understanding human actions with 2d and 3d sensors: part i · • part 2: action analysis with 3d...
TRANSCRIPT

Understanding Human Actions
with 2D and 3D Sensors: Part I
Junsong Yuan
Nanyang Technological University
and
Zicheng Liu
Microsoft Research Redmond

• Huge amount of videos from many cameras
• Problems:
– Bottleneck at storage and transmission
– Extensive human monitoring of the video streams is
impractical and ineffective
Why understanding human actions

Why understanding human actions
– Discard none-informative visual contents, so that only preserve and
transmit videos of potential interests
Big Visual Data Analytics
Big Video Data
• Easy data capture
• Convenient data storage
Increasing Computing Power
• Moore’s law
• Cloud computing
Big Visual Data Analytics
How to harvest knowledge via Video Analytics?
Big Video Data
• Easy data capture
• Convenient data storage
Increasing Computing Power
• Moore’s law
• Cloud computing

Microsoft Kinect
Human Computer Interaction

Outline
• Part 1: Video-based action analysis
– Action Detection and Localization
• Mutual information maximization
• Spatio-temporal bounding box search
• Spatio-temporal path search
• Structured output learning
– Action Detection with Limited Training Data
• Multiple visual vocabularies
• Propagative Hough Voting
• Action prediction
• Part 2: Action analysis with 3D sensors

PART 1: VIDEO-BASED ACTION
ANALYSIS

Action Recognition
• Training
• Testing
9

Action Detection
• Training
• Testing
10

Action Detection
Y. Cong, J. Yuan, and J. Liu, CVPR’11 and PR’13

Detection is difficult for machines
Courtesy of Ivan Laptev

From object detection to
action detection
� CMU action dataset (Ke Yan et al. ICCV07)� Subject appearance
changes
� View point changes
� Spatial scale variations
� Partial occlusion
� Capture environment
� Moving camera
� Low resolution video
� Clutter and moving background
� Multiple class action

Challenges of action detection
• Action pattern variations– Performing speed and style variations
– Subject appearance variations
– View point changes
– Spatial scale variations
– Partial occlusion
• Capture environment – Moving camera
– Low resolution video
– Clutter and moving background
– Multiple actions happen simultaneously

Action Recognition by Local
Feature Matching

Interest point based approach

Advantages of Interest-Point Based
Approach
• Flexibility
– Handling crowded environment
– Not requiring tracking
– Not requiring foreground/background separation

Interest Point Detectors
• Harris Corner Detector
• Dollar detector
– Harris corner detector
– Filtered by motion information
• Laptev detector
– 3D Harris corner detector
• Hierarchical filtered motion field detector
– Tian et al, Trans. SMC., 2012.
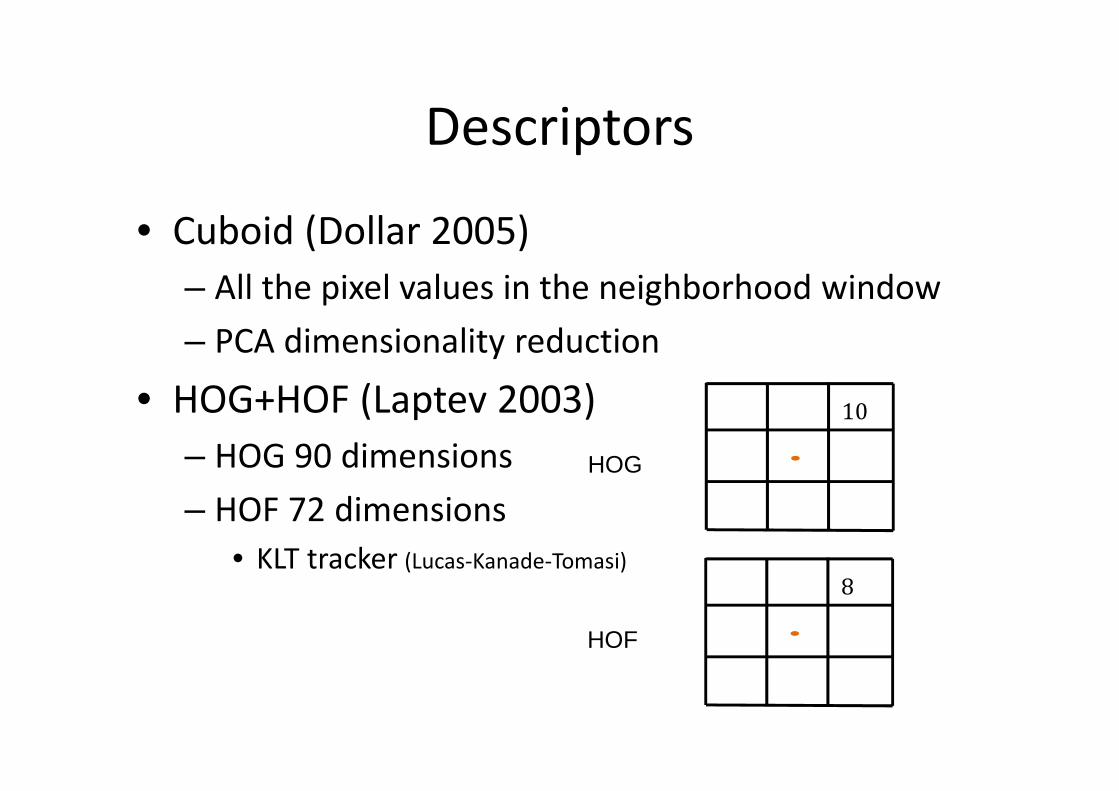
Descriptors
• Cuboid (Dollar 2005)
– All the pixel values in the neighborhood window
– PCA dimensionality reduction
• HOG+HOF (Laptev 2003)
– HOG 90 dimensions
– HOF 72 dimensions
• KLT tracker (Lucas-Kanade-Tomasi)
10
HOG
8
HOF

Descriptors
• 3DSIFT (Scovanner et al 2007)
– Histogram of 3D directions
• Trajectories of interest points (Sun et al 2009)
– Tracking interest points
• Contextual info (Kovashka&Grauman2010)
– Dependence between interest points
• HOG-MHI (Tian et al 2012)
– Motion history image

Bag-of-Words Representation
• Codebook
– K-means
• Word histogram per video clip
– Codeword assignment for each interest point
– Histogram of all the feature vectors in the video
clip
�Number of codewords:
Word histogram: � dimensional vector

Classifier
• Each video clip: one word histogram vector
• Training 1-against-all SVM classifier for each
class
• Laptev et al’98, KTH: 91.8%

Naïve Bayes Maximum Mutual
Information (NBMIM)
• Given a video clip
• Predict its class label
Each point contributes a vote

Local Evidence
A negative vote
A positive vote

Likelihood Ratio Test
• Kernel density estimation
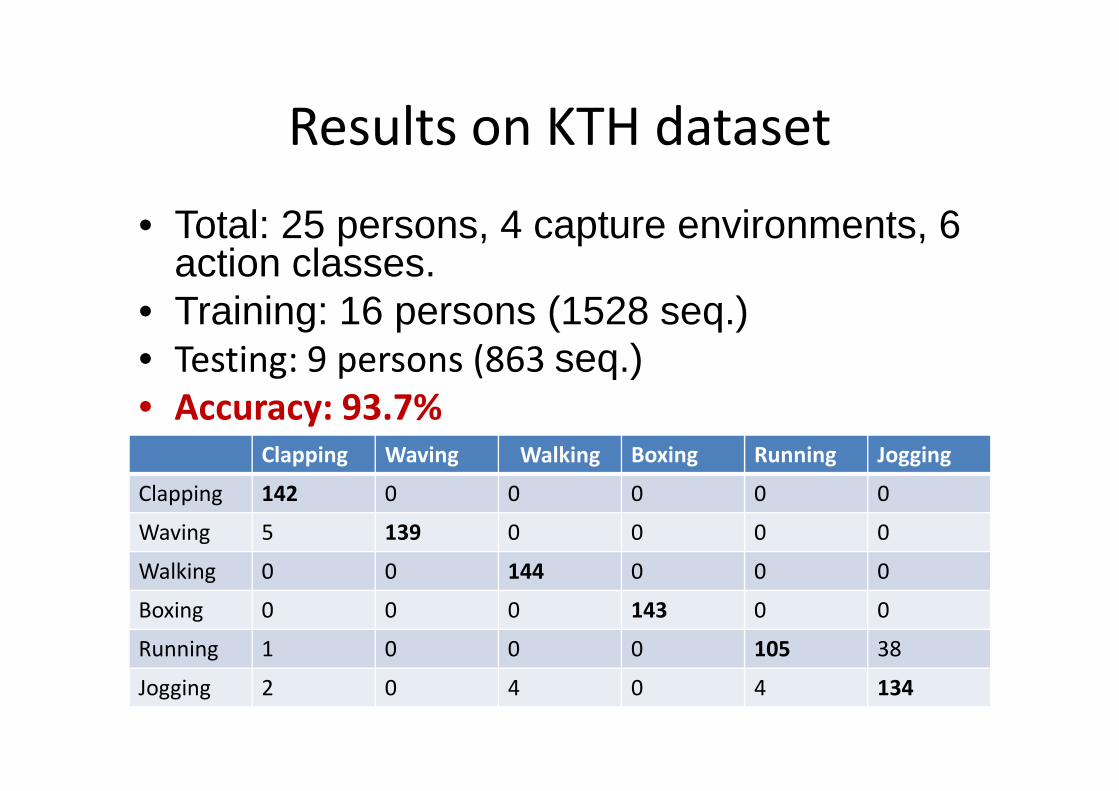
Results on KTH dataset
Clapping Waving Walking Boxing Running Jogging
Clapping 142 0 0 0 0 0
Waving 5 139 0 0 0 0
Walking 0 0 144 0 0 0
Boxing 0 0 0 143 0 0
Running 1 0 0 0 105 38
Jogging 2 0 4 0 4 134
• Total: 25 persons, 4 capture environments, 6 action classes.
• Training: 16 persons (1528 seq.)• Testing: 9 persons (863 seq.)• Accuracy: 93.7%
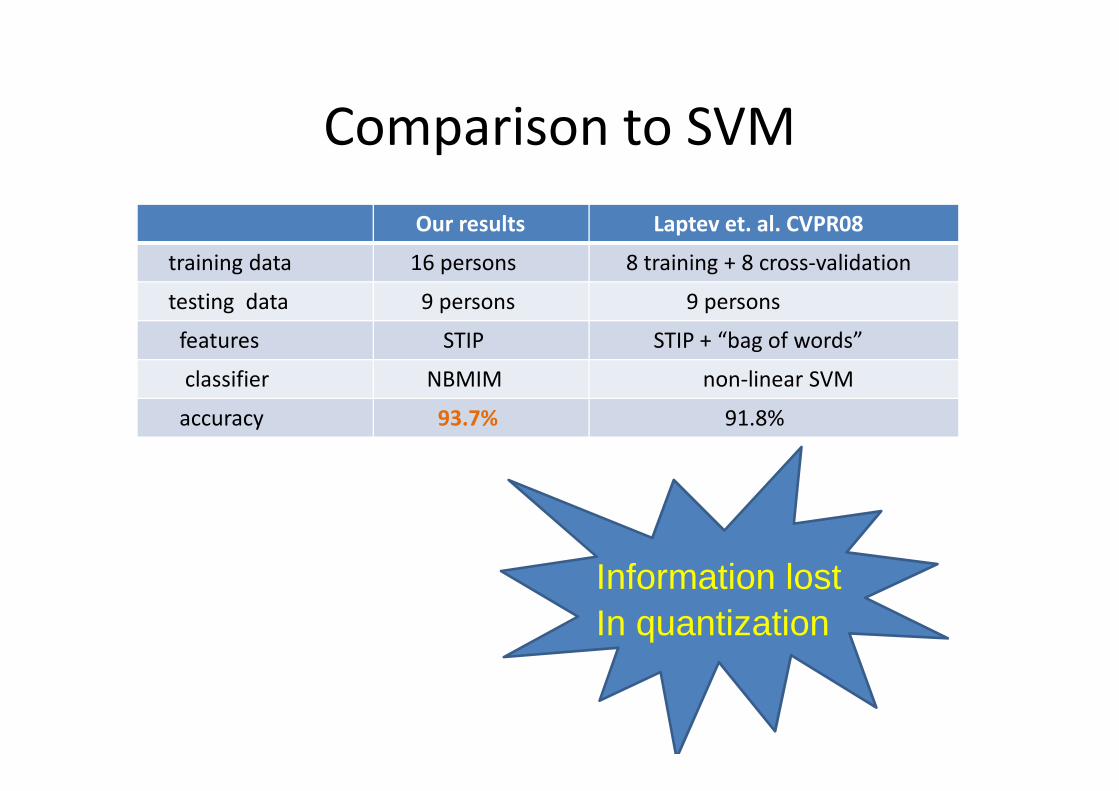
Comparison to SVM
Our results Laptev et. al. CVPR08
training data 16 persons 8 training + 8 cross-validation
testing data 9 persons 9 persons
features STIP STIP + “bag of words”
classifier NBMIM non-linear SVM
accuracy 93.7% 91.8%
Information lost In quantization

Action Detection by Video
Subvolume Search
J. Yuan, Z. Liu, and Y. Wu, CVPR’09 and T-PAMI’11G. Yu, Norberto. A., J. Yuan, and Z. Liu, T-MM’11

Sliding window for action detection
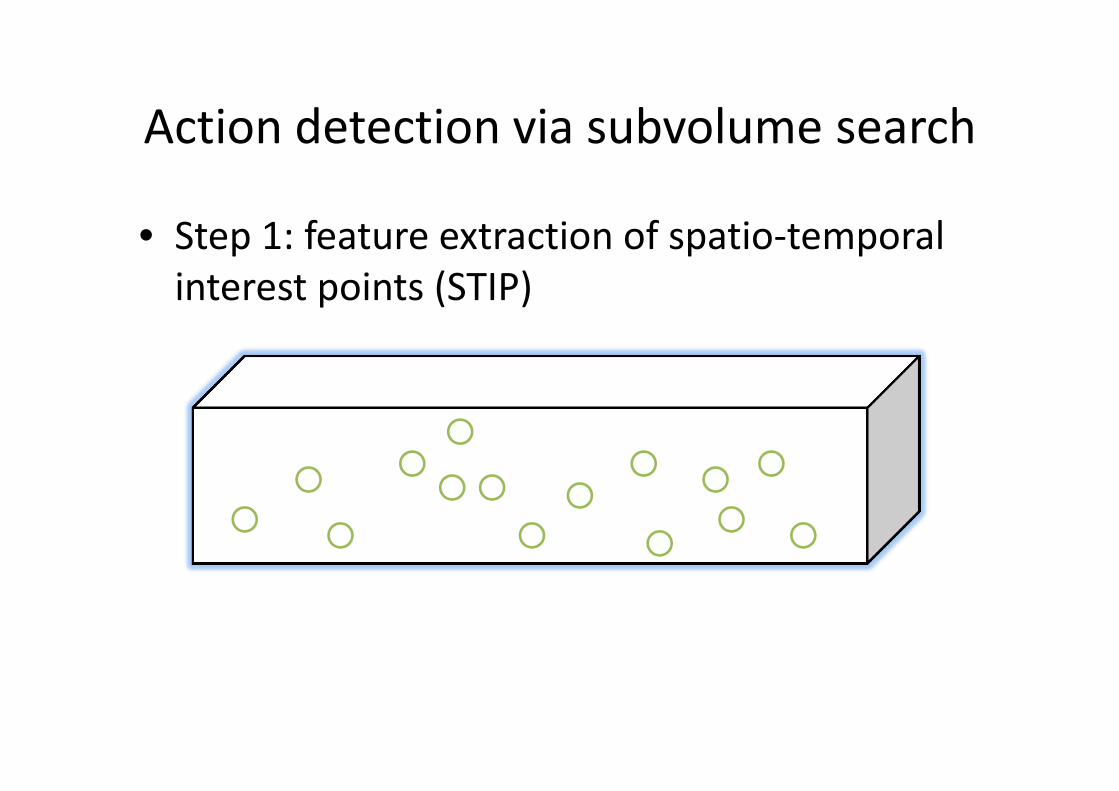
Action detection via subvolume search
• Step 1: feature extraction of spatio-temporal
interest points (STIP)
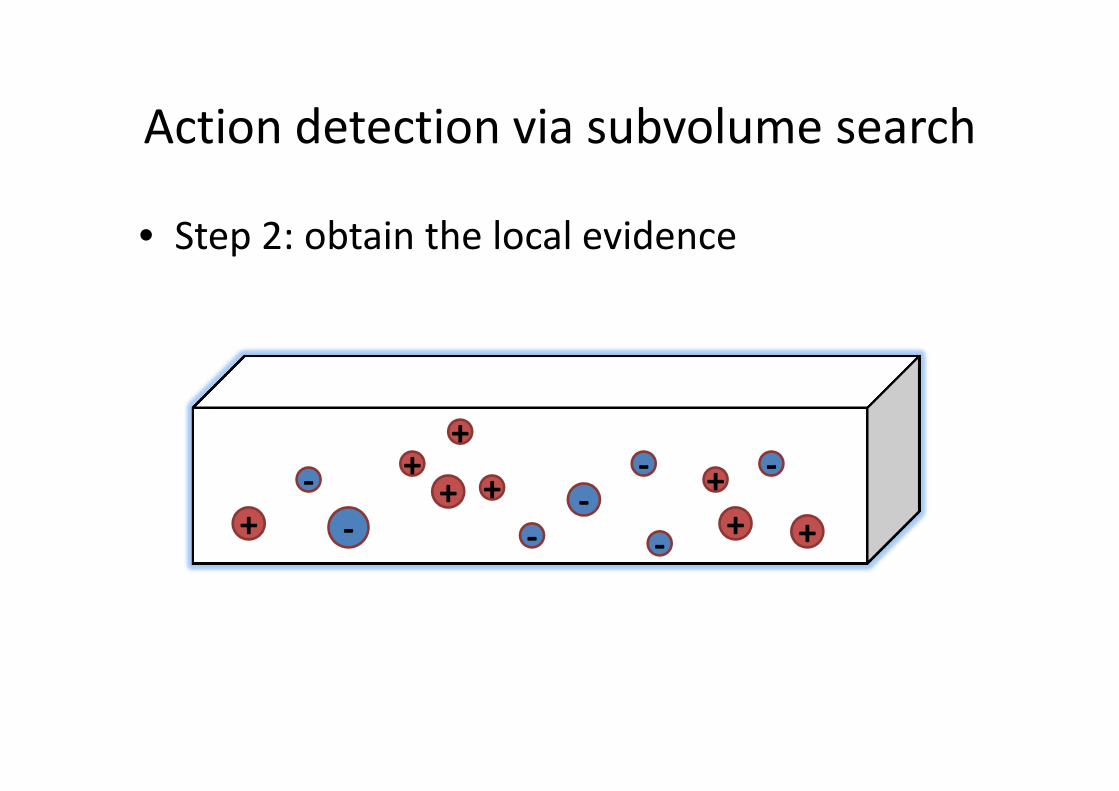
Action detection via subvolume search
• Step 2: obtain the local evidence
++
+ +
+ +
-
-
-
-
-+
+-
-
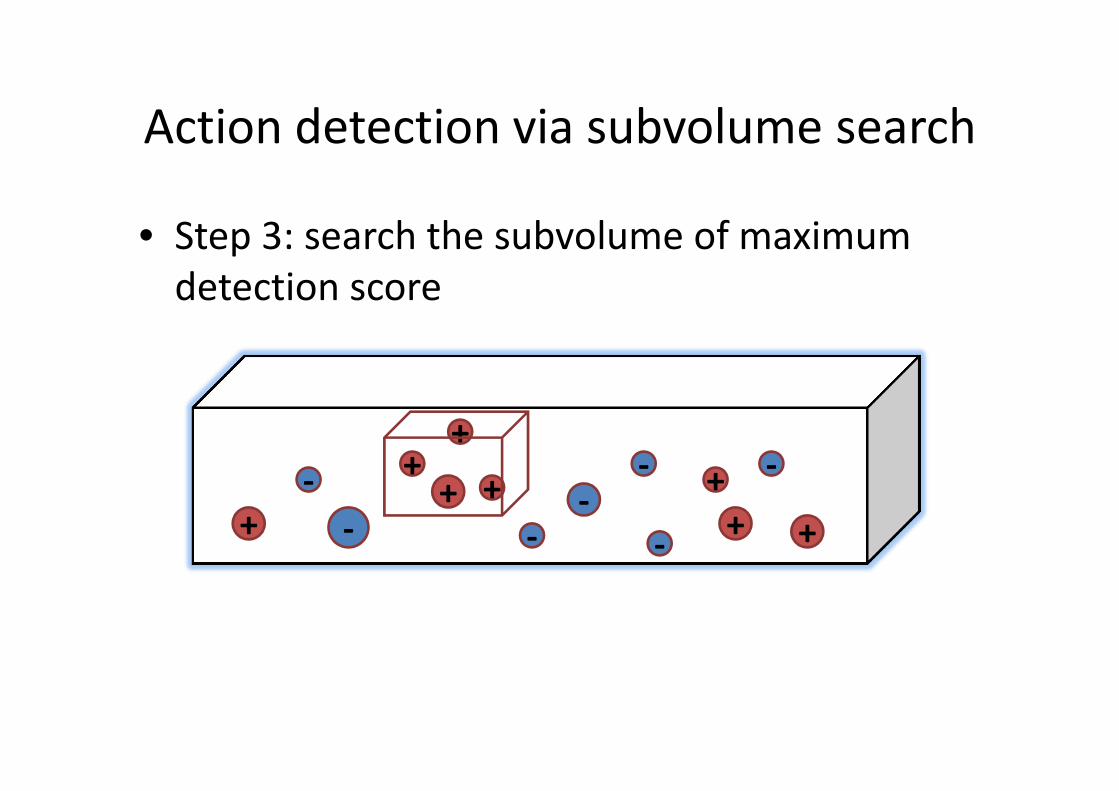
Action detection via subvolume search
• Step 3: search the subvolume of maximum
detection score
++
+ +
+ +
-
-
-
-
-+
+-
-
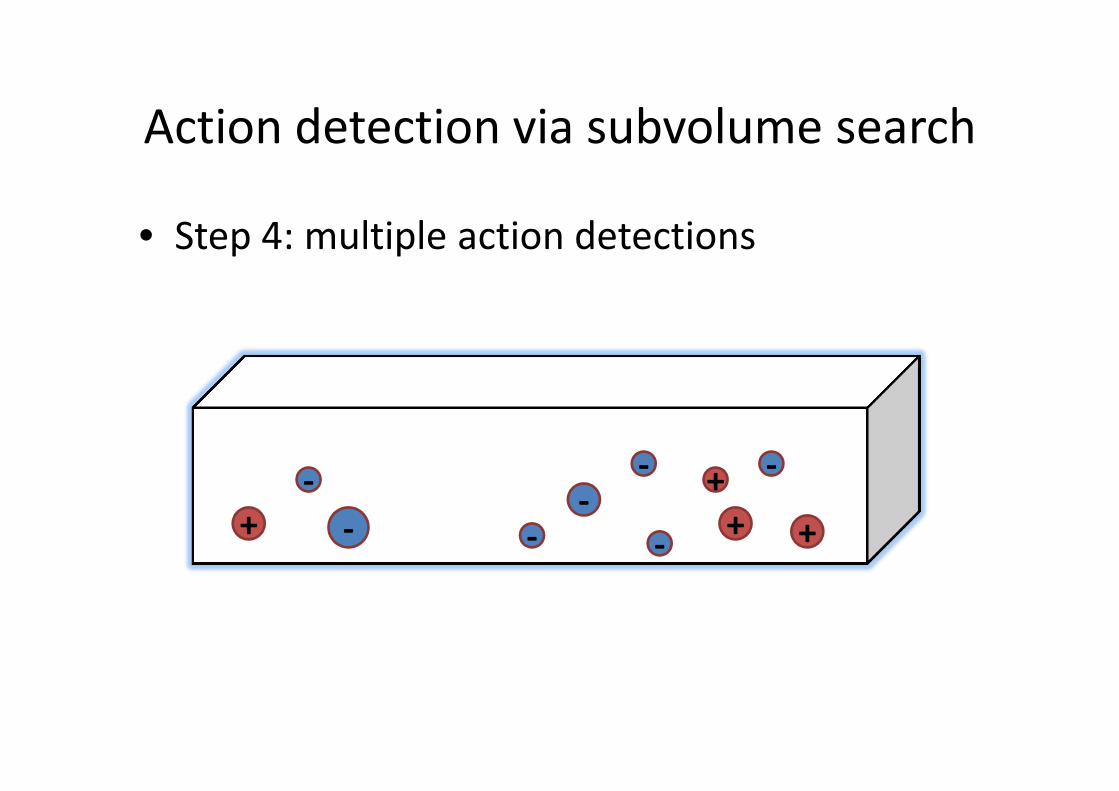
Action detection via subvolume search
• Step 4: multiple action detections
+
+ +
-
-
-
-
-
+-
-
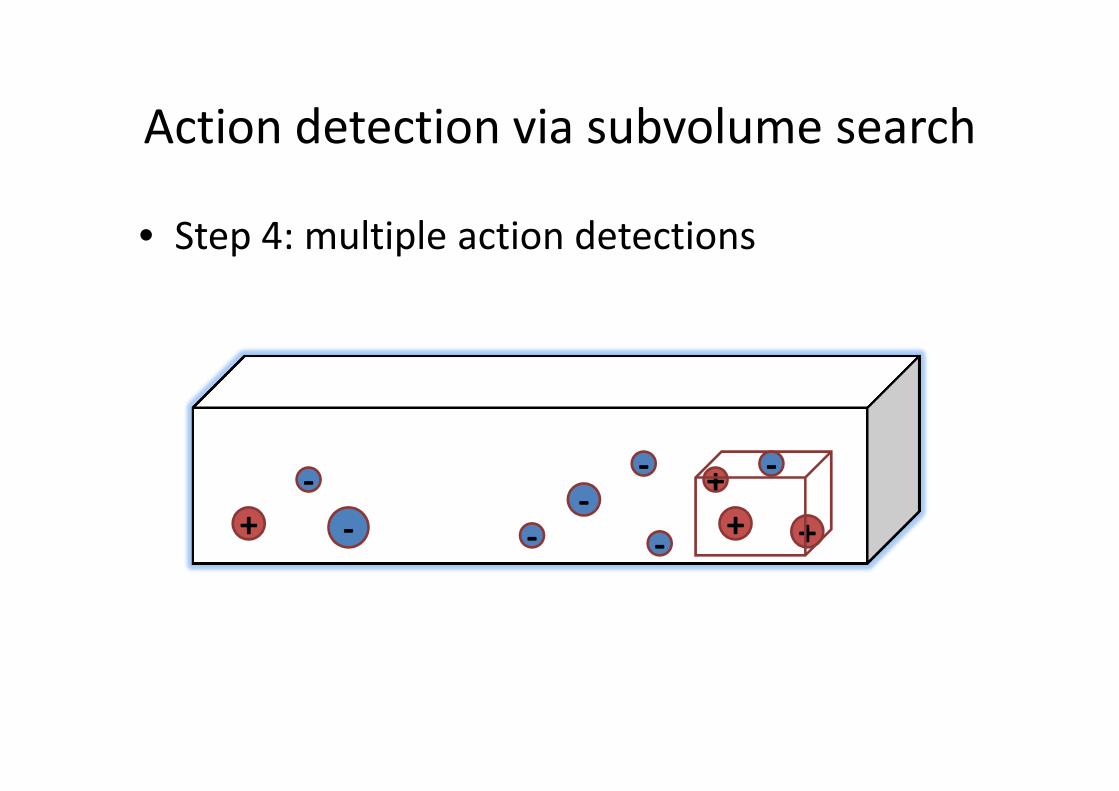
Action detection via subvolume search
• Step 4: multiple action detections
+
+ +
-
-
-
-
-
+-
-

