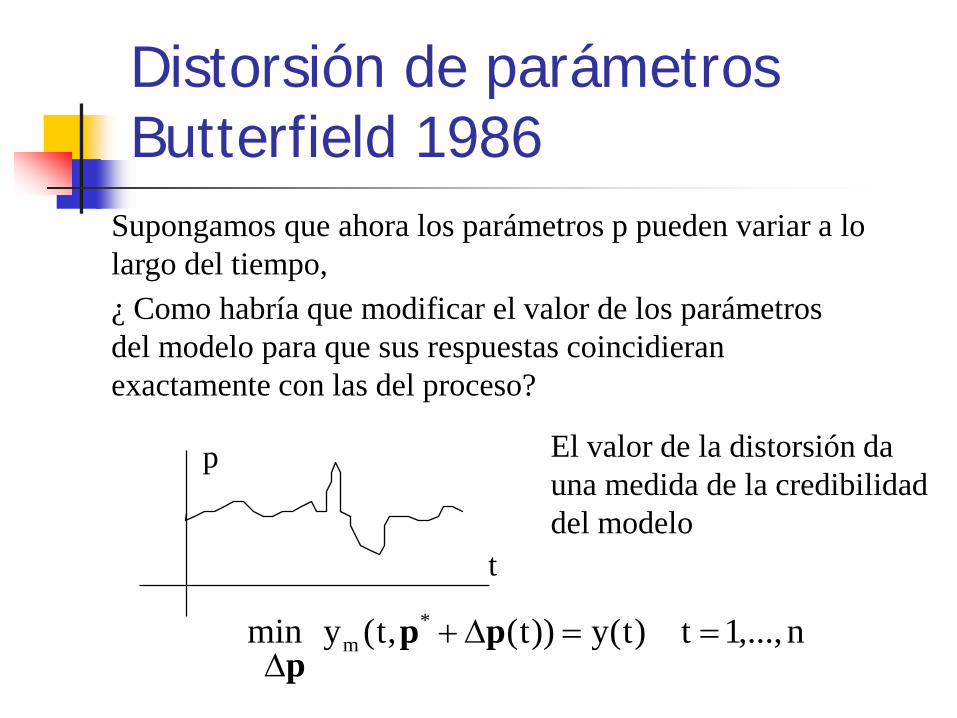
Distorsión de parámetros Butterfield 1986
¿ Como habría que modificar el valor de los parámetros del modelo para que sus respuestas coincidieran exactamente con las del proceso?
t
p El valor de la distorsión da una medida de la credibilidad del modelo
n,...,1t)t(y))t(,t(ymin *m ==∆+
∆pp
p
Supongamos que ahora los parámetros p pueden variar a lo largo del tiempo,
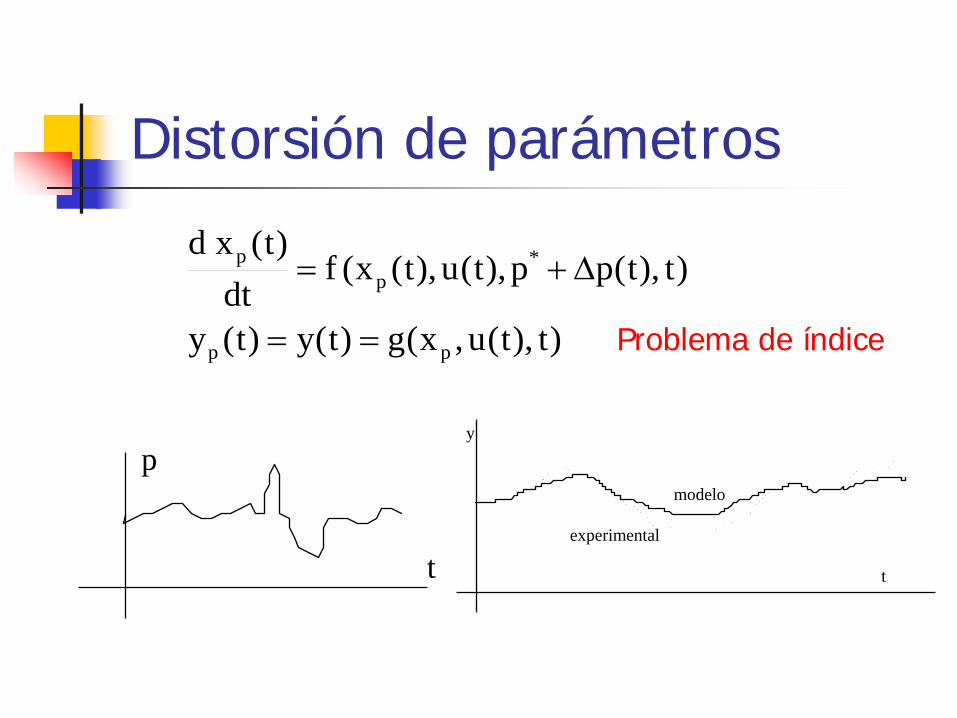
Distorsión de parámetros
)t),t(u,x(g)t(y)t(y
)t),t(pp),t(u),t(x(fdt
)t(xd
pp
*p
p
==
∆+=
t
p y
modelo
experimental
t
Problema de índice

