tutorial on recurrent neural networks - jordi pons · utotrial on recurrent neural networks jordi...
TRANSCRIPT

1/37
Tutorial on recurrent neural networks
Jordi Pons
Music Technology Group
DTIC - Universitat Pompeu Fabra
January 16th, 2017

2/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode problem
Gated units: LSTM & GRU
Other solutions
Jordi Pons Tutorial on recurrent neural networks

3/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Recurrent Neural Networks?
Figure : Unfolded recurrent neural network
h(t) = σ(b+Wh(t−1) +Ux(t))
o(t) = c+ Vh(t)
Throughout this presentation we assume single layer RNNs!
Jordi Pons Tutorial on recurrent neural networks

4/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Recurrent Neural Networks? Annotation
h(t) = σ(b+Wh(t−1) +Ux(t)) o(t) = c+ Vh(t)
I x ∈ IRdinx1 y ∈ IR
doutx1
I b ∈ IRdhx1 h ∈ IR
dhx1
I U ∈ IRdhxdin W ∈ IR
dhxdh
I V ∈ IRdoutxdh σ: element-wise non-linearity.
Where din, dh and dout correspond to the dimensions of the inputlayer, hidden layer and output layer, respectively.
Jordi Pons Tutorial on recurrent neural networks

5/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Recurrent Neural Networks?
Figure : Unfolded recurrent neural network
Jordi Pons Tutorial on recurrent neural networks

6/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: forward � backward path
Figure : Forward and backward path for time-step t + 1 (yellow).
Jordi Pons Tutorial on recurrent neural networks
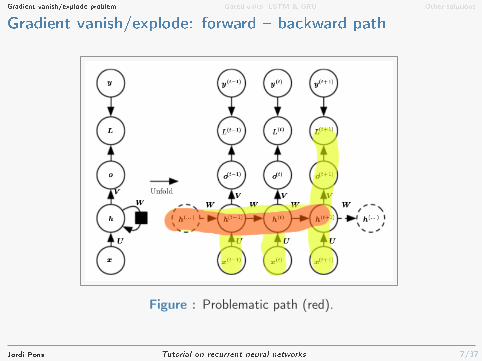
7/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: forward � backward path
Figure : Problematic path (red).
Jordi Pons Tutorial on recurrent neural networks

8/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: intuition from the forward linear case
I Study case: forward problematic path for the linear case.h(t) = σ(b+Wh(t−1) +Ux(t)) → h(t) = Wh(t−1)
I After t steps, this is equivalent to multiply Wt .
I Suppose that W has eigendecomposition W = Qdiag(λ)QT .
I Then: Wt = (Qdiag(λ)QT )t = Qdiag(λ)tQT .
Jordi Pons Tutorial on recurrent neural networks

9/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: intuition from the forward linear case
h(t) = W h(t−1) → h(t) = Wt h(0)
Remember: Wt = Qdiag(λ)tQT ,
then: h(t) = Qdiag(λ)t QT h(0).
I Any eighenvalues λi < 1 (and consequently h(t)) will vanish.I Any eighenvalues λi > 1 (and consequently h(t)) will explode.
Jordi Pons Tutorial on recurrent neural networks

10/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: intuition from the forward linear case
Observation 1:
I power method algorithm: �nd the largest eigenvalue of amatrix W. → Method very similar to Wt !
I Therefore, for: h(t) = Qdiag(λ)t QT h(0)
→ Any component of h(0) that is not aligned with thelargest eigenvector will eventually be discarded.
Observation 2:
I Recurrent networks use the same matrix W at each time step.
I Feedforward networks do not use the same matrix W:→ Very deep feedforward networks can avoid thevanishing and exploding gradient problem.→ if an appropriate scaling for W's variance is chosen.
Jordi Pons Tutorial on recurrent neural networks

11/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: back-propagation with non-linearities
→ Consider the backward pass when non-linearities are present.→ This will allow to explicitly describe the gradients issue.
∂L
∂W=∂L(o(t+1), y(t+1)
)∂W
+∂L(o(t), y(t)
)∂W
+∂L(o(t−1), y(t−1)
)∂W
=
=tmax∑
k=tmin
∂L(o(t−k), y(t−k)
)∂W
where S ∈ [tmin, tmax ] - S being the horizon of the BPTT alghoritm.
Jordi Pons Tutorial on recurrent neural networks

12/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: back-propagation with non-linearities
Let's now focus on time-step t + 1:
∂L(o(t−1), y(t−1)
)∂W
Jordi Pons Tutorial on recurrent neural networks

13/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: back-propagation with non-linearities
∂L(o(t+1), y(t+1)
)∂W
=∂L(o(t+1), y(t+1)
)∂o(t+1)
∂o(t+1)
∂h(t+1)
∂h(t+1)
∂W+
+∂L(o(t+1), y(t+1)
)∂o(t+1)
∂o(t+1)
∂h(t+1)
∂h(t+1)
∂h(t)∂h(t)
∂W+
+∂L(o(t+1), y(t+1)
)∂o(t+1)
∂o(t+1)
∂h(t+1)
∂h(t+1)
∂h(t)∂h(t)
∂h(t−1)∂h(t−1)
∂W+...
Jordi Pons Tutorial on recurrent neural networks

14/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: back-propagation with non-linearities
Previous equation can be summarized as follows:
∂L(o(t+1), y(t+1)
)∂W
=
=1∑
k=tmin
∂L(o(t+1), y(t+1)
)∂o(t+1)
∂o(t+1)
∂h(t+1)
∂h(t+1)
∂h(t+k)
∂h(t+k)
∂W
where:
∂h(t+1)
∂h(t+k)=
1∏s=k+1
∂h(t+s)
∂h(t+s−1) =1∏
s=k+1
WT diag [σ′(b+W h(t+s−1)+Ux(t+s))]
h(t+s) = σ(b+Wh(t+s−1) +Ux(t+s))
f (x) = h(g(x))→ f ′(x) = h′(g(x)) · g ′(x)
Jordi Pons Tutorial on recurrent neural networks

15/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: back-propagation with non-linearities
∂h(t+1)
∂h(t+k)=
1∏s=k+1
∂h(t+s)
∂h(t+s−1) =1∏
s=k+1
WT diag [σ′(b+W h(t+s−1)+Ux(t+s))]
the L2 norm de�nes an upper bound for the jacobians:∥∥∥∥∥ ∂h(t+s)
∂h(t+s−1)
∥∥∥∥∥2
≤∥∥∥WT
∥∥∥2
∥∥diag [σ′(·)]∥∥2≡ γwγσ
→ γw ≡ L2 norm of a matrix. → γσ ∈ [0, 1].≡ highest eigenvalue.≡ spectral radius.
and therefore: ∥∥∥∥∥∂h(t+1)
∂h(t+k)
∥∥∥∥∥2
≤ (γwγσ)|k−1|
Jordi Pons Tutorial on recurrent neural networks

16/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: back-propagation with non-linearities
then, consider:∥∥∥ ∂h(t+1)
∂h(t+k)
∥∥∥2≤ (γwγσ)
|k−1|
γwγσ � 1:
∥∥∥∥ ∂h(1)(t)
∂h(1)(k)
∥∥∥∥2
→ ∂L(o(t+1), y(t+1))∂W → ∂L
∂W explodes!
γwγσ � 1:
∥∥∥∥ ∂h(1)(t)
∂h(1)(k)
∥∥∥∥2
→ ∂L(o(t+1), y(t+1))∂W → ∂L
∂W vanishes!
γwγσ ≈ 1: gradients should propagate well until the past
Jordi Pons Tutorial on recurrent neural networks

17/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode: take away message
→ Vanishing gradients make it di�cult to know which directionthe parameters should move to improve the cost function.
→ While exploding gradients can make learning unstable.
→ The vanishing and exploding gradient problem refers to thefact that gradients are scaled according to:∥∥∥∥∥∂h(t+1)
∂h(t+k)
∥∥∥∥∥2
≤ (γwγσ)|k−1| with, tipically : γσ ∈ [0, 1]
→ Eigenvalues are specially relevant for this analysis:
γw ≡∥∥WT
∥∥2≡ largest eigenvalue ≡W t ≡ diag(λ)t .
Jordi Pons Tutorial on recurrent neural networks

18/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode problem
Gated units: LSTM & GRU
Other solutions
Jordi Pons Tutorial on recurrent neural networks

19/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gated units: intuition
1. Accumulating is just a bad memory?
W = I and linear ∼= γwγσ = 1 · 1 = 1RNNs can accumulate but it might be useful to forget.
sequence is made of sub-sequences ≡ text is made of sentences
Forget is a good reason for willing the gradient to vanish?
2. Creating paths through time where derivatives can �ow.
3. Learn when to forget!
Gates allow learning how to read, write and forget!
Two di�erent gated units will be presented:
Long Short-Term Memory (LSTM)Gated Recurrent Unit (GRU)
Jordi Pons Tutorial on recurrent neural networks

20/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
LSTM - block diagram 1
Figure : Traditional LSTM diagram.
Jordi Pons Tutorial on recurrent neural networks

21/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
LSTM - block diagram 2
Figure : LSTM diagram as in the Deep Learning Book.
Jordi Pons Tutorial on recurrent neural networks

22/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
LSTM - block diagram 3
Figure : LSTM diagram as in colah.github.io
Jordi Pons Tutorial on recurrent neural networks

23/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
LSTM key notes
I Two recurrences!→ Two past informations, through: W and direct.
I 1 unit ≡ 1cell.
Formulation for a single cell:
State : s(t) = g(t)f s(t−1) + g
(t)i i (t)
Output : h(t) = θ(s(t))g(t)o
Input : i (t) = θ(b +Ux(t) +Wh(t−1))
Gate : g(t)? = σ(b? +U?x
(t) +W?h(t−1))
Where for g(t)? gate:
? can be f/i/o � standing for forget/input/output.
Gates use sigmoid nonlinearities: σ(·) ∈ [0, 1]Input/output nonlinearities are typically a tanh(·)
Jordi Pons Tutorial on recurrent neural networks

24/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
LSTM - block diagram 4
Figure : Simplified diagram – as in my mind.
Blue dots represent gates!
Jordi Pons Tutorial on recurrent neural networks

25/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
GRU: Gated Recurrent Units
Which pieces of the LSTM architecture are actually necessary?
Figure : GRU simplified diagram, blue dots represent gates.
h(t) = g(t−1)u h(t−1) + (1− g
(t−1)u ) θ(b +Ux(t) +Wg
(t−1)r h(t−1))
g(t)? = σ(b? +U?x
(t) +W?h(t−1))
Where for g(t)? gate: ? can be u/r � standing for update/reset.
Less computation and less number of parameters!
Jordi Pons Tutorial on recurrent neural networks

26/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Gradient vanish/explode problem
Gated units: LSTM & GRU
Other solutions
Jordi Pons Tutorial on recurrent neural networks

27/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Recursive Neural Networks
I Variable size sequences can be mapped to a �xed sizerepresentation.
I Structured as a deep tree that shares weights.I Depth (over many time steps) is drastically reduced.
Jordi Pons Tutorial on recurrent neural networks

28/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Echo State Networks
I Learn only the output weights.
I Easy : train can be a convex optimization problem.
I Di�cult: set Win and Wrec .∥∥∥∥∥∂h(t+1)
∂h(t+k)
∥∥∥∥∥2
≤ (γwγσ)|k−1| with, tipically : γσ ∈ [0, 1]
then, set : γw ≈ 3
Jordi Pons Tutorial on recurrent neural networks

29/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Leaky units
Goal :
∥∥∥∥∥∂h(t+1)
∂h(t+k)
∥∥∥∥∥2
≤ (γwγσ)|k−1| ≈ 1
Proposal: linear units (γσ = 1) and weights near one (γw ≈ 1).
Hidden units with linear self-connections.
I h(t) ← αh(t−1) + (1− α)x (t) running average!
I h(t) ← wh(t−1) + ux (t)
I When w and α are ≈ 1 the network remembers informationabout the past.
I w and α can be �xed or learned.
(leaky - with wholes)
Jordi Pons Tutorial on recurrent neural networks

30/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Models to operate at multiple time scales
Adding skip connections through time
I Connections with a time-delay try to mitigate the gradientvanish or explode problem.
I Gradients may still vanish/explode. For some intuition, thinkabout the problematic forward path: W t .
I Learn in�uenced by the past.
Removing connections
I Forcing to operate at longer (coarse) time dependencies.
I For some intuition, think about the problematic forward path:W t where the t horizon is kept, without paying the cost ofdoing all the multiplications.
Jordi Pons Tutorial on recurrent neural networks

31/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Optimization strategies for RNNs: second order methods
Why don't we improve the optimization by usingsecond order methods?
I These have high computational cost.
I Require a large mini-batch.
I Tendency to be attracted by saddle points.
I Simpler methods with careful initialization can achievesimilar results!
Research done during 2011-2013.
Jordi Pons Tutorial on recurrent neural networks

32/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Optimization strategies for RNNs: clipping gradients
Basic idea:
I To bound the gradient per minibatch.
I Avoids doing a detrimental step when the gradient explodes.
Introduces an heuristic bias that is known to be useful.
Jordi Pons Tutorial on recurrent neural networks

33/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Optimization strategies for RNNs: regularization
Goal: encourage creating paths in the unfolded recurrentarchitecture along which the product of gradients is near 1.
Proposal: regularize to encourage "information �ow".
The gradient vector being propagated should maintain itsmagnitude.
∥∥∥∥∥ ∂h(t)
∂h(t−1)
∥∥∥∥∥2
≈
∥∥∥∥∥ ∂h(t)
∂h(t−1)
∥∥∥∥∥2
·
∥∥∥∥∥∂h(t+1)
∂h(t)
∥∥∥∥∥2
≈ 1
Jordi Pons Tutorial on recurrent neural networks

34/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Explicit memory
Figure : Schematic of a network with explicit memory with the keyelements of the neural Turin machine: (RNN) control network – CPU;and memory part – RAM.
Two main approaches:I Memory networks: supervised instructions in how to use the
memory.I Neural Turing machine: learns to read/write memory.
Jordi Pons Tutorial on recurrent neural networks

35/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Explicit memory: Neural Turing machine
I Everything is di�erentiable: back-propagation learning.→ di�cult to optimize functions that produce an exact integermemory address.→ solution: read/write many memory cells simultaneously.
I Where to read/write?→ One doesn't want to read/write all the memory at once.→ Attention model based on:
I content: "Retrieve the lyrics of the song that has the chorus’we all live in a yellow submarine’".
I location: "Retrieve the lyrics of the song in slot 347".I both.
Read: r =∑
i w[i ]M[i ]Write: M[i ]←M[i ](1−w[i ]e) +w[i ]a
e � erase vector a � add vector.
Jordi Pons Tutorial on recurrent neural networks

36/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
Wrapping up..
Gradient vanish/explode problem
Gated units: LSTM & GRU
Other solutions
Jordi Pons Tutorial on recurrent neural networks

37/37
Gradient vanish/explode problem Gated units: LSTM & GRU Other solutions
..thanks! :)
Credit: most �gures are from the Deep Learning Book .It is also useful to see this video by Nando de Freitas.
Tutorial on recurrent neural networks
Jordi Pons
Music Technology Group
DTIC - Universitat Pompeu Fabra
January 16th, 2017
Jordi Pons Tutorial on recurrent neural networks