Complexity analysis
• A video clip of size 160x120x1000 (33 seconds)
• Exhaustive check � Number of candidates:
160x160x120x120x1000x1000/8 =4.608 x 1013
• Suppose 10,000,000 check per second:
160x160x120x120x1000x1000/8x10,000,000 =
4.608 x 106 seconds = 1.78 months

How to speed up the search ?
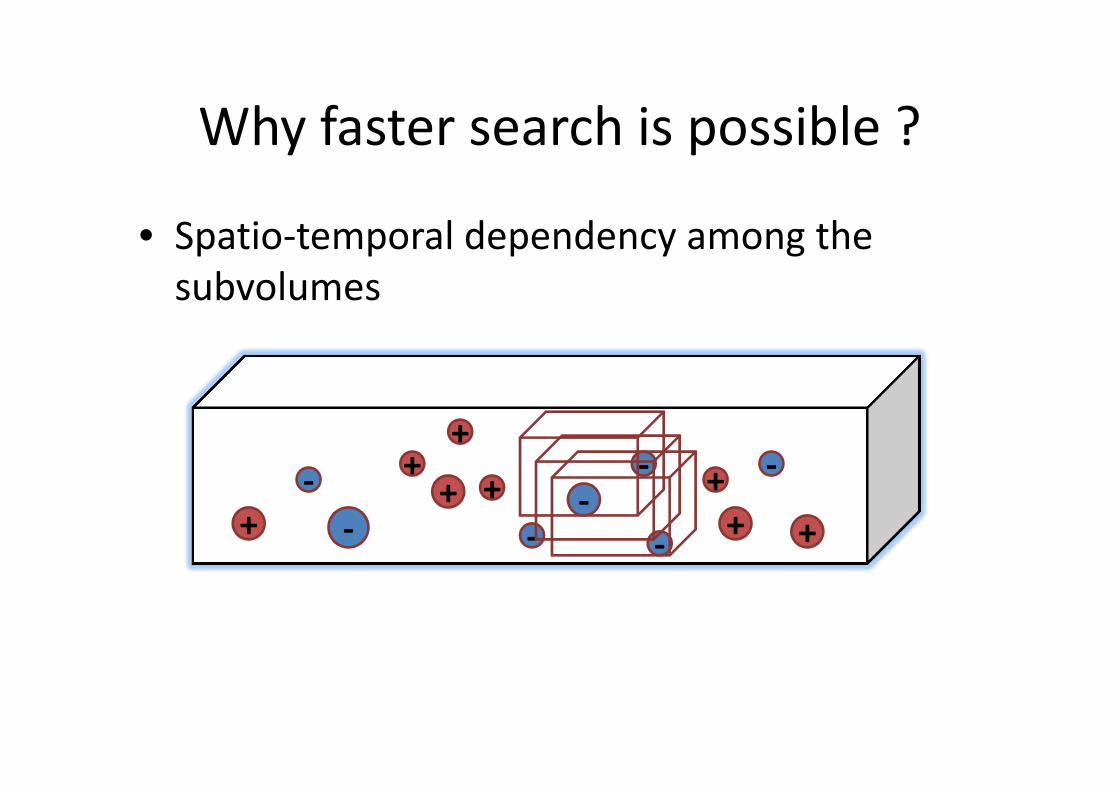
Why faster search is possible ?
• Spatio-temporal dependency among the
subvolumes
++
+ +
+ +
-
-
-
-
-+
+-
-

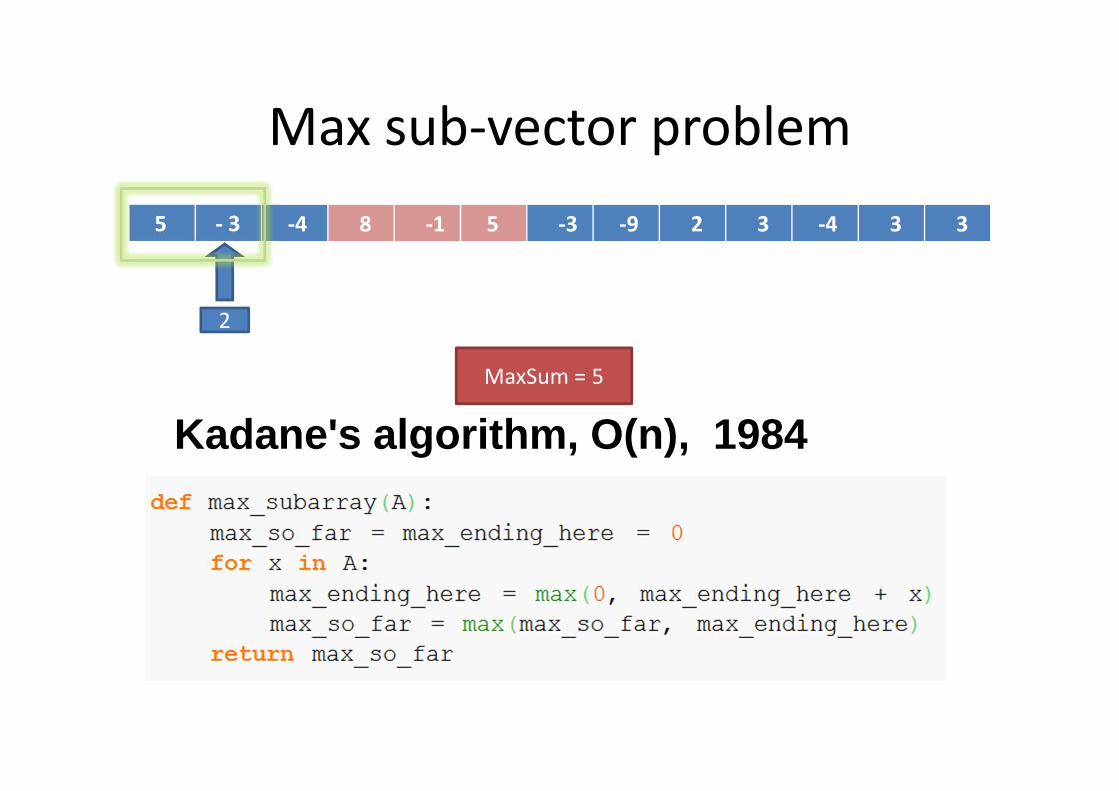
1D Max Sum
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
Brute-force: O(nxn )
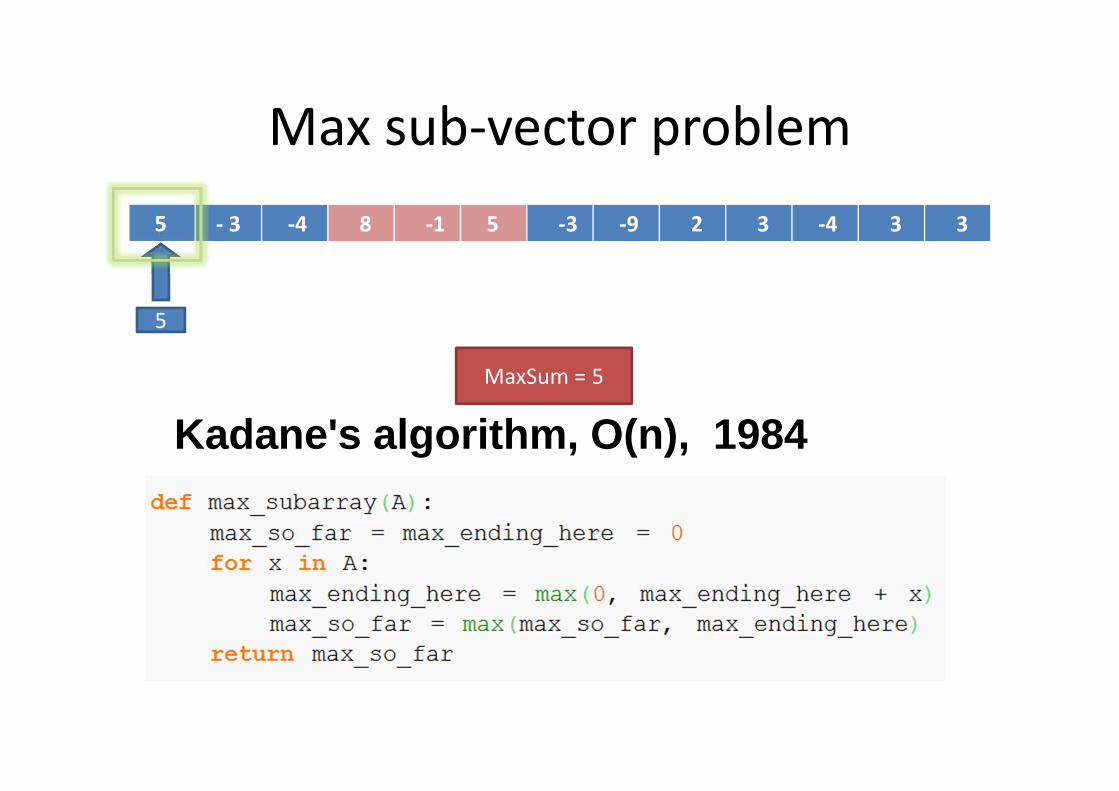
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
5
MaxSum = 5
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
2
MaxSum = 5
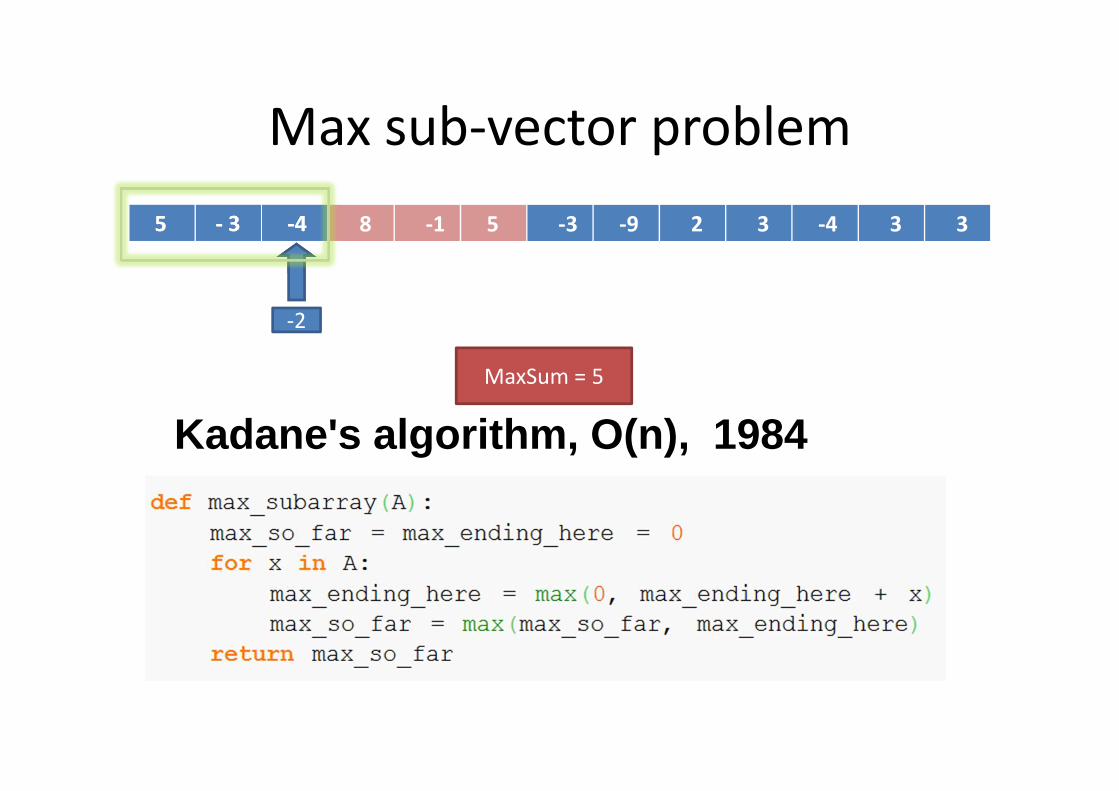
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
-2
MaxSum = 5
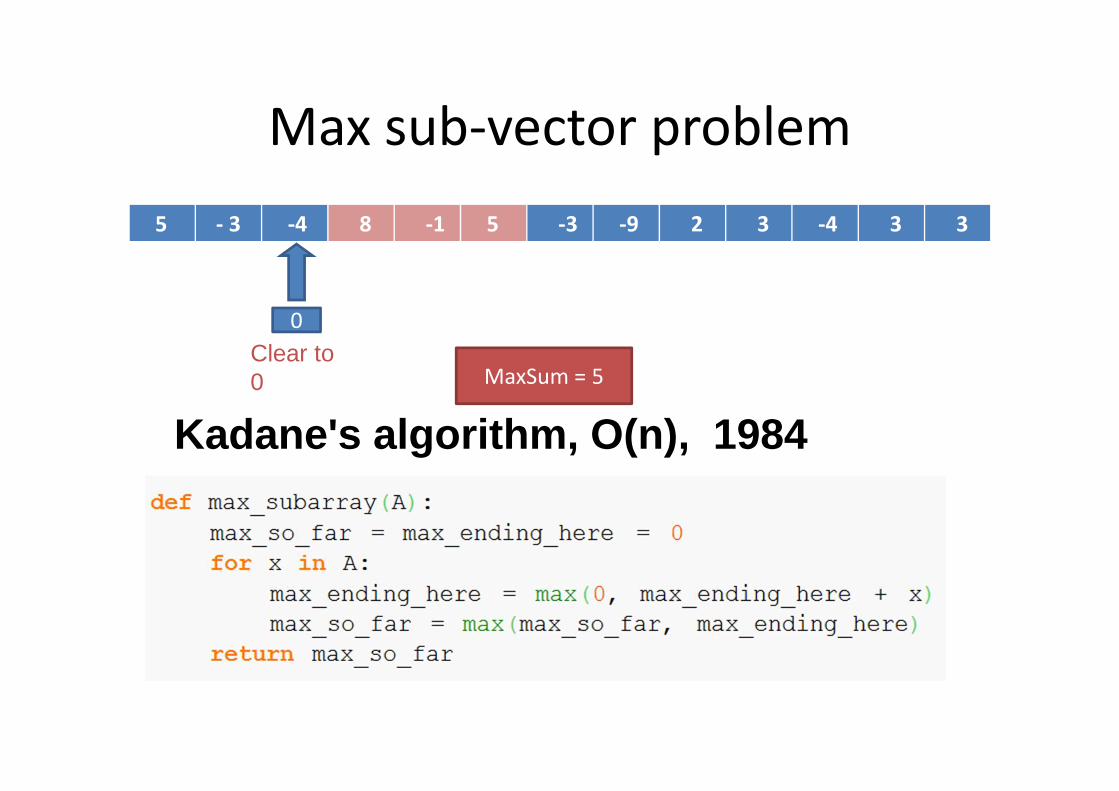
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
0
MaxSum = 5Clear to 0
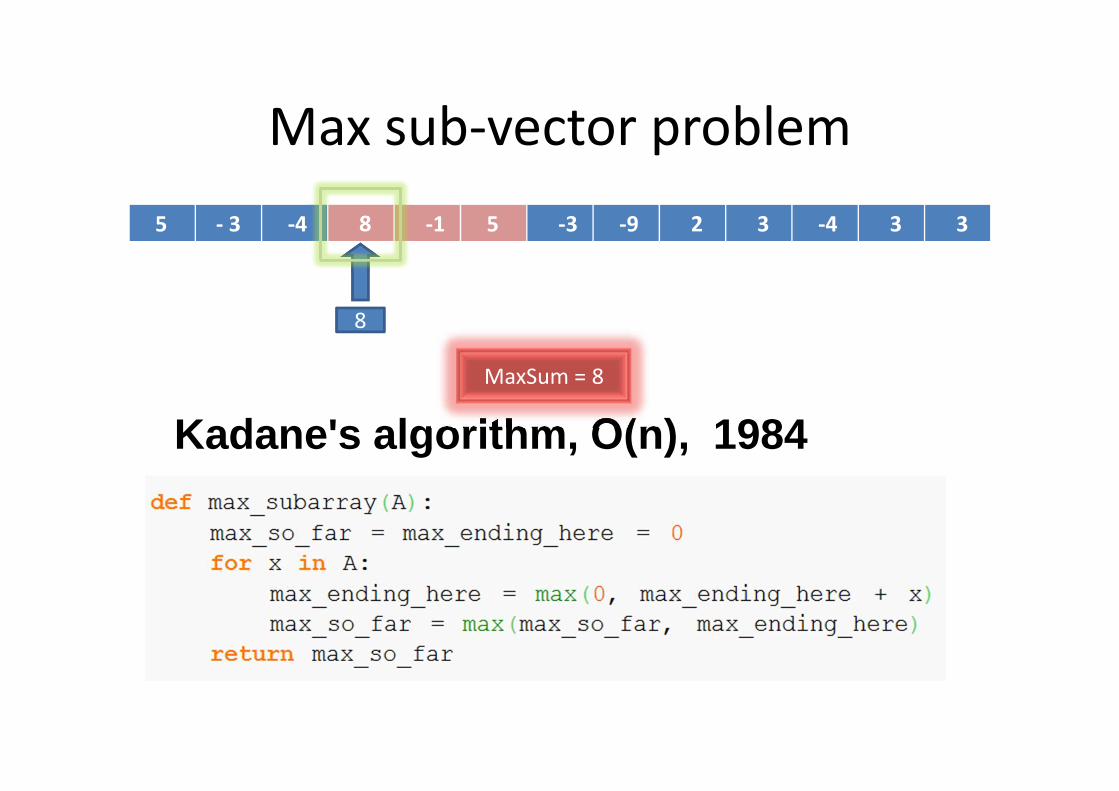
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
8
MaxSum = 8
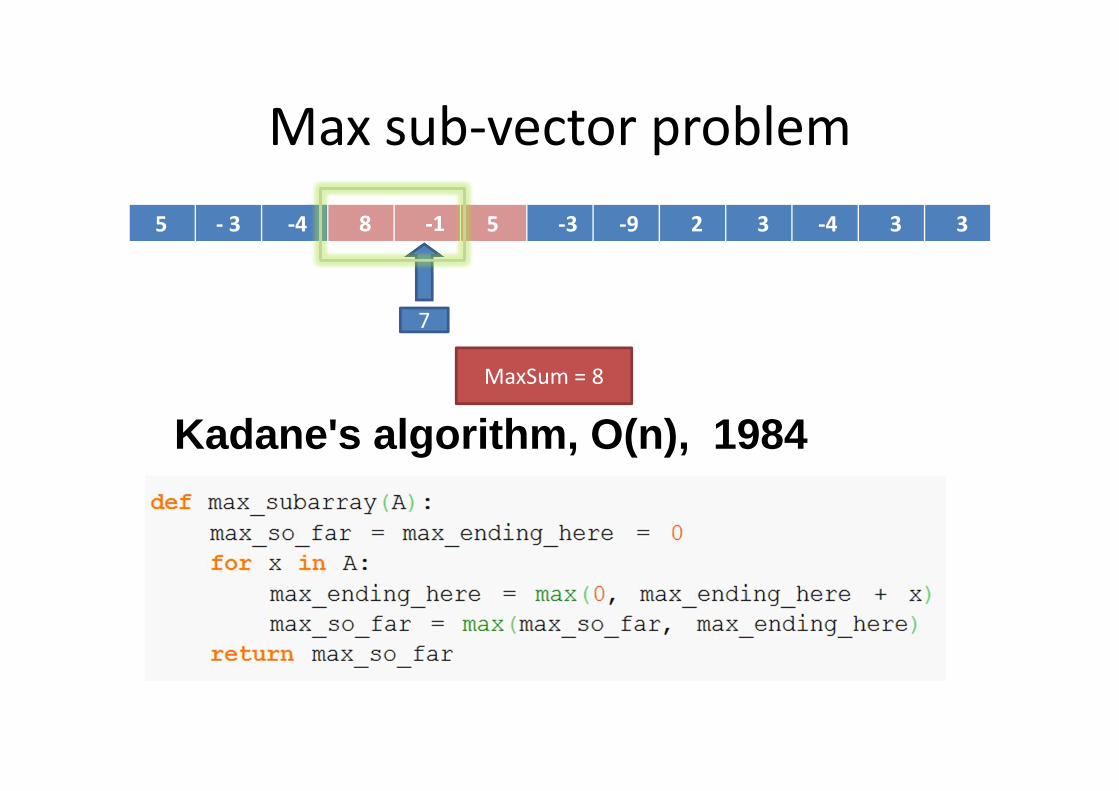
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
7
MaxSum = 8
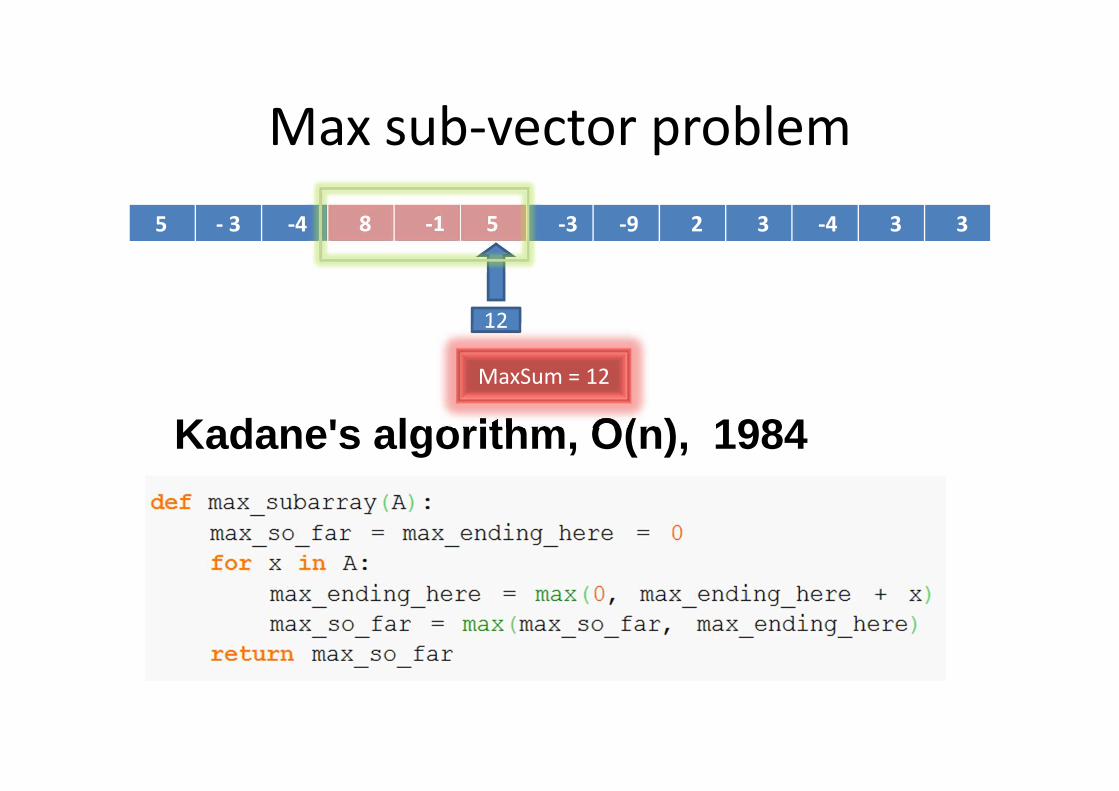
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
12
MaxSum = 12
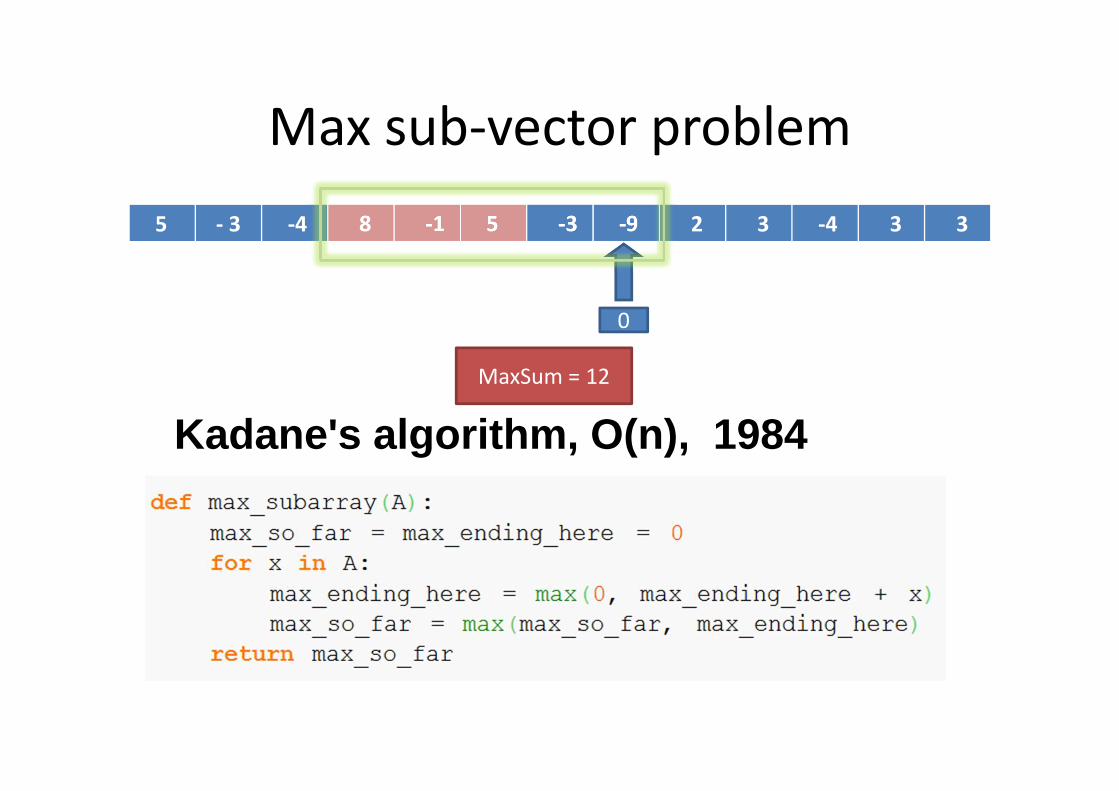
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
0
MaxSum = 12
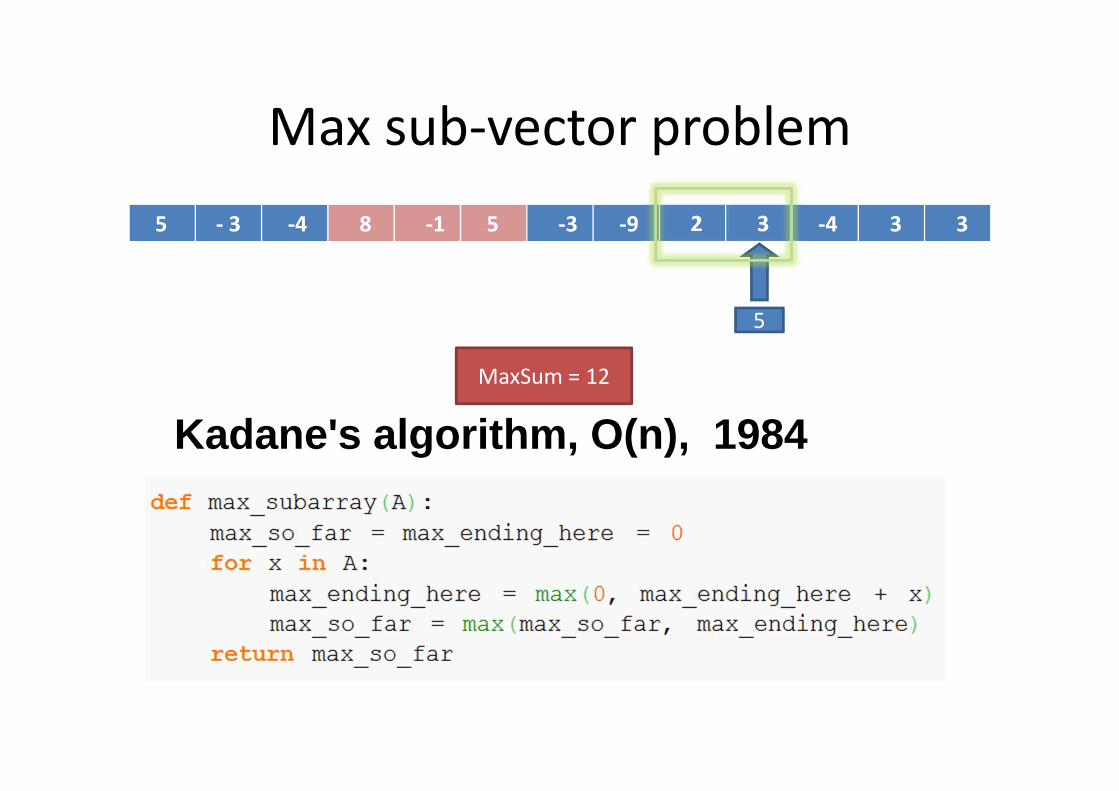
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
5
MaxSum = 12
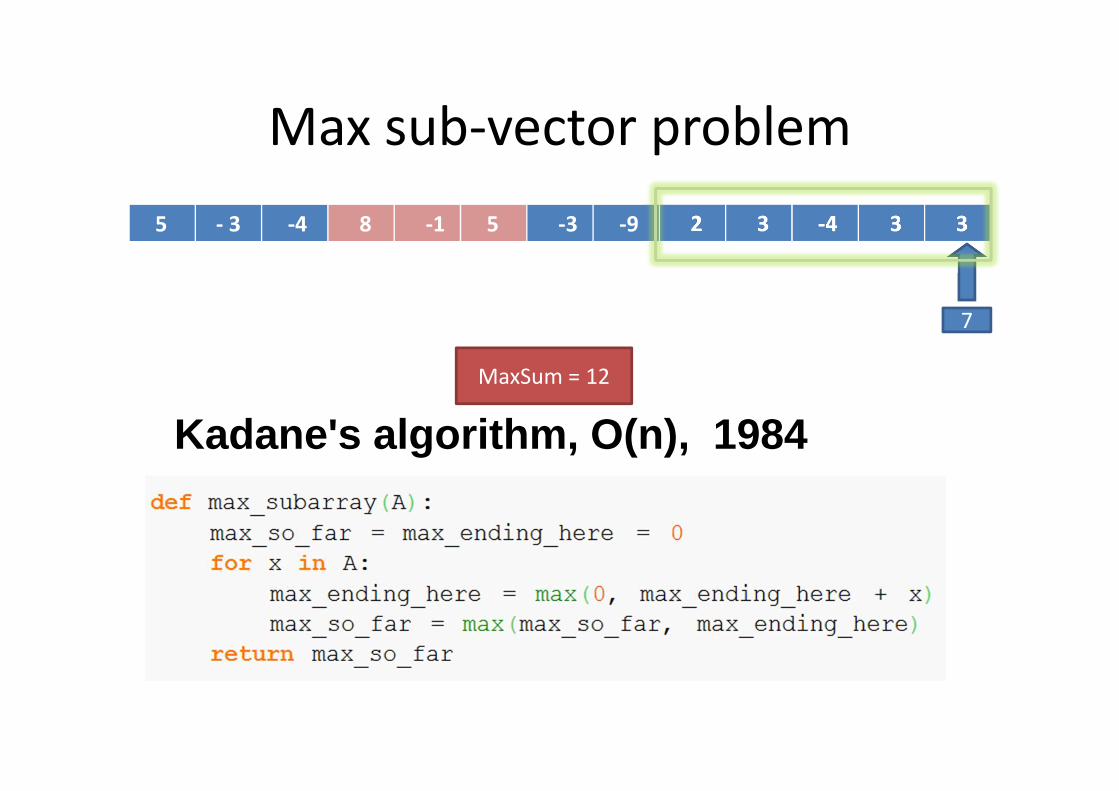
Max sub-vector problem
5 - 3 -4 8 -1 5 -3 -9 2 3 -4 3 3
Kadane's algorithm, O(n), 1984
7
MaxSum = 12

2D Max Sum
-15 5 -1 3 3
2 -5 1 -8 -9
-1 -6 10 -5 -7
3 2 35 20 4
-9 -5 -45 7 6
Brute-force: O( n4)
• Follow Kadane's algorithm: O(n3)• Best so far, Takaoka, 2002 : O(n3 (loglog n / logn)1/2)
• Branch and bound, Lampert et.al., CVPR’08: • they report O(n2) in practice• Worst case is O(n4)
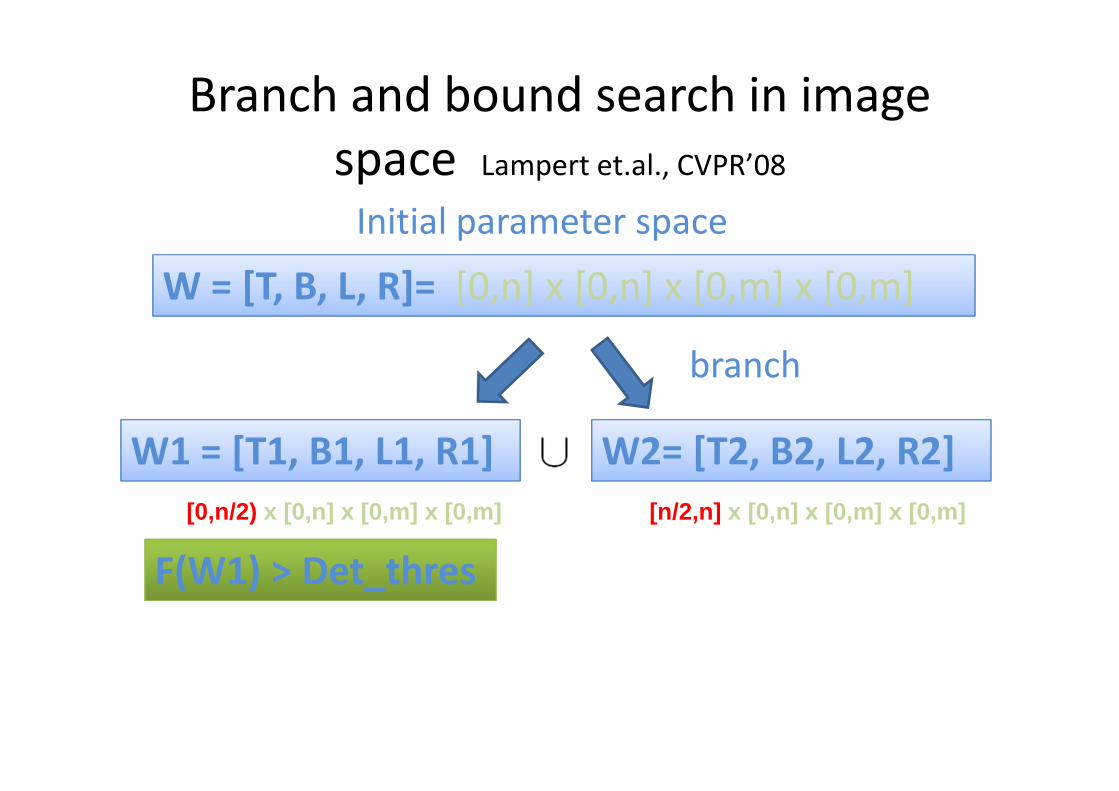
Branch and bound search in image
space Lampert et.al., CVPR’08
Initial parameter space
branch
[0,n/2) x [0,n] x [0,m] x [0,m] [n/2,n] x [0,n] x [0,m] x [0,m]
W = [T, B, L, R]= [0,n] x [0,n] x [0,m] x [0,m]
W1 = [T1, B1, L1, R1] W2= [T2, B2, L2, R2]
F(W1) > Det_thres
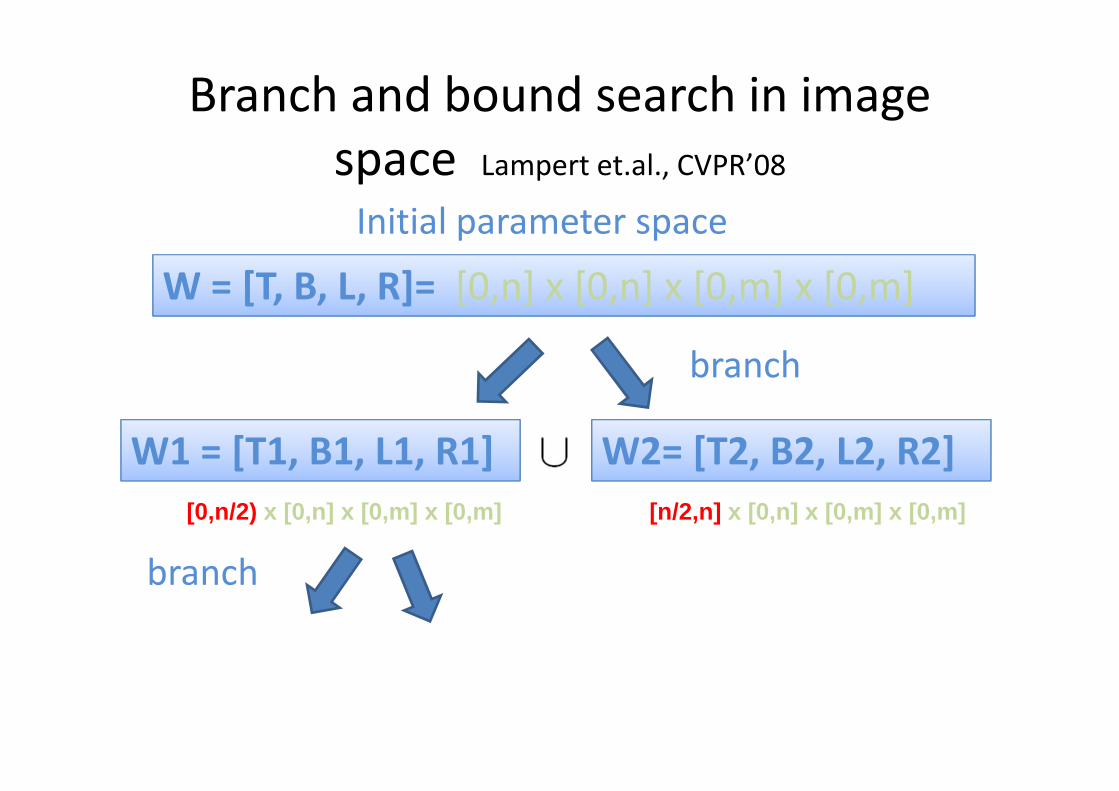
Branch and bound search in image
space Lampert et.al., CVPR’08
Initial parameter space
[0,n/2) x [0,n] x [0,m] x [0,m] [n/2,n] x [0,n] x [0,m] x [0,m]
W = [T, B, L, R]= [0,n] x [0,n] x [0,m] x [0,m]
W1 = [T1, B1, L1, R1] W2= [T2, B2, L2, R2]
branch
branch
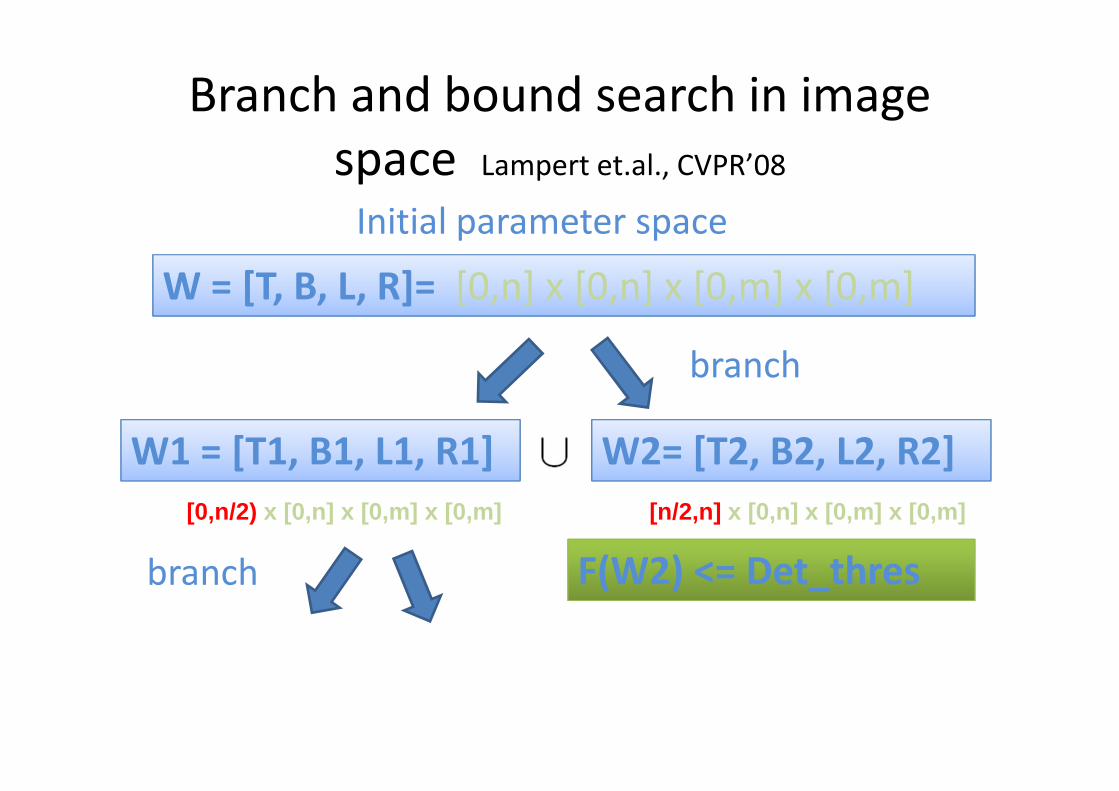
Branch and bound search in image
space Lampert et.al., CVPR’08
Initial parameter space
[0,n/2) x [0,n] x [0,m] x [0,m] [n/2,n] x [0,n] x [0,m] x [0,m]
W = [T, B, L, R]= [0,n] x [0,n] x [0,m] x [0,m]
W1 = [T1, B1, L1, R1] W2= [T2, B2, L2, R2]
branch F(W2) <= Det_thres
branch
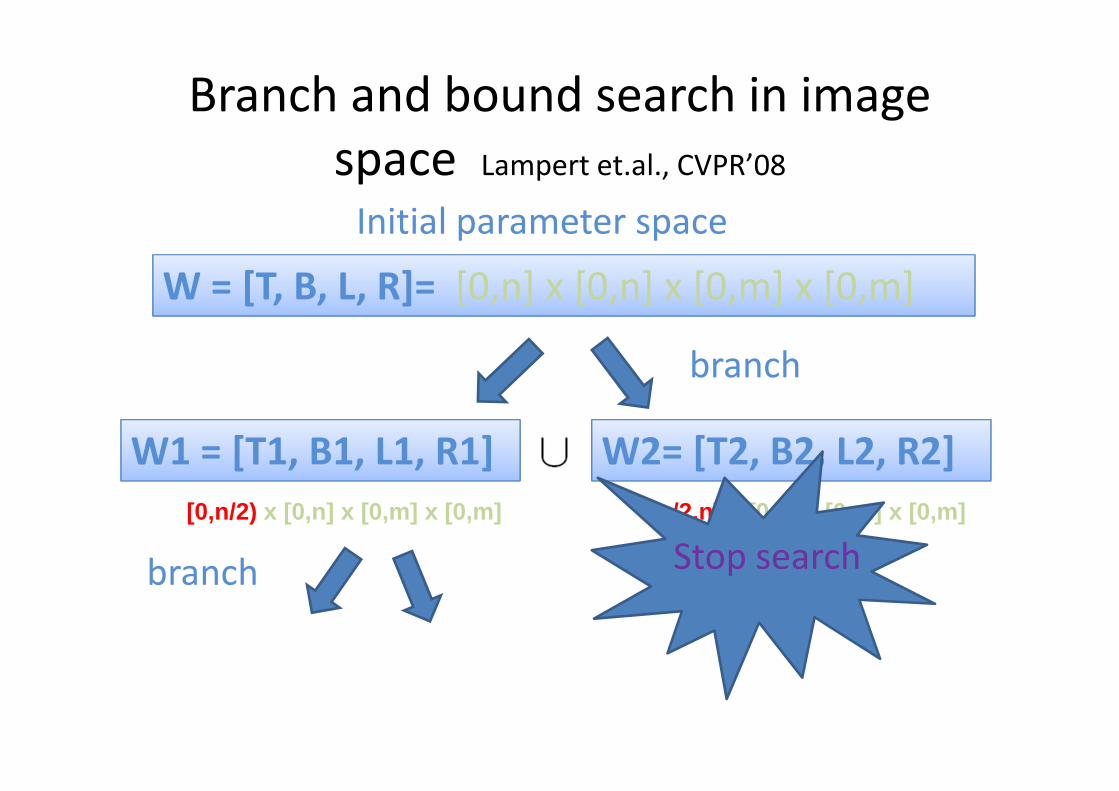
Branch and bound search in image
space Lampert et.al., CVPR’08
Initial parameter space
[0,n/2) x [0,n] x [0,m] x [0,m] [n/2,n] x [0,n] x [0,m] x [0,m]
W = [T, B, L, R]= [0,n] x [0,n] x [0,m] x [0,m]
W1 = [T1, B1, L1, R1] W2= [T2, B2, L2, R2]
branch Stop search
branch
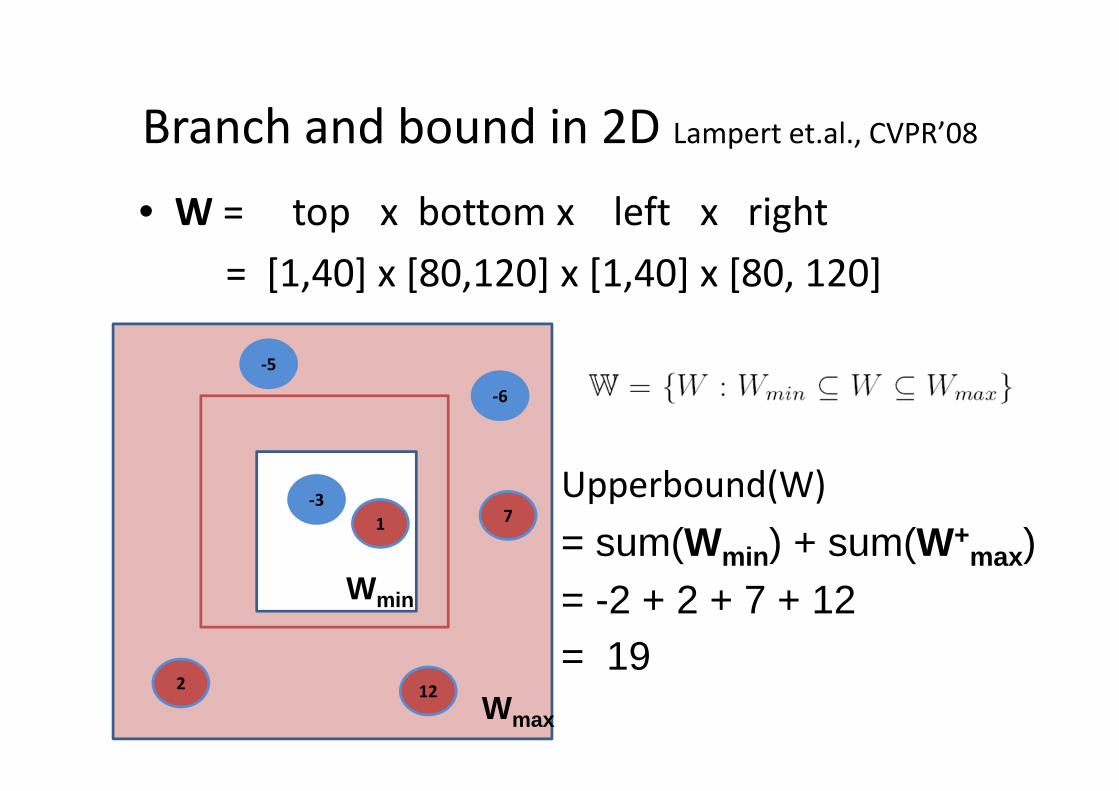
Branch and bound in 2D Lampert et.al., CVPR’08
• W = top x bottom x left x right
= [1,40] x [80,120] x [1,40] x [80, 120]
-3
1
12
7
-5
2
-6
Upperbound(W)
= sum(Wmin ) + sum(W+max)
= -2 + 2 + 7 + 12= 19
Wmin
Wmax
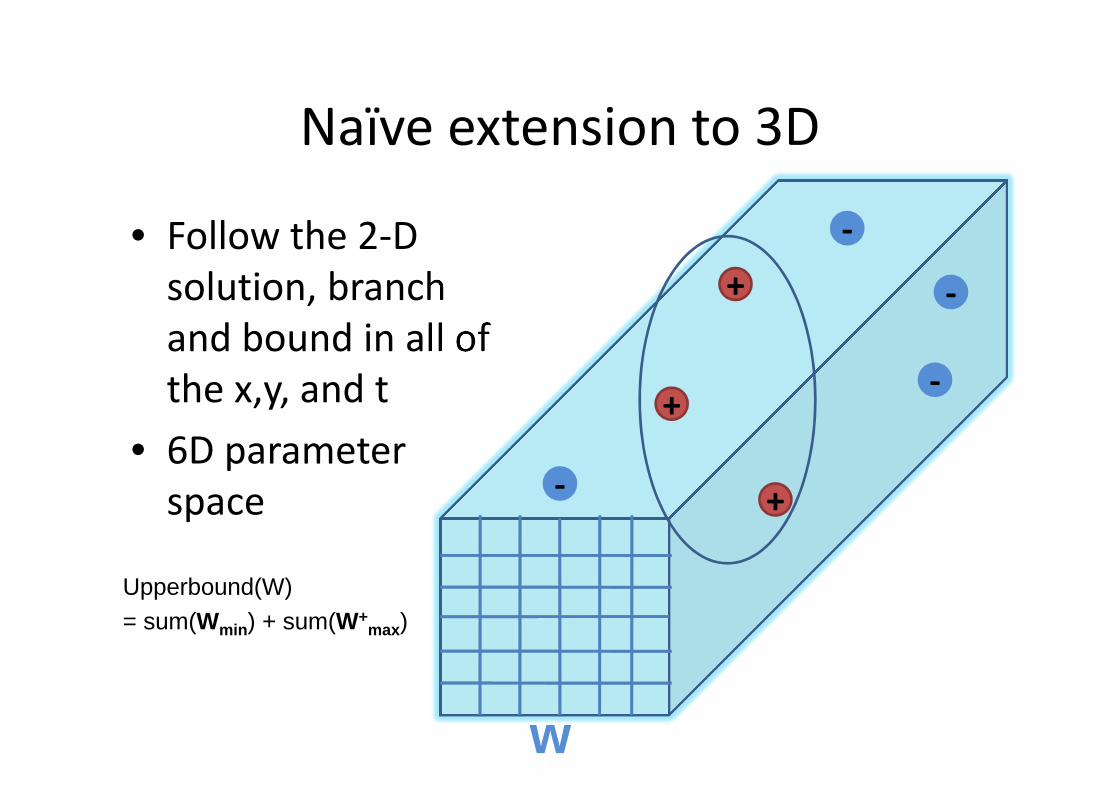
Naïve extension to 3D
• Follow the 2-D
solution, branch
and bound in all of
the x,y, and t
• 6D parameter
space
w
+
+
+
-
-
-
-
Upperbound(W)= sum(Wmin ) + sum(W+
max)
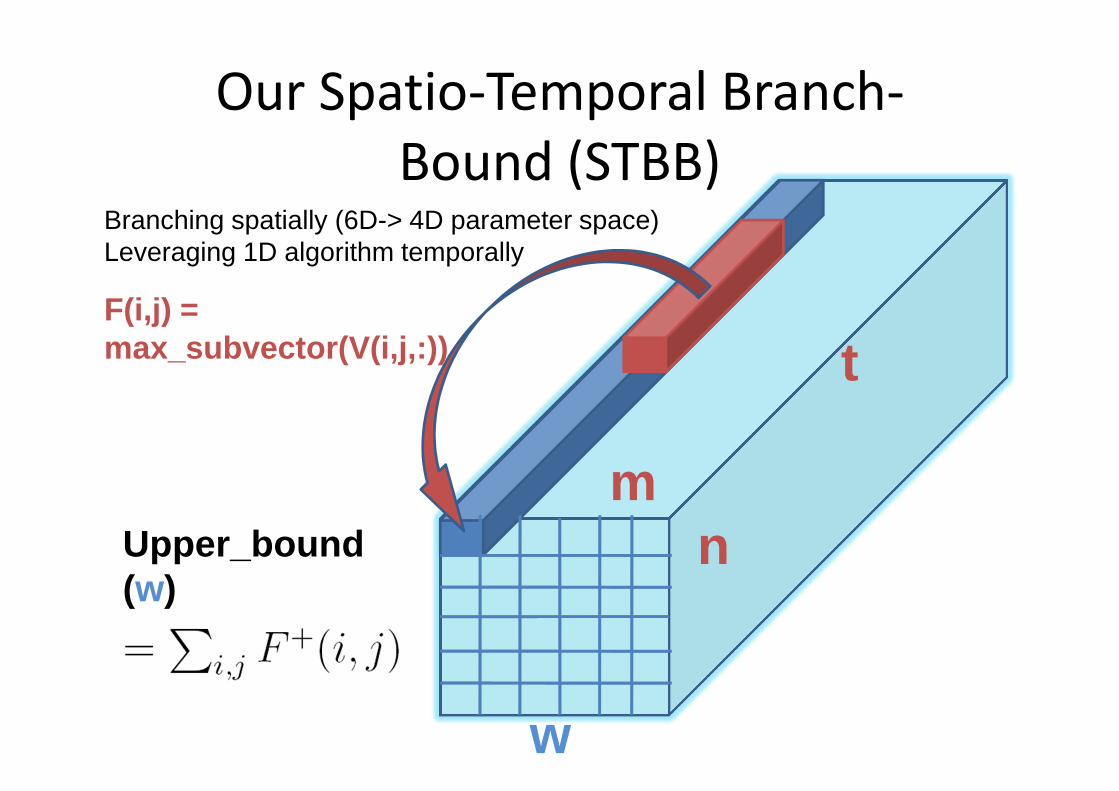
Our Spatio-Temporal Branch-
Bound (STBB)
F(i,j) = max_subvector(V(i,j,:))
mn
t
w
Upper_bound(w)
Branching spatially (6D-> 4D parameter space)Leveraging 1D algorithm temporally

Upper Bound in STBB
• A further development of the upper bound
• The minimum of the above two is the final upper bound
J. Yuan, Z. Liu, Y. Wu “Discriminative Subvolume Se arch for Efficient Action Detection”, T-PAIM 2011

Complexity Comparison
STBB Naïve extension
Dimensions for
Branch and bound
4 (spatial domain) 6 (spatial - temporal)
Cost for estimating
the upper bound
O(T) O(1)
worst case O(N4T) O(N4T2)
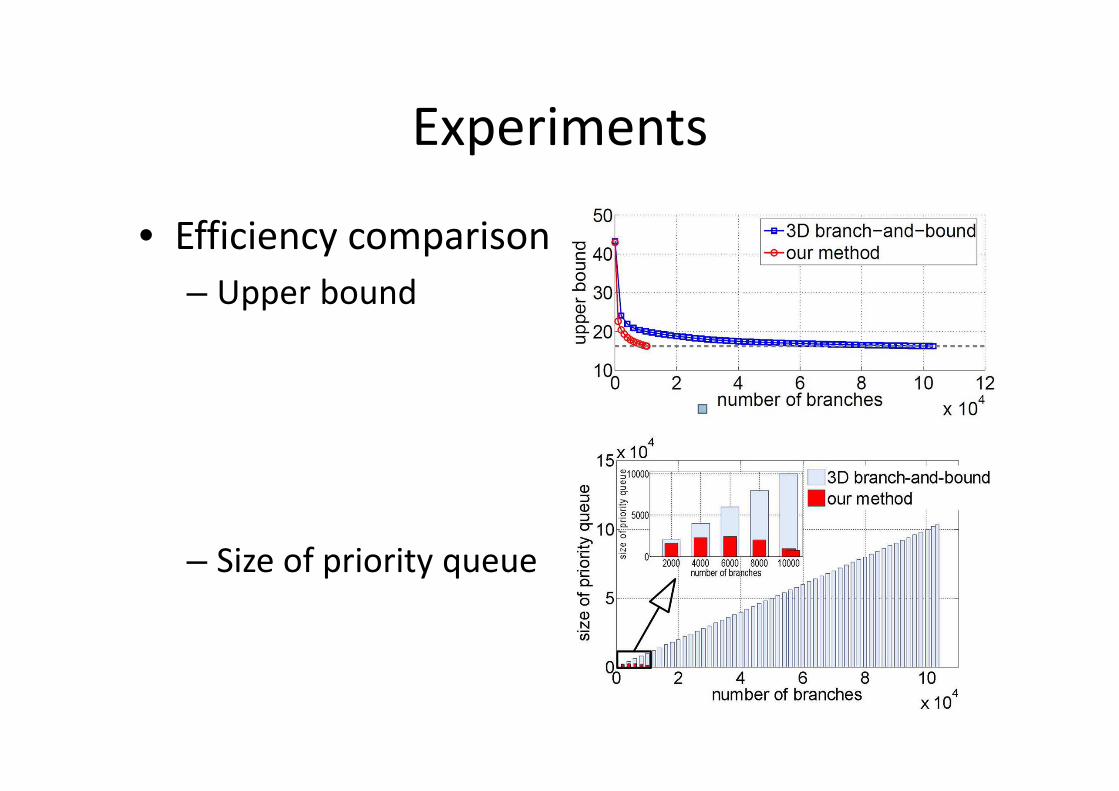
Experiments
• Efficiency comparison
– Upper bound
– Size of priority queue

Experiments
• Training KTH
• Testing
– CMU dataset (handwaving)
– MSRII action dataset (handclapping, handwaving,
boxing)
• 54 videos, 1 min each
• 320x240
• Multiple action instances on each video

KTH MSRII
MSRII: multiple actions in the same scene

Two-hand waving detection

Multi-class action detection
Hand waving boxing
Hand clapping
Dr. Junsong Yuan / NTU
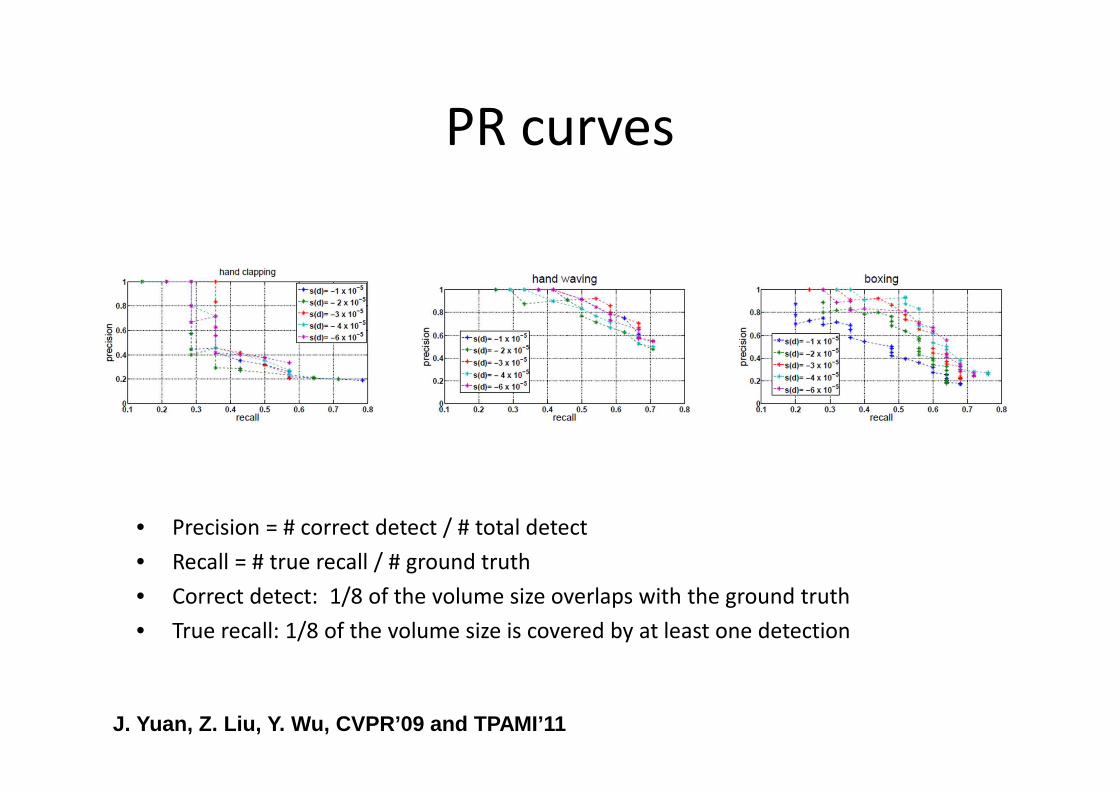
PR curves
• Precision = # correct detect / # total detect
• Recall = # true recall / # ground truth
• Correct detect: 1/8 of the volume size overlaps with the ground truth
• True recall: 1/8 of the volume size is covered by at least one detection
J. Yuan, Z. Liu, Y. Wu, CVPR’09 and TPAMI’11

Limitations of subvolume search
�Pros:
� Data-driven methods
� Fast search with global optimality
�Cons:
� subvolume assumption
� nearest neighbor matching is time consuming
� require sufficient training data
� do not consider the spatio-temporal structure

Action Detection by Video
Spatio-Temporal Path Search
D. Tran and J. Yuan, CVPR’11 and NIPS’12
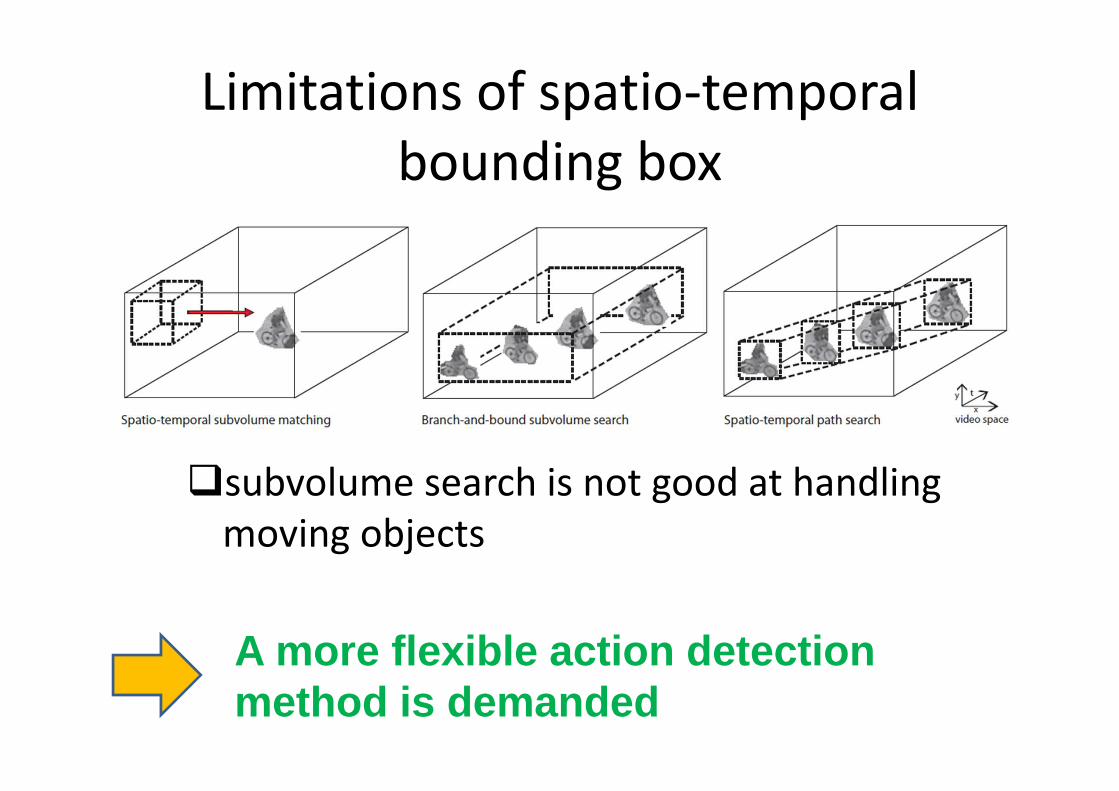
Limitations of spatio-temporal
bounding box
�subvolume search is not good at handling
moving objects
A more flexible action detection method is demanded

Action Detection as Spatio-Temporal
Path Search
�Search for the spatio-temporal path that maximizes the summation score.
�This problem is HARD:o The search space is
exponential
o The event varies in both scales and shapes
o The event may have arbitrary length
D. Tran and J. Yuan, “Optimal Spatio-Temporal Path Discovery for Video Event Detection”, CVPR 2011
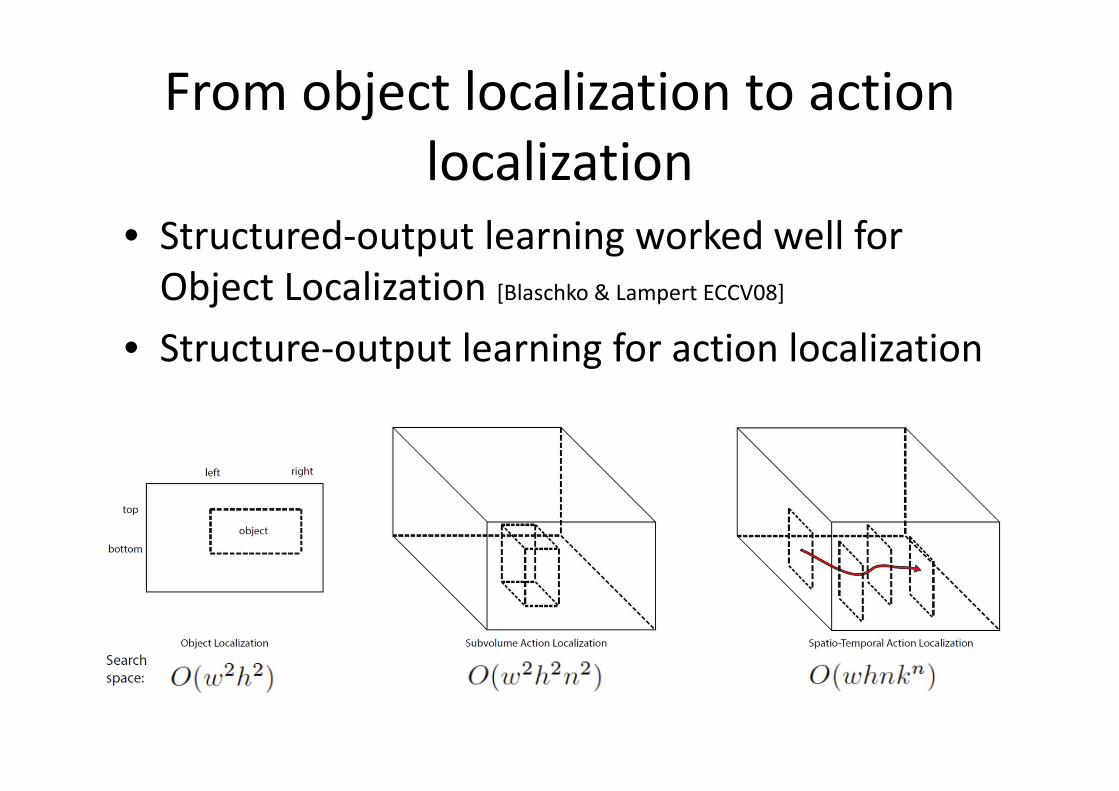
From object localization to action
localization
• Structured-output learning worked well for
Object Localization [Blaschko & Lampert ECCV08]
• Structure-output learning for action localization

Advantages
�Spatio-temporal path search for human
action and video event detection
�Handle multiple scales, shapes, and action
instances
�Global optimality and lowest complexity
guaranteed
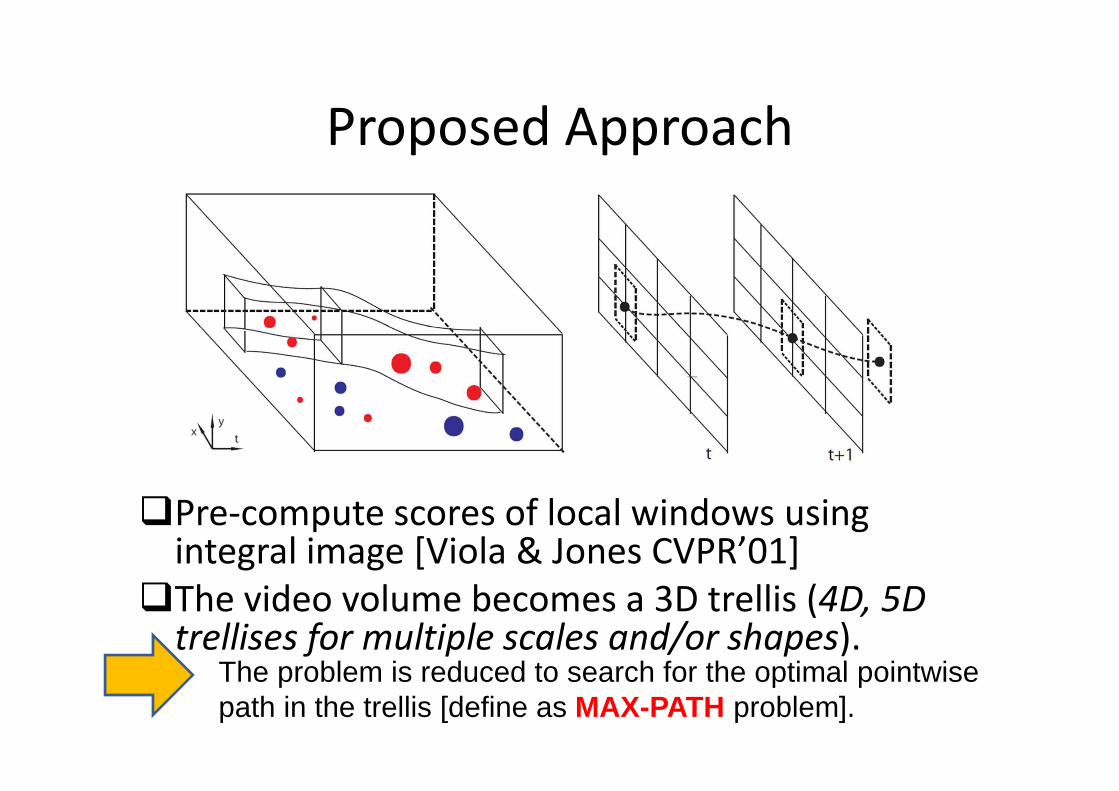
Proposed Approach
�Pre-compute scores of local windows using integral image [Viola & Jones CVPR’01]
�The video volume becomes a 3D trellis (4D, 5D trellises for multiple scales and/or shapes).
The problem is reduced to search for the optimal pointwise path in the trellis [define as MAX-PATH problem].

MAX-PATH Search Problem
�Dynamic programming approach: O(whn2)
�Our proposed message passing: O(whn),
attains the lowest complexity for this
problem. �advantages1. Handle multiple
scales and shapes2. Automatically detect
starting and ending location
3. Allow multiple instance detection
D. Tran and J. Yuan, “Optimal Spatio-Temporal Path Discovery for Video Event Detection ”, CVPR 2011 (PAMI under minor revision)

MAX-PATH Search
• Given 3D trellis of local discriminative scores
� visualized in upper numbers
• At each node, compute the accumulated score
of the best path leads to it � visualized in
lower numbers
• After all nodes’ accumulated scores are
evaluated, look for the highest accumulated
score, then trace back to localize the best path

3D trellis with local + and - scores
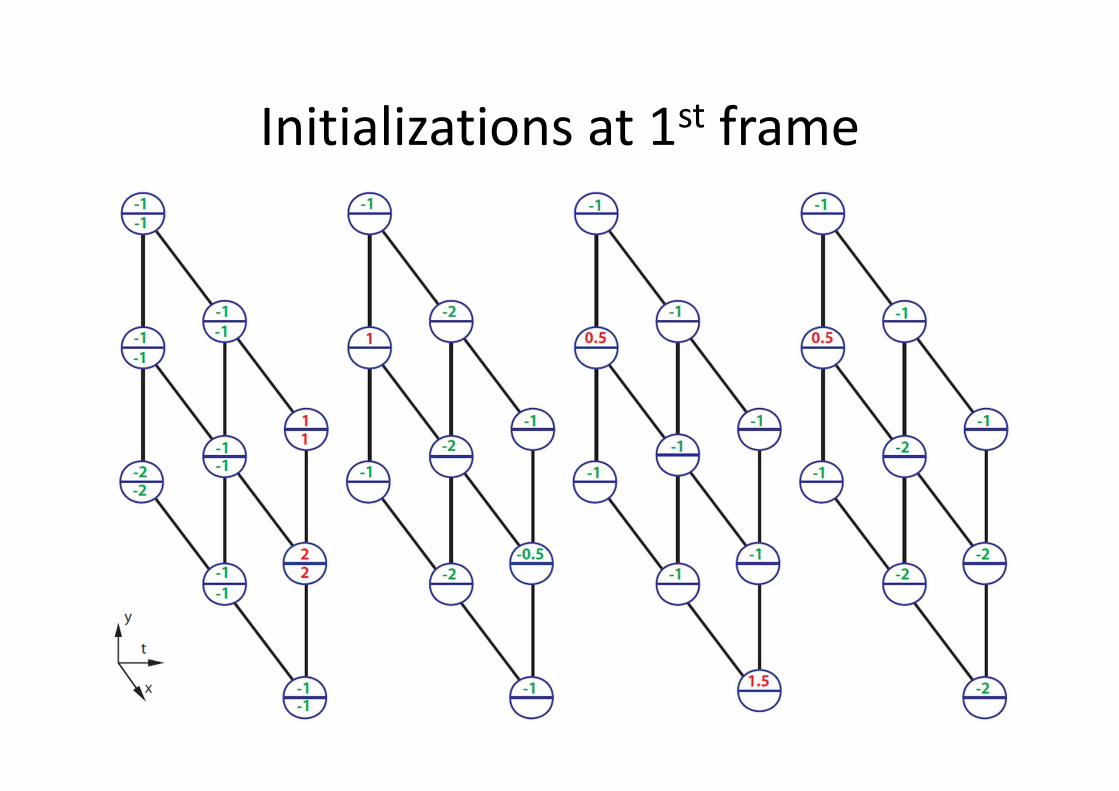
Initializations at 1st frame
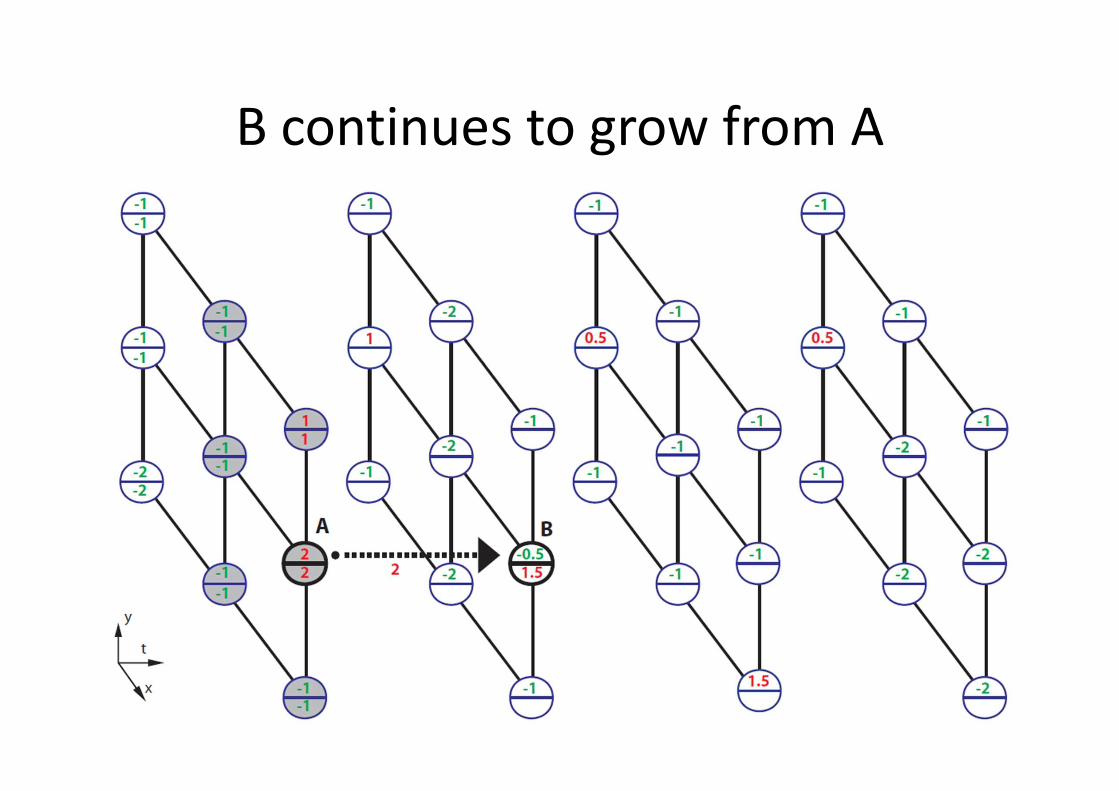
B continues to grow from A
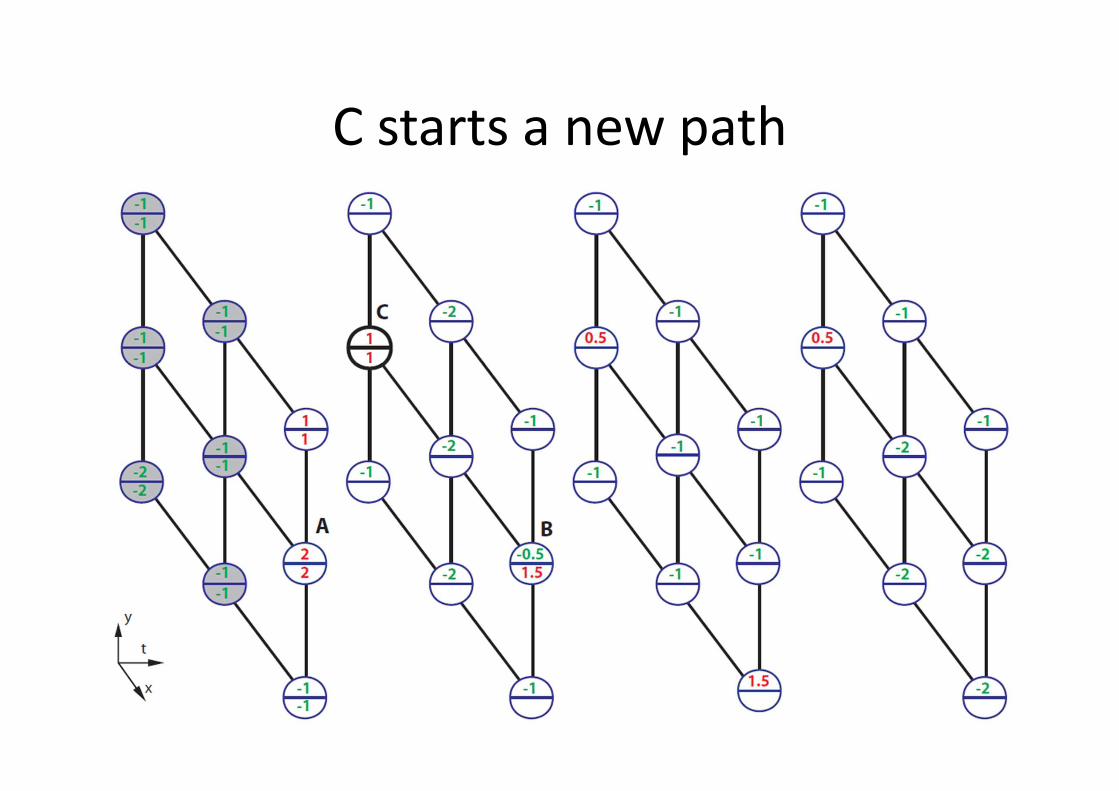
C starts a new path
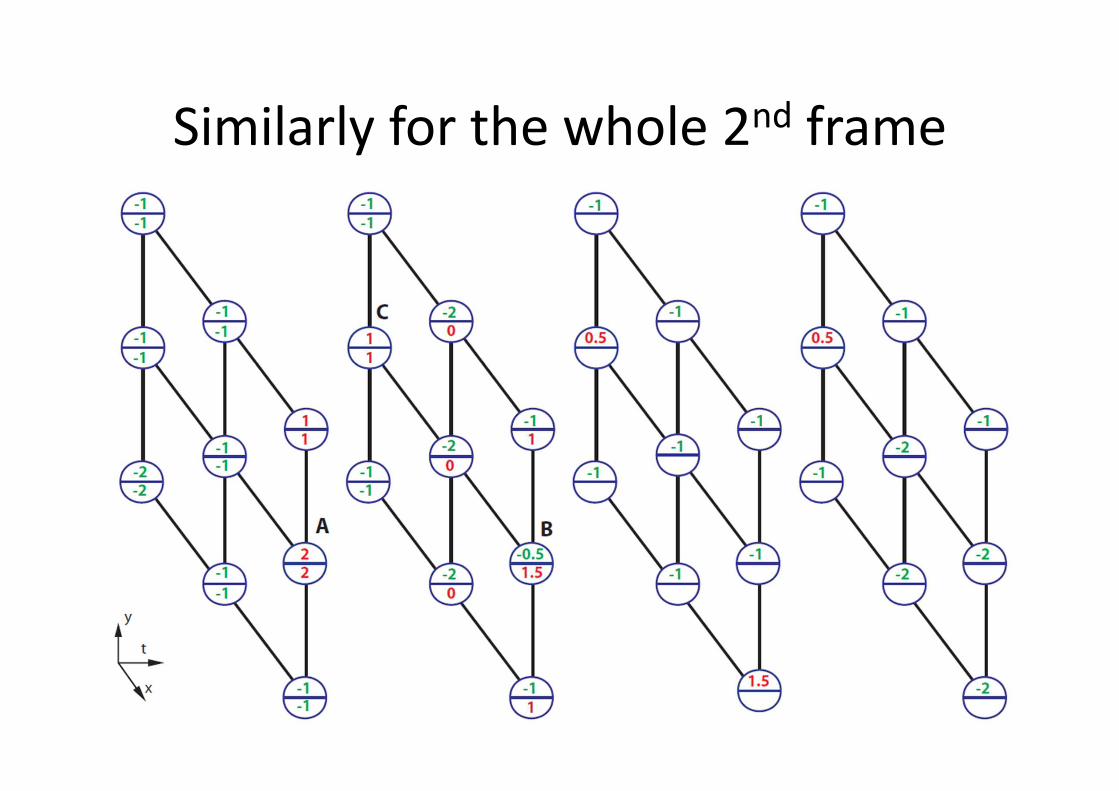
Similarly for the whole 2nd frame
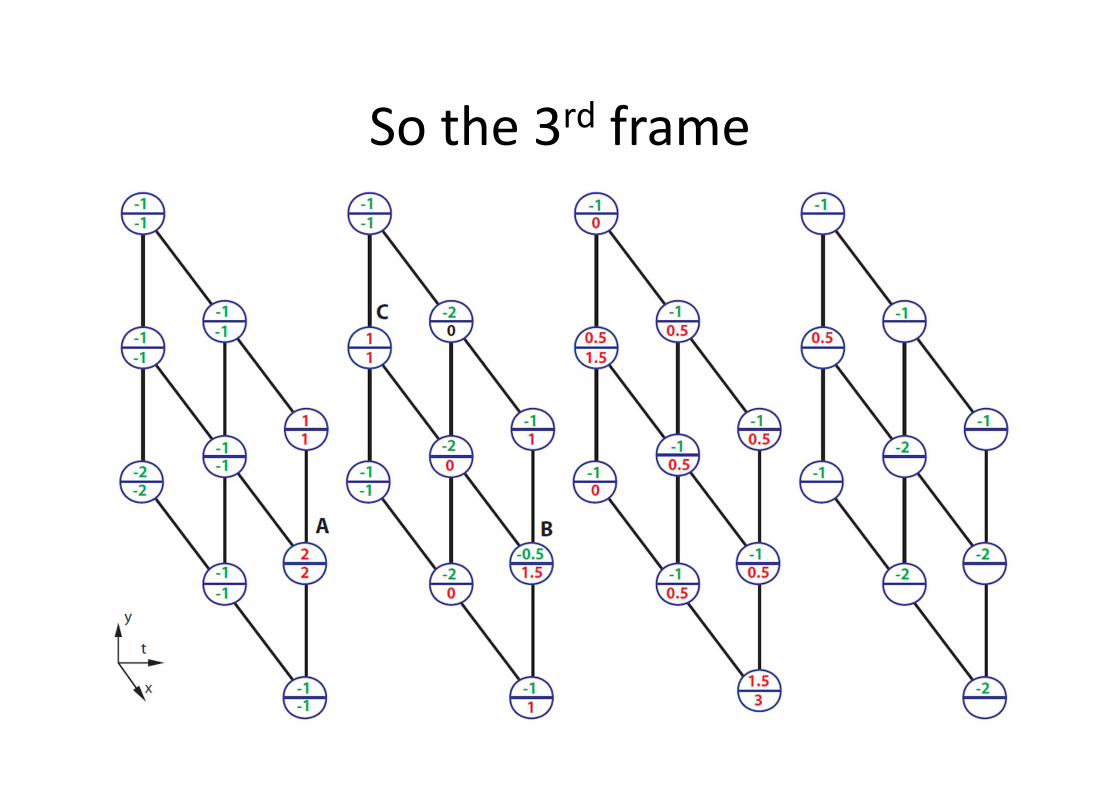
So the 3rd frame
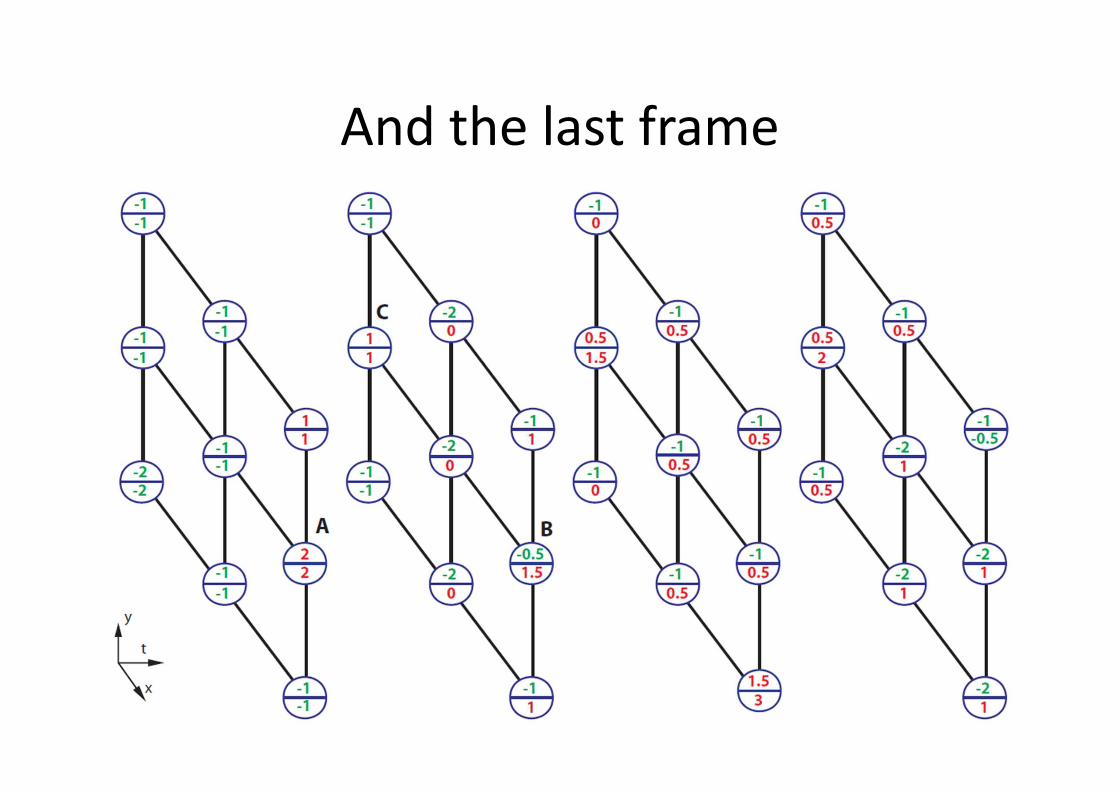
And the last frame
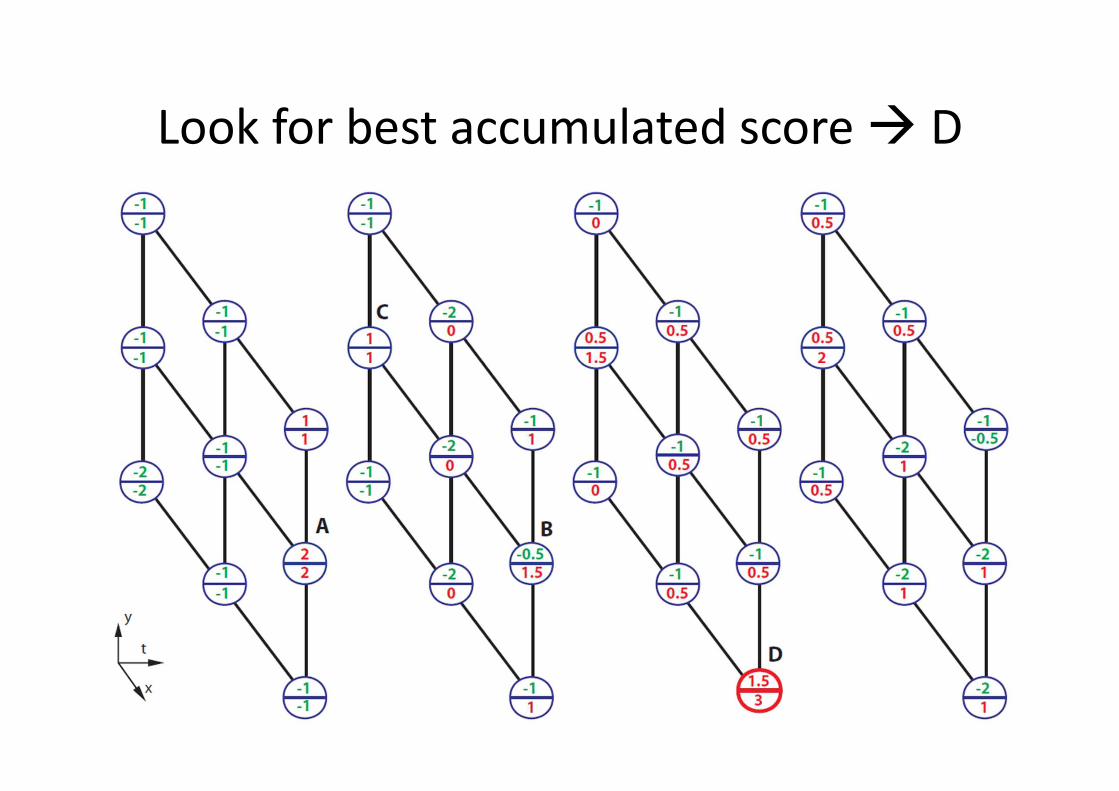
Look for best accumulated score � D
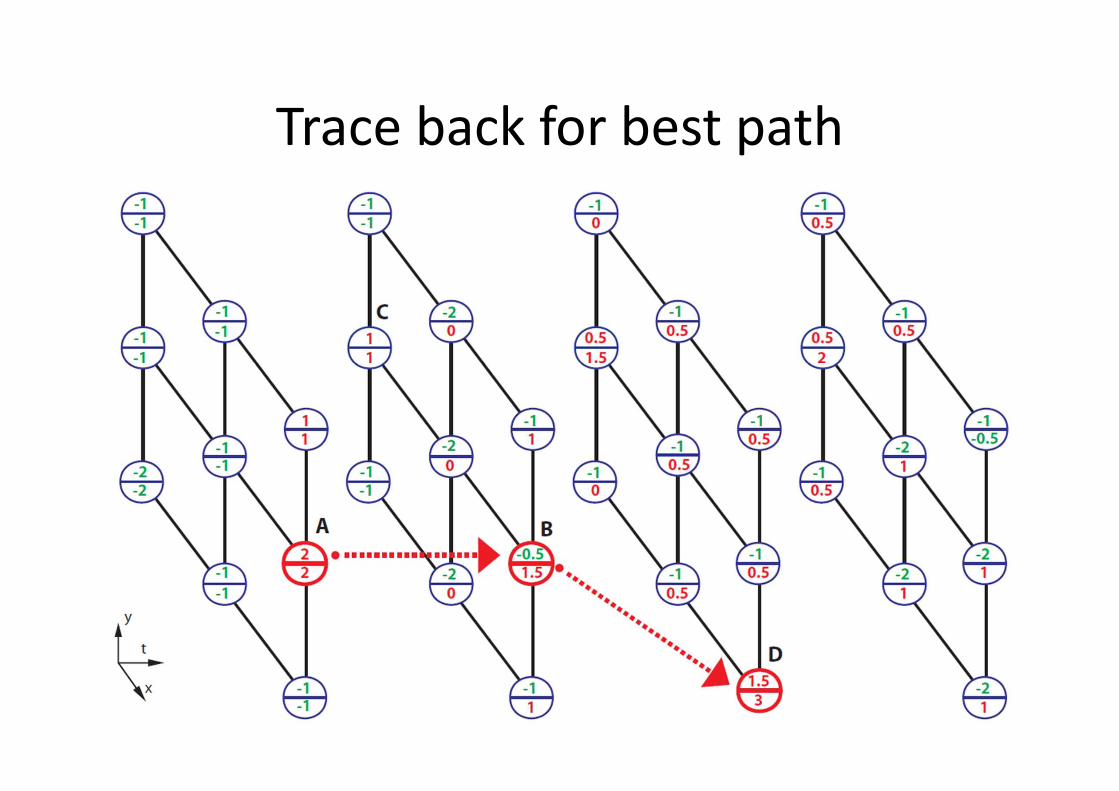
Trace back for best path
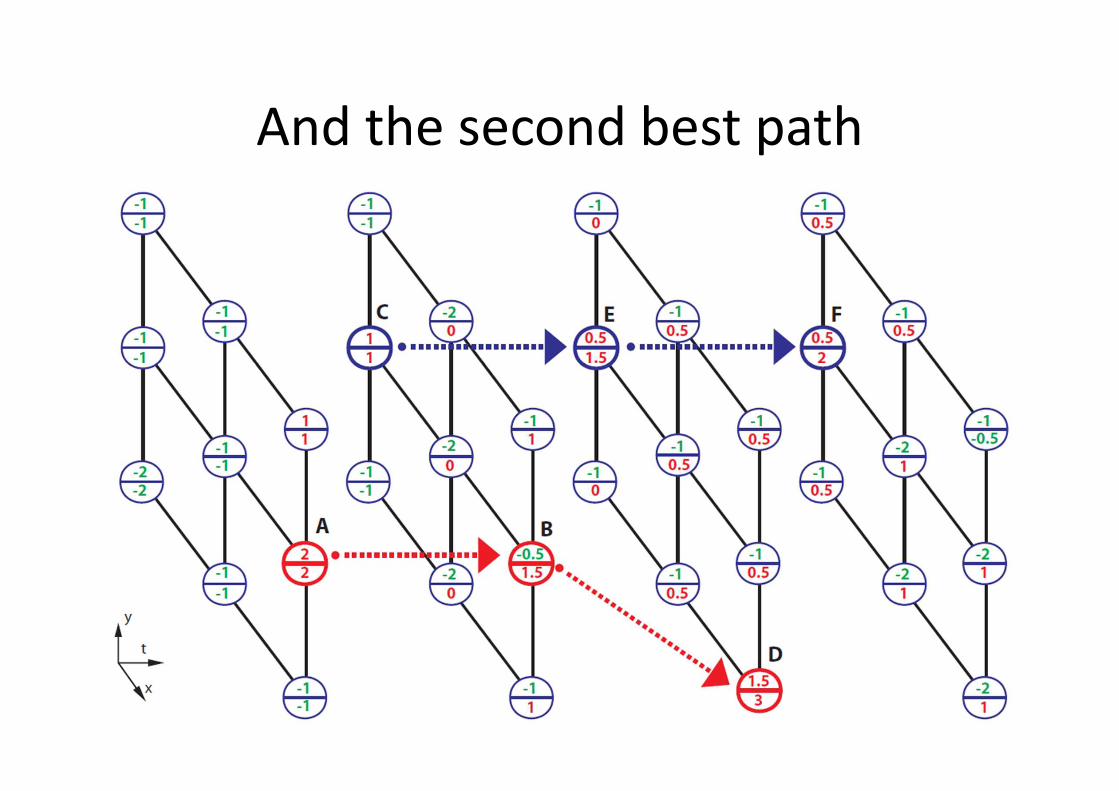
And the second best path
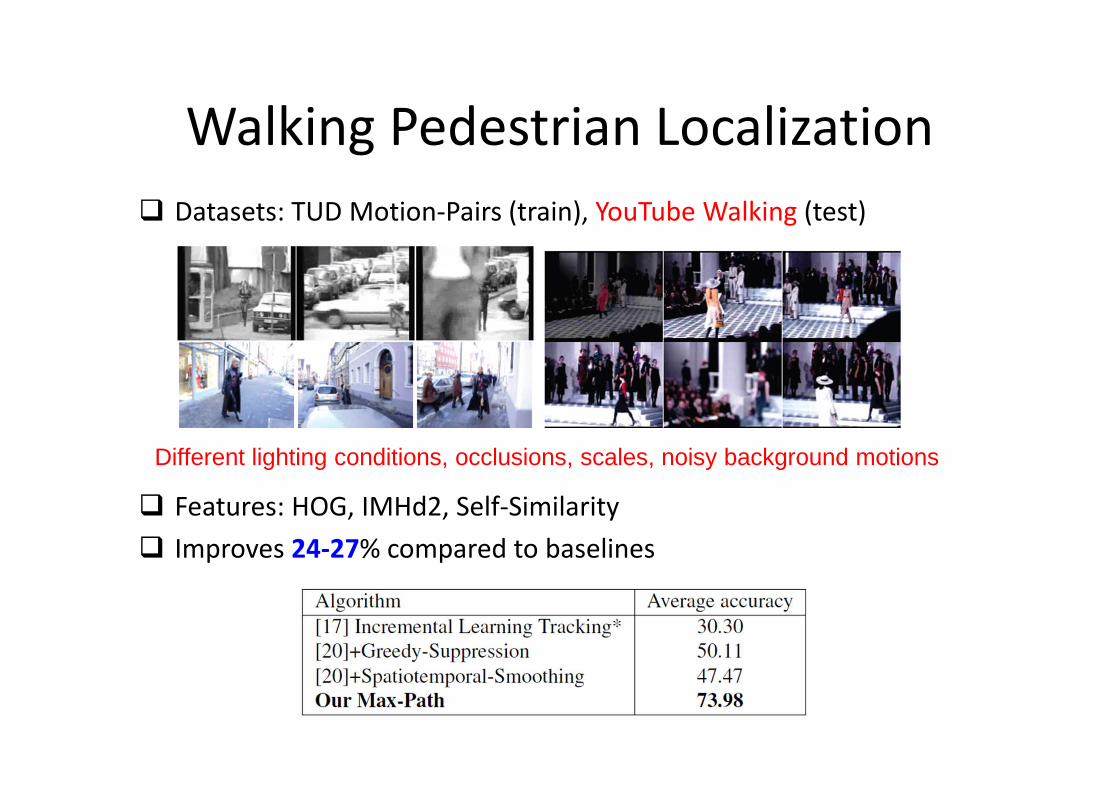
Walking Pedestrian Localization
� Datasets: TUD Motion-Pairs (train), YouTube Walking (test)
� Features: HOG, IMHd2, Self-Similarity
� Improves 24-27% compared to baselines
Different lighting conditions, occlusions, scales, noisy background motions

Walking Pedestrian Localization (cont.)

Multiple Walking Localization


Abnormal Event Detection
�Dataset: UCSD abnormal event dataset
[Mahadevan et al CVPR’10]
�Features: HOG, HOF
�Improves 36.22% compared to subvolume
search
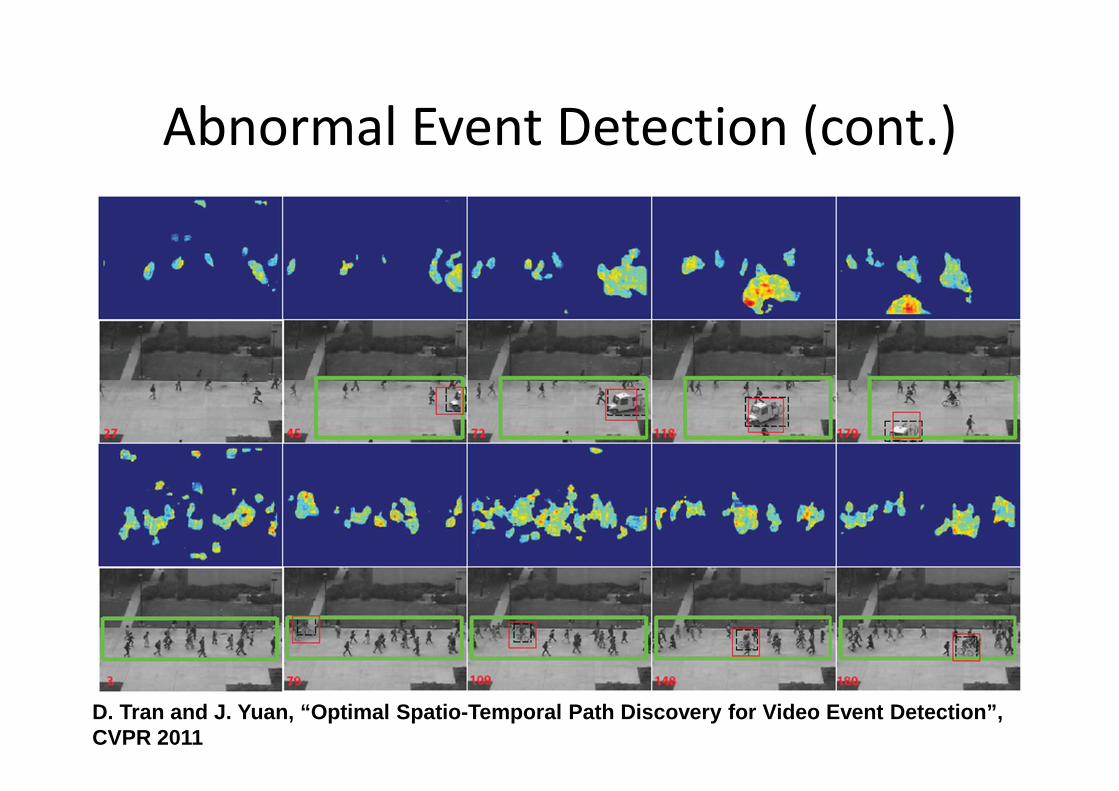
Abnormal Event Detection (cont.)
D. Tran and J. Yuan, “Optimal Spatio-Temporal Path Discovery for Video Event Detection”, CVPR 2011


Limitations of spatio-temporal path
search
• Assuming local detection is independent: only
care about the total sum
• The spatio-temporal structure information of
the action is lost

Structured-Output Learning
•
InferenceLearning
Learning & inference are efficiently solved by Max-Path search [Tran & Yuan CVPR11]
D. Tran and J. Yuan, NIPS 2012

Advantages
o detects and localizes actions spatially andtemporally
o is structurally optimized within a large search space
o needs neither human detector norbackground subtraction
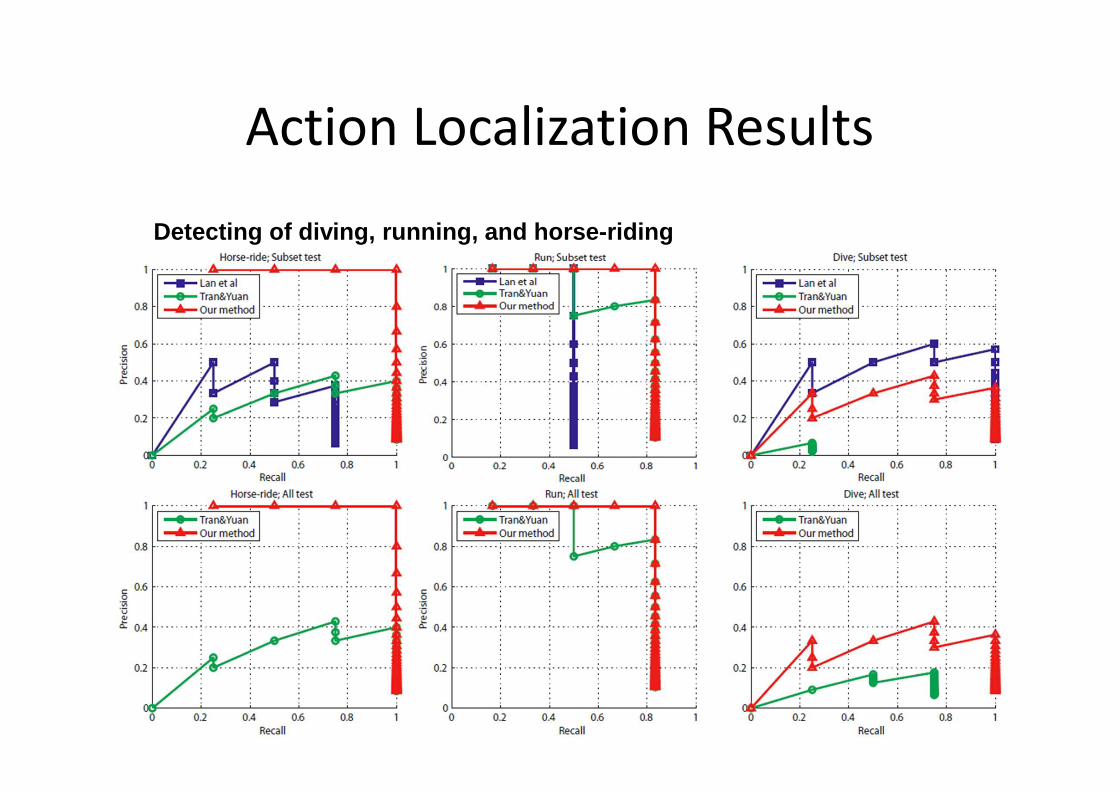
Action Localization Results
Detecting of diving, running, and horse-riding

Action Localization Results
Detecting of diving, running, and horse-riding
Our method also allows multiple detections
T. Du and J. Yuan, NIPS’12

Kiss Detection
T. Du and J. Yuan, NIPS’12

Structure Output learning for
action localization
T. Du and J. Yuan, NIPS’12
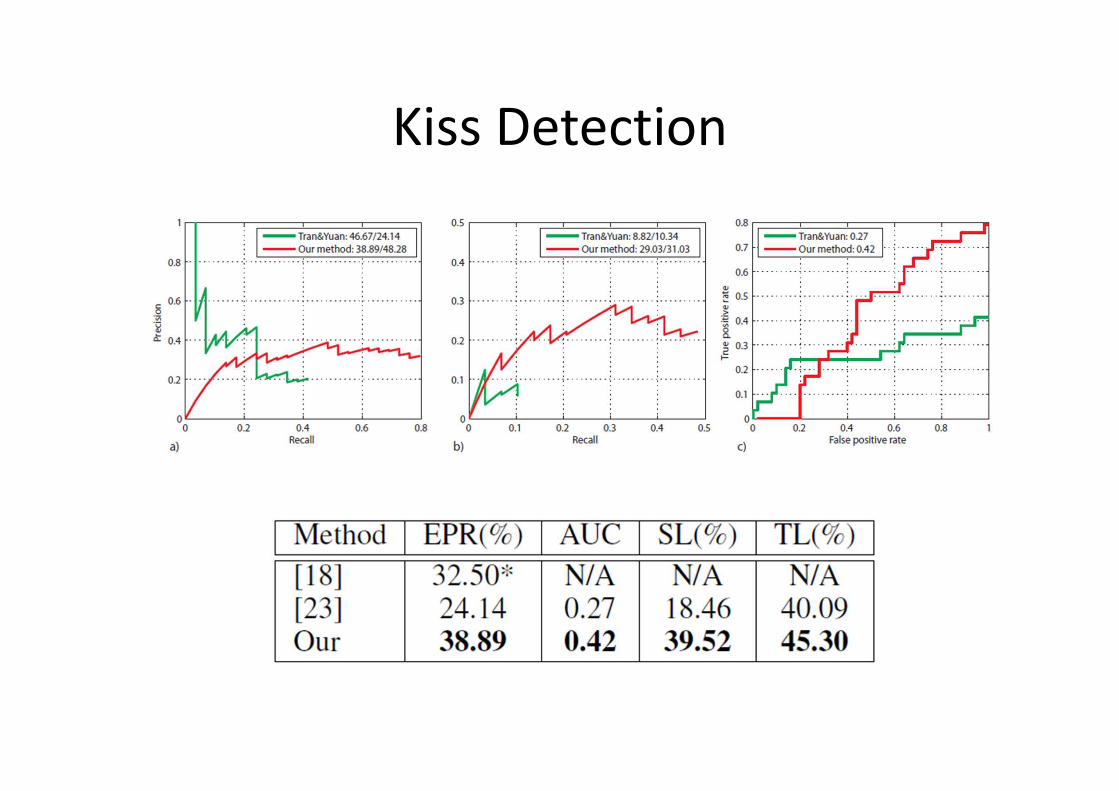
Kiss Detection

Conclusions
�Contributions:
o Naïve-Bayes Mutual Information scoring
o Human action event detection as spatio-temporal
bounding box/path search
o Attain global optimality and lowest complexity
o Can be structurally optimized within a large search
space
o Handle multiple scales, shapes, and action instances
�More information:
o Datasets, source code, and binary code are online

Action Detection with Limited
Training Data
G. Yu, J. Yuan, and Z. Liu, CVPR’11 and TIP’13

Action Detection with Limited
Training Examples• Large-scale video dataset
• Query action
101

Challenges
• Few query examples for training
• Accurate spatio-temporal localization required
• Fast response of query examples required
• Effective user feedback preferred
102

Our method
• Matching and Indexing
– Multiple visual vocabularies
• Large in-class variations
• User interaction and feedback
– Mutual information based formulation
• Search
– Coarse-to-fine Branch & Bound Search
• Fast response time
103

Indexing
• Nearest neighbor search
– Accurate matching but high computational cost
• “Bag of words” model
– Fast matching but inevitable quantization Error
• Multiple (independent) copies of visual vocabularies
– Support fast matching
– Support accurate matching by reducing the quantization error
104

Randomized visual vocabularies
• Implementation:
– Random Indexing Trees (Unsupervised: different
from Random Forest)
• Tree structure: fast
• Randomness: reduce the biases
• Unsupervised: applicable to any query action type
105

Random Indexing Trees
• Splitting criteria:
– We generate around 50 hypotheses
– Select the one with the large variance
106
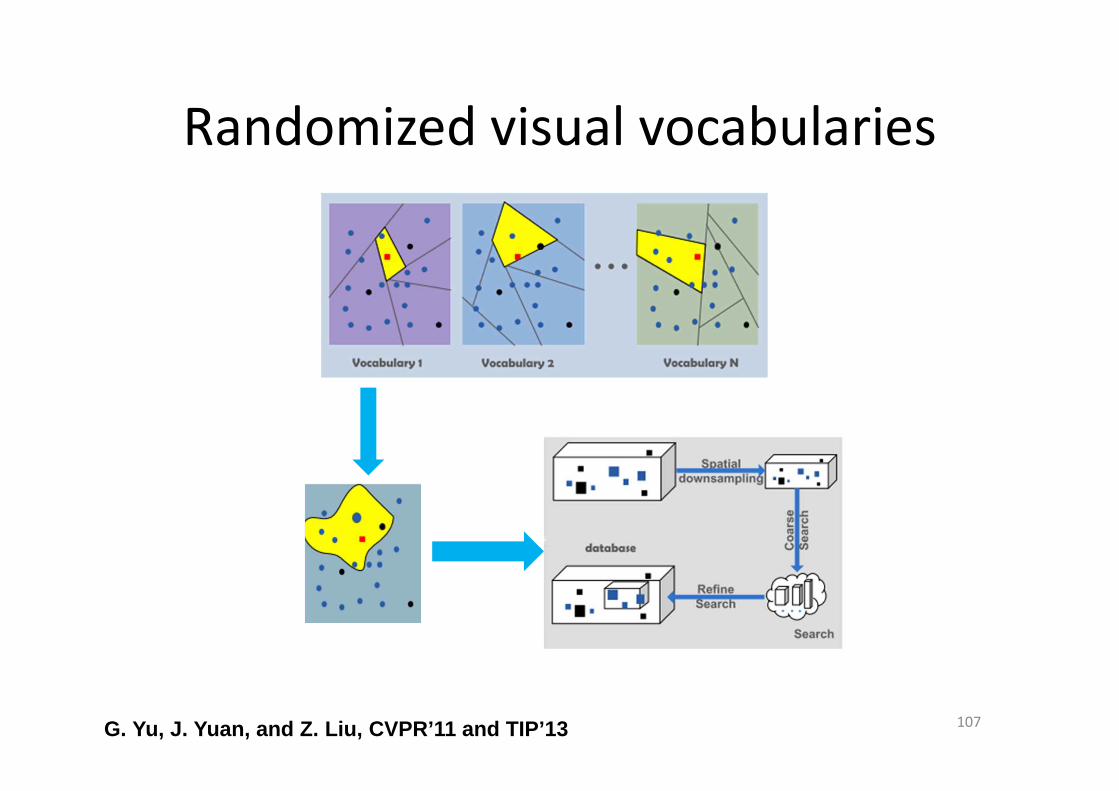
Randomized visual vocabularies
107G. Yu, J. Yuan, and Z. Liu, CVPR’11 and TIP’13
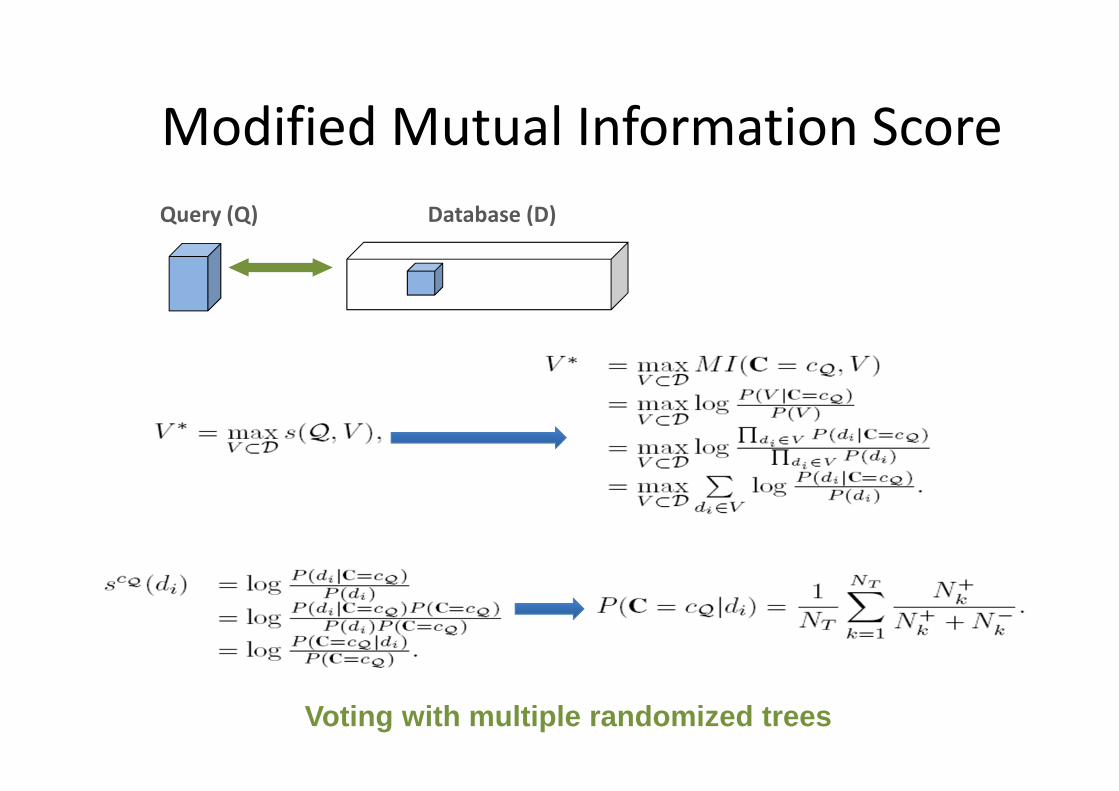
Modified Mutual Information Score
Query (Q) Database (D)
Voting with multiple randomized trees

Coarse-to-Fine Branch and Bound
Search
• Error bound of spatial down-sampling
109G. Yu, J. Yuan, and Z. Liu, TMM’11

Coarse-to-Fine Branch and Bound
Search• Coarse search:
– Set downsampling factor of 2s, B&B search to filter the
first round of results
• Fine Search:
– Suppose we want to get the top K results, keep the first K’
(based on error bound) and re-rank them with
downsampling factor s and lambda search
• Trade-off
– Speed and accuracy
110

Experiments:
• Dataset
111
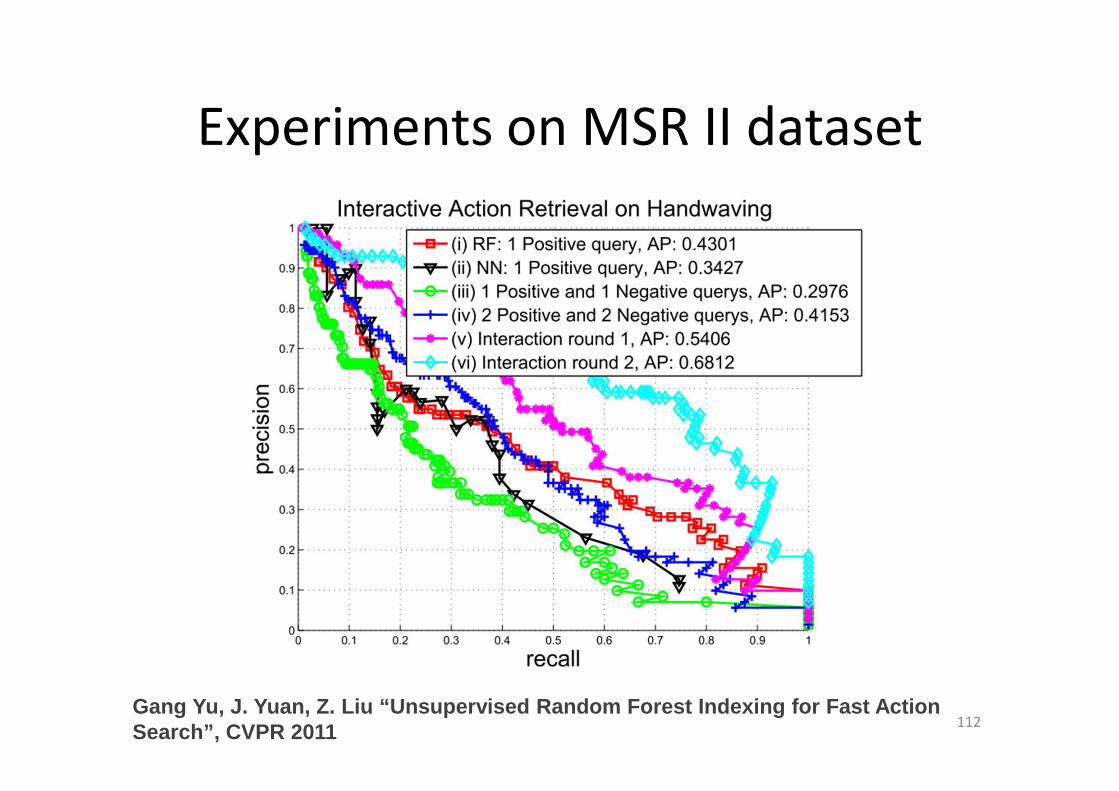
Experiments on MSR II dataset
112Gang Yu, J. Yuan, Z. Liu “Unsupervised Random Fores t Indexing for Fast Action Search”, CVPR 2011

Experiments on CMU dataset
113
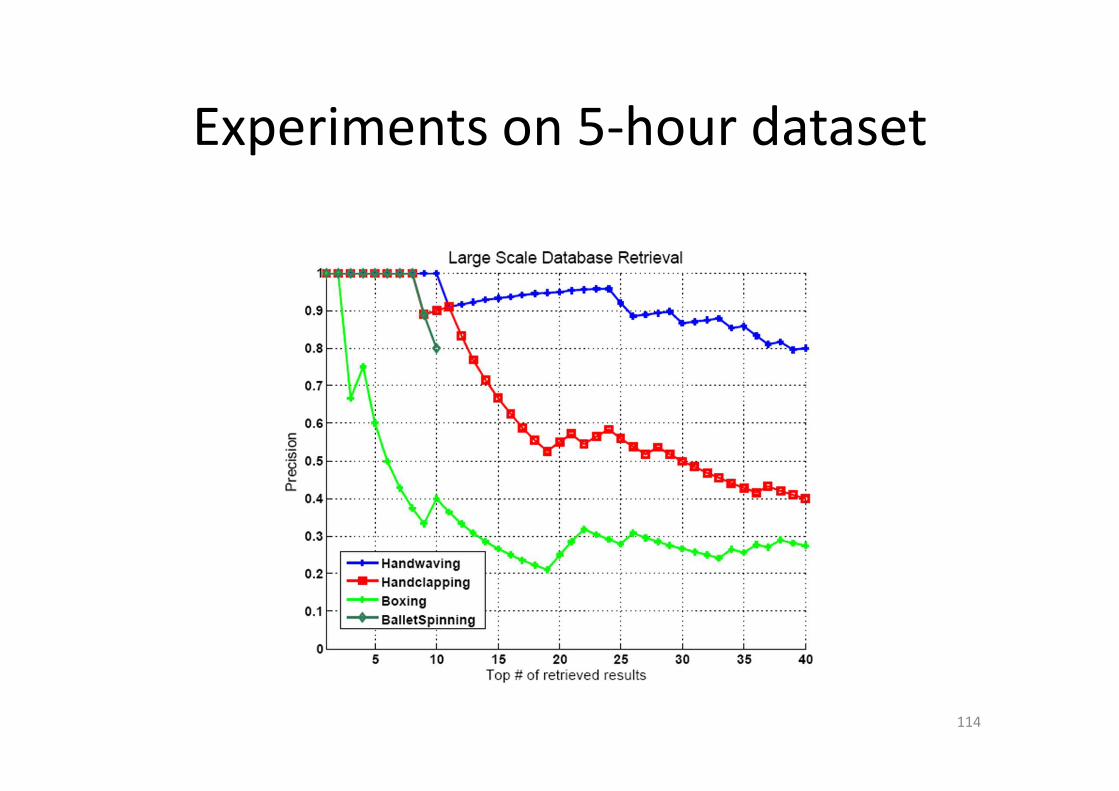
Experiments on 5-hour dataset
114
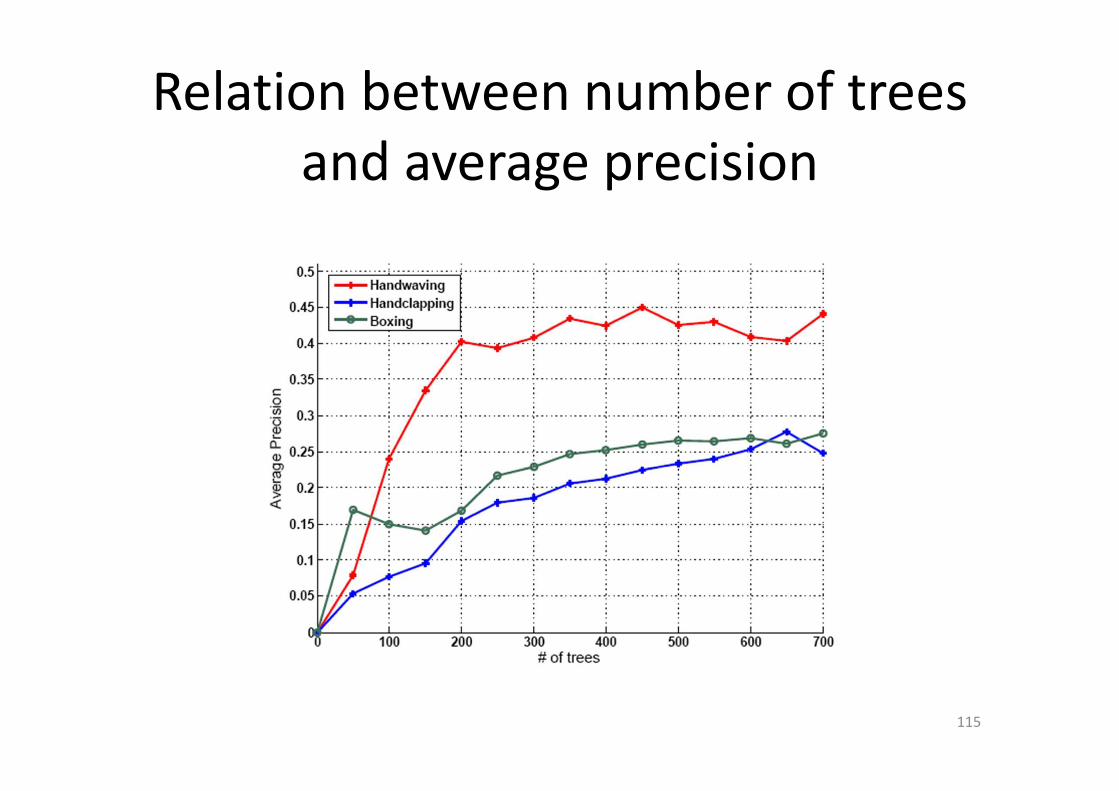
Relation between number of trees
and average precision
115
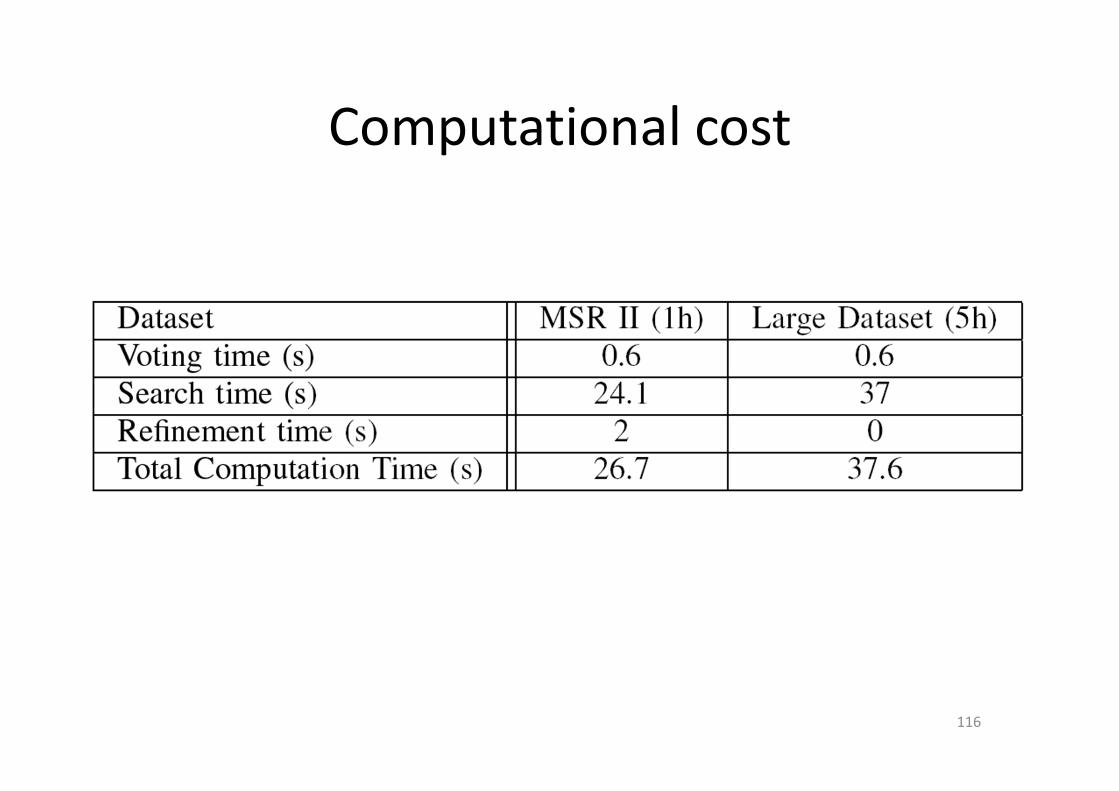
Computational cost
116

Action Detection by Spatio-
Temporal Hough Voting
J. Yuan, Z. Liu, and Y. Wu, ACM MM’12 and ECCV’12
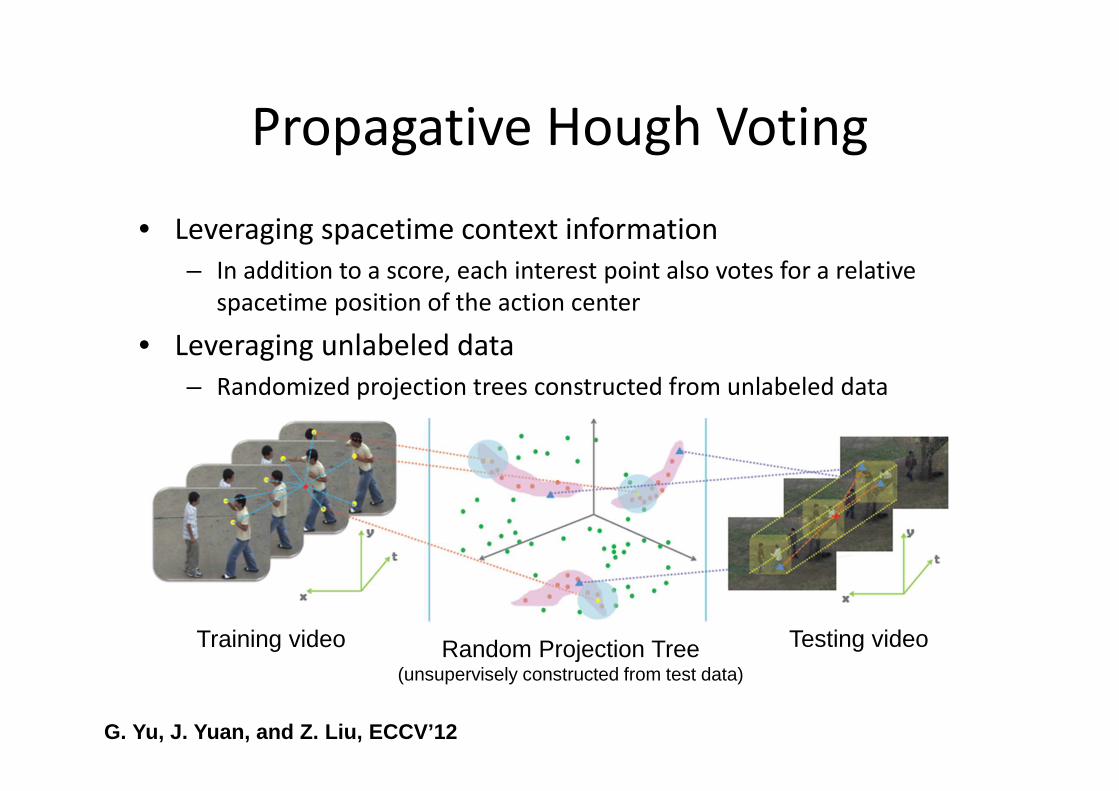
Propagative Hough Voting
• Leveraging spacetime context information
– In addition to a score, each interest point also votes for a relative
spacetime position of the action center
• Leveraging unlabeled data
– Randomized projection trees constructed from unlabeled data
Training video Testing videoRandom Projection Tree(unsupervisely constructed from test data)
G. Yu, J. Yuan, and Z. Liu, ECCV’12

Formulation: interest points in training videos: a test video
: subvolume parameterized by its center location: x=(u,v), t, and scale � � �width, height, duration)
Action localization: finding subvolume V with maximum similarity score to the specified action type
�: ��� ��� ��� ��, �: ���� ���

�: normalization constant
#: bandwidth parameters
�� �*
�*
�* u − l- u = ./[� � − � � ]
�* v − l- v = .3[� � − � � ]
�* t − l- t = .4[� − � ]
5( 6, , � �*, � =1
��
7
64 789
:
;:
./, .3, .4 : scale ratio between <*��< <

Random Projection Trees (RPTs) for
Feature Matching
• Constructed from unlabeled data in an
unsupervised way
• RPTs adapt to the low-dimensional manifold in
the high dimensional feature space, Dasgupta&Freund2008

RPT Construction
Algorithm

Analogy to Graph-Based Label
Propagation
• Label Propagation
– Build a graph by using data (labeled and
unlabeled) without using label information
– Propagate labels from labeled data to unlabeled
data by leveraging the graph structure
• Propagative Hough Voting
– Build RPTs by using unlabeled data (ok to use
labeled)
– Propagate votes from labeled data to unlabeled
data

Practical Consideration:
Avoid Scale Voting
• Simultaneously voting for 6 parameters: not
practical due to noises in voting scores
• Remedy:
– Initialize scale parameters
– Voting for position
– Refine scale parameters (back projection)
– Voting for position again
– …
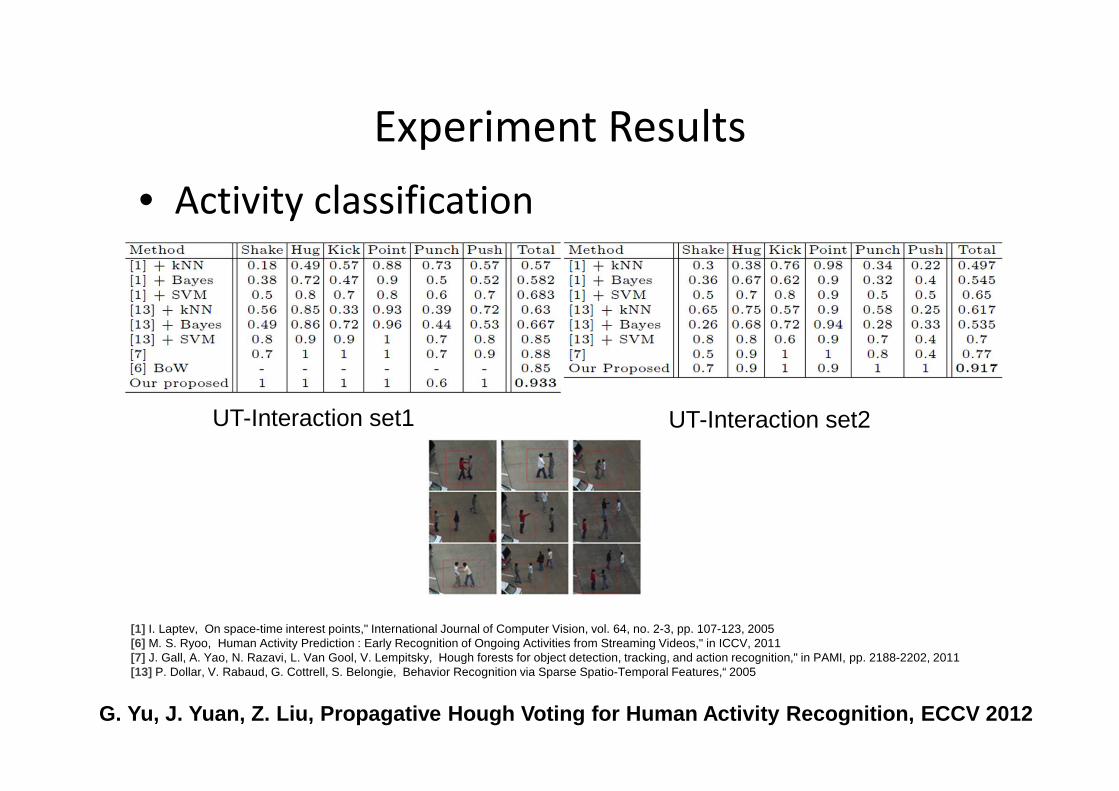
Experiment Results
• Activity classification
G. Yu, J. Yuan, Z. Liu, Propagative Hough Voting fo r Human Activity Recognition, ECCV 2012
[1] I. Laptev, On space-time interest points," International Journal of Computer Vision, vol. 64, no. 2-3, pp. 107-123, 2005[6] M. S. Ryoo, Human Activity Prediction : Early Recognition of Ongoing Activities from Streaming Videos," in ICCV, 2011[7] J. Gall, A. Yao, N. Razavi, L. Van Gool, V. Lempitsky, Hough forests for object detection, tracking, and action recognition," in PAMI, pp. 2188-2202, 2011 [13] P. Dollar, V. Rabaud, G. Cottrell, S. Belongie, Behavior Recognition via Sparse Spatio-Temporal Features,“ 2005
UT-Interaction set1 UT-Interaction set2
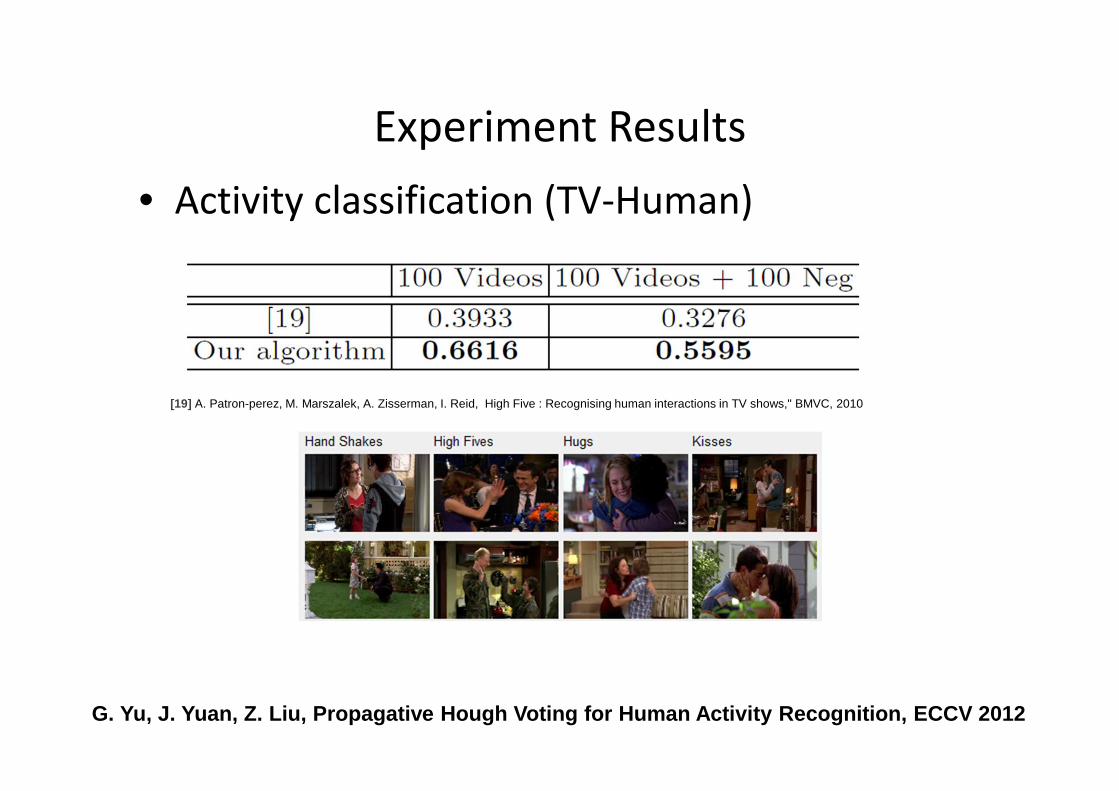
Experiment Results
• Activity classification (TV-Human)
[19] A. Patron-perez, M. Marszalek, A. Zisserman, I. Reid, High Five : Recognising human interactions in TV shows," BMVC, 2010
G. Yu, J. Yuan, Z. Liu, Propagative Hough Voting fo r Human Activity Recognition, ECCV 2012
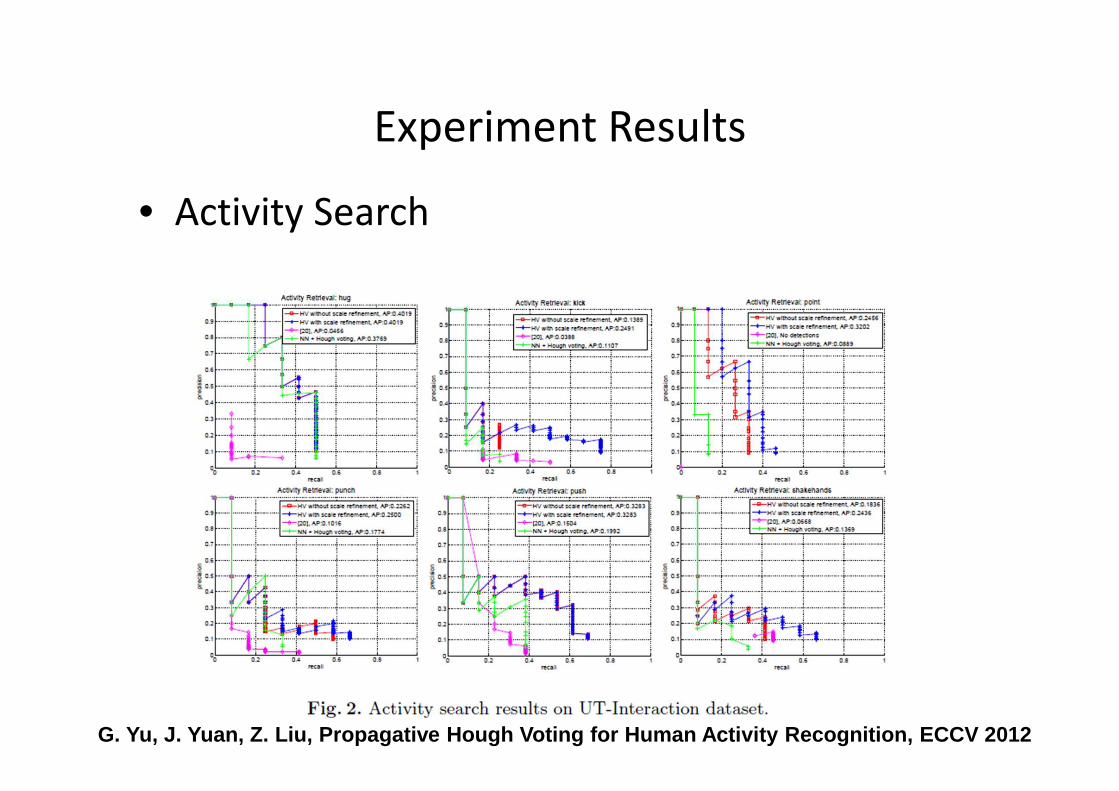
Experiment Results
• Activity Search
G. Yu, J. Yuan, Z. Liu, Propagative Hough Voting fo r Human Activity Recognition, ECCV 2012
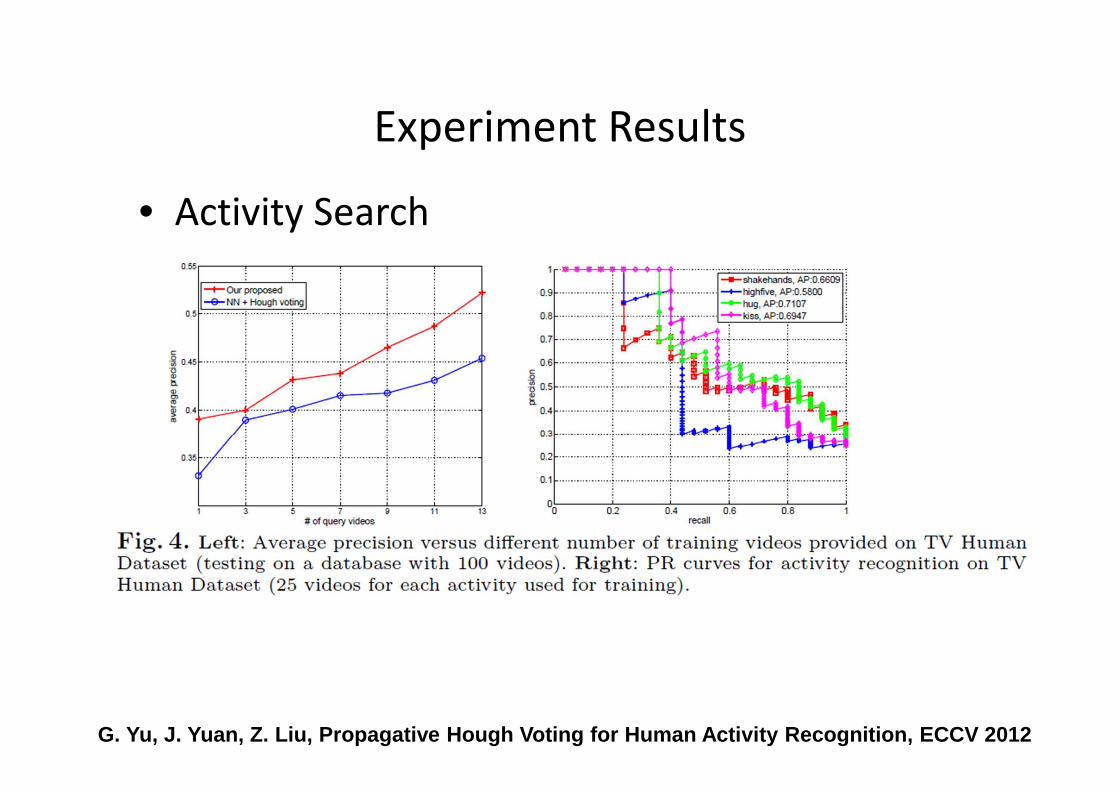
Experiment Results
• Activity Search
G. Yu, J. Yuan, Z. Liu, Propagative Hough Voting fo r Human Activity Recognition, ECCV 2012

queryvideo
queryvideo
search results search results
G. Yu, J. Yuan, Z. Liu, Propagative Hough Voting fo r Human Activity Recognition, ECCV 2012
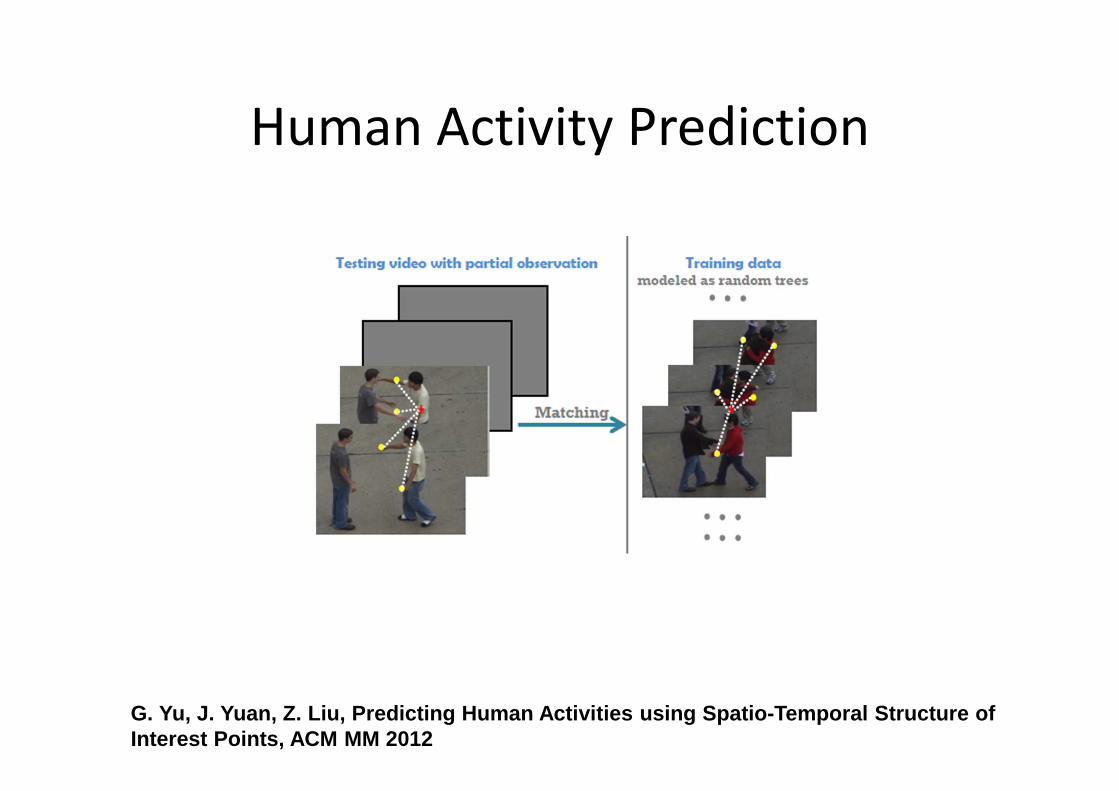
Human Activity Prediction
G. Yu, J. Yuan, Z. Liu, Predicting Human Activities using Spatio-Temporal Structure of Interest Points, ACM MM 2012
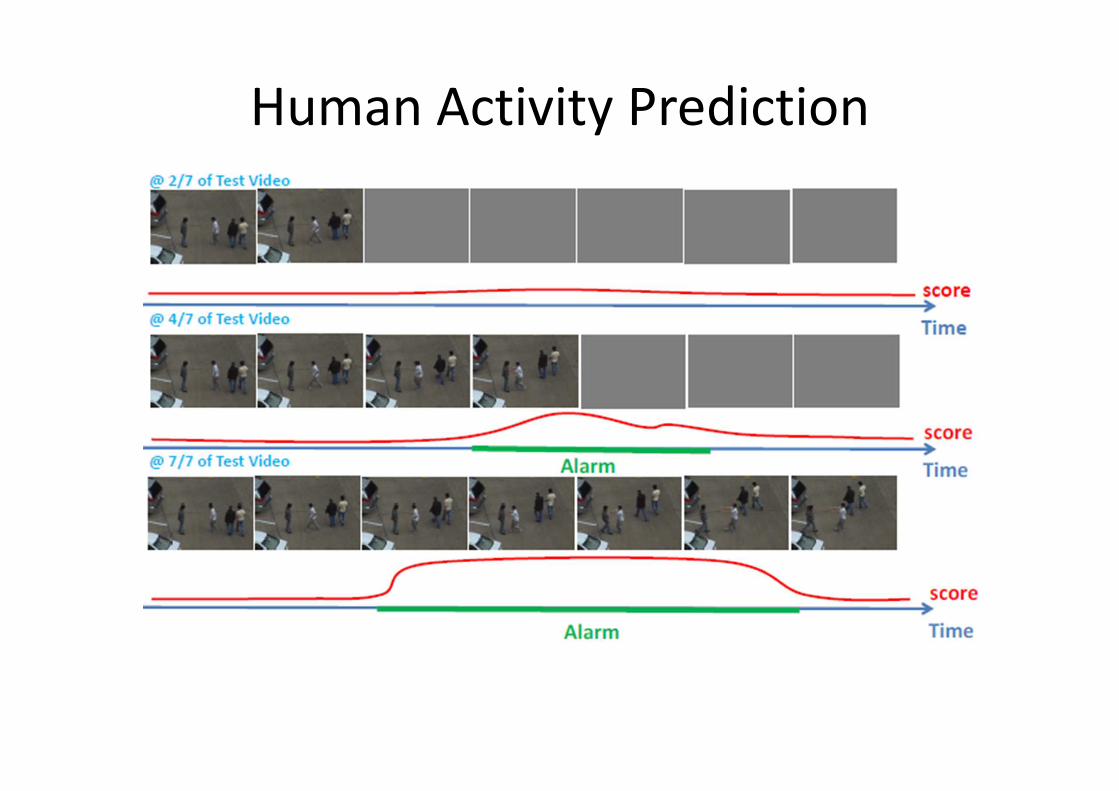
Human Activity Prediction

Summary of Part 1
• Voting with NBMIM – discriminative NN
• Action Localization: Subvolume and ST-path
search
• Structured output learning for action localization
• Multiple visual vocabularies using RPT
• Propagative Hough voting using Context
• Tasks
– classification, detection, search, prediction
Future Directions
• Recognizing not just what, but also how
• Person-person interaction
• Human-object interaction
– Taking Medicine or drinking water?
• Action recognition helping human detection?
– Crowded environment
• Lexicon of human actions