Métodos de solución (1)
)t),t(u,x(g)t(y p=
1 Calcular xp a partir de
)t),t(pp),t(u),t(x(fdt
)t(xd *p
p ∆+=
2 Calcular dxp /dt a partir de xp
3 Calcular ∆p(t) a partir de
Imprecisión en el cálculo de la derivada

Métodos de solución (2)
)xx(xg)t),t(u,x(g)t(y
ppf)xx(
xf)t,p),t(u),t(x(f
dt)t(xd
)t(y)t),t(u,x(g)t(y
)t),t(pp),t(u),t(x(fdt
)t(xd
p
p,xpp
p,xp
p,xp
*p
pp
*p
p
*
**
−∂∂
+=
∆∂∂
+−∂∂
+=
==
∆+=
Aproximación lineal sobre la respuesta base p*

Linealización sobre una trayectoria
x base
x
tiempo
)t(x∆
p
t
)t(p∆

Métodos de solución (2)
)t),t(u,x(g)t(y
)t),t(pp),t(u),t(x(fdt
)t(xd
p
*p
p
=
∆+=
)t),t(u,x(g)t(y
)t,p),t(u),t(x(fdt
)t(xd
m =
=
∗
∗
ppf
xf
dtd
)t,p),t(u),t(x(fppf)xx(
xf)t,p),t(u),t(x(f
dtdx
dtdx
dtdxx
**
**
p,xp,xp
*
p,xp
p,xp
*
pp
∆∂∂
+φ∂∂
=φ
−∆∂∂
+−∂∂
+≈
=−=φ
−=φ

Metodos de solución (2)
φ∂∂
=−=−
−−∂∂
+=
=−=−
*
*
p,xpmmp
p
p,xp
pmp
xg)t(y)t(y)t(y)t(y
)t),t(u,x(g)xx(xg)t),t(u,x(g
)t),t(u,x(g)t),t(u,x(g)t(y)t(y

Metodos de solución (2)
φ∂∂
=−
∆∂∂
+φ∂∂
=φ
−=φ
*
**
p,xpmp
p,xp,xp
p
xg)t(y)t(y
ppf
xf
dtd
xx
R ∆p
+ -
e* yp-ym
Resolución como un problema de control
*mmp e)t(y)t(y)t(y)t(y =−=−
Si ∆p es correcto:

Métodos de solución (3)
)t),t(pp),t(u),t(x(fdt
)t(xd *p
p ∆+=
Puede plantearse también como un problema de optimización
∑=
∆−λ+∆β+−α
N
1tp
22pp
))t(y)t(y(p))t(x)t(x(min
Multiplicador de Lagrange
Problema de optimización dinámica
Se calculan las menores distorsiones de parámetros y estados compatibles con la restricción de igualdad de las salidas del modelo distorsionado y del proceso
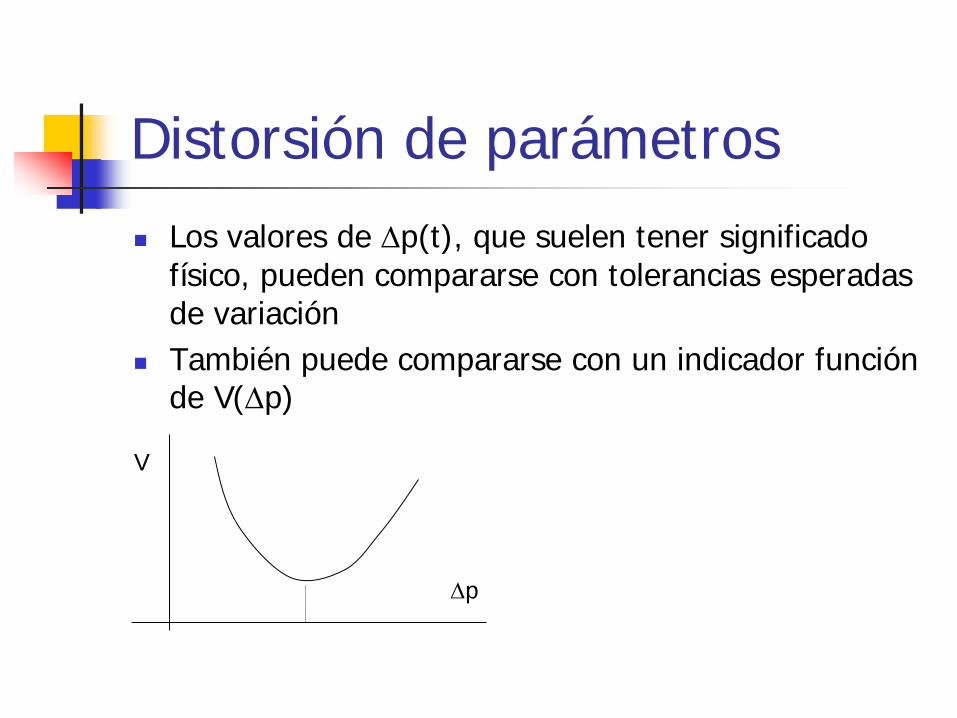
Distorsión de parámetros Los valores de ∆p(t), que suelen tener significado
físico, pueden compararse con tolerancias esperadas de variación
También puede compararse con un indicador función de V(∆p)
V
∆